recent advances in hierarchical reinforcement learningprlt.dei.polimi.it/upload/5/5c/hrl.pdf ·...
TRANSCRIPT

PIGML Seminar - AirLab
Recent Advances in HierarchicalReinforcement Learning
Authors:Andrew Barto
Sridhar Mahadevan
Speaker:Alessandro Lazaric

PIGML Seminar - AirLab
Outline
Introduction to Reinforcement Learning• Reinforcement Learning Inspirations and Foundations• Markov Decision Processes (MDPs) and Q-learning
Hierarchical Reinforcement Learning• From MDPs to SMDPs• Option Framework• MAXQ Value Function Decomposition• Other Approaches to Hierarchical Reinforcement
Learning• Future/Current/Past Research

PIGML Seminar - AirLab
Outline
Introduction to Reinforcement Learning• Reinforcement Learning Inspirations and Foundations• Markov Decision Processes (MDPs) and Q-learning
Hierarchical Reinforcement Learning• From MDPs to SMDPs• Option Framework• MAXQ Value Function Decomposition• Other Approaches to Hierarchical Reinforcement
Learning• Future/Current/Past Research

PIGML Seminar - AirLab
RL as… Animal Psychology
Of several responses [actions] made tothe same situation, those which arefollowed by satisfaction to the animalwill be more firmly connected with thesituation, so that, when it recurs, theywill be more likely to recur; those whichare followed by discomfort to theanimal will have their connections withthat situation weakened, so that, whenit recurs, they will be less likely tooccur. The greater the satisfaction ordiscomfort, the greater thestrengthening or weakening of thebond. (Thorndike, 1911, p. 244)
PIGML Seminar - AirLab
RL as… Neuroscience
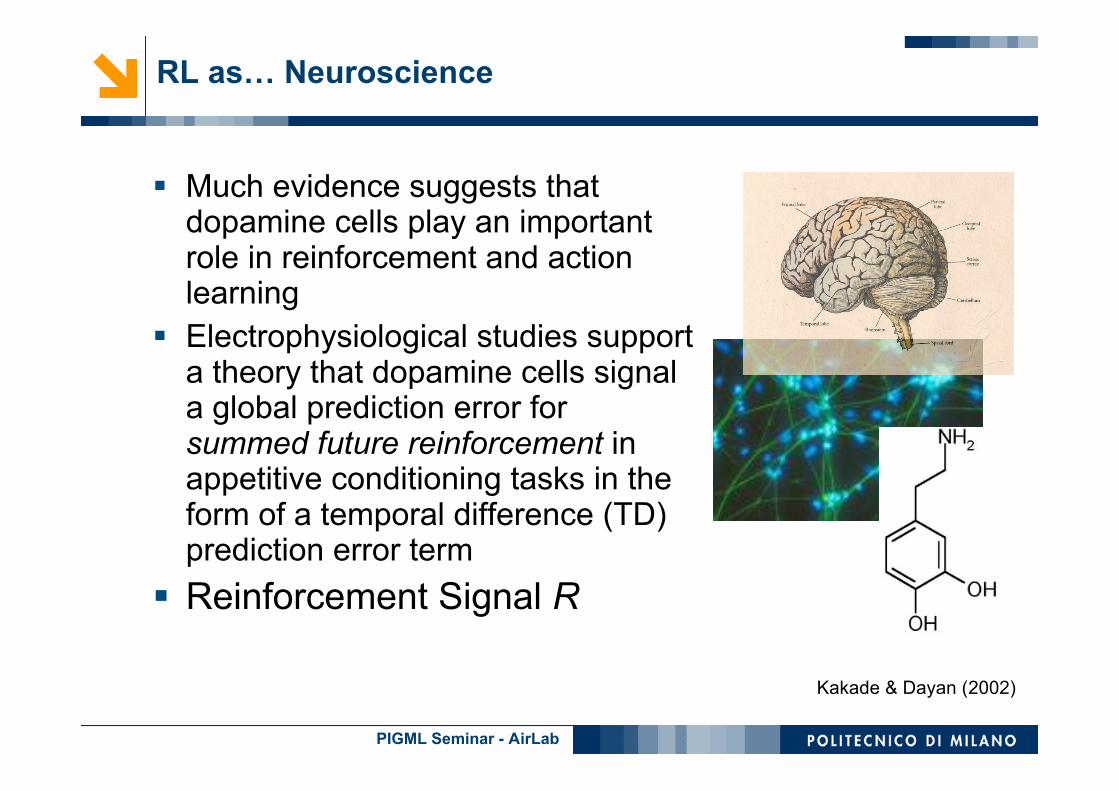
Much evidence suggests thatdopamine cells play an importantrole in reinforcement and actionlearning
Electrophysiological studies supporta theory that dopamine cells signala global prediction error forsummed future reinforcement inappetitive conditioning tasks in theform of a temporal difference (TD)prediction error term
Reinforcement Signal R
Kakade & Dayan (2002)

PIGML Seminar - AirLab
RL as… Artificial Intelligence
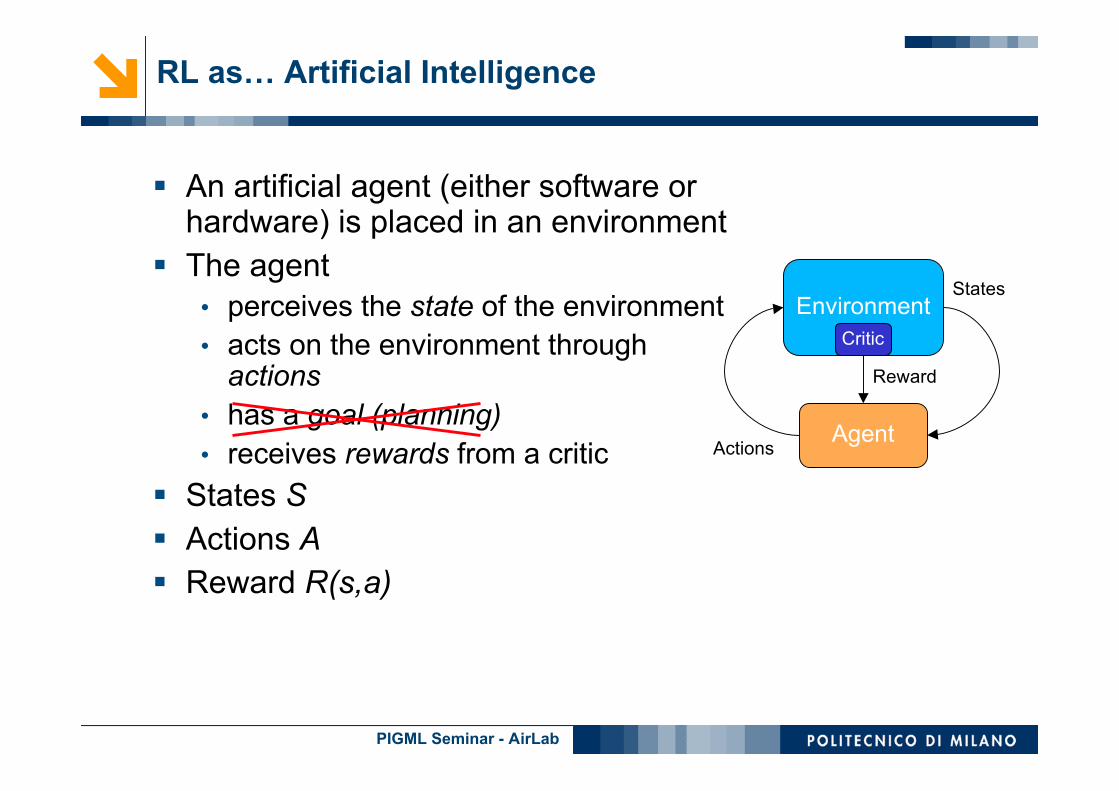
An artificial agent (either software orhardware) is placed in an environment
The agent• perceives the state of the environment• acts on the environment through
actions• has a goal (planning)
States S Actions A
Environment
Agent
States
Actions
PIGML Seminar - AirLab
RL as… Artificial Intelligence
An artificial agent (either software orhardware) is placed in an environment
The agent• perceives the state of the environment• acts on the environment through
actions• has a goal (planning)• receives rewards from a critic
States S Actions A Reward R(s,a)
Environment
Agent
Critic
States
Actions
Reward

PIGML Seminar - AirLab
RL as… Optimal Control
A control system has sensor (i.e.,states), actuators (i.e., actions) andcosts (i.e., rewards)
The environment is a dynamicalstochastic system
Often, the system can beformalized as Markov DecisionProcess
Optimal control

PIGML Seminar - AirLab
RL as… Discrete Time Differential Equations
Value function
Action value function
Bellman equations
Bellman (1957a)

PIGML Seminar - AirLab
RL as… Operations Research
Optimal functions
Dynamic Programming (given P and R)
Bellman (1957b)
PIGML Seminar - AirLab
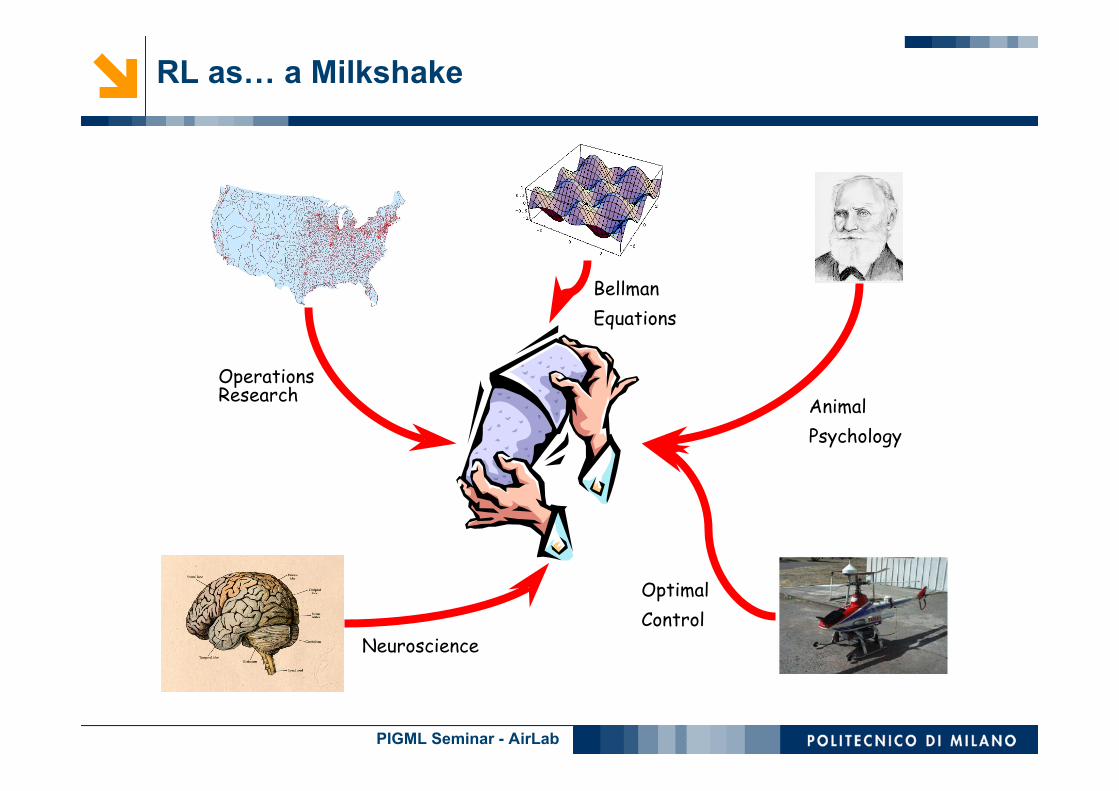
RL as… a Milkshake
OperationsResearch
BellmanEquations
AnimalPsychology
OptimalControl
Neuroscience

PIGML Seminar - AirLab
RL as… a Machine Learning Paradigm!
Reinforcement Learning is the mostgeneral Machine Learning paradigm
RL is how to map states to actions, soas to maximize a numerical reward inthe long run
RL is a multi-step decision-makingprocess (often Markovian)
An RL agent learns through a model-free trial-and-error process
Actions may affect not only theimmediate reward but alsosubsequent rewards (delayed effect)

PIGML Seminar - AirLab
Reinforcement Learning Framework
Markov Decision Process (MDP)

PIGML Seminar - AirLab
Reinforcement Learning Framework
Markov Decision Process (MDP)• Set of states
0 1 2 3 4
5 6 7 8 9
10 11 12 13 14
15 16 17 18 19
20 21 22 23 24
PIGML Seminar - AirLab
Reinforcement Learning Framework
Markov Decision Process (MDP)• Set of states• Set of actions
0 1 2 3 4
5 6 7 8 9
10 11 12 13 14
15 16 17 18 19
20 21 22 23 24
PIGML Seminar - AirLab
Reinforcement Learning Framework
Markov Decision Process (MDP)• Set of states• Set of actions• Transition model
0 1 2 3 4
5 6 7 8 9
10 11 12 13 14
15 16 17 18 19
20 21 22 23 24
PIGML Seminar - AirLab
Reinforcement Learning Framework
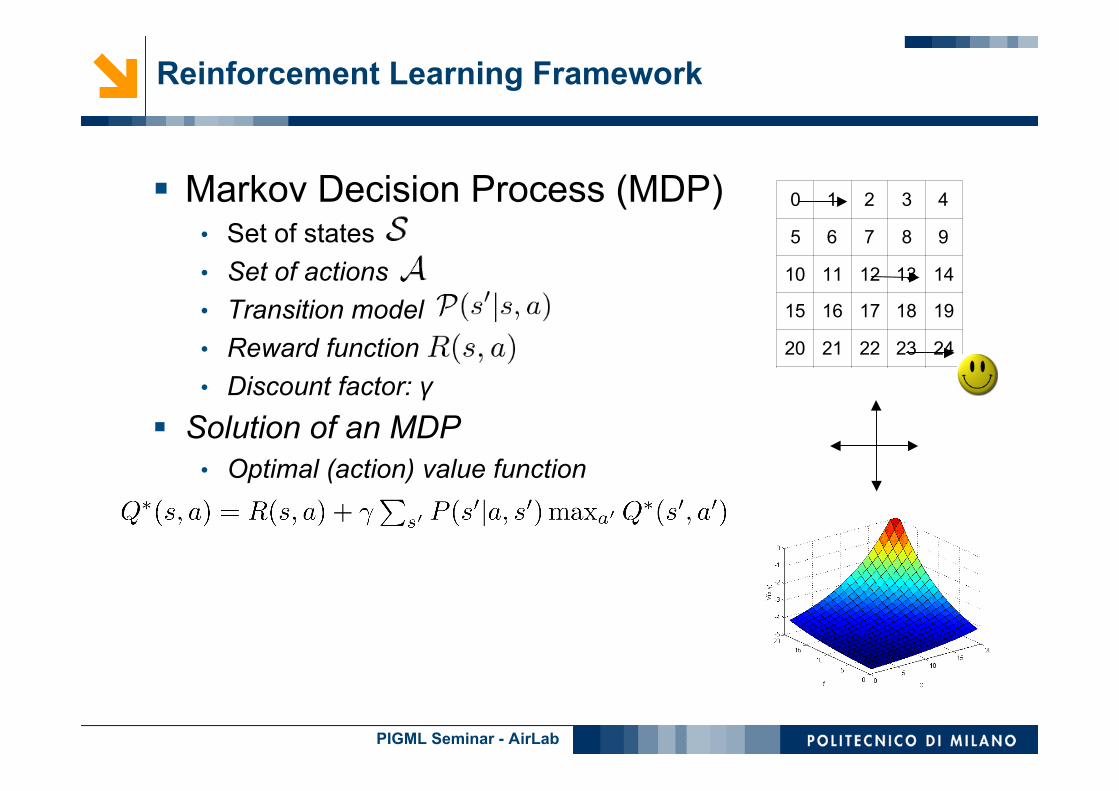
Markov Decision Process (MDP)• Set of states• Set of actions• Transition model• Reward function• Discount factor: γ
0 1 2 3 4
5 6 7 8 9
10 11 12 13 14
15 16 17 18 19
20 21 22 23 24
PIGML Seminar - AirLab
Reinforcement Learning Framework
Markov Decision Process (MDP)• Set of states• Set of actions• Transition model• Reward function• Discount factor: γ
Solution of an MDP• Optimal (action) value function
0 1 2 3 4
5 6 7 8 9
10 11 12 13 14
15 16 17 18 19
20 21 22 23 24

PIGML Seminar - AirLab
Reinforcement Learning Framework
Markov Decision Process (MDP)• Set of states• Set of actions• Transition model• Reward function• Discount factor: γ
Solution of an MDP• Optimal (action) value function
• Optimal policy
0 1 2 3 4
5 6 7 8 9
10 11 12 13 14
15 16 17 18 19
20 21 22 23 24

PIGML Seminar - AirLab
Reinforcement Learning: Q-learning
Q-learning

PIGML Seminar - AirLab
An Example of Reinforcement Learning
http://www.fe.dis.titech.ac.jp/~gen/robot/robodemo.html

PIGML Seminar - AirLab
Outline
Introduction to Reinforcement Learning• Reinforcement Learning Inspirations and Foundations• Markov Decision Processes (MDPs) and Q-learning
Hierarchical Reinforcement Learning• From MDPs to SMDPs• Option Framework• MAXQ Value Function Decomposition• Other Approaches to Hierarchical Reinforcement
Learning• Future/Current/Past Research

PIGML Seminar - AirLab
The need for Hierarchical RL
Curse of dimensionality: the application ofReinforcement Learning to the problems withlarge action and/or state space is infeasible
Abstraction: state and temporal abstractions allowto simplify the problem
Prior knowledge: complex tasks can be oftendecomposed in a hierarchy of sub-tasks
Solution: sub-tasks can be effectively solved byReinforcement Learning approaches
Reuse: sub-tasks and abstract actions can beused in different tasks on the same domain

PIGML Seminar - AirLab
Hierarchical Reinforcement Learning
Hierarchical approach to RL is the introduction oftemporal abstraction to Reinforcement Learningframework
Temporal abstraction is• Macro-operators• Temporally extended actions• Options• Sub-tasks• Skills• Behaviors• Modes
PIGML Seminar - AirLab
Hierarchical Reinforcement Learning
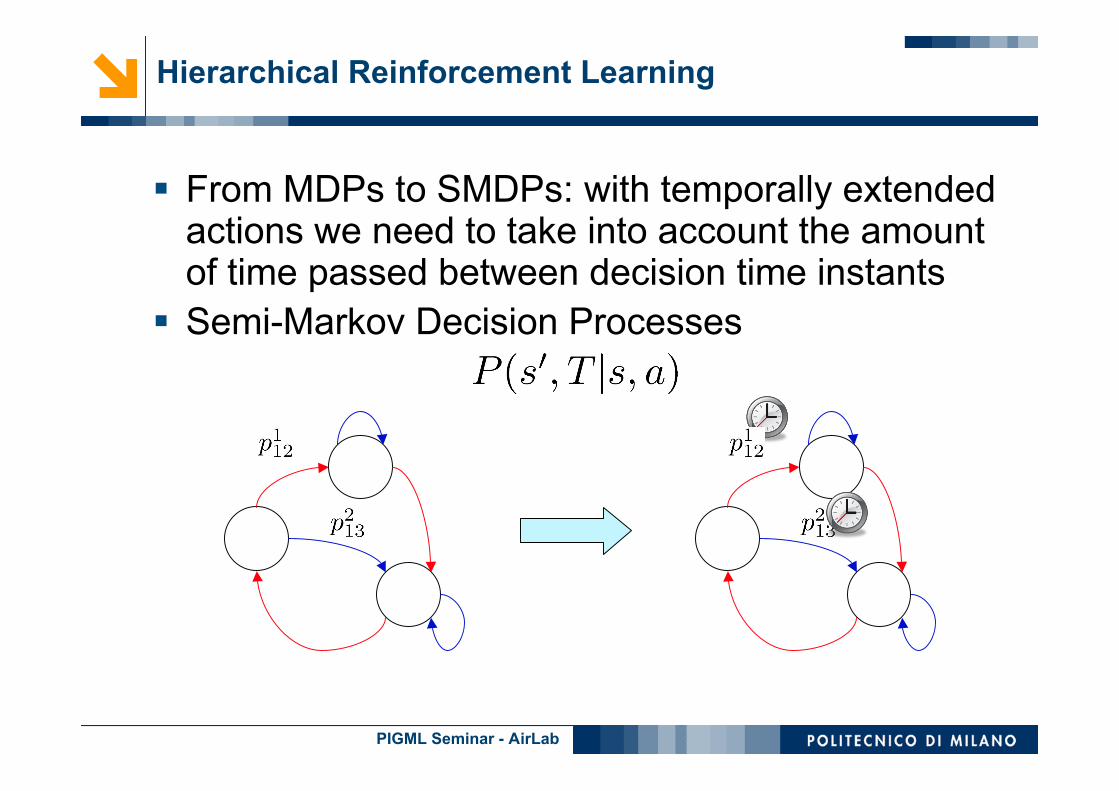
From MDPs to SMDPs: with temporally extendedactions we need to take into account the amountof time passed between decision time instants
Semi-Markov Decision Processes

PIGML Seminar - AirLab
Hierarchical RL Approaches
Options Framework
MAXQ Value Function Decomposition
Hierachies of Abstract Machines

PIGML Seminar - AirLab
Options Framework
An option o is defined as:

PIGML Seminar - AirLab
Options Framework
An option o is defined as:

PIGML Seminar - AirLab
Options Framework
An option o is defined as:

PIGML Seminar - AirLab
Options Framework
An option o is defined as:

PIGML Seminar - AirLab
Options Framework
Between MDPs and SMDPs
Continuous timeDiscrete eventsInterval-dependent discount
Discrete timeOverlaid discrete eventsInterval-dependent discount
MDP
SMDP
Options
over MDP
State
Time
Discrete timeHomogeneous discount
Sutton (1999)

PIGML Seminar - AirLab
Options Framework
The introduction of options leads to a straightforwardredefinition of all the elements
Option reward:
Option transition model:
(Hierarchical) Policy over options:

PIGML Seminar - AirLab
Options Framework
Value Function
Action Value Function
SMDP Q-learning

PIGML Seminar - AirLab
Options Framework
Option optimizations• Intra option learning: after each primitive action, update
all the options that could have taken that action
Option 1
Option 2
Intra-optionupdate
PIGML Seminar - AirLab
range (input set) of eachrun-to-landmark controller
landmarks
S
G
Options Framework
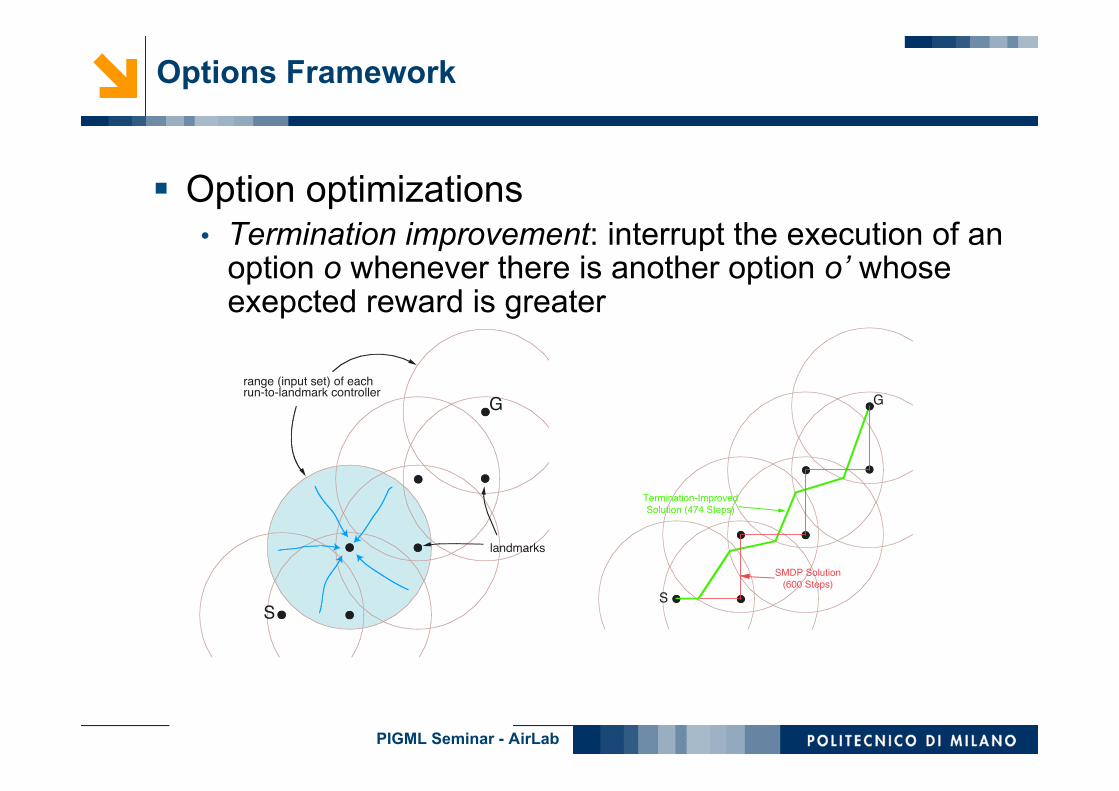
Option optimizations• Termination improvement: interrupt the execution of an
option o whenever there is another option o’ whoseexepcted reward is greater
S
G
SMDP Solution
(600 Steps)
Termination-Improved
Solution (474 Steps)

PIGML Seminar - AirLab
Options Framework
Pros• Options are very simple to implement• Options are effective in defining high-level skills• Options improve the speed of convergence• Options can be used to define hierarchies of options
Cons• Options do not simplify but augment the MDP• Options do not explicitly address the problem of task
decomposition
PIGML Seminar - AirLab
MAXQ Value Function Decomposition
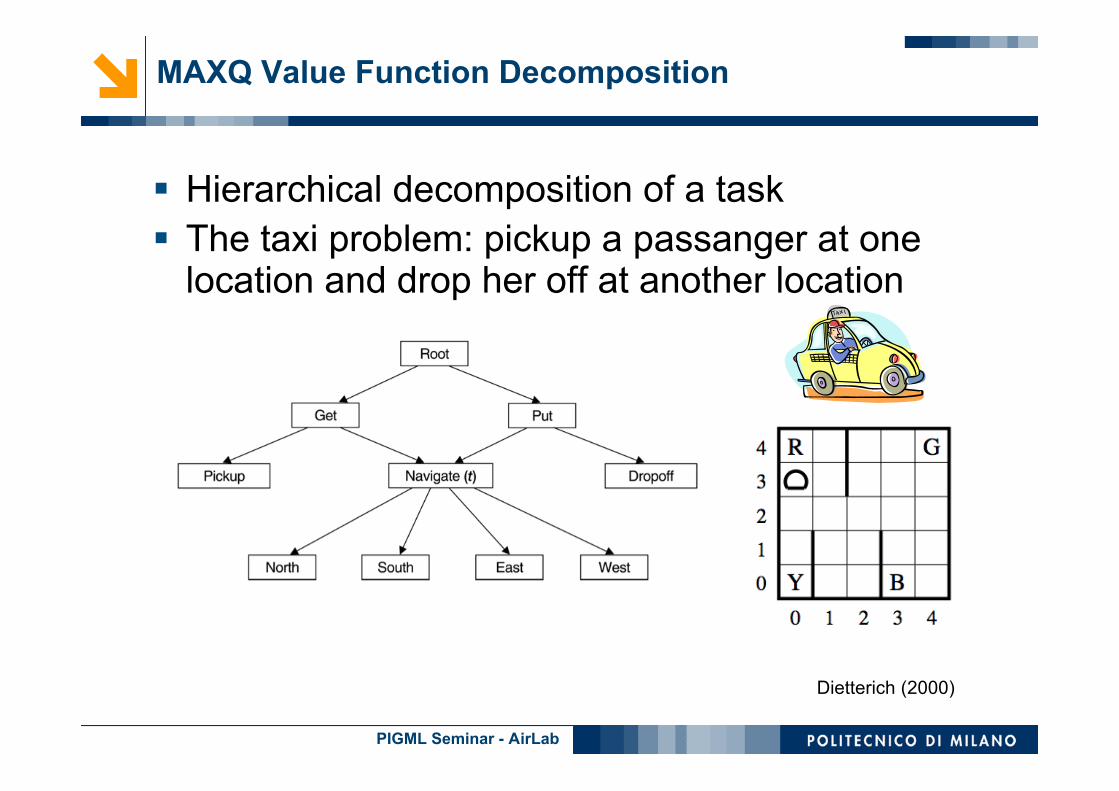
Hierarchical decomposition of a task The taxi problem: pickup a passanger at one
location and drop her off at another location
Dietterich (2000)

PIGML Seminar - AirLab
MAXQ Value Function Decomposition
Original MDP M is decomposed in a finite set ofsubtasks
Each subtask is formalized as• Termination predicate• Set of actions• Pseudo reward
Hierarchical policy

PIGML Seminar - AirLab
MAXQ Value Function Decomposition
Hierarchical value function
Projected value function
Projected action value function
Completion function

PIGML Seminar - AirLab
MAXQ Value Function Decomposition
Hierarchical optimal policy: the policy that isoptimal among all the policies that can beexpressed given the hierarchical structure
Recursively optimal policy: the policy that isoptimal for each SMDP corresponding to each ofthe subtasks in the decomposition

PIGML Seminar - AirLab
MAXQ Value Function Decomposition
Pros• Real hierarchical decomposition of a task• It can realize both temporal and spatial abstraction• Easy reuse of sub-policies
Cons• Very complex structure• Recursively optimal policies may be highly suboptimal
policies
PIGML Seminar - AirLab
Hierarchical Abstract Machines
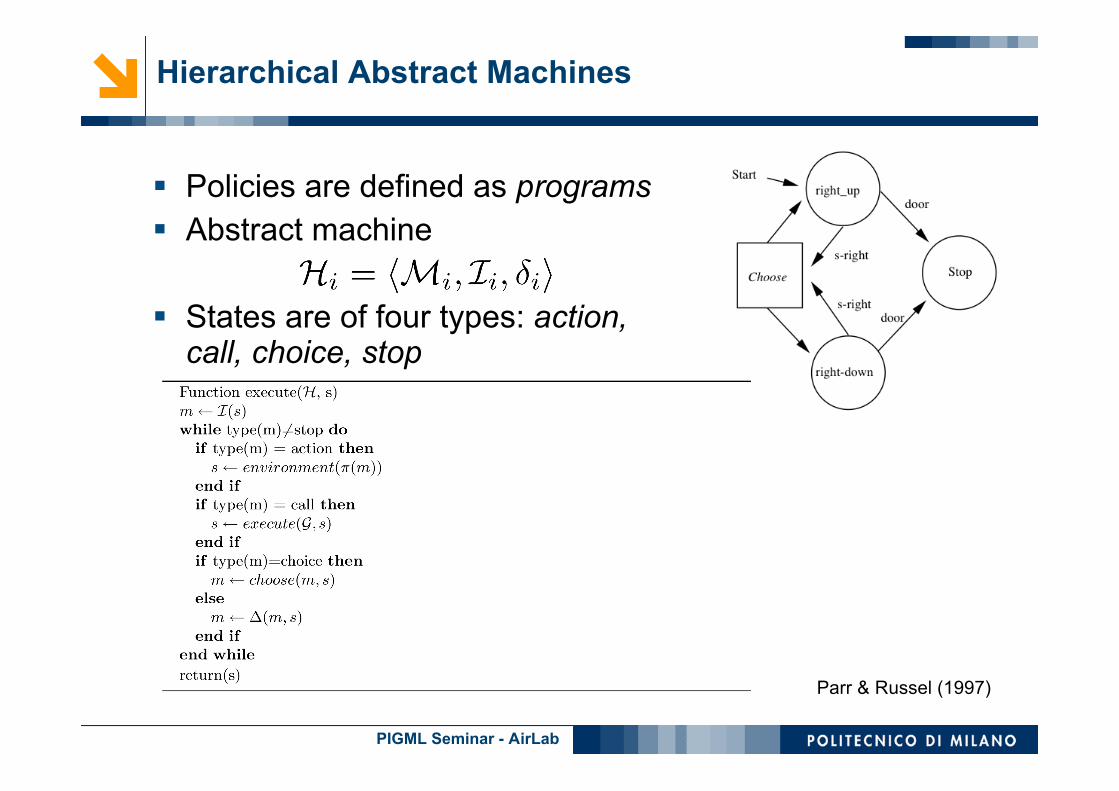
Policies are defined as programs Abstract machine
States are of four types: action,call, choice, stop
Parr & Russel (1997)

PIGML Seminar - AirLab
Hierarchical Abstract Machines
Pros• HAMs simplify the MDP by restricting the class of
realizable policies• Theoretical guarantees of optimality
Cons• HAMs are difficult to design and implement• No significant application is available

PIGML Seminar - AirLab
Other Topics in Hierarchical RL
Concurrent activities• SMDP model• Definition of multi-option• Termination condition
PIGML Seminar - AirLab
Other Topics in Hierarchical RL
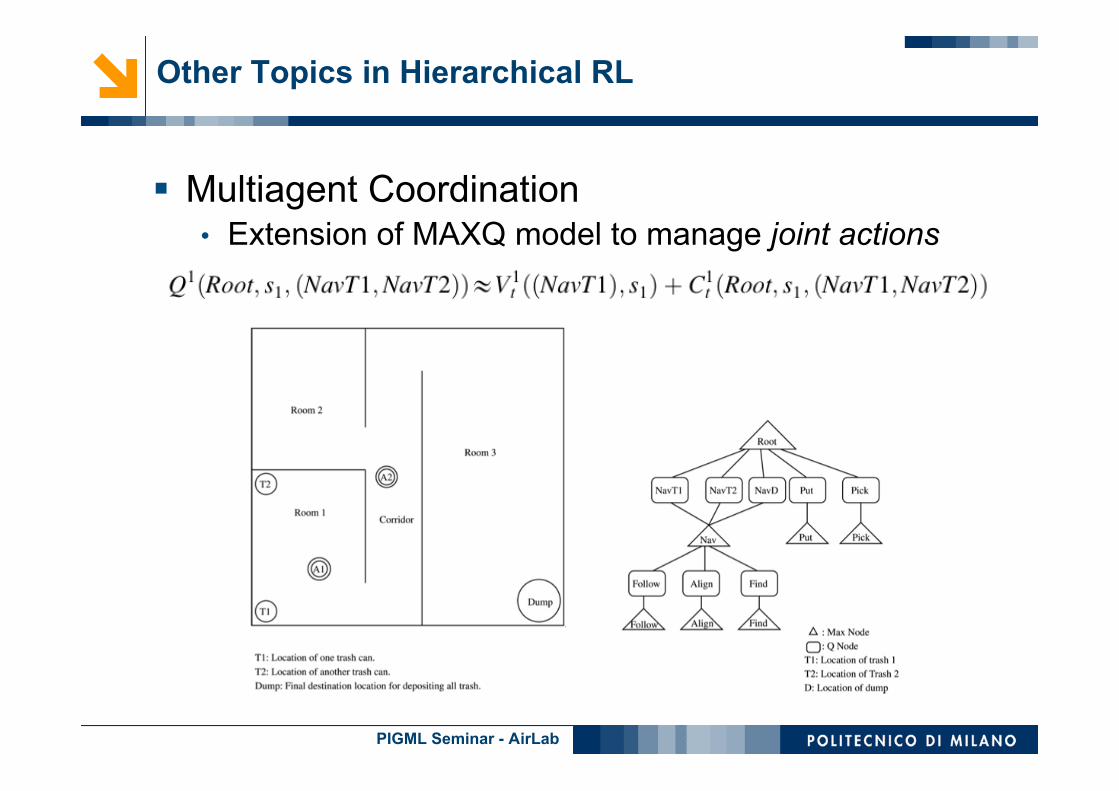
Multiagent Coordination• Extension of MAXQ model to manage joint actions

PIGML Seminar - AirLab
Other Topics in Hierarchical RL
Hierarchical Memory• Partially Observable MDPs (belief states)• Exploitation of a hierarchical structure to reduce the
complexity of the estimation of the model• Different models
−Hierarchical Suffix Memory−H-POMDP−Hierarchical U-Trees

PIGML Seminar - AirLab
Applications
Keepaway (Stone & Sutton, 2002) Autonomous Guided Vehicle
(Makar et al, 2001) Learning of a Stand-up Behavior
(Morimoto, 2000) Real-time Strategic Games
(Neville&Tadepalli, 2005) Spoken Dialogue Management
(Cuayahuitl, 2005)

PIGML Seminar - AirLab
Future (current&past) works
Dynamic state abstraction in HRL Options
• Sub-goal Discovery• Intrinsically Motivated Reinforcement Learning
MAXQ• Automatic Task Decomposition• Transfer in Hierarchical Reinforcement Learning

PIGML Seminar - AirLab
Conclusions
RL is a very general Machine Learning paradigm RL is bedeviled by the curse of dimensionality A careful hierarchical decomposition of problems
at hand allows the application of RL even to verycomplex problems
Options framework and MAXQ decomposition areeffective in providing designers with very powerfulmodels for a hierarchical description of a problem

PIGML Seminar - AirLab
References
Thorndike, E. (1911), Animal Intelligence, Hafner, Darien. Kakade, S. & Dayan, P. (2002), Dopamine: generalization and bonuses, Neural Netw. 15(4), 549-
559. Bellman, R. (1957a), Dynamic Programming, Princeton University Press, Princeton. Bellman, R. (1957b), A Markov Decision Process, journal of Mathematical Mechanics 6, 679-684. Sutton, R. S.; Precup, D. & Singh, S. (1999), Between MDPs and Semi-MDPs: a Framework for
Temporal Abstraction in Reinforcement Learning, Artificial Intelligence 112, 181-211. Parr, R. & Russel, S. (1997),Reinforcement Learning with Hierarchies of Machines, in 'Advances in
Neural Information Processing Systems 10'. Dietterich, T. G. (2000), Hierarchical Reinforcement Learning with the MAXQ Value Function
Decomposition, Journal of Artificial Intelligence Research 13, 227-303. Metha, N.; Natarajan, S.; Tadepalli, P. & Fern, A. Transfer in Variable-Reward Hierarchical
Reinforcement Learning Inductive Transfer : 10 Years Later, NIPS 2005 Workshop, 2005. J. Morimoto and K. Doya, "Robust reinforcement learning," in Advances in Neural Information
Processing Systems 13, pp. 1061--1067, MIT Press, 2001. Stone, P. & Sutton, R. S. Keepaway Soccer: A Machine Learning Testbed. RoboCup, 2001, 214-
223 H. Cuayahuitl, Spoken Dialogue Management Using Hierarchical Reinforcement Learning and
Dialogue Simulation. PhD Thesis, University of Edinburgh, 2005.

PIGML Seminar - AirLab
Questions?