presented by- harsh singh a random walk approach to sampling hidden databases by arjun dasgupta, dr....
TRANSCRIPT

PRESENTED BY- HARSH SINGH
A Random Walk Approach to Sampling Hidden Databases
By Arjun Dasgupta, Dr. Gautam Das and Heikki Mannila

Contents
• Introduction• Problem Definition• Problem Specification• Random Walk Based Sampling• Extensions• Experimentation and Results• Conclusion

Introduction : The Deep Web• A large portion of data available on the web is present
in the so called deep web (or invisible web or hidden web).
• Ex. Dynamic contents, unlinked pages, private web, contextual web, etc.
• Hidden Databases are a major part of the deep web.
• These are usually hidden behind form –like interfaces.
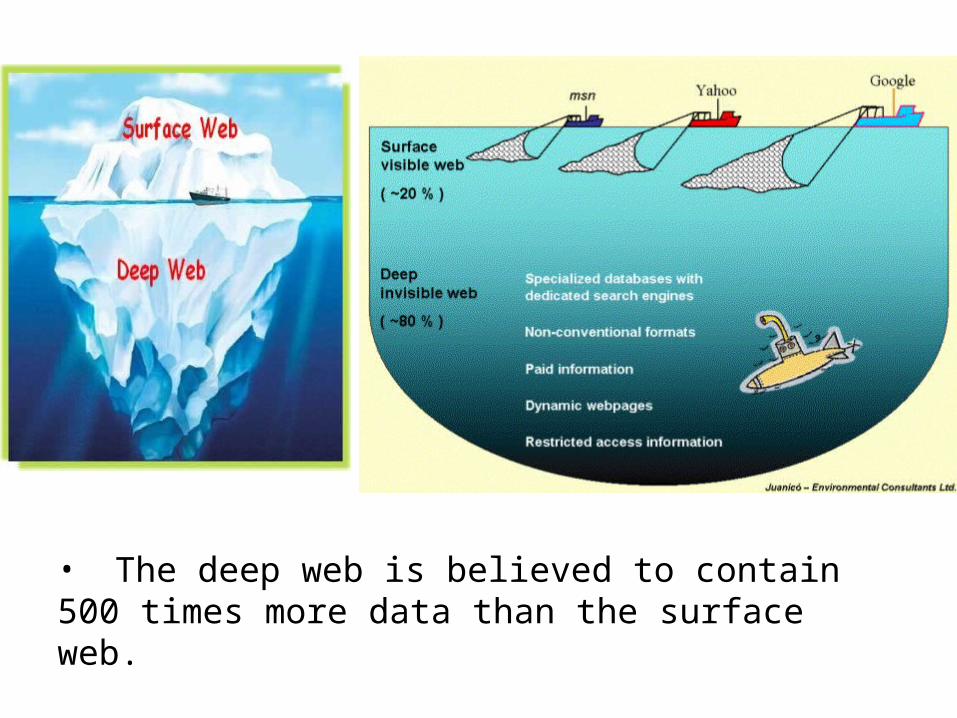
• The deep web is believed to contain 500 times more data than the surface web.
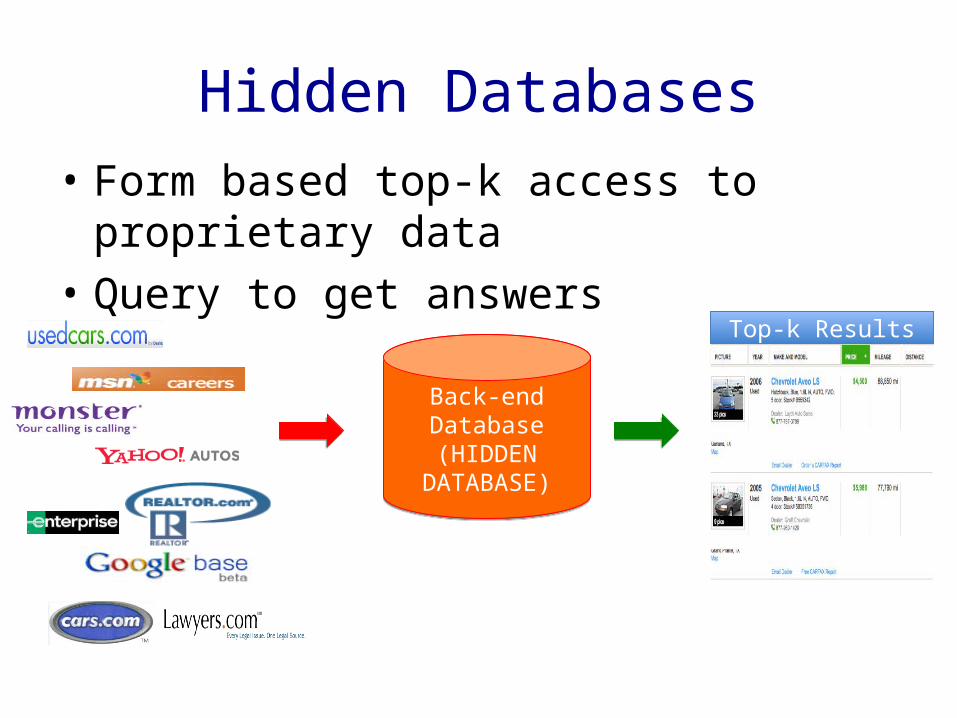
Hidden Databases• Form based top-k access to proprietary data• Query to get answers
Back-end Database(HIDDEN
DATABASE)
Back-end Database(HIDDEN
DATABASE)
Top-k ResultsTop-k Results

Why sample hidden databases?
• To gather statistical information from databases.• Statistics about a third party database can be used to
obtain quality, freshness and size information inside web sources.
• It can be used to identify uniformity or biases of topics.
• To answer questions like- What is the real size of the hidden database? Or Which flight at which date is more likely to be
relatively empty?

Access to Hidden Database
• Top-k restriction• Restriction on query overloads (user profiling)• Access only through front end forms • Access costs.
Access RestrictionsAccess Restrictions

Sampling Hidden Databases Through Public Interfaces
• Problem definition– given such restricted query interfaces, how can
one efficiently obtain a uniform random sample of the backend database by only accessing the database via the public front end interface?

Performance Measures Of Sampling Hidden Databases
• Quality of the Sample– Over- or under-representing a portion of the
population– Objective: minimize sample bias
• Efficiency (query cost)– The number of queries issued to the web interface of
a hidden database– Note: many hidden databases charge for each issued
query or have limits on the number of queries one can issue per day.
– Objective: minimize query cost

ALGORITHM• The algorithm is designed to achieve both goals-it is very
efficient and produces samples with small skew. • It is based on performing random walks over the space
of queries, such that each execution of the algorithm returns a random tuple of the database.
• It is based on 3 main ideas- a)Early termination b)Ordering of attributes c)Parameter to tradeoff skew versus efficiency

PROBLEM SPECIFICATION• We start by defining the simplest problem instance of a
database table D with n tuples {t1, …, tn} over a set of m attributes A = {A1, …, Am}.
• We assume that the attributes are Boolean and later we extend it to attributes that may be categorical or numeric.
• Users query the database by specifying the values of a subset of attributes.
• For ease of exposition, we restrict our attention to the case when the front end interface restricts k = 1 and later extend it to k>1.

Querying mechanism
• Result– Overflow– Underflow– Valid
• Conjunctive queries• Specify value on a field or leave it
empty

BASELINE ALGORITHM: Brute Force Sampler
A1 A2 A3
t1 0 0 1
t2 0 1 0
t3 0 1 1
t4 1 1 0
000 001 010 011 100 101 110 111
t1 t2 t3 t4

BASELINE ALGORITHM: Brute Force Sampler
• Randomly generate a potential tuple and query the database to examine its presence
–Query either underflows, or is valid
– This produces unbiased samples
Problem with Efficiency database size n << the size of space of all possible tuples
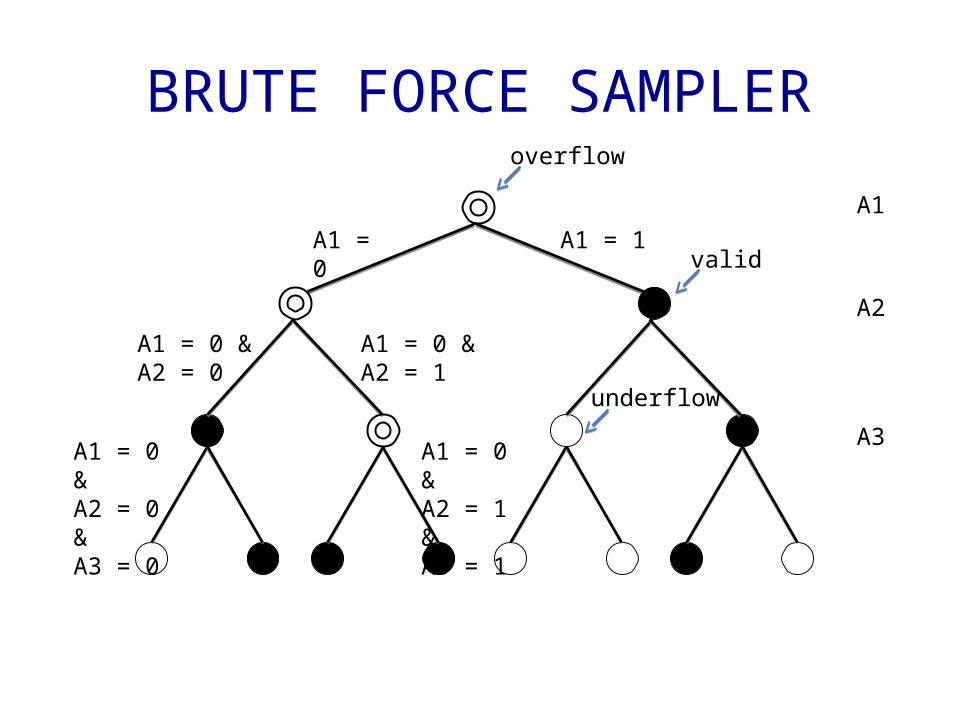
BRUTE FORCE SAMPLER
A1 = 0 &A2 = 0
A1 = 0 A1 = 1A1
A2
A3
A1 = 0 &A2 = 1
A1 = 0 &A2 = 0 &A3 = 0
A1 = 0 &A2 = 1 &A3 = 1
valid
underflow
overflow

Hidden-DB-Sampler
• Improving efficiency: Early Detection of UNDERFLOW and VALID tuples
• Reducing SKEW: Random Ordering of Attributes
• Reducing SKEW: Acceptance/Rejection Sampling

IMPROVING EFFICIENCY: Early Detection
• Random Walks leading to UNDERFLOW can be fairly short
• New Strategy leading to valid tuples
Ask query after choosing one of two branches with equal probability
Ask query after choosing one of two branches with equal probability
Ask QueryAsk Query
Ask QueryAsk Query
Ask QueryAsk Query

Results on IID Data
),()1(),(
1),0(
0),1(
0
piFppi
npnF
pF
pF
inin
i
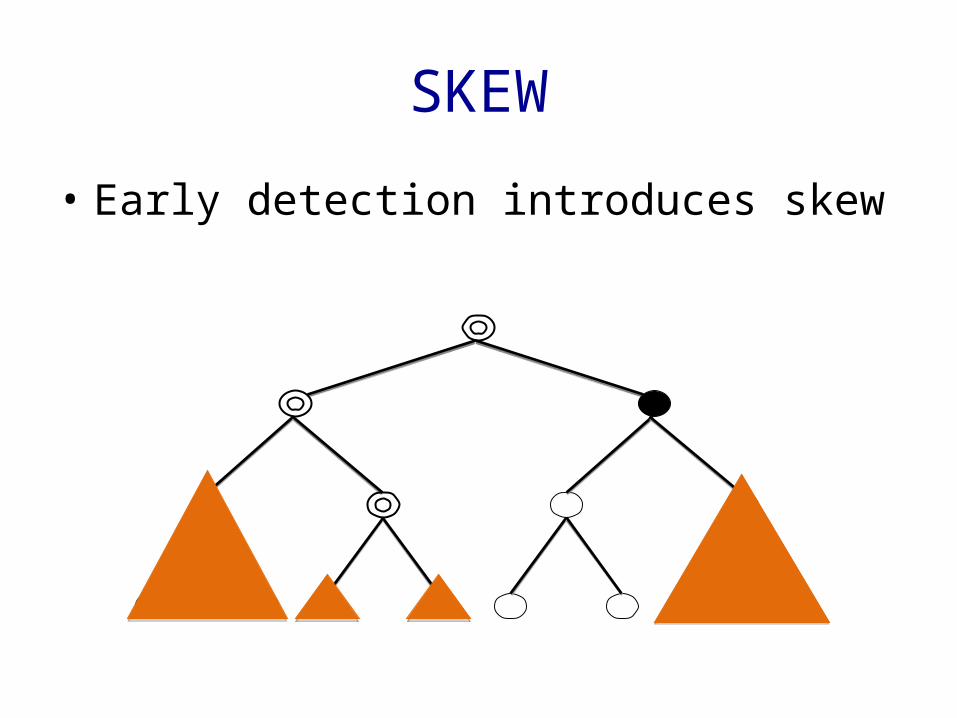
SKEW
• Early detection introduces skew

REDUCING SKEW – Random Ordering of Attributes
Given an i.i.d. Boolean dataset with p=0.5 and a random sampler with random reordering of attributes as well as early termination, the resulting skew = 0
– For a balanced distribution of tuples, a random attribute distribution leads to no skew in the resulting samples
– Random ordering compensates for bad orderings

REDUCING SKEW – Acceptance/Rejection Sampling
• Skew is the result of variance among the access probabilities • To account for skew and to compensate for the deviation in the access
probabilities, Acceptance/Rejection Sampling is introduced
Acceptance Probability
a(t) = 2d(t)/2dmax
dmax: NOT KNOWN
C = Scaling Factor
}1,2min{)( )(tdCta

Algorithm Hidden-DB-SAMPLERAlgorithm HIDDEN-DB-SAMPLER for Boolean databases1. Generate random permutation [A1A2…Am]2. Q = {}3. for i = 1 to m4. xi = random bit 0 or 15. Q = Q AND (Ai = xi)6. Execute Q7. if underflow8. go to 19. else if overflow10. continue11. else { t = Sel(Q) //when k=1, Sel(Q) // has one tuple12. Toss coin with bias min{C*2^i , 1}13. if head return t14. else start again from 1 }

EXTENSIONS: Generalizing for k > 1
• VALID result set is when the interface returns k’ results, where k’<=k
• The algorithm is the same as before, but the random walk terminates either when there is an underflow, or when a valid result set is returned
• Efficiency increases as K increases

EXTENSIONS: Categorical Databases
• One where each attribute Ai can take one of several values from a multi-valued categorical domain .
• In a scenario where there is a large variance in between the number of values of each attribute, a fixed ordering of attributes from the smallest to largest domain produces smaller skew than random ordering
• Inversely, ordering the attributes from largest to smallest domains will be more efficient but will produce larger skew.

EXTENSIONS: Numerical Databases
• Query interfaces reveal the domain of such attributes.
• Users specify numeric ranges they desire.• Each numeric domain can be partitioned into
suitable discrete ranges.• Random sampler treats each discrete range as
a categorical value.

EXTENSIONS: Numerical Databases
• Alternate approach- do not discretize numeric columns in advance.
• Instead, repeatedly keep narrowing the specified range in the query during the random walk.

EXTENSIONS: Interfaces that Return Result Counts
• Some query interfaces return the total count of all tuples that satisfy the query condition, |Sel(Q)|.
• A weighted random walk performed is guaranteed to reach an actual leaf tuple on every attempt.
• At every node u, either the left or right branch with probability n(left(u))/n(u) and n(right(u))/n(u) respectively is selected.
• Selection probability of each tuple is 1/n, thus guaranteeing no skew.

EXTENSIONS: Interfaces that only Allow “Positive” Values
• Some web query interfaces only allow the user to select “positive” Boolean values.
• It is not always possible to collect a uniform random sample from such databases.
• If a tuple t1 “dominates” another tuple t2 and if k=1, then t2 can be permanently hidden from the user.

EXPERIMENTATION AND RESULTS
• We describe our results using the HIDDEN-DB-SAMPLER, and draw conclusions on the quality and performance of our technique.
• Algorithm was run over two major groups of databases – a set of small Boolean datasets with 500 tuples and 15 attributes each(i.i.d data with p=0.5 and 0.3 and also a mixed dataset) and
– large datasets of sizes between 300,000 and 500,000 each(mostly synthetically generated).

Quality of the samplesa)Small databases

b)Large databases

Performance of the Methodsa)Small databases

b)Large databases

CONCLUSION• We initiated an investigation of the problem of
random sampling of hidden databases on the web. • We proposed random walk schemes over the query
space provided by the interface to sample such databases.
• We gave simple methods for the sampling and provided some theoretical analysis of the quantitative impact of the ideas on improving efficiency and quality of the resultant samples.
• We also described a comprehensive set of experiments that demonstrate the effectiveness of our sampling approach.

REFERENCES
• Z. Bar-Yossef and M. Gurevich. Random Sampling from a Search Engine’s Index. In Proceedings of WWW, 2006, 367–376.
• Google's Deep-Web Crawl , VLDB 2008• http://www.deeppeep.org/• K. Bharat and A. Broder. A Technique for Measuring the
Relative Size and Overlap of Public Web Search Engines. In Proceedings of WWW, 1998, 379–388.
• http://www.completeplanet.com/Tutorials/DeepWeb• MSR ppt, Data Analytics over Hidden Databases by Arjun Das
Gupta.