peer-to-peer systems chapter 10 b. ramamurthy. 6/25/2015b.ramamurthypage 2 introduction monolithic...
Post on 21-Dec-2015
219 views
TRANSCRIPT

Peer-To-Peer Systems
Chapter 10B. Ramamurthy

04/18/23B.RamamurthyPage 2
Introduction
• Monolithic application• Simple client-server• Multi-tier client-server• Request-response
– Pull /Push mode– Tightly/loosely coupled
• Centralized/distributed systems• Master-slave systems• Peer-to-peer systems• The concept of overlays

04/18/23B.RamamurthyPage 3
Peer-to-peer systems
• Represents a paradigm for construction of distributed systems and applications in which data and computational resources are contributed by many hosts on the internet.
• Key issues:– Placement of data objects among many hosts– Provision for accessing data that assures
balanced workload and availability– Low overhead

04/18/23B.RamamurthyPage 4
P2P Systems
• Exploit existing naming, routing, data replication, and security techniques to provide reliable resource sharing layer over an unreliable and untrusted collection of computers and networks.
• They are more suitable for immutable data.
• Fully decentralized and self-organizing.• Important issues are placement and
delivery of data.

04/18/23B.RamamurthyPage 5
Three Generations of P2P
• First generation is Napster music exchange server
• Second generation: file sharing with greater scalability, anonymity, and fault tolerance– Freenet, Gnutella, Kazaa, BitTorrent
• Third generation characterized by emergence of middleware for application independence– Pastry, Tapestry, …

04/18/23B.RamamurthyPage 6
IP vs. overlay routing for peer-to-peer applications
IP Application-level routing overlay
Scale IPv4 is limited to 232 addressable nodes. The IPv6 name space is much more generous (2128 ), but addresses in both versions are hierarchically structured and much of the space is pre-allocated according to administrative requirements.
Peer-to-peer systems can address more objects. The GUID name space is very large and flat (>2 128 ), allowing it to be much more fully occupied.
Load balancing Loads on routers are determined by network topology and associated traffic patterns.
Object locations can be randomized and hence traffic patterns are divorced from the network topology.
Network dynamics (addition/deletion of objects/nodes)
IP routing tables are updated asynchronously on a best-efforts basis with time constants on the order of 1 hour.
Routing tables can be updated synchronously or asynchronously with fractions of a second delays.
Fault tolerance Redundancy is designed into the IP network by its managers, ensuring tolerance of a single router or network connectivity failure. n-fold replication is costly.
Routes and object references can be replicated n-fold, ensuring tolerance of n failures of nodes or connections.
Target identification Each IP address maps to exactly one target node.
Messages can be routed to the nearest replica of a target object.
Security and anonymity Addressing is only secure when all nodes are trusted. Anonymity for the owners of addresses is not achievable.
Security can be achieved even in environments with limited trust. A limited degree of anonymity can be provided.

04/18/23B.RamamurthyPage 7
Determine the values for the UTC-based timestamp and clock sequence to be used in the UUID•For the purposes of this algorithm, consider the timestamp to be a 60-bit unsigned integer and the clock sequence to be a 14-bit unsigned integer. Sequentially number the bits in a field, starting with zero for the least significant bit.•Set the time_low field equal to the least significant 32 bits (bits zero through 31) of the timestamp in the same order of significance.•Set the time_mid field equal to bits 32 through 47 from the timestamp in the same order of significance. •Set the 12 least significant bits (bits zero through 11) of the time_hi_and_version field equal to bits 48 through 59 from the timestamp in the same order of significance.•Set the four most significant bits (bits 12 through 15) of the time_hi_and_version field to the 4-bit version number corresponding to the UUID version being created, as shown in the table above.•Set the clock_seq_low field to the eight least significant bits (bits zero through 7) of the clock sequence in the same order of significance.
Curious to know how GUID is generated?

04/18/23B.RamamurthyPage 8
More on GUID
• Are usually secure hash of attributes of the resource: so you don’t expect the state of the resource to change.
• Hash of global clock + resource state + ip address +
http://www.famkruithof.net/uuid/uuidgen• Remember N-fold replication possible,
thus many replications of an object of a given GUID may be present.

04/18/23B.RamamurthyPage 9
Overlay Routing
• It is different than IP routing however is strongly influenced by IP routing.
• Routing tables may be updated synchronously or asynchronously.
• N-fold replication affects the routing.
04/18/23B.RamamurthyPage 10
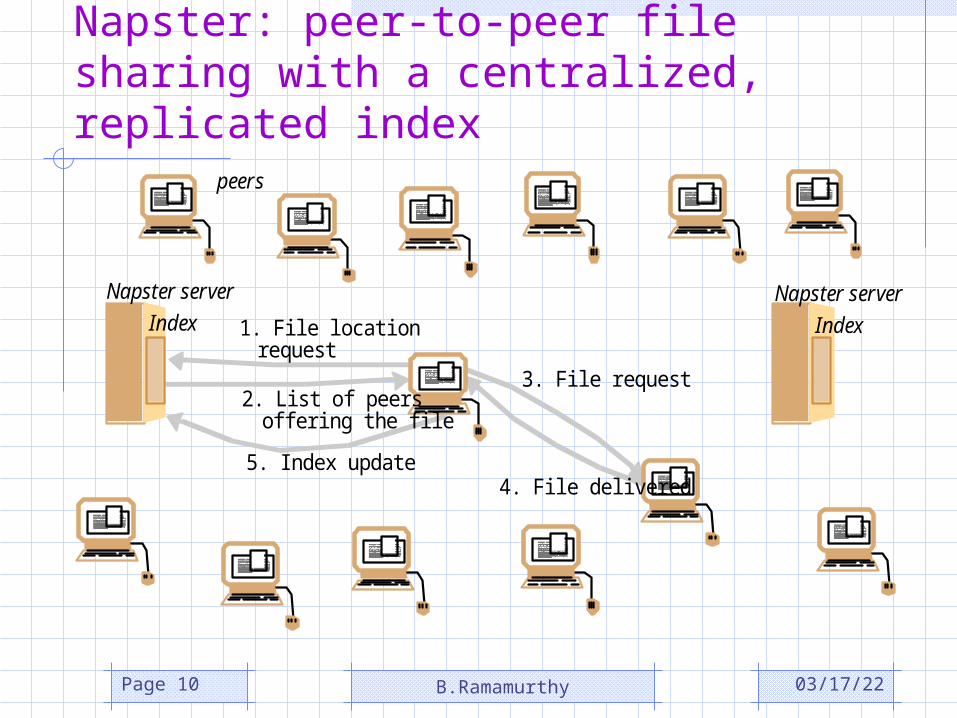
Napster: peer-to-peer file sharing with a centralized, replicated index
Napster serverIndex1. File location
2. List of peers
request
offering the file
peers
3. File request
4. File delivered5. Index update
Napster serverIndex

04/18/23B.RamamurthyPage 11
Napster (contd.)
• Napster demonstrated the feasibility of building a useful large-scale service which depends wholly on individual computers.
• Music files are not updated; state of resource stable
• No guarantees about availability; it fit well for music files

04/18/23B.RamamurthyPage 12
Freenet and Gnutella
• Napster maintained a unified index of available files (resources)
• Gnutella and Freenet used partitioned and distributed indexes and algorithms specific to each system
• “file location” problem: NFS like system requires substantial configuration.

04/18/23B.RamamurthyPage 13
Peer-to-Peer Middleware
• Functional requirements:– Enable clients to locate and communicate
with any individual resource– Add and remove nodes– Add and remove resources– Simple API
• Non-functional requirements: global scalability, load balancing, accommodating to highly dynamic host availability, trust, anonymity, deniability…
• Active research issue: routing overlay

04/18/23B.RamamurthyPage 14
Routing Overlay
• Routing overlay locates nodes and objects. It is middleware layer responsible for routing requests from clients to hosts that holds the object to which request is addressed.
• Main difference is that routing is implemented is in application layer (besides the IP routing at network layer)

04/18/23B.RamamurthyPage 15
Distribution of information in a routing overlay
Object:
Node:
D
C’s routing knowledge
D’s routing knowledgeA’s routing knowledge
B’s routing knowledge
C
A
B

04/18/23B.RamamurthyPage 16
Basic programming interface for a distributed hash table (DHT) as implemented by the PAST API over Pastry
put(GUID, data) The data is stored in replicas at all nodes responsible for the object identified by GUID.remove(GUID)Deletes all references to GUID and the associated data.value = get(GUID)The data associated with GUID is retrieved from one of the nodes responsible it.

04/18/23B.RamamurthyPage 17
Basic programming interface for distributed object location and routing (DOLR) as implemented by Tapestry
publish(GUID ) GUID can be computed from the object (or some part of it, e.g. its name). This function makes the node performing a publish operation the host for the object corresponding to GUID.unpublish(GUID)Makes the object corresponding to GUID inaccessible.sendToObj(msg, GUID, [n])Following the object-oriented paradigm, an invocation message is sent to an object in order to access it. This might be a request to open a TCP connection for data transfer or to return a message containing all or part of the object’s state. The final optional parameter [n], if present, requests the delivery of the same message to n replicas of the object.

04/18/23B.RamamurthyPage 18
Pastry & Tapestry Routing
• Prefix routing based on GUIDs• Narrow search for next node along
the route by applying a binary mask that selects an increasing number of hexadecimal digits from the destination GUID after each hop.

04/18/23B.RamamurthyPage 19
Figure 10.7: First four rows of a Pastry routing table

04/18/23B.RamamurthyPage 20
Figure 10.8: Pastry routing example Based on Rowstron and Druschel [2001]
0 FFFFF....F (2128-1)
65A1FC
D13DA3
D4213F
D462BA
D471F1
D467C4D46A1C
Routing a message from node 65A1FC to D46A1C.With the aid of a well-populated routing table themessage can be delivered in ~ log 16(N ) hops.

Figure 10.9: Pastry’s routing algorithm
• To handle a message M addressed to Node D (where R[p,i] is the element at column i of row p of the routing table):1. If (L-l < D< Ll ) { // the destination is within the leaf set of or is the current
node.
forward M to the element Li of the leaf set with GUID closest to D or current node A. }
2. Else { // use routing table to dispatch M to node with closer GUID 2a. Find p, the length of the longest common prefix of D and A. and i, the
(p+1)th hexadecimal digit of D. 2b. If (R[p,i] ≠ null) forward M to R[p,i] // route it to node with longest
common prefix 2c. Else { // there is no entry in the routing table 3a. Forward M to a node in L or R with common prefix length i, but
GUID that is numerically closer. }}
04/18/23B.RamamurthyPage 21
04/18/23B.RamamurthyPage 22
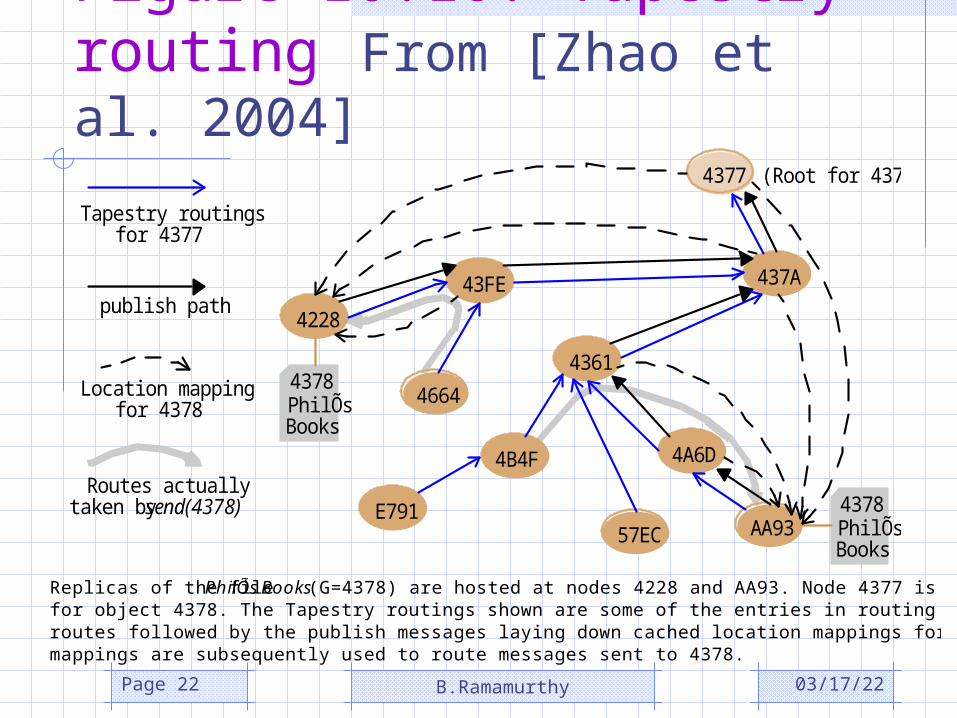
Figure 10.10: Tapestry routing From [Zhao et al. 2004]
4228
4377
437A
4361
43FE
4664
4B4F
E791
4A6D
AA9357EC
4378PhilÕsBooks
4378PhilÕsBooks
(Root for 4378)
publish path
Tapestry routingsfor 4377
Location mappingfor 4378
Routes actually taken by send(4378)
Replicas of the file PhilÕs Books (G=4378) are hosted at nodes 4228 and AA93. Node 4377 is the root nodefor object 4378. The Tapestry routings shown are some of the entries in routing tables. The publish paths showroutes followed by the publish messages laying down cached location mappings for object 4378. The locationmappings are subsequently used to route messages sent to 4378.

Summary• Napster: Central index server: request location, get location, download,
update index (why?); need was for sharing music files (immutable); study Napster vs. copyright ownership legal issues (p.403); index servers are not distributed but replicated. Music files identified by GUID a secure hash code generated out of the features of the file.
• Next generation: Gnutella and Freenet: Distributed index; designed to meet the need for automatic placement and subsequent location of distributed objects; middleware providing API to the services;
• Distributed algorithm called routing overlay takes responsibility of locating nodes and objects;
• Pastry routing algorithm O(log16N): 10.9 and the related explanation.
• Host integration, host failure, locality (/redundancy), fault tolerance, dependability.
• Circular and linear address space. Compare this with IP address space?
04/18/23B.RamamurthyPage 23