reducción de dimensiones supervisada para datos económicos
TRANSCRIPT

Reduccion de Dimensiones Supervisadapara Datos Economicos
Rodrigo Garcıa ArancibiaInstituto de Economıa Aplicada Litoral, FCE-UNL & CONICET
Trabajo conjunto con
Liliana Forzani, Pamela Llop y Diego TomassiDepartamento de Matematica, FIQ-UNL & CONICET
Workshop del IEF, FCE-UNC, Julio de 2017

Economıa y Metodos Estadısticos para Datos de AltaDimension
Revolucion del Big Data −→ Creciente interes en metodos de reduccion yseleccion de variables (Varian, 2014) −→ Clasificacion y Prediccion.
Numeros especiales: Journal of Economics Perspectives (vol. 28 (2),2014), Journal of Econometrics (vol. 186 (2), 2015), The EconometricsJournal (vol. 19(1), 2016), Journal of Business and Economic Statistics(vol. 34, 2016).
Aplicaciones usuales:
Construccion de ındices SES para describir o predecir diferentescomportamientos o fenomenos sociales (e.g. Murasko, 2009;Kolenikov & Angeles, 2009).Analisis de pobreza y bienestar vıa clasificacion (e.g. Feeny et al.,2014; Sosa Escudero et al., 2015).Reduccion o Seleccion de variables en modelos de precios hedonicos(e.g. Galbraith & Hodgson 2012, Panduro & Thorsen 2014; Ho,2016)Consumo y sistemas de demanda (e.g. Hoderlein & Lewbel, 2012;Bajari et al.,2015)

Economıa y Metodos Estadısticos para Datos de AltaDimension
Revolucion del Big Data −→ Creciente interes en metodos de reduccion yseleccion de variables (Varian, 2014) −→ Clasificacion y Prediccion.
Numeros especiales: Journal of Economics Perspectives (vol. 28 (2),2014), Journal of Econometrics (vol. 186 (2), 2015), The EconometricsJournal (vol. 19(1), 2016), Journal of Business and Economic Statistics(vol. 34, 2016).
Aplicaciones usuales:
Construccion de ındices SES para describir o predecir diferentescomportamientos o fenomenos sociales (e.g. Murasko, 2009;Kolenikov & Angeles, 2009).Analisis de pobreza y bienestar vıa clasificacion (e.g. Feeny et al.,2014; Sosa Escudero et al., 2015).Reduccion o Seleccion de variables en modelos de precios hedonicos(e.g. Galbraith & Hodgson 2012, Panduro & Thorsen 2014; Ho,2016)Consumo y sistemas de demanda (e.g. Hoderlein & Lewbel, 2012;Bajari et al.,2015)

Economıa y Metodos Estadısticos para Datos de AltaDimension
Revolucion del Big Data −→ Creciente interes en metodos de reduccion yseleccion de variables (Varian, 2014) −→ Clasificacion y Prediccion.
Numeros especiales: Journal of Economics Perspectives (vol. 28 (2),2014), Journal of Econometrics (vol. 186 (2), 2015), The EconometricsJournal (vol. 19(1), 2016), Journal of Business and Economic Statistics(vol. 34, 2016).
Aplicaciones usuales:
Construccion de ındices SES para describir o predecir diferentescomportamientos o fenomenos sociales (e.g. Murasko, 2009;Kolenikov & Angeles, 2009).Analisis de pobreza y bienestar vıa clasificacion (e.g. Feeny et al.,2014; Sosa Escudero et al., 2015).Reduccion o Seleccion de variables en modelos de precios hedonicos(e.g. Galbraith & Hodgson 2012, Panduro & Thorsen 2014; Ho,2016)Consumo y sistemas de demanda (e.g. Hoderlein & Lewbel, 2012;Bajari et al.,2015)

Problema Aplicado a Considerar
Asignar una ayuda economica a hogares o individuos que viven ensituacion de pobreza
Polıticas o Programas Focalizados(Ejemplos reales: CAS in Chile, Sisben en Colombia, SISFOH en
Peru, Tekopora en Paraguay, SIERP en Honduras, PANES enUruguay, entre otros)
Aquı pobreza es pobreza monetaria
Un hogar j es pobre si su ingreso monetario Yj no alcanza paracubrir las necesidades basicas, i.e. Yj ≤ LP donde LP es el ingresoque determina la lınea de pobreza.

Problema Aplicado a Considerar
Asignar una ayuda economica a hogares o individuos que viven ensituacion de pobreza
Polıticas o Programas Focalizados(Ejemplos reales: CAS in Chile, Sisben en Colombia, SISFOH en
Peru, Tekopora en Paraguay, SIERP en Honduras, PANES enUruguay, entre otros)
Aquı pobreza es pobreza monetaria
Un hogar j es pobre si su ingreso monetario Yj no alcanza paracubrir las necesidades basicas, i.e. Yj ≤ LP donde LP es el ingresoque determina la lınea de pobreza.

Problema Aplicado a Considerar
Asignar una ayuda economica a hogares o individuos que viven ensituacion de pobreza
Polıticas o Programas Focalizados(Ejemplos reales: CAS in Chile, Sisben en Colombia, SISFOH en
Peru, Tekopora en Paraguay, SIERP en Honduras, PANES enUruguay, entre otros)
Aquı pobreza es pobreza monetaria
Un hogar j es pobre si su ingreso monetario Yj no alcanza paracubrir las necesidades basicas, i.e. Yj ≤ LP donde LP es el ingresoque determina la lınea de pobreza.

Solucion con Situacion Ideal
Conocemos el valor exacto de ingreso monetario de cadahogar Si Yj ≤ LP le asigno la ayuda prevista.
Pero...
Existen varios problemas en la captacion del ingreso comomedida creıble o fiable (reporting biases):
Incentivos a revelar el valor verdadero.Uso del Gasto en Consumo −→ recoleccion costosa.Economıa informal u oculta (ej. pagos en especie(trueque),auto-provision).Estacionalidad (ej. changas, empleos rurales).
Elevado costos en obtener una medida fiable del ingreso paratodos los hogares que quiero evaluar

Solucion con Situacion Ideal
Conocemos el valor exacto de ingreso monetario de cadahogar Si Yj ≤ LP le asigno la ayuda prevista.
Pero...
Existen varios problemas en la captacion del ingreso comomedida creıble o fiable (reporting biases):
Incentivos a revelar el valor verdadero.Uso del Gasto en Consumo −→ recoleccion costosa.Economıa informal u oculta (ej. pagos en especie(trueque),auto-provision).Estacionalidad (ej. changas, empleos rurales).
Elevado costos en obtener una medida fiable del ingreso paratodos los hogares que quiero evaluar

Solucion con Situacion Ideal
Conocemos el valor exacto de ingreso monetario de cadahogar Si Yj ≤ LP le asigno la ayuda prevista.
Pero...
Existen varios problemas en la captacion del ingreso comomedida creıble o fiable (reporting biases):
Incentivos a revelar el valor verdadero.Uso del Gasto en Consumo −→ recoleccion costosa.Economıa informal u oculta (ej. pagos en especie(trueque),auto-provision).Estacionalidad (ej. changas, empleos rurales).
Elevado costos en obtener una medida fiable del ingreso paratodos los hogares que quiero evaluar

Solucion con Situacion Ideal
Conocemos el valor exacto de ingreso monetario de cadahogar Si Yj ≤ LP le asigno la ayuda prevista.
Pero...
Existen varios problemas en la captacion del ingreso comomedida creıble o fiable (reporting biases):
Incentivos a revelar el valor verdadero.Uso del Gasto en Consumo −→ recoleccion costosa.Economıa informal u oculta (ej. pagos en especie(trueque),auto-provision).Estacionalidad (ej. changas, empleos rurales).
Elevado costos en obtener una medida fiable del ingreso paratodos los hogares que quiero evaluar

¿Que hacer?
Construir un ındice (I ∈ R) como proxy de ingreso o riqueza
Si I ≤ LP∗ asigno la ayuda (para un LP∗ determinado)

El como
Miramos otras variables del hogar, de observacion mas directa y engeneral mas faciles de recolectar, que en conjunto son proxy delbienestar economico del mismo. Ej:
Vivienda (materiales del techo, materiales del suelo, forma deacceso al agua potable, etc.).Activos fısicos (tiene radio?, tiene TV?, tiene internet? tienemoto? tienen auto?)Otras socio-demograficas (cant. de miembros, escolaridad,situacion ocupacional, etc.)
Definicion del Indice (I )
Sean X1, . . . ,Xp diferentes variables que caracterizan al hogar enterminos economicos y sociales, se define por ındice de estatussocieconomico (SES), a la combinacion lineal de dichas variablespara un determinado vector de pesos fijos (a1, . . . , ap), i.e.
I = a1X1 + · · ·+ apXp = aTX

El como
Miramos otras variables del hogar, de observacion mas directa y engeneral mas faciles de recolectar, que en conjunto son proxy delbienestar economico del mismo. Ej:
Vivienda (materiales del techo, materiales del suelo, forma deacceso al agua potable, etc.).Activos fısicos (tiene radio?, tiene TV?, tiene internet? tienemoto? tienen auto?)Otras socio-demograficas (cant. de miembros, escolaridad,situacion ocupacional, etc.)
Definicion del Indice (I )
Sean X1, . . . ,Xp diferentes variables que caracterizan al hogar enterminos economicos y sociales, se define por ındice de estatussocieconomico (SES), a la combinacion lineal de dichas variablespara un determinado vector de pesos fijos (a1, . . . , ap), i.e.
I = a1X1 + · · ·+ apXp = aTX

El como
Miramos otras variables del hogar, de observacion mas directa y engeneral mas faciles de recolectar, que en conjunto son proxy delbienestar economico del mismo. Ej:
Vivienda (materiales del techo, materiales del suelo, forma deacceso al agua potable, etc.).Activos fısicos (tiene radio?, tiene TV?, tiene internet? tienemoto? tienen auto?)Otras socio-demograficas (cant. de miembros, escolaridad,situacion ocupacional, etc.)
Definicion del Indice (I )
Sean X1, . . . ,Xp diferentes variables que caracterizan al hogar enterminos economicos y sociales, se define por ındice de estatussocieconomico (SES), a la combinacion lineal de dichas variablespara un determinado vector de pesos fijos (a1, . . . , ap), i.e.
I = a1X1 + · · ·+ apXp = aTX

Solucion con Situacion Casi Ideal
Un Ser omnisciente me dicta los verdaderos valores de lospesos: a∗1, a
∗2, . . . , a
∗p.
Para un cierto hogar j miro sus X ′s, i.e. si tiene auto,internet, TV, materiales del techo, de los pisos, etc.
Luego computo el ındicea∗1auto + a∗2internet + a∗3TV + a∗4techo + a∗5pisos + . . . y yapuedo clasificar.
Vida real...
Con una muestra (denominada de entrenamiento) deboestimar (a1, . . . , ap) y que me de un buen ındice paraimplementar de mejor manera el programa focalizado (i.e.evitar falsos-positivos o falsos-negativos)

Solucion con Situacion Casi Ideal
Un Ser omnisciente me dicta los verdaderos valores de lospesos: a∗1, a
∗2, . . . , a
∗p.
Para un cierto hogar j miro sus X ′s, i.e. si tiene auto,internet, TV, materiales del techo, de los pisos, etc.
Luego computo el ındicea∗1auto + a∗2internet + a∗3TV + a∗4techo + a∗5pisos + . . . y yapuedo clasificar.
Vida real...
Con una muestra (denominada de entrenamiento) deboestimar (a1, . . . , ap) y que me de un buen ındice paraimplementar de mejor manera el programa focalizado (i.e.evitar falsos-positivos o falsos-negativos)

Solucion con Situacion Casi Ideal
Un Ser omnisciente me dicta los verdaderos valores de lospesos: a∗1, a
∗2, . . . , a
∗p.
Para un cierto hogar j miro sus X ′s, i.e. si tiene auto,internet, TV, materiales del techo, de los pisos, etc.
Luego computo el ındicea∗1auto + a∗2internet + a∗3TV + a∗4techo + a∗5pisos + . . . y yapuedo clasificar.
Vida real...
Con una muestra (denominada de entrenamiento) deboestimar (a1, . . . , ap) y que me de un buen ındice paraimplementar de mejor manera el programa focalizado (i.e.evitar falsos-positivos o falsos-negativos)

Solucion con Situacion Casi Ideal
Un Ser omnisciente me dicta los verdaderos valores de lospesos: a∗1, a
∗2, . . . , a
∗p.
Para un cierto hogar j miro sus X ′s, i.e. si tiene auto,internet, TV, materiales del techo, de los pisos, etc.
Luego computo el ındicea∗1auto + a∗2internet + a∗3TV + a∗4techo + a∗5pisos + . . . y yapuedo clasificar.
Vida real...
Con una muestra (denominada de entrenamiento) deboestimar (a1, . . . , ap) y que me de un buen ındice paraimplementar de mejor manera el programa focalizado (i.e.evitar falsos-positivos o falsos-negativos)

Solucion con Situacion Casi Ideal
Un Ser omnisciente me dicta los verdaderos valores de lospesos: a∗1, a
∗2, . . . , a
∗p.
Para un cierto hogar j miro sus X ′s, i.e. si tiene auto,internet, TV, materiales del techo, de los pisos, etc.
Luego computo el ındicea∗1auto + a∗2internet + a∗3TV + a∗4techo + a∗5pisos + . . . y yapuedo clasificar.
Vida real...
Con una muestra (denominada de entrenamiento) deboestimar (a1, . . . , ap) y que me de un buen ındice paraimplementar de mejor manera el programa focalizado (i.e.evitar falsos-positivos o falsos-negativos)

Solucion Real Convencional: Uso de ComponentesPrincipales
Idea de PCA: Para las variables originales X = (X1, . . . ,Xp)T ,PCA define un nuevo conjunto de k variables (k ≤ p),(P1, . . . ,Pk) no correlacionadas y con varianza decreciente,dadas por Pj = aT
j X siendo aj el j-esimo autovector de lamatriz Cov(X).
PCA en ındices: Se toma el autovalor corresponiente al mayorautovalor:
I ≡ P1 = a11X1 + a12X2 + · · ·+ a1pXp
donde a1 = (a11, a12, . . . , a1p)T es el autovector del mayorautovalor λ1 = Var(P1).

Solucion Real Convencional: Uso de ComponentesPrincipales
Idea de PCA: Para las variables originales X = (X1, . . . ,Xp)T ,PCA define un nuevo conjunto de k variables (k ≤ p),(P1, . . . ,Pk) no correlacionadas y con varianza decreciente,dadas por Pj = aT
j X siendo aj el j-esimo autovector de lamatriz Cov(X).
PCA en ındices: Se toma el autovalor corresponiente al mayorautovalor:
I ≡ P1 = a11X1 + a12X2 + · · ·+ a1pXp
donde a1 = (a11, a12, . . . , a1p)T es el autovector del mayorautovalor λ1 = Var(P1).

Solucion Real Convencional: Uso de ComponentesPrincipales
Idea de PCA: Para las variables originales X = (X1, . . . ,Xp)T ,PCA define un nuevo conjunto de k variables (k ≤ p),(P1, . . . ,Pk) no correlacionadas y con varianza decreciente,dadas por Pj = aT
j X siendo aj el j-esimo autovector de lamatriz Cov(X).
PCA en ındices: Se toma el autovalor corresponiente al mayorautovalor:
I ≡ P1 = a11X1 + a12X2 + · · ·+ a1pXp
donde a1 = (a11, a12, . . . , a1p)T es el autovector del mayorautovalor λ1 = Var(P1).

Ventajas y Desventajas del PCA
Buen criterio para la obtencion de los pesos a’s del I : Logroreducir la informacion de las X en una sola dimensionmaximizando la varianza (informacion contenida en ellas), sinestar correlacionada con las componentes restantes.
Facil de aplicar y comprender.
Pero...
Que ocurre si en la muestra de entrenamiento tenemosinformacion de la variable respuesta que buscamos predecir(e.j. ingreso o pobreza)? PCA no usa tal informacion!

Ventajas y Desventajas del PCA
Buen criterio para la obtencion de los pesos a’s del I : Logroreducir la informacion de las X en una sola dimensionmaximizando la varianza (informacion contenida en ellas), sinestar correlacionada con las componentes restantes.
Facil de aplicar y comprender.
Pero...
Que ocurre si en la muestra de entrenamiento tenemosinformacion de la variable respuesta que buscamos predecir(e.j. ingreso o pobreza)? PCA no usa tal informacion!

Ventajas y Desventajas del PCA
Buen criterio para la obtencion de los pesos a’s del I : Logroreducir la informacion de las X en una sola dimensionmaximizando la varianza (informacion contenida en ellas), sinestar correlacionada con las componentes restantes.
Facil de aplicar y comprender.
Pero...
Que ocurre si en la muestra de entrenamiento tenemosinformacion de la variable respuesta que buscamos predecir(e.j. ingreso o pobreza)? PCA no usa tal informacion!

Toy Example
Supongamos que queremos predecir la capacidad de ahorro(Y ) con dos variables: el ingreso (X1) y el gasto total ( X2):
X = (X1,X2)T , X ∼ N
(0,
(1 rr 1
) )con r cercano a 1.
modelo en mente: Y = X1 − X2 + ε
1era Componente Principal: X1 + X2 (con peso 1+r2 )
2da Componente Principal: X1 − X2 (con peso 1−r2 )

Nuevo Enfoque: Usando informacion de la respuesta
Reduccion Suficiente de Dimensiones (RSD)
Reducir la dimension de un vector de predictores X ∈ R sin perderinformacion sobre la respuesta Y
Si quiero predecir el nivel de ingreso per capita en el hogar o si estees pobre o no (i.e. Y = 1, 0) tomando variables de la calidad de lavivienda y de la posesion de activos economicos y sociales, uso lainformacion de dicha respuesta (ingreso o pobreza) contenida en lamuestra de entrenamiento, para elegir los (a1, . . . , ap) y asıconstruir el ındice I y clasificar a cualquier hogar I contiene lamayor informacion posible de X que es relevante para Y .

Nuevo Enfoque: Usando informacion de la respuesta
Reduccion Suficiente de Dimensiones (RSD)
Reducir la dimension de un vector de predictores X ∈ R sin perderinformacion sobre la respuesta Y
Si quiero predecir el nivel de ingreso per capita en el hogar o si estees pobre o no (i.e. Y = 1, 0) tomando variables de la calidad de lavivienda y de la posesion de activos economicos y sociales, uso lainformacion de dicha respuesta (ingreso o pobreza) contenida en lamuestra de entrenamiento, para elegir los (a1, . . . , ap) y asıconstruir el ındice I y clasificar a cualquier hogar I contiene lamayor informacion posible de X que es relevante para Y .

Reduccion Suficiente de Dimensiones
Para X ∈ Rp, una reduccion R(X) ∈ Rd , d ≤ p, es suficientepara la regresion de Y |X
X puede ser reemplazado por R(X) para la regresion de Y |Xsin perder informacion sobre Y
(i.e. Y |X ∼ Y |R(X) )
X|(R(X),Y ) ∼ X|R(X)
RSD Podemos mirar la distribucion de X|Y sin necesidadde asumir una distribucion o modelo para Y |X (Cook, 2007).

Reduccion Suficiente de Dimensiones
Para X ∈ Rp, una reduccion R(X) ∈ Rd , d ≤ p, es suficientepara la regresion de Y |X
X puede ser reemplazado por R(X) para la regresion de Y |Xsin perder informacion sobre Y
(i.e. Y |X ∼ Y |R(X) )
X|(R(X),Y ) ∼ X|R(X)
RSD Podemos mirar la distribucion de X|Y sin necesidadde asumir una distribucion o modelo para Y |X (Cook, 2007).

Reduccion Suficiente de Dimensiones
Para X ∈ Rp, una reduccion R(X) ∈ Rd , d ≤ p, es suficientepara la regresion de Y |X
X puede ser reemplazado por R(X) para la regresion de Y |Xsin perder informacion sobre Y
(i.e. Y |X ∼ Y |R(X) )
X|(R(X),Y ) ∼ X|R(X)
RSD Podemos mirar la distribucion de X|Y sin necesidadde asumir una distribucion o modelo para Y |X (Cook, 2007).

Reduccion Suficiente de Dimensiones
Para X ∈ Rp, una reduccion R(X) ∈ Rd , d ≤ p, es suficientepara la regresion de Y |X
X puede ser reemplazado por R(X) para la regresion de Y |Xsin perder informacion sobre Y
(i.e. Y |X ∼ Y |R(X) )
X|(R(X),Y ) ∼ X|R(X)
RSD Podemos mirar la distribucion de X|Y sin necesidadde asumir una distribucion o modelo para Y |X (Cook, 2007).

Reduccion suficiente de dimensiones
Especial interes en reducciones lineales: R(X) = αTX,α ∈ Rp×d
Si A es d × d invertible, αTX y AαTX tienen la mismainformacion sobre Y miramos el span(α) ≡ Sα(Subespacio de reduccion de dimensiones).
Metodologıa de RSD basada en la regresion inversa de Xsobre Y (X|Y ) sin necesidad de asumir alguna distribucionpara Y |X.
Estimacion: para predictores continuos (ej. caso de X|Ynormal, Cook & Forzani, 2008; 2009). Extensiones parapredictores no (necesariamente) continuos, Cook & Li (2009)y Bura, Duarte & Forzani (2015) para FE.

Reduccion suficiente de dimensiones
Especial interes en reducciones lineales: R(X) = αTX,α ∈ Rp×d
Si A es d × d invertible, αTX y AαTX tienen la mismainformacion sobre Y miramos el span(α) ≡ Sα(Subespacio de reduccion de dimensiones).
Metodologıa de RSD basada en la regresion inversa de Xsobre Y (X|Y ) sin necesidad de asumir alguna distribucionpara Y |X.
Estimacion: para predictores continuos (ej. caso de X|Ynormal, Cook & Forzani, 2008; 2009). Extensiones parapredictores no (necesariamente) continuos, Cook & Li (2009)y Bura, Duarte & Forzani (2015) para FE.

Reduccion suficiente de dimensiones
Especial interes en reducciones lineales: R(X) = αTX,α ∈ Rp×d
Si A es d × d invertible, αTX y AαTX tienen la mismainformacion sobre Y miramos el span(α) ≡ Sα(Subespacio de reduccion de dimensiones).
Metodologıa de RSD basada en la regresion inversa de Xsobre Y (X|Y ) sin necesidad de asumir alguna distribucionpara Y |X.
Estimacion: para predictores continuos (ej. caso de X|Ynormal, Cook & Forzani, 2008; 2009). Extensiones parapredictores no (necesariamente) continuos, Cook & Li (2009)y Bura, Duarte & Forzani (2015) para FE.

Reduccion suficiente de dimensiones
Especial interes en reducciones lineales: R(X) = αTX,α ∈ Rp×d
Si A es d × d invertible, αTX y AαTX tienen la mismainformacion sobre Y miramos el span(α) ≡ Sα(Subespacio de reduccion de dimensiones).
Metodologıa de RSD basada en la regresion inversa de Xsobre Y (X|Y ) sin necesidad de asumir alguna distribucionpara Y |X.
Estimacion: para predictores continuos (ej. caso de X|Ynormal, Cook & Forzani, 2008; 2009). Extensiones parapredictores no (necesariamente) continuos, Cook & Li (2009)y Bura, Duarte & Forzani (2015) para FE.

Caracterısticas de las variables socio-economicas
Ejemplos:
pisos= 1 (tierra/ladrillos sueltos), 2 (cemento o ladrillo fijo), 3(mosaicos o baldosas), 4(madera/ceramica y alfombra).
techo= 1 (cana o paja), 2 (chapa de carton), 3 (chapa defibrocemento o de metal),...
agua= 1 (perforacion con bomba manual), 2 (perforacion conbomba a motor), 3( red publica).
bano= 1 (letrina), 2 (inodoro sin boton o cadena -balde), 3(inodoro boton/cadena/mochila).
TV-CPU-auto-moto= 1 (no tiene), 2 (si tiene).
escolaridad=: 1 (sin inst.), 2(primaria incompleta), 3 (primariacompleta), 4 (secundaria incomp.),..
Variables Categoricas Ordinales

Caracterısticas de las variables socio-economicas
Ejemplos:
pisos= 1 (tierra/ladrillos sueltos), 2 (cemento o ladrillo fijo), 3(mosaicos o baldosas), 4(madera/ceramica y alfombra).
techo= 1 (cana o paja), 2 (chapa de carton), 3 (chapa defibrocemento o de metal),...
agua= 1 (perforacion con bomba manual), 2 (perforacion conbomba a motor), 3( red publica).
bano= 1 (letrina), 2 (inodoro sin boton o cadena -balde), 3(inodoro boton/cadena/mochila).
TV-CPU-auto-moto= 1 (no tiene), 2 (si tiene).
escolaridad=: 1 (sin inst.), 2(primaria incompleta), 3 (primariacompleta), 4 (secundaria incomp.),..
Variables Categoricas Ordinales

Caracterısticas de las variables socio-economicas
Ejemplos:
pisos= 1 (tierra/ladrillos sueltos), 2 (cemento o ladrillo fijo), 3(mosaicos o baldosas), 4(madera/ceramica y alfombra).
techo= 1 (cana o paja), 2 (chapa de carton), 3 (chapa defibrocemento o de metal),...
agua= 1 (perforacion con bomba manual), 2 (perforacion conbomba a motor), 3( red publica).
bano= 1 (letrina), 2 (inodoro sin boton o cadena -balde), 3(inodoro boton/cadena/mochila).
TV-CPU-auto-moto= 1 (no tiene), 2 (si tiene).
escolaridad=: 1 (sin inst.), 2(primaria incompleta), 3 (primariacompleta), 4 (secundaria incomp.),..
Variables Categoricas Ordinales

Caracterısticas de las variables socio-economicas
Ejemplos:
pisos= 1 (tierra/ladrillos sueltos), 2 (cemento o ladrillo fijo), 3(mosaicos o baldosas), 4(madera/ceramica y alfombra).
techo= 1 (cana o paja), 2 (chapa de carton), 3 (chapa defibrocemento o de metal),...
agua= 1 (perforacion con bomba manual), 2 (perforacion conbomba a motor), 3( red publica).
bano= 1 (letrina), 2 (inodoro sin boton o cadena -balde), 3(inodoro boton/cadena/mochila).
TV-CPU-auto-moto= 1 (no tiene), 2 (si tiene).
escolaridad=: 1 (sin inst.), 2(primaria incompleta), 3 (primariacompleta), 4 (secundaria incomp.),..
Variables Categoricas Ordinales

Caracterısticas de las variables socio-economicas
Ejemplos:
pisos= 1 (tierra/ladrillos sueltos), 2 (cemento o ladrillo fijo), 3(mosaicos o baldosas), 4(madera/ceramica y alfombra).
techo= 1 (cana o paja), 2 (chapa de carton), 3 (chapa defibrocemento o de metal),...
agua= 1 (perforacion con bomba manual), 2 (perforacion conbomba a motor), 3( red publica).
bano= 1 (letrina), 2 (inodoro sin boton o cadena -balde), 3(inodoro boton/cadena/mochila).
TV-CPU-auto-moto= 1 (no tiene), 2 (si tiene).
escolaridad=: 1 (sin inst.), 2(primaria incompleta), 3 (primariacompleta), 4 (secundaria incomp.),..
Variables Categoricas Ordinales

Caracterısticas de las variables socio-economicas
Ejemplos:
pisos= 1 (tierra/ladrillos sueltos), 2 (cemento o ladrillo fijo), 3(mosaicos o baldosas), 4(madera/ceramica y alfombra).
techo= 1 (cana o paja), 2 (chapa de carton), 3 (chapa defibrocemento o de metal),...
agua= 1 (perforacion con bomba manual), 2 (perforacion conbomba a motor), 3( red publica).
bano= 1 (letrina), 2 (inodoro sin boton o cadena -balde), 3(inodoro boton/cadena/mochila).
TV-CPU-auto-moto= 1 (no tiene), 2 (si tiene).
escolaridad=: 1 (sin inst.), 2(primaria incompleta), 3 (primariacompleta), 4 (secundaria incomp.),..
Variables Categoricas Ordinales

Caracterısticas de las variables socio-economicas
Ejemplos:
pisos= 1 (tierra/ladrillos sueltos), 2 (cemento o ladrillo fijo), 3(mosaicos o baldosas), 4(madera/ceramica y alfombra).
techo= 1 (cana o paja), 2 (chapa de carton), 3 (chapa defibrocemento o de metal),...
agua= 1 (perforacion con bomba manual), 2 (perforacion conbomba a motor), 3( red publica).
bano= 1 (letrina), 2 (inodoro sin boton o cadena -balde), 3(inodoro boton/cadena/mochila).
TV-CPU-auto-moto= 1 (no tiene), 2 (si tiene).
escolaridad=: 1 (sin inst.), 2(primaria incompleta), 3 (primariacompleta), 4 (secundaria incomp.),..
Variables Categoricas Ordinales

Problema Estadıstico
Desarrollar un metodo de reduccion basado en el enfoque de RSDpara X ordinales
Forzani, Garcıa Arancibia, LLop & Tomassi (2016)
PCA para ordinales, ej. Kolenikov & Angeles (2009).

Problema Estadıstico
Desarrollar un metodo de reduccion basado en el enfoque de RSDpara X ordinales
Forzani, Garcıa Arancibia, LLop & Tomassi (2016)
PCA para ordinales, ej. Kolenikov & Angeles (2009).

Problema Estadıstico
Desarrollar un metodo de reduccion basado en el enfoque de RSDpara X ordinales
Forzani, Garcıa Arancibia, LLop & Tomassi (2016)
PCA para ordinales, ej. Kolenikov & Angeles (2009).

Modelo de Variable Latente
p variables latentes Z = (Z1,Z2, . . . ,Zp)T continuas:
Z|Y ∼ N(µY ,∆)
conjunto de umbrales θ(j) para cada j = 1, 2, . . . , p
−∞ = θ(j)0 < θ
(j)1 < · · · < θ
(j)Kj−1 < θ
(j)Gj
= +∞
Xj = g ⇐⇒ Zj ∈ [θ(j)g−1, θ
(j)g )
Pr(Xj = g |Y ) = Pr(θ(j)g−1 ≤ Zj < θ
(j)g |Y )
Θ.
= {θ(1), . . . ,θ(p)} = {θ(1)0 , . . . , θ
(1)G1, . . . . . . , θ
(p)0 , . . . , θ
(p)Gp}
Identificabilidad: [∆]jj.
= δj = 1 y E (Z) = 0.

Modelo de Variable Latente
p variables latentes Z = (Z1,Z2, . . . ,Zp)T continuas:
Z|Y ∼ N(µY ,∆)
conjunto de umbrales θ(j) para cada j = 1, 2, . . . , p
−∞ = θ(j)0 < θ
(j)1 < · · · < θ
(j)Kj−1 < θ
(j)Gj
= +∞
Xj = g ⇐⇒ Zj ∈ [θ(j)g−1, θ
(j)g )
Pr(Xj = g |Y ) = Pr(θ(j)g−1 ≤ Zj < θ
(j)g |Y )
Θ.
= {θ(1), . . . ,θ(p)} = {θ(1)0 , . . . , θ
(1)G1, . . . . . . , θ
(p)0 , . . . , θ
(p)Gp}
Identificabilidad: [∆]jj.
= δj = 1 y E (Z) = 0.

Modelo de Variable Latente
p variables latentes Z = (Z1,Z2, . . . ,Zp)T continuas:
Z|Y ∼ N(µY ,∆)
conjunto de umbrales θ(j) para cada j = 1, 2, . . . , p
−∞ = θ(j)0 < θ
(j)1 < · · · < θ
(j)Kj−1 < θ
(j)Gj
= +∞
Xj = g ⇐⇒ Zj ∈ [θ(j)g−1, θ
(j)g )
Pr(Xj = g |Y ) = Pr(θ(j)g−1 ≤ Zj < θ
(j)g |Y )
Θ.
= {θ(1), . . . ,θ(p)} = {θ(1)0 , . . . , θ
(1)G1, . . . . . . , θ
(p)0 , . . . , θ
(p)Gp}
Identificabilidad: [∆]jj.
= δj = 1 y E (Z) = 0.

Modelo de Variable Latente
p variables latentes Z = (Z1,Z2, . . . ,Zp)T continuas:
Z|Y ∼ N(µY ,∆)
conjunto de umbrales θ(j) para cada j = 1, 2, . . . , p
−∞ = θ(j)0 < θ
(j)1 < · · · < θ
(j)Kj−1 < θ
(j)Gj
= +∞
Xj = g ⇐⇒ Zj ∈ [θ(j)g−1, θ
(j)g )
Pr(Xj = g |Y ) = Pr(θ(j)g−1 ≤ Zj < θ
(j)g |Y )
Θ.
= {θ(1), . . . ,θ(p)} = {θ(1)0 , . . . , θ
(1)G1, . . . . . . , θ
(p)0 , . . . , θ
(p)Gp}
Identificabilidad: [∆]jj.
= δj = 1 y E (Z) = 0.

Relacion entre ordinales observadas y latentes continuas
Pr(Xj = g |Y ) = Pr(θ(j)g−1 ≤ Zj < θ
(j)g |Y )
KARINA RDZ-NAVARRO Y RODRIGO A. ASÚN
4
constituyen los puntos de corte de la variable continua que dieron lugar a la distribución de frecuencias observada en la variable ordinal. De este modo, distintos valores de parámetros umbrales darán origen a distintas distribuciones de las variables ordinales efectivamente medidas, como se muestra en la Figura 1.
Figura 1. Relación entre la variable continua normal
subyacente y las variables observadas ordinales. De este modo, en lugar de centrarse en el cálculo de la correlación entre las variables observadas, las correlaciones policóricas permiten estimar la relación existente entre las variables continuas subyacentes, de modo que la estimación de la magnitud de la relación entre las variables no se vea afectada por el grado de asimetría introducido por la recodificación arbitraria de las variables que generan los parámetros umbrales. En consecuencia, actualmente se recomienda que toda vez que se esté en presencia de ítems ordinales, se empleen matrices de correlaciones policóricas para estimar la magnitud de la relación entre las variables. El interés de los científicos sociales no sólo se centra en el análisis de la relación entre variables observadas sino principalmente en el análisis de variables latentes. Como se mencionó previamente, las variables latentes son constructos que no tienen un correlato empírico directo, por lo que deben ser medidos a partir de múltiples indicadores o ítems que son manifestaciones empíricas de la variable latente. Así por ejemplo, en investigación por encuestas, se suelen medir variables latentes a través de escalas tipo Likert, es decir, de un conjunto preguntas simples con respuesta cerrada que se suponen miden el mismo constructo complejo, ante las cuales las personas manifiestan su grado de acuerdo seleccionando una respuesta dentro de una serie de categorías generalmente ordenadas en función de su intensidad (Likert, 1932). Se ha demostrado que el uso múltiples preguntas o ítems para la medición de constructos latentes contiene menos error de medida que intentar medir una variable latente con una sola pregunta, pues los errores de medida introducidos en el fraseo o la respuesta a cada uno de ellos tiende a compensarse con los errores en direcciones opuestas de los otros ítems (Likert, Roslow & Murphy, 1934), pero ello sólo es cierto si es que se puede obtener evidencia de que realmente se está midiendo el mismo constructo latente con el conjunto de

Modelo
Sea SΓ = span{µY − E(µY )|Y ∈ Y}.Si Γ ∈ Rp×d , con d ≤ p, es una matriz semi-ortogonal, cuyas columnasforman una base para el subespacio d-dimensional SΓ, luego (por Cook yForzani, 2008)
Z|Y = ΓνY + ε
Donde νY = ΓTµY ∈ Rd con E(νY ) = 0, var(νY ) > 0 y ε ∼ N(0,∆)
Aquı modelamosνY = ξ{fY − E(fY )}
donde fY ∈ Rr es un vector de r funciones conocidas de Y tales queE((fY − E(fY )(fY − E(fY ))T ) conforma una matriz definida positiva yξ ∈ Rd×r es una matriz de rango completo d , con d ≤ r
Luego:Z|Y = Γξ{fY − E(fY )}+ ε

Modelo
Sea SΓ = span{µY − E(µY )|Y ∈ Y}.Si Γ ∈ Rp×d , con d ≤ p, es una matriz semi-ortogonal, cuyas columnasforman una base para el subespacio d-dimensional SΓ, luego (por Cook yForzani, 2008)
Z|Y = ΓνY + ε
Donde νY = ΓTµY ∈ Rd con E(νY ) = 0, var(νY ) > 0 y ε ∼ N(0,∆)
Aquı modelamosνY = ξ{fY − E(fY )}
donde fY ∈ Rr es un vector de r funciones conocidas de Y tales queE((fY − E(fY )(fY − E(fY ))T ) conforma una matriz definida positiva yξ ∈ Rd×r es una matriz de rango completo d , con d ≤ r
Luego:Z|Y = Γξ{fY − E(fY )}+ ε

Modelo
Sea SΓ = span{µY − E(µY )|Y ∈ Y}.Si Γ ∈ Rp×d , con d ≤ p, es una matriz semi-ortogonal, cuyas columnasforman una base para el subespacio d-dimensional SΓ, luego (por Cook yForzani, 2008)
Z|Y = ΓνY + ε
Donde νY = ΓTµY ∈ Rd con E(νY ) = 0, var(νY ) > 0 y ε ∼ N(0,∆)
Aquı modelamosνY = ξ{fY − E(fY )}
donde fY ∈ Rr es un vector de r funciones conocidas de Y tales queE((fY − E(fY )(fY − E(fY ))T ) conforma una matriz definida positiva yξ ∈ Rd×r es una matriz de rango completo d , con d ≤ r
Luego:Z|Y = Γξ{fY − E(fY )}+ ε

Modelo
Sea SΓ = span{µY − E(µY )|Y ∈ Y}.Si Γ ∈ Rp×d , con d ≤ p, es una matriz semi-ortogonal, cuyas columnasforman una base para el subespacio d-dimensional SΓ, luego (por Cook yForzani, 2008)
Z|Y = ΓνY + ε
Donde νY = ΓTµY ∈ Rd con E(νY ) = 0, var(νY ) > 0 y ε ∼ N(0,∆)
Aquı modelamosνY = ξ{fY − E(fY )}
donde fY ∈ Rr es un vector de r funciones conocidas de Y tales queE((fY − E(fY )(fY − E(fY ))T ) conforma una matriz definida positiva yξ ∈ Rd×r es una matriz de rango completo d , con d ≤ r
Luego:Z|Y = Γξ{fY − E(fY )}+ ε

Reduccion propuesta para predictores ordinales
Z|Y ∼ N(µY ,∆)⇔ Z|Y ∼ N(Γξ(fY − fY ),∆)
Cook and Forzani (2008)
R(Z) = ΓT∆−1Z, con span{∆−1Γ} = span{µY − E (µY ),Y ∈ Y} esuna RSD para Y |Z
Reduccion Supervisada para Y |XUna reduccion para la regresion Y |X is
R(X) = αTE (Z|X) ∈ Rd
donde span{α} = ∆−1span{µY − µ,Y ∈ SY } y α ≡ ∆−1Γ.
Queremos Estimar span(α)!

Reduccion propuesta para predictores ordinales
Z|Y ∼ N(µY ,∆)⇔ Z|Y ∼ N(Γξ(fY − fY ),∆)
Cook and Forzani (2008)
R(Z) = ΓT∆−1Z, con span{∆−1Γ} = span{µY − E (µY ),Y ∈ Y} esuna RSD para Y |Z
Reduccion Supervisada para Y |XUna reduccion para la regresion Y |X is
R(X) = αTE (Z|X) ∈ Rd
donde span{α} = ∆−1span{µY − µ,Y ∈ SY } y α ≡ ∆−1Γ.
Queremos Estimar span(α)!

Reduccion propuesta para predictores ordinales
Z|Y ∼ N(µY ,∆)⇔ Z|Y ∼ N(Γξ(fY − fY ),∆)
Cook and Forzani (2008)
R(Z) = ΓT∆−1Z, con span{∆−1Γ} = span{µY − E (µY ),Y ∈ Y} esuna RSD para Y |Z
Reduccion Supervisada para Y |XUna reduccion para la regresion Y |X is
R(X) = αTE (Z|X) ∈ Rd
donde span{α} = ∆−1span{µY − µ,Y ∈ SY } y α ≡ ∆−1Γ.
Queremos Estimar span(α)!

Estimacion: PFCord
Sean yi , xi = (xi1, . . . , xip) las realizaciones de y y x ,respectivamente, i = 1, . . . , n.
Queremos maximizar:
n∑i=1
log fX(xi |yi ,Θ,∆,α, ξ)
↓Θ, α, ∆, ξ

Estimacion: PFCord
Sean yi , xi = (xi1, . . . , xip) las realizaciones de y y x ,respectivamente, i = 1, . . . , n.
Queremos maximizar:
n∑i=1
log fX(xi |yi ,Θ,∆,α, ξ)
↓Θ, α, ∆, ξ

Estimacion: PFCord
Por los supuestos del modelo fX,Z(xi , zi |yi ,∆,Θ,α, ξ) es igual a
(2π)−p/2|∆|−1/2e−12tr(∆−1
(zi−∆αξfyi )(zi−∆αξfyi )T )I{zi∈C(xi ,Θ)}
Necesitamos calcular
fX(xi |yi ,∆,Θ,α, ξ) =
∫fX,Z(xi , zi |yi ,∆,Θ,α, ξ) dzi !!!
Solucion: Algoritmo Iterativo:
EM Algorithm
Estimacion con seleccion de variable tipo LASSO en αsiguiendo a Chen et al. (2010)

Estimacion: PFCord
Por los supuestos del modelo fX,Z(xi , zi |yi ,∆,Θ,α, ξ) es igual a
(2π)−p/2|∆|−1/2e−12tr(∆−1
(zi−∆αξfyi )(zi−∆αξfyi )T )I{zi∈C(xi ,Θ)}
Necesitamos calcular
fX(xi |yi ,∆,Θ,α, ξ) =
∫fX,Z(xi , zi |yi ,∆,Θ,α, ξ) dzi !!!
Solucion: Algoritmo Iterativo:
EM Algorithm
Estimacion con seleccion de variable tipo LASSO en αsiguiendo a Chen et al. (2010)

Estimacion: PFCord
Por los supuestos del modelo fX,Z(xi , zi |yi ,∆,Θ,α, ξ) es igual a
(2π)−p/2|∆|−1/2e−12tr(∆−1
(zi−∆αξfyi )(zi−∆αξfyi )T )I{zi∈C(xi ,Θ)}
Necesitamos calcular
fX(xi |yi ,∆,Θ,α, ξ) =
∫fX,Z(xi , zi |yi ,∆,Θ,α, ξ) dzi !!!
Solucion: Algoritmo Iterativo:
EM Algorithm
Estimacion con seleccion de variable tipo LASSO en αsiguiendo a Chen et al. (2010)

Estimacion: PFCord
Por los supuestos del modelo fX,Z(xi , zi |yi ,∆,Θ,α, ξ) es igual a
(2π)−p/2|∆|−1/2e−12tr(∆−1
(zi−∆αξfyi )(zi−∆αξfyi )T )I{zi∈C(xi ,Θ)}
Necesitamos calcular
fX(xi |yi ,∆,Θ,α, ξ) =
∫fX,Z(xi , zi |yi ,∆,Θ,α, ξ) dzi !!!
Solucion: Algoritmo Iterativo:
EM Algorithm
Estimacion con seleccion de variable tipo LASSO en αsiguiendo a Chen et al. (2010)

Estimacion: PFCord
Por los supuestos del modelo fX,Z(xi , zi |yi ,∆,Θ,α, ξ) es igual a
(2π)−p/2|∆|−1/2e−12tr(∆−1
(zi−∆αξfyi )(zi−∆αξfyi )T )I{zi∈C(xi ,Θ)}
Necesitamos calcular
fX(xi |yi ,∆,Θ,α, ξ) =
∫fX,Z(xi , zi |yi ,∆,Θ,α, ξ) dzi !!!
Solucion: Algoritmo Iterativo:
EM Algorithm
Estimacion con seleccion de variable tipo LASSO en αsiguiendo a Chen et al. (2010)

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC).
11 predictores ordinales.
Heterogeneidad regional Estimacion de diferentes I para 5regiones (GBA, Pampeana, NOA, NEA y Patagonia).
2 tipos de respuesta (Y ): una continua (ingreso per capita delhogar) y una dicotomica (pobreza).
Estimacion: EM + seleccion de variables (Ver Forzani et al.,2016).
Evaluacion: El metodo aquı propuesto PFCord vs. 2 variantesdel PCA que contemplan predictores categoricos: no lineal(NLPCA) y con polychoric correlations (PCApoly)

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC).
11 predictores ordinales.
Heterogeneidad regional Estimacion de diferentes I para 5regiones (GBA, Pampeana, NOA, NEA y Patagonia).
2 tipos de respuesta (Y ): una continua (ingreso per capita delhogar) y una dicotomica (pobreza).
Estimacion: EM + seleccion de variables (Ver Forzani et al.,2016).
Evaluacion: El metodo aquı propuesto PFCord vs. 2 variantesdel PCA que contemplan predictores categoricos: no lineal(NLPCA) y con polychoric correlations (PCApoly)

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC).
11 predictores ordinales.
Heterogeneidad regional Estimacion de diferentes I para 5regiones (GBA, Pampeana, NOA, NEA y Patagonia).
2 tipos de respuesta (Y ): una continua (ingreso per capita delhogar) y una dicotomica (pobreza).
Estimacion: EM + seleccion de variables (Ver Forzani et al.,2016).
Evaluacion: El metodo aquı propuesto PFCord vs. 2 variantesdel PCA que contemplan predictores categoricos: no lineal(NLPCA) y con polychoric correlations (PCApoly)

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC).
11 predictores ordinales.
Heterogeneidad regional Estimacion de diferentes I para 5regiones (GBA, Pampeana, NOA, NEA y Patagonia).
2 tipos de respuesta (Y ): una continua (ingreso per capita delhogar) y una dicotomica (pobreza).
Estimacion: EM + seleccion de variables (Ver Forzani et al.,2016).
Evaluacion: El metodo aquı propuesto PFCord vs. 2 variantesdel PCA que contemplan predictores categoricos: no lineal(NLPCA) y con polychoric correlations (PCApoly)

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC).
11 predictores ordinales.
Heterogeneidad regional Estimacion de diferentes I para 5regiones (GBA, Pampeana, NOA, NEA y Patagonia).
2 tipos de respuesta (Y ): una continua (ingreso per capita delhogar) y una dicotomica (pobreza).
Estimacion: EM + seleccion de variables (Ver Forzani et al.,2016).
Evaluacion: El metodo aquı propuesto PFCord vs. 2 variantesdel PCA que contemplan predictores categoricos: no lineal(NLPCA) y con polychoric correlations (PCApoly)

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC).
11 predictores ordinales.
Heterogeneidad regional Estimacion de diferentes I para 5regiones (GBA, Pampeana, NOA, NEA y Patagonia).
2 tipos de respuesta (Y ): una continua (ingreso per capita delhogar) y una dicotomica (pobreza).
Estimacion: EM + seleccion de variables (Ver Forzani et al.,2016).
Evaluacion: El metodo aquı propuesto PFCord vs. 2 variantesdel PCA que contemplan predictores categoricos: no lineal(NLPCA) y con polychoric correlations (PCApoly)

Performance del metodo
0.0 0.2 0.4 0.6 0.8 1.0
010
2030
SES_PCApoly
ipcf
^0.3
3
Data Model
0.0 0.2 0.4 0.6 0.8 1.0
05
1015
2025
3035
SES_PFCord
ipcf
^0.3
3
Data Model
Figura: Comparacion de Ajuste de modelo lineal (Ingreso ∼ I ) PCA(izquierda) vs. PFCord (derecha)

Performance del metodo: Errores de prediccion
Cuadro: Validacion Cruzada de 10 particiones (10-fold) para el ındiceSES. Respuesta: Pobreza
Metodo GBA Pampeana NOA NEA Patagonia
Sin reduccion 0.202 0.162 0.274 0.287 0.129PCApoly 0.229 0.204 0.366 0.390 0.132
NLPCA 0.228 0.186 0.302 0.290 0.161PFCord 0.208 0.167 0.279 0.287 0.129

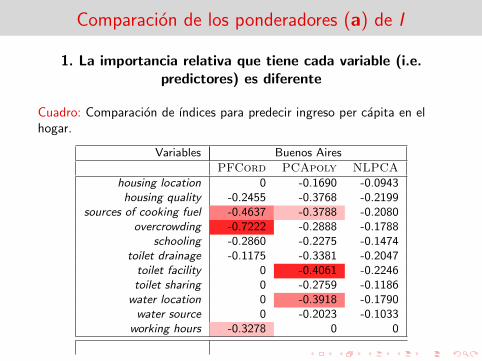
Comparacion de los ponderadores (a) de I
1. La importancia relativa que tiene cada variable (i.e.predictores) es diferente
Cuadro: Comparacion de ındices para predecir ingreso per capita en elhogar.
Variables Buenos Aires
PFCord PCApoly NLPCA
housing location 0 -0.1690 -0.0943housing quality -0.2455 -0.3768 -0.2199
sources of cooking fuel -0.4637 -0.3788 -0.2080overcrowding -0.7222 -0.2888 -0.1788
schooling -0.2860 -0.2275 -0.1474toilet drainage -0.1175 -0.3381 -0.2047toilet facility 0 -0.4061 -0.2246toilet sharing 0 -0.2759 -0.1186
water location 0 -0.3918 -0.1790water source 0 -0.2023 -0.1033
working hours -0.3278 0 0

Comparacion de los ponderadores (a) de I
1. La importancia relativa que tiene cada variable (i.e.predictores) es diferente
Cuadro: Comparacion de ındices para predecir ingreso per capita en elhogar.
Variables Buenos Aires
PFCord PCApoly NLPCA
housing location 0 -0.1690 -0.0943housing quality -0.2455 -0.3768 -0.2199
sources of cooking fuel -0.4637 -0.3788 -0.2080overcrowding -0.7222 -0.2888 -0.1788
schooling -0.2860 -0.2275 -0.1474toilet drainage -0.1175 -0.3381 -0.2047toilet facility 0 -0.4061 -0.2246toilet sharing 0 -0.2759 -0.1186
water location 0 -0.3918 -0.1790water source 0 -0.2023 -0.1033
working hours -0.3278 0 0
Comparacion de los ponderadores (a) de I
1. La importancia relativa que tiene cada variable (i.e.predictores) es diferente
Cuadro: Comparacion de ındices para predecir ingreso per capita en elhogar.
Variables Buenos Aires
PFCord PCApoly NLPCA
housing location 0 -0.1690 -0.0943housing quality -0.2455 -0.3768 -0.2199
sources of cooking fuel -0.4637 -0.3788 -0.2080overcrowding -0.7222 -0.2888 -0.1788
schooling -0.2860 -0.2275 -0.1474toilet drainage -0.1175 -0.3381 -0.2047toilet facility 0 -0.4061 -0.2246toilet sharing 0 -0.2759 -0.1186
water location 0 -0.3918 -0.1790water source 0 -0.2023 -0.1033
working hours -0.3278 0 0

Comparacion de los ponderadores (a) de I
1. La importancia relativa que tiene cada variable (i.e.predictores) es diferente
Cuadro: Comparacion de ındices para predecir ingreso per capita en elhogar.
Variables Buenos Aires
PFCord PCApoly NLPCA
housing location 0 -0.1690 -0.0943housing quality -0.2455 -0.3768 -0.2199
sources of cooking fuel -0.4637 -0.3788 -0.2080overcrowding -0.7222 -0.2888 -0.1788
schooling -0.2860 -0.2275 -0.1474toilet drainage -0.1175 -0.3381 -0.2047toilet facility 0 -0.4061 -0.2246toilet sharing 0 -0.2759 -0.1186
water location 0 -0.3918 -0.1790water source 0 -0.2023 -0.1033
working hours -0.3278 0 0

Comparacion de los ponderadores (a) de I
2. Mientras que PCA da pesos muy similares para lasdiferentes regiones, el ındice PFCord logra captar las
divergencias regionales
Ejemplo: PCA
Cuadro: Indice PCApoly por regiones. Respuesta Ingreso per capita
Variables GBA Pampeana NOA NEA Patag.PCA PCA PCA PCA PCA
housing location -0.1690 -0.1903 -0.1068 -0.1809 -0.1437housing quality -0.3768 -0.3557 -0.3278 -0.3727 -0.3258
sources of cooking fuel -0.3788 -0.3609 -0.3287 -0.1648 -0.4026overcrowding -0.2888 -0.2351 -0.1991 -0.2025 -0.2207
schooling -0.2275 -0.2075 -0.2197 -0.1869 -0.1284toilet drainage -0.3381 -0.3519 -0.3623 -0.3572 -0.4122toilet facility -0.4061 -0.4105 -0.4217 -0.4383 -0.4376toilet sharing -0.2759 -0.3176 -0.2579 -0.2921 -0.2937
water location -0.3918 -0.3933 -0.4202 -0.4227 -0.4169water source -0.2023 -0.2461 -0.3646 -0.3733 -0.1525
working hours 0 0 0 0 0

Comparacion de los ponderadores (a) de I
2. Mientras que PCA da pesos muy similares para lasdiferentes regiones, el ındice PFCord logra captar las
divergencias regionales
Ejemplo: PCA
Cuadro: Indice PCApoly por regiones. Respuesta Ingreso per capita
Variables GBA Pampeana NOA NEA Patag.PCA PCA PCA PCA PCA
housing location -0.1690 -0.1903 -0.1068 -0.1809 -0.1437housing quality -0.3768 -0.3557 -0.3278 -0.3727 -0.3258
sources of cooking fuel -0.3788 -0.3609 -0.3287 -0.1648 -0.4026overcrowding -0.2888 -0.2351 -0.1991 -0.2025 -0.2207
schooling -0.2275 -0.2075 -0.2197 -0.1869 -0.1284toilet drainage -0.3381 -0.3519 -0.3623 -0.3572 -0.4122toilet facility -0.4061 -0.4105 -0.4217 -0.4383 -0.4376toilet sharing -0.2759 -0.3176 -0.2579 -0.2921 -0.2937
water location -0.3918 -0.3933 -0.4202 -0.4227 -0.4169water source -0.2023 -0.2461 -0.3646 -0.3733 -0.1525
working hours 0 0 0 0 0

Comparacion de los ponderadores (a) de I
2. Mientras que PCA da pesos muy similares para lasdiferentes regiones, el ındice PFCord logra captar las
divergencias regionales
Ejemplo: PCA
Cuadro: Indice PCApoly por regiones. Respuesta Ingreso per capita
Variables GBA Pampeana NOA NEA Patag.PCA PCA PCA PCA PCA
housing location -0.1690 -0.1903 -0.1068 -0.1809 -0.1437housing quality -0.3768 -0.3557 -0.3278 -0.3727 -0.3258
sources of cooking fuel -0.3788 -0.3609 -0.3287 -0.1648 -0.4026overcrowding -0.2888 -0.2351 -0.1991 -0.2025 -0.2207
schooling -0.2275 -0.2075 -0.2197 -0.1869 -0.1284toilet drainage -0.3381 -0.3519 -0.3623 -0.3572 -0.4122toilet facility -0.4061 -0.4105 -0.4217 -0.4383 -0.4376toilet sharing -0.2759 -0.3176 -0.2579 -0.2921 -0.2937
water location -0.3918 -0.3933 -0.4202 -0.4227 -0.4169water source -0.2023 -0.2461 -0.3646 -0.3733 -0.1525
working hours 0 0 0 0 0

Comparacion de los ponderadores (a) de I
Para nuestro metodo propuesto:
Cuadro: Indice con PFCord por regiones. Respuesta Ingreso per capita
Variables GBA Pampeana NOA NEA Patag.
PFC PFC PFC PFC PFC
housing location 0 0 -0.1412 -0.1677 -0.1105housing quality -0.2455 -0.3077 -0.1195 -0.0858 -0.3341
sources of cooking fuel -0.4637 -0.3735 -0.1340 -0.0920 -0.1926overcrowding -0.7222 -0.8086 -0.8556 -0.8367 -0.7447
schooling -0.2860 -0.2703 -0.3556 -0.3364 -0.3807toilet drainage -0.1175 0 -0.1153 0 -0.1406toilet facility 0 -0.1214 -0.0927 -0.0743 0toilet sharing 0 0 0 -0.2369 -0.1242
water location 0 0 -0.2119 -0.1058 0water source 0 0 -0.0787 -0.2423 0.1956
working hours -0.3278 -0.1555 -0.1279 -0.1054 -0.2570

Comparacion de los ponderadores (a) de I
Para nuestro metodo propuesto:
Cuadro: Indice con PFCord por regiones. Respuesta Ingreso per capita
Variables GBA Pampeana NOA NEA Patag.
PFC PFC PFC PFC PFC
housing location 0 0 -0.1412 -0.1677 -0.1105housing quality -0.2455 -0.3077 -0.1195 -0.0858 -0.3341
sources of cooking fuel -0.4637 -0.3735 -0.1340 -0.0920 -0.1926overcrowding -0.7222 -0.8086 -0.8556 -0.8367 -0.7447
schooling -0.2860 -0.2703 -0.3556 -0.3364 -0.3807toilet drainage -0.1175 0 -0.1153 0 -0.1406toilet facility 0 -0.1214 -0.0927 -0.0743 0toilet sharing 0 0 0 -0.2369 -0.1242
water location 0 0 -0.2119 -0.1058 0water source 0 0 -0.0787 -0.2423 0.1956
working hours -0.3278 -0.1555 -0.1279 -0.1054 -0.2570

Comparacion de los ponderadores (a) de I
3. Impacto de la variable respuesta
Cuadro: PFCord ordinal segun Variable respuesta.
Respuesta: Ingreso (pc) Pobreza
GBA Pampeana GBA Pampeana
housing location 0 0 0 0housing quality -0.2455 -0.3077 -0.3940 -0.3561
sources of cooking fuel -0.4637 -0.3735 -0.4629 -0.3490overcrowding -0.7222 -0.8086 -0.6865 -0.7133
schooling -0.2860 -0.2703 0 0toilet drainage -0.1175 0 0 0toilet facility 0 -0.1214 -0.2426 -0.3538toilet sharing 0 0 -0.1729 -0.1350
water location 0 0 -0.2231 -0.2612water source 0 0 0 0
working hours -0.3278 -0.1555 -0.2378 -0.1557

Comparacion de los ponderadores (a) de I
3. Impacto de la variable respuesta
Cuadro: PFCord ordinal segun Variable respuesta.
Respuesta: Ingreso (pc) Pobreza
GBA Pampeana GBA Pampeana
housing location 0 0 0 0housing quality -0.2455 -0.3077 -0.3940 -0.3561
sources of cooking fuel -0.4637 -0.3735 -0.4629 -0.3490overcrowding -0.7222 -0.8086 -0.6865 -0.7133
schooling -0.2860 -0.2703 0 0toilet drainage -0.1175 0 0 0toilet facility 0 -0.1214 -0.2426 -0.3538toilet sharing 0 0 -0.1729 -0.1350
water location 0 0 -0.2231 -0.2612water source 0 0 0 0
working hours -0.3278 -0.1555 -0.2378 -0.1557

Comparacion de los ponderadores (a) de I
3. Impacto de la variable respuesta
Cuadro: PFCord ordinal segun Variable respuesta.
Respuesta: Ingreso (pc) Pobreza
GBA Pampeana GBA Pampeana
housing location 0 0 0 0housing quality -0.2455 -0.3077 -0.3940 -0.3561
sources of cooking fuel -0.4637 -0.3735 -0.4629 -0.3490overcrowding -0.7222 -0.8086 -0.6865 -0.7133
schooling -0.2860 -0.2703 0 0toilet drainage -0.1175 0 0 0toilet facility 0 -0.1214 -0.2426 -0.3538toilet sharing 0 0 -0.1729 -0.1350
water location 0 0 -0.2231 -0.2612water source 0 0 0 0
working hours -0.3278 -0.1555 -0.2378 -0.1557

Pero en la aplicacion con datos economicos tenemos queen general...
Como antes, categoricas ordinales.
Sexo jefe/jefa de hogar = 0 (mujer), 1 (hombre)
Situacion laboral = 0 (ocupado), 1 (desocupado)
Cantidad de personas por metro cuadrado de la vivienda
Cantidad de horas trabajadas por semana
Edad
Variables Ordinales
+ Dicotomicas + Continuas
X
H W

Pero en la aplicacion con datos economicos tenemos queen general...
Como antes, categoricas ordinales.
Sexo jefe/jefa de hogar = 0 (mujer), 1 (hombre)
Situacion laboral = 0 (ocupado), 1 (desocupado)
Cantidad de personas por metro cuadrado de la vivienda
Cantidad de horas trabajadas por semana
Edad
Variables Ordinales + Dicotomicas
+ Continuas
X H
W

Pero en la aplicacion con datos economicos tenemos queen general...
Como antes, categoricas ordinales.
Sexo jefe/jefa de hogar = 0 (mujer), 1 (hombre)
Situacion laboral = 0 (ocupado), 1 (desocupado)
Cantidad de personas por metro cuadrado de la vivienda
Cantidad de horas trabajadas por semana
Edad
Variables Ordinales + Dicotomicas + Continuas
X H W

RD para variables mixtos - trabajo en proceso-
RD para X,W,H simultaneamente
Proponer un modelo para X,W,H|Y
Consideramos la siguiente factorizacion:f (X,W,H|Y ) = f (X,W|H,Y )f (H|Y )

RD para variables mixtos - trabajo en proceso-
RD para X,W,H simultaneamente
Proponer un modelo para X,W,H|Y
Consideramos la siguiente factorizacion:f (X,W,H|Y ) = f (X,W|H,Y )f (H|Y )

RD para variables mixtos - trabajo en proceso-
RD para X,W,H simultaneamente
Proponer un modelo para X,W,H|Y
Consideramos la siguiente factorizacion:f (X,W,H|Y ) = f (X,W|H,Y )f (H|Y )

Reduccion de Dimensiones para predictores mixtos
H|Y Multivariate Bernoulli model (Ising Model)
X Enfoque de Variable Latente (Z)
(Z,W)|H,Y Multivariate Normal model
f (Z,W,H|Y ) = h(Z,W,H) exp{T (Z,W,H)TηY −ψ(ηY )}
with
T (Z,W,H) =
ZWH
vech(HHT )

Reduccion de Dimensiones para predictores mixtos
H|Y Multivariate Bernoulli model (Ising Model)
X Enfoque de Variable Latente (Z)
(Z,W)|H,Y Multivariate Normal model
f (Z,W,H|Y ) = h(Z,W,H) exp{T (Z,W,H)TηY −ψ(ηY )}
with
T (Z,W,H) =
ZWH
vech(HHT )

Reduccion de Dimensiones para predictores mixtos
H|Y Multivariate Bernoulli model (Ising Model)
X Enfoque de Variable Latente (Z)
(Z,W)|H,Y Multivariate Normal model
f (Z,W,H|Y ) = h(Z,W,H) exp{T (Z,W,H)TηY −ψ(ηY )}
with
T (Z,W,H) =
ZWH
vech(HHT )

Reduccion de Dimensiones para predictores mixtos
Bura, Duarte and Forzani (2016)
R(Z,W,H) = aT (T(Z,W,H)− E(T(Z,W,H))), cona = span{ηY − η,Y ∈ SY }
La reduccion supervisada que proponemos para la regresionY |(X,W,H) es
R(Z,W,H) = aT (T(E (Z|X),W,H)− E(T(E (Z|X),W,H)))

Reduccion de Dimensiones para predictores mixtos
Bura, Duarte and Forzani (2016)
R(Z,W,H) = aT (T(Z,W,H)− E(T(Z,W,H))), cona = span{ηY − η,Y ∈ SY }
La reduccion supervisada que proponemos para la regresionY |(X,W,H) es
R(Z,W,H) = aT (T(E (Z|X),W,H)− E(T(E (Z|X),W,H)))

Estimacion: PFCmix
{(Xi ,Wi ,Hi ,Yi )}ni=1
Estimamos los parametros correspondientes(τ 0, κ, ι, Θ, µ, α, ∆, ξ)
Multivariate Bernoulli model τ 0, κ, ι Ising concovariables (Cheng, et al. 2012) Estimacion MV viaconditional logits
Multivariate Normal model Θ, µ, α, ∆, ξ MetodoIterativo - Algoritmo EM.

Estimacion: PFCmix
{(Xi ,Wi ,Hi ,Yi )}ni=1
Estimamos los parametros correspondientes(τ 0, κ, ι, Θ, µ, α, ∆, ξ)
Multivariate Bernoulli model τ 0, κ, ι Ising concovariables (Cheng, et al. 2012) Estimacion MV viaconditional logits
Multivariate Normal model Θ, µ, α, ∆, ξ MetodoIterativo - Algoritmo EM.

Estimacion: PFCmix
{(Xi ,Wi ,Hi ,Yi )}ni=1
Estimamos los parametros correspondientes(τ 0, κ, ι, Θ, µ, α, ∆, ξ)
Multivariate Bernoulli model τ 0, κ, ι Ising concovariables (Cheng, et al. 2012) Estimacion MV viaconditional logits
Multivariate Normal model Θ, µ, α, ∆, ξ MetodoIterativo - Algoritmo EM.

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC)
Predictores: 8 ordinales, 7 binarios y 4 continuos. Respuesta:binaria (pobreza)
Ahora comparamos el metodo mas completo PFCmix con elPFCord y el NLPCA.
Opciones para comparar:
Solo ordinales con el PFCord PFCord(X).Incluyo las binarias en el PFCord (i.e. las trato comoordinales) PFCord(X,H).Considero solo ordinales y binarias con el PFCmix PFCmix(X,H).Tomo tambien las continuas en el PFCmix PFCmix (W,X,H).Realizo PCA no lineal para todas las variables NLPCA(W,X,H).

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC)
Predictores: 8 ordinales, 7 binarios y 4 continuos. Respuesta:binaria (pobreza)
Ahora comparamos el metodo mas completo PFCmix con elPFCord y el NLPCA.
Opciones para comparar:
Solo ordinales con el PFCord PFCord(X).Incluyo las binarias en el PFCord (i.e. las trato comoordinales) PFCord(X,H).Considero solo ordinales y binarias con el PFCmix PFCmix(X,H).Tomo tambien las continuas en el PFCmix PFCmix (W,X,H).Realizo PCA no lineal para todas las variables NLPCA(W,X,H).

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC)
Predictores: 8 ordinales, 7 binarios y 4 continuos. Respuesta:binaria (pobreza)
Ahora comparamos el metodo mas completo PFCmix con elPFCord y el NLPCA.
Opciones para comparar:
Solo ordinales con el PFCord PFCord(X).Incluyo las binarias en el PFCord (i.e. las trato comoordinales) PFCord(X,H).Considero solo ordinales y binarias con el PFCmix PFCmix(X,H).Tomo tambien las continuas en el PFCmix PFCmix (W,X,H).Realizo PCA no lineal para todas las variables NLPCA(W,X,H).

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC)
Predictores: 8 ordinales, 7 binarios y 4 continuos. Respuesta:binaria (pobreza)
Ahora comparamos el metodo mas completo PFCmix con elPFCord y el NLPCA.
Opciones para comparar:
Solo ordinales con el PFCord PFCord(X).Incluyo las binarias en el PFCord (i.e. las trato comoordinales) PFCord(X,H).Considero solo ordinales y binarias con el PFCmix PFCmix(X,H).Tomo tambien las continuas en el PFCmix PFCmix (W,X,H).Realizo PCA no lineal para todas las variables NLPCA(W,X,H).

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC)
Predictores: 8 ordinales, 7 binarios y 4 continuos. Respuesta:binaria (pobreza)
Ahora comparamos el metodo mas completo PFCmix con elPFCord y el NLPCA.
Opciones para comparar:
Solo ordinales con el PFCord PFCord(X).
Incluyo las binarias en el PFCord (i.e. las trato comoordinales) PFCord(X,H).Considero solo ordinales y binarias con el PFCmix PFCmix(X,H).Tomo tambien las continuas en el PFCmix PFCmix (W,X,H).Realizo PCA no lineal para todas las variables NLPCA(W,X,H).

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC)
Predictores: 8 ordinales, 7 binarios y 4 continuos. Respuesta:binaria (pobreza)
Ahora comparamos el metodo mas completo PFCmix con elPFCord y el NLPCA.
Opciones para comparar:
Solo ordinales con el PFCord PFCord(X).Incluyo las binarias en el PFCord (i.e. las trato comoordinales) PFCord(X,H).
Considero solo ordinales y binarias con el PFCmix PFCmix(X,H).Tomo tambien las continuas en el PFCmix PFCmix (W,X,H).Realizo PCA no lineal para todas las variables NLPCA(W,X,H).

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC)
Predictores: 8 ordinales, 7 binarios y 4 continuos. Respuesta:binaria (pobreza)
Ahora comparamos el metodo mas completo PFCmix con elPFCord y el NLPCA.
Opciones para comparar:
Solo ordinales con el PFCord PFCord(X).Incluyo las binarias en el PFCord (i.e. las trato comoordinales) PFCord(X,H).Considero solo ordinales y binarias con el PFCmix PFCmix(X,H).
Tomo tambien las continuas en el PFCmix PFCmix (W,X,H).Realizo PCA no lineal para todas las variables NLPCA(W,X,H).

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC)
Predictores: 8 ordinales, 7 binarios y 4 continuos. Respuesta:binaria (pobreza)
Ahora comparamos el metodo mas completo PFCmix con elPFCord y el NLPCA.
Opciones para comparar:
Solo ordinales con el PFCord PFCord(X).Incluyo las binarias en el PFCord (i.e. las trato comoordinales) PFCord(X,H).Considero solo ordinales y binarias con el PFCmix PFCmix(X,H).Tomo tambien las continuas en el PFCmix PFCmix (W,X,H).
Realizo PCA no lineal para todas las variables NLPCA(W,X,H).

Aplicacion usando EPH-Argentina
EPH 3er. trimestre de 2013 (INDEC)
Predictores: 8 ordinales, 7 binarios y 4 continuos. Respuesta:binaria (pobreza)
Ahora comparamos el metodo mas completo PFCmix con elPFCord y el NLPCA.
Opciones para comparar:
Solo ordinales con el PFCord PFCord(X).Incluyo las binarias en el PFCord (i.e. las trato comoordinales) PFCord(X,H).Considero solo ordinales y binarias con el PFCmix PFCmix(X,H).Tomo tambien las continuas en el PFCmix PFCmix (W,X,H).Realizo PCA no lineal para todas las variables NLPCA(W,X,H).

Predictores ordinales:
Ubicacion del agua potable (3 cat.)Forma de obtencion del agua potable (3 cat.)Tipo de bano (3 cat.)Desague del bano (4 cat.)Forma de compartir el bano (3 cat.)Calidad de la Vivienda (4 cat)Combustible predominante para cocinar alimentos (3 cat.)Escolaridad jefe/a de hogar (7 cat.)
Predictores binarios:
Actividad jefe/a (Ocupado o no)Vivienda cercana a basurales (si-no)Vivienda ubicada en zona inundable (si-no)Vivienda ubicada en villa de emergencia (si-no)Sexo del Jefe/a de hogar (hombre o mujer)propietario de vivienda (si-no)cobertura medica (si-no)
Predictores continuos:
Hacinamiento: ratio entre ambientes de la vivienda y cantidad de miembros del hogarHoras trabajadas por el jefe/a en la ultima semanaEdad del jefe/a de hogarCantidad de menores en el hogar

Performance del PFCmix: errores de prediccion
Metodo GBA Pampeana NOA NEA Patagonia
PFCord(X) 0.2159 0.1933 0.3299 0.3892 0.1359
PFCord(X,H) 0.2008 0.1781 0.2751 0.3043 0.1277
PFCmix(X,H) 0.1711 0.1435 0.2703 0.2997 0.0822
PFCmix(X,H,W) 0.1643 0.1312 0.2469 0.2419 0.0805
NLPCA(X,H,W) 0.2335 0.2052 0.3727 0.3887 0.1318

Performance del PFCmix: errores de prediccion
Metodo GBA Pampeana NOA NEA Patagonia
PFCord(X) 0.2159 0.1933 0.3299 0.3892 0.1359
PFCord(X,H) 0.2008 0.1781 0.2751 0.3043 0.1277
PFCmix(X,H) 0.1711 0.1435 0.2703 0.2997 0.0822
PFCmix(X,H,W) 0.1643 0.1312 0.2469 0.2419 0.0805
NLPCA(X,H,W) 0.2335 0.2052 0.3727 0.3887 0.1318

Performance del PFCmix: errores de prediccion
Metodo GBA Pampeana NOA NEA Patagonia
PFCord(X) 0.2159 0.1933 0.3299 0.3892 0.1359
PFCord(X,H) 0.2008 0.1781 0.2751 0.3043 0.1277
PFCmix(X,H) 0.1711 0.1435 0.2703 0.2997 0.0822
PFCmix(X,H,W) 0.1643 0.1312 0.2469 0.2419 0.0805
NLPCA(X,H,W) 0.2335 0.2052 0.3727 0.3887 0.1318

Performance del PFCmix: errores de prediccion
Metodo GBA Pampeana NOA NEA Patagonia
PFCord(X) 0.2159 0.1933 0.3299 0.3892 0.1359
PFCord(X,H) 0.2008 0.1781 0.2751 0.3043 0.1277
PFCmix(X,H) 0.1711 0.1435 0.2703 0.2997 0.0822
PFCmix(X,H,W) 0.1643 0.1312 0.2469 0.2419 0.0805
NLPCA(X,H,W) 0.2335 0.2052 0.3727 0.3887 0.1318

Performance del PFCmix: errores de prediccion
Metodo GBA Pampeana NOA NEA Patagonia
PFCord(X) 0.2159 0.1933 0.3299 0.3892 0.1359
PFCord(X,H) 0.2008 0.1781 0.2751 0.3043 0.1277
PFCmix(X,H) 0.1711 0.1435 0.2703 0.2997 0.0822
PFCmix(X,H,W) 0.1643 0.1312 0.2469 0.2419 0.0805
NLPCA(X,H,W) 0.2335 0.2052 0.3727 0.3887 0.1318

Performance del PFCmix: errores de prediccion
Metodo GBA Pampeana NOA NEA Patagonia
PFCord(X) 0.2159 0.1933 0.3299 0.3892 0.1359
PFCord(X,H) 0.2008 0.1781 0.2751 0.3043 0.1277
PFCmix(X,H) 0.1711 0.1435 0.2703 0.2997 0.0822
PFCmix(X,H,W) 0.1643 0.1312 0.2469 0.2419 0.0805
NLPCA(X,H,W) 0.2335 0.2052 0.3727 0.3887 0.1318
