reporter: li, fong ruei national taiwan university of science and technology 9/19/2015slide 1 (of...
TRANSCRIPT

Reporter: Li, Fong RueiNational Taiwan University of Science and Technology
04/19/23 Slide 1 (of 32)

Large-Scale Automatic Classification of Phishing Pages, Colin Whittaker, Brian Ryner, Marria Nazif, NDSS '10, 2010
04/19/23 Slide 2 (of 32)

IntroductionPhishing Classifier InfrastructureEvaluationConclusion
04/19/23 Slide 3 (of 32)

Phishing is form of identity theft social engineering techniques sophisticated attack vectors
To harvest financial information from unsuspecting consumers.
Often a phisher tries to lure her victim into clicking a URL pointing to a rogue page.
04/19/23 Slide 4 (of 32)

Overall System Design Our system classifies web pages
submitted by end users and collected from Gmail’s spam filters.
These features describe the composition ▪ the web page’s URL▪ the hosting of the page▪ the page’s HTML content as collected by a
crawler
04/19/23 Slide 5 (of 32)

Classification Workflow The first process extracts features about
the URL of the page. The second process obtains domain
information about the page and crawls it The final process assigns the page a
score based on the collected features representing the probability that the page is phishing
04/19/23 Slide 6 (of 32)

Candidate URL Collection We receive new potential phishing URLs
in reports ▪ from users of our blacklist▪ from spam messages collected by Gmail
04/19/23 Slide 7 (of 32)

URL Feature Extraction The first process in the workflow, the
URL Feature Extractor, looks only at the URL of the page to determine features.
If it matches a whitelist of high profile, safe sites, then the URL Feature Extractor drops the URL from the workflow entirely.
We manually compile this whitelist of 2778 sites
04/19/23 Slide 8 (of 32)

URL Feature Extraction One feature this process extracts is
whether the URL contains an IP address for its hostname.
04/19/23 Slide 9 (of 32)

URL Feature Extraction▪ Another feature this process extracts is whether
the page has many host components▪ Phishers commonly use a long hostname,
prepending an authentic-sounding host to their fixed domain name, to confuse viewers into believing that the page is legitimate.
04/19/23 Slide 10 (of 32)

URL Feature Extraction Phishers often include characteristic strings
in their URLs to mislead viewers. These can include the trademarks of the
phishing target, like “abbeynational” in the example above, or more general phrases associated with phishing targets, like “login”.
The feature extractor transforms each of these tokens into a boolean feature, such as “The path contains the token ‘login.’”
04/19/23 Slide 11 (of 32)

Fetching Page Content The URL Feature Extractor also collects
URL metadata, including PageRank, from Google proprietary infrastructure
We also use a domain reputation score computed by the Gmail anti spam system as a feature.▪ This score is roughly the percentage of emails
from a domain which are not spam
04/19/23 Slide 12 (of 32)

Hosting and Page Feature Extraction The Content Fetcher process crawls the
page and gathers its hosting information.▪ It records the returned IPs, name servers, and
name server IPs. ▪ It also geo locates these IPs, recording the
city, region, and country
04/19/23 Slide 13 (of 32)

Machine Learning and Bioinformatics Laboratory
Hosting and Page Feature Extraction The Content Fetcher sends the URL to a pool
of headless web browsers to render the page content.
After the browser renders the page, the Content Fetcher receives and records the page HTML, as well as all iframe, image, and javascript content embedded in the page
04/19/23 Slide 14 (of 32)

Machine Learning and Bioinformatics Laboratory
Page Classification To compute the score for the page in log
odds, the classifier combines these values using a logistic regression
The score translates to the computed probability that the page is phishing
04/19/23 Slide 15 (of 32)

Page Classification Before the classifier automatically
blacklists the page, it checks to make sure that the page does not have a high PageRank
04/19/23 Slide 16 (of 32)

Evaluation Dataset First▪ contains data collected between April 16,
2009 and July 14, 2009 with labes from July 15, 2009.▪ examine our selected features and train our
evaluation models Second▪ collected during the first two weeks of
August, 2009, as a validation dataset.
04/19/23 Slide 17 (of 32)

04/19/23 Slide 18 (of 32)

04/19/23 Slide 19 (of 32)

04/19/23 Slide 20 (of 32)
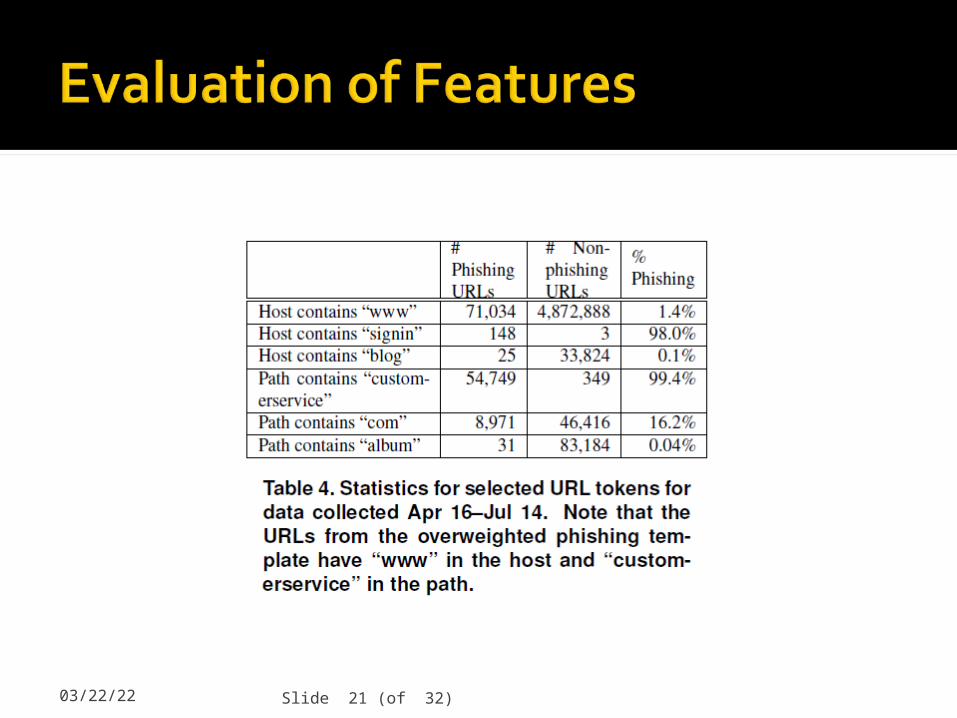
04/19/23 Slide 21 (of 32)

Machine Learning and Bioinformatics Laboratory
04/19/23 Slide 22 (of 32)

Machine Learning and Bioinformatics Laboratory
04/19/23 Slide 23 (of 32)
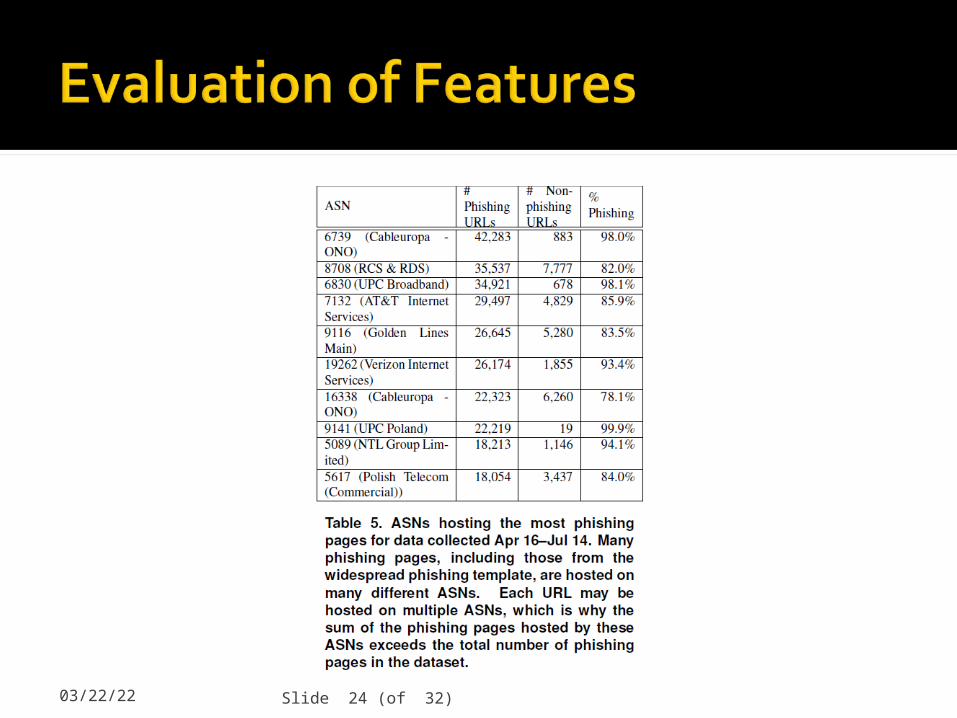
04/19/23 Slide 24 (of 32)
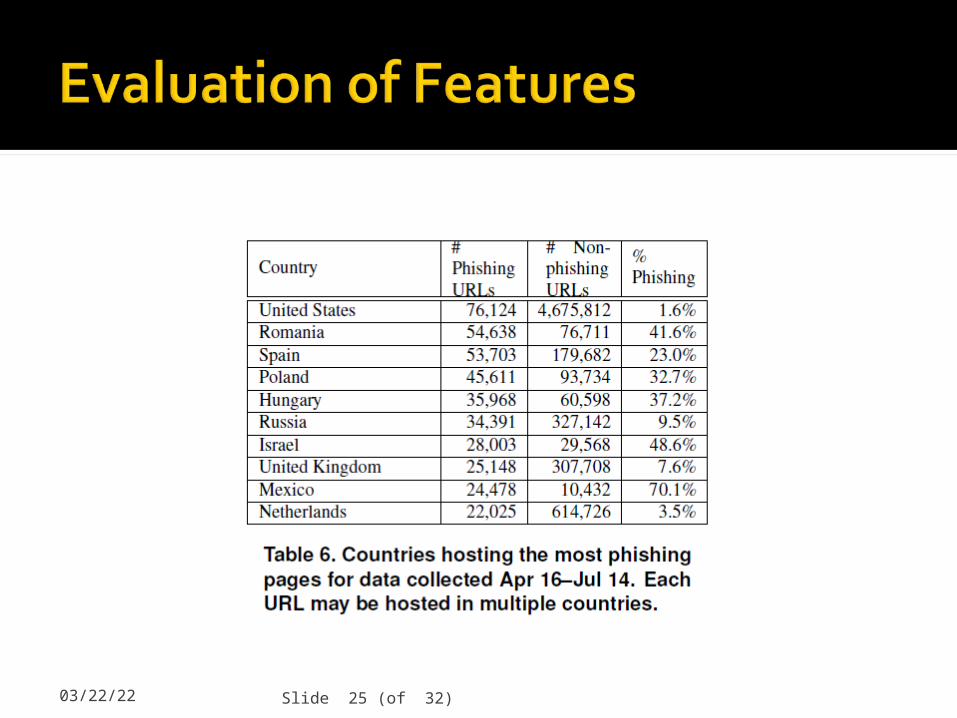
04/19/23 Slide 25 (of 32)

04/19/23 Slide 26 (of 32)

04/19/23 Slide 27 (of 32)
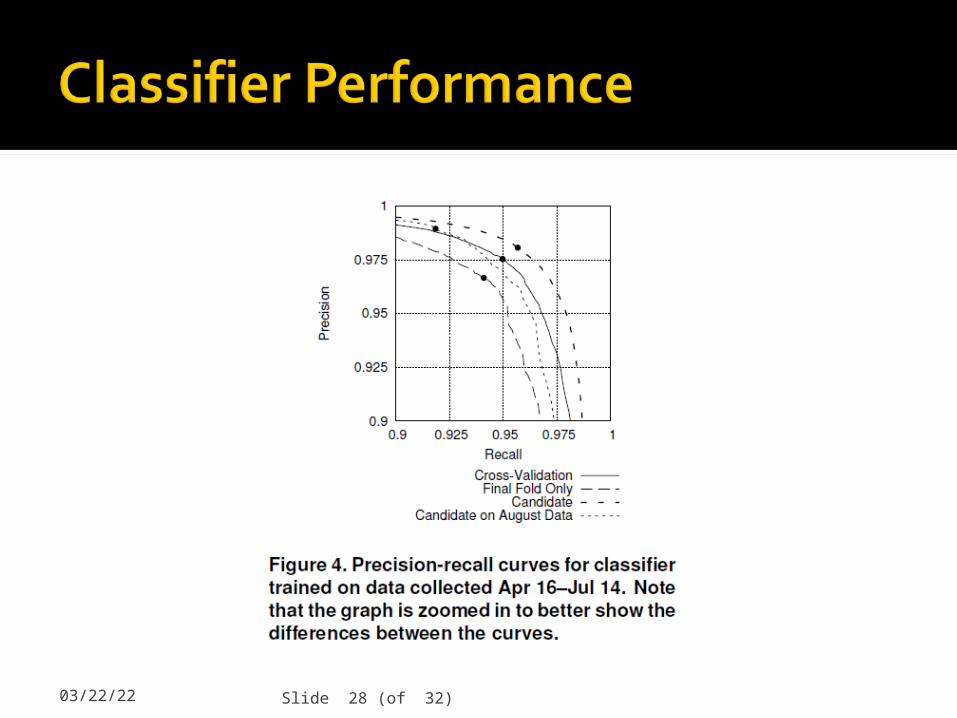
04/19/23 Slide 28 (of 32)

04/19/23 Slide 29 (of 32)

04/19/23 Slide 30 (of 32)

we describe our large-scale system for automatically classifying phishing pages which maintains a false positive rate below 0.1%.
Our classification system examines millions of potential phishing pages daily in a fraction of the time of a manual review process
04/19/23 Slide 31 (of 32)

04/19/23 Slide 32 (of 32)