relatÓrio de graduaÇÃo em geofÍsica · “a melhor coisa a fazer quando se está triste é...
TRANSCRIPT

UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
CENTRO DE CIÊNCIAS EXATAS E DA TERRA CURSO DE GRADUAÇÃO EM GEOFÍSICA
RELATÓRIO DE GRADUAÇÃO EM GEOFÍSICA
ANÁLISE DA MIGRAÇÃO REVERSA NO TEMPO EM
ARQUITETURAS PARALELAS
Autor: Daniel Araújo de Medeiros
Orientador: João Medeiros de Araújo
Relatório N 37
Natal/RN Dezembro de 2013

UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
CENTRO DE CIÊNCIAS EXATAS E DA TERRA CURSO DE GRADUAÇÃO EM GEOFÍSICA
ANÁLISE DA MIGRAÇÃO REVERSA NO TEMPO EM
ARQUITETURAS PARALELAS
POR
Daniel Araújo de Medeiros
Relatório N 37
Comissão examinadora:
______________________ Dr. João Medeiros de Araújo (DFTE/UFRN) – Orientador
______________________ Dr. Madras Viswanathan Gandhi Mohan (DFTE/UFRN)
______________________ MSc. Heron Antônio Schots (CPGeo)
Data da aprovação: __________

“Àqueles que fazem parte da minha vida.”

“A melhor coisa a fazer quando se está triste é aprender algo.
Essa é a única coisa que nunca falha. Você pode ficar velho e trêmulo em sua
anatomia, pode passar a noite acordado escutando a desordem de suas veias, pode
sentir saudades de seu único amor, pode ver o mundo a seu redor ser devastado por
lunáticos malvados ou saber que sua honra foi pisoteada no esgoto das mentes
baixas. Só há uma coisa para isso: aprender. Aprender por que o mundo gira e o que
o faz girar. Essa é a única coisa da qual a mente não pode jamais se cansar, nem se
alienar, nem se torturar, nem temer ou descrer, e nunca sonhar em se arrepender.
Aprender é o que lhe resta.”
Mago Merlin para um futuro Rei Arthur.
T.H. White, “A Espada na Pedra”.

UFRN/CCET– Relatório de Graduação em Geofísica Agradecimentos
Agradecimentos
Existem inúmeras maneiras as quais se pode agradecer a alguém por
qualquer contribuição no seu crescimento intelectual, e até mesmo humano, durante
um curso de graduação. Citar tais pessoas em um trabalho de conclusão de curso,
definitivamente, não é a maneira mais apropriada – mas seguem-se aqui aquelas
pessoas que considero como sendo as mais importantes ao longo de minha vida
acadêmica.
Primeiramente à minha família, o que inclui principalmente meus pais (Hild e
Ana), além de minha irmã mais nova (Maria Clara) e meu irmão mais velho (Bruno).
É desnecessário dizer o porquê deste agradecimento, já que sem a família, não se
consegue ir a lugar algum. O apoio deles foi fundamental em qualquer coisa que eu
tenha feito – por mais impulsiva que tenha sido, sempre recebi algo como um
“estamos sempre ao seu lado, independente de sua decisão”. Caso algum tio, tia,
avô, avó, primo, prima ou qualquer pessoa relacionada por sangue à minha pessoa
ler este trabalho de conclusão de curso, o que não deve acontecer, sinta-se incluído
nesta categoria – e incluo aqui também meus dois amigos de infância que considero
como meus irmãos, Mateus Alves e Breno Sabino.
Meu segundo agradecimento segue para um grupo de pessoas que, ao longo
de quase sete anos, se tornaram parte essencial de mim também, antes mesmo de
eu entrar na universidade. Estas pessoas, que conheci na internet, sempre me
“aturaram” por mais impossível ou nervoso que eu estivesse, e sempre estão juntas
comigo para me dar conselhos ou fazer alguma besteira que possa gerar risadas,
desde procurar falhas em websites até ficar discutindo coisas totalmente irrelevantes
para a humanidade ou, simplesmente, nossas vidas. Essas pessoas me viram
entrando na faculdade, como também estão me vendo sair dela. Por isso, referindo-
me aos membros diretos e indiretos do grupo morningspeed, gostaria de citar os
amigos Artur Moura, Cainã Costa, Éberson Polita, Edmilson Júnior, Ernesto Kado,
Fabrício Webber, George Wesley, Giuseppe Angeli, Gustavo Bennemann, Gustavo
Hoffmann, Gustavo José, Jacques Szmelcynger, Johannes Lochter, Leandro
Menezes, Renato Schmidt, Rodrigo Nonose e Tiago Scaranelo.

Medeiros, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Agradecimentos
página ii
Podemos seguir para as pessoas da universidade agora, falando sempre das
que, junto a mim, enfrentaram os “trancos e barrancos” ao longo dos quatro anos de
curso. Devo meus maiores cumprimentos aos amigos Adler Araújo, Arthur Messias e
Diego Galdino (este último resolveu perseguir seus sonhos e virar um Engenheiro
Civil) por sempre matarem comigo aquelas aulas tediosamente chatas de Cálculo e
renderem bons momentos de risadas, além de pagarem meus almoços no
Restaurante Universitário ou na cantina, já que eu quase sempre andava (e ando,
até hoje!) sem dinheiro na carteira. Ao Yago Medeiros, Querzia Soares, Pedro
Augusto, Carlos Fernandes e Rener Antônio (vulgo Caicó) por sempre discutirem
comigo sempre que estou na iminência de fazer besteiras e, de certa forma,
acabarem me convencendo a desistir de certas ideias. Também não posso me
esquecer de pessoas como Amanda Barbosa, Bruno Vasconcelos, Camila Medeiros,
Dário Guedes, Giankarlo Rocha, Igor Galvão, Jerbeson Santana, Joilderson de
Paula, Juliana Alves, Humberto Mendes, Maria Denize, Naira Freire, Rosana
Nascimento e Sofia Coelho que quase sempre tinham algo para compartilhar
referente às disciplinas ou, simplesmente, me contavam boas histórias durante os
intervalos no departamento de Geofísica ou Setor III.
Existem também aquelas pessoas que já estavam na universidade antes de
mim, e que tive o grande prazer de conhecer, em especial em meio às dificuldades
das disciplinas de Geofísica Matemática (que estava mais para “Geofísica
Problemática”) e Geodinâmica; em especial com ideias que podem ser consideradas
no mínimo excepcionais para o estudo conjunto destas disciplinas. Cito aqui: Átila
Torres, Arthur Gerard, Eliebe Matias, Isaac Vinícius, João Paulo Ferreira, Marcus
Magnum, Ricardo Tenório, Rodrigo Revoredo e Tiago Rafael.
Já que falei das pessoas que chegaram antes de mim, não posso esquecer-
me das grandes amizades que fiz com as pessoas de entrada posterior à minha na
UFRN. Elas foram indispensáveis para que eu olhasse novamente o mundo com um
misto de seriedade e ingenuidade, virtudes as quais acabaram sendo esquecidas no
decorrer de determinadas experiências. E é bastante importante lembrar de amigos
como o Douglas Marcondes, Klinger Cruz e Yago Martins, pelas saídas a rodízios
após uma ida a academia e com comilanças até passarmos mal, além do Oscar
Neto com a Aline Tavares, Isabella Gama e a Thayane Samara, que me
acompanharam todo o tempo durante o 13º Congresso Internacional da Sociedade
Brasileira de Geofísica no Rio de Janeiro. Agradeço aos valorosos conselhos da

Medeiros, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Agradecimentos
página iii
Victória Cedraz, que foram extremamente úteis em determinados momentos, além
do Diego Soares e da Sabrina Luz por sempre trocarem boas ideias comigo quando
nos encontramos. Também é interessante citar os companheiros Bruno Araújo,
David Wendell, Danyelle Cristiny, Flávia Valânea, Gilsijane Vieira, Jefferson Moura,
Mara Cristina, Maria Luíza Cardoso, Mariana Mamede e Raphael Carvalho que,
durante o decorrer destes longos (ou curtos, em uma perspectiva geológica) quatro
anos, se tornaram companhias indispensáveis.
Agradeço também aos mentores durante o curso. Inicialmente, os externos ao
meu departamento, sendo do Departamento de Computação e Automação da
UFRN: Paulo Motta, pelo exemplo de pessoa que ele é, e Diogo Pedrosa, por ter me
concedido meu primeiro projeto de Iniciação Científica quando me veio à cabeça a
ideia de mudar de curso para Engenharia Elétrica – que não deu muito certo, mas
sou extremamente feliz por este fracasso. Ao professor Marcos Nascimento, do
Departamento de Geologia da UFRN, por me dar uma perspectiva um pouco
diferente sobre o uso da geologia, uma vez que eu não era (e continuo sem ser) fã
da mesma. Em seguida, aos internos do departamento de Geofísica: Carlos César
Nascimento da Silva, pelas tentativas incansáveis de injetar um pouco de juízo na
minha cabeça (apesar de que admito me divertir com as reações dele, mesmo indo
um pouco longe demais vez por outra) e pelos incríveis conselhos que me fez tomar
sábias decisões em determinadas horas complicadas da minha trajetória acadêmica,
e que me fizeram, mesmo sem nunca ter explicitado isso diretamente, ser bastante
grato ao mesmo. Ao José Antônio de Morais Moreira por mostrar que a persistência
sempre tem um retorno no final, principalmente nas disciplinas que ministrou.
Também agradeço aos professores Aderson do Nascimento, Jordi Julià, Josibel
Gomes e Walter Medeiros por passarem (muito bem) seus conhecimentos em sala
de aula. Um agradecimento em especial à professora Rosângela Correa Maciel por
realmente me dar uma chance e ter acreditado em mim desde o início, onde sem tal
apoio não teria conseguido absolutamente nada do que consegui hoje e, por isso,
sou extremamente grato a ela. Aos funcionários do departamento Mateus Carlos,
Otto Araújo e Taynara Souza por me deixarem invadir a secretaria e passar o tempo
vago por lá trocando ideias enquanto não havia nada para fazer. À Huganisa Dantas
que, apesar de não deixar fazer o mesmo que os outros secretários, ela me ajudou
bastante sempre que precisei perturbar com assuntos como a colação de grau
individual ou meus processos de dispensa de disciplina.

Medeiros, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Agradecimentos
página iv
Agradeço também ao meu orientador, João Medeiros de Araújo, por
realmente TUDO que aconteceu durante o ano de 2013 – e ressalto que foram
somente coisas boas – e gostaria de deixar registrado que palavras são insuficientes
para expressar o quão sou grato a ele. Um obrigado também à banca de avaliação
deste trabalho, composta pelo Madras Gandhi e pelo Heron Schots, por aceitarem
avaliá-lo (e espero que o apreciem).
Por fim, gostaria de citar o apoio financeiro do Centro Potiguar de
Geociências pelo ano de 2013 e, também, da Agência Nacional de Petróleo, Gás
Natural e Biocombustível em conjunto com a Financiadora de Estudos e Projetos e o
Ministério de Ciência e Tecnologia por meio do Programa de Recursos Humanos 22
referente ao ano de 2012. Algumas partes do trabalho foram realizadas com a ajuda
do supercomputador do Instituto Internacional de Física e do sistema distribuído do
Programa de Pós-graduação em Ciências Climáticas.
É isso. That’s it. Ijou desu.

UFRN/CCET– Relatório de Graduação em Geofísica Resumo
Resumo
A Migração Reversa no Tempo é um processo que consiste na relocalização
de eventos para onde de fato eles ocorreram. Este processo está começando a ser
bastante recorrente na indústria do petróleo graças à sua grande capacidade de
imagear locais de alta complexidade geológica e estrutural, tais como regiões em
que existam falhas ou que exista uma grande variação no gradiente de velocidades,
muitas vezes associada à presença de domos salinos. Contudo, tal poder em
resolução lateral e horizontal possui a grande desvantagem do alto custo
computacional devido à sua intensividade de cálculos advindos pela resolução da
equação de onda através do uso do método de diferenças finitas e das condições de
contorno comumente impostas. Desta forma, na busca de uma maior eficiência
computacional, alternativas como computação paralela e distribuída, juntamente
com a implementação de algoritmos em outras arquiteturas computacionais – como
x86_64 e GPU – começaram a surgir, visando sempre diminuir ao máximo o tempo
de execução dos algoritmos. Sendo assim, este trabalho propõe uma abordagem
comparativa das arquiteturas e paradigmas acima citados de forma a verificar quais
são as alternativas mais interessantes e viáveis a serem utilizadas e, por fim, discutir
os diversos desafios aos quais a indústria do petróleo deve enfrentar para conseguir
resultados ainda melhores.
Palavras-chave: Processamento sísmico, Migração Reversa no Tempo,
computação de alta performance, GPU.

UFRN/CCET – Relatório de Graduação em Geofísica Abstract
Abstract
The Reverse Time Migration is a process which relocates events to where
they did de-facto occur. This process is beginning to be very recurrent at the oil
industry due to its great capability of imaging high-complexity places with either
structural or geological features, such as places where faults occurrences can be
observed or regions where a great velocity gradient exists, which is usually
associated to salt domes. However, such powerful horizontal and vertical resolutions
have the big drawback of the high-computational cost due to the algorithm being very
calculus-intensive which is a result from the solution of the wave equation through
the finite differences method plus the boundary conditions that were imposed. Hence,
in the search for a computational efficiency increase, options like parallel/distributed
computing alongside the implementation of algorithms in others computational
architectures such as x86_64 and GPUs, began to arise and try to low the
computational runtime at maximum. Thus, this work tries to propose a comparative
approach of the above cited architectures and paradigms in order to verify which
ones are the most interesting and viable. By the end of the work, it’s noticed that
there are challenges to be perceived by the oil industry in order to improve results
even more.
Key-words: Seismic processing, Reverse Time Migration, high-performance
computing, GPU.

UFRN/CCET– Relatório de Graduação em Geofísica Índice
Índice
Agradecimentos . pág. i
Resumo pág. v
Abstract pág. vi
Lista de Figuras pág. ix
Lista de Algoritmos, Equações e Tabelas pág. xi
Lista de Abreviações pág. xii
Capítulo I – Introdução
1.1 – Um breve histórico pág. 01
1.2 – Motivação e Objetivos pág. 04
1.3 – Estrutura do Trabalho de Conclusão de Curso pág. 04
1.4 – Direitos Autorais pág. 05
Capítulo II – Sísmica Aplicada à Prospecção de Petróleo
2.1 – Por que sísmica, afinal? pág. 06
2.2 – Fundamentos da Técnica CDP pág. 08
2.3 – Análise de Dados Reais e Sintéticos; Softwares pág. 09
2.4 – Processamento Sísmico pág. 11
2.4.1 – Uma tentativa de fluxograma pág. 11
2.4.2 – Setup pág. 12
2.4.3 – Correções Estáticas pág. 13
2.4.4 – Análise de Velocidade e Correção NMO pág. 14
2.4.5 – Filtro de Frequência pág. 15
2.4.6 – Deconvolução e o Modelo Convolucional pág. 16
2.4.7 – Correção dos Fatores de Propagação pág. 19
2.4.8 – Migração pág. 20
2.4.9 – Empilhamento pág. 22
2.5 – Controle de Qualidade pág. 22
2.6 – Interpretação pág. 23

Medeiros, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Índice
página ix
Capítulo III – Migração Reversa no Tempo pág. 24
Capítulo IV – Arquiteturas de Computadores
4.1 – O modelo de um computador pág. 31
4.2 – Arquiteturas x86 e x86_64 pág. 34
4.3 – Unidade de Processamento Gráfico pág. 35
4.5 – Outras Arquiteturas pág. 38
Capítulo V – Paralelismo Aplicado
5.1 – A Geofísica e a Computação de Alta Performance pág. 39
5.2 – Fundamentos de Computação Paralela pág. 40
5.2.1 – Tasks e Threads pág. 40
5.2.2 – Condições de Corrida pág. 41
5.2.3 – Métricas pág. 42
5.3 – Bibliotecas Paralelas pág. 44
5.3.1 – OpenMP / OpenACC pág. 44
5.3.2 – Message-Parsing Interface pág. 45
5.3.3 – Computer Unified Device Architecture pág. 46
Capítulo VI – Performance de um Algoritmo de Migração Reversa no
Tempo a partir de Computação Distribuída e Paralela
6.1 – Medindo Tempos pág. 47
6.2 – Modelo e Parametrização pág. 48
6.3 – Condições de Processamento pág. 49
6.4 – Registros de Desempenhos pág. 50
6.4.1 – x86_64 single-core pág. 50
6.4.2 – x86_64 paralelizado em OpenMP pág. 52
6.4.3 – Tarefas Distribuídas pág. 55
6.4.4 – GPUs pág. 58
Capítulo VII – Análise dos Resultados Obtidos pág. 61
Capítulo VIII – Desafios pág. 73
Capítulo IX – Referências Bibliográficas pág. 75

UFRN/CCET – Relatório de Graduação em Geofísica Lista de Figuras
Lista de Figuras
Figura 1.1 – Diagrama de distribuição de tarefas no esquema master-slave. pág. 02
Figura 1.2 – Diagrama de dificuldade de implementação em variadas arquiteturas. pág. 03
Figura 2.1 – Diagrama de relação entre as cadeias de processos na sísmica. pág. 07
Figura 2.2 – Exemplo esquemático de uma aquisição sísmica . pág. 08
Figura 2.3 – Comparação entre CMP e CDP . pág. 09
Figura 2.4 – Modelo de velocidades do Marmousi. pág. 10
Figura 2.5 – Fluxograma básico para dados terrestres e de geologia complexa. pág. 11
Figura 2.6 – Estrutura computacional do SEG-Y. pág. 12
Figura 2.7 – Dado sísmico no domínio da CMP antes e depois da correção NMO. pág. 14
Figura 2.8 – Análise de velocidade pelo método de semblance no Seismic Unix. pág. 15
Figura 2.9 – Modelo convolucional simplificado. pág. 17
Figura 2.10 – Deconvolução através de um filtro Wiener-Levinson. pág. 18
Figura 2.11 – Função Ricker. pág. 18
Figura 2.12 – Correção da Divergência Esférica. pág. 19
Figura 2.13 – Gráfico de indicação para tipos de migração. pág. 20
Figura 2.14 – Modelo Marmousi suavizado migrado em profundidade. pág. 21
Figura 2.15 – Diferentes tipos de empilhamento em comparação. pág. 22
Figura 3.1 – Algoritmo RTM para diversos tiros. pág. 25
Figura 3.2 – Correlação de Imagem. pág. 27
Figura 3.3 – Fluxograma operacional da Migração Reversa no Tempo pág. 29
Figura 4.1 – Arquitetura de von Neumann e a relação entre componentes. pág. 32
Figura 4.2 – Processador Intel 8086. pág. 34
Figura 4.3 – Relação de recursos de GPU ao longo dos anos. pág. 36
Figura 4.4 – Arquitetura de uma GPU. pág. 37
Figura 4.5 – Relação de grids, blocos e threads em uma GPU. pág. 37
Figura 5.1 – Algoritmo de matriz. pág. 40
Figura 5.2 – Gráfico da Lei de Amdahl. pág. 43
Figura 5.3 – Modelo de execução do OpenMP. pág. 45
Figura 5.4 – Modelo de execução do MPI. pág. 46
Figura 6.1 – Fluxograma de medidas dos tempos do algoritmo RTM. pág. 47
Figura 6.2 – Modelo utilizado para a simulação RTM. pág. 49

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET – Relatório de Graduação em Geofísica Lista de Figuras
página x
Figura 6.3 – Imageamento do algoritmo RTM em single-core. pág. 51
Figura 6.4 – Imageamento do algoritmo RTM utilizando 4 threads. pág. 54
Figura 6.5 – Alguns tiros diretos simulados pelo algoritmo RTM em MPI. pág. 57
Figura 6.6 – Imagem final da migração por uma GPU. pág. 60
Figura 7.1 – Gráfico de Speedup por Threads para a implementação do OpenMP pág. 61
Figura 7.2 – Gráfico de Speedups obtidos com o uso de MPI pág. 67
Figura 7.3 – Tempo por processo da propagação direta do campo de ondas pág. 67
Figura 7.4 – Tempo por processo da propagação inversa do campo de ondas pág. 68
Figura 7.5 – Modelo esquemático de um grid CUDA pág. 70
Figura 7.6 – Gráfico comparativo de speedups obtidos em cada tipo de paralelização pág. 72
Figura 8.1 – Nível computacional exigido por diferentes algoritmos de migração pág. 73

UFRN/CCET– Relatório de Graduação em Geofísica Lista de Abreviações
Lista de Abreviações
Abaixo, a lista de abreviações utilizadas durante o decorrer do trabalho. A
tradução para o português encontra-se sempre que o termo está consagrado na
língua em questão.
AMD - Advanced Micro Devices
ARM - Advanced RISC Machines
APU - Accelerated Processing Unit
AVO - Amplitude versus Offset
ASIC - Application Specific Integrated Circuit
CDP - Common Dip Point (Ponto Médio em Profundidade)
CMP - Common Mid-Point (Ponto Médio Comum)
CGG - Compagnie Générale de Géophysique
CISC - Complex Instruction Set Computer
CPU - Central Processing Unit (Unidade de Processamento Central)
CRP - Common Receiver Point
CRS - Common Reflection Surface
CUDA - Computer Unified Device Architecture
CPGeo - Centro Potiguar de Geociências
DGPS - Diferential Global Positioning System (Sistema de Posicionamento Global Diferencial)
DMO - Dip Move-out
EBCDIC - Extended Binary Coded Decimal Interchange Code
ENIAC - Eletronic Numerical Integrator and Calculator
(f-k) - Domínio da frequência-número de onda
FBI - Frame buffer Interface
FFT - Fast Fourier Transform (Transformada Rápida de Fourier)
FPGA - Field-programmable Gate Array
FWI - Full Waveform Inversion (Inversão da Forma de Onda)
GCC - GNU Compiler Collection
GPGPU - General Purpose Graphics Processing Unit
GPL - General Public Licence
GPU - Graphics Processing Unit (Unidade de Processamento Gráfico)
HD - Hard-disk (Disco Rígido)
IBM - International Business Machine

Medeiros, D.A. Relatório No. 37 dezembro/2013
página xiii
IEEE - Instituto de Engenheiros Eletrônicos e Elétricos
IIF - Instituto Internacional de Física
INPE - Instituto Nacional de Pesquisas Espaciais
LSI - Large Scale Integration
MP - Memória Primária
MPI - Message-Parsing Interface
MSI - Medium Scale Integration
NMO - Normal Move-out (Sobretempo Normal)
NVCC - NVIDIA C Compiler
OpenCL - Open Computing Language
OpenMP - Open Multi-Processing
PSPI - Phase Shift Plus Interpolation
RISC - Reduced Instruction Set Computer
RAM - Random Access Memory (Memória de Acesso Aleatório)
ROP - Raster Operation
RTM - Reverse Time Migration (Migração Reversa no Tempo)
SDK - Software Development Kit
SDM - Seismic Depth Migration (Migração Sísmica em Profundidade)
SO - Sistema Operacional
STM - Seismic Time Migration (Migração Sísmica em Tempo)
SSE - Streaming SIMD Extensions
SSI - Small Scale Integration
SU - Seismic Unix
(t-x) - Domínio do tempo-distância
ULA - Unidade Lógico-Aritmética
UC - Unidade de Controle
UES - Unidade de Entrada e Saída
UFRN - Universidade Federal do Rio Grande do Norte
VHDL - VHSIC Hardware Description Language
VHSIC - Very-high-speed Integrated Circuits
VLSI - Very Large Scale Integration
VS/T&L - Vertex shading transform and lightning
WE - Wave Equation (Equação da Onda)
WEM - Wave Equation Migration (Migração da Equação da Onda)

UFRN/CCET– Relatório de Graduação em Geofísica Lista de Algoritmos, Equações e Tabelas
Lista de Algoritmos, Equações e Tabelas
Algoritmo 5.1 – Calculador de produto escalar entre duas matrizes. pág. 41
Algoritmo 6.1 – Uso da biblioteca “time.h” para medir tempo. pág. 48
Algoritmo 7.1 – Convolução tridimensional. pág. 63
Algoritmo 7.2 – Distribuição de tarefas do MPI. pág. 66
Equação 3.1 – Equação Escalar de Onda. pág. 25
Equação 3.2 – Equação Escalar da Onda com uma Fonte. pág. 26
Equação 3.3 – Discretização da Equação de Onda. pág. 26
Equação 3.4 – Correlação contínua de Imagem Receptor-Fonte. pág. 27
Equação 3.5 – Correlação discreta de Imagem Receptor-Fonte. pág. 27
Equação 3.6 – Perfect Matched Boundary. pág. 28
Equação 5.1 – Formulação matemática do Speedup. pág. 42
Equação 5.2 – Formulação matemática da Lei de Amdahl. pág. 42
Equação 5.3 – Cálculo do Speedup máximo. pág. 43
Equação 5.4 – Eficiência computacional. pág. 43
Tabela 3.1 – Descrição dos processos existentes na imagem 3.3. pág. 30
Tabela 4.1 – História da computação. pág. 31
Tabela 6.1 – Configurações das máquinas do IIF. pág. 50
Tabela 6.2 – Configurações das máquinas do laboratório CoRoT. pág. 50
Tabela 6.3 – Tempo de processamento utilizando um único núcleo. pág. 51
Tabela 6.4 – Tempos de processamento da propagação direta em múltiplos núcleos. pág. 52
Tabela 6.5 – Tempos de processamento da propagação inversa em múltiplos núcleos. pág. 52
Tabela 6.6 – Tempos de processamento da correlação em múltiplos núcleos. pág. 53
Tabela 6.7 – Tempos de processamento de propagação direta em MPI. pág. 55
Tabela 6.8 – Tempos de processamento de propagação inversa em MPI. pág. 56
Tabela 6.9 – Configurações do sistema do device. pág. 58
Tabela 6.10 – Tempos relativos a execução do algoritmo RTM em uma GPU. pág. 59

UFRN/CCET– Relatório de Graduação em Geofísica Capítulo I – Introdução
Capítulo I – Introdução
1.1 – Um breve histórico
Dentre os mais variados métodos de prospecção geofísica, a sísmica de reflexão
– método geofísico que tem como base a propagação da onda acústica em uma
determinada região - destaca-se na indústria do hidrocarboneto devido a sua boa
capacidade de imagear a subsuperfície. Entretanto, juntamente a tal acurácia, existe
um problema intrínseco: o tratamento dos dados do respectivo método é
particularmente custoso graças ao grande volume de informações exigido pelo
mesmo e do processamento relacionado que é minucioso e detalhado, o que quase
sempre está diretamente ligado a uma gama de cálculos matemáticos no domínio
discreto.
À medida que este nível de minuciosidade do processamento cresce, a
quantidade de informações extraídas de um determinado dado tende a seguir o
mesmo caminho. Nunes do Rosário (2012) cita o exemplo da empresa de
consultoria de processamento sísmico CGG (ex-CGGVeritas), a qual anunciou que
realizou testes de reprocessamentos do levantamento sísmico 3D realizados nos
anos de 2001 e 2002 no mega-campo de Tupi, na bacia de Santos, onde houve um
aumento expressivo da qualidade da imagem do reservatório abaixo da camada de
sal e que, baseado neste sucesso, a empresa está reprocessando todos os dados
de tal levantamento que exibem os reservatórios de hidrocarbonetos no pré-sal
brasileiro a uma profundidade de 8.000 metros da superfície. Esta realização por
parte da empresa acima citada acaba por estimular mais e mais pesquisas na área
de forma a aumentar a quantidade de informação extraída do mesmo dado.
Entretanto, o fator tempo também é fundamental para a indústria e, com o
consequente aumento da carga computacional dos algoritmos utilizados, o tempo de
processamento acaba por se elevar de alguma maneira. Desta forma, a indústria
procurou, e ainda procura, alternativas que possam minimizar o tempo de execução
(runtime) dos algoritmos executados. Citando não só a indústria da sísmica, mas a
de computação de alto desempenho ao todo, uma abordagem tradicional para a
resolução deste problema foi o aumento da frequência do processador. Tal
abordagem, entretanto, falhou, visto que os mesmos tendiam a dissipar mais energia

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo I – Introdução
página 2
e, consequentemente, superaquecer e derreter. A tentativa seguinte pela indústria
foi a introdução de múltiplos núcleos de processamento, abordagem que ainda é
utilizada nos dias de hoje e que introduziu o paradigma de programação paralela;
desta forma, muitos problemas matemáticos estão sendo modelados para fazer uso
destes recursos provenientes dos processadores, muitas vezes através dos padrões
OpenMP (acrônimo para Open Multi-Processing), OpenCL (Open Computing
Language) e do kit de desenvolvimento da NVIDIA, CUDA (Compute Unified Device
Architecture), dentre várias outras. Nos capítulos seguintes, cada paradigma será
discutido e analisado, mas é interessante explicitar que a implementação de um
determinado problema usando algum dos mesmos pode aumentar significativamente
a dificuldade de programação, mas também possibilitar uma diminuição imediata em
seu runtime.
Outra abordagem da programação paralela, porém em uma granularidade maior,
é a chamada programação distribuída, a qual consiste em diversos processadores
agrupados, podendo ter memórias e discos compartilhados ou não, onde são
delegadas tarefas que são realizadas por cada um independentemente para, depois,
concatenar-se todos os resultados em um só, conforme se pode observar no
diagrama da figura 1.1. O padrão MPI (Message Passing Interface) é o mais
utilizado na programação para tal finalidade, mas programadores com objetivos mais
diferenciados podem também recorrer ao uso do shell script, presente no Linux.
Figura 1.1: Diagrama de distribuição de tarefas no sistema master-slave (mestre-escravo) com
retroalimentação, onde o resultado processado pelos computadores escravos
irão ser reutilizados pelo mestre para outras finalidades ou não.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo I – Introdução
página 3
No workshop de Computação de Alto Desempenho do 13º Congresso
Internacional de Geofísica, ocorrido em 2013, foram bastante citadas duas
promissoras tecnologias: FPGAs e Co-processadores (através do Intel® Xeon
Phi™). Apesar de não se encontrarem dentro do escopo deste trabalho, vale
salientar que a primeira tecnologia é de difícil implementação devido a necessidade
de se lidar com um menor nível de abstração na programação, conforme mostrado
por Che et al. (2008), porém seus resultados iniciais são animadores, mostrando
uma eficiência maior que até mesmo as GPGPUs mais modernas. Já a segunda
tecnologia em questão trata de processadores tradicionais de alto desempenho e
que ficam latentes esperando ordens, onde também alcançam bons resultados. Um
diagrama de dificuldade de programação versus eficiência baseado no estudo
realizado por Che et al. (2008) para CPUs, GPUs e FPGAs pode ser visto abaixo.
Figura 1.2: Diagrama de dificuldade de implementação em determinada
arquitetura pela performance obtida. Gerado a partir de Che et al. (2008).
Saindo da computação e tratando de sísmica, o processo de migração é um dos
mais importantes dentre todo o fluxo de processamento, ao qual visa mover eventos
sísmicos para as suas supostas posições originais em subsuperfície e, desta forma,
gerar-se uma imagem das interfaces no tempo ou na profundidade. Este processo

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo I – Introdução
página 4
está inserido em um fluxo de processamento que visa corrigir diversos efeitos, tais
como o introduzido pela diferença de elevação entre receptores, da zona de baixa
velocidade, da perda de energia sofrida durante a propagação da onda, dentre
outros. Tais técnicas demandam um grande custo computacional, normalmente
atrelado ao aumento da precisão do algoritmo e a complexidade do meio geológico
em questão (exemplo: existência de falhas, gradiente irregular de velocidade) e tal
tarefa pode ser bastante demorada, levando dias, semanas ou até meses de
execução ininterrupta.
Companhias da área de processamento sísmico têm, cada vez mais, aderido aos
paradigmas computacionais acima discutidos de forma a tornar tais processos mais
rápidos, além de conjuntamente melhorar a precisão de seus algoritmos.
1.2 – Motivação e Objetivos
Este relatório surgiu como fruto de uma pesquisa de Iniciação Científica
realizada ao longo de oito meses na Universidade Federal do Rio Grande do Norte
(UFRN), de forma que o mesmo acaba por ter objetivos de cunho didático-científico.
Inicialmente em relação ao objetivo científico, este trabalho consistiu na
implementação e análise de um algoritmo de migração sísmica em profundidade que
foi testado em arquiteturas tradicionais de CPU (mais especificamente, x86_64) e de
GPUs (do inglês, Graphics Processing Unit), juntamente em diversos clusters, de
forma a comparar seus respectivos desempenhos.
Já no tocante ao objetivo didático, temos a atuação deste documento como
sendo um relatório de conclusão do Curso de Graduação de Bacharel em Geofísica
da Universidade Federal do Rio Grande do Norte através da disciplina obrigatória
GEF0161 – RELATÓRIO DE GRADUAÇÃO EM GEOFÍSICA, além de também servir
como relatório da bolsa de Iniciação Científica para o Centro Potiguar de
Geociências (CPGeo), financiador deste projeto.
1.3 – Estrutura do Trabalho de Conclusão de Curso
Este trabalho foi desenvolvido em oito capítulos aos quais os que incluem
fundamentações teóricas procuram ser o mais independente possível uns dos
outros, fugindo do tradicional desenvolvimento linear de conhecimentos. Leitores
com conhecimento prévios nos assuntos a serem tratados em cada capítulo podem
pular a leitura de cada capítulo referente ao mesmo.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo I – Introdução
página 5
O capítulo II trata de aspectos de aquisição e processamento sísmico
fundamentados na técnica CDP, construindo uma base qualitativa e dando uma
breve introdução em alguns dos métodos utilizados nos resultados apresentados
adiante.
O terceiro capítulo envolve diretamente a base teórica por trás do algoritmo de
Migração Reversa no Tempo, foco principal deste relatório, cuja eficiência é
analisada mais a frente. O desenvolvimento da análise da base teórica é fortemente
pautado tanto na física (princípio da reversão temporal de uma onda) quanto na
matemática.
Enquanto isso, os capítulos IV e V possuem um aspecto computacional e
abordam, respectivamente, arquiteturas de computadores, juntamente com um
pouco de história e estrutura dos mesmos, além de recursos de computação
paralela e distribuída através de CPUs e GPUs.
Por fim, os capítulos restantes tratam dos resultados obtidos no decorrer do
trabalho, juntamente com discussões dos resultados e seus possíveis desafios e
sugestões futuras para outras pesquisas que possam a ser de interesse do leitor.
1.4 – Direitos Autorais
Este é um trabalho acadêmico que não visa lucro e que respeita os direitos
autorais. Todas as imagens são de fonte própria (recriadas a partir de uma base ou
não) ou, caso contrário, a imagem terá a fonte explicitada e cairá em um dos
seguintes casos:
Houve permissão para reprodução por parte da fonte.
A imagem encontra-se em domínio público (licenças GPL, Creative
Commons, dentre outras) ou a permissão para uso acadêmico/sem fins
lucrativos não é necessária.

UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada a Prospecção de Óleo
Capítulo II – Sísmica Aplicada à Prospecção de Óleo
2.1 – Por que sísmica, afinal?
O método sísmico de reflexão – ou simplesmente a sísmica de reflexão – é o
método geofísico mais utilizado para problemas de exploração envolvendo a detecção
e o mapeamento de interfaces, identificando as propriedades físicas de cada unidade
abaixo da subsuperfície, as quais se incluem sequências sedimentares, o que fazem
com que os mesmos sejam bastante utilizados na prospecção de hidrocarbonetos.
Isso deriva do fato de que é possível ter boas resoluções lateral e horizontal, além de
excelente profundidade de investigação referente ao reservatório, o que induz a um
ótimo custo/benefício. Tal método também é particularmente eficaz no imageamento
de regiões com geologia complexa, principalmente em relação a outros métodos,
como o gravimétrico ou eletromagnético.
Segundo Kearey et al. (2011), o primeiro levantamento sísmico foi realizado no
início da década de 1920, já representando um desenvolvimento natural dos já
estabelecidos métodos de sismologia de terremotos, aos quais invertia-se os tempos
de percurso das ondas de forma a obter informações crustrais do planeta. Com o
advento da era digital, tal método sofreu uma incrível explosão tecnológica, visto que
existia uma maior possibilidade de armazenamento de dados e, desta forma, técnicas
de aquisição 3D se popularizam e que acabaram por culminar a um custo financeiro
maior para o processo de aquisição. Na Rússia, o custo de um levantamento 2D
costuma variar de 60.000 rublos (R$ 4.200 reais) por km² na região central a até
100.000 rublos (R$ 7.000 reais) por km² na região do oeste da Sibéria, enquanto que
um levantamento 3D na região da península de Iamal, também na Rússia, varia para
algo em torno de 600.000 rublos (42.000 reais). A rápida necessidade de uma
tecnologia mais eficiente faz com que a tecnologia dos dias atuais logo se barateie
por ficar obsoleta diante às mais recentes; porém, Garg et al. (2008) cita que é
possível diminuir em até 43% o custo por traço de uma aquisição somente através do
aumento da produtividade.
Teoricamente, a sísmica de reflexão fundamenta-se a partir da propagação de uma
onda gerada por uma fonte, podendo esta ser explosiva (dinamites) ou não-explosiva
(como o Vibroseis, desenvolvido pela Continental Oil Company durante os anos 1950,

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 7
ou o air gun, usado em levantamentos sísmicos marinhos). Tais ondas, ao encontrar
interfaces em que um contraste de impedância acústica seja existente, serão
refratadas e/ou refletidas e, assim, terão sua amplitude, além de seu tempo de
chegada, registradas por sensores, normalmente compostos por transdutores
associados a sismógrafos.
Apesar de uma fonte apropriada gerar majoritariamente ondas transversais e
longitudinais, parte da energia da fonte será convertida para a criação de ondas de
superfície, que serão detectadas pelo sensor em questão e, à essa energia
indesejável, damos o nome de ruído coerente. Também vale citar a diferença de
nivelamento (em terrenos irregulares) dos sensores, além das zonas de baixa
velocidade (comumente geradas pelo intemperismo), e a perda de energia da onda
ao se propagar. Sendo assim, o processamento sísmico visa atenuar tais problemas
da aquisição e aumentar a razão sinal/ruído.
Após toda a fase de aquisição e processamento, o resultado final da sísmica é
uma seção sísmica, onde esta permite ao intérprete tentar retirar o máximo de
informações existentes na região do levantamento, como a existência de falhas,
fraturas ou mesmo de um possível reservatório de hidrocarbonetos.
Os tópicos que se seguem ao longo deste capítulo tratam em detalhes de toda a
cadeia de processos dominada pelas fases de aquisição, processamento e
interpretação, sendo ambas relacionadas segundo o diagrama abaixo.
Figura 2.1: Diagrama de relação entre a cadeia de processos em uma sísmica,
é vital reparar que existe uma comunicação constante entre todos.
2.2 – Fundamentos da Técnica CDP

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 8
Antes de adentrar na parte de processamento, é necessário entender como é feita
a aquisição dos dados, uma vez que muitos dos processos realizados na sísmica se
baseiam na técnica de Ponto de Profundidade Comum – em inglês, Common Dip Point
(CDP). Tal técnica foi idealizada inicialmente por Harry Mayne no início dos anos 1950
e começou a ser aplicada em escala de produção a partir da década de 60 (Rosa,
2011).
Uma sísmica de reflexão tem um princípio simples, conforme indicado na figura
2.2: faz-se uma perturbação, através de uma fonte, no meio que desejamos investigar
e, graças à mesma, ondas começarão a se propagar na subsuperfície. À medida que
tais ondas encontram um contraste de impedância nas interfaces, parte delas sofre
refração, onde continuam a descer pela subsuperfície, ou reflexão, voltando para a
superfície onde sensores estão monitorando as amplitudes e as fases de onda, além
do tempo que elas levaram para ir e voltar. A figura 2.2 ilustra um cenário de aquisição
terrestre com quatro tiros e quatro receptores.
Figura 2.2: Exemplo esquemático de uma aquisição sísmica.
A multiplicidade inerente a esta técnica faz com que os traços sísmicos de um
agrupamento CMP (abreviação para Common Mid Point) possam ser empilhados (i.e.
sobrepostos) de forma a reforçar as reflexões. Para que tal fato possa ocorrer, é
necessário que cada amostra registrada em um tempo t seja deslocada para o tempo
t0 e acumulada em um novo traço, o qual se situa na posição do ponto médio entre a
fonte e o receptor. Entretanto, este princípio falha na presença de mergulho porque o

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 9
ponto comum em profundidade não mais se encontra diretamente sob o ponto médio
entre tiro e o receptor, e o ponto de reflexão difere para raios que chegam a diferentes
afastamentos, conforme se pode observar na figura 2.3.
Figura 2.3: (a) O ponto médio comum é igual ao ponto de profundidade comum.
(b) Devido a camadas mergulhantes, os dois pontos não são iguais.
Imagem baseada em Kearey et al., 2009
Desta forma, como será discutido mais adiante, é necessário corrigir este efeito
através de um processo chamado Correção Dip Move-out, para fluxos com uma
migração pós-empilhamento, ou a correção ficará a cargo de uma possível migração
pré-empilhamento.
2.3 – Análise de Dados Reais e Sintéticos; Softwares
É de importância ressaltar que a totalidade dos dados mostrados aqui será, para
fins didáticos, sintéticos. Isso ocorre porque tais tipos de dados são mais simples de
serem trabalhados além de também serem largamente empregados por
pesquisadores para a verificação da eficiência de técnicas como algoritmos de
migração ou deconvolução.
Dentre os dados mostrados na próxima seção, destaca-se o modelo Marmousi.
Segundo Tariq Alkhalifah, da Universidade de Stanford, tal composição virou sinônimo
da frase “informação complexa”, uma vez que a colossal quantidade de dobras e
falhas introduzidas no modelo criou uma interessante distribuição de anomalias de
velocidade laterais e horizontal, além de descontinuidades, servindo, assim, como
uma ferramenta de calibração para testar algoritmos de tempo de percurso e migração
por anos. Este modelo foi criado em 1988 pelo Instituto Francês de Petróleo (IFP,

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 10
Institut Français du Pétrole) e sua geometria é baseada em um perfil transversal da
bacia de Cuanza, em Angola.
Figura 2.4: Modelo de Velocidades do Marmousi, reconstruído pelo software Madagascar.
Uma vez que seu uso é relativamente mais simples, o processamento de dados
sísmicos é feito majoritariamente através de softwares interativos, como o SeisSpace,
da Landmark, ou do Echos, da Paradigm. Entretanto, tais softwares possuem preços
demasiadamente altos, normalmente compatíveis com o padrão da indústria do
petróleo, o que faz com que eles sejam inacessíveis para a maioria dos pesquisadores
localizados em Academias. Sendo assim, o Center for Wave Phenomena, da Colorado
School of Mines, desenvolveu o Seismic Unix (SU) como uma alternativa gratuita e de
código-fonte aberto para processamento de dados sísmicos. O SU faz 27 anos em
2013 e, apesar de não ter recursos de processamento mais avançados (como
processamento paralelo, foco deste trabalho, ou algoritmos de migração como RTM),
ele se tornou uma alternativa bastante viável para pesquisa e ensino. É de importância
ressaltar que muitos dados mostrados neste capítulo foram
processados/reconstruídos utilizando o Seismic Unix.
Outro pacote que vem se tornando popular na área de processamento de dados,
tanto por ser de código-fonte aberto quanto eficiente, é o Madagascar. Lançado em
2006 por Sergey Fomel, o software conta com um código ligeiramente mais moderno
e simplificado, graças ao fato de ter sido desenvolvido por uma equipe menor e mais
recentemente.
2.4 – Processamento Sísmico

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 11
2.4.1 – Uma tentativa de fluxograma
Existem inúmeras maneiras de se processar um dado sísmico, e tudo isso
depende tanto de quem o processa (assim como o conhecimento geofísico e
geológico desta pessoa) quanto de como o dado é: envolve geologia complexa? As
interfaces são plano-paralelas? O dado a ser processado é terrestre ou marítimo?
Esse tipo de questionamento acaba por se tornar importante porque no momento em
que, por exemplo, o dado que estivermos trabalhando for marítimo, é muito pouco
provável que precisemos fazer uma correção estática para anular o efeito de elevação
e de zonas de baixa velocidade, mas talvez tenhamos que lidar com as múltiplas de
reverberação. Tais tipos de dados, por serem adquiridos em alto mar, também
costumam possuir uma qualidade muito melhor, uma vez que o barco de aquisição,
em alto mar, pode se mover e adquirir o dado continuamente sem a necessidade de
skips (“pulos” de certos geofones), o que pode deixar inúmeras pessoas com um pé
atrás antes de aplicar qualquer tipo de filtragem nele. Tal hesitação dificilmente ocorre
com dados terrestres, uma vez que, neste, a existência de diversos problemas
relativos à aquisição é mais proeminente. O fluxograma abaixo consiste em uma
demonstração das etapas relativas ao dado sísmico durante a etapa de
processamento e que serão discutidas neste trabalho.
Figura 2.5: Fluxograma básico para dados terrestres e de geologia complexa, o que faz com
que a correção estática e a migração pré-empilhamento sejam necessárias.
Vale ressaltar que este trabalho aborda casos de alta complexidade, com a
presença de sais e falhas, além de variações de velocidade laterais e verticais, onde
nesses casos dá-se preferência a usar migração pré-empilhamento para aumentar a
qualidade final do dado sísmico.
2.4.2 – Setup

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 12
Um ponto crucial para o início do processamento de dados consiste na
conversão do dado bruto para o padrão do software a ser utilizado, seja o SeisSpace
ou o Seismic Unix, sendo este último utilizando um cabeçalho próprio no formato *.su.
Por convenção, o dado bruto de aquisição encontra-se no padrão da Society of
Exploration Geophysicists, SEG-Y, desenvolvido em 1973 (com as especificações
publicadas dois anos depois) para armazenar dados em fitas magnéticas. Tal formato
encontra-se com a seguinte estrutura:
Figura 2.6: Estrutura do SEG-Y. Adaptado de SEG Technical Standards Committee, 2002.
O formato contém um cabeçalho EBCDIC (Extended Binary Coded Decimal
Interchange Code), seguido por um cabeçalho de 400 bytes binário, que contém
dados gerais sobre o dado, como o número de amostras por traço. Segue-se, então,
mais um cabeçalho, desta vez de 240 bytes sobre o traço, ao qual contém informações
como a ordenação do mesmo e, por fim, o dado sobre o traço em si, ao qual costuma
ser armazenado no padrão de ponto flutuante da IBM.
Apesar de o arquivo convertido possuir bastante informação, ele por si só não
será de muita utilidade se não pudermos carregar a geometria: inserir informações
relativas à aquisição é de fundamental importância no processamento. Dentre as
geometrias mais utilizadas para aquisições 2D, estão a split-spread e a end-on. A
primeira consiste em geofones localizados nos dois lados da fonte, enquanto a
primeira trata de geofones somente em um dos lados da mesma. Após a inserção da
geometria, é importante ressaltar que normalmente, antes de se começar a processar,
também se costuma retirar artefatos de ruído que são mais visíveis e fáceis de
remover, processo comumente chamado de edição.
2.4.3 - Correções Estáticas
As Correções Estáticas consistem em compensar dois tipos de efeitos: o
referente à diferença de elevação de receptores (geofones ou hidrofones) e, o
segundo, para compensar a zona de baixa velocidade. Tais correções são feitas

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 13
majoritariamente em dados do tipo terrestre, visto que dados marinhos não costumam
possuir os problemas citados (há exceções, como as realizadas através de cabos de
fundo oceânico, mas a discussão sobre isso não é o foco deste trabalho).
O primeiro efeito em discussão ocorre quando não temos uma superfície plana
para todos os receptores, de forma que alguns ficam mais elevados que outros. Com
isso, ondas refletidas exatamente no mesmo ponto terão tempos de trânsito
diferentes. A correção para este efeito é normalmente a primeira a ser aplicada no
dado e é comumente realizada com o auxílio de um GPS Diferencial (DGPS), as quais
posições e altitudes podem ser determinadas com bastante precisão.
O segundo efeito ocorre devido à zona de baixa velocidade, normalmente
causada graças à ação do intemperismo físico-químico que acaba por gerar uma
camada anômala de algumas poucas dezenas de metros. Nesta zona, como o próprio
nome diz, a onda perde bastante velocidade em relação ao resto da subsuperfície e,
logo, a velocidade anomalamente baixa causa grandes atrasos no tempo das ondas
que a atravessam. Assim sendo, caso não seja corrigida, as variações em espessura
da camada intemperizada podem levar a um falso relevo estrutural nos refletores
subjacentes. De forma a corrigir tal efeito, é necessário o conhecimento das variações
de velocidade e espessura desta camada, sendo uma das alternativas utilizadas para
tal é o uso da sísmica de refração, a qual usa o princípio que as primeiras chegadas
de energia nos detectores em um lanço de reflexão são normalmente raios que foram
refratados pelo topo da camada de rocha não-intemperizada.
2.4.4 – Análise de Velocidade e Correção NMO
Um dos fundamentos da técnica CDP está no fato de que um mesmo tiro será
amostrado várias vezes por diferentes receptores. Entretanto, estes receptores
encontram-se espaçados a diferentes distâncias, de forma que comparar um mesmo
tiro da forma que o mesmo foi adquirido acaba por se tornar inviável. Conforme pode
ser visto na figura 2.7, o conjunto de traços sísmicos em uma mesma família CMP
tende por formar uma hipérbole. Para corrigir este sobretempo normal, realiza-se a
Análise de Velocidade, como pode ser visto na figura 2.8, na qual definimos o
gradiente de velocidade em determinados pontos de forma a equiparar todas as
CMPs. Assim, teremos as hipérboles sendo convertidas em retas, ficando possível
comparar os tempos de trânsito de cada traço sísmico.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 14
Figura 2.7: Dado sísmico no domínio da CMP antes e depois
da correção de sobretempo normal.
Em eventos mais rasos e/ou offsets mais distantes, a correção de sobretempo
normal acaba por causar uma modificação no sinal das reflexões: o tempo de trânsito
tende a se alongar, distorcendo-se, assim, em relação ao seu conteúdo de
frequências. Buscando minimizar este efeito de distorção, aplica-se a técnica de
silenciamento (do inglês, mute), que apaga as regiões em que os traços sísmicos
encontram-se demasiadamente distorcidos acima de um valor de estiramento
estabelecido anteriormente, evitando a degradação das amplitudes no dado
empilhado.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 15
Figura 2.8: Análise de Velocidade pelo método de
semblance no Seismic Unix.
Apesar de tal discussão estar fora do escopo deste trabalho, é de importância
citar que existem diversos métodos para se realizar uma Análise de Velocidade, entre
as quais é possível citar a análise (t²-x²), Painéis de Velocidade Constante (do inglês,
Constant velocity panels), empilhamento de velocidade constante (Constant velocity
stack) e pelo espectro de velocidade, este último sendo bastante utilizado por parte
de softwares interativos, como o Seismic Unix (através da função semblance, como
visto na figura 2.8) ou o ProMAX/SeisSpace, da Landmark.
2.4.5 – Filtro de Frequência
Segundo Kearey et al. (2011), qualquer ruído, seja este coerente ou incoerente,
que possua uma frequência dominante diferente daquela das chegadas refletidas,
pode ser suprimido pela filtragem de frequência. De uma forma geral, tal filtro é
aplicado através de uma Transformada de Fourier Direta (no domínio discreto,
comumente usa-se a técnica denominada Fast Fourier Transform), ao qual se
transforma o presente traço no domínio t-x para o domínio f-k, aplica-se uma janela

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 16
de filtragem e, então, é realizada uma Transformada de Fourier Inversa. A janela de
filtragem é comumente classificada em uma das três opções abaixo:
Janela passa-alta (high-pass): Somente as frequências acima de um
determinado valor “x” serão aceitas, enquanto o restante é rejeitado.
Janela passa-baixa (low-pass): Somente as frequências abaixo de um
valor “x” especificado serão aceitas, enquanto o restante é rejeitado.
Janela passa-banda (band-pass): Somente as frequências
compreendidas dentro de um intervalo [x;y] serão aceitas, enquanto o
resto é rejeitado.
Normalmente, tais filtros são aplicados em um estágio inicial do
processamento, apesar de poderem ser realizados em vários estágios da sequência
de processamento. O rolamento superficial (em inglês, ground roll), caracterizado por
baixas frequências e altas amplitudes, pode ser atenuado com o uso de uma janela
passa-alta, assim como os ruídos gerados pelo navio em levantamento sísmicos
marinhos. De modo similar, o efeito gerado pelo ruído do vento, composto
majoritariamente por altas frequências, pode ser reduzido com um filtro corta-alta.
2.4.6 – Deconvolução e o Modelo Convolucional
Duarte (2007) descreve a deconvolução como o ato de desfazer ou neutralizar
o efeito de uma convolução anterior, e isso tem como efeito o encurtamento do
comprimento do pulso sísmico (spiking) nas seções sísmicas, de forma que a
resolução vertical acaba por melhorar. Para que seja possível entender o processo de
deconvolução, é necessário entender o modelo convolucional do traço sísmico, ao
qual estabelece que um pulso sísmico pode ser representado pelas seguintes
componentes, ilustradas pela figura 2.9.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 17
Figura 2.9: Modelo Convolucional simplificado. Adaptado de Partryka, Gridley e Lopez, 1999.
Na realidade, Rosa (2011) define o pulso sísmico como sendo a convolução da
assinatura da fonte com o instrumento (sismógrafo) e seus filtros convolvidos com o
receptor, a combinação dos fantasmas da fonte e dos receptores, a combinação dos
arranjos de tiro e receptores além do filtro da terra. Sendo assim, a ideia básica da
deconvolução é uma convolução com o filtro inverso, em uma suposição de que isso
irá desfazer os efeitos de um filtro anterior, como a Terra ou o do sismômetro.
Entretanto, dificilmente sabemos as propriedades ou a forma do filtro que desejamos
remover, de forma que modelar um filtro inverso para esta finalidade acaba por se
tornar uma tarefa relativamente árdua. Um exemplo de deconvolução no traço sísmico
é mostrado na figura 2.10, onde o tipo utilizado foi o Wiener-Levinson (deconvolução
preditiva).

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 18
Figura 2.10: Deconvolução através de um filtro Wiener-Levinson.
A assinatura da fonte é normalmente conhecida em diversos casos,
principalmente na modelagem, e se encontra em formato de função gaussiana ou de
uma fonte Ricker (“sobrero” ou “chaupéu mexicano”), normalmente a 40 Hz, de forma
que o que nos resta é determinar a função refletividade, enquanto a maioria dos filtros
intrínsecos ao pulso costumam ser aleatórios.
Figura 2.11: Função Ricker. Fonte: Wikimedia Commons.
Sheriff (2004) afirma que a qualidade da sísmica moderna deve bastante ao
sucesso da deconvolução. Dentre os exemplos de efeitos específicos a qual a
deconvolução é utilizada, podemos citar os seguintes:

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 19
Derreverberação: Remove a ressonância, associada a reflexões múltiplas em
uma lâmina d’água.
Deghosting: Deconvolução para eliminar o efeito da reflexão fantasma.
Whitening: Equaliza a amplitude de todos os componentes de frequência dentro
da banda.
A deconvolução é comumente realizada sobre os traços sísmicos individuais antes
do empilhamento ou depois do empilhamento e é utilizada em quaisquer estágios do
processamento de dados.
2.4.7 – Correção dos Fatores de Propagação
Devido ao fato de nos encontramos em um meio anisotrópico, a onda não irá
se propagar de forma esférica. Entretanto, segundo o princípio de Huygens, é de
conhecimento geral que a energia em toda frente de onda mantém-se constante para
todos os pontos. Rosa (2011) enuncia três diferentes enfoques de se corrigir as perdas
de amplitude por transmissão através das interfaces: o primeiro consiste em desprezar
o fenômeno, o segundo consiste em incluir a perda por transmissão no processo de
migração e o terceiro trata de corrigir as perdas juntamente com o filtro estratigráfico.
Figura 2.12: Correção da Divergência Esférica.
Os demais enfoques, como múltiplas, absorção e filtro estratigráficos, tendem
a ser tratados de forma explícita, já que inclui-los na migração e acabar por errar a
parametrização pode levar a uma repetição de um processo que possui um alto custo

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 20
computacional, o que não é interessante para a indústria. A correção da divergência
esférica (geometrical spreading) é aplicada para eliminar a redução de amplitude
decorrente da expansão de onda, aplicando ganhos de acordo com o modelo de
velocidades preliminar gerado anteriormente; tais ganhos são ilustrados na figura
2.12.
2.4.8 – Migração
A migração relocaliza os eventos de reflexão para onde eles de fato ocorreram,
gerando uma imagem direta da subsuperfície e consistindo, desta forma, em um dos
processos mais importantes da sísmica.
Existem vários tipos de migração, e estas podem se classificar de diversas
formas. Yilmaz (2001) classifica os algoritmos de migração em três categorias: os que
são baseadas na solução integral da equação escalar de onda, aqueles que são
baseados na solução por diferenças finitas e aqueles que são baseados em
implementações de frequência-número de onda. Outras classificações incluem as
migrações 2D versus 3D, as migrações pré e pós-empilhamento, além das migrações
em tempo e em profundidade, podendo variar de migrações 2D pós-empilhamento
(computacionalmente mais simples) até migrações 3D pré-empilhamento.
Figura 2.13: Gráfico de indicação para tipos de migração. Adaptado de Liner, 2009.
De uma forma geral, as migrações em áreas mais complexas são realizadas
em profundidade, uma vez que estas também são as mais indicadas para lidar com

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 21
fortes variações laterais de velocidade, entretanto costumam ser computacionalmente
mais intensivas, já que se baseiam, em geral, na resolução da equação de onda por
meio de métodos como o de diferenças finitas. Já em regiões mais simples, é comum
usar algoritmos de migrações em tempo. Um esquema comparativo de algoritmos de
migrações pode ser visto na figura 2.13.
Alguns dos métodos de migração consistem em colapsar difrações (Kirchhoff),
resolver o problema de equação da onda através de mudança de domínio espacial
(PSPI) ou, como será abordado neste trabalho, pela resolução discreta da equação
de onda em um algoritmo de Migração Reversa no Tempo. Cada um tem suas
vantagens e desvantagens, além de regiões de aplicação recomendadas, porém tal
discussão não se encontra no escopo deste trabalho.
Figura 2.14: Modelo Marmousi (suavizado) com uma migração Kirchhoff em profundidade.
É importante ressaltar que, para migrações pré-empilhamento, a correção Dip
Moveout (DMO) costuma estar sempre intrínseca. Para casos pós-empilhamentos,
explicita-se tal processo de forma a corrigir os mergulhos das interfaces na
subsuperfície, conforme já foi ilustrado na figura 2.3.
2.4.9 – Empilhamento

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 22
Este processo pode ser feito antes ou depois da migração, e consiste de somar
(empilhar) vários traços sísmicos de uma mesma CRP (Common Reflection Point,
Pontos Comuns de Reflexão) de forma que os ruídos de fundo tendem a se atenuar
enquanto os pontos de reflexão têm suas amplitudes aumentadas, assim
incrementando a razão sinal/ruído. Tal processo costuma ser um dos últimos a serem
aplicados e, uma vez que vários dados estão sendo juntados em um só, normalmente
resulta em um arquivo computacional de tamanho menor, o que leva às etapas de
análise após o empilhamento serem computacionalmente mais rápidas. Assim como
os vários outros processos envolvidos dentro da cadeia de processamento, o
empilhamento possui diversas técnicas, sendo duas ilustradas na figura 2.14. A
terceira seção à direita ilustra traços empilhados com pesos iguais, enquanto, na
segunda, foram dados pesos maiores aos melhores traços, tendo resultado bem
superiores. A técnica CRS (do inglês, Common Reflection Surface) também costuma
se destacar bastante entre pesquisadores e na indústria em geral.
Figura 2.15: Diferentes tipos de empilhamento, com diferentes resultados.
2.5 – Controle de Qualidade
Conforme discutido por Olhoeft (2008), uma vez que estamos com todo o
processamento finalizado, é necessário verificar se tudo foi feito corretamente. Caso
sim, podemos enviar para a interpretação; caso contrário, é necessário refazer todo
ou parcialmente o processamento. É possível notar que nosso dado foi processado

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo II – Sísmica Aplicada à Prospecção de Óleo
página 23
de forma errônea no momento que o resultado final para de corresponder às
observações in-situ, muitas vezes através da correlação com a perfilagem de poços,
que existem no local do levantamento, e diversas vezes tais erros podem ser
atribuídos a uma má correção estática ou erro na configuração de parâmetros para a
geometria de aquisição, ou mesmo de migração. Além disso, é de importância
comentar que uma boa análise de velocidades é a base para o empilhamento,
migração e uma conversão apropriada do domínio do tempo para a profundidade,
então tal processo acaba por se tornar bastante crucial no processamento como um
todo.
2.6 – Interpretação
Com a seção sísmica processada e aprovada pelo controle de qualidade, o último
passo compreendido dentre a cadeia do método sísmico é a interpretação, conforme
citado por Kearey et al. (2002). Na verdade, a interpretação está diretamente ligada
com as abordagens de análise estrutural e a análise estratigráfica, sendo ambas
assistidas pela modelagem sísmica (a qual sismogramas sintéticos são criados para
se compreender melhor o significado físico dos eventos de reflexão contido nas
seções sísmicas). O primeiro tipo de análise é focado majoritariamente para a
investigação de trapas estruturais que possam conter hidrocarbonetos, enquanto que
a análise estratigráfica procura subdividir a seção sísmica de forma que a sequência
de reflexões seja interpretada como sendo a expressão sísmica de sequências
sedimentares geneticamente relacionadas.
Por fim, vale falar que atributos sísmicos – operações matemáticas realizadas
sobre o dado sísmico que procuram enfatizar determinadas propriedades - podem ser
especialmente úteis no diagnóstico na distinção entre efeitos na amplitude por
variação na matriz da rocha e aqueles resultantes da presença de fluidos nos poros
(neste caso, sendo a situação de interesse para a indústria do hidrocarboneto), sendo
estes uma ferramenta bastante utilizada.

UFRN/CCET– Relatório de Graduação em Geofísica Capítulo III – Migração Reversa no Tempo
Capítulo III – Migração Reversa no Tempo
O processo de Migração Reversa no Tempo (em inglês, Reverse Time Migration,
comumente abreviada como RTM) foi inicialmente idealizada por Hemon (1973), que
teve a ideia de resolver a equação de onda usando diferenças finitas. Entretanto,
somente em 1983, nos trabalhos de Kosloff e Baysal (1983) e Baysal, Kosloff e
Sherwood (1983) foi que surgiu a aplicação para a exploração sísmica e que era,
originalmente, relacionados à migração pós-empilhamento.
De uma forma geral, a RTM consiste em uma técnica de migração sísmica que
utiliza o Método de Diferenças Finitas para fazer a extrapolação numérica do campo
de ondas no tempo através da discretização da equação de onda. tem como objetivo
realizar a extrapolação dos campos de ondas emitidos pelas fontes sísmicas e pelo
campo de ondas registrados nos geofones. Tal processo continua até que o mesmo
atinja as fontes refletoras de uma subsuperfície, onde este processo denomina-se de
príncipio da reversão temporal.
A ideia para a aplicação do princípio acima citada para a migração foi
inicialmente proposta por Claerbout (1971) fazendo uso da teoria de diferenças
finitas para a propagação dos campos de ondas. Após a extrapolação direta e
inversa e com uma condição de imagem imposta, como a correlação cruzada, é
possível gerar a imagem em cada ponto da malha, obtendo como resultado a seção
sísmica migrada. A figura 3.1 ilustra um fluxograma simplificado de como o algoritmo
roda para cada tiro.
Costa (2012) destaca que, dentre as vantagens da RTM, estão o fato da mesma
trabalhar com a equação de onda completa, conseguir lidar com campos de
velocidade com forte contraste e imagear bem eventos com mergulhos arbitrários. Já
entre as desvantagens, encontram-se o fato da mesma trabalhar com uma menor
banda espectral, possuir o ruído devido ao espalhamento e ao retro-espalhamento,
como será visto adiante, e, finalmente, seu alto custo computacional – o que a ainda
a torna um pouco impraticável para a indústria como um todo.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo III – Migração Reversa no Tempo
página 25
Figura 3.1: Algoritmo RTM para vários tiros.
Adentrando na fundamentação teórica, Loewenthal et al. (1976) afirma que a
base para a migração de seções empilhadas em tempo é o “modelo de refletores
explosivos” ao qual assume que toda a energia em um presente tempo t no dado
empilhado provém de um tempo de reflexão em um tempo t/2 e então a amplitude
do coeficiente de reflexão pode ser determinado ao retropropagar essa energia de
volta à subsuperfície com metade do seu tempo de chegada.
Baseado no modelo dos refletores explosivos, o propósito da migração é
recuperar as amplitudes no tempo zero, que dá a localização e a força dos
refletores. Segundo Weglein, Stolt e Mayhan (2010), para calcular o campo de
ondas da fonte em questão, é necessário injetar no modelo uma fonte padrão (como
a fonte Ricker, ilustrada pela figura 2.11) na posição original do tiro sísmico.
Caso considerermos P(z, x, t) como sendo o campo de ondas e c(z, x), o campo
de velocidades, é possível chegar à equação de onda de Gazdag (1981) para
mergulhos de 90 graus:
𝜕2𝑃(𝑧, 𝑥, 𝑡)
𝜕𝑥2+
𝜕2𝑃(𝑧, 𝑥, 𝑡)
𝜕𝑧²−
1
𝑐2(𝑧, 𝑥)
𝜕2𝑃(𝑧, 𝑥, 𝑡)
𝜕𝑡2= 0
Equação 3.1: Equação Escalar da Onda.
Nunes do Rosário (2012) nota que, matematicamente, o tensor de Green – que
consiste em uma matriz cujos elementos correspondem a relação entre uma fonte

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo III – Migração Reversa no Tempo
página 26
pontual e a força do campo de ondas resultante em uma região finita ou semi-infinita
- no problema em questão implicará na modelagem da equação 3.1 na seguinte
forma:
𝜕2𝑃(𝑧, 𝑥, 𝑡)
𝜕𝑥2+
𝜕2𝑃(𝑧, 𝑥, 𝑡)
𝜕𝑧²−
1
𝑐2(𝑧, 𝑥)
𝜕2𝑃(𝑧, 𝑥, 𝑡)
𝜕𝑡2= 𝑓(𝑡)𝛿(𝑥 − 𝑥𝑓)(𝑧 − 𝑧𝑓)
Equação 3.2: Equação Escalar da Onda com uma Fonte.
Na equação 3.2, 𝛿 é a função delta de Dirac, f é a fonte e xf e zf são suas
respectivas posições para um modelo 2D. Nunes do Rosário (2012) indica que, ao
observarmos que a wavelet fonte é a fonte do campo de pressão, é possível notar a
implicação que a resolução do problema da migração reversa no tempo é, na
realidade, a resolução de um problema de valor sobre o contorno, onde a resposta
ao impulso de um meio qualquer é uma função de Green que consegue identificar as
reflexões, difrações, ondas guiadas, dentre outros.
Assim, usando a equação acima, uma estimativa numérica pode ser feita da
derivada temporal de P no tempo T através de uma série de Taylor, discretizando-a
com a considerando uma expansão central de dois termos nas derivadas temporais
e uma expansão central de oito termos nas derivadas espaciais para a
implementação numérica por diferenças finitas, cujo resultado pode ser visto na
equação 3.3 e a demonstração pode ser vista com mais detalhes nos trabalhos de
Fornberg (1988), Liu et al. (2010) e de Nunes do Rosário (2012).
𝑃𝑖,𝑗𝑛+1 = (
Δ𝑡
ℎ𝑐𝑖,𝑗)
2
[(−1
560) {𝑃𝑖,𝑗−4
𝑛 + 𝑃𝑖,𝑗+4𝑛 + 𝑃𝑖−4,𝑗
𝑛 + 𝑃𝑖+4,𝑗𝑛 } + (−
8
375) {𝑃𝑖,𝑗−3
𝑛 + 𝑃𝑖,𝑗+3𝑛 + 𝑃𝑖−3,𝑗
𝑛 + 𝑃𝑖+3,𝑗𝑛 }
+ (−1
5) {𝑃𝑖,𝑗−2
𝑛 + 𝑃𝑖,𝑗+2𝑛 + 𝑃𝑖−2,𝑗
𝑛 + 𝑃𝑖+2,𝑗𝑛 } + (−
8
5) {𝑃𝑖,𝑗−1
𝑛 + 𝑃𝑖,𝑗+1𝑛 + 𝑃𝑖−1,𝑗
𝑛 + 𝑃𝑖+1,𝑗𝑛 }
+ (−205
72) {2𝑃𝑖,𝑗
𝑛 } − (Δ𝑑)2𝑓(𝑡)𝛿(𝑥 − 𝑥𝑓)𝛿(𝑧 − 𝑧𝑓) ] + [(−1) ∗ 𝑃𝑖,𝑗𝑛−1 + (2) ∗ 𝑃𝑖,𝑗
𝑛 ]
Equação 3.3: Discretização da Equação de Onda.
Com a equação acima, realiza-se a propagação da onda até um certo tempo de
registro nt. Assim, dado que Ps seja o campo de ondas da fonte e Pr trata do campo
de ondas do receptor, a correlação de imagem poderá ser dada pela equação 3.4,
onde I(z,x) é a imagem resultante e tmax é o tempo máximo de propagação dos
dados:

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo III – Migração Reversa no Tempo
página 27
𝐼(𝑧, 𝑥) = ∫ 𝑃𝑠(𝑧, 𝑥, 𝑡) ∗ 𝑃𝑟(𝑧, 𝑥, 𝑡)𝑑𝑡𝑡max
0
Equação 3.4: Correlação contínua de Imagem receptor-fonte
No domínio discreto, temos que a integral da equação 3.4 se transforma em um
triplo somatório em z, x e t, conforme ilustrado pela equação 3.5.
𝐼(𝑧, 𝑥) = ∑ ∑ ∑ 𝑃𝑠(𝑧, 𝑥, 𝑡) ∗ 𝑃𝑟(𝑧, 𝑥, 𝑡)
𝑛𝑧
𝑧=0
𝑛𝑥
𝑖𝑥=0
𝑛𝑡
𝑡=0
Equação 3.5: Correlação discreta de Imagem receptor-fonte.
As implicações da equação 3.5 podem ser vistas na sua versão contínua, a
equação 3.4 e trata da relação entre campos, conforme pode ser visto pela figura
3.2, onde o último campo propagado deve ser correlacionado com o primeiro
retropropagado, o segundo com o antepenúltimo, etc. Desta forma, nos pontos em
que os campos diretos e inversos forem coincidentes, ter-se-á existência de um
ponto refletor em subsuperfície. Costa (2012) ressalta que existem vários outros
métodos para a condição de imagem, destacando-se a correlação cruzada por
suavização e por meio do vetor de Poynting, esta última usada principalmente para a
mitigação do ruído de retro-espalhamento.
Figura 3.2: Correlação de Imagem.
Adaptado de Costa, 2012.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo III – Migração Reversa no Tempo
página 28
Um ponto importante a ser destacado advém das condições de estabilidade para
o método das diferenças finitas, advindos do fato de que tal método requer que os
campos de espaçamento mínimos possuam um espaçamento mínimo h entre pontos
consecutivos da malha, onde a razão entre a velocidade mínima do campo de
velocidades pelo produto da frequência de corte da fonte com uma constante de
pontos da malha deve ser sempre maior que este valor h, e um intervalo de tempo
mínimo Δ𝑡 para a propagação de um campo de ondas no tempo, onde a razão entre
o espaçamento espacial e o produto da velocidade máxima por uma constante de
tempo deve ser sempre maior. Liu et al. (2010) ilustra que quanto maior a ordem do
método de diferenças finitas e quanto maior a dimensão do dado, menor será o
coeficiente de condição de estabilidade e, juntamente a isso, o passo temporal é
menor, o que leva a um custo computacional e demanda de memória maiores.
Clapp (2009) destaca que, idealmente, gostaríamos de emular um domínio
computacional infinito quando propagamos nosso campo de ondas – entretanto, isso
é computacionalmente impossível, já que iria requerer também recursos infinitos, de
forma que a abordagem utilizada é a tentativa de se minimizar artefatos causados
por nosso domínio computacional limitado. Reynolds (1978) aponta que uma
possível solução é ampliar a malha numérica, o que atrasaria as reflexões ocorridas
no tempo posterior ao da simulação, mas isso pode também consumir demasiados
recursos computacionais, o que não é interessante para a indústria. Já da
comunidade eletromagnética, surgiu o método Perfectly Matched Boundary, que
acabou por se tornar o método mais eficaz para a solução desse problema
(Berenger, 1994), além de ser de fácil implementação numérica. Tal método foi
introduzido na sísmica através dos trabalhos de Collino e Tsogka (2001) e seu
princípio consiste em mapear o sistema coordenado no domínio complexo e, assim,
mudar o campo de ondas propagante para um campo de ondas decainte segundo a
seguinte expressão:
𝑦(𝑥) = {𝜋𝑓𝑝𝑖𝑐𝑜Δ (𝑋
𝐿)
2
, 𝑛𝑎𝑠 𝑏𝑜𝑟𝑑𝑎𝑠
0, 𝑑𝑜𝑚í𝑛𝑖𝑜 𝑑𝑒 𝑖𝑛𝑡𝑒𝑟𝑒𝑠𝑠𝑒
Equação 3.6: Perfect Matched Boundary.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo III – Migração Reversa no Tempo
página 29
Dentre outras técnicas efetivas, encontram-se a introdução de uma região de
amortecimento nas bordas do domínio computacional (e muitas vezes combinada
com o anulamento de ondas que se propagam perpendicularmente à fronteira
computacional) ou, mais recentemente, a introdução de fronteiras aleatórias,
proposta por Clapp (2009).
Por fim, o dado final é gravado no disco do computador. Conforme Costa (2012)
destaca, a propagação e a retropropagação, ao serem realizadas, acabam por
introduzir problemas relativos ao grande volume de dados armazenados na
memória, de forma que acaba por ser necessário a introdução de checkups para a
escrita dos dados no disco ao longo do processo; outro problema que pode
acontecer se o dado for processado por um cluster, ao qual o grande volume de
arquivos podem congestionar uma determinada rede.
De forma a resumir este capítulo, um fluxograma do algoritmo utilizado neste
trabalho é ilustrado na figura 3.3, juntamente com a tabela 3.1 que registra as
descrições referentes a cada passo.
Figura 3.3: Fluxograma operacional da Migração Reversa no Tempo.
Função Descrição
Leitura de Dados Lê o arquivo com os dados de entrada (valores relativos à malha do dado,
fonte utilizada, absorção por parte das camadas) e o modelo de velocidade.
Cálculo de
Parâmetros da Malha
e da Fonte
Aloca memória para os principais vetores a serem utilizados e calcula
determinadas variáveis que serão utilizadas durante o processamento (e.x.:
tamanho total da malha).
Contenção da
Dispersão Numérica
Busca satisfazer a restrição temporal para que não exista o efeito de
dispersão numérica.
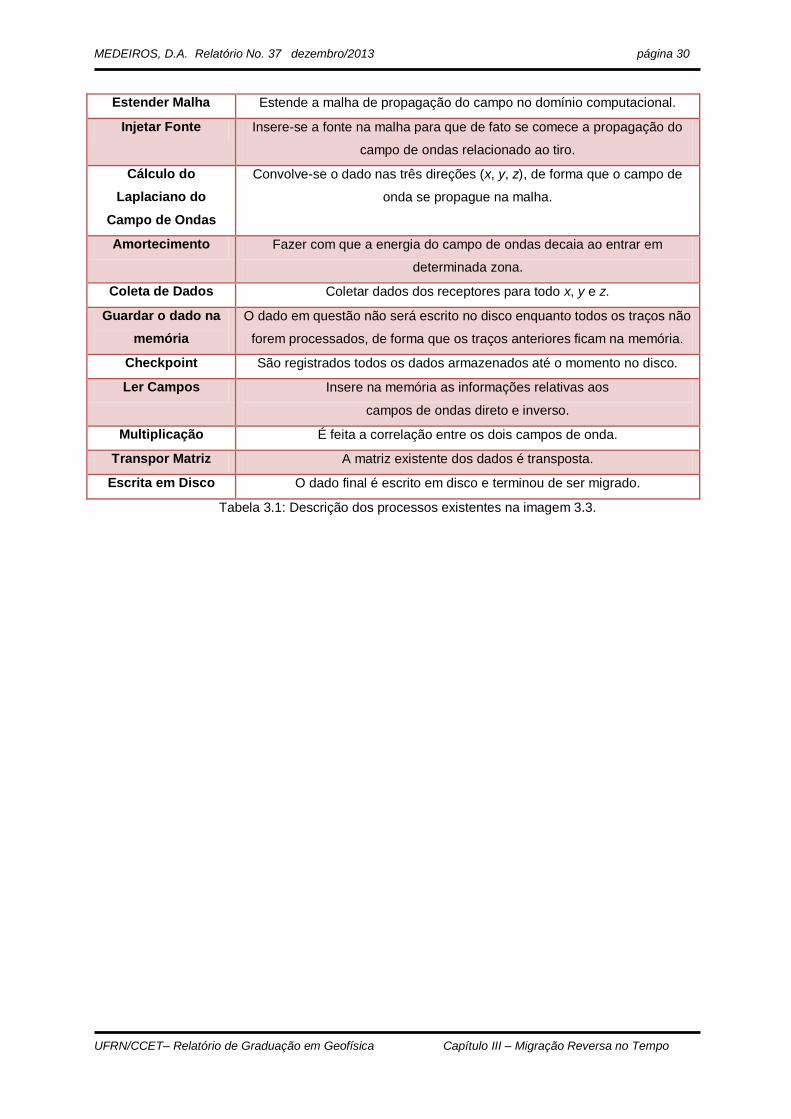
MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo III – Migração Reversa no Tempo
página 30
Estender Malha Estende a malha de propagação do campo no domínio computacional.
Injetar Fonte Insere-se a fonte na malha para que de fato se comece a propagação do
campo de ondas relacionado ao tiro.
Cálculo do
Laplaciano do
Campo de Ondas
Convolve-se o dado nas três direções (x, y, z), de forma que o campo de
onda se propague na malha.
Amortecimento Fazer com que a energia do campo de ondas decaia ao entrar em
determinada zona.
Coleta de Dados Coletar dados dos receptores para todo x, y e z.
Guardar o dado na
memória
O dado em questão não será escrito no disco enquanto todos os traços não
forem processados, de forma que os traços anteriores ficam na memória.
Checkpoint São registrados todos os dados armazenados até o momento no disco.
Ler Campos Insere na memória as informações relativas aos
campos de ondas direto e inverso.
Multiplicação É feita a correlação entre os dois campos de onda.
Transpor Matriz A matriz existente dos dados é transposta.
Escrita em Disco O dado final é escrito em disco e terminou de ser migrado.
Tabela 3.1: Descrição dos processos existentes na imagem 3.3.

UFRN/CCET– Relatório de Graduação em Geofísica Capítulo IV – Arquitetura de Computadores
Capítulo IV – Arquitetura de Computadores
Este capítulo tem o objetivo de fazer uma revisão bibliográfica referente às
arquiteturas computacionais de forma a delinear características de estruturas
referentes às CPUs e GPUs.
4.1 – O modelo de um computador
De modo geral, define-se o computador como sendo uma máquina capaz de
realizar variados tipos de tratamento de informações ou processamento de dados e
os mesmos vêm sendo inventados e desenvolvidos ao longo de toda a história da
humanidade, conforme se pode ver na tabela 4.1 abaixo.
data inventor: máquina capacidade inovações
1642 Pascal: Calculadora adição, subtração Transferência automática de
vai-um
1671 Leibnitz: Calculadora adição, subtração,
multiplicação e divisão
mecanismo de multiplicação e
divisão
1827 Babbage: Difference Engine avaliação polinomial por
diferenças finitas
operação automática com
diversos passos
1834 Babbage: Analytical Engine computador de
propósitos gerais
mecanismo automático de
controle de sequência
1941 Zuse: Z3 computador de
propósitos gerais
primeiros computadores de
propósitos gerais operacionais
1944 Aiken: Harward Mark I computador de
propósitos gerais
primeiros computadores de
propósitos gerais operacionais
Tabela 4.1: História da computação, baseada na originada de Weber (2012).
Apesar de tentativas anteriores para a construção de computadores eletrônicos,
declara-se que o ENIAC (acrônimo para Eletronic Numerical Integrator and
Calculator), desenvolvido entre 1943 e 1946, como sendo o primeiro computador
para propósitos gerais, sendo sua motivação a necessidade de construir tabelas de
forma automática por interesse do sistema militar estadunidense durante a segunda
guerra mundial (Webber, 2012).
Ao longo do tempo, o avanço tecnológico dos computadores pôde ser dividido
em cinco gerações, onde as respectivas tecnologias presentes em cada uma

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo IV – Arquitetura de Computadores
página 32
consistiu em válvulas e memórias de tubos catódicos (primeira geração), de
transistores e discos magnéticos (segunda geração), de circuitos integrados (SSI e
MSI), de circuitos LSI (Large Scale Integration) e memórias semi-condutoras (quarta
geração) e a quinta geração consiste em circuitos do tipo VLSI (Very Large Scale
Integration), tecnologia ainda usada nos dias de hoje.
Antes de discutir a arquitetura computacional de CPUs (como as fabricadas pela
Intel e AMD) e GPUs (referente às da NVIDIA), é necessário compreender alguns
conceitos advindos a partir da “arquitetura de von Neumann”, a qual foi desenvolvida
por John von Neumann durante a construção do ENIAC, em meados dos anos 40. A
ideia central era modelar a arquitetura do computador segundo o sistema nervoso
central humano, de forma a transformar as “calculadoras eletrônicas” em “cérebros
eletrônicos”. Para que tal feito fosse alcançado, seriam necessárias três
características: codificar as instruções de forma possível a ser armazenada no
computador (neste caso, foi usado o sistema binário), armazenar as instruções na
memória, assim como toda e qualquer informação necessária para a execução de
determinada tarefa e, por fim, ao processar o programa, buscar as instruções
diretamente na própria memória. Juntas, estas características acabaram por definir o
chamado “computador programável”.
Para que fosse possível atingir estas três características, com a dissolução do
projeto ENIAC, von Neumann e sua equipe iniciaram em 1946 um projeto no
Instituto de Estudos Avançados de Princeton: o computador IAS. Este computador
consistia em quatro seções: uma unidade de processamento central para a
execução de operações lógico-aritméticas, uma unidade de controle de programa,
uma unidade de memória principal e uma unidade de entrada e saída. A figura 4.1
ilustra melhor a inter-relação entre cada seção.
Figura 4.1: Arquitetura de von Neumann e a relação entre os componentes.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo IV – Arquitetura de Computadores
página 33
A Unidade Lógico-Aritmética (ULA) é, como seu próprio nome diz, responsável
pelas operações aritméticas e lógicas (verdadeiro, falso) entre dois números,
possuindo também um terceiro parâmetro (resultado), um comando da unidade de
controle e o estado do comando após a operação. O conjunto de operações
aritméticas na ULA pode ser limitado à adição e a subtração, podendo também
incluir multiplicação, divisão, funções trigonométricas e raízes quadradas, assim
como o conjunto de números as quais as mesmas podem operar (inteiros, racionais,
reais, etc) ou o nível de precisão envolvido. Presente na ULA também se encontra o
acumulador, que é um registrador (ou um conjunto deles, em computadores mais
complexos) com a função de armazenar um operando e/ou um resultado fornecido
pela ULA.
Já a Unidade de Controle (UC) fornece sinais, conhecidos como sinais de
controle, aos quais gerenciam o fluxo interno de dados e o instante preciso ao qual
ocorrem as transferências entre uma unidade e outra. Indo mais adentro, cada sinal
de controle comanda uma micro-operação, responsável pela realização de carga em
um registrador, uma seleção de um dado para entrada em um determinado
componente, dentre outras funções.
Em relação à memória, esta é a responsável por armazenar elementos de
informação, sendo divididas em palavras que são univocamente identificadas por
endereços. O conteúdo armazenado em tais palavras pode tanto representar dados
como instruções.
A unidade de controle de programa juntamente com a unidade lógico-aritmética
formam a chamada Unidade Central de Processamento, ou, pela sua sigla
consagrada, CPU (do inglês, Central Processing Unit) ou, ainda, processador. Estes,
até meados da década de 1970, eram constituídos de diversos componentes
separados, mas, com o advento da miniaturização do transistor, eles começaram a
ser fabricados em circuitos integrados, sendo posteriormente denominados de
microprocessadores.
Com as configurações acima, a única linguagem que um processador é capaz de
entender é a chamada linguagem de máquina, a qual é uma imagem numérica
(binária) e representa a codificação do conjunto de instruções de um computador.
Entretanto, o uso de tal linguagem é particularmente difícil para a criação, alteração
e validação. Desta forma, o uso de mnemônicos foram associados aos códigos das
instruções, nomes aos operandos e labels às posições ocupadas pelo programa e,

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo IV – Arquitetura de Computadores
página 34
assim, não é mais necessário trabalhar com códigos numéricos, linguagem de baixo
nível denominada assembly. Um programa escrito com a ajuda destes símbolos
precisa ser traduzido para binário de forma a ser executado, processo denominado
montagem e, quando automatizado, o programa que a realiza é denominado
assembler (montador).
Por fim, uma vez que a quantidade de processadores disponíveis para uso é
enorme e não necessariamente existe uma equivalência entre os endereços de
memórias e outras instruções entre eles, foram criados os compiladores, aos quais
geram rotinas em linguagem de máquina para cada instrução da linguagem de alto
nível, otimizando posteriormente código e alocação de variáveis. O desempenho de
códigos rodados através de um compilador (ex.: feitos em C ou FORTRAN) acaba
por ter um desempenho menor que em relação aos escritos diretamente em
assembly (cuja tradução para código de máquina acaba por ser “um para um”).
4.2 – Arquiteturas x86 e x86_64
A arquitetura x86 é o nome dado à arquitetura de processadores baseados no
Intel 8086, da Intel Corporation, que foi desenvolvido em 1978. Apesar de ser
baseada em processadores antigos, diversos incrementos foram feitos a esta
arquitetura, quase sempre com compatibilidade retroativa. A x86 foi substituída em
detrimento à arquitetura x86_64 (ou x64) criada pela AMD, mas ainda possui suporte
nos processadores modernos.
O modelo 8086 original possui 8 registradores de uso geral (sendo 4 referente a
dados e 4 referentes ao endereço), 4 registradores de segmento, um apontador de
instruções e um registrador de flags, cada um com 16 bits de tamanho. Além disso,
existe o barramento externo de endereço de 20 bits, a memória endereçada a bytes
e organizada em segmentos de 64 kbytes (que estão em MOD16).
Figura 4.2: Processador Intel 8086, visivelmente maior que os processadores atuais.
Foto: Konstantin Lanzet / Wikimedia Commons.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo IV – Arquitetura de Computadores
página 35
À medida que se foi crescendo a necessidade de tratar com mais informações e
maiores números, os registradores de 16 e 32-bits da arquitetura x86 acabaram por
se tornar insuficientes. Sendo assim, a arquitetura x86_64 acabou por surgir de
forma a suportar maiores valores de memória virtual e real. Entretanto, a
incompatibilidade dentre softwares gerados na arquitetura x86 e x64 fez com que
fosse adotada uma retrocompatibilidade para a arquitetura anterior.
Especificamente falando, a arquitetura x86_64 tem como característica primária a
disponibilidade de uso de registradores de uso geral com 64-bits (como endereços
virtuais de 64-bits ou aritmética de inteiros), além de instruções SSE (Streaming
SIMD Extensions).
Empresas como a Sony e a Microsoft utilizam a arquitetura x86_64 para o
desenvolvimento de hardware de ponta, como o Playstation 4 e o Xbox One, a
serem lançados no final de novembro deste ano.
4.3 – Unidade de Processamento Gráfico
A indústria do entretenimento – principalmente voltada a jogos e animações – se
utiliza de bastantes cálculos matemáticos para a renderização de texturas,
iluminação, tesselation e shading, por exemplo. Da forma que um processador
convencional é projetado, não é possível se ter a realização de uma grande gama de
cálculos simultâneos, visto que normalmente eles possuem apenas um valor limitado
de núcleos de processamento, comumente variando de um a dezesseis, e
normalmente operam em instruções lineares.
Sendo assim, as GPUs – termo para “Unidade de Processamento Gráfico”
popularizado pela Nvidia em 1999 – surgiram de forma a serem dedicadas para
problemas gráficos. A primeira GPU foi inclusa no computador Commodore®
Amiga™, a qual era capaz de desenhar retas, preencher áreas e incluía um
processador de fluxo capaz de acelerar o movimento, manipulação e combinação de
bitmaps. Já em 1999, a Nvidia lançou a GeForce 256, que já possuía transformadas
integradas, iluminação, renderização de triângulos e engines de renderização
capazes de processar um mínimo de 10 milhões de polígonos por segundo. Zahran
(2012) descreve a história dos recursos adicionados nas GPUs da seguinte forma:

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo IV – Arquitetura de Computadores
página 36
Figura 4.3: Relação de recursos de GPUs ao longo dos anos.
Para as siglas, verificar lista de abreviações e símbolos.
Adaptado de Zahran, 2012.
Entretanto, a utilização de GPUs por parte de cientistas para a resolução de
problemas físicos acabou por ser demasiadamente complicado e somente no ano de
2006 foi que as mesmas acabaram por se tornar um dispositivo mais genérico,
conhecidos como GPGPU (do inglês, General Purpose Graphics Processing Unit) e
começaram a ter ferramentas das fabricantes das mesmas, entre as quais se
destacam o CUDA, modelo de programação mais adotado nos dias de hoje, e o
OpenCL, gerenciado pelo consórcio Khronos Group.
O modelo de funcionamento de uma GPGPU é relativamente simples de se
entender. Basicamente, existe o host, consistindo do componente de CPU ao qual é
possível configurar kernels (leia-se funções) para o device, que é a unidade de
processamento gráfico propriamente dita. Conforme pode ser visto na figura 4.4, a
ideia consiste em alocar espaço de memória previamente determinado pela CPU na
GPU, transferir a informação, executar o kernel, retransferir a informação da GPU
para a CPU e, por fim, desalocar o espaço de memória reservado.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo IV – Arquitetura de Computadores
página 37
Figura 4.4: Arquitetura de uma GPU.
Dentro do device, são executadas as funções previamente estabelecidas pela
CPU – os kernels – as quais determinam os cálculos a serem realizados. A estrutura
de GPUs é dividida em processos (threads), blocos e grids, onde cada grid comporta
vários blocos e cada bloco possui suas próprias threads. Não existe comunicação
entre threads de blocos diferentes, apesar de ser possível sincronizá-las (ou seja,
dado que o modelo utilizado seja assíncrono, é possível aguardar que todos os
processos sejam finalizados de forma a continuar para a próxima ação), sendo
somente possível através do barramento L2 (ou memória compartilhada) a qual se
configura de alguns poucos kilobytes a depender do hardware utilizado.
Figura 4.5: Relação de grids, blocos e threads em uma GPU.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo IV – Arquitetura de Computadores
página 38
Conforme poderá ser visto no capítulo seguinte, o nível de paralelismo de uma
GPU está ligado ao número de threads e blocos as quais o programador deseja, e
nem sempre é óbvio determinar como paralelizar um determinado problema.
Outro problema comum se refere à alocação manual de memória por parte do
programador, o que faz com que os erros de overflow sejam comumente incidentes.
Além disso, até recentemente, existia o problema de que o device só executava um
kernel por vez, e a transferência de dados host-device e device-host acabava por se
tornar incômoda para experimentos complexos; tal problema foi recentemente
solucionado com a introdução da versão 5.0 do CUDA através do recurso de
Paralelismo Dinâmico (Dynamic Parallelism).
Em questão de adoção pela indústria/academia, a utilização de GPUs é de alta
adoção, onde são empregadas em um clusters heterogêneos, primariamente de
CPUs e GPUs. A título de curiosidade, o Instituto Internacional de Física, da UFRN,
conta com 4 placas NVIDIA Tesla combinadas com 64 CPUs do modelo Intel Xeon,
enquanto um dos clusters da Petrobrás, denominado Grifo04, conta com 1088 GPUs
do modelo NVIDIA M2050 e 544 CPUs, sendo que a quantidade de núcleos de
processamento somados acaba por ser um valor aproximado de 487 mil.
4.4 – Outras Arquiteturas
Apesar de serem bastante utilizadas em sistemas desktop ou mesmo em
mainframes, as arquiteturas acima discutidas começaram a entrar em declínio diante
a outras em questão de popularidade ou de eficiência. Mesmo não estando no foco
deste trabalho, duas arquiteturas relativamente modernas merecem ser citadas.
Em questão de popularidade, as arquiteturas tradicionais de CPUs (x86 e
x86_64) começaram a ser superadas pela arquitetura ARM, desenhada e fabricada
pela empresa homônima, inicialmente na década de 1980. Tal arquitetura usa o
conjunto de instruções computacionais reduzidas (RISC), o que faz com que elas
usem menos transistores que os processadores modernos (CISC), e isso leva ao
fato de uma maior eficiência energética, além de custos mais baixos de fabricação e
menor dissipação energética, o que praticamente induz ao fato que a mesma seja
bastante utilizada em dispositivos embarcáveis, como tablets e celulares. Segundo a
própria ARM, os modelos mais recentes, como o ARMv6 ou o Cortex-A8, fogem do
modelo de computador de von Neumann e seguem em direção à arquitetura
computacional Harvard.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo IV – Arquitetura de Computadores
página 39
Outra tecnologia em ascensão para o uso em computação de alta performance
são as FPGAs (Field-Programmable Gate Array). Segundo a Gidel, empresa de
desenvolvimento de ferramentas para FPGAs, a implementação de um algoritmo
RTM em uma FPGA pode ser até cerca de 2 vezes mais eficiente em relação a uma
GPGPU, o que faz com que as FPGAs acabem por se tornar bastante pesquisadas
na indústria. Ainda assim, Singh (2011) destaca que programadores tem dificuldades
de utilizá-las como dispositivos multinúcleos para acelerar aplicações paralelas,
onde FPGAs rodam em torno de linguagens de programação RTL (VHDL / Verilog)
que podem ser tão complexas quanto código de máquina.

UFRN/CCET– Relatório de Graduação em Geofísica Capítulo V – Paralelismo Aplicado
Capítulo V – Paralelismo Aplicado
5.1 – A Geofísica e a Computação de Alto Desempenho
Boa parte dos supercomputadores hoje em dia, aqueles realmente incríveis, são
usados para a geofísica – tanto para a pura quanto a aplicada. No tocante à
geofísica pura, temos a meteorologia, a qual tenta prever o tempo a partir de
modelos extremamente complexos e bastante fundamentados em cálculos
matemáticos, sendo um exemplo o supercomputador Tupã, localizado no Instituto
Nacional de Pesquisas Espaciais (INPE). Já quanto à geofísica aplicada, temos os
clusters utilizados por empresas de processamento sísmico, onde os mais diversos
algoritmos são rodados em pesados dados obtidos com técnicas de aquisição 3D.
Tais supercomputadores são formados a partir da união de diversos elementos de
computadores – como processadores, memórias e discos rígidos.
Segundo Grama et al (2003), o papel da concorrência em acelerar elementos
computacionais foi reconhecido ao longo de décadas, sendo a importância da
mesma ficando atrelada à Lei de Moore com o passar do tempo. Esta lei, que na
realidade deve ser considerada mais uma conjectura do que uma lei, foi concebida
em 1965 por Gordon Moore (co-fundador da Intel) e trata sobre o número de
transistores em um chip, que deveria duplicar a cada aproximadamente dois anos.
Entretanto, Borkar e Chien (2011) citam que a quantidade exponencial de
transistores presentes em um chip nem sempre se traduz em um ganho prático de
desempenho de CPU – na verdade, em um sistema mononuclear, se dobrarmos a
densidade de transistores, o circuito ficará 40% mais rápido enquanto o consumo
energético manter-se-á constante.
Sutter (2005) comenta que, nos últimos 30 anos, as fabricantes de CPUs
conseguiam aumentar a performance da CPU através da frequência de ciclos
(clock), da otimização de execuções e do cache, de forma que códigos
mononucleares acabavam por se tornar nativamente mais rápidos sem nenhuma
alteração. Entretanto, existe um limite para o qual um clock pode ser aumentado – e
quanto maior o valor deste clock, normalmente dado em gigahertz, mais eficiente
deve ser o sistema de resfriamento – de forma que para gerenciar melhor o
problema da dissipação térmica, as fabricantes começaram a favorecer o modelo

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo V – Paralelismo Aplicado
página 40
multinuclear. Sendo assim, softwares devem ser escritos para tirar proveito disso,
uma vez que o uso de multinúcleos não é intrínseco às instruções contidas no
processador e/ou compilador nativamente.
Este capítulo visa fazer uma revisão bibliográfica sobre os principais conceitos de
paralelismo em processadores convencionais e gráficos, citando também as
diversas ferramentas que são utilizadas por desenvolvedores.
5.2 – Fundamentos de Computação Paralela
5.2.1 – Tasks e Threads
Uma vez que os processadores começaram a ter diversos núcleos de
processamento, foi possível começar a criar concorrência de forma que cada
processador seja capaz de executar atividades (id est, cálculos) diferentes. A
paralelização de um algoritmo está intrinsicamente ligada à decomposição do
mesmo em diversas tarefas (do inglês, tasks). Em um exemplo básico, podemos
ilustrar a distribuição de tarefas relacionadas a uma soma de uma matriz segundo o
algoritmo abaixo.
Figura 5.1: Algoritmo de matriz.
Existem diversas técnicas de decomposição de dados para tarefas, dentre
estas se encontram as recursivas, decomposição de dados, decomposição
exploratória e especulativa. Segundo Grama et al. (2003), a primeira técnica é
utilizada em problemas que podem ser resolvidos através da estratégia de dividir-e-
conquistar, dividindo um problema maior em subproblemas independentes,
redividindo novamente até que se tenha um resultado, ao qual resolverá os
problemas maiores através de recursividade. A técnica de decomposição de dados
consiste em dois passos: no primeiro, o dado é particionado e, na segunda, a
partição do dado é usada para induzir a partição de computação em tarefas, que

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo V – Paralelismo Aplicado
página 41
costumam ser similares (um exemplo básico desta técnica é a usada no algoritmo
demonstrado acima). Já a decomposição exploratória é usada para decompor
problemas computacionais que correspondam a uma busca em um espaço de
soluções, enquanto a decomposição especulativa fundamenta-se em criar
paralelismo quando um programa escolhe usar um dos ramos processados
dependendo do cálculo precedente a esta escolha.
Threads consistem em instâncias geradas por cada cálculo, como, por
exemplo, no código abaixo:
Algoritmo 5.1: Calculador de Produto Escalar entre duas matrizes.
Neste caso, o loop deste código terá n² instruções, onde cada sequência é
executada independente e idealmente ao mesmo tempo, sendo denominada thread,
onde cada thread gerada poderá ser responsável pelo código executado em i=0 e
j=0, outra por i=0 e j=1, até o final da rotina em questão.
5.2.2 – Condições de Corrida
O manual do sistema operacional FreeBSD (2013) define a condição de
corrida (do inglês, race condition) como sendo o “comportamento anômalo causado
por uma dependência inesperada dos timings relativos dos eventos”, e pode ocorrer
em circuitos lógicos, sistemas eletrônicos e em sistemas distribuídos ou paralelos.
Em processamento paralelo, ele ocorre quando diferentes threads em
execução dependem de um estado compartilhado, e o resultado final depende do
escalonamento dos processos.
Panetta (2012) estabelece o seguinte exemplo para descrever uma condição
de corrida em processadores múltinucleos:
“Duas pessoas retiram, simultaneamente, R$ 100 da mesma conta em dois
terminais bancários (M1 e M2) conectadas ao mesmo tempo no computador central.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo V – Paralelismo Aplicado
página 42
O saldo da conta era R$ 1000 antes dos saques, e cada um obtém R$ 100 e o novo
saldo fica como sendo R$ 900!”
Tal problema ocorre pelo fato que ao ter um pedido de saque, o computador
central passa simultaneamente a informação de que a conta tem 1000 reais, e
atualiza o novo valor para 900 (1000 – 100) duas vezes. Desta forma, foi gerada
uma condição de corrida, já que o valor correto (R$ 800) não foi alcançado.
Estes tipos de situação podem ser evitados facilmente através de boas
práticas de programação e o entendimento necessário de técnicas de programação
concorrente.
5.2.3 – Métricas
Existem várias métricas para se verificar o quão efetiva foi a paralelização de um
determinado algoritmo. Aqui, vamos denotar o tempo de execução serial como
sendo Ts e o tempo de execução paralelo como sendo Tp. A primeira métrica mais
recorrente é o Speedup, denotada por S, que basicamente trata do ganho de
performance ao paralelizarmos determinada aplicação em detrimento à sua
execução serial. Matematicamente, é definida como sendo a razão do tempo gasto
em um processador pelo tempo gasto em N processadores.
𝑆 =𝑇𝑠𝑇𝑝
Equação 5.1: Formulação matemática do Speedup.
Um speedup ideal, ou linear, ocorre somente quando S = N; ou seja, dobrar o
número de processadores implica em dobrar a velocidade de execução. Entretanto,
a Lei de Amdahl, apresentada em 1967 por Gene Amdahl, estabelece que o
speedup de um programa com N processadores é limitado pelo tempo necessário
pela fração sequencial do programa a ser executada, de forma que acaba por ser
impossível ter um speedup ideal. Sendo assim, a fórmula acima seria transformada
em:
𝑆 =1
𝐵 +1𝑛 (1 − 𝐵)
Equação 5.2: Formulação matemática da Lei de Amdahl.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo V – Paralelismo Aplicado
página 43
No caso da paralelização, a Lei de Amdahl declara que se P é a proporção
paralela e (1 – P) a proporção que não pode ser paralelizada (serial), então o
máximo speedup que pode ser atingido é dado por:
𝑆 =1
(1 − 𝑃) +𝑃𝑁
Equação 5.3: Cálculo do speedup máximo.
Em um gráfico, como visto abaixo, teremos que à medida que N tende a infinito,
o máximo speedup tende a 1/(1-P), onde o interesse acaba por fazer com que a
parte serial seja o menor valor possível, mas que o mesmo tende a ficar constante
independente do número de processadores utilizados.
Figura 5.2: Gráfico da Lei de Amdahl.
Modificado de Wikimedia Commons.
Outras métricas de paralelismo são a eficiência e o custo. A primeira mede a
fração do tempo para qual um elemento de processamento é empregado de forma
útil, sendo matematicamente definido como a razão entre o speedup e a quantidade
p de processadores.
𝐸 =𝑆
𝑝
Equação 5.4: Eficiência computacional.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo V – Paralelismo Aplicado
página 44
A eficiência é um valor que varia entre 0 e 1, sendo o valor ideal ocorrendo
quando S = p = 1.
Por fim, existe o custo de resolver um problema em um sistema paralelo como
sendo o produto do tempo de execução paralela pelo número de elementos
processados usados. Tal produto reflete a soma do tempo que cada processador
usou para resolver o problema.
5.3 – Bibliotecas Paralelas
5.3.1 – OpenMP / OpenACC
O OpenMP (Open Multi-Processing), desenvolvido por um consórcio
composto de empresas como AMD, IBM, Intel e Cray, consiste em uma
implementação de multithreading para CPU no método fork-join (“dividir e
conquistar”) e acabou se tornando um padrão de-facto. Existem diversas
implementações, sendo as mais populares estando em C e FORTRAN, mas não é
raro encontrar integrações com linguagens como Python. A versão 3.1 é suportada
pelos mais diversos compiladores, entre os quais é possível citar o GCC 4.3.1, os
compiladores da Intel® (icc e ifort) além do Visual Studio™, da Microsoft.
No modelo de execução determinado pelo OpenMP, ilustrado na figura 5.3,
temos a divisão do programa dividido em partes sequenciais e partes paralelas. Na
porção paralela do código, normalmente determinado pela diretiva
, temos o mesmo código executado simultaneamente por diversas
instâncias, cujo número é previamente definido pelo programador, e que serão
diferentes basicamente a partir de determinadas variáveis que dependem do número
da instância no processador. Após isso, os resultados são juntados na parte serial
onde pode ou não ter mais regiões paralelas.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo V – Paralelismo Aplicado
página 45
Figura 5.3: Modelo de execução do OpenMP, onde cada triângulo representa
um núcleo (ou processador) de uma CPU qualquer.
Mais recentemente, o padrão OpenACC, desenvolvido pela Cray, CAPS,
Nvidia e PGI veio a tentar simplificar a programação paralela em sistemas
heterogêneos, como GPUs, através de uma fácil implementação aos moldes do
OpenMP, e atualmente é planejado a fusão do OpenACC com o OpenMP.
5.3.2 – MPI
Assim como o OpenMP, o MPI (Message Passing Interface) teve sua versão
1.0 apresentada em 1993 e acabou por se tornar um padrão de-facto, sendo
basicamente um protocolo de comunicações usado para computação distribuída.
Sua versão mais estável, em dezembro de 2013, é a 1.6.5.
O MPI consiste em rotinas para computação distribuída, estando disponível
nativamente em um grande número de linguagens de programação, tais como
Python, Java, C e FORTRAN (através, respectivamente, das implementações
mpi4py, Open MPI Java, MPICH e Open MPI FORTRAN).
Seu modelo de implementação está ilustrado na figura 5.4, onde cada
máquina associada (ou núcleo de processamento) é definida por um “rank” (i.e.
número de identificação) e, entre a comunicação de cada uma existirá um “Sender”,
responsável pelo envio de determinada informação (buffer), e um “Receiver”, que é a
máquina responsável pelo recebimento da mesma; elas se comunicam entre si
alternando seus papeis.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo V – Paralelismo Aplicado
página 46
Figura 5.4: Modelo de execução do MPI.
Adaptado de Thomadakis, 2010.
Uma vez que o protocolo MPI trata de computação distribuída, onde
normalmente muitas máquinas estão juntas em uma única rede, existe o problema
de possíveis gargalos na mesma durante uma troca massiva de informações entre
diversos computadores. Como solução, é comum associar o uso de MPI a sistemas
de rede no padrão InfiniBand ou Ethernet de altas velocidades (10 gbps, por
exemplo), o que faz com que o custo operacional do cluster em questão seja alto.
Sur, Koop e Panda (2007) citam o MPI como sendo o modelo mais dominante
usado na computação de alto desempenho nos dias de hoje. É também de
importância ressaltar que é bastante comum associar o MPI a outros modelos de
programação paralela, como o OpenMP.
Em determinados softwares mais independentes, e dependendo do sistema
operacional, o MPI pode ser substituído por alternativas mais simples e rápidas de
implementação, como o shell script (bash) do Linux, ao qual o gerenciamento das
tarefas fica a cargo do próprio cerne do sistema operacional, e não do software
desenvolvido; tal gerenciamento costuma ser muito mais propenso a falhas por não
ter, por exemplo, um mecanismo eficiente de sincronização, mas, mesmo assim,
possui um ótimo custo/benefício em relação ao tempo levado para programar.
5.3.3 – CUDA
Esta linguagem foi criada primariamente pela NVIDIA para GPUs de forma a
facilitar o uso de processamento paralelo tanto por parte da comunidade científica
quanto pela indústria do entretenimento. Sua linguagem de programação se baseia
fortemente no ANSI C, com algumas ligeiras modificações em relação ao C puro,

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo V – Paralelismo Aplicado
página 47
sendo compilado através do nvcc (NVIDIA C Compiler), mas também existem
implementações para outras linguagens como FORTRAN, Java, Ruby e MATLAB,
sendo a primeira oferecida pelo compilador PGI e as outras, respectivamente,
possuindo interfaces que são denominadas jcuda, sgc-ruby-cuda e a última
integrada ao próprio MATLAB.
O princípio básico do CUDA trata de transferir as informações existentes em
um dado host para o device (neste caso, a GPU em si) e, em seguida, fazer as
operações nestas, denominadas kernels, e, por fim, transferir a informação desejada
fazendo a operação inversa, do device para o host.
As threads encontram dentro de blocos que, por sua vez, encontram se
dentro de um grid. A paralelização está ligada a quantos blocos ou threads devem
ser iniciados e como eles devem se comportar – cada thread e cada bloco é
identificado por um próprio número de identificação, conforme será mostrado
adiante. Apesar de pouco abstrair em questão de gerenciamento direto de recursos,
o CUDA deixa o programador relativamente livre para escolher como deseja
gerenciar o seu software.
Existem alguns fatores limitantes em termos de hardware e software com o
CUDA. O primeiro trata que as instâncias geradas pelo kernel – as threads – não se
comunicam entre si caso estejam em diferentes blocos, somente através de um
recurso denominado memória compartilhada, que normalmente é um valor bastante
diminuto a depender da placa; tal volume de dados é relativamente pequeno se
comparado à necessidade de quando lidando com matrizes voltadas para o
processamento sísmico. Ainda sobre threads e blocos, segundo a Documentação do
CUDA (NVIDIA, 2013), existe um limite imposto pelo próprio hardware na quantidade
existente de cada um, o que pode dificultar a vida do programador quando lidando
com laços que requeiram uma paralelização mais complexa. Além disso, alocação
de memória também é bastante sujeita a overflows, caso se não tenha o devido
cuidado ao se transferir dados do host para o device.

UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
Capítulo VI - Performance de um Algoritmo de RTM a
partir de Computação Distribuída e Paralela
6.1 – Medindo Tempos
O algoritmo RTM utilizado para este trabalho foi fornecido pelo Centro
Potiguar de Geociências, através de projeto de iniciação científica, e o mesmo é
composto de três etapas básicas:
1. Extrapolação do campo da fonte
2. Extrapolação do campo do receptor
3. Correlação
Cada uma das etapas encontra-se totalmente independente uma da outra –
ou seja, é executada uma de cada vez - para fins de checkpoints, já que, sem eles, é
possível existir gargalos na memória ou no HD, além da susceptibilidade dos
arquivos a erros de escrita/leitura (o que nos levaria a procurar algum método de
verificação de redundância cíclica).
A figura 6.1 ilustra a partir de que ponto cada tempo é medido em seus
respectivos programas.
Figura 6.1: Fluxograma de medida dos tempos do algoritmo RTM

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 48
O tempo total de execução do algoritmo RTM utilizado é dado pelo intervalo
transcorrido na medida 1 somado com o intervalo transcorrido nas medidas 2 e 3. A
unidade de medida utilizada foi segundos e dada pelo seguinte código em C:
Algoritmo 6.1: Uso da biblioteca time.h para medir tempos.
Como a ideia é estudar os diferentes tipos de arquiteturas computacionais,
optou-se por deixar de fora o tempo utilizado nos processos de leitura/escrita pelo
simples fato de que estes estão normalmente condicionados à velocidade do disco
rígido, que normalmente é limitada – o que não é interessante para este trabalho.
6.2 – Modelo e Parametrização
De forma a testar o algoritmo em questão, foi utilizado o que é conhecido
informalmente como “modelo do sal”. Trata-se de um dado 2D sintético com ampla
variação de velocidade e marcado principalmente pela existência de um domo de
sal. A visualização do modelo pode ser visto na imagem 6.2.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 49
Figura 6.2: Modelo utilizado para o processamento dos algoritmos.
A fonte utilizada para a simulação foi uma Ricker, cujo desenho pode ser visto
na imagem 2.11, com frequência máxima de 30 Hertz. A simulação do tiro para as
implementações single-core, OpenMP e GPU encontra-se localizada centralmente
de forma a tentar captar a maior quantidade de informações relativas ao sal.
6.3 – Condições de Processamento
Para os dados processados em plataformas x86_64, deu-se preferência a
utilizar o supercomputador do Instituto Internacional de Física, da Universidade
Federal do Rio Grande do Norte, por se tratar de uma combinação de processadores
ao invés de diferentes computadores. A especificação dessa máquina pode ser visto
na tabela 6.1:

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 50
CPU 128x Intel® Xeon™ E7
8837 @ 2.67 GHz
Memória RAM 1.96 terabytes
HD 17.5 terabytes
GPU NVIDIA Tesla S2050
SO SUSE Linux ES11
Tabela 6.1: Configurações da máquina do IIF.
Para testes de computação distribuída, optou-se pelo cluster do Programa de
Pós-Graduação em Ciências Climáticas, conhecido popularmente como laboratório
do CoRoT, composto por 20 máquinas de nível workstation, todas devidamente
conectadas com um switch de 1 gbps de forma a evitar gargalos na rede. As
configurações destas máquinas podem ser vistas na tabela 6.2:
CPU Intel® Xeon™ E3-1270
V2 @ 3.50 GHz
Memória RAM 16 gigabytes
HD 1 terabyte
GPU NVIDIA Quadro 600
SO Ubuntu 12.04 LTS
Tabela 6.2: Configurações das máquinas do laboratório CoRoT.
6.4 – Registros de Desempenho
Para fins de simplificação, estaremos usando a nomenclatura “Direto” como
referência ao processamento da propagação direta da onda no algoritmo RTM;
“Inverso” para tempo de processamento da propagação inversa da onda no RTM e
“Correlação” como o tempo de correlação cruzada levado pelo algoritmo em
questão. Além disso, para o OpenMP e para a GPU, cada medida foi repetida 5
vezes, sendo registradas conforme o algoritmo 6.1, de forma a aumentar sua
confiabilidade média.
6.4.1 – x86_64 single-core
O tempo single-core é o básico para comparação de ganho (speedup) em
relação ao processamento paralelo em múltiplos núcleos de CPU ou GPU. O tiro foi

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 51
executado nas posições x = 6.25, y = 0.00 e z = 0.02, o que condiz com parâmetros
de aquisição reais. A tabela 6.3 ilustra os tempos obtidos, juntamente com o desvio
padrão médio de cada um dos processos.
Processo Tempo Médio Desvio Padrão
Direto 189 segundos 4.41 segundos
Inverso 172 segundos 1.94 segundos
Correlação 8 segundos 6.05 segundos
Total 369 segundos
Tabela 6.3: Tempo de processamento utilizando um único núcleo
O resultado final pode ser visto abaixo:
Figura 6.3: Imageamento do algoritmo RTM em single-core.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 52
O proporcionalmente enorme desvio padrão para a medida de correlação
pode ser observado devido à latência presente no servidor de processamento
naquele momento, sendo posteriormente compensado por medidas posteriores.
6.4.2 – x86_64 paralelizado em OpenMP
Para os arquivos compilados em OpenMP, utilizou-se os compiladores da
GNU Compiler Colection (gcc) versão 4.7.3, com suporte ao OpenMP 3.1 onde todo
o código realizado no mesmo está de acordo com o padrão. Os objetos foram
compilados usando a flag , e a linkagem dos objetos ao programa
principal também foi realizada usando tal flag.
A paralelização foi feita majoritariamente nas funções que refletem a
propagação e retropropagação dos dados, tendo pouca expressão em funções
menores e mais rápidas mesmo em modo serial, o que refletiria pouco em resultados
expressivos no runtime. Entretanto, o compilador disponível na máquina em questão
encontrava-se na versão legada 4.3.2, que ainda não possuia algumas
implementações do padrão, de forma que foi necessário remover o código existente
em algumas regiões.
As tabelas 6.4, 6.5 e 6.6 ilustram os tempos de execução do algoritmo em
seus processos diretos, inversos, correlação e total, associados a determinados
núcleos de processamento (1 núcleo de processamento = 1 thread), assim como o
seu ganho de performance em relação ao processamento em single-core.
Nº de Núcleos Tempo Médio Desvio Padrão Speedup
2 núcleos 175 segundos 22.1 segundos 1,08x
4 núcleos 438 segundos 24.7 segundos 0,43x
8 núcleos 1066 segundos 44.2 segundos 0,17x
16 núcleos 322 segundos 50.1 segundos 0,58x
32 núcleos 315 segundos 33.2 segundos 0,6x
64 núcleos 345 segundos 28.6 segundos 0,54x
Tabela 6.4: Tempos de processamento de propagação direta utilizando múltiplos núcleos.
Nº de Núcleos Tempo Médio Desvio Padrão Speedup
2 núcleos 177 segundos 31.5 segundos 0,97x

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 53
4 núcleos 474 segundos 38.2 segundos 0,36x
8 núcleos 846 segundos 27.1 segundos 0,20x
16 núcleos 451 segundos 4.4 segundos 0,38x
32 núcleos 287 segundos 3.9 segundos 0,59x
64 núcleos 372 segundos 9.8 segundos 0,46x
Tabela 6.5: Tempos de processamento de propagação inversa da onda utilizando múltiplos núcleos.
Nº de Núcleos Tempo Médio Desvio Padrão Speedup
2 núcleos 8 segundos 1 segundo 1x
4 núcleos 7 segundos 1 segundo 1,14x
8 núcleos 7 segundos 1 segundo 1,14x
16 núcleos 10 segundos 2 segundos 0,8x
32 núcleos 8 segundos 0 segundo 1x
64 núcleos 10 segundos 2 segundos 0,8x
Tabela 6.6: Tempos de processamento de correlação utilizando múltiplos núcleos.
Excetuando o algoritmo de correlação entre campos, ao qual é imperceptível
o ganho de velocidade para o dado em questão a medida que o número de threads
aumenta, os resultados contra-intuitivos para a escalabilidade, juntamente com
aspectos técnicos da implementação realizada em OpenMP, são discutidos no
capítulo 7 deste trabalho.
O resultado da migração pode ser visto pela figura 6.4, que é claramente
consistente com a do algoritmo original em processamento serial. Trata-se de uma
imagem genérica para 4 núcleos de processamento, mas que se estende para
quaisquer outros valores.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 54
Figura 6.4: Imageamento do algoritmo RTM utilizando 4 threads.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 55
6.4.3 – Tarefas Distribuídas
Para os arquivos compilados no padrão MPI, usou primariamente as libraries
fornecidas pelo repositório do Ubuntu: libcr-dev e mpich2, e todo o código está de
conformidade com a versão 1.6.5 do padrão. O código-fonte utilizado foi compilado
utilizando as mesmas flags do sistema single-core, que inicialmente foi invocado o
mpicc, para a compilação de objetos em C, e o mpic++ para a linkagem dos objetos
em C++. Tais programas invocados servem apenas para inserir parâmetros nos
compiladores originais gcc e g++ (na máquina utilizada, ambos se encontram na
versão 4.5.2). A seguir, usava-se o programa mpirun para rodar os arquivos
desejados, assim como o número de processos executado pelo mesmo.
A ideia básica nesta sessão era de simular um ambiente computacional com
máquinas independentes onde cada uma recebia uma tarefa – neste caso, um tiro –
para processar independentemente uma da outra. A grande questão é que a
implementação por protocolo TCP (ou mesmo por uma rede) é relativamente
complexa, de forma que foram usados núcleos latentes de uma máquina de oito
núcleos para simular máquinas independentes (neste caso, single-core). Tais testes
não possuem nenhuma relação com o OpenMP acima desenvolvido e se rodou 56
tiros ao todo, que foram distribuídos a um determinado número de processos
previamente especificados e, então, foi registrado o tempo de execução de cada um,
conforme especificado na figura 6.1. Os tiros tinham início na posição de fonte x = 0,
y = 0 e z = 0.02 e cada tiro possuía um incremento de 0.25 no eixo x em relação ao
anterior, sendo os valores em y e em z mantidos constantes.
As tabelas 6.7 e 6.8 ilustram, respectivamente, o tempo levado para se
processar o tempo de propagação da onda direta, o tempo de propagação de onda
inversa e seus speedups em relação ao tempo em um único núcleo.
Nº de Processos Tempo de Execução Speedup
1 processo 3604 segundos 1x
2 processos 1847 segundos 1,95x
3 processos 1232 segundos 2,92x
4 processos 1044 segundos 3,45x
5 processos 954 segundos 3,77x
6 processos 828 segundos 4,35x

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 56
7 processos 744 segundos 4,84x
Tabela 6.7: Tempo total levado por um determinado número de processos na
implementação de computação distribuída para o algoritmo de propagação direta do
campo de onda.
Nº de Processos Tempo de Execução Speedup
1 processo 3881 segundos 1x
2 processos 2024 segundos 1,91x
3 processos 1451 segundos 2,67x
4 processos 1171 segundos 3,31x
5 processos 1032 segundos 3,76x
6 processos 931 segundos 4,16x
7 processos 796 segundos 4,87x
Tabela 6.8: Tempo total levado por um determinado número de processos na
implementação de computação distribuída para o algoritmo de propagação inversa
do campo de onda.
Não foi gerada uma tabela de tempos para o processo de correlação entre
campos, uma vez que o mesmo não possui um grande peso computacional e, por
isso, seu speedup acaba crescendo em uma forma quase linear com o número de
processadores envolvidos.
Os resultados individuais para alguns tiros diretos da migração estão
mostrados na figura 6.5. É interessante notar que, idealmente, as migrações
individuais geradas devem ser somadas de forma a gerar a melhor imagem sísmica
possível (com as melhores amplitudes), mas tal processo não foi feito porque não
está dentro do interesse deste trabalho.
Por fim, é de relevância salientar que a discussão detalhada sobre os
resultados obtidos individualmente por cada processo, sobre a técnica de
implementação do código em MPI, juntamente a fatores que possam afetar o
desempenho do mesmo, são discutidos ao longo do sétimo capítulo deste trabalho.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 57
Figura 6.5: Alguns tiros diretos gerados pelo algoritmo RTM em MPI,
usando a opção para visualização.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 58
6.4.4 – GPU
Os códigos relativos ao código para uma GPU (device) encontram-se sempre
em arquivos no formato .cu, por exigência própria do compilador – o NVIDIA C
Compiler (nvcc) – para a geração de objetos. Após isso, os objetos são todos
linkados usando o compilador g++ e as flags e .
A implementação do código CUDA foi totalmente realizada segundo a versão
5.0, mas buscando sempre a retrocompatibilidade com a 4.0, que é a versão do SDK
(Software Development Kit) presente na máquina utilizada. As especificações
técnicas do device seguem na tabela 6.9.
Capacidade CUDA 2.1
Memória Global 1024 megabytes
Número de Núcleos 288 núcleos CUDA
Tamanho do
barramento L2
520 kilobytes
Número máximo de threads
por blocos
1024 threads
Dimensão máxima de cada
dimensão por bloco
1024 x 1024 x 64
Tamanho máximo de cada
dimensão de um grid
65535 x 65535 x 65535
Tabela 6.9: Configurações do sistema do device.
Não houve qualquer controle do número de threads ou blocos gerados pela
GPU, como realizado nas implementações anteriores, dando preferência a usá-la no
seu limite de capacidade para fins de discussões no capítulo seguinte. Foram
transformadas em kernels as funções mais recorrentes (e/ou mais
computacionalmente intensivas), enquanto as que são rapidamente calculadas por
uma própria CPU foram deixadas da forma que existem. O recurso de Paralelismo
Dinâmico – que consiste em um kernel poder chamar outro kernel no próprio device
– não foi utilizado pelo fato da máquina em questão não estar utilizando a versão 5.0
do CUDA, ao qual esta capacidade foi implementada.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 59
A tabela 6.10 ilustra o tempo do processamento levado para se propagar
diretamente, inversamente e correlacionar o campo de ondas, juntamente com o
speedup em relação ao sistema single-core. Foi simulado um tiro no centro do
modelo (posição x = 6.25, y = 0, z = 0.02) e os tempos foram medidos de acordo
com o algoritmo expresso pela figura 6.1. De forma a calcular o desvio padrão,
foram realizadas 5 medidas.
Processo Tempo Médio Desvio Padrão Speedup
Direto 13 segundos 2.69 segundos 14,53x
Inverso 15 segundos 4.11 segundos 11,46x
Correlação 3 segundos 2.07 segundos 2,67x
Total 21 segundos
Tabela 6.10: Tempos relativos à execução do algoritmo RTM em uma GPU.
A figura 6.6 ilustra o resultado final da migração realizada através de GPU e é
facilmente visível que o resultado é facilmente comparável ao da versão single-core,
o que nos leva a induzir o fato de que a paralelização não prejudicou o algoritmo. A
discussão sobre a implementação, análise dos resultados obtidos e uma
comparação com outras metodologias pode ser vista no próximo capítulo.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VI – Performance de um Algoritmo de RTM
a partir de Computação Distribuída e Paralela
página 60
Figura 6.6: Resultado do modelo migrado pelo algoritmo RTM paralelizado em CUDA.

UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
Capítulo VII – Análise dos Resultados Obtidos
Este capítulo tem por objetivo a discussão dos resultados obtidos e mostrados
ao longo deste trabalho.
Foram testados implementações de computação paralela em processadores
convencionais, computação distribuída e, por fim, o uso de GPUs para o algoritmo
de migração. Os benchmarks provam facilmente que a última alternativa dá um
retorno muito maior, apesar de ter uma complexidade para implementação muito
maior graças a um alto grau de abstração envolvida por parte do CUDA e até da
biblioteca para arquiteturas heterogêneas, a OpenCL. É natural imaginar que quanto
mais complexo o modelo, tanto geologicamente quanto computacionalmente, mais
expressivo será o tempo de processamento, ainda mais se tratando de um sistema
de um único núcleo de processamento.
A maior surpresa, no entanto, resume-se à implementação através do
OpenMP ao qual se obteve o resultado totalmente oposto ao desejado, um
decréscimo no Speedup, ao invés de aumento, como ilustrado pela figura 7.1.
Figura 7.1: Gráfico de Speedup por Threads (até 64 threads) para a implementação
do OpenMP para o algoritmo de propagação direta da onda.
Pelo gráfico, é fácil observar que o speedup cai a partir de 4 threads e, a partir
de 16 threads, mantém-se quase constante em um valor próximo a 0,6. Existem uma
gama de possíveis motivos para se ilustrar esse fato; entre os quais, vamos citar o
compilador utilizado e a própria especificação da biblioteca de paralelização.
0
0,2
0,4
0,6
0,8
1
1,2
0 10 20 30 40 50 60 70
Threads x Speedup

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 62
Inicialmente, o compilador utilizado (gcc versão 4.3.x) sequer tem a
especificação da versão do OpenMP 3.0 implementadas. Segundo o changelog, tal
fato foi realizado apenas na versão 4.4, o que deixa implícito que a compilação não
foi totalmente otimizada para o código em questão, que foi projetado na
especificação 3.0, deixando-o mais lento – inclusive, a priori da execução na
máquina, parte do código paralelizado teve que ser removido por não ser compatível
com o OMP 2.5 existente no compilador em questão. Entretanto, mesmo usando
compiladores em versão mais recente, o ganho de speedup é notável, mas o padrão
do gráfico acaba por se repetir, o que leva ao segundo motivo em questão: o
algoritmo, da forma que é estruturado, não possui escalabilidade, esbarrando nas
limitações do OpenMP.
A princípio, o fenômeno de speedup de um determinado número de threads
maior ter menor speedup que um número menor de threads não é incomum mesmo
em códigos que são perfeitamente paralelizáveis e escaláveis, como ilustrado por
Dalke (2012) quando tentou comparar implementações através de POSIX, que são
comumente mais utilizadas a nível de programação de sistemas, e de OpenMP de
forma a verificar a eficiência de cada uma, notando que, para o algoritmo de busca
de Tanimoto, o uso de 5 threads possui um runtime consideravelmente mais rápido
que com o uso de 8 threads.
Outro problema advém da própria limitação da especificação. Grama et al
(2003) e o Manual do OpenMP 3.1 (2011) ilustram diversas situações em que se
possui problemas com o paralelismo: mais especificamente, no loop nesting (em
tradução livre, encadeamento de loops) – uma situação em que lidamos com
sistemas de mais de uma dimensão (em que percorremos linhas e colunas de uma
matriz, por exemplo) e tal situação é extremamente recorrente no algoritmo em
questão, muitas vezes em escala pior.
Para fins de implementação, todas as variáveis foram declaradas
manualmente como (onde cada thread possui uma cópia própria da
variável) ou (variável compartilhada) e o número de threads era definido no
próprio código de paralelismo através de uma única variável inteira; desta forma, a
única diferença entre o código feito para rodar em 8 threads para o de 16 threads é o
valor desta variável.
Sendo assim, tomemos como exemplo a função de convolução de pixels
tridimensional, ilustrada pelo algoritmo 7.1 e que é crítica para o desempenho do

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 63
processo de migração. Tal função é composta por 3 laços que variam de 0 até o
tamanho da malha em seu respectivo eixo (x, y, z), o que é algo relativamente
considerável mesmo para um dado sísmico 2D e, logo a seguir, são realizadas
convoluções em cada direção, onde os resultados são somados e insertos em uma
matriz r. Após isso, o loop se repete até que toda a malha do dado tenha sido
percorrida.
Algoritmo 7.1: Convolução tridimensional.
A primeira abordagem para a solução deste algoritmo foi dividir cada
convolução, que também se tratam de laços, em seções independentes (através da
construct) que seriam inicialmente distribuídas para as threads em um
formato de tarefas (tasks) e, após a execução das tarefas, seriam posteriormente
sincronizadas através da construct para ser realizada a soma de forma a
atualizar a matriz em questão. Entretanto, existiram dois problemas intrínsecos a
esta tentativa de implementação: o primeiro quanto ao fato de que não é possível
sincronizar as threads na região desejada – neste caso, dentro de uma -
por limitação da própria biblioteca e nem quanto ao uso de regiões de operação
ou . O segundo problema encontrado decorre ao fato de que
cada thread é independente e não compartilha memória: neste caso, como fazer a
soma de valores em cada convolução individual? À medida que cada laço de
convolução ocorre, um variável soma é atualizada dentro do mesmo; se cada thread
independe uma da outra em um único laço, vamos ter inúmeras variáveis desse tipo
alocada na memória, de diferentes valores, mas sem nenhuma relação entre si. Para
contornar esse problema, lidamos com a cláusula , a qual permite

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 64
armazenar valores em uma variável e, ao fim, fazer uma determinada operação com
todas as existentes. Infelizmente, o OpenMP não permite usar esta cláusula em
cada seção, e sim no conjunto total, o que acaba por se tornar inviável.
A segunda abordagem foi o uso da cláusula , recomendado por
programadores para diversas situações no popular website de perguntas e
respostas StackOverflow. Entretanto, o algoritmo em questão trata de situações em
que os loops não estão associados, sendo impossível o uso deste recurso.
Outra alternativa utilizada foi a paralelização de cada laço existente, o que se
tornou totalmente inviável devido ao grande número de threads gerados, o que
sobrecarregaria bastante cada processador e deixaria o processo mais lento como
um todo. No CUDA, tal problema se torna relativamente mais simples graças à
própria estrutura do grid de paralelização, que é tridimensional; tal fato será discutido
adiante. Juntamente ao problema acima, paralelizar os laços mais internos são
técnicas não recomendadas por programadores mais experientes devido a
comportamento anômalos do OpenMP; além disso, nenhum resultado satisfatório foi
encontrado usando tal abordagem.
A “solução” encontrada – que acabou por não se tornar muito efetiva - foi a
paralelização do loop mais externo usando a cláusula , que
permite o uso ótimo de todos os processadores simultaneamente, reduzindo o efeito
borda (do inglês, edge effect). O uso da função para dar display no número
das threads ativas em diversas fases do algoritmo mostra que a tarefa é bem
distribuída entre os processadores, mas, por algum motivo, o gerenciamento
existente pela biblioteca não é bom, o que acaba por gerar o problema ilustrado pela
figura 7.1.
O problema das threads serem independentes se torna ainda maior quando
lidamos com funções causais ou em que os loops não estejam perfeitamente
alinhados – ou seja, existe algum comando relacionado a uma variável entre um laço
e outro, o que torna a paralelização ainda mais difícil. Tal situação existe em várias
outras regiões do código, e uma abordagem similar à descrita acima foi utilizada,
novamente sem os resultados desejados.
Um pequeno ganho pode ser atribuído ao paralelismo de funções
relativamente mais simples que incluem um laço, mas, infelizmente, tais funções não
são de importância no tempo de execução do algoritmo.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 65
Em suma, a falta de controle sob as threads do OpenMP exigiria o uso de
outra biblioteca de menor nível de abstração, como a OpenCL ou o uso de threads
POSIX, ou que o código, da forma que se encontra, fosse parcialmente, ou até
totalmente, reescrito conforme Nunes do Rosário (2012) detalha em sua dissertação
de mestrado.
No tocante à implementação usando o MPI – que o faz através do paradigma
SPMD (single program, multiple data) - a ideia era simular o uso de máquinas
diferentes através da designação de tarefas (neste caso, tiros) a núcleos de
processamentos latentes, além de também servir para verificar a eficiência deste tipo
de paralelização em comparação a granularidade fina exigida pelo OpenMP. A
implementação realizada, de certa forma, obteve mais êxito que um possível uso do
protocolo de TCP para transmissão de dados na rede do cluster ao qual o dado foi
processado; isso se dá primariamente graças ao fato de que a rede provavelmente
em questão não aguentaria o volume de dados sendo transmitidos de um local ao
outro, o que não é interessante para este trabalho (ao qual o acesso a um único HD
e uma única memória acaba por ser mais útil).
Foi inicialmente criada uma nova função main que é responsável por
inicialmente verificar o rank da máquina que a executou e, com isso, atribuir uma
das atribuições aos processos em questão, podendo estas ser de “supervisor” ou de
“escravo”. O algoritmo 7.2 ilustra através de um fluxograma como o sistema
funciona.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 66
Algoritmo 7.2: Distribuição de tarefas do MPI.
Em uma explicação mais detalhada, só existe um processo que terá a
atribuição de supervisor: o de rank 0, que nada mais é do que o próprio processo
que deu início ao programa em questão. Esse programa é iniciado através da
interface mpirun, ao qual o parâmetro (number of processes) indica quantos
processos desejamos que sejam iniciados paralelamente (e cada um terá um rank
diferente, obviamente). Ao restante dos processos iniciados será atribuída a função
de escravo, a qual os mesmos ficarão esperando uma mensagem proveniente do
supervisor para começar a fazer o que esteja designado para si.
Falando agora sobre o cerne do sistema, é através da função que
o supervisor envia um tiro, neste caso ilustrado pela posição da fonte no eixo x, y e
z, para cada escravo que foi iniciado junto a ele. Nesse meio tempo, os processos
escravo, que inicialmente encontravam-se latentes, recebem um buffer do
coordenador – através da função – e, em seguida, iniciam seus trabalhos
de processar a função do campo de propagação direta ou inversa do campo de
ondas. Ao terminar, tal fato é comunicado ao supervisor que designa outro tiro, com
uma posição de fonte distinta, ao processo comunicante e tal ciclo se repete até que
o número estipulado de tiros seja alcançado. Ao fim, todos os processos são mortos
e o programa, enfim, se encerra.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 67
Foram rodados de 2 até 8 processos simultaneamente, ambos simulando os
56 tiros. Dessa forma, como 1 processo é sempre designado para coordenar tudo,
temos de 1 ( ) até 7 processos ( ) rodando concomitantemente para
processar o tiro propriamente dito. O speedup médio obtido ao se executar o
algoritmo de propagação direta e inversa segue ilustrado pelo gráfico da figura 7.2.
Figura 7.2: Gráfico de speedups obtidos.
Ao fim de cada tiro, o tempo levado por cada processo foi medido e
armazenado; plotando tais 56 valores de cada ciclo, gerou-se os gráficos ilustrados
pelas figuras 7.3 e 7.4.
Figura 7.3: Tempo por processo da propagação direta (em segundos) do campo de ondas.
0
1
2
3
4
5
6
0 2 4 6 8
Speedup x Processos
Propagação direta
Propagaçãoinversa

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 68
Figura 7.4: Tempo por processo da propagação inversa (em segundos) do campo de ondas.
É interessante analisar o padrão existente e que se repete nos quatro
gráficos. A partir de quatros processos, o tempo médio (e, consequentemente, o
speedup) para a execução de um tiro começa a crescer de forma notável, indo de
uma média de 65 segundos, ao usarmos 3 processos escravos, para algo em torno
de 92 segundos quando em vista do tempo de execução com a parametrização
np=8. Graficamente, o padrão do speedup para de se comportar linearmente e
começa a rumar à estabilização.
Existem diversas possíveis explicações para o fenômeno acima ocorrido,
conforme apontadas por Kauer et al (2013), citando problemas relativos à leitura de
memória e do gargalo de comunicação, como o realizado pelo HD em comum, que
possa ser compartilhado entre os vários processadores.
Já Garcia (2013) aponta que um possível problema ocorre devido ao
escalonamento de processos por parte do cerne do sistema operacional, neste caso,
o Linux, que não é capaz de fazê-lo de forma totalmente eficiente.
Outra possível explicação é o uso da tecnologia hyper-threading usado pelos
processadores Intel em questão. Tal tecnologia permite criar, a partir de um núcleo
físico, dois núcleos virtuais (ou lógicos) para o sistema operacional e dividir o
trabalho entre eles. Tais núcleos virtuais são independentes, da forma que se um
falhar, o outro não necessariamente seguirá o mesmo destino. Em curiosidade, a

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 69
edição 01 do volume 06 do Intel Technology Journal (2002) afirma que a primeira
implementação dessa tecnologia usou apenas 5% a mais de área no processador,
enquanto a performance aumentou em torno de 10 a 30% e Casey (2011) sugere
novas métricas para a avaliação de desempenho em sistemas com hyper-threading,
dentre as quais se destacando a Hyper-threading Effectiveness, que é uma revisão
da Lei de Amdahl, discutida previamente em outros capítulos.
Antes de continuar, é necessário observar que o processador em questão tem
4 núcleos reais e, graças a isso, o fato acima citado pode ser facilmente comprovado
através de uma análise simples do número de processos atuantes: quando temos
até três processos escravos (ou seja, quatro ao todo, já que existe um supervisor
atuante), o tempo mantém-se aproximadamente constante para todos eles – e isso é
esperado, já que cada núcleo de processamento está correspondendo a um núcleo
físico. Do quarto em diante, começa-se a usar os núcleos lógicos, que são mais
lentos que os reais – e quanto mais processos, mais núcleos desse tipo serão
usados, até o ponto em que . A partir de então, o tempo de processamento
por tiro deve começar a subir de uma forma mais rápida, já que um mesmo núcleo
estará realizando mais de uma tarefa simultaneamente.
Finalizando o ciclo de implementações, foi realizada a conversão de parte do
código das funções do algoritmo em questão – mais precisamente as que
necessitavam uma grande gama de cálculos matemáticos - para CUDA C enquanto
outra parte ficava em modo serial.
Diferentemente do OpenMP, esta tecnologia para arquiteturas heterogêneas
confere maior poder ao programador, podendo o próprio ter controle das threads a
uma granularidade bastante fina, ao mesmo tempo que aumenta a dificuldade de
programação; porém, tal dificuldade pode facilitar a abordagem de paralelização de
determinados problemas, mais precisamente aqueles que são bi ou tridimensionais.
Inicialmente, temos que a estrutura de um grid CUDA é ilustrado pela figura
7.5:

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 70
Figura 7.5: Modelo esquemático de um grid CUDA.
Imagem: Anvar Karimson.
Existem duas principais abordagens para a resolução de problemas de
paralelização em CUDA: a primeira consiste em linearizar todos elementos
existentes em uma dada matriz, enquanto o segundo trata de usar a própria função
x, y, z referente à posição do bloco e da thread, que tem posição única, como pivô
para determinadas operações. É importante ressaltar que foi somente a partir de
dispositivos com Capacidade CUDA 2.0 em diante foi que existiu a possibilidade de
se usar um grid tridimensional; os anteriores a esta versão eram bidimensionais e,
em problemas tridimensionais, era necessário recorrer a alternativas de
programação.
Em um caráter mais técnico, o CUDA C se traduz como sendo um
superconjunto do C convencional (ANSI C/ISO C98), aceitando toda (ou a maioria)
da sintaxe envolvida e, ao mesmo tempo, estendendo as funções intrínsecas à
linguagem. Isso se traduz em uma facilidade de programação para pessoas que já
estão acostumadas a um baixo nível de abstração em termos de hardware, já que
também será necessário a alocação de memória por parte do host no device e
copiar dados para lá e vice-versa que quando mal realizadas podem induzir a um
overflow de memória.
Assim como todos os outros paradigmas analisados, as threads invocadas
pelo kernel em questão são independentes e assíncronas umas das outras, de
forma que a paralelização de sistemas causais ou que dependam de valores de

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 71
outras threads pode ser problemática. De forma a contornar esses inconvenientes,
existe a função de sincronização ( ) e o conceito de memória
compartilhada; entretanto, o volume disponível para tal é relativamente pequeno, o
que não pode ser interessante para aplicações que lidem com uma grande
quantidade de informações.
Para o algoritmo deste trabalho, a implementação CUDA nas funções
desejadas consistiu nas ideias já previamente abordadas, sem nenhum problema
maior, ficando todo o código contido em um único arquivo *.cu que era devidamente
prototipado e os kernels contendo o prefixo de acesso Em poucas
situações foram necessário usar recursos de linearização de matriz para identificar
threads que estejam acima de valores máximos suportados pela GPU, mas foi
bastante comum o uso do fato de threads e blocos estarem em dimensões
diferentes, além de poderem estar localizados, cada um, em duas dimensões,
quando era necessário paralelizar um loop que se encontrava em mais de uma
dimensão.
Os resultados obtidos através da implementação de GPU foram, em sua
totalidade, excelentes, alcançando ótimas métricas de speedup em todas as etapas
do algoritmo. Isso se dá primariamente a grande quantidade de threads que podem
ser executadas simultaneamente, uma vez que o algoritmo realiza operações em um
grid de tamanho do produto das dimensões das malhas nos eixos x, y e z – ou seja,
mesmo que um ótimo sistema computacional serial processasse-o, ele teria que
executar um valor nx*ny*nz de operações que, mesmo que cada uma
individualmente seja rápida, ainda levará um oneroso tempo, enquanto que a
estrutura da GPU permite que esses cálculos sejam divididos por um grande
número, já que muitos cálculos são realizados paralelamente.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VII – Análise dos Resultados Obtidos
página 72
Figura 7.6: Gráfico comparativo de speedups obtidos em cada tipo de paralelização.
É simples notar que as GPUs obtiveram o melhor desempenho, mas a
pergunta que fica é: qual o custo/benefício, em termos computacionais, desse tipo
de implementação?
Em uma resposta prática: muito alto. Tal performance em GPUs foi obtida em
apenas uma placa de vídeo e que sequer é considerada high-end nos dias de hoje,
e o código sequer está superotimizado para tirar vantagens de recursos mais novos
das mesmas. Na indústria do petróleo, onde se existe muito mais recursos que na
Academia, um cluster de GPUs pode ser facilmente montado e programado a um
custo menor do que a mesma quantidade de processadores convencionais para a
montagem de um sistema através de MPI ou OpenMP, já que estes são limitados
pelo número de núcleos (que comumente é baixo) existente e tendem a rumar para
a estabilidade no valor de speedup rapidamente.
Uma boa sugestão é a utilização dos três paradigmas conjuntamente, onde o
OpenMP ficaria responsável pela distribuição de tarefas em loops seriais, o MPI se
encontraria como distribuidor de tarefas a diversos processadores em uma rede e o
CUDA estaria realizando, juntamente a esses dois, cálculos computacionais mais
intensos.

UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VIII – Desafios
Capítulo VIII – Desafios
Apesar de todas as conclusões obtidas no capítulo anterior, chegamos a uma
pergunta básica: devemos parar por aqui?
Quando confrontados com esta pergunta, diversos especialistas – pertencentes
tanto a empresas de óleo e gás quanto de computação – no 13º Congresso
Internacional da Sociedade Brasileira de Geofísica, foram unânimes em responder a
pergunta acima com um sonoro não. Ainda se existe uma dificuldade enorme para
se imagear regiões de alta complexidade estrutural e/ou estratigráfica, e o algoritmo
RTM por si só, apesar de ser um ótimo algoritmo, não é o suficiente para a tarefa em
questão. A imagem abaixo ilustra o poder computacional de acordo com cada
algoritmo.
Figura 8.1: Nível computacional exigido por diferentes algoritmos de migração e
seu respectivo ano ao qual tal nível foi atingido.
Adaptado de Ty McKercher, NVIDIA; Fonte: TOTAL.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET– Relatório de Graduação em Geofísica Capítulo VIII – Desafios
página 74
Algoritmos como o FWI (do inglês, Full Waveform Inversion) possuem uma
resolução de imageamento superior à da RTM, mas é fácil observar que a carga
computacional segue, a partir de 2010, quase que uma reta – e precisamos de
maneiras para lidar com ela além de, ao mesmo tempo, mantermos o runtime sob
controle, ou ao menos em um valor relativamente viável (em termos práticos: não
adianta deixar um dado rodando por dois anos, a chance de ocorrerem problemas
por força maior se torna enorme). O FWI já começa a aparecer em diversos
trabalhos e aos poucos está substituindo o RTM como o padrão-ouro da indústria,
mas isso não importa muito, já que ele será substituído novamente em breve, e tal
ciclo acabará sendo interminável. Para o futuro, têm-se poucas informações do que
está sendo feito por parte das indústrias, mas é interessante ressaltar que
companhias como a Petrobrás testam rotineiramente novas tecnologias, como o
processador Cell, usado no Playstation 3, da Sony, o IBM PowerPC ou o IBM
BlueGene ou até mesmo técnicas de resfriamento por imersão em óleo (neste caso,
usado pela CGG). Universidades e Centros de Pesquisas no mundo inteiro também
desempenham um papel fundamental na formação de mão-de-obra qualificada e
geração de ideias para este ramo. O que é visto atualmente é a tendência de rumo
para uma integração entre CPUs convencionais com GPUs em um único chip,
criando, desta forma, arquiteturas heterogêneas, como o que já é feito com as APUs
(do inglês, Accelerated Processing Unit) da AMD. A pesquisa de materiais que
possam substituir o silício (com um destaque para o grafeno) em termos de
desempenho também é bastante recorrente e isso é bom porque, por exemplo, um
processador de um material que tenha calor específico maior que o silício pode
aguentar uma frequência de processamento também maior, o que induz quase
sempre a uma crescente velocidade. A introdução de um número cada vez mais
superior de núcleos de processamento em GPUs, juntamente com um maior
acoplamento de unidades computacionais para a utilização de computação
distribuída, consistem também dentre o grupo de alternativas usadas para diminuir o
tempo de processamento. Provavelmente, a longo prazo, devemos lidar com todas
essas alternativas acima citadas, com a sobressaliência de uma ou outra. Qual? Só
o tempo dirá.
E de qualquer forma, a jornada é longa, mas as recompensas, definitivamente,
valem a pena.

UFRN/CCET – Relatório de Graduação em Geofísica Referências Bibliográficas
Referências Bibliográficas
BAYSAL, E.; KOSLOFF, D.D.; SHERWOOD, J.W.C. Reverse time
migration. Geophysics, v. 48, n. 11, p. 1514-1524. Society of Exploration
Geophysicists, 1983.
BERENGER, J. A perfectly matched layer for the absorption of
electromagnetic waves. Journal of Computational Physics, v. 114, p. 185-200.
1994.
BORKAR, S.; CHIEN, A.A. The Future of Microprocessors. Disponível em:
http://cacm.acm.org/magazines/2011/5/107702-the-future-of-microprocessors/fulltext
2011.
CLAERBOUT, J. F. Toward a Unified Theory of Reflector Mapping.
Geophysics, v. 36, p. 467-481, 1971.
CHE, S.; LI, J.; SHEAFFER, J.W.; SKADRON, K.; LACH, J. Accelerating
Compute-Intensive Applications with GPUs and FPGAs. Simpósio: Application
Specific Processors. 2008.
CLAPP, R.G. Reverse time migration with random boundaries. SEG
Houston 2009 International Exposition and Annual Meeting. Society of Exploration
Geophysicists, 2009.
COHEN, J.K.; STOCKWELL, J.W.J. The New SU User’s Manual. Colorado
School of Mines, 2008.
COLLINO, F.; TSOGKA, C. Application of the PML absorbing layer model
to the linear elastodynamic problem in anisotropic heterogeneous media.
Institut National de Recherche en Informatique et en Automatique, França. 1998.
COSTA, J.C. Aspectos da Modelagem e Imageamento usando a Equação
de Onda. Apresentação. III Semana de Inverno da UNICAMP. Campinas, 2012.
DALKE, A. OpenMP vs POSIX Threads. Disponível em:
http://www.dalkescientific.com/writings/diary/archive/2012/01/13/openmp_vs_posix_t
hreads.html, acesso em 4 de novembro de 2013.
DUARTE, O.O.D. Dicionário Enciclopédico Inglês-Português – Geologia e
Geofísica. Rio de Janeiro: Sociedade Brasileira de Geofísica, 2007.
FORNBERG, B. Generation of finite difference formulas on arbitrarily
spaced grids. Mathematics of Computation, v. 51, p. 699-706. 1998.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
UFRN/CCET – Relatório de Graduação em Geofísica Referências Bibliográficas
página 76
FREE SOFTWARE FOUNDATION. GCC 4.4 Release Series. Changes, New
Features, and Fixes. Disponível em: http://gcc.gnu.org/gcc-4.4/changes.html,
acesso em 4 de novembro de 2013.
GARCIA, I.C. Sistemas Operacionais: História e Escalonamento de
Processos. UNICAMP: Campinas, 2013.
GARG, H.N.; SINGH, A.; RAMAMURTHY, G.B.; MARKANDEYULU, C. Cost
Effective Land Seismic Data Acquisition by Geophysical Services of WON
Basin, Gujarat, India. HYDERABAD, 2008. Índia.
GAZDAG, J. Wave equation migration with the phase-shift method.
Geophysics, v. 43, p. 1342-1351. 1978.
GRAMA, A.; GUPTA, A.; KARYPIS, G.; KUMAR, V. Introduction to Parallel
Computing. UK: Pearson Education Ltd, 2003.
HEMON, C. Equations d’onde et modeles. Geophysical Prospecting, 1976,
v. 26, p. 790-821.
KAUER, A.U.; SIQUEIRA, M.L. Escalonamento em Arquiteturas
Heterogêneas – APUs. 13ª Escola de Alto Desempenho do Rio Grande do Sul, p.
135-138. 2013.
KEAREY, P; BROOKS, M.; HILL, I. An introduction to Geophysical
Exploration. UK: Blackwell Science Ltd, 2002.
KOSLOFF, D.D.; BAYSAL, E. Migration with the full acoustic wave
equation. Geophysics, v. 48, p. 677-687.
LIU, H.; LI, B.; LIU, H.; TONG, X.; LIU, Q. The Algorithm of High Order
Finite Differences Pre-Stack Reverse Time Migration and GPU Implementation.
Chinese Journal of Geophysics, v. 53, n. 4, p: 600-610. 2010.
LOEWENTHAL, D. Reversed time migration in spatial frequency domain.
Geophysics, v. 48, p. 627-635.
MCKERCHER, T. How GPU Accelerated Computing Improves
Visualization in E&P Workflow. Apresentação, NVIDIA.
NVIDIA. CUDA TOOLKIT DOCUMENTATION. Disponível em:
http://docs.nvidia.com/cuda/index.html. 2013.
OLHOEFT,G.R. Quality Control in Geophysics. Federal Highway
Administration, U.S. Department of Transportation. Estados Unidos: 2008.
OPENMP ARCHITECTURE REVIEW BOARD. OpenMP Application
Program Interface. Versão 3.1. 2011.

MEDEIROS, D.A. Relatório No. 37 dezembro/2013
página 77
PANETTA, J. Excursionando por OpenMP. III Semana de Inverno de
Geofísica da UNICAMP. Campinas, 2012.
ROSA, A.L.R. Análise do sinal sísmico. Rio de Janeiro, RJ: Sociedade
Brasileira de Geofísica, 2010.
NUNES DO ROSÁRIO, D.A. Escalabilidade Paralela de um Algoritmo de
Migração Reversa no Tempo (RTM) Pré-Empilhamento. Dissertação de Mestrado.
Universidade Federal do Rio Grande do Norte: Natal, 2012.
SEG TECHNICAL STANDARDS COMMITEE. SEG-Y rev 1 Data Exchange
format. Tulsa: Society of Exploration Geophysicists, 2002.
SINGH, D. Higher Level Programming Abstractions for FPGAs using
OpenCL. ALTERA. Apresentação, 2011.
SUR, S; KOOP, M.J; PANDA, D.K. Zero-Copy Protocol for MPI using
InfiniBand Unreliable Datagram. Ohio State University, 2007.
The FreeBSD Documentation Project. FreeBSD Developers’ Handbook.
Disponível em: http://www.freebsd.org/doc/en/books/developers-handbook/. 2013.
THOMADAKIZ, M.E. A High-Performance IBM Power5+ p5-575 Cluster
1600 and DDN S2A9550 Storage for Texas A&M University. Disponível em:
http://sc.tamu.edu/systems/hydra/. 2010.
WEBER, R.F. Fundamentos de Arquitetura de Computadores. Porto
Alegre, RS: Bookman Companhia Editora Ltda, 2012.
YILMAZ, O. Seismic data analysis: processing, inversion and interpretation
of seismic data. Tulsa: Society of Exploration Geophysicists, 2001.
ZAHRAN, M. History of GPU Computing. Notas de aula, New York
University.