repeatable and reliable search system evaluation using crowdsourcing
TRANSCRIPT

Repeatable and Reliable
Search System Evaluation
using Crowdsourcing
Roi Blanco (Yahoo! Research)
Harry Halpin (University of Edinburgh)
Daniel M. Herzig (Institute AIFB)
Peter Mika (Yahoo! Research)
Jeffrey Pound (University of Waterloo)
Henry S. Thompson (University of Edinburgh)
Than Tran Duc (Institute AIFB)

- 2 -
Motivation
• Boot-strap a new evaluation campaign using crowdsourced relevance judgments
– Ad-hoc object retrieval using RDF data
• Are results repeatable?
– What happens if we re-run the evaluation at a different time?
• Are results reliable?
– How do results change with respects to expert judges evaluating?

- 3 -
Ad-Hoc Object Retrieval
• Field of “Semantic Search”
– Retrieve a “ranked list of objects” from the Web of Data in response to free keyword queries
– Related to TREC’s entity track, but on Linked Open Data
– Related to INEX
– Related to keyword search in DBs
• Different classes of information needs:
– Entity queries: parcel 104 Santa Clara
– Type queries: north texas eye doctors eye surgery
– Relation queries
• We focused on entity queries (and extended to type/list queries)

- 4 -
Resource Description Framework (RDF)
• Each resource (thing, entity) is identified by a URI
– Globally unique identifiers
– Locators of information
• Data is broken down into individual facts
– Triples of (subject, predicate, object)
• A set of triples (an RDF graph) is published together in an RDF document
example:roi
“Roi Blanco”
name
typefoaf:Person
RDF document

- 5 -
Example: Yahoo! Vertical Intent Search
Related actors and movies

- 6 -
Example: Yahoo! Enhanced Results
Enhanced result with deep links, rating, address.

- 7 -
Data-set
• Retrieval of RDF data related to a single entity
• 92 selected queries that name an entity explicitly (but may also provide context)
• Selected 42 from the Search Query Tiny Sample v1.0 dataset, provided by the Yahoo! Webscope program and 52 from Microsoft Live Search
• Queries asked by at least three different users
• Billion Triples Challenge (BTC) 2009 data-set
• Group RDF triples with the same subject into a single object
• 247GB, 1.4B RDF triples, 114M objects
• Crawls of multiple semantic search engines

- 8 -
Mechanical turk
• Ups:
– Flexible: you decide how much you evaluate
– There is and infinite pool of judges
– Could repeat the experimentation at any time
– Low-cost
• Downs:
– Non-trained evaluators
– Spammers
– Is it a representative sample?
– Is it reliable?

- 9 -
Assessments with Amazon Mechanical Turk
• Unit of work is a “Human Intelligence Task” (HIT)
• 6 systems, up 3 submissions per system
• Grouped each 10 results (+2 “gold” questions) into 1 HIT
– $0.2 per 12 results (1 HIT)
– Financial incentives increase quantity not quality
• Evaluated results using a 3-point scale
– Excellent, Not Bad and Poor
• Average voting to decide (3+ judges)
• Reported performance using NDCG, MAP, p@10
• Total cost ~350$

- 10 -
Result display

- 11 -
Catching the bad guys …
• Spam detection based on
– average and standard deviation performance on “gold questions”
– task completion time
– score distribution
• Agreement in gold assessment is high (>95% for faithful judges)
– After 6 months there was a sharp increase in the number of spammers

- 12 -
Research questions
• Two sets of experiments (MT1 – MT2), six months apart
• Experts re-evaluated the results (EXP)
• Repeatability
– Is the agreement in MT1 and MT2 comparable?
– Does the system ranking from MT1 and MT2 agree?
• Reliability
– Do MT1/MT2 and EXP agree?
– Does the system ranking from MT1/MT2 and EXP agree?
• Can worker evaluations produce the same results in terms of our relevance metrics and the rank-order of the evaluated systems?
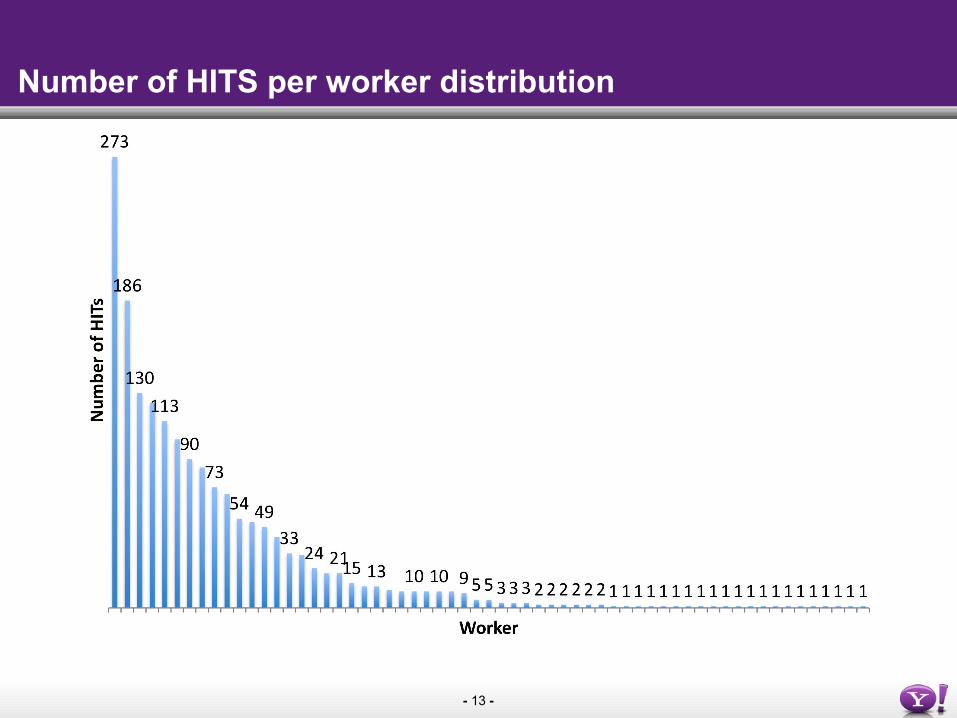
- 13 -
Number of HITS per worker distribution

- 14 -
Repeatibility
• Measure of how inter-changeable are judges
• Problems computing agreement:
– Kappa assumes the same judges assess all the items
– Using crowd-sourcing workers judge a wildly varying number of items
• We report Fleiss’ Kappa distribution over HITs
• Agreement is exactly the same in MT1 and MT2
– In a 2 (kappa ~ 0.44) or 3 (kappa ~ 0.36) point scale
– Results are repeatable (same agreement distributions)

- 15 -
Fleiss’ kappa distribution per HIT

- 16 -
Ranking systems
• System ordering doesn’t change when using MT1 or MT2 (or EXP)

- 17 -
Reliability
• Same system order using EXP or MT
• Kappa between experts is higher (~0.57 2 point, ~0.56 3 point scale)
– Less problems in using the middle judgment
• Kappa between experts and MT ~0.42
• Differences in performance ~12% for P@10, ~2% for MAP, ~3.5% for NDCG
• How does the performance vary with the number of judges?
• Sampled 100 times from pool of 6 crowd-sourced judges
– Computed statistics on retrieval performance using 1-6 judges (mean, deviation, …)

- 18 -
Differences in systems ranking using MT and experts

- 19 -
Average performance change (EXP vs MT2)

- 20 -
Conclusions
• Empirical evidence that bootstraping a new evaluation campaign over MT is repeatable and reliable (and quick)
– Fast, scalable, just-in-time evaluation (less than 2 months)
• MT agreement is comparable but experts agree more
– After 6 months the system ordering doesn’t change (despite the increase of spammers)
• Crowd-sourced judges are less accurate and have more false positives but differences drown out into data
– Ranking ordering between MT and EXP is the same
• At least 3 judges needed, but more can help: P@10 is more brittle than measures such as MAP and nDCG.

- 21 -
Future work
• Repeated the evaluation campaign this year
– Prizes sponsored by Yahoo!
– Also as part of the TREC entity track this year
• Included the “list queries” task in the evaluation
– Queries that describe a set of entities, like “Apollo astronauts who walked on the Moon”
• Future evaluation, schema.org related?

- 22 -
Evaluation background
• Harter(1996) - people disagree significantly when judging relevance
• Agreement between judges and its influence in system ranking
• Lesk and Salton (1969) / Cleverdon (1970)
– Systems remain rank invariant wrt precision and recall
• Bailey et al (2008) gold-silver-bronze judges
– Significant differences among the topic/task expertise levels
– Cranfield-style evaluation somewhat robust to variations

- 23 -
Agreement using average voting

- 24 -
Experts are harsher (perceived relevance)
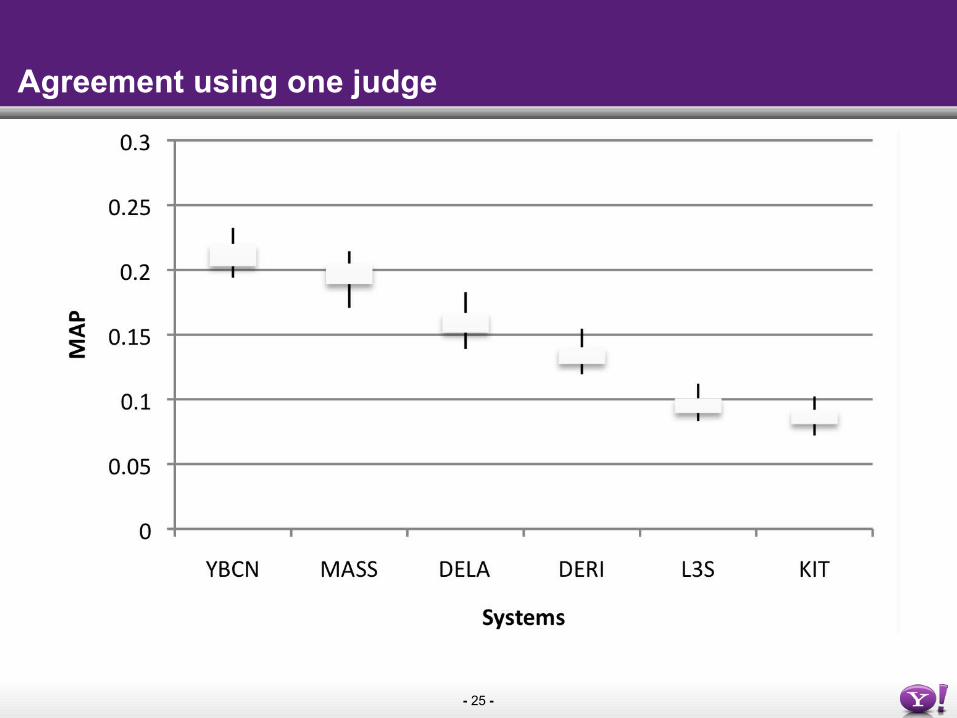
- 25 -
Agreement using one judge

- 26 -
Linked Data: interlinked RDF documents
example:roi
“Roi Blanco”
namefoaf:Person
sameAs
example:roi2worksWith
example:peter
type
type
Roi’s homepage
Yahoo
Friend-of-a-Friend ontology

- 27 -
Average performance deviation
• Sampling judgments 100 times using a pool of 6 workers
– little average deviation between performance measured in MAP, NDCG, P@10

- 28 -
Example: schema.org