prml4.4 ラプラス近似~ベイズロジスティック回帰
TRANSCRIPT

PRML4.4-4.5ラプラス近似~ベイズロジスティック回帰
Yuki

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
4.4ラプラス近似
事後確率分布がもはやガウス分布ではないので
パラメータw上で正確に積分することができない
ベイズロジスティック回帰
ラプラス近似: :
近似する必要がある!
確率密度関数をガウス分布で近似する
まず,1変数zの場合を考え分布p(z)を仮定する
p(z) =1
Zf(z) Z =
Zf(z)dz
Zの値は未知であると仮定する
ラプラス近似とは、分布p(z)のモードを中心とする ガウス分布による近似を見つけることである
4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
4.4ラプラス近似
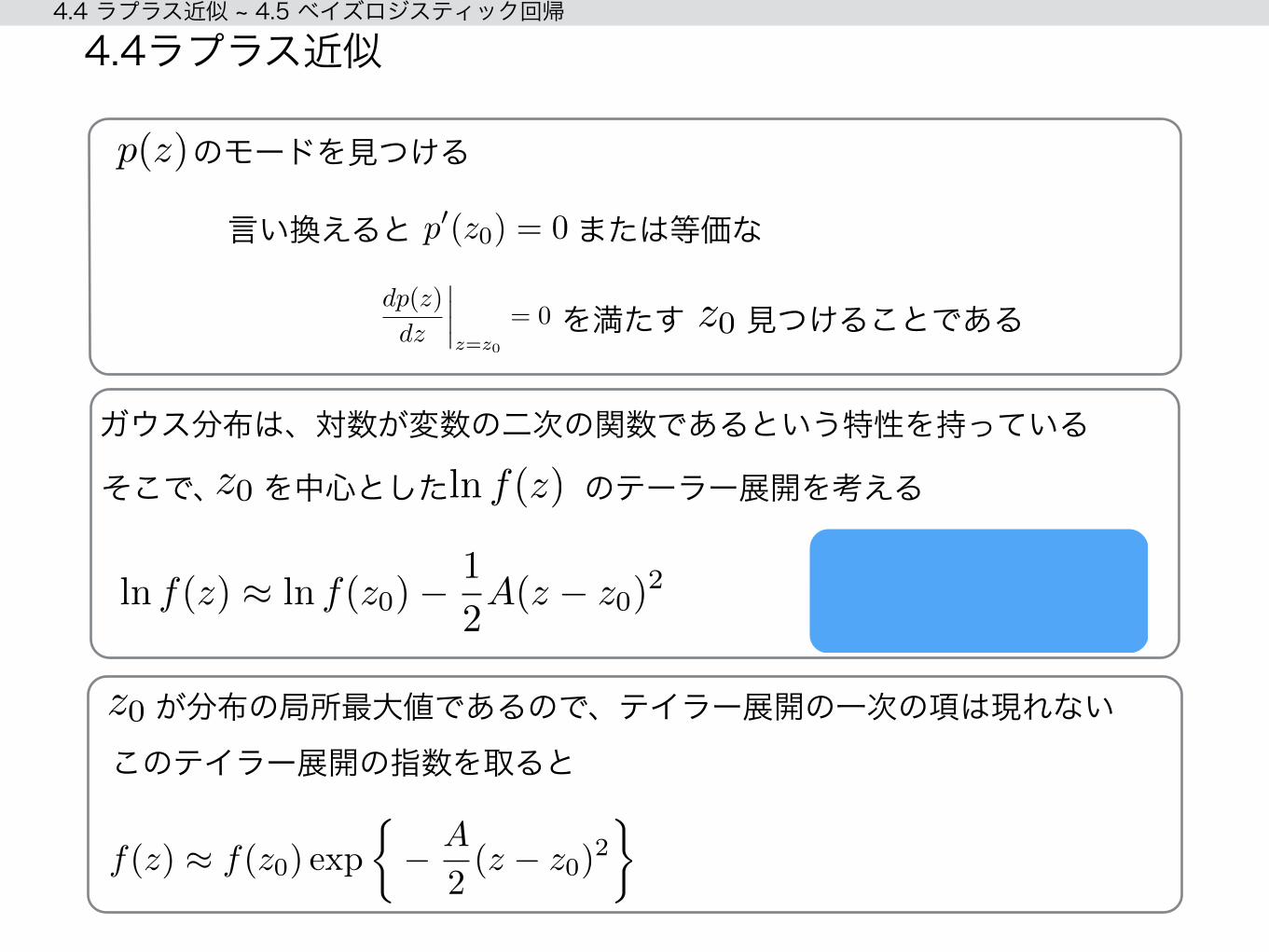
p(z)のモードを見つける
p0(z0) = 0
dp(z)
dz
����z=z0
= 0
言い換えると または等価な
を満たす z0 見つけることである
ガウス分布は、対数が変数の二次の関数であるという特性を持っている
そこで、z0 を中心としたln f(z) のテーラー展開を考える
A =d2
dz2ln f(z)
����z=z0
が分布の局所最大値であるので、テイラー展開の一次の項は現れないz0このテイラー展開の指数を取ると
ln f(z) ⇡ ln f(z0)�1
2A(z � z0)
2
f(z) ⇡ f(z0) exp
⇢� A
2
(z � z0)2
�

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
4.4ラプラス近似
ガウス分布の正規化のための標準的な結果を利用すると、正規化分布 q(z)
q(z) =
✓A
2⇡
◆1/2
exp
⇢� A
2
(z � z0)2
�
A > 0
を得る。
ガウス分布による近似が適切に定義されるのは の場合のみである
言い換えると、定常点 が局所最大である場合で、 その点での二階微分が負となる場合である。
z0

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
4.4ラプラス近似
ラプラス法を拡張しM次元空間 上で定義される分布z
p(z) = f(z)/Z を近似する
同様に で対数を取りテイラー展開z0
A = rr ln f(z)|z=z0
q(z) =|A|1/2
(2⇡)M/2exp
⇢� 1
2
(z� z0)TA(z� z0)
�= N (z|z0,A�1
)
M×Mヘッセ行列∇は勾配オペレータ
両辺の指数を取る
比例している
正規化
で表される精度行列が正定値行列 定常点 が局所最大である場合にガウス分布が適切に定義されるA
z0
ln f(z) ⇡ ln f(z0)�1
2(z� z0)
TA(z� z0)
f(z) ⇡ f(z0) exp
⇢� 1
2
(z� z0)TA(z� z0)
�

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
4.4ラプラス近似
ラプラス近似を適用する
モードz0を見つけるそのモードでヘッセ行列を評価する
モードは数値最適で求められる(Bishop and Nabney, 2008)
・現実の分布は多峰的 ・中心極限定理より 観測データが増えるほど ガウス分布による近似 が良くなると期待される
・相対的にデータが多いと 良い近似となる
・実数変数のみにしか適用できない
・ある一点における 局面にのみ基づいてしまう
・全体的特性を捉えられない
・多峰な分布の場合どのモードを選択するか 考慮する必要がある
欠点 利点

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
4.4.1モデルの比較とBIC
データの集合
パラメータ モデル尤度関数 事前確率p(✓i|Mi)p(D|✓i,Mi)
✓iMi
p(D|Mi)
D
p(D) =
Zp(D|✓)p(✓)d✓
モデルエビデンス
=
f(✓) = p(D|✓)p(✓)
係数
Z = f(z0)(2⇡)M/2
|A|1/2…4.135
= Z
lnZ =
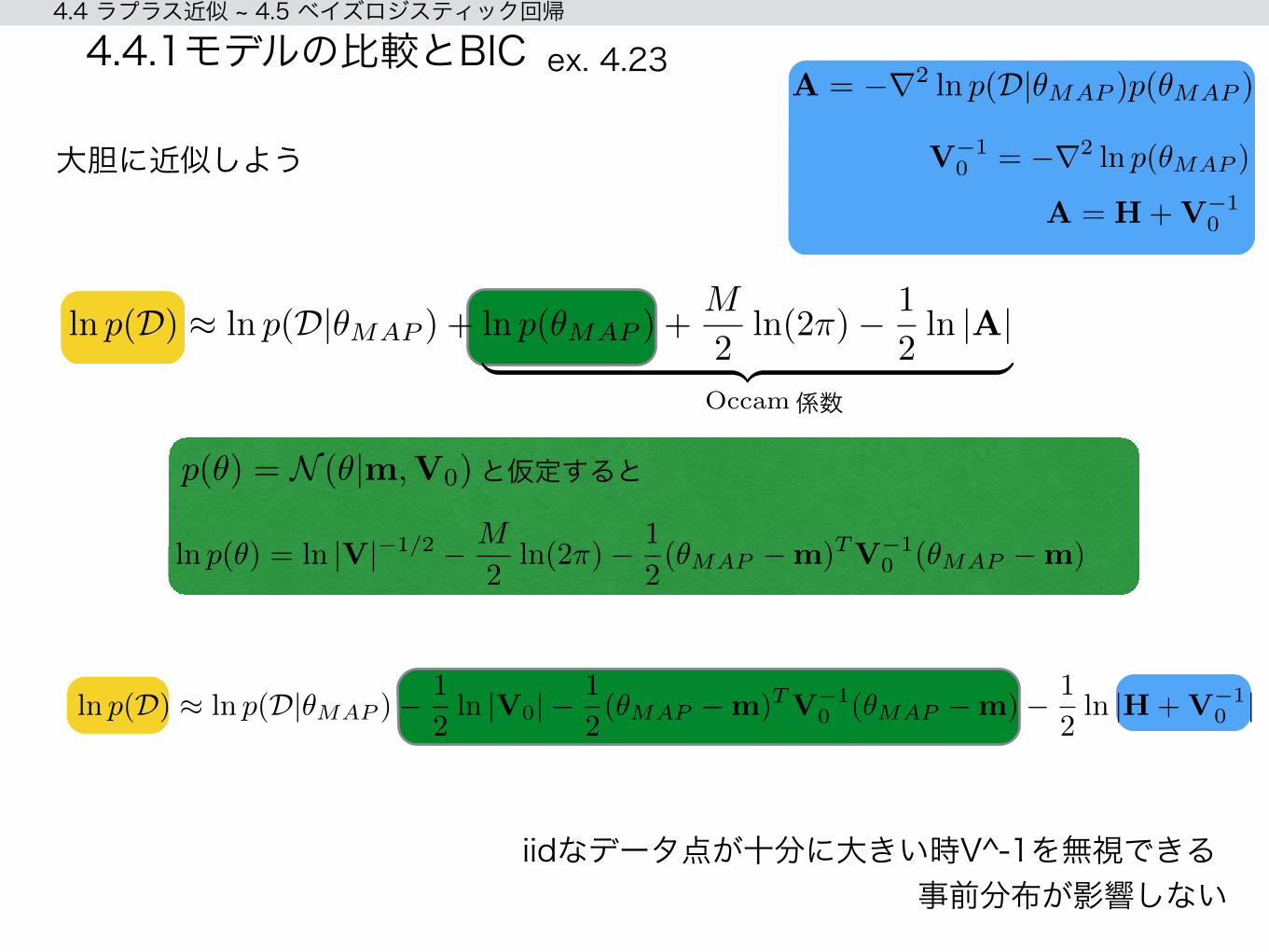
A = �r2 ln p(D|✓MAP )p(✓MAP )
ex. 4.22
ln p(D) ⇡ ln p(D|✓MAP ) + ln p(✓MAP ) +M
2ln(2⇡)� 1
2ln |A|
| {z }Occam
4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
4.4.1モデルの比較とBICA = �r2 ln p(D|✓MAP )p(✓MAP )
と仮定すると
A = H+V�10
ln p(✓) = ln |V|�1/2 � M
2ln(2⇡)� 1
2(✓MAP �m)TV�1
0 (✓MAP �m)
係数
p(✓) = N (✓|m,V0)
ex. 4.23
V�10 = �r2 ln p(✓MAP )
iidなデータ点が十分に大きい時V^-1を無視できる
大胆に近似しよう
事前分布が影響しない
ln p(D) ⇡ ln p(D|✓MAP ) + ln p(✓MAP ) +M
2ln(2⇡)� 1
2ln |A|
| {z }Occam
ln p(D) ⇡ ln p(D|✓MAP )�1
2ln |V0|�
1
2(✓MAP �m)TV�1
0 (✓MAP �m)� 1
2ln |H+V�1
0 |

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
ln |H|の近似に焦点を当てる
H =NX
i=1
Hi Hi = r2 ln p(Di|✓)
H はフルランク行列
ln |H|
ln |H| = ln |NHi| = ln(NM |H|) = M lnN + ln |H|
固定された行列で近似できるとし
を得る
M = dim(✓) であり であると仮定します
すると データ数に対して独立なのでデータ数が増加すれば 無視することができます
従って
と近似できます
H =NX
i=1
Hi = NH
ln p(D) ⇡ ln p(D|✓)� 1
2M lnN

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
4.5 ベイズロジスティック回帰 ~ 4.5.1 ラプラス近似
p(w) = N (w|m0,S0)
対数尤度
likelihood Prior
ln p(w|t) = �1
2(w �m0)
TS�10 (w �m0)
yn = �(wT�n)
+NX
n=1
{tn ln yn + (1� tn) ln(1� yn)}+ const
一般的にm_0=0かな?勾配
ヘッセ行列
r2 ln p(w|t) = �NX
n=1
yn(1� yn)�n�Tn � S�1
0
勾配とヘッセ行列を使って 数値最適化でW_MAPを探索し
ガウス分布の平均とする ガウス分布の分散には
ヘッセ行列に-1をかけたものを用いる
ラプラス近似
p(t|w) =NY
n=1
Bern(yn)
r ln p(w|t) = �NX
n=1
(yn � tn)�n � S�10 (w �m0)

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
4.5.2 予測分布p(t|w) =
NY
n=1
Bern(yn) =NY
n=1
ytnn (1� yn)1�tn
p(w) = N (w|m0,S0)q(w) = N (w|wMAP ,SN )
事後分布(MAP推定)
についての予測分布
a = wT�
=
Z ✓Z�(a�wT�)q(w)dw
◆�(a)da =
Zp(a)�(a)da
デルタ関数の性質Z 1
�1f(x)�(x� µ)dx = f(µ)
C1
ガウス分布
p(C1|�, t) =Z
p(C1|�,w)p(w|t)dw ⇡Z
�(wT�)q(w)dw
p(C1|�, t) ⇡Z ✓Z
�(a�wT�)�(a)q(w)dw
◆da

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
p(a) =
Z�(a�wT�)q(w)dw
=
✓Zq(w)wdw
◆T
� = E[w]T� = wTMAP�
p(a)の平均
=
Z ✓Z�(a�wT�)ada
◆q(w)dw =
Zq(w)(wT�)dw
µa = E[a] =Z
p(a)ada =
Z Z�(a�wT�)q(w)adwda
q(w) = N (w|wMAP ,SN ) 4.5.2 予測分布

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
分散
�2 = var[a] =
Zp(a){a2 � E[a]2}da
=
Z ✓�(a�wT�)a2da
◆q(w)dw �
Z ✓�(a�wT�)E[a]2da
◆q(w)dw
=
Zq(w)(wT�)2dw �
Zq(w)(wT
MAP�)2dw
=
Zq(w)�TwwT�dw �
Zq(w)�TwMAPw
TMAP�dw
= �T
✓Zq(w)(wwT �wMAPw
TMAP )dw
◆�
Zq(w)(wwT �wMAPw
TMAP )dw = E[wwT ]�wMAPw
TMAP
Zq(w)dw
= wMAPwTMAP + SN �wMAPw
TMAP = SN
�2 = �TSN�
p(a) =
Z�(a�wT�)q(w)dw
…2.62E[xxT ] = µµT + ⌃
q(w) = N (w|wMAP ,SN )
4.5.2 予測分布

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
p(C1|t) =Z
�(a)p(a)da =
Z�(a)N (a|µa,�
2a)da
予測分布の変分近似は
a上での積分は、ロジスティックシグモイド関数でのガウス分布の畳み込み積分を 表しており、解析的に評価することはできない。
最も良い近似を得るために によって を近似できるようにする
そのために、原点で2つの関数が同じ傾きを持つことを要請することにより の適切な値を見つけることができ となる
�(�a)�(a)
� �2 = ⇡/8
シグモイド関数をプロビット関数の逆関数で近似しよう

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
Z�(�a)N (a|µ,�2)da = �
✓µ
(��2 + �2)1/2
◆ガウス分布とプロビト関数の逆関数の畳み込み積分は以下のように表せられる
従ってシグモイド関数に対する近似はZ
�(a)N (a|µ,�2)da ⇡ �((�2)µ)
(�2) = (1 + ⇡�2/8)�1/2
p(C1|�, t) = �((�2a)µa)
で与えられ
予測分布は
µa = wTMAP�
�2a = �TSN�
S�1N = S�1
0 +NX
n=1
yn(1� yn)�n�Tn
4.5.2 予測分布

4.4 ラプラス近似 ~ 4.5 ベイズロジスティック回帰
変数変換使って導出 ex.4.24
ex. 4.25
�(a) =
Z a
�1N (✓|0, 1)d✓
�(a) =1
1 + exp(�a)
二つの微分がa=0で等しいように を選ぶ
@�(a)
@a
����a=0
= �(0)(1� �(0) =1
2
✓1� 1
2
◆=
1
4
�(�a) =
Z �a
�1
1
Z
exp(�1
2
x
2)dx
�
0(�a) =
1
Zexp
⇢� 1
2
(�a)2�
Z =
Z 1
�1exp
⇢� 1
2
(�a)2�da
=
� =p⇡/8
�
@�(�a)
@�a
����a=0
=�p2x
N (w|wMAP ,SN ) N (a|wTMAP�,�
TSN�)a = �Tw
d
dx
Zx
a
f(t)dt = f(x)
多分2.115
Appendix