presentation on: “a shortest path dependency kernel for relation...
TRANSCRIPT

PRESENTATION ON:“A SHORTEST PATH DEPENDENCY KERNEL FOR RELATION EXTRACTION”
DEPENDENCY PARSING KERNEL METHODS PAPER
**Taken from CS388 by Raymond J. Mooney University of Texas at Austin
• Hypothesis
• Dependency Parsing - CFG vs CCG
• Kernel
• Evaluation
DEPENDENCY PARSING
DEPENDENCY PARSING KERNEL METHODS PAPER
*Taken from CS388 by Raymond J. Mooney University of Texas at Austin
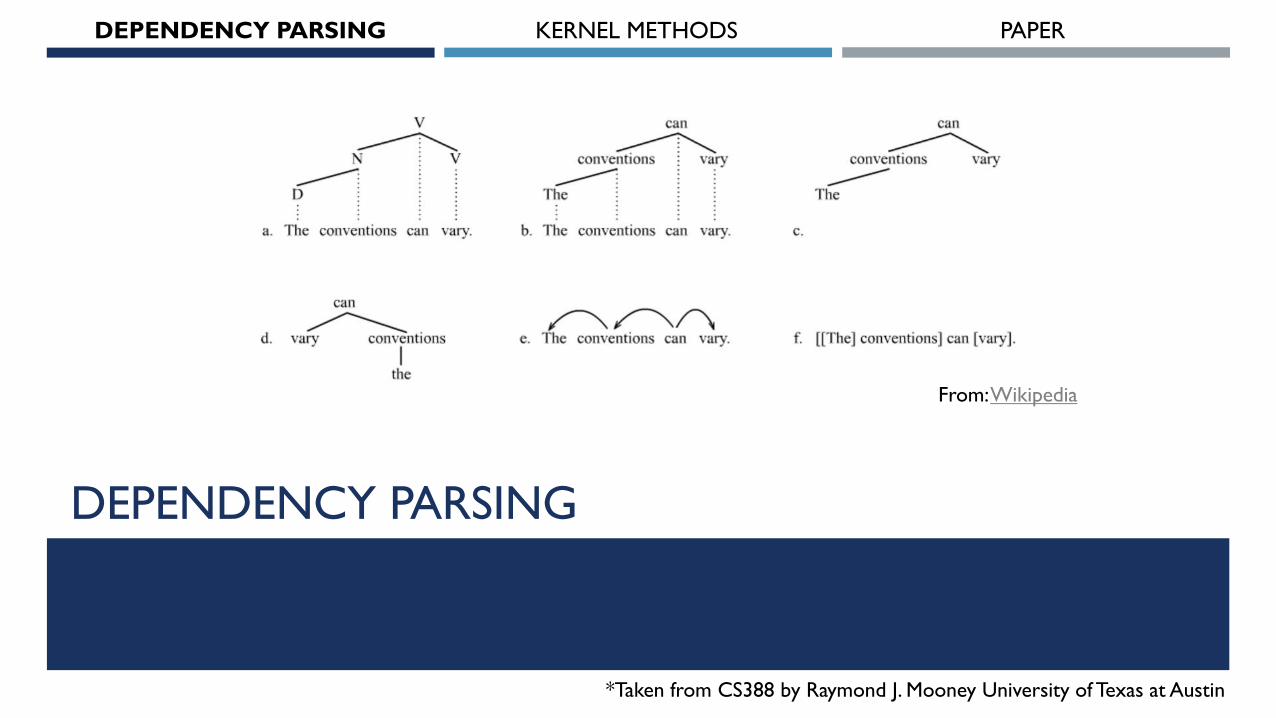
From: Wikipedia

For sentence: John liked the dog in the pen.
S
NP VP
John V NP
liked the dog in the pen
Sliked-VBD
VP
VP PP
DT Nominalliked
IN NP
in
the
dog
NN
DT Nominal
NNthe
pen
NP
John
pen-NN
pen-NN
in-IN
dog-NN
dog-NN
liked-VBDJohn-NNP
NPVBD
liked-VBD
liked
John dog
pen
in
the
the
nsubj dobj
det
det
DEPENDENCY PARSING KERNEL METHODS PAPER
Parse Trees* Typed Dependency Parse Trees*
• Represent structure in sentences using “lexical terms” linked by binary relations called “dependencies”
• Labelled Case v/s unlabeled
• Throw in a ROOT
• Can be generated from parse trees. Can be generated directly (Collins’ NLP course has more)

DEPENDENCY PARSING KERNEL METHODS PAPER
Parse Trees using CFG – with heads and without.• Created using PCFGs – using the CKY algorithm.
• Weights for hand-written rules are obtained through trained.
• Problem is that production used to expand a non-terminal is independent of context – solution? add heads
• Even with heads, it doesn’t really care about semantics.
Sliked-VBD
VP
VP PP
DT Nominalliked
IN NP
in
the
dog
NN
DT Nominal
NNthe
pen
NP
John
pen-NN
pen-NN
in-IN
dog-NN
dog-NN
liked-VBDJohn-NNP
NPVBD
liked-VBD
liked
John dog
pen
in
the
the
nsubj dobj
det
det
Can convert a phrase structure parse to a dependency tree by making the
head of each non-head child of a node depend on the head of the head child.*
Example PCFG rules (no heads) with weights

DEPENDENCY PARSING KERNEL METHODS PAPER
Combinatory Categorial Grammars• Phrase structure grammar, not dependency based
• Can be converted to dependency parse
• Based on application on different types of combinators.
• Combinators act on 𝑎𝑟𝑔𝑢𝑚𝑒𝑛𝑡 and have a 𝑓𝑢𝑛𝑐𝑡𝑜𝑟• Think 𝜆-calculus
• Special syntactic category for relative pronouns + using heads = long range (?)
from Steedman, and wikipedia
Bunescu and Mooney, 2005
Unclear how to go from
phrasal parse to
dependency parse
Gagan: Interesting
Rishab: Better CCG parser
Modern day parser?

KERNEL METHODS
Adapted from:
ACL’04 tutorial
Jean-michel Renders
Xerox research center europe (france)
DEPENDENCY PARSING KERNEL METHODS PAPER
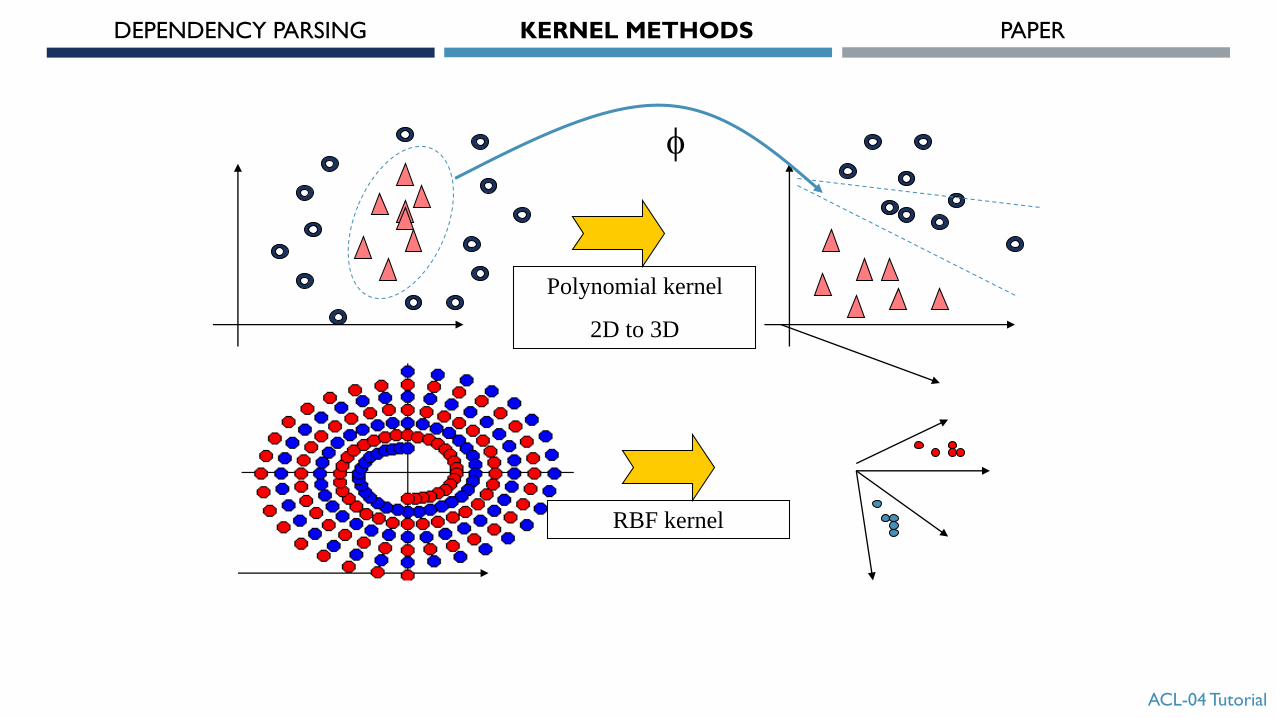
Polynomial kernel
2D to 3D
f
RBF kernel
DEPENDENCY PARSING KERNEL METHODS PAPER
ACL-04 Tutorial

ACL-04 Tutorial
KERNEL METHODS : INTUITIVE IDEA
Find a mapping f such that, in the new space, problem solving is easier
(e.g. linear) … mapping is similar to features.
The kernel represents the similarity between two objects (documents,
terms, …), defined as the dot-product in this new vector space
The mapping is left implicit – Avoid expensive transformation.
Easy generalization of a lot of dot-product (or distance) based algorithms
DEPENDENCY PARSING KERNEL METHODS PAPER

KERNEL : FORMAL
A kernel 𝑘(𝑥, 𝑦) is a similarity measure
defined by an implicit mapping f,
from the original space to a vector space (feature space)
such that: 𝑘(𝑥, 𝑦)=f(𝑥)•f(𝑦)
This similarity measure and the mapping include:
Simpler structure (linear representation of the data)
Possibly infinite dimension (hypothesis space for learning)
… but still computational efficiency when computing 𝑘(𝑥, 𝑦)
Valid Kernel: Any kernel that satisfies Mercer’s theorem
ACL-04 Tutorial
DEPENDENCY PARSING KERNEL METHODS PAPER

KERNELS FOR TEXT
Seen as ‘bag of words’ : dot product or polynomial kernels (multi-words)
Seen as set of concepts : GVSM kernels, Kernel LSI (or Kernel PCA), Kernel ICA, …possibly multilingual
Seen as string of characters: string kernels
Seen as string of terms/concepts: word sequence kernels
Seen as trees (dependency or parsing trees): tree kernels
Seen as the realization of probability distribution (generative model)
DEPENDENCY PARSING KERNEL METHODS PAPER
ACL-04 Tutorial

DEPENDENCY PARSING KERNEL METHODS PAPER
Tree Kernels
• Special case of general kernels defined on discrete structures (graphs).
• Consider the following example:
𝑘 𝜏1, 𝜏2 = #𝑐𝑜𝑚𝑚𝑜𝑛 𝑠𝑢𝑏𝑡𝑟𝑒𝑒𝑠 𝑏𝑒𝑡𝑤𝑒𝑒𝑛 𝜏1, 𝜏2• Feature space is space of all subtrees. (huge)
• Kernel is computed in polynomial time using:
𝑘 𝑇1, 𝑇2 =
𝑛1∈𝑇1
𝑛2∈𝑇2
𝑘𝑐𝑜−𝑟𝑜𝑜𝑡𝑒𝑑(𝑛1, 𝑛2)
𝑘𝑐𝑜−𝑟𝑜𝑜𝑡𝑒𝑑 =
0, 𝑛1𝑜𝑟 𝑛2 𝑖𝑠 𝑎 𝑙𝑒𝑎𝑓 𝑜𝑟 𝑛1 ≠ 𝑛2
𝑖∈𝑐ℎ𝑖𝑙𝑑𝑟𝑒𝑛
1 + 𝑘𝑐𝑜−𝑟𝑜𝑜𝑡𝑒𝑑(𝑐ℎ 𝑛1, 𝑖 , 𝑐ℎ(𝑛2, 𝑖)) , 𝑜𝑤
From ACL tutorial 2004 wikipedia
#common subtrees = 7
Similar ideas used in Culotta and Sorensen, 2004
Shantanu: not intuitive

DEPENDENCY PARSING KERNEL METHODS PAPER
Interesting:
• Remembers training data unlike other methods (regression, GDA)
• Nice theoretical properties
• Dual space
• Most popular kernel method is SVMs
• Kernel trick can lift other linear methods into 𝜙 space – PCA, for
example
Multiclass SVM:Given classes 0,1,2…𝐿
One-vs-all: learn 𝑔𝑖 𝑖𝐿 which are functions on input space, and assign label that
gives maximum 𝑔𝑖 - 𝑂(𝐿) classifiers
One-vs-one: learn 𝑔𝑖𝑗 𝑖,𝑗𝐿,𝐿
, one function for each pair of classes. Assign label
with most “votes”. - 𝑂(𝐿2) classifiers
How does hierarchy help? (think S1 vs S2)
Anshul: Multiclass SVM blows up
for many classes. No finer
relations.

A SHORTEST PATH
DEPENDENCY KERNEL FOR
RELATION EXTRACTION
DEPENDENCY PARSING KERNEL METHODS PAPER
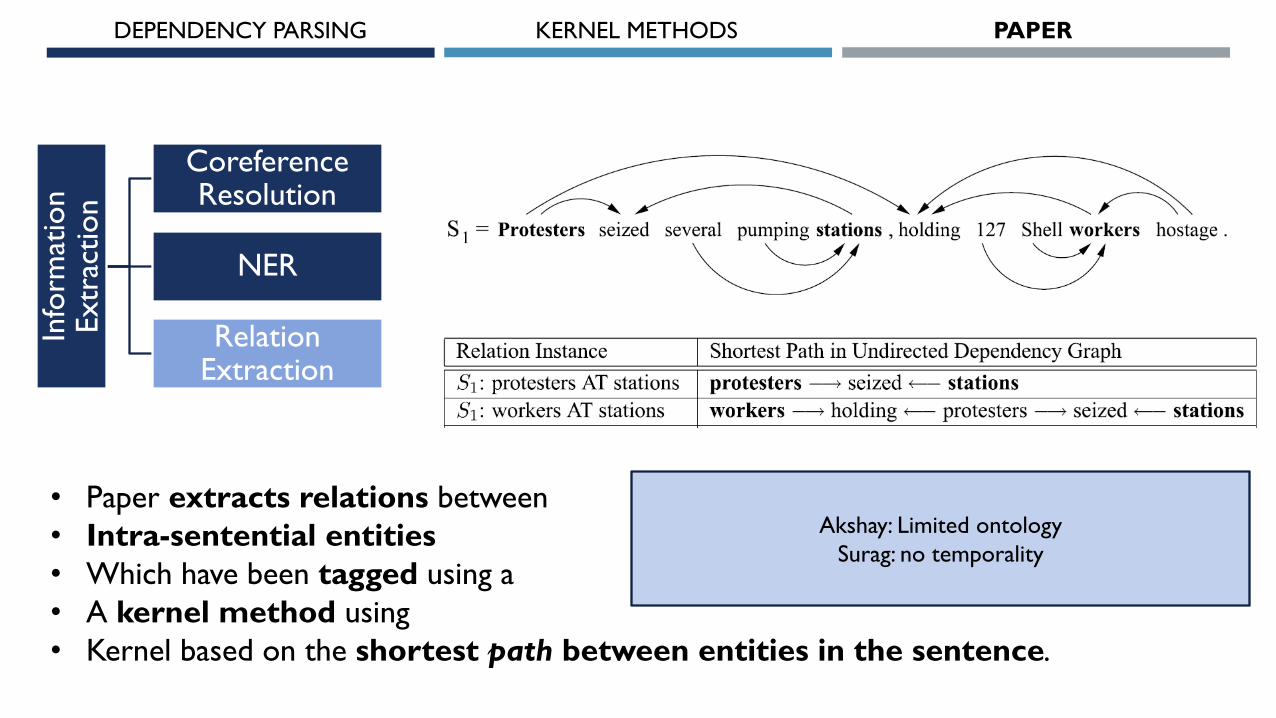
HYPOTHESIS: If 𝑒1 and 𝑒2 are entities in a sentence related by 𝑅, then hypothesize that contribution of sentence
dependency graph to establishing 𝑅(𝑒1, 𝑒2) is almost exclusively concentrated in the shortest path between 𝑒1 and 𝑒2in the undirected dependency graph.
Arindam: over simplified
Nupur: didn’t verify hypothesis
Barun: Useful. No statistical backing
Swarnadeep: More examples/backing for hypothesis
Dhruvin: When does it fail?
Happy: intuition
All figures and tables from Bunescu and Mooney, 2005
Info
rmat
ion
Extr
action
Coreference Resolution
NER
Relation Extraction
DEPENDENCY PARSING KERNEL METHODS PAPER
• Paper extracts relations between
• Intra-sentential entities
• Which have been tagged using a
• A kernel method using
• Kernel based on the shortest path between entities in the sentence.
Akshay: Limited ontology
Surag: no temporality
PoS
Chunking
Shallow Parse Trees
Dependency Trees
DEPENDENCY PARSING KERNEL METHODS PAPER
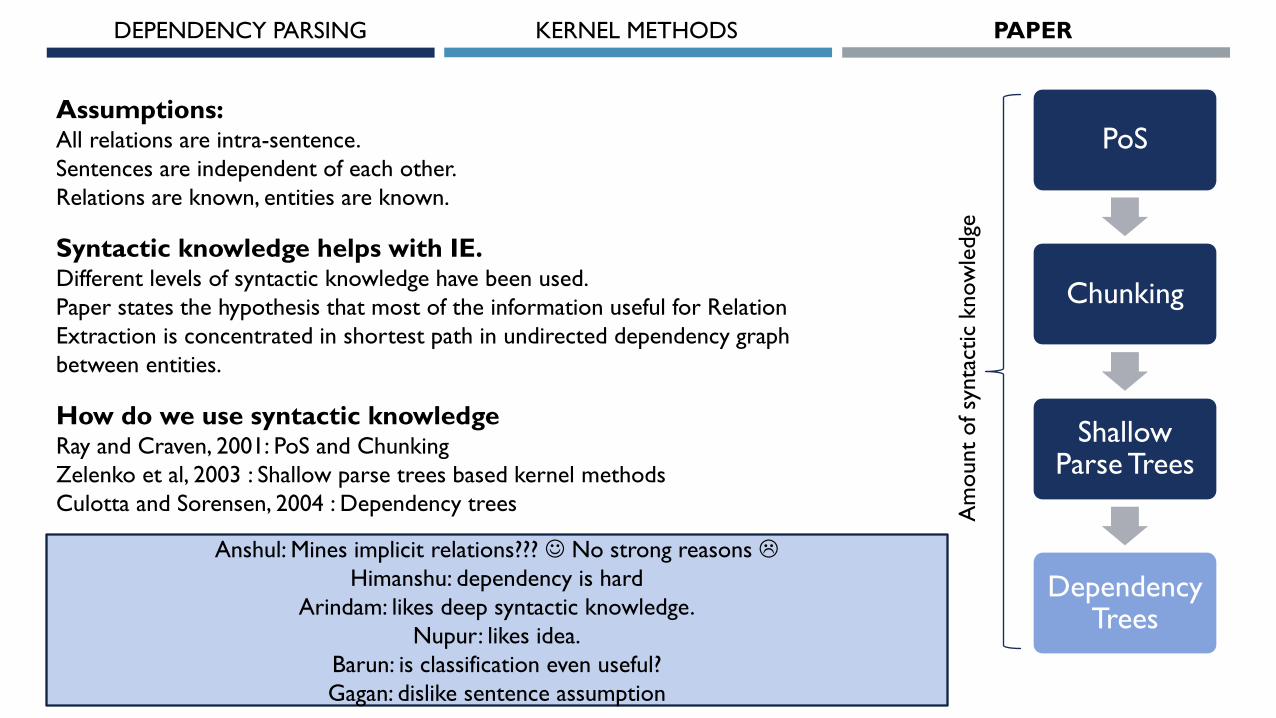
Syntactic knowledge helps with IE.Different levels of syntactic knowledge have been used.
Paper states the hypothesis that most of the information useful for Relation
Extraction is concentrated in shortest path in undirected dependency graph
between entities.
Am
ount
of sy
nta
ctic
know
ledge
Assumptions:All relations are intra-sentence.
Sentences are independent of each other.
Relations are known, entities are known.
How do we use syntactic knowledgeRay and Craven, 2001: PoS and Chunking
Zelenko et al, 2003 : Shallow parse trees based kernel methods
Culotta and Sorensen, 2004 : Dependency trees
Anshul: Mines implicit relations??? No strong reasons
Himanshu: dependency is hard
Arindam: likes deep syntactic knowledge.
Nupur: likes idea.
Barun: is classification even useful?
Gagan: dislike sentence assumption

DEPENDENCY PARSING KERNEL METHODS PAPER
Mathematical! – Before the KernelOriginal Training Data: Articles, with entities and relations
Processed Training data: (𝒙𝑖 , 𝑦𝑖)𝑖=0
𝑁where 𝒙𝑖 is shortest path with types. – Will go through SVM in a bit.
𝑦𝑖 - 5+1 top level relations; 24 fine relation types.
𝑦𝑖 top level = {ROLE, PART, LOCATED, NEAR, SOCIAL}
Handles negation – Attach (-) suffix to words modified by negative determiners.
𝒙𝑖
𝜙(𝒙𝑖)?
Nupur, Gagan: nots!
Anshul: more nots?
Yashoteja: general – add more
features!
Prachi: what happened to 𝑒3?Happy: verb semantics? Use
markov logic?
Anshul: intrasentence context
; no novel relations ;

Mathematical! –The Kernel
DEPENDENCY PARSING KERNEL METHODS PAPER
𝒙, 𝒚 are vectors
Comments:
• Don’t longer paths produce higher kernel score? Yeah, but doesn’t matter because different set of features
entirely… and hence lower SVM weights?
• Normalization of kernel – produces drop in accuracy.
• Empirically set it to 0 for longer chains. (intuitively good?)
SVM:
• S1: One multi-class SVM to do relation detection and relation extraction
• S2: One SVM to do relation detection, another SVM to classify relation after detection
Himanshu, Barun: Other similarity metrics? Semantics?
Rishab: Theoretically SVMs are awesome; efficient ; synonyms?
Nupur,Akshay,…: antonyms, synonyms etc? 0 if m!=n?
Ankit: use redundancy?
… : word2vec too?
Prachi: Words + classes against sparsity ;
Happy: RBF kernel?
Shantanu: It isn’t using feature space fully. Weight it?
Anshul: handle multiple shortest paths
Surag: Lexical and unlexical features. Additional layer of inference?

DEPENDENCY PARSING KERNEL METHODS PAPER
Experiments
ACE Corpus
422 documents + 97 test documents
6k training relation instances + 1.5k test
Dependency Parsers:
• CCG: Long range dependencies. Forms a DAG.
• CFG: Local dependencies. Forms a tree. Used Collins’ parser.
SVMs:
• S1 – normal multiclass SVM
• S2 – To help increase recall
Kernel:
• 0 for paths longer than 10, 0 if unequal lengths.
Comparision:
• S1: Simple multiclass SVM
• S2: Hierarchical SVM
• K4: Sum of BoW kernel and dependency kernel from Culotta and Sorensen, 2004
RECALL: Assuming that independent
sentences and only intra-sentential
relations
Akshay, Ankit: Limited dataset
Rishab: something between CCG and
CFG?; 5 classes ; likes 2 step.
Gagan: CCGs are interesting. Why 10
Ankit: likes hierarchy
Yashoteja: A lot of dot products are 0.
Mess around with optimizer?
DEPENDENCY PARSING KERNEL METHODS PAPER
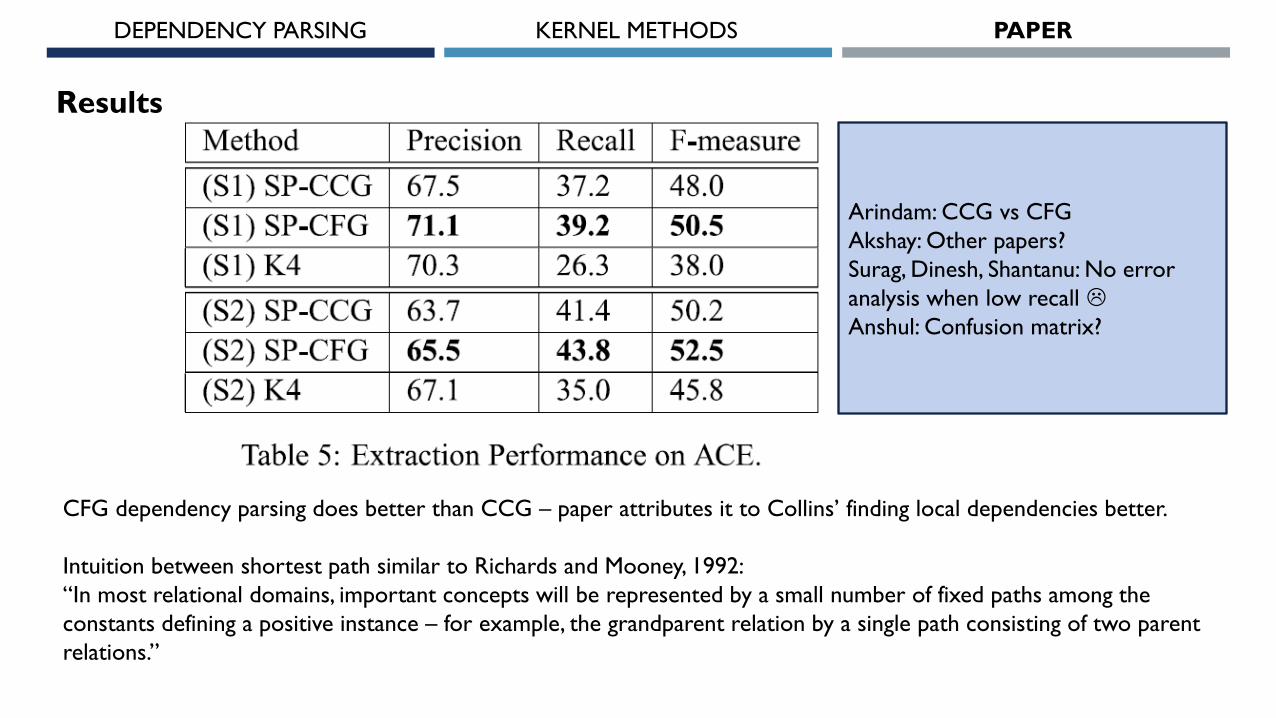
Results
CFG dependency parsing does better than CCG – paper attributes it to Collins’ finding local dependencies better.
Intuition between shortest path similar to Richards and Mooney, 1992:
“In most relational domains, important concepts will be represented by a small number of fixed paths among the
constants defining a positive instance – for example, the grandparent relation by a single path consisting of two parent
relations.”
Arindam: CCG vs CFG
Akshay: Other papers?
Surag, Dinesh, Shantanu: No error
analysis when low recall
Anshul: Confusion matrix?

Extensions:A summary of a lot of people’s comments
• Completeness:What about the finer classes?
• Scale: NELL? OpenIE? Larger datasets? SVM might not work? A lot of features means no large scale?
• System: combine with NER and Coreference? Entity and Relation extraction at the same time?
• Dependency Parser: How does it do today? Better CCG parsers? Deeper semantic parsers?
• Kernel: Convex combination of common kernels? RBF? (How?)
• Data: Unstructured data/twitter [Gagan]
• Setting: Is treating it as classification even a good idea? [Barun]
DEPENDENCY PARSING KERNEL METHODS PAPER