programming principle- introduction to c++ pdf
TRANSCRIPT

PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information.PDF generated at: Wed, 21 Jul 2010 12:42:21 UTC
DAT10603 PROGRAMMINGPRINCIPLEIntroduction to C++

ContentsArticlesIntroduction 1
History of computing hardware 1History of general purpose CPUs 23Computer programming 31Programming paradigm 36Systems Development Life Cycle 39Software development process 46Waterfall model 52
Problem Solving 57
Problem solving 57
Algorithm 66
Algorithm 66Flowchart 83Pseudocode 88
Basic Programming Structure 91
C (programming language) 91C++ 107C syntax 117C preprocessor 139
Data Input Output 156
C variable types and declarations 156Operators in C and C++ 162C file input/output 170
Control Statement 175
?: 175
Functions 180
Procedural programming 180Subroutine 183

ReferencesArticle Sources and Contributors 193Image Sources, Licenses and Contributors 198
Article LicensesLicense 199

1
Introduction
History of computing hardware
Computing hardware is a platform for information processing (block diagram)
The history of computing hardwareis the record of the constant drive tomake computer hardware faster,cheaper, and store more data.
Before the development of thegeneral-purpose computer, mostcalculations were done by humans.Tools to help humans calculate were then called calculating machines, by proprietary names, or even as they arenow, calculators. It was those humans who used the machines who were then called computers; there are pictures ofenormous rooms filled with desks at which computers (often young women) used their machines to jointly performcalculations, as for instance, aerodynamic ones required for in aircraft design.
Calculators have continued to develop, but computers add the critical element of conditional response and largermemory, allowing automation of both numerical calculation and in general, automation of manysymbol-manipulation tasks. Computer technology has undergone profound changes every decade since the 1940s.Computing hardware has become a platform for uses other than mere computation, such as process automation,electronic communications, equipment control, entertainment, education, etc. Each field in turn has imposed its ownrequirements on the hardware, which has evolved in response to those requirements.Aside from written numerals, the first aids to computation were purely mechanical devices which required theoperator to set up the initial values of an elementary arithmetic operation, then manipulate the device through manualmanipulations to obtain the result. A sophisticated (and comparatively recent) example is the slide rule in whichnumbers are represented as lengths on a logarithmic scale and computation is performed by setting a cursor andaligning sliding scales, thus adding those lengths. Numbers could be represented in a continuous "analog" form, forinstance a voltage or some other physical property was set to be proportional to the number. Analog computers, likethose designed and built by Vannevar Bush before WWII were of this type. Or, numbers could be represented in theform of digits, automatically manipulated by a mechanical mechanism. Although this last approach required morecomplex mechanisms in many cases, it made for greater precision of results.Both analog and digital mechanical techniques continued to be developed, producing many practical computingmachines. Electrical methods rapidly improved the speed and precision of calculating machines, at first by providingmotive power for mechanical calculating devices, and later directly as the medium for representation of numbers.Numbers could be represented by voltages or currents and manipulated by linear electronic amplifiers. Or, numberscould be represented as discrete binary or decimal digits, and electrically controlled switches and combinationalcircuits could perform mathematical operations.The invention of electronic amplifiers made calculating machines much faster than their mechanical orelectromechanical predecessors. vacuum tube (thermionic valve) amplifiers gave way to solid state transistors, andthen rapidly to integrated circuits which continue to improve, placing millions of electrical switches (typicallytransistors) on a single elaborately manufactured piece of semi-conductor the size of a fingernail. By defeating thetyranny of numbers, integrated circuits made high-speed and low-cost digital computers a widespread commodity.

History of computing hardware 2
This article covers major developments in the history of computing hardware, and attempts to put them in context.For a detailed timeline of events, see the computing timeline article. The history of computing article treats methodsintended for pen and paper, with or without the aid of tables. Since all computers rely on digital storage, and tend tobe limited by the size and speed of memory, the history of computer data storage is tied to the development ofcomputers.
Earliest true hardwareDevices have been used to aid computation for thousands of years, mostly using one-to-one correspondence with ourfingers. The earliest counting device was probably a form of tally stick. Later record keeping aids throughout theFertile Crescent included calculi (clay spheres, cones, etc.) which represented counts of items, probably livestock orgrains, sealed in containers.[1] [2] Counting rods is one example.The abacus was early used for arithmetic tasks. What we now call the Roman abacus was used in Babylonia as earlyas 2400 BC. Since then, many other forms of reckoning boards or tables have been invented. In a medieval Europeancounting house, a checkered cloth would be placed on a table, and markers moved around on it according to certainrules, as an aid to calculating sums of money.Several analog computers were constructed in ancient and medieval times to perform astronomical calculations.These include the Antikythera mechanism and the astrolabe from ancient Greece (c. 150–100 BC), which aregenerally regarded as the earliest known mechanical analog computers.[3] Other early versions of mechanical devicesused to perform one or another type of calculations include the planisphere and other mechanical computing devicesinvented by Abū Rayhān al-Bīrūnī (c. AD 1000); the equatorium and universal latitude-independent astrolabe byAbū Ishāq Ibrāhīm al-Zarqālī (c. AD 1015); the astronomical analog computers of other medieval Muslimastronomers and engineers; and the astronomical clock tower of Su Song (c. AD 1090) during the Song Dynasty.The "castle clock", an astronomical clock invented by Al-Jazari in 1206, is thought to be the earliest programmableanalog computer.[4] It displayed the zodiac, the solar and lunar orbits, a crescent moon-shaped pointer travelingacross a gateway causing automatic doors to open every hour,[5] [6] and five robotic musicians who play music whenstruck by levers operated by a camshaft attached to a water wheel. The length of day and night could bere-programmed every day in order to account for the changing lengths of day and night throughout the year.[4]
Suanpan (the number represented on this abacusis 6,302,715,408)
Scottish mathematician and physicist John Napier noted multiplicationand division of numbers could be performed by addition andsubtraction, respectively, of logarithms of those numbers. Whileproducing the first logarithmic tables Napier needed to perform manymultiplications, and it was at this point that he designed Napier's bones,an abacus-like device used for multiplication and division.[7] Since realnumbers can be represented as distances or intervals on a line, the sliderule was invented in the 1620s to allow multiplication and divisionoperations to be carried out significantly faster than was previouslypossible.[8] Slide rules were used by generations of engineers and other
mathematically involved professional workers, until the invention of the pocket calculator.[9]

History of computing hardware 3
Yazu Arithmometer. Patented in Japan in 1903.Note the lever for turning the gears of the
calculator.
Wilhelm Schickard, a German polymath, designed a calculating clockin 1623, unfortunately a fire destroyed it during its construction in1624 and Schickard abandoned the project. Two sketches of it werediscovered in 1957; too late to have any impact on the development ofmechanical calculators[10] .
In 1642, while still a teenager, Blaise Pascal started some pioneeringwork on calculating machines and after three years of effort and 50prototypes[11] he invented the mechanical calculator[12] [13] . He builttwenty of these machines (called the Pascaline) in the following tenyears[14] .
Gottfried Wilhelm von Leibniz invented the Stepped Reckoner and hisfamous cylinders around 1672 while adding direct multiplication and division to the Pascaline. Leibniz once said "Itis unworthy of excellent men to lose hours like slaves in the labour of calculation which could safely be relegated toanyone else if machines were used."[15]
Around 1820, Charles Xavier Thomas created the first successful, mass-produced mechanical calculator, the ThomasArithmometer, that could add, subtract, multiply, and divide.[16] It was mainly based on Leibniz' work. Mechanicalcalculators, like the base-ten addiator, the comptometer, the Monroe, the Curta and the Addo-X remained in use untilthe 1970s. Leibniz also described the binary numeral system,[17] a central ingredient of all modern computers.However, up to the 1940s, many subsequent designs (including Charles Babbage's machines of the 1822 and evenENIAC of 1945) were based on the decimal system;[18] ENIAC's ring counters emulated the operation of the digitwheels of a mechanical adding machine.In Japan, Ryoichi Yazu patented a mechanical calculator called the Yazu Arithmometer in 1903. It consisted of asingle cylinder and 22 gears, and employed the mixed base-2 and base-5 number system familiar to users to thesoroban (Japanese abacus). Carry and end of calculation were determined automatically.[19] More than 200 unitswere sold, mainly to government agencies such as the Ministry of War and agricultural experiment stations.[20] [21] .

History of computing hardware 4
1801: punched card technologyMain article: Analytical engine. See also: Logic piano
Punched card system of a music machine, alsoreferred to as Book music
In 1801, Joseph-Marie Jacquard developed a loom in which the patternbeing woven was controlled by punched cards. The series of cardscould be changed without changing the mechanical design of the loom.This was a landmark achievement in programmability.
In 1833, Charles Babbage moved on from developing his differenceengine (for navigational calculations) to a general purpose design, theAnalytical Engine, which drew directly on Jacquard's punched cardsfor its program storage.[22] In 1835, Babbage described his analyticalengine. It was a general-purpose programmable computer, employingpunch cards for input and a steam engine for power, using the positionsof gears and shafts to represent numbers. His initial idea was to usepunch-cards to control a machine that could calculate and printlogarithmic tables with huge precision (a special purpose machine).Babbage's idea soon developed into a general-purpose programmablecomputer. While his design was sound and the plans were probablycorrect, or at least debuggable, the project was slowed by variousproblems included disputes with the chief machinist building parts forit. Babbage was a difficult man to work with and argued with anyone.All the parts for his machine had to be made by hand. Small errors in each item might sometimes sum to cause largediscrepancies. In a machine with thousands of parts, which required these parts to be much better than the usualtolerances needed at the time, this was a major problem. The project dissolved in disputes with the artisan who builtparts and ended with the decision of the British Government to cease funding. Ada Lovelace, Lord Byron's daughter,translated and added notes to the "Sketch of the Analytical Engine" by Federico Luigi, Conte Menabrea. this appearsto be the first published description of programming.[23]
IBM 407 tabulating machine, (1961)
A reconstruction of the Difference Engine II, an earlier, more limiteddesign, has been operational since 1991 at the London ScienceMuseum. With a few trivial changes, it works exactly as Babbagedesigned it and shows that Babbage's design ideas were correct, merelytoo far ahead of his time. The museum used computer-controlledmachine tools to construct the necessary parts, using tolerances a goodmachinist of the period would have been able to achieve. Babbage'sfailure to complete the analytical engine can be chiefly attributed todifficulties not only of politics and financing, but also to his desire todevelop an increasingly sophisticated computer and too move aheadfaster than anyone else could follow.
Following Babbage, although unaware of his earlier work, was PercyLudgate, an accountant from Dublin, Ireland. He independentlydesigned a programmable mechanical computer, which he described ina work that was published in 1909.
In the late 1880s, the American Herman Hollerith invented data storage on a medium that could then be read by amachine. Prior uses of machine readable media had been for control (automatons such as piano rolls or looms), not
data. "After some initial trials with paper tape, he settled on punched cards..."[24] Hollerith came to use punched cards after observing how railroad conductors encoded personal characteristics of each passenger with punches on

History of computing hardware 5
their tickets. To process these punched cards he invented the tabulator, and the key punch machine. These threeinventions were the foundation of the modern information processing industry. His machines used mechanical relays(and solenoids) to increment mechanical counters. Hollerith's method was used in the 1890 United States Census andthe completed results were "... finished months ahead of schedule and far under budget".[25] Indeed years faster thanthe prior census had required. Hollerith's company eventually became the core of IBM. IBM developed punch cardtechnology into a powerful tool for business data-processing and produced an extensive line of unit recordequipment. By 1950, the IBM card had become ubiquitous in industry and government. The warning printed on mostcards intended for circulation as documents (checks, for example), "Do not fold, spindle or mutilate," became a catchphrase for the post-World War II era.[26]
Punched card with the extended alphabet
Leslie Comrie's articles on punched card methods and W.J. Eckert'spublication of Punched Card Methods in Scientific Computation in 1940,described punch card techniques sufficiently advanced to solve somedifferential equations[27] or perform multiplication and division usingfloating point representations, all on punched cards and unit recordmachines. Those same machines had been used during WWII forcryptographic statistical processing. In the image of the tabulator (seeleft), note the patch panel, which is visible on the right side of thetabulator. A row of toggle switches is above the patch panel. The ThomasJ. Watson Astronomical Computing Bureau [28], Columbia Universityperformed astronomical calculations representing the state of the art incomputing.[29]
Computer programming in the punch card era was centered in the"computer center". Computer users, for example science and engineeringstudents at universities, would submit their programming assignments totheir local computer center in the form of a stack of punched cards, onecard per program line. They then had to wait for the program to be read in,queued for processing, compiled, and executed. In due course, a printoutof any results, marked with the submitter's identification, would be placedin an output tray, typically in the computer center lobby. In many casesthese results would be only a series of error messages, requiring yetanother edit-punch-compile-run cycle.[30] Punched cards are still used andmanufactured to this day, and their distinctive dimensions (and 80-columncapacity) can still be recognized in forms, records, and programs aroundthe world. They are the size of American paper currency in Hollerith's time, a choice he made because there wasalready equipment available to handle bills.

History of computing hardware 6
Desktop calculators
The Curta calculator can also do multiplicationand division
By the 1900s, earlier mechanical calculators, cash registers, accountingmachines, and so on were redesigned to use electric motors, with gearposition as the representation for the state of a variable. The word"computer" was a job title assigned to people who used thesecalculators to perform mathematical calculations. By the 1920s LewisFry Richardson's interest in weather prediction led him to proposehuman computers and numerical analysis to model the weather; to thisday, the most powerful computers on Earth are needed to adequatelymodel its weather using the Navier-Stokes equations.[31]
Companies like Friden, Marchant Calculator and Monroe madedesktop mechanical calculators [32] from the 1930s that could add,subtract, multiply and divide. During the Manhattan project, futureNobel laureate Richard Feynman was the supervisor of the roomful ofhuman computers, many of them female mathematicians, whounderstood the use of differential equations which were being solvedfor the war effort.
In 1948, the Curta was introduced. This was a small, portable, mechanical calculator that was about the size of apepper grinder. Over time, during the 1950s and 1960s a variety of different brands of mechanical calculatorsappeared on the market. The first all-electronic desktop calculator was the British ANITA Mk.VII, which used aNixie tube display and 177 subminiature thyratron tubes. In June 1963, Friden introduced the four-function EC-130.It had an all-transistor design, 13-digit capacity on a 5-inch (130 mm) CRT, and introduced Reverse Polish notation(RPN) to the calculator market at a price of $2200. The EC-132 model added square root and reciprocal functions. In1965, Wang Laboratories produced the LOCI-2, a 10-digit transistorized desktop calculator that used a Nixie tubedisplay and could compute logarithms.
Advanced analog computers
Cambridge differential analyzer, 1938
Before World War II, mechanical and electrical analog computers wereconsidered the "state of the art", and many thought they were the futureof computing. Analog computers take advantage of the strongsimilarities between the mathematics of small-scale properties—theposition and motion of wheels or the voltage and current of electroniccomponents—and the mathematics of other physical phenomena, forexample, ballistic trajectories, inertia, resonance, energy transfer,momentum, and so forth. They model physical phenomena withelectrical voltages and currents[33] as the analog quantities.
Centrally, these analog systems work by creating electrical analogs ofother systems, allowing users to predict behavior of the systems of interest by observing the electrical analogs.[34]
The most useful of the analogies was the way the small-scale behavior could be represented with integral anddifferential equations, and could be thus used to solve those equations. An ingenious example of such a machine,using water as the analog quantity, was the water integrator built in 1928; an electrical example is the Mallockmachine built in 1941. A planimeter is a device which does integrals, using distance as the analog quantity. Unlike
modern digital computers, analog computers are not very flexible, and need to be rewired manually to switch them from working on one problem to another. Analog computers had an advantage over early digital computers in that

History of computing hardware 7
they could be used to solve complex problems using behavioral analogues while the earliest attempts at digitalcomputers were quite limited.Some of the most widely deployed analog computers included devices for aiming weapons, such as the Nordenbombsight[35] and the fire-control systems,[36] such as Arthur Pollen's Argo system for naval vessels. Some stayed inuse for decades after WWII; the Mark I Fire Control Computer was deployed by the United States Navy on a varietyof ships from destroyers to battleships. Other analog computers included the Heathkit EC-1, and the hydraulicMONIAC Computer which modeled econometric flows.[37]
The art of analog computing reached its zenith with the differential analyzer,[38] invented in 1876 by James Thomsonand built by H. W. Nieman and Vannevar Bush at MIT starting in 1927. Fewer than a dozen of these devices wereever built; the most powerful was constructed at the University of Pennsylvania's Moore School of ElectricalEngineering, where the ENIAC was built. Digital electronic computers like the ENIAC spelled the end for mostanalog computing machines, but hybrid analog computers, controlled by digital electronics, remained in substantialuse into the 1950s and 1960s, and later in some specialized applications. But like all digital devices, the decimalprecision of a digital device is a limitation, as compared to an analog device, in which the accuracy is a limitation.[39]
As electronics progressed during the twentieth century, its problems of operation at low voltages while maintaininghigh signal-to-noise ratios[40] were steadily addressed, as shown below, for a digital circuit is a specialized form ofanalog circuit, intended to operate at standardized settings (continuing in the same vein, logic gates can be realizedas forms of digital circuits). But as digital computers have become faster and use larger memory (for example, RAMor internal storage), they have almost entirely displaced analog computers. Computer programming, or coding, hasarisen as another human profession.
Electronic digital computation
Punched tape programs would be much longerthan the short fragment of yellow paper tape
shown.
The era of modern computing began with a flurry of developmentbefore and during World War II, as electronic circuit elements replacedmechanical equivalents, and digital calculations replaced analogcalculations. Machines such as the Z3, the Atanasoff–Berry Computer,the Colossus computers, and the ENIAC were built by hand usingcircuits containing relays or valves (vacuum tubes), and often usedpunched cards or punched paper tape for input and as the main(non-volatile) storage medium. Defining a single point in the series asthe "first computer" misses many subtleties (see the table "Definingcharacteristics of some early digital computers of the 1940s" below).
Alan Turing's 1936 paper[41] proved enormously influential incomputing and computer science in two ways. Its main purpose was toprove that there were problems (namely the halting problem) that could not be solved by any sequential process. Indoing so, Turing provided a definition of a universal computer which executes a program stored on tape. Thisconstruct came to be called a Turing machine.[42] Except for the limitations imposed by their finite memory stores,modern computers are said to be Turing-complete, which is to say, they have algorithm execution capabilityequivalent to a universal Turing machine.

History of computing hardware 8
Nine-track magnetic tape
For a computing machine to be a practical general-purpose computer,there must be some convenient read-write mechanism, punched tape,for example. With a knowledge of Alan Turing's theoretical 'universalcomputing machine' John von Neumann defined an architecture whichuses the same memory both to store programs and data: virtually allcontemporary computers use this architecture (or some variant). Whileit is theoretically possible to implement a full computer entirelymechanically (as Babbage's design showed), electronics made possiblethe speed and later the miniaturization that characterize moderncomputers.
There were three parallel streams of computer development in theWorld War II era; the first stream largely ignored, and the secondstream deliberately kept secret. The first was the German work ofKonrad Zuse. The second was the secret development of the Colossus computers in the UK. Neither of these hadmuch influence on the various computing projects in the United States. The third stream of computer development,Eckert and Mauchly's ENIAC and EDVAC, was widely publicized.[43] [44]
George Stibitz is internationally recognized as one of the fathers of the modern digital computer. While working atBell Labs in November 1937, Stibitz invented and built a relay-based calculator that he dubbed the "Model K" (for"kitchen table", on which he had assembled it), which was the first to calculate using binary form.[45]
Zuse
A reproduction of Zuse's Z1 computer
Working in isolation in Germany, Konrad Zuse started construction in1936 of his first Z-series calculators featuring memory and (initiallylimited) programmability. Zuse's purely mechanical, but already binaryZ1, finished in 1938, never worked reliably due to problems with theprecision of parts.
Zuse's later machine, the Z3,[46] was finished in 1941. It was based ontelephone relays and did work satisfactorily. The Z3 thus became thefirst functional program-controlled, all-purpose, digital computer. Inmany ways it was quite similar to modern machines, pioneeringnumerous advances, such as floating point numbers. Replacement of the hard-to-implement decimal system (used inCharles Babbage's earlier design) by the simpler binary system meant that Zuse's machines were easier to build andpotentially more reliable, given the technologies available at that time.
Programs were fed into Z3 on punched films. Conditional jumps were missing, but since the 1990s it has beenproved theoretically that Z3 was still a universal computer (as always, ignoring physical storage limitations). In two1936 patent applications, Konrad Zuse also anticipated that machine instructions could be stored in the same storageused for data—the key insight of what became known as the von Neumann architecture, first implemented in theBritish SSEM of 1948.[47] Zuse also claimed to have designed the first higher-level programming language, whichhe named Plankalkül, in 1945 (published in 1948) although it was implemented for the first time in 2000 by a teamaround Raúl Rojas at the Free University of Berlin—five years after Zuse died.Zuse suffered setbacks during World War II when some of his machines were destroyed in the course of Alliedbombing campaigns. Apparently his work remained largely unknown to engineers in the UK and US until muchlater, although at least IBM was aware of it as it financed his post-war startup company in 1946 in return for anoption on Zuse's patents.

History of computing hardware 9
Colossus
Colossus was used to break German ciphersduring World War II.
During World War II, the British at Bletchley Park (40 miles north ofLondon) achieved a number of successes at breaking encryptedGerman military communications. The German encryption machine,Enigma, was attacked with the help of electro-mechanical machinescalled bombes. The bombe, designed by Alan Turing and GordonWelchman, after the Polish cryptographic bomba by Marian Rejewski(1938), came into productive use in 1941.[48] They ruled out possibleEnigma settings by performing chains of logical deductionsimplemented electrically. Most possibilities led to a contradiction, andthe few remaining could be tested by hand.
The Germans also developed a series of teleprinter encryption systems, quite different from Enigma. The Lorenz SZ40/42 machine was used for high-level Army communications, termed "Tunny" by the British. The first intercepts ofLorenz messages began in 1941. As part of an attack on Tunny, Professor Max Newman and his colleagues helpedspecify the Colossus.[49] The Mk I Colossus was built between March and December 1943 by Tommy Flowers andhis colleagues at the Post Office Research Station at Dollis Hill in London and then shipped to Bletchley Park inJanuary 1944.Colossus was the world's first totally electronic programmable computing device. The Colossus used a large numberof valves (vacuum tubes). It had paper-tape input and was capable of being configured to perform a variety ofboolean logical operations on its data, but it was not Turing-complete. Nine Mk II Colossi were built (The Mk I wasconverted to a Mk II making ten machines in total). Details of their existence, design, and use were kept secret wellinto the 1970s. Winston Churchill personally issued an order for their destruction into pieces no larger than a man'shand, which was to ensure the fact the British were capable of cracking Lorenz was kept secret during the oncomingcold war. Due to this secrecy, the Colossi were not included in many histories of computing. A reconstructed copy ofone of the Colossus machines is now on display at Bletchley Park.
American developmentsIn 1937, Claude Shannon showed there is a one-to-one correspondence between the concepts of Boolean logic andcertain electrical circuits, now called logic gates, which are now ubiquitous in digital computers.[50] In his master'sthesis[51] at MIT, for the first time in history, Shannon showed that electronic relays and switches can realize theexpressions of Boolean algebra. Entitled A Symbolic Analysis of Relay and Switching Circuits, Shannon's thesisessentially founded practical digital circuit design. George Stibitz completed a relay-based computer he dubbed the"Model K" at Bell Labs in November 1937. Bell Labs authorized a full research program in late 1938 with Stibitz atthe helm. Their Complex Number Calculator,[52] completed January 8, 1940, was able to calculate complex numbers.In a demonstration to the American Mathematical Society conference at Dartmouth College on September 11, 1940,Stibitz was able to send the Complex Number Calculator remote commands over telephone lines by a teletype. It wasthe first computing machine ever used remotely, in this case over a phone line. Some participants in the conferencewho witnessed the demonstration were John von Neumann, John Mauchly, and Norbert Wiener, who wrote about itin their memoirs.

History of computing hardware 10
Atanasoff–Berry Computer replica at 1st floor ofDurham Center, Iowa State University
In 1939, John Vincent Atanasoff and Clifford E. Berry of Iowa StateUniversity developed the Atanasoff–Berry Computer (ABC),[53] TheAtanasoff-Berry Computer was the world's first electronic digitalcomputer.[54] The design used over 300 vacuum tubes and employedcapacitors fixed in a mechanically rotating drum for memory. Thoughthe ABC machine was not programmable, it was the first to useelectronic tubes in an adder. ENIAC co-inventor John Mauchlyexamined the ABC in June 1941, and its influence on the design of thelater ENIAC machine is a matter of contention among computerhistorians. The ABC was largely forgotten until it became the focus ofthe lawsuit Honeywell v. Sperry Rand, the ruling of which invalidatedthe ENIAC patent (and several others) as, among many reasons, havingbeen anticipated by Atanasoff's work.
In 1939, development began at IBM's Endicott laboratories on the Harvard Mark I. Known officially as theAutomatic Sequence Controlled Calculator,[55] the Mark I was a general purpose electro-mechanical computer builtwith IBM financing and with assistance from IBM personnel, under the direction of Harvard mathematician HowardAiken. Its design was influenced by Babbage's Analytical Engine, using decimal arithmetic and storage wheels androtary switches in addition to electromagnetic relays. It was programmable via punched paper tape, and containedseveral calculation units working in parallel. Later versions contained several paper tape readers and the machinecould switch between readers based on a condition. Nevertheless, the machine was not quite Turing-complete. TheMark I was moved to Harvard University and began operation in May 1944.
ENIAC
ENIAC performed ballistics trajectorycalculations with 160 kW of power
The US-built ENIAC (Electronic Numerical Integrator and Computer)was the first electronic general-purpose computer. It combined, for thefirst time, the high speed of electronics with the ability to beprogrammed for many complex problems. It could add or subtract5000 times a second, a thousand times faster than any other machine.(Colossus couldn't add). It also had modules to multiply, divide, andsquare root. High speed memory was limited to 20 words (about 80bytes). Built under the direction of John Mauchly and J. Presper Eckertat the University of Pennsylvania, ENIAC's development andconstruction lasted from 1943 to full operation at the end of 1945. Themachine was huge, weighing 30 tons, and contained over 18,000vacuum tubes. One of the major engineering feats was to minimizetube burnout, which was a common problem at that time. The machine was in almost constant use for the next tenyears.
ENIAC was unambiguously a Turing-complete device. It could compute any problem (that would fit in memory). A"program" on the ENIAC, however, was defined by the states of its patch cables and switches, a far cry from thestored program electronic machines that evolved from it. Once a program was written, it had to be mechanically setinto the machine. Six women did most of the programming of ENIAC. (Improvements completed in 1948 made itpossible to execute stored programs set in function table memory, which made programming less a "one-off" effort,and more systematic).
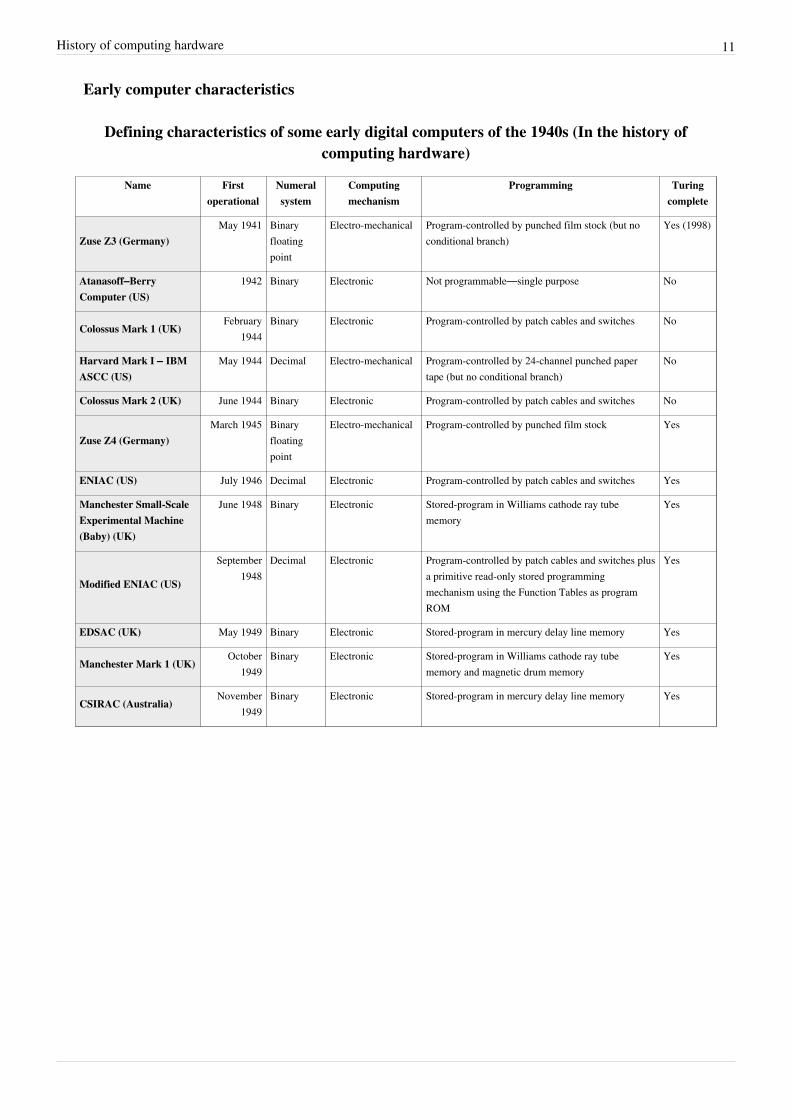
History of computing hardware 11
Early computer characteristics
Defining characteristics of some early digital computers of the 1940s (In the history ofcomputing hardware)
Name Firstoperational
Numeralsystem
Computingmechanism
Programming Turingcomplete
Zuse Z3 (Germany)May 1941 Binary
floatingpoint
Electro-mechanical Program-controlled by punched film stock (but noconditional branch)
Yes (1998)
Atanasoff–BerryComputer (US)
1942 Binary Electronic Not programmable—single purpose No
Colossus Mark 1 (UK)February
1944Binary Electronic Program-controlled by patch cables and switches No
Harvard Mark I – IBMASCC (US)
May 1944 Decimal Electro-mechanical Program-controlled by 24-channel punched papertape (but no conditional branch)
No
Colossus Mark 2 (UK) June 1944 Binary Electronic Program-controlled by patch cables and switches No
Zuse Z4 (Germany)March 1945 Binary
floatingpoint
Electro-mechanical Program-controlled by punched film stock Yes
ENIAC (US) July 1946 Decimal Electronic Program-controlled by patch cables and switches Yes
Manchester Small-ScaleExperimental Machine(Baby) (UK)
June 1948 Binary Electronic Stored-program in Williams cathode ray tubememory
Yes
Modified ENIAC (US)
September1948
Decimal Electronic Program-controlled by patch cables and switches plusa primitive read-only stored programmingmechanism using the Function Tables as programROM
Yes
EDSAC (UK) May 1949 Binary Electronic Stored-program in mercury delay line memory Yes
Manchester Mark 1 (UK)October
1949Binary Electronic Stored-program in Williams cathode ray tube
memory and magnetic drum memoryYes
CSIRAC (Australia)November
1949Binary Electronic Stored-program in mercury delay line memory Yes

History of computing hardware 12
First-generation machines
Design of the von Neumann architecture (1947)
Even before the ENIAC was finished, Eckert and Mauchly recognizedits limitations and started the design of a stored-program computer,EDVAC. John von Neumann was credited with a widely circulatedreport describing the EDVAC design in which both the programs andworking data were stored in a single, unified store. This basic design,denoted the von Neumann architecture, would serve as the foundationfor the worldwide development of ENIAC's successors.[56] In thisgeneration of equipment, temporary or working storage was providedby acoustic delay lines, which used the propagation time of soundthrough a medium such as liquid mercury (or through a wire) to brieflystore data. A series of acoustic pulses is sent along a tube; after a time,as the pulse reached the end of the tube, the circuitry detected whetherthe pulse represented a 1 or 0 and caused the oscillator to re-send thepulse. Others used Williams tubes, which use the ability of a small cathode-ray tube (CRT) to store and retrieve dataas charged areas on the phosphor screen. By 1954, magnetic core memory[57] was rapidly displacing most otherforms of temporary storage, and dominated the field through the mid-1970s.
Magnetic core memory. Each core is one bit.
EDVAC was the first stored-program computer designed; however itwas not the first to run. Eckert and Mauchly left the project and itsconstruction floundered. The first working von Neumann machine wasthe Manchester "Baby" or Small-Scale Experimental Machine,developed by Frederic C. Williams and Tom Kilburn at the Universityof Manchester in 1948 as a test bed for the Williams tube;[58] it wasfollowed in 1949 by the Manchester Mark 1 computer, a completesystem, using Williams tube and magnetic drum memory, andintroducing index registers.[59] The other contender for the title "firstdigital stored-program computer" had been EDSAC, designed andconstructed at the University of Cambridge. Operational less than one
year after the Manchester "Baby", it was also capable of tackling real problems. EDSAC was actually inspired byplans for EDVAC (Electronic Discrete Variable Automatic Computer), the successor to ENIAC; these plans werealready in place by the time ENIAC was successfully operational. Unlike ENIAC, which used parallel processing,EDVAC used a single processing unit. This design was simpler and was the first to be implemented in eachsucceeding wave of miniaturization, and increased reliability. Some view Manchester Mark 1 / EDSAC / EDVAC asthe "Eves" from which nearly all current computers derive their architecture. Manchester University's machinebecame the prototype for the Ferranti Mark 1. The first Ferranti Mark 1 machine was delivered to the University inFebruary, 1951 and at least nine others were sold between 1951 and 1957.
The first universal programmable computer in the Soviet Union was created by a team of scientists under directionof Sergei Alekseyevich Lebedev from Kiev Institute of Electrotechnology, Soviet Union (now Ukraine). Thecomputer MESM (МЭСМ, Small Electronic Calculating Machine) became operational in 1950. It had about 6,000vacuum tubes and consumed 25 kW of power. It could perform approximately 3,000 operations per second. Anotherearly machine was CSIRAC, an Australian design that ran its first test program in 1949. CSIRAC is the oldestcomputer still in existence and the first to have been used to play digital music.[60]

History of computing hardware 13
Commercial computersThe first commercial computer was the Ferranti Mark 1, which was delivered to the University of Manchester inFebruary 1951. It was based on the Manchester Mark 1. The main improvements over the Manchester Mark 1 werein the size of the primary storage (using random access Williams tubes), secondary storage (using a magnetic drum),a faster multiplier, and additional instructions. The basic cycle time was 1.2 milliseconds, and a multiplication couldbe completed in about 2.16 milliseconds. The multiplier used almost a quarter of the machine's 4,050 vacuum tubes(valves).[61] A second machine was purchased by the University of Toronto, before the design was revised into theMark 1 Star. At least seven of the these later machines were delivered between 1953 and 1957, one of them to Shelllabs in Amsterdam.[62]
In October 1947, the directors of J. Lyons & Company, a British catering company famous for its teashops but withstrong interests in new office management techniques, decided to take an active role in promoting the commercialdevelopment of computers. The LEO I computer became operational in April 1951 [63] and ran the world's firstregular routine office computer job. On 17 November 1951, the J. Lyons company began weekly operation of abakery valuations job on the LEO (Lyons Electronic Office). This was the first business application to go live on astored program computer.[64]
In June 1951, the UNIVAC I (Universal Automatic Computer) was delivered to the U.S. Census Bureau. RemingtonRand eventually sold 46 machines at more than $1 million each ($8.38 million as of 2010).[65] UNIVAC was the first"mass produced" computer. It used 5,200 vacuum tubes and consumed 125 kW of power. Its primary storage wasserial-access mercury delay lines capable of storing 1,000 words of 11 decimal digits plus sign (72-bit words). A keyfeature of the UNIVAC system was a newly invented type of metal magnetic tape, and a high-speed tape unit, fornon-volatile storage. Magnetic media are still used in many computers.[66] In 1952, IBM publicly announced theIBM 701 Electronic Data Processing Machine, the first in its successful 700/7000 series and its first IBM mainframecomputer. The IBM 704, introduced in 1954, used magnetic core memory, which became the standard for largemachines. The first implemented high-level general purpose programming language, Fortran, was also beingdeveloped at IBM for the 704 during 1955 and 1956 and released in early 1957. (Konrad Zuse's 1945 design of thehigh-level language Plankalkül was not implemented at that time.) A volunteer user group, which exists to this day,was founded in 1955 to share their software and experiences with the IBM 701.
IBM 650 front panel
IBM introduced a smaller, more affordable computer in 1954 thatproved very popular.[67] The IBM 650 weighed over 900 kg, theattached power supply weighed around 1350 kg and both were held inseparate cabinets of roughly 1.5 meters by 0.9 meters by 1.8 meters. Itcost $500,000 ($4.05 million as of 2010) or could be leased for $3,500a month ($30 thousand as of 2010).[65] Its drum memory was originally2,000 ten-digit words, later expanded to 4,000 words. Memorylimitations such as this were to dominate programming for decadesafterward. The program instructions were fetched from the spinningdrum as the code ran. Efficient execution using drum memory wasprovided by a combination of hardware architecture: the instructionformat included the address of the next instruction; and software: theSymbolic Optimal Assembly Program, SOAP,[68] assigned instructionsto optimal address (to the extent possible by static analysis of thesource program). Thus many instructions were, when needed, located in the next row of the drum to be read andadditional wait time for drum rotation was not required.
In 1955, Maurice Wilkes invented microprogramming,[69] which allows the base instruction set to be defined orextended by built-in programs (now called firmware or microcode).[70] It was widely used in the CPUs andfloating-point units of mainframe and other computers, such as the Manchester Atlas [71] and the IBM 360 series.[72]

History of computing hardware 14
IBM introduced its first magnetic disk system, RAMAC (Random Access Method of Accounting and Control) in1956. Using fifty 24-inch (610 mm) metal disks, with 100 tracks per side, it was able to store 5 megabytes of data ata cost of $10,000 per megabyte ($80 thousand as of 2010).[65] [73]
Second generation: transistors
A bipolar junction transistor
The bipolar transistor was invented in 1947. From 1955 onwardstransistors replaced vacuum tubes in computer designs,[74] giving riseto the "second generation" of computers. Initially the only devicesavailable were germanium point-contact transistors, which althoughless reliable than the vacuum tubes they replaced had the advantage ofconsuming far less power.[75] The first transistorised computer wasbuilt at the University of Manchester and was operational by 1953;[76]
a second version was completed there in April 1955. The later machineused 200 transistors and 1,300 solid-state diodes and had a powerconsumption of 150 watts. However, it still required valves to generatethe clock waveforms at 125 kHz and to read and write on the magneticdrum memory, whereas the Harwell CADET operated without any valves by using a lower clock frequency, of58 kHz when it became operational in February 1955.[77] Problems with the reliability of early batches of pointcontact and alloyed junction transistors meant that the machine's mean time between failures was about 90 minutes,but this improved once the more reliable bipolar junction transistors became available.[78]
Compared to vacuum tubes, transistors have many advantages: they are smaller, and require less power than vacuumtubes, so give off less heat. Silicon junction transistors were much more reliable than vacuum tubes and had longer,indefinite, service life. Transistorized computers could contain tens of thousands of binary logic circuits in arelatively compact space. Transistors greatly reduced computers' size, initial cost, and operating cost. Typically,second-generation computers were composed of large numbers of printed circuit boards such as the IBM StandardModular System[79] each carrying one to four logic gates or flip-flops.A second generation computer, the IBM 1401, captured about one third of the world market. IBM installed morethan one hundred thousand 1401s between 1960 and 1964.
This RAMAC DASD is being restored at theComputer History Museum
Transistorized electronics improved not only the CPU (CentralProcessing Unit), but also the peripheral devices. The IBM 350RAMAC was introduced in 1956 and was the world's first disk drive.The second generation disk data storage units were able to store tens ofmillions of letters and digits. Next to the fixed disk storage units,connected to the CPU via high-speed data transmission, wereremovable disk data storage units. A removable disk stack can beeasily exchanged with another stack in a few seconds. Even if theremovable disks' capacity is smaller than fixed disks,' theirinterchangeability guarantees a nearly unlimited quantity of data closeat hand. Magnetic tape provided archival capability for this data, at alower cost than disk.
Many second generation CPUs delegated peripheral devicecommunications to a secondary processor. For example, while the communication processor controlled card readingand punching, the main CPU executed calculations and binary branch instructions. One databus would bear data
between the main CPU and core memory at the CPU's fetch-execute cycle rate, and other databusses would typically serve the peripheral devices. On the PDP-1, the core memory's cycle time was 5 microseconds; consequently most

History of computing hardware 15
arithmetic instructions took 10 microseconds (100,000 operations per second) because most operations took at leasttwo memory cycles; one for the instruction, one for the operand data fetch.During the second generation remote terminal units (often in the form of teletype machines like a FridenFlexowriter) saw greatly increased use. Telephone connections provided sufficient speed for early remote terminalsand allowed hundreds of kilometers separation between remote-terminals and the computing center. Eventually thesestand-alone computer networks would be generalized into an interconnected network of networks—the Internet.[80]
Post-1960: third generation and beyond
Intel 8742 eight-bit microcontroller IC
The explosion in the use of computers began with "third-generation"computers, making use of Jack St. Clair Kilby's[81] and RobertNoyce's[82] independent invention of the integrated circuit (ormicrochip), which later led to the invention of the microprocessor,[83]
by Ted Hoff, Federico Faggin, and Stanley Mazor at Intel.[84] Theintegrated circuit in the image on the right, for example, an Intel 8742,is an 8-bit microcontroller that includes a CPU running at 12 MHz, 128bytes of RAM, 2048 bytes of EPROM, and I/O in the same chip.
During the 1960s there was considerable overlap between second andthird generation technologies.[85] IBM implemented its IBM SolidLogic Technology modules in hybrid circuits for the IBM System/360in 1964. As late as 1975, Sperry Univac continued the manufacture of second-generation machines such as theUNIVAC 494. The Burroughs large systems such as the B5000 were stack machines, which allowed for simplerprogramming. These pushdown automatons were also implemented in minicomputers and microprocessors later,which influenced programming language design. Minicomputers served as low-cost computer centers for industry,business and universities.[86] It became possible to simulate analog circuits with the simulation program withintegrated circuit emphasis, or SPICE (1971) on minicomputers, one of the programs for electronic designautomation (EDA). The microprocessor led to the development of the microcomputer, small, low-cost computersthat could be owned by individuals and small businesses. Microcomputers, the first of which appeared in the 1970s,became ubiquitous in the 1980s and beyond. Steve Wozniak, co-founder of Apple Computer, is sometimeserroneously credited with developing the first mass-market home computers. However, his first computer, the AppleI, came out some time after the MOS Technology KIM-1 and Altair 8800, and the first Apple computer with graphicand sound capabilities came out well after the Commodore PET. Computing has evolved with microcomputerarchitectures, with features added from their larger brethren, now dominant in most market segments.
Systems as complicated as computers require very high reliability. ENIAC remained on, in continuous operationfrom 1947 to 1955, for eight years before being shut down. Although a vacuum tube might fail, it would be replacedwithout bringing down the system. By the simple strategy of never shutting down ENIAC, the failures weredramatically reduced. Hot-pluggable hard disks, like the hot-pluggable vacuum tubes of yesteryear, continue thetradition of repair during continuous operation. Semiconductor memories routinely have no errors when theyoperate, although operating systems like Unix have employed memory tests on start-up to detect failing hardware.Today, the requirement of reliable performance is made even more stringent when server farms are the deliveryplatform.[87] Google has managed this by using fault-tolerant software to recover from hardware failures, and is evenworking on the concept of replacing entire server farms on-the-fly, during a service event.[88] [89]
In the twenty-first century, multi-core CPUs became commercially available.[90] Content-addressable memory (CAM)[91] has become inexpensive enough to be used in networking, although no computer system has yet implemented hardware CAMs for use in programming languages. Currently, CAMs (or associative arrays) in software are programming-language-specific. Semiconductor memory cell arrays are very regular structures, and

History of computing hardware 16
manufacturers prove their processes on them; this allows price reductions on memory products. During the 1980's,CMOS logic gates developed into devices that could be made as fast as other circuit types; computer powerconsumption could therefore be decreased dramatically. Unlike the continuous current draw of a gate based on otherlogic types, a CMOS gate only draws significant current during the 'transition' between logic states, except forleakage.This has allowed computing to become a commodity which is now ubiquitous, embedded in many forms, fromgreeting cards and telephones to satellites. Computing hardware and its software have even become a metaphor forthe operation of the universe.[92] Although DNA-based computing and quantum qubit computing are years ordecades in the future, the infrastructure is being laid today, for example, with DNA origami on photolithography.[93]
Fast digital circuits (including those based on Josephson junctions and rapid single flux quantum technology) arebecoming more nearly realizable with the discovery of nanoscale superconductors.[94]
An indication of the rapidity of development of this field can be inferred by the history of the seminal article.[95] Bythe time that anyone had time to write anything down, it was obsolete. After 1945, others read John von Neumann'sFirst Draft of a Report on the EDVAC, and immediately started implementing their own systems. To this day, thepace of development has continued, worldwide.[96] [97]
See also• History of computing• Information Age• IT History Society• The Secret Guide to Computers (book)• Timeline of computing
References• Backus, John (August 1978), "Can Programming be Liberated from the von Neumann Style?" [98],
Communications of the ACM 21 (8): 613, doi:10.1145/359576.359579, 1977 ACM Turing Award Lecture.• Bell, Gordon; Newell, Allen (1971), Computer Structures: Readings and Examples [99], New York:
McGraw-Hill, ISBN 0-07-004357-4.• Bergin, Thomas J. (ed.) (November 13 and 14, 1996), Fifty Years of Army Computing: from ENIAC to MSRC
[100], A record of a symposium and celebration, Aberdeen Proving Ground.: Army Research Laboratory and theU.S.Army Ordnance Center and School., retrieved 2008-05-17.
• Bowden, B. V. (1970), "The Language of Computers" [101], American Scientist 58: 43–53, retrieved 2008-05-17.• Burks, Arthur W.; Goldstine, Herman; von Neumann, John (1947), Preliminary discussion of the Logical Design
of an Electronic Computing Instrument [102], Princeton, NJ: Institute for Advanced Study, retrieved 2008-05-18.• Chua, Leon O (September 1971), "Memristor—The Missing Circuit Element" [103], IEEE Transactions on Circuit
Theory CT-18 (5): 507–519, doi:10.1109/TCT.1971.1083337.• Cleary, J. F. (1964), GE Transistor Manual (7th ed.), General Electric, Semiconductor Products Department,
Syracuse, NY, pp. 139–204, OCLC 223686427.• Copeland, B. Jack (ed.) (2006), Colossus: The Secrets of Bletchley Park's Codebreaking Computers, Oxford,
England: Oxford University Press, ISBN 019284055X.• (French) Coriolis, Gaspard-Gustave (1836), "Note sur un moyen de tracer des courbes données par des équations
différentielles" [104], Journal de Mathématiques Pures et appliquées series I 1: 5–9, retrieved 2008-07-06.• ( – Scholar search [105]) CSIRAC: Australia’s first computer [106], Commonwealth Scientific and Industrial Research
Organisation (CSIRAC), June 3, 2005, retrieved 2007-12-21.• Da Cruz, Frank (February 28, 2008), "The IBM Automatic Sequence Controlled Calculator (ASCC)" [107],
Columbia University Computing History: A Chronology of Computing at Columbia University (Columbia

History of computing hardware 17
University ACIS), retrieved 2008-05-17.• Davenport, Wilbur B., Jr; Root, William L. (1958), An Introduction to the theory of Random Signals and Noise,
McGraw-Hill, pp. 112–364, OCLC 573270.• Eckert, Wallace (1935), "The Computation of Special Perturbations by the Punched Card Method.", Astronomical
Journal 44 (1034): 177, doi:10.1086/105298.• Eckert, Wallace (1940), "XII: "The Computation of Planetary Pertubations"", Punched Card Methods in Scientific
Computation, Thomas J. Watson Astronomical Computing Bureau, Columbia University, pp. 101–114,OCLC 2275308.
• Eckhouse, Richard H., Jr.; Morris, L. Robert (1979), Minicomputer Systems: organization, programming, andapplications (PDP-11), Prentice-Hall, pp. 1–2, ISBN 0135839149.
• Enticknap, Nicholas (Summer 1998), "Computing's Golden Jubilee" [108], Resurrection (The ComputerConservation Society) (20), ISSN 0958-7403, retrieved 2008-04-19.
• Feynman, R. P.; Leighton, Robert; Sands, Matthew (1965), Feynman Lectures on Physics, Reading, Mass:Addison-Wesley, pp. III 14–11 to 14–12, ISBN 0201020106, OCLC 531535.
• Fisk, Dale (2005), Punch cards [109], Columbia University ACIS, retrieved 2008-05-19.• Hollerith, Herman (1890) (Ph.D. dissertation), In connection with the electric tabulation system which has been
adopted by U.S. government for the work of the census bureau, Columbia University School of Mines.• Horowitz, Paul; Hill, Winfield (1989), The Art of Electronics (2nd ed.), Cambridge University Press,
ISBN 0521370957.• Hunt, J. C. R. (1998), "Lewis Fry Richardson and his contributions to Mathematics, Meteorology and Models of
Conflict" [110], Ann. Rev. Fluid Mech. 30: XIII–XXXVI, doi:10.1146/annurev.fluid.30.1.0, retrieved 2008-06-15.• IBM_SMS (1960), IBM Standard Modular System SMS Cards [111], IBM, retrieved 2008-03-06.• IBM (September, 1956), IBM 350 disk storage unit [112], IBM, retrieved 2008-07-01.• IEEE_Annals (Series dates from 1979), Annals of the History of Computing [113], IEEE, retrieved 2008-05-19.• Ifrah, Georges (2000), The Universal History of Numbers: From prehistory to the invention of the computer.,
John Wiley and Sons, p. 48, ISBN 0-471-39340-1. Translated from the French by David Bellos, E.F. Harding,Sophie Wood and Ian Monk. Ifrah supports his thesis by quoting idiomatic phrases from languages across theentire world.
• Intel_4004 (November 1971), Intel's First Microprocessor—the Intel 4004 [114], Intel Corp., retrieved2008-05-17.
• Jones, Douglas W, Punched Cards: A brief illustrated technical history [115], The University of Iowa, retrieved2008-05-15.
• Kalman, R.E. (1960), "A new approach to linear filtering and prediction problems" [116], Journal of BasicEngineering 82 (1): 35–45, retrieved 2008-05-03.
• Kells; Kern; Bland (1943), The Log-Log Duplex Decitrig Slide Rule No. 4081: A Manual [117], Keuffel & Esser,p. 92.
• Kilby, Jack (2000), Nobel lecture [118], Stockholm: Nobel Foundation, retrieved 2008-05-15.• Kohonen, Teuvo (1980), Content-addressable memories, Springer-Verlag, p. 368, ISBN 0387098232.• Lavington, Simon (1998), A History of Manchester Computers (2 ed.), Swindon: The British Computer Society• Lazos (1994), The Antikythera Computer (Ο ΥΠΟΛΟΓΙΣΤΗΣ ΤΩΝ ΑΝΤΙΚΥΘΗΡΩΝ),, ΑΙΟΛΟΣ PUBLICATIONS GR.• Leibniz, Gottfried (1703), Explication de l'Arithmétique Binaire.• Lubar, Steve (May 1991) ( – Scholar search [119]), "Do not fold, spindle or mutilate": A cultural history of the
punched card [120], retrieved 2006-10-31• Manchester (1998, 1999), Mark 1 [121], Computer History Museum, The University of Manchester, retrieved
2008-04-19• Marguin, Jean (1994) (in fr), Histoire des instruments et machines à calculer, trois siècles de mécanique pensante
1642-1942, Hermann, ISBN 978-2705661663

History of computing hardware 18
• Martin, Douglas (June 29, 2008), "David Caminer, 92 Dies; A Pioneer in Computers", New York Times: 24• Mead, Carver; Conway, Lynn (1980), Introduction to VLSI Systems, Reading, Mass.: Addison-Wesley,
ISBN 0201043580.• Menabrea, Luigi Federico; Lovelace, Ada (1843), "Sketch of the Analytical Engine Invented by Charles
Babbage" [122], Scientific Memoirs 3. With notes upon the Memoir by the Translator.• Menninger, Karl (1992), Number Words and Number Symbols: A Cultural History of Numbers, Dover
Publications. German to English translation, M.I.T., 1969.• Montaner; Simon (1887), Diccionario Enciclopédico Hispano-Americano (Hispano-American Encyclopedic
Dictionary).• Moye, William T. (January 1996), ENIAC: The Army-Sponsored Revolution [123], retrieved 2008-05-17.• Norden, M9 Bombsight [124], National Museum of the USAF, retrieved 2008-05-17.• Noyce, Robert "Semiconductor device-and-lead structure" US patent 2981877 [125], issued 1961-04-25, assigned
to Fairchild Semiconductor Corporation.• Patterson, David; Hennessy, John (1998), Computer Organization and Design, San Francisco: Morgan
Kaufmann, ISBN 1-55860-428-6.• Mourlevat, Guy (1988) (in fr), Les machines arithmétiques de Blaise Pascal, Clermont-Ferrand: La Française
d'Edition et d'Imprimerie• Pellerin, David; Thibault, Scott (April 22, 2005), Practical FPGA Programming in C, Prentice Hall Modern
Semiconductor Design Series Sub Series: PH Signal Integrity Library, pp. 1–464, ISBN 0-13-154318-0.• Phillips, A.W.H., The MONIAC [126], Reserve Bank Museum, retrieved 2006-05-17.• Rojas, Raul; Hashagen, Ulf (eds., 2000). The First Computers: History and Architectures. Cambridge: MIT Press.
ISBN 0-262-68137-4.• Schmandt-Besserat, Denise (1981), "Decipherment of the earliest tablets", Science 211 (4479): 283–285,
doi:10.1126/science.211.4479.283, PMID 17748027.• Schmidhuber, Jürgen, Wilhelm Schickard (1592–1635) Father of the computer age [127], retrieved 2008-05-15.• Shankland, Stephen (May 30, 2008), Google spotlights data center inner workings [128], Cnet, retrieved
2008-05-31.• Shankland, Stephen (April 1, 2009), Google uncloaks once-secret server [129], Cnet, retrieved 2009-04-01.• Shannon, Claude (1940), A symbolic analysis of relay and switching circuits, Massachusetts Institute of
Technology, Dept. of Electrical Engineering.• Simon, Herbert (1991), Models of My Life, Basic Books, Sloan Foundation Series.• Singer (1946), Singer in World War II, 1939–1945 — the M5 Director [130], Singer Manufacturing Co., retrieved
2008-05-17.• Smith, David Eugene (1929), A Source Book in Mathematics, New York: McGraw-Hill, pp. 180–181.• Smolin, Lee (2001), Three roads to quantum gravity, Basic Books, pp. 53–57, ISBN 0-465-07835-4. Pages
220–226 are annotated references and guide for further reading.• Steinhaus, H. (1999), Mathematical Snapshots (3rd ed.), New York: Dover, pp. 92–95, p. 301.• Stern, Nancy (1981), From ENIAC to UNIVAC: An Appraisal of the Eckert-Mauchly Computers, Digital Press,
ISBN 0-932376-14-2.• Stibitz, George "Complex Computer" US patent 2668661 [131], issued 1954-02-09, assigned to AT&T.• Taton, René (1969) (in fr), Histoire du calcul. Que sais-je ? n° 198, Presses universitaires de France• Turing, A.M. (1936), "On Computable Numbers, with an Application to the Entscheidungsproblem", Proceedings
of the London Mathematical Society, 2 42: 230–65, 1937, doi:10.1112/plms/s2-42.1.230 (and Turing, A.M.(1938), "On Computable Numbers, with an Application to the Entscheidungsproblem: A correction", Proceedingsof the London Mathematical Society, 2 43: 544–6, 1937, doi:10.1112/plms/s2-43.6.544)Other online versions:Proceedings of the London Mathematical Society [132] Another link online. [133]
• Ulam, Stanisław (1976), Adventures of a Mathematician, New York: Charles Scribner's Sons, (autobiography).

History of computing hardware 19
• von Neumann, John (June 30, 1945), First Draft of a Report on the EDVAC, Moore School of ElectricalEngineering: University of Pennsylvania.
• Wang, An "Pulse transfer controlling devices" US patent 2708722 [134], issued 1955-05-17.• Welchman, Gordon (1984), The Hut Six Story: Breaking the Enigma Codes, Harmondsworth, England: Penguin
Books, pp. 138–145, 295–309.• Wilkes, Maurice (1986), "The Genesis of Microprogramming", Ann. Hist. Comp. 8 (2): 115–126.• Ziemer, Roger E.; Tranter, William H.; Fannin, D. Ronald (1993), Signals and Systems: Continuous and Discrete,
Macmillan, p. 370, ISBN 0-02-431641-5.• Zuse, Z3 Computer (1938–1941) [135], retrieved 2008-06-01.
Further reading• Ceruzzi, Paul E., A History of Modern Computing [136], MIT Press, 1998
External links• Obsolete Technology — Old Computers [137]
• Historic Computers in Japan [138]
• The History of Japanese Mechanical Calculating Machines [139]
• Computer History [140] — a collection of articles by Bob Bemer• 25 Microchips that shook the world [141] — a collection of articles by the Institute of Electrical and Electronics
Engineers• History of Computers and Calculators [142]
References[1] According to Schmandt-Besserat 1981, these clay containers contained tokens, the total of which were the count of objects being transferred.
The containers thus served as something of a bill of lading or an accounts book. In order to avoid breaking open the containers, marks wereplaced on the outside of the containers, for the count. Eventually ( Schmandt-Besserat estimates it took 4000 years (http:/ / www. utexas. edu/friends/ popups/ research_19. html)) the marks on the outside of the containers were all that were needed to convey the count, and the claycontainers evolved into clay tablets with marks for the count.
[2] Eleanor Robson (2008), Mathematics in Ancient Iraq ISBN 978-0-691-09182-2 p.5: these calculi were in use in Iraq for primitive accountingsystems as early as 3200–3000 BCE, with commodity-specific counting representation systems. Balanced accounting was in use by3000–2350 BCE, and a sexagesimal number system was in use 2350–2000 BCE.
[3] Lazos 1994[4] [[Ancient Discoveries (http:/ / www. youtube. com/ watch?v=rxjbaQl0ad8)], Episode 11: Ancient Robots], History Channel, , retrieved
2008-09-06[5] Howard R. Turner (1997), Science in Medieval Islam: An Illustrated Introduction, p. 184, University of Texas Press, ISBN 0-292-78149-0[6] Donald Routledge Hill, "Mechanical Engineering in the Medieval Near East", Scientific American, May 1991, pp. 64–9 (cf. Donald
Routledge Hill, Mechanical Engineering (http:/ / home. swipnet. se/ islam/ articles/ HistoryofSciences. htm))[7] A Spanish implementation of Napier's bones (1617), is documented in Montaner & Simon 1887, pp. 19–20.[8] Kells, Kern & Bland 1943, p. 92[9] Kells, Kern & Bland 1943, p. 82[10] René Taton, p. 81 (1969)[11] (fr) La Machine d’arithmétique, Blaise Pascal (http:/ / fr. wikisource. org/ wiki/ La_Machine_dâ��arithmétique), Wikisource[12] Jean Marguin (1994), p. 48[13] Maurice d'Ocagne (1893), p. 245 Copy of this book found on the CNAM site (http:/ / cnum. cnam. fr/ CGI/ fpage. cgi?8KU54-2. 5/ 248/
150/ 369/ 363/ 369)[14] Guy Mourlevat, p. 12 (1988)[15] As quoted in Smith 1929, pp. 180–181[16] Discovering the Arithmometer (http:/ / www. cis. cornell. edu/ boom/ 2005/ ProjectArchive/ arithometer/ ), Cornell University[17] Leibniz 1703[18] Binary-coded decimal (BCD) is a numeric representation, or character encoding, which is still widely used.

History of computing hardware 20
[19] Yamada, Akihiko, Biquinary mechanical calculating machine,“Jido-Soroban” (automatic abacus), built by Ryoichi Yazu (http:/ / sts. kahaku.go. jp/ temp/ 5. pdf), National Science Museum of Japan, p. 8,
[20] "The History of Japanese Mechanical Calculating Machines" (http:/ / www. xnumber. com/ xnumber/ japanese_calculators. htm).Xnumber.com. 2000-04-10. . Retrieved 2010-01-30.
[21] Mechanical Calculator, "JIDOSOROBAN" (http:/ / www. jsme. or. jp/ kikaiisan/ data/ no_030. html), The Japan Society of MechanicalEngineers (in Japanese)
[22] Jones[23] Menabrea & Lovelace 1843[24] "Columbia University Computing History — Herman Hollerith" (http:/ / www. columbia. edu/ acis/ history/ hollerith. html). Columbia.edu.
. Retrieved 2010-01-30.[25] U.S. Census Bureau: Tabulation and Processing (http:/ / www. census. gov/ history/ www/ technology/ 010873. html)[26] Lubar 1991[27] Eckert 1935[28] http:/ / www. columbia. edu/ acis/ history/[29] Eckert 1940, pp. 101=114. Chapter XII is "The Computation of Planetary Pertubations".[30] Fisk 2005[31] Hunt 1998, pp. xiii–xxxvi[32] http:/ / www. oldcalculatormuseum. com/ fridenstw. html[33] Chua 1971, pp. 507–519[34] See, for example,Horowitz & Hill 1989, pp. 1–44[35] Norden[36] Singer 1946[37] Phillips[38] (French)Coriolis 1836, pp. 5–9[39] The noise level, compared to the signal level, is a fundamental factor, see for example Davenport & Root 1958, pp. 112–364.[40] Ziemer, Tranter & Fannin 1993, p. 370.[41] Turing 1937, pp. 230–265. Online versions: Proceedings of the London Mathematical Society (http:/ / plms. oxfordjournals. org/ cgi/
reprint/ s2-42/ 1/ 230) Another version online. (http:/ / www. thocp. net/ biographies/ papers/ turing_oncomputablenumbers_1936. pdf)[42] Kurt Gödel (1964), p. 71, "Postscriptum" in Martin Davis (ed., 2004), The Undecidable (http:/ / books. google. com/
books?id=qW8x7sQ4JXgC& dq=#+ #+ Martin+ Davis+ editor,+ The+ Undecidable,+ Basic+ Papers+ on+ Undecidable+ Propositions,+Unsolvable+ Problems+ And+ Computable+ Functions,& printsec=frontcover& source=bn& hl=en& ei=Cf1cStGfN6TIMrmbgZIH& sa=X&oi=book_result& ct=result& resnum=4) Fundamental papers by papers by Gödel, Church, Turing, and Post on this topic and the relationshipto computability. ISBN 0-486-43228-9, as summarized in Church-Turing thesis.
[43] Moye 1996[44] Bergin 1996[45] Inventor Profile: George R. Stibitz (http:/ / www. invent. org/ hall_of_fame/ 140. html), National Inventors Hall of Fame Foundation, Inc.,[46] Zuse[47] "Electronic Digital Computers" (http:/ / www. computer50. org/ kgill/ mark1/ natletter. html), Nature 162: 487, 25 September 1948, ,
retrieved 2009-04-10[48] Welchman 1984, pp. 138–145, 295–309[49] Copeland 2006[50] Claude Shannon, "A Symbolic Analysis of Relay and Switching Circuits", Transactions of the American Institute of Electrical Engineers,
Vol. 57,(1938), pp. 713–723[51] Shannon 1940[52] George Stibitz, "Complex Computer" US patent 2668661 (http:/ / v3. espacenet. com/ textdoc?DB=EPODOC& IDX=US2668661), issued
1954-02-09, assigned to AT&T, 102 pages.[53] January 15, 1941 notice in the Des Moines Register.[54] The First Electronic Computer By Arthur W. Burks[55] Da Cruz 2008[56] von Neumann 1945, p. 1. The title page, as submitted by Goldstine, reads: "First Draft of a Report on the EDVAC by John von Neumann,
Contract No. W-670-ORD-4926, Between the United States Army Ordnance Department and the University of Pennsylvania Moore School ofElectrical Engineering".
[57] An Wang filed October 1949, "Pulse transfer controlling devices" US patent 2708722 (http:/ / v3. espacenet. com/ textdoc?DB=EPODOC&IDX=US2708722), issued 1955-05-17
[58] Enticknap 1998, p. 1; Baby's 'first good run' was June 21, 1948.[59] Manchester 1998, by R.B.E. Napper, et al. (http:/ / www. computer50. org/ mark1/ acknowledge. mark1. html)[60] CSIRAC 2005[61] Lavington 1998, p. 25

History of computing hardware 21
[62] Computer Conservation Society, Our Computer Heritage Pilot Study: Deliveries of Ferranti Mark I and Mark I Star computers. (http:/ /www. ourcomputerheritage. org/ wp/ ), , retrieved 9 January 2010
[63] Lavington, Simon. "A brief history of British computers: the first 25 years (1948–1973)." (http:/ / www. bcs. org/ server. php?). BritishComputer Society. . Retrieved 10 January 2010.
[64] Martin 2008, p. 24 notes that David Caminer (1915–2008) served as the first corporate electronic systems analyst, for this first businesscomputer system, a Leo computer, part of J. Lyons & Company. LEO would calculate an employee's pay, handle billing, and other officeautomation tasks.
[65] Consumer Price Index (estimate) 1800–2008 (http:/ / www. minneapolisfed. org/ community_education/ teacher/ calc/ hist1800. cfm).Federal Reserve Bank of Minneapolis. Retrieved March 8, 2010.
[66] Magnetic tape will be the primary data storage mechanism when CERN's Large Hadron Collider comes online in 2008.[67] For example, Kara Platoni's article on Donald Knuth stated that "there was something special about the (http:/ / www. stanfordalumni. org/
news/ magazine/ 2006/ mayjun/ features/ knuth. html) IBM 650", Stanford Magazine, May/June 2006[68] IBM (1957) (PDF), SOAP II for the IBM 650 (http:/ / www. bitsavers. org/ pdf/ ibm/ 650/ 24-4000-0_SOAPII. pdf), C24-4000-0,[69] Wilkes 1986, pp. 115–126[70] Horowitz & Hill 1989, p. 743[71] The microcode was implemented as extracode on Atlas (http:/ / www. chilton-computing. org. uk/ acl/ technology/ atlas/ p019. htm)
accessdate=20100209[72] Patterson & Hennessy 1998, p. 424[73] IBM 1956[74] Feynman, Leighton & Sands 1965, pp. III 14-11 to 14–12[75] Lavington 1998, pp. 34–35[76] Lavington 1998, p. 37[77] Cooke-Yarborough, E.H. (June 1998), "Some early transistor applications in the UK." (http:/ / ieeexplore. ieee. org/ stamp/ stamp.
jsp?arnumber=00689507), Engineering and Science Education Journal (London, UK: IEE) 7 (3): 100–106, doi:10.1049/esej:19980301,ISSN 0963-7346, , retrieved 2009-06-07
[78] Lavington 1998, pp. 36–37[79] IBM_SMS 1960[80] Mayo & Newcomb 2008, pp. 96–117; Jimbo Wales is quoted on p. 115.[81] Kilby 2000[82] Robert Noyce's Unitary circuit, "Semiconductor device-and-lead structure" US patent 2981877 (http:/ / v3. espacenet. com/
textdoc?DB=EPODOC& IDX=US2981877), issued 1961-04-25, assigned to Fairchild Semiconductor Corporation[83] Intel_4004 1971[84] The Intel 4004 (1971) die was , composed of 2300 transistors; by comparison, the Pentium Pro was , composed of
5.5 million transistors, according to Patterson & Hennessy 1998, pp. 27–39[85] In the defense field, considerable work was done in the computerized implementation of equations such as Kalman 1960, pp. 35–45[86] Eckhouse & Morris 1979, pp. 1–2[87] "Since 2005, its [Google's] data centers have been composed of standard shipping containers—each with 1,160 servers and a power
consumption that can reach 250 kilowatts." — Ben Jai of Google, as quoted in Shankland 2009[88] "If you're running 10,000 machines, something is going to die every day." —Jeff Dean of Google, as quoted in Shankland 2008.[89] However, when an entire server farm fails today, the recovery procedures are currently still manual procedures, with the need for training
the recovery team, even for the most advanced facilities. The initial failure was a power failure; the recovery procedure cited an inconsistentbackup site, and the inconsistent backup site was outdated. Accessdate=2010-03-08 (https:/ / groups. google. com/ group/ google-appengine/browse_thread/ thread/ a7640a2743922dcf?pli=1)
[90] Intel has unveiled a single-chip version of a 48-core CPU (http:/ / www. pcper. com/ article. php?aid=825) for software and circuit researchin cloud computing: accessdate=2009-12-02. Intel has loaded Linux on each core; each core has an X86 architecture (http:/ / news. bbc. co.uk/ 2/ hi/ technology/ 8392392. stm): accessdate=2009-12-3
[91] Kohonen 1980, pp. 1–368[92] Smolin 2001, pp. 53–57.Pages 220–226 are annotated references and guide for further reading.[93] Ryan J. Kershner, Luisa D. Bozano, Christine M. Micheel, Albert M. Hung, Ann R. Fornof, Jennifer N. Cha, Charles T. Rettner, Marco
Bersani, Jane Frommer, Paul W. K. Rothemund & Gregory M. Wallraff (16 August 2009) "Placement and orientation of individual DNAshapes on lithographically patterned surfaces" Nature Nanotechnology publication information (http:/ / www. nature. com/ nnano/ journal/vaop/ ncurrent/ suppinfo/ nnano. 2009. 220_S1. html), supplementary information: DNA origami on photolithography (http:/ / www. nature.com/ nnano/ journal/ vaop/ ncurrent/ extref/ nnano. 2009. 220-s1. pdf) doi:10.1038/nnano.2009.220
[94] Saw-Wai Hla et. al., Nature Nanotechnology March 31, 2010 http:/ / www. thinq. co. uk/ news/ 2010/ 3/ 30/worlds-smallest-superconductor-discovered/ Four pairs of certain molecules have been shown to form a nanoscale superconductor, at adimension of 0.87 nanometers. Accessdate=2010-03-31
[95] Burks, Goldstine & von Neumann 1947, pp. 1–464 reprinted in Datamation, September–October 1962. Note that preliminarydiscussion/design was the term later called system analysis/design, and even later, called system architecture.

History of computing hardware 22
[96] IEEE_Annals 1979 Online access to the IEEE Annals of the History of Computing here (http:/ / csdl2. computer. org/ persagen/DLPublication. jsp?pubtype=m& acronym=an). DBLP summarizes the Annals of the History of Computing (http:/ / www. informatik.uni-trier. de/ ~ley/ db/ journals/ annals/ ) year by year, back to 1996, so far.
[97] The fastest supercomputer of the top 500 is expected to be Cray XT5, topping IBM Roadrunner as of November 20, 2009.[98] http:/ / www. stanford. edu/ class/ cs242/ readings/ backus. pdf[99] http:/ / research. microsoft. com/ ~gbell/ Computer_Structures__Readings_and_Examples/ index. html[100] http:/ / www. arl. army. mil/ www/ DownloadedInternetPages/ CurrentPages/ AboutARL/ eniac. pdf[101] http:/ / groups-beta. google. com/ group/ net. misc/ msg/ 00c91c2cc0896b77[102] http:/ / www. cs. unc. edu/ ~adyilie/ comp265/ vonNeumann. html[103] http:/ / ieeexplore. ieee. org/ xpls/ abs_all. jsp?arnumber=1083337[104] http:/ / visualiseur. bnf. fr/ ConsulterElementNum?O=NUMM-16380& Deb=11& Fin=15& E=PDF[105] http:/ / scholar. google. co. uk/ scholar?hl=en& lr=& q=intitle%3ACSIRAC%3A+ Australia%E2%80%99s+ first+ computer&
as_publication=& as_ylo=2005& as_yhi=2005& btnG=Search[106] http:/ / www. csiro. au/ science/ ps4f. html[107] http:/ / www. columbia. edu/ acis/ history/ ssec. html[108] http:/ / www. cs. man. ac. uk/ CCS/ res/ res20. htm#d[109] http:/ / www. columbia. edu/ acis/ history/ fisk. pdf[110] http:/ / www. cpom. org/ people/ jcrh/ AnnRevFluMech(30)LFR. pdf[111] http:/ / ed-thelen. org/ 1401Project/ Sched2006November. html[112] http:/ / www-03. ibm. com/ ibm/ history/ exhibits/ storage/ storage_350. html[113] http:/ / csdl2. computer. org/ persagen/ DLPublication. jsp?pubtype=m& acronym=an[114] http:/ / www. intel. com/ museum/ archives/ 4004. htm[115] http:/ / www. cs. uiowa. edu/ ~jones/ cards/ history. html[116] http:/ / www. elo. utfsm. cl/ ~ipd481/ Papers%20varios/ kalman1960. pdf[117] http:/ / www. mccoys-kecatalogs. com/ K& EManuals/ 4081-3_1943/ 4081-3_1943. htm[118] http:/ / nobelprize. org/ nobel_prizes/ physics/ laureates/ 2000/ kilby-lecture. pdf[119] http:/ / scholar. google. co. uk/ scholar?hl=en& lr=& q=author%3ALubar+ intitle%3A%22Do+ not+ fold%2C+ spindle+ or+
mutilate%22%3A+ A+ cultural+ history+ of+ the+ punched+ card& as_publication=& as_ylo=1991& as_yhi=1991& btnG=Search[120] http:/ / ccat. sas. upenn. edu/ slubar/ fsm. html[121] http:/ / www. computer50. org/ mark1/ MM1. html[122] http:/ / www. fourmilab. ch/ babbage/ sketch. html[123] http:/ / ftp. arl. army. mil/ ~mike/ comphist/ 96summary/[124] http:/ / www. nationalmuseum. af. mil/ factsheets/ factsheet. asp?id=8056[125] http:/ / v3. espacenet. com/ textdoc?DB=EPODOC& IDX=US2981877[126] http:/ / www. rbnz. govt. nz/ about/ museum/ 3121411. pdf[127] http:/ / www. idsia. ch/ ~juergen/ schickard. html[128] http:/ / news. cnet. com/ 8301-10784_3-9955184-7. html?tag=nefd. lede[129] http:/ / news. cnet. com/ 8301-1001_3-10209580-92. html[130] http:/ / home. roadrunner. com/ ~featherweight/ m5direct. htm[131] http:/ / v3. espacenet. com/ textdoc?DB=EPODOC& IDX=US2668661[132] http:/ / plms. oxfordjournals. org/ cgi/ reprint/ s2-42/ 1/ 230[133] http:/ / www. thocp. net/ biographies/ papers/ turing_oncomputablenumbers_1936. pdf[134] http:/ / v3. espacenet. com/ textdoc?DB=EPODOC& IDX=US2708722[135] http:/ / www. computermuseum. li/ Testpage/ Z3-Computer-1939. htm[136] http:/ / books. google. com/ books?id=x1YESXanrgQC& printsec=frontcover[137] http:/ / www. oldcomputers. net/[138] http:/ / museum. ipsj. or. jp/ en/ computer/ index. html[139] http:/ / www. xnumber. com/ xnumber/ japanese_calculators. htm[140] http:/ / www. trailing-edge. com/ ~bobbemer/ HISTORY. HTM[141] http:/ / spectrum. ieee. org/ 25chips[142] http:/ / www. techbites. com/ 200911151052/ myblog/ articles/ z0031-the-history-of-computers-timeline. html

History of general purpose CPUs 23
History of general purpose CPUsThe history of general purpose CPUs is a continuation of the earlier history of computing hardware.
1950s: early designsEach of the computer designs of the early 1950s was a unique design; there were no upward-compatible machines orcomputer architectures with multiple, differing implementations. Programs written for one machine would not run onanother kind, even other kinds from the same company. This was not a major drawback at the time because therewas not a large body of software developed to run on computers, so starting programming from scratch was not seenas a large barrier.The design freedom of the time was very important, for designers were very constrained by the cost of electronics,yet just beginning to explore how a computer could best be organized. Some of the basic features introduced duringthis period included index registers (on the Ferranti Mark 1), a return-address saving instruction (UNIVAC I),immediate operands (IBM 704), and the detection of invalid operations (IBM 650)By the end of the 1950s commercial builders had developed factory-constructed, truck-deliverable computers. Themost widely installed computer was the IBM 650, which used drum memory onto which programs were loadedusing either paper tape or punched cards. Some very high-end machines also included core memory which providedhigher speeds. Hard disks were also starting to become popular.Computers are automatic abaci. The type of number system affects the way they work. In the early 1950s mostcomputers were built for specific numerical processing tasks, and many machines used decimal numbers as theirbasic number system – that is, the mathematical functions of the machines worked in base-10 instead of base-2 as iscommon today. These were not merely binary coded decimal. Most machines actually had ten vacuum tubes perdigit in each register. Some early Soviet computer designers implemented systems based on ternary logic; that is, abit could have three states: +1, 0, or -1, corresponding to positive, zero, or negative voltage.An early project for the U.S. Air Force, BINAC attempted to make a lightweight, simple computer by using binaryarithmetic. It deeply impressed the industry.As late as 1970, major computer languages were unable to standardize their numeric behavior because decimalcomputers had groups of users too large to alienate.Even when designers used a binary system, they still had many odd ideas. Some used sign-magnitude arithmetic (-1= 10001), or ones' complement (-1 = 11110), rather than modern two's complement arithmetic (-1 = 11111). Mostcomputers used six-bit character sets, because they adequately encoded Hollerith cards. It was a major revelation todesigners of this period to realize that the data word should be a multiple of the character size. They began to designcomputers with 12, 24 and 36 bit data words (e.g. see the TX-2).In this era, Grosch's law dominated computer design: Computer cost increased as the square of its speed.
1960s: the computer revolution and CISCOne major problem with early computers was that a program for one would not work on others. Computercompanies found that their customers had little reason to remain loyal to a particular brand, as the next computerthey purchased would be incompatible anyway. At that point, price and performance were usually the only concerns.In 1962, IBM tried a new approach to designing computers. The plan was to make an entire family of computers thatcould all run the same software, but with different performances, and at different prices. As users' requirements grewthey could move up to larger computers, and still keep all of their investment in programs, data and storage media.In order to do this they designed a single reference computer called the System/360 (or S/360). The System/360 was a virtual computer, a reference instruction set and capabilities that all machines in the family would support. In order

History of general purpose CPUs 24
to provide different classes of machines, each computer in the family would use more or less hardware emulation,and more or less microprogram emulation, to create a machine capable of running the entire System/360 instructionset.For instance a low-end machine could include a very simple processor for low cost. However this would require theuse of a larger microcode emulator to provide the rest of the instruction set, which would slow it down. A high-endmachine would use a much more complex processor that could directly process more of the System/360 design, thusrunning a much simpler and faster emulator.IBM chose to make the reference instruction set quite complex, and very capable. This was a conscious choice. Eventhough the computer was complex, its "control store" containing the microprogram would stay relatively small, andcould be made with very fast memory. Another important effect was that a single instruction could describe quite acomplex sequence of operations. Thus the computers would generally have to fetch fewer instructions from the mainmemory, which could be made slower, smaller and less expensive for a given combination of speed and price.As the S/360 was to be a successor to both scientific machines like the 7090 and data processing machines like the1401, it needed a design that could reasonably support all forms of processing. Hence the instruction set wasdesigned to manipulate not just simple binary numbers, but text, scientific floating-point (similar to the numbersused in a calculator), and the binary coded decimal arithmetic needed by accounting systems.Almost all following computers included these innovations in some form. This basic set of features is now called a"complex instruction set computer," or CISC (pronounced "sisk"), a term not invented until many years later.In many CISCs, an instruction could access either registers or memory, usually in several different ways. This madethe CISCs easier to program, because a programmer could remember just thirty to a hundred instructions, and a setof three to ten addressing modes rather than thousands of distinct instructions. This was called an "orthogonalinstruction set." The PDP-11 and Motorola 68000 architecture are examples of nearly orthogonal instruction sets.There was also the BUNCH (Burroughs, UNIVAC, NCR, Control Data Corporation, and Honeywell) that competedagainst IBM at this time though IBM dominated the era with S/360.The Burroughs Corporation (which later merged with Sperry/Univac to become Unisys) offered an alternative toS/360 with their B5000 series machines. In 1961, the B5000 had virtual memory, symmetric multiprocessing, amulti-programming operating system (Master Control Program or MCP), written in ALGOL 60, and the industry'sfirst recursive-descent compilers as early as 1963.
1970s: Large Scale IntegrationIn the 1960s, the Apollo guidance computer and Minuteman missile made the integrated circuit economical andpractical.Around 1971, the first calculator and clock chips began to show that very small computers might be possible. Thefirst microprocessor was the Intel 4004, designed in 1971 for a calculator company (Busicom), and produced byIntel. In 1972, Intel introduced a microprocessor having a different architecture: the 8008. The 8008 is the directancestor of the current Intel Core 2, even now maintaining code compatibility (every instruction of the 8008'sinstruction set has a direct equivalent in the Intel Core 2's much larger instruction set, although the opcode values aredifferent).By the mid-1970s, the use of integrated circuits in computers was commonplace. The whole decade consists ofupheavals caused by the shrinking price of transistors.It became possible to put an entire CPU on a single printed circuit board. The result was that minicomputers, usuallywith 16-bit words, and 4k to 64K of memory, came to be commonplace.CISCs were believed to be the most powerful types of computers, because their microcode was small and could bestored in very high-speed memory. The CISC architecture also addressed the "semantic gap" as it was perceived atthe time. This was a defined distance between the machine language, and the higher level language people used to

History of general purpose CPUs 25
program a machine. It was felt that compilers could do a better job with a richer instruction set.Custom CISCs were commonly constructed using "bit slice" computer logic such as the AMD 2900 chips, withcustom microcode. A bit slice component is a piece of an ALU, register file or microsequencer. Most bit-sliceintegrated circuits were 4-bits wide.By the early 1970s, the PDP-11 was developed, arguably the most advanced small computer of its day. Almostimmediately, wider-word CISCs were introduced, the 32-bit VAX and 36-bit PDP-10.Also, to control a cruise missile, Intel developed a more-capable version of its 8008 microprocessor, the 8080.IBM continued to make large, fast computers. However the definition of large and fast now meant more than amegabyte of RAM, clock speeds near one megahertz [1][2], and tens of megabytes of disk drives.IBM's System 370 was a version of the 360 tweaked to run virtual computing environments. The virtual computerwas developed in order to reduce the possibility of an unrecoverable software failure.The Burroughs B5000/B6000/B7000 series reached its largest market share. It was a stack computer whose OS wasprogrammed in a dialect of Algol.All these different developments competed for market share.
Early 1980s: the lessons of RISCIn the early 1980s, researchers at UC Berkeley and IBM both discovered that most computer language compilers andinterpreters used only a small subset of the instructions of a CISC. Much of the power of the CPU was simply beingignored in real-world use. They realized that by making the computer simpler and less orthogonal, they could makeit faster and less expensive at the same time.At the same time, CPU calculation became faster in relation to the time for necessary memory accesses. Designersalso experimented with using large sets of internal registers. The idea was to cache intermediate results in theregisters under the control of the compiler. This also reduced the number of addressing modes and orthogonality.The computer designs based on this theory were called Reduced Instruction Set Computers, or RISC. RISCsgenerally had larger numbers of registers, accessed by simpler instructions, with a few instructions specifically toload and store data to memory. The result was a very simple core CPU running at very high speed, supporting theexact sorts of operations the compilers were using anyway.A common variation on the RISC design employs the Harvard architecture, as opposed to the Von Neumann orStored Program architecture common to most other designs. In a Harvard Architecture machine, the program anddata occupy separate memory devices and can be accessed simultaneously. In Von Neumann machines the data andprograms are mixed in a single memory device, requiring sequential accessing which produces the so-called "VonNeumann bottleneck."One downside to the RISC design has been that the programs that run on them tend to be larger. This is becausecompilers have to generate longer sequences of the simpler instructions to accomplish the same results. Since theseinstructions need to be loaded from memory anyway, the larger code size offsets some of the RISC design's fastmemory handling.Recently, engineers have found ways to compress the reduced instruction sets so they fit in even smaller memorysystems than CISCs. Examples of such compression schemes include the ARM's "Thumb" instruction set. Inapplications that do not need to run older binary software, compressed RISCs are coming to dominate sales.Another approach to RISCs was the MISC, "niladic" or "zero-operand" instruction set. This approach realized that the majority of space in an instruction was to identify the operands of the instruction. These machines placed the operands on a push-down (last-in, first out) stack. The instruction set was supplemented with a few instructions to fetch and store memory. Most used simple caching to provide extremely fast RISC machines, with very compact code. Another benefit was that the interrupt latencies were extremely small, smaller than most CISC machines (a rare

History of general purpose CPUs 26
trait in RISC machines). The Burroughs large systems architecture uses this approach. The B5000 was designed in1961, long before the term "RISC" was invented. The architecture puts six 8-bit instructions in a 48-bit word, andwas a precursor to VLIW design (see below: 1990 to Today).The Burroughs architecture was one of the inspirations for Charles H. Moore's Forth programming language, whichin turn inspired his later MISC chip designs. For example, his f20 cores had 31 5-bit instructions, which were fit fourto a 20-bit word.RISC chips now dominate the market for 32-bit embedded systems. Smaller RISC chips are even becoming commonin the cost-sensitive 8-bit embedded-system market. The main market for RISC CPUs has been systems that requirelow power or small size.Even some CISC processors (based on architectures that were created before RISC became dominant) translateinstructions internally into a RISC-like instruction set. These CISC chips include newer x86 and VAX models.These numbers may surprise many, because the "market" is perceived to be desktop computers. With Intel x86designs dominating the vast majority of all desktop sales, RISC is found in some of the Apple, Sun and SGI desktopcomputer lines. However, desktop computers are only a tiny fraction of the computers now sold. Most people inindustrialised countries own more computers in embedded systems in their car and house than on their desks.
Mid-to-late 1980s: exploiting instruction level parallelismIn the mid-to-late 1980s, designers began using a technique known as "instruction pipelining", in which theprocessor works on multiple instructions in different stages of completion. For example, the processor may beretrieving the operands for the next instruction while calculating the result of the current one. Modern CPUs may useover a dozen such stages. MISC processors achieve single-cycle execution of instructions without the need forpipelining.A similar idea, introduced only a few years later, was to execute multiple instructions in parallel on separatearithmetic logic units (ALUs). Instead of operating on only one instruction at a time, the CPU will look for severalsimilar instructions that are not dependent on each other, and execute them in parallel. This approach is calledsuperscalar processor design.Such techniques are limited by the degree of instruction level parallelism (ILP), the number of non-dependentinstructions in the program code. Some programs are able to run very well on superscalar processors due to theirinherent high ILP, notably graphics. However more general problems do not have such high ILP, thus making theachievable speedups due to these techniques to be lower.Branching is one major culprit. For example, the program might add two numbers and branch to a different codesegment if the number is bigger than a third number. In this case even if the branch operation is sent to the secondALU for processing, it still must wait for the results from the addition. It thus runs no faster than if there were onlyone ALU. The most common solution for this type of problem is to use a type of branch prediction.To further the efficiency of multiple functional units which are available in superscalar designs, operand registerdependencies was found to be another limiting factor. To minimize these dependencies, out-of-order execution ofinstructions was introduced. In such a scheme, the instruction results which complete out-of-order must bere-ordered in program order by the processor for the program to be restartable after an exception. Out-of-Orderexecution was the main advancement of the computer industry during the 1990s. A similar concept is speculativeexecution, where instructions from one direction of a branch (the predicted direction) are executed before the branchdirection is known. When the branch direction is known, the predicted direction and the actual direction arecompared. If the predicted direction was correct, the speculatively-executed instructions and their results are kept; ifit was incorrect, these instructions and their results are thrown out. Speculative execution coupled with an accuratebranch predictor gives a large performance gain.

History of general purpose CPUs 27
These advances, which were originally developed from research for RISC-style designs, allow modern CISCprocessors to execute twelve or more instructions per clock cycle, when traditional CISC designs could take twelveor more cycles to execute just one instruction.The resulting instruction scheduling logic of these processors is large, complex and difficult to verify. Furthermore,the higher complexity requires more transistors, increasing power consumption and heat. In this respect RISC issuperior because the instructions are simpler, have less interdependence and make superscalar implementationseasier. However, as Intel has demonstrated, the concepts can be applied to a CISC design, given enough time andmoney.
Historical note: Some of these techniques (e.g. pipelining) were originally developed in the late 1950s by IBMon their Stretch mainframe computer.
1990 to today: looking forward
VLIW and EPICThe instruction scheduling logic that makes a superscalar processor is just boolean logic. In the early 1990s, asignificant innovation was to realize that the coordination of a multiple-ALU computer could be moved into thecompiler, the software that translates a programmer's instructions into machine-level instructions.This type of computer is called a very long instruction word (VLIW) computer.Statically scheduling the instructions in the compiler (as opposed to letting the processor do the schedulingdynamically) can reduce CPU complexity. This can improve performance, reduce heat, and reduce cost.Unfortunately, the compiler lacks accurate knowledge of runtime scheduling issues. Merely changing the CPU corefrequency multiplier will have an effect on scheduling. Actual operation of the program, as determined by input data,will have major effects on scheduling. To overcome these severe problems a VLIW system may be enhanced byadding the normal dynamic scheduling, losing some of the VLIW advantages.Static scheduling in the compiler also assumes that dynamically generated code will be uncommon. Prior to thecreation of Java, this was in fact true. It was reasonable to assume that slow compiles would only affect softwaredevelopers. Now, with JIT virtual machines for Java and .NET, slow code generation affects users as well.There were several unsuccessful attempts to commercialize VLIW. The basic problem is that a VLIW computer doesnot scale to different price and performance points, as a dynamically scheduled computer can. Another issue is thatcompiler design for VLIW computers is extremely difficult, and the current crop of compilers (as of 2005) don'talways produce optimal code for these platforms.Also, VLIW computers optimise for throughput, not low latency, so they were not attractive to the engineersdesigning controllers and other computers embedded in machinery. The embedded systems markets had oftenpioneered other computer improvements by providing a large market that did not care about compatibility with oldersoftware.In January 2000, a company called Transmeta took the interesting step of placing a compiler in the centralprocessing unit, and making the compiler translate from a reference byte code (in their case, x86 instructions) to aninternal VLIW instruction set. This approach combines the hardware simplicity, low power and speed of VLIWRISC with the compact main memory system and software reverse-compatibility provided by popular CISC.Intel's Itanium chip is based on what they call an Explicitly Parallel Instruction Computing (EPIC) design. Thisdesign supposedly provides the VLIW advantage of increased instruction throughput. However, it avoids some of theissues of scaling and complexity, by explicitly providing in each "bundle" of instructions information concerningtheir dependencies. This information is calculated by the compiler, as it would be in a VLIW design. The earlyversions are also backward-compatible with current x86 software by means of an on-chip emulation mode. Integerperformance was disappointing and despite improvements, sales in volume markets continue to be low.

History of general purpose CPUs 28
Multi-threadingCurrent designs work best when the computer is running only a single program, however nearly all modern operatingsystems allow the user to run multiple programs at the same time. For the CPU to change over and do work onanother program requires expensive context switching. In contrast, multi-threaded CPUs can handle instructionsfrom multiple programs at once.To do this, such CPUs include several sets of registers. When a context switch occurs, the contents of the "workingregisters" are simply copied into one of a set of registers for this purpose.Such designs often include thousands of registers instead of hundreds as in a typical design. On the downside,registers tend to be somewhat expensive in chip space needed to implement them. This chip space might otherwisebe used for some other purpose.
Multi-coreMulti-core CPUs are typically multiple CPU cores on the same die, connected to each other via a shared L2 or L3cache, an on-die bus, or an on-die crossbar switch. All the CPU cores on the die share interconnect components withwhich to interface to other processors and the rest of the system. These components may include a front side businterface, a memory controller to interface with DRAM, a cache coherent link to other processors, and anon-coherent link to the southbridge and I/O devices. The terms multi-core and MPU (which stands forMicro-Processor Unit) have come into general usage for a single die that contains multiple CPU cores.
Intelligent RAM
One way to work around the von Neumann bottleneck is to mix a processor and DRAM all on one chip.• The Berkeley Intelligent RAM (IRAM) project [3]• eDRAM• computational RAM
Reconfigurable logicAnother track of development is to combine reconfigurable logic with a general-purpose CPU. In this scheme, aspecial computer language compiles fast-running subroutines into a bit-mask to configure the logic. Slower, orless-critical parts of the program can be run by sharing their time on the CPU. This process has the capability tocreate devices such as software radios, by using digital signal processing to perform functions usually performed byanalog electronics.
Open source processorsAs the lines between hardware and software increasingly blur due to progress in design methodology and availabilityof chips such as FPGAs and cheaper production processes, even open source hardware has begun to appear.Loosely-knit communities like OpenCores have recently announced completely open CPU architectures such as theOpenRISC which can be readily implemented on FPGAs or in custom produced chips, by anyone, without payinglicense fees, and even established processor manufacturers like Sun Microsystems have released processor designs(e.g. OpenSPARC) under open-source licenses.

History of general purpose CPUs 29
Asynchronous CPUsYet another possibility is the "clockless CPU" (asynchronous CPU). Unlike conventional processors, clocklessprocessors have no central clock to coordinate the progress of data through the pipeline. Instead, stages of the CPUare coordinated using logic devices called "pipe line controls" or "FIFO sequencers." Basically, the pipelinecontroller clocks the next stage of logic when the existing stage is complete. In this way, a central clock isunnecessary.It might be easier to implement high performance devices in asynchronous logic as opposed to clocked logic:• components can run at different speeds in the clockless CPU. In a clocked CPU, no component can run faster than
the clock rate.• In a clocked CPU, the clock can go no faster than the worst-case performance of the slowest stage. In a clockless
CPU, when a stage finishes faster than normal, the next stage can immediately take the results rather than waitingfor the next clock tick. A stage might finish faster than normal because of the particular data inputs(multiplication can be very fast if it is multiplying by 0 or 1), or because it is running at a higher voltage or lowertemperature than normal.
Asynchronous logic proponents believe these capabilities would have these benefits:• lower power dissipation for a given performance level• highest possible execution speedsThe biggest disadvantage of the clockless CPU is that most CPU design tools assume a clocked CPU (a synchronouscircuit), so making a clockless CPU (designing an asynchronous circuit) involves modifying the design tools tohandle clockless logic and doing extra testing to ensure the design avoids metastable problems.Even so, several asynchronous CPUs have been built, including• the ORDVAC and the identical ILLIAC I (1951)• the ILLIAC II (1962), the fastest computer in the world at the time• The Caltech Asynchronous Microprocessor, the world-first asynchronous microprocessor (1988)• the ARM-implementing AMULET (1993 and 2000)• the asynchronous implementation of MIPS R3000, dubbed MiniMIPS [4] (1998)• the SEAforth multi-core processor from Charles H. Moore [5]
Optical communicationOne interesting possibility would be to eliminate the front side bus. Modern vertical laser diodes enable this change.In theory, an optical computer's components could directly connect through a holographic or phased open-airswitching system. This would provide a large increase in effective speed and design flexibility, and a large reductionin cost. Since a computer's connectors are also its most likely failure point, a busless system might be more reliable,as well.In addition, current (2010) modern processors use 64- or 128-bit logic. Wavelength superposition could allow fordata lanes and logic many orders of magnitude higher, without additional space or copper wires.
Optical processorsAnother farther-term possibility is to use light instead of electricity for the digital logic itself. In theory, this couldrun about 30% faster and use less power, as well as permit a direct interface with quantum computational devices.The chief problem with this approach is that for the foreseeable future, electronic devices are faster, smaller (i.e.cheaper) and more reliable. An important theoretical problem is that electronic computational elements are alreadysmaller than some wavelengths of light, and therefore even wave-guide based optical logic may be uneconomiccompared to electronic logic. The majority of development effort, as of 2006 is focused on electronic circuitry. Seealso optical computing.

History of general purpose CPUs 30
Time of events• 1971. Intel released the Intel 4004, the worlds first commercially available microprocessor.• 1977. First VAX sold, a VAX-11/780.• 1978. Intel introduces the Intel 8086 and Intel 8088, the first x86 chips.• 1981. Stanford MIPS introduced, one of the first RISC designs.• 1982. Intel introduces the Intel 80286, which was the first Intel processor that could run all the software written
for its predecessors, the 8086 and 8088.• 1985. Intel introduces the Intel 80386, which adds a 32-bit instruction set to the x86 microarchitecture.• 1993. Intel launches the original Pentium microprocessor, the first processor with a x86 superscalar
microacrhitecture.• 2000. AMD announced x86-64 extension to the x86 microarchitecture.• 2000. Analog devices introduces the Blackfin architecture.• 2002. Intel releases a Pentium 4 with Hyper-Threading, the first modern desktop processor to implement
simultaneous multithreading (SMT).• 2005. AMD announced Athlon 64 X2, the first x86 dual-core processor.• 2008. About ten billion CPUs were manufactured in 2008.[6]
External links• Great moments in microprocessor history by W. Warner, 2004 [7]
• Great Microprocessors of the Past and Present (V 13.4.0) by: John Bayko, 2003 [8]
References[1] http:/ / www. hometoys. com/ mentors/ caswell/ sep00/ trends01. htm[2] http:/ / research. microsoft. com/ users/ GBell/ Computer_Structures_Principles_and_Examples/ csp0727. htm[3] http:/ / iram. cs. berkeley. edu/[4] http:/ / www. async. caltech. edu/ mips. html[5] SEAforth Overview (http:/ / www. intellasys. net/ index. php?option=com_content& task=view& id=21& Itemid=41) "... asynchronous
circuit design throughout the chip. There is no central clock with billions of dumb nodes dissipating useless power. ... the processor cores areinternally asynchronous themselves."
[6] "Real men program in C" (http:/ / www. embedded. com/ columns/ barrcode/ 218600142?pgno=2) by Michael Barr 2009[7] http:/ / www-128. ibm. com/ developerworks/ library/ pa-microhist. html[8] http:/ / jbayko. sasktelwebsite. net/ cpu. html

Computer programming 31
Computer programmingComputer programming (often shortened to programming or coding) is the process of designing, writing, testing,debugging / troubleshooting, and maintaining the source code of computer programs. This source code is written in aprogramming language. The code may be a modification of an existing source or something completely new. Thepurpose of programming is to create a program that exhibits a certain desired behaviour (customization). The processof writing source code often requires expertise in many different subjects, including knowledge of the applicationdomain, specialized algorithms and formal logic.
OverviewWithin software engineering, programming (the implementation) is regarded as one phase in a software developmentprocess.There is an ongoing debate on the extent to which the writing of programs is an art, a craft or an engineeringdiscipline.[1] In general, good programming is considered to be the measured application of all three, with the goal ofproducing an efficient and evolvable software solution (the criteria for "efficient" and "evolvable" varyconsiderably). The discipline differs from many other technical professions in that programmers, in general, do notneed to be licensed or pass any standardized (or governmentally regulated) certification tests in order to callthemselves "programmers" or even "software engineers." However, representing oneself as a "Professional SoftwareEngineer" without a license from an accredited institution is illegal in many parts of the world. However, because thediscipline covers many areas, which may or may not include critical applications, it is debatable whether licensing isrequired for the profession as a whole. In most cases, the discipline is self-governed by the entities which require theprogramming, and sometimes very strict environments are defined (e.g. United States Air Force use of AdaCore andsecurity clearance).Another ongoing debate is the extent to which the programming language used in writing computer programs affectsthe form that the final program takes. This debate is analogous to that surrounding the Sapir-Whorf hypothesis [2] inlinguistics, that postulates that a particular language's nature influences the habitual thought of its speakers. Differentlanguage patterns yield different patterns of thought. This idea challenges the possibility of representing the worldperfectly with language, because it acknowledges that the mechanisms of any language condition the thoughts of itsspeaker community.Said another way, programming is the craft of transforming requirements into something that a computer canexecute.
History of programming
Wired plug board for an IBM 402 AccountingMachine.
The concept of devices that operate following a pre-defined set ofinstructions traces back to Greek Mythology, notably Hephaestus, theGreek Blacksmith God, and his mechanical slaves.[3] The Antikytheramechanism from ancient Greece was a calculator utilizing gears ofvarious sizes and configuration to determine its operation.[4] Al-Jazaribuilt programmable Automata in 1206. One system employed in thesedevices was the use of pegs and cams placed into a wooden drum atspecific locations. which would sequentially trigger levers that in turnoperated percussion instruments. The output of this device was a smalldrummer playing various rhythms and drum patterns.[5] [6] The

Computer programming 32
Jacquard Loom, which Joseph Marie Jacquard developed in 1801, uses a series of pasteboard cards with holespunched in them. The hole pattern represented the pattern that the loom had to follow in weaving cloth. The loomcould produce entirely different weaves using different sets of cards. Charles Babbage adopted the use of punchedcards around 1830 to control his Analytical Engine. The synthesis of numerical calculation, predetermined operationand output, along with a way to organize and input instructions in a manner relatively easy for humans to conceiveand produce, led to the modern development of computer programming. Development of computer programmingaccelerated through the Industrial Revolution.In the late 1880s, Herman Hollerith invented the recording of data on a medium that could then be read by amachine. Prior uses of machine readable media, above, had been for control, not data. "After some initial trials withpaper tape, he settled on punched cards..."[7] To process these punched cards, first known as "Hollerith cards" heinvented the tabulator, and the keypunch machines. These three inventions were the foundation of the moderninformation processing industry. In 1896 he founded the Tabulating Machine Company (which later became the coreof IBM). The addition of a control panel (plugboard) to his 1906 Type I Tabulator allowed it to do different jobswithout having to be physically rebuilt. By the late 1940s, there were a variety of plug-board programmablemachines, called unit record equipment, to perform data-processing tasks (card reading). Early computerprogrammers used plug-boards for the variety of complex calculations requested of the newly invented machines.
Data and instructions could be stored on externalpunched cards, which were kept in order and
arranged in program decks.
The invention of the von Neumann architecture allowed computerprograms to be stored in computer memory. Early programs had to bepainstakingly crafted using the instructions (elementary operations) ofthe particular machine, often in binary notation. Every model ofcomputer would likely use different instructions (machine language) todo the same task. Later, assembly languages were developed that letthe programmer specify each instruction in a text format, enteringabbreviations for each operation code instead of a number andspecifying addresses in symbolic form (e.g., ADD X, TOTAL).Entering a program in assembly language is usually more convenient,faster, and less prone to human error than using machine language, butbecause an assembly language is little more than a different notationfor a machine language, any two machines with different instructionsets also have different assembly languages.
In 1954, FORTRAN was invented; it was the first high levelprogramming language to have a functional implementation, as
opposed to just a design on paper.[8] [9] (A high-level language is, in very general terms, any programming languagethat allows the programmer to write programs in terms that are more abstract than assembly language instructions,i.e. at a level of abstraction "higher" than that of an assembly language.) It allowed programmers to specifycalculations by entering a formula directly (e.g. Y = X*2 + 5*X + 9). The program text, or source, is converted intomachine instructions using a special program called a compiler, which translates the FORTRAN program intomachine language. In fact, the name FORTRAN stands for "Formula Translation". Many other languages weredeveloped, including some for commercial programming, such as COBOL. Programs were mostly still entered usingpunched cards or paper tape. (See computer programming in the punch card era). By the late 1960s, data storagedevices and computer terminals became inexpensive enough that programs could be created by typing directly intothe computers. Text editors were developed that allowed changes and corrections to be made much more easily thanwith punched cards. (Usually, an error in punching a card meant that the card had to be discarded and an new onepunched to replace it.)
As time has progressed, computers have made giant leaps in the area of processing power. This has brought about newer programming languages that are more abstracted from the underlying hardware. Although these high-level

Computer programming 33
languages usually incur greater overhead, the increase in speed of modern computers has made the use of theselanguages much more practical than in the past. These increasingly abstracted languages typically are easier to learnand allow the programmer to develop applications much more efficiently and with less source code. However,high-level languages are still impractical for a few programs, such as those where low-level hardware control isnecessary or where maximum processing speed is vital.Throughout the second half of the twentieth century, programming was an attractive career in most developedcountries. Some forms of programming have been increasingly subject to offshore outsourcing (importing softwareand services from other countries, usually at a lower wage), making programming career decisions in developedcountries more complicated, while increasing economic opportunities in less developed areas. It is unclear how farthis trend will continue and how deeply it will impact programmer wages and opportunities.
Modern programming
Quality requirementsWhatever the approach to software development may be, the final program must satisfy some fundamentalproperties. The following properties are among the most relevant:• Efficiency/performance: the amount of system resources a program consumes (processor time, memory space,
slow devices such as disks, network bandwidth and to some extent even user interaction): the less, the better. Thisalso includes correct disposal of some resources, such as cleaning up temporary files and lack of memory leaks.
• Reliability: how often the results of a program are correct. This depends on conceptual correctness of algorithms,and minimization of programming mistakes, such as mistakes in resource management (e.g., buffer overflows andrace conditions) and logic errors (such as division by zero or off-by-one errors).
• Robustness: how well a program anticipates problems not due to programmer error. This includes situations suchas incorrect, inappropriate or corrupt data, unavailability of needed resources such as memory, operating systemservices and network connections, and user error.
• Usability: the ergonomics of a program: the ease with which a person can use the program for its intendedpurpose, or in some cases even unanticipated purposes. Such issues can make or break its success even regardlessof other issues. This involves a wide range of textual, graphical and sometimes hardware elements that improvethe clarity, intuitiveness, cohesiveness and completeness of a program's user interface.
• Portability: the range of computer hardware and operating system platforms on which the source code of aprogram can be compiled/interpreted and run. This depends on differences in the programming facilities providedby the different platforms, including hardware and operating system resources, expected behaviour of thehardware and operating system, and availability of platform specific compilers (and sometimes libraries) for thelanguage of the source code.
• Maintainability: the ease with which a program can be modified by its present or future developers in order tomake improvements or customizations, fix bugs and security holes, or adapt it to new environments. Goodpractices during initial development make the difference in this regard. This quality may not be directly apparentto the end user but it can significantly affect the fate of a program over the long term.
Algorithmic complexityThe academic field and the engineering practice of computer programming are both largely concerned withdiscovering and implementing the most efficient algorithms for a given class of problem. For this purpose,algorithms are classified into orders using so-called Big O notation, O(n), which expresses resource use, such asexecution time or memory consumption, in terms of the size of an input. Expert programmers are familiar with avariety of well-established algorithms and their respective complexities and use this knowledge to choose algorithmsthat are best suited to the circumstances.

Computer programming 34
MethodologiesThe first step in most formal software development projects is requirements analysis, followed by testing todetermine value modeling, implementation, and failure elimination (debugging). There exist a lot of differingapproaches for each of those tasks. One approach popular for requirements analysis is Use Case analysis.Popular modeling techniques include Object-Oriented Analysis and Design (OOAD) and Model-Driven Architecture(MDA). The Unified Modeling Language (UML) is a notation used for both the OOAD and MDA.A similar technique used for database design is Entity-Relationship Modeling (ER Modeling).Implementation techniques include imperative languages (object-oriented or procedural), functional languages, andlogic languages.
Measuring language usageIt is very difficult to determine what are the most popular of modern programming languages. Some languages arevery popular for particular kinds of applications (e.g., COBOL is still strong in the corporate data center, often onlarge mainframes, FORTRAN in engineering applications, scripting languages in web development, and C inembedded applications), while some languages are regularly used to write many different kinds of applications.Methods of measuring programming language popularity include: counting the number of job advertisements thatmention the language,[10] the number of books teaching the language that are sold (this overestimates the importanceof newer languages), and estimates of the number of existing lines of code written in the language (thisunderestimates the number of users of business languages such as COBOL).
Debugging
A bug, which was debugged in 1947.
Debugging is a very important task in the softwaredevelopment process, because an incorrect program canhave significant consequences for its users. Somelanguages are more prone to some kinds of faultsbecause their specification does not require compilersto perform as much checking as other languages. Useof a static analysis tool can help detect some possibleproblems.
Debugging is often done with IDEs like Visual Studio,NetBeans, and Eclipse. Standalone debuggers like gdbare also used, and these often provide less of a visualenvironment, usually using a command line.
Programming languages
Different programming languages support different styles of programming (called programming paradigms). Thechoice of language used is subject to many considerations, such as company policy, suitability to task, availability ofthird-party packages, or individual preference. Ideally, the programming language best suited for the task at handwill be selected. Trade-offs from this ideal involve finding enough programmers who know the language to build ateam, the availability of compilers for that language, and the efficiency with which programs written in a givenlanguage execute.
Allen Downey, in his book How To Think Like A Computer Scientist, writes:The details look different in different languages, but a few basic instructions appear in just about everylanguage:

Computer programming 35
• input: Get data from the keyboard, a file, or some other device.• output: Display data on the screen or send data to a file or other device.• arithmetic: Perform basic arithmetical operations like addition and multiplication.• conditional execution: Check for certain conditions and execute the appropriate sequence of statements.• repetition: Perform some action repeatedly, usually with some variation.
Many computer languages provide a mechanism to call functions provided by libraries. Provided the functions in alibrary follow the appropriate run time conventions (e.g., method of passing arguments), then these functions may bewritten in any other language.
ProgrammersComputer programmers are those who write computer software. Their jobs usually involve:• Coding• Compilation• Documentation• Integration• Maintenance• Requirements analysis• Software architecture• Software testing• Specification• Debugging
See also• ACCU• Association for Computing Machinery• Computer programming in the punch card era• Hello world program• List of basic computer programming topics• List of computer programming topics• Programming paradigms• Software engineering• The Art of Computer Programming
Further reading• Weinberg, Gerald M., The Psychology of Computer Programming, New York: Van Nostrand Reinhold, 1971
External links• Programming Wikia [11]
• How to Think Like a Computer Scientist [12] - by Jeffrey Elkner, Allen B. Downey and Chris Meyers
References[1] Paul Graham (2003). Hackers and Painters (http:/ / www. paulgraham. com/ hp. html). . Retrieved 2006-08-22.[2] Kenneth E. Iverson, the originator of the APL programming language, believed that the Sapir–Whorf hypothesis applied to computer
languages (without actually mentioning the hypothesis by name). His Turing award lecture, "Notation as a tool of thought", was devoted to this theme, arguing that more powerful notations aided thinking about computer algorithms. Iverson K.E.," Notation as a tool of thought (http:/

Computer programming 36
/ elliscave. com/ APL_J/ tool. pdf)", Communications of the ACM, 23: 444-465 (August 1980).[3] New World Encyclopedia Online Edition (http:/ / www. newworldencyclopedia. org/ entry/ Hephaestus) New World Encyclopedia[4] " Ancient Greek Computer's Inner Workings Deciphered (http:/ / news. nationalgeographic. com/ news/ 2006/ 11/ 061129-ancient-greece.
html)". National Geographic News. November 29, 2006.[5] A 13th Century Programmable Robot (http:/ / www. shef. ac. uk/ marcoms/ eview/ articles58/ robot. html), University of Sheffield[6] Fowler, Charles B. (October 1967). "The Museum of Music: A History of Mechanical Instruments" (http:/ / jstor. org/ stable/ 3391092).
Music Educators Journal (Music Educators Journal, Vol. 54, No. 2) 54 (2): 45–49. doi:10.2307/3391092.[7] "Columbia University Computing History - Herman Hollerith" (http:/ / www. columbia. edu/ acis/ history/ hollerith. html). Columbia.edu. .
Retrieved 2010-04-25.[8] 12:10 p.m. ET (2007-03-20). "Fortran creator John Backus dies - Tech and gadgets- msnbc.com" (http:/ / www. msnbc. msn. com/ id/
17704662/ ). MSNBC. . Retrieved 2010-04-25.[9] "CSC-302 99S : Class 02: A Brief History of Programming Languages" (http:/ / www. math. grin. edu/ ~rebelsky/ Courses/ CS302/ 99S/
Outlines/ outline. 02. html). Math.grin.edu. . Retrieved 2010-04-25.[10] Survey of Job advertisements mentioning a given language (http:/ / www. computerweekly. com/ Articles/ 2007/ 09/ 11/ 226631/
sslcomputer-weekly-it-salary-survey-finance-boom-drives-it-job. htm)>[11] http:/ / programming. wikia. com/ wiki/ Main_Page[12] http:/ / openbookproject. net/ thinkCSpy
Programming paradigmA programming paradigm is a fundamental style of computer programming. (Compare with a methodology, whichis a style of solving specific software engineering problems.) Paradigms differ in the concepts and abstractions usedto represent the elements of a program (such as objects, functions, variables, constraints, etc.) and the steps thatcompose a computation (assignment, evaluation, continuations, data flows, etc.).
OverviewProgramming model: Abstraction of a computer system, for example the "von Neumann model" used in traditionalsequential computers. For parallel computing, there are many possible models typically reflecting different waysprocessors can be interconnected. The most common are based on shared memory, distributed memory with messagepassing, or a hybrid of the two.A programming language can support multiple paradigms. For example programs written in C++ or Object Pascalcan be purely procedural, or purely object-oriented, or contain elements of both paradigms. Software designers andprogrammers decide how to use those paradigm elements.In object-oriented programming, programmers can think of a program as a collection of interacting objects, while infunctional programming a program can be thought of as a sequence of stateless function evaluations. Whenprogramming computers or systems with many processors, process-oriented programming allows programmers tothink about applications as sets of concurrent processes acting upon logically shared data structures.Just as different groups in software engineering advocate different methodologies, different programming languagesadvocate different programming paradigms. Some languages are designed to support one particular paradigm(Smalltalk supports object-oriented programming, Haskell supports functional programming), while otherprogramming languages support multiple paradigms (such as Object Pascal, C++, C#, Visual Basic, Common Lisp,Scheme, Perl, Python, Ruby, Oz and F Sharp).Many programming paradigms are as well known for what techniques they forbid as for what they enable. Forinstance, pure functional programming disallows the use of side-effects; structured programming disallows the use ofthe goto statement. Partly for this reason, new paradigms are often regarded as doctrinaire or overly rigid by thoseaccustomed to earlier styles.[1] Avoiding certain techniques can make it easier to prove theorems about a program'scorrectness—or simply to understand its behavior.

Programming paradigm 37
Multi-paradigm programming languageA multi-paradigm programming language is a programming language that supports more than one programmingparadigm. As Leda designer Timothy Budd holds it: The idea of a multiparadigm language is to provide aframework in which programmers can work in a variety of styles, freely intermixing constructs from differentparadigms. The design goal of such languages is to allow programmers to use the best tool for a job, admitting thatno one paradigm solves all problems in the easiest or most efficient way.An example is Oz, which has subsets that are a logic language (Oz descends from logic programming), a functionallanguage, an object-oriented language, a dataflow concurrent language, and more. Oz was designed over a ten-yearperiod to combine in a harmonious way concepts that are traditionally associated with different programmingparadigms.
HistoryInitially, computers were hard-wired and then later programmed using binary code that represented controlsequences fed to the computer CPU. This was difficult and error-prone. Programs written in binary are said to bewritten in machine code, which is a very low-level programming paradigm.To make programming easier, assembly languages were developed. These replaced machine code functions withmnemonics and memory addresses with symbolic labels. Assembly language programming is considered a low-levelparadigm although it is a 'second generation' paradigm. Even assembly languages of the 1960s actually supportedlibrary COPY and quite sophisticated conditional macro generation and pre-processing capabilities. They alsosupported modular programming features such as CALL (subroutines), external variables and common sections(globals), enabling significant code re-use and isolation from hardware specifics via use of logical operators asREAD/WRITE/GET/PUT. Assembly was, and still is, used for time critical systems and frequently in embeddedsystems.The next advance was the development of procedural languages. These third-generation languages (the firstdescribed as high-level languages) use vocabulary related to the problem being solved. For example,• COBOL (Common Business Oriented Language) - uses terms like file, move and copy.• FORTRAN (FORmula TRANslation) and• ALGOL (ALGOrithmic Language) - both using mathematical language terminology, were developed mainly for
commercial or scientific and engineering problems, although one of the ideas behind the development of ALGOLwas that it was an appropriate language to define algorithms.
• PL/1 (Programming language 1) - a hybrid commercial/scientific general purpose language supporting pointers• BASIC (Beginners All purpose Symbolic Instruction Code) - was developed to enable more people to write
programs.All these languages follow the procedural paradigm. That is, they describe, step by step, exactly the procedure thatshould, according to the particular programmer at least, be followed to solve a specific problem. The efficacy andefficiency of any such solution are both therefore entirely subjective and highly dependent on that programmer'sexperience, inventiveness and ability.Later, object-oriented languages (like Simula, Smalltalk, Eiffel and Java) were created. In these languages, data,and methods of manipulating the data, are kept as a single unit called an object. The only way that a user can accessthe data is via the object's 'methods' (subroutines). Because of this, the internal workings of an object may bechanged without affecting any code that uses the object. There is still some controversy by notable programmerssuch as Alexander Stepanov, Richard Stallman[2] and others, concerning the efficacy of the OOP paradigm versusthe procedural paradigm. The necessity of every object to have associative methods leads some skeptics to associateOOP with Software bloat. Polymorphism was developed as one attempt to resolve this dilemma.

Programming paradigm 38
Since object-oriented programming is considered a paradigm, not a language, it is possible to create even anobject-oriented assembler language. High Level Assembly (HLA) is an example of this that fully supports advanceddata types and object-oriented assembly language programming - despite its early origins. Thus, differingprogramming paradigms can be thought of as more like 'motivational memes' of their advocates - rather thannecessarily representing progress from one level to the next. Precise comparisons of the efficacy of competingparadigms are frequently made more difficult because of new and differing terminology applied to similar (but notidentical) entities and processes together with numerous implementation distinctions across languages.Within imperative programming, an alternative to the computer-centered hierarchy of structured programming isliterate programming, which structures programs instead as a human-centered web, as in a hypertext essay –documentation is integral to the program, and the program is structured following the logic of prose exposition,rather than compiler convenience.Independent of the imperative branch based on procedural languages, declarative programming paradigms weredeveloped. In these languages the computer is told what the problem is, not how to solve the problem - the programis structured as a collection of properties to find in the expected result, not as a procedure to follow. Given a databaseor a set of rules, the computer tries to find a solution matching all the desired properties. The archetypical example ofa declarative language is the fourth generation language SQL, as well as the family of functional languages and logicprogramming.Functional programming is a subset of declarative programming. Programs written using this paradigm usefunctions, blocks of code intended to behave like mathematical functions. Functional languages discourage changesin the value of variables through assignment, making a great deal of use of recursion instead.The logic programming paradigm views computation as automated reasoning over a corpus of knowledge. Factsabout the problem domain are expressed as logic formulas, and programs are executed by applying inference rulesover them until an answer to the problem is found, or the collection of formulas is proved inconsistent.
See also• Architecture description language• Comparison of programming paradigms• Domain-specific language• Mindset• Modeling language• Paradigm• Programming domain• Turing completeness
External links• Programming paradigms [3]
• Programming Languages [4]
• Classification of the principal programming paradigms [5]
References[1] Frank Rubin published a criticism of Dijkstra's letter in the March 1987 CACM where it appeared under the title 'GOTO Considered Harmful'
Considered Harmful. Frank Rubin (March 1987). "'GOTO Considered Harmful' Considered Harmful" (http:/ / www. ecn. purdue. edu/ParaMount/ papers/ rubin87goto. pdf) (PDF). Communications of the ACM 30 (3): 195–196. doi:10.1145/214748.315722. .
[2] "Mode inheritance, cloning, hooks & OOP (Google Groups Discussion)" (http:/ / groups. google. com/ group/ comp. emacs. xemacs/browse_thread/ thread/ d0af257a2837640c/ 37f251537fafbb03?lnk=st& q="Richard+ Stallman"+ oop& rnum=5& hl=en#37f251537fafbb03)..

Programming paradigm 39
[3] http:/ / www. infocheese. com/ programmingparadigms. html[4] http:/ / www. hypernews. org/ HyperNews/ get/ computing/ lang-list. html[5] http:/ / www. info. ucl. ac. be/ ~pvr/ paradigms. html
Systems Development Life Cycle
Model of the Systems Development Life Cycle with theMaintenance bubble highlighted.
The Systems Development Life Cycle (SDLC), orSoftware Development Life Cycle in systems engineering,information systems and software engineering, is theprocess of creating or altering systems, and the modelsand methodologies that people use to develop thesesystems. The concept generally refers to computer orinformation systems.
In software engineering the SDLC concept underpinsmany kinds of software development methodologies.These methodologies form the framework for planningand controlling the creation of an information system[1] :the software development process.
Overview
Systems Development Life Cycle (SDLC) is a processused by a systems analyst to develop an informationsystem, including requirements, validation, training, anduser (stakeholder) ownership. Any SDLC should result in a high quality system that meets or exceeds customerexpectations, reaches completion within time and cost estimates, works effectively and efficiently in the current andplanned Information Technology infrastructure, and is inexpensive to maintain and cost-effective to enhance.[2]
Computer systems are complex and often (especially with the recent rise of Service-Oriented Architecture) linkmultiple traditional systems potentially supplied by different software vendors. To manage this level of complexity, anumber of SDLC models have been created: "waterfall"; "fountain"; "spiral"; "build and fix"; "rapid prototyping";"incremental"; and "synchronize and stabilize".SDLC models can be described along a spectrum of agile to iterative to sequential. Agile methodologies, such as XPand Scrum, focus on light-weight processes which allow for rapid changes along the development cycle. Iterativemethodologies, such as Rational Unified Process and Dynamic Systems Development Method, focus on limitedproject scopes and expanding or improving products by multiple iterations. Sequential or big-design-upfront (BDUF)models, such as Waterfall, focus on complete and correct planning to guide large projects and risks to successful andpredictable results . Other models, such as Anamorphic Development, tend to focus on a form of development that isguided by project scope and adaptive iterations of feature development.In project management a project can be defined both with a project life cycle (PLC) and an SDLC, during whichslightly different activities occur. According to Taylor (2004) "the project life cycle encompasses all the activities ofthe project, while the systems development life cycle focuses on realizing the product requirements".[3]

Systems Development Life Cycle 40
HistoryThe systems development life cycle (SDLC) is a type of methodology used to describe the process for buildinginformation systems, intended to develop information systems in a very deliberate, structured and methodical way,reiterating each stage of the life cycle. The systems development life cycle, according to Elliott & Strachan &Radford (2004), "originated in the 1960s to develop large scale functional business systems in an age of large scalebusiness conglomerates. Information systems activities revolved around heavy data processing and numbercrunching routines".[4]
Several systems development frameworks have been partly based on SDLC, such as the Structured Systems Analysisand Design Method (SSADM) produced for the UK government Office of Government Commerce in the 1980s.Ever since, according to Elliott (2004), "the traditional life cycle approaches to systems development have beenincreasingly replaced with alternative approaches and frameworks, which attempted to overcome some of theinherent deficiencies of the traditional SDLC".[4]
Systems development phasesA Systems Development Life Cycle (SDLC) adheres to important phases that are essential for developers, such asplanning, analysis, design, and implementation, and are explained in the section below. Several SystemsDevelopment Life Cycle Models exist, the oldest of which — originally regarded as "the Systems Development LifeCycle" — is the waterfall model: a sequence of stages in which the output of each stage becomes the input for thenext. These stages generally follow the same basic steps, but many different waterfall methodologies give the stepsdifferent names and the number of steps seems to vary between four and seven. There is no one correct SystemsDevelopment Life Cycle model.
The SDLC can be divided into ten phases during which defined IT work products are created or modified. The tenth phase occurs when the system isdisposed of and the task performed is either eliminated or transferred to other systems. The tasks and work products for each phase are described in
subsequent chapters. Not every project will require that the phases be sequentially executed. However, the phases are interdependent. Depending uponthe size and complexity of the project, phases may be combined or may overlap.[5]

Systems Development Life Cycle 41
Requirements gathering and analysisThe goal of systems analysis is to determine where the problem is in an attempt to fix the system. This step involves"breaking down" the system in different pieces to analyze the situation, analyzing project goals, "breaking down"what needs to be created and attempting to engage users so that definite requirements can be defined (Decompositioncomputer science). Requirements Gathering sometimes requires individuals/teams from client as well as serviceprovider sides to get detailed and accurate requirements.
DesignIn systems, design functions and operations are described in detail, including screen layouts, business rules, processdiagrams and other documentation. The output of this stage will describe the new system as a collection of modulesor subsystems.The design stage takes as its initial input the requirements identified in the approved requirements document. Foreach requirement, a set of one or more design elements will be produced as a result of interviews, workshops, and/orprototype efforts. Design elements describe the desired software features in detail, and generally include functionalhierarchy diagrams, screen layout diagrams, tables of business rules, business process diagrams, pseudocode, and acomplete entity-relationship diagram with a full data dictionary. These design elements are intended to describe thesoftware in sufficient detail that skilled programmers may develop the software with minimal additional input.
Build or codingModular and subsystem programming code will be accomplished during this stage. Unit testing and module testingare done in this stage by the developers. This stage is intermingled with the next in that individual modules will needtesting before integration to the main project.
TestingThe code is tested at various levels in software testing. Unit, system and user acceptance testings are oftenperformed. This is a grey area as many different opinions exist as to what the stages of testing are and how much ifany iteration occurs. Iteration is not generally part of the waterfall model, but usually some occur at this stage.Below are the following types of testing:• Data set testing.• Unit testing• System testing• Integration testing• Black box testing• White box testing• Regression testing• Automation testing• User acceptance testing• Performance testing• Production

Systems Development Life Cycle 42
Operations and maintenanceThe deployment of the system includes changes and enhancements before the decommissioning or sunset of thesystem. Maintaining the system is an important aspect of SDLC. As key personnel change positions in theorganization, new changes will be implemented, which will require system updates.
Systems development life cycle topics
Management and control
SDLC Phases Related to Management Controls.[6]
The Systems Development Life Cycle(SDLC) phases serve as aprogrammatic guide to project activityand provide a flexible but consistentway to conduct projects to a depthmatching the scope of the project. Eachof the SDLC phase objectives aredescribed in this section with keydeliverables, a description ofrecommended tasks, and a summary ofrelated control objectives for effectivemanagement. It is critical for theproject manager to establish andmonitor control objectives during eachSDLC phase while executing projects.Control objectives help to provide aclear statement of the desired result or purpose and should be used throughout the entire SDLC process. Controlobjectives can be grouped into major categories (Domains), and relate to the SDLC phases as shown in the figure.[6]
To manage and control any SDLC initiative, each project will be required to establish some degree of a WorkBreakdown Structure (WBS) to capture and schedule the work necessary to complete the project. The WBS and allprogrammatic material should be kept in the “Project Description” section of the project notebook. The WBS formatis mostly left to the project manager to establish in a way that best describes the project work. There are some keyareas that must be defined in the WBS as part of the SDLC policy. The following diagram describes three key areasthat will be addressed in the WBS in a manner established by the project manager.[6]
Work breakdown structure organization

Systems Development Life Cycle 43
Work Breakdown Structure.[6]
The upper section of the WorkBreakdown Structure (WBS) shouldidentify the major phases andmilestones of the project in a summaryfashion. In addition, the upper sectionshould provide an overview of the fullscope and timeline of the project andwill be part of the initial projectdescription effort leading to projectapproval. The middle section of theWBS is based on the seven SystemsDevelopment Life Cycle (SDLC)phases as a guide for WBS task development. The WBS elements should consist of milestones and “tasks” asopposed to “activities” and have a definitive period (usually two weeks or more). Each task must have a measurableoutput (e.g. document, decision, or analysis). A WBS task may rely on one or more activities (e.g. softwareengineering, systems engineering) and may require close coordination with other tasks, either internal or external tothe project. Any part of the project needing support from contractors should have a Statement of work (SOW)written to include the appropriate tasks from the SDLC phases. The development of a SOW does not occur during aspecific phase of SDLC but is developed to include the work from the SDLC process that may be conducted byexternal resources such as contractors.[6]
Baselines in the SDLCBaselines are an important part of the Systems Development Life Cycle (SDLC). These baselines are establishedafter four of the five phases of the SDLC and are critical to the iterative nature of the model [7] . Each baseline isconsidered as a milestone in the SDLC.• Functional Baseline: established after the conceptual design phase.• Allocated Baseline: established after the preliminary design phase.• Product Baseline: established after the detail design and development phase.• Updated Product Baseline: established after the production construction phase.
Complementary to SDLCComplementary Software development methods to Systems Development Life Cycle (SDLC) are:• Software Prototyping• Joint Applications Design (JAD)• Rapid Application Development (RAD)• Extreme Programming (XP); extension of earlier work in Prototyping and RAD.• Open Source Development• End-user development• Object Oriented Programming

Systems Development Life Cycle 44
Comparison of Methodologies (Post, & Anderson 2006)[8]
SDLC RAD OpenSource
Objects JAD Prototyping EndUser
Control Formal MIS Weak Standards Joint User User
Time Frame Long Short Medium Any Medium Short Short
Users Many Few Few Varies Few One or Two One
MIS staff Many Few Hundreds Split Few One or Two None
Transaction/DSS Transaction Both Both Both DSS DSS DSS
Interface Minimal Minimal Weak Windows Crucial Crucial Crucial
Documentation andtraining
Vital Limited Internal InObjects
Limited Weak None
Integrity and security Vital Vital Unknown InObjects
Limited Weak Weak
Reusability Limited Some Maybe Vital Limited Weak None
New Ideas created by Shriram
Strengths and weaknessesFew people in the modern computing world would use a strict waterfall model for their Systems Development LifeCycle (SDLC) as many modern methodologies have superseded this thinking. Some will argue that the SDLC nolonger applies to models like Agile computing, but it is still a term widely in use in Technology circles. The SDLCpractice has advantages in traditional models of software development, that lends itself more to a structuredenvironment. The disadvantages to using the SDLC methodology is when there is need for iterative development or(i.e. web development or e-commerce) where stakeholders need to review on a regular basis the software beingdesigned. Instead of viewing SDLC from a strength or weakness perspective, it is far more important to take the bestpractices from the SDLC model and apply it to whatever may be most appropriate for the software being designed.A comparison of the strengths and weaknesses of SDLC:
Strength and Weaknesses of SDLC
Strengths Weaknesses
Control. Increased development time.
Monitor Large projects. Increased development cost.
Detailed steps. Systems must be defined up front.
Evaluate costs and completion targets. Rigidity.
Documentation. Hard to estimate costs, project overruns.
Well defined user input. User input is sometimes limited.
Ease of maintenance.
Development and design standards.
Tolerates changes in MIS staffing.
An alternative to the SDLC is Rapid Application Development, which combines prototyping, Joint ApplicationDevelopment and implementation of CASE tools. The advantages of RAD are speed, reduced development cost, andactive user involvement in the development process.

Systems Development Life Cycle 45
It should not be assumed that just because the waterfall model is the oldest original SDLC model that it is the mostefficient system. At one time the model was beneficial mostly to the world of automating activities that wereassigned to clerks and accountants. However, the world of technological evolution is demanding that systems have agreater functionality that would assist help desk technicians/administrators or information technologyspecialists/analysts.
See also• Application Lifecycle Management• OpenSDLC.org [9]
Further reading• Blanchard, B. S., & Fabrycky, W. J.(2006) Systems engineering and analysis (4th ed.) New Jersey: Prentice Hall.• Cummings, Haag (2006). Management Information Systems for the Information Age. Toronto, McGraw-Hill
Ryerson• Beynon-Davies P. (2009). Business Information Systems. Palgrave, Basingstoke. ISBN: 978-0-230-20368-6• Computer World, 2002 [10], Retrieved on June 22, 2006 from the World Wide Web:• Management Information Systems, 2005 [11], Retrieved on June 22, 2006 from the World Wide Web:• This article was originally based on material from the Free On-line Dictionary of Computing, which is licensed
under the GFDL.
External links• US Department of Education - Lifecycle Management Document [12]
• System Development Lifecycle (SDLC) Review Document G23 from the Information Systems Audit and ControlAssociation (ISACA) [13]
• The Agile System Development Lifecycle [14]
• Software as a Service Application Service Provider Systems Development Lifecycle [15]
• Pension Benefit Guaranty Corporation - Information Technology Solutions Lifecycle Methodology [16]
• SDLC Industry Interest Group [17]
• State of Maryland SDLC [18]
• HHS Enterprise Performance Life Cycle Framework [19]
• CMS Integrated IT Investment & System Life Cycle Framework [20]
• Collection of All SDLC Models in One Place With External Good Resources [21]
References[1] SELECTING A DEVELOPMENT APPROACH (http:/ / www. cms. hhs. gov/ SystemLifecycleFramework/ Downloads/
SelectingDevelopmentApproach. pdf). Retrieved 27 October 2008.[2] "Systems Development Life Cycle" (http:/ / foldoc. org/ foldoc. cgi?Systems+ Development+ Life+ Cycle). In: Foldoc(2000-12-24)[3] James Taylor (2004). Managing Information Technology Projects. p.39..[4] Geoffrey Elliott & Josh Strachan (2004) Global Business Information Technology. p.87.[5] US Department of Justice (2003). INFORMATION RESOURCES MANAGEMENT (http:/ / www. usdoj. gov/ jmd/ irm/ lifecycle/ ch1. htm)
Chapter 1. Introduction.[6] U.S. House of Representatives (1999). Systems Development Life-Cycle Policy (http:/ / www. house. gov/ cao-opp/ PDFSolicitations/
SDLCPOL. pdf). p.13.[7] Blanchard, B. S., & Fabrycky, W. J.(2006) Systems engineering and analysis (4th ed.) New Jersey: Prentice Hall. p.31[8] Post, G., & Anderson, D., (2006). Management information systems: Solving business problems with information technology. (4th ed.). New
York: McGraw-Hill Irwin.[9] http:/ / OpenSDLC. org[10] http:/ / www. computerworld. com/ developmenttopics/ development/ story/ 0,10801,71151,00. html

Systems Development Life Cycle 46
[11] http:/ / www. cbe. wwu. edu/ misclasses/ MIS320_Spring06_Bajwa/ Chap006. ppt[12] http:/ / www. ed. gov/ fund/ contract/ about/ acs/ acsocio1106. doc[13] http:/ / www. isaca. org/ Template. cfm?Section=Home& Template=/ ContentManagement/ ContentDisplay. cfm& ContentID=18676[14] http:/ / www. ambysoft. com/ essays/ agileLifecycle. html[15] http:/ / www. SaaSSDLC. com[16] http:/ / www. pbgc. gov/ docs/ ITSLCM%20V2007. 1. pdf[17] http:/ / www. gantthead. com/ gig/ gigDisplay. cfm?gigID=234& profileID=[18] http:/ / doit. maryland. gov/ policies/ Pages/ sdlc. aspx[19] http:/ / www. hhs. gov/ ocio/ eplc/ eplc_framework_v1point2. pdf[20] http:/ / www. cms. hhs. gov/ SystemLifecycleFramework/ 01_overview. asp[21] http:/ / eclecticcolors. blogspot. com/ 2010/ 01/ sdlc-models. html
Software development process' A software development process is a structure imposed on the development of a software product. Similar termsinclude software life cycle and software process. There are several models for such processes, each describingapproaches to a variety of tasks or activities that take place during the process. Some people consider a lifecyclemodel a more general term and a software development process a more specific term. For example, there are manyspecific software development processes that 'fit' the spiral lifecycle model.
OverviewThe large and growing body of software development organizations implement process methodologies. Many ofthem are in the defense industry, which in the U.S. requires a rating based on 'process models' to obtain contracts.The international standard for describing the method of selecting, implementing and monitoring the life cycle forsoftware is ISO 12207.A decades-long goal has been to find repeatable, predictable processes that improve productivity and quality. Sometry to systematize or formalize the seemingly unruly task of writing software. Others apply project managementtechniques to writing software. Without project management, software projects can easily be delivered late or overbudget. With large numbers of software projects not meeting their expectations in terms of functionality, cost, ordelivery schedule, effective project management appears to be lacking.Organizations may create a Software Engineering Process Group (SEPG), which is the focal point for processimprovement. Composed of line practitioners who have varied skills, the group is at the center of the collaborativeeffort of everyone in the organization who is involved with software engineering process improvement.

Software development process 47
Software development activities
The activities of the software development process represented in the waterfall model.There are several other models to represent this process.
=== Planning === The importanttask in creating a software product isextracting the requirements orrequirements analysis. Customerstypically have an abstract idea of whatthey want as an end result, but not whatsoftware should do.Incomplete,ambiguous, or evencontradictory requirements arerecognized by skilled and experiencedsoftware engineers at this point.Frequently demonstrating live codemay help reduce the risk that therequirements are incorrect.
Once the general requirements aregathered from the client, an analysis ofthe scope of the development should bedetermined and clearly stated. This isoften called a scope document.Certain functionality may be out of scope of the project as a function of cost or as a result of unclear requirements atthe start of development. If the development is done externally, this document can be considered a legal document sothat if there are ever disputes, any ambiguity of what was promised to the client can be clarified.
Implementation, testing and documentingImplementation is the part of the process where software engineers actually program the code for the project.Software testing is an integral and important part of the software development process. This part of the processensures that defects are recognized as early as possible.Documenting the internal design of software for the purpose of future maintenance and enhancement is donethroughout development. This may also include the writing of an API, be it external or internal. It is very importantto document everything in the project.
Deployment and maintenanceDeployment starts after the code is appropriately tested, is approved for release and sold or otherwise distributed intoa production environment.Software Training and Support is important and a lot of developers fail to realize that. It would not matter how muchtime and planning a development team puts into creating software if nobody in an organization ends up using it.People are often resistant to change and avoid venturing into an unfamiliar area, so as a part of the deploymentphase, it is very important to have training classes for new clients of your software.Maintaining and enhancing software to cope with newly discovered problems or new requirements can take far moretime than the initial development of the software. It may be necessary to add code that does not fit the original designto correct an unforeseen problem or it may be that a customer is requesting more functionality and code can be addedto accommodate their requests. If the labor cost of the maintenance phase exceeds 25% of the prior-phases' laborcost, then it is likely that the overall quality of at least one prior phase is poor. In that case, management shouldconsider the option of rebuilding the system (or portions) before maintenance cost is out of control.

Software development process 48
Bug Tracking System tools are often deployed at this stage of the process to allow development teams to interfacewith customer/field teams testing the software to identify any real or perceived issues. These software tools, bothopen source and commercially licensed, provide a customizable process to acquire, review, acknowledge, andrespond to reported issues.
Software Development ModelsSeveral models exist to streamline the development process. Each one has its pros and cons, and it's up to thedevelopment team to adopt the most appropriate one for the project. Sometimes a combination of the models may bemore suitable.
Waterfall ModelThe waterfall model shows a process, where developers are to follow these phases in order:1. Requirements specification (Requirements analysis)2. Software Design3. Implementation (or Coding)4. Integration5. Testing (or Validation)6. Deployment (or Installation)7. MaintenanceIn a strict Waterfall model, after each phase is finished, it proceeds to the next one. Reviews may occur beforemoving to the next phase which allows for the possibility of changes (which may involve a formal change controlprocess). Reviews may also be employed to ensure that the phase is indeed complete; the phase completion criteriaare often referred to as a "gate" that the project must pass through to move to the next phase. Waterfall discouragesrevisiting and revising any prior phase once it's complete. This "inflexibility" in a pure Waterfall model has been asource of criticism by other more "flexible" models.
Spiral ModelThe key characteristic of a Spiral model is risk management at regular stages in the development cycle. In 1988,Barry Boehm published a formal software system development "spiral model", which combines some key aspect ofthe waterfall model and rapid prototyping methodologies, but provided emphasis in a key area many felt had beenneglected by other methodologies: deliberate iterative risk analysis, particularly suited to large-scale complexsystems.The Spiral is visualized as a process passing through some number of iterations, with the four quadrant diagramrepresentative of the following activities:1. formulate plans to: identify software targets, selected to implement the program, clarify the project development
restrictions;2. Risk analysis: an analytical assessment of selected programs, to consider how to identify and eliminate risk;3. the implementation of the project: the implementation of software development and verification;Risk-driven spiral model, emphasizing the conditions of options and constraints in order to support software reuse,software quality can help as a special goal of integration into the product development. However, the spiral modelhas some restrictive conditions, as follows:1. spiral model emphasize risk analysis, but require customers to accept and believe that much of this analysis, and
make the relevant response is not easy, therefore, this model is often adapted to large-scale internal softwaredevelopment.

Software development process 49
2. If the implementation of risk analysis will greatly affect the profits of the project, then risk analysis ismeaningless, therefore, spiral model is only suitable for large-scale software projects.
3. Good software developers should look for possible risks, an accurate analysis of risk, otherwise it will lead togreater risk.
First stage is to determine the stage of the goal of accomplishing these objectives, options and constraints, and thenfrom the perspective of risk analysis program, development strategy, and strive to remove all potential risks, andsometimes necessary to achieve through the construction of the prototype. If some risk can not be ruled out, theprogram to end immediately, or else start the development of the next steps. Finally, evaluation results of the stage,and the design of the next phase.
Iterative and Incremental DevelopmentIterative development[1] prescribes the construction of initially small but ever larger portions of a software project tohelp all those involved to uncover important issues early before problems or faulty assumptions can lead to disaster.Iterative processes are preferred by commercial developers because it allows a potential of reaching the design goalsof a customer who does not know how to define what they want.
Agile DevelopmentAgile software development uses iterative development as a basis but advocates a lighter and more people-centricviewpoint than traditional approaches. Agile processes use feedback, rather than planning, as their primary controlmechanism. The feedback is driven by regular tests and releases of the evolving software.There are many variations of agile processes:• In Extreme Programming (XP), the phases are carried out in extremely small (or "continuous") steps compared to
the older, "batch" processes. The (intentionally incomplete) first pass through the steps might take a day or aweek, rather than the months or years of each complete step in the Waterfall model. First, one writes automatedtests, to provide concrete goals for development. Next is coding (by a pair of programmers), which is completewhen all the tests pass, and the programmers can't think of any more tests that are needed. Design and architectureemerge out of refactoring, and come after coding. Design is done by the same people who do the coding. (Onlythe last feature — merging design and code — is common to all the other agile processes.) The incomplete butfunctional system is deployed or demonstrated for (some subset of) the users (at least one of which is on thedevelopment team). At this point, the practitioners start again on writing tests for the next most important part ofthe system.
• Rational Unified Process• Scrum
Process Improvement ModelsCapability Maturity Model Integration
The Capability Maturity Model Integration (CMMI) is one of the leading models and based on best practice.Independent assessments grade organizations on how well they follow their defined processes, not on thequality of those processes or the software produced. CMMI has replaced CMM.
ISO 9000ISO 9000 describes standards for a formally organized process to manufacture a product and the methods ofmanaging and monitoring progress. Although the standard was originally created for the manufacturing sector,ISO 9000 standards have been applied to software development as well. Like CMMI, certification with ISO9000 does not guarantee the quality of the end result, only that formalized business processes have beenfollowed.

Software development process 50
ISO 15504ISO 15504, also known as Software Process Improvement Capability Determination (SPICE), is a "frameworkfor the assessment of software processes". This standard is aimed at setting out a clear model for processcomparison. SPICE is used much like CMMI. It models processes to manage, control, guide and monitorsoftware development. This model is then used to measure what a development organization or project teamactually does during software development. This information is analyzed to identify weaknesses and driveimprovement. It also identifies strengths that can be continued or integrated into common practice for thatorganization or team.
Formal methodsFormal methods are mathematical approaches to solving software (and hardware) problems at the requirements,specification and design levels. Examples of formal methods include the B-Method, Petri nets, Automated theoremproving, RAISE and VDM. Various formal specification notations are available, such as the Z notation. Moregenerally, automata theory can be used to build up and validate application behavior by designing a system of finitestate machines.Finite state machine (FSM) based methodologies allow executable software specification and by-passing ofconventional coding (see virtual finite state machine or event driven finite state machine).Formal methods are most likely to be applied in avionics software, particularly where the software is safety critical.Software safety assurance standards, such as DO178B demand formal methods at the highest level of categorization(Level A).Formalization of software development is creeping in, in other places, with the application of Object ConstraintLanguage (and specializations such as Java Modeling Language) and especially with Model-driven architectureallowing execution of designs, if not specifications.Another emerging trend in software development is to write a specification in some form of logic (usually a variationof FOL), and then to directly execute the logic as though it were a program. The OWL language, based onDescription Logic, is an example. There is also work on mapping some version of English (or another naturallanguage) automatically to and from logic, and executing the logic directly. Examples are Attempto ControlledEnglish, and Internet Business Logic, which does not seek to control the vocabulary or syntax. A feature of systemsthat support bidirectional English-logic mapping and direct execution of the logic is that they can be made to explaintheir results, in English, at the business or scientific level.The Government Accountability Office, in a 2003 report on one of the Federal Aviation Administration’s air trafficcontrol modernization programs,[2] recommends following the agency’s guidance for managing major acquisitionsystems by• establishing, maintaining, and controlling an accurate, valid, and current performance measurement baseline,
which would include negotiating all authorized, unpriced work within 3 months;• conducting an integrated baseline review of any major contract modifications within 6 months; and• preparing a rigorous life-cycle cost estimate, including a risk assessment, in accordance with the Acquisition
System Toolset’s guidance and identifying the level of uncertainty inherent in the estimate.

Software development process 51
See also
Some more development methods:
• Evolutionary Development model• Model driven development• User experience• Top-down and bottom-up design• Chaos model• Evolutionary prototyping• Prototyping• ICONIX Process (UML-based object modeling with use cases)• Unified Process• V-model• Extreme Programming• Software Development Rhythms• Specification and Description Language• Incremental funding methodology• Verification and Validation (software)• Service-Oriented Modeling Framework
Related subjects:
• Rapid application development• Software design• Software development• Software Estimation• Abstract Model• Development stage• IPO+S Model• List of software engineering topics• Performance engineering• Process• Programming paradigm• Programming productivity• Project• Systems Development Life Cycle (SDLC)• Software documentation• Systems design• List of software development philosophies• Test effort• Best Coding Practices• Service-Oriented Modeling Framework• Bachelor of Science in Information Technology
External links• Don't Write Another Process [3]
• No Silver Bullet: Essence and Accidents of Software Engineering [4]", 1986• Gerhard Fischer, "The Software Technology of the 21st Century: From Software Reuse to Collaborative Software
Design" [5], 2001• Lydia Ash: The Web Testing Companion: The Insider's Guide to Efficient and Effective Tests, Wiley, May 2,
2003. ISBN 0-471-43021-8• SaaSSDLC.com [6] — Software as a Service Systems Development Life Cycle Project• Software development life cycle (SDLC) [visual image], software development life cycle [7]
• Selecting an SDLC [8]", 2009
References[1] ieeecomputersociety.org (http:/ / doi. ieeecomputersociety. org/ 10. 1109/ MC. 2003. 1204375)[2] Government Accountability Report (January 2003). Report GAO-03-343, National Airspace System: Better Cost Data Could Improve FAA’s
Management of the Standard Terminal Automation Replacement System. Retrieved from http:/ / www. gao. gov/ cgi-bin/ getrpt?GAO-03-343[3] http:/ / www. methodsandtools. com/ archive/ archive. php?id=16[4] http:/ / virtualschool. edu/ mon/ SoftwareEngineering/ BrooksNoSilverBullet. html[5] http:/ / l3d. cs. colorado. edu/ ~gerhard/ papers/ isfst2001. pdf[6] http:/ / SaaSSDLC. com/[7] http:/ / www. notetech. com/ images/ software_lifecycle. jpg[8] http:/ / www. gem-up. com/ PDF/ SK903V0-WP-ChoosingSDLC. pdf

Waterfall model 52
Waterfall modelThe waterfall model is a sequential software development process, in which progress is seen as flowing steadilydownwards (like a waterfall) through the phases of Conception, Initiation, Analysis, Design, Construction, Testingand Maintenance.
The unmodified "waterfall model". Progress flows from the top to the bottom, like awaterfall.
The waterfall development model hasits origins in the manufacturing andconstruction industries; highlystructured physical environments inwhich after-the-fact changes areprohibitively costly, if not impossible.Since no formal software developmentmethodologies existed at the time, thishardware-oriented model was simplyadapted for software development.
The first formal description of thewaterfall model is often cited to be anarticle published in 1970 by WinstonW. Royce,[1] although Royce did notuse the term "waterfall" in this article.Royce was presenting this model as anexample of a flawed, non-workingmodel (Royce 1970). This is in fact theway the term has generally been used in writing about software development—as a way to criticize a commonlyused software practice.[2]
ModelIn Royce's original waterfall model, the following phases are followed in order:1. Requirements specification2. Design3. Construction (AKA implementation or coding)4. Integration5. Testing and debugging (AKA Validation)6. Installation7. MaintenanceTo follow the waterfall model, one proceeds from one phase to the next in a sequential manner. For example, onefirst completes requirements specification, which after sign-off are considered "set in stone." When the requirementsare fully completed, one proceeds to design. The software in question is designed and a blueprint is drawn forimplementers (coders) to follow — this design should be a plan for implementing the requirements given. When thedesign is fully completed, an implementation of that design is made by coders. Towards the later stages of thisimplementation phase, separate software components produced are combined to introduce new functionality andreduced risk through the removal of errors.Thus the waterfall model maintains that one should move to a phase only when its preceding phase is completed andperfected. However, there are various modified waterfall models (including Royce's final model) that may includeslight or major variations upon this process.

Waterfall model 53
Supporting argumentsTime spent early in the software production cycle can lead to greater economy at later stages. It has been shown thata bug found in the early stages (such as requirements specification or design) is cheaper in terms of money, effortand time, to fix than the same bug found later on in the process. ([McConnell 1996], p. 72, estimates that "arequirements defect that is left undetected until construction or maintenance will cost 50 to 200 times as much to fixas it would have cost to fix at requirements time.") To take an extreme example, if a program design turns out to beimpossible to implement, it is easier to fix the design at the design stage than to realize months later, when programcomponents are being integrated, that all the work done so far has to be scrapped because of a broken design.This is the central idea behind Big Design Up Front (BDUF) and the waterfall model - time spent early on makingsure that requirements and design are absolutely correct will save you much time and effort later. Thus, the thinkingof those who follow the waterfall process goes, one should make sure that each phase is 100% complete andabsolutely correct before proceeding to the next phase of program creation. Program requirements should be set instone before design is started (otherwise work put into a design based on incorrect requirements is wasted); theprogram's design should be perfect before people begin work on implementing the design (otherwise they areimplementing the wrong design and their work is wasted), etc.A further argument for the waterfall model is that it places emphasis on documentation (such as requirementsdocuments and design documents) as well as source code. In less designed and documented methodologies, shouldteam members leave, much knowledge is lost and may be difficult for a project to recover from. Should a fullyworking design document be present (as is the intent of Big Design Up Front and the waterfall model) new teammembers or even entirely new teams should be able to familiarize themselves by reading the documents.As well as the above, some prefer the waterfall model for its simple approach and argue that it is more disciplined.Rather than what the waterfall adherent sees as chaos, the waterfall model provides a structured approach; the modelitself progresses linearly through discrete, easily understandable and explainable phases and thus is easy tounderstand; it also provides easily markable milestones in the development process. It is perhaps for this reason thatthe waterfall model is used as a beginning example of a development model in many software engineering texts andcourses.It is argued that the waterfall model and Big Design up Front in general can be suited to software projects which arestable (especially those projects with unchanging requirements, such as with shrink wrap software) and where it ispossible and likely that designers will be able to fully predict problem areas of the system and produce a correctdesign before implementation is started. The waterfall model also requires that implementers follow the well made,complete design accurately, ensuring that the integration of the system proceeds smoothly.
CriticismThe waterfall model is argued by many to be a bad idea in practice. This is mainly because of their belief that it isimpossible for any non-trivial project to get one phase of a software product's lifecycle perfected, before moving onto the next phases and learning from them.For example, clients may not be aware of exactly what requirements they need before reviewing a working prototypeand commenting on it; they may change their requirements constantly. Designers and programmers may have littlecontrol over this. If clients change their requirements after the design is finalized, the design must be modified toaccommodate the new requirements. This effectively means invalidating a good deal of working hours, which meansincreased cost, especially if a large amount of the project's resources has already been invested in Big Design UpFront.Designers may not be aware of future implementation difficulties when writing a design for an unimplementedsoftware product. That is, it may become clear in the implementation phase that a particular area of programfunctionality is extraordinarily difficult to implement. If this is the case, it is better to revise the design than to persist

Waterfall model 54
in using a design that was made based on faulty predictions and that does not account for the newly discoveredproblem areas.Even without such changing of the specification during implementation, there is the option either to start a newproject from scratch, "on a green field", or to continue some already existing, "a brown field" (from constructionagain). The waterfall methodology can be used for continuous enhancement, even for existing software, originallyfrom another team. As well as in the case when the system analyst fails to capture the customer requirementscorrectly, the resulting impacts on the following phases (mainly the coding) still can be tamed by this methodology,in practice: A challenging job for a QA team.Steve McConnell in Code Complete (a book which criticizes the widespread use of the waterfall model) refers todesign as a "wicked problem" — a problem whose requirements and limitations cannot be entirely known beforecompletion. The implication of this is that it is impossible to perfect one phase of software development, thus it isimpossible if using the waterfall model to move on to the next phase.David Parnas, in "A Rational Design Process: How and Why to Fake It", writes:[3]
“Many of the [system's] details only become known to us as we progress in the [system's]implementation. Some of the things that we learn invalidate our design and we must backtrack.”
Expanding the concept above, the project stakeholders (non-IT personnel) may not be fully aware of the capabilitiesof the technology being implemented. This can lead to their expectations, and requirements, being defined by whatthey "think is possible". Which may not take advantage of the full potential of what the new technology can deliver,or simply be trying to replicate the existing application or process with the new technology. This can result insubstantial changes to the implementation requirements once the stakeholders become more aware of thefunctionality available from the new technology. An example is where an organisation is migrating from a paperbased process to an electronic process. While the key deliverables of the paper process should be maintained, thebenefits of real-time data input validation, traceability, and automated decision point routing may not be anticipatedat the early planning stages of the project.The idea behind the waterfall model may be "measure twice; cut once", and those opposed to the waterfall modelargue that this idea tends to fall apart when the problem being measured is constantly changing due to requirementmodifications and new realizations about the problem itself. A potential solution is for an experienced developer tospend time up front on refactoring to consolidate the software, and to prepare it for a possible update, no matter ifsuch is planned already. Another approach is to use a design targeting modularity with interfaces, to increase theflexibility of the software with respect to the design.
Modified modelsIn response to the perceived problems with the pure waterfall model, many modified waterfall models have beenintroduced. These models may address some or all of the criticisms of the pure waterfall model. Many differentmodels are covered by Steve McConnell in the "lifecycle planning" chapter of his book Rapid Development: TamingWild Software Schedules.While all software development models will bear some similarity to the waterfall model, as all software developmentmodels will incorporate at least some phases similar to those used within the waterfall model, this section will dealwith those closest to the waterfall model. For models which apply further differences to the waterfall model, or forradically different models seek general information on the software development process.

Waterfall model 55
Sashimi modelThe Sashimi model (so called because it features overlapping phases, like the overlapping fish of Japanese sashimi)was originated by Peter DeGrace. It is sometimes referred to as the "waterfall model with overlapping phases" or"the waterfall model with feedback". Since phases in the sashimi model overlap, information of problem spots can beacted upon during phases that would typically, in the pure waterfall model, precede others. For example, since thedesign and implementation phases will overlap in the sashimi model, implementation problems may be discoveredduring the design and implementation phase of the development process. This helps alleviate many of the problemsassociated with the Big Design Up Front philosophy of the waterfall model.
See also• Agile software development• Big Design Up Front• Chaos model• Iterative and incremental development• Iterfall development• Rapid application development• Software development process• Spiral model• System Development Methodology,• V-model• Dual Vee Model• List of software development philosophies
Further readingThis article was originally based on material from the Free On-line Dictionary of Computing, which is licensedunder the GFDL.
• McConnell, Steve (2006). Software Estimation: Demystifying the Black Art. Microsoft Press.ISBN 0-7356-0535-1.
• McConnell, Steve (2004). Code Complete, 2nd edition. Microsoft Press. ISBN 1-55615-484-4.• McConnell, Steve (1996). Rapid Development: Taming Wild Software Schedules. Microsoft Press.
ISBN 1-55615-900-5.• Parnas, David, A rational design process and how to fake it (PDF) [4] An influential paper which criticises the
idea that software production can occur in perfectly discrete phases.• Royce, Winston (1970), "Managing the Development of Large Software Systems" [5], Proceedings of IEEE
WESCON 26 (August): 1–9.• "Why people still believe in the waterfall model" [6]
• The standard waterfall model for systems development [7] NASA webpage, archived on Internet Archive March10, 2005.
• Parametric Cost Estimating Handbook [8], NASA webpage based on the waterfall model, archived on InternetArchive March 8, 2005.

Waterfall model 56
External links• Understanding the pros and cons of the Waterfall Model of software development [9]
• "Waterfall model considered harmful" [10]
• Project lifecycle models: how they differ and when to use them [11]
• Going Over the Waterfall with the RUP [12] by Philippe Kruchten• CSC and IBM Rational join to deliver C-RUP and support rapid business change [13]
References[1] Wasserfallmodell > Entstehungskontext (http:/ / cartoon. iguw. tuwien. ac. at/ fit/ fit01/ wasserfall/ entstehung. html), Markus Rerych, Institut
für Gestaltungs- und Wirkungsforschung, TU-Wien. Accessed on line November 28, 2007.[2] Conrad Weisert, Waterfall methodology: there's no such thing! (http:/ / www. idinews. com/ waterfall. html)[3] "A Rational Design Process: How and Why to Fake It" (http:/ / www. cs. tufts. edu/ ~nr/ cs257/ archive/ david-parnas/ fake-it. pdf), David
Parnas (PDF file)[4] http:/ / users. ece. utexas. edu/ ~perry/ education/ SE-Intro/ fakeit. pdf[5] http:/ / www. cs. umd. edu/ class/ spring2003/ cmsc838p/ Process/ waterfall. pdf[6] http:/ / tarmo. fi/ blog/ 2005/ 09/ 09/ dont-draw-diagrams-of-wrong-practices-or-why-people-still-believe-in-the-waterfall-model/[7] http:/ / web. archive. org/ web/ 20050310133243/ http:/ / asd-www. larc. nasa. gov/ barkstrom/ public/
The_Standard_Waterfall_Model_For_Systems_Development. htm[8] http:/ / cost. jsc. nasa. gov/ PCEHHTML/ pceh. htm[9] http:/ / articles. techrepublic. com. com/ 5100-10878_11-6118423. html?part=rss& tag=feed& subj=tr[10] http:/ / www. it-director. com/ technology/ productivity/ content. php?cid=7865[11] http:/ / www. business-esolutions. com/ islm. htm[12] http:/ / www-128. ibm. com/ developerworks/ rational/ library/ 4626. html[13] http:/ / www. ibm. com/ developerworks/ rational/ library/ 3012. html

57
Problem Solving
Problem solvingProblem solving is a mental process and is part of the larger problem process that includes problem finding andproblem shaping. Considered the most complex of all intellectual functions, problem solving has been defined ashigher-order cognitive process that requires the modulation and control of more routine or fundamental skills.[1]
Problem solving occurs when an organism or an artificial intelligence system needs to move from a given state to adesired goal state.
OverviewThe nature of human problem solving methods has been studied by psychologists over the past hundred years. Thereare several methods of studying problem solving, including; introspection, behaviorism, simulation, computermodeling and experiment.Beginning with the early experimental work of the Gestaltists in Germany (e.g. Duncker, 1935 [2] ), and continuingthrough the 1960s and early 1970s, research on problem solving typically conducted relatively simple, laboratorytasks (e.g. Duncker's "X-ray" problem; Ewert & Lambert's 1932 "disk" problem, later known as Tower of Hanoi)that appeared novel to participants (e.g. Mayer, 1992 [3] ). Various reasons account for the choice of simple noveltasks: they had clearly defined optimal solutions, they were solvable within a relatively short time frame, researcherscould trace participants' problem-solving steps, and so on. The researchers made the underlying assumption, ofcourse, that simple tasks such as the Tower of Hanoi captured the main properties of "real world" problems, and thatthe cognitive processes underlying participants' attempts to solve simple problems were representative of theprocesses engaged in when solving "real world" problems. Thus researchers used simple problems for reasons ofconvenience, and thought generalizations to more complex problems would become possible. Perhaps thebest-known and most impressive example of this line of research remains the work by Allen Newell and HerbertSimon [4] .Simple laboratory-based tasks can be useful in explicating the steps of logic and reasoning that underlie problemsolving; however, they omit the complexity and emotional valence of "real-world" problems. In clinical psychology,researchers have focused on the role of emotions in problem solving (D'Zurilla & Goldfried, 1971; D'Zurilla &Nezu, 1982), demonstrating that poor emotional control can disrupt focus on the target task and impede problemresolution (Rath, Langenbahn, Simon, Sherr, & Diller, 2004). In this conceptualization, human problem solvingconsists of two related processes: problem orientation, the motivational/attitudinal/affective approach to problematicsituations and problem-solving skills, the actual cognitive-behavioral steps, which, if successfully implemented, leadto effective problem resolution. Working with individuals with frontal lobe injuries, neuropsychologists havediscovered that deficits in emotional control and reasoning can be remediated, improving the capacity of injuredpersons to resolve everyday problems successfully (Rath, Simon, Langenbahn, Sherr, & Diller, 2003).

Problem solving 58
EuropeIn Europe, two main approaches have surfaced, one initiated by Donald Broadbent (1977; see Berry & Broadbent,1995) in the United Kingdom and the other one by Dietrich Dörner (1975, 1985; see Dörner & Wearing, 1995) inGermany. The two approaches have in common an emphasis on relatively complex, semantically rich, computerizedlaboratory tasks, constructed to resemble real-life problems. The approaches differ somewhat in their theoreticalgoals and methodology, however. The tradition initiated by Broadbent emphasizes the distinction between cognitiveproblem-solving processes that operate under awareness versus outside of awareness, and typically employsmathematically well-defined computerized systems. The tradition initiated by Dörner, on the other hand, has aninterest in the interplay of the cognitive, motivational, and social components of problem solving, and utilizes verycomplex computerized scenarios that contain up to 2,000 highly interconnected variables (e.g., Dörner, Kreuzig,Reither & Stäudel's 1983 LOHHAUSEN project; Ringelband, Misiak & Kluwe, 1990). Buchner (1995) describes thetwo traditions in detail.To sum up, researchers' realization that problem-solving processes differ across knowledge domains and acrosslevels of expertise (e.g. Sternberg, 1995) and that, consequently, findings obtained in the laboratory cannotnecessarily generalize to problem-solving situations outside the laboratory, has during the past two decades led to anemphasis on real-world problem solving. This emphasis has been expressed quite differently in North America andEurope, however. Whereas North American research has typically concentrated on studying problem solving inseparate, natural knowledge domains, much of the European research has focused on novel, complex problems, andhas been performed with computerized scenarios (see Funke, 1991, for an overview).
USA and CanadaIn North America, initiated by the work of Herbert Simon on learning by doing in semantically rich domains (e.g.Anzai & Simon, 1979; Bhaskar & Simon, 1977), researchers began to investigate problem solving separately indifferent natural knowledge domains – such as physics, writing, or chess playing – thus relinquishing their attemptsto extract a global theory of problem solving (e.g. Sternberg & Frensch, 1991). Instead, these researchers havefrequently focused on the development of problem solving within a certain domain, that is on the development ofexpertise (e.g. Anderson, Boyle & Reiser, 1985; Chase & Simon, 1973; Chi, Feltovich & Glaser, 1981).Areas that have attracted rather intensive attention in North America include such diverse fields as:• Problem Solving (Kepner& Tregoe, 1958)• Reading (Stanovich & Cunningham, 1991)• Writing (Bryson, Bereiter, Scardamalia & Joram, 1991)• Calculation (Sokol & McCloskey, 1991)• Political decision making (Voss, Wolfe, Lawrence & Engle, 1991)• Managerial problem solving (Wagner, 1991)• Lawyers' reasoning (Amsel, Langer & Loutzenhiser, 1991)• Mechanical problem solving (Hegarty, 1991)• Problem solving in electronics (Lesgold & Lajoie, 1991)• Computer skills (Kay, 1991)• Game playing (Frensch & Sternberg, 1991)• Personal problem solving (Heppner & Krauskopf, 1987)• Mathematical problem solving (Polya, 1945; Schoenfeld, 1985)• Social problem solving (D'Zurilla & Goldfreid, 1971; D'Zurilla & Nezu, 1982)• Problem solving for innovations and inventions: TRIZ (Altshuller, 1973, 1984, 1994)

Problem solving 59
Characteristics of difficult problemsAs elucidated by Dietrich Dörner and later expanded upon by Joachim Funke, difficult problems have some typicalcharacteristics that can be summarized as follows:• Intransparency (lack of clarity of the situation)
• commencement opacity• continuation opacity
• Polytely (multiple goals)• inexpressiveness• opposition• transience
• Complexity (large numbers of items, interrelations and decisions)• enumerability• connectivity (hierarchy relation, communication relation, allocation relation)• heterogeneity
• Dynamics (time considerations)• temporal constraints• temporal sensitivity• phase effects• dynamic unpredictability
The resolution of difficult problems requires a direct attack on each of these characteristics that are encountered.In reform mathematics, greater emphasis is placed on problem solving relative to basic skills, where basic operationscan be done with calculators. However some "problems" may actually have standard solutions taught in highergrades. For example, kindergarteners could be asked how many fingers are there on all the gloves of 3 children,which can be solved with multiplication.[5]
Problem-solving techniques• Abstraction: solving the problem in a model of the system before applying it to the real system• Analogy: using a solution that solved an analogous problem• Brainstorming: (especially among groups of people) suggesting a large number of solutions or ideas and
combining and developing them until an optimum is found• Divide and conquer: breaking down a large, complex problem into smaller, solvable problems• Hypothesis testing: assuming a possible explanation to the problem and trying to prove (or, in some contexts,
disprove) the assumption• Lateral thinking: approaching solutions indirectly and creatively• Means-ends analysis: choosing an action at each step to move closer to the goal• Method of focal objects: synthesizing seemingly non-matching characteristics of different objects into something
new• Morphological analysis: assessing the output and interactions of an entire system• Reduction: transforming the problem into another problem for which solutions exist• Research: employing existing ideas or adapting existing solutions to similar problems• Root cause analysis: eliminating the cause of the problem• Trial-and-error: testing possible solutions until the right one is found

Problem solving 60
Problem-solving methodologies• Eight Disciplines Problem Solving• GROW model• How to solve it• Kepner-Tregoe• Southbeach Notation• PDCA• RPR Problem Diagnosis• TRIZ (Teoriya Resheniya Izobretatelskikh Zadatch, "theory of solving inventor's problems")
Example applicationsProblem solving is of crucial importance in engineering when products or processes fail, so corrective action can betaken to prevent further failures. Perhaps of more value, problem solving can be applied to a product or process priorto an actual fail event ie. a potential problem can be predicted, analyzed and mitigation applied so the problem neveractually occurs. Techniques like Failure Mode Effects Analysis can be used to proactively reduce the likelihood ofproblems occurring. Forensic engineering is an important technique of failure analysis which involves tracingproduct defects and flaws. Corrective action can then be taken to prevent further failures.
See also• Artificial intelligence• C-K theory• Creative problem solving• Divergent thinking• Educational psychology• Executive function• Forensic engineering• Heuristics• Innovation• Intelligence amplification• Inquiry• Logical reasoning• Problem statement• Herbert Simon• Thought• Transdisciplinary studies• Troubleshooting• Wicked problem

Problem solving 61
References• Amsel, E., Langer, R., & Loutzenhiser, L. (1991). Do lawyers reason differently from psychologists? A
comparative design for studying expertise. In R. J. Sternberg & P. A. Frensch (Eds.), Complex problem solving:Principles and mechanisms (pp. 223-250). Hillsdale, NJ: Lawrence Erlbaum Associates. ISBN978-0-8058-1783-6
• Anderson, J. R., Boyle, C. B., & Reiser, B. J. (1985). "Intelligent tutoring systems". Science 228 (4698): 456–462.doi:10.1126/science.228.4698.456. PMID 17746875.
• Anzai, K., & Simon, H. A. (1979) (1979). "The theory of learning by doing". Psychological Review 86 (2):124–140. doi:10.1037/0033-295X.86.2.124. PMID 493441.
• Beckmann, J. F., & Guthke, J. (1995). Complex problem solving, intelligence, and learning ability. In P. A.Frensch & J. Funke (Eds.), Complex problem solving: The European Perspective (pp. 177-200). Hillsdale, NJ:Lawrence Erlbaum Associates.
• Berry, D. C., & Broadbent, D. E. (1995). Implicit learning in the control of complex systems: A reconsiderationof some of the earlier claims. In P.A. Frensch & J. Funke (Eds.), Complex problem solving: The EuropeanPerspective (pp. 131-150). Hillsdale, NJ: Lawrence Erlbaum Associates.
• Bhaskar, R., & Simon, H. A. (1977). Problem solving in semantically rich domains: An example fromengineering thermodynamics. Cognitive Science, 1, 193-215.
• Brehmer, B. (1995). Feedback delays in dynamic decision making. In P. A. Frensch & J. Funke (Eds.), Complexproblem solving: The European Perspective (pp. 103-130). Hillsdale, NJ: Lawrence Erlbaum Associates.
• Brehmer, B., & Dörner, D. (1993). Experiments with computer-simulated microworlds: Escaping both the narrowstraits of the laboratory and the deep blue sea of the field study. Computers in Human Behavior, 9, 171-184.
• Broadbent, D. E. (1977). Levels, hierarchies, and the locus of control. Quarterly Journal of ExperimentalPsychology, 29, 181-201.
• Bryson, M., Bereiter, C., Scardamalia, M., & Joram, E. (1991). Going beyond the problem as given: Problemsolving in expert and novice writers. In R. J. Sternberg & P. A. Frensch (Eds.), Complex problem solving:Principles and mechanisms (pp. 61-84). Hillsdale, NJ: Lawrence Erlbaum Associates.
• Buchner, A. (1995). Theories of complex problem solving. In P. A. Frensch & J. Funke (Eds.), Complex problemsolving: The European Perspective (pp. 27-63). Hillsdale, NJ: Lawrence Erlbaum Associates.
• Buchner, A., Funke, J., & Berry, D. C. (1995). Negative correlations between control performance andverbalizable knowledge: Indicators for implicit learning in process control tasks? Quarterly Journal ofExperimental Psychology, 48A, 166-187.
• Chase, W. G., & Simon, H. A. (1973). Perception in chess. Cognitive Psychology, 4, 55-81.• Chi, M. T. H., Feltovich, P. J., & Glaser, R. (1981). "Categorization and representation of physics problems by
experts and novices" [6]. Cognitive Science 5: 121–152. doi:10.1207/s15516709cog0502_2.• Dörner, D. (1975). Wie Menschen eine Welt verbessern wollten [How people wanted to improve the world]. Bild
der Wissenschaft, 12, 48-53.• Dörner, D. (1985). Verhalten, Denken und Emotionen [Behavior, thinking, and emotions]. In L. H. Eckensberger
& E. D. Lantermann (Eds.), Emotion und Reflexivität (pp. 157-181). München, Germany: Urban &Schwarzenberg.
• Dörner, D. (1992). Über die Philosophie der Verwendung von Mikrowelten oder "Computerszenarios" in derpsychologischen Forschung [On the proper use of microworlds or "computer scenarios" in psychologicalresearch]. In H. Gundlach (Ed.), Psychologische Forschung und Methode: Das Versprechen des Experiments.Festschrift für Werner Traxel (pp. 53-87). Passau, Germany: Passavia-Universitäts-Verlag.
• Dörner, D., Kreuzig, H. W., Reither, F., & Stäudel, T. (Eds.). (1983). Lohhausen. Vom Umgang mitUnbestimmtheit und Komplexität [Lohhausen. On dealing with uncertainty and complexity]. Bern, Switzerland:Hans Huber.

Problem solving 62
• Dörner, D., & Wearing, A. (1995). Complex problem solving: Toward a (computer-simulated) theory. In P. A.Frensch & J. Funke (Eds.), Complex problem solving: The European Perspective (pp. 65-99). Hillsdale, NJ:Lawrence Erlbaum Associates.
• Duncker, K. (1935). Zur Psychologie des produktiven Denkens [The psychology of productive thinking]. Berlin:Julius Springer.
• Ewert, P. H., & Lambert, J. F. (1932). Part II: The effect of verbal instructions upon the formation of a concept.Journal of General Psychology, 6, 400-411.
• Eyferth, K., Schömann, M., & Widowski, D. (1986). Der Umgang von Psychologen mit Komplexität [On howpsychologists deal with complexity]. Sprache & Kognition, 5, 11-26.
• Frensch, P. A., & Funke, J. (Eds.). (1995). Complex problem solving: The European Perspective. Hillsdale, NJ:Lawrence Erlbaum Associates.
• Frensch, P. A., & Sternberg, R. J. (1991). Skill-related differences in game playing. In R. J. Sternberg & P. A.Frensch (Eds.), Complex problem solving: Principles and mechanisms (pp. 343-381). Hillsdale, NJ: LawrenceErlbaum Associates.
• Funke, J. (1991). Solving complex problems: Human identification and control of complex systems. In R. J.Sternberg & P. A. Frensch (Eds.), Complex problem solving: Principles and mechanisms (pp. 185-222). Hillsdale,NJ: Lawrence Erlbaum Associates.
• Funke, J. (1993). Microworlds based on linear equation systems: A new approach to complex problem solvingand experimental results. In G. Strube & K.-F. Wender (Eds.), The cognitive psychology of knowledge (pp.313-330). Amsterdam: Elsevier Science Publishers.
• Funke, J. (1995). Experimental research on complex problem solving. In P. A. Frensch & J. Funke (Eds.),Complex problem solving: The European Perspective (pp. 243-268). Hillsdale, NJ: Lawrence ErlbaumAssociates.
• Funke, U. (1995). Complex problem solving in personnel selection and training. In P. A. Frensch & J. Funke(Eds.), Complex problem solving: The European Perspective (pp. 219-240). Hillsdale, NJ: Lawrence ErlbaumAssociates.
• Goldstein F. C., & Levin H. S. (1987). Disorders of reasoning and problem-solving ability. In M. Meier, A.Benton, & L. Diller (Eds.), Neuropsychological rehabilitation. London: Taylor & Francis Group.
• Groner, M., Groner, R., & Bischof, W. F. (1983). Approaches to heuristics: A historical review. In R. Groner, M.Groner, & W. F. Bischof (Eds.), Methods of heuristics (pp. 1-18). Hillsdale, NJ: Lawrence Erlbaum Associates.
• Halpern, Diane F. (2002).Thought & Knowledge. Lawrence Erlbaum Associates. Worldcat Library Catalog [7]
• Hayes, J. (1980). The complete problem solver. Philadelphia: The Franklin Institute Press.• Hegarty, M. (1991). Knowledge and processes in mechanical problem solving. In R. J. Sternberg & P. A. Frensch
(Eds.), Complex problem solving: Principles and mechanisms (pp. 253-285). Hillsdale, NJ: Lawrence ErlbaumAssociates.
• Heppner, P. P., & Krauskopf, C. J. (1987). An information-processing approach to personal problem solving. TheCounseling Psychologist, 15, 371-447.
• Huber, O. (1995). Complex problem solving as multi stage decision making. In P. A. Frensch & J. Funke (Eds.),Complex problem solving: The European Perspective (pp. 151-173). Hillsdale, NJ: Lawrence ErlbaumAssociates.
• Hübner, R. (1989). Methoden zur Analyse und Konstruktion von Aufgaben zur kognitiven Steuerungdynamischer Systeme [Methods for the analysis and construction of dynamic system control tasks]. Zeitschrift fürExperimentelle und Angewandte Psychologie, 36, 221-238.
• Hunt, E. (1991). Some comments on the study of complexity. In R. J. Sternberg, & P. A. Frensch (Eds.), Complexproblem solving: Principles and mechanisms (pp. 383-395). Hillsdale, NJ: Lawrence Erlbaum Associates.
• Hussy, W. (1985). Komplexes Problemlösen - Eine Sackgasse? [Complex problem solving - a dead end?].Zeitschrift für Experimentelle und Angewandte Psychologie, 32, 55-77.

Problem solving 63
• Kay, D. S. (1991). Computer interaction: Debugging the problems. In R. J. Sternberg & P. A. Frensch (Eds.),Complex problem solving: Principles and mechanisms (pp. 317-340). Hillsdale, NJ: Lawrence ErlbaumAssociates.
• Kluwe, R. H. (1993). Knowledge and performance in complex problem solving. In G. Strube & K.-F. Wender(Eds.), The cognitive psychology of knowledge (pp. 401-423). Amsterdam: Elsevier Science Publishers.
• Kluwe, R. H. (1995). Single case studies and models of complex problem solving. In P. A. Frensch & J. Funke(Eds.), Complex problem solving: The European Perspective (pp. 269-291). Hillsdale, NJ: Lawrence ErlbaumAssociates.
• Kolb, S., Petzing, F., & Stumpf, S. (1992). Komplexes Problemlösen: Bestimmung der Problemlösegüte vonProbanden mittels Verfahren des Operations Research ? ein interdisziplinärer Ansatz [Complex problem solving:determining the quality of human problem solving by operations research tools - an interdisciplinary approach].Sprache & Kognition, 11, 115-128.
• Krems, J. F. (1995). Cognitive flexibility and complex problem solving. In P. A. Frensch & J. Funke (Eds.),Complex problem solving: The European Perspective (pp. 201-218). Hillsdale, NJ: Lawrence ErlbaumAssociates.
• Lesgold, A., & Lajoie, S. (1991). Complex problem solving in electronics. In R. J. Sternberg & P. A. Frensch(Eds.), Complex problem solving: Principles and mechanisms (pp. 287-316). Hillsdale, NJ: Lawrence ErlbaumAssociates.
• Mayer, R. E. (1992). Thinking, problem solving, cognition. Second edition. New York: W. H. Freeman andCompany.
• Müller, H. (1993). Komplexes Problemlösen: Reliabilität und Wissen [Complex problem solving: Reliability andknowledge]. Bonn, Germany: Holos.
• Newell, A., & Simon, H. A. (1972). Human problem solving. Englewood Cliffs, NJ: Prentice-Hall.• Paradies, M.W., & Unger, L. W. (2000). TapRooT - The System for Root Cause Analysis, Problem Investigation,
and Proactive Improvement. Knoxville, TN: System Improvements.• Putz-Osterloh, W. (1993). Strategies for knowledge acquisition and transfer of knowledge in dynamic tasks. In G.
Strube & K.-F. Wender (Eds.), The cognitive psychology of knowledge (pp. 331-350). Amsterdam: ElsevierScience Publishers.
• Riefer, D.M., & Batchelder, W.H. (1988). Multinomial modeling and the measurement of cognitive processes.Psychological Review, 95, 318-339.
• Ringelband, O. J., Misiak, C., & Kluwe, R. H. (1990). Mental models and strategies in the control of a complexsystem. In D. Ackermann, & M. J. Tauber (Eds.), Mental models and human-computer interaction (Vol. 1, pp.151-164). Amsterdam: Elsevier Science Publishers.
• Schaub, H. (1993). Modellierung der Handlungsorganisation. Bern, Switzerland: Hans Huber.• Sokol, S. M., & McCloskey, M. (1991). Cognitive mechanisms in calculation. In R. J. Sternberg & P. A. Frensch
(Eds.), Complex problem solving: Principles and mechanisms (pp. 85-116). Hillsdale, NJ: Lawrence ErlbaumAssociates.
• Stanovich, K. E., & Cunningham, A. E. (1991). Reading as constrained reasoning. In R. J. Sternberg & P. A.Frensch (Eds.), Complex problem solving: Principles and mechanisms (pp. 3-60). Hillsdale, NJ: LawrenceErlbaum Associates.
• Sternberg, R. J. (1995). Conceptions of expertise in complex problem solving: A comparison of alternativeconceptions. In P. A. Frensch & J. Funke (Eds.), Complex problem solving: The European Perspective (pp.295-321). Hillsdale, NJ: Lawrence Erlbaum Associates.
• Sternberg, R. J., & Frensch, P. A. (Eds.). (1991). Complex problem solving: Principles and mechanisms.Hillsdale, NJ: Lawrence Erlbaum Associates.
• Strauß, B. (1993). Konfundierungen beim Komplexen Problemlösen. Zum Einfluß des Anteils der richtigen Lösungen (ArL) auf das Problemlöseverhalten in komplexen Situationen [Confoundations in complex problem

Problem solving 64
solving. On the influence of the degree of correct solutions on problem solving in complex situations]. Bonn,Germany: Holos.
• Strohschneider, S. (1991). Kein System von Systemen! Kommentar zu dem Aufsatz "Systemmerkmale alsDeterminanten des Umgangs mit dynamischen Systemen" von Joachim Funke [No system of systems! Reply tothe paper "System features as determinants of behavior in dynamic task environments" by Joachim Funke].Sprache & Kognition, 10, 109-113.
• Van Lehn, K. (1989). Problem solving and cognitive skill acquisition. In M. I. Posner (Ed.), Foundations ofcognitive science (pp. 527-579). Cambridge, MA: MIT Press.
• Voss, J. F., Wolfe, C. R., Lawrence, J. A., & Engle, R. A. (1991). From representation to decision: An analysis ofproblem solving in international relations. In R. J. Sternberg & P. A. Frensch (Eds.), Complex problem solving:Principles and mechanisms (pp. 119-158). Hillsdale, NJ: Lawrence Erlbaum Associates.
• Wagner, R. K. (1991). Managerial problem solving. In R. J. Sternberg & P. A. Frensch (Eds.), Complex problemsolving: Principles and mechanisms (pp. 159-183). Hillsdale, NJ: Lawrence Erlbaum Associates.
• Wisconsin Educational Media Association. (1993). "Information literacy: A position paper on informationproblem-solving." Madison, WI: WEMA Publications. (ED 376 817). (Portions adapted from Michigan StateBoard of Education's Position Paper on Information Processing Skills, 1992).
• Altshuller, Genrich (1973). Innovation Algorithm. Worcester, MA: Technical Innovation Center.ISBN 0-9640740-2-8.
• Altshuller, Genrich (1984). Creativity as an Exact Science. New York, NY: Gordon & Breach.ISBN 0-677-21230-5.
• Altshuller, Genrich (1994). And Suddenly the Inventor Appeared. translated by Lev Shulyak. Worcester, MA:Technical Innovation Center. ISBN 0-9640740-1-X.
• D’Zurilla, T. J., & Goldfried, M. R. (1971). Problem solving and behavior modification. Journal of AbnormalPsychology, 78, 107-126.
• D'Zurilla, T. J., & Nezu, A. M. (1982). Social problem solving in adults. In P. C. Kendall (Ed.), Advances incognitive-behavioral research and therapy (Vol. 1, pp. 201–274). New York: Academic Press.
• Rath J. F.; Langenbahn D. M.; Simon D.; Sherr R. L.; Fletcher J.; Diller L. (2004). The construct of problemsolving in higher level neuropsychological assessment and rehabilitation. Archives of Clinical Neuropsychology,19, 613-635. doi:10.1016/j.acn.2003.08.006
• Rath, J. F.; Simon, D.; Langenbahn, D. M.; Sherr, R. L.; Diller, L. (2003). Group treatment of problem-solvingdeficits in outpatients with traumatic brain injury: A randomised outcome study. NeuropsychologicalRehabilitation, 13, 461-488.
External links• Computer Skills for Information Problem-Solving: Learning and Teaching Technology in Context [8]
• Problem solving-Elementary level [9]
• CROP (Communities Resolving Our Problems) [10]
• The Altshuller Institute for TRIZ Studies, Worcester, MA [11]
References[1] Goldstein F. C., & Levin H. S. (1987). Disorders of reasoning and problem-solving ability. In M. Meier, A. Benton, & L. Diller (Eds.),
Neuropsychological rehabilitation. London: Taylor & Francis Group.[2] Duncker, K. (1935). Zur Psychologie des produktiven Denkens [The psychology of productive thinking]. Berlin: Julius Springer.[3] Mayer, R. E. (1992). Thinking, problem solving, cognition. Second edition. New York: W. H. Freeman and Company.[4] *Newell, A., & Simon, H. A. (1972). Human problem solving. Englewood Cliffs, NJ: Prentice-Hall.[5] 2007 Draft, Washington State Revised Mathematics Standard[6] http:/ / www. usabilityviews. com/ uv007206. html[7] http:/ / worldcat. org/ oclc/ 50065032& tab=holdings

Problem solving 65
[8] http:/ / www. ericdigests. org/ 1996-4/ skills. htm[9] http:/ / moodle. ed. uiuc. edu/ wiked/ index. php/ Problem_solving-Elementary_level[10] http:/ / ceap. wcu. edu/ houghton/ Learner/ basicidea. html[11] http:/ / www. aitriz. org

66
Algorithm
Algorithm
This is an algorithm that tries to figure out whythe lamp doesn't turn on and tries to fix it using
the steps. Flowcharts are often used to graphicallyrepresent algorithms.
In mathematics, computer science, and related subjects, an 'algorithm'is an effective method for solving a problem expressed as a finitesequence of instructions. Algorithms are used for calculation, dataprocessing, and many other fields. (In more advanced or abstractsettings, the instructions do not necessarily constitute a finite sequence,and even not necessarily a sequence; see, e.g., "nondeterministicalgorithm".)
Each algorithm is a list of well-defined instructions for completing atask. Starting from an initial state, the instructions describe acomputation that proceeds through a well-defined series of successivestates, eventually terminating in a final ending state. The transitionfrom one state to the next is not necessarily deterministic; somealgorithms, known as randomized algorithms, incorporate randomness.
A partial formalization of the concept began with attempts to solve theEntscheidungsproblem (the "decision problem") posed by DavidHilbert in 1928. Subsequent formalizations were framed as attempts todefine "effective calculability"[1] or "effective method";[2] thoseformalizations included the Gödel–Herbrand–Kleene recursivefunctions of 1930, 1934 and 1935, Alonzo Church's lambda calculus of1936, Emil Post's "Formulation 1" of 1936, and Alan Turing's Turing machines of 1936–7 and 1939.
The adjective "continuous" when applied to the word "algorithm" can mean: 1) An algorithm operating on data thatrepresents continuous quantities, even though this data is represented by discrete approximations – such algorithmsare studied in numerical analysis; or 2) An algorithm in the form of a differential equation that operates continuouslyon the data, running on an analog computer.[3]
EtymologyAl-Khwārizmī (in Persian: یمزراوخ), Persian astronomer and mathematician, wrote a treatise in the Arabic language in825 AD, On Calculation with Hindu–Arabic numeral system. (See algorism). It was translated from Arabic intoLatin in the 12th century as Algoritmi de numero Indorum (al-Daffa 1977), whose title is supposedly likely intendedto mean "Algoritmi on the numbers of the Indians", where "Algoritmi" was the translator's rendition of the author'sname; but people misunderstanding the title treated Algoritmi as a Latin plural and this led to the word "algorithm"(Latin algorismus) coming to mean "calculation method". The intrusive "th" is most likely due to a false cognatewith the Greek ἀριθμός (arithmos) meaning "numbers".

Algorithm 67
Why algorithms are necessary: an informal definitionFor a detailed presentation of the various points of view around the definition of "algorithm" see Algorithmcharacterizations. For examples of simple addition algorithms specified in the detailed manner described inAlgorithm characterizations, see Algorithm examples.
While there is no generally accepted formal definition of "algorithm," an informal definition could be "a process thatperforms some sequence of operations." For some people, a program is only an algorithm if it stops eventually. Forothers, a program is only an algorithm if it stops before a given number of calculation steps.A prototypical example of an algorithm is Euclid's algorithm to determine the maximum common divisor of twointegers.We can derive clues to the issues involved and an informal meaning of the word from the following quotation fromBoolos & Jeffrey (1974, 1999) (boldface added):
No human being can write fast enough, or long enough, or small enough† ( †"smaller and smallerwithout limit ...you'd be trying to write on molecules, on atoms, on electrons") to list all members of anenumerably infinite set by writing out their names, one after another, in some notation. But humans cando something equally useful, in the case of certain enumerably infinite sets: They can give explicitinstructions for determining the nth member of the set, for arbitrary finite n. Such instructions are tobe given quite explicitly, in a form in which they could be followed by a computing machine, or by ahuman who is capable of carrying out only very elementary operations on symbols[4]
The term "enumerably infinite" means "countable using integers perhaps extending to infinity." Thus Boolos andJeffrey are saying that an algorithm implies instructions for a process that "creates" output integers from an arbitrary"input" integer or integers that, in theory, can be chosen from 0 to infinity. Thus we might expect an algorithm to bean algebraic equation such as y = m + n — two arbitrary "input variables" m and n that produce an output y. As wesee in Algorithm characterizations — the word algorithm implies much more than this, something on the order of(for our addition example):
Precise instructions (in language understood by "the computer") for a "fast, efficient, good" process thatspecifies the "moves" of "the computer" (machine or human, equipped with the necessary internally containedinformation and capabilities) to find, decode, and then munch arbitrary input integers/symbols m and n,symbols + and = ... and (reliably, correctly, "effectively") produce, in a "reasonable" time, output-integer y ata specified place and in a specified format.
The concept of algorithm is also used to define the notion of decidability. That notion is central for explaining howformal systems come into being starting from a small set of axioms and rules. In logic, the time that an algorithmrequires to complete cannot be measured, as it is not apparently related with our customary physical dimension.From such uncertainties, that characterize ongoing work, stems the unavailability of a definition of algorithm thatsuits both concrete (in some sense) and abstract usage of the term.
FormalizationAlgorithms are essential to the way computers process information. Many computer programs contain algorithmsthat specify the specific instructions a computer should perform (in a specific order) to carry out a specified task,such as calculating employees' paychecks or printing students' report cards. Thus, an algorithm can be considered tobe any sequence of operations that can be simulated by a Turing-complete system. Authors who assert this thesisinclude Minsky (1967), Savage (1987) and Gurevich (2000):
Minsky: "But we will also maintain, with Turing . . . that any procedure which could "naturally" becalled effective, can in fact be realized by a (simple) machine. Although this may seem extreme, thearguments . . . in its favor are hard to refute".[5]

Algorithm 68
Gurevich: "...Turing's informal argument in favor of his thesis justifies a stronger thesis: every algorithmcan be simulated by a Turing machine ... according to Savage [1987], an algorithm is a computationalprocess defined by a Turing machine".[6]
Typically, when an algorithm is associated with processing information, data is read from an input source, written toan output device, and/or stored for further processing. Stored data is regarded as part of the internal state of the entityperforming the algorithm. In practice, the state is stored in one or more data structures.For any such computational process, the algorithm must be rigorously defined: specified in the way it applies in allpossible circumstances that could arise. That is, any conditional steps must be systematically dealt with,case-by-case; the criteria for each case must be clear (and computable).Because an algorithm is a precise list of precise steps, the order of computation will always be critical to thefunctioning of the algorithm. Instructions are usually assumed to be listed explicitly, and are described as starting"from the top" and going "down to the bottom", an idea that is described more formally by flow of control.So far, this discussion of the formalization of an algorithm has assumed the premises of imperative programming.This is the most common conception, and it attempts to describe a task in discrete, "mechanical" means. Unique tothis conception of formalized algorithms is the assignment operation, setting the value of a variable. It derives fromthe intuition of "memory" as a scratchpad. There is an example below of such an assignment.For some alternate conceptions of what constitutes an algorithm see functional programming and logic programming.
TerminationSome writers restrict the definition of algorithm to procedures that eventually finish. In such a category Kleeneplaces the "decision procedure or decision method or algorithm for the question".[7] Others, including Kleene,include procedures that could run forever without stopping; such a procedure has been called a "computationalmethod"[8] or "calculation procedure or algorithm (and hence a calculation problem) in relation to a generalquestion which requires for an answer, not yes or no, but the exhibiting of some object".[9]
Minsky makes the pertinent observation, in regards to determining whether an algorithm will eventually terminate(from a particular starting state):
But if the length of the process isn't known in advance, then "trying" it may not be decisive, because ifthe process does go on forever—then at no time will we ever be sure of the answer.[5]
As it happens, no other method can do any better, as was shown by Alan Turing with his celebrated result on theundecidability of the so-called halting problem. There is no algorithmic procedure for determining of arbitraryalgorithms whether or not they terminate from given starting states. The analysis of algorithms for their likelihood oftermination is called termination analysis.See the examples of (im-)"proper" subtraction at partial function for more about what can happen when an algorithmfails for certain of its input numbers—e.g., (i) non-termination, (ii) production of "junk" (output in the wrong formatto be considered a number) or no number(s) at all (halt ends the computation with no output), (iii) wrong number(s),or (iv) a combination of these. Kleene proposed that the production of "junk" or failure to produce a number issolved by having the algorithm detect these instances and produce e.g., an error message (he suggested "0"), orpreferably, force the algorithm into an endless loop.[10] Davis (1958) does this to his subtraction algorithm—he fixeshis algorithm in a second example so that it is proper subtraction and it terminates.[11] Along with the logicaloutcomes "true" and "false" Kleene (1952) also proposes the use of a third logical symbol "u" — undecided[12] —thus an algorithm will always produce something when confronted with a "proposition". The problem of wronganswers must be solved with an independent "proof" of the algorithm e.g., using induction:
We normally require auxiliary evidence for this [that the algorithm correctly defines a mu recursive function], e.g., in the form of an inductive proof that, for each argument value, the computation

Algorithm 69
terminates with a unique value.[13]
Expressing algorithmsAlgorithms can be expressed in many kinds of notation, including natural languages, pseudocode, flowcharts,programming languages or control tables (processed by interpreters). Natural language expressions of algorithmstend to be verbose and ambiguous, and are rarely used for complex or technical algorithms. Pseudocode, flowchartsand control tables are structured ways to express algorithms that avoid many of the ambiguities common in naturallanguage statements, while remaining independent of a particular implementation language. Programming languagesare primarily intended for expressing algorithms in a form that can be executed by a computer, but are often used asa way to define or document algorithms.There is a wide variety of representations possible and one can express a given Turing machine program as asequence of machine tables (see more at finite state machine and state transition table), as flowcharts (see more atstate diagram), or as a form of rudimentary machine code or assembly code called "sets of quadruples" (see more atTuring machine).Sometimes it is helpful in the description of an algorithm to supplement small "flow charts" (state diagrams) withnatural-language and/or arithmetic expressions written inside "block diagrams" to summarize what the "flow charts"are accomplishing.Representations of algorithms are generally classed into three accepted levels of Turing machine description:[14]
• 1 High-level description:"...prose to describe an algorithm, ignoring the implementation details. At this level we do not need tomention how the machine manages its tape or head."
• 2 Implementation description:"...prose used to define the way the Turing machine uses its head and the way that it stores data on itstape. At this level we do not give details of states or transition function."
• 3 Formal description:Most detailed, "lowest level", gives the Turing machine's "state table".
For an example of the simple algorithm "Add m+n" described in all three levels see Algorithm examples.
Computer algorithmsIn computer systems, an algorithm is basically an instance of logic written in software by software developers to beeffective for the intended "target" computer(s), in order for the software on the target machines to do something. Forinstance, if a person is writing software that is supposed to print out a PDF document located at the operating systemfolder "/My Documents" at computer drive "D:" every Friday at 10 pm, they will write an algorithm that specifiesthe following actions: "If today's date (computer time) is 'Friday,' open the document at 'D:/My Documents' and callthe 'print' function". While this simple algorithm does not look into whether the printer has enough paper or whetherthe document has been moved into a different location, one can make this algorithm more robust and anticipate theseproblems by rewriting it as a formal CASE statement[15] or as a (carefully crafted) sequence of IF-THEN-ELSEstatements.[16] For example the CASE statement might appear as follows (there are other possibilities):
CASE 1: IF today's date is NOT Friday THEN exit this CASE instruction ELSECASE 2: IF today's date is Friday AND the document is located at 'D:/My Documents' AND there is paper inthe printer THEN print the document (and exit this CASE instruction) ELSECASE 3: IF today's date is Friday AND the document is NOT located at 'D:/My Documents' THEN display'document not found' error message (and exit this CASE instruction) ELSE

Algorithm 70
CASE 4: IF today's date is Friday AND the document is located at 'D:/My Documents' AND there is NO paperin the printer THEN (i) display 'out of paper' error message and (ii) exit.
Note that CASE 3 includes two possibilities: (i) the document is NOT located at 'D:/My Documents' AND there'spaper in the printer OR (ii) the document is NOT located at 'D:/My Documents' AND there's NO paper in the printer.The sequence of IF-THEN-ELSE tests might look like this:
TEST 1: IF today's date is NOT Friday THEN done ELSE TEST 2:TEST 2: IF the document is NOT located at 'D:/My Documents' THEN display 'document not found'error message ELSE TEST 3:
TEST 3: IF there is NO paper in the printer THEN display 'out of paper' error message ELSE printthe document.
These examples' logic grants precedence to the instance of "NO document at 'D:/My Documents' ". Also observe thatin a well-crafted CASE statement or sequence of IF-THEN-ELSE statements the number of distinct actions—4 inthese examples: do nothing, print the document, display 'document not found', display 'out of paper' – equals thenumber of cases.Given unlimited memory, a computational machine with the ability to execute either a set of CASE statements or asequence of IF-THEN-ELSE statements is Turing complete. Therefore, anything that is computable can be computedby this machine. This form of algorithm is fundamental to computer programming in all its forms (see more atMcCarthy formalism).
ImplementationMost algorithms are intended to be implemented as computer programs. However, algorithms are also implementedby other means, such as in a biological neural network (for example, the human brain implementing arithmetic or aninsect looking for food), in an electrical circuit, or in a mechanical device.
Example
An animation of the quicksort algorithm sortingan array of randomized values. The red bars mark
the pivot element; at the start of the animation,the element farthest to the right hand side is
chosen as the pivot.
One of the simplest algorithms is to find the largest number in an(unsorted) list of numbers. The solution necessarily requires looking atevery number in the list, but only once at each. From this follows asimple algorithm, which can be stated in a high-level descriptionEnglish prose, as:High-level description:
1. Assume the first item is largest.2. Look at each of the remaining items in the list and if it is larger than
the largest item so far, make a note of it.3. The last noted item is the largest in the list when the process is
complete.(Quasi-)formal description: Written in prose but much closer to thehigh-level language of a computer program, the following is the moreformal coding of the algorithm in pseudocode or pidgin code:
Algorithm LargestNumber
Input: A non-empty list of numbers L.
Output: The largest number in the list L.

Algorithm 71
largest ← L0
for each item in the list (Length(L)≥1), do if the item > largest, then
largest ← the item return largest
• "←" is a loose shorthand for "changes to". For instance, "largest ← item" means that the value of largest changes to the value of item.
• "return" terminates the algorithm and outputs the value that follows.
For a more complex example of an algorithm, see Euclid's algorithm for the greatest common divisor, one of theearliest algorithms known.
Algorithmic analysisIt is frequently important to know how much of a particular resource (such as time or storage) is theoreticallyrequired for a given algorithm. Methods have been developed for the analysis of algorithms to obtain suchquantitative answers (estimates); for example, the algorithm above has a time requirement of O(n), using the big Onotation with n as the length of the list. At all times the algorithm only needs to remember two values: the largestnumber found so far, and its current position in the input list. Therefore it is said to have a space requirement ofO(1), if the space required to store the input numbers is not counted, or O(n) if it is counted.Different algorithms may complete the same task with a different set of instructions in less or more time, space, or'effort' than others. For example, a binary search algorithm will usually outperform a brute force sequential searchwhen used for table lookups on sorted lists.
Formal versus empiricalThe analysis and study of algorithms is a discipline of computer science, and is often practiced abstractly without theuse of a specific programming language or implementation. In this sense, algorithm analysis resembles othermathematical disciplines in that it focuses on the underlying properties of the algorithm and not on the specifics ofany particular implementation. Usually pseudocode is used for analysis as it is the simplest and most generalrepresentation. However, ultimately, most algorithms are usually implemented on particular hardware / softwareplatforms and their algorithmic efficiency is eventually put to the test using real code.Empirical testing is useful because it may uncover unexpected interactions that affect performance. For instance analgorithm that has no locality of reference may have much poorer performance than predicted because it 'thrashes thecache'. Benchmarks may be used to compare before/after potential improvements to an algorithm after programoptimization.
ClassificationThere are various ways to classify algorithms, each with its own merits.
By implementationOne way to classify algorithms is by implementation means.• Recursion or iteration: A recursive algorithm is one that invokes (makes reference to) itself repeatedly until a
certain condition matches, which is a method common to functional programming. Iterative algorithms userepetitive constructs like loops and sometimes additional data structures like stacks to solve the given problems.Some problems are naturally suited for one implementation or the other. For example, towers of Hanoi is wellunderstood in recursive implementation. Every recursive version has an equivalent (but possibly more or lesscomplex) iterative version, and vice versa.

Algorithm 72
• Logical: An algorithm may be viewed as controlled logical deduction. This notion may be expressed as:Algorithm = logic + control.[17] The logic component expresses the axioms that may be used in the computationand the control component determines the way in which deduction is applied to the axioms. This is the basis forthe logic programming paradigm. In pure logic programming languages the control component is fixed andalgorithms are specified by supplying only the logic component. The appeal of this approach is the elegantsemantics: a change in the axioms has a well defined change in the algorithm.
• Serial or parallel or distributed: Algorithms are usually discussed with the assumption that computers executeone instruction of an algorithm at a time. Those computers are sometimes called serial computers. An algorithmdesigned for such an environment is called a serial algorithm, as opposed to parallel algorithms or distributedalgorithms. Parallel algorithms take advantage of computer architectures where several processors can work on aproblem at the same time, whereas distributed algorithms utilize multiple machines connected with a network.Parallel or distributed algorithms divide the problem into more symmetrical or asymmetrical subproblems andcollect the results back together. The resource consumption in such algorithms is not only processor cycles oneach processor but also the communication overhead between the processors. Sorting algorithms can beparallelized efficiently, but their communication overhead is expensive. Iterative algorithms are generallyparallelizable. Some problems have no parallel algorithms, and are called inherently serial problems.
• Deterministic or non-deterministic: Deterministic algorithms solve the problem with exact decision at everystep of the algorithm whereas non-deterministic algorithms solve problems via guessing although typical guessesare made more accurate through the use of heuristics.
• Exact or approximate: While many algorithms reach an exact solution, approximation algorithms seek anapproximation that is close to the true solution. Approximation may use either a deterministic or a randomstrategy. Such algorithms have practical value for many hard problems.
By design paradigmAnother way of classifying algorithms is by their design methodology or paradigm. There is a certain number ofparadigms, each different from the other. Furthermore, each of these categories will include many different types ofalgorithms. Some commonly found paradigms include:• Brute-force or exhaustive search. This is the naïve method of trying every possible solution to see which is
best.[18]
• Divide and conquer. A divide and conquer algorithm repeatedly reduces an instance of a problem to one or moresmaller instances of the same problem (usually recursively) until the instances are small enough to solve easily.One such example of divide and conquer is merge sorting. Sorting can be done on each segment of data afterdividing data into segments and sorting of entire data can be obtained in the conquer phase by merging thesegments. A simpler variant of divide and conquer is called a decrease and conquer algorithm, that solves anidentical subproblem and uses the solution of this subproblem to solve the bigger problem. Divide and conquerdivides the problem into multiple subproblems and so the conquer stage will be more complex than decrease andconquer algorithms. An example of decrease and conquer algorithm is the binary search algorithm.
• Dynamic programming. When a problem shows optimal substructure, meaning the optimal solution to a problem can be constructed from optimal solutions to subproblems, and overlapping subproblems, meaning the same subproblems are used to solve many different problem instances, a quicker approach called dynamic programming avoids recomputing solutions that have already been computed. For example, the shortest path to a goal from a vertex in a weighted graph can be found by using the shortest path to the goal from all adjacent vertices. Dynamic programming and memoization go together. The main difference between dynamic programming and divide and conquer is that subproblems are more or less independent in divide and conquer, whereas subproblems overlap in dynamic programming. The difference between dynamic programming and straightforward recursion is in caching or memoization of recursive calls. When subproblems are independent and there is no repetition, memoization does not help; hence dynamic programming is not a solution for all complex

Algorithm 73
problems. By using memoization or maintaining a table of subproblems already solved, dynamic programmingreduces the exponential nature of many problems to polynomial complexity.
• The greedy method. A greedy algorithm is similar to a dynamic programming algorithm, but the difference isthat solutions to the subproblems do not have to be known at each stage; instead a "greedy" choice can be made ofwhat looks best for the moment. The greedy method extends the solution with the best possible decision (not allfeasible decisions) at an algorithmic stage based on the current local optimum and the best decision (not allpossible decisions) made in a previous stage. It is not exhaustive, and does not give accurate answer to manyproblems. But when it works, it will be the fastest method. The most popular greedy algorithm is finding theminimal spanning tree as given by Kruskal.
• Linear programming. When solving a problem using linear programming, specific inequalities involving theinputs are found and then an attempt is made to maximize (or minimize) some linear function of the inputs. Manyproblems (such as the maximum flow for directed graphs) can be stated in a linear programming way, and then besolved by a 'generic' algorithm such as the simplex algorithm. A more complex variant of linear programming iscalled integer programming, where the solution space is restricted to the integers.
• Reduction. This technique involves solving a difficult problem by transforming it into a better known problemfor which we have (hopefully) asymptotically optimal algorithms. The goal is to find a reducing algorithm whosecomplexity is not dominated by the resulting reduced algorithm's. For example, one selection algorithm forfinding the median in an unsorted list involves first sorting the list (the expensive portion) and then pulling out themiddle element in the sorted list (the cheap portion). This technique is also known as transform and conquer.
• Search and enumeration. Many problems (such as playing chess) can be modeled as problems on graphs. Agraph exploration algorithm specifies rules for moving around a graph and is useful for such problems. Thiscategory also includes search algorithms, branch and bound enumeration and backtracking.
1. Randomized algorithms are those that make some choices randomly (or pseudo-randomly); for some problems, itcan in fact be proven that the fastest solutions must involve some randomness. There are two large classes of suchalgorithms:1. Monte Carlo algorithms return a correct answer with high-probability. E.g. RP is the subclass of these that run
in polynomial time)2. Las Vegas algorithms always return the correct answer, but their running time is only probabilistically bound,
e.g. ZPP.2. In optimization problems, heuristic algorithms do not try to find an optimal solution, but an approximate solution
where the time or resources are limited. They are not practical to find perfect solutions. An example of this wouldbe local search, tabu search, or simulated annealing algorithms, a class of heuristic probabilistic algorithms thatvary the solution of a problem by a random amount. The name "simulated annealing" alludes to the metallurgicterm meaning the heating and cooling of metal to achieve freedom from defects. The purpose of the randomvariance is to find close to globally optimal solutions rather than simply locally optimal ones, the idea being thatthe random element will be decreased as the algorithm settles down to a solution. Approximation algorithms arethose heuristic algorithms that additionally provide some bounds on the error. Genetic algorithms attempt to findsolutions to problems by mimicking biological evolutionary processes, with a cycle of random mutations yieldingsuccessive generations of "solutions". Thus, they emulate reproduction and "survival of the fittest". In geneticprogramming, this approach is extended to algorithms, by regarding the algorithm itself as a "solution" to aproblem.

Algorithm 74
By field of studyEvery field of science has its own problems and needs efficient algorithms. Related problems in one field are oftenstudied together. Some example classes are search algorithms, sorting algorithms, merge algorithms, numericalalgorithms, graph algorithms, string algorithms, computational geometric algorithms, combinatorial algorithms,machine learning, cryptography, data compression algorithms and parsing techniques.Fields tend to overlap with each other, and algorithm advances in one field may improve those of other, sometimescompletely unrelated, fields. For example, dynamic programming was invented for optimization of resourceconsumption in industry, but is now used in solving a broad range of problems in many fields.
By complexityAlgorithms can be classified by the amount of time they need to complete compared to their input size. There is awide variety: some algorithms complete in linear time relative to input size, some do so in an exponential amount oftime or even worse, and some never halt. Additionally, some problems may have multiple algorithms of differingcomplexity, while other problems might have no algorithms or no known efficient algorithms. There are alsomappings from some problems to other problems. Owing to this, it was found to be more suitable to classify theproblems themselves instead of the algorithms into equivalence classes based on the complexity of the best possiblealgorithms for them.
By computing powerAnother way to classify algorithms is by computing power. This is typically done by considering some collection(class) of algorithms. A recursive class of algorithms is one that includes algorithms for all Turing computablefunctions. Looking at classes of algorithms allows for the possibility of restricting the available computationalresources (time and memory) used in a computation. A subrecursive class of algorithms is one in which not allTuring computable functions can be obtained. For example, the algorithms that run in polynomial time suffice formany important types of computation but do not exhaust all Turing computable functions. The class of algorithmsimplemented by primitive recursive functions is another subrecursive class.Burgin (2005, p. 24) uses a generalized definition of algorithms that relaxes the common requirement that the outputof the algorithm that computes a function must be determined after a finite number of steps. He defines asuper-recursive class of algorithms as "a class of algorithms in which it is possible to compute functions notcomputable by any Turing machine" (Burgin 2005, p. 107). This is closely related to the study of methods ofhypercomputation.
Legal issuesSee also: Software patents for a general overview of the patentability of software, includingcomputer-implemented algorithms.
Algorithms, by themselves, are not usually patentable. In the United States, a claim consisting solely of simplemanipulations of abstract concepts, numbers, or signals does not constitute "processes" (USPTO 2006), and hencealgorithms are not patentable (as in Gottschalk v. Benson). However, practical applications of algorithms aresometimes patentable. For example, in Diamond v. Diehr, the application of a simple feedback algorithm to aid inthe curing of synthetic rubber was deemed patentable. The patenting of software is highly controversial, and thereare highly criticized patents involving algorithms, especially data compression algorithms, such as Unisys' LZWpatent.Additionally, some cryptographic algorithms have export restrictions (see export of cryptography).

Algorithm 75
History: Development of the notion of "algorithm"
Discrete and distinguishable symbolsTally-marks: To keep track of their flocks, their sacks of grain and their money the ancients used tallying:accumulating stones or marks scratched on sticks, or making discrete symbols in clay. Through the Babylonian andEgyptian use of marks and symbols, eventually Roman numerals and the abacus evolved (Dilson, p. 16–41). Tallymarks appear prominently in unary numeral system arithmetic used in Turing machine and Post–Turing machinecomputations.
Manipulation of symbols as "place holders" for numbers: algebraThe work of the ancient Greek geometers (Euclidean algorithm), Persian mathematician Al-Khwarizmi (from whosename the terms "algorism" and "algorithm" are derived), and Western European mathematicians culminated inLeibniz's notion of the calculus ratiocinator (ca 1680):
A good century and a half ahead of his time, Leibniz proposed an algebra of logic, an algebra that wouldspecify the rules for manipulating logical concepts in the manner that ordinary algebra specifies the rules formanipulating numbers.[19]
Mechanical contrivances with discrete statesThe clock: Bolter credits the invention of the weight-driven clock as "The key invention [of Europe in the MiddleAges]", in particular the verge escapement[20] that provides us with the tick and tock of a mechanical clock. "Theaccurate automatic machine"[21] led immediately to "mechanical automata" beginning in the thirteenth century andfinally to "computational machines" – the difference engine and analytical engines of Charles Babbage and CountessAda Lovelace.[22]
Logical machines 1870 – Stanley Jevons' "logical abacus" and "logical machine": The technical problem was toreduce Boolean equations when presented in a form similar to what are now known as Karnaugh maps. Jevons(1880) describes first a simple "abacus" of "slips of wood furnished with pins, contrived so that any part or class ofthe [logical] combinations can be picked out mechanically . . . More recently however I have reduced the system to acompletely mechanical form, and have thus embodied the whole of the indirect process of inference in what may becalled a Logical Machine" His machine came equipped with "certain moveable wooden rods" and "at the foot are 21keys like those of a piano [etc] . . .". With this machine he could analyze a "syllogism or any other simple logicalargument".[23]
This machine he displayed in 1870 before the Fellows of the Royal Society.[24] Another logician John Venn,however, in his 1881 Symbolic Logic, turned a jaundiced eye to this effort: "I have no high estimate myself of theinterest or importance of what are sometimes called logical machines ... it does not seem to me that any contrivancesat present known or likely to be discovered really deserve the name of logical machines"; see more at Algorithmcharacterizations. But not to be outdone he too presented "a plan somewhat analogous, I apprehend, to Prof. Jevon'sabacus ... [And] [a]gain, corresponding to Prof. Jevons's logical machine, the following contrivance may bedescribed. I prefer to call it merely a logical-diagram machine ... but I suppose that it could do very completely allthat can be rationally expected of any logical machine".[25]
Jacquard loom, Hollerith punch cards, telegraphy and telephony—the electromechanical relay: Bell andNewell (1971) indicate that the Jacquard loom (1801), precursor to Hollerith cards (punch cards, 1887), and"telephone switching technologies" were the roots of a tree leading to the development of the first computers.[26] Bythe mid-1800s the telegraph, the precursor of the telephone, was in use throughout the world, its discrete anddistinguishable encoding of letters as "dots and dashes" a common sound. By the late 1800s the ticker tape (ca1870s) was in use, as was the use of Hollerith cards in the 1890 U.S. census. Then came the Teletype (ca. 1910) withits punched-paper use of Baudot code on tape.

Algorithm 76
Telephone-switching networks of electromechanical relays (invented 1835) was behind the work of George Stibitz(1937), the inventor of the digital adding device. As he worked in Bell Laboratories, he observed the "burdensome'use of mechanical calculators with gears. "He went home one evening in 1937 intending to test his idea... When thetinkering was over, Stibitz had constructed a binary adding device".[27]
Davis (2000) observes the particular importance of the electromechanical relay (with its two "binary states" open andclosed):
It was only with the development, beginning in the 1930s, of electromechanical calculators using electricalrelays, that machines were built having the scope Babbage had envisioned."[28]
Mathematics during the 1800s up to the mid-1900sSymbols and rules: In rapid succession the mathematics of George Boole (1847, 1854), Gottlob Frege (1879), andGiuseppe Peano (1888–1889) reduced arithmetic to a sequence of symbols manipulated by rules. Peano's Theprinciples of arithmetic, presented by a new method (1888) was "the first attempt at an axiomatization ofmathematics in a symbolic language".[29]
But Heijenoort gives Frege (1879) this kudos: Frege's is "perhaps the most important single work ever written inlogic. ... in which we see a " 'formula language', that is a lingua characterica, a language written with specialsymbols, "for pure thought", that is, free from rhetorical embellishments ... constructed from specific symbols thatare manipulated according to definite rules".[30] The work of Frege was further simplified and amplified by AlfredNorth Whitehead and Bertrand Russell in their Principia Mathematica (1910–1913).The paradoxes: At the same time a number of disturbing paradoxes appeared in the literature, in particular theBurali-Forti paradox (1897), the Russell paradox (1902–03), and the Richard Paradox.[31] The resultantconsiderations led to Kurt Gödel's paper (1931) — he specifically cites the paradox of the liar—that completelyreduces rules of recursion to numbers.Effective calculability: In an effort to solve the Entscheidungsproblem defined precisely by Hilbert in 1928,mathematicians first set about to define what was meant by an "effective method" or "effective calculation" or"effective calculability" (i.e., a calculation that would succeed). In rapid succession the following appeared: AlonzoChurch, Stephen Kleene and J.B. Rosser's λ-calculus[32] a finely honed definition of "general recursion" from thework of Gödel acting on suggestions of Jacques Herbrand (cf. Gödel's Princeton lectures of 1934) and subsequentsimplifications by Kleene.[33] Church's proof[34] that the Entscheidungsproblem was unsolvable, Emil Post'sdefinition of effective calculability as a worker mindlessly following a list of instructions to move left or rightthrough a sequence of rooms and while there either mark or erase a paper or observe the paper and make a yes-nodecision about the next instruction.[35] Alan Turing's proof of that the Entscheidungsproblem was unsolvable by useof his "a- [automatic-] machine"[36] – in effect almost identical to Post's "formulation", J. Barkley Rosser's definitionof "effective method" in terms of "a machine".[37] S. C. Kleene's proposal of a precursor to "Church thesis" that hecalled "Thesis I",[38] and a few years later Kleene's renaming his Thesis "Church's Thesis"[39] and proposing"Turing's Thesis".[40]
Emil Post (1936) and Alan Turing (1936–7, 1939)Here is a remarkable coincidence of two men not knowing each other but describing a process of men-as-computersworking on computations—and they yield virtually identical definitions.Emil Post (1936) described the actions of a "computer" (human being) as follows:
"...two concepts are involved: that of a symbol space in which the work leading from problem to answer is tobe carried out, and a fixed unalterable set of directions.
His symbol space would be

Algorithm 77
"a two way infinite sequence of spaces or boxes... The problem solver or worker is to move and work in thissymbol space, being capable of being in, and operating in but one box at a time.... a box is to admit of but twopossible conditions, i.e., being empty or unmarked, and having a single mark in it, say a vertical stroke."One box is to be singled out and called the starting point. ...a specific problem is to be given in symbolic formby a finite number of boxes [i.e., INPUT] being marked with a stroke. Likewise the answer [i.e., OUTPUT] isto be given in symbolic form by such a configuration of marked boxes...."A set of directions applicable to a general problem sets up a deterministic process when applied to eachspecific problem. This process will terminate only when it comes to the direction of type (C ) [i.e., STOP]".[41]
See more at Post–Turing machineAlan Turing's work[42] preceded that of Stibitz (1937); it is unknown whether Stibitz knew of the work of Turing.Turing's biographer believed that Turing's use of a typewriter-like model derived from a youthful interest: "Alan haddreamt of inventing typewriters as a boy; Mrs. Turing had a typewriter; and he could well have begun by askinghimself what was meant by calling a typewriter 'mechanical'".[43] Given the prevalence of Morse code andtelegraphy, ticker tape machines, and Teletypes we might conjecture that all were influences.Turing—his model of computation is now called a Turing machine — begins, as did Post, with an analysis of ahuman computer that he whittles down to a simple set of basic motions and "states of mind". But he continues a stepfurther and creates a machine as a model of computation of numbers.[44]
"Computing is normally done by writing certain symbols on paper. We may suppose this paper is divided intosquares like a child's arithmetic book....I assume then that the computation is carried out on one-dimensionalpaper, i.e., on a tape divided into squares. I shall also suppose that the number of symbols which may beprinted is finite...."The behavior of the computer at any moment is determined by the symbols which he is observing, and his"state of mind" at that moment. We may suppose that there is a bound B to the number of symbols or squareswhich the computer can observe at one moment. If he wishes to observe more, he must use successiveobservations. We will also suppose that the number of states of mind which need be taken into account isfinite..."Let us imagine that the operations performed by the computer to be split up into 'simple operations' which areso elementary that it is not easy to imagine them further divided".[45]
Turing's reduction yields the following:"The simple operations must therefore include:
"(a) Changes of the symbol on one of the observed squares"(b) Changes of one of the squares observed to another square within L squares of one of the previouslyobserved squares.
"It may be that some of these change necessarily invoke a change of state of mind. The most general single operationmust therefore be taken to be one of the following:
"(A) A possible change (a) of symbol together with a possible change of state of mind."(B) A possible change (b) of observed squares, together with a possible change of state of mind"
"We may now construct a machine to do the work of this computer"[45] .A few years later, Turing expanded his analysis (thesis, definition) with this forceful expression of it:
"A function is said to be "effectively calculable" if its values can be found by some purely mechanical process. Although it is fairly easy to get an intuitive grasp of this idea, it is nevertheless desirable to have some more definite, mathematical expressible definition . . . [he discusses the history of the definition pretty much as presented above with respect to Gödel, Herbrand, Kleene, Church, Turing and Post] . . . We may take this statement literally, understanding by a purely mechanical process one which could be carried out by a

Algorithm 78
machine. It is possible to give a mathematical description, in a certain normal form, of the structures of thesemachines. The development of these ideas leads to the author's definition of a computable function, and to anidentification of computability † with effective calculability . . . .
"† We shall use the expression "computable function" to mean a function calculable by a machine, andwe let "effectively calculable" refer to the intuitive idea without particular identification with any one ofthese definitions".[46]
J. B. Rosser (1939) and S. C. Kleene (1943)J. Barkley Rosser boldly defined an 'effective [mathematical] method' in the following manner (boldface added):
"'Effective method' is used here in the rather special sense of a method each step of which is preciselydetermined and which is certain to produce the answer in a finite number of steps. With this special meaning,three different precise definitions have been given to date. [his footnote #5; see discussion immediatelybelow]. The simplest of these to state (due to Post and Turing) says essentially that an effective method ofsolving certain sets of problems exists if one can build a machine which will then solve any problem ofthe set with no human intervention beyond inserting the question and (later) reading the answer. Allthree definitions are equivalent, so it doesn't matter which one is used. Moreover, the fact that all three areequivalent is a very strong argument for the correctness of any one." (Rosser 1939:225–6)
Rosser's footnote #5 references the work of (1) Church and Kleene and their definition of λ-definability, in particularChurch's use of it in his An Unsolvable Problem of Elementary Number Theory (1936); (2) Herbrand and Gödel andtheir use of recursion in particular Gödel's use in his famous paper On Formally Undecidable Propositions ofPrincipia Mathematica and Related Systems I (1931); and (3) Post (1936) and Turing (1936–7) in theirmechanism-models of computation.Stephen C. Kleene defined as his now-famous "Thesis I" known as the Church–Turing thesis. But he did this in thefollowing context (boldface in original):
"12. Algorithmic theories... In setting up a complete algorithmic theory, what we do is to describe aprocedure, performable for each set of values of the independent variables, which procedure necessarilyterminates and in such manner that from the outcome we can read a definite answer, "yes" or "no," to thequestion, "is the predicate value true?"" (Kleene 1943:273)
History after 1950A number of efforts have been directed toward further refinement of the definition of "algorithm", and activity ison-going because of issues surrounding, in particular, foundations of mathematics (especially the Church–TuringThesis) and philosophy of mind (especially arguments around artificial intelligence). For more, see Algorithmcharacterizations.
See also• Abstract machine• Algorithm characterizations• Algorithm design• Algorithmic efficiency• Algorithm engineering• Algorithm examples• Algorithmic music• Algorithmic synthesis• Algorithmic trading

Algorithm 79
• Data structure• Garbage In, Garbage Out• Heuristics• Important algorithm-related publications• Introduction to Algorithms• List of algorithm general topics• List of algorithms• List of terms relating to algorithms and data structures• Numerical Mathematics Consortium• Partial function• Profiling (computer programming)• Program optimization• Randomized algorithm and quantum algorithm• Theory of computation
• Computability (part of computability theory)• Computational complexity theory
References• Axt, P. (1959) On a Subrecursive Hierarchy and Primitive Recursive Degrees, Transactions of the American
Mathematical Society 92, pp. 85–105• Bell, C. Gordon and Newell, Allen (1971), Computer Structures: Readings and Examples, McGraw-Hill Book
Company, New York. ISBN 0-07-004357-4}.• Blass, Andreas; Gurevich, Yuri (2003). "Algorithms: A Quest for Absolute Definitions" [47]. Bulletin of European
Association for Theoretical Computer Science 81. Includes an excellent bibliography of 56 references.• Boolos, George; Jeffrey, Richard (1974, 1980, 1989, 1999). Computability and Logic (4th ed.). Cambridge
University Press, London. ISBN 0-521-20402-X.: cf. Chapter 3 Turing machines where they discuss "certainenumerable sets not effectively (mechanically) enumerable".
• Burgin, M. Super-recursive algorithms, Monographs in computer science, Springer, 2005. ISBN 0-387-95569-0• Campagnolo, M.L., Moore, C., and Costa, J.F. (2000) An analog characterization of the subrecursive functions. In
Proc. of the 4th Conference on Real Numbers and Computers, Odense University, pp. 91–109• Church, Alonzo (1936a). "An Unsolvable Problem of Elementary Number Theory" [48]. The American Journal of
Mathematics 58 (2): 345–363. doi:10.2307/2371045. Reprinted in The Undecidable, p. 89ff. The first expressionof "Church's Thesis". See in particular page 100 (The Undecidable) where he defines the notion of "effectivecalculability" in terms of "an algorithm", and he uses the word "terminates", etc.
• Church, Alonzo (1936b). "A Note on the Entscheidungsproblem" [49]. The Journal of Symbolic Logic 1 (1):40–41. doi:10.2307/2269326. Church, Alonzo (1936). "Correction to a Note on the Entscheidungsproblem" [50].The Journal of Symbolic Logic 1 (3): 101–102. doi:10.2307/2269030. Reprinted in The Undecidable, p. 110ff.Church shows that the Entscheidungsproblem is unsolvable in about 3 pages of text and 3 pages of footnotes.
• Daffa', Ali Abdullah al- (1977). The Muslim contribution to mathematics. London: Croom Helm.ISBN 0-85664-464-1.
• Davis, Martin (1965). The Undecidable: Basic Papers On Undecidable Propositions, Unsolvable Problems andComputable Functions. New York: Raven Press. ISBN 0486432289. Davis gives commentary before each article.Papers of Gödel, Alonzo Church, Turing, Rosser, Kleene, and Emil Post are included; those cited in the article arelisted here by author's name.
• Davis, Martin (2000). Engines of Logic: Mathematicians and the Origin of the Computer. New York: W. W. Nortion. ISBN 0393322297. Davis offers concise biographies of Leibniz, Boole, Frege, Cantor, Hilbert, Gödel and Turing with von Neumann as the show-stealing villain. Very brief bios of Joseph-Marie Jacquard, Babbage,

Algorithm 80
Ada Lovelace, Claude Shannon, Howard Aiken, etc.• This article incorporates public domain material from the NIST document "algorithm" [51] by Paul E. Black
(Dictionary of Algorithms and Data Structures).• Dennett, Daniel (1995). Darwin's Dangerous Idea. New York: Touchstone/Simon & Schuster.
ISBN 0684802902.• Yuri Gurevich, Sequential Abstract State Machines Capture Sequential Algorithms [52], ACM Transactions on
Computational Logic, Vol 1, no 1 (July 2000), pages 77–111. Includes bibliography of 33 sources.• Kleene C., Stephen (1936). "General Recursive Functions of Natural Numbers". Mathematische Annalen 112 (5):
727–742. doi:10.1007/BF01565439. Presented to the American Mathematical Society, September 1935.Reprinted in The Undecidable, p. 237ff. Kleene's definition of "general recursion" (known now as mu-recursion)was used by Church in his 1935 paper An Unsolvable Problem of Elementary Number Theory that proved the"decision problem" to be "undecidable" (i.e., a negative result).
• Kleene C., Stephen (1943). "Recursive Predicates and Quantifiers" [53]. American Mathematical SocietyTransactions 54 (1): 41–73. doi:10.2307/1990131. Reprinted in The Undecidable, p. 255ff. Kleene refined hisdefinition of "general recursion" and proceeded in his chapter "12. Algorithmic theories" to posit "Thesis I"(p. 274); he would later repeat this thesis (in Kleene 1952:300) and name it "Church's Thesis"(Kleene 1952:317)(i.e., the Church thesis).
• Kleene, Stephen C. (First Edition 1952). Introduction to Metamathematics (Tenth Edition 1991 ed.).North-Holland Publishing Company. ISBN 0720421039. Excellent—accessible, readable—reference source formathematical "foundations".
• Knuth, Donald (1997). Fundamental Algorithms, Third Edition. Reading, Massachusetts: Addison–Wesley.ISBN 0201896834.
• Kosovsky, N. K. Elements of Mathematical Logic and its Application to the theory of Subrecursive Algorithms,LSU Publ., Leningrad, 1981
• Kowalski, Robert (1979). "Algorithm=Logic+Control". Communications of the ACM 22 (7): 424–436.doi:10.1145/359131.359136. ISSN 0001-0782.
• A. A. Markov (1954) Theory of algorithms. [Translated by Jacques J. Schorr-Kon and PST staff] ImprintMoscow, Academy of Sciences of the USSR, 1954 [i.e., Jerusalem, Israel Program for Scientific Translations,1961; available from the Office of Technical Services, U.S. Dept. of Commerce, Washington] Description 444p. 28 cm. Added t.p. in Russian Translation of Works of the Mathematical Institute, Academy of Sciences of theUSSR, v. 42. Original title: Teoriya algerifmov. [QA248.M2943 Dartmouth College library. U.S. Dept. ofCommerce, Office of Technical Services, number OTS 60-51085.]
• Minsky, Marvin (1967). Computation: Finite and Infinite Machines (First ed.). Prentice-Hall, Englewood Cliffs,NJ. ISBN 0131654497. Minsky expands his "...idea of an algorithm—an effective procedure..." in chapter 5.1Computability, Effective Procedures and Algorithms. Infinite machines."
• Post, Emil (1936). "Finite Combinatory Processes, Formulation I" [54]. The Journal of Symbolic Logic 1 (3):103–105. doi:10.2307/2269031. Reprinted in The Undecidable, p. 289ff. Post defines a simple algorithmic-likeprocess of a man writing marks or erasing marks and going from box to box and eventually halting, as he followsa list of simple instructions. This is cited by Kleene as one source of his "Thesis I", the so-called Church–Turingthesis.
• Rosser, J.B. (1939). "An Informal Exposition of Proofs of Godel's Theorem and Church's Theorem". Journal ofSymbolic Logic 4. Reprinted in The Undecidable, p. 223ff. Herein is Rosser's famous definition of "effectivemethod": "...a method each step of which is precisely predetermined and which is certain to produce the answer ina finite number of steps... a machine which will then solve any problem of the set with no human interventionbeyond inserting the question and (later) reading the answer" (p. 225–226, The Undecidable)
• Sipser, Michael (2006). Introduction to the Theory of Computation. PWS Publishing Company.ISBN 053494728X.

Algorithm 81
• Stone, Harold S. (1972). Introduction to Computer Organization and Data Structures (1972 ed.). McGraw-Hill,New York. ISBN 0070617260. Cf. in particular the first chapter titled: Algorithms, Turing Machines, andPrograms. His succinct informal definition: "...any sequence of instructions that can be obeyed by a robot, iscalled an algorithm" (p. 4).
• Turing, Alan M. (1936–7). "On Computable Numbers, With An Application to the Entscheidungsproblem".Proceedings of the London Mathematical Society, Series 2 42: 230–265. doi:10.1112/plms/s2-42.1.230..Corrections, ibid, vol. 43(1937) pp. 544–546. Reprinted in The Undecidable, p. 116ff. Turing's famous papercompleted as a Master's dissertation while at King's College Cambridge UK.
• Turing, Alan M. (1939). "Systems of Logic Based on Ordinals". Proceedings of the London MathematicalSociety, Series 2 45: 161–228. doi:10.1112/plms/s2-45.1.161. Reprinted in The Undecidable, p. 155ff. Turing'spaper that defined "the oracle" was his PhD thesis while at Princeton USA.
• United States Patent and Trademark Office (2006), 2106.02 **>Mathematical Algorithms< - 2100 Patentability[55], Manual of Patent Examining Procedure (MPEP). Latest revision August 2006
Secondary references• Bolter, David J. (1984). Turing's Man: Western Culture in the Computer Age (1984 ed.). The University of North
Carolina Press, Chapel Hill NC. ISBN 0807815640., ISBN 0-8078-4108-0 pbk.• Dilson, Jesse (2007). The Abacus ((1968,1994) ed.). St. Martin's Press, NY. ISBN 031210409X., ISBN
0-312-10409-X (pbk.)• van Heijenoort, Jean (2001). From Frege to Gödel, A Source Book in Mathematical Logic, 1879–1931 ((1967)
ed.). Harvard University Press, Cambridge, MA. ISBN 0674324498., 3rd edition 1976[?], ISBN 0-674-32449-8(pbk.)
• Hodges, Andrew (1983). Alan Turing: The Enigma ((1983) ed.). Simon and Schuster, New York.ISBN 0671492071., ISBN 0-671-49207-1. Cf. Chapter "The Spirit of Truth" for a history leading to, and adiscussion of, his proof.
Further reading• David Harel, Yishai A. Feldman, Algorithmics: the spirit of computing, Edition 3, Pearson Education, 2004, ISBN
0-321-11784-0• Jean-Luc Chabert, Évelyne Barbin, A history of algorithms: from the pebble to the microchip, Springer, 1999,
ISBN 3-540-63369-3
External links• The Stony Brook Algorithm Repository [56]
• Weisstein, Eric W., "Algorithm [57]" from MathWorld.• Algorithms in Everyday Mathematics [58]
• Algorithms [59] at the Open Directory Project• Sortier- und Suchalgorithmen (German) [60]
• Jeff Erickson Algorithms course material [61]
• Algorithms [62] – an Open Access journal

Algorithm 82
References[1] Kleene 1943 in Davis 1965:274[2] Rosser 1939 in Davis 1965:225[3] Adaptation and learning in automatic systems (http:/ / books. google. com/ books?id=sgDHJlafMskC), page 54, Ya. Z. Tsypkin, Z. J. Nikolic,
Academic Press, 1971, ISBN 978-0-12-702050-1[4] Boolos and Jeffrey 1974,1999:19[5] Minsky 1967:105[6] Gurevich 2000:1, 3[7] Kleene 1952:136[8] Knuth 1997:5[9] Boldface added, Kleene 1952:137[10] Kleene 1952:325[11] Davis 1958:12–15[12] Kleene 1952:332[13] Minsky 1967:186[14] Sipser 2006:157[15] Kleene 1952:229 shows that "Definition by cases" is primitive recursive. CASES requires that the list of testable instances within the CASE
definition to be (i) mutually exclusive and (ii) collectively exhaustive i.e. it must include or "cover" all possibility. The CASE statementproceeds in numerical order and exits at the first successful test; see more at Boolos–Burgess–Jeffrey Fourth edition 2002:74
[16] An IF-THEN-ELSE or "logical test with branching" is just a CASE instruction reduced to two outcomes: (i) test is successful, (ii) test isunsuccessful. The IF-THEN-ELSE is closely related to the AND-OR-INVERT logic function from which all 16 logical "operators" of one ortwo variables can be derived; see more at Propositional formula. Like definition by cases, a sequence of IF-THEN-ELSE logical tests must bemutually exclusive and collectively exhaustive over the variables tested.
[17] Kowalski 1979[18] Sue Carroll, Taz Daughtrey (2007-07-04). Fundamental Concepts for the Software Quality Engineer (http:/ / books. google. com/
?id=bz_cl3B05IcC& pg=PA282). pp. 282 et seq.. ISBN 9780873897204. .[19] Davis 2000:18[20] Bolter 1984:24[21] Bolter 1984:26[22] Bolter 1984:33–34, 204–206)[23] All quotes from W. Stanley Jevons 1880 Elementary Lessons in Logic: Deductive and Inductive, Macmillan and Co., London and New
York. Republished as a googlebook; cf Jevons 1880:199–201. Louis Couturat 1914 the Algebra of Logic, The Open Court PublishingCompany, Chicago and London. Republished as a googlebook; cf Couturat 1914:75–76 gives a few more details; interestingly he comparesthis to a typewriter as well as a piano. Jevons states that the account is to be found at Jan . 20, 1870 The Proceedings of the Royal Society.
[24] Jevons 1880:199–200[25] All quotes from John Venn 1881 Symbolic Logic, Macmillan and Co., London. Republished as a googlebook. cf Venn 1881:120–125. The
interested reader can find a deeper explanation in those pages.[26] Bell and Newell diagram 1971:39, cf. Davis 2000[27] * Melina Hill, Valley News Correspondent, A Tinkerer Gets a Place in History, Valley News West Lebanon NH, Thursday March 31, 1983,
page 13.[28] Davis 2000:14[29] van Heijenoort 1967:81ff[30] van Heijenoort's commentary on Frege's Begriffsschrift, a formula language, modeled upon that of arithmetic, for pure thought in van
Heijenoort 1967:1[31] Dixon 1906, cf. Kleene 1952:36–40[32] cf. footnote in Alonzo Church 1936a in Davis 1965:90 and 1936b in Davis 1965:110[33] Kleene 1935–6 in Davis 1965:237ff, Kleene 1943 in Davis 1965:255ff[34] Church 1936 in Davis 1965:88ff[35] cf. "Formulation I", Post 1936 in Davis 1965:289–290[36] Turing 1936–7 in Davis 1965:116ff[37] Rosser 1939 in Davis 1965:226[38] Kleene 1943 in Davis 1965:273–274[39] Kleene 1952:300, 317[40] Kleene 1952:376[41] Turing 1936–7 in Davis 1965:289–290[42] Turing 1936 in Davis 1965, Turing 1939 in Davis 1965:160[43] Hodges, p. 96[44] Turing 1936–7:116)

Algorithm 83
[45] Turing 1936–7 in Davis 1965:136[46] Turing 1939 in Davis 1965:160[47] http:/ / research. microsoft. com/ ~gurevich/ Opera/ 164. pdf[48] http:/ / jstor. org/ stable/ 2371045[49] http:/ / jstor. org/ stable/ 2269326[50] http:/ / jstor. org/ stable/ 2269030[51] http:/ / www. nist. gov/ dads/ HTML/ algorithm. html[52] http:/ / research. microsoft. com/ ~gurevich/ Opera/ 141. pdf[53] http:/ / jstor. org/ stable/ 1990131[54] http:/ / jstor. org/ stable/ 2269031[55] http:/ / www. uspto. gov/ web/ offices/ pac/ mpep/ documents/ 2100_2106_02. htm[56] http:/ / www. cs. sunysb. edu/ ~algorith/[57] http:/ / mathworld. wolfram. com/ Algorithm. html[58] http:/ / everydaymath. uchicago. edu/ educators/ Algorithms_final. pdf[59] http:/ / www. dmoz. org/ Computers/ Algorithms/ /[60] http:/ / sortieralgorithmen. de/[61] http:/ / compgeom. cs. uiuc. edu/ ~jeffe/ / teaching/ algorithms/[62] http:/ / www. mdpi. com/ journal/ algorithms/
Flowchart
A simple flowchart representing a process fordealing with a non-functioning lamp.
A flowchart is a common type of diagram, that represents analgorithm or process, showing the steps as boxes of various kinds, andtheir order by connecting these with arrows. This diagrammaticrepresentation can give a step-by-step solution to a given problem.Data is represented in these boxes, and arrows connecting themrepresent flow / direction of flow of data. Flowcharts are used inanalyzing, designing, documenting or managing a process or programin various fields.[1]
History
The first structured method for documenting process flow, the "flowprocess chart", was introduced by Frank Gilbreth to members of theAmerican Society of Mechanical Engineers (ASME) in 1921 in thepresentation “Process Charts—First Steps in Finding the One BestWay”. Gilbreth's tools quickly found their way into industrialengineering curricula. In the early 1930s, an industrial engineer, AllanH. Mogensen began training business people in the use of some of thetools of industrial engineering at his Work Simplification Conferences in Lake Placid, New York.
A 1944 graduate of Mogensen's class, Art Spinanger, took the tools back to Procter and Gamble where he developedtheir Deliberate Methods Change Program. Another 1944 graduate, Ben S. Graham, Director of FormcraftEngineering at Standard Register Corporation, adapted the flow process chart to information processing with hisdevelopment of the multi-flow process chart to display multiple documents and their relationships.[2] In 1947, ASMEadopted a symbol set derived from Gilbreth's original work as the ASME Standard for Process Charts by Mishad,Ramsan & Raiaan.Douglas Hartree explains that Herman Goldstine and John von Neumann developed the flow chart (originally, diagram) to plan computer programs.[3] His contemporary account is endorsed by IBM engineers[4] and by Goldstine's personal recollections.[5] The original programming flow charts of Goldstine and von Neumann can be

Flowchart 84
seen in their unpublished report, "Planning and coding of problems for an electronic computing instrument, Part II,Volume 1" (1947), which is reproduced in von Neumann's collected works.[6]
Flowcharts used to be a popular means for describing computer algorithms and are still used for this purpose.[7]
Modern techniques such as UML activity diagrams can be considered to be extensions of the flowchart. In the 1970sthe popularity of flowcharts as an own method decreased when interactive computer terminals and third-generationprogramming languages became the common tools of the trade, since algorithms can be expressed much moreconcisely and readably as source code in such a language. Often pseudo-code is used, which uses the commonidioms of such languages without strictly adhering to the details of a particular one.
Flowchart building blocks
Examples
A simple flowchart for computing factorial N(10!)
A flowchart for computing factorial N (10!) where N! =(1*2*3*4*5*6*7*8*9*10), see image. This flowchart represents a"loop and a half" — a situation discussed in introductory programmingtextbooks that requires either a duplication of a component (to be bothinside and outside the loop) or the component to be put inside a branchin the loop. (Note: Some textbooks recommend against this "loop and ahalf" since it is considered bad structure, instead a 'priming read'should be used and the loop should return back to the original questionand not above it.[8] )
panda.Start and end symbols
Represented as circles, ovals or rounded rectangles, usuallycontaining the word "Start" or "End", or another phrase signalingthe start or end of a process, such as "submit enquiry" or "receiveproduct".
ArrowsShowing what's called "flow of control" in computer science. Anarrow coming from one symbol and ending at another symbolrepresents that control passes to the symbol the arrow points to.
Processing stepsRepresented as rectangles. Examples: "Add 1 to X"; "replaceidentified part"; "save changes" or similar.
Input/OutputRepresented as a parallelogram. Examples: Get X from the user; display X.
Conditional or decisionRepresented as a diamond (rhombus). These typically contain a Yes/No question or True/False test. Thissymbol is unique in that it has two arrows coming out of it, usually from the bottom point and right point, onecorresponding to Yes or True, and one corresponding to No or False. The arrows should always be labeled.Adecision is necessary in a flowchart. More than two arrows can be used, but this is normally a clear indicatorthat a complex decision is being taken, in which case it may need to be broken-down further, or replaced withthe "pre-defined process" symbol.
A number of other symbols that have less universal currency, such as:

Flowchart 85
• A Document represented as a rectangle with a wavy base;• A Manual input represented by parallelogram, with the top irregularly sloping up from left to right. An example
would be to signify data-entry from a form;• A Manual operation represented by a trapezoid with the longest parallel side at the top, to represent an operation
or adjustment to process that can only be made manually.• A Data File represented by a cylinder.Flowcharts may contain other symbols, such as connectors, usually represented as circles, to represent convergingpaths in the flowchart. Circles will have more than one arrow coming into them but only one going out. Someflowcharts may just have an arrow point to another arrow instead. These are useful to represent an iterative process(what in Computer Science is called a loop). A loop may, for example, consist of a connector where control firstenters, processing steps, a conditional with one arrow exiting the loop, and one going back to the connector.Off-page connectors are often used to signify a connection to a (part of another) process held on another sheet orscreen. It is important to remember to keep these connections logical in order. All processes should flow from top tobottom and left to right.
Types of flowchart
Example of a system flowchart.
Sterneckert (2003) suggested that flowcharts can be modelled from theperspective of different user groups (such as managers, system analystsand clerks) and that there are four general types:[9]
• Document flowcharts, showing controls over a document-flowthrough a system
• Data flowcharts, showing controls over a data flows in a system• System flowcharts showing controls at a physical or resource level• Program flowchart, showing the controls in a program within a
system
Notice that every type of flowchart focusses on some kind of control,rather than on the particular flow itself.[9]
However there are several of these classifications. For example Andrew Veronis (1978) named three basic types offlowcharts: the system flowchart, the general flowchart, and the detailed flowchart.[10] That same year Marilyn Bohl(1978) stated "in practice, two kinds of flowcharts are used in solution planning: system flowcharts and programflowcharts...".[11] More recently Mark A. Fryman (2001) stated that there are more differences: "Decisionflowcharts, logic flowcharts, systems flowcharts, product flowcharts, and process flowcharts are just a few of thedifferent types of flowcharts that are used in business and government".[12]
In addition, many diagram techniques exist that are similar to flowcharts but carry a different name, such as UMLactivity diagrams.

Flowchart 86
Software
A paper-and-pencil template for drawingflowcharts, late 1970's.
Any drawing program can be used to create flowchart diagrams, butthese will have no underlying data model to share data with databasesor other programs such as project management systems orspreadsheets. Some tools offer special support for flowchart drawing.Many software packages exist that can create flowcharts automatically,either directly from source code, or from a flowchart descriptionlanguage. On-line Web-based versions of such programs are available
See also
Related diagrams
• Control flow diagram• Control flow graph• Data flow diagram• Deployment flowchart• Flow map• Functional flow block diagram• Nassi–Shneiderman diagram• N2 Chart• Petri nets• Sankey diagram• State diagram• Warnier-Orr
Related subjects
• Augmented transition network• Business process illustration• Business Process Mapping• Diagramming software• Process architecture• Pseudocode• Recursive transition network• Unified Modeling Language (UML)
Further reading• ISO (1985). Information processing -- Documentation symbols and conventions for data, program and system
flowcharts, program network charts and system resources charts [13]. International Organization forStandardization. ISO 5807:1985.
• ISO 10628: Flow Diagrams For Process Plants - General Rules
External links• Flowcharting Techniques [14] An IBM manual from 1969 (5MB PDF format)• Introduction to Programming in C++ flowchart and pseudocode [15] (PDF)• Advanced Flowchart [16] - Why and how to create advanced flowchart• Algorithm simulator and editor software [17] - Designing and analyzing algorithms

Flowchart 87
• Create and Edit Flowcharts, Interpret into C++ Programming Language [18] - Designing and Interpretingalgorithms
References[1] SEVOCAB: Software and Systems Engineering Vocabulary (http:/ / pascal. computer. org/ sev_display/ index. action). Term: Flow chart.
Retrieved 31 July 2008.[2] Graham, Jr., Ben S. (10 June 1996). "People come first" (http:/ / www. worksimp. com/ articles/ keynoteworkflowcanada. htm). Keynote
Address at Workflow Canada. .[3] Hartree, Douglas (1949). Calculating Instruments and Machines. The University of Illinois Press. p. 112.[4] Bashe, Charles (1986). IBM's Early Computers. The MIT Press. p. 327.[5] Goldstine, Herman (1972). The Computer from Pascal to Von Neumann. Princeton University Press. pp. 266–267. ISBN 0-691-08104-2.[6] Taub, Abraham (1963). John von Neumann Collected Works. 5. Macmillan. pp. 80–151.[7] Bohl, Rynn: "Tools for Structured and Object-Oriented Design", Prentice Hall, 2007.[8] Farrell, Joyce (2008). "Programming Logic and Design, 5th ed". Comprehensive[9] Alan B. Sterneckert (2003)Critical Incident Management. p. 126 (http:/ / books. google. co. uk/ books?id=8z93xStbEpAC& lpg=PP126&
pg=PA126#v=onepage& q=& f=false)[10] Andrew Veronis (1978) Microprocessors: Design and Applications. p. 111 (http:/ / books. google. co. uk/ books?id=GZ9QAAAAMAAJ&
q="three+ basic+ types+ of+ flowcharts+ (ie,+ the+ system+ flowchart,+ the+ general+ flowchart,+ and+ the+ detailed+ flowchart). "&dq="three+ basic+ types+ of+ flowcharts+ (ie,+ the+ system+ flowchart,+ the+ general+ flowchart,+ and+ the+ detailed+ flowchart). "&as_brr=0)
[11] Marilyn Bohl (1978) A Guide for Programmers. p. 65.[12] Mark A. Fryman (2001) Quality and Process Improvement. p. 169 (http:/ / books. google. co. uk/ books?id=M-_B7czAy0kC&
pg=PA169#v=onepage& q=& f=false).[13] http:/ / www. iso. org/ iso/ iso_catalogue/ catalogue_tc/ catalogue_detail. htm?csnumber=11955[14] http:/ / www. fh-jena. de/ ~kleine/ history/ software/ IBM-FlowchartingTechniques-GC20-8152-1. pdf[15] http:/ / www. allclearonline. com/ applications/ DocumentLibraryManager/ upload/ program_intro. pdf[16] http:/ / www. tipskey. com/ manufacturing/ advanced_flowchart. htm[17] http:/ / eri. edu. pl/ articles. php?cat_id=7[18] http:/ / vardanyan. am/ fi/

Pseudocode 88
PseudocodePseudocode is a compact and informal high-level description of a computer programming algorithm that uses thestructural conventions of a programming language, but is intended for human reading rather than machine reading.Pseudocode typically omits details that are not essential for human understanding of the algorithm, such as variabledeclarations, system-specific code and subroutines. The programming language is augmented with natural languagedescriptions of the details, where convenient, or with compact mathematical notation. The purpose of usingpseudocode is that it is easier for humans to understand than conventional programming language code, and that it isa compact and environment-independent description of the key principles of an algorithm. It is commonly used intextbooks and scientific publications that are documenting various algorithms, and also in planning of computerprogram development, for sketching out the structure of the program before the actual coding takes place.No standard for pseudocode syntax exists, as a program in pseudocode is not an executable program. Pseudocoderesembles, but should not be confused with, skeleton programs including dummy code, which can be compiledwithout errors. Flowcharts can be thought of as a graphical alternative to pseudocode.
ApplicationTextbooks and scientific publications related to computer science and numerical computation often use pseudocodein description of algorithms, so that all programmers can understand them, even if they do not all know the sameprogramming languages. In textbooks, there is usually an accompanying introduction explaining the particularconventions in use. The level of detail of such languages may in some cases approach that of formalizedgeneral-purpose languages — for example, Knuth's seminal textbook The Art of Computer Programming describesalgorithms in a fully-specified assembly language for a non-existent microprocessor.A programmer who needs to implement a specific algorithm, especially an unfamiliar one, will often start with apseudocode description, and then simply "translate" that description into the target programming language andmodify it to interact correctly with the rest of the program. Programmers may also start a project by sketching out thecode in pseudocode on paper before writing it in its actual language, as a top-down structuring approach.
SyntaxAs the name suggests, pseudocode generally does not actually obey the syntax rules of any particular language; thereis no systematic standard form, although any particular writer will generally borrow style and syntax for examplecontrol structures from some conventional programming language. Popular syntax sources include Pascal, BASIC,C, C++, Java, Lisp, and ALGOL. Variable declarations are typically omitted. Function calls and blocks of code, forexample code contained within a loop, is often replaced by a one-line natural language sentence.Depending on the writer, pseudocode may therefore vary widely in style, from a near-exact imitation of a realprogramming language at one extreme, to a description approaching formatted prose at the other.
ExamplesPascal style pseudocode example:
<variable> = <expression>
if <condition>
do stuff;
else
do other stuff;

Pseudocode 89
while <condition>
do stuff;
for <variable> from <first value> to <last value> by <step>
do stuff with variable;
function <function name>(<arguments>)
do stuff with arguments;
return something;
<function name>(<arguments>) // Function call
For more examples, see articles with example pseudocode.
Mathematical style pseudocodeIn numerical computation, pseudocode often consists of mathematical notation, typically from set and matrix theory,mixed with the control structures of a conventional programming language, and perhaps also natural languagedescriptions. This is a compact and often informal notation that can be understood by a wide range of mathematicallytrained people, and is frequently used as a way to describe mathematical algorithms. For example, the sum operator(capital-sigma notation) or the product operator (capital-pi notation) may represent a for loop and perhaps a selectionstructure in one expression:
Return
Normally non-ASCII typesetting is used for the mathematical equations, for example by means of TeX or MathMLmarkup, or proprietary formula editors.Mathematical style pseudocode is sometimes referred to as pidgin code, for example pidgin ALGOL (the origin ofthe concept), pidgin Fortran, pidgin BASIC, pidgin Pascal, pidgin C, and pidgin Ada.
Machine compilation of pseudo-code style languages
Natural language grammar in programming languagesVarious attempts to bring elements of natural language grammar into computer programming have producedprogramming languages such as HyperTalk, Lingo, AppleScript, SQL and Inform. In these languages, parenthesesand other special characters are replaced by prepositions, resulting in quite talkative code. This may make it easierfor a person without knowledge about the language to understand the code and perhaps also to learn the language.However, the similarity to natural language is usually more cosmetic than genuine. The syntax rules are just as strictand formal as in conventional programming, and do not necessarily make development of the programs easier.

Pseudocode 90
Mathematical programming languagesAn alternative to using mathematical pseudocode (involving set theory notation or matrix operations) fordocumentation of algorithms is to use a formal mathematical programming language that is a mix of non-ASCIImathematical notation and program control structures. Then the code can be parsed and interpreted by a machine.Several formal specification languages include set theory notation using special characters. Examples are:• Z notation• Vienna Development Method Specification Language (VDM-SL).Some array programming languages include vectorized expressions and matrix operations as non-ASCII formulas,mixed with conventional control structures. Examples are:• A programming language (APL), and its dialects APLX and A+.• MathCAD.
Alternative forms of pseudocodeSince the usual aim of pseudocode is to present a simple form of some algorithm, you could use a language syntaxcloser to the problem domain. This would make the expression of ideas in the pseudocode simpler to convey in thosedomains.
See also• Literate programming• Short Code• Dummy code• Pidgin code• Program Design Language (PDL)• Skeleton program• Structured English• Concept programming• WALGOL
External links• A pseudocode standard [1]
• Collected Algorithms of the [[Association for Computing Machinery|ACM [2]]]• Pseudocode Guidelines [3], PDF file.• Pseudocode Programming Process [4] base on data from Code Complete book
References[1] http:/ / www. csc. calpoly. edu/ ~jdalbey/ SWE/ pdl_std. html[2] http:/ / calgo. acm. org/[3] http:/ / www. cs. cornell. edu/ Courses/ cs482/ 2003su/ handouts/ pseudocode. pdf[4] http:/ / www. coderookie. com/ 2006/ tutorial/ the-pseudocode-programming-process/

91
Basic Programming Structure
C (programming language)
The C Programming Language[1] (aka "K&R") is the seminal book on C.Paradigm Imperative (procedural), structured
Appeared in 1972
Designed by Dennis Ritchie
Developer Originally:Dennis Ritchie & Bell LabsANSI C: ANSI X3J11ISO C: ISO/IEC JTC1/SC22/WG14
Stable release C99 (March 2000)
Preview release C1X
Typing discipline Static, weak, manifest
Majorimplementations
Clang, GCC, MSVC, Turbo C, Watcom C
Dialects Cyclone, Unified Parallel C, Split-C, Cilk, C*
Influenced by B (BCPL, CPL), ALGOL 68,[2] Assembly, PL/I, FORTRAN
Influenced Numerous: AWK, csh, C++, C-- , C#, Objective-C, BitC, D, Go, Java, JavaScript, Limbo, LPC, Perl, PHP,Pike, Processing, Python
OS Cross-platform (multi-platform)
Usual file extensions .h .c
C Programming at Wikibooks
C (pronounced /ˈsiː/ see) is a general-purpose computer programming language developed in 1972 by DennisRitchie at the Bell Telephone Laboratories for use with the Unix operating system.[3]
Although C was designed for implementing system software,[4] it is also widely used for developing portableapplication software.C is one of the most popular programming languages of all time[5] [6] and there are very few computer architecturesfor which a C compiler does not exist. C has greatly influenced many other popular programming languages, mostnotably C++, which began as an extension to C.

C (programming language) 92
DesignC is an imperative (procedural) systems implementation language. It was designed to be compiled using a relativelystraightforward compiler, to provide low-level access to memory, to provide language constructs that map efficientlyto machine instructions, and to require minimal run-time support. C was therefore useful for many applications thathad formerly been coded in assembly language.Despite its low-level capabilities, the language was designed to encourage machine-independent programming. Astandards-compliant and portably written C program can be compiled for a very wide variety of computer platformsand operating systems with little or no change to its source code. The language has become available on a very widerange of platforms, from embedded microcontrollers to supercomputers.
MinimalismC's design is tied to its intended use as a portable systems implementation language. It provides simple, direct accessto any addressable object (for example, memory-mapped device control registers), and its source-code expressionscan be translated in a straightforward manner to primitive machine operations in the executable code. Some early Ccompilers were comfortably implemented (as a few distinct passes communicating via intermediate files) on PDP-11processors having only 16 address bits. C compilers for several common 8-bit platforms have been implemented aswell.
CharacteristicsLike most imperative languages in the ALGOL tradition, C has facilities for structured programming and allowslexical variable scope and recursion, while a static type system prevents many unintended operations. In C, allexecutable code is contained within functions. Function parameters are always passed by value. Pass-by-reference issimulated in C by explicitly passing pointer values. Heterogeneous aggregate data types (struct) allow related dataelements to be combined and manipulated as a unit. C program source text is free-format, using the semicolon as astatement terminator.C also exhibits the following more specific characteristics:• Variables may be hidden in nested blocks• Partially weak typing; for instance, characters can be used as integers• Low-level access to computer memory by converting machine addresses to typed pointers• Function and data pointers supporting ad hoc run-time polymorphism• array indexing as a secondary notion, defined in terms of pointer arithmetic• A preprocessor for macro definition, source code file inclusion, and conditional compilation• Complex functionality such as I/O, string manipulation, and mathematical functions consistently delegated to
library routines• A relatively small set of reserved keywords• A large number of compound operators, such as +=, -=, *= and ++ etc.C's lexical structure resembles B more than ALGOL. For example:• { ... } rather than either ALGOL 60's begin ... end or ALGOL 68's ( ... )• = is used for assignment (copying), like Fortran, rather than ALGOL's :=• == is used to test for equality (rather than .EQ. in Fortran, or = in BASIC and ALGOL)• Logical "and" and "or" are represented with && and ||; Note that the doubled-up operators don't evaluate the right
operand if the result can be determined from the left alone (short-circuit evaluation), and are semantically distinctfrom the bit-wise operators & and |

C (programming language) 93
Absent featuresThe relatively low-level nature of the language affords the programmer close control over what the computer does,and allows special tailoring and aggressive optimization for a particular platform. This allows the code to runefficiently on very limited hardware, such as embedded systems, and keeps the language definition small enough toallow the programmer to understand most or all of the language, but at the cost of some features not being includedthat are available in other languages:• No nested function definitions• No direct assignment of arrays or strings (copying can be done via standard functions; assignment of objects
having struct or union type is supported)• No automatic garbage collection• No requirement for bounds checking of arrays• No operations on whole arrays at the language level• No syntax for ranges, such as the A..B notation used in several languages• Prior to C99, no separate Boolean type (1 (true) and 0 (false) are used instead)[7]
• No formal closures or functions as parameters (only function and variable pointers)• No generators or coroutines; intra-thread control flow consists of nested function calls, except for the use of the
longjmp or setcontext library functions• No exception handling; standard library functions signify error conditions with the global errno variable and/or
special return values, and library functions provide non-local gotos• Only rudimentary support for modular programming• No compile-time polymorphism in the form of function or operator overloading• Very limited support for object-oriented programming with regard to polymorphism and inheritance• Limited support for encapsulation• No native support for multithreading and networking• No standard libraries for computer graphics and several other application programming needsA number of these features are available as extensions in some compilers, or are provided in some operatingenvironments (e.g., POSIX), or are supplied by third-party libraries, or can be simulated by adopting certain codingdisciplines, or may be considered detrimental to good programming practice.
Undefined behaviorMany operations in C that have undefined behavior are not required to be diagnosed at compile time. In the case ofC, "undefined behavior" means that the exact behavior which arises is not specified by the standard, and exactlywhat will happen does not have to be documented by the C implementation. A famous and humorous expression inthe newsgroups [news:comp.std.c comp.std.c] and [news:comp.lang.c comp.lang.c] is that the program could cause"demons to fly out of your nose".[8] Sometimes in practice what happens for an instance of undefined behavior is abug that is hard to track down and which may corrupt the contents of memory. Sometimes a particular compilergenerates reasonable and well-behaved actions that are completely different from those that would be obtained usinga different C compiler. The reason some behavior has been left undefined is to allow compilers for a wide variety ofinstruction set architectures to generate more efficient executable code for well-defined behavior, which was deemedimportant for C's primary role as a systems implementation language; thus C makes it the programmer'sresponsibility to avoid undefined behavior, possibly using tools to find parts of a program whose behavior isundefined. Examples of undefined behavior are:• accessing outside the bounds of an array• overflowing a signed integer• reaching the end of a non-void function without finding a return statement, when the return value is used• reading the value of a variable before initializing it

C (programming language) 94
These operations are all programming errors that could occur using many programming languages; C draws criticismbecause its standard explicitly identifies numerous cases of undefined behavior, including some where the behaviorcould have been made well defined, and does not specify any run-time error handling mechanism.Invoking fflush() on a stream opened for input is an example of a different kind of undefined behavior, notnecessarily a programming error but a case for which some conforming implementations may provide well-defined,useful semantics (in this example, presumably discarding input through the next new-line) as an allowed extension.Over-reliance on nonstandard extensions undermines software portability.
History
Early developmentsThe initial development of C occurred at AT&T Bell Labs between 1969 and 1973;[2] according to Ritchie, the mostcreative period occurred in 1972. It was named "C" because its features were derived from an earlier language called"B", which according to Ken Thompson was a stripped-down version of the BCPL programming language.The origin of C is closely tied to the development of the Unix operating system, originally implemented in assemblylanguage on a PDP-7 by Ritchie and Thompson, incorporating several ideas from colleagues. Eventually theydecided to port the operating system to a PDP-11. B's lack of functionality taking advantage of some of the PDP-11'sfeatures, notably byte addressability, led to the development of an early version of C.The original PDP-11 version of the Unix system was developed in assembly language. By 1973, with the addition ofstruct types, the C language had become powerful enough that most of the Unix kernel was rewritten in C. This wasone of the first operating system kernels implemented in a language other than assembly. (Earlier instances includethe Multics system (written in PL/I), and MCP (Master Control Program) for the Burroughs B5000 written inALGOL in 1961.)
K&R CIn 1978, Brian Kernighan and Dennis Ritchie published the first edition of The C Programming Language.[9] Thisbook, known to C programmers as "K&R", served for many years as an informal specification of the language. Theversion of C that it describes is commonly referred to as K&R C. The second edition of the book[1] covers the laterANSI C standard.K&R introduced several language features:• standard I/O library• long int data type• unsigned int data type• compound assignment operators of the form =op (such as =-) were changed to the form op= to remove the
semantic ambiguity created by such constructs as i=-10, which had been interpreted as i =- 10 instead of thepossibly intended i = -10
Even after the publication of the 1989 C standard, for many years K&R C was still considered the "lowest commondenominator" to which C programmers restricted themselves when maximum portability was desired, since manyolder compilers were still in use, and because carefully written K&R C code can be legal Standard C as well.In early versions of C, only functions that returned a non-integer value needed to be declared if used before thefunction definition; a function used without any previous declaration was assumed to return an integer, if its valuewas used.For example:
long int SomeFunction();
/* int OtherFunction(); */

C (programming language) 95
/* int */ CallingFunction()
{
long int test1;
register /* int */ test2;
test1 = SomeFunction();
if (test1 > 0)
test2 = 0;
else
test2 = OtherFunction();
return test2;
}
All the above commented-out int declarations could be omitted in K&R C.Since K&R function declarations did not include any information about function arguments, function parameter typechecks were not performed, although some compilers would issue a warning message if a local function was calledwith the wrong number of arguments, or if multiple calls to an external function used different numbers or types ofarguments. Separate tools such as Unix's lint utility were developed that (among other things) could check forconsistency of function use across multiple source files.In the years following the publication of K&R C, several unofficial features were added to the language, supportedby compilers from AT&T and some other vendors. These included:• void functions• functions returning struct or union types (rather than pointers)• assignment for struct data types• enumerated typesThe large number of extensions and lack of agreement on a standard library, together with the language popularityand the fact that not even the Unix compilers precisely implemented the K&R specification, led to the necessity ofstandardization.
ANSI C and ISO CDuring the late 1970s and 1980s, versions of C were implemented for a wide variety of mainframe computers,minicomputers, and microcomputers, including the IBM PC, as its popularity began to increase significantly.In 1983, the American National Standards Institute (ANSI) formed a committee, X3J11, to establish a standardspecification of C. In 1989, the standard was ratified as ANSI X3.159-1989 "Programming Language C". Thisversion of the language is often referred to as ANSI C, Standard C, or sometimes C89.In 1990, the ANSI C standard (with formatting changes) was adopted by the International Organization forStandardization (ISO) as ISO/IEC 9899:1990, which is sometimes called C90. Therefore, the terms "C89" and "C90"refer to the same programming language.ANSI, like other national standards bodies, no longer develops the C standard independently, but defers to the ISO Cstandard. National adoption of updates to the international standard typically occurs within a year of ISO publication.One of the aims of the C standardization process was to produce a superset of K&R C, incorporating many of the unofficial features subsequently introduced. The standards committee also included several additional features such as function prototypes (borrowed from C++), void pointers, support for international character sets and locales, and preprocessor enhancements. The syntax for parameter declarations was also augmented to include the style used in

C (programming language) 96
C++, although the K&R interface continued to be permitted, for compatibility with existing source code.C89 is supported by current C compilers, and most C code being written nowadays is based on it. Any programwritten only in Standard C and without any hardware-dependent assumptions will run correctly on any platform witha conforming C implementation, within its resource limits. Without such precautions, programs may compile only ona certain platform or with a particular compiler, due, for example, to the use of non-standard libraries, such as GUIlibraries, or to a reliance on compiler- or platform-specific attributes such as the exact size of data types and byteendianness.In cases where code must be compilable by either standard-conforming or K&R C-based compilers, the __STDC__macro can be used to split the code into Standard and K&R sections to take advantage of features available only inStandard C.
C99After the ANSI/ISO standardization process, the C language specification remained relatively static for some time,whereas C++ continued to evolve, largely during its own standardization effort. In 1995 Normative Amendment 1 tothe 1990 C standard was published, to correct some details and to add more extensive support for internationalcharacter sets. The C standard was further revised in the late 1990s, leading to the publication of ISO/IEC 9899:1999in 1999, which is commonly referred to as "C99". It has since been amended three times by Technical Corrigenda.The international C standard is maintained by the working group ISO/IEC JTC1/SC22/WG14.C99 introduced several new features, including inline functions, several new data types (including long long int anda complex type to represent complex numbers), variable-length arrays, support for variadic macros (macros ofvariable arity) and support for one-line comments beginning with //, as in BCPL or C++. Many of these had alreadybeen implemented as extensions in several C compilers.C99 is for the most part backward compatible with C90, but is stricter in some ways; in particular, a declaration thatlacks a type specifier no longer has int implicitly assumed. A standard macro __STDC_VERSION__ is defined withvalue 199901L to indicate that C99 support is available. GCC, Sun Studio and other C compilers now support manyor all of the new features of C99.
C1XIn 2007, work began in anticipation of another revision of the C standard, informally called "C1X". The C standardscommittee has adopted guidelines to limit the adoption of new features that have not been tested by existingimplementations.
UsesC is often used for "system programming", including implementing operating systems and embedded systemapplications, due to a combination of desirable characteristics such as code portability and efficiency, ability toaccess specific hardware addresses, ability to pun types to match externally imposed data access requirements, andlow runtime demand on system resources. C can also be used for website programming using CGI as a "gateway" forinformation between the Web application, the server, and the browser.[10] Some factors to choose C over Interpretedlanguages are its speed, stability and less susceptibility to changes in operating environments due to its compilednature.[11]
One consequence of C's wide acceptance and efficiency is that compilers, libraries, and interpreters of otherprogramming languages are often implemented in C. For example, many Eiffel compilers output C source code as anintermediate language, to submit to a C compiler. The primary implementations of Python (CPython), Perl 5, andPHP are all written in C.

C (programming language) 97
Due to its thin layer of abstraction and low overhead, C allows efficient implementations of algorithms and datastructures, which is useful for programs that have to perform a lot of computations. For example, the GNUMulti-Precision Library, the GNU Scientific Library, Mathematica and MATLAB are completely or partially writtenin C.C is sometimes used as an intermediate language by implementations of other languages. This approach may be usedfor portability or convenience; by using C as an intermediate language, it is not necessary to developmachine-specific code generators. Some compilers which use C this way are BitC, Gambit, the Glasgow HaskellCompiler, Squeak, and Vala. However, C was designed as a programming language, not as a compiler targetlanguage, and is thus less than ideal for use as an intermediate language. This has led to development of C-basedintermediate languages such as C--.C has also been widely used to implement end-user applications, but much of that development has shifted to otherlanguages that have come along, such as C++, C# and Visual Basic.
SyntaxUnlike languages such as FORTRAN 77, C source code is free-form which allows arbitrary use of whitespace toformat code, rather than column-based or text-line-based restrictions. Comments may appear either between thedelimiters /* and */, or (in C99) following // until the end of the line.Each source file contains declarations and function definitions. Function definitions, in turn, contain declarations andstatements. Declarations either define new types using keywords such as struct, union, and enum, or assign types toand perhaps reserve storage for new variables, usually by writing the type followed by the variable name. Keywordssuch as char and int specify built-in types. Sections of code are enclosed in braces ({ and }, sometimes called "curlybrackets") to limit the scope of declarations and to act as a single statement for control structures.As an imperative language, C uses statements to specify actions. The most common statement is an expressionstatement, consisting of an expression to be evaluated, followed by a semicolon; as a side effect of the evaluation,functions may be called and variables may be assigned new values. To modify the normal sequential execution ofstatements, C provides several control-flow statements identified by reserved keywords. Structured programming issupported by if(-else) conditional execution and by do-while, while, and for iterative execution (looping). The forstatement has separate initialization, testing, and reinitialization expressions, any or all of which can be omitted.break and continue can be used to leave the innermost enclosing loop statement or skip to its reinitialization. There isalso a non-structured goto statement which branches directly to the designated label within the function. switchselects a case to be executed based on the value of an integer expression.Expressions can use a variety of built-in operators (see below) and may contain function calls. The order in whicharguments to functions and operands to most operators are evaluated is unspecified. The evaluations may even beinterleaved. However, all side effects (including storage to variables) will occur before the next "sequence point";sequence points include the end of each expression statement, and the entry to and return from each function call.Sequence points also occur during evaluation of expressions containing certain operators(&&, ||, ?: and the commaoperator). This permits a high degree of object code optimization by the compiler, but requires C programmers totake more care to obtain reliable results than is needed for other programming languages.Although mimicked by many languages because of its widespread familiarity, C's syntax has often been criticized.For example, Kernighan and Ritchie say in the Introduction of The C Programming Language, "C, like any otherlanguage, has its blemishes. Some of the operators have the wrong precedence; some parts of the syntax could bebetter."Some specific problems worth noting are:• Not checking number and types of arguments when the function declaration has an empty parameter list. (This
provides backward compatibility with K&R C, which lacked prototypes.)

C (programming language) 98
• Some questionable choices of operator precedence, as mentioned by Kernighan and Ritchie above, such as ==binding more tightly than & and | in expressions like x & 1 == 0, which would need to be written (x & 1) == 0 tobe properly evaluated.
• The use of the = operator, used in mathematics for equality, to indicate assignment, following the precedent ofFortran, PL/I, and BASIC, but unlike ALGOL and its derivatives. Ritchie made this syntax design decisionconsciously, based primarily on the argument that assignment occurs more often than comparison.
• Similarity of the assignment and equality operators (= and ==), making it easy to accidentally substitute one forthe other. In many cases, each may be used in the context of the other without a compilation error (althoughcompilers generally produce warnings). For example, the conditional expression in if (a=b) is true if a is not zeroafter the assignment.[12] However, this flaw may be useful for short-coding in some case.
• A lack of infix operators for complex objects, particularly for string operations, making programs which relyheavily on these operations (implemented as functions instead) somewhat difficult to read.
• A declaration syntax that some find unintuitive, particularly for function pointers. (Ritchie's idea was to declareidentifiers in contexts resembling their use: "declaration reflects use".)
OperatorsC supports a rich set of operators, which are symbols used within an expression to specify the manipulations to beperformed while evaluating that expression. C has operators for:• arithmetic (+, -, *, /, %)• assignment (=)• augmented assignment (+=, -=, *=, /=, %=, &=, |=, ^=, <<=, >>=)• bitwise logic (~, &, |, ^)• bitwise shifts (<<, >>)• boolean logic (!, &&, ||)• conditional evaluation (? :)• equality testing (==, !=)• function argument collection (( ))• increment and decrement (++, --)• member selection (., ->)• object size (sizeof)• order relations (<, <=, >, >=)• reference and dereference (&, *, [ ])• sequencing (,)• subexpression grouping (( ))• type conversion (( ))C has a formal grammar,[13] specified by the C standard.
Integer-float conversion and roundingThe type casting syntax can be used to convert values between an integer type and a floating-point type, or betweentwo integer types or two float types with different sizes; e.g. (long int)sqrt(1000.0), (double)(256*256), or(float)sqrt(1000.0). Conversions are implicit in several contexts, e.g. when assigning a value to a variable or to afunction parameter, when using a floating-point value as index to a vector, or in arithmetic operations on operandwith different types.Unlike some other cases of type casting (where the bit encoding of the operands are simply re-interpreted according to the target type), conversions between integers and floating-point values generally change the bit encoding so as to preserve the numerical value of the operand, to the extent possible. In particular, conversion from an integer to a

C (programming language) 99
floating-point type will preserve its numeric value exactly—unless the number of fraction bits in the target type isinsufficient, in which case the least-significant bits are lost.Conversion from a floating-point value to an integer type entails truncation of any fractional part (i.e. the value isrounded "towards zero"). For other kinds of rounding, the C99 standard specifies (in <math.h>) the followingfunctions:• round(): round to nearest integer, halfway away from zero• rint(), nearbyint(): round according to current floating-point rounding direction• ceil(): smallest integral value not less than argument (round up)• floor(): largest integral value (in double representation) not greater than argument (round down)• trunc(): round towards zero (same as typecasting to an int)All these functions take a double argument and return a double result, which may then be cast to an integer ifnecessary.The conversion of a float value to the double type preserves the numerical value exactly, while the oppositeconversion rounds the value to fit in the smaller number of fraction bits, usually towards zero. (Since float also has asmaller exponent range, the conversion may yield an infinite value.) Some compilers will silently convert floatvalues to double in some contexts, e.g. function parameters declared as float may be actually passed as double.In machines that comply with the IEEE floating point standard, some rounding events are affected by the currentrounding mode (which includes round-to-even, round-down, round-up, and round-to-zero), which may be retrievedand set using the fegetround()/fesetround() functions defined in <fenv.h>.
"Hello, world" exampleThe "hello, world" example which appeared in the first edition of K&R has become the model for an introductoryprogram in most programming textbooks, regardless of programming language. The program prints "hello, world" tothe standard output, which is usually a terminal or screen display.The original version was:
main()
{
printf("hello, world\n");
}
A standard-conforming "hello, world" program is:[14]
#include <stdio.h>
int main(void)
{
printf("hello, world\n");
return 0;
}
The first line of the program contains a preprocessing directive, indicated by #include. This causes thepreprocessor—the first tool to examine source code as it is compiled—to substitute the line with the entire text of thestdio.h standard header, which contains declarations for standard input and output functions such as printf. The anglebrackets surrounding stdio.h indicate that stdio.h is located using a search strategy that prefers standard headers toother headers having the same name. Double quotes may also be used to include local or project-specific headerfiles.

C (programming language) 100
The next line indicates that a function named main is being defined. The main function serves a special purpose in Cprograms; the run-time environment calls the main function to begin program execution. The type specifier intindicates that the return value, the value that is returned to the invoker (in this case the run-time environment) as aresult of evaluating the main function, is an integer. The keyword void as a parameter list indicates that the mainfunction takes no arguments.[15]
The opening curly brace indicates the beginning of the definition of the main function.The next line calls (diverts execution to) a function named printf, which was declared in stdio.h and is supplied froma system library. In this call, the printf function is passed (provided with) a single argument, the address of the firstcharacter in the string literal "hello, world\n". The string literal is an unnamed array with elements of type char, setup automatically by the compiler with a final 0-valued character to mark the end of the array (printf needs to knowthis). The \n is an escape sequence that C translates to a newline character, which on output signifies the end of thecurrent line. The return value of the printf function is of type int, but it is silently discarded since it is not used. (Amore careful program might test the return value to determine whether or not the printf function succeeded.) Thesemicolon ; terminates the statement.The return statement terminates the execution of the main function and causes it to return the integer value 0, whichis interpreted by the run-time system as an exit code indicating successful execution.The closing curly brace indicates the end of the code for the main function.
Type systemC has a static weak typing type system that shares some similarities with that of other ALGOL descendants such asPascal. There are built-in types for integers of various sizes, both signed and unsigned, floating-point numbers,characters, and enumerated types (enum). C99 added a boolean datatype. There are also derived types includingarrays, pointers, records (struct), and untagged unions (union).C is often used in low-level systems programming where escapes from the type system may be necessary. Thecompiler attempts to ensure type correctness of most expressions, but the programmer can override the checks invarious ways, either by using a type cast to explicitly convert a value from one type to another, or by using pointersor unions to reinterpret the underlying bits of a value in some other way.
Pointers
C supports the use of pointers, a very simple type of reference that records, in effect, the address or location of anobject or function in memory. Pointers can be dereferenced to access data stored at the address pointed to, or toinvoke a pointed-to function. Pointers can be manipulated using assignment and also pointer arithmetic. Therun-time representation of a pointer value is typically a raw memory address (perhaps augmented by anoffset-within-word field), but since a pointer's type includes the type of the thing pointed to, expressions includingpointers can be type-checked at compile time. Pointer arithmetic is automatically scaled by the size of the pointed-todata type. (See Array-pointer interchangeability below.) Pointers are used for many different purposes in C. Textstrings are commonly manipulated using pointers into arrays of characters. Dynamic memory allocation, which isdescribed below, is performed using pointers. Many data types, such as trees, are commonly implemented asdynamically allocated struct objects linked together using pointers. Pointers to functions are useful for callbacksfrom event handlers.A null pointer is a pointer value that points to no valid location (it is represented by value 0).[16] Dereferencing a nullpointer is therefore meaningless, typically resulting in a run-time error. Null pointers are useful for indicating specialcases such as no next pointer in the final node of a linked list, or as an error indication from functions returningpointers.

C (programming language) 101
Void pointers (void *) point to objects of unknown type, and can therefore be used as "generic" data pointers. Sincethe size and type of the pointed-to object is not known, void pointers cannot be dereferenced, nor is pointerarithmetic on them allowed, although they can easily be (and in many contexts implicitly are) converted to and fromany other object pointer type.Careless use of pointers is potentially dangerous. Because they are typically unchecked, a pointer variable can bemade to point to any arbitrary location, which can cause undesirable effects. Although properly-used pointers pointto safe places, they can be made to point to unsafe places by using invalid pointer arithmetic; the objects they pointto may be deallocated and reused (dangling pointers); they may be used without having been initialized (wildpointers); or they may be directly assigned an unsafe value using a cast, union, or through another corrupt pointer. Ingeneral, C is permissive in allowing manipulation of and conversion between pointer types, although compilerstypically provide options for various levels of checking. Some other programming languages address these problemsby using more restrictive reference types.
Arrays
Array types in C are traditionally of a fixed, static size specified at compile time. (The more recent C99 standard alsoallows a form of variable-length arrays.) However, it is also possible to allocate a block of memory (of arbitrary size)at run-time, using the standard library's malloc function, and treat it as an array. C's unification of arrays and pointers(see below) means that true arrays and these dynamically-allocated, simulated arrays are virtually interchangeable.Since arrays are always accessed (in effect) via pointers, array accesses are typically not checked against theunderlying array size, although the compiler may provide bounds checking as an option. Array bounds violations aretherefore possible and rather common in carelessly written code, and can lead to various repercussions, includingillegal memory accesses, corruption of data, buffer overruns, and run-time exceptions.C does not have a special provision for declaring multidimensional arrays, but rather relies on recursion within thetype system to declare arrays of arrays, which effectively accomplishes the same thing. The index values of theresulting "multidimensional array" can be thought of as increasing in row-major order.Although C supports static arrays, it is not required that array indices be validated (bounds checking). For example,one can try to write to the sixth element of an array with five elements, generally yielding undesirable results. Thistype of bug, called a buffer overflow or buffer overrun, is notorious for causing a number of security problems. Sincebounds checking elimination technology was largely nonexistent when C was defined, bounds checking came with asevere performance penalty, particularly in numerical computation. A few years earlier, some Fortran compilers hada switch to toggle bounds checking on or off; however, this would have been much less useful for C, where arrayarguments are passed as simple pointers.Multidimensional arrays are commonly used in numerical algorithms (mainly from applied linear algebra) to storematrices. The structure of the C array is well suited to this particular task. However, since arrays are passed merelyas pointers, the bounds of the array must be known fixed values or else explicitly passed to any subroutine thatrequires them, and dynamically sized arrays of arrays cannot be accessed using double indexing. (A workaround forthis is to allocate the array with an additional "row vector" of pointers to the columns.)C99 introduced "variable-length arrays" which address some, but not all, of the issues with ordinary C arrays.

C (programming language) 102
Array-pointer interchangeability
A distinctive (but potentially confusing) feature of C is its treatment of arrays and pointers. The array-subscriptnotation x[i] can also be used when x is a pointer; the interpretation (using pointer arithmetic) is to access the (i +1)th object of several adjacent data objects pointed to by x, counting the object that x points to (which is x[0]) as thefirst element of the array.Formally, x[i] is equivalent to *(x + i). Since the type of the pointer involved is known to the compiler at compiletime, the address that x + i points to is not the address pointed to by x incremented by i bytes, but rather incrementedby i multiplied by the size of an element that x points to. The size of these elements can be determined with theoperator sizeof by applying it to any dereferenced element of x, as in n = sizeof *x or n = sizeof x[0].Furthermore, in most expression contexts (a notable exception is sizeof x), the name of an array is automaticallyconverted to a pointer to the array's first element; this implies that an array is never copied as a whole when namedas an argument to a function, but rather only the address of its first element is passed. Therefore, although functioncalls in C use pass-by-value semantics, arrays are in effect passed by reference.The number of elements in a declared array x can be determined as sizeof x / sizeof x[0].An interesting demonstration of the interchangeability of pointers and arrays is shown below. The four assignmentsare equivalent and each is valid C code.
/* x is an array OR a pointer. i is an integer. */
x[i] = 1; /* equivalent to *(x + i) */
*(x + i) = 1;
*(i + x) = 1;
i[x] = 1; /* equivalent to *(i + x) */
Note that although all four assignments are equivalent, only the first represents good coding style. The last line mightbe found in obfuscated C code.Despite this apparent equivalence between array and pointer variables, there is still a distinction to be made betweenthem. Even though the name of an array is, in most expression contexts, converted into a pointer (to its firstelement), this pointer does not itself occupy any storage, unlike a pointer variable. Consequently, what an array"points to" cannot be changed, and it is impossible to assign a value to an array variable. (Array values may becopied, however, e.g., by using the memcpy function.)
Memory managementOne of the most important functions of a programming language is to provide facilities for managing memory andthe objects that are stored in memory. C provides three distinct ways to allocate memory for objects:• Static memory allocation: space for the object is provided in the binary at compile-time; these objects have an
extent (or lifetime) as long as the binary which contains them is loaded into memory• Automatic memory allocation: temporary objects can be stored on the stack, and this space is automatically freed
and reusable after the block in which they are declared is exited• Dynamic memory allocation: blocks of memory of arbitrary size can be requested at run-time using library
functions such as malloc from a region of memory called the heap; these blocks persist until subsequently freedfor reuse by calling the library function free
These three approaches are appropriate in different situations and have various tradeoffs. For example, staticmemory allocation has no allocation overhead, automatic allocation may involve a small amount of overhead, anddynamic memory allocation can potentially have a great deal of overhead for both allocation and deallocation. On

C (programming language) 103
the other hand, stack space is typically much more limited and transient than either static memory or heap space, anddynamic memory allocation allows allocation of objects whose size is known only at run-time. Most C programsmake extensive use of all three.Where possible, automatic or static allocation is usually preferred because the storage is managed by the compiler,freeing the programmer of the potentially error-prone chore of manually allocating and releasing storage. However,many data structures can grow in size at runtime, and since static allocations (and automatic allocations in C89 andC90) must have a fixed size at compile-time, there are many situations in which dynamic allocation must be used.Prior to the C99 standard, variable-sized arrays were a common example of this (see malloc for an example ofdynamically allocated arrays).Automatically and dynamically allocated objects are only initialized if an initial value is explicitly specified;otherwise they initially have indeterminate values (typically, whatever bit pattern happens to be present in thestorage, which might not even represent a valid value for that type). If the program attempts to access anuninitialized value, the results are undefined. Many modern compilers try to detect and warn about this problem, butboth false positives and false negatives occur.Another issue is that heap memory allocation has to be manually synchronized with its actual usage in any programin order for it to be reused as much as possible. For example, if the only pointer to a heap memory allocation goesout of scope or has its value overwritten before free() has been called, then that memory cannot be recovered for laterreuse and is essentially lost to the program, a phenomenon known as a memory leak. Conversely, it is possible torelease memory too soon and continue to access it; however, since the allocation system can re-allocate or itself usethe freed memory, unpredictable behavior is likely to occur in this circumstance. Typically, the symptoms willappear in a portion of the program far removed from the actual error, making it difficult to track down the problem.Such issues are ameliorated in languages with automatic garbage collection or RAII.
LibrariesThe C programming language uses libraries as its primary method of extension. In C, a library is a set of functionscontained within a single "archive" file. Each library typically has a header file, which contains the prototypes of thefunctions contained within the library that may be used by a program, and declarations of special data types andmacro symbols used with these functions. In order for a program to use a library, it must include the library's headerfile, and the library must be linked with the program, which in many cases requires compiler flags (e.g., -lm,shorthand for "math library").The most common C library is the C standard library, which is specified by the ISO and ANSI C standards andcomes with every C implementation (“freestanding” [embedded] C implementations may provide only a subset of thestandard library). This library supports stream input and output, memory allocation, mathematics, character strings,and time values.Another common set of C library functions are those used by applications specifically targeted for Unix andUnix-like systems, especially functions which provide an interface to the kernel. These functions are detailed invarious standards such as POSIX and the Single UNIX Specification.Since many programs have been written in C, there are a wide variety of other libraries available. Libraries are oftenwritten in C because C compilers generate efficient object code; programmers then create interfaces to the library sothat the routines can be used from higher-level languages like Java, Perl, and Python.

C (programming language) 104
Language toolsTools have been created to help C programmers avoid some of the problems inherent in the language, such asstatements with undefined behavior or statements that are not a good practice because they are more likely to resultin unintended behavior or run-time errors.Automated source code checking and auditing are beneficial in any language, and for C many such tools exist, suchas Lint. A common practice is to use Lint to detect questionable code when a program is first written. Once aprogram passes Lint, it is then compiled using the C compiler. Also, many compilers can optionally warn aboutsyntactically valid constructs that are likely to actually be errors. MISRA C is a proprietary set of guidelines to avoidsuch questionable code, developed for embedded systems.There are also compilers, libraries and operating system level mechanisms for performing array bounds checking,buffer overflow detection, serialization and automatic garbage collection, that are not a standard part of C.Tools such as Purify, Valgrind, and linking with libraries containing special versions of the memory allocationfunctions can help uncover runtime memory errors.
Related languagesC has directly or indirectly influenced many later languages such as Java, Perl, PHP, JavaScript, LPC, C# and Unix'sC Shell. The most pervasive influence has been syntactical: all of the languages mentioned combine the statementand (more or less recognizably) expression syntax of C with type systems, data models and/or large-scale programstructures that differ from those of C, sometimes radically.When object-oriented languages became popular, C++ and Objective-C were two different extensions of C thatprovided object-oriented capabilities. Both languages were originally implemented as source-to-source compilers --source code was translated into C, and then compiled with a C compiler.The C++ programming language was devised by Bjarne Stroustrup as one approach to providing object-orientedfunctionality with C-like syntax. C++ adds greater typing strength, scoping and other tools useful in object-orientedprogramming and permits generic programming via templates. Nearly a superset of C, C++ now supports most of C,with a few exceptions (see Compatibility of C and C++ for an exhaustive list of differences).Objective-C was originally a very "thin" layer on top of, and remains a strict superset of C that permitsobject-oriented programming using a hybrid dynamic/static typing paradigm. Objective-C derives its syntax fromboth C and Smalltalk: syntax that involves preprocessing, expressions, function declarations and function calls isinherited from C, while the syntax for object-oriented features was originally taken from Smalltalk.The D programming language makes a clean break with C while maintaining the same general syntax, unlike C++,which maintains nearly complete backwards compatibility with C. D abandons a number of features of C whichWalter Bright (the designer of D) considered undesirable, including the C preprocessor and trigraphs. Some, but notall, of D's extensions to C overlap with those of C++.Limbo is a language developed by the same team at Bell Labs that was responsible for C and Unix, and whileretaining some of the syntax and the general style, also includes garbage collection and CSP based concurrency.Python has a different sort of C heritage. While the syntax and semantics of Python are radically different from C,the most widely used Python implementation, CPython, is an open source C program. This allows C users to extendPython with C, or embed Python into C programs. This close relationship is one of the key factors leading toPython's success as a general-use dynamic language.Perl is another example of a popular programming language rooted in C. However, unlike Python, Perl's syntax doesclosely follow C syntax. The standard Perl implementation is written in C and supports extensions written in C.

C (programming language) 105
See also• C preprocessor• C standard library• C syntax• Comparison of Pascal and C• Comparison of programming languages• International Obfuscated C Code Contest• List of compilers• List of C-based programming languages
Further reading• Banahan, M.; Brady, D.; Doran, M. (1991). The C Book [17] (2nd ed.). Addison-Wesley.• Ritchie, Dennis M. (1993). "The Development of the C Language" [18]. The second ACM SIGPLAN History of
Programming Languages Conference (HOPL-II) (ACM): 201–208. doi:10.1145/154766.155580.• Jones, Derek M.. The New C Standard: A Cultural and Economic Commentary [19]. Addison-Wesley.
ISBN 0-201-70917-1.• Thompson, Ken. A New C Compiler [20]. Murray Hill, New Jersey: AT&T Bell Laboratories.
External links• ISO C Working Group official website [21]
• comp.lang.c Frequently Asked Questions [22]
• ISO/IEC 9899 [23]. Official C99 documents.• The current draft Standard (C99 with Technical corrigenda TC1, TC2, and TC3 included) [24]PDF (3.61 MB)• ANSI C Standard (ANSI X3J11/88-090) [25] (Published May 13, 1988), Third Public Review [26]
• ANSI C Rationale (ANSI X3J11/88-151) [27] (Published Nov 18, 1988)
References[1] Kernighan; Dennis M. Ritchie (March 1988). [[The C Programming Language (book)|The C Programming Language (http:/ / cm. bell-labs.
com/ cm/ cs/ cbook/ )]] (2nd ed.). Englewood Cliffs, NJ: Prentice Hall. ISBN 0-13-110362-8. . Regarded by many to be the authoritativereference on C.
[2] Dennis M. Ritchie (January 1993). "The Development of the C Language" (http:/ / cm. bell-labs. com/ cm/ cs/ who/ dmr/ chist. html). .Retrieved Jan 1 2008. "The scheme of type composition adopted by C owes considerable debt to Algol 68, although it did not, perhaps,emerge in a form that Algol's adherents would approve of."
[3] Stewart, Bill (January 7, 2000). "History of the C Programming Language" (http:/ / www. livinginternet. com/ i/ iw_unix_c. htm). LivingInternet. . Retrieved 2006-10-31.
[4] Patricia K. Lawlis, c.j. kemp systems, inc. (1997). "Guidelines for Choosing a Computer Language: Support for the Visionary Organization"(http:/ / archive. adaic. com/ docs/ reports/ lawlis/ k. htm). Ada Information Clearinghouse. . Retrieved 2006-07-18.
[5] "Programming Language Popularity" (http:/ / www. langpop. com/ ). 2009. . Retrieved 2009-01-16.[6] "TIOBE Programming Community Index" (http:/ / www. tiobe. com/ index. php/ content/ paperinfo/ tpci/ index. html). 2009. . Retrieved
2009-05-06.[7] "comp.lang.c FAQ entry concerning boolean values" (http:/ / c-faq. com/ bool/ booltype. html). . Retrieved 2010-07-05.[8] "Jargon File entry for nasal demons" (http:/ / www. catb. org/ jargon/ html/ N/ nasal-demons. html). .[9] Kernighan, Brian W.; Dennis M. Ritchie (February 1978). The C Programming Language (1st ed.). Englewood Cliffs, NJ: Prentice Hall.
ISBN 0-13-110163-3.This book was the first widely available book on the C programming language. The version of C described in this bookis often referred to as K&R C.
[10] Dr. Dobb's Sourcebook. U.S.A.: Miller Freeman, Inc.. Nov/Dec 1995 issue.[11] "Using C for CGI Programming" (http:/ / www. linuxjournal. com/ article/ 6863). linuxjournal.com. 2005-03-01. . Retrieved 2010-01-04.[12] "10 Common Programming Mistakes in C" (http:/ / www. cs. ucr. edu/ ~nxiao/ cs10/ errors. htm). Cs.ucr.edu. . Retrieved 2009-06-26.[13] Harbison, Samuel P.; Guy L. Steele (2002). C: A Reference Manual (5th ed.). Englewood Cliffs, NJ: Prentice Hall. ISBN 0-13-089592-X.
This book is excellent as a definitive reference manual, and for those working on C compilers. The book contains a BNF grammar for C.

C (programming language) 106
[14] The original example code will compile on most modern compilers that are not in strict standard compliance mode, but it does not fullyconform to the requirements of either C89 or C99. In fact, C99 requires that a diagnostic message be produced.
[15] The main function actually has two arguments, int argc and char *argv[], respectively, which can be used to handle command linearguments. The C standard requires that both forms of main be supported, which is special treatment not afforded any other function.
[16] ISO/IEC 9899:1999 specification (http:/ / www. open-std. org/ jtc1/ sc22/ wg14/ www/ docs/ n1124. pdf): "An integer constant expressionwith the value 0, or such an expression cast to type void *, is called a null pointer constant. If a null pointer constant is converted to a pointertype, the resulting pointer, called a null pointer, is guaranteed to compare unequal to a pointer to any object or function."
[17] http:/ / publications. gbdirect. co. uk/ c_book/[18] http:/ / cm. bell-labs. com/ cm/ cs/ who/ dmr/ chist. html[19] http:/ / www. coding-guidelines. com/ cbook/ cbook1_2. pdf[20] http:/ / doc. cat-v. org/ bell_labs/ new_c_compilers/ new_c_compiler. pdf[21] http:/ / www. open-std. org/ jtc1/ sc22/ wg14/[22] http:/ / www. c-faq. com/[23] http:/ / www. open-std. org/ JTC1/ SC22/ WG14/ www/ standards[24] http:/ / www. open-std. org/ JTC1/ SC22/ WG14/ www/ docs/ n1256. pdf[25] http:/ / flash-gordon. me. uk/ ansi. c. txt[26] http:/ / groups. google. com/ group/ comp. lang. c/ msg/ 20b174b18cdd919d?hl=en[27] http:/ / www. scribd. com/ doc/ 16306895/ Draft-ANSI-C-Rationale

C++ 107
C++
The C++ Programming Language, written by its architect, is the seminal book on the language.Paradigm Multi-paradigm:[1] procedural, object-oriented, generic
Appeared in 1983
Designed by Bjarne Stroustrup
Developer Bjarne StroustrupBell LabsISO/IEC JTC1/SC22/WG21
Stable release ISO/IEC 14882:2003 (2003)
Preview release C++0x
Typing discipline Static, unsafe, nominative
Majorimplementations
Borland C++ Builder, GCC, Intel C++ Compiler, Microsoft Visual C++, Sun Studio, Turbo C++, ComeauC/C++, clang
Dialects ISO/IEC C++ 1998, ISO/IEC C++ 2003
Influenced by C, Simula, Ada 83, ALGOL 68, CLU, ML[1]
Influenced Perl, LPC, Lua, Pike, Ada 95, Java, PHP, D, C99, C#, Aikido, Falcon
OS Cross-platform (multi-platform)
Usual file extensions .h .hh .hpp .hxx .h++ .cc .cpp .cxx .c++
C++ Programming at Wikibooks
C++ (pronounced see plus plus) is a statically typed, free-form, multi-paradigm, compiled, general-purposeprogramming language. It is regarded as a "middle-level" language, as it comprises a combination of both high-leveland low-level language features.[2] It was developed by Bjarne Stroustrup starting in 1979 at Bell Labs as anenhancement to the C programming language and originally named C with Classes. It was renamed C++ in 1983.[3]
As one of the most popular programming languages ever created,[4] [5] C++ is widely used in the software industry.Some of its application domains include systems software, application software, device drivers, embedded software,high-performance server and client applications, and entertainment software such as video games. Several groupsprovide both free and proprietary C++ compiler software, including the GNU Project, Microsoft, Intel and Borland.C++ has greatly influenced many other popular programming languages, most notably Java.C++ is also used for hardware design, where design is initially described in C++, then analyzed, architecturallyconstrained, and scheduled to create a register transfer level hardware description language via high-level synthesis.The language began as enhancements to C, first adding classes, then virtual functions, operator overloading, multiple inheritance, templates, and exception handling among other features. After years of development, the C++ programming language standard was ratified in 1998 as ISO/IEC 14882:1998. That standard is still current, but is amended by the 2003 technical corrigendum, ISO/IEC 14882:2003. The next standard version (known informally as

C++ 108
C++0x) is in development.
History
Bjarne Stroustrup, creator of C++
Bjarne Stroustrup began work on "C with Classes" in 1979. The idea ofcreating a new language originated from Stroustrup's experience inprogramming for his Ph.D. thesis. Stroustrup found that Simula hadfeatures that were very helpful for large software development, but thelanguage was too slow for practical use, while BCPL was fast but toolow-level to be suitable for large software development. WhenStroustrup started working in AT&T Bell Labs, he had the problem ofanalyzing the UNIX kernel with respect to distributed computing.Remembering his Ph.D. experience, Stroustrup set out to enhance theC language with Simula-like features. C was chosen because it wasgeneral-purpose, fast, portable and widely used. Besides C and Simula,some other languages that inspired him were ALGOL 68, Ada, CLU and ML. At first, the class, derived class, strongtype checking, inlining, and default argument features were added to C via Stroustrup's C++ to C compiler, Cfront.The first commercial implementation of C++ was released in October 1985.[6]
In 1983, the name of the language was changed from C with Classes to C++ (++ being the increment operator in C).New features were added including virtual functions, function name and operator overloading, references, constants,user-controlled free-store memory control, improved type checking, and BCPL style single-line comments with twoforward slashes (//). In 1985, the first edition of The C++ Programming Language was released, providing animportant reference to the language, since there was not yet an official standard. Release 2.0 of C++ came in 1989.New features included multiple inheritance, abstract classes, static member functions, const member functions, andprotected members. In 1990, The Annotated C++ Reference Manual was published. This work became the basis forthe future standard. Late addition of features included templates, exceptions, namespaces, new casts, and a Booleantype.As the C++ language evolved, the standard library evolved with it. The first addition to the C++ standard library wasthe stream I/O library which provided facilities to replace the traditional C functions such as printf and scanf. Later,among the most significant additions to the standard library, was the Standard Template Library.C++ continues to be used and is one of the preferred programming languages to develop professional applications.The popularity of the language continues to grow.[7]
Language standardIn 1998, the C++ standards committee (the ISO/IEC JTC1/SC22/WG21 working group) standardized C++ andpublished the international standard ISO/IEC 14882:1998 (informally known as C++98[8] ). For some years after theofficial release of the standard, the committee processed defect reports, and published a corrected version of the C++standard, ISO/IEC 14882:2003, in 2003. In 2005, a technical report, called the "Library Technical Report 1" (oftenknown as TR1 for short), was released. While not an official part of the standard, it specified a number of extensionsto the standard library, which were expected to be included in the next version of C++. Support for TR1 is growingin almost all currently maintained C++ compilers.The standard for the next version of the language (known informally as C++0x) is in development.

C++ 109
EtymologyAccording to Stroustrup: "the name signifies the evolutionary nature of the changes from C".[9] During C++'sdevelopment period, the language had been referred to as "new C", then "C with Classes". The final name is creditedto Rick Mascitti (mid-1983) and was first used in December 1983. When Mascitti was questioned informally in 1992about the naming, he indicated that it was given in a tongue-in-cheek spirit. It stems from C's "++" operator (whichincrements the value of a variable) and a common naming convention of using "+" to indicate an enhanced computerprogram. There is no language called "C plus". ABCL/c+ was the name of an earlier, unrelated programminglanguage.
PhilosophyIn The Design and Evolution of C++ (1994), Bjarne Stroustrup describes some rules that he used for the design ofC++:• C++ is designed to be a statically typed, general-purpose language that is as efficient and portable as C• C++ is designed to directly and comprehensively support multiple programming styles (procedural programming,
data abstraction, object-oriented programming, and generic programming)• C++ is designed to give the programmer choice, even if this makes it possible for the programmer to choose
incorrectly• C++ is designed to be as compatible with C as possible, therefore providing a smooth transition from C• C++ avoids features that are platform specific or not general purpose• C++ does not incur overhead for features that are not used (the "zero-overhead principle")• C++ is designed to function without a sophisticated programming environmentStroustrup also mentions that C++ was always intended to make programming more fun and that many of the doublemeanings in the language are intentional.Inside the C++ Object Model (Lippman, 1996) describes how compilers may convert C++ program statements intoan in-memory layout. Compiler authors are, however, free to implement the standard in their own manner.
Standard libraryThe 1998 ANSI/ISO C++ standard consists of two parts: the core language and the C++ Standard Library; the latterincludes most of the Standard Template Library (STL) and a slightly modified version of the C standard library.Many C++ libraries exist which are not part of the standard, and, using linkage specification, libraries can even bewritten in languages such as C, Fortran, Pascal, or BASIC. Which of these are supported is compiler dependent.The C++ standard library incorporates the C standard library with some small modifications to make it optimizedwith the C++ language. Another large part of the C++ library is based on the STL. This provides such useful tools ascontainers (for example vectors and lists), iterators to provide these containers with array-like access and algorithmsto perform operations such as searching and sorting. Furthermore (multi)maps (associative arrays) and (multi)sets areprovided, all of which export compatible interfaces. Therefore it is possible, using templates, to write genericalgorithms that work with any container or on any sequence defined by iterators. As in C, the features of the libraryare accessed by using the #include directive to include a standard header. C++ provides 69 standard headers, ofwhich 19 are deprecated.The STL was originally a third-party library from HP and later SGI, before its incorporation into the C++ standard.The standard does not refer to it as "STL", as it is merely a part of the standard library, but many people still use thatterm to distinguish it from the rest of the library (input/output streams, internationalization, diagnostics, the C librarysubset, etc.).Most C++ compilers provide an implementation of the C++ standard library, including the STL. Compiler-independent implementations of the STL, such as STLPort,[10] also exist. Other projects also produce

C++ 110
various custom implementations of the C++ standard library and the STL with various design goals.
Language featuresC++ inherits most of C's syntax. The following is Bjarne Stroustrup's version of the Hello world program which usesthe C++ standard library stream facility to write a message to standard output:[11] [12]
#include <iostream>
int main()
{
std::cout << "Hello, world!\n";
}
Within functions that define a non-void return type, failure to return a value before control reaches the end of thefunction results in undefined behaviour (compilers typically provide the means to issue a diagnostic in such acase).[13] The sole exception to this rule is the main function, which implicitly returns a value of zero.[14]
Operators and operator overloadingC++ provides more than 30 operators, covering basic arithmetic, bit manipulation, indirection, comparisons, logicaloperations and others. Almost all operators can be overloaded for user-defined types, with a few notable exceptionssuch as member access (. and .*). The rich set of overloadable operators is central to using C++ as a domain specificlanguage. The overloadable operators are also an essential part of many advanced C++ programming techniques,such as smart pointers. Overloading an operator does not change the precedence of calculations involving theoperator, nor does it change the number of operands that the operator uses (any operand may however be ignored bythe operator, though it will be evaluated prior to execution). Overloaded "&&" and "||" operators lose theirshort-circuit evaluation property.
TemplatesC++ templates enable generic programming. C++ supports both function and class templates. Templates may beparameterized by types, compile-time constants, and other templates. C++ templates are implemented byinstantiation at compile-time. To instantiate a template, compilers substitute specific arguments for a template'sparameters to generate a concrete function or class instance. Some substitutions are not possible; these are eliminatedby an overload resolution policy described by the phrase "Substitution failure is not an error" (SFINAE). Templatesare a powerful tool that can be used for generic programming, template metaprogramming, and code optimization,but this power implies a cost. Template use may increase code size, since each template instantiation produces acopy of the template code: one for each set of template arguments. This is in contrast to run-time generics seen inother languages (e.g. Java) where at compile-time the type is erased and a single template body is preserved.Templates are different from macros: while both of these compile-time language features enable conditionalcompilation, templates are not restricted to lexical substitution. Templates are aware of the semantics and typesystem of their companion language, as well as all compile-time type definitions, and can perform high-leveloperations including programmatic flow control based on evaluation of strictly type-checked parameters. Macros arecapable of conditional control over compilation based on predetermined criteria, but cannot instantiate new types,recurse, or perform type evaluation and in effect are limited to pre-compilation text-substitution andtext-inclusion/exclusion. In other words, macros can control compilation flow based on pre-defined symbols butcannot, unlike templates, independently instantiate new symbols. Templates are a tool for static polymorphism (seebelow) and generic programming.

C++ 111
In addition, templates are a compile time mechanism in C++ which is Turing-complete, meaning that anycomputation expressible by a computer program can be computed, in some form, by a template metaprogram prior toruntime.In summary, a template is a compile-time parameterized function or class written without knowledge of the specificarguments used to instantiate it. After instantiation the resulting code is equivalent to code written specifically for thepassed arguments. In this manner, templates provide a way to decouple generic, broadly applicable aspects offunctions and classes (encoded in templates) from specific aspects (encoded in template parameters) withoutsacrificing performance due to abstraction.
ObjectsC++ introduces object-oriented (OO) features to C. It offers classes, which provide the four features commonlypresent in OO (and some non-OO) languages: abstraction, encapsulation, inheritance, and polymorphism. Objectsare instances of classes created at runtime. The class can be thought of as a template from which many differentindividual objects may be generated as a program runs.
Encapsulation
Encapsulation is the hiding of information in order to ensure that data structures and operators are used as intendedand to make the usage model more obvious to the developer. C++ provides the ability to define classes and functionsas its primary encapsulation mechanisms. Within a class, members can be declared as either public, protected, orprivate in order to explicitly enforce encapsulation. A public member of the class is accessible to any function. Aprivate member is accessible only to functions that are members of that class and to functions and classes explicitlygranted access permission by the class ("friends"). A protected member is accessible to members of classes thatinherit from the class in addition to the class itself and any friends.The OO principle is that all of the functions (and only the functions) that access the internal representation of a typeshould be encapsulated within the type definition. C++ supports this (via member functions and friend functions),but does not enforce it: the programmer can declare parts or all of the representation of a type to be public, and isallowed to make public entities that are not part of the representation of the type. Because of this, C++ supports notjust OO programming, but other weaker decomposition paradigms, like modular programming.It is generally considered good practice to make all data private or protected, and to make public only those functionsthat are part of a minimal interface for users of the class. This hides all the details of data implementation, allowingthe designer to later fundamentally change the implementation without changing the interface in any way.[15] [16]
Inheritance
Inheritance allows one data type to acquire properties of other data types. Inheritance from a base class may bedeclared as public, protected, or private. This access specifier determines whether unrelated and derived classes canaccess the inherited public and protected members of the base class. Only public inheritance corresponds to what isusually meant by "inheritance". The other two forms are much less frequently used. If the access specifier is omitted,a "class" inherits privately, while a "struct" inherits publicly. Base classes may be declared as virtual; this is calledvirtual inheritance. Virtual inheritance ensures that only one instance of a base class exists in the inheritance graph,avoiding some of the ambiguity problems of multiple inheritance.Multiple inheritance is a C++ feature not found in most other languages. Multiple inheritance allows a class to be derived from more than one base class; this allows for more elaborate inheritance relationships. For example, a "Flying Cat" class can inherit from both "Cat" and "Flying Mammal". Some other languages, such as Java or C#, accomplish something similar (although more limited) by allowing inheritance of multiple interfaces while restricting the number of base classes to one (interfaces, unlike classes, provide only declarations of member functions, no implementation or member data). An interface as in Java and C# can be defined in C++ as a class

C++ 112
containing only pure virtual functions, often known as an abstract base class or "ABC". The member functions ofsuch an abstract base classes are normally explicitly defined in the derived class, not inherited implicitly.
PolymorphismPolymorphism enables one common interface for many implementations, and for objects to act differently underdifferent circumstances.C++ supports several kinds of static (compile-time) and dynamic (run-time) polymorphisms. Compile-timepolymorphism does not allow for certain run-time decisions, while run-time polymorphism typically incurs aperformance penalty.
Static polymorphism
Function overloading allows programs to declare multiple functions having the same name (but with differentarguments). The functions are distinguished by the number and/or types of their formal parameters. Thus, the samefunction name can refer to different functions depending on the context in which it is used. The type returned by thefunction is not used to distinguish overloaded functions.When declaring a function, a programmer can specify default value for one or more parameters. Doing so allows theparameters with defaults to optionally be omitted when the function is called, in which case the default argumentswill be used. When a function is called with fewer arguments than there are declared parameters, explicit argumentsare matched to parameters in left-to-right order, with any unmatched parameters at the end of the parameter list beingassigned their default arguments. In many cases, specifying default arguments in a single function declaration ispreferable to providing overloaded function definitions with different numbers of parameters.Templates in C++ provide a sophisticated mechanism for writing generic, polymorphic code. In particular, throughthe Curiously Recurring Template Pattern it's possible to implement a form of static polymorphism that closelymimics the syntax for overriding virtual functions. Since C++ templates are type-aware and Turing-complete theycan also be used to let the compiler resolve recursive conditionals and generate substantial programs throughtemplate metaprogramming.
Dynamic polymorphism
Inheritance
Variable pointers (and references) to a base class type in C++ can refer to objects of any derived classes of that typein addition to objects exactly matching the variable type. This allows arrays and other kinds of containers to holdpointers to objects of differing types. Because assignment of values to variables usually occurs at run-time, this isnecessarily a run-time phenomenon.C++ also provides a dynamic_cast operator, which allows the program to safely attempt conversion of an object intoan object of a more specific object type (as opposed to conversion to a more general type, which is always allowed).This feature relies on run-time type information (RTTI). Objects known to be of a certain specific type can also becast to that type with static_cast, a purely compile-time construct which is faster and does not require RTTI.
Virtual member functions
Ordinarily when a function in a derived class overrides a function in a base class, the function to call is determined by the type of the object. A given function is overridden when there exists no difference, in the number or type of parameters, between two or more definitions of that function. Hence, at compile time it may not be possible to determine the type of the object and therefore the correct function to call, given only a base class pointer; the decision is therefore put off until runtime. This is called dynamic dispatch. Virtual member functions or methods[17]
allow the most specific implementation of the function to be called, according to the actual run-time type of the object. In C++ implementations, this is commonly done using virtual function tables. If the object type is known, this

C++ 113
may be bypassed by prepending a fully qualified class name before the function call, but in general calls to virtualfunctions are resolved at run time.In addition to standard member functions, operator overloads and destructors can be virtual. A general rule of thumbis that if any functions in the class are virtual, the destructor should be as well. As the type of an object at its creationis known at compile time, constructors, and by extension copy constructors, cannot be virtual. Nonetheless asituation may arise where a copy of an object needs to be created when a pointer to a derived object is passed as apointer to a base object. In such a case a common solution is to create a clone() (or similar) function and declare thatas virtual. The clone() method creates and returns a copy of the derived class when called.A member function can also be made "pure virtual" by appending it with = 0 after the closing parenthesis and beforethe semicolon. Objects cannot be created of a class with a pure virtual function and are called abstract data types.Such abstract data types can only be derived from. Any derived class inherits the virtual function as pure and mustprovide a non-pure definition of it (and all other pure virtual functions) before objects of the derived class can becreated. A program that attempts to create an object of a class with a pure virtual member function or inherited purevirtual member function is ill-formed.
Parsing and processing C++ source codeIt is relatively difficult to write a good C++ parser with classic parsing algorithms such as LALR(1).[18] This is partlybecause the C++ grammar is not LALR. Because of this, there are very few tools for analyzing or performingnon-trivial transformations (e.g., refactoring) of existing code. One way to handle this difficulty is to choose adifferent syntax, such as Significantly Prettier and Easier C++ Syntax, which is LALR(1) parsable. More powerfulparsers, such as GLR parsers, can be substantially simpler (though slower).Parsing (in the literal sense of producing a syntax tree) is not the most difficult problem in building a C++ processingtool. Such tools must also have the same understanding of the meaning of the identifiers in the program as a compilermight have. Practical systems for processing C++ must then not only parse the source text, but be able to resolve foreach identifier precisely which definition applies (e.g. they must correctly handle C++'s complex scoping rules) andwhat its type is, as well as the types of larger expressions.Finally, a practical C++ processing tool must be able to handle the variety of C++ dialects used in practice (such asthat supported by the GNU Compiler Collection and that of Microsoft's Visual C++) and implement appropriateanalyzers, source code transformers, and regenerate source text. Combining advanced parsing algorithms such asGLR with symbol table construction and program transformation machinery can enable the construction of arbitraryC++ tools.
CompatibilityProducing a reasonably standards-compliant C++ compiler has proven to be a difficult task for compiler vendors ingeneral. For many years, different C++ compilers implemented the C++ language to different levels of compliance tothe standard, and their implementations varied widely in some areas such as partial template specialization. Recentreleases of most popular C++ compilers support almost all of the C++ 1998 standard.[19]
In order to give compiler vendors greater freedom, the C++ standards committee decided not to dictate theimplementation of name mangling, exception handling, and other implementation-specific features. The downside ofthis decision is that object code produced by different compilers is expected to be incompatible. There are, however,third party standards for particular machines or operating systems which attempt to standardize compilers on thoseplatforms (for example C++ ABI[20] ); some compilers adopt a secondary standard for these items.

C++ 114
With CC++ is often considered to be a superset of C, but this is not strictly true.[21] Most C code can easily be made tocompile correctly in C++, but there are a few differences that cause some valid C code to be invalid in C++, or tobehave differently in C++.One commonly encountered difference is that C allows implicit conversion from void* to other pointer types, butC++ does not. Another common portability issue is that C++ defines many new keywords, such as new and class,that may be used as identifiers (e.g. variable names) in a C program.Some incompatibilities have been removed by the latest (C99) C standard, which now supports C++ features such as// comments and mixed declarations and code. On the other hand, C99 introduced a number of new features that C++does not support, such as variable-length arrays, native complex-number types, designated initializers and compoundliterals.[22] However, at least some of the new C99 features will likely be included in the next version of the C++standard, C++0x.In order to intermix C and C++ code, any function declaration or definition that is to be called from/used both in Cand C++ must be declared with C linkage by placing it within an extern "C" {/*...*/} block. Such a function may notrely on features depending on name mangling (i.e., function overloading).
CriticismCritics of the language raise several points. First, since C++ includes C as a subset, it inherits many of the criticismsleveled at C. For its large feature set, it is criticized as being over-complicated, and difficult to fully master.[23]
Bjarne Stroustrup points out that resultant executables do not support these claims of bloat: "I have even seen theC++ version of the 'hello world' program smaller than the C version."[24] An Embedded C++ standard was proposedto deal with part of this, but criticized for leaving out useful parts of the language that incur no runtime penalty.[25]
Other criticism stems from what is missing from C++. For example, the current version of Standard C++ provides nolanguage features to create multi-threaded software. These facilities are present in some other languages includingJava, Ada, and C# (see also Lock). It is possible to use operating system calls or third party libraries to domulti-threaded programming, but both approaches may create portability concerns. The new C++0x standardaddresses this matter by extending the language with threading facilities.C++ is also sometimes compared unfavorably with languages such as Smalltalk, Java, or Eiffel on the basis that itenables programmers to "mix and match" object-oriented programming, procedural programming, genericprogramming, functional programming, declarative programming, and others, rather than strictly enforcing a singlestyle, although C++ is intentionally a multi-paradigm language.[1]
A fraudulent article was written wherein Bjarne Stroustrup is supposedly interviewed for a 1998 issue of IEEE's'Computer' magazine[26] . In this article, the interviewer expects to discuss the successes of C++ now that severalyears had passed after its introduction. Instead, Stroustrup proceeds to confess that his invention of C++ wasintended to create the most complex and difficult language possible to weed out amateur programmers and raise thesalaries of the few programmers who could master the language. The article contains various criticisms of C++'scomplexity and poor usability, most false or exaggerated. In reality, Stroustrup wrote no such article, and due to thepervasiveness of the hoax, was compelled to publish an official denial on his website.[27] .C++ is commonly criticized for lacking built in garbage collection. On his website, Stroustrup explains thatautomated memory management is routinely implemented directly in C++, without need for a built-in collector,using "smart pointer" classes.[28] Garbage collection not based on reference counting is possible in C++ throughexternal libraries.[29]

C++ 115
See also• The C++ Programming Language• C++0x, the planned new standard for C++• Comparison of integrated development environments for C/C++• Comparison of programming languages• List of C++ compilers• List of C++ template libraries• Comparison of Java and C++
Further reading• Abrahams, David; Aleksey Gurtovoy. C++ Template Metaprogramming: Concepts, Tools, and Techniques from
Boost and Beyond. Addison-Wesley. ISBN 0-321-22725-5.• Alexandrescu, Andrei (2001). Modern C++ Design: Generic Programming and Design Patterns Applied.
Addison-Wesley. ISBN 0-201-70431-5.• Alexandrescu, Andrei; Herb Sutter (2004). C++ Design and Coding Standards: Rules and Guidelines for Writing
Programs. Addison-Wesley. ISBN 0-321-11358-6.• Becker, Pete (2006). The C++ Standard Library Extensions : A Tutorial and Reference. Addison-Wesley.
ISBN 0-321-41299-0.• Brokken, Frank (2010). C++ Annotations [30]. University of Groningen. ISBN 90 367 0470 7.• Coplien, James O. (1992, reprinted with corrections 1994). Advanced C++: Programming Styles and Idioms.
ISBN 0-201-54855-0.• Dewhurst, Stephen C. (2005). C++ Common Knowledge: Essential Intermediate Programming. Addison-Wesley.
ISBN 0-321-32192-8.• Information Technology Industry Council (15 October 2003). Programming languages — C++ (Second edition
ed.). Geneva: ISO/IEC. 14882:2003(E).• Josuttis, Nicolai M. The C++ Standard Library. Addison-Wesley. ISBN 0-201-37926-0.• Koenig, Andrew; Barbara E. Moo (2000). Accelerated C++ - Practical Programming by Example.
Addison-Wesley. ISBN 0-201-70353-X.• Lippman, Stanley B.; Josée Lajoie, Barbara E. Moo (2005). C++ Primer. Addison-Wesley. ISBN 0-201-72148-1.• Lippman, Stanley B. (1996). Inside the C++ Object Model. Addison-Wesley. ISBN 0-201-83454-5.• Stroustrup, Bjarne (2000). The C++ Programming Language (Special Edition ed.). Addison-Wesley.
ISBN 0-201-70073-5.• Stroustrup, Bjarne (1994). The Design and Evolution of C++. Addison-Wesley. ISBN 0-201-54330-3.• Stroustrup, Bjarne. Programming Principles and Practice Using C++. Addison-Wesley. ISBN 0321543726.• Sutter, Herb (2001). More Exceptional C++: 40 New Engineering Puzzles, Programming Problems, and
Solutions. Addison-Wesley. ISBN 0-201-70434-X.• Sutter, Herb (2004). Exceptional C++ Style. Addison-Wesley. ISBN 0-201-76042-8.• Vandevoorde, David; Nicolai M. Josuttis (2003). C++ Templates: The complete Guide. Addison-Wesley.
ISBN 0-201-73484-2.• Scott Meyers (2005). Effective C++. Third Edition. Addison-Wesley. ISBN 0-321-33487-6

C++ 116
External links• JTC1/SC22/WG21 [31] - The ISO/IEC C++ Standard Working Group
• n3092.pdf [32] - Final Committee Draft of "ISO/IEC IS 14882 - Programming Languages - C++" (26 March2010)
• A paper by Stroustrup showing the timeline of C++ evolution (1979-1991) [33]
• Bjarne Stroustrup's C++ Style and Technique FAQ [34]
• C++ FAQ Lite by Marshall Cline [35]
• Computer World interview with Bjarne Stroustrup [36]
• CrazyEngineers.com interview with Bjarne Stroustrup [37]
• The State of the Language: An Interview with Bjarne Stroustrup (August 15, 2008) [38]
• Code practices for not breaking binary compatibility between releases of C++ libraries [39] (from KDE Techbase)
References[1] Stroustrup, Bjarne (1997). "1". The C++ Programming Language (Third ed.). ISBN 0201889544. OCLC 59193992.[2] C++ The Complete Reference Third Edition, Herbert Schildt, Publisher: Osborne McGraw-Hill.[3] ATT.com (http:/ / www2. research. att. com/ ~bs/ bs_faq. html#invention)[4] "Programming Language Popularity" (http:/ / www. langpop. com/ ). 2009. . Retrieved 2009-01-16.[5] "TIOBE Programming Community Index" (http:/ / www. tiobe. com/ index. php/ content/ paperinfo/ tpci/ index. html). 2009. . Retrieved
2009-05-06.[6] "Bjarne Stroustrup's FAQ — When was C++ invented?" (http:/ / public. research. att. com/ ~bs/ bs_faq. html#invention). . Retrieved 30 May
2006.[7] "Trends on C++ Programmers, Developers & Engineers" (http:/ / www. odesk. com/ trends/ c+ + ). . Retrieved 1 December 2008.[8] Stroustrup, Bjarne. "C++ Glossary" (http:/ / www. research. att. com/ ~bs/ glossary. html). . Retrieved 8 June 2007.[9] "Bjarne Stroustrup's FAQ — Where did the name "C++" come from?" (http:/ / public. research. att. com/ ~bs/ bs_faq. html#name). .
Retrieved 16 January 2008.[10] STLPort home page (http:/ / www. stlport. org/ ), quote from "The C++ Standard Library" by Nicolai M. Josuttis, p138., ISBN 0-201
37926-0, Addison-Wesley, 1999: "An exemplary version of STL is the STLport, which is available for free for any platform"[11] Stroustrup, Bjarne (2000). The C++ Programming Language (Special Edition ed.). Addison-Wesley. p. 46. ISBN 0-201-70073-5.[12] Open issues for The C++ Programming Language (3rd Edition) (http:/ / www. research. att. com/ ~bs/ 3rd_issues. html) - This code is
copied directly from Bjarne Stroustrup's errata page (p. 633). He addresses the use of '\n' rather than std::endl. Also see www.research.att.com(http:/ / www. research. att. com/ ~bs/ bs_faq2. html#void-main) for an explanation of the implicit return 0; in the main function. This implicitreturn is not available in other functions.
[13] ISO/IEC (2003). ISO/IEC 14882:2003(E): Programming Languages - C++ §6.6.3 The return statement [stmt.return] para. 2[14] ISO/IEC (2003). ISO/IEC 14882:2003(E): Programming Languages - C++ §3.6.1 Main function [basic.start.main] para. 5[15] Sutter, Herb; Alexandrescu, Andrei (2004). C++ Coding Standards: 101 Rules, Guidelines, and Best Practices. Addison-Wesley.[16] Henricson, Mats; Nyquist, Erik (1997). Industrial Strength C++. Prentice Hall. ISBN ISBN 0-13-120965-5.[17] Stroustrup, Bjarne (2000). The C++ Programming Language (Special Edition ed.). Addison-Wesley. p. 310. ISBN 0-201-70073-5. "A
virtual member function is sometimes called a method."[18] Andrew Birkett. "Parsing C++ at nobugs.org" (http:/ / www. nobugs. org/ developer/ parsingcpp/ ). Nobugs.org. . Retrieved 3 July 2009.[19] Herb Sutter (15 April 2003). "C++ Conformance Roundup" (http:/ / www. ddj. com/ dept/ cpp/ 184401381). Dr. Dobb's Journal. . Retrieved
30 May 2006.[20] "C++ ABI" (http:/ / www. codesourcery. com/ cxx-abi/ ). . Retrieved 30 May 2006.[21] "Bjarne Stroustrup's FAQ - Is C a subset of C++?" (http:/ / public. research. att. com/ ~bs/ bs_faq. html#C-is-subset). . Retrieved 18 January
2008.[22] "C9X -- The New C Standard" (http:/ / home. datacomm. ch/ t_wolf/ tw/ c/ c9x_changes. html). . Retrieved 27 December 2008.[23] Morris, Richard (July 2, 2009). "Niklaus Wirth: Geek of the Week" (http:/ / www. simple-talk. com/ opinion/ geek-of-the-week/
niklaus-wirth-geek-of-the-week/ ). . Retrieved 8 August 2009. "C++ is a language that was designed to cater to everybody’s perceived needs.As a result, the language and even more so its implementations have become complex and bulky, difficult to understand, and likely to containerrors for ever."
[24] Why is the code generated for the "Hello world" program ten times larger for C++ than for C? (http:/ / www. research. att. com/ ~bs/ bs_faq.html#Hello-world)
[25] What do you think of EC++? (http:/ / www. research. att. com/ ~bs/ bs_faq. html#EC+ + )[26] Unattributed. Previously unpublished interview with Bjarne Stroustroup, designer of C++ (http:/ / flinflon. brandonu. ca/ dueck/ 1997/
62285/ stroustroup. html).

C++ 117
[27] Stroustrup, Bjarne. Stroustrup FAQ: Did you really give an interview to IEEE? (http:/ / www2. research. att. com/ ~bs/ bs_faq. html#IEEE)[28] http:/ / www2. research. att. com/ ~bs/ bs_faq. html.[29] http:/ / www. hpl. hp. com/ personal/ Hans_Boehm/ gc/[30] http:/ / www. icce. rug. nl/ documents/ cplusplus/[31] http:/ / www. open-std. org/ jtc1/ sc22/ wg21/[32] http:/ / www. open-std. org/ jtc1/ sc22/ wg21/ docs/ papers/ 2010/ n3092. pdf[33] http:/ / www. research. att. com/ ~bs/ hopl2. pdf[34] http:/ / www. research. att. com/ ~bs/ bs_faq2. html[35] http:/ / www. parashift. com/ c%2B%2B-faq-lite/[36] http:/ / www. computerworld. com. au/ index. php/ id;408408016;pp;1;fp;16;fpid;1[37] http:/ / www. crazyengineers. com/ small-talk/ 1-cover-story/ 24-small-talk-with-dr-bjarne-stroustrup[38] http:/ / www. devx. com/ SpecialReports/ Article/ 38813/ 0/ page/ 1[39] http:/ / techbase. kde. org/ Policies/ Binary_Compatibility_Issues_With_C+ +
C syntaxThe syntax of the C programming language is a set of rules that specifies whether the sequence of characters in afile is conforming C source code. The rules specify how the character sequences are to be chunked into tokens (thelexical grammar), the permissible sequences of these tokens and some of the meaning to be attributed to thesepermissible token sequences (additional meaning is assigned by the semantics of the language).C syntax makes use of the maximal munch principle.
Data structures
Primitive data typesThe C language represents numbers in three forms: integral, real and complex. This distinction reflects similardistinctions in the instruction set architecture of most central processing units. Integral data types store numbers inthe set of integers, while real and complex numbers represent numbers (or pair of numbers) in the set of real numbersin floating point form.All C integer types have signed and unsigned variants. If signed or unsigned is not specified explicitly, in mostcircumstances signed is assumed. However, for historic reasons plain char is a type distinct from both signed charand unsigned char. It may be a signed type or an unsigned type, depending on the compiler and the character set (Cguarantees that members of the C basic character set have positive values). Also, bit field types specified as plain intmay be signed or unsigned, depending on the compiler.
Integral types
The integral types come in different sizes, with varying amounts of memory usage and range of representablenumbers. Modifiers are used to designate the size: short, long and long long[1] . The character type, whose specifieris char, represents the smallest addressable storage unit, which is most often an 8-bit byte (its size must be at least7-bit to store the basic character set, or larger) The standard header limits.h defines the minimum and maximumvalues of the integral primitive data types, amongst other limits.The following table provides a list of the integral types and their common storage sizes. The first listed number ofbits is also the minimum required by ISO C. The last column is the equivalent exact-width C99 types from thestdint.h header.

C syntax 118
Common definitions of integral types
Implicit specifier(s) Explicit specifier Number of bits Unambiguous type
signed char same 8 int8_t
unsigned char same 8 uint8_t
char one of the above 8 int8_t or uint8_t
short signed short int 16 int16_t
unsigned short unsigned short int 16 uint16_t
int signed int 16 or 32 int16_t or int32_t
unsigned unsigned int 16 or 32 uint16_t or uint32_t
long signed long int 32 or 64 int32_t or int64_t
unsigned long unsigned long int 32 or 64 uint32_t or uint64_t
long long[1] signed long long int 64 int64_t
unsigned longlong[1]
unsigned long long int 64 uint64_t
The size and limits of the plain int type (without the short, long, or long long modifiers) vary much more than theother integral types among C implementations. The Single UNIX Specification specifies that the int type must be atleast 32 bits, but the ISO C standard only requires 16 bits. Refer to limits.h for guaranteed constraints on these datatypes. On most existing implementations, two of the five integral types have the same bit widths.Integral type literal constants may be represented in one of two ways, by an integer type number, or by a singlecharacter surrounded by single quotes. Integers may be represented in three bases: decimal (48 or -293), octal with a"0" prefix (0177), or hexadecimal with a "0x" prefix (0x3FE). A character in single quotes ('F'), called a "characterconstant," represents the value of that character in the execution character set (often ASCII). In C, characterconstants have type int (in C++, they have type char).
Enumerated type
The enumerated type in C, specified with the enum keyword, and often just called an "enum," is a type designed torepresent values across a series of named constants. Each of the enumerated constants has type int. Each enum typeitself is compatible with char or a signed or unsigned integer type, but each implementation defines its own rules forchoosing a type.Some compilers warn if an object with enumerated type is assigned a value that is not one of its constants. However,such an object can be assigned any values in the range of their compatible type, and enum constants can be usedanywhere an integer is expected. For this reason, enum values are often used in place of the preprocessor #definedirectives to create a series of named constants.An enumerated type is declared with the enum specifier, an optional name for the enum, a list of one or moreconstants contained within curly braces and separated by commas, and an optional list of variable names. Subsequentreferences to a specific enumerated type use the enum keyword and the name of the enum. By default, the firstconstant in an enumeration is assigned value zero, and each subsequent value is incremented by one over theprevious constant. Specific values may also be assigned to constants in the declaration, and any subsequent constantswithout specific values will be given incremented values from that point onward.For example, consider the following declaration:
enum colors { RED, GREEN, BLUE = 5, YELLOW } paint_color;

C syntax 119
Which declares the enum colors type; the int constants RED (whose value is zero), GREEN (whose value is onegreater than RED, one), BLUE (whose value is the given value, five), and YELLOW (whose value is one greaterthan BLUE, six); and the enum colors variable paint_color. The constants may be used outside of the context of theenum, and values other than the constants may be assigned to paint_color, or any other variable of type enum colors.
Floating point types
The floating-point form is used to represent numbers with a fractional component. They do not however representmost rational numbers exactly; they are a close approximation instead. There are three types of real values, denotedby their specifier: single-precision (specifier float), double-precision (double) and double-extended-precision (longdouble). Each of these may represent values in a different form, often one of the IEEE floating point formats.Floating-point constants may be written in decimal notation, e.g. 1.23. Scientific notation may be used by adding e orE followed by a decimal exponent, e.g. 1.23e2 (which has the value 123). Either a decimal point or an exponent isrequired (otherwise, the number is an integer constant). Hexadecimal floating-point constants follow similar rulesexcept that they must be prefixed by 0x and use p to specify a hexadecimal exponent. Both decimal and hexadecimalfloating-point constants may be suffixed by f or F to indicate a constant of type float, by l or L to indicate type longdouble, or left unsuffixed for a double constant.The standard header file float.h defines the minimum and maximum values of the floating-point types float, double,and long double. It also defines other limits that are relevant to the processing of floating-point numbers.
Storage duration specifiers
Every object has a storage class, which may be automatic, static, or allocated. Variables declared within a block bydefault have automatic storage, as do those explicitly declared with the auto[2] or register storage class specifiers.The auto and register specifiers may only be used within functions and function argument declarations; as such, theauto specifier is always redundant. Objects declared outside of all blocks and those explicitly declared with the staticstorage class specifier have static storage duration.Objects with automatic storage are local to the block in which they were declared and are discarded when the blockis exited. Additionally, objects declared with the register storage class may be given higher priority by the compilerfor access to registers; although they may not actually be stored in registers, objects with this storage class may notbe used with the address-of (&) unary operator. Objects with static storage persist upon exit from the block in whichthey were declared. In this way, the same object can be accessed by a function across multiple calls. Objects withallocated storage duration are created and destroyed explicitly with malloc, free, and related functions.The extern storage class specifier indicates that the storage for an object has been defined elsewhere. When usedinside a block, it indicates that the storage has been defined by a declaration outside of that block. When used outsideof all blocks, it indicates that the storage has been defined outside of the file. The extern storage class specifier isredundant when used on a function declaration. It indicates that the declared function has been defined outside of thefile.
Type qualifiers
Objects can be qualified to indicate special properties of the data they contain. The const type qualifier indicates thatthe value of an object should not change once it has been initialized. Attempting to modify an object qualified withconst yields undefined behavior, so some C implementations store them in read-only segments of memory. Thevolatile type qualifier indicates that the value of an object may be changed externally without any action by theprogram (see volatile variable); it may be completely ignored by the compiler.

C syntax 120
PointersIn declarations the asterisk modifier (*) specifies a pointer type. For example, where the specifier int would refer tothe integer type, the specifier int * refers to the type "pointer to integer". Pointer values associate two pieces ofinformation: a memory address and a data type. The following line of code declares a pointer-to-integer variablecalled ptr:
int *ptr;
Referencing
When a non-static pointer is declared, it has an unspecified value associated with it. The address associated withsuch a pointer must be changed by assignment prior to using it. In the following example, ptr is set so that it points tothe data associated with the variable a:
int *ptr;
int a;
ptr = &a;
In order to accomplish this, the "address-of" operator (unary &) is used. It produces the memory location of the dataobject that follows.
Dereferencing
The pointed-to data can be accessed through a pointer value. In the following example, the integer variable b is set tothe value of integer variable a, which is 10:
int *p;
int a, b;
a = 10;
p = &a;
b = *p;
In order to accomplish that task, the dereference operator (unary *) is used. It returns the data to which itsoperand—which must be of pointer type—points. Thus, the expression *p denotes the same value as a.
Arrays
Array definition
Arrays are used in C to represent structures of consecutive elements of the same type. The definition of a (fixed-size)array has the following syntax:
int array[100];
which defines an array named array to hold 100 values of the primitive type int. If declared within a function, thearray dimension may also be a non-constant expression, in which case memory for the specified number of elementswill be allocated. In most contexts in later use, a mention of the variable array is converted to a pointer to the firstitem in the array. The sizeof operator is an exception: sizeof array yields the size of the entire array (that is, 100times the size of an int). Another exception is the & (address-of) operator, which yields a pointer to the entire array(e.g. int (*ptr_to_array)[100] = &array;).

C syntax 121
Accessing elements
The primary facility for accessing the values of the elements of an array is the array subscript operator. To access thei-indexed element of array, the syntax would be array[i], which refers to the value stored in that array element.Array subscript numbering begins at 0. The largest allowed array subscript is therefore equal to the number ofelements in the array minus 1. To illustrate this, consider an array a declared as having 10 elements; the first elementwould be a[0] and the last element would be a[9]. C provides no facility for automatic bounds checking for arrayusage. Though logically the last subscript in an array of 10 elements would be 9, subscripts 10, 11, and so forth couldaccidentally be specified, with undefined results.Due to array↔pointer interchangeability, the addresses of each of the array elements can be expressed in equivalentpointer arithmetic. The following table illustrates both methods for the existing array:
Array subscripts vs. pointer arithmetic
Element index 1 2 3 n
Array subscript array[0] array[1] array[2] array[n-1]
Dereferenced pointer *array *(array +1)
*(array +2)
*(array +n-1)
Similarly, since the expression a[i] is semantically equivalent to *(a+i), which in turn is equivalent to *(i+a), theexpression can also be written as i[a] (although this form is rarely used).
Dynamic arrays
A constant value is required for the dimension in a declaration of a static array. A desired feature is the ability to setthe length of an array dynamically at run-time instead:
int n = ...;
int a[n];
a[3] = 10;
This behavior can be simulated with the help of the C standard library. The malloc function provides a simplemethod for allocating memory. It takes one parameter: the amount of memory to allocate in bytes. Upon successfulallocation, malloc returns a generic (void *) pointer value, pointing to the beginning of the allocated space. Thepointer value returned is converted to an appropriate type implicitly by assignment. If the allocation could not becompleted, malloc returns a null pointer. The following segment is therefore similar in function to the above desireddeclaration:
#include <stdlib.h> /* declares malloc */
…int *a;
a = malloc(n * sizeof(int));
a[3] = 10;
The result is a "pointer to int" variable (a) that points to the first of n contiguous int objects; due to array↔pointerequivalence this can be used in place of an actual array name, as shown in the last line. The advantage in using thisdynamic allocation is that the amount of memory that is allocated to it can be limited to what is actually needed atrun time, and this can be changed as needed (using the standard library function realloc).When the dynamically-allocated memory is no longer needed, it should be released back to the run-time system. This is done with a call to the free function. It takes a single parameter: a pointer to previously allocated memory. This is the value that was returned by a previous call to malloc. It is considered good practice to then set the pointer variable

C syntax 122
to NULL so that further attempts to access the memory to which it points will fail. If this is not done, the variablebecomes a dangling pointer, and such errors in the code (or manipulations by an attacker) might be very hard todetect and lead to obscure and potentially dangerous malfunction caused by memory corruption.
free(a);
a = NULL;
Standard C-99 also supports variable-length arrays (VLAs) within block scope. Such array variables are allocatedbased on the value of an integer value at runtime upon entry to a block, and are deallocated at the end of the block.
float read_and_process(int sz)
{
float vals[sz]; // VLA, size determined at runtime
for (int i = 0; i < sz; i++)
vals[i] = read_value();
return process(vals, sz);
}
Multidimensional arrays
In addition, C supports arrays of multiple dimensions, which are stored in row-major order. Technically, Cmultidimensional arrays are just one-dimensional arrays whose elements are arrays. The syntax for declaringmultidimensional arrays is as follows:
int array2d[ROWS][COLUMNS];
(where ROWS and COLUMNS are constants); this defines a two-dimensional array. Reading the subscripts from leftto right, array2d is an array of length ROWS, each element of which is an array of COLUMNS ints.To access an integer element in this multidimensional array, one would use
array2d[4][3]
Again, reading from left to right, this accesses the 5th row, 4th element in that row (array2d[4] is an array, which weare then subscripting with the [3] to access the fourth integer).Higher-dimensional arrays can be declared in a similar manner.A multidimensional array should not be confused with an array of references to arrays (also known as Iliffe vectorsor sometimes array of arrays). The former is always rectangular (all subarrays must be the same size), and occupiesa contiguous region of memory. The latter is a one-dimensional array of pointers, each of which may point to thefirst element of a subarray in a different place in memory, and the sub-arrays do not have to be the same size. Thelatter can be created by multiple use of malloc.

C syntax 123
StringsIn C, string literals (constants) are surrounded by double quotes ("), e.g. "Hello world!" and are compiled to an arrayof the specified char values with an additional null terminating character (0-valued) code to mark the end of thestring.String literals may not contain embedded newlines; this proscription somewhat simplifies parsing of the language.To include a newline in a string, the backslash escape \n may be used, as below.There are several standard library functions for operating with string data (not necessarily constant) organized asarray of char using this null-terminated format; see below.C's string-literal syntax has been very influential, and has made its way into many other languages, such as C++,Perl, Python, PHP, Java, Javascript, C#, Ruby. Nowadays, almost all new languages adopt or build upon C-stylestring syntax. Languages that lack this syntax tend to precede C.
Backslash escapes
If you wish to include a double quote inside the string, that can be done by escaping it with a backslash (\), forexample, "This string contains \"double quotes\".". To insert a literal backslash, one must double it, e.g. "A backslashlooks like this: \\".Backslashes may be used to enter control characters, etc., into a string:
Escape Meaning
\\ Literal backslash
\" Double quote
\' Single quote
\n Newline (line feed)
\r Carriage return
\b Backspace
\t Horizontal tab
\f Form feed
\a Alert (bell)
\v Vertical tab
\? Question mark (used to escape trigraphs)
\nnn Character with octal value nnn
\xhh Character with hexadecimal value hh
The use of other backslash escapes is not defined by the C standard, although compiler vendors often provideadditional escape codes as language extensions.

C syntax 124
String literal concatenation
Adjacent string literals are concatenated at compile time; this allows long strings to be split over multiple lines, andalso allows string literals resulting from C preprocessor defines and macros to be appended to strings at compiletime:
printf(__FILE__ ": %d: Hello "
"world\n", __LINE__);
will expand to
printf("helloworld.c" ": %d: Hello "
"world\n", 10);
which is syntactically equivalent to
printf("helloworld.c: %d: Hello world\n", 10);
Character constants
Individual character constants are represented by single-quotes, e.g. 'A', and have type int (in C++ char). Thedifference is that "A" represents a pointer to the first element of a null-terminated array, whereas 'A' directlyrepresents the code value (65 if ASCII is used). The same backslash-escapes are supported as for strings, except that(of course) " can validly be used as a character without being escaped, whereas ' must now be escaped. A characterconstant cannot be empty (i.e. '' is invalid syntax), although a string may be (it still has the null terminatingcharacter). Multi-character constants (e.g. 'xy') are valid, although rarely useful — they let one store severalcharacters in an integer (e.g. 4 ASCII characters can fit in a 32-bit integer, 8 in a 64-bit one). Since the order inwhich the characters are packed into one int is not specified, portable use of multi-character constants is difficult.
Wide character strings
Since type char is usually 1 byte wide, a single char value typically can represent at most 255 distinct charactercodes, not nearly enough for all the characters in use worldwide. To provide better support for internationalcharacters, the first C standard (C89) introduced wide characters (encoded in type wchar_t) and wide characterstrings, which are written as L"Hello world!"Wide characters are most commonly either 2 bytes (using a 2-byte encoding such as UTF-16) or 4 bytes (usuallyUTF-32), but Standard C does not specify the width for wchar_t, leaving the choice to the implementor. MicrosoftWindows generally uses UTF-16, thus the above string would be 26 bytes long for a Microsoft compiler; the Unixworld prefers UTF-32, thus compilers such as GCC would generate a 52-byte string. A 2-byte wide wchar_t suffersthe same limitation as char, in that certain characters (those outside the BMP) cannot be represented in a singlewchar_t; but must be represented using surrogate pairs.The original C standard specified only minimal functions for operating with wide character strings; in 1995 thestandard was modified to include much more extensive support, comparable to that for char strings. The relevantfunctions are mostly named after their char equivalents, with the addition of a "w" or the replacement of "str" with"wcs"; they are specified in <wchar.h>, with <wctype.h> containing wide-character classification and mappingfunctions.

C syntax 125
Variable width strings
A common alternative to wchar_t is to use a variable-width encoding, whereby a logical character may extend overmultiple positions of the string. Variable-width strings may be encoded into literals verbatim, at the risk of confusingthe compiler, or using numerical backslash escapes (e.g. "\xc3\xa9" for "é" in UTF-8). The UTF-8 encoding wasspecifically designed (under Plan 9) for compatibility with the standard library string functions; supporting featuresof the encoding include a lack of embedded nulls, no valid interpretations for subsequences, and trivialresynchronisation. Encodings lacking these features are likely to prove incompatible with the standard libraryfunctions; encoding-aware string functions are often used in such case.
Library functions
Strings, both constant and variable, may be manipulated without using the standard library. However, the librarycontains many useful functions for working with null-terminated strings. It is the programmer's responsibility toensure that enough storage has been allocated to hold the resulting strings.The most commonly used string functions are:• strcat(dest, source) - appends the string source to the end of string dest• strchr(s, c) - finds the first instance of character c in string s and returns a pointer to it or a null pointer if c is not
found• strcmp(a, b) - compares strings a and b (lexicographical ordering); returns negative if a is less than b, 0 if equal,
positive if greater.• strcpy(dest, source) - copies the string source onto the string dest• strlen(st) - return the length of string st• strncat(dest, source, n) - appends a maximum of n characters from the string source to the end of string dest and
null terminates the string at the end of input or at index n+1 when the max length is reached• strncmp(a, b, n) - compares a maximum of n characters from strings a and b (lexical ordering); returns negative if
a is less than b, 0 if equal, positive if greater• strrchr(s, c) - finds the last instance of character c in string s and returns a pointer to it or a null pointer if c is not
foundOther standard string functions include:• strcoll(s1, s2) - compare two strings according to a locale-specific collating sequence• strcspn(s1, s2) - returns the index of the first character in s1 that matches any character in s2• strerror(errno) - returns a string with an error message corresponding to the code in errno• strncpy(dest, source, n) - copies n characters from the string source onto the string dest, substituting null bytes
once past the end of source; does not null terminate if max length is reached• strpbrk(s1, s2) - returns a pointer to the first character in s1 that matches any character in s2 or a null pointer if not
found• strspn(s1, s2) - returns the index of the first character in s1 that matches no character in s2• strstr(st, subst) - returns a pointer to the first occurrence of the string subst in st or a null pointer if no such
substring exists• strtok(s1, s2) - returns a pointer to a token within s1 delimited by the characters in s2• strxfrm(s1, s2, n) - transforms s2 onto s1, such that s1 used with strcmp gives the same results as s2 used with
strcollThere is a similar set of functions for handling wide character strings.

C syntax 126
Structures and unions
Structures
Structures in C are defined as data containers consisting of a sequence of named members of various types. They aresimilar to records in other programming languages. The members of a structure are stored in consecutive locations inmemory, although the compiler is allowed to insert padding between or after members (but not before the firstmember) for efficiency. The size of a structure is equal to the sum of the sizes of its members, plus the size of thepadding.
Unions
Unions in C are related to structures and are defined as objects that may hold (at different times) objects of differenttypes and sizes. They are analogous to variant records in other programming languages. Unlike structures, thecomponents of a union all refer to the same location in memory. In this way, a union can be used at various times tohold different types of objects, without the need to create a separate object for each new type. The size of a union isequal to the size of its largest component type.
Declaration
Structures are declared with the struct keyword and unions are declared with the union keyword. The specifierkeyword is followed by an optional identifier name, which is used to identify the form of the structure or union. Theidentifier is followed by the declaration of the structure or union's body: a list of member declarations, containedwithin curly braces, with each declaration terminated by a semicolon. Finally, the declaration concludes with anoptional list of identifier names, which are declared as instances of the structure or union.For example, the following statement declares a structure named s that contains three members; it will also declarean instance of the structure known as t:
struct s
{
int x;
float y;
char *z;
} t;
And the following statement will declare a similar union named u and an instance of it named n:
union u
{
int x;
float y;
char *z;
} n;
Once a structure or union body has been declared and given a name, it can be considered a new data type using thespecifier struct or union, as appropriate, and the name. For example, the following statement, given the abovestructure declaration, declares a new instance of the structure s named r:
struct s r;
It is also common to use the typedef specifier to eliminate the need for the struct or union keyword in later referencesto the structure. The first identifier after the body of the structure is taken as the new name for the structure type. Forexample, the following statement will declare a new type known as s_type that will contain some structure:

C syntax 127
typedef struct {…} s_type;
Future statements can then use the specifier s_type (instead of the expanded struct … specifier) to refer to thestructure.
Accessing members
Members are accessed using the name of the instance of a structure or union, a period (.), and the name of themember. For example, given the declaration of t from above, the member known as y (of type float) can be accessedusing the following syntax:
t.y
Structures are commonly accessed through pointers. Consider the following example that defines a pointer to t,known as ptr_to_t:
struct s *ptr_to_t = &t;
Member y of t can then be accessed by dereferencing ptr_to_t and using the result as the left operand:
(*ptr_to_t).y
Which is identical to the simpler t.y above as long as ptr_to_t points to t. Because this operation is common, Cprovides an abbreviated syntax for accessing a member directly from a pointer. With this syntax, the name of theinstance is replaced with the name of the pointer and the period is replaced with the character sequence ->. Thus, thefollowing method of accessing y is identical to the previous two:
ptr_to_t->y
Members of unions are accessed in the same way.
Initialization
A structure can be initialized in its declarations using an initializer list, similar to arrays. If a structure is notinitialized, the values of its members are undefined until assigned. The components of the initializer list must agree,in type and number, with the components of the structure itself.The following statement will initialize a new instance of the structure s from above known as pi:
struct s pi = { 3, 3.1415, "Pi" };
Designated initializers allow members to be initialized by name. The following initialization is equivalent to theprevious one.
struct s pi = { .x = 3, .y = 3.1415, .z = "Pi" };
Members may be initialized in any order, and those that are not explicitly mentioned are set to zero.Any one member of a union may be initialized using designated initializers.
union u value = { .y = 3.1415 };
In C89, a union could only be initialized with a value of the type of its first member. That is, the union u from abovecan only be initialized with a value of type int.
union u value = { 3 };

C syntax 128
Assignment
Assigning values to individual members of structures and unions is syntactically identical to assigning values to anyother object. The only difference is that the lvalue of the assignment is the name of the member, as accessed by thesyntax mentioned above.A structure can also be assigned as a unit to another structure of the same type. Structures (and pointers to structures)may also be used as function parameter and return types.For example, the following statement assigns the value of 74 (the ASCII code point for the letter 't') to the membernamed x in the structure t, from above:
t.x = 74;
And the same assignment, using ptr_to_t in place of t, would look like:
ptr_to_t->x = 74;
Assignment with members of unions is identical, except that each new assignment changes the current type of theunion, and the previous type and value are lost.
Other operations
According to the C standard, the only legal operations that can be performed on a structure are copying it, assigningto it as a unit (or initializing it), taking its address with the address-of (&) unary operator, and accessing its members.Unions have the same restrictions. One of the operations implicitly forbidden is comparison: structures and unionscannot be compared using C's standard comparison facilities (==, >, <, etc.).
Bit fields
C also provides a special type of structure member known as a bit field, which is an integer with an explicitlyspecified number of bits. A bit field is declared as a structure member of type int, signed int, unsigned int, or _Bool,following the member name by a colon (:) and the number of bits it should occupy. The total number of bits in asingle bit field must not exceed the total number of bits in its declared type.As a special exception to the usual C syntax rules, it is implementation-defined whether a bit field declared as typeint, without specifying signed or unsigned, is signed or unsigned. Thus, it is recommended to explicitly specifysigned or unsigned on all structure members for portability.Empty entries consisting of just a colon followed by a number of bits are also allowed; these indicate padding.The members of bit fields do not have addresses, and as such cannot be used with the address-of (&) unary operator.The sizeof operator may not be applied to bit fields.The following declaration declares a new structure type known as f and an instance of it known as g. Commentsprovide a description of each of the members:
struct f
{
unsigned int flag : 1; /* a bit flag: can either be on (1) or off
(0) */
signed int num : 4; /* a signed 4-bit field; range -7...7 or
-8...7 */
: 3; /* 3 bits of padding to round out 8 bits
*/
} g;

C syntax 129
Incomplete types
The body of a struct or union declaration, or a typedef thereof, may be omitted, yielding an incomplete type. Such atype may not be instantiated (its size is not known), nor may its members be accessed (they, too, are unknown);however, the derived pointer type may be used (but not dereferenced).Incomplete types are used to implement recursive structures; the body of the type declaration may be deferred tolater in the translation unit:
typedef struct Bert Bert;
typedef struct Wilma Wilma;
struct Bert
{
Wilma *wilma;
};
struct Wilma
{
Bert *bert;
};
Incomplete types are also used for data hiding; the incomplete type is defined in a header file, and the body onlywithin the relevant source file.
Control structuresC is a free-form language.Bracing style varies from programmer to programmer and can be the subject of debate. See Indent style for moredetails.
Compound statementsIn the items in this section, any <statement> can be replaced with a compound statement. Compound statementshave the form:
{
<optional-declaration-list>
<optional-statement-list>
}
and are used as the body of a function or anywhere that a single statement is expected. The declaration-list declaresvariables to be used in that scope, and the statement-list are the actions to be performed. Brackets define their ownscope, and variables defined inside those brackets will be automatically deallocated at the closing bracket.Declarations and statements can be freely intermixed within a compound statement (as in C++).

C syntax 130
Selection statementsC has two types of selection statements: the if statement and the switch statement.The if statement is in the form:
if (<expression>)
<statement1>
else
<statement2>
In the if statement, if the <expression> in parentheses is nonzero (true), control passes to <statement1>. If the elseclause is present and the <expression> is zero (false), control will pass to <statement2>. The "else <statement2> partis optional, and if absent, a false <expression> will simply result in skipping over the <statement1>. An else alwaysmatches the nearest previous unmatched if; braces may be used to override this when necessary, or for clarity.The switch statement causes control to be transferred to one of several statements depending on the value of anexpression, which must have integral type. The substatement controlled by a switch is typically compound. Anystatement within the substatement may be labeled with one or more case labels, which consist of the keyword casefollowed by a constant expression and then a colon (:). The syntax is as follows:
switch (<expression>)
{
case <label1> :
<statements 1>
case <label2> :
<statements 2>
break;
default :
<statements 3>
}
No two of the case constants associated with the same switch may have the same value. There may be at most onedefault label associated with a switch - if none of the case labels are equal to the expression in the parenthesesfollowing switch, control passes to the default label, or if there is no default label, execution resumes just beyond theentire construct. Switches may be nested; a case or default label is associated with the innermost switch that containsit. Switch statements can "fall through", that is, when one case section has completed its execution, statements willcontinue to be executed downward until a break; statement is encountered. Fall-through is useful in somecircumstances, but is usually not desired. In the preceding example, if <label2> is reached, the statements<statements 2> are executed and nothing more inside the braces. However if <label1> is reached, both <statements1> and <statements 2> are executed since there is no break to separate the two case statements.
Iteration statementsC has three forms of iteration statement:
do
<statement>
while ( <expression> ) ;
while ( <expression> )
<statement>

C syntax 131
for ( <expression> ; <expression> ; <expression> )
<statement>
In the while and do statements, the substatement is executed repeatedly so long as the value of the expressionremains nonzero (true). With while, the test, including all side effects from the expression, occurs before eachexecution of the statement; with do, the test follows each iteration. Thus, a do statement always executes itssubstatement at least once, whereas while may not execute the substatement at all.If all three expressions are present in a for, the statement
for (e1; e2; e3)
s;
is equivalent to
e1;
while (e2)
{
s;
e3;
}
except for the behavior of a continue; statement (which in the for loop jumps to e3 instead of e2).Any of the three expressions in the for loop may be omitted. A missing second expression makes the while testalways nonzero, creating a potentially infinite loop.Since C99, the first expression may take the form of a declaration, typically including an initializer, such as
for (int i=0; i< limit; i++){
...
}
The declaration's scope is limited to the extent of the for loop.
Jump statementsJump statements transfer control unconditionally. There are four types of jump statements in C: goto, continue,break, and return.The goto statement looks like this:
goto <identifier> ;
The identifier must be a label (followed by a colon) located in the current function. Control transfers to the labeledstatement.A continue statement may appear only within an iteration statement and causes control to pass to theloop-continuation portion of the innermost enclosing iteration statement. That is, within each of the statements
while (expression)
{
/* ... */
cont: ;
}
do

C syntax 132
{
/* ... */
cont: ;
} while (expression);
for (expr1; expr2; expr3) {
/* ... */
cont: ;
}
a continue not contained within a nested iteration statement is the same as goto cont.The break statement is used to end a for loop, while loop, do loop, or switch statement. Control passes to thestatement following the terminated statement.A function returns to its caller by the return statement. When return is followed by an expression, the value isreturned to the caller as the value of the function. Encountering the end of the function is equivalent to a return withno expression. In that case, if the function is declared as returning a value and the caller tries to use the returnedvalue, the result is undefined.
Storing the address of a label
GCC extends the C language with a unary && operator that returns the address of a label. This address can be storedin a void* variable type and may be used later in a goto instruction. For example, the following prints "hi " in aninfinite loop:
void *ptr = &&J1;
J1: printf("hi ");
goto *ptr;
This feature can be used to implement a jump table.
Functions
SyntaxA C function definition consists of a return type (void if no value is returned), a unique name, a list of parameters inparentheses, and various statements. A function with non-void return type should include at least one returnstatement.
<return-type> functionName( <parameter-list> )
{
<statements>
return <expression of type return-type>;
}
where <parameter-list> variables is a comma separated list of parameter declarations, each item in the list being adata type followed by an identifier: data-type variable, data-type variable,.... If there are no parameters theparameter-list may left empty or optionally be specified with the single word void. It is possible to define a functionas taking a variable number of parameters by providing the ... keyword as the last parameter instead of a data typeand variable name. A commonly used function that does this is the standard library function printf, which has thedeclaration:

C syntax 133
int printf (const char*, ...);
Manipulation of these parameters can be done by using the routines in the standard library header <stdarg.h>.
Function Pointers
A pointer to a function can be declared as follows:
<return-type> (*functionName)(<parameter-list>);
The following program shows use of a function pointer for selecting between addition and subtraction:
#include <stdio.h>
int (*operation)(int x, int y);
int add(int x, int y)
{
return x + y;
}
int subtract(int x, int y)
{
return x - y;
}
int main(int argc, char* args[])
{
int foo = 1, bar = 1;
operation = add;
printf("%d + %d = %d\n", foo, bar, operation(foo, bar));
operation = subtract;
printf("%d - %d = %d\n", foo, bar, operation(foo, bar));
return 0;
}
Global structureAfter preprocessing, at the highest level a C program consists of a sequence of declarations at file scope. These maybe partitioned into several separate source files, which may be compiled separately; the resulting object modules arethen linked along with implementation-provided run-time support modules to produce an executable image.The declarations introduce functions, variables and types. C functions are akin to the subroutines of Fortran or theprocedures of Pascal.A definition is a special type of declaration. A variable definition sets aside storage and possibly initializes it, afunction definition provides its body.An implementation of C providing all of the standard library functions is called a hosted implementation. Programswritten for hosted implementations are required to define a special function called main, which is the first functioncalled when execution of the program begins.

C syntax 134
Hosted implementations start program execution by invoking the main function, which must be defined followingone of these prototypes:
int main() {...}
int main(void) {...}
int main(int argc, char *argv[]) {...}
(int main(int argc, char **argv) is also allowed). The first two definitions are equivalent (and both are compatiblewith C++). It is probably up to individual preference which one is used (the current C standard contains twoexamples of main() and two of main(void), but the draft C++ standard uses main()). The return value of main (whichshould be int) serves as termination status returned to the host environment. The C standard defines return values 0and EXIT_SUCCESS as indicating success and EXIT_FAILURE as indicating failure. (EXIT_SUCCESS andEXIT_FAILURE are defined in <stdlib.h>). Other return values have implementation defined meanings; forexample, under Linux a program killed by a signal yields a return code of the numerical value of the signal plus 128.A minimal C program would consist only of an empty main routine:
int main(){}
The main function will usually call other functions to help it perform its job.Some implementations are not hosted, usually because they are not intended to be used with an operating system.Such implementations are called free-standing in the C standard. A free-standing implementation is free to specifyhow it handles program startup; in particular it need not require a program to define a main function.Functions may be written by the programmer or provided by existing libraries. Interfaces for the latter are usuallydeclared by including header files—with the #include preprocessing directive—and the library objects are linkedinto the final executable image. Certain library functions, such as printf, are defined by the C standard; these arereferred to as the standard library functions.A function may return a value to caller (usually another C function, or the hosting environment for the functionmain). The printf function mentioned above returns how many characters were printed, but this value is oftenignored.
Argument passingIn C, arguments are passed to functions by value while other languages may pass variables by reference. Thismeans that the receiving function gets copies of the values and has no direct way of altering the original variables.For a function to alter a variable passed from another function, the caller must pass its address (a pointer to it),which can then be dereferenced in the receiving function (see Pointers for more info):
void incInt(int *y)
{
(*y)++; // Increase the value of 'x', in main, by one
}
int main(void)
{
int x = 0;
incInt(&x); // pass a reference to the var 'x'
return 0;
}
The function scanf works the same way:

C syntax 135
int x;
scanf("%d", &x);
In order to pass an editable pointer to a function you have to pass a pointer to that pointer; its address:
#include <stdio.h>
#include <stdlib.h>
void setInt(int **p, int n)
{
*p = malloc(sizeof(int)); // allocate a memory area, saving the
pointer in the
// location pointed to by the
parameter "p"
if (*p == NULL)
{
perror("malloc");
exit(EXIT_FAILURE);
}
// dereference the given pointer that has been assigned an address
// of dynamically allocated memory and set the int to the value of
n (42)
**p = n;
}
int main(void)
{
int *p; // create a pointer to an integer
setInt(&p, 42); // pass the address of 'p'
free(p);
return 0;
}
int **p defines a pointer to a pointer, which is the address to the pointer p in this case.
Array parameters
Function parameters of array type may at first glance appear to be an exception to C's pass-by-value rule. Thefollowing program will print 2, not 1:
#include <stdio.h>
void setArray(int array[], int index, int value)
{
array[index] = value;
}
int main(void)
{

C syntax 136
int a[1] = {1};
setArray(a, 0, 2);
printf ("a[0]=%d\n", a[0]);
return 0;
}
However, there is a different reason for this behavior. In fact, a function parameter declared with an array type istreated almost exactly like one declared to be a pointer. That is, the preceding declaration of setArray is equivalent tothe following:
void setArray(int *array, int index, int value)
At the same time, C rules for the use of arrays in expressions cause the value of a in the call to setArray to beconverted to a pointer to the first element of array a. Thus, in fact this is still an example of pass-by-value, with thecaveat that it is the address of the first element of the array being passed by value, not the contents of the array.
Miscellaneous
Reserved keywordsThe following words are reserved, and may not be used as identifiers:
auto
_Bool
break
case
char
_Complex
const
continue
default
do
double
else
enum
extern
float
for
goto
if
_Imaginary
inline
int
long
register
restrict
return
short
signed
sizeof
static
struct
switch
typedef
union
unsigned
void
volatile
while
Implementations may reserve other keywords, such as asm, although implementations typically providenon-standard keywords that begin with one or two underscores.
Case sensitivityC identifiers are case sensitive (e.g., foo, FOO, and Foo are the names of different objects). Some linkers may mapexternal identifiers to a single case, although this is uncommon in most modern linkers.
CommentsText starting with /* is treated as a comment and ignored. The comment ends at the next */; it can occur withinexpressions, and can span multiple lines. Accidental omission of the comment terminator is problematic in that thenext comment's properly constructed comment terminator will be used to terminate the initial comment, and all codein between the comments will be considered as a comment. C-style comments do not "nest".C++ style line comments start with // and extend to the end of the line:
// this line will be ignored by the compiler
/* these lines

C syntax 137
will be ignored
by the compiler */
x = *p/*q; /* note: this comment starts after the 'p' */
Command-line argumentsThe parameters given on a command line are passed to a C program with two predefined variables - the count of thecommand-line arguments in argc and the individual arguments as character strings in the pointer array argv. So thecommand
myFilt p1 p2 p3
results in something like
m y F i l t \0 p 1 \0 p 2 \0 p 3 \0
argv[0] argv[1] argv[2] argv[3]
(Note: While individual strings are contiguous arrays of char, there is no guarantee that the strings are stored as acontiguous group.)The name of the program, argv[0], may be useful when printing diagnostic messages or for making one binary servemultiple purposes. The individual values of the parameters may be accessed with argv[1], argv[2], and argv[3], asshown in the following program:
#include <stdio.h>
int main(int argc, char *argv[])
{
int i;
printf ("argc\t= %d\n", argc);
for (i = 0; i < argc; i++)
printf ("argv[%i]\t= %s\n", i, argv[i]);
return 0;
}
Evaluation orderIn any reasonably complex expression, there arises a choice as to the order in which to evaluate the parts of theexpression: (1+1)+(3+3) may be evaluated in the order (1+1)+(3+3), (2)+(3+3), (2)+(6), 8 or in the order(1+1)+(3+3), (1+1)+(6), (2)+(6), 8. Formally, a conforming C compiler may evaluate expressions in any orderbetween sequence points. Sequence points are defined by:• Statement ends at semicolons.• The sequencing operator: a comma. However, commas that delimit function arguments are not sequence points.• The short-circuit operators: logical and (&&) and logical or (||).• The conditional operator (?:): This operator evaluates its first sub-expression first, and then its second or third
(never both of them) based on the value of the first.• Entry to and exit from a function call (but not between evaluations of the arguments).Expressions before a sequence point are always evaluated before those after a sequence point. In the case ofshort-circuit evaluation, the second expression may not be evaluated depending on the result of the first expression.

C syntax 138
For example, in the expression (a() || b()), if the first argument evaluates to nonzero (true), the result of the entireexpression will also be true, so b() is not evaluated.The arguments to a function call may be evaluated in any order, as long as they are all evaluated by the time thefunction call takes place. The following expression, for example, has undefined behavior:
printf("%s %s\n", argv[i = 0], argv[++i]);
Undefined behaviorAn aspect of the C standard (not unique to C) is that the behavior of certain code is said to be "undefined". Inpractice, this means that the program produced from this code can do anything, from working as the programmerintended, to crashing every time it is run.For example, the following code produces undefined behavior, because the variable b is modified more than oncewith no intervening sequence point:
#include <stdio.h>
int main(void)
{
int a, b = 1;
a = b++ + b++;
printf("%d\n", a);
return 0;
}
Because there is no sequence point between the modifications of b in b++ + b++, it is possible to perform theevaluation steps in more than one order, resulting in an ambiguous statement. This can be fixed by rewriting the codeto insert a sequence point:
a = b++;
a += b++;
See also• C programming language• C variable types and declarations• Operators in C and C++• Blocks (C language extension)
References• Kernighan, Brian W.; Ritchie, Dennis M. (1988). The C Programming Language (2nd Edition ed.). Upper Saddle
River, New Jersey: Prentice Hall PTR. ISBN 0131103709.• American National Standard for Information Systems - Programming Language - C - ANSI X3.159-1989[1] The long long modifier was introduced in the C99 standard.[2] The meaning of auto is a type specifier rather than a storage class specifier in C++0x

C syntax 139
External links• The syntax of C in Backus-Naur form (http:/ / www. cs. manchester. ac. uk/ ~pjj/ bnf/ c_syntax. bnf)• Programming in C (http:/ / www. cs. cf. ac. uk/ Dave/ C/ CE. html)• The comp.lang.c Frequently Asked Questions Page (http:/ / c-faq. com/ )
C preprocessorThe C preprocessor (cpp) is the preprocessor for the C programming language. In many C implementations, it is aseparate program invoked by the compiler as the first part of translation. The preprocessor handles directives forsource file inclusion (#include), macro definitions (#define), and conditional inclusion (#if). The language ofpreprocessor directives is agnostic to the grammar of C, so the C preprocessor can also be used independently toprocess other types of files.The transformations it makes on its input form the first four of C's so-called Phases of Translation. Though animplementation may choose to perform some or all phases simultaneously, it must behave as if it performed themone-by-one in order.
PhasesThe following are the first four (of eight) phases of translation specified in the C Standard:1. Trigraph Replacement - The preprocessor replaces trigraph sequences with the characters they represent.2. Line Splicing - Physical source lines that are continued with escaped newline sequences are spliced to form
logical lines.3. Tokenization - The preprocessor breaks the result into preprocessing tokens and whitespace. It replaces
comments with whitespace.4. Macro Expansion and Directive Handling - Preprocessing directive lines, including file inclusion and conditional
compilation, are executed. The preprocessor simultaneously expands macros and, in the 1999 version of the Cstandard, handles _Pragma operators.
Including filesThe most common use of the preprocessor is to include another file:
#include <stdio.h>
int main (void)
{
printf("Hello, world!\n");
return 0;
}
The preprocessor replaces the line #include <stdio.h> with the system header file of that name, which declares theprintf() function among other things. More precisely, the entire text of the file 'stdio.h' replaces the #includedirective.This can also be written using double quotes, e.g. #include "stdio.h". If the filename is enclosed within angle brackets, the file is searched for in the standard compiler include paths. If the filename is enclosed within double quotes, the search path is expanded to include the current source directory. C compilers and programming environments all have a facility which allows the programmer to define where include files can be found. This can

C preprocessor 140
be introduced through a command line flag, which can be parameterized using a makefile, so that a different set ofinclude files can be swapped in for different operating systems, for instance.By convention, include files are given a .h extension, and files not included by others are given a .c extension.However, there is no requirement that this be observed. Occasionally you will see files with other extensionsincluded, in particular files with a .def extension may denote files designed to be included multiple times, each timeexpanding the same repetitive content.#include often compels the use of #include guards or #pragma once to prevent double inclusion.
Conditional compilationThe #if, #ifdef, #ifndef, #else, #elif and #endif directives can be used for conditional compilation.
#ifdef _WIN32 // _WIN32 is defined by all Windows 32 compilers, but not
by others.
#include <windows.h>
#else
#include <unistd.h>
#endif
#if VERBOSE >= 2
print("trace message");
#endif
Note that comparison operations only work with integers
#if VERBOSE == "on" // NOT ALLOWED
print("trace message");
#endif
#if VERBOSE >= 2.0 // NOT ALLOWED
print("trace message");
#endif
Some compilers targeting Windows define WIN32, but all should define _WIN32[1] This allows code, includingpreprocessor commands, to compile only when targeting Windows systems. Alternatively, the macro WIN32 couldbe defined implicitly by the compiler, or specified on the compiler's command line, perhaps to control compilation ofthe program from a makefile.The example code tests if a macro _WIN32 is defined. If it is, the file <windows.h> is included, otherwise<unistd.h>.A more complex example might be something like
#if !defined(WIN32) || defined(__MINGW32__)
...
#endif
You can also cause compilation to halt by using the #error directive:
#if RUBY_VERSION == 190
# error 1.9.0 not supported
#endif

C preprocessor 141
Macro definition and expansionThere are two types of macros, object-like and function-like. Object-like macros do not take parameters;function-like macros do. The generic syntax for declaring an identifier as a macro of each type is, respectively,
#define <identifier> <replacement token list>
#define <identifier>(<parameter list>) <replacement token list>
Note that the function-like macro declaration must not have any whitespace between the identifier and the first,opening, parenthesis. If whitespace is present, the macro will be interpreted as object-like with everything startingfrom the first parenthesis added to the token list.Whenever the identifier appears in the source code it is replaced with the replacement token list, which can beempty. For an identifier declared to be a function-like macro, it is only replaced when the following token is also aleft parenthesis that begins the argument list of the macro invocation. The exact procedure followed for expansion offunction-like macros with arguments is subtle.Object-like macros were conventionally used as part of good programming practice to create symbolic names forconstants, e.g.
#define PI 3.14159
... instead of hard-coding those numbers throughout one's code. An alternative in both C and C++ is to apply theconst qualifier to a global variable.An example of a function-like macro is:
#define RADTODEG(x) ((x) * 57.29578)
This defines a radians to degrees conversion which can be written subsequently, e.g. RADTODEG(34) orRADTODEG (34). This is expanded in-place, so the caller does not need to litter copies of the multiplicationconstant all over his code. The macro here is written as all uppercase to emphasize that it is a macro, not a compiledfunction.
Standard predefined positioning macrosCertain symbols are required to be defined by an implementation during preprocessing. These include __FILE__ and__LINE__, predefined by the preprocessor itself, which expand into the current file and line number. For instancethe following:
// debugging macros so we can pin down message provenance at a glance
#define WHERESTR "[file %s, line %d]: "
#define WHEREARG __FILE__, __LINE__
#define DEBUGPRINT2(...) fprintf(stderr, __VA_ARGS__)
#define DEBUGPRINT(_fmt, ...) DEBUGPRINT2(WHERESTR _fmt, WHEREARG,
__VA_ARGS__)
//...
DEBUGPRINT("hey, x=%d\n", x);
prints the value of x, preceded by the file and line number to the standard error stream, allowing quick access towhich line the message was produced on. Note that the WHERESTR argument is concatenated with the string

C preprocessor 142
following it.The first C Standard specified that the macro __STDC__ be defined to 1 if the implementation conforms to the ISOStandard and 0 otherwise, and the macro __STDC_VERSION__ defined as a numeric literal specifying the versionof the Standard supported by the implementation. Standard C++ compilers support the __cplusplus macro.Compilers running in non-standard mode, with advanced or reduced language features that may be conflicting withthe essential standard, might not set these macros or should define others to exhibit the differences.Other Standard macros include __DATE__ and __TIME__, which expand to the date and time of translationrespectivelyThe second edition of the C Standard, C99, added support for __func__, which contains the name of the functiondefinition it is contained within, but due to preprocessor is agnostic to the grammar of C, this must be done in thecompiler itself using a local variable of the function.
PrecedenceNote that the example macro RADTODEG(x) given above uses seemingly superfluous parentheses both around theargument and around the entire expression. Omitting either of these can lead to unexpected results. For example:• Macro defined as
#define RADTODEG(x) (x * 57.29578)
will expand
RADTODEG(a + b)
to
(a + b * 57.29578)
• Macro defined as
#define RADTODEG(x) (x) * 57.29578
will expand
1 / RADTODEG(a)
to
1 / (a) * 57.29578
neither of which give the intended result.

C preprocessor 143
Multiple linesA macro can be extended over as many lines as required using a backslash escape character at the end of each line.The macro ends after the first line which does not end in a backslash.The extent to which multi-line macros enhance or reduce the size and complexity of the source of a C program, or itsreadability and maintainability is open to debate (there is no experimental evidence on this issue). Techniques suchas X-Macros are occasionally used to address these potential issues.
Multiple evaluation of side effectsAnother example of a function-like macro is:
#define MIN(a,b) ((a)>(b)?(b):(a))
Notice the use of the ternary conditional ?: operator. This illustrates one of the dangers of using function-likemacros. One of the arguments, a or b, will be evaluated twice when this "function" is called. So, if the expressionMIN(++firstnum,secondnum) is evaluated, then firstnum may be incremented twice, not once as would be expected.A safer way to achieve the same would be to use a typeof-construct:
#define max(a,b) \
({ typeof (a) _a = (a); \
typeof (b) _b = (b); \
_a > _b ? _a : _b; })
This will cause the arguments to be evaluated only once, and it will not be type-specific anymore. This construct isnot legal ANSI C; both the typeof keyword, and the construct of placing a compound statement within parentheses,are non-standard extensions implemented in the popular GNU C compiler (GCC). If you are using GCC, the samegeneral problem can also be solved using a static inline function, which is as efficient as a #define. The inlinefunction allows the compiler to check/coerce parameter types—in this particular example this appears to be adisadvantage, since the 'max' function as shown works equally well with different parameter types, but in generalhaving the type coercion is often an advantage.Within ANSI C, there is no reliable general solution to the issue of side-effects in macro arguments.
Token concatenationToken concatenation, also called token pasting, is one of the most subtle — and easy to abuse — features of the Cmacro preprocessor. Two arguments can be 'glued' together using ## preprocessor operator; this allows two tokens tobe concatenated in the preprocessed code. This can be used to construct elaborate macros which act like a crudeversion of C++ templates.For instance:
#define MYCASE(item,id) \
case id: \
item##_##id = id;\
break
switch(x) {
MYCASE(widget,23);
}
The line MYCASE(widget,23); gets expanded here into

C preprocessor 144
case 23:
widget_23 = 23;
break;
(The semicolon following the invocation of MYCASE becomes the semicolon that completes the break statement.)Only function-like parameters can be pasted in a macro, and the parameters are not parsed for macro replacementfirst, so the following somewhat non-intuitive behavior occurs:
enum {
OlderSmall = 0,
NewerLarge = 1
};
#define Older Newer
#define Small Large
#define _replace_1(Older, Small) Older##Small
#define _replace_2(Older, Small) _replace_1(Older, Small)
void printout( void )
{
// _replace_1( Older, Small ) becomes OlderSmall (not
NewerLarge),
// despite the #define calls above.
printf("Check 1: %d\n", _replace_1( Older, Small ) );
// The parameters to _replace_2 are substituted before the call
// to _replace_1, so we get NewerLarge.
printf("Check 2: %d\n", _replace_2( Older, Small ) );
}
results in
Check 1: 0
Check 2: 1
SemicolonsOne stylistic note about the above macro is that the semicolon on the last line of the macro definition is omitted sothat the macro looks 'natural' when written. It could be included in the macro definition, but then there would be linesin the code without semicolons at the end which would throw off the casual reader. Worse, the user could be temptedto include semicolons anyway; in most cases this would be harmless (an extra semicolon denotes an emptystatement) but it would cause errors in control flow blocks:
#define PRETTY_PRINT(msg) printf(msg);
if (n < 10)

C preprocessor 145
PRETTY_PRINT("n is less than 10");
else
PRETTY_PRINT("n is at least 10");
This expands to give two statements – the intended printf and an empty statement – in each branch of the if/elseconstruct, which will cause the compiler to give an error message similar to:
error: expected expression before ‘else’—gcc 4.1.1
Multiple statements
Inconsistent use of multiple-statement macros can result in unintended behaviour. The code
#define CMDS \
a = b; \
c = d
if (var == 13)
CMDS;
else
return;
will expand to
if (var == 13)
a = b;
c = d;
else
return;
which is a syntax error (the else is lacking a matching if).The macro can be made safe by replacing the internal semicolon with the comma operator, since two operandsconnected by a comma form a single statement. The comma operator is the lowest precedence operator. In particular,its precedence is lower than the assignment operator's, so that a = b, c = d does not parse as a = (b,c) = d. Therefore,
#define CMDS a = b, c = d
if (var == 13)
CMDS;
else
return;
will expand to
if (var == 13)
a = b, c = d;
else
return;

C preprocessor 146
The problem can also be fixed without using the comma operator:
#define CMDS \
do { \
a = b; \
c = d; \
} while (0)
expands to
if (var == 13)
do {
a = b;
c = d;
} while (0);
else
return;
The do and while (0) are needed to allow the macro invocation to be followed by a semicolon; if they were omittedthe resulting expansion would be
if (var == 13) {
a = b;
c = d;
}
;
else
return;
The semicolon in the macro's invocation above becomes an empty statement, causing a syntax error at the else bypreventing it matching up with the preceding if.A cleaner way, using the non-standard GNU C compiler (GCC) compound statement within parentheses compilerextension:
#define CMDS \
({ \
a = b; \
c = d; \
})
expands to
if (var == 13)
({
a = b;
c = d;
});
else

C preprocessor 147
return;
Quoting macro argumentsAlthough macro expansion does not occur within a quoted string, the text of the macro arguments can be quoted andtreated as a string literal by using the "#" directive (also known as the "Stringizing Operator"). For example, with themacro
#define QUOTEME(x) #x
the code
printf("%s\n", QUOTEME(1+2));
will expand to
printf("%s\n", "1+2");
This capability can be used with automatic string literal concatenation to make debugging macros. For example, themacro in
#define dumpme(x, fmt) printf("%s:%u: %s=" fmt, __FILE__, __LINE__, #x,
x)
int some_function() {
int foo;
/* [a lot of complicated code goes here] */
dumpme(foo, "%d");
/* [more complicated code goes here] */
}
would print the name of an expression and its value, along with the file name and the line number.
Indirectly quoting macro arguments
The "#" directive can also be used indirectly, in order to quote the "value" of a macro instead of the name of thatmacro. For example, with the macro:
#define FOO bar
#define QUOTEME_(x) #x
#define QUOTEME(x) QUOTEME_(x)
the code
printf("FOO=%s\n", QUOTEME(FOO));
will expand to

C preprocessor 148
printf("FOO=%s\n", "bar");
One common use for this technique is to convert the __LINE__ macro to a string. Eg:
QUOTEME(__LINE__);
is converted to:
"34"
if __LINE__ happens to have the value 34 when QUOTEME() is called. On the other handQUOTEME_(__LINE__) will expand to "__LINE__"
Brainteaser
The "#" directive is also used to solve the following preprocessor brainteaser (involving characters, as opposed tostrings): Define a macro, CHAR(), which takes a single input character X in the source program text and converts itinto the C-language character value of X; that is, such that
printf("%c\n", CHAR(a))
printf("%c\n", CHAR(b))
yields
a
b
Solution:
#define CHAR(X) #X[0]
Variadic macrosMacros that can take a varying number of arguments (variadic macros) are not allowed in C89, but were introducedby a number of compilers and standardised in C99. Variadic macros are particularly useful when writing wrappers tovariable parameter number functions, such as printf, for example when logging warnings and errors.
X-MacrosOne little-known usage pattern of the C preprocessor is known as "X-Macros".[2] [3] [4] An X-Macro is a header file(commonly using a ".def" extension instead of the traditional ".h") that contains a list of similar macro calls (whichcan be referred to as "component macros"). The include file is then referenced repeatedly in the following pattern:(Given that the include file is "xmacro.def" and it contains a list of component macros of the style "foo(x, y, z)")
#define foo(x, y, z) doSomethingWith(x, y, z);
#include "xmacro.def"
#undef foo
#define foo(x, y, z) doSomethingElseWith(x, y, z);

C preprocessor 149
#include "xmacro.def"
#undef foo
(etc...)
The most common usage of X-Macros is to establish a list of C objects and then automatically generate code foreach of them. Some implementations also perform any #undefs they need inside the X-Macro, as opposed toexpecting the caller to undefine them.Common sets of objects are a set of global configuration settings, a set of members of a struct, a list of possibleXML tags for converting an XML file to a quickly-traversable tree, or the body of an enum declaration; other listsare possible.Once the X-Macro has been processed to create the list of objects, the component macros can be redefined togenerate, for instance, accessor and/or mutator functions. Structure serializing and deserializing are also commonlydone.Here is an example of an X-Macro that establishes a struct and automatically creates serialize/deserialize functions:(Note: for simplicity, this example doesn't account for endianness or buffer overflows)File star.def:
EXPAND_EXPAND_STAR_MEMBER(x, int)
EXPAND_EXPAND_STAR_MEMBER(y, int)
EXPAND_EXPAND_STAR_MEMBER(z, int)
EXPAND_EXPAND_STAR_MEMBER(radius, double)
#undef EXPAND_EXPAND_STAR_MEMBER
File star_table.c:
typedef struct {
#define EXPAND_EXPAND_STAR_MEMBER(member, type) type member;
#include "star.def"
} starStruct;
void serialize_star(const starStruct *const star, unsigned char
*buffer) {
#define EXPAND_EXPAND_STAR_MEMBER(member, type) \
memcpy(buffer, &(star->member), sizeof(star->member)); \
buffer += sizeof(star->member);
#include "star.def"
}
void deserialize_star(starStruct *const star, const unsigned char
*buffer) {
#define EXPAND_EXPAND_STAR_MEMBER(member, type) \
memcpy(&(star->member), buffer, sizeof(star->member)); \
buffer += sizeof(star->member);
#include "star.def"
}

C preprocessor 150
Handlers for individual data types may be created and accessed using token concatenation ("##") and quoting ("#")operators. For example, the following might be added to the above code:
#define print_int(val) printf("%d", val)
#define print_double(val) printf("%g", val)
void print_star(const starStruct *const star) {
/* print_##type will be replaced with print_int or print_double */
#define EXPAND_EXPAND_STAR_MEMBER(member, type) \
printf("%s: ", #member); \
print_##type(star->member); \
printf("\n");
#include "star.def"
}
Note that in this example you can also avoid the creation of separate handler functions for each datatype in thisexample by defining the print format for each supported type, with the additional benefit of reducing the expansioncode produced by this header file:
#define FORMAT_(type) FORMAT_##type
#define FORMAT_int "%d"
#define FORMAT_double "%g"
void print_star(const starStruct *const star) {
/* FORMAT_(type) will be replaced with FORMAT_int or FORMAT_double */
#define EXPAND_EXPAND_STAR_MEMBER(member, type) \
printf("%s: " FORMAT_(type) "\n", #member, star->member);
#include "star.def"
}
The creation of a separate header file can be avoided by creating a single macro containing what would be thecontents of the file. For instance, the above file "star.def" could be replaced with this macro at the beginning of:File star_table.c:
#define EXPAND_STAR \
EXPAND_STAR_MEMBER(x, int) \
EXPAND_STAR_MEMBER(y, int) \
EXPAND_STAR_MEMBER(z, int) \
EXPAND_STAR_MEMBER(radius, double)
and then all calls to #include "star.def" could be replaced with a simple EXPAND_STAR statement. The rest of theabove file would become:
typedef struct {
#define EXPAND_STAR_MEMBER(member, type) type member;
EXPAND_STAR
#undef EXPAND_STAR_MEMBER
} starStruct;
void serialize_star(const starStruct *const star, unsigned char

C preprocessor 151
*buffer) {
#define EXPAND_STAR_MEMBER(member, type) \
memcpy(buffer, &(star->member), sizeof(star->member)); \
buffer += sizeof(star->member);
EXPAND_STAR
#undef EXPAND_STAR_MEMBER
}
void deserialize_star(starStruct *const star, const unsigned char
*buffer) {
#define EXPAND_STAR_MEMBER(member, type) \
memcpy(&(star->member), buffer, sizeof(star->member)); \
buffer += sizeof(star->member);
EXPAND_STAR
#undef EXPAND_STAR_MEMBER
}
and the print handler could be added as well as:
#define print_int(val) printf("%d", val)
#define print_double(val) printf("%g", val)
void print_star(const starStruct *const star) {
/* print_##type will be replaced with print_int or print_double */
#define EXPAND_STAR_MEMBER(member, type) \
printf("%s: ", #member); \
print_##type(star->member); \
printf("\n");
EXPAND_STAR
#undef EXPAND_STAR_MEMBER
}
or as:
#define FORMAT_(type) FORMAT_##type
#define FORMAT_int "%d"
#define FORMAT_double "%g"
void print_star(const starStruct *const star) {
/* FORMAT_(type) will be replaced with FORMAT_int or FORMAT_double */
#define EXPAND_STAR_MEMBER(member, type) \
printf("%s: " FORMAT_(type) "\n", #member, star->member);
EXPAND_STAR
#undef EXPAND_STAR_MEMBER
}
A variant which avoids needing to know the members of any expanded sub-macros is to accept the operators as anargument to the list macro:File star_table.c:

C preprocessor 152
/*
Generic
*/
#define STRUCT_MEMBER(member, type, dummy) type member;
#define SERIALIZE_MEMBER(member, type, obj, buffer) \
memcpy(buffer, &(obj->member), sizeof(obj->member)); \
buffer += sizeof(obj->member);
#define DESERIALIZE_MEMBER(member, type, obj, buffer) \
memcpy(&(obj->member), buffer, sizeof(obj->member)); \
buffer += sizeof(obj->member);
#define FORMAT_(type) FORMAT_##type
#define FORMAT_int "%d"
#define FORMAT_double "%g"
/* FORMAT_(type) will be replaced with FORMAT_int or FORMAT_double */
#define PRINT_MEMBER(member, type, obj) \
printf("%s: " FORMAT_(type) "\n", #member, obj->member);
/*
starStruct
*/
#define EXPAND_STAR(_, ...) \
_(x, int, __VA_ARGS__) \
_(y, int, __VA_ARGS__) \
_(z, int, __VA_ARGS__) \
_(radius, double, __VA_ARGS__)
typedef struct {
EXPAND_STAR(STRUCT_MEMBER, )
} starStruct;
void serialize_star(const starStruct *const star, unsigned char
*buffer) {
EXPAND_STAR(SERIALIZE_MEMBER, star, buffer)
}
void deserialize_star(starStruct *const star, const unsigned char
*buffer) {
EXPAND_STAR(DESERIALIZE_MEMBER, star, buffer)
}
void print_star(const starStruct *const star) {
EXPAND_STAR(PRINT_MEMBER, star)

C preprocessor 153
}
This approach can be dangerous in that the entire macro set is always interpreted as if it was on a single source line,which could encounter compiler limits with complex component macros and/or long member lists.
Compiler-specific predefined macrosCompiler-specific predefined macros are usually listed in the compiler documentation, although this is oftenincomplete. The Pre-defined C/C++ Compiler Macros project [5] lists "various pre-defined compiler macros that canbe used to identify standards, compilers, operating systems, hardware architectures, and even basic run-time librariesat compile-time".Some compilers can be made to dump at least some of their useful predefined macros, for example:GNU C Compiler
gcc -dM -E - < /dev/nullHP-UX ansi C compiler
cc -v fred.c (where fred.c is a simple test file)SCO OpenServer C compiler
cc -## fred.c (where fred.c is a simple test file)Sun Studio C/C++ compiler
cc -## fred.c (where fred.c is a simple test file)IBM AIX XL C/C++ compiler
cc -qshowmacros -E fred.c (where fred.c is a simple test file)
User-defined compilation errors and warningsThe #error directive inserts an error message into the compiler output.
#error "Gaah!"
This prints "Gaah!" in the compiler output and halts the computation at that point. This is extremely useful fordetermining whether a given line is being compiled or not. It is also useful if you have a heavily parameterized bodyof code and want to make sure a particular #define has been introduced from the makefile, e.g.:
#ifdef WINDOWS
... /* Windows specific code */
#elif defined(UNIX)
... /* Unix specific code */
#else
#error "What's your operating system?"
#endif
Most implementations (including e.g. the C-compilers by GNU, Intel, IBM, Microsoft and Apple) provide anon-standard #warning directive to print out a warning message in the compiler output, but not stop the compilationprocess. A typical use is to warn about the usage of some old code, which is now deprecated and only included forcompatibility reasons, e.g.:

C preprocessor 154
#warning "Do not use ABC, which is deprecated. Use XYZ instead."
Although the text following the #error or #warning directive does not have to be quoted, it is good practice to do so.Otherwise, there may be problems with apostrophes and other characters that the preprocessor tries to interpret.Microsoft C uses #pragma message ( "text" ) instead of #warning.
Compiler-specific preprocessor featuresThe #pragma directive is a compiler specific directive which compiler vendors may use for their own purposes. Forinstance, a #pragma is often used to allow suppression of specific error messages, manage heap and stack debugging,etc.C99 introduced a few standard #pragma directives, taking the form #pragma STDC …, which are used to control thefloating-point implementation.
As a general-purpose preprocessorSince the C preprocessor can be invoked independently to process files other than those containing to-be-compiledsource code, it can also be used as a "general purpose preprocessor" for other types of text processing. Oneparticularly notable example is the now-deprecated imake system; more examples are listed at General purposepreprocessor.CPP does work acceptably with most assembly languages. GNU mentions assembly as one of the target languagesamong C, C++ and Objective-C in the documentation of its implementation of the preprocessor. This requires thatthe assembler syntax not conflict with cpp's syntax, which means no lines starting with # and that double quotes,which cpp interprets as string literals and thus ignores, don't have syntactical meaning other than that.
See also• C syntax• Make• Preprocessor
External links• ISO/IEC 9899 [23]. The official C:1999 standard, along with defect reports and a rationale. As of 2005 the latest
version is ISO/IEC 9899:TC2 [6].• GNU CPP online manual [7]
• Visual Studio .NET preprocessor reference [8]
• Collection of pre-defined macros [5]

C preprocessor 155
References[1] List of predefined ANSI C and Microsoft C++ implementation macros. (http:/ / msdn. microsoft. com/ en-us/ library/ b0084kay. aspx)[2] C Preprocessor Trick For Implementing Similar Data Types (http:/ / liw. iki. fi/ liw/ texts/ cpp-trick. html)[3] Meyers, Randy (May 2001). "The New C: X Macros" (http:/ / www. ddj. com/ cpp/ 184401387). Dr. Dobb's Journal. . Retrieved 1 May
2008.[4] Beal, Stephan (August 2004). Supermacros (http:/ / wanderinghorse. net/ computing/ papers/ #supermacros). . Retrieved 27 October 2008.[5] http:/ / predef. sourceforge. net/[6] http:/ / www. open-std. org/ jtc1/ sc22/ wg14/ www/ docs/ n1124. pdf[7] http:/ / gcc. gnu. org/ onlinedocs/ cpp/ index. html[8] http:/ / msdn. microsoft. com/ en-us/ library/ y4skk93w(VS. 80). aspx

156
Data Input Output
C variable types and declarationsThe C programming language has an extensive system for declaring variables of different types. The rules for themore complex types can be confusing at times, due to the decisions taken over their design. The principal decision isthat the declaration of a variable should be similar, syntactically, to its use (declaration reflects use). This articlepresents a collection of variable declarations, starting at simple types, and proceeding to more complex types. Noattempt is made to present code which actually uses the variables declared.
Basic typesThere are four basic types of variable in C; they are: char, int, double and float.
Type name Meaning
char The most basic unit addressable by the machine; typically a single octet(one byte). This is an integral type.
int The most natural size of integer for the machine; typically a whole 16, 32 or 64-bit(2, 4, or 8 bytes respectively) addressable word.
float A single-precision floating point value.
double A double-precision floating point value.
To declare a variable of any of these basic types, the name of the type is given first, then the name of the newvariable second.
char red;
int i;
Various qualifiers can be placed on these basic types, in order to further describe their type.
Signednessunsigned int x;
signed int y;
int z; /* Same as "signed int" */
unsigned char grey;
signed char white;
If signed, the most significant bit designates a positive or negative value leaving the remaining bits to be used to holda designated value. Unsigned integers can only take non-negative values (positive or zero), while signed integers(default) can take both positive and negative values. The advantage of unsigned integers is to allow a greater rangeof positive values (e.g., 0 → +65535 depending on the size of the integer), whereas signed integers allow only up tohalf the same number as positive integers and the other half as negative integers (e.g., −32768 → +32767).An unsigned character, depending on the code page, might access an extended range of characters from 0 → +255,instead of that accessible by a signed char from −128 → +127, or it might simply be used as a small integer. Thestandard requires char, signed char, unsigned char to be different types. Since most standardized string functions takepointers to plain char, many C compilers correctly complain if one of the other character types is used for stringspassed to these functions.

C variable types and declarations 157
SizeThe int type can also be given a size qualifier, to specify more precisely the range of values (and memory sizerequirements) of the value stored.
short int yellow;
long int orange;
long long int red;
When declaring a short int or long int, it is permissible to omit the int, as this is implied. The following twodeclarations are equivalent.
long int brown;
long brown;
Novice C programmers may be confused as to how big these types are. The standard is specifically vague in thisarea:• A short int must not be larger than an int.• An int must not be larger than a long int.• A short int must be at least 16 bits long.• An int must be at least 16 bits long.• A long int must be at least 32 bits long.• A long long int must be at least 64 bits long.The standard does not require that any of these sizes be necessarily different. It is perfectly valid, for example, if allfour types are 64 bits long. In order to allow a simple and concise description of the sizes a compiler will apply toeach of the four types (and the size of a pointer type; see below), a simple naming scheme has been devised; see64-Bit Programming Models [1]. Two popular schemes are ILP32, in which int, long int and pointer types are 32 bitslong; and LP64, in which long int and pointers are 64 bits, and int are 32 bits. Most implementations under theseschemes use 16-bit short ints.A double variable can be marked as being a long double, which the compiler may use to select a larger floating pointrepresentation than a plain double. Again, the standard is unspecific on the relative sizes of the floating point values,and only requires a float not to be larger than a double, which should not be larger than a long double.
Type qualifiersTo help promote safety in programs, values can be marked as being constant with the const type qualifier. Compilersmust diagnose, usually with an error, attempts to modify such variables. Since const variables cannot be assigned to,they must be initialized at the point of declaration.The C standard permits arbitrary ordering of type qualifiers, such as const, and type specifiers, such as int. Both ofthe following declarations are therefore equivalent:
int const black = 12;
const int black = 12;
While the former more closely reflects the use of const marking when used in pointer types, the latter form is morenatural and almost ubiquitous.

C variable types and declarations 158
Pointer typesVariables can be declared as being pointers to values of various types, by means of the * type declarator. To declarea variable as a pointer, immediately precede its name with an asterisk.
char *square;
long *circle;
K&R gives a good explanation for the slightly odd use of asterisks in this way, as well as a motivation for why theyattach the asterisk onto the name of the variable, when it might seem to make more sense being attached to the nameof the type. This is, that when you dereference the pointer, it has the type of the thing it points at. In this case, *circleis a value of type long. While this may be a subtle point to raise in this case, it starts to show its worth when morecomplex types are used. This is the reason for C's slightly odd way of declaring more complex types, when the nameof the actual variable gets hidden within the type declaration, as further examples will show. However, the standardalso allows you to attach the asterisk to the name of the type such as long* circle. This form is usually discouragedsince it can confuse the novice when multiple pointers are declared on the same line:
long* first, second;
will result in first being a pointer to a long, but second being a long itself, which is likely not what a beginnerexpects.There is a special type of value which cannot be directly used as a variable type, but only as pointed type in the caseof pointer declarations.
void *triangle;
The pointed value here cannot be used directly; attempts to dereference this pointer will result in a compiler error.The utility here is that this is a generic pointer; useful when the pointed type does not matter, simply the pointeraddress is needed. It is usually used to store pointers in utility types, such as linked lists, or hash tables, where thecode using the utility will typecast it to a pointer of some specific type (moreover, this casting may be implicit,meaning that the cast operator isn't needed when the new type is obvious, for example in variable assignments).The pointed type can take all of the usual markings given above; the following are all valid pointer declarations.
long int *rectangle;
unsigned short int *rhombus;
const char *kite;
Note specifically the use of const in this last case. Here, kite is a (non-const) pointer to a const char. The value ofkite itself is not a constant, only the value of the char to which it points. The placement of const before the type, asnoted above, gives motivation for the way a constant pointer is declared. As it is constant, it must be initialised whenit is declared.
char * const pentagon = &some_char;
Here, pentagon is a constant pointer, which points at a char. The value at which it points is not a constant; it will notbe an error to modify the pointed character; only to modify the pointer itself. It is also possible to declare both thepointer and the pointed value as being constant. The following two declarations are equivalent.
char const * const hexagon = &some_char;
const char * const hexagon = &some_char;

C variable types and declarations 159
Pointers to pointersBecause, for example, char * is itself a type, pointer variables can be declared which point at values of such a type.These are pointers to pointers.
char **septagon;
As before, the usual type qualifiers and const marking can be applied.
unsigned long const int * const *octagon;
This declares octagon as a pointer to a constant pointer to a constant unsigned long integer. Pointer types can bearbitrarily nested below this, but with each level of indirection their use is increasingly harder to think clearly about.Any code using more than two levels of pointer probably requires a redesign, in terms of struct pointers, or the use ofthe typedef keyword.See also Three Star Programmer [2] at the WikiWikiWeb.
ArraysAn array is a collection of values, all of the same type, stored contiguously in memory. In C, arrays are implementedas pointers, with some syntactic sugar to simplify memory allocation.Some C-like languages, such as Java or C#, separate their array declarations into a type followed by a list of variablenames. In these languages, an array of 10 integer values may be declared this way:
int[10] cat; /* THIS IS NOT VALID C CODE */
However, as noted above, C's declaration syntax aims to make declarations resemble use. Because an access into thisarray would look like cat[i], it is declared in a different syntax in C.
int cat[10]; /* THIS IS VALID C CODE */
Arrays of arraysSince they are pointers, arrays can be nested. Because the array notation, using square brackets ([]), is a postfixnotation, the size of the inner nested array types is given after the outer type.
double dog[5][12];
This declares that dog is an array containing 5 elements. Each element is an array of 12 double values.
Arrays of pointersBecause the element in an array is itself a C type, arrays of pointers can be constructed.
char *mice[10];
This declares mice to be a 10 element array, where each element is a pointer to a char.
Pointers to arraysAs stated before, a bare array name (ie. without a subscription) is simply a pointer and can be passed around as such:
double dbls[20];
...
myFunc(dbls);
...

C variable types and declarations 160
To declare a variable as being a pointer to an array, we must make use of parentheses. This is because in C brackets([]) have higher precedence than the asterisk (*). So if we wish to declare a pointer to an array, we need to supplyparentheses to override this:
double (*elephant)[20];
This declares that elephant is a pointer, and the type it points at is an array of 20 double values.To declare a pointer to an array of pointers, simply combine the notations.
int *(*crocodile)[15];
Arrays are pointersThe square-bracket array subscription notation, such as my_array[5] can be thought of as "take element number 5from my_array", but it is also just as valid to think of this operation as "dereference the pointer which is equal to'my_array + 5'". In fact, the following is perfectly valid code:
int *start_pointer = malloc(5*sizeof(int)); // Allocate memory,
giving a pointer to the start
start_pointer[3] = 42; // Put the integer '42' in the fourth
position of the allocated memory
This shows how a pointer can be used as an array, although the memory allocation must be given explicitly (and thusthe memory must later be freed to prevent a memory leak). In a similar fashion, dereferencing a pointer using*pointer_name can be done by asking for the "first element of the array" (ie. treating a pointer as a 1-element array)like this pointer_name[0]. Both are valid, as long as C's precedence rules are followed.
FunctionsA function is an example of a derived type. The type of each parameter to a function is ordinarily specified, althoughstrictly speaking it is not required for most functions. Specifying the name of each parameter is optional in a functiondeclaration without a function body. The following declarations are equivalent:
long int bat(char);
long int bat(char c);
While both forms are syntactically correct, it is usually considered bad form to omit the names of the parameterswhen writing function declarations in header files. These names can provide valuable clues to readers of such files,as to their meaning and operation.Functions can take and return pointer types using the usual notation for a pointer:
const int *ball(long int l, int i, unsigned char *s);
The special type void is useful for declaring functions which do not take any parameters at all:
char *wicket(void);
This is quite different from the empty set of parentheses used in C to declare a function without information on itsparameter types:
double umpire();
This declaration declares a function called umpire which returns a double, but says nothing about the parameters thefunction takes. (In C++, however, this declaration means that umpire takes no parameters, the same as thedeclaration that uses void.)

C variable types and declarations 161
In C, functions cannot directly take other functions as parameters, or return functions as results. However, they cantake or return pointers to them. To declare that a function takes a function pointer as an argument, use the standardnotation as given above:
int crowd(char p1, int (*p2)(void));
Here, we have a function which takes two arguments. Its first argument, p1, is a plain char. Its second argument, p2is a pointer to a function. This pointed-to function should be given no arguments, and will return an int.As a special case, C implementations treat function parameters declared with a function type as pointer-to-functiontypes. Thus, the following declaration and the preceding declaration are equivalent:
int crowd(char p1, int p2(void));
To declare a function returning a function pointer (a so-called functional) again requires parentheses, to properlyapply the function markings:
long int (*boundary(int height, int width))(int x, int y);
As there are two sets of argument lists, this declaration should be read carefully, as it is quite subtle. Here, we aredefining a function called boundary. This function takes two integer parameters, height and width, and returns afunction pointer. The returned pointer points at a function that itself takes two integer parameters, x and y, andreturns a long.This type of marking can be arbitrarily extended, to make functions that return pointers to functions that returnpointers to functions, and so on, but it quickly gets very unreadable, and prone to bugs. Use of a typedef improvesreadability, as shown by the following declarations that are equivalent to the previous declaration:
typedef long int return_func(int x, int y);
return_func *boundary(int height, int width);
See also• C syntax• uninitialized variable• Blocks (C language extension)
References[1] http:/ / archive. opengroup. org/ public/ tech/ aspen/ lp64_wp. htm[2] http:/ / c2. com/ cgi/ wiki?ThreeStarProgrammer

Operators in C and C++ 162
Operators in C and C++This is a list of operators in the C/C++ programming language. All the operators listed exist in C++; the fourthcolumn 'Included in C', dictates whether an operator is also present in C. Note that C does not support operatoroverloading.When not overloaded, for the operators &&, ||, ?: (the Ternary operator), and , (the comma operator), there is asequence point after the evaluation of the first operand.C++ also contains the type conversion operators const_cast, static_cast, dynamic_cast, and reinterpret_cast whichare not listed in the table for brevity. The formatting of these operators means that their precedence level isunimportant.Most of the operators available in C and C++ are also available in other languages such as Java, Perl, C#, and PHPwith the same precedence, associativity, and semantics.
TableFor the purposes of this table, a, b, and c represent valid values (literals, values from variables, or return value),object names, or lvalues, as appropriate."Overloadable" means that the operator is overloadable in C++. "Included in C" means that the operator exists andhas a semantic meaning in C (operators are not overloadable in C).
Arithmetic operators
Operator name Syntax Overloadable Includedin C
Prototype examples (T is any type)
As member of T Outside class definitions
Basic assignment a = bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> R T1::operator =(T2);</syntaxhighlight>
N/A
Addition a + bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator +(constT& b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T operator +(const T& a,const T& b); </syntaxhighlight>
Subtraction a - bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator -(constT& b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T operator -(const T& a,const T& b); </syntaxhighlight>
Unary minus (additiveinverse)
-aYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator -() const;</syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T operator -(const T&a); </syntaxhighlight>
Multiplication a * bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator *(constT& b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T operator *(const T &a,const T& b); </syntaxhighlight>
Division a / bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator /(constT& b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T operator /(const T& a,const T& b); </syntaxhighlight>
Modulo (remainder) a % bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator %(constT& b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T operator %(const T&a, const T& b); </syntaxhighlight>

Operators in C and C++ 163
Increment Prefix ++aYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator ++();</syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator ++(T& a);</syntaxhighlight>
Postfix a++
Yes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator ++(int);</syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T operator ++(T& a,int); </syntaxhighlight>
Note: C++ uses the unnamed dummy-parameter <syntaxhighlight lang="cpp"enclose="none"> int </syntaxhighlight> to differentiate between prefix and postfixincrement operators.
Decrement Prefix --aYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator --();</syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator --(T& a);</syntaxhighlight>
Postfix a--
Yes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator --(int);</syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T operator --(T& a, int);</syntaxhighlight>
Note: C++ uses the unnamed dummy-parameter <syntaxhighlight lang="cpp"enclose="none"> int </syntaxhighlight> to differentiate between prefix and postfixdecrement operators.
Comparison operators/Relational operators
Operatorname
Syntax Overloadable Includedin C
Prototype examples (T is any type)
As member of T Outside class definitions
Equal to a == bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> bool T::operator ==(constT& b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">bool operator ==(const T& a, const T& b);</syntaxhighlight>
Not equal to a != bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> bool T::operator !=(constT& b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">bool operator !=(const T& a, const T& b);</syntaxhighlight>
Greater than a > bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> bool T::operator >(const T&b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">bool operator >(const T& a, const T& b);</syntaxhighlight>
Less than a < bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> bool T::operator <(const T&b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">bool operator <(const T& a, const T& b);</syntaxhighlight>
Greater thanor equal to
a >= bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> bool T::operator >=(constT& b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">bool operator >=(const T& a, const T& b);</syntaxhighlight>
Less than orequal to
a <= bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> bool T::operator <=(constT& b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">bool operator <=(const T& a, const T& b);</syntaxhighlight>
Logical operators

Operators in C and C++ 164
Operatorname
Syntax Overloadable Includedin C
Prototype examples (T is any type)
As member of T Outside class definitions
Logicalnegation(NOT)
!a
Yes Yes
<syntaxhighlightlang="cpp"enclose="none"> boolT::operator !() const;</syntaxhighlight>
<syntaxhighlightlang="cpp"enclose="none"> booloperator !(const T& a);</syntaxhighlight>
LogicalAND
a &&b
Yes Yes
<syntaxhighlightlang="cpp"enclose="none"> boolT::operator &&(constT& b) const;</syntaxhighlight>
<syntaxhighlightlang="cpp"enclose="none"> booloperator &&(const T& a,const T& b);</syntaxhighlight>
LogicalOR
a || b
Yes Yes
<syntaxhighlightlang="cpp"enclose="none"> boolT::operator
(const T& b) const;</syntaxhighlight>
<syntaxhighlightlang="cpp"enclose="none">bool operator
(const T& a, constT& b);</syntaxhighlight>
Bitwise operators
Operatorname
Syntax Overloadable Includedin C
Prototype examples (T is any type)
As member of T Outside class definitions
Bitwise NOT ~aYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator ~() const;</syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">T operator ~(const T& a); </syntaxhighlight>
BitwiseAND
a & bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator &(const T& b)const; </syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">T operator &(const T& a, const T& b);</syntaxhighlight>
Bitwise OR a | b Yes Yes (const T& b) const; </syntaxhighlight> (const T& a, const T& b); </syntaxhighlight>
Bitwise XOR a ^ bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator ^(const T& b)const; </syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">T operator ^(const T& a, const T& b);</syntaxhighlight>
Bitwise leftshift[1]
a << bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator <<(const T&b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">T operator <<(const T& a, const T& b);</syntaxhighlight>
Bitwise rightshift[1]
a >> bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T T::operator >>(const T&b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp" enclose="none">T operator >>(const T& a, const T& b);</syntaxhighlight>
Compound-assignment operators

Operators in C and C++ 165
Operator name Syntax Overloadable Includedin C
Prototype examples (T is any type)
As member of T Outside class definitions
Additionassignment
a += bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator +=(constT& b); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator +=(T& a,const T& b); </syntaxhighlight>
Subtractionassignment
a -= bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator -=(constT& b); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator -=(T& a,const T& b); </syntaxhighlight>
Multiplicationassignment
a *= bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator *=(constT& b); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator *=(T& a,const T& b); </syntaxhighlight>
Divisionassignment
a /= bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator /=(constT& b); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator /=(T& a,const T& b); </syntaxhighlight>
Moduloassignment
a %=b Yes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator %=(constT& b); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator %=(T& a,const T& b); </syntaxhighlight>
Bitwise ANDassignment
a &= bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator &=(constT& b); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator &=(T& a,const T& b); </syntaxhighlight>
Bitwise ORassignment
a |= bYes Yes
=(const T& b); </syntaxhighlight> =(T& a, const T& b); </syntaxhighlight>
Bitwise XORassignment
a ^= bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator ^=(constT& b); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator ^=(T& a,const T& b); </syntaxhighlight>
Bitwise left shiftassignment
a <<=b Yes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator<<=(const T& b); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator <<=(T& a,const T& b); </syntaxhighlight>
Bitwise right shiftassignment
a >>=b Yes Yes
<syntaxhighlight lang="cpp"enclose="none"> T& T::operator>>=(const T& b); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T& operator >>=(T& a,const T& b); </syntaxhighlight>
Member and pointer operators
Operator name Syntax Overloadable Includedin C
Prototype examples
As member of T or T1 Outside class definitions
Array subscript a[b]Yes Yes
<syntaxhighlight lang="cpp"enclose="none"> R T1::operator [](T2);</syntaxhighlight>
N/A
Indirection ("variablepointed by a")
*aYes Yes
<syntaxhighlight lang="cpp"enclose="none"> R T::operator *();</syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> R operator *(T);</syntaxhighlight>
Reference ("address ofa")
&aYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T* T::operator &();</syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T* operator &(T& a);</syntaxhighlight>
member b of objectpointed to by a
a->bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T2* T1::operator ->();</syntaxhighlight>
N/A

Operators in C and C++ 166
member b of object a a.b No Yes N/A
of object pointed to bya, the member pointedto by b
a->*bYes No
<syntaxhighlight lang="cpp"enclose="none"> R T1::operator->*(T2);</syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> R operator->*(T1, T2);</syntaxhighlight>
of object a, the memberpointed to by b
a.*b No No N/A
Other operators
Operator name Syntax Overloadable Includedin C
Prototype examples
As member of T or T1 Outside class definitions
Function callSee Functionobject.
a()Yes Yes
<syntaxhighlight lang="cpp"enclose="none"> R T1::operator ()(T2,T3, …); </syntaxhighlight>
N/A
comma a, bYes Yes
<syntaxhighlight lang="cpp"enclose="none"> T2& T1::operator ,(T2&b) const; </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> T2& operator ,(constT1& a, T2& b); </syntaxhighlight>
ternaryconditional
a ? b : c No Yes N/A
Scope resolution a::b No No N/A
size-of sizeof(a)sizeof(type)
No Yes N/A
Typeidentification
typeid(a)typeid(type)
No No N/A
cast (type) a
Yes Yes
<syntaxhighlight lang="cpp"enclose="none"> T1::operator T2() const;</syntaxhighlight>
N/A
Note: for user-defined conversions, the return type implicitly and necessarily matchesthe operator name.
Allocate storage new typeYes No
<syntaxhighlight lang="cpp"enclose="none"> void* T::operatornew(size_t x); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> void* operatornew(size_t x); </syntaxhighlight>
Allocate storage(array)
new type[n]Yes No
<syntaxhighlight lang="cpp"enclose="none"> void* T::operatornew[](size_t x); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> void* operatornew[](size_t x); </syntaxhighlight>
Deallocatestorage
delete aYes No
<syntaxhighlight lang="cpp"enclose="none"> void T::operatordelete(void* x); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> void operatordelete(void* x); </syntaxhighlight>
Deallocatestorage (array)
delete[] aYes No
<syntaxhighlight lang="cpp"enclose="none"> void T::operatordelete[](void* x); </syntaxhighlight>
<syntaxhighlight lang="cpp"enclose="none"> void operatordelete[](void* x); </syntaxhighlight>
Notes:[1] In the context of iostreams, writers often will refer to <syntaxhighlight lang="cpp" enclose="none"> << </syntaxhighlight> and
<syntaxhighlight lang="cpp" enclose="none"> >> </syntaxhighlight> as the “put-to” or "stream insertion" and “get-from” or "streamextraction" operators, respectively.

Operators in C and C++ 167
Operator precedenceThe following is a table that lists the precedence and associativity of all the operators in the C++ and C programminglanguages (when the operators also exist in Java, Perl, PHP and many other recent languages the precedence is thesame as that given). Operators are listed top to bottom, in descending precedence. Descending precedence refers tothe priority of evaluation. Considering an expression, an operator which is listed on some row will be evaluated priorto any operator that is listed on a row further below it. Operators that are in the same cell (there may be several rowsof operators listed in a cell) are evaluated with the same precedence, in the given direction. An operator's precedenceis unaffected by overloading.The syntax of expressions in C and C++ is specified by a context-free grammar. The table given here has beeninferred from the grammar. For the ISO C 1999 standard, section 6.5.6 note 71 states that the C grammar providedby the specification defines the precedence of the C operators, and also states that the operator precedence resultingfrom the grammar closely follows the specification's section ordering:"The [C] syntax [i.e., grammar] specifies the precedence of operators in the evaluation of an expression, which is thesame as the order of the major subclauses of this subclause, highest precedence first."A precedence table, while mostly adequate, cannot resolve a few details. In particular, note that the ternary operatorallows any arbitrary expression as its middle operand, despite being listed as having higher precedence than theassignment and comma operators. Thus a ? b , c : d is interpreted as a ? (b, c) : d, and not as the meaningless (a ? b),(c : d). Also, note that the immediate, unparenthesized result of a C cast expression cannot be the operand of sizeof.Therefore, sizeof (int) * x is interpreted as (sizeof(int)) * x and not sizeof ((int) *x).
Precedence Operator Description Associativity
1 :: Scope resolution (C++ only) Left-to-right
2 ++ -- Postfix increment and decrement
() Function call
[] Array subscripting
. Element selection by reference
-> Element selection through pointer
typeid() Run-time type information (C++ only)
const_cast Type cast (C++ only)
dynamic_cast Type cast (C++ only)
reinterpret_cast Type cast (C++ only)
static_cast Type cast (C++ only)
3 ++ -- Prefix increment and decrement Right-to-left
+ - Unary plus and minus
! ~ Logical NOT and bitwise NOT
(type) Type cast
* Indirection (dereference)
& Address-of
sizeof Size-of
new, new[] Dynamic memory allocation (C++ only)
delete, delete[] Dynamic memory deallocation (C++ only)

Operators in C and C++ 168
4 .* ->* Pointer to member (C++ only) Left-to-right
5 * / % Multiplication, division, and modulus (remainder)
6 + - Addition and subtraction
7 << >> Bitwise left shift and right shift
8 < <= For relational operators < and ≤ respectively
> >= For relational operators > and ≥ respectively
9 == != For relational = and ≠ respectively
10 & Bitwise AND
11 ^ Bitwise XOR (exclusive or)
12 | Bitwise OR (inclusive or)
13 && Logical AND
14 || Logical OR
15 c ? t : f Ternary conditional (see ?:) Right-to-Left
16 = Direct assignment (provided by default for C++ classes)
+= -= Assignment by sum and difference
*= /= %= Assignment by product, quotient, and remainder
<<= >>= Assignment by bitwise left shift and right shift
&= ^= |= Assignment by bitwise AND, XOR, and OR
17 throw Throw operator (exceptions throwing, C++ only)
18 , Comma Left-to-right
NotesThe precedence table determines the order of binding in chained expressions, when it is not expressly specified byparentheses.• For example, ++x*3 is ambiguous without some precedence rule(s). The precedence table tells us that: x is
'bound' more tightly to ++ than to *, so that whatever ++ does (now or later—see below), it does it ONLY to x(and not to x*3); it is equivalent to (++x, x*3).
• Similarly, with 3*x++, where though the post-fix ++ is designed to act AFTER the entire expression isevaluated, the precedence table makes it clear that ONLY x gets incremented (and NOT 3*x); it is functionallyequivalent to something like (tmp=3*x, x++, tmp) with tmp being a temporary value.
Precedence and bindings
• Abstracting the issue of precedence or binding, consider the diagram above. The compiler's job is to resolve thediagram into an expression, one in which several unary operators ( call them 3+( . ), 2*( . ), ( . )++ and ( . )[ i ] )

Operators in C and C++ 169
are competing to bind to y. The order of precedence table resolves the final sub-expression they each act upon: ( .)[ i ] acts only on y, ( . )++ acts only on y[i], 2*( . ) acts only on y[i]++ and 3+( . ) acts 'only' on 2*((y[i])++). It'simportant to note that WHAT sub-expression gets acted on by each operator is clear from the precedence table butWHEN each operator acts is not resolved by the precedence table; in this example, the ( . )++ operator acts onlyon y[i] by the precedence rules but binding levels alone do not indicate the timing of the postfix ++ (the ( . )++operator acts only after y[i] is evaluated in the expression).
Many of the operators containing multi-character sequences are given "names" built from the operator name of eachcharacter. For example, += and -= are often called plus equal(s) and minus equal(s), instead of the more verbose"assignment by addition" and "assignment by subtraction".The binding of operators in C and C++ is specified (in the corresponding Standards) by a factored languagegrammar, rather than a precedence table. This creates some subtle conflicts. For example, in C, the syntax for aconditional expression is:
logical-OR-expression ? expression : conditional-expression
while in C++ it is:
logical-or-expression ? expression : assignment-expression
Hence, the expression:
e = a < d ? a++ : a = d
is parsed differently in the two languages. In C, this expression is a syntax error, but many compilers parse it as:
e = ((a < d ? a++ : a) = d)
which is a semantic error, since the result of the conditional-expression (which might be a++) is not an lvalue. InC++, it is parsed as:
e = (a < d ? a++ : (a = d))
which is a valid expression.The precedence of the bitwise logical operators has been criticized. (http:/ / cm. bell-labs. com/ cm/ cs/ who/ dmr/chist. html) Conceptually, & and | are arithmetic operators like + and *.The expression <syntaxhighlight lang="cpp" enclose="none"> a & b == 7 </syntaxhighlight> is syntactically parsedas <syntaxhighlight lang="cpp" enclose="none"> a & (b == 7) </syntaxhighlight> whereas the expression<syntaxhighlight lang="cpp" enclose="none"> a + b == 7 </syntaxhighlight> is parsed as <syntaxhighlightlang="cpp" enclose="none"> (a + b) == 7 </syntaxhighlight>. This requires parentheses to be used more often thanthey otherwise would.
C++ operator synonymsC++ defines[1] keywords to act as aliases for a number of symbols that function as operators: and (&&), bitand (&),and_eq (&=), or (||), bitor (|), or_eq (|=), xor (^), xor_eq (^=), not (!), not_eq (!=), compl (~). These are parsedexactly like their symbolic equivalents, and can be used in place of the symbol they replace. It is the character orstring that is aliased, not the operator. As a result, bitand is used to replace the bitwise AND operator, the address-ofoperator, and can be used to specify reference types (e.g. int bitand ref = n;).The ANSI C specification makes allowance for these keywords as preprocessor macros in the header file iso646.h.For compatibility with C, C++ provides the header ciso646; inclusion of which has no effect.

Operators in C and C++ 170
External links• Basic types & Operators (http:/ / mycplus. com/ tutorials/ c-programming-tutorials/
basic-dataypes-and-operators-in-c-programming/ )• Prefix vs. postfix operators in C and C++ (http:/ / msdn. microsoft. com/ en-us/ library/ e1e3921c(VS. 80). aspx)
References[1] ISO/IEC JTC1/SC22/WG21 - The C++ Standards Committee (http:/ / www. open-std. org/ jtc1/ sc22/ wg21/ ) (1 September 1998). ISO/IEC
14882:1998(E) Programming Language C++. International standardization working group for the programming language C++. pp. 40–41.
C file input/outputThe C programming language provides many standard library functions for file input and output. These functionsmake up the bulk of the C standard library header <stdio.h>.The I/O functionality of C is fairly low-level by modern standards; C abstracts all file operations into operations onstreams of bytes, which may be "input streams" or "output streams". Unlike some earlier programming languages, Chas no direct support for random-access data files; to read from a record in the middle of a file, the programmer mustcreate a stream, seek to the middle of the file, and then read bytes in sequence from the stream.The stream model of file I/O was popularized by the Unix operating system, which was developed concurrently withthe C programming language itself. The vast majority of modern operating systems have inherited streams fromUnix, and many languages in the C programming language family have inherited C's file I/O interface with few ifany changes (for example, PHP). The C++ standard library reflects the "stream" concept in its syntax; see iostream.
Opening a file using fopenA file is opened using fopen, which returns an I/O stream attached to the specified file or other device from whichreading and writing can be done. If the function fails, it returns a null pointer.The related C library function freopen performs the same operation after first closing any open stream associatedwith its parameters.They are defined as
FILE *fopen(const char *path, const char *mode);
FILE *freopen(const char *path, const char *mode, FILE *fp);
The fopen function is essentially a slightly higher-level wrapper for the open system call of Unix operating systems.In the same way, fclose is often a thin wrapper for the Unix system call close, and the C FILE structure itself oftencorresponds to a Unix file descriptor. In POSIX environments, the fdopen function can be used to initialize a FILEstructure from a file descriptor; however, file descriptors are a purely Unix concept not present in standard C.The mode parameter to fopen and freopen must be a string that begins with one of the following sequences:

C file input/output 171
mode description starts..
r rb open for reading beginning
w wb open for writing (creates file if it doesn't exist). Deletes content and overwrites the file. beginning
a ab open for appending (creates file if it doesn't exist) end
r+ rb+ r+b open for reading and writing beginning
w+ wb+ w+b open for reading and writing. Deletes content and overwrites the file. beginning
a+ ab+ a+b open for reading and writing (append if file exists) end
The "b" stands for binary. The C standard provides for two kinds of files—text files and binary files—althoughoperating systems are not required to distinguish between the two. A text file is a file consisting of text arranged inlines with some sort of distinguishing end-of-line character or sequence (in Unix, a bare line feed character; inMicrosoft Windows, a carriage return followed by a line feed). When bytes are read in from a text file, an end-of-linesequence is usually mapped to a linefeed for ease in processing. When a text file is written to, a bare linefeed ismapped to the OS-specific end-of-line character sequence before writing. A binary file is a file where bytes are readin "raw", and delivered "raw", without any kind of mapping.When a file is opened with update mode ( '+' as the second or third character in the mode argument), both input andoutput may be performed on the associated stream. However, writes cannot be followed by reads without anintervening call to fflush or to a file positioning function (fseek, fsetpos, or rewind), and reads cannot be followed bywrites without an intervening call to a file positioning function.[1]
Writing and appending modes will attempt to create a file of the given name, if no such file already exists. Asmentioned above, if this operation fails, fopen will return NULL.
Closing a stream using fcloseThe fclose function takes one argument: a pointer to the FILE structure of the stream to close.
int fclose(FILE *fp);
The function returns zero on success, or EOF on failure.It is sometimes accompanied by a preceding fflush call, for streams open to writing.
Reading from a stream using fgetcThe fgetc function is used to read a character from a stream.
int fgetc(FILE *fp);
If successful, fgetc returns the next byte or character from the stream (depending on whether the file is "binary" or"text", as discussed under fopen above). If unsuccessful, fgetc returns EOF. (The specific type of error can bedetermined by calling ferror or feof with the file pointer.)The standard macro getc, also defined in <stdio.h>, behaves in almost the same way as fgetc, except that—being amacro—it may evaluate its arguments more than once.The standard function getchar, also defined in <stdio.h>, takes no arguments, and is equivalent to getc(stdin).

C file input/output 172
EOF pitfallA common mistake when using fgetc, getc, or getchar is to assign the result to a variable of type char beforecomparing it to EOF. The following code fragments exhibit this mistake, and then show the correct approach (usingtype int):
Mistake Correction
char c;while ((c = getchar()) != EOF) putchar(c);
int c;while ((c = getchar()) != EOF) putchar(c);
Consider a system in which the type char is 8 bits wide, representing 256 different values. getchar may return any ofthe 256 possible characters, and it also may return EOF to indicate end-of-file, for a total of 257 different possiblereturn values.When getchar's result is assigned to a char, which can represent only 256 different values, there is necessarily someloss of information—when packing 257 items into 256 slots, there must be a collision. The EOF value, whenconverted to char, becomes indistinguishable from whichever one of the 256 characters shares its numerical value. Ifthat character is found in the file, the above example may mistake it for an end-of-file indicator; or, just as bad, iftype char is unsigned, then because EOF is negative, it can never be equal to any unsigned char, so the aboveexample will not terminate at end-of-file. It will loop forever, repeatedly printing the character which results fromconverting EOF to char.However, this worry is allayed if the char definition is signed (as it is unless preceded by "unsigned" in thedeclaration "unsigned char c." A signed char is 8-bits wide, with a sign bit, leaving seven bits available to hold avalue ranging from -128 to 127. Since EOF is -1, specifying "c" as a char or int makes no difference; either data typeis wide enough to hold that value, with no danger of colliding with some other char.On systems where int and char are the same size, even the "good" example will suffer from the indistinguishabilityof EOF and some character's value. The proper way to handle this situation is to check feof and ferror after getcharreturns EOF. If feof indicates that end-of-file has not been reached, and ferror indicates that no errors have occurred,then the EOF returned by getchar can be assumed to represent an actual character. These extra checks are rarelydone, because most programmers assume that their code will never need to run on one of these "big char" systems.Another way is to use a compile-time assertion to make sure that UINT_MAX > UCHAR_MAX, which at leastprevents a program with such an assumption from compiling in such a system.
fwriteIn the C programming language, the fread and fwrite functions respectively provide the file operations of input andoutput. fread and fwrite are declared in <stdio.h>.
Writing a file using fwritefwrite is defined as
size_t fwrite (const void *array, size_t size, size_t count, FILE
*stream);
fwrite function writes a block of data to the stream. It will write an array of count elements to the current position inthe stream. For each element, it will write size bytes. The position indicator of the stream will be advanced by thenumber of bytes written successfully.The function will return the number of elements written successfully. The return value will be equal to count if thewrite completes successfully. In case of a write error, the return value will be less than count.

C file input/output 173
The following program opens a file named sample.txt, writes a string of characters to the file, then closes it.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main(void)
{
FILE *fp;
size_t count;
const char *str = "hello\n";
fp = fopen("sample.txt", "w");
if(fp == NULL) {
perror("failed to open sample.txt");
return EXIT_FAILURE;
}
count = fwrite(str, 1, strlen(str), fp);
printf("Wrote %zu bytes. fclose(fp) %s.\n", count, fclose(fp) == 0
? "succeeded" : "failed");
return EXIT_SUCCESS;
}
Writing to a stream using fputcThe fputc function is used to write a character to a stream.
int fputc(int c, FILE *fp);
The parameter c is silently converted to an unsigned char before being output. If successful, fputc returns thecharacter written. If unsuccessful, fputc returns EOF.The standard macro putc, also defined in <stdio.h>, behaves in almost the same way as fputc, except that—being amacro—it may evaluate its arguments more than once.The standard function putchar, also defined in <stdio.h>, takes only the first argument, and is equivalent to putc(c,stdout) where c is that argument.
Example usageThe following C program opens a binary file called myfile, reads five bytes from it, and then closes the file.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char buffer[5] = {0}; /* initialized to zeroes */
int i, rc;
FILE *fp = fopen("myfile", "rb");
if (fp == NULL) {
perror("Failed to open file \"myfile\"");

C file input/output 174
return EXIT_FAILURE;
}
for (i = 0; (rc = getc(fp)) != EOF && i < 5; buffer[i++] = rc)
;
fclose(fp);
if (i == 5) {
puts("The bytes read were...");
printf("%x %x %x %x %x\n", buffer[0], buffer[1], buffer[2],
buffer[3], buffer[4]);
} else
fputs("There was an error reading the file.\n", stderr);
return EXIT_SUCCESS;
}
ftellThe function ftell returns the current offset in a stream in relation to the first byte.
long ftell ( FILE * stream );
See also• printf
External links• fclose(3) [2] – Linux Library Functions Manual• fflush(3) [3] – Linux Library Functions Manual• fgetc(3) [4] – Linux Library Functions Manual• fopen(3) [5] – Linux Library Functions Manual• fputc(3) [6] – Linux Library Functions Manual• (comp.lang.c FAQ list) Question 12.1 [7] in the C FAQ: using char to hold getc's return value• (comp.lang.c FAQ list) Question 12.26a [8] in the C FAQ: fflush on stdin• Source code [9]
References[1] http:/ / www. opengroup. org/ onlinepubs/ 009695399/ functions/ fopen. html[2] http:/ / linux. die. net/ man/ 3/ fclose[3] http:/ / linux. die. net/ man/ 3/ fflush[4] http:/ / linux. die. net/ man/ 3/ fgetc[5] http:/ / linux. die. net/ man/ 3/ fopen[6] http:/ / linux. die. net/ man/ 3/ fputc[7] http:/ / c-faq. com/ stdio/ getcharc. html[8] http:/ / c-faq. com/ stdio/ stdinflush. html[9] http:/ / www. koders. com/ c/ fid4AC8E5A6CAFCF1D081122F3CA5866F8ADCA5D1C4. aspx

175
Control Statement
?:In computer programming, ?: is a ternary operator that is part of the syntax for a basic conditional expression inseveral programming languages. It is commonly referred to as the conditional operator.It originally comes from BCPL, whose equivalent syntax for e1 ? e2 : e3 was e1 -> e2, e3[1] . Languages derivedfrom BCPL tend to feature this operator.
Conditional assignment?: is used as follows:
condition ? value if true : value if false
The condition is evaluated true or false as a Boolean expression. On the basis of the evaluation of the Booleancondition, the entire expression returns value if true if condition is true, but value if false otherwise. Usually the twosub-expressions value if true and value if false must have the same type, which determines the type of the wholeexpression. The importance of this type-checking lies in the operator's most common use—in conditional assignmentstatements. In this usage it appears as an expression on the right side of an assignment statement, as follows:
variable = condition ? value if true : value if false
The ?: operator is similar to the way conditional expressions (if-then-else constructs) work in functionalprogramming languages, like Scheme, ML, and Haskell, since if-then-else forms an expression instead of a statementin those languages.
UsageThis ternary operator's most common usage is to make a terse simple conditional assignment statement. For example,if we wish to implement some C code to change a shop's opening hours to 12 o'clock in weekends, and 9 o'clock onweekdays, we may use
int opening_time = (day == WEEKEND) ? 12 : 9;
instead of the more verbose
int opening_time;
if (day == WEEKEND)
opening_time = 12;
else
opening_time = 9;
The two forms are nearly equivalent. Keep in mind that the ?: is an expression and if-then-else is a statement. Notethat neither value if true nor value if false expressions can be omitted from the ternary operator without an errorreport upon parsing. This contrasts with if..else statements, where the else clause can be omitted.

?: 176
C VariantsA GNU extension to C allows the second operand to be omitted, and the first operand is implicitly used as thesecond as well:
a = x ? : y;
The expression is equivalent to
a = x ? x : y;
except that if x is an expression, it is evaluated only once. The difference is significant if evaluating the expressionhas side effects.C# (and Perl) provide similar functionality with their coalescing operator
a= x ?? y;
(Unlike the above usage of "x ?: y", ?? will only test if x is non-null, as opposed to non-false.)
C++In C++ there are conditional assignment situations where use of the if-else statement is not possible, since thislanguage explicitly distinguishes between initialization and assignment. In such case it is always possible to use afunction call, but this can be cumbersome and inelegant. For example, if you want to pass conditionally differentvalues as an argument for a constructor of a field or a base class, it is not possible to use a plain if-else statement; inthis case we can use a conditional assignment expression, or a function call. Mind also that some types allowinitialization, but do not allow assignment, or even the assignment operator does totally different things than theconstructor. The latter is true for reference types, for example:
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
int main(int argc, char *argv[])
{
string name;
ofstream fout;
if (argc > 1 && argv[1])
{
name = argv[1];
fout.open(name.c_str(), ios::out | ios::app);
}
ostream &sout = name.empty() ? cout : fout;
}
In this case there's no possibility to replace the use of ?: operator with if-else statement. (Although we can replace theuse of ?: with a function call, inside of which can be an if-else statement.)

?: 177
Furthermore, the ternary operator can yield an lvalue, i.e. a value to which another value can be assigned. Considerthe following example:
#include <iostream>
int main () {
int a=0, b=0;
const bool cond = ...;
(cond ? a : b) = 1;
std::cout << "a=" << a << ','
<< "b=" << b << '\n';
}
In this example, if the boolean variable cond yields the value true in line 5, the value 1 is assigned to the variable a,otherwise, it is assigned to b.
PythonThe Python programming language uses a different syntax for this operator:
value_when_true if condition else value_when_false
This feature is not available for Python versions prior to 2.5, however. The Python programming FAQ [2] mentionsseveral possible workarounds for these versions.
Visual Basic .NETAlthough it doesn't use ?: per se, Microsoft Visual Basic .NET has a very similar implementation of this shorthandif...else statement. Using the first example provided in this article, you can do:
Dim opening_time As Integer = IIf((day = WEEKEND), 12, 9)
'general syntax is IIf(condition, value_if_true, value_if_false)
In the above example, IIf is a function, and not an actual ternary operator. As a function, the values of all threeportions are evaluated before the function call occurs. This imposed limitations, and in Visual Basic .Net 9.0,released with Visual Studio 2008, an actual ternary operator was introduced, using the If keyword instead of IIf. Thisallows the following example code to work:
Dim name As String = If(person Is Nothing, "", person.Name)
Using IIf, person.Name would be evaluated even if person is null (Nothing), causing an exception. With a trueshort-circuiting ternary operator, person.Name is not evaluated unless person is not null.
PHP<?php
$arg = "T";
$vehicle = ( ( $arg == 'B' ) ? 'bus' :
( $arg == 'A' ) ? 'airplane' :
( $arg == 'T' ) ? 'train' :
( $arg == 'C' ) ? 'car' :
( $arg == 'H' ) ? 'horse' :

?: 178
'feet' );
echo $vehicle;
?>
Due to an unfortunate error in the language grammar, the implementation of ?: in PHP uses the incorrectassociativity when compared to other languages, and given a value of T for arg, the PHP equivalent of the aboveexample would yield the value horse instead of train as one would expect. To avoid this, nested parenthesis areneeded, as in this example:
<?php
$arg = "T";
$vehicle = ($arg == 'B') ? 'bus' :
(($arg == 'A') ? 'airplane' :
(($arg == 'T') ? 'train' :
(($arg == 'C') ? 'car' :
(($arg == 'H') ? 'horse' :
'feet'))));
echo $vehicle;
?>
This will produce the correct result of train being printed to the screen.
CFML (Railo only)<cfscript>
arg = "T";
vehicle = ( ( arg == 'B' ) ? 'bus' :
( arg == 'A' ) ? 'airplane' :
( arg == 'T' ) ? 'train' :
( arg == 'C' ) ? 'car' :
( arg == 'H' ) ? 'horse' :
'feet' );
</cfscript>
<cfoutput>#vehicle#</cfoutput>
Result typeClearly the type of the result of the ?: operator must be in some sense the type unification of the types of its secondand third operands. In C this is accomplished for numeric types by arithmetic promotion; since C does not have atype hierarchy for pointer types, pointer operands may only be used if they are of the same type (ignoring typequalifiers) or one is void or NULL. It is undefined behaviour to mix pointer and integral or incompatible pointertypes; thus
number = spell_out_numbers ? "forty-two" : 42;
will result in a compile-time error in most compilers.

?: 179
?: in style guidelinesSome corporate programming guidelines list the use of the conditional operator as bad practice because it can harmreadability and long-term maintainability. Conditional operators are widely used and can be useful in certaincircumstances to avoid the use of an if statement, either because the extra verbiage would be too lengthy or becausethe syntactic context does not permit a statement. For example:
#define MAX(a, b) (((a)>(b)) ? (a) : (b))
or
for (i = 0; i < MAX_PATTERNS; i++)
c_patterns[i].ShowWindow(m_data.fOn[i] ? SW_SHOW : SW_HIDE);
(The latter example uses the Microsoft Foundation Classes Framework for Win32.)When properly formatted, the conditional operator can be used to write simple and coherent case selectors. Forexample:
vehicle = arg == 'B' ? bus :
arg == 'A' ? airplane :
arg == 'T' ? train :
arg == 'C' ? car :
arg == 'H' ? horse :
feet;
Appropriate use of the conditional operator in a variable assignment context reduces the probability of a bug from afaulty assignment as the assigned variable is stated just once as opposed to multiple times.
See also• ?? Operator
References[1] "BCPL Ternary operator (page 15)" (http:/ / cm. bell-labs. com/ cm/ cs/ who/ dmr/ bcpl. pdf). BCPL Reference Manual. .[2] http:/ / www. python. org/ doc/ faq/ programming/ #is-there-an-equivalent-of-c-s-ternary-operator

180
Functions
Procedural programmingProcedural programming can sometimes be used as a synonym for imperative programming (specifying the stepsthe program must take to reach the desired state), but can also refer (as in this article) to a programming paradigm,derived from structured programming, based upon the concept of the procedure call. Procedures, also known asroutines, subroutines, methods, or functions (not to be confused with mathematical functions, but similar to thoseused in functional programming) simply contain a series of computational steps to be carried out. Any givenprocedure might be called at any point during a program's execution, including by other procedures or itself.[1]
Procedures and modularityModularity is generally desirable, especially in large, complicated programs. Inputs are usually specifiedsyntactically in the form of arguments and the outputs delivered as return values.Scoping is another technique that helps keep procedures strongly modular. It prevents the procedure from accessingthe variables of other procedures (and vice-versa), including previous instances of itself, without explicitauthorization.Less modular procedures, often used in small or quickly written programs, tend to interact with a large number ofvariables in the execution environment, which other procedures might also modify.Because of the ability to specify a simple interface, to be self-contained, and to be reused, procedures are aconvenient vehicle for making pieces of code written by different people or different groups, including throughprogramming libraries.(See Module and Software package.)
Comparison with imperative programmingProcedural programming languages are also imperative languages, because they make explicit references to the stateof the execution environment. This could be anything from variables (which may correspond to processor registers)to something like the position of the "turtle" in the Logo programming language.
Comparison with object-oriented programmingThe focus of procedural programming is to break down a programming task into a collection of variables, datastructures, and subroutines, whereas in object-oriented programming it is to break down a programming task intoobjects with each "object" encapsulating its own data and methods (subroutines). The most important distinction iswhereas procedural programming uses procedures to operate on data structures, object-oriented programmingbundles the two together so an "object" operates on its "own" data structure.Nomenclature varies between the two, although they have much the same semantics:

Procedural programming 181
object-oriented procedural
method function
object module
message function call
attribute variable
See Algorithms + Data Structures = Programs.
Comparison with functional programmingThe principles of modularity and code reuse in practical functional languages are fundamentally the same as inprocedural languages, since they both stem from structured programming. So for example:• Procedures correspond to functions. Both allow the reuse of the same code in various parts of the programs, and
at various points of its execution.• By the same token, procedure calls correspond to function application.• Functions and their invocations are modularly separated from each other in the same manner, by the use of
function arguments, return values and variable scopes.The main difference between the styles is that functional programming languages remove or at least deemphasize theimperative elements of procedural programming. The feature set of functional languages is therefore designed tosupport writing programs as much as possible in terms of pure functions:• Whereas procedural languages model execution of the program as a sequence of imperative commands that may
implicitly alter shared state, functional programming languages model execution as the evaluation of complexexpressions that only depend on each other in terms of arguments and return values. For this reason, functionalprograms can have a freer order of code execution, and the languages may offer little control over the order inwhich various parts of the program are executed. (For example, the arguments to a procedure invocation inScheme are executed in an arbitrary order.)
• Functional programming languages support (and heavily use) first-class functions, anonymous functions andclosures.
• Functional programming languages tend to rely on tail call optimization and higher-order functions instead ofimperative looping constructs.
Many functional languages, however, are in fact impurely functional and offer imperative/procedural constructs thatallow the programmer to write programs in procedural style, or in a combination of both styles. It is common forinput/output code in functional languages to be written in a procedural style.There do exist a few esoteric functional languages (like Unlambda) that eschew structured programming precepts forthe sake of being difficult to program in (and therefore challenging). These languages are the exception to thecommon ground between procedural and functional languages.

Procedural programming 182
Comparison with logic programmingIn logic programming, a program is a set of premises, and computation is performed by attempting to provecandidate theorems. From this point of view, logic programs are declarative, focusing on what the problem is, ratherthan on how to solve it.However, the backward reasoning technique, implemented by SLD resolution, used to solve problems in logicprogramming languages such as Prolog, treats programs as goal-reduction procedures. Thus clauses of the form:
H :- B1, …, B
n.
have a dual interpretation, both as proceduresto show/solve H, show/solve B
1 and … and B
n
and as logical implications:B1 and … and B
n implies H.
Experienced logic programmers use the procedural interpretation to write programs that are effective and efficient,and they use the declarative interpretation to help ensure that programs are correct.
See also• Comparison of programming paradigms• Functional programming (contrast)• Imperative programming• Logic programming• Object-oriented programming• Programming paradigms• Programming language• Structured programming
External links• Programming Styles: Procedural, OOP, and AOP [2]
• Procedural Languages [3] at the Open Directory Project
References[1] "Welcome to IEEE Xplore 2.0: Use of procedural programming languages for controlling productionsystems" (http:/ / ieeexplore. ieee. org/
xpl/ freeabs_all. jsp?arnumber=120848). ieeexplore.ieee.org. . Retrieved 2008-04-06.[2] http:/ / www. dreamincode. net/ forums/ blog/ gabehabe/ index. php?showentry=1016[3] http:/ / www. dmoz. org/ Computers/ Programming/ Languages/ Procedural/

Subroutine 183
SubroutineIn computer science, a subroutine (also called procedure, method, function, or routine) is a portion of code withina larger program, which performs a specific task and is relatively independent of the remaining code.As the name "subprogram" suggests, a subroutine behaves in much the same way as a computer program that is usedas one step in a larger program or another subprogram. A subroutine is often coded so that it can be started ("called")several times and/or from several places during a single execution of the program, including from other subroutines,and then branch back (return) to the next instruction after the "call" once the subroutine's task is done.Subroutines are a powerful programming tool [1] , and the syntax of many programming languages includes supportfor writing and using them. Judicious use of subroutines (for example, through the structured programmingapproach) will often substantially reduce the cost of developing and maintaining a large program, while increasingits quality and reliability [2] . Subroutines, often collected into libraries, are an important mechanism for sharing andtrading software. The discipline of object-oriented programming is based on objects and methods (which aresubroutines attached to these objects or object classes).In the compilation technique called threaded code, the executable program is basically a sequence of subroutinecalls. Maurice Wilkes, David Wheeler, and Stanley Gill are credited with the invention of this concept, which theyreferred to as closed subroutine [3] .
Main conceptsThe content of a subroutine is its body, the piece of program code that is executed when the subroutine is called orinvoked.A subroutine may be written so that it expects to obtain one or more data values from the calling program (itsarguments or parameters). It may also return a computed value to its caller (its return value), or provide variousresult values or out(put) parameters. Indeed, a common use of subroutines is to implement mathematical functions,in which the purpose of the subroutine is purely to compute one or more results whose values are entirely determinedby the parameters passed to the subroutine. (Examples might include computing the logarithm of a number or thedeterminant of a matrix.However, a subroutine call may also have side effects, such as modifying data structures in the computer's memory,reading from or writing to a peripheral device, creating a file, halting the program or the machine, or even delayingthe program's execution for a specified time. A subprogram with side effects may return different results each time itis called, even if it is called with the same arguments. An example is a random number function, available in manylanguages, that returns a different random-looking number each time it is called. The widespread use of subroutineswith side effects is a characteristic of imperative programming languages.A subroutine can be coded so that it may call itself recursively, at one or more places, in order to perform its task.This technique allows direct implementation of functions defined by mathematical induction and recursive divideand conquer algorithms.A subroutine whose purpose is to compute a single boolean-valued function (that is, to answer a yes/no question) iscalled a predicate. In logic programming languages, often all subroutines are called "predicates", since theyprimarily determine success or failure.

Subroutine 184
Language supportHigh-level programming languages usually include specific constructs for• delimiting the part of the program (body) that comprises the subroutine,• assigning a name to the subroutine,• specifying the names and/or types of its parameters and/or return values,• providing a private naming scope for its temporary variables,• identifying variables outside the subroutine which are accessible within it,• calling the subroutine,• providing values to its parameters,• specifying the return values from within its body,• returning to the calling program,• disposing of the values returned by a call,• handling any exceptional conditions encountered during the call,• packaging subroutines into a module, library, object, class, etc.Some programming languages, such as Visual Basic .NET, Pascal , Fortran, and Ada, distinguish between"functions" or "function subprograms", which provide an explicit return value to the calling program, and"subroutines" or "procedures", which do not. In those languages, function calls are normally embedded inexpressions (e.g., a sqrt function may be called as y = z + sqrt(x)); whereas procedure calls behave syntactically asstatements (e.g., a print procedure may be called as if x > 0 then print(x). Other languages, such as C and Lisp, donot make this distinction, and treat those terms as synonymous.In strictly functional programming languages such as Haskell, subprograms can have no side effects, and will alwaysreturn the same result if repeatedly called with the same arguments. Such languages typically only support functions,since subroutines that do not return a value have no use unless they can cause a side effect.A language's compiler will usually translate procedure calls and returns into machine instructions according to awell-defined calling convention, so that subroutines can be compiled separately from the programs that call them.The instruction sequences corresponding to call and return statements are called the procedure's prologue andepilogue.
AdvantagesThe advantages of breaking a program into subroutines include:• decomposition of a complex programming task into simpler steps: this is one of the two main tools of structured
programming, along with data structures.• reducing the duplication of code within a program,• enabling the reuse of code across multiple programs,• dividing a large programming task among various programmers, or various stages of a project,• hiding implementation details from users of the subroutine.

Subroutine 185
Disadvantages• The invocation of a subroutine (rather than using in-line code) imposes some computational overhead in the call
mechanism itself• The subroutine typically requires standard housekeeping code - both at entry to, and exit from, the function
(function prologue and epilogue -usually saving general purpose registers and return address as a minimum)
History
Language supportIn the (very) early assemblers, subroutine support was limited. Subroutines were not explicitly separated from eachother or from the main program, and indeed the source code of a subroutine could be interspersed with that of othersubprograms. Some assemblers would offer predefined macros to generate the call and return sequences. Laterassemblers (1960s) had much more sophisticated support for both in-line and separately assembled subroutines thatcould be linked together.
Self-modifying codeThe first use of subprograms was on early computers that were programmed in machine code or assembly language,and did not have a specific call instruction . On those computers, each subroutine call had to be implemented as asequence of lower level machine instructions which relied on self-modifying code. The replacing the operand of abranch instruction at the end of the procedure's body so that it would return to the proper location in the callingprogram (the return address, usually just after the instruction that jumped into the subroutine).
Subroutine librariesEven with this cumbersome approach, subroutines proved very useful. For one thing they allowed the same code tobe used in many different programs. Morever, memory was a very scarce resource on early computers, andsubroutines allowed significant savings in program size.In many early computers, the program instructions were entered into memory from a punched paper tape. Eachsubroutine could then be provided by a separate piece of tape, loaded or spliced before or after the main program;and the same subroutine tape could then be used by many different programs. A similar approach was used incomputers whose main input was through punched cards. The name "subroutine library" originally meant a library,in the literal sense, which kept indexed collections of such tapes or card decks for collective use.
Return by indirect jumpTo remove the need for self-modifying code, computer designers eventually provided an "indirect jump" instruction,whose operand, instead of being the return address, was the location of a variable or processor register that containedsaid address.In those computers, instead of modifying the subroutine's return jump, the calling program would store the returnaddress in some predefined location. When done, the subroutine had only to execute an indirect jump through thatlocation.

Subroutine 186
Jump to subroutineAnother advance was the "jump to subroutine" instruction, which combined the saving of the return address with thecalling jump, thereby minimizing overhead significantly.In the IBM System/360, for example, the branch instructions BAL or BALR, designed for procedure calling, wouldsave the return address in a processor register specified in the instruction. To return, the subroutine had only toexcute an indirect branch instruction (BR) through that register. If the subroutine needed that register for some otherpurpose (such as calling another subroutine), it would save the register's contents to a private memory location or aregister stack.In the HP 2100, the JSB instruction would perform a similar task, except that the return address was stored in thememory location that was the target of the branch. Execution of the procedure would actually begin at the nextmemory location. In the HP 2100 assembly language, one would write, for example
...
JSB MYSUB (Calls subroutine MYSUB.)
BB ... (Will return here after MYSUB is done.)
to call a subroutine called MYSUB from the main program. The subroutine would be coded as
MYSUB NOP (Storage for MYSUB's return address.)
AA ... (Start of MYSUB's body.)
...
JMP MYSUB,I (Returns to the calling program.)
The JSB instruction placed the address of the NEXT instruction (namely, BB) into the location specified as itsoperand (namely, MYSUB), and then branched to the NEXT location after that (namely, AA = MYSUB + 1). Thesubroutine could then return to the main program by executing the indirect jump JMP MYSUB,I which branched tothe location stored at location MYSUB.Compilers for FORTRAN and other languages could easily make use of these instructions when available. Thisapproach supported multiple levels of calls; however, since the return address, parameters, and return values of asubroutine were assigned fixed memory locations, it did not allow for recursive calls.Incidentally, a similar technique was used by Lotus 1-2-3, in the early 1980s, to discover the recalculationdependencies in a spreadsheet. Namely, a location was reserved in each cell to store the "return" address. Sincecircular references are not allowed for natural recalculation order, this allows a tree walk without reserving space fora stack in memory which was very limited on small computers such as the IBM PC.
Call stackMost modern implementations use a call stack, a special case of the stack data structure, to implement subroutinecalls and returns. Each procedure call creates a new entry, called a stack frame, at the top of the stack; when theprocedure returns, its stack frame is deleted from the stack, and its space may be used for other procedure calls. Eachstack frame contains the private data of the corresponding call, which typically includes the procedure's parametersand internal variables, and the return address.The call sequence can be implemented by a sequence of ordinary instructions (an approach still used in RISC andVLIW architectures), but many traditional machines designed since the late 1960s have included special instructionsfor that purpose.The call stack is usually implemented as a contiguous area of memory. It is an arbitrary design choice whether thebottom of the stack is the lowest or highest address within this area, so that the stack may grow forwards orbackwards in memory; however, many architectures chose the latter .

Subroutine 187
Some designs, notably some Forth implementations, used two separate stacks, one mainly for control information(like return addresses and loop counters) and the other for data. The former was, or worked like, a call stack and wasonly indirectly accessible to the programmer through other language constructs while the latter was more directlyaccessible.When stack-based procedure calls were first introduced, an important motivation was to save precious memory .With this scheme, the compiler does not have to reserve separate space in memory for the private data (parameters,return address, and local variables) of each procedure. At any moment, the stack contains only the private data of thecalls that are currently active (namely, which have been called but haven't returned yet). Because of the ways inwhich programs were usually assembled from libraries, it was (and still is) not uncommon to find programs whichinclude thousands of subroutines, of which only a handful are active at any given moment . For such programs, thecall stack mechanism could save significant amounts of memory. Indeed, the call stack mechanism can be viewed asthe earliest and simplest method for automatic memory management.However, another advantage of the call stack method is that it allows recursive subroutine calls, since each nestedcall to the same procedure gets a separate instance of its private data.
Delayed stackingOne disadvantage of the call stack mechanism is the increased cost of a procedure call and its matching return. Theextra cost includes incrementing and decrementing the stack pointer (and, in some architectures, checking for stackoverflow), and accessing the local variables and parameters by frame-relative addresses, instead of absoluteaddresses. The cost may be realized in increased execution time, or increased processor complexity, or both.This overhead is most obvious and objectionable in leaf procedures which return without making any procedurecalls themselves. To reduce that overhead, many modern compilers try to delay the use of a call stack until it is reallyneeded. For example, the call of a procedure P may store the return address and parameters of the called procedure incertain processor registers, and transfer control to the procedure's body by a simple jump. If procedure P returnswithout making any other call, the call stack is not used at all. If P needs to call another procedure Q, it will then usethe call stack to save the contents of any registers (such as the return address) which will be needed after Q returns.
C and C++ examplesIn the C and C++ programming languages, subprograms are referred to as "functions" (or "member functions" whenassociated with a class). Note that these languages use the special keyword void to indicate that a function takes noparameters (especially in C) and/or does not return any value. Note that C/C++ functions can have side-effects,including modifying any variables whose addresses are passed as parameters (i.e. "passed by reference"). Examples:
void function1(void) { /* some code */ }
The function does not return a value and has to be called as a stand-alone function, e.g., function1();
int function2(void)
{ return 5; }
This function returns a result (the number 5), and the call can be part of an expression, e.g., x + function2()
char function3 (int number)
{ char selection[] = {'M','T','W','T','F','S','S'};
return selection[number];
}
This function converts a number between 0 to 6 into the initial letter of the corresponding day of the week, namely 0to 'M', 1 to 'T', ..., 6 to 'S'. The result of calling it might be assigned to a variable, e.g., num_day =

Subroutine 188
function3(number);.
void function4 (int* pointer_to_var)
{ (*pointer_to_var)++; }
This function does not return a value but modifies the variable whose address is passed as the parameter; it would becalled with "function4(&variable_to_increment);".
Visual Basic 6 examplesIn the Visual Basic 6 programming language, subprograms are referred to as "functions" or "subs" (or "methods"when associated with a class). Visual Basic 6 uses various terms called "types" to define what is being passed as aparameter. By default, an unspecified variable is registered as a Variant type and can be passed as "ByRef" (default)or "ByVal". Also, when a function or sub is declared, it is given a public, private, or friend designation whichdetermines whether it can be accessed outside the module and/or project that it was declared in.
By value [ByVal]A way of passing the value of an argument to a procedure instead of passing the address. This allows the procedureto access a copy of the variable. As a result, the variable's actual value can't be changed by the procedure to which itis passed.
By reference [ByRef]A way of passing the address of an argument to a procedure instead of passing the value. This allows the procedureto access the actual variable. As a result, the variable's actual value can be changed by the procedure to which it ispassed. Unless otherwise specified, arguments are passed by reference.
Public (optional)Indicates that the Function procedure is accessible to all other procedures in all modules. If used in a module thatcontains an Option Private, the procedure is not available outside the project.
Private (optional)Indicates that the Function procedure is accessible only to other procedures in the module where it is declared.
Friend (optional)Used only in a class module. Indicates that the Function procedure is visible throughout the project, but not visible toa controller of an instance of an object.
Private Function Function1()
' Some Code Here
End Function
The function does not return a value and has to be called as a stand-alone function, e.g., Function1
Private Function Function2() as Integer
Function2 = 5
End Function
This function returns a result (the number 5), and the call can be part of an expression, e.g., x + Function2()

Subroutine 189
Private Function Function3(ByVal intValue as Integer) as String
Dim strArray(6) as String
strArray = Array("M", "T", "W", "T", "F", "S", "S")
Function3 = strArray(intValue)
End Function
This function converts a number between 0 and 6 into the initial letter of the corresponding day of the week, namely0 to 'M', 1 to 'T', ..., 6 to 'S'. The result of calling it might be assigned to a variable, e.g., num_day =Function3(number).
Private Function Function4(ByRef intValue as Integer)
intValue = intValue + 1
End Function
This function does not return a value but modifies the variable whose address is passed as the parameter; it would becalled with "Function4(variable_to_increment)".
Local variables, recursion and re-entrancyA subprogram may find it useful to make use of a certain amount of "scratch" space; that is, memory used during theexecution of that subprogram to hold intermediate results. Variables stored in this scratch space are referred to aslocal variables, and the scratch space itself is referred to as an activation record. An activation record typically hasa return address that tells it where to pass control back to when the subprogram finishes.A subprogram may have any number and nature of call sites. If recursion is supported, a subprogram may even callitself, causing its execution to suspend while another nested execution of the same subprogram occurs. Recursion is auseful technique for simplifying some complex algorithms, and breaking down complex problems. Recursivelanguages generally provide a new copy of local variables on each call. If the programmer desires the value of localvariables to stay the same between calls, they can be declared "static" in some languages, or global values orcommon areas can be used.Early languages like Fortran did not initially support recursion because variables were statically allocated, as well asthe location for the return address. Most computers before the late 1960s such as the PDP-8 did not have support forhardware stack registers.Modern languages after ALGOL such as PL/1 and C almost invariably use a stack, usually supported most moderncomputer instruction sets to provide a fresh activation record for every execution of a subprogram. That way, thenested execution is free to modify its local variables without concern for the effect on other suspended executions inprogress. As nested calls accumulate, a call stack structure is formed, consisting of one activation record for eachsuspended subprogram. In fact, this stack structure is virtually ubiquitous, and so activation records are commonlyreferred to as stack frames.Some languages such as Pascal and Ada also support nested subroutines, which are subroutines callable only withinthe scope of an outer (parent) subroutine. Inner subroutines have access to the local variables of the outer subroutinewhich called them. This is accomplished by storing extra context information within the activation record, alsoknown as a display.If a subprogram can function properly even when called while another execution is already in progress, thatsubprogram is said to be re-entrant. A recursive subprogram must be re-entrant. Re-entrant subprograms are alsouseful in multi-threaded situations, since multiple threads can call the same subprogram without fear of interferingwith each other. In the IBM CICS transaction processing system, "quasi-reentrant" was a slightly less restrictive, butsimilar, requirement for application programs that were shared by many threads.

Subroutine 190
In a multi-threaded environment, there is generally more than one stack. An environment which fully supportscoroutines or lazy evaluation may use data structures other than stacks to store their activation records.
OverloadingIn strongly typed languages, it is sometimes desirable to have a number of functions with the same name, butoperating on different types of data, or with different parameter profiles. For example, a square root function mightbe defined to operate on reals, complex values or matrices. The algorithm to be used in each case is different, and thereturn result may be different. By writing three separate functions with the same name, the programmer has theconvenience of not having to remember different names for each type of data. Further if a subtype can be defined forthe reals, to separate positive and negative reals, two functions can be written for the reals, one to return a real whenthe parameter is positive, and another to return a complex value when the parameter is negative.In Object-oriented programming, when a series of functions with the same name can accept different parameterprofiles or parameters of different types, each of the functions is said to be overloaded .As another example, a subroutine might construct an object that will accept directions, and trace its path to thesepoints on screen. There are a plethora of parameters that could be passed in to the constructor (colour of the trace,starting x and y co-ordinates, trace speed). If the programmer wanted the constructor to be able to accept only thecolor parameter, then he could call another constructor that accepts only color, which in turn calls the constructorwith all the parameters passing in a set of "default values" for all the other parameters (X and Y would generally becentered on screen or placed at the origin, and the speed would be set to another value of the coder's choosing).
ClosuresA closure is a subprogram together with the values of some of its variables captured from the environment in whichit was created. Closures were a notable feature of the Lisp programming language, introduced by John McCarthy.
ConventionsA number of conventions for the coding of subprograms have been developed. It has been commonly preferable thatthe name of a subprogram should be a verb when it does a certain task, an adjective when it makes some inquiry, anda noun when it is used to substitute variables.Experienced programmers recommend that a subprogram perform only one task. If a subprogram performs morethan one task, it should be split up into more subprograms. They argue that subprograms are key components inmaintaining code and their roles in the program must be distinct.Some advocate that each subprogram should have minimal dependency on other pieces of code. For example, theysee the use of global variables as unwise because it adds tight-coupling between subprograms and global variables. Ifsuch coupling is not necessary at all, they advise to refactor subprograms to take parameters instead. This practice iscontroversial because it tends to increase the number of passed parameters to subprograms.

Subroutine 191
Return codesBesides its "main" or "normal" effect, a subroutine may need to inform the calling program about "exceptional"conditions that may have occurred during its execution. In some languages and/or programming standards, this isoften done through a "return code", an integer value placed by the subroutine in some standard location, whichencodes the normal and exceptional conditions.In the IBM S/360, where a return code was expected from the subroutine, the return value was often designed to be amultiple of 4 - so that it could be used as a direct branch table index into a branch table often located immediatelyafter the call instruction to avoid extra conditional tests, further improving efficiency. In the System/360 assemblylanguage, one would write, for example: BAL 14,SUBRTN01 go to sub-routine , using reg 14 as save register (sets reg 15 to 0,4,8 as return value)
B TABLE(15) use returned value in reg 15 to index the branch table, branching to the appropriate branch instr.
TABLE B OK return code =00 GOOD }
B BAD return code =04 Invalid input } Branch table
B ERROR return code =08 Unexpected condition }
Optimization of subroutine callsThere is a significant runtime overhead in a calling a subroutine, including passing the arguments, branching to thesubprogram, and branching back to the caller. The overhead often includes saving and restoring certain processorregisters, allocating and reclaiming call frame storage, etc.. In some languages, each subroutine calls also impliesautomatic testing of the subroutine's return code, or the handling of exceptions that it may raise. In object-orientedlanguages, a significant source of overhead is the intensively used dynamic dispatch for method calls.There are some seemingly obvious optimizations of procedure calls that cannot be applied if the procedures mayhave side effects. For example, in the expression (f(x)-1)/(f(x)+1), the function f must be called twice, because thetwo calls may return different results. Moreover, the value of x must be fetched again before the second call, sincethe first call may have changed it. Determining whether a subprogram may have a side effect is very difficult(indeed, undecidable). So, while those optimizations are safe in purely functional programming languages, compilersof typical imperative programming usually have to assume the worst.
InliningA technique used to eliminate this overhead is inline expansion or inlining of the subprogram's body at each call site(rather than branching to the subroutine and back). Not only does this avoid the call overhead, but it also allows thecompiler to optimize the procedure's 'body' more effectively by taking into account the context and arguments at thatcall. The inserted body can be optimized by the compiler. Inlining however, will usually increase the code size,unless the program contains only a single call to the subroutine, or the subroutine body is less code than the calloverhead.

Subroutine 192
Related terms and clarificationDifferent programming languages and methodologies possess notions and mechanisms related to subprograms. Thename "subroutine" was prevalent in assembly languages and Fortran.A subroutine is sometimes called a callable unit.[4]
See also• Function (mathematics)• Method (computer science)• Module (programming)• Transclusion• Operator overloading• Functional programming• Command-Query Separation• Coroutines, subprograms that call each other as if both were the main programs.• Event handler, a subprogram that is called in response to an input event or Interrupt.
References[1] Donald E. Knuth. The Art of Computer Programming, Volume I: Fundamental Algorithms. Addison-Wesley. ISBN ISBN 0-201-89683-4.[2] O.-J. Dahl; E. W. Dijkstra, C. A. R. Hoare (1972). Structured Programming. Academic Press. ISBN 0-12-200550-3.[3] Wilkes, M. V.; Wheeler, D. J., Gill, S. (1951). Preparation of Programs for an Electronic Digital Computer. Addison-Wesley.[4] U.S. Election Assistance Commission (2007). "Definitions of Words with Special Meanings" (http:/ / www. eac. gov/ vvsg/ g). Voluntary
Voting System Guidelines. . Retrieved 2008-02-02.

Article Sources and Contributors 193
Article Sources and ContributorsHistory of computing hardware Source: http://en.wikipedia.org/w/index.php?oldid=374001470 Contributors: 0, 193.133.134.xxx, 7265, Aceofspades1217, Addshore, Adicarlo, AdmiralNorton, Adrian g. abac, AdultSwim, After Midnight, Ahoerstemeier, Alancookie, Alansohn, Aldie, Aleksandar Šušnjar, Alexius08, Alphachimp, AmiDaniel, Anarchist42, Ancheta Wis,Andrewpmk, AngelOfSadness, Angela, Angr, Apantomimehorse, Arch dude, ArielGold, Arno, ArnoldReinhold, Arpingstone, Artaxiad, Arvindn, Asav, Austinmurphy, AxelBoldt, Babedacus,Balancer, Ballas, Barnas, Beland, Bevo, Bhaak, Billy9999, Birkett, Bitjungle, Blainster, Blake-, Blinx283, Blow of Light, Bobblewik, Bobo192, Bookinvestor, Borgx, Brian R Hunter,Brighterorange, Bronco66, Brunnock, Bubba73, Camw, Can't sleep, clown will eat me, CanisRufus, Capek, CaptainTickles, Caribbean H.Q., Cbdorsett, CharacterZero, CharlesGillingham,Chinju, Chowbok, Chris55, Chrishaw, Chrisjj, Cimon Avaro, Ckatz, Coffeehood, Commander, Computerhistory, Condem, Conversion script, Crotalus horridus, Crystallina, Cyan, Cyfal,Dalakov, Dancter, Daniel C, Dante Alighieri, Darkwind, Darvinkevin, Davechatting, Davehi1, David Eppstein, David Gerard, David jones, David.Monniaux, Davidkazuhiro, Degress,DelaneyAdams, DemonStar55, Denni, Denorris, DerHexer, Diderot, Dmsar, Docey, Dominus, Don Braffitt, Download, Driftwoodzebulin, Drjan, Dulciana, Dune, Dwo, Ecksemmess, EdH,Eddie.willers, Eeekster, Ejosse1, ElBenevolente, Ellmist, Emijrp, Encyclopedia Master, Eng.ahmedm, Enigmaman, Enirac Sum, Everyking, EvilMoFo, Ezrdr, FactChecker1199, Fanf,Fieldday-sunday, Firdaus065, Flewis, FlyTexas, Frecklefoot, Funky Monkey, G7huiben, Gaius Cornelius, Gandalf61, Gdr, Gene s, Geniac, GeoGreg, George The Dragon, Ghettoblaster, Giftlite,Gigantic Killerdong, Glen, Glenn, Gnangarra, Goldom, Gradient drift, Greg321, Groogle, Gunter, Gurch, Gurko, Guy Harris, Haeleth, Haguraa, Hairy Dude, Halibutt, Harris7, Harryboyles,Harryzilber, Harthacnut, Hasek is the best, Haseo9999, Hpmemproject, Humble Scribe, I already forgot, Ian Dalziel, Ian Dunster, Ian.thomson, Iluvcapra, Imasleepviking, Indicer, Inferno, Lordof Penguins, Intranetusa, Iridescent, Iroony, Itub, Ivan Štambuk, J.delanoy, JForget, JaGa, Jacek Kendysz, Jacj, JackyR, Jacobolus, Jagged 85, Jeff G., JeffW, Jennavecia, Jerome Charles Potts,Jerry, Jerry teps, Jmabel, Jmarcus1256, Jnc, Joanjoc, Joao200, JonHarder, Jorgenumata, Josephbui, Josephs1, Josh Parris, Jpbowen, Jrgetsin, Kablammo, Karada, Kariandelos, Ke4roh, KenEstabrook, Kerred1O1, Ketiltrout, Khendon, KnowledgeOfSelf, Kokin, Kozuch, Krp, Ksyrie, Kubanczyk, Kyrstymoon, Lakhim, Laurens, LeaveSleaves, Lee.crabtree, Leibniz, Lexor, Liftarn,Lightdarkness, Lightmouse, Lights, Lilac Soul, Lisiate, Lissajous, LittleOldMe, Loginer, Lonestarnot, LordJeff, LouI, Loudsox, Lowellian, Lucinos, LukeTheSpook, Lupin, Lysander89, Lysy,MER-C, Mackensen, Macmanui, Maddogprod, Magioladitis, Mailer diablo, Malcolmxl5, Malleus Fatuorum, Manop, Marc Mongenet, Marcelo1229, Marek69, Margin1522, Markus Kuhn,Martial75, Marysunshine, Mathew Rammer, Matt Crypto, Matthew Fennell, Matusz, Mav, Max The Magnificent, Maxis ftw, Mdd, Meaghan, MeltBanana, Messybeast, Mfc, Michael Hardy,Michael Rowe, Michael Zimmermann, Michaelwilson, Michal.Pohorelsky, Midgitman(REAL), MigueldelosSantos, Mintguy, Miym, Mjposner, Mouse Nightshirt, Mr Rookles, Mr. Lefty,MrBurns, Myanw, Myscrnnm, Namazu-tron, NawlinWiki, NellieBly, Neptune5000, Neutrality, NickdeClaw, Nixdorf, Nixiebunny, Noctibus, Notafish, Notheruser, Nzeemin, Oblivious,Octahedron80, Officiallyover, Ohms law, Oicumayberight, OlEnglish, Omegatron, Omicronpersei8, OnPatrol, OrangeDog, Pakistan566, Parsiferon, Paul August, PaulLambert, Petri Krohn,Peyre, Pharaoh of the Wizards, Philip Baird Shearer, Philip Trueman, Piano non troppo, PierreAbbat, Pilotguy, Pinethicket, Pixel8, Pixeltoo, Pmcm, Polyphilo, Primate, Public Kanonkas,Quadell, Que, QueenCake, Qwertyrandom, RDBrown, RJBurkhart, RJaguar3, RTC, Rada, Radon210, Raistolo, Raul654, Raven4x4x, Redvers, Rgoodermote, Rich Farmbrough, Rieger, Rilak,Rjwilmsi, Rnt20, Rob Hooft, Robert K S, Robert Merkel, RobertG, Ron cool1, Roundhouse0, Rrburke, Ruddyflipper, Ruud Koot, Rwwww, Saga City, SallyForth123, Samsara, Samuel Tan,SandyGeorgia, Satori Son, Sbwoodside, SchfiftyThree, Science History, Secretlondon, Seeaxid, Selfworm, Sergei Frolov, Sfmammamia, Shadowjams, Shadowlynk, Sheepdontswim, SilkTork,SimonP, Snareshane, Snigbrook, Softtest123, Softy, Solphusion, SpigotMap, Spinality, Splash, Spondoolicks, StephenBuxton, Stephenb, Steven CO2, Stolensoul, StoneProphet, Stw, Superm401,Suruena, Susurrus, Sverdrup, Tangocz, TedColes, Tempshill, TenOfAllTrades, Terrek, Terry0051, Th1rt3en, The Epopt, The Hybrid, The Merciful, The Thing That Should Not Be, Theundertow, TheCoffee, TheDJ, TheProject, Themfromspace, Thincat, This user has left wikipedia, Thue, Tide rolls, Timneu22, Timothy Muggli, Timwi, Tivedshambo, Tom harrison, TomaszProchownik, Tony1, Topynate, Torc2, Tpbradbury, TraceyR, Tree Hugger, Trovatore, TweeterMan, Ukexpat, Ultima1209, Uncle Dick, Utcursch, Veinor, Verbose, Vinhtantran, Viridae,Vmlinuz, Vossman, Vroman, WRK, Wackymacs, Wackyvorlon, Wavelength, Wellington, Wernher, Wgungfu, WhiteDragon, Who, Widefox, Wikiklrsc, Witchwooder, Wpedzich, Wrelwser43,Wtshymanski, Ww, X201, Yamamoto Ichiro, Yintan, Yoganate79, Yonaa, Z3, Zebbie, Zscout370, Zven, Zygmunt lozinski, Zzuuzz, ^demon, 943 anonymous edits
History of general purpose CPUs Source: http://en.wikipedia.org/w/index.php?oldid=373308216 Contributors: Andreas Kaufmann, Babedacus, Bcbell, Bookalign, Chbarts, David Edgar,Dominic, Dyl, Frap, Ghettoblaster, Harryboyles, IanOsgood, J.delanoy, JHunterJ, Liao, Muhherfuhher, Public Menace, QTCaptain, RTC, Rilak, Rwwww, Sfan00 IMG, StuartBrady, TedColes,Twas Now, Vincent stehle, Woohookitty, 33 anonymous edits
Computer programming Source: http://en.wikipedia.org/w/index.php?oldid=373829879 Contributors: *drew, 206.26.152.xxx, 209.157.137.xxx, 64.24.16.xxx, 84user, ABF, AKGhetto,AbstractClass, Acalamari, Acroterion, AdamCox9, Adw2000, Aeram16, Aeternus, AgentCDE, Ahoerstemeier, Aitias, Akanemoto, Al Lemos, AlanH, Alansohn, Alberto Orlandini, Alex.g,AlistairMcMillan, AllCalledByGod, Alyssa3467, Amire80, Ancheta Wis, AndonicO, Andrejj, Andres, AndrewHowse, Andy Dingley, AnnaFrance, Antonielly, Antonio Lopez, AquaFox,ArnoldReinhold, Arvindn, Asijut, AtticusX, Auroranorth, Bakabaka, Bangsanegara, Betterworld, Bevo, BiT, Bigk105, Blackworld2005, Bluemoose, Bobo192, Bonadea, Bookofjude, Bootedcat,Boson, Bougainville, Breadbaker444, Brianga, Brichard12, Brighterorange, Brother Dysk, Bubba hotep, Bucephalus, BurntSky, Butterflylunch, C550456, CRGreathouse, Caltas, Can't sleep,clown will eat me, CanadianLinuxUser, Cander0000, Capi, Capi crimm, Capricorn42, Captain Disdain, Centrx, Cflm001, Cgmusselman, CharlesC, CharlotteWebb, Chirp Cricket, Chocolateboy,Chovain, ChrisLoosley, Christopher Agnew, Christopher Fairman, Chriswiki, Chuck369, Ciaccona, Cmtam922, Cnilep, Colonies Chris, Cometstyles, Conversion script, Crazytales, Cstlarry,Curps, Curvers, Cybercobra, CzarB, DMacks, DVD R W, Daekharel, Damian Yerrick, Damieng, DanP, Danakil, Dante Alighieri, Daverose 33, DavidCary, DavidLevinson, Davidwil,Daydreamer302000, Dcljr, Deepakr, Dekisugi, DerHexer, Derek farn, Deryck Chan, Dfmclean, Dialectric, Diberri, Diego Moya, Digitize, Discospinster, Dkasak, Dominic7848, Donald Albury,Donhalcon, DoorsRecruiting.com, Dougofborg, Downtownee, Dr Dec, Dravir5, Drphilharmonic, Dureo, Dusto4, Dylan Lake, Dysprosia, ERcheck, Ed Poor, Edward, Edward Z. Yang, Eeekster,Eiwot, El C, ElAmericano, Elektrik Shoos, Elendal, Elf, Elkman, Emperorbma, Epbr123, Ephidel, Epolk, Essexmutant, Etphonehome, Extremist, F41t3r, Fakhr245, Falcon Kirtaran, Falcon8765,Fazilati, Femto, Fg, Fratrep, Frecklefoot, FreplySpang, Frosted14, FunPika, Fvw, Galoubet, Gamernotnerd, Gandalf61, Garik, Gary2863, Garzo, GeorgeBills, Geremy659, Ghewgill, Ghyll,Giftlite, Gildos, Gilliam, Glass Tomato, GoodDamon, Goodvac, Goooogler, Gploc, Gracenotes, GraemeL, Graham87, Granpire Viking Man, Gregsometimes, Grison, Grouf, Guaka, Guanaco,Gwernol, Gökhan, Habbo sg, Hadal, Hairy Dude, Hanberke, Handbuddy, Hannes Hirzel, Harvester, Heltzgersworld, Henry Flower, Hermione1980, Heron, Hipocrite, Hustlestar4,Iamjakejakeisme, Igoldste, Ikanreed, Imroy, Intgr, InvertRect, Inzy, Ivan Štambuk, Ixfd64, J.delanoy, J3ff, JLaTondre, Jackal2323, Jackol, Jacob.jose, Jagged 85, Jason4789, Jason5ayers, Jatos,Jaysweet, Jedediah Smith, Jeff02, Jmundo, Joedaddy09, Jojhutton, Josh1billion, JoshCarter15, Jpbowen, Jph, Jwestbrook, Jwh335, K.Nevelsteen, KHaskell, KJS77, KMurphyP, Kaare, Keilana,Kenny sh, Kglavin, Kifcaliph, Klutzy, Konstable, Laurusnobilis, Lee J Haywood, Leedeth, Leibniz, LeinadSpoon, Lemlwik, Lerdsuwa, Levineps, Lgrover, Lightmouse, LilHelpa, LittleOldMe,LittleOldMe old, Loadmaster, Loren.wilton, Luckdao, Luk, Lumos3, Luna Santin, Lysander89, M4573R5H4K3, MER-C, MacMed, Macrakis, Macy, Mahanga, Marek69, Mark Renier, Maroux,Marquez, Maryreid, Matthew, Matthew Stannard, Mauler90, Maury Markowitz, Maximaximax, Mdd, Mentifisto, Metalhead816, Mets501, MiCovran, Michael Drüing, Michael93555,MichaelBillington, Michal Jurosz, MikeDogma, Mindmatrix, Minghong, Minimac, Mipadi, Mjchonoles, Mr Stephen, MrFish, Msikma, Mwanner, Mxn, NERIUM, Nagy, Nanshu, Narayanese,Neilc, Nephtes, Nertzy, Netkinetic, Netsnipe, Neurovelho, Nigholith, Nikai, Ningauble, Nk, Notheruser, Nubiatech, Nuno Tavares, Nwbeeson, OSXfan, Obli, Ohnoitsjamie, Optim, Orangutan,Orlady, Oxymoron83, P.jansson, Paul D. Buck, Paxse, Pcu123456789, Peberdah, Pedro, Philip Trueman, PhilipO, Phoe6, Piet Delport, Pilotguy, Pimpedshortie99, Plugwash, Poco a poco,Pointillist, Poor Yorick, Poweroid, Prashanthellina, Premvvnc, Prgrmr@wrk, PrimeHunter, Pt9 9, Qirex, Qrex123, Quadell, RCX, Ragib, Rajnishbhatt, Rama's Arrow, Rasmus Faber,RaveTheTadpole, Rawling, RedWolf, RedWordSmith, RexNL, Ricky15233, Rl, Rmayo, Robert Bond, Robert L, Robert Merkel, Rodolfo miranda, Ronz, Rrelf, Rror, Rsg, Ruud Koot, Rwwww,S.K., S0ulfire84, SDC, Salv236, Sanbeg, Sardanaphalus, Satansrubberduck, SchfiftyThree, Schwarzbichler, SciAndTech, Scoop Dogy, Sean7341, Senator Palpatine, Seyda, Shahidsidd, Shanak,Shappy, Shirik, Simeon, SimonEast, SkyWalker, Someone42, SpacemanSpiff, Splang, Starionwolf, SteinbDJ, Stephen Gilbert, Stephenb, Stephenbooth uk, Steven Zhang, Studerby, Suisui,Suruena, Svemir, Tablizer, TakuyaMurata, Tanalam, Tangent747, TarkusAB, Tedickey, Teo64x, TestPilot, Texture, The Divine Fluffalizer, The Mighty Clod, The Thing That Should Not Be, TheTranshumanist (AWB), TheRanger, TheTito, Thedjatclubrock, Thedp, Thingg, Thisma, Tide rolls, Tifego, Timhowardriley, Tnxman307, Tobby72, Tobias Bergemann, Tom2we, TomasBat,Tpbradbury, Trusilver, Turnstep, Tushar.kute, TuukkaH, Tweak232, Tysto, Tyw7, Udayabdurrahman, Ukexpat, Umofomia, Uncle Dick, Unforgettableid, Uniquely Fabricated, Unknown Interval,Userabc, Versus22, Vipinhari, Viriditas, Vladimer663, WBP Boy, Wadamja, WadeSimMiser, Wangi, Whiskey in the Jar, Wiki alf, Wikiklrsc, Wilku997, Wing (usurped), Witchwooder,Wizard191, Wj32, Worldeng, Wre2wre, Wtf242, Wtmitchell, Wwagner, Xagyg creator programmer, YellowMonkey, Yintan, Yk Yk Yk, Youssefsan, Yummifruitbat, Zeboober, Zkac050,Zoul1380, Zsinj, Zvn, 908 anonymous edits
Programming paradigm Source: http://en.wikipedia.org/w/index.php?oldid=370846784 Contributors: .:Ajvol:., AThing, Aarsanjani, AbramDemski, Adamd1008, Aeternus, Agnistus, Alfio,Amoss, Ancheta Wis, Angr, Antonielly, Ap, Arabic Pilot, ArneBab, Arny, Badly Bradley, BenFrantzDale, Bkell, BlueAmethyst, Bonus Onus, BrianDeacon, Britannica, Burschik, CarlHewitt,Chalst, Christian.heller, Clubmarx, Comperr, Cwolfsheep, Danakil, David Eppstein, Decltype, Demitsu, Dianoetic, Diego Moya, DragonRidr, Ejhewy, Elkman, Elockid, Eng.ahmedm,Faradayplank, FatalError, FlyHigh, Fredrik, Fubar Obfusco, Geregen2, Gragragra, Gruu, Gwizard, Hede2000, HoodedMan, Isaac Sanolnacov, JDubman, Jdh30, Jerroleth, JohnJSal, Jonnyapple,JulesH, Junegold, K.lee, Kdakin, Kendrick Hang, Kenny Moens, Knuckles, LedgendGamer, LinguistAtLarge, Luís Felipe Braga, Madmardigan53, Mark Renier, MartinHarper, MartinSpamer,Maxim.mazin, Mdd, Metalpasman, Michael Hardy, Msreeharsha, Murray Langton, Musiphil, Nath1991, Natkeeran, Nbarth, Nixdorf, Njk, Norandav, Oicumayberight, Oleg Alexandrov,Omicronpersei8, Only2sea, Orang Hutan, Orderud, Ospalh, ParkerJones2007, Pcap, Pengo, Perlyn06, Pete Wall, Peter Van Roy, Ph4nToM89, Pheeror, Pluke, Quuxplusone, Randomalious,Retired username, Robwe, RoyArne, Rumping, Rursus, S.K., Saquigley, Seizethedave, Semifinalist, Sergey Dmitriev, Shinji14, Sibian, SkyCaptain, Steveozone, Suruena, TakuyaMurata, Thosewords, Tonyfaull, Torc2, Unara, Unfree, VKokielov, Vespine, VictorAnyakin, VirEximius, WadeSimMiser, Wavehunter, Wlievens, WriterHound, Yhever, Zeus-chu, Zickzack, Zorabi, Zowie,anonymous edits 175 ,لیقع فشاک
Systems Development Life Cycle Source: http://en.wikipedia.org/w/index.php?oldid=374615770 Contributors: ABF, Adamgibb, Ahoerstemeier, Aitias, Ajbrulez, Albanaco, AlephGamma, Allan McInnes, Allstarecho, Andaryj, Anonymous Dissident, Ansell, Arjun01, BasilBoom, Bfigura's puppy, Bobo192, BrianY, CFMWiki1, CalebNoble, Cbdorsett, Chris 73, Chrislk02, Closedmouth, Cochiloco, Cody574, Copyeditor22, Croepha, DGJM, Dandv, Danielphin, David.alex.lamb, DavidDouthitt, DeadEyeArrow, Djsasso, DrKranium, DuncanHill, ESkog, Eastlaw, Ebessman, Enauspeaker, Epbr123, Erkan Yilmaz, FiRe, GD 6041, Gaff, GarbagEcol, Gilliam, Happysailor, Hydrogen Iodide, HyperSonic X, Informatwr, IvanLanin, J.delanoy, J04n, JaGa, JamesBWatson, Jdg12345, Jeff G., Jeremy Visser, Jinian, Joe4210, John Vandenberg, John.stark, Jonverve, Josephedouard, Jpbowen, Kalai545, Kenyon, Kesla, Kevin, Khalid hassani, Kingpin13, KnowledgeOfSelf, Kr suraesh, Kuru, Kurumban, LAX, Latka, Lectonar, Liftarn, Little Mountain 5, Luna Santin, Maghnus, Marek69, Mark Renier, Mdd, Meisterflexer, Michael

Article Sources and Contributors 194
Hardy, Mick1990, Mikesc86, MrOllie, Mrwojo, Mummy34, Natkeeran, Natl1, Neurophyre, Niaz, Nkattari, NuclearWarfare, OMouse, Octahedron80, Oliverclews, Omicronpersei8, Paxsimius,Philip Trueman, Piano non troppo, Pikajedi3, Pingveno, Pip2andahalf, RadioFan2 (usurped), Raymondwinn, Recognizance, Rich Farmbrough, Rjwilmsi, Ronz, Rooseveltavi, Rwwww, SamHobbs, Sarloth, Satishshah123, SchmuckyTheCat, ScottWAmbler, Seth Ilys, Shadowjams, ShwetaCool, Sigma 7, SigmaJargon, Srushe, Steelchain, Stickee, Strawny02, Swep01, Syrthiss, TanvirAhmmed, Tee Owe, Teohhanhui, The Anome, ThePointblank, TheProject, TheTallOne, Thomasjeffreyandersontwin, Throwaway85, Tide rolls, Tonyshan, Transcendence, TwilligToves,Vashtihorvat, VectorThorn, Versus22, WikHead, Wiki alf, Wimt, Wspencer11, Wtmitchell, Xphile2868, Xsmith, Yeng-Wang-Yeh, Yogi de, Zondor, 750 anonymous edits
Software development process Source: http://en.wikipedia.org/w/index.php?oldid=374481557 Contributors: 123admin, 146.227.71.xxx, AFFAN HASAN, AGK, Ab762, Acockrum,Adrian.walker, Ahoerstemeier, Alansohn, Aleenf1, AlephGamma, Alex.key, Allan McInnes, Amalas, Ancheta Wis, Andy1618, Angr, Ansell, Ap, Aront54, Ash zz, Axd, Ayonbd2000, Az1568,Bassbonerocks, Baygun, Beland, Belinrahs, BenAveling, Bensel, Biasoli, Boing! said Zebedee, Brighterorange, BryceHarrington, Bstpierre, Canderra, Capricorn42, CatWikiEdit, CattleGirl,Cburnett, Chairboy, Chanti naresh, Charles Sturm, Chiranthan, Choggo, Cholmes75, Chowbok, ChrisLoosley, ChrisSteinbach, Christian75, Closedmouth, Cmmiloveprocess, Conversion script,Cory Donnelly, Cpl Syx, Crickel, DRogers, DXBari, Darth Panda, David.alex.lamb, DavidBailey, Dawidl, Degger, Delimata, Demiane, Devilgate, Dfrg.msc, Discospinster, Dpbsmith, Dybdahl,Dysprosia, EatMyShortz, Ebde, Edward, Egbsystem, Ehheh, Elkman, Elockid, Ency, Ennetws, Epbr123, Eric B. and Rakim, Erkan Yilmaz, Frecklefoot, Freedomlinux, Furrykef, Garde, Gdavidp,Glenn4pr, Graham87, Grandtheftwalrus, Guppie, Gökhan, Harald Hansen, Hdante, He Who Is, Hede2000, HienTau, Hsorbu, Hu12, Hzhbcl, IRP, Ian Bailey, Ilario, Intodevel, Isaacdealey,IvanLanin, J00tel, J04n, JLaTondre, Jaiquois, Jamestochter, Jaydec, John Broughton, Jojhutton, Jpbowen, Juliancolton, K.Nevelsteen, Kazvorpal, Kbdank71, Kchampcal, Keilana, Kenny sh,Kesla, Khalid hassani, Khsdrummer2001, KnightRider, Knownot, Kuru, Larry_Sanger, Leafyplant, Leebo, Leibniz, Leif, Leolaursen, Limbo socrates, M ajith, M.e, MER-C, Majkiw, MalcolmFarmer, Mannojshukla, Mark Renier, Martin451, MaxHund, Mboverload, Mcorazao, Mdd, Michig, Midoladido, Mild Bill Hiccup, Mk*, Mos3ab, MrOllie, Mrdempsey, Mrh30, Myasuda,Natkeeran, NatusRoma, Nefuchs, Neokilly, Nigosh, Niteowlneils, Nixdorf, OMouse, Octahedron80, Ohnoitsjamie, Oicumayberight, Paviagrawal, Petra.hegarty, Phil webster, Philip Trueman,Pmtoolbox, Psb777, Pstraton, Pvazteixeira, RekishiEJ, Richard R White, Ripogenus77, RonLichty, Rursus, Rwgreen1173, Safemariner, Sagaciousuk, Sardanaphalus, Shadowjams, Shirik,SimonMorgan, SiobhanHansa, Skarebo, SkyWalker, Slayemin, Softtest123, Sourcejedi, Spinality, Stephen Gilbert, Stephen e nelson, SunSw0rd, Supersteve04038, Suruena, Tasc, Teryx, TheThing That Should Not Be, Theleftorium, Thowa, Tide rolls, Timneu22, Tobias Bergemann, Tommy2010, Tonyshan, Toothmarks1111, Turkishbob, Tvarnoe, Ukexpat, Ulric1313, Umapathy,Valafar, VanDingo, Vary, Versageek, Vicenarian, VoteLibertarian, Voyagerfan5761, Waggers, Walter Görlitz, WalterGR, Whitepaw, WikiNC, WikipedianYknOK, William Avery, Wykis,Yngvarr, Yop83, Ywarnier, Ziphon, Zondor, ZooFari, 620 ,ןרע anonymous edits
Waterfall model Source: http://en.wikipedia.org/w/index.php?oldid=371899310 Contributors: Aamahdys, Ageekgal, Alarob, Alienus, Alitheg, Alksub, AnthonyQBachler, Ap, Arwel Parry,Avenged Eightfold, Averisk, BarretBonden, Benabomb1, BigC9heese, Binksternet, Binrapt, Bobo192, Brick Thrower, Brockert, Camw, Carlif, Ceyockey, Charles Matthews, Chris G,Cmdrjameson, Conversion script, Crinoidgirl, Cwenger, David.alex.lamb, Deep vnw, Deor, DhirajGupta, Donald Duck, DoubleBlue, Doulos Christos, Duminda1986, Dysprosia, Earlypsychosis,EatMyShortz, Ed Poor, Edward, Emperorbma, Emvee, Epbr123, Eric B. and Rakim, Erkan Yilmaz, Eugene van der Pijll, Faradayplank, Favonian, Feyandstrange, Folajimi, Frankenpuppy,Frankieroberto, Freedom to share, GFLewis, Gendut, GeorgeBills, Greghc, GregorB, Halcyon1234, Halmir, Hamtechperson, Harryboyles, Hendrik Brummermann, Hooperbloob, Hut 6.5, Huwr, Ido not exist, IRKAIN2, Iftikharzafar, Ilario, Inteligente, Isaacdealey, J.delanoy, JCLately, Jackol, JayEsJay, Jeff G., JeremyA, Jerome Charles Potts, Jim Huggins, Jimmykaw, Jjhrogers, Jmabel,Jonnalagaddaharish, Joyous!, Jpgordon, K.Nevelsteen, K.lee, Karmona, Kbdank71, Kedarthatte, Kim Bruning, KimBecker, Kku, KnowledgeOfSelf, Koavf, Korny O'Near, Kthnxrick,Kuratowski's Ghost, Kuroboushi, Largestill, Learntruck, LeaveSleaves, Lerdthenerd, LiDaobing, Lvmeijer, MER-C, MIT Trekkie, Manop, Mark Foskey, Mdd, Mebden, Mentifisto, Merenta,MichaK, Michael Devore, Michael Hardy, Mikething, Nick UA, Niteowlneils, Nzeemin, OMouse, Oashi, Oicumayberight, Omicronpersei8, PanagosTheOther, Pascal.Tesson, PaulGarner,PaulHoadley, Paulsmith99, Pebkac, Pevernagie, Piano non troppo, Pinethicket, Pm master, Profdhiren, Qirtaiba, RadioFan2 (usurped), Razimantv, Rbrewer42, Reyk, Rich Farmbrough, Rich257,Rick.G, Rjwilmsi, Rodney Boyd, Rollotomnasi, Ronz, Rrburke, Ryulong, Saaga, Salmar, Sardanaphalus, Schmiteye, Sean.cavanagh, Shanemcd, Slicing, Soup man, Spacepotato, Stumps, Tarmo,Technocratic, Tee Owe, Teoryn, TeunSpaans, That Guy, From That Show!, The Anome, Themaxviwe, Themfromspace, ThomasOwens, Thunderboltz, Titoxd, Tjamesjones, Trevor MacInnis,Trivialist, Tvarnoe, Ungoliant13, Veinor, Viento, Vincehk, Vinjosh, Viriditas, Wdyoung, Wikiuser183, William Avery, William Pietri, Xeolyte, Yangy0514, Yaronf, Yaxu, Yworo, Zaffman, 485anonymous edits
Problem solving Source: http://en.wikipedia.org/w/index.php?oldid=373476385 Contributors: 2D, 2spyra, AbsolutDan, Action potential, Adapt, AdjustShift, Agbormbai, Ahoerstemeier, AlexKosorukoff, Ancheta Wis, AndriuZ, Angr, Anna512, Antaeus Feldspar, Ap, Arjun G. Menon, Astral, Ayda D, Bachcell, Beanary, Billfmsd, Bobblewik, Boxplot, BrotherGeorge, Bufar,Celestianpower, ChemGardener, Cielomobile, Clhtnk, Cmcurrie, Coachuk, Corza, Credible58, D. Tchurovsky, DBragagnolo, Dave6, Dawn Bard, Dbfirs, Ddr, Derekristow, Destynova, Djcremer,Djdrew76, DoctorW, Download, Eric-Wester, Eve Teschlemacher, Everyking, Extremecircuitz, Facilitation Author, Ferris37, Forenti, Frazzydee, Fvw, Genegorp, Giftlite, Gioto, GlassCobra,Good Vibrations, Graham87, Guggenheim, Gunnar Hendrich, HGB, Harald.schaub, Hari, Heron, Houghton, Hu12, Hydrogen Iodide, IceCreamAntisocial, Iggynelix, Ingi.b, Inter, IvR, IvanLanin,JForget, JaGa, Jacopo, Jan Tik, Jaranda, Jd2718, Jeames, JimmyShelter, JoachimFunke, JoeC 4321, Johnkarp, Jon Awbrey, Jose Icaza, Jrmindlesscom, Jtneill, Juanscott, Kazooou, Keilana,KillerChihuahua, Kizor, Kku, Kosebamse, Ksyrie, LaurensvanLieshout, Laxerf, Leestubbs, Letranova, Leuko, Levineps, Liao, LilHelpa, Lord Bane, Lupin, MCrawford, MMSequeira,Majorclanger, Marc Venot, Marek69, Markstrom, Marsbound2024, Marx01, Mattisse, Matty Austwick, Mbonline, McGeddon, Merlion444, Mgret07, Michael Hardy, Michaeldeutch, Mild BillHiccup, Moeron, Mr.Z-man, Nesbit, New Thought, Nicearma, Nikolas Stephan, Novum, Oda Mari, Oleg Alexandrov, Ott, Paranomia, ParisianBlade, Pavel Vozenilek, Pedant17, Peter gk,Peterlewis, Philip Trueman, Pickledh, Pilgrim27, Pioneer-12, Possum, Ralphruyters, Rapdetty, RaseaC, Reinyday, Richard001, RichardF, Rick Sidwell, Rjwilmsi, Ronz, Rsrikanth05, Ruud Koot,SLcomp, Saga City, Samhere, Saxifrage, Scoutersig, Sengkang, Sg gower, Shanes, SheldonN, Shimgray, Shoessss, Sidaki, Spalding, Srikeit, Stifle, Stone, Suidafrikaan, Tagishsimon, Tarquin,Tassedethe, TexasAndroid, The Evil IP address, TheEgyptian, Theresa knott, Thiseye, ThreePD, Vaughan, VodkaJazz, VoteFair, Whatfg, Wikilibrarian, Wimbojambo, Woohookitty, YammyYamathorn, YellowMonkey, Yhkhoo, ZimZalaBim, Ziphon, 254 anonymous edits
Algorithm Source: http://en.wikipedia.org/w/index.php?oldid=374243474 Contributors: "alyosha", 0, 12.35.86.xxx, 128.214.48.xxx, 151.26.10.xxx, 161.55.112.xxx, 204.248.56.xxx,24.205.7.xxx, 747fzx, 84user, 98dblachr, APH, Aarandir, Abovechief, Abrech, Acroterion, Adam Marx Squared, Adamarthurryan, Adambiswanger1, Addshore, Aekamir, Agasta, Agent phoenex,Ahy1, Alcalazar, Ale2006, Alemua, Alexandre Bouthors, Alexius08, Algogeek, Allan McInnes, Amberdhn, AndonicO, Andre Engels, Andreas Kaufmann, Andrejj, Andres, Anomalocaris,Antandrus, Anthony, Anthony Appleyard, Anwar saadat, Apofisu, Arvindn, Athaenara, AxelBoldt, Azurgi, B4hand, Bact, Bart133, Bb vb, Benn Adam, Bethnim, Bill4341, BillC, Billcarr178,Blankfaze, Bob1312, Bobblewik, Boing! said Zebedee, Bonadea, BorgQueen, Boud, Brenont, BriEnBest, Brion VIBBER, Brutannica, Bryan Derksen, Bth, Bucephalus, CBM, CRGreathouse,Cameltrader, CarlosMenendez, Cascade07, Cbdorsett, Cedars, Chadernook, Chamal N, Charles Matthews, Charvex, Chasingsol, Chatfecter, Chinju, Chris 73, Chris Roy, Citneman, Ckatz,Clarince63, Closedmouth, Cmdieck, Colonel Warden, Conversion script, Cornflake pirate, Corti, CountingPine, Crazysane, Cremepuff222, Curps, Cybercobra, Cyberjoac, DASSAF, DAndC,DCDuring, Danakil, Daven200520, David Eppstein, David Gerard, Dbabbitt, Dcoetzee, DeadEyeArrow, Deadcracker, Deeptrivia, Delta Tango, Den fjättrade ankan, Deor, Depakote, DerHexer,Derek farn, DevastatorIIC, Dgrant, Dinsha 89, Discospinster, Dmcq, DopefishJustin, Dreftymac, Drilnoth, DslIWG,UF, Duncharris, Dwheeler, Dylan Lake, Dysprosia, EconoPhysicist, Ed Poor,Ed g2s, Editorinchief1234, Eequor, Efflux, El C, ElectricRay, Electron9, ElfMage, Ellegantfish, Eloquence, Emadfarrokhih, Epbr123, Eric Wester, Eric.ito, Erik9, Essjay, Eubulides, Everythingcounts, Evil saltine, EyeSerene, Fabullus, Falcon Kirtaran, Fantom, Farosdaughter, Farshadrbn, Fastfission, Fastilysock, Fernkes, FiP, FlyHigh, Fragglet, Frecklefoot, Fredrik, Friginator, Frikle,GOV, GRAHAMUK, Gabbe, Gaius Cornelius, Galoubet, Gandalf61, Geniac, Geo g guy, Geometry guy, Ghimboueils, Gianfranco, Giantscoach55, Giftlite, Gilgamesh, Giminy, Gimme danger,Gioto, Gogo Dodo, Goochelaar, Goodnightmush, Googl, GraemeL, Graham87, Gregbard, Groupthink, Grubber, Gubbubu, Gurch, Guruduttmallapur, Guy Peters, Guywhite, H3l1x, Hadal, HairyDude, Hamid88, Hannes Eder, Hannes Hirzel, Harryboyles, Harvester, HenryLi, HereToHelp, Heron, Hexii, Hfastedge, Hiraku.n, Hu12, Hurmata, Iames, Ian Pitchford, Imfa11ingup, Inkling,InterruptorJones, Intgr, Iridescent, Isis, Isofox, Ixfd64, J.delanoy, JForget, JIP, JSimmonz, Jacomo, Jacoplane, Jagged 85, Jaredwf, Jeff Edmonds, Jeronimo, Jersey Devil, Jerzy, Jidan, JoanneB,Johan1298, Johantheghost, Johneasley, Johnsap, Jojit fb, Jonik, Jonpro, Jorvik, Josh Triplett, Jpbowen, Jtvisona, Jusdafax, Jóna Þórunn, K3fka, KHamsun, Kabton14, Kanags, Kanjy, Kanzure,Keilana, Kenbei, Kevin Baas, Kh0061, Khakbaz, Kku, Kl4m, Klausness, Kntg, Kozuch, Kragen, Krellis, LC, Lambiam, LancerSix, Larry R. Holmgren, Ldo, Ldonna, Leszek Jańczuk, Levineps,Lexor, Lhademmor, Lightmouse, Lilwik, Ling.Nut, Lissajous, Lumidek, Lumos3, Lupin, Luís Felipe Braga, MARVEL, MSPbitmesra, MagnaMopus, Makewater, Makewrite, Maldoddi, MalleusFatuorum, Mange01, Mani1, ManiF, Manik762007, Marek69, Mark Dingemanse, Markaci, Markh56, Markluffel, Marysunshine, MathMartin, Mathviolintennis, Matt Crypto, MattOates, Mav,Maxamegalon2000, McDutchie, Meowist, Mfc, Michael Hardy, Michael Slone, Michael Snow, MickWest, Miguel, Mikeblas, Mindmatrix, Mission2ridews, Miym, Mlpkr, Mpeisenbr, MrOllie,Mttcmbs, Multipundit, MusicNewz, MustangFan, Mxn, Nanshu, Napmor, Nikai, Nikola Smolenski, Nil Einne, Nmnogueira, Noisy, Nummer29, Obradovic Goran, Od Mishehu, Odin ofTrondheim, Ohnoitsjamie, Onorem, OrgasGirl, Orion11M87, Ortolan88, Oskar Sigvardsson, Oxinabox, Oxymoron83, P Carn, PAK Man, PMDrive1061, Paddu, PaePae, Pascal.Tesson, PaulAugust, Paul Foxworthy, Paxinum, Pb30, Pcap, Pde, Penumbra2000, Persian Poet Gal, Pgr94, Philip Trueman, Pit, Plowboylifestyle, Poor Yorick, Populus, Possum, PradeepArya1109, Quendus,Quintote, Quota, Qwertyus, R. S. Shaw, Raayen, RainbowOfLight, Randomblue, Raul654, Rdsmith4, Reconsider the static, Rejka, Rettetast, RexNL, Rgoodermote, Rholton, Riana, RichFarmbrough, Rizzardi, RobertG, RobinK, Rpwikiman, Rror, RussBlau, Ruud Koot, Ryguasu, SJP, Salix alba, Salleman, SamShearman, SarekOfVulcan, Savidan, Scarian, Seb, Sesse,Shadowjams, Shipmaster, Silly rabbit, SilverStar, Sitharama.iyengar1, SlackerMom, Snowolf, Snoyes, Sonjaaa, Sophus Bie, Sopoforic, Spankman, Speck-Made, Spellcast, Spiff, Splang,Sridharinfinity, Stephan Leclercq, Storkk, Sundar, Susurrus, Swerdnaneb, Systemetsys, TakuyaMurata, Tarquin, Taw, The Firewall, The Fish, The Nut, The Thing That Should Not Be, Theansible, TheGWO, TheNewPhobia, Thecarbanwheel, Theodore7, Tiddly Tom, Tide rolls, Tim Marklew, Timc, Timhowardriley, Timir2, Tizio, Tlesher, Tlork Thunderhead, Tobby72, Toncek,Tony1, Trevor MacInnis, Treyt021, TuukkaH, UberScienceNerd, Urenio, User A1, V31a, Vasileios Zografos, Vikreykja, Vildricianus, Wainkelly, Waltnmi, Wavelength, Wayiran, Waynefan23,Weetoddid, Wellithy, Wexcan, Who, Whosyourjudas, WhyDoIKeepForgetting, WikHead, Willking1979, WillowW, Winston365, Woohookitty, Wvbailey, Xashaiar, Yamamoto Ichiro, Yintan,Ysindbad, Zfr, Zocky, Zondor, Zoney, Zundark, 885 anonymous edits
Flowchart Source: http://en.wikipedia.org/w/index.php?oldid=374641913 Contributors: 4twenty42o, A3RO, Aaron Brenneman, Abednigo, Agent phoenex, Ajikoe, Akamad, Aki009, Alksub, Alx xlA, Amniarix, Ancos, Andreas Kaufmann, Andromeda, Antandrus, Anthony, Aoreias, Apsio, Artem M. Pelenitsyn, Avono, Ayda D, Beniganj, Bensaccount, Bergsten, Bevo, BiT, Bjornwireen, Blehfu, Blue.eyed.girly, BoP, Bobo192, Bonadea, Booyabazooka, Borgx, Bücherwürmlein, Calvin 1998, Capricorn42, Cassovian, Cflm001, Chartex, Chendy, ChrisHodgesUK, Chsimps, Ckatz, Closedmouth, Cocytus, Cometstyles, CommonsDelinker, Csodessa, Cycn, Daa89563, DaisyN, Damian Yerrick, DanielJudeCook, Darrellswain, Davandron, Davidfstr, Davidobrisbane, Dcandeto, DeadEyeArrow, DeltaQuad, Demoeconomist, DerHexer, DiamFC, Dixius99, Doodle77, Dpdearing, Dreadstar, Dreftymac, Dusti, Dylan Lake, ERK, Ebyabe, Economist332, Edcolins, Edrawing, Eliz81, Emufarmers, EnOreg, Epbr123, Erkan Yilmaz, Eye of slink, Falcon8765, FelisLeo, FirefoxRocks, Fireman.sparkey, Forteblast, Fourchannel, Frieda,

Article Sources and Contributors 195
Frymaster, GTBacchus, GainLine, Gary King, GateKeeper, Geni, GeordieMcBain, Georgie30.11.96, Gesslein, Giftlite, Gilliam, Ginsengbomb, Gogo Dodo, Goodgerster, Gramware, Green TeaWriter, Gurch, Haakon, Haris.tv, Hawky, Headbomb, Hpmagic, Hu12, IRP, Iain marcuson, Inc ru, Indon, Informavores, Insanity Incarnate, Iridescent, Irrelative, Isilanes, Isnow,Iwillgoogleitforyou, J.delanoy, J04n, JBakaka, JForget, Jadster, Jamesontai, Jfgrcar, Jhedemann, Jimmcgovern15, Jimrogerz, Jjalexand, Jmundo, Jobarts, Jon1012, JonHarder, Jost Riedel,Jsvforever, Juzzierules97, Jzylstra, Kaizer1784, Kallerdis, Kane5187, Kaziali, Kazvorpal, Kim Bruning, Kostmo, Kukini, Kuppuz, Kuru, Lampak, Lazyquasar, LeeHunter, Leon7, Levineps,Ligulem, Luvcraft, LéonTheCleaner, MER-C, MK8, Madhero88, Mandarax, Marek69, Martynas Patasius, Mauler90, Mdd, Mentifisto, Metacomet, Michael Hardy, Michael Slone, Mikhailcazi,Minghong, Minion o' Bill, Mintleaf, Mjchonoles, Mkoyle, Mormegil, MrStalker, Mygerardromance, Mysdaao, Nabla, Nacimota, Nae'blis, NathanWalther, NawlinWiki, Ndyguy, NellieBly,Norm, Numbo3, Nuno Tavares, Ohedland, Ohnoitsjamie, OnePt618, Oxymoron83, Persian Poet Gal, Phatsphere, PhilKnight, Philip Baird Shearer, Piano non troppo, Pimlottc, Pinar, Pixel8,Planetary Chaos, Pmarc, Pmiller42au, Poor Yorick, Priyanshu hbti, Proofreader77, Pweemz, Qst, RUL3R, Raanoo, Rklawton, Rob cowie, RockfangSemi, Romanm, Ronz, Roundand, Rp,Rrburke, SCB '92, Sbasan, Sbwoodside, Schaaftin, SchfiftyThree, ScotS, SeanGustafson, Seattlenow, Shadowjams, Shiva.rock, Sidonuke, Silly rabbit, Sin-man, Skarebo, Skew-t, Skier Dude,Slash454, SoCalSuperEagle, SoftwareSalesRep, Sotruetwo, SpaceFlight89, Spidern, Squirepants101, Steve5682, Stevertigo, Stratocracy, Suffusion of Yellow, Sumsum2010, Supercuban,SuzanneKn, Swpb, Sychen, Taffykins, Tbhotch, Tbone762, Tcreg010, Techturtle, Tels, Tfinneid, The sock that should not be, The wub, TheInfluence, ThomasO1989, ThreeVryl, Threner, Tiderolls, Tobias Bergemann, Toddintr, Tom harrison, Trapolator, Triddle, TriniTriggs, Trusilver, Ttwaring, UnitedStatesian, VectorPosse, Viswanath1947, Void Ptr, Vonkje, Wapcaplet, Welsh,WikHead, WikiLeon, Wikidrone, Wortech tom, Wtshymanski, Xchbla423, Xinit, Yaxh, YewBowman, Zeborah, ZeroOne, Zfang, Zhenqinli, 656 anonymous edits
Pseudocode Source: http://en.wikipedia.org/w/index.php?oldid=374586090 Contributors: 61.9.128.xxx, AKGhetto, Abednigo, Aiyizo, Alchemist Jack, Alexcstrassa, Andre Engels, AndreasKaufmann, Andrejj, Antandrus, Anthony, Artwholeflaffer, AxelBoldt, Baruneju, Beno1000, Bfinn, Blashyrk, Blaxthos, Bobo192, Boccobrock, Bunnyhop11, CRGreathouse, Capricorn42,ChangChienFu, Chrisd87, Condem, Conti, Conversion script, Coolstoryhansel, Corti, Cwenger, Cwolfsheep, DanielCD, Dcljr, Dcoetzee, Derbeth, Dr.alf, Dragonskin29, EChronicle,Earthlingzed, EconoPhysicist, Edward Z. Yang, Efflux, El C, Escape Orbit, Fafner, Feezo, Fredrik, FrenchIsAwesome, Gennaro Prota, Giftlite, Gondooley, Graham87, Gubbubu, H, Haeleth,Heirpixel, Helpsloose, Hetzer, Inkington, Iridescent, Ivan Akira, J.delanoy, JBakaka, JForget, JIP, Jaalto, Jakeleonard, Jleedev, KeithH, Kingpin13, Kkkdc, Krzyk2, L Kensington, Leithp, LelandMcInnes, Leotohill, Lilac Soul, LittleDan, LoveEncounterFlow, Lysdexia, MER-C, Magustrench, Mange01, Marudubshinki, Mav, Mdd, Meisam, Michael Hardy, Michagal, Minesweeper,Miquonranger03, Mlpearc, Monkeynerd, Mortense, Mr. XYZ, Mrberryman, Mwtoews, Nburden, NetRolller 3D, Nmcmurdo, Nuttyskin, Obradovic Goran, Pakaran, Peni, PerryTachett, Pol098,Porges, Projectautoman, Quinxorin, Quuxplusone, Random832, Rbonvall, Rory096, Ruakh, Saga City, Shizhao, Skyezx, Stephenb, Stevertigo, Stikonas, TakuyaMurata, Tarquin, The Anome,The Thing That Should Not Be, Tim32, Toniher, Trancelis, User A1, Vinhtantran, Vsrawat, WLU, Wapcaplet, Wernher, WhiteShark, Wile E. Heresiarch, Yaronf, Yohan (China), ZeroOne,Zeus-chu, Zntrip, Zomno, 216 anonymous edits
C (programming language) Source: http://en.wikipedia.org/w/index.php?oldid=374466500 Contributors: (aeropagitica), -Barry-, 11.58, 144.132.75.xxx, 16@r, 1exec1, 213.253.39.xxx, A DMonroe III, ACM2, AJim, Aarchiba, Abaddon, Abbyjoe45, Abdull, Abeliavsky, Abigail-II, Abilina, Ablonus, AdShea, Adam majewski, Adrian Sampson, Adrianwn, Aeon1006, Aeons, Afog,Ahy1, Ais523, Aj00200, Ajk, Ajrisi, Akamad, Akella, Akihabara, Alansohn, Albertgenii12, Alexthe5th, Alfakim, Alhoori, AlistairMcMillan, Alksentrs, Allan McInnes, Allen3, Alonzia,Alphachimp, Altenmann, Amelio Vázquez, Anabus, Anaraug, Ancheta Wis, Andre Engels, Andrejj, Andries, Andrwsc, Anetode, AngelOfSadness, Angus Lepper, Anon E Mouse,AnthonyQBachler, AntoineL, Applet, Appraiser, Apwestern, Aragorn2, Arch dude, Arcnova, Arekku, Arthur Rubin, Arvindn, Ataru, Atlant, Auroreon, Avsharath, Awickert, AxelBoldt, B k,Babkock, Bact, Bahonesi, Bakilas, Bart133, Bassbonerocks, Baszoetekouw, Baudway, BazookaJoe, Ben Karel, BenFrantzDale, BenM, Benhocking, Beno1000, Bentler, Bernfarr, Bevo, Bfrbfr,Bhadani, BigChicken, Bigk105, Billposer, Bkell, Blueyoshi321, Bmicomp, Bobblewik, Bobo192, Boredzo, Borislav, Born2cycle, Brion VIBBER, Byrial, C. A. Russell, CPMcE, CRGreathouse,CYD, Cadae, Cadr, Caltas, Can't sleep, clown will eat me, CanadianLinuxUser, CanisRufus, CapitalSasha, Casey Abell, Cctoide, Cdc, Cedars, Cfailde, Cgranade, Chandrasekar78, Chaos5023,Charlesjia, CharlotteWebb, Chbarts, Cheesy123456789, Chocolateboy, Chris Burrows, ChristTrekker, Christian75, Chun-hian, Cjosefy, Cjworden, Codeman, ColtM4, Comatose51, Como,Conan, Corti, Csmaster2005, Curps, Cybercobra, Cyoung, Cyp, D, D6, DAGwyn, DAndC, DE, DJ Clayworth, DMG413, DMacks, Daf, DailyBlip, Daivox, Damian Yerrick, Dan Granahan,Dan100, Dan198792, Danakil, Danallen46, Daniel Quinlan, DanielCristofani, Darius Bacon, David Gerard, Davtom, Dcljr, Dcoetzee, Dead3y3, Dekisugi, Delibebek, Derek Ross, Derek farn,Desivenkatesh, DevastatorIIC, Dieter Simon, Disavian, Discospinster, Dispenser, Dkasak, Docu, Dodo bird, Doradus, DougsTech, Download, Dowsiewuwu, Dpv, DragonHawk, Drbrain, Drj,Druiloor, Dusik, Dwheeler, Dysprosia, E0steven, ESkog, Eagleal, EatMyShortz, EdC, Edward, Eequor, Electron9, Eloquence, Elz dad, Emperorbma, Emre furtana, EncMstr, Ennui93, Epl18,Eric119, Erik9, Erpingham, EugeneZelenko, Evercat, Evice, Evil Monkey, Ewok18, Excirial, Exert, Faisal.akeel, Falcon8765, FastLizard4, Fawcett5, Fbergo, Feb30th1712, Feedmecereal,Felixdakat, Fibonacci, Fireice, Firetrap9254, Flash200, Fleminra, Flockmeal, Flubeca, Fluggo, Foobaz, Fractal3, Frank4ever, Frappucino, Freakofnurture, Frecklefoot, Frederico1234, Fredrik,Free Software Knight, FreedomByDesign, FrenchIsAwesome, Fresheneesz, Fritzpoll, Fsiler, Ftdftd, Ftiercel, FullMetal Falcon, Furrykef, Fuzzy, Fırat KÜÇÜK, GLaDOS, GMcGath, Gagewyn,Gail, Gamma, Gareth Owen, Garyzx, Gaspercat, Gavenko a, Gazimoff, Gene s, Gesslein, Getyoursuresh, Ggurbet, Ghettoblaster, Ghoseb, Giftlite, Gilgamesh, Gimmetrow, Gjd001, Gludwiczak,GnuDoyng, Gogo Dodo, Gpietsch, Graham87, Graingert, Graue, Greg L, GregorB, Griba2010, Gtrmp, Gustavb, Gustavh, Gwinkless, H2g2bob, Hadal, Haeleth, Haikupoet, HairyWombat,Hakkinen, Halo, Hard Backrest, Harryboyles, Hashar, Hayabusa future, Hdante, HellDragon, HenkeB, Henning Makholm, HenryLi, HerbEA6, Hervegirod, Hgabor, Hirzel, Hmains, Hmd,Hokanomono, Homerjay, Hqb, Hu12, Huffers, Husky, Hyad, I already forgot, I-20, INkubusse, IanOsgood, Ideogram, Idknow, Ilgiz, Iluvcapra, In2dair, InShaneee, InfinityAndBeyond,Information Center, Infrogmation, Intangir, Iridescence, Irish Souffle, Isilanes, Itai, Itmozart, J.delanoy, JJIG, JPINFV, Jamesooders, Jay, Jc4p, Jcarroll, Jeffadams78, Jeltz, Jengod, JensenDied,Jerryobject, Jfdsmit, Jhevodisek, Jiang, Jiddisch, JimWae, Jla, Jleedev, Jm34harvey, Jmath666, Jmnbatista, Jni, Joeblakesley, John Fader, John Vandenberg, JohnJSal, Johndci, Johnuniq,Jojo-schmitz, Jok2000, Joke137, JonMcLoone, Jordandanford, Jorge Stolfi, JorgePeixoto, Josemanimala, Joseph Myers, João Jerónimo, Jrthorpe, Jscipione, Jubair.pk, Jumbuck, Jusdafax, Jutta,Juuitchan, Jwzxgo, Kapil87852007, Karen Johnson, Katanzag, Kate, Katieh5584, Kbolino, KenshinWithNoise, Kenyon, Kerotan, Kevin B12, Kgasso, Kimiko, Kinema, King of Hearts (oldaccount 2), Kjak, Kkm010, Klhuillier, KnowledgeOfSelf, Kooldeep, Koyaanis Qatsi, Kreca, Kri, Kushal kumaran, Kusunose, Kwamikagami, LAAFan, LOL, Lainproliant, Larry Hastings,Laundrypowder, Lbraglia, Lecanard, Lee Daniel Crocker, Lee1026, Leibniz, LeoNerd, Leontios, Lfwlfw, Liftarn, Lightdarkness, LilHelpa, Linus M., Lir, Lloydd, Loadmaster, Lockley,Lost.goblin, Lotje, Luk, Lupin, Lvl, MDoko, MTizz1, Mac c, Mackstann, Magic Window, Malfuf, Marc Mongenet, Mark Renier, MarkS, Marskell, Martijn Hoekstra, Martinjakubik, MattOates,Matusz, Maustrauser, Mav, MaxEnt, MaxSem, Mboverload, Mcaruso, Mdsawyer58, Mellum, Merphant, MertyWiki, Methcub, Mgmei, Michael.Paoli, MichaelBillington, Michaeln,MichalJurosz, Mickraus, Mikademus, Mike Jones, Mike92591, Mikeloco14, MilesMi, Minesweeper, Minghong, Mipadi, Mirror Vax, Miterdale, Miym, Mk*, Modulatum, Monobi, Morwen,Moskvax, Mrjeff, Msikma, Msreeharsha, MuZemike, Muhandis, Mumuwenwu, Museak, Musicomputer, MustafaeneS, Mux, Mxn, Mycplus, N5iln, Naidim, Nanshu, Napi, NapoliRoma,NauarchLysander, Neckelmann, Neilc, NeoAdonis, Nephtes, NevilleDNZ, NewEnglandYankee, Nick8325, Nickj, Nikai, NikonMike, Ninly, Nixeagle, NixonB, Njyoder, Nk.sheridan, Nn123645,Nnp, Norm, Notedgrant, Notyourhoom, NubKnacker, Numbo3, Nv8200p, Oblivious, Obradovic Goran, Octahedron80, Oddity-, Odinjobs, Ohnoitsjamie, Olivier, Ollydbg, Omicronpersei8,OnePt618, Opabinia regalis, Opelio, OrangUtanUK, Orderud, Orthoepy, Orthogonal, OwenBlacker, Oxymoron83, Oysterguitarist, Ozzmosis, P Carn, Pamri, Papa November, Paul-L, Paulsheer,Pcovello, Penubag, Peter Fleet, Pgk, Pharos, Phgao, Phuzion, Piet Delport, Pizza Puzzle, Pjvpjv, Plugwash, Poor Yorick, Postdlf, Potatoj316, Potatoswatter, Praveenp, Pripat2001, Prosfilaes,Proub, PseudoSudo, Pseudomonas, Psychotic Spoon, Psyco Fish, Qbg, Qed, Quantumobserver, Quimn, Quuxplusone, Qwertyus, RCX, RN, RTC, Radagast83, Rahinreza, Rainier002, Ralmin,Rama, RandomStringOfCharacters, Ranjithkh, RedWolf, Redf0x, Reisio, Rekh, Reverendgraham, ReyBrujo, Rhsimard, Rich257, RichW, Richard001, Richfife, Richw33, Rjwilmsi, Rl, Rlbyrne,Rlee0001, Robert Merkel, RobertG, RogueMomen, Rokfaith, Rosa67, RoyBoy, Rrelf, Rrjanbiah, Ruakh, Rudderpost, Rumping, Runtime, Rursus, Rwwww, Ryulong, SAE1962, SOMNIVM,SUCKISSTAPLES, Sac.education, Samiam95124, Sampalmer4, Samuel, Sandahl, Sanjay742, Schmid, Scientizzle, SeanProctor, Sebastiangarth, Sen Mon, Sephiroth storm, Serge Stinckwich,Shaan myself, Shadowjams, Shanes, SheepNotGoats, Shekure, Shijualex, Shirik, Shmget, Sigil2, Sigma 7, Simetrical, Simoncpu, Sin Harvest, Sir Lewk, Skier Dude, Sladen, Smyth, Snaxe920,Somercet, Soptep, Spacepotato, Sphivo, Spl, Spolstra, Spoon!, SpuriousQ, Stan Shebs, Stephan Schulz, Stephenb, Stephenbez, Steppres, Stevenj, Steveozone, Stormie, Strait, Stratocracy,Straussian, Sundaryourfriend, Sunny sin2005, SuperTails92, Susvolans, SvGeloven, THEN WHO WAS PHONE?, Tados, TakuyaMurata, Tariqabjotu, Taw, Tcascardo, Tdudkowski, Technion,Teddks, Tedickey, Template namespace initialisation script, Teryx, Tetraedycal, The Divine Fluffalizer, The Real Walrus, The Thing That Should Not Be, The wub, The751,TheBoardWalkInAC, TheMandarin, ThePCKid, TheParanoidOne, Thebrid, Thegroove, Thingg, Thumperward, Thunderbrand, Tiggerjay, Tim Starling, Timneu22, Tobias Bergemann, Tom 99,Tom harrison, Tomgreeny, Tommy, Tommy2010, Tompsci, Tony1, Torc2, Toussaint, Toxygen, Trachtemacht, Traroth, Trevor Andersen, Trevyn, Tripodics, Troysteinbauer, Tsavage,Tsunaminoai, Tualha, Tushar.kute, TuukkaH, Twobitsprite, UU, Ultimus, Ultra two, Ummit, Uncle G, Unixplumber, Urhixidur, Uriyan, Urod, Useight, Usien6, Utcursch, UtherSRG, UtilityMonster, Utkarsh kapadia, Uukgoblin, Val42, Valermos, VasilievVV, VbAlex, Versus22, Vicu9Mx, Vijay2421, Vijoeyz, Vinodxx1, Voice of All, Warlordwolf, Wdfarmer, Web-CrawlingStickler, Weevil, Wellithy, Wernher, Who, WikHead, Wiki alf, Wikipelli, Wikiwonky, Wimt, Wipe, Woohookitty, World eagle, Worthawholebean, Wrp103, XJamRastafire, Xcentaur, Xemnas 57, Xiahou, Xiong Chiamiov, Xp54321, Yamaguchi先生, Yamla, Ybenharim, Yelyos, Yogeendra, Yosri, Ysangkok, Yuzhong, Zanimum, Zeno Gantner, Zenohockey, Zhelmcleod, Zhenqinli,ZimZalaBim, Zorothez, Zundark, Zvn, Ævar Arnfjörð Bjarmason, 1599 ,ינמיתה למגה anonymous edits
C++ Source: http://en.wikipedia.org/w/index.php?oldid=374538072 Contributors: -Barry-, 12.21.224.xxx, 223ankher, 4jobs, 4th-otaku, 7DaysForgotten, @modi, A D Monroe III, A.A.Graff, AIOS, ALOTOFTOMATOES, AMackenzie, AThing, ATren, Aandu, Abdull, Abi79, Adam12901, Addihockey10, Adi211095, Adorno rocks, Ae-a, Aesopos, Agasta, AgentFriday, Ahmadmashhour, Ahoerstemeier, Ahy1, Akeegazooka, Akersmc, Akhristov, Akihabara, Akuyume, Alan D, AlbertCahalan, AlecSchueler, Aleenf1, AlexKarpman, Alexf, Alexius08, Alexkon, Alfio, Alhoori, Aliekens, AlistairMcMillan, Allstarecho, AltiusBimm, Alxeedo, AnAccount2, AnOddName, Andante1980, Andre Engels, Andreaskem, Andrew Delong, Andrew1, AndrewHowse, AndrewKepert, Andyluciano, AngelOfSadness, Angela, Anoko moonlight, Anonymous Dissident, Antandrus, Aparna.amar.patil, Apexofservice, Arabic Pilot, Aragorn2, Arcadie, Arctic.gnome, Ardonik, Asimzb, Atjesse, Atlant, Auntof6, Austin Hair, Autopilot, Avoran, Axecution, AxelBoldt, BMW Z3, Baa, Babija, Babjisit, Bahram.zahir, Barek, Baronnet, Bart133, Bartosz, Bdragon, Belem tower, BenFrantzDale, Benhocking, Bento00, Beowulf king, Bevo, Beyondthislife, Bfzhao, Biblioth3que, Bigk105, Bill gates69, Bineet, Bkil, Blaisorblade, Bluemoose, Bluezy, Bobazoid, Bobblewik, Bobo192, Bobthebill, Bodkinator, Boffob, Boing! said Zebedee, Bomarrow1, Bongwarrior, Booklegger, Boseko, Bovineone, Brion VIBBER, Btx40, C Labombard, C++ Template, C.Fred, CALR, CIreland, CPMcE, CRGreathouse, CWY2190, Caesura, Caiaffa, Callek, Caltas, Can't sleep, clown will eat me, CanisRufus, Cap'n Refsmmat, Capi crimm, CapitalR, Capricorn42, Captainhampton, Carabinieri, Card Zero, Carlson-steve, Catgut, Cathack, CecilWard, Cedars, CesarB, Cetinsert, Cfeet77, Cflm001, Cgranade, Chaos5023, CharlotteWebb, Chealer, Chocolateboy, Chrisandtaund, Christian List, Chuq, Ckburke, Cleared as filed, Closedmouth, Clsdennis2007, Cometstyles, Comperr, Conversion script, Coolwanglu, Coosbane, Coq Rouge, CordeliaNaismith, Corrector7007, Corti, Cowsnatcher27, Craig Stuntz, Crotmate, Csmaster2005, Ctu2485, Cubbi, Curps, Cwitty, Cybercobra, Cyclonenim, Cyde, CyrilleDunant, Cyrius, DAGwyn, DJ Clayworth, DVD R W, Dallison999, Damian Yerrick, Damien.c.sadler, Dan Brown123, Dan100, Danakil, Daniel Earwicker, Daniel.Cardenas, DanielNuyu, Dario D., DarkHorizon, Darkmonkeyz321, Darolew, Dave Runger, Daverose 33, David A Bozzini, David H Braun (1964), Dawn Bard, Dch888, Dcoetzee, Decltype, Deibid, Delirium, Delldot, Denelson83, DerHexer, Derek Ross, Deryck Chan, DevSolar, DevastatorIIC, Dibash, Diego pmc, Discospinster, Dlae, Dlfkja;lskj, Dmharvey, Dogcow, DominicConnor, DonelleDer, Donhalcon,

Article Sources and Contributors 196
Doofenschmirtzevilinc, DoubleRing, Doug Bell, Dougjih, Doulos Christos, Drangon, Drewcifer3000, Drrngrvy, Dylnuge, Dysprosia, E Wing, ESkog, Eagleal, Earle Martin, EatMyShortz,Ebeisher, Eco84, Ecstatickid, Ed Brey, Edward Z. Yang, Eelis, Eelis.net, Ehn, Elliskev, Elysdir, Enarsee, EncMstr, Enerjazzer, EngineerScotty, Eric119, ErikHaugen, Esanchez7587, Esben,Esmito, Esrogs, Eternaldescent08, Ethan, EvanED, Evice, Evil Monkey, Ewok18, Excirial, FW4NK, Fa2sA, Facorread, Faithlessthewonderboy, Faizni, Falcon300000, Fanf, Fashionslide,FatalError, Favonian, Fistboy, Fizzackerly, Flamingantichimp, Flash200, Flewis, Flex, Flyingprogrammer, FrancoGG, Freakofnurture, Frecklefoot, Free Software Knight, Fresheneesz, Fritzpoll,Ftbhrygvn, Furby100, Furrykef, Fuzzybyte, GLari, Gaul, Gauss, Geeoharee, Gene.thomas, Gengiskanhg, Giftlite, Gil mo, Gildos, Gilgamesh, Gilliam, Gimili2, Gimme danger, Gmcfoley, God OfAll, Gogo Dodo, GoodSirJava, Graue, Greatdebtor, GregorB, Gremagor, Grenavitar, Grey GosHawk, Grigor The Ox, Gsonnenf, Gusmoe, Gwern, Gwjames, Hairy Dude, Hakkinen,HappyCamper, Harald Hansen, Harinisanthosh, Harryboyles, HebrewHammerTime, HeikoEvermann, Hemanshu, HenryLi, Herorev, Hervegirod, Hetar, Hgfernan, HideandLeek, Hihahiha474,Hiraku.n, Hmains, Hobartimus, Hogman500, Horselover Frost, Hoss7994, Hu, Hu12, Husond, Hyad, Hyperfusion, I already forgot, ISoLoveHer, Iamninja91, Ibroadfo, Imc, Immunize,InShaneee, Innoncent, Insanity Incarnate, Intangir, Iphoneorange, Iridescence, Iridescent, Irish Souffle, Ironholds, Isaacl, Ixfd64, J Casanova, J Di, J-A-V-A, J.delanoy, JForget, JNighthawk,Jackelfive, Jafet, Jaredwf, Jatos, Javiercastillo73, Javierito92, Jawed, Jayaram ganapathy, Jdent29, Jdowland, Jeff G., JeffTL, Jeltz, Jerry teps, Jerryobject, Jeshan, Jesse Viviano, JesseW,Jgamer509, Jgrahn, Jgroenen, Jh51681, Jimsve, Jizzbug, Jlin, Jnestorius, Johndci, Johnsolo, Johnuniq, Jok2000, Jonathan Grynspan, Jonathanischoice, Jonel, Jonmon6691, Jorend, Josh Cherry,Juliano, Julienlecomte, Junkyboy55, Jyotirmay dewangan, K3rb, KJK::Hyperion, KTC, Kaimason1, Kajasudhakarababu, Kalanaki, Kapil87852007, Kashami, Kate, Keilana, Kentij, KhymChanur, Kifcaliph, King of Hearts, Kinu, Klassobanieras, KnowledgeOfSelf, Kogz, Kooky, Korath, Koyaanis Qatsi, Krelborne, Krich, Krischik, Kristjan.Jonasson, Ksam, Kuru, Kusunose,Kwamikagami, Kwertii, Kxx, Kyle2^32-1, Kyleahampton, Landon1980, Larry V, Lars Washington, Lastplacer, Le Funtime Frankie, Lee Daniel Crocker, LeinadSpoon, Liao, Liftarn,Lightmouse, Ligulem, Lilac Soul, Lilpony6225, Lir, Liujiang, Lkdude, Lloyd Wood, Loadmaster, Logixoul, Lotje, Lowellian, Luks, Lvella, Lysander89, MER-C, Mabdul, Machekku,MadCow257, Mahanga, Maheshchowdary, Male1979, Malfuf, Malhonen, Malleus Fatuorum, Mani1, Manjo mandruva, Manofabluedog, MarSch, Marc Mongenet, Marc-André Aßbrock, MarceloPinto, Mark Foskey, Marktillinghast, Marqmike2, Martarius, Masterkilla, Mathrick, Mav, Mavarok, Max Schwarz, Maxim, Mayank15 5, Mbecker, Mccoyst, Mcorazao, Mcstrother, Mellum,MeltBanana, Mentifisto, Mephistophelian, Metamatic, Methcub, MetsFan76, Mhnin0, MichaelJHuman, Micphi, Mifter, MihaS, Mikademus, Mike Van Emmerik, Mike92591, MikrosamAkademija 7, MilesMi, Mindmatrix, Minesweeper, Minghong, Mipadi, Miqademus, Miranda, Mirror Vax, Mistersooreams, Mjquinn id, Mkarlesky, Mkcmkc, Mmeijeri, MoA)gnome, Moanzhu,Modify, Mohamed Magdy, Mole2386, Morwen, Moxfyre, Mptb3, Mr MaRo, Mr.GATES987, MrJeff, MrSomeone, Mrjeff, Mrwes95, Ms2ger, Muchness, Mukis, Muralive, MustafaeneS, Mxn,Myasuda, Mycplus, Mystìc, N111111KKKKKKKooooo, Naddy, Nanshu, Napi, Nasa-verve, Natdaniels, NawlinWiki, Neilc, Neurolysis, NevilleDNZ, Newsmen, Nick, Nicsterr, Ninly,Nintendude, Nirdh, Nisheet88, Nixeagle, Njaard, Nma wiki, Nohat, Noldoaran, Non-dropframe, Noobs2007, Noosentaal, Northernhenge, ORBIT, Oddity-, Odinjobs, Ohnoitsjamie, Ojuice,OldakQuill, Oleg Alexandrov, Oliver202, Oneiros, Orderud, Ouraqt, OutRIAAge, OverlordQ, OwenBlacker, Ozzmosis, Paddu, Pak21, Pankajwillis, ParallelWolverine, Paul Stansifer, Paul evans,Paulius2003, Pavel Vozenilek, Pawanindia2009, Pbroks13, Pcb21, Pde, PeaceNT, Pedant17, Peruvianllama, Peterl, Peteturtle, Pgk, Pharaoh of the Wizards, Pharos, Phil Boswell, Philip Trueman,PhilippWeissenbacher, Pi is 3.14159, Pit, Pizza Puzzle, Plasticup, Pogipogi, Poldi, Polluxian, Polonium, Poor Yorick, Prashan08, PrincessofLlyr, Prohlep, ProvingReliabilty, Punctilius, Quadell,Quinsareth, Quuxplusone, Qwertyus, R3m0t, R4rtutorials, REggert, RN, Raghavkvp, RainbowOfLight, Ravisankarvn, Rbonvall, Rdsmith4, RedWolf, Rehabe, Reinderien, Remember the dot,Requestion, Rethnor, RexNL, Rgb1110, Rich Farmbrough, Richard Simons, Ritualizer, Rjbrock, Rjwilmsi, Roadrunner, Robdumas, Robertd, RodneyMyers, RogueMomen, Ronark, Ronhjones,Ronnyim12345, Ronyclau, Root@localhost, Rosive, Rossami, Rprpriya, Rror, Rtfb, Rursus, Ruud Koot, RyanCross, Ryty01, SJP, STL, Sachin Joseph, Sadday, Saimhe, Samuel, Sandahl, SashaSlutsker, Sbisolo, Sbvb, SchfiftyThree, Schiralli, SchnitzelMannGreek, Schumi555, ScoPi, Scoops, Scorp.pankaj, Scottlemke, Scythe33, SebastianHelm, Sebastiangarth, Sebor, Sentense12,Seraphim, Sfxdude, Sg227, Shadowblade0, Shadowjams, Shawnc, SheffieldSteel, ShellCoder, Shinjiman, Sidhantx, Sigma 7, Silsor, Simetrical, Simon G Best, SimonP, Sinternational, Sirex98,Sishgupta, Sitethief, Skew-t, Skizzik, SkyWalker, Sl, Sleep pilot, Sligocki, Slothy13, Smyth, Snaxe920, Sneftel, Snigbrook, Snowolf, Sohmc, SomeRandomPerson23, Sommers, Spaz man, Spiel,Spitfire, SplinterOfChaos, SpuriousQ, Stanthejeep, SteinbDJ, Stephan Schulz, Stephenb, Steve carlson, Steven Zhang, Stevenj, StewartMH, Stheller, Stoni, StoptheDatabaseState, Strangnet,Stringle, Stuartclift, Style, Suffusion of Yellow, Supertouch, Suppa chuppa, Surv1v4l1st, Sutambe, SvGeloven, Svick, Swalot, Sydius, T0pem0, T4bits, TCorp, THEN WHO WAS PHONE?,Takis, TakuyaMurata, Tattema, Tbleher, TeaDrinker, Technion, Tedickey, Template namespace initialisation script, Tero, Tetra HUN, TexMurphy, The 888th Avatar, The Anome, The InedibleBulk, The Minister of War, The Nameless, The Thing That Should Not Be, TheDeathCard, TheIncredibleEdibleOompaLoompa, TheMandarin, TheNightFly, TheSuave, TheTim, Theatrus,Thebrid, Thematrixv, Thiagomael, Thumperward, Tietew, Tifego, Tim Starling, Tim32, TingChong Ma, Tinus, Tobias Bergemann, Toffile, TomBrown16, TomCat2800, Tombrown16, Tompsci,Tony Sidaway, Torc2, Tordek ar, Toussaint, Traroth, Trevor MacInnis, TreyHarris, Troels Arvin, Ts4z, Tslocum, Turdboy3900, Turian, TuukkaH, Ubardak, Umapathy, Unendra, Ungahbunga,Urod, UrsaFoot, Useight, Userabc, UtherSRG, Utnapistim, Val42, Vchimpanzee, Vincenzo.romano, Vinci0008, Viperez15, VladV, Vladimir Bosnjak, Wangi, Wavelength, Wazzup80, Werdna,Westway50, Whalelover Frost, Who, WikHead, Wikidemon, Wikidrone, Wikipendant, Wikiwonky, Willbennett2007, Wilson44691, Winchelsea, Wj32, Wknight94, Wlievens, Woohookitty,Wsikard, XJamRastafire, Xerxesnine, Xoaxdotnet, Yamla, Yankees26, Yboord028, Ybungalobill, Yoshirules367, Ysangkok, Yt95, Yurik, Zck, Zed toocool, Zenohockey, Zigmar, Zlog3, Zoe,Zr2d2, Zrs 12, Zundark, ZungBang, Zvn, Ævar Arnfjörð Bjarmason, Александър, ПешСай, Ἀγάπη, 无名氏, 1802 anonymous edits
C syntax Source: http://en.wikipedia.org/w/index.php?oldid=369957712 Contributors: ABCD, ANONYMOUS COWARD0xC0DE, Abaddon314159, Abdull, Acdx, Adashiel, Ahy1,Akihabara, Alex Ruddick, Andreas Kaufmann, AndrewHowse, Arvindn, B k, Bevo, BillC, Billyoneal, Btx40, Btyner, CPMcE, Charles Matthews, Chungyan5, Cleared as filed, Cmdrjameson,Corti, Crazycomputers, Cutler, DAGwyn, Daghall, Darrien, Dcoetzee, Der schiefe Turm, Derek farn, DervishD, Dhrubnarayan, Dkasak, DmitTrix, EatMyShortz, EdC, Edward, Flash200,Flipjargendy, Fratrep, Frederico1234, Fresheneesz, Gennaro Prota, Hdante, HeroTsai, Hvn0413, IanOsgood, Iandiver, JF Bastien, Jni, John of Reading, Jonsafari, Joyous!, Kbolino, Keegscee,Kevin Saff, Kristjan.Jonasson, LeoNerd, Loadmaster, MER-C, Marc Kupper, MichaelJanich, Mick8882003, Mikeblas, Miklcct, Ms2ger, Mxn, Myrdred, Neilc, Nick, Nono64, Oerjan, PapaNovember, Pfaffben, Pip2andahalf, Qutezuce, R'n'B, RedHillian, RedWolf, Ritchie333, RobertG, Rotring, SkyWalker, Spoon!, SteinbDJ, StuartBrady, TakuyaMurata, The Anome,TheIncredibleEdibleOompaLoompa, Tobias Bergemann, Tobycat, TomJF, Toussaint, Trevyn, 132 anonymous edits
C preprocessor Source: http://en.wikipedia.org/w/index.php?oldid=371211684 Contributors: 0x6adb015, Abdull, Akihabara, Alotau, Alvin-cs, Andyluciano, Archimerged, Atomafr, B k,BenBac, Bevo, BradDoty, Btx40, C. A. Russell, CiaPan, Circuitjaya, Cmh, Constantine lisiy, CyberShadow, Dagoldman, Darklilac, DataWraith, DavidCary, Debresser, Derek farn,DevastatorIIC, Dicklyon, Digana, Djfeldman, Dreftymac, EdC, Eeekster, Emperorbma, Flameass, Fragglet, Frangibility, Frappucino, FrenchIsAwesome, Furrykef, Garion96, Gesslein, Giftlite,Hairy Dude, Hq3473, Immibis, Isidore, JacobBramley, Jesin, Joeblakesley, Joel Saks, Karelklic, Karl Dickman, Komap, Krauss, Larry Hastings, Lino Mastrodomenico, Marnanel, Mecej4,Mernen, Neilc, Nroets, OMouse, Oliver Lineham, Ollydbg, Pete142, Pfaffben, Plop, Rdk, Rich Farmbrough, Richfife, Rjwilmsi, Rlbyrne, Rogerdpack, Rursus, TakuyaMurata, Tardis, Tedcarter1, The Thing That Should Not Be, ThePCKid, Tobias Bergemann, Tomer shalev, Toussaint, Tubeliar, Verdy p, Vigneshs, Viswanath Vellaiappan, XChaos, Zawersh, Zfr, 165 anonymousedits
C variable types and declarations Source: http://en.wikipedia.org/w/index.php?oldid=369138997 Contributors: Abdull, Ahoerstemeier, Akihabara, Alksentrs, Andy.coombes, Chris the speller,Chuunen Baka, Cmdrjameson, Dar-Ape, EdC, JorisW, João Jerónimo, Karl Dickman, LeoNerd, Mild Bill Hiccup, Mxn, Neilc, Pfaffben, Phantomsteve, Sam Hocevar, SourSW, Spoon!,Stupefaction, Superm401, The Anome, The Storm Surfer, Torc2, Toussaint, Vedranf, 48 anonymous edits
Operators in C and C++ Source: http://en.wikipedia.org/w/index.php?oldid=373673335 Contributors: 3ICE, AJim, ANONYMOUS COWARD0xC0DE, Abdull, Aidarhaynes5, Akilaa,Andrew1, AoV2, Arabic Pilot, Archimerged, Azdruid, Bevo, Bobo192, Bryan Derksen, Btyner, Cgranade, Coppro, Curps, D0762, Daarklord, Dante Alighieri, Decltype, Der schiefe Turm, Derekfarn, Deryck Chan, Dkasak, EdC, Egriffin, Ensign beedrill, Eric119, Fanf, Ferfish, Flash200, Fresheneesz, Gerbrant, Gerold Broser, GlowBee, GregorB, Hairy Dude, Ilgiz, Iridescent, Jaalto, Jafet,Jasondet, Jengelh, Jni, Jokes Free4Me, Jordsan, K7.india, Kbolino, Kenny Moens, Kenyon, Killy mcgee, King Mir, Lalaith, LesPaul75, LizardJr8, Loadmaster, LokiClock, Lulzmango, Male1979,Mark Foskey, Mgsloan, Michael Safyan, Mike Rosoft, Mikrosam Akademija 8, Mipadi, Mohamed Magdy, Mrjeff, Mwtoews, Myork, Nick, Oliphaunt, Orderud, OwenBlacker, PL290, Phatom87,Potatoswatter, Quadramble, Quuxplusone, Raiker, Regression Tester, Salamurai, Seav, Serendipity33, SimonTrew, Smjg, Solysk, Spoon!, Sundar2000, Thinkingatoms, Torc2, Toussaint,Travelan, Visor, Wikieditoroftoday, Wim Leers, Woong.jun, Xeno, Xuinkrbin., Zenohockey, Zigger, 218 anonymous edits
C file input/output Source: http://en.wikipedia.org/w/index.php?oldid=372463387 Contributors: 16@r, BL, Damian Yerrick, Dampam, Deryck Chan, Dkasak, Eric119, Evercat, Ewlyahoocom,Fibonacci, Fresheneesz, Furrykef, Ghettoblaster, Gnawthos, Heron, Icoolucool, Jni, JorgePeixoto, Justinhaynes, Karl Dickman, Ktracy, Kylu, LOL, Maclary, Masterfreek64, Milan Keršláger,Mwtoews, Pitel, Quuxplusone, Radagast83, RedWolf, Sgeureka, TakuyaMurata, Tannin, Unara, Usien6, Woohookitty, X-Destruction, Xtremecoder007, Yaronf, 52 anonymous edits
?: Source: http://en.wikipedia.org/w/index.php?oldid=355828431 Contributors: ABCD, Aaron Rotenberg, Alerante, Alf, Anakin101, Ancheta Wis, Anonymous Dissident, ArielGold, Btx40,BunsenH, Cap601, Capi, Carychan, Charles Matthews, Curps, Cybercobra, Dan Pelleg, Daniel.Cardenas, DavidHalton, Decltype, Dpbsmith, Dysprosia, Exe, Faya, Fieldday-sunday, Geary, Gigs,Greenrd, IAlex, Jesin, Jkl, Jruderman, KingJason, Labalius, Marudubshinki, Merovingian, Minghong, Miranda, Moggie2002, Mrwojo, NathanBeach, Noodle snacks, Orderud, Phresnel,Qwertyus, Salvar, Sevcsik, Shlakoblock, Simeon, Spoon!, Sverdrup, The Anome, The Thing That Should Not Be, The Wild Falcon, Thumperward, Tobias Bergemann, Torc2, WOT, Warren,Whiner01, Woohookitty, Xiong Chiamiov, Zanimum, ZeroOne, 74 anonymous edits
Procedural programming Source: http://en.wikipedia.org/w/index.php?oldid=373601596 Contributors: 16@r, A Keshavarz, AJR, Aarghdvaark, Ajh16, Ancheta Wis, Andrew Eisenberg,AndrewHowse, AstroPig7, Baseballdude, Beakerboy, Beland, Beliavsky, Benandorsqueaks, Bevo, Blonkm, Bryan Derksen, Burchard, Burschik, CALR, CONFIQ, CambridgeBayWeather,CapitalR, CapitalSasha, Chbarts, Cheshins, ClickRick, Cokehabit, Colonies Chris, Conversion script, CrazyMYKL, Cybercobra, DKEdwards, Danakil, Davou, Deewiant, Dex1337, Dylanmcd,EugeneZelenko, FatalError, Felixdakat, Gazpacho, Gilliam, HKT, Hmrox, Ian Pitchford, JAF1970, JDowning, JLaTondre, Jalesh, Jamelan, Jobers, Joe Sewell, Jons63, Jrtayloriv, Katr67, Kavadicarrier, Keith D, Kowey, Kusunose, Kylehuang, LOL, LeaveSleaves, LilHelpa, LinguistAtLarge, Logperson, Loudsox, MaNeMeBasat, Marco Krohn, Max42, Meanskeeps, Mmortal03, Mnsc,Modulatum, Mrtrumbe, Msikma, Ndenison, Nixdorf, Only2sea, Or-whatever, OrangUtanUK, Orderud, PJTraill, PhilKnight, PradeepArya1109, Raboof, Rade Kutil, Redaktor, Renku, Rgamble,Rhopkins8, Rich Farmbrough, Rlee0001, Ruud Koot, Ryuukuro, Sean Whitton, Shadowcode, Sibidiba, Simon80, SimonTrew, SkyWalker, Sykopomp, TakuyaMurata, Taw, The Anome, TheRambling Man, The Wordsmith, The sock that should not be, Thivierr, Thsgrn, Torc2, Totakeke423, Toussaint, TuukkaH, Uucp, VKokielov, WalterGR, Wfox, Windharp, Work permit,Yacoubean, Yuanchosaan, ZMaen, ZeroOne, 251 ,دمحأ anonymous edits

Article Sources and Contributors 197
Subroutine Source: http://en.wikipedia.org/w/index.php?oldid=371903644 Contributors: 16@r, Aaronbrick, Abednigo, AdmN, Admijr, Akamad, Alex Brookes, Alfio, Altenmann,AlunSimpson, Andre Engels, Argentium, ArglebargleIV, Atlant, Beland, Bevo, Brichard37, CSWarren, Cacycle, CecilWard, Cerberus0, CraigNobbs, Damian Yerrick, Damieng, Dcoetzee, Derekfarn, Donhalcon, Drhex, Dysprosia, EatMyShortz, Edward, Elkman, Elliottcable, Falcon8765, Fetofs, Finlay McWalter, Fredrik, Function.Name, Furrykef, Garkbit, Georg Peter, Gilliam, GlassTomato, Greenrd, Hgfernan, Hyad, Incripshin, Interiot, JLaTondre, JaGa, Jayden54, Jb-adder, Jeltz, Jni, Jorge Stolfi, Jpbowen, K.lee, Kbdank71, Kdakin, Kelson, Kowey, Lightbound, LilHelpa,Lir, Loadmaster, Lysdexia, M4gnum0n, Mahanga, Mani1, ManuelGR, Mark Renier, Marudubshinki, Max Terry, Methcub, Michael Hardy, Mike Van Emmerik, Mikethegreen, Mikewax, MildBill Hiccup, Mintleaf, Mitch Ames, Mmmpie, Mpost89, MystRivenExile, Neilc, Norm, Obradovic Goran, Oleksii0, Orderud, PMLawrence, Patrick, Pcb21, Peak, Pichu826, Piet Delport, Pnm,Pointillist, Poppafuze, Quuxplusone, R. S. Shaw, RedWolf, Rheun, RobertG, Rror, Ruud Koot, Rwwww, Sangwine, Sarten-X, SeanProctor, Seqsea, Shantavira, Shirik, Shutranm, Sibi antony,Skittleys, Slipstream, Spitfire, Ssd, StanContributor, Stefan, SteveBaker, Synthem3sc, Tablizer, TakuyaMurata, Tam, TankMiche, Tedp, Temoto, Theccoder, Thincat, Thomas H. Larsen,TimBentley, Tobias Bergemann, Tompsci, Una Smith, Upholder, Volfy, Wavelength, Wernher, Whatfg, Wiarthurhu, Wik, WikHead, WorldlyWebster, Zeimusu, Zondor, Zé da Silva, 140anonymous edits

Image Sources, Licenses and Contributors 198
Image Sources, Licenses and ContributorsFile:Information processing system (english).svg Source: http://en.wikipedia.org/w/index.php?title=File:Information_processing_system_(english).svg License: Public Domain Contributors:Original uploader was Gradient drift at en.wikipediaFile:Abacus 6.png Source: http://en.wikipedia.org/w/index.php?title=File:Abacus_6.png License: unknown Contributors: Flominator, German, Grön, Luestling, RHorningFile:Patented Yazu Arithmometer.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Patented_Yazu_Arithmometer.jpg License: Public Domain Contributors: Up loaded byNamazu-tronFile:Lochkarte Tanzorgel.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Lochkarte_Tanzorgel.jpg License: Creative Commons Attribution-Sharealike 2.5 Contributors:User:Stefan KühnFile:Ibm407 tabulator 1961 01.redstone.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Ibm407_tabulator_1961_01.redstone.jpg License: Public Domain Contributors: Edward,Infrogmation, Liftarn, NekoJaNekoJaFile:Blue-punch-card-front.png Source: http://en.wikipedia.org/w/index.php?title=File:Blue-punch-card-front.png License: Public Domain Contributors: GwernFile:Curta01.JPG Source: http://en.wikipedia.org/w/index.php?title=File:Curta01.JPG License: Creative Commons Attribution-Sharealike 2.5 Contributors: Larry McElhineyFile:Cambridge differential analyser.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Cambridge_differential_analyser.jpg License: Creative Commons Attribution 2.0 Contributors: University of CambridgeFile:Punched tape puncher.JPG Source: http://en.wikipedia.org/w/index.php?title=File:Punched_tape_puncher.JPG License: Public Domain Contributors: Indolences, WikipediaMaster, 1anonymous editsFile:Largetape.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Largetape.jpg License: GNU Free Documentation License Contributors: User:PoilFile:Zuse Z1.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Zuse_Z1.jpg License: GNU Free Documentation License Contributors: StahlkocherFile:Colossus.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Colossus.jpg License: unknown Contributors: Conscious, Edward, Hellisp, Ian Dunster, Ibonzer, Man vyiFile:Atanasoff-Berry Computer at Durhum Center.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Atanasoff-Berry_Computer_at_Durhum_Center.jpg License: CreativeCommons Attribution-Sharealike 2.5 Contributors: User:ManopFile:Eniac.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Eniac.jpg License: Public Domain Contributors: unknownFile:von Neumann architecture.svg Source: http://en.wikipedia.org/w/index.php?title=File:Von_Neumann_architecture.svg License: GNU Free Documentation License Contributors:Booyabazooka, Pieter KuiperFile:Magnetic core.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Magnetic_core.jpg License: Creative Commons Attribution 2.5 Contributors: Fayenatic london, Gribozavr,UberpenguinFile:IBM-650-panel.jpg Source: http://en.wikipedia.org/w/index.php?title=File:IBM-650-panel.jpg License: GNU Free Documentation License Contributors: User:mfcFile:Transistor-die-KSY34.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Transistor-die-KSY34.jpg License: Public Domain Contributors: NEON ja, Shaddack, WikipediaMasterFile:IBM 350 RAMAC.jpg Source: http://en.wikipedia.org/w/index.php?title=File:IBM_350_RAMAC.jpg License: Creative Commons Attribution-Sharealike 2.5 Contributors: Originaluploader was Vladnik at en.wikipediaFile:153056995 5ef8b01016 o.jpg Source: http://en.wikipedia.org/w/index.php?title=File:153056995_5ef8b01016_o.jpg License: Creative Commons Attribution-Sharealike 2.0 Contributors:Ioan SameliImage:IBM402plugboard.Shrigley.wireside.jpg Source: http://en.wikipedia.org/w/index.php?title=File:IBM402plugboard.Shrigley.wireside.jpg License: Creative Commons Attribution 2.5 Contributors: User:ArnoldReinholdImage:PunchCardDecks.agr.jpg Source: http://en.wikipedia.org/w/index.php?title=File:PunchCardDecks.agr.jpg License: Creative Commons Attribution-Sharealike 2.5 Contributors: ArnoldReinholdImage:H96566k.jpg Source: http://en.wikipedia.org/w/index.php?title=File:H96566k.jpg License: Public Domain Contributors: Courtesy of the Naval Surface Warfare Center, Dahlgren, VA.,1988.Image:SDLC-Maintenance-Highlighted.png Source: http://en.wikipedia.org/w/index.php?title=File:SDLC-Maintenance-Highlighted.png License: Creative Commons Attribution-Sharealike3.0 Contributors: User:DzonatasImage:Systems Development Life Cycle.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Systems_Development_Life_Cycle.jpg License: Public Domain Contributors: User:MddImage:SDLC Phases Related to Management Controls.jpg Source: http://en.wikipedia.org/w/index.php?title=File:SDLC_Phases_Related_to_Management_Controls.jpg License: PublicDomain Contributors: U.S. House of RepresentativesImage:SDLC Work Breakdown Structure.jpg Source: http://en.wikipedia.org/w/index.php?title=File:SDLC_Work_Breakdown_Structure.jpg License: Public Domain Contributors: U.S.House of RepresentativesImage:Waterfall model.png Source: http://en.wikipedia.org/w/index.php?title=File:Waterfall_model.png License: Creative Commons Attribution-Sharealike 2.5 Contributors: Originaluploader was PaulHoadley at en.wikipediaImage:Waterfall model.svg Source: http://en.wikipedia.org/w/index.php?title=File:Waterfall_model.svg License: Creative Commons Attribution 3.0 Contributors: Paul SmithImage:LampFlowchart.svg Source: http://en.wikipedia.org/w/index.php?title=File:LampFlowchart.svg License: GNU Free Documentation License Contributors: User:BooyabazookaFile:Sorting quicksort anim.gif Source: http://en.wikipedia.org/w/index.php?title=File:Sorting_quicksort_anim.gif License: Creative Commons Attribution-Sharealike 2.5 Contributors:Berrucomons, Cecil, Chamie, Davepape, Diego pmc, Editor at Large, German, Gorgo, Howcheng, Jago84, Jutta234, Lokal Profil, MaBoehm, Minisarm, Miya, Mywood, NH, PatríciaR, Qyd,Soroush83, Stefeck, Str4nd, W like wiki, 11 anonymous editsImage:PD-icon.svg Source: http://en.wikipedia.org/w/index.php?title=File:PD-icon.svg License: Public Domain Contributors: User:Duesentrieb, User:RflImage:FlowchartExample.png Source: http://en.wikipedia.org/w/index.php?title=File:FlowchartExample.png License: Public Domain Contributors: Johnuniq, Phy1729, Rimshot, Yaxh, 3anonymous editsFile:(1) 2008-04-07 Information Management- Help Desk.jpg Source: http://en.wikipedia.org/w/index.php?title=File:(1)_2008-04-07_Information_Management-_Help_Desk.jpg License:Public Domain Contributors: User:MPRI SandraFile:Flowchart-template.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Flowchart-template.jpg License: Public Domain Contributors: User:WtshymanskiFile:kr c prog lang.jpg Source: http://en.wikipedia.org/w/index.php?title=File:Kr_c_prog_lang.jpg License: unknown Contributors: ConradPino, Cybercobra, Jafet, Melesse, 8 anonymouseditsFile:Wikibooks-logo-en.svg Source: http://en.wikipedia.org/w/index.php?title=File:Wikibooks-logo-en.svg License: logo Contributors: User:Bastique, User:RamacImage:C plus plus book.jpg Source: http://en.wikipedia.org/w/index.php?title=File:C_plus_plus_book.jpg License: unknown Contributors: Cybercobra, ICReal, Jusjih, Michaelas10, NAHID,Skier Dude, Storkk, Suffusion of Yellow, Yamla, 5 anonymous editsImage:BjarneStroustrup.jpg Source: http://en.wikipedia.org/w/index.php?title=File:BjarneStroustrup.jpg License: GNU Free Documentation License Contributors: -Image:Precedence_2.png Source: http://en.wikipedia.org/w/index.php?title=File:Precedence_2.png License: Public Domain Contributors: User:ModernMajor

License 199
LicenseCreative Commons Attribution-Share Alike 3.0 Unportedhttp:/ / creativecommons. org/ licenses/ by-sa/ 3. 0/