reported by richard jones gluex collaboration meeting, newport news, may 13, 2009 collaborative...
Post on 21-Dec-2015
216 views
TRANSCRIPT

1
reported by Richard JonesGlueX collaboration meeting, Newport News, May 13, 2009
Collaborative Analysis Toolkitfor
Partial Wave Analysis

2
Overview
GOAL: Develop a framework for amplitude analysis that is modular and independent of experiment. scales to very large data sets. accommodates increased computational demands. allows amplitudes to be written by the physicist. encourages a closer theory-experiment collaboration.
GlueX collaboration meeting, Newport News, May 13, 2009
GRIDGRID
courtesy of Ryan Mitchell, Munich PWA workshop

3
OverviewCOLLABORATION: Funded by the National Science Foundation (NSF)
Physics at the Information Frontier (PIF) program. Indiana University: R. Mitchell, M. Shepherd, A.
Szczepaniak Carnegie Mellon University: C. Meyer, M. Williams University of Connecticut: R. Jones, J. Yang Plus: 2 more postdocs
courtesy of Ryan Mitchell, Munich PWA workshop
GlueX collaboration meeting, Newport News, May 13, 2009
4
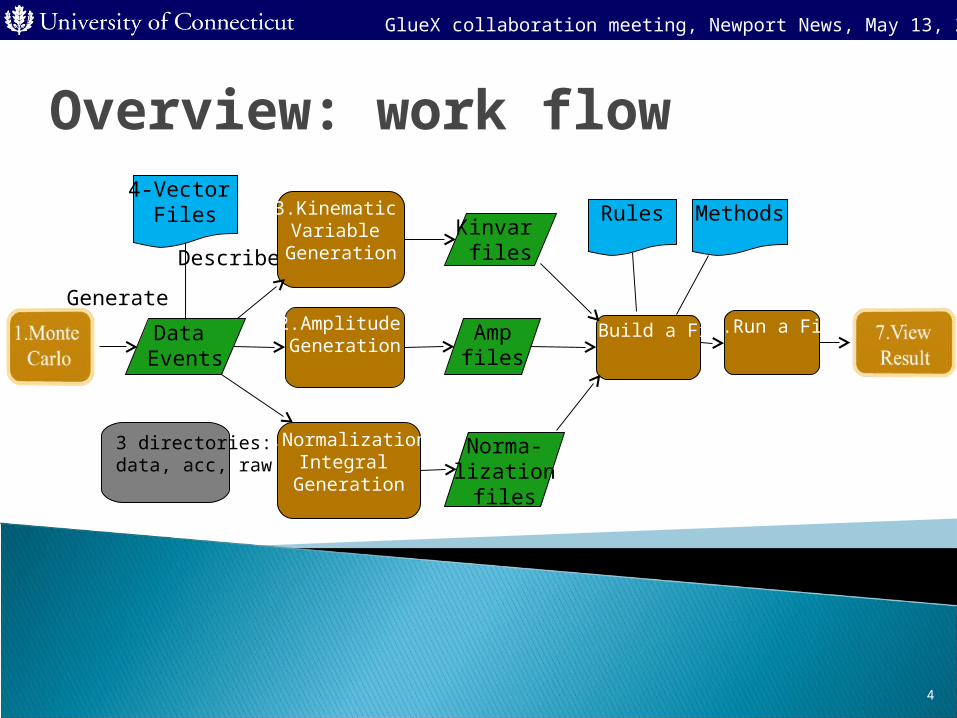
Overview: work flow
GlueX collaboration meeting, Newport News, May 13, 2009
Data Events
4-Vector Files
Generate
Describe
2.Amplitude Generation
Ampfiles
3.Kinematic Variable
GenerationKinvar
files
4.Normalization Integral
Generation
Norma-lization
files
5.Build a Fit
Rules Methods
6.Run a Fit
3 directories: data, acc, raw

5
GlueX collaboration meeting, Newport News, May 13, 2009
Layout of the Framework
9
Highlights for this talk:
(1) Distributed Data and Computing.
(2) The Amplitude Interface.
courtesy of Ryan Mitchell, Munich PWA workshop

6
GlueX collaboration meeting, Newport News, May 13, 2009
courtesy of Ryan Mitchell, Munich PWA workshop

7
GlueX collaboration meeting, Newport News, May 13, 2009
courtesy of Ryan Mitchell, Munich PWA workshop

8
GlueX collaboration meeting, Newport News, May 13, 2009
courtesy of Ryan Mitchell, Munich PWA workshop

9
GlueX collaboration meeting, Newport News, May 13, 2009
courtesy of Ryan Mitchell, Munich PWA workshop

10
GlueX collaboration meeting, Newport News, May 13, 2009
Ongoing work on 3 system: Peng et.al.

11
GlueX collaboration meeting, Newport News, May 13, 2009
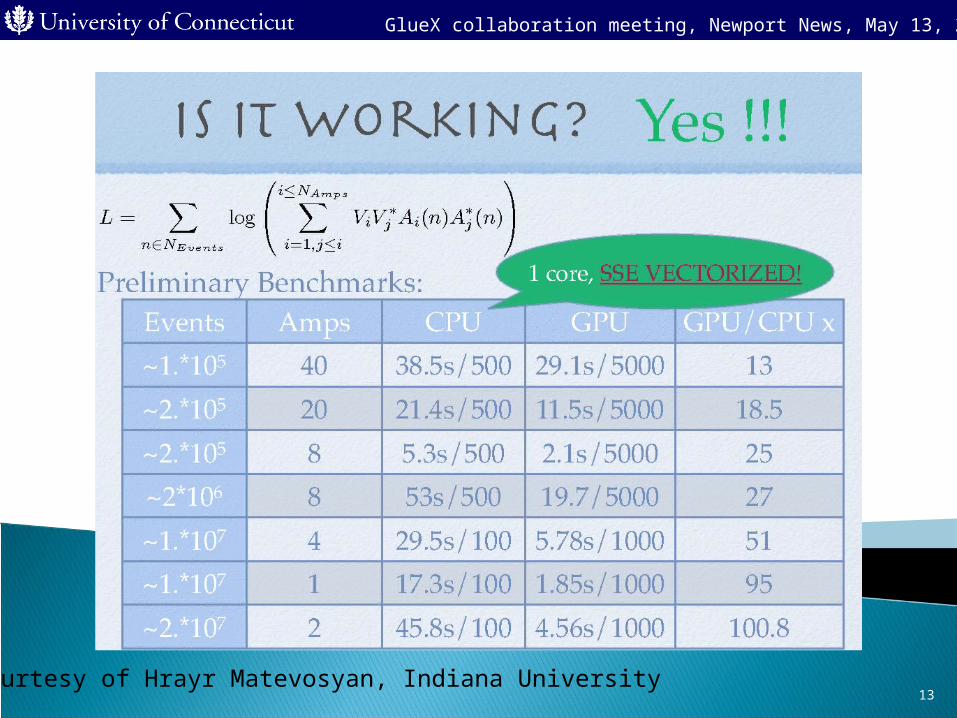
courtesy of Hrayr Matevosyan, Indiana University

12
GlueX collaboration meeting, Newport News, May 13, 2009
courtesy of Hrayr Matevosyan, Indiana University
13
GlueX collaboration meeting, Newport News, May 13, 2009
courtesy of Hrayr Matevosyan, Indiana University

14
1. Porting the Ruby-PWA toolkit to the grid1.1 Install the Ruby-PWA software bundle on the UConn site1.2 Benchmark and scaling studies1.3 Parallel Ruby-PWA
2. Integration of grid storage into Ruby-PWA framework2.1 Upgrade to the latest version of RedHat Linux2.2 Monitoring data integrity of dCache pools2.3 Grid data storage platform benchmarks
3. Extending the UConn cluster for use as a grid testbed3.1 Installation3.2 Tuning
GlueX collaboration meeting, Newport News, May 13, 2009
Ongoing work at ConnecticutOngoing work at Connecticut

15
1.1 Install the Ruby-PWA software bundle on the UConn site◦ Ruby-PWA
A flexible framework for doing partial wave analysis fits Written in Ruby C++ classes wrapped as Ruby objects
◦ Installation Prerequisite: ruby-minuit Updated version of crenlib root package A number of build errors had to be investigated and solved Run Ruby-PWA test fits
GlueX collaboration meeting, Newport News, May 13, 2009

16
1.2 Benchmark and scaling studies◦ Test data bundle from CMU◦ Original test data: 2188 simulated data events◦ Create test samples of size x10, x20, x30, and x50 by duplicating
Original test data◦ More extensive scaling studies with statistically independent data will be
carried out once the code is ported to a parallel platform.
GlueX collaboration meeting, Newport News, May 13, 2009

17
1.3 Parallel Ruby-PWA◦ MPI 2.0 new features
Dynamic process management "the ability of an MPI process to participate in the creation of new
MPI processes or to establish communication with MPI processes that have been started separately.“ – From MPI-2 specification
One-sided communication Three one-sided communications operations, Put, Get, and
Accumulate, being a write to remote memory, a read from remote memory, and a reduction operation on the same memory across a number of tasks
Three different methods for synchronizing this communication - global, pairwise, and remote locks.
Collective extensions In MPI-2, most collective operations apply also to
intercommunicators
GlueX collaboration meeting, Newport News, May 13, 2009

18
1.3 Parallel Ruby-PWA◦ Comparison of OpenMPI 1.3 and MPICH 2
OpenMPI 1.3 Open MPI is an open source, production quality MPI-2
implementation Developed and maintained by a consortium of academic, research,
and industry partners OpenMPI design is centered around component concepts. Network connection devices: Shared memory, TCP, Myrinet, and
Infiniband Network connection devices are dynamically selected in run time. We have tested this feature of OpenMPI. We also tested other basic
functions of MPI, and got good performance We are now incorporating OpenMPI into Condor
GlueX collaboration meeting, Newport News, May 13, 2009

19
1.3 Parallel Ruby-PWA◦ Comparison of OpenMPI 1.3 and MPICH 2(cont.)
MPICH 2 High-performance implementations of MPI-1 and MPI-2 functionality MPICH2 separates communication from process management. MPICH 2 channel devices such as sock, ssm, shm, etc…, can be
specified on installation. We select OpenMPI for future development of ruby-pwa
Advanced component architecture Dynamic communications features Broad support from academic and industry partners.
GlueX collaboration meeting, Newport News, May 13, 2009

20
1.3 Parallel Ruby-PWA◦ Hybrid programming model : OpenMP + MPI
OpenMP defines an API for writing multithreaded applications for running specifically on shared memory architectures.
Greatly simplifies writing multi-thread programs in Fortran, C and C++.
gcc version 3.4 and above on Linux supports OpenMP. The hybrid programming model, OpenMP + MPI, combines the shared-
memory and distributed-memory programming models. In our tests, OpenMP implementation ran very efficiently on up to 8
processes. OpenMPI implementation ran with essentially 100% scaling, provided
that all of the communications channels were tcp-ip sockets. OpenMPI tests using a mixture of shared-memory and tcp-ip
communcations channels showed markedly lower performance. We are still investigating its cause.
GlueX collaboration meeting, Newport News, May 13, 2009

21
1.3 Parallel Ruby-PWA◦ GPU Computing
From Graphics Processing to Parallel Computing GPU (Graphic Processor Unit) has evolved into a highly parallel,
multithreaded, manycore processor with tremendous computational horsepower and very high memory bandwidth
In November 2006, NVIDIA introduced CUDA™, a general purpose parallel computing architecture – with a new parallel programming model and instruction set architecture.
The initial CUDA SDK was made public 15 February 2007. NVIDIA has released versions of the CUDA API for Microsoft Windows, Linux and Mac OS X.
Our test platform GeForce 9800 GT(14 multiprocessors, 112 cores, 512MB memory) Intel(R) Core(TM)2 CPU 6600 @ 2.40GHz 8GB memory
GlueX collaboration meeting, Newport News, May 13, 2009

22
1.3 Parallel Ruby-PWA◦ GPU Computing (cont.)
Benchmark: Matrix Multiplication
GlueX collaboration meeting, Newport News, May 13, 2009

23
1.3 Parallel Ruby-PWA◦ GPU Computing (cont.)
Constraints of GPU computing One GPU can only be used by one process, it can not be shared by other
processes. Developers should design delicate programs to parallel their applications to
overlap the latency of global memory. CUDA uses a recursive-free, function-point-free subset of C language. The programming skill for CUDA is new to developers. The learning cure
may be steep for developers. In some applications, it’s difficult for CUDA to achieve so high performance
as matrix multiplication does. Challenges
How to incorporate GPU computing into paralleling Ruby-PWA How to explore, share and manage GPU resources on grid How to hide the complexity of GPU computing to developers
GlueX collaboration meeting, Newport News, May 13, 2009

24
2.1 Upgrade to the latest version of Redhat Linux◦ Upgrade operating systems to latest version of Redhat
Linux (CentOS 5 distribution)◦ Upgrade Linux kernel to 2.6.26◦ The upgrades are deployed to more than 80 nodes on
UConn site.
GlueX collaboration meeting, Newport News, May 13, 2009

25
2.2 Monitoring data integrity of dCache pools◦ dCache
Single 'rooted' file system name space tree Supports multiple internal and external copies of a single file Data may be distributed among a huge amount of disk servers. Automatic load balancing by cost metric and interpool transfers Distributed Access Points (Doors) Automatic HSM migration and restore Widely used at Tier II and Tier III centers in the LHC data grid.
◦ We have adopted dCache as the network data storage infrastructure at UConn site
◦ We developed scripts to monitor the integrity for all files stored in dCache pools
GlueX collaboration meeting, Newport News, May 13, 2009

26
2.3 Grid data storage platform benchmarks◦ Mechanisms for reading data stored in dCache pools
Similar methods to unix streams: open, read blocks of data, and close.
File transfer program like rft.◦ Protocols
dCap: dCap API provides an easy way to access dCache files as if they were traditional unix stream files
gsidCap: secure version of dCap gridftp: the standard protocol to transfer files on the grid
platform. ◦ Performance test
Open a file, read one block of data, and close the file. 600 files tested
GlueX collaboration meeting, Newport News, May 13, 2009

27
2.3 Grid data storage platform benchmarks◦ dCap
Avg. 690ms for access one block of a file
GlueX collaboration meeting, Newport News, May 13, 2009

28
2.3 Grid data storage platform benchmarks◦ gsidCap
Avg. 750ms for access one block of a file
GlueX collaboration meeting, Newport News, May 13, 2009

29
2.3 Grid data storage platform benchmarks◦ GridFTP
Avg. 1700ms for access one block of a file
GlueX collaboration meeting, Newport News, May 13, 2009

30
3.1 Installation New cluster is added to UConn physics grid platform
32 DELL PowerEdge 1435 servers quad core processors per node 8 GB memory per node One 320GB hard disk per node Two gigabit network interfaces per node
3.2 Tuning◦ To reduce the cost of maintenance, we use NFS root file system◦ Tune TCP settings to make the new cluster stable
GlueX collaboration meeting, Newport News, May 13, 2009

31
GlueX collaboration meeting, Newport News, May 13, 2009