proteus mirabilis urease: nucleotide sequence determination and
TRANSCRIPT

Vol. 171, No. 12JOURNAL OF BACTERIOLOGY, Dec. 1989, p. 6414-64220021-9193/89/126414-09$02.00/0Copyright © 1989, American Society for Microbiology
Proteus mirabilis Urease: Nucleotide Sequence Determination andComparison with Jack Bean Urease
BRADLEY D. JONES AND HARRY L. T. MOBLEY*Division ofInfectious Diseases, Department of Medicine, University of Maryland School of Medicine,
10 South Pine Street, Baltimore, Maryland 21201
Received 3 July 1989/Accepted 5 September 1989
Proteus mirabilis, a common cause of urinary tract infection, produces a potent urease that hydrolyzes ureato NH3 and C02, initiating kidney stone formation. Urease genes, which were localized to a 7.6-kilobase-pairregion of DNA, were sequenced by using the dideoxy method. Six open reading frames were found within aregion of 4,952 base pairs which were predicted to encode polypeptides of 31.0 (ureD), 11.0 (ureA), 12.2 (ureB),61.0 (ureC), 17.9 (ureE), and 23.0 (ureF) kilodaltons (kDa). Each open reading frame was preceded by aribosome-binding site, with the exception of ureE. Putative promoterlike sequences were identified upstream ofureD, ureA, and ureF. Possible termination sites were found downstream of ureD, ureC, and ureF. Structuralsubunits of the enzyme were encoded by ureA, ureB, and ureC and were translated from a single transcript inthe order of 11.0, 12.2, and 61.0 kDa. When the deduced amino acid sequences of the P. mirabiis ureasesubunits were compared with the amino acid sequence of the jack bean urease, significant amino acid similaritywas observed (58% exact matches; 73% exact plus conservative replacements). The 11.0-kDa polypeptidealigned with the N-terminal residues of the plant enzyme, the 12.2-kDa polypeptide lined up with internalresidues, and the 61.0-kDa polypeptide matched with the C-terminal residues, suggesting an evolutionaryrelationship of the urease genes of jack bean and P. miabilis.
Urinary tract infection with Proteus mirabilis can lead toserious complications, including cystitis, prostatitis, urolithi-asis, pyelonephritis, bacteremia, and death (30, 38). Theenzyme urease is recognized as an important virulencefactor for this uropathogenic bacterial species and, indeed,as the causative agent of infection-induced kidney andbladder stones, which are estimated to represent 20 to 40%of all urinary stones (14). Alkalinization of the urine byhydrolysis of urea to carbon dioxide and ammonia facilitatesprecipitation of struvite, MgNH4PO4 6H20 and carbonate-apatite, Ca1O(PO4CO3OH)6(OH). Furthermore, in catheter-ized patients, precipitation of urinary stones results in en-crustation and blockage of indwelling urinary catheters. Thiscomplication has been uniquely correlated with the presenceof P. mirabilis but not other ureolytic organisms (23).Further evidence suggests that the ammonia per se gener-ated by ureolysis may be toxic to the kidney epithelia (5).Recent work has begun to yield an understanding of the
biochemistry and genetics of ureases produced by membersof the Proteeae tribe (21). Urease gene sequences fromProvidencia stuartii (22), P. mirabilis (15, 37), and Mor-ganella morganii (L. Hu, B. Jones, M. Fox, E. Nicholson,and H. Mobley, Abstr. Annu. Meet. Am. Soc. Microbiol.1989, B64, p. 41) have been identified by cloning andexpression in Escherichia coli. Genetic analyses of thecloned ureases of Providencia stuartii and P. mirabilis haveidentified the coding regions for the structural subunits of theenzyme as well as the accessory polypeptides which arerequired for expression of enzyme activity in vivo (15, 25,37). Mulrooney and co-workers (25) have purified the clonedurease of Providencia stuartii and determined its biochemi-cal properties. In addition, they have demonstrated that thenative enzyme possesses a heteromeric subunit structure ofone large and two small polypeptides and contains fournickel ions per active enzyme molecule.
* Corresponding author.
Ostensibly, bacterial and jack bean ureases appear to bedistinct with respect to subunit structure, subunit stoichiom-etry, and native molecular weight. Several purified bacterialureases have been shown to have similar heteromeric sub-unit structures (6, 25, 33, 34; Hu et al., Abstr. Annu. Meet.Am. Soc. Microbiol. 1989). In P. mirabilis and Providenciastuartii, the three subunit polypeptides are transcribed on asingle mRNA molecule from the smallest to the largestsubunit (15, 25). In contrast to the heteromeric bacterialureases, jack bean urease is composed of six identicalsubunits. Despite this difference, we present evidence that astriking similarity exists between the deduced amino acidsequence for the three subunits of the P. mirabilis urease andthe known amino acid sequence of the jack bean ureasesubunit.
In this report we present the complete nucleotide se-quence of the region of the recombinant plasmid pMID1003which encodes active urease. The operon encoded openreading frames (ORFs) for six polypeptides with molecularsizes, ordered as they appear in the operon, of 31.0, 11.0,12.2, 61.0, 17.9, and 23.0 kilodaltons (kDa). The 11.0-, 12.2-,and 61.0-kDa polypeptides represented the subunits of the P.mirabilis urease and exhibited a high degree of homologywith the jack bean urease subunit at the amino acid level.Evidence is presented that suggests that the three bacterialurease subunits merged to form the single plant ureasesubunit.
MATERIALS AND METHODSBacterial strains and plasmids. E. coli HB101 (F- hsdR
hsdM proA2 leuB6 rpsL20 recA13) was used as a host forrecombinant plasmids. E. coli DH5aF' [F' hsdR 480dlacZAM15 (lacZYA-argF)U169 recAl] was used as the host ofM13 derivatives (Bethesda Research Laboratories, Inc.,Gaithersburg, Md.). Plasmid pMID1003 encodes the ureaseof P. mirabilis H14320 and has been described previously(15).
6414

P. MIRABILIS UREASE GENE SEQUENCE 6415
DNA isolation. Replicative forms of the M13 vectors mpl8and mpl9 were obtained from J. B. Kaper (University ofMaryland School of Medicine). M13 DNA was isolated fromcultures of E. coli DHSaF' that was grown for 6 h in 2xtryptone-yeast medium (3) by alkaline sodium dodecyl sul-fate extraction (4) and purified by centrifugation to equilib-rium in cesium chloride-ethidium bromide density gradients(18).
Molecular cloning and production of sequential deletions.Specific DNA fragments (1.95-kilobase [kb] Hindlll, 1.5-kbHindIll, 0.9-kb PstI-XhoI, and 2.5-kb HindIlI-BamHI frag-ments) derived from pMID1003 were subcloned into eitherM13mpl8 or M13mpl9, so that both strands of the entireurease genetic sequences were represented. Deletions werecreated by cutting the M13 derivatives with appropriaterestriction enzymes (see Fig. 1), religating, and transformingthe new derivatives into DH5aF'. This method allowedapproximately 80% of the 4,952-base-pair (bp) length to besequenced. In regions where no useful restriction enzymesites existed to create deletions, oligonucleotides were syn-thesized for use as primers to determine these sequences(see Fig. 1).
Labeling and electrophoresis of templates. Dideoxy se-quencing was carried out by using Sequenase as specified bythe commercial supplier of the kit (U.S. Biochemicals,Cleveland, Ohio). [a-35S]dATP (ca. 800 to 1,000 Ci/mmol)was purchased from Dupont, NEN Research Products (Bos-ton, Mass.). The labeled DNA reaction mixtures were sep-arated by electrophoresis in one of two types of gels. (i) Gelsof 50% urea-7.2% acrylamide (bisacrylamide-acrylamide[1:20] [1]) were poured with wedge spacers (width, 0.4 to 1.2mm), and samples were electrophoresed for 2.5 h to resolveup to 250 bases from the primer; or (ii) gels of 50% urea-6.0% acrylamide were poured with straight spacers (width,0.4 mm), and samples were electrophoresed for 5.5 h toresolve up to 400 bases from the primer. The gel wasdialyzed with 10% acetic acid-12% methanol for 1 h, driedunder vacuum, and exposed to film (XAR-2; Eastman KodakCo., Rochester, N.Y.) for 18 h before reading the sequencedirectly from the autoradiograph.DNA and amino acid sequence analysis. The DNA-protein
sequence analysis software programs, version 2.02, of Inter-national Biotechnologies Inc. and Pustell and Kafatos (28)were used for analysis of the DNA sequence for restrictionenzyme sites, ORFs, ribosome-binding sites, promoterlikesequences, catabolite repressor protein-binding sites, andnitrogen regulation sequences. The deduced amino acidsequences of the ORFs were analyzed for signal sequences,ATP-binding sites, divalent cation-binding sites, amino acidcomposition, isoelectric points, and hydropathy. The Genet-ics Computer Group sequence analysis software package,version 5 (University of Wisconsin, Madison, Wis.), wasused to screen the National Biomedical Research Founda-tion protein sequence bank for sequence similarities toUreA, UreB, UreC, UreD, UreE, and UreF, as well as toconstruct hydropathy plots.
RESULTS
DNA sequence of the P. mirabiis urease. The series ofoverlapping M13 subclones created by restriction enzymedeletions on DNA spanning urease-encoding regions ofplasmid pMID1003 is shown in Fig. 1. In addition, 10synthetic oligonucleotide primers were synthesized to gen-erate sequence where no suitable restriction enzyme sitesexisted. The nucleotide sequence determined from these
H HH B EV pBR322 EV
0 2 3 4 5
BomHI4-4 -4--5 Bcl
Bst Ells-. EcoRV
4-. ' -+----~ 4--"-----@ Hind III4-4----4> Nrul
Nsi---------3. @ Pst
_NO-00-~ Synthetic Primers
FIG. 1. Sequencing scheme of the P. mirabilis urease operon.The urease gene boundaries were previously determined by Tn5transposon insertions. The 5.0-kb region that was sequenced isexpanded in the lower portion of the figure (numbered vertical linesrepresent 1 kb of DNA). The direction of sequencing on the DNA isshown by the arrows; restriction endonucleases on the right refer tothe enzyme used to create the deletion for sequencing that particularregion. Restriction endonuclease abbreviations: H, HindIII; B,BamHI; EV, EcoRV.
subclones covered a 4,952-bp region (Fig. 2). Both strands ofDNA were completely sequenced, except for the last 60 bpof the noncoding strand. The sequence on the coding strandwas confirmed in this area by two overlapping subclones.ORFs associated with multiple polypeptides in the urease
operon. The DNA sequence (Fig. 2) encoded six ORFs ofgreater than 95 codons, each beginning with the character-istic ATG start codon. No ORF of any significant length(>50 codons) was found on the reverse complement of thesequence shown in Fig. 2. We identified sites similar to theE. coli consensus ribosome-binding sequence (Shine-Dal-garno sequence) (31) that were present immediately up-stream of the methionine start codon for five of the six ORFs(ureD, bp 431 to 436; ureA, bp 1277 to 1282; ureB, bp 1585 to1590; ureC, bp 1908 to 1913; ureF, bp 4159 to 4164) (Fig. 2).The ORF (ureE) encoding a 17.9-kDa polypeptide lacked adetectable Shine-Dalgarno sequence. The predicted molec-ular masses of the polypeptides encoded by the six ORFs, insequential order (5' to 3') as found on the coding strand ofDNA, were 31.0, 11.0, 12.2, 61.0, 17.9, and 23.0 kDa.DNA sequence features. A search of the urease operon for
putative transcriptional initiation sequences was carried outby using E. coli consensus promoter sequences (29), -35(TT*G*ACA) and -10 (T*A*ATAAT*), with a -35 to -10spacing of 17 + 2 bp. Conditions of the search for a possiblepromoter were that eight or more matches of the possible 12nucleotides were required, with exact matches at the nucle-otides marked with asterisks. We were unable to locate anyputative promoter sequences until we reduced the requirednumber of nucleotide matches to seven, relaxed the require-ment for exact matches at the nucleotides marked withasterisks, and allowed the gap between the -35 and -10sequences to extend to 23 bp. Using these modified searchconditions, we located five promoterlike sequences (Fig. 3).Two sequences were found upstream of ureD (-35, bp 307;-10, bp 335; and -35, bp 354; -10, bp 381), one upstream ofureA (-35, bp 1232; -10, bp 1261), and two upstream ofureF (-35, bp 4019; -10, bp 4044; and -35, bp 4107; -10,bp 4136). No promoterlike sequences were found upstreamof the ureE ORF by using these conditions; we did notexpect or find any promoterlike regions upstream of ureBand ureC since they are transcribed with ureA on a singlemRNA (15).Urease is known to have a role in the nitrogen regulation
pathway of some microorganisms such as the bacterium
VOL. 171, 1989

10 20 30 40 50* * * *a
AA OCT TAA ACT TA% CCA CT? AAT TTC TCA ACT TAT AAC CAC TAA CCA TGG CTT TTA TTA
60 70 so 90 100 110* * * * * aTCA CAA TAT TCC TAT TCC CAL ACC CCC TCC TSA TAC CCA ATA CTA TAA GAC TGG CTC
120 130 140 150 160 170* * * * *
ACA ATA TAA TCT TCT TOC TCA CCA ATA ACA ATA TCG ATA TCT CT? CAT TTS TTA CTT
10 190 200 210 220 230
TTA TTT TTA CCA TTC TTA TT? TTT CTA AAC AAA TC CTCTmT ATT TAA AAC GCA T
240 250 260 270 280a a * a
TTT GMA ACT COO TOT AAA ATC aCC CGO CAT TGA TOO AGC OCT TTA TCC TOT TTG AGG
290 300 310 320 330 340
AAL ATO CAA TTT ATC TI' ATT CAC aCC CTA CCC AAC ATT CAT TIC ATT AT? TIC TCG
350 360 370 380 390 400* * a a . *
OT ATT TTG AAT CAC ATA ATC TOL TOO OTA GTG COG TAT ATA TTC GTC TAT TIC CTG
410 420 430 440 450
ATT TAT TTC ATC AAT TTT GCC AAL TTC WCA GGA GTO CGT ATO CCT GAC TTT TCT GAGNot Pro Asp Ph. Sar Glu
460 470 480 490 500 S10* * * * * *
AAG GOT TOG CTT OCT CAC ATC aCT TTA CCA TAT GAC TTA AAG CCA GCG AAO ACA TGTLys Gly Trp Lou Ala Asp I1. Ala Lau Arg Tyr Clu Lou Lys Arg 0ly Lys Thr cys
520 530 540 550 560 570
CTT ACT GAA AAA COT CAT CTC GGC CCC TTA ATG CTT CAC CCA CCT TI' TAT CCA GAGLou Thr Olu Lys Arg Hia Lou Cly Pro Lou Mat Val Gln Arg Pro Ph, Tyr Pro Glu
S00 590 600 610 620
CAL GOT OTT GCA CAT AC: TAT TO TTG CAT COT OCT GOT CGG GTG GTC GGT GCT CATGin Gly Val Ala His Thr Tyr Lou Lou His Pro Pro Cly G1y Vol Val Cly Gly Asp630 640 650 660 670 680
Lcc TTA TCC AT? ALT AT? ALT OTO CAA CCT TAC GCA CAT GCC CTA TTA ACA ACG CCGThr Lou Bor 01 Lan I1 Asn Val Gln Pro Tyr Ala His Ala Lou Lou Thr Thr Pro
690 700 710 720 730 740
O0GC000 CA ALL TI' TAT COT ALT OCA aG" GOT ACT OCA TCC CAA ACG CAG ACA TTMGly Ala Thr Lyo PSi Tyr Arg Nr Al Gly Gly Thr Ala $or Gln Thr Gln Thr Lou
750 760 770 780 790 800
ALO OTT BOA CAA GAG 0c TT? TTA GA: TOO TTA CCC CAAGAG AALT TC TT' mT CCTTSr Vol Ala Gin 0lu 0ly Pbe Lou Olu Trp Lou Pro Gln Glu Lan I1- Pho Phb Pro
010 820 030 840 850
OAT GOT CAA GTO TOT TTA ACC ACA CAT ATT CAT TTA CCC TCA TCA GCC AAA TTT ATCAsp Ala aln Vol Cys Lou TSr Tr HNs I11 His Lou Ala Ser Sar Ala Lys Phe Ile
860 070 000 890 900 910
000 TO GAL ATG CAG TOT TT GLA COO CCA GTTTTAAAT GAG TOO TI? GAA ACT GGC0ly Trp 0lu Not Gln Cyo Pb. Oly Arg Pro Val Lou ALn Glu Trp Pho Clu Thr Cly
920 930 940 950 960 970
AAG OTA ALA 00 C0C TTA AAT TI' TAT GTT CAT CGA AOA TTA ATT TTA ACA CAC TCALys Val Lys Gly Arg Lou Asn Ph0 Tyr Vol Ap Glu Arg Lou I1e Lou Thr Glu Ser
980 990 1000 1010 1020
ATO CO6 OTT GA CC TSTA CAL AAA CAA OC 0CC CA ATG COT GAA TTT CCT ATC Tnot Arq Val alu aly Lou aln Lys Gln Ala Ala Ala Nat Arg Glu Ph. Pro Not Phe
1030 1040 1050 1060 1070 1080
00C TOO CTT TAT ATT TAT CCT CCA ACC GAT CCA TTa AAA CAC ATT ATT CAA CAC CAT0ly Bor Lou Tyr I1e Tyr Pro lab Thr Asp Ala Lou Lys Clu 01l Ila Cln His Ilis
1090 1100 1110 1120 1130 1140
TTA GAO AAG OTA ALT CCC CTA GTT GAA TAT CGT TTA ACG CAT GTT CAT CCC ATT TTALou Glu Lys Val AnL Pro Lou Val Clu Tyr 0ly Lou Thr Asp Val Asp Gly Ile Let
1150 1160 1170 1180 1190
aT TTTA CT OTA TTA GGGC AC CAA ACC GAC CCG ATO ATG GCc TOT T?T CCC CAA GTAVal LOu Arq Val Lou Gly Thr Gin Thr Glu Pro Not Nat Ala Cya Pha Ala Gin Val
1200 1210 1220 1230 1240 1250
TOG CAA ATC GTC AOL CACAC TOG CTA GGT TAT TGC CCT GAC CCA CCC CCC ATC TGGTrp Gln IIo Val Arg Gin Hib Trp Lou 0ly Tyr Cya Pro Glu Pro Pro Arg; 11- Trp
1260
CCC ACA TAAAla Thr ---
1270 1200 1290 1300 1310 1320
TCG T;T ATT TTA GCA GCC CAA ATO GAA TTA AOA CCA AOA GaA aAA OAT AAA TTACnot Glu Lou Thr Pro Arg;luLyG ALp Lys Lou Lou
1330 1340 1350 1360 1370
CT? TTT ACT CCA GCO CT? CTT CCA CGA AOA COT TTA OCT AAL CCa TTA AAA CTT aATLou Ph TShr Ala 0ly Lou Val Ala Clu Ar; Arg Lou Ala Lys 0ly LOu Ly7 Lou Asn
1380 1390 1400 1410 1420 1430
TAC CCT CAA CGT GTC CCC TTC AT? AGT TOO CCO AT? ATG CAA CCC CCA CCA CAG GGGTyr Pro Clu Arg Val Ala Lou I1- SOr Cy0 Ala 11l Not Clu 0ly Ala Arg Clu Gly
1440 1450 1460 1470 1480 1490* a * * *a
AAa AOA OTT GCT CLA TTA ATO ACT CAA CCA CGT ACT OTT TTa ACC CCA GAG CAL GTALys Thr Vol Ala Gln Lou Nt S-r Glu Gly Arg Thr Vol Lou Thr Ala Clu Gln Val
1500 1510 1520 1530 1540 1550ATG GAA GGG GTG CCA GAG ATG ATA AAA GAT GTT CAA GTA CAG TOC ACT TTC CCC GATNot Glu Gly Vol Pro Glu Mat Ile Lys ASp Val Gln Vol Glu Cy0 Thr Pho Pro Asp
1560 1570 1580
GGC ACC AAA TTG GTT TCA ATT CAC TCA CCT ATT GTC TAGGly Thr Lya Lou Vol Bar Il* His Ser Pro I1e Val ---
1600 1610 1620 1630 1640
CT AAT AAC ATO ATC CCC OCT CAL ATT AOA CTT AAT GCA CCA TTA CaC OAT ATT CAA CTOnot I10 Pro Gly Glu 010 Arg Val Asn Ala Ala Lou 0ly Asp I1 Clu Lou
1650 1660 1670 1680 1690 1700
AAT OCT OCT CCC CGA ACA AAA ACC ATA CAG GTG COT AAT CAT GCC GAT AGA CCT CTAAen Ala 0ly Arg Clu Thr Lys Thr I10 Gln Vol Ala Asn His Gly Ap Arg Pro Vol
1710 1720 1730 1740 1750 1760
CAA CTC GCC TCT CAT TAC CAC TI' TAT GAA GTG AAT CAG CCLA OT AGO TI' GCA CCAGln Val Cly Ser His Tyr His Ph. Tyr GIU Val Assn GIu Ala L*u Arq Po Ala Arg
1770 1780 1790 1800 1010
ALA CAG ACA TTA OCT mT' CGT TTA AAT AT? CTC CT OCT ATO OCT GTT CCC TTC GAGLys Glu Thr Lou Gly Ph. Arg Lou Asn I01 Pro Ala 0ly Not Ala Vol Arg Ph. Clu
1820 1830 1840 1850 1860 1070
CCC CGT CAA ACT CCC ACT CT? GAT CAG TTA OTG OCT TI' CCA CCA AAA CT GMA ATTPro 0ly Gln Ser Arg Thr Val Ap Glu Lou Vol Ala Ph0 Ala 0ly Lys Arg Clu I10
1s80 1890 1900 1910 1920* a a sa|
TAT OCT TTT CAT CCC AAA GTO ATO GCT ALA TIC GAG ACT GAO ALL MA TGATyr Gly Ph- His 0ly Lys Vol Not GCy Lys Lou Glu Bar Glu Lys Ly ---
1930 1940 1950 1960 1970 1980
ATG AAA ACT ATC TCA CGT CAA COT TAT CCC CAT ATG TTT 0OC CCA ACA ACA aaC GATNot Lys Thr I10 Ser Arg GCn Ala Tyr Ala LAp Not Ph- 0ly Pro Thr Thr Gly Asp
1990 2000 2010 2020 2030
CGT TTI CGA TTA CCA OAT ACC GML CTO 'TI CTT CAA ATT GAA AAA OAT TIC ACC ACTAr; Lou Arg Lou Ala Asp Thr Glu Lou Ph. Lou Glu 010 Clu Lys Asp Pho Thr Thr2040 2050 2060 2070 2060 2090
TAT GCC GAA CAC GTC AAA TT' COT OCT COT AAL CT ATT COT OAT GOT ATO 0O0 CAATyr 0ly Glu Clu Vol Lys Ph. Gly Gly 0ly Lys Vol I1e Arg Asp 0ly Not Gly Gln
2100 2110 2120 2130 2140 2150
AGC CAA CTT GT? ALOT Oc GAO TOT GTC OAT CT? CTO ATC ACC AAT 0cc AT? AT? TTABar Gln Vol Vol Sr Ala Olu Cyo Vol ALp Vol Lou I1 TShr Asn Ala I1. I01 Lou
2160 2170 2180 2190 2200
OAT TAT TOC 00c AT? OTA AAA OCA OAT ATT 00c AT? AaA GAT 00C COT ATS OTC OOTAp Tyr Trp Gly I01 Val Lys Ala Asp I1 0ly 010 Lys Asp 0ly Ar; I1e Vol 0ly
2210 2220 2230 2240 2250 2260
AT? CCC AAG GCC GOT AAT CCA CAT CT? CAG CCC AAT aTO OAT ATT OTM ATT CGC CCCI1 0ly Lys Al. Gly asn Pro Ap Vol Gln Pro Asn Vol asp I1 Vol 1o01ly Pro
2270 2280 2290 2300 2310 2320
CCA AOL OLA STT 0TC COT GGA GAA GOT ALA ATA GTC ACT GOCT G4 GOT AT? OAT ACC0ly Thr Glu Vol Vol Ala Gly Glu Gly Lys I1e Vol Thr Ala 0ly 0ly I01 ALp TShr
2330 2340 2350 2360 2370
CAT ATC CAC TTT AT? TOT CCA CAL CLA GOCC CAA GAA GOT CTC O TOCT 0C OTA ACCilia I0 His Ph. I01 Cys Pro Gln Gln Ala Gln Glu 0ly Lou Vol Sr Gly Vol Thr
2380 2390 2400 2410 2420 2430
ACC TT' ATT CGT GGA GCA ACA CGC OCT OTG GCO COT ACT ALT OCA ACC ACO OTT ACCThr Ph I1e Gly Gly Gly TShr Gly Pro Vl Ala Gly TShr An Ala Thr TShr Vol Thr
2440 2450 2460 2470 2400 2490
CCC GOT ATT TGO A;T ATG TAC COO ATO TSA GAG 000 OTO OAT GA TSA COT AT? AATPro Gly I1. Trp Asn Not Tyr Arg Not Lou Glu Ala Vol Asp Glu Lou Pro I1. Lan
2500 2510 2520 2530 2540 2550
GTG GGT TTA T' GGC LAL GGT TGT GTC AGT CAG CCC GAA GCA ATC COC GAL CAA ATAVaol ly Lou Ph. Gly Lys Gly Cys Vol B8r Gln Pro Glu Ala I01 Ar alu aln I1e
2560 2570 2580 2590 2600
ACA GCO GCT GCT ATA GGT CTT ALA ATA CAT GAA CAC TOO acG WCA ALG CCA ATO OcAThr Ala 0ly Alb Il1 Gly Lou Lys 1. His Glu ALp Trp 0ly Ala Tbr Pro Not Ala
2610 2620 2630 2640 2650 2660
ATT CAC AAT TGC CTT AAT GTC 0CC OAT CAA ATO GAT GTA CAL GTO GCT ATT CAC TCTIla Hi: Asn Cy- Lou Asn Vol Ala Asp Glu ot Asp Vol Oln Val Ala Ile H81 for
2670 2680 2690 2700 2710 2720
GAC ACC TTA AAT GCA GCT GOT TTT TAT GAA GAG ACA GTA AAA 0CC ATT 0CC CGT CCAAp Thr Lou Asn Clu Gly Gly Ph. Tyr Clu Glu Thr Vol Lym Ala Il1 Ala 0ly Ar;
2730 2740 2750 2760 2770
GTG ATC CAT GTA TTC CAT ACC GAA GGC GOA OGT G0C CCOTOAT 0CC CCT OAT aTO ATCVol lI ills Val Ph. Hi. Thr Clu aly Ala 0ly Gly0 ly H1s Ala Pro asp Vol Ile
2780 2790 2300 2010 2020 2030
AOG TCG GTA GCA CAG CCC AAT AT? TTA CCT GCA TCA ACC ALC CCA LCO ATO OCT TATLys 8ar Vol 0ly Glu Pro Asn Ile Lou Pro Ala 8ar TShr an Pro Thr Not Pro Tyr
2840 2850 2860 2070 2800 2090
ACC AT? ALT ACC GTGCGA CAG CAT CST CAT ATG TIC ATG OTC TOT CAT CAT CTC OATThr I1- Asn Thr Val Asp Glu His Lou Asp Not Lou Not Vl Cy-HNs HNi Lou LAp
2900 2910 2920 2930 2040
CCC TOT AT OCT CLA OAT OGT GCA TTT OCT GCA TCT CST AT? COT COO GA ACc AT?Pro Sor Ile Pro Glu Asp Vol Ala Pha Ala Glu S-r Arg Ile Arg Ar; Olu Tbr I1l
2950 2960 2970 2980 2990 3000* * a a a aGCT GCA GCA GAT ATC TTA CAT GAT ATOG (tGi; GcA AT? TCG GOTO ATO TCG TCL GAC TCAAla Ala Clu Asp Ila Lou Ilia LAp Net Gly Ala I1-Bar Val Not b-r aer Ap Sar
FIG. 2. Nucleotide sequence of the P. mirabilis urease genes. Numbers above the sequence indicate the nucleotide position. Predictedamino acid sequences, in sequential order, for UreD (bp 441 to 1262), UreA (bp 1287 to 1586), UreB (bp 1598 to 1924), UreC (bp 1924 to 3624),UreE (bp 3655 to 4137), and UreF (bp 4168 to 4782) are shown below the DNA sequence. Putative ribosome-binding sequences(Shine-Dalgarno [S.D.] sites) are shown above the DNA sequence preceding each gene.
6416

P. MIRABILIS UREASE GENE SEQUENCE 6417
3010 3020 3030 3040 3050 3060
CAA GCC ATG GGA CGA GTC GGA GAM GTT ATC TTA CGC ACT TGGCAG TGT GCA CAT MAAGln Ala Met Gly Arg Val Gly Glu Val le Leo ArgThr Trp Gln Cys Ala His Lys
3070 3080 3090 3100 3130 3120
ATGAAATTG CAA CGA GGC ACA TTA GCG GGT GAT AGC GCA GAT AAT GAT T AAT CGTMet Lys Leu Gln Arg Gly Thr Leu Ala Gly Asp Ser Ala Asp Asn Asp Asn Asn Arg
3130 3140 3150 3160 3170
ATT AAA CGT TAT ATC GCT AMA TAC ACGATT AAC CCG GCA CTG GCA CAT GGC ATT GCTIle Lys Arg Tyr le Ala LysTyr Thr Ie Asn Pro Ala Leu Ala His Gly Ile Ala
3180 3190 3200 3210 3220 3230
CAT ACG GTG GGA TCA ATA GAA AAA GGT AAA CTT GCG GAT ATC GTG CTA TGG GAT CCT
Hiis Thr Val Gly Ser Ie Glu Lye Gly Lys Leu Ala Asp Ile Val Leu Trp Asp Pro
3240 3250 3260 3270 3280 3290
GCT TTC TTT GGC GTC AAA CCG GCA CTT ATC ATA AAM GGT GGT ATG GTC tGT TAT GCGAla Phe Ph. Gly Val Lys Pro Ala Leu Ile Ile Lys Gly Gly Met Val Arg Tyr Ala
3300 3310 3320 3330 3340
CCA ATG GGG GAT ATT AAT GCG GCT ATT CCA ACC CCG CAA CCG GTT CAT TAT 'CGT CCAPro Met Gly Asp Ile Asn Ala Ala Ile Pro Thr Pro Gln Pro Val His Tyr Arg Pro
3350 3360 3370 3380 3390
ATG TAT GCC TGT CTA GGA AAA GCC AAA TAT CAA ACG TCG ATG ATC TTT ATG TCA AAAMet Tyr Ala Cys Leu Gly Lys Ala Lys Tyr Gln Thr Ser Met Ile Phe Met Ser Lys
3410 3420 3430 3440 3450 3460
GCG GGT ATT GAG GCG GGA GTG CCA GAA AAA TTA GGC TTA AAA AGC TTA ATT GGT CGTAla Gly Ile Glu Ala Gly Val Pro Glu Lys Leu Gly Leu Lys Ser Lou Ile Gly Arg
3470 3480 3490 3500 3510
GTG GAG GGC TGT CGT CAT ATC ACA AAA GCT TCG ATG ATC CAC AAT AAC TAT GTT CCTVal Glu Gly Cys Arg His Ile Thr Lys Ala Ser Met Ile His Asn Asn Tyr Val Pro
3520 3530 3540 3550 3560 3570
CAT ATC GAG TTA GAT CCA CAA ACT TAC ATT GTT AAA GCG GAT GGT GTA CCA CTG GTTHis Ile Glu Leu Asp Pro Gln Thr Tyr Ile Val Lys Ala Asp Gly Val Pro Leu Val
3580 3590 3600 3610 3520
TGT GAG CCA GCG ACT GAA TTA CCG ATG GCT CAA CGC TAT TTC TTA TTT TAACys Glu Pro Ala Thr Glu Leu Pro Met Ala Gln Arg Tyr Phe Leu Phe ---
3630 3640 3650 3660 3670 3680
CCA GCG TTT TTA TTG AGA ATT TAT TGA ATG AAA AAA TTT ACT CAG ATT ATT GAT CAA
Met Lys Lys Phe Thr Gln Ile Ile Asp Gln
3690 3700 3710 3720 3730 3740
CAA AAA GCG CTT GAA CTA ACC TCT ACA GAA AAG CCA AAG TTA ACC CTT TGT CTT ACC
Gln Lys Ala Leu Glu Leu Thr Ser Thr Glu Lys Pro Lys Leu Thr Leu Cys Leu Thr
3750 3760 3770 3780 3790
ATG GAT GAG CGC ACC AAA AGT CGC TTA AAA GTG GCT TTA AGT GAC GGG CAA GAA GCCMet Asp Glu Arg Thr Lys Ser Arg Leu Lys Val Ala Leu Ser Asp Gly Gln Glu Ala
3800 3810 3820 3830 3840 3850
0G0 CTA TTT TTG CCT CGA GGC ACC GTA CTT AAA GAG GGG GAT ATT CTG CTG TCA GAAGly Leu Phe Leu Pro Arg Gly Thr Val Lou Lys Glu Gly Asp Ile Leu Leu Ser Glu
3860 3870 3880 3890 3900 391C
GAO GGC GAT GTT GTC ACC ATT GAA GCG GCT AAA GAG CAA GTA TCA ACG GTT TAT AGTGlu Gly Asp Val Val Thr Ile Glu Ala Ala Lys Glu Gln Val Ser Thr Val Tyr Ser
3920 3930 3940 3950 3960
GAC GAT CCA TTA TTG CTT GCT CGT GTT TGT TAT CAC TTA GGT AAC CGA CAT GTA CCA
Asp Asp Pro Lou LOu Leu Ala Arg Val Cys Tyr His Leu Gly Asn Arg His Val Pro
4030 4040 4050 4060 4070 4080
GCT CGC GGC TTA GGG GCT ACG GTG GTG GTT GGC TTA GAA AAA TAC CAA CCT GAG CCG
Ala Arg Gly Leu Gly Ala Thr Val Val Val Gl- Leu Glu Lys Tyr Gln Pro Glu Pro
4090 4100 4110 4120 4130 4140
GGG GCT TAT GGT GGG TCA TCC GGT GGT CAT CAC CAC CAC CAT GAT CAC CAC CAT TAA
Gly Ala Tyr Gly Gly Ser Ser Gly Gly His His His His His Asp His His His ---
4150 4160 4170 4180 4190* SD *
A TGG CAC TGC GAT CAT CAA AGG AGG TGC ATG ATG CTA GCT GAT CTG CGC TTA TAT' CAAMet Met Leu Ala Asp Leu Arg Leu Tyr Gln
4200 4210 4220 4230 4240 4250
TTA GTT AGC CCC TCT CTT CCG GTA GGT GCT TTT ACT TAT TCT CAA GGG TTA GAG TGGLeu Val Ser Pro Ser Leu Pro Val Gly Ala Phe Thr Tyr SOr Gln Gly Leu Glu Trp
4260 4270 4280 4290 4300 4310
GCC ATT GAA AAA GGT TGG GTA TGC TCA GCA GAA ACC TTG TCA GAT TGG TTA AGC GCAAla Ile Glu Lys Gly Trp Val Cya Ser Ala Glu Thr Leu Ser Asp Trp Leu Ser Ala
4320 4330 4340 4350 4360
CAA ATG ACC CGA ACA TTA GCC ACA CTC GAG CTT CCT ATA TTG CGG CAA TTA CAA ACGGln Met Thr Gly Thr Leu Ala Tlhr Leu Glu Leu Pro Ile Leu Arg Gln Leu Gln Thr
4370 4380 4390 4400 4410 4420
AGT TTG GCA AAG GGT GAT AGC GAT ACA GTG AAA TAT TGG TGT GAC TTT ATG GTC SCASer Leu Ala Lys Gly Asp Ser Asp Thr Val Lys Tyr Trp Cys Asp Ph. Met Val Ala
4430 4440 4450 4460 4470 1490
AGT CGC GAA ACC AAA GAG TTA AGG CAG GiAA GAG CGT CAA CCG GGG ATC GCT TTT CCCSer Arg Glu Thr Lys Glu Leu Arg Gln Glu Glu Arg Gln Pro Gly Ile Ala Phe Pro
4490 4500 4510 4520 4530
CGT TTA CTT CCT CAA TTA GGC ATT GAA TTA GAC GAT ACG TTA CAA CAG CGG GTT AAAArg Leu Leu Pro Gln Leu Gly Ile Glu Lou Asp Asp Thr LOu Gln Gln Arg Val Lys
4540 4550 4560 4570 4580 4590
CAG ACG CAA TTA ATG GCG TTT GCG TTA GCT GCC GTG CAT TGG CAT ATC GAT AGT GAAGln TtSr Gln Leu Met Ala Phe Ala Leu Ala Ala Val His Trp His Ile Asp Ser Glu
4600 4610 4620 4630 4640 4650
AAG CTC TGT TGT GCC TAT GTT TGG GGC TGG TTA GAA AAT ACG GTG ATG TCT GGG GTALys Leu Cys Cys Ala Tyr Val Trp Gly Trp Leu Glu Asn Thr Val Met Ser Gly Val
4660 4670 4680 4690 4700 4710
AAA CTG GTG CCA TTA GGG CAA AGC GCA GGG CAA AAA ATG TTG TTT GCT CTA GCT GAGLys Leu Val Pro Leu Gly Gln Ser Ala Gly Gln Lys Met Leu Phe Ala Leu Ala Glu
4720 4730 4740 4750 4760
CAG ATC CCC, GCT ATT GTT GAG TTA TCG GCA CAT TGG CCA CAA GAG GAT ATT GGC AGTGin Ile Pro Ala Ile Val Glu Leu Ser Ala His Trp Pro Gln Glu Asp Ile Gly Ser4770 4780 4790 4800 4810 4820
TTA CGC CAG CTC AAG TGA TCG CCA GTA GTC GCC ATG AAA CTC AAT ATA CTC GAC TTTLou Arg Gin Lou Lys--
4830 4840 4850 4860 4870 4880
TTC GTT CAT GAG ATA AAG AGA TGC AAG AAT ATA ATC AAC CAC TOC GTA TTG GTG TT
4890 4900 4910 4920 4930
GTG 0CC CTG TTG GTT CAG GAA AAA CAG CAC TAT TAG AAG TTC TTT GTA AAG CTA TGC
4940 4950*
GCG ATA OTT ACC AA
3970 3980 3990 4000 4010 4020
TTG CAA ATA GAA 0CG GOT TGG TOT CGT TAT rTT CAC GAT CAT GTA TTA GAT GAT ATGLeu Gln Ile Clu Al. Gly Trp Cys Arg Tyr Phe His Asp His Val Iou Asp Asp Met
FIG. 2-Continued
Klebsiella aerogenes (13) and the fungus Aspergillus nidu-lans (19). A search for nitrogen regulation sites with thesequence TGGYARN4TTGCA (2), where Y is a pyrimidineand R is a purine, was carried out in the regions upstream ofeach ORF in the P. mirabilis gene complex. A site upstreamof the ureA locus at bp 1221 was found which matched 13 of16 bases in the sequence. Preliminary physiological experi-ments indicated, however, that the operon was not undernitrogen regulation control (E. Nicholson, G. Chippendale,and H. Mobley, Abstr. Annu. Meet. Am. Soc. Microbiol.1989, H126, p. 190). Another possible mechanism for operonregulation was through the CRP-cyclic AMP cascade. Wewere unable, however, to find sequences similar to thecatabolite repressor protein-binding site (AANTGTGAN2TN4CA) (10) in the putative promoter regions for any ofthe cistrons.Sequences downstream of each cistron were analyzed for
transcription termination signals similar to those established
for E. coli genes (29). Characteristically, these rho-indepen-dent signals formed a secondary structure in the mRNAwhich consists of a stem-loop structure followed by a stringof uridylates. Regions downstream of the ureD (bp 1306 to1328), ureC (bp 3791 to 3809), and ureF (bp 4804 to 4826)were found that could form small stem-loop structuresfollowed by 4 to 6 uridylates. No such sites were found forthe ureA, ureB, or ureE ORFs.
Previous work has not delineated the ends of the ureasegene complex. We demonstrated that DNA sequences 5' tothe ureD ORF are unnecessary for an active urease bydeletion of upstream sequences. pMID1003 was partiallydigested with ClaI to form a linear plasmid, followed bydigestion with AccI and religation. When assayed for theability to synthesize urease, the resulting plasmid producedactive enzyme at the same level as the parent plasmid. Inaddition, we confirmed that DNA sequences downstream ofthe 23.0-kDa ORF were not required for urease activity. A
VOL. 171, 1989

6418 JONES AND MOBLEY
Cigg~~~~~~~~I I *{o={IY111 11r~zwum~ UUU~-._ . Ili,ZWZ0 ZXxzW m
I D77Al8I1 c n ILF IkDa 31.0 11.0 12.2 61.0 17.9 23.0 kb
P p pso n lSD so SD
FIG. 3. Physical map of the urease gene complex. The rectangu-lar boxes labeled D, A, B, C, E, and F indicate the physical positionsin the operon of each of the ure ORFs. Numbers beneath eachrectangle correspond to the predicted molecular size for eachpolypeptide. The lines with arrows beneath the map indicate thedirection and predicted length of each transcript. Two putativepromoter sites were found upstream for both ureD and ureF (seetext for positions). Restriction endonuclease sites are indicatedabove the line. P, Promoter; SD, Shine-Dalgarno sites.
BalI deletion of pMID1003, which removed all sequences
downstream of the urease operon, including a portion of thevector and the last 12 codons of the UreE protein, was
constructed. This deletion plasmid also conferred an activeurease phenotype to E. coli HB101, although with enzyme
activity that was two- to threefold lower than that of theparent plasmid, presumably because of a truncated UreFprotein (Fig. 3).The G+C content of the P. mirabilis urease gene se-
quences (43%) was not significantly different from the pre-
viously determined G+C content of the genomic DNA (39%)(12).
Predicted amino acid sequence features. With the use of thepredicted amino acid content, pIs were determined for eachof the polypeptides. The ORFs for ureA-, ureC-, ureD-,ureE-, and ureF-encoded acidic proteins (pl values of 5.8,5.4, 6.3, 6.0, and 4.9, respectively), whereas the polypeptideproduced from ureB was basic (pI 9.0). We also noted thatthe UreB polypeptide contained no cysteine residues in itssequence and the UreE protein had a string of eight histidineresidues at its COOH terminus. Other than these two fea-
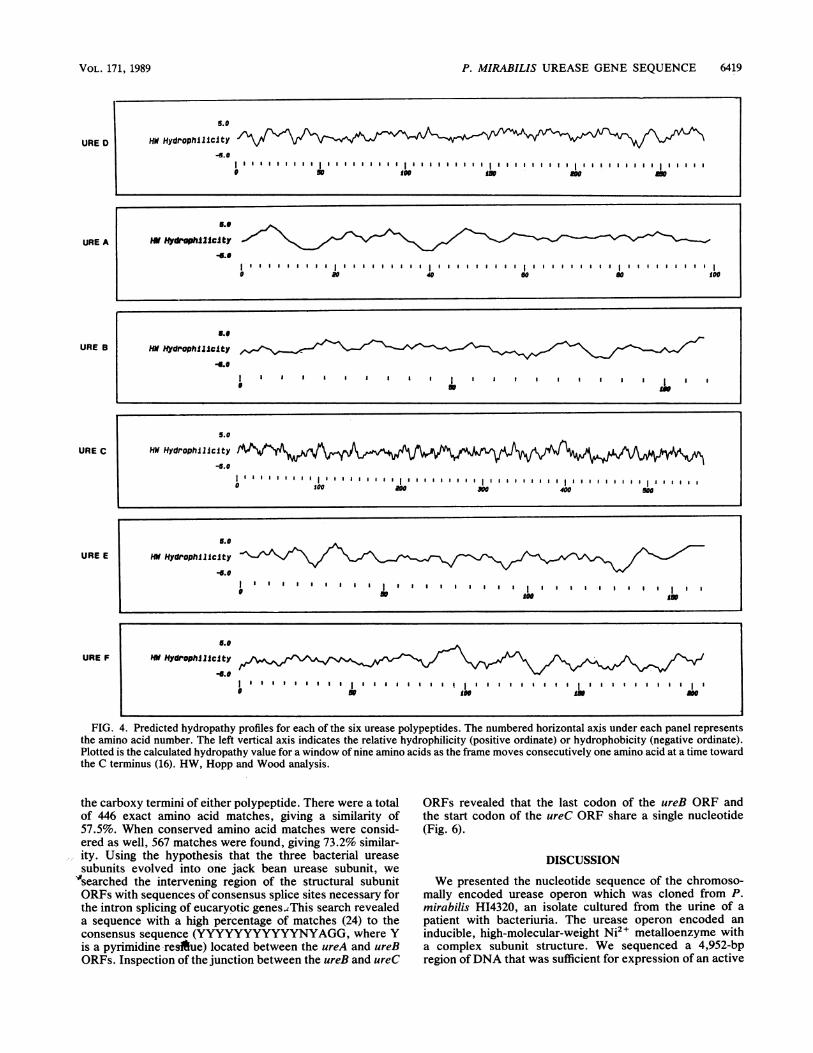
tures, nothing was remarkable about the amino acid compo-sitions of the proteins. The amino acid composition of eachORF is shown in Table 1. Shown in Fig. 4 are the hydropathyplots of each polypeptide based on the prediction of Kyteand Doolittle (16). The plots for the three structural subunitswere consistent with plots for cytoplasmic polypeptides. Theplots for UreD and UreE contained both hydrophilic andhydrophobic regions, while the plot for UreF contained twolarge hydrophobic regions, residues 1to 25 and residues 168to 190, which indicated possible membrane-spanning do-mains. An examination of the predicted N-terminal regionsof the polypeptides revealed a possible signal sequence inthe UreE protein (20, 27, 32, 35). This region possessed thegeneral properties of a leader sequence with charged resi-dues near the N terminus followed by eight nonpolar andhydrophobic residues. These residues were followed by ashort-side-chain amino acid (alanine) which was five resi-dues from a serine at residue 18, the putative cleavage site.In addition, we searched the predicted amino acid sequencesfor metal-binding sites (C-X2-C-X3-F-X5-L-X2-H-X3-H) (11)and ATP-binding sites (GKGGVGKT) (36). No matcheswere found for these sequences in any of the polypeptides.
Sequence homology. The NBRF-PIR protein data base wassearched for similarities with the deduced amino acid se-quences of each ORF. The deduced amino acid sequences ofthe ORFs for ureA, ureB, and ureC had'a high similarity tothe amino acid sequence of jack bean urease (Fig. 5). Nostriking sequence similarity was found for UreD, UreE, orUreF with protein sequences in the gene bank. Closerexamination of the similarity between the jack bean ureasesubunit and the three subunits of the P. mirabilis ureaserevealed that the P. mirabilis subunits aligned with the jackbean subunit in a nonoverlapping fashion in the order thatthe P. mirabilis subunits were transcribed, UreA, UreB, andUreC. UreA (100 amino acids) aligned with the first 100amino acids of the jack bean subunit (840 amino acids) (17).Following a gap of 28 amino acids, UreB (109 amino acids)aligned with the next 109 amino acids, followed by a gap of33 amino acid residues. Lastly, the UreC polypeptide (567amino acids) matched with the last 567 amino acids of thejack bean urease subunit with no unmatched amino acids at
TABLE 1. Predicted amino acid compositions of UreA, UreB, UreC, UreD, UreE, and UreF
Mol% (no. of amino acid residues) of:Amino acid
UreA (100) UreB (109) UreC (567) UreD (274) UreE (161) UreF (205)
Ala 8.00 (8) 9.17 (10) 9.17 (52) 7.30 (20) 6.21 (10) 9.27 (19)Val 10.00 (10) 8.26 (9) 8.11 (46) 6.57 (18) 7.45 (12) 5.85 (12)Leu 12.00 (12) 6.42 (7) 5.82 (33) 10.95 (30) 12.42 (20) 15.12 (31)Ile 5.00 (5) 5.50 (6) 9.52 (54) 4.74 (13) 3.11 (5) 3.90 (8)Pro 5.00 (5) 3.67 (4) 5.47 (31) 6.57 (18) 3.73 (6) 4.39 (9)Met 5.00 (5) 2.75 (3) 3.70 (21) 2.92 (8) 1.86 (3) 3.41 (7)Phe 2.00 (2) 6.50 (6) 2.65 (15) 4.74 (13) 1.86 (3) 2.44 (5)Trp 0.00 (0) 0.00 (0) 0.88 (5) 2.55 (7) 0.62 (1) 3.90 (8)Gly 7.00 (7) 11.01 (12) 10.76 (61) 8.03 (22) 9.32 (15) 5.85 (12)Ser 4.00 (4) 2.75 (3) 3.53 (20) 2.92 (8) 4.97 (8) 6.83 (14)Thr 7.00 (7) 3.67 (4) 6.35 (36) 7.30 (20) 6.21 (1) 5.37 (11)Cys 2.00 (2) 0.00 (0) 1.59 (9) 1.82 (5) 1.86 (3) 1.95 (4)Tyr 1.00 (1) 2.75 (3) 2.65 (15) 3.65 (10) 3.11 (5) 1.95 (4)Asn 1.00 (1) 4.59 (5) 3.35 (19) 2.19 (6) 0.62 (1) 0.49 (1)Gln 3.00 (3) 2.75 (3) 3.00 (17) 5.84 (16) 4.35 (7) 8.29 (17)Asp 3.00 (3) 2.75 (3) 5.82 (33) 2.92 (8) 6.83 (11) 4.39 (9)Glu 11.00 (11) 10.09 (11) 5.82 (33) 6.93 (19) 7.45 (12) 6.83 (14)Lys 7.00 (7) 6.42 (7) 4.76 (27) 4.01 (11) 6.21 (10) 4.39 (9)Arg 6.00 (6) 8.26 (9) 3.70 (21) 4.74 (13) 4.35 (7).* 3.90 (8)His 1.00 (1) 3.67 (4) 3.35 (19) 3.28 (9) 7.45 (12) 1.46 (3)
are
J. BACTERIOL.
P. MIRABILIS UREASE GENE SEQUENCE 6419
URE D
URE A
URE B
URE C
URE E
URE F
5.0
Wl Hydrophlllclty
H#E HYdPOPhi1lCltY
S.o
HN Hydophilicity-I.e
l il l ll., ll,l11 Bll l l ll l l l l l l l l l l l l l l l l l lllllB1 11 1 1 BllB I B I B l111 lB0 20 40 60 6 100
5..
Hi ftyd&ophlllcSty
5.0
HW HydrophlBJIclty
* 100 aoo see 400 600
|Hit Hydrophlllclty/ l
6.e9Hi Hydrophi1Jc1fty _ j|
* 50 slee -e -
FIG. 4. Predicted hydropathy profiles for each of the six urease polypeptides. The numbered horizontal axis under each panel representsthe amino acid number. The left vertical axis indicates the relative hydrophilicity (positive ordinate) or hydrophobicity (negative ordinate).Plotted is the calculated hydropathy value for a window of nine amino acids as the frame moves consecutively one amino acid at a time towardthe C terminus (16). HW, Hopp and Wood analysis.
the carboxy termini of either polypeptide. There were a totalof 446 exact amino acid matches, giving a similarity of57.5%. When conserved amino acid matches were consid-ered as well, 567 matches were found, giving 73.2% similar-ity. Using the hypothesis that the three bacterial ureasesubunits evolved into one jack bean urease subunit, we"searched the intervening region of the structural subunitORFs with sequences of consensus splice sites necessary forthe intron splicing of eucaryotic genes..This search revealeda sequence with a high percentage of matches (24) to theconsensus sequence (YYYYYYYYYYYNYAGG, where Yis a pyrimidine-restue) located between the ureA and ureBORFs. Inspection of the junction between the ureB and ureC
ORFs revealed that the last codon of the ureB ORF andthe start codon of the ureC ORF share a single nucleotide(Fig. 6).
DISCUSSION
We presented the nucleotide sequence of the chromoso-mally encoded urease operon which was cloned from P.mirabilis HI4320, an isolate cultured from the urine of apatient with bacteriuria. The urease operon encoded aninducible, high-molecular-weight Ni2" metalloenzyme witha complex subunit structure. We sequenced a 4,952-bpregion ofDNA that was sufficient for expression of an active
VOL. 171, 1989

6420 JONES AND MOBLEY
P. mirabilis urease
A B C-0 40 ago m
I,
I_Mlm1 |1-1S,!1 mIWu nn im m r iniiuilI
o3 00 600So o 700 m
Jack bean ureaseFIG. 5. Amino acid sequence similarity between P. mirabilis urease subunits and jack bean urease subunit. The letters A, B, and C above
the lines refer to the structural subunits of the P. mirabilis urease encoded by ureA, ureB, and ureC, respectively. Numbers above and belowthe horizontal lines represent amino acid positions. The sequences of the three P. mirabilis subunits were combined and numberedsequentially to facilitate analysis. Black vertical lines between the sequences represent an exact amino acid match or conservativereplacement.
urease protein. The sequence revealed that the operonencoded six ORFs which were named ureA, ureB, ureC,ureD, ureE, and ureF. The polypeptides UreA, UreB, UreC,UreD, and UreF were required for enzyme activity in E. coliHB101. The molecular sizes of the polypeptides which werecalculated from the deduced amino acid sequences weresimilar in size to polypeptides previously identified as be-longing to the urease operon (15, 37). Each of these poly-peptides was previously mapped to a position within theoperon by TnS transposon insertions which was the same asthe position of the corresponding ORF revealed by sequenc-ing (15, 37). The similarity between the P. mirabilis ureasegenes that we sequenced and those that Walz et al. (37)cloned was not surprising since it has recently been demon-strated by Southern hybridization that the urease genesencoded by nearly 100 different isolates of P. mirabilis are
z/re ID 1@ C E1FII1kb
-..
X ureA end =1 start urek-OS P V MTCA CCT ATT GTG TAG GTAATAAC ATG ATC
Splice - Accept A
ure I D lf ZIXC I1EZ Fkb
E2> start ureCCM K TATG AAA ACT ATC
GAG AAA AAA TGAE K K -
=4ureB end B
FIG. 6. DNA sequence characteristics at the junctions of thestructural genes. (A) Junction between ureA and ureB. A region ofDNA similar to a eucaryotic mRNA splice-acceptor site (13 of 16nucleotides) (24), near the end of the ureA ORF and extending intothe untranslated nucleotides, is underlined. (B) Junction betweenureB and ureC. The last nucleotide of the last codon for ureB is thefirst nucleotide of the start codon for ureC. Letters in the rectanglesrefer to the polypeptides. Letters above and below the DNAsequence are standard single-letter amino acid codes.
highly conserved with respect to specific urease gene restric-tion fragments recognized by DNA probes (H. L. T. Mobleyand G. Chippendale, submitted for publication).We have demonstrated (15) that the gamma, beta, and
alpha subunits (11.0, 12.2, and 61.0 kDa, respectively)represent the three structural subunits of the urease enzyme,are transcribed on a single mRNA, and are translated in theorder of the smallest to the largest subunit. This explainswhy a single transposon insertion in ureA or ureB had a polareffect on the translation of downstream ORFs. It is unclearwhether ureD is encoded on the same transcript as thestructural subunits or is translated from a unique mRNA. Wewere unable to determine whether transposon insertions inureD exert a downstream polar effect on translation of thestructural subunits. However, DNA sequences just down-stream of the stop codon of the 31.0-kDa polypeptide (bp1306 to 1328) resembled a rho-independent transcriptionaltermination region similar to those found in many E. coligenes. If termination of ureD transcription occurred at thispoint, the enzyme subunits would necessarily be transcribedon a separate message. In contrast, the 23.0-kDa polypeptidewas produced from its own promoter. Insertion of a trans-poson in the ureE ORF (37), which would have a down-stream polar effect on transcription of ureF if ureE and ureFshared the same transcript, did not affect urease expression.Therefore, transcription of the ureF cistron, which is re-quired for urease activity, begins downstream of the 17.9-kDa ORF. No promoter could be found for the ureE ORF,and the 17.9-kDa gene product is not required for ureaseactivity in the recombinant host E. coli HB101, as shown byWalz et al. (37). However, the involvement of this polypep-tide in some aspect of ureolysis cannot be ruled out since theloss of this protein in the recombinant host may be comple-mented in trans by a homologous E. coli protein. Currentstudies are aimed at studying the expression and regulationof UreD, UreE, and UreF, as well as identifying the func-tions that they perform. The possible roles being investi-gated for these proteins include urea transport, nickel trans-port, nickel insertion, and enzyme assembly.The enzyme is comprised of three different subunits
previously designated gamma, beta, and alpha that areencoded by ureA, ureB, and ureC, respectively, which havepredicted molecular sizes of 11.0, 12.2, and 61.0 kDa. Wepropose that the names of the polypeptide subunits bechanged to be consistent with the genetic designations forthe individual cistrons, so that future confusion will be
1oo 200
J. BACTERIOL.
Jr

P. MIRABILIS UREASE GENE SEQUENCE 6421
avoided when referring to the operon and its translationproducts. The gamma subunit will become UreA, the betasubunit UreB, and the alpha subunit UreC (Fig. 3).The general structure of one large subunit and two smaller
subunits has been observed in other bacterial ureases, withfew exceptions. The enzymes of Selenomonas ruminantium,Klebsiella aerogenes, Sporosarcina ureae, P. mirabilis (6,34), Ureaplasma urealyticum (33), Providencia stuartii (25),and M. morganii (Hu et al., Abstr. Annu. Meet. Am. Soc.Microbiol. 1989) have all been shown to have this subunitstructure. In contrast, reports have been published of ure-ases with only a single large subunit for Bacillus pasteurii(8), Brevibacterium ammoniagenes (26), and Spirulina max-
ima (7). A possible explanation for this difference may bethat small subunits were overlooked on low-percentagepolyacrylamide gels. A true exception to this subunit struc-ture in bacteria appears to be the urease from Campylobac-ter pylori, which has been reported to have only twosubunits of 65 and 31 kDa (9; L. Hu and H. L. T. Mobley,unpublished data). With the assumption that the P. mirabilisurease is similar to the ureases produced by K. aerogenesand Providencia stuartii, the probable stoichiometry of thenative enzyme would be two of the large subunits and four ofeach of the smaller subunits, to give a native molecularweight of approximately 215 kDa.Perhaps the most surprising and interesting result was the
high percentage of similarity between the three subunits ofthe P. mirabilis urease and the subunit of the jack beanurease. This similarity suggests an evolutionary relationshipbetween the eucaryotic jack bean urease and the procaryoticP. mirabilis urease. Interestingly, sequences which werevery similar to the intron splice acceptor concensus se-quence were found in the DNA between the ureA and ureBORFs of P. mirabilis. One could speculate that this region isa remnant of sequences which allowed ancestral genes ofthese two cistrons to be spliced, resulting in the formation ofa fusion UreA-UreB subunit. Examination of the junctionbetween the ureB and ureC cistrons showed that the twoORFs share a single nucleotide. The third residue (adeno-sine) in the codon of the last amino acid of UreB was the firstresidue of the start codon of UreC. Further evolution to a
single urease ORF from the hypothetical fusion ureA-ureBORF and the remaining ureC gene could occur most simplyby an insertion of an adenosine residue after bp 1924,resulting in a frameshift mutation which would allow trans-lation of a single large urease subunit of 83.5 kDa.Sequence analysis of the P. mirabilis urease gene complex
provided information which will be valuable for future studyof the operon. The coordinates of each ORF were deter-mined, making it possible to isolate and study specificgene-polypeptide relationships and identify the function foreach gene product. The location and regulation of promoterscan be investigated to determine the transcriptional organi-zation of the operon and to provide insight as to how theoperon is controlled in the pathogenic process.
ACKNOWLEDGMENTS
This work was supported in part by Public Health Service grantsA123328 and AG04393 from the National Institutes of Health.We thank Merrill Snyder and Robert Hausinger for editorial
review and Jim Kaper for assistance with data analysis.
LITERATURE CITED1. Ansorge, W., and S. Labeit. 1984. Field gradients improve
resolution on DNA sequencing gels. J. Biochem. Biophys.Methods 10:237-243.
2. Ausubel, F. M. 1984. Regulation of nitrogen fixation genes. Cell37:5-6.
3. Ausubel, F. M., R. Brent, R. E. Kingston, D. D. Moore, J. A.Smith, J. G. Seidman, and K. Struhl (ed). 1987. Current proto-cols in molecular biology, p. 1.1.3. Greene Publishing Associ-ates and John Wiley & Sons, Inc., New York.
4. Birnboim, H. C., and J. Doly. 1979. A rapid alkaline extractionprocedure for screening recombinant plasmid DNA. NucleicAcids Res. 7:1513-1523.
5. Braude, A. I., and J. Siemienenski. 1960. Role of bacterialurease in experimental pyelonephritis. J. Bacteriol. 80:171-179.
6. Brietenbach, J. M., and R. P. Hausinger. 1988. Proteus mirabilisurease: partial purification and inhibition by boric and boronicacids. Biochem. J. 250:917-920.
7. Carvajal, N., M. Fernandez, J. P. Rodriguez, and M. Donoso.1982. Urease of Spirulina maxima. Phytochemistry 21:2821-2823.
8. Christians, S., and H. Kaltwasser. 1986. Nickel-content ofurease from Bacillus pasteurii. Arch. Microbiol. 145:51-55.
9. Clayton, C. L., B. W. Bren, P. Muliany, A. Topping, and S.Tabaqchali. 1989. Molecular cloning and expression of Cam-pylobacter pylori species-specific antigens in Escherichia coliK-12. Infect. Immun. 57:623-629.
10. Ebright, R. H. 1982. Sequence homologies in the DNA of sixsites known to bind to the catabolite activator protein ofEscherichia coli, p. 91-99. In J. P. Griffin and W. L. Duax (ed.),Molecular structure and biological activity. Elsevier SciencePublishing, Inc., New York.
11. Evans, R. M., and S. M. Hollenberg. 1988. Zinc fingers: gilt byassociation. Cell 52:1-3.
12. Fasman, G. (ed.). 1976. CRC handbook of biochemistry andmolecular biology, nucleic acids, vol. 2, p. 104-114, CRC Press,Inc., Cleveland, Ohio.
13. Friedrich, B., and B. Magasanik. 1977. Urease of Klebsiellaaerogenes: control of its synthesis by glutamine synthetase. J.Bacteriol. 131:446-452.
14. Griffith, D. P., D. M. Musher, and C. Itin. 1976. Urease. Theprimary cause of infection-induced urinary stones. Invest. Urol.13:346-350.
15. Jones, B. D., and H. L. T. Mobley. 1988. Proteus mirabilisurease: genetic organization, regulation, and expression ofstructural genes. J. Bacteriol. 170:3342-3349.
16. Kyte, J., and R. F. Doolittle. 1982. A simple method fordisplaying the hydropathic character of a protein. J. Mol. Biol.156:105-132.
17. Mamiya, G., K. Takishima, M. Masakuni, T. Kayumi, K.Ogawa, and T. Sekita. 1985. Complete amino acid sequence ofjack bean urease. Proc. Jpn. Acad. 61:395-398.
18. Maniatis, T., E. F. Fritsch, and J. Sambrook. 1982. Molecularcloning: a laboratory manual. Cold Spring Harbor Laboratory,Cold Spring Harbor, N.Y.
19. Marzluff, G. A. 1981. Regulation of nitrogen metabolism andgene expression in fungi. Microbiol. Rev. 45:437-461.
20. Michaelis, S., and J. Beckwith. 1982. Mechanism of incorpora-tion of cell envelope proteins in Escherichia coli. Annu. Rev.Microbiol. 36:435-465.
21. Mobley, H. L. T., and R. P. Hausinger. 1988. Microbial ureases:
significance, regulation, and molecular characterization. Micro-biol. Rev. 53:85-108.
22. Mobley, H. L. T., B. D. Jones, and A. E. Jerse. 1986. Cloning ofurease gene sequences from Providencia stuartii. Infect. Im-mun. 54:161-169.
23. Mobley, H. L. T., and J. W. Warren. 1987. Urease-positivebacteriuria and obstruction of long-term urinary catheters. J.Clin. Microbiol. 25:2216-2217.
24. Mount, S. M. 1982. A catalogue of splice junction sequences.Nucleic Acids Res. 10:459-472.
25. Mulrooney, S. B., M. J. Lynch, H. L. T. Mobley, and R. P.Hausinger. 1988. Purification, characterization, and genetic or-
ganization of recombinant Providencia stuartii urease expressedby Escherichia coli. J. Bacteriol. 170:2202-2207.
26. Nakano, H., S. Takenishi, and Y. Watanabe. 1984. Purificationand properties of urease from Brevibacterium ammoniagenes.
VOL. 171, 1989

6422 JONES AND MOBLEY
Agric. Biol. Chem. 48:1495-1502.27. Perlman, D., and H. 0. Halvorson. 1983. A putative signal
peptidase recognition site and sequence in eucaryotic andprocaryotic signal peptides. J. Mol. Biol. 167:391-409.
28. Pusteli, J., and F. C. Kafatos. 1984. A convenient and adaptablepackage of computer programs for DNA and protein sequencemanagement, analysis, and homology determination. NucleicAcids Res. 12:643-655.
29. Rosenberg, M., and D. Court. 1979. Regulatory sequencesinvolved in the promotion and termination of RNA transcrip-tion. Annu. Rev. Genet. 13:319-353.
30. Rubin, R. H., N. E. Tolkoff-Rubin, and R. S. Cotran. 1986.Urinary tract infection, pyelonephritis, and reflux nephropathy,p. 1085-1141. In B. M. Brenner and F. C. Rector (ed.), Thekidney. The W. B. Saunders Co., Philadelphia.
31. Shine, J., and L. Dalgarno. 1974. The 3'-terminal sequence ofEscherichia coli 16S ribosomal RNA: complementarity to non-sense triplets and ribosome binding sites. Proc. Natl. Acad. Sci.USA 71:1342-1346.
32. Silhavy, T., S. Benson, and S. Emr. 1983. Mechanisms of protein
localization. Microbiol. Rev. 47:313-344.33. Thirkeli, D., A. D. Myles, B. L. Precious, J. S. Frost, J. C.
Woodall, M. G. Burdon, and W. C. RusseUl. 1989. The urease ofUreaplasma urealyticum. J. Gen. Microbiol. 135:315-323.
34. Todd, M. J., and R. P. Hausinger. 1987. Purification andcharacterization of the nickel-containing multicomponent ure-
ase from Klebsiella aerogenes. J. Biol. Chem. 262:5963-5967.35. Von Heijne, G. 1983. Patterns of amino acids near signal-
sequence cleavage sites. Eur. J. Biochem. 133:17-21.36. Walker, J. E., M. Saraste, M. J. Runswick, and N. J. Gay. 1982.
The ATP operon-nucleotide-sequence of the genes for thegamma-subunit, beta-subunit, epsilon-subunit of Escherichiacoli ATP synthase. EMBO J. 1:945-951.
37. Walz, S. E., S. K. Wray, S. I. Hull, and R. A. Hull. 1988.Multiple proteins encoded within the urease gene complex ofProteus mirabilis. J. Bacteriol. 170:1027-1033.
38. Warren, J. W., D. Damron, J. H. Tenney, J. M. Hoopes, B.Deforge, and H. L. Muncie, Jr. 1987. Fever, bacteremia, anddeath as complications of bacteriuria in women with long-termurethral catheters. J. Infect. Dis. 155:1151-1158.
J. BACTERIOL.