pythonによる機械学習入門〜基礎からdeep learningまで〜
TRANSCRIPT

Pythonによる機械学習⼊⾨〜基礎からDeep Learningまで〜
電⼦情報通信学会総合⼤会 2016 企画セッション「パターン認識・メディア理解」必須ソフトウェアライブラリ ⼿とり⾜とりガイド
名古屋⼤学 情報科学研究科 メディア科学専攻 助教川⻄康友
1

⾃⼰紹介l経歴
Ø2012年 京都⼤学⼤学院 情報学研究科 博⼠後期課程修了Ø2012年 京都⼤学 学術情報メディアセンター 特定研究員Ø2014年 名古屋⼤学 未来社会創造機構 特任助教Ø2015年 名古屋⼤学 情報科学研究科 助教
l研究テーマØ⼈物画像処理
²⼈物検出²⼈物追跡²⼈物検索²⼈物照合²歩⾏者属性認識
Ø背景画像推定
2
← PRMUでサーベイ発表しています
← PRMUでサーベイ発表しています ← Pythonを使用
← 一部Pythonを使用
← 一部Pythonを使用

本チュートリアルの流れlPython⼊⾨編
ØPythonの簡単な説明ØPythonでのデータ(⾏列)の扱い
l機械学習編Øトイデータで機械学習にチャレンジØ実際のデータの読み込みØ学習した識別器の保存,読み込みØ結果の集計ØクロスバリデーションØDeep Learningを試してみる
3
理論の話は殆どありません

Python⼊⾨編
4

Pythonを勉強するための資料集l@shima__shimaさん
Ø機械学習の Python との出会い²numpyと簡単な機械学習への利⽤
l@payashimさんØPyConJP 2014での「OpenCVのpythonインター
フェース⼊⾨」の資料²Pythonユーザ向けの,OpenCVを使った画像処理解説
lPython Scientific Lecture NotesØ⽇本語訳Ø⾮常におすすめØnumpy/scipyから画像処理,
3D可視化まで幅広く学べる

Pythonの簡単な説明
lまずはHello world!lスクリプトの作成と保存l基本的な型,制御構⽂,関数lモジュールとパッケージlよく使うパッケージ
6

まずはHello world!
lSpyderの起動
7
ランチャーに登録してあるSpyderをクリックします

まずはHello world!
lSpyderの使い⽅
8
コードを書く画面
変数などの情報が表示される画面
1行ずつ実行できる対話型シェル

まずはHello world!
lipythonの起動
9
高機能なシェルのipythonを使う場合

まずはHello world!
l対話型シェルでHello world!
10
Print(“Helloworld”)と入力してEnter
結果が表示される

まずはHello world!
lファイルに記述して実⾏する場合
11
書いて
実行!
結果が表示される

スクリプトの作成と保存 12
新規作成

スクリプトの作成と保存 13
新しいファイルができる(untitled)

スクリプトの作成と保存 14
保存

スクリプトの作成と保存 15
このチュートリアルでは,この場所(/home/tutorial/python )にファイルを保存してください
ファイル名を入力

スクリプトの作成と保存 16
ファイルを保存した場所に作業ディレクトリを移動
現在の作業ディレクトリ

基本的な型,制御構⽂,関数l数値型
Ø整数,浮動⼩数点数,複素数,真偽値lコンテナ
Øリスト,タプル,集合,辞書²基本的にどんな型でも⼊れられる(型の混在可)
Ø⽂字列l定数
ØTrue, False²真偽値のリテラル
ØNone²C⾔語でいうNULLのようなもの
17

基本的な型,制御構⽂,関数
l⽂字列の連結Ø+ 演算⼦で連結可能
l⽂字列の整形⽅法ØC⾔語でのprintf系関数の処理Ø % 演算⼦を利⽤
Ø複数の場合は ( ) で囲む
18
str = "文字列" + "別の文字列"
val = 10str = "整数: %d" % val
val = 10; f = 0.01; s = "abc"str = "整数: %d, 浮動小数点数: %f, 文字列: %s" % (val, f, s)

基本的な型,制御構⽂,関数
lif⽂
lwhile⽂
lfor⽂
19
if 条件1:条件1の場合の処理
elif 条件2:条件2の場合の処理
else:それ以外の場合の処理
while 条件:条件が真の間繰り返し
c = [0.1, 2.34, 5.6, 7.89] # コンテナfor x in c:
# c の要素を x で参照しながら繰り返しprint(x)
スペース4個分
コロン

基本的な型,制御構⽂,関数
l関数の定義
l関数の呼び出し
20
a = 10b = 20c = sample(a, b)
def sample(x, y):# 色々な処理z = x + yreturn z
スペース4個分

その他 tipsl多重代⼊
ØC⾔語等と違い,複数の値を同時にreturnできる
Øswapも可能
21
def test(a, b):c = a + 1d = b * 2return c, d
x, y = test(1, 2)
a, b = b, a
x, y には 2 と 4 がそれぞれ⼊る

その他 tips
lリストの⽣成 range 関数
lリストの要素とインデックスを取得
22
range(5)# [0, 1, 2, 3, 4]
for i in range(10):print(i)
a = ["a", "b", "c"]for i, v in enumerate(a):
print("a[%d]=%s" % (i, v))多重代⼊
インデックスと要素の値を i, vで参照可能

その他 tips
lオプション引数Øデフォルト値の指定
l名前付き引数
23
def func(a, b=10, c=False):# 関数
# 関数呼び出し時func(10, c=True)
引数 b には指定せず引数 c だけ値を指定するとき
引数を指定しないとb=10, c=False となる

モジュールとパッケージ
lモジュールØPythonで書いた関数やクラスをまとめた
1つのファイルlパッケージ
Øモジュールが複数まとめられたものl使い⽅
Øインポートすれば利⽤可能
24
import モジュール名from モジュール名 import 関数名from パッケージ名 import モジュール名import モジュール名 as 別名

Pythonでのデータ(⾏列)の扱い
l数値計算ライブラリ numpyØnumpyの⾏列Ø⾏列に対する演算
25

numpyの⾏列lN次元配列 ndarray
ØOpenCVの cv::Mat みたいな感じで利⽤²今回は特徴量やラベルの配列として利⽤²1⾏が1つの特徴量
Ø通常のリストとは違い,型は統⼀
26
import numpy as np
a = np.array([[0,0,1],[0,0,2]], dtype=np.float32)b = np.array([[1,2,3],[4,5,6]], dtype=np.float32)
c = a + bd = a * be = np.dot(a, b.T)
要素ごとの演算
⾏列の積を求める場合はnp.dot関数.T は転置⾏列
型を指定(np.float32, np.int8など)

numpyの⾏列l インデキシング(特定の要素の値を取り出す)
l スライシング(特定の範囲を取り出す)Ø 特徴量のうち特定のサンプルだけ使う,特定の次元だけ使う,など
l ファンシーインデキシング(条件に合う⾏,列を取り出す)Ø 認識失敗したものに対応する特徴量を取り出す,など
27
a[i, j] # 行列 a の (i, j) 要素
a[i, :] # 行列 a の i 行目(のベクトル)a[:, j] # 行列 a の j 列目a[:, 0:3] # 行列 a の 0, 1, 2列目の部分行列
a[b==1, :] # 行列 a のうち,# 行列 b の要素が 1 であるものに# 対応する行列

⾏列に対する演算
lユニバーサル関数Ø⾏列の各要素に関数を適⽤,⾏列を返す
l集計⽤の関数
28
import numpy as np
a = np.array([[0,0,1],[0,0,2]])print(np.count_nonzero(a))
⾮ゼロの要素数を返す
import numpy as npa = np.array([[1,2,3],[4,5,6]], dtype=np.int32)b = np.power(a, 2.0)
⾏列 a の各要素を2乗した⾏列を返す

機械学習編
29

機械学習ライブラリ
lscikit-learnØhttp://scikit-learn.org/Ø機械学習に関する
様々な⼿法が実装されたライブラリ²クラス分類²クラスタリング²回帰²データマイニング
ØBSDライセンス
30

機械学習ガイド 31
解きたい問題に対して何を使えば良いのかのガイドも載っています

今回チャレンジする問題
l多クラス分類問題Ø⼊⾨編
²Iris Dataset– 花(あやめ)の3クラス分類
Ø実践編²Pedestrian Direction Classification Dataset
– 歩⾏者の向き8⽅向分類
32

機械学習ガイド 33
解きたい問題に対して何を使えば良いのかのガイドも載っています
ここに相当する問題です

使⽤するクラス分類器
lクラス分類器ØLinear SVMØk Nearest NeighborsØ(Kernel) SVMØAdaBoostØRandom ForestØNeural NetworkØConvolutional Neural Network
34
この部分は chainerというパッケージを利用

クラス分類器(乱暴に図と⼀⾔で表しています) 35
Linear SVM
Kernel SVMk-NN
AdaBoost
Random Forest
Neural Network CNN
・・・
弱識別器
苦⼿な問題を他の弱識別器へ
多数決
マージン最⼤化
⾮線形の識別平⾯ 複数の決定⽊をランダムに⽣成
畳み込み層による特徴抽出も⾏う線形結合と活性化関数
アンサンブル学習
DeepLearning

機械学習にチャレンジ
lIris DatasetØクラス
²3種類のあやめ
Ø特徴量(4次元)²がくの⻑さ,幅²花弁の⻑さ,幅
l⼊⼿⽅法,使い⽅Øscikit-learnでは, sklearn.datasets.load_iris()
という関数でデータを読み込みできる
36

機械学習にチャレンジ
l機械学習の流れØ特徴量の読み込み
²学習データ,学習データのラベル²テストデータ,テストデータのラベル
Ø識別器の準備Ø識別器の学習Øテストデータの評価Ø結果の出⼒
37

機械学習にチャレンジ
l特徴量の読み込み
l特徴量の分割
from sklearn.datasets import load_iris
dataset = load_iris()features = np.array(dataset["data"], dtype=np.float32)labels = np.array(dtaset["target"], dtype=np.int32)
#学習データとテストデータに分けるtrain_features,test_features,train_labels,test_labels =(行続く)train_test_split(features,labels,test_size=0.3)
scikit-learnに用意されている,IrisDatasetを読み込むための関数
型を修正しておく
特徴量とラベルを取り出す
特徴量を学習用とテスト用に分割する関数何割をテストに使うかの引数(この例だと3割)

機械学習にチャレンジ
l識別器の準備
l識別器の学習
39
fromsklearn.svm importLinearSVC
#識別器の用意classifier=LinearSVC()
#学習classifier.fit(train_features, train_labels)
識別器のインスタンスを生成
引数で色々なオプションがあるので調べてみてください
特徴量と,そのクラスラベルを渡す
使いたい識別器を予めインポートしておく(ここではLinearSVC)

機械学習にチャレンジ
lテストデータの評価
l結果の出⼒
40
#テストresults=classifier.predict(test_features)
fromsklearn.metrics importaccuracy_score
#認識率を計算score=accuracy_score(test_labels,results)print(score)
認識率を計算してくれる関数
テスト用のデータを渡すだけ
各データに対する認識結果が返る

【実践1】試してみましょう 41
線形SVM識別器を利用して,IrisDatasetの認識率を評価しましょうLinearSVC()にパラメータを渡して結果の違いを見てみましょう
スライシングを使い,4次元の特徴量のうち幾つかの特徴量だけを用いて認識率を評価しましょう
train_test_splitの前に実行

実際のデータの読み込み
l普通は事前にOpenCVなどで特徴抽出Ø特徴量を保存しておくØ保存形式は svmlight / libsvm の形式が便利
²特徴量とラベルを分けて読み込めるlscikit-learnには以下の関数が存在
42
from sklearn.datasets import load_svmlight_filefrom sklearn.datasets import dump_svmlight_file# 読み込みdata = load_svmlight_file("ファイル名")features = data[0].todense()labels = data[1]# 書き出しdump_svmlight_file(features, labels, "ファイル名")
SparseMatなのでdenseに変換

svmlight / libsvm 形式
llibsvmなどのツールで利⽤されている形式Øそのまま svm-train などのコマンドで利⽤可
43
1 1:0.111 2:0.253 3:0.123 4:-0.641 …1 1:0.121 2:0.226 3:0.143 4:-0.661 …-1 1:0.511 2:-0.428 3:0.923 4:0.348 …-1 1:0.751 2:-0.273 3:0.823 4:0.632 …
クラスラベル
特徴量の次元番号:特徴量の値の組が次元数分ある

学習した識別器の保存,読み込み
l普通は学習した識別器を保存して別途テストØ保存にはPythonでは⼀般的にシリアライズ関数
(オブジェクトをそのまま保存)を利⽤することが多い²pickleというパッケージ
lscikit-learnには以下の関数が存在Øpickleよりも効率的らしい
44
# 保存from sklearn.externals import joblibjoblib.dump(classifier, "ファイル名")
# 読み込みclassifier = joblib.load("ファイル名")

学習した識別器の保存,読み込み
l保存ができると…Ø学習スクリプトと評価スクリプトを分離可能
45
from sklearn.svm import LinearVCfrom sklearn.externals import joblib
# 学習classifier = SVC()classifier.fit(X, t)
# 保存joblib.dump(classifier, "svc.model")
from sklearn.externals import joblib
# 読み込みclassifier = joblib.load("svc.model")
# 評価result = classifier.predict(X)
学習スクリプト 評価スクリプト
学習まで終わった段階で識別器の状態を保存
学習済みの識別器を読み込んですぐに評価

【実践2】試してみましょう
lデータを読み込んで認識Ø今回の課題
²歩⾏者向き認識– samples/images/ に 8⽅向別の画像
²HOG特徴量を抽出済みØ⽤意したデータ
²学習⽤:samples/features/train.scale²評価⽤:samples/features/test.scale
46

識別器を切り替えてみる
l今までの説明は線形SVMを利⽤l他の識別器を使ってみよう
Ø書き換えるべき部分は以下の3⾏だけ!
47
from sklearn.svm import LinearSVC
〜中略〜
# 学習classifier = SVC()
〜中略〜
# 保存joblib.dump(classifier, "svc.model")

識別器
l使いたい識別器を決める
l保存ファイル名を識別器に合わせて変える
48
from sklearn.svm import LinearSVC # 線形SVMfrom sklearn.svm import SVC # 非線形SVMfrom sklearn.neighbors import KNeighborsClassifier # kNN識別器from sklearn.ensemble import AdaBoostClassifier # AdaBoostfrom sklearn.ensemble import RandomForestClassifier # Random Forest
classifier = LinearSVC()classifier = SVC()classifier = KNeighborsClassifier()classifier = AdaBoostClassifier()classifier = RandomForestClassifier()
joblib.dump(classifier, "svc.model")
使いたいものをインポート
使いたいものをclassifierに代入

Confusion Matrix
l結果の集計Ø全体の平均スコアだけでなく,
クラスごとの誤りを知りたい場合²Confusion Matrixの利⽤
lsklearn.metrics 内に confusion_matrix 関数が存在Øconfusion_matrix(test_labels, results)
²正解と認識結果を⼊れると結果の ndarray が返る²printすれば表⽰可能
49
クラス0 クラス1 クラス2クラス0 13 0 0クラス1 0 11 3クラス2 0 3 15

【実践3】試してみましょう 50
複数の識別器を切り替えて学習し,認識率を比較してみましょう
ConfusionMatrixを表示して結果を見てみましょう

クロスバリデーション
l1つの学習・テストデータセットでは結果がかたよる可能性Øデータを複数個に分割し,
何回か学習・テストを試して平均を取るØ例:10-fold cross validation
²100個のデータを10分割– 90個で学習→10個でテスト– テストに使うセットを替えて10回実⾏
51

lsklearn.cross_validation 内にcross_val_score という関数が存在
result =cross_val_score(clf,data_x,data_y,cv=10)
print(“accuracy:%f±%f”%(result.mean(),result.std())
クロスバリデーション 52
10-foldcrossvalidationを実行好きなクラス分類器
学習用のデータセット
平均と標準偏差を表示

【実践4】試してみましょう
l好きな識別器を使い,10-fold cross validationしてみよう
Øこれまでの,「学習」「評価」の部分を,前述の corss_validation_score 関数に置換
53

Deep Learningを試してみる
lDeep Learningの代表的なパッケージØcaffe (by BVLC)Øchainer (by Preferred Networks)ØTensorFlow (by Google)
54

ニューラルネットワークの基礎
l多層パーセプトロン
55
重み付き和→活性化関数 重み付き和→活性化関数
多クラス分類の場合,クラス数分の出力ユニット
特徴量の次元数分の入力ユニット
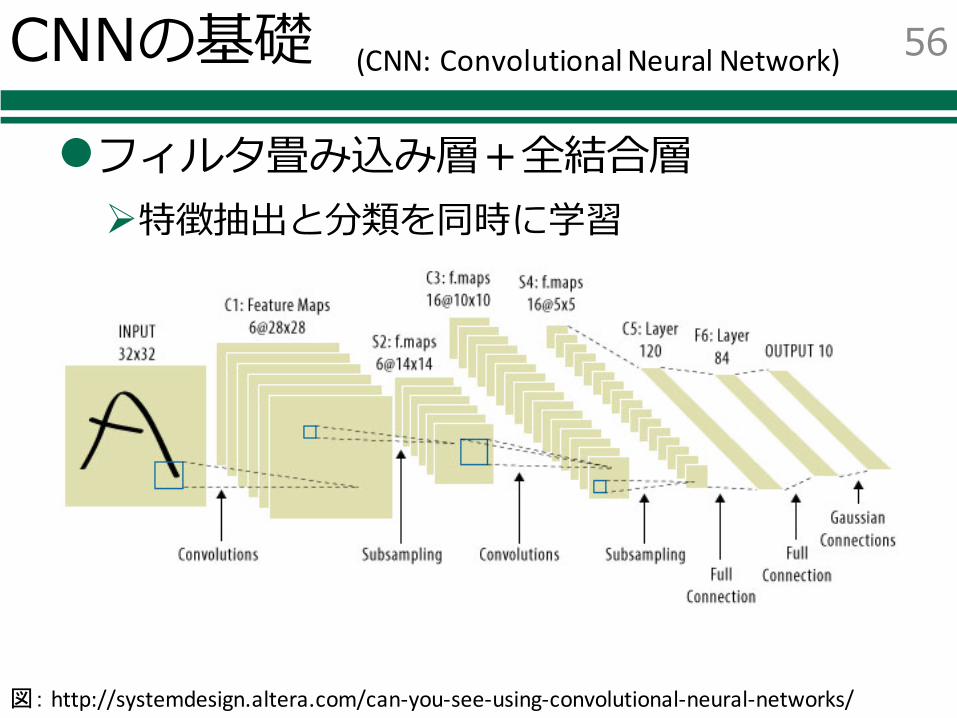
CNNの基礎
lフィルタ畳み込み層+全結合層Ø特徴抽出と分類を同時に学習
56
図: http://systemdesign.altera.com/can-you-see-using-convolutional-neural-networks/
(CNN:ConvolutionalNeuralNetwork)

Deep Learningでのキーワードl活性化関数
Ø線形結合した後に適⽤する関数Ø例
²シグモイド関数²ReLU (Rectified Linear Unit)²maxout
lバックプロパゲーション(誤差逆伝播法)Øネットワークの出⼒値と正解値との誤差を逆伝播Ø誤差が⼩さくなるようにパラメータを更新
57

Deep Learningでのキーワード
lドロップアウトØ学習時に⼀部のノードの出⼒を0にするØ過学習を防ぎ,汎化性能を向上させる
l確率的勾配法(ミニバッチ)Ø⼤量データの場合,メモリの制限で⼀括で学
習できないØ学習データを⼩さく分割し,
少しずつ学習してパラメータ更新を⾏う
58

chainerを使ってみる
lchainerでの処理⼿順Øネットワークの構築Ø最適化⼿法の選択Øミニバッチの作成・学習Ø評価
l今回の課題Øirisをニューラルネットで識別ØPDCをCNNで識別
59

ネットワークの構築
l決めないといけないことØ層数Ø各層のユニット数Ø層間に適⽤する関数
60
from chainer import FunctionSetimport chainer.functions as F
model = FunctionSet(l1=F.Linear(4, 200),l2=F.Linear(200, 100),l3=F.Linear(100, 3))
入力層=特徴量次元
線形結合を3層
4次元(入力)→200次元
200次元→100次元
100次元→3次元(出力)
層数
ユニット数 ユニット数
・・・
・・・
関数 関数

ネットワークの構築l伝播のさせ⽅
Ø活性化関数,ドロップアウトなどの設定Ø評価関数の設定
61
from chainer import Variable
def forward(feature, label, train=True):x = Variable(feature)y = Variable(label)
h1 = F.dropout(F.relu(model.l1(x)), train=train)h2 = F.dropout(F.relu(model.l2(h1)), train=train)p = model.l3(h2)
return F.softmax_cross_entropy(p, y), F.accuracy(p, y)
Dropoutをする場合chainer用の変数へ変換
活性化関数
train=Trueの時のみDropoutを実行
引数の初期値
学習データでの予測精度誤差関数としてsoftmaxのcross_entropyを利用

最適化⼿法の選択
loptimizersで定義されているØ⾊々なパラメータ更新⽅法
²SGD ( Stochastic Gradient Descent)²AdaGrad²RMSprop²Adam (ADAptive Moment estimation)
62
from chainer import optimizers
optimizer = optimizers.Adam()optimizer.setup(model.collect_parameters())
適化のモジュール
modelのパラメータを登録する
学習率を自動的に調整する改良

ミニバッチの作成・学習l データを分割して順番に伝播,誤差逆伝播
63
import numpy as npn_epoch = 100batchsize = 20N = len(features)for epoch in range(n_epoch):
print('epoch: %d' % (epoch+1))perm = np.random.permutation(N)sum_accuracy = 0sum_loss = 0for i in range(0, N, batchsize):
x_batch = features[perm[i:i+batchsize]]y_batch = labels[perm[i:i+batchsize]]optimizer.zero_grads()loss, acc = forward(x_batch, y_batch)loss.backward()optimizer.update()sum_loss += float(loss.data) * batchsizesum_accuracy += float(acc.data) * batchsize
print("loss: %f, accuracy: %f", sum_loss / N, sum_accuracy / N)
繰り返し回数
ミニバッチの分割
各ミニバッチ毎にパラメータ更新
勾配の初期化順伝播
誤差の逆伝播パラメータの更新

評価
lテストデータをネットワークに通す
64
#%%# 伝播のさせ方def forward_predict(features, label, train=True):
x = Variable(features)y = Variable(label)
h1 = F.max_pooling_2d(F.relu(model.conv1(x)), ksize=5)h2 = F.max_pooling_2d(F.relu(model.conv2(h1)), ksize=5)h3 = F.dropout(F.relu(model.fc1(h2)), train=train)p = model.fc2(h3)return p.data
#%%# テストresult_scores = forward_predict(test_features, train=False)results = np.argmax(result_scores, axis=1)
各クラスのスコアが出てくるので argmaxを取る
ネットワークの出力を返すように修正

【実践5】試してみましょう 65
IrisDatasetをニューラルネットワークで学習・評価してみましょう
これまでの識別器の代わりにNeuralNetworkを利用
層数やユニット数を変えてみて結果の違いを見てみましょう

CNNを試してみるl変更点
Ø特徴量ではなく,画像を読み込む²これまでは抽出済みの特徴量を読み込んでいた
– サンプル数 x 特徴量次元数 の ndarray を利⽤²CNNでは2次元の画像を読み込む
– サンプル数 x チャンネル数 x 画像の⾼さ x 画像の幅 のndarray を利⽤
ØConvolution層を追加²Convolution+ReLU+Maxout
– フィルタ畳み込み– 活性化関数を通して– 領域内の最⼤値を出⼒
66

CNNの構築
l画像の読み込み
lネットワークの構造
67
from chainer import FunctionSetimport chainer.functions as F
#ネットワークの構築model=FunctionSet(
conv1=F.Convolution2D(1, 32,3),conv2=F.Convolution2D(32, 64,3),fc1=F.Linear(512,200),fc2=F.Linear(200,8))
入力層=1チャンネル(モノクロ画像)
Convolution層が2つ,全結合層が2つ
1→32チャンネル
32→64チャンネル
512次元→200次元
200次元→8次元(出力)
##画像ファイル分の容量を確保##画像枚数xチャンネル数(1)x高さx幅features=np.ndarray((len(filenames), 1,96,48),dtype=np.float32)labels=np.ndarray((len(filenames),), dtype=np.int32)

CNNの構築l伝播のさせ⽅
Ø活性化関数,ドロップアウトなどの設定Ø評価関数の設定
68
from chainer import Variable
def forward(feature, label, train=True):x = Variable(feature)y = Variable(label)
h1 = F.max_pooling_2d(F.relu(model.conv1(x)), ksize=5)h2 = F.max_pooling_2d(F.relu(model.conv2(h1)), ksize=5)h3 = F.dropout(F.relu(model.fc1(h2)), train=train)p = model.fc2(h3)return F.softmax_cross_entropy(p, y), F.accuracy(p, y)
chainer用の変数へ変換
学習データでの予測精度誤差関数としてsoftmaxのcross_entropyを利用
カーネルサイズ5でmaxpooling

【実践6】試してみましょう
lCNNを⽤いて歩⾏者向き認識Øコードが少し⻑いので
サンプルコードをダウンロードして動かしてみましょう
Ø/home/tutorial/python へ保存Øspyder で開いて実⾏してみましょう
69
http://www.murase.m.is.nagoya-u.ac.jp/~kawanishiy/data/cnn.py
実⾏にかなり時間がかかるので,学習のエポックごとに徐々に誤差が減っていく様⼦を確認できればOK

まとめ
lPythonによる機械学習Ønumpyによるデータの扱いØscikit-learnによる各種機械学習ØchainerによるDeep Learning
70

71

様々な⾔語でのライブラリ紹介lC++⽤
ØCaffe²http://caffe.berkeleyvision.org/
lJava⽤ØDeep Learning 4j
²http://deeplearning4j.org/ja-index.htmllLua⽤
ØTorch²http://torch.ch
lPython⽤Øchainer
²http://chainer.org
72

メモ
lGDとSGDの違いØhttp://sinhrks.hatenablog.com/entry/201
4/11/24/205305lchainerからcaffemodel読み込み
Øhttp://d.hatena.ne.jp/shi3z/20150711/1436566217
73