resource to performance tradeoff adjustment for fine-grained architectures ─a design methodology
DESCRIPTION
Resource to Performance TradeoffAdjustment for Fine-Grained Architectures─A Design MethodologyWhen implementing computation-intensive algorithms on finegrainedparallel architectures, adjustment of resource toperformance tradeoff is a big challenge. This paper proposes amethodology for dealing with some of these performance tradeoffsby adjusting parallelism at different levels. In a case study,interpolation kernels are implemented on a fine-grainedarchitecture (FPGA) using a high level language (Mitrion-C).For both cubic and bi-cubic interpolation, one single-kernel, onecross-kernel and two multi-kernel parallel implementations aredesigned and evaluated. Our results demonstrate that no singlelevel of parallelism can be used for trade-off adjustment. Instead,the appropriate degree of parallelism on each level, according toavailable resources and the performance requirements of theapplication, needs to be found. Basing the design on high-levelprogramming simplifies the trade-off process. This research is astep towards automation of the choice of parallelization based ona combination of parallelism levels.TRANSCRIPT

Resource to Performance Tradeoff Adjustment for Fine-Grained Architectures─A Design Methodology
Fahad Islam Cheema, Zain-Ul-Abdin, Professor Bertil Svensson
Halmstad University, Halmstad, Sweden

Engr. Fahad Islam Cheema 4-Year Bachelor in Computer Engineering (BCE) from COMSATS Lahore in 2006 2-Year Industrial Experience as Embedded Software/System Engineer in Lahore
and Islamabad Five Rivers Technologies Lahore Streaming Networks Islamabad Delta Indus Systems Lahore
Masters in Computer System Engineering from Halmstad University of Sweden in 2009
Masters standalone thesis accepted for publication in FPGAWorld 2010 international conference www.fpgaworld2010.com Copenhagen, Denmark in September,10
1-Year Academic Experience Halmstad University Sweden LUMS Lahore Bahria University Islamabad
2

Engr. Fahad Islam Cheema 3-Year Experience (Embedded Systems)
2-year Industrial (Streaming Networks) 1-Year Academic
Universities (Halmstad, LUMS, Bahria) Courses
Linux Programming and shell Scripting, Administration of OS, Databases Embedded Systems System Programming
17-Year Education (Computer Engineering) Masters From Sweden Computer Engineering from COMSATS Specialization in Embedded Systems PEC # Comp/6774
1 Publication Masters thesis accepted for publication in FPGAWorld2010 3

Resource to Performance Tradeoff Adjustment for Fine-Grained Architectures─A Design Methodology
Fahad Islam Cheema, Zain-Ul-Abdin, Professor Bertil Svensson
Halmstad University, Halmstad, Sweden

Agenda Overview and Problem Definition Main Idea Experimental SetupMitrion Parallel Architecture Interpolation Kernels
Parallelization Levels Conclusions Future Work
5

6
Overview
MotivationComputation intensive algorithmsFine grained architectures
Problem DefinitionParallelismResource to Performance Tradeoffs
Hardware/logic gates to performance tradeoffs Memory to performance tradeoffs

Problem Defination
d0 = x_int - x0; d1 = x_int - x1;d2 = x_int - x2;d3 = x_int - x3;
p01 = (y0*d1 - y1*d0) / (x0 - x1);p12 = (y1*d2 - y2*d1) / (x1 - x2);p23 = (y2*d3 - y3*d2) / (x2 - x3);
p02 = (p01*d2 - p12*d0) / (x0 - x2);p13 = (p12*d3 - p23*d1) / (x1 - x3);
p03 = (p02*d3 - p13*d0) / (x0 - x3);
Pipeline Step1
(First data independent Block)
Step2
Step3
Step4
Figure-1: Problem at Kernel Level

8
Problem Defination (Conti.)
Points to consider for Parallelism Performance Required Hardware resourses
Hardware Gates Memory interface Memory Size Memory access speed
Improved
Increased
TradeOffs
Fine-Grained Reconfigurable Architectures

Problem Defination (Conti.)
d0 = x_int - x0; d1 = x_int - x1;d2 = x_int - x2;d3 = x_int - x3;
p01 = (y0*d1 - y1*d0) / (x0 - x1);p12 = (y1*d2 - y2*d1) / (x1 - x2);p23 = (y2*d3 - y3*d2) / (x2 - x3);
p02 = (p01*d2 - p12*d0) / (x0 - x2);p13 = (p12*d3 - p23*d1) / (x1 - x3);
p03 = (p02*d3 - p13*d0) / (x0 - x3);
Pipeline Step1
Step2
Step3
Step4
for(i in <0 .. 90000>){
}
Problem Level Parallelism (PLP)
Kernel Level Parallelism (KLP)
Figure-2: Parallelism at different levels

10
Main Idea Parallelism Levels
Bit Level Parallelism (BLP) Kernel Level Parallelism (KLP) Problem Level Parallelism (PLP)
Maximum parallelism at one level is not ultimate solution Customized parallelism at different levels Can better adjust Resource-performance tradoffs
Gates-performance tradeoff

11
Main idea (Conti.)
Maximum parallelism at one level is not ultimate solution Combine parallelism at different parallelism levels to
produce parallelization levels Parallelization Levels
Single Kernel (SKZ) Cross Kernel (CKZ) Multi-SKZ Multi-CKZ
Figure-3: Parallelism and Parallelization Levels

12
Experimental Setup
Computation intensive algorithms Interpolation Kernels
Fine Grained Architecture FPGA
Fine Grained ParallelismMitrion virtual processor
Extract fine grained parallelismMitrion-C high level language (HLL)
Hardware Platform Cray XD1 Supercomputer with Vertex-4 FPGA

13
Interpolation Kernels
What is interpolation Process of calculating new values within the range of
available values [1] Cubic interpolation Bi-cubic interpolation
Applying cubic in 2D 5 cubic kernels
Figure-4: 2D Interpolation

14
Mitrion Parallel Architecture
Mitrion Virtual Processor (MVP) Fine-Grained, Soft-Core Processor Almost 60 IP blocks defined in HDL [2] Non von-neumann architecture
Mitrion-C HLL for FPGA Data dependence instead of order-of-execution Parallelism Language Constructs [3] Pipelining
15
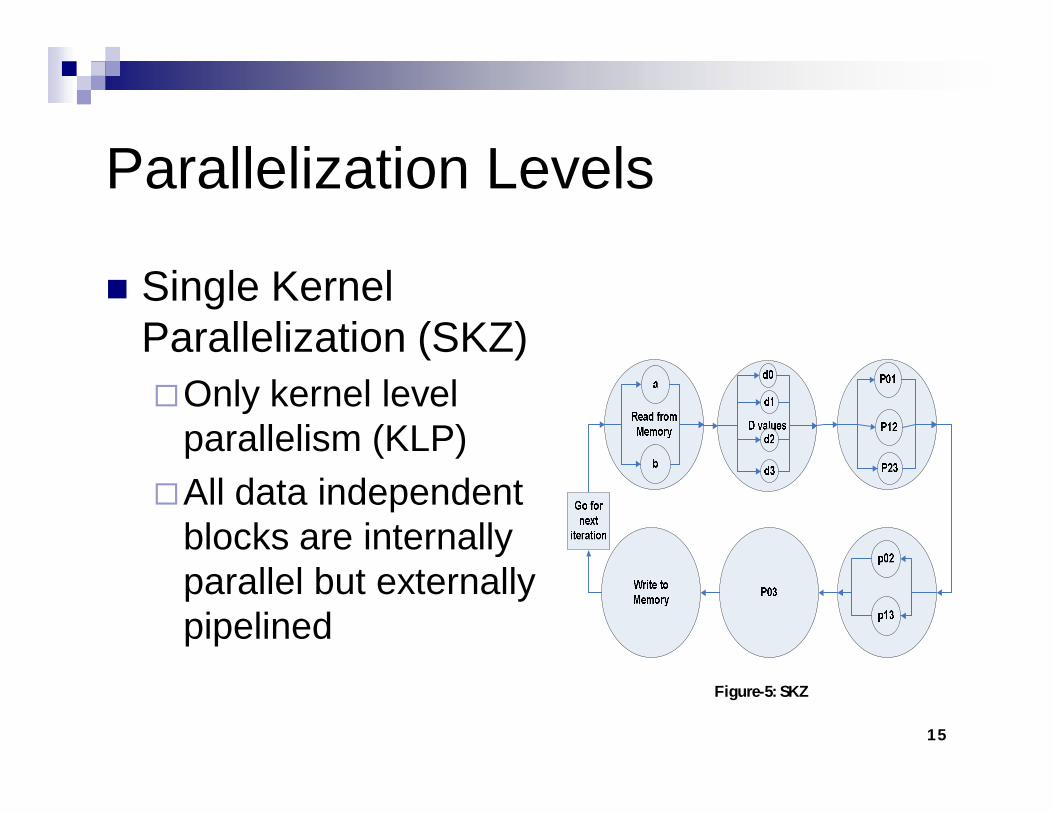
Parallelization Levels
Single Kernel Parallelization (SKZ)Only kernel level
parallelism (KLP)All data independent
blocks are internally parallel but externally pipelined
Figure-5: SKZ

16
Parallelization Levels (Conti.)
Cross Kernel Parallelization (CKZ)Extend kernel by Mixing
more than one kernelsReplicate computation
intensive data independent blocks
Resource computation balance
Figure-6: CKZ

17
Parallelization Levels (Conti.)
Multi-SKZ Replicate kernels which
already have SKZ
Figure-7: Multi-SKZ

18
Parallelization Levels (Conti.)
Multi-CKZ Replicate kernels which
already have CKZ
Figure-8:Multi-CKZ
Read from Memory
Go for next
iteration
a
b
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03Write to Memory
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03
Read from Memory
Go for next
iteration
a
b
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03Write to Memory
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03
Read from Memory
Go for next
iteration
a
b
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03Write to Memory
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03
Read from Memory
Go for next
iteration
a
b
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03Write to Memory
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03
Read from Memory
Go for next
iteration
a
b
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03Write to Memory
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03
Read from Memory
Go for next
iteration
a
b
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03Write to Memory
D values
d0
d2
d1
d3
P01
P23
P12
p02
p13
P03

19
Results
Table-1 : Results

20
Conclusions Specific conclusions
For very limited resources, SKZ is better CKZ is better for applications with high unbalanced computation
distribution SKZ and CKZ are better for large size applications Multi-CKZ can provide high level of parallelism at cost of design
complexity Multi-SKZ and Multi-CKZ are attractive for small size Real-Time
applications Using parallelization levels
Can adjust trade-offs Can achieve highly custom parallelism
Mix of parallelization levels can produce Application-specific parallelism Resource-specific parallelism

21
Future Work
Automation of parallelization levels Parallelization levels to deal with other tradeoffs Generalized parallelization levels for all
application Generalized parallelization levels for graphical
processors to adjust tradeoffs Floating point and accuracy

22
References[1] William H. Press Brian P. Flannery, Saul A. Teukolsky William
T.Vetterling “Numerical Recipes, Art of Scientific Computing”, Cambridge University Press
[2] Stefan Möhl, “The Mitrion Virtual Processor, Using FPGAs in HPC” Sixteenth ACM/SIGDA International Symposium on FPGAs <http://www.ece.wisc.edu/~kati/fpga2008/fpga2008%20workshop%20-%2005%20Mitrionics%20-%20Mohl.pdf> Date 14-05-2009
[3] “Mitrion User Guide”, Copyright © 2005 - 2008 by Mitrionics AB. <http://www.mitrionics.com/?page=developers_resources> Date 03-03-2009

Tack(Hope you enjoyed)