pydata london 2014 martin goodson- most a/b testing results are illusory
TRANSCRIPT

Most A/B testing results are IllusoryMartin Goodson, Skimlinks

These are my opinions - not those of my
employer!

What’s an A/B test?Example: Free delivery
A: ControlB: Variant

‘How can you talk for 40 minutes about A/B testing?’

A/B tests are very easy to get wrong

What my experience is based on


What this talk is about
3 Statistical conceptsErrors and consequencesThese errors are exactly how A/B testing software works

What this talk is about
Statistical PowerMultiple TestingRegression to the Mean

What is Statistical Power?The probability that you will detect a true difference between two samples

What is Statistical Power?Example: are men taller than women, on average?

What is Statistical Power?Example: free delivery on a website

Why is Statistical Power important?1. False negatives2. False positives

Precision
Proportion of true positives in the positive results
Its a function of power, significance level and prevalence.

If you have good power?
Out of 100 tests10 really drive upliftYou detect 85 false positives8/13 of positive tests are real

If you have bad power?
Out of 100 tests10 really drive upliftYou detect 35 false positives3/8 of winning tests are real!

Marketer: ‘We need results in 2 weeks time’
Me: ‘We can’t run this test for only two weeks - we won’t get robust results’

Marketer: ‘We need results in 2 weeks time’
Me: ‘We can’t run this test for only two weeks - we won’t get robust results’
Marketer: ‘Why are you being so negative?’

Calculating PowerAlpha: probability of a positive result when the null hypothesis is true (5%)
Beta: probability of not seeing a positive result when the null hypothesis is true
Power = 1- Beta (80-90%)

Calculating Power
Use a power calculator:Online R (power.prop.test)python (statsmodels.stats.power)

Approximate sample sizes
Using a power calculator and asking for 80% power and significance level of 5%:
6000 conversions to detect 5% uplift1600 conversions to detect 10% uplift





Multiple testing

Effect of multiple testing
if you run 20 tests at a significance level of 5% you will obtain 1 win, just by chance.


Giving targets for successful tests.


Stopping tests early

Stopping tests early
Simulations show that stopping an A/A test when you see a positive results will result in successful test 41% of the time.

Stopping tests early
That works out to a precision of 20%


Negative uplift.
Stopping an A/B test with negative effect results in a win 9% of the time!

A True Story

Regression to the mean
Give 100 students a true/false testThey all answer randomlyTake only the top scoring 10% of the classTest them againWhat will the results be?


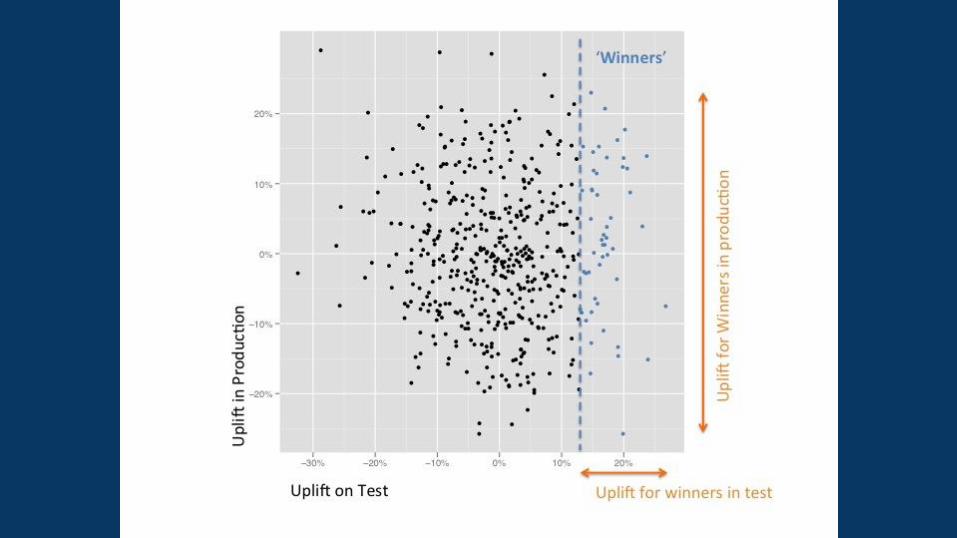

Estimates of uplift are generally wrong.

What you need to do to get it right
● Do a power calculation first to estimate sample size
● Use a valid hypothesis - don’t use a scattergun approach
● Do not stop the test early● Perform a second ‘validation’ test


Skimlinks After Party!
Levante Bar 5 minutes awayCome hungry!Invites + Map at the boothhttp://skimlinks.com/jobs