phonetic features in asr
DESCRIPTION
Phonetic features in ASR. Intensive course Dipartimento di Elettrotecnica ed Elettronica Politecnica di Bari 22 – 26 March 1999 Jacques Koreman Institute of Phonetics University of the Saarland P.O. Box 15 11 50 D - 66041 Saarbrücken E-mail : [email protected]. - PowerPoint PPT PresentationTRANSCRIPT

Phonetic features in ASR
Intensive course Dipartimento di Elettrotecnica ed ElettronicaPolitecnica di Bari22 – 26 March 1999
Jacques KoremanInstitute of PhoneticsUniversity of the SaarlandP.O. Box 15 11 50D - 66041 Saarbrücken E-mail: Germany [email protected]

Organisation of the course
• Tuesday – Friday:- First half of each session: theory- Second half of each session: practice
• Interruptions invited!!!

Overview of the course
1. Variability in the signal
2. Phonetic features in ASR
3. Deriving phonetic features from the acoustic signal by a Kohonen network
4. ICSLP’98: “Exploiting transitions and focussing on linguistic properties for ASR”
5. ICSLP’98: “Do phonetic features help to improve consonant identification in ASR?”

The goal of ASR systems
• Input: spectral description of microphone signal, typically- energy in band-pass filters- LPC coefficients- cepstral coefficients
• Output: linguistic units, usually phones or phonemes (on the basis of which words can be recognised)

Variability in the signal (1)
Main problem in ASR: variability in the input signal
Example: /k/ has very different realisations in different contexts. Its place ofarticulation varies from velar before
back vowels to pre-velar before front vowels(own articulation of “keep”,“cool”)

Variability in the signal (2)
Main problem in ASR: variability in the input signal
Example: /g/ in canonical form is sometimes realised as a fricative or approximant ,e.g. intervocalically (OE. regen > E.rain). In Danish, this happens to all intervocalic voiced plosives; also, voiceless plosives become voiced.

Variability in the signal (3)
Main problem in ASR: variability in the input signal
Example: /h/ has very different realisations in different contexts. It can be considered as a voiceless realisation of the surrounding vowels.(spectrograms “ihi”, “aha”, “uhu”)

Variability in the signal (3a)
i: h i: a: a: hh u: u:[]] ][[

Variability in the signal (4)
Main problem in ASR: variability in the input signal
Example: deletion of segments due to articulat-ory overlap. Friction is superimposed on the vowel signal.
(spectrogram G.“System”)
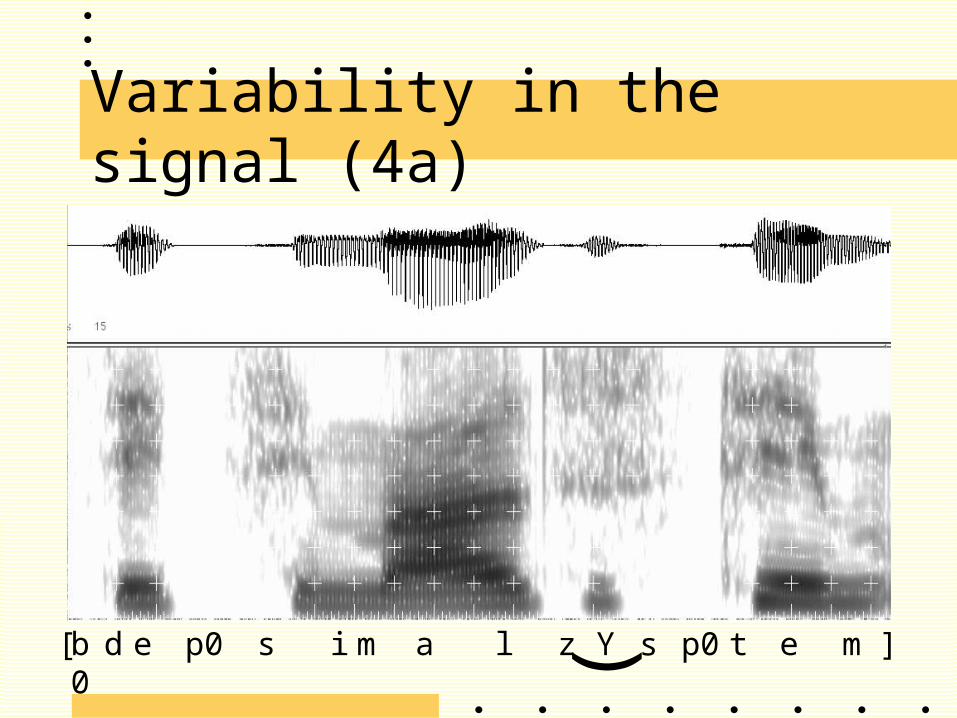
Variability in the signal (4a)
d e p0 s i m a l z Yb0 s p0 t e m[ ](

Variability in the signal (5)
Main problem in ASR: variability in the input signal
Example: the same vowel /a:/ is realised differ-ently dependent on its context.
(spectrogram “aba”, “ada”, “aga”)
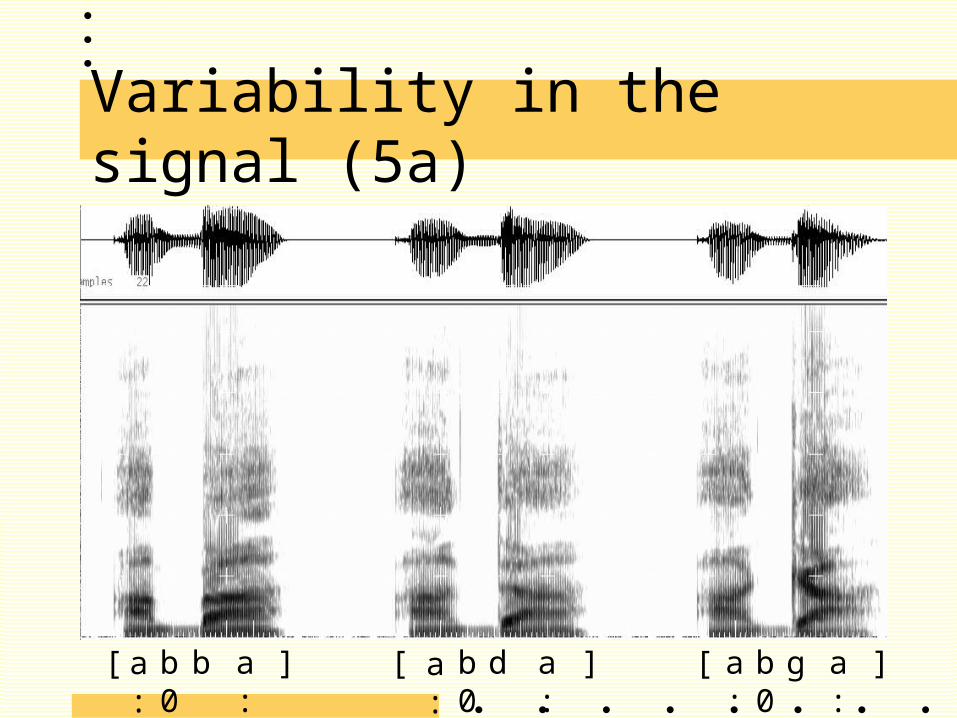
Variability in the signal (5a)
a: a:a:a:a:a:b0 d g[ ] [ [] ]b0 b0b
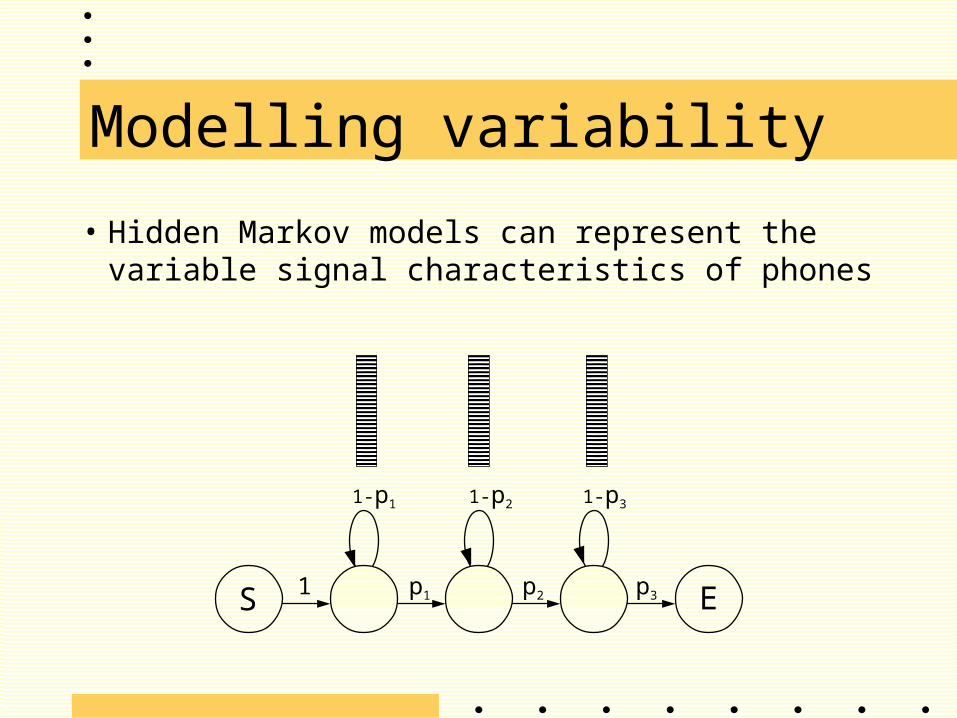
Modelling variability
• Hidden Markov models can represent the variable signal characteristics of phones
S E
1-p3
1 p1 p3p2
1-p21-p1

Lexicon and language model (1)
• Linguistic knowledge about phone sequences (lexicon, language model) improves word recognition
• Without linguistic knowledge, low phone accuracy

Lexicon and language model (2)
Using a lexicon and/or language model is not a top-down solution to all problems: sometimes pragmatic knowledge needed.
Example:
Recognise speech
Wreck a nice beach

Lexicon and language model (3)
Using a lexicon and/or language model is not a top-down solution to all problems: sometimes pragmatic knowledge needed.
Example: []
Get up at eight o’clock
Get a potato clock

CONCLUSIONS• The acoustic parameters (e.g. MFCC) are
very variable.
• We must try to improve phone accuracy by extracting linguistic information.
• Rationale: word recognition rates will increase if phone accuracy improves
• BUT: not all our problems can be solved
Practical:

Phonetic features in ASR
• Assumption: phone accuracy can be improved by deriving phonetic features from the spectral representation of the speech signal
• What are phonetic features?

A phonetic description of sounds• The articulatory organs

A phonetic description of sounds• The articulation of consonants
velum (= soft palate)
tongue

A phonetic description of sounds• The articulation of vowels

Phonetic features: IPA
• IPA (International Phonetic Alphabet) chart- consonants and vowels- only phonemic distinctions
(http://www.arts.gla.ac.uk/IPA/ipa.html)

The IPA chart (consonants)

The IPA chart (other consonants)

The IPA chart (non-pulm. cons.)
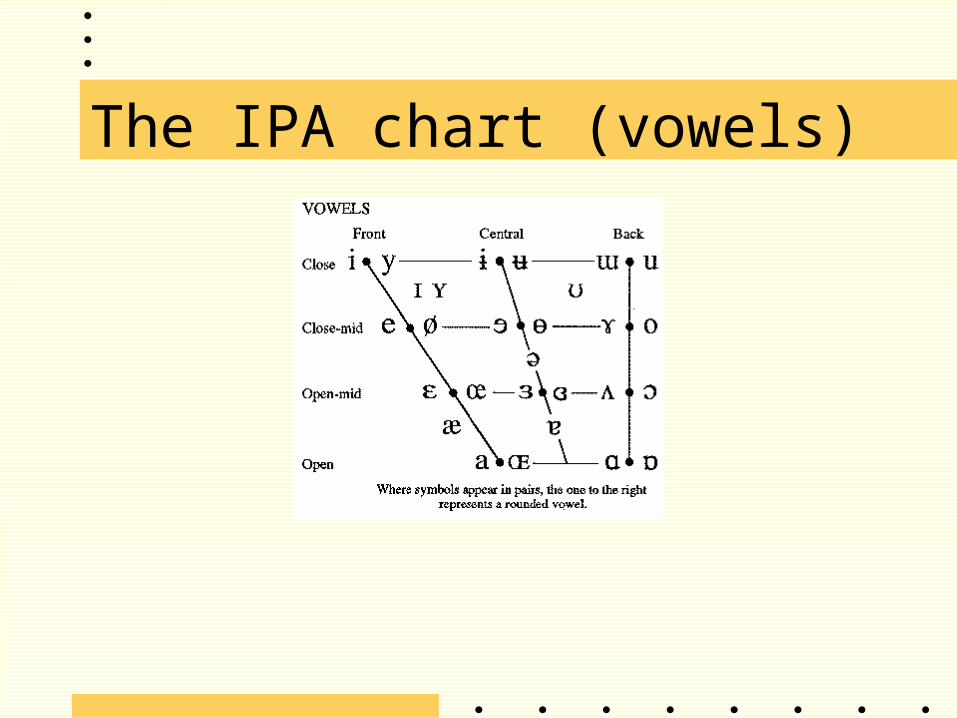
The IPA chart (vowels)

The IPA chart (diacritics)

IPA features (obstruents) l d a p v u g p f n l a t v a e l a e v l l r a a p r o b n v l l u o o i s t r i ip0 0 0 0 0 0 -1 -1 1 0 0 0 0 0 -1b0 0 -1 0 0 0 -1 -1 1 0 0 0 0 0 1p 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1t -1 -1 1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1k -1 -1 -1 -1 1 -1 -1 1 -1 -1 -1 -1 -1 -1b 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1d -1 -1 1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1g -1 -1 -1 -1 1 -1 -1 1 -1 -1 -1 -1 -1 1f 1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1T -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1s -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1S -1 -1 1 1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 C -1 -1 -1 1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 x -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 vfri 1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 1 vapr 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 Dfri -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 1 z -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 1 Z -1 -1 1 1 -1 -1 -1 -1 1 -1 -1 -1 -1 1

IPA features (sonorants) l d a p v u g p f n l a t v a e l a e v l l r a a p r o b n v l l u o o i s t r i im 1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 n -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 J -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 N -1 -1 -1 -1 1 -1 -1 -1 -1 1 -1 -1 -1 1 l -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 1 -1 1 L -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 1 -1 1 rret -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 ralv -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 1 Ruvu -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 1 j -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 w 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 1 -1 1 h -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1... 0 0 0 0 0 0 0 0 0 0 0 0 0 0
A zero value is assigned to all vowel features (not listed here)

IPA features (vowels)
A zero value is assigned to all consonant features (not listed here)
m o f c r m o f c r i p r e o i p r e o d e o n u d e o n u i -1 -1 1 -1 -1 I -1 -1 1 1 -1 y -1 -1 1 -1 1 Y -1 -1 1 1 1 u -1 -1 -1 -1 1 U -1 -1 -1 1 1 e 1 -1 1 -1 -1 2 1 -1 1 -1 1 o 1 -1 -1 -1 1 O 1 1 -1 -1 1 V 1 1 -1 -1 -1 Q -1 1 -1 -1 1 Uschwa 1 -1 -1 1 1 { -1 1 1 -1 -1 a -1 1 1 1 -1 A -1 1 -1 -1 -1 E 1 1 1 -1 -1 9 1 1 1 -1 1 3 1 1 1 1 -1 @ 1 1 -1 1 -1 6 -1 1 -1 1 -1

Phonetic features
• Phonetic features- different systems (JFH, SPE, art. feat.)- distinction between “natural classes” which undergo the same phonological processes

SPE features (obstruents) c s n s l h c b r a c c v l s t n y a o o i e a o n o n o a t e s l s n w g n c u t r t i t r n
p0 1 -1 -1 -1 -1 0 0 0 -1 0 0 -1 -1 -1 -1 1b0 1 -1 -1 -1 -1 0 0 0 -1 0 0 -1 1 -1 -1 -1p 1 -1 -1 -1 -1 -1 0 -1 -1 1 -1 -1 -1 -1 -1 1b 1 -1 -1 -1 -1 -1 0 -1 -1 1 -1 -1 1 -1 -1 -1tden 1 -1 -1 -1 -1 -1 0 -1 -1 1 1 -1 -1 -1 -1 1t 1 -1 -1 -1 -1 -1 0 -1 -1 1 1 -1 -1 -1 -1 1d 1 -1 -1 -1 -1 -1 0 -1 -1 1 1 -1 1 -1 -1 -1k 1 -1 -1 -1 -1 1 0 1 -1 -1 -1 -1 -1 -1 -1 1g 1 -1 -1 -1 -1 1 0 1 -1 -1 -1 -1 1 -1 -1 -1f 1 -1 -1 -1 -1 -1 0 -1 -1 1 -1 1 -1 -1 1 1vfri 1 -1 -1 -1 -1 -1 0 -1 -1 1 -1 1 1 -1 1 -1T 1 -1 -1 -1 -1 -1 0 -1 -1 1 1 1 -1 -1 -1 1Dfri 1 -1 -1 -1 -1 -1 0 -1 -1 1 1 1 1 -1 -1 -1s 1 -1 -1 -1 -1 -1 0 -1 -1 1 1 1 -1 -1 1 1z 1 -1 -1 -1 -1 -1 0 -1 -1 1 1 1 1 -1 1 -1S 1 -1 -1 -1 -1 1 0 -1 -1 -1 1 1 -1 -1 1 1Z 1 -1 -1 -1 -1 1 0 -1 -1 -1 1 1 1 -1 1 -1C 1 -1 -1 -1 -1 1 0 -1 -1 -1 -1 1 -1 -1 1 1x 1 -1 -1 -1 -1 1 0 1 -1 -1 -1 1 -1 -1 1 1

SPE features (sonorants) c s n s l h c b r a c c v l s t n y a o o i e a o n o n o a t e s l s n w g n c u t r t i t r nm 1 -1 1 1 -1 -1 0 -1 -1 1 -1 -1 1 -1 -1 0n 1 -1 1 1 -1 -1 0 -1 -1 1 1 -1 1 -1 -1 0J 1 -1 1 1 -1 1 0 -1 -1 -1 -1 -1 1 -1 -1 0N 1 -1 1 1 -1 1 0 1 -1 -1 -1 -1 1 -1 -1 0l 1 -1 -1 1 -1 -1 0 -1 -1 1 1 1 1 1 -1 0L 1 -1 -1 1 -1 1 0 -1 -1 -1 -1 1 1 1 -1 0ralv 1 -1 -1 1 -1 -1 0 -1 -1 1 1 1 1 -1 -1 0Ruvu 1 -1 -1 1 -1 -1 0 1 -1 -1 -1 1 1 -1 -1 0rret 1 -1 -1 1 -1 -1 0 -1 -1 -1 1 1 1 -1 -1 0j -1 -1 -1 1 -1 1 0 -1 -1 -1 -1 1 1 -1 -1 0vapr -1 -1 -1 1 -1 -1 0 -1 -1 1 -1 1 1 -1 -1 0w -1 -1 -1 1 -1 1 0 1 1 1 -1 1 1 -1 -1 0h -1 -1 -1 1 1 -1 0 -1 -1 -1 -1 1 -1 -1 -1 0XXX 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0

SPE features (vowels) c s n s l h c b r a c c v l s t n y a o o i e a o n o n o a t e s l s n w g n c u t r t i t r ni -1 1 -1 1 -1 1 -1 -1 -1 -1 -1 1 1 -1 -1 1I -1 1 -1 1 -1 1 -1 -1 -1 -1 -1 1 1 -1 -1 -1e -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 1 -1 -1 1E -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 1 -1 -1 -1{ -1 1 -1 1 1 -1 -1 -1 -1 -1 -1 1 1 -1 -1 -1a -1 1 -1 1 1 -1 -1 -1 -1 -1 -1 1 1 -1 -1 1y -1 1 -1 1 -1 1 -1 -1 1 -1 -1 1 1 -1 -1 1Y -1 1 -1 1 -1 1 -1 -1 1 -1 -1 1 1 -1 -1 -12 -1 1 -1 1 -1 -1 -1 -1 1 -1 -1 1 1 -1 -1 19 -1 1 -1 1 -1 -1 -1 -1 1 -1 -1 1 1 -1 -1 -1A -1 1 -1 1 1 -1 -1 1 -1 -1 -1 1 1 -1 -1 -1Q -1 1 -1 1 1 -1 -1 1 1 -1 -1 1 1 -1 -1 -1V -1 1 -1 1 -1 -1 -1 1 -1 -1 -1 1 1 -1 -1 -1O -1 1 -1 1 -1 -1 -1 1 1 -1 -1 1 1 -1 -1 -1o -1 1 -1 1 -1 -1 -1 1 1 -1 -1 1 1 -1 -1 1U -1 1 -1 1 -1 1 -1 1 1 -1 -1 1 1 -1 -1 -1u -1 1 -1 1 -1 1 -1 1 1 -1 -1 1 1 -1 -1 1Uschwa -1 1 -1 1 -1 -1 1 -1 1 -1 -1 1 1 -1 -1 -13 -1 1 -1 1 -1 -1 1 -1 -1 -1 -1 1 1 -1 -1 1@ -1 1 -1 1 -1 -1 1 -1 -1 -1 -1 1 1 -1 -1 -16 -1 1 -1 1 1 -1 1 -1 -1 -1 -1 1 1 -1 -1 -1

CONCLUSION
• Different feature matrices have different implications for relations between phones
Practical:

Kohonen networks
• Kohonen networks are unsupervised neural networks
• Our Kohonen networks take vectors of acoustic parameters (MFCC_E_D) as input and output phonetic feature vectors
• Network size: 50 x 50 neurons

Training the Kohonen network
1. Self-organisation results in a phonotopic map
2. Phone calibration attaches array of phones to each winning neuron
3. Feature calibration replaces array of phones by array of phonetic feature vectors
4. Averaging of phonetic feature vectors for each neuron

Mapping with the Kohonen network
• Acoustic parameter vector belonging to one frame activates neuron
• Weighted average of phonetic feature vector attached to winning neuron and K-nearest neurons is output

Advantages of Kohonen networks
• Reduction of features dimensions possible
• Mapping onto linguistically meaningful dimensions (phonetically less severe confusions)
• Many-to-one mapping allows mapping of different allophones (acoustic variability) onto the same phonetic feature values
• automatic and fast mapping

Disadvantages of Kohonen networks
• They need to be trained on manually segmented and labelled material
• BUT: cross-language training has been shown to be succesful

Hybrid ASR system
hidden Markov modelling
language model
lexicon
phonetic features
phone
Kohonen network
BASELINE
Kohonen network
MFCC’s + energy delta parameters
BASELINE
Kohonen network
phone

CONCLUSION
Practical:
• Acoustic-phonetic mapping extracts linguistically relevant information from the variable input signal.

ICSLP’98Exploiting transitions and focussing on linguistic properties for ASR
Jacques KoremanWilliam J. BarryBistra Andreeva
Institute of Phonetics, University of the SaarlandSaarbrücken, Germany

Variation in the speech signal caused by coarticulat-ion between sounds is one of the main challenges in ASR.
• Exploit variation if you cannot reduce itCoarticulatory variation causes vowel transitions to be acoustically less homogeneous, but at the same time provides information about neighbour-ing sounds whichcan be exploited (experiment 1).
• Reduce variation if you cannot exploit itSome of the variation is not relevant for the phon-emic identity of the sounds. Mapping of acousticparameters onto IPA-based phonetic features like[± plosive] and [± alveolar] extracts only linguist-ically relevant properties before hidden Markov modelling is applied (experiment 2).
INTRODUCTION

INTRODUCTION
The controlled experiments presented here reflect our general aim of using phonetic knowledge to improve the ASR system architecture. In order to evaluate the effect of the changes in bottom-up processing, no lexicon or language model is used. Both improve phone identification in a top-down manner by preventing the identification of inadmissible words (lexical gaps or phonotactic restrictions) or word sequences.
No lexicon or language model

DATA
Hamming window: 15 msstep size: 5 mspre-emphasis: 0.97
English, German, Italian and Dutch texts from the EUROM0 database, read by 2 male + 2 female speakers per language
Texts

DATA
• 12 mel-frequency cepstral coefficients (MFCC’s)• energy• corresponding delta parameters
16 kHz microphone signals
Hamming window: 15 msstep size: 5 mspre-emphasis: 0.97
Signals

DATA
Hamming window: 15 msstep size: 5 mspre-emphasis: 0.97
• Intervocalic consonants labelled with SAMPA symbols, except plosives and affricates, which are divided into closure and frication subphone units
• 35-ms vowel transitions labelled asi_lab, alv_O (experiment 1)V_lab, alv_V (experiment 2)
where lab, alv = cons. generalized across placeV = generalized vowel
Labels

EXPERIMENT 1: SYSTEM
Hamming window: 15 msstep size: 5 mspre-emphasis: 0.97
consonant
hidden Markov modelling
BASE
LIN
E
lexicon
Voffset - C - Vonset
MFCC’s + energy +delta parameters
C
language model
MFCC’s + energy +delta parameters

EXPERIMENT 1: RESULTS
15,8
3
44,7
8
41,9
7
46,7
9
13,1
7 26,5
7
0102030405060708090
100
consonant place manner
no V transitions
V transitions

EXPERIMENT 1: CONCLUSIONSWhen vowel transitions are used:• consonant identification rate improves• place better identified• manner identified worse, because hidden Markov
models for vowel transitions generalize across all consonants sharing the same place of articul-ation (solution: do not pool consonants sharing the same place of articulation)
• vowel transitions can be exploited for identification of the consonant, particularly its place of articulation

EXPERIMENT 2: SYSTEMconsonant
language model
lexicon
phonetic features
hidden Markov modelling
C
Kohonen network
BASELINE
Kohonen network
MFCC’s + energy delta parameters
BASELINE
Kohonen network

EXPERIMENT 2: RESULTS
52,0
0 66,1
2 77,7
0
46,7
9
13,1
7 26,5
7
0102030405060708090
100
consonant place manner
no mapping
mapping

EXPERIMENT 2: CONCLUSIONS
• phonetic features better address linguistically relevant information than acoustic parameters
When acoustic-phonetic mapping is applied:• consonant identification rate improves strongly• place better identified• manner better identified

EXPERIMENT 3: SYSTEMconsonant
language model
lexicon
phonetic features
hidden Markov modelling
Kohonen networkKohonen network
Kohonen network
BASELINE
Voffset - C - VonsetC
MFCC’s + energy delta parameters

EXPERIMENT 3: RESULTS
52,2
3
67,7
1 76,6
7
77,7
0
52,0
0 66,1
2
0102030405060708090
100
consonant place manner
mapping, no V transitions
mapping; V transitions

EXPERIMENT 3: CONCLUSIONS
vowel transitions do not increase identification rate:• because baseline identification rate is already high• vowel transitions are undertrained in the Kohonen networks
When transitions are used for acoustic-phonetic mapping:• consonant identification rate does not improve• place identification improves slightly• manner identification rate decreases slightly

INTERPRETATION (1)• The greatest improvement in consonant identification is
achieved in experiment 2. By mapping acoustically different realisations of consonants onto more similar phonetic features, the input to hidden Markov modelling becomes more homogeneous, leading to a higher consonant identification rate.
• Using vowel transitions also leads to a higher consonant identification rate in experiment 1. It was shown that particularly the consonants’ place is identified better. Findings confirm the importance of transitions as known from perceptual experiments.

INTERPRETATION (2)• The additional use of vowel transitions when acoustic-
phonetic mapping is applied does not improve the identification results. Two possible explanations for this have been suggested:
The latter interpretation is currently being verified by Sibylle Kötzer by applying the methodology to a larger database (TIMIT).
the identification rates are high anyway when mapping is applied, so that it is less likely that large improvements are found
the generalized vowel transitions are undertrained in the Kohonen networks, because the intrinsically variable frames are spread over a larger area in the phonotopic map.

REFERENCES (1)Bitar, N. & Espy-Wilson, C. (1995a). Speech parameterization based on phonetic features: application to speech recognition. Proc. 4th Eurospeech, 1411-1414.
Cassidy, S & Harrington, J. (1995). The place of articulation distinction in voiced oral stops: evidence from burst spectra and formant transitions. Phonetica 52, 263-284.
Delattre, P., Liberman, A. & Cooper, F. (1955). Acoustic loci and transitional cues for consonants. JASA 27(4), 769-773.
Furui, S. (1986). On the role of spectral transitions for speech preception. JASA 80(4), 1016-1025.
Koreman, J., Andreeva, B. & Barry, W.J. (1998). Do phonetic features help to improve consonant identification in ASR? Proc. ICSLP.

REFERENCES (2)Koreman, J., Barry, W.J. & Andreeva, B. (1997). Relational phonetic features for consonant identification in a hybrid ASR system. PHONUS 3, 83-109. Saarbrücken (Germany): Institute of Phonetics, University of the Saarland.
Koreman, J., Erriquez, A. & W.J. Barry (to appear ). On the selective use of acoustic parameters for consonant identification. PHONUS 4. Saarbrücken (Germany): Institute of Phonetics, University of the Saarland.
Stevens, K. & Blumstein, S. (1978). Invariant cues for place of articulation in stop consonants. JASA 64(5), 1358-1368.

SUMMARY
Practical:
• Acoustic-phonetic mapping by a Kohonen network improves consonant identification rates.

ICSLP’98Do phonetic features help to improve consonant identification in ASR?
Jacques KoremanBistra AndreevaWilliam J. Barry
Institute of Phonetics, University of the SaarlandSaarbrücken, Germany

INTRODUCTIONVariation in the acoustic signal is not a problem for human perception, but causes inhomogeneity in the phone models for ASR, leading to poor consonant identification. We should
Bitar & Espy-Wilson do this by using a knowledge-based event-seeking approach for extracting phonetic features from the microphone signal on the basis of acoustic cues.We propose an acoustic-phonetic mapping procedure on the basis of a Kohonen network.
“directly target the linguistic information in the signal and ... minimize other extra-linguistic information that may yield large speech variability”
(Bitar & Espy-Wilson 1995a, p. 1411)

DATA
English, German, Italian and Dutch texts from the EUROM0 database, read by 2 male + 2 female speakers per language
Texts

DATA
• 12 mel-frequency cepstral coefficients (MFCC’s)• energy• corresponding delta parameters
16 kHz microphone signals
Hamming window: 15 msstep size: 5 mspre-emphasis: 0.97
Signals

DATA (1)
Labels
• plosives and afficates are subdivided into a closure (“p0” = voiceless closure; “b0” = voiced closure) and a burst-plus-aspiration (“p”, “t”, “k”) or frication part (“f”, “s”, “S”, “z”, “Z”)
• Italian geminates were pooled with non-geminates to prevent undertraining of geminate consonants
• The Dutch voiced velar fricative [], which only occurs in some dialects, was pooled with its voiceless counterpart to prevent undertraining
The consonants were transcribed with SAMPA symbols, except:

DATA (2)
Labels• SAMPA symbols are phonemic within a language, but can
represent different allophones cross-linguistically. These were relabelled as shown in the table below:
SAMPA allophone label description languagerapralv. approx. Englishralvalveolar trill It., DutchRuvuuvular trill G., Dutchvaprlabiod. approx. Germanvfrivd. labiod. fric. E., It., NLvaprlabiod. approx. Dutchwbilab. approx.Engl., It.

SYSTEM ARCHITECTUREconsonant
language model
lexicon
phonetic features
hidden Markov modelling
C
Kohonen network
BASELINE
Kohonen network
MFCC’s + energy delta parameters
BASELINE
Kohonen network

CONFUSIONS BASELINE
phonetic categories: manner, place, voicing 1 category wrong 2 categories wrong 3 categories wrong
(by Attilio Erriquez)

CONFUSIONS MAPPING
phonetic categories: manner, place, voicing 1 category wrong 2 categories wrong 3 categories wrong
(by Attilio Erriquez)

ACIS =
Baseline system: 31.22 %
Mapping system:
68.47 %
total of all correct identification percentagesnumber of consonants to be identified
The Average Correct Identification Score compensates for the number of occurrences in the database, giving each consonant equal weight.It is the total of all percentage numbers along the diagonal of the confusion matrix divided by the number of consonants.

BASELINE SYSTEM
• good identification of language-specific phones• reason: acoustic homogeneity• poor identification of other phones
% correctcons. baseline mapping language 100.0 75.0 German 100.0 100.0 Italian 100.0 100.0 Italian 97.8 91.3 English 94.1 100.0 Engl., It. 91.2 96.5 English 88.2 93.4 G, NL

MAPPING SYSTEM
• good identification, also of acoustically variable phones• reason: variable acoustic parameters are mapped onto
homogenous, distinctive phonetic features
% correctcons. baseline mapping language 6.7 86.7 E,G, NL 0.0 58.2 all 0.0 44.0 all0.4 36.9 all 5.9 38.3 all 1.4 33.3 alletc.

AFFRICATES (1) % correct cons. baseline mapping language0.0 100.0 German
1.2 64.4 all0.0 72.2German, It.
3.1 64.7 all0.0 40.2E., G., It.
78.1 90.6 all0.0 70.3 Italian
10.4 50.5 all28.0 96.0English, It.
no intervocalic realisations

AFFRICATES (2)
• affricates, although restricted to fewer languages, are recognised poorly in the baseline system
• reason: they are broken up into closure and frication segments, which are trained separately in the Kohonen networks; these segments occur in all languages and are acoustically variable, leading to poor identification
• this is corroborated by the poor identification rates for fricatives in the baseline system (exception: //, which only occurs rarely)
• after mapping, both fricatives and affricates are identified well

APMS =
Baseline system: 1.79
Mapping system:
1.57
The Average Phonetic Misidentification Score gives a measure of the severity of the consonant confusions in terms of phonetic features.The multiple is the sum of all products of the misidentification percentages (in the non-diagonal cells) times the number of misidentified phonetic categories (manner, place and voicing). It is divided by the total of all the percentage numbers in the non-diagonal cells.
phonetic misidentification coefficientsum of the misidentification percentages

APMS =
• after mapping, incorrectly identified consonant is on average closer to the phonetic identity of the consonant which was produced
• reason: the Kohonen network is able to extract linguistically distinctive phonetic features which allow for a better separation of the consonants in hidden Markov modelling.
phonetic misidentification coefficientsum of the misidentification percentages

CONSONANT CONFUSIONS
cons. identified as (84%), (5%), l (4%) (94%), (6%) (63%), (11%), (10%),
(6%) (26%), (21%), (20%),
(6%) (46%), (23%), (15%),
(8%)
cons. identified as (61%), (16%), (13%) (53%), (18%), (12%),
(6%), (6%), (6%) (23%), (18%), (16%),
(13%), (10%) (28%), (18%), (16%),
(12%), (8%), (8%) (42%), (15%), (15%), (8%), (8%), (8%)
BASELINE
MAPPING

CONCLUSIONS
Acoustic-phonetic mapping helps to address linguistically relevant information in the speech signal, ignoring extra-linguistic sources of variation.
The advantages of mapping are reflected in the two measures which we have presented:
• ACIS shows that mapping leads to better consonant identification rates for all except a few of the language-specific consonants. The improvement can be put down to the system’s ability to map acoustically variable consonant realisations to more homogeneous phonetic feature vectors.

CONCLUSIONS
Acoustic-phonetic mapping helps to address linguistically relevant information in the speech signal, ignoring extra-linguistic sources of variation.
The advantages of mapping are reflected in the two measures which we have presented:
• APMS shows that the confusions which occur in the mapping experiment are less severe than in the baseline experiment from a phonetic point of view. There are fewer confusions on the phonetic dimensions manner, place and voicing when mapping is applied, because the system focuses on distinctive information in the acoustic signals.

REFERENCES (1)
Bitar, N. & Espy-Wilson, C. (1995a). Speech parameterization based on phonetic features: application to speech recognition. Proc. 4th European Conference on Speech Communication and Technology, 1411-1414.
Bitar, N. & Espy-Wilson, C. (1995b). A signal representation of speech based on phonetic features. Proc. 5th Annual Dual-Use Techn. and Applications Conf., 310-315.
Kirchhoff, K. (1996). Syllable-level desynchronisation of phonetic features for speech recognition. Proc. ICSLP., 2274-2276.
Dalsgaard, P. (1992). Phoneme label alignment using acoustic-phonetic features and Gaussian probability density functions. Computer Speech and Language 6, 303-329.

REFERENCES (2)
Koreman, J., Barry, W.J. & Andreeva, B. (1997). Relational phonetic features for consonant identification in a hybrid ASR system. PHONUS 3, 83-109. Saarbrücken (Germany): Institute of Phonetics, University of the Saarland.
Koreman, J., Barry, W.J., Andreeva, B. (1998). Exploiting transitions and focussing on linguistic properties for ASR. Proc ICSLP. (these proceedings).

SUMMARY
Acoustic-phonetic mapping leads to fewer and phonetically less severe consonant confusions.
Practical:

THE END