r. de simone inria epi aoste semi-technical considerations
TRANSCRIPT

AAA
which a
pplic
ation
form
?
R. de SimoneINRIA EPI Aoste
semi-technical considerations

Adequation Algorithme-ArchitectureAllocation Application / Architecture
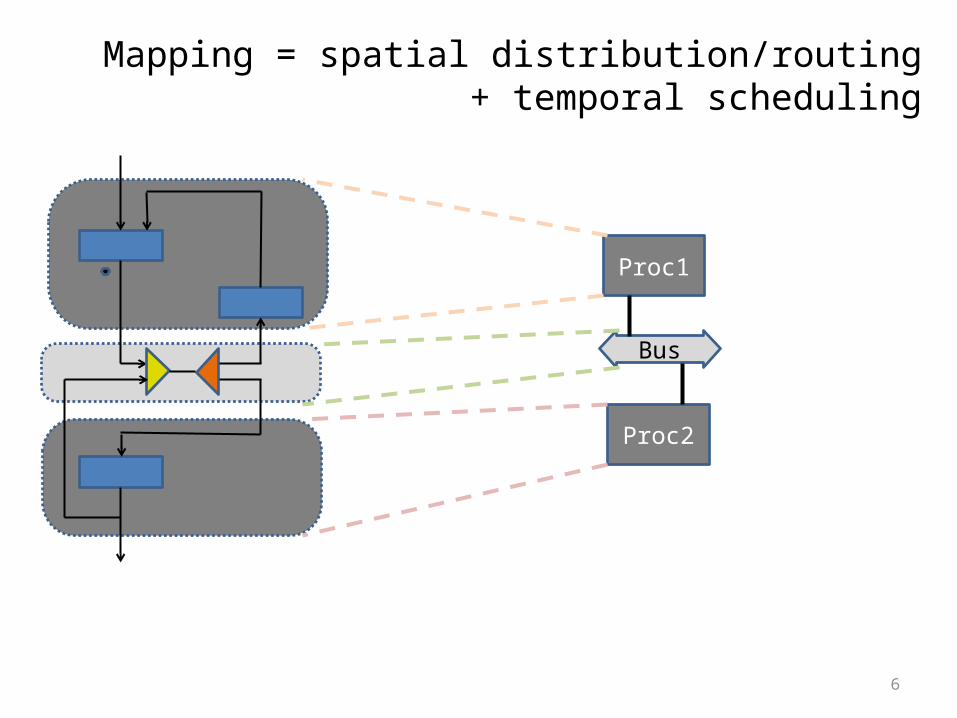
mapping comprises:– spatial allocation: distribution, placement (of tasks on resources)
– temporal allocation: scheduling
original formulation: Yves Sorel (1988)since then rephrased as Platform-based design, Y-Chart approach,…
ArchitectureApplicationmapping
adequation

Adequation Algorithme-ArchitectureAllocation Application / Architecture
mapping comprises:– spatial allocation: distribution, placement (of tasks on resources)
– temporal allocation: scheduling
architecture trends: – networks of processors (multicore, GPGPU/MIC, many-buzz)– communication bandwith the issue, on-chip networks… spatial routing, temporal arbitration, what else ?
ArchitectureApplicationmapping

Adequation Algorithme-ArchitectureAllocation Application / Architecture
what kind of application description models ?– where concurrency and timing could be extracted, made explicit– Under favorable conditions, could be performed at compile time
(static, time-predictable)– Dimensioning should be feasible to optimally fit the architecture
(cache sizes, PRET notions,…) – (Existing theories developed in neighboring domains could be
combined and adaptedGOAL is to refine the application so it reflects the architecture
ArchitectureApplicationmapping

5
Draft example: Mapping
Bus
Proc1
Proc2
6
Mapping = spatial distribution/routing + temporal scheduling
Bus
Proc1
Proc2

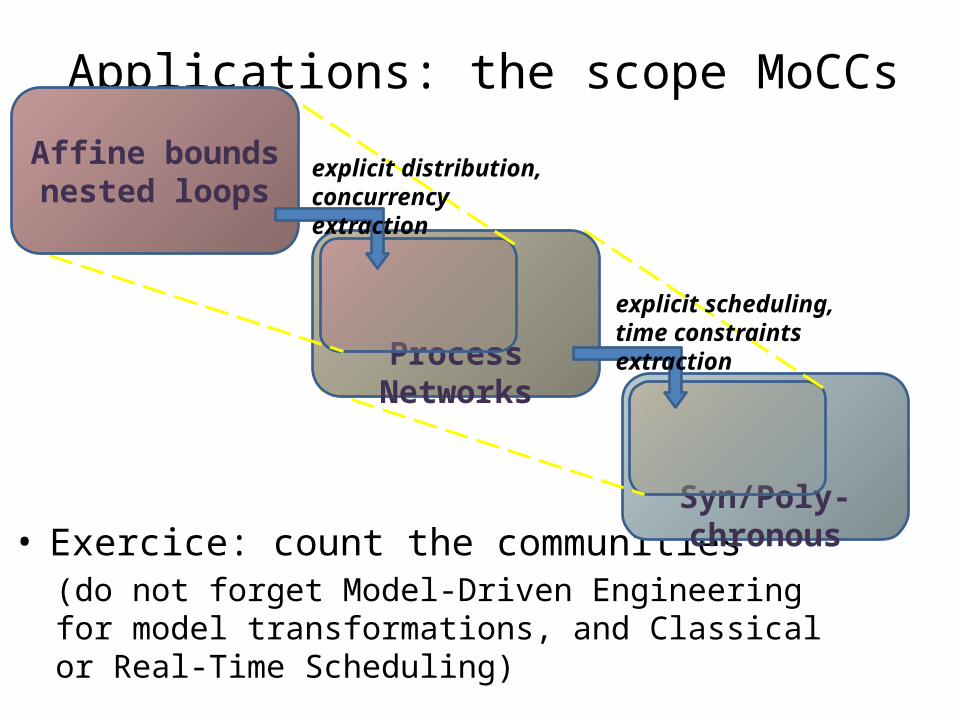
Applications: the scope MoCCs
Syn/Poly-chronous
Process Networks
Affine bounds nested loops
explicit distribution, concurrency extraction
explicit scheduling, time constraints extraction
Applications: the scope MoCCs
• Exercice: count the communities(do not forget Model-Driven Engineering for model transformations, and Classical or Real-Time Scheduling)
Syn/Poly-chronous
Process Networks
Affine bounds nested loops
explicit distribution, concurrency extraction
explicit scheduling, time constraints extraction

Motivations for the joint use of these models
• Similar restrictions !!– little (in fact no) concern for data values– control largely data-independent (uninterpreted functions)– finite-state control property– role of conflict-freeness as functional determinism– Formal models and mathematical analysis– Issues tacked at compile time
but…– Largely developed independently (even if in neighboring groups)– Lack of common vocabulary, or of common framework, or
common drive (risks to loose AAA grade ?)
…Or is it just me who needs to go back to school ?

Process Networks
• Data-flow: computations triggered by data availability– Pure Data-Flow: Marked Graphs, SDF extension
– w/ data route switches: Boolean DF, CycloStatic DF, Kahn PNs
• Conflict-freeness: all computations amount to same partial order, only different scheduling/time assignments
• ASAP schedule: provides best throughput
• correctness issues: safety and liveness
• Optimization issues: optimize buffer sizes while preserving throughput
Second-level semantics: computations according to schedules (activation conditions) Representation as polychronous descriptions

Explicit timing for Process Networks
• Classical scheduling of Marked Graphs, Synchronous Data Flow graphs
• Latency-Insensitive Design– Ultimately k-periodic schedules
Represented with– N-synchronous formalisms– Signal and affine clock calculus
Syn/Poly-chronous
Process Networks

Ultimately k-periodic scheduling
f
g1,1
1
31
2,1
1,1
1,11
bf
ef111
(11010)
(10101)
(10110)
(01101)
(01011)
(11010)
[00100]
loop pause; emit clk; pause; pause; emit clk; pause; emit clk; pause;
endloop

Explicit routing
• Regular switching patterns in BDF, CSDF, KPNs– Extending scheduling with similar expressivity (ultimately
periodic infinite binary words)KRGs (K-periodically) Routed Graphs– Axiomatics for an equational theory of communication re-wiring
• Allows to consider sharing of communications (on common interconnect structures– Interplay of scheduling and routing (arbitration between
communications using the same channels)
Syn/Poly-chronous
Process Networks

Interconnect modeling and optimization
•On-Chip Networks
•Switching conditions of Select/Marge nodes can configure
different communication paths, possibly overlapping in time
•Predictable routing schemes (ultimately k-periodic) will match the
temporal schedules obtained in classical Process Network scheduling
theory
C1
C2
C3
C4 Merge node
Select node

C1
C2
C3
C4
one possible routing configuration
1
0
0
0
0
0
0
00
1
1
1
1
1
1
1

C1
C2
C3
C4
another possible configuration
1
0
1
11
111
1 1
11
1
0 0
0
0
0
0
0
0
0
00
0

Nested loops with affine bounds
•Parallel compilation models– static control (regular indices, not while (data_cond) loops)
– Iteration space (multidimensional arrays, polyhedra)
– Source-to-source transformations (rewrite as program, only with DOSEQ and DOPAR at various levels)
– Improving data locality
• Variants– Systems of Uniform Recurrence Equations (SUREs, MMAlpha)– Geometrical description formalisms (Array-OL)

Example + Reduced Data Graphs
Process Network
Affine bounds
nested loops
loop i = 1 to N loop j = 1 to N a(i,j) := a(i-1,j-1) + a(i, j-1) endend
dependence levels
2 1
direction vectors
01
11
DOSEQ j = 1 to N DOPAR i = 1 to N a(i,j) := a(i-1,j-1) + a(i, j-1) endend

From Nested Loops to Process Networks
• Existing efforts: basic idea is to assign one computing node to each assignment
• COMPAAN, Pico Express• Tiling, chunking • Stefanov, et al, Polyhedral Process Networks• Multidimensional SDF for Array-OL/Gaspard
Process Network
Affine bounds
nested loops

21
Dream (or nightmare?)• How can one produce Process Network descriptions from
nested loops (or better said, SUREs or RDGs)• Of course limited, but very often already polyhedra (for
bounds) separated from dependency graphs (for computations)
• Needs to split clearly between (sequential) iterations and parallel ones (currently expanded)• Issue of potential (application) vs real
(architecture) concurrency/parallelisma(i,j)
i
j
a(i,j-1)a(i-1,j-1)
8
4

22
Dream (or nightmare?)• Greenish nodes provide constants (in parallel at the
bottom, sequentially on the left)• Blue nodes each compute 4 values in parallel, shifts the
last right across the borderLack of generality certainly when values to be sent across boundaries are not ordered as expected at target
a(i,j)
i
j
a(i,j-1)a(i-1,j-1)
8
4
a[1,1..4] a[1,5..8]
4a[1..4,0])
1 1
3 34
0.(1) 0.(1)

Challenges of it
• Not entirely clear (to me at least) how data locality and transfer (if any) is dealt with in different works
• Typical: a data block is transfered in some order (row), and consumed in different order (column)

SoC/NoC intelligent routers ?
• To match (and be programmed from) the application, routers – should be able to fork the data,– Should only care about directions (not single target)– Should let ccommunications cross one another if not using same lines– Should be able to buffer values (at least in the size of the processor array)
P Core P Core P Core P Core
P Core P Core P Core P Core
P Core P Core P Core P Core

ThA Ank You
Questions anybody ?
ThAAAnk YouA