part 2: part-based models by rob fergus (mit). problem with bag-of-words all have equal probability...
Post on 19-Dec-2015
220 views
TRANSCRIPT

Part 2: part-based models
by Rob Fergus (MIT)

Problem with bag-of-words
• All have equal probability for bag-of-words methods
• Location information is important

Overview of section
• Representation– Computational complexity– Design choices
• Recognition
• Learning– Automated methods

Representation

Model: Parts and Structure

Representation• Object as set of parts
– Generative representation
• Model:
– Relative locations between parts
– Appearance of part
• Issues:
– How to model location
– How to represent appearance
– Sparse or dense (pixels or regions)
– How to handle occlusion/clutter
Figure from [Fischler73]

Example scheme• Model shape using Gaussian
distribution on location between parts
• Model appearance as pixel templates
• Represent image as collection of regions
– Extracted by template matching: normalized-cross correlation
• Manually trained model– Click on training images

Sparse representation+ Computationally tractable (105 pixels 101 -- 102 parts)
+ Generative representation of class
+ Avoid modeling global variability
+ Success in specific object recognition
- Throw away most image information
- Parts need to be distinctive to separate from other classes

History of Idea
• Fischler & Elschlager 1973
• Yuille ‘91• Brunelli & Poggio ‘93• Lades, v.d. Malsburg et al. ‘93• Cootes, Lanitis, Taylor et al. ‘95• Amit & Geman ‘95, ‘99 • Perona et al. ‘95, ‘96, ’98, ’00• Felzenszwalb & Huttenlocher ’00
• Many papers since 2000

The correspondence problem• Model with P parts• Image with N possible locations for each part
• NP combinations!!!
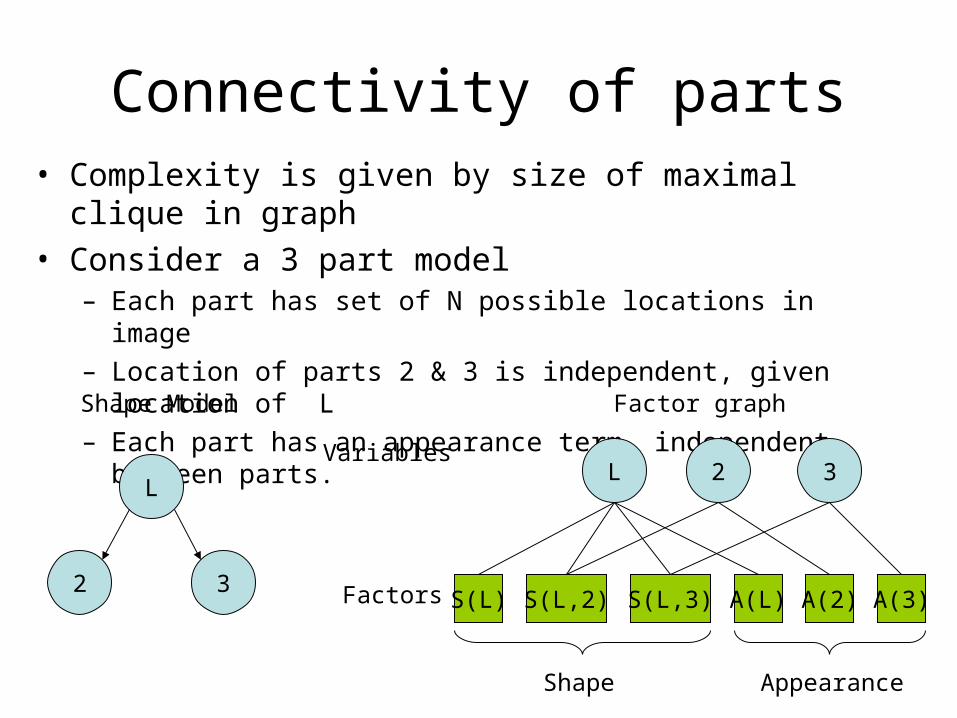
Connectivity of parts• Complexity is given by size of maximal clique in graph• Consider a 3 part model
– Each part has set of N possible locations in image– Location of parts 2 & 3 is independent, given location of L– Each part has an appearance term, independent between parts.
L
32
Shape Model
S(L,2) S(L,3) A(L) A(2) A(3)
L 32Variables
Factors
Shape Appearance
Factor graph
S(L)

Connectivity of parts• To find best match in image, we want most probable
state of L, • Run max-product message passing
Take O(N2) to compute:
For each of the N values of L, need to find max over N states
S(L,2) S(L,3) A(L) A(2) A(3)
L 32
mbmc
md
S(L)
ma

Different graph structures
1
3
4 5
6
2
1
3
4 5
6
2
Fully connected Star structure
1
3
4
5
6
2
Tree structure
O(N6) O(N2) O(N2)
• Sparser graphs cannot capture all interactions between parts

from Sparse Flexible Models of Local FeaturesGustavo Carneiro and David Lowe, ECCV 2006
Different connectivity structures
O(N6) O(N2) O(N3)
O(N2)
Fergus et al. ’03Fei-Fei et al. ‘03
Crandall et al. ‘05Fergus et al. ’05
Crandall et al. ‘05Felzenszwalb & Huttenlocher ‘00
Bouchard & Triggs ‘05 Carneiro & Lowe ‘06Csurka ’04Vasconcelos ‘00

Some class-specific graphs• Articulated motion
– People– Animals
• Special parameterisations– Limb angles
Images from [Kumar05, Felzenszwalb05]

Regions or pixels• # Regions << # Pixels• Regions increase tractability
but lose information• Generally use regions:
– Local maxima of interest operators
– Can give scale/orientation invariance
Figures from [Kadir04]

Hierarchical representations
• Pixels Pixel groupings Parts Object
Images from [Amit98,Bouchard05]
• Multi-scale approach increases number of low-level features
• Amit and Geman ’98• Ullman et al. • Bouchard & Triggs ’05• Zhu and Mumford• Jin & Geman ‘06• Zhu & Yuille ’07• Fidler & Leonardis ‘07

How to model location?
• Explicit: Probability density functions
• Implicit: Voting scheme
• Invariance– Translation– Scaling– Similarity/affine– Viewpoint
Similarity transformationTranslation and ScalingTranslationAffine transformation

• Probability densities– Continuous (Gaussians)– Analogy with springs
• Parameters of model, and – Independence corresponds to zeros in
Explicit shape model

Shape• Shape is “what remains after differences due to translation,
rotation, and scale have been factored out”. [Kendall84]
• Statistical theory of shape [Kendall, Bookstein, Mardia & Dryden]
X
Y
Figure SpaceU
V
Shape Space
N
N
y
yx
x
X
1
13
3
N
N
u
uU
v
v
Figures from [Leung98]

Euclidean & Affine Shape• Translation, rotation and scaling Euclidean Shape
• Removal of camera foreshortenings Affine Shape
• Assume Gaussian density in figure space
• What is the probability density for the shape variables in each of the different spaces?
Feature space
TNN yyxx ],,,,,[ 11
Euclidean shape
TNN vvuu ],,,,,[ 33
Affine shape
TNN vvuu ],,,,,[ 44
Translation Invariant shape
TNN vvuu ],,,,,[ 22
Figures from [Leung98]

Translation-invariant shape• Figure space density:
• Translation-invariant form
• Shape space density is still Gaussian
e.g. P=3, move 1st part to origin

Affine Shape Density• Affine Shape density (Dryden-Mardia):
• Euclidean Shape density is of similar form
}2
{||
||)!3()(
2
},,{
4
1)3(
2/
4,321
ik
kkkk i
kiN
g
i
ieN
p
LC
Uu
[Leung98],[Welling05]• Can learnt parameters of DM density with EM!

Other invariance methods• Search over transformations
– Large space (# pixels x # scales ….)
– Closed form solution for translation and scale (Helmer and Lowe ’04)
• Features give information– Characteristic scale
– Characteristic orientation (noisy)
Figures from Mikolajczyk & Schmid

Implicit shape model
Spatial occurrence distributions
x
y
s
x
y
sx
y
s
x
y
s
Probabilistic Voting
Interest PointsMatched Codebook Entries
Recognition
Learning• Learn appearance codebook
– Cluster over interest points on training images
• Learn spatial distributions– Match codebook to training images– Record matching positions on object– Centroid is given
• Use Hough space voting to find object • Leibe and Schiele ’03,’05

Deformable Template Matching
QueryTemplate
Berg et al. CVPR 2005
• Formulate problem as Integer Quadratic Programming• O(NP) in general• Use approximations that allow P=50 and N=2550 in <2 secs

Multiple views
Component 1
Component 2
• Full 3-D location model• Mixture of 2-D models
– Weber CVPR ‘00
Frontal Profile
0 20 40 60 80 10050
55
60
65
70
75
80
85
90
95
100Orientation Tuning
angle in degrees
% C
orre
ct

Representation of appearance
• Dependencies between parts– Common to assume independence– Need not be – Symmetry
•Needs to handle intra-class variation
–Task is no longer matching of descriptors–Implicit variation (VQ appearance)–Explicit probabilistic model of appearance (e.g. Gaussians in SIFT space or PCA space)

Representation of appearance• Invariance needs to match that of
shape model
• Insensitive to small shifts in translation/scale– Compensate for jitter of features– e.g. SIFT
• Illumination invariance– Normalize out– Condition on illumination of
landmark part

Appearance representation
• Decision trees
Figure from Winn & Shotton, CVPR ‘06
• SIFT
• PCA
[Lepetit and Fua CVPR 2005]

Representation of occlusion
• Explicit– Additional match of each part to missing state
• Implicit– Truncated minimum probability of appearance
Log
prob
abili
ty
Appearance spaceµpart

Representation of background clutter
• Explicit model– Generative model for clutter as well as foreground
object
• Use a sub-window– At correct position,
no clutter is present

Hierarchical representations
• Pixels Pixel groupings Parts Object
Images from [Amit98,Bouchard05]
• Multi-scale approach increases number of low-level features
• Amit and Geman ’98• Ullman et al. • Bouchard & Triggs ’05• Zhu and Mumford• Jin & Geman ‘06• Zhu & Yuille ’07• Fidler & Leonardis ‘07

Felzenszwalb, Mcallester, Ramanan, CVPR 2008
• 2-scale model– Whole object– Parts
• HOG representation +SVM training to obtainrobust part detectors
• Distancetransforms allowexamination of every location in the image

Felzenszwalb, Mcallester, Ramanan, CVPR 2008

Stochastic Grammar of ImagesS.C. Zhu and D. Mumford

A Stochastic Grammar of Images
• Grammar– Hierarchical representation– Embodied in a simple And–Or graph
representation– A probabilistic model for the natural
occurrence frequency of objects and parts as well as their relations
– Includes a series of visual dictionaries and organizes them through graph composition

animal head instantiated by tiger head
animal head instantiated by bear head
e.g. discontinuities, gradient
e.g. linelets, curvelets, T-junctions
e.g. contours, intermediate objects
e.g. animals, trees, rocks
Context and Hierarchy in a Probabilistic Image ModelJin & Geman (2006)
Constructing probabilistic hierarchical image models,
Designed to accommodate arbitrary contextual relationships

A Hierarchical Compositional System for Rapid Object Detection
Long Zhu, Alan L. Yuille, 2007.
Able to learn #parts at each level
• Objects are represented by graphical models
• Hierarchical tree– Root: full object
– Lower-level elements: simpler features
• Passing simple messages up and down the tree

A Hierarchical Compositional System for Rapid Object Detection
Long Zhu, Alan L. Yuille, 2007.
Able to learn #parts at each level

A Hierarchical Compositional System for Rapid Object Detection
Long Zhu, Alan L. Yuille, 2007.

Learning a Compositional Hierarchy of Object Structure
Fidler & Leonardis, CVPR’07; Fidler, Boben & Leonardis, CVPR 2008Fidler & Leonardis, CVPR’07; Fidler, Boben & Leonardis, CVPR 2008
The architecture
Parts model
Learned parts

Learning Hierarchical CompositionalRepresentations of Object Structure
• Hierarchical compositionality, statistical, bottom-up learning.
• The nodes are formed as compositions that, recursively, model loose spatial relationships between their constituent components.
Oriented Edge
Contour compositions
Fidler & Leonardis, CVPR’07; Fidler, Boben & Leonardis, CVPR 2008Fidler & Leonardis, CVPR’07; Fidler, Boben & Leonardis, CVPR 2008

Learning Hierarchical CompositionalRepresentations of Object Structure
Fidler & Leonardis, CVPR’07; Fidler, Boben & Leonardis, CVPR 2008Fidler & Leonardis, CVPR’07; Fidler, Boben & Leonardis, CVPR 2008

Learning Hierarchical CompositionalRepresentations of Object Structure
• Cross-layered compositional representation learned from the visual data.
• The category-specific layers can make use of all the necessary features stemming from all hierarchical layers
Fidler & Leonardis, CVPR’07; Fidler, Boben & Leonardis, CVPR 2008Fidler & Leonardis, CVPR’07; Fidler, Boben & Leonardis, CVPR 2008

Repeatability of parts by using calculated similarity
’Circle’ part detections across different layers
Fidler & Leonardis, CVPR’07; Fidler, Boben & Leonardis, CVPR 2008Fidler & Leonardis, CVPR’07; Fidler, Boben & Leonardis, CVPR 2008

Recognition

What task?
• Classification– Object present/absent– Sum over all matches (Bayesian)– Take best
• Detection– Localize object within the frame– Slide sub-window across image– Use features to define a basis

Efficient search methods• Interpretation tree (Grimson ’87)
– Condition on assigned parts to give search regions for remaining ones
– Branch & bound, A*

Distance transforms
• Distance transforms– O(N2P) O(NP) for tree structured models
• How it works– Assume location model is Gaussian (i.e. e-d2 )– Consider a two part model with µ=0, σ=1 on a 1-D image
f(d) = -d2
Appearance log probability at xi for part 2 = A2(xi)
xi
Image pixel
Log
prob
abili
ty
L
2
Model
• Felzenszwalb and Huttenlocher ’00 & ’05

Distance transforms 2• For each position of landmark part, find best position for part 2
– Finding most probable xi is equivalent finding maximum over set of offset parabolas
– Upper envelope computed in O(N) rather than obvious O(N2) via distance transform (see Felzenszwalb and Huttenlocher ’05).
• Add AL(x) to upper envelope (offset by µ) to get overall probability map
xixg xj xlxh
A2(xi)
A2(xl)
A2(xj)A2(xg)
A2(xh)A2(xk)
xk
Log
prob
abili
ty
Image pixel

Demo: efficient methods

How much does shape help?• Crandall, Felzenszwalb, Huttenlocher CVPR’05 (CODE)• Shape variance increases with increasing model complexity• Do get some benefit from shape
http://www.cs.cornell.edu/~dph/papers/kfans.pdf

Learning

Learning situations
• Varying levels of supervision– Unsupervised– Image labels– Object centroid/bounding box– Segmented object– Manual correspondence
(typically sub-optimal)
• Generative models naturally incorporate labelling information (or lack of it)
• Discriminative schemes require labels for all data points
Contains a motorbike


• Task: Estimation of model parameters
Learning using EM
• Let the assignments be a hidden variable and use EM algorithm to learn them and the model parameters
• Chicken and Egg type problem, since we initially know neither:
- Model parameters
- Assignment of regions to parts

Learning procedure
E-step: Compute assignments for which regions belong to which part
M-step: Update model parameters
• Find regions & their location & appearance
• Initialize model parameters
• Use EM and iterate to convergence:
• Trying to maximize likelihood – consistency in shape & appearance

Example scheme, using EM for maximum likelihood learning
...
Image 1 Image 2 Image i
2. Assign probabilities to constellations
Large P
Small P
1. Current estimate of
3. Use probabilities as weights to re-estimate parameters. Example:
Large P x + Small P x
new estimate of
+ … =

Priors• Implicit
– Structure of dependencies in model– Parameterisation of model– Feature detectors
• Explicit– p()– MAP / Bayesian learning– Fei-Fei ‘03
model () space
1
2n
p( n
)
p(2 )
p(1 )
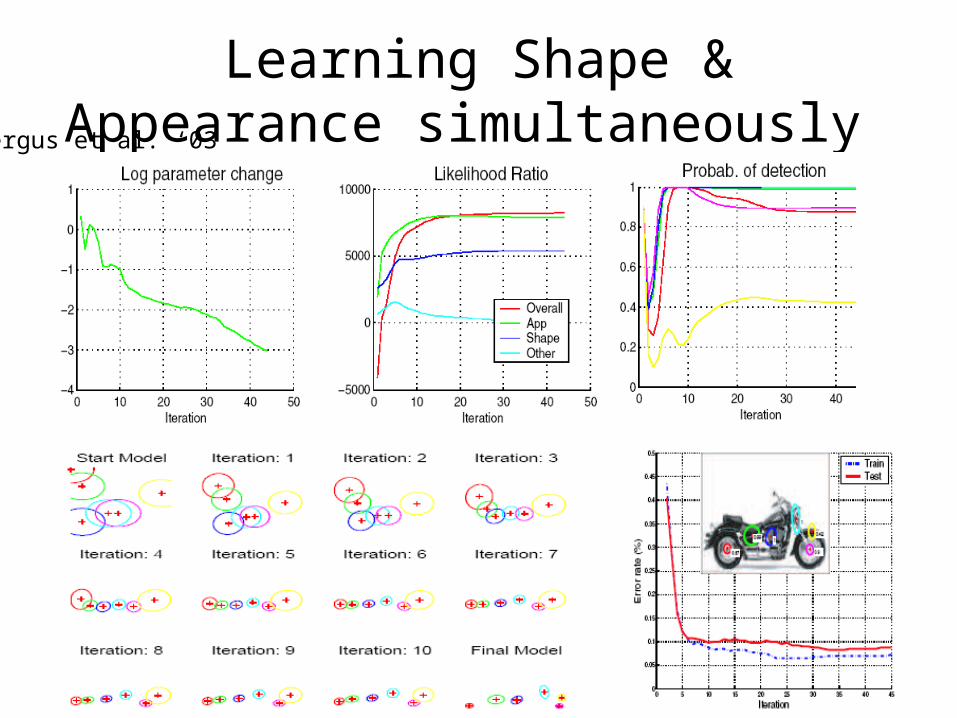
Learning Shape & Appearance simultaneously Fergus et al. ‘03

Learn appearance then shape
ParameterEstimation
Choice 1
Model 1
Choice 2ParameterEstimation
Model 2
Predict / measure model performance(validation set or directly from model)
Preselected Parts (100)
Weber et al. ‘00

Discriminative training• Sparse so parts need to be distinctive of class
• Boosted parts and structure models– Amores et al. CVPR 2005– Bar Hillel et al. CVPR 2005
• Discriminative features– Weber et al. 2000– Ullman et al.
• Train discriminatively on parameters of generative model– Holub, Welling,
Perona ICCV 2005

Number of training images
• More supervision, fewer images needed– Few unknown parameters
• Less supervision, more images.– Lots of unknown parameters
• Over-fitting problems

Number of training examples
Priors
6 part Motorbike model

Parts and Structure modelsSummary
• Hierarchical models allow for more parts • Correspondence problem between image and model• Efficient methods for large # parts and # positions in image• Challenge to get representation with desired invariance • Minimal supervision
Future directions:• Multiple views• Approaches to learning • Multiple category training

References
2. Parts and Structure

[Agarwal02] S. Agarwal and D. Roth. Learning a sparse representation for object detection. In Proceedingsof the 7th European Conference on Computer Vision, Copenhagen, Denmark,pages 113-130, 2002.[Agarwal_Dataset] Agarwal, S. and Awan, A. and Roth, D. UIUC Car dataset. http://l2r.cs.uiuc.edu/~cogcomp/Data/Car, 2002.[Amit98] Y. Amit and D. Geman. A computational model for visual selection. Neural Computation,11(7):1691-1715, 1998.[Amit97] Y. Amit, D. Geman, and K. Wilder. Joint induction of shape features and tree classi-ers. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(11):1300-1305,1997.[Amores05] J. Amores, N. Sebe, and P. Radeva. Fast spatial pattern discovery integrating boostingwith constellations of contextual discriptors. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, San Diego, volume 2, pages 769-774, 2005.[Bar-Hillel05] A. Bar-Hillel, T. Hertz, and D. Weinshall. Object class recognition by boosting a part based model. In Proceedings of the IEEE Conference on Computer Vision and PatternRecognition, San Diego, volume 1, pages 702-709, 2005.[Barnard03] K. Barnard, P. Duygulu, N. de Freitas, D. Forsyth, D. Blei, and M. Jordan. Matchingwords and pictures. JMLR, 3:1107-1135, February 2003.[Berg05] A. Berg, T. Berg, and J. Malik. Shape matching and object recognition using low distortioncorrespondence. In Proceedings of the IEEE Conference on Computer Vision andPattern Recognition, San Diego, CA, volume 1, pages 26-33, June 2005.[Biederman87] I. Biederman. Recognition-by-components: A theory of human image understanding.Psychological Review, 94:115-147, 1987.[Biederman95] I. Biederman. An Invitation to Cognitive Science, Vol. 2: Visual Cognition, volume 2,chapter Visual Object Recognition, pages 121-165. MIT Press, 1995.

[Blei03] D. Blei, A. Ng, and M. Jordan. Latent Dirichlet allocation. Journal of Machine LearningResearch, 3:993-1022, January 2003.[Borenstein02] E. Borenstein. and S. Ullman. Class-specic, top-down segmentation. In Proceedings ofthe 7th European Conference on Computer Vision, Copenhagen, Denmark, pages 109-124,2002.[Burl96] M. Burl and P. Perona. Recognition of planar object classes. In Proc. Computer Visionand Pattern Recognition, pages 223-230, 1996.[Burl96a] M. Burl, M. Weber, and P. Perona. A probabilistic approach to object recognition usinglocal photometry and global geometry. In Proc. European Conference on Computer Vision,pages 628-641, 1996.[Burl98] M. Burl, M. Weber, and P. Perona. A probabilistic approach to object recognition usinglocal photometry and global geometry. In Proceedings of the European Conference onComputer Vision, pages 628-641, 1998.[Burl95] M.C. Burl, T.K. Leung, and P. Perona. Face localization via shape statistics. In Int.Workshop on Automatic Face and Gesture Recognition, 1995.[Canny86] J. F. Canny. A computational approach to edge detection. IEEE Transactions on PatternAnalysis and Machine Intelligence, 8(6):679-698, 1986.[Crandall05] D. Crandall, P. Felzenszwalb, and D. Huttenlocher. Spatial priors for part-based recognitionusing statistical models. In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition, San Diego, volume 1, pages 10-17, 2005. [Csurka04] G. Csurka, C. Bray, C. Dance, and L. Fan. Visual categorization with bags of keypoints.In Workshop on Statistical Learning in Computer Vision, ECCV, pages 1-22, 2004.[Dalal05] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition, San Diego,CA, pages 886--893, 2005.[Dempster76] A. Dempster, N. Laird, and D. Rubin. Maximum likelihood from incomplete data via theEM algorithm. JRSS B, 39:1-38, 1976.[Dorko04] G. Dorko and C. Schmid. Object class recognition using discriminative local features.IEEE Transactions on Pattern Analysis and Machine Intelligence, Review(Submitted), 2004.

[FeiFei03] L. Fei-Fei, R. Fergus, and P. Perona. A Bayesian approach to unsupervised one-shot learningof object categories. In Proceedings of the 9th International Conference on ComputerVision, Nice, France, pages 1134-1141, October 2003.[FeiFei04] L. Fei-Fei, R. Fergus, and P. Perona. Learning generative visual models from few trainingexamples: an incremental bayesian approach tested on 101 object categories. In Workshopon Generative-Model Based Vision, 2004.[FeiFei05] L. Fei-Fei and P. Perona. A Bayesian hierarchical model for learning natural scene categories.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,San Diego, CA, volume 2, pages 524-531, June 2005.[Felzenszwalb00] P. Felzenszwalb and D. Huttenlocher. Pictorial structures for object recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages2066-2073, 2000.[Felzenszwalb05] P. Felzenszwalb and D. Huttenlocher. Pictorial structures for object recognition. InternationalJournal of Computer Vision, 61:55-79, January 2005.[Fergus_Datasets] R. Fergus and P. Perona. Caltech Object Category datasets. http://www.vision.caltech.edu/html-files/archive.html, 2003.[Fergus03] R. Fergus, P. Perona, and P. Zisserman. Object class recognition by unsupervised scaleinvariantlearning. In Proceedings of the IEEE Conference on Computer Vision and PatternRecognition, volume 2, pages 264-271, 2003.[Fergus04] R. Fergus, P. Perona, and A. Zisserman. A visual category lter for google images. InProceedings of the 8th European Conference on Computer Vision, Prague, Czech Republic,pages 242-256. Springer-Verlag, May 2004.[Fergus05 R. Fergus, P. Perona, and A. Zisserman. A sparse object category model for ecientlearning and exhaustive recognition. In Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition, San Diego, volume 1, pages 380-387, 2005.[Fergus_Technote] R. Fergus, M. Weber, and P. Perona. Ecient methods for object recognition using theconstellation model. Technical report, California Institute of Technology, 2001. [Fischler73] M.A. Fischler and R.A. Elschlager. The representation and matching of pictorial structures.IEEE Transactions on Computer, c-22(1):67-92, Jan. 1973.

[Grimson87] W. E. L. Grimson and T. Lozano-Perez. Localizing overlapping parts by searching theinterpretation tree. IEEE Transactions on Pattern Analysis and Machine Intelligence,9(4):469-482, 1987.[Harris98] C. J. Harris and M. Stephens. A combined corner and edge detector. In Proceedings ofthe 4th Alvey Vision Conference, Manchester, pages 147-151, 1988.[Hart68] P.E. Hart, N.J. Nilsson, and B. Raphael. A formal basis for the determination of minimumcost paths. IEEE Transactions on SSC, 4:100-107, 1968.[Helmer04] S. Helmer and D. Lowe. Object recognition with many local features. In Workshop onGenerative Model Based Vision 2004 (GMBV), Washington, D.C., July 2004.[Hofmann99] T. Hofmann. Probabilistic latent semantic indexing. In SIGIR '99: Proceedings of the22nd Annual International ACM SIGIR Conference on Research and Development inInformation Retrieval, August 15-19, 1999, Berkeley, CA, USA, pages 50-57. ACM, 1999.[Holub05] A. Holub and P. Perona. A discriminative framework for modeling object classes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, SanDiego, volume 1, pages 664-671, 2005.[Kadir01] T. Kadir and M. Brady. Scale, saliency and image description. International Journal ofComputer Vision, 45(2):83-105, 2001.[Kadir_Code] T. Kadir and M. Brady. Scale Scaliency Operator. http://www.robots.ox.ac.uk/~timork/salscale.html, 2003.[Kumar05] M. P. Kumar, P. H. S. Torr, and A. Zisserman. Obj cut. In Proceedings of IEEE Conferenceon Computer Vision and Pattern Recognition, San Diego, pages 18-25, 2005.[Leibe04] B. Leibe, A. Leonardis, and B. Schiele. Combined object categorization and segmentationwith an implicit shape model. In Workshop on Statistical Learning in Computer Vision,ECCV, 2004.[Leung98] T. Leung and J. Malik. Contour continuity and region based image segmentation. InProceedings of the 5th European Conference on Computer Vision, Freiburg, Germany,LNCS 1406, pages 544-559. Springer-Verlag, 1998.[Leung95] T.K. Leung, M.C. Burl, and P. Perona. Finding faces in cluttered scenes using randomlabeled graph matching. Proceedings of the 5th International Conference on ComputerVision, Boston, pages 637-644, June 1995.

[Leung98] T.K. Leung, M.C. Burl, and P. Perona. Probabilistic ane invariants for recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages678-684, 1998.[Lindeberg98] T. Lindeberg. Feature detection with automatic scale selection. International Journal ofComputer Vision, 30(2):77-116, 1998.[Lowe99] D. Lowe. Object recognition from local scale-invariant features. In Proceedings of the7th International Conference on Computer Vision, Kerkyra, Greece, pages 1150-1157,September 1999.[Lowe01] D. Lowe. Local feature view clustering for 3D object recognition. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition, Kauai, Hawaii, pages682-688. Springer, December 2001.[Lowe04] D. Lowe. Distinctive image features from scale-invariant keypoints. International Journalof Computer Vision, 60(2):91-110, 2004.[Mardia89] K.V. Mardia and I.L. Dryden. \Shape Distributions for Landmark Data". Advances inApplied Probability, 21:742-755, 1989.[Sivic05] J. Sivic, B. Russell, A. Efros, A. Zisserman, and W. Freeman. Discovering object categoriesin image collections. Technical Report A. I. Memo 2005-005, Massachusetts Institute ofTechnology, 2005.[Sivic03] J. Sivic and A. Zisserman. Video Google: A text retrieval approach to object matchingin videos. In Proceedings of the International Conference on Computer Vision, pages1470-1477, October 2003.[Sudderth05] E. Sudderth, A. Torralba, W. Freeman, and A. Willsky. Learning hierarchical modelsof scenes, objects, and parts. In Proceedings of the IEEE International Conference onComputer Vision, Beijing, page To appear, 2005.[Torralba04] A. Torralba, K. P. Murphy, and W. T. Freeman. Sharing features: ecient boostingprocedures for multiclass object detection. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, Washington, DC, pages 762-769, 2004.

[Viola01] P. Viola and M. Jones. Rapid object detection using a boosted cascade of simple features.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 511{518, 2001.[Weber00] M.Weber. Unsupervised Learning of Models for Object Recognition. PhD thesis, CaliforniaInstitute of Technology, Pasadena, CA, 2000.[Weber00a] M. Weber, W. Einhauser, M. Welling, and P. Perona. Viewpoint-invariant learning anddetection of human heads. In Proc. 4th IEEE Int. Conf. Autom. Face and Gesture Recog.,FG2000, pages 20{27, March 2000.[Weber00b] M. Weber, M. Welling, and P. Perona. Towards automatic discovery of object categories.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 2101{2108, June 2000.[Weber00c] M. Weber, M. Welling, and P. Perona. Unsupervised learning of models for recognition.In Proc. 6th Europ. Conf. Comp. Vis., ECCV2000, volume 1, pages 18{32, June 2000.[Welling05] M. Welling. An expectation maximization algorithm for inferring oset-normal shapedistributions. In Tenth International Workshop on Articial Intelligence and Statistics,2005.[Winn05] J. Winn and N. Joijic. Locus: Learning object classes with unsupervised segmentation.In Proceedings of the IEEE International Conference on Computer Vision, Beijing, pageTo appear, 2005