parsing compiler baojian hua [email protected]. front end source code abstract syntax tree lexical...
Post on 20-Dec-2015
244 views
TRANSCRIPT


Front End
source code
abstract syntax
tree
lexical analyzer
parser
tokens
IRsemantic analyzer

Parsing The parser translates the source progr
am into abstract syntax trees Token sequence:
from the lexer abstract syntax trees:
check validity of programs cook compiler internal data structures for pro
grams Must take account the program syntax

Conceptually
token sequence
abstract
syntax tree
parser
language syntax

Syntax: Context-free Grammar
Context-free grammars are (often) given by BNF expressions (Backus-Naur Form) read Dragon sec 2.2
More powerful than RE in theory Good for defining language syntax

Context-free Grammar (CFG)
A CFG consists of 4 components: a set of terminals (tokens): T a set of nonterminals: N a set of production rules: P
s -> t1 t2 … tn with sN, and t1, …, tn (T∪N)
a unique start nonterminal: S

Example// Recall the min-ML language in “code3” // (simplified)N = {decs, dec, exp}T = {SEMICOLON, VAL, ID, ASSIGN, NUM}S = decsdecs -> dec SEMICOLON decs |dec -> VAL ID ASSIGN expexp -> ID | NUM

Derivation
A derivation: Starts with the unique start nonterminal S repeatedly replacing a right-hand nonter
minal s by the body of a production rule of the nonterminal s
stop when right-hand are all terminals The final string consists of terminals o
nly and is called a sentence (program)
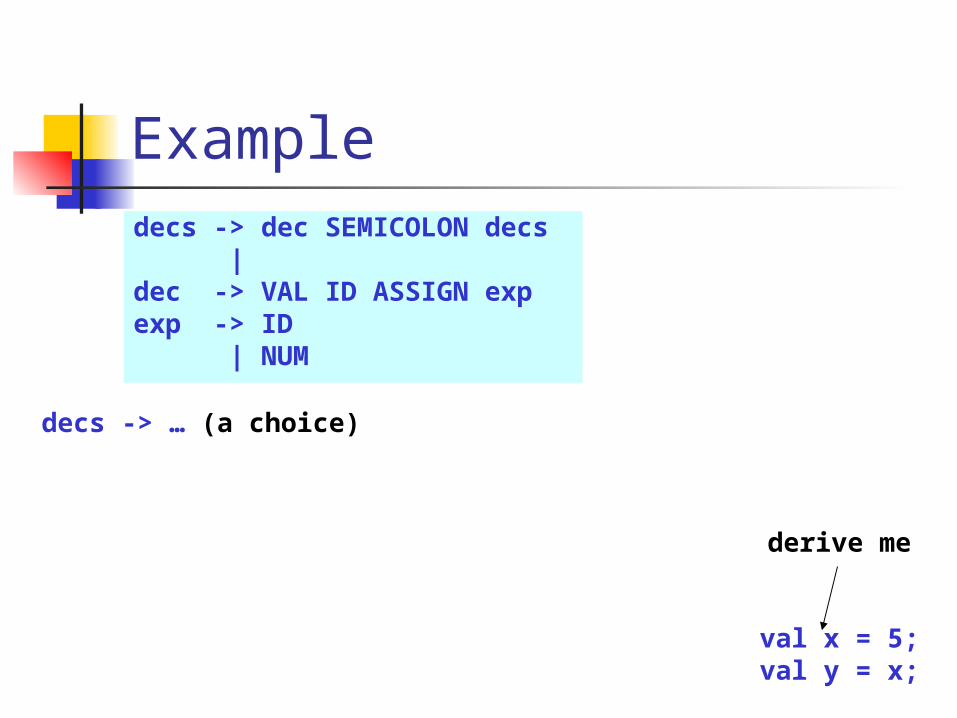
Exampledecs -> dec SEMICOLON decs |dec -> VAL ID ASSIGN expexp -> ID | NUM
val x = 5;val y = x;
derive me
decs -> … (a choice)

Exampledecs -> dec SEMICOLON decs |dec -> VAL ID ASSIGN expexp -> ID | NUM
val x = 5;val y = x;
derive me
decs -> dec SEMICOLON decs -> VAL ID ASSIGN exp SEMICOLON decs -> VAL ID ASSIGN NUM SEMICOLON decs -> VAL ID ASSIGN NUM SEMICOLON dec SEMICOLON decs -> … -> VAL ID ASSIGN NUM SEMICOLON VAL ID ASSIGN ID SEMICOLON decs

Another Way to Derive the same Programdecs -> dec SEMICOLON decs |dec -> VAL ID ASSIGN expexp -> ID | NUM
val x = 5;val y = x;
derive me
decs -> dec SEMICOLON decs -> dec SEMICOLON dec SEMICOLON decs -> …

Derivation For same string, there may exist
many derivations left-most derivation right-most derivation
Parsing is the problem of taking a string of terminals and figure out whether it could be derived from a CFG error-detection

Parse Trees Derivation can also be represented as
trees useful to understand AST (discussed later)
Idea: each internal node is labeled with a non-
terminal each leaf node is labeled with a terminal each use of a rule in a derivation explains
how to generate children in the parse tree from the parents

Exampledecs -> dec SEMICOLON decs |dec -> VAL ID ASSIGN expexp -> ID | NUM
val x = 5;val y = x;
derive me
decs
dec SEMI decs
VAL ID = exp
5
dec SEMI decs
similar case

Different Derivations, same Tree
decs -> dec SEMICOLON decs -> VAL ID ASSIGN exp SEMICOLON decs -> …
decs -> dec SEMICOLON decs -> dec SEMICOLON dec SEMICOLON decs -> …
val x = 5;val y = x;
derive me
decs
dec SEMI decs
VAL ID = exp
5
dec SEMI decs
similar case

Parse Tree has Meanings:post-order traversal
decs -> dec SEMICOLON decs -> VAL ID ASSIGN exp SEMICOLON decs -> …
decs -> dec SEMICOLON decs -> dec SEMICOLON dec SEMICOLON decs -> …
val x = 5;val y = x;
derive me
decs
dec SEMI decs
VAL ID = exp
5
dec SEMI decs
similar case

Ambiguous Grammars
A grammar is ambiguous if the same sequence of tokens can give rise to two or more different parse trees

Exampleexp -> num -> id -> exp + exp -> exp * exp
3+4*5
derive me
exp -> exp + exp -> 3 + exp -> 3 + exp * exp -> 3 + 4 * exp -> 3 + 4 * 5exp -> exp * exp -> exp + exp * exp -> 3 + exp * exp -> 3 + 4 * exp -> 3 + 4 * 5

Exampleexp -> num -> id -> exp + exp -> exp * exp
exp -> exp + exp -> 3 + exp -> 3 + exp * exp -> 3 + 4 * exp -> 3 + 4 * 5exp -> exp * exp -> exp + exp * exp -> 3 + exp * exp -> 3 + 4 * exp -> 3 + 4 * 5
exp
exp + exp
3 exp * exp
54
exp
exp * exp
5exp + exp
43

Ambiguous Grammars Problem: compilers make use of parse trees
to interpret the meaning of parsed programs different parse trees have different meanings eg: 4 + 5 * 6 is not (4 + 5) * 6 languages with ambiguous grammars are DISAST
ROUS; the meaning of programs isn’t well-defined! You can’t tell what your program might do!
Solution: rewrite grammar to equivalent forms

Eliminating ambiguity In programming language syntax, am
biguity often arises from missing operator precedence or associativity * is of high precedence than + both + and * are left-associative Why or why not?
Rewrite grammar to take account of this

Exampleexp -> num -> id -> exp + exp -> exp * exp
exp -> exp + term -> termterm -> term * factor -> factorfactor -> num -> id
Q: is the right grammar ambiguous? Why or why not?

Parser A program to check whether a program is d
erivable from a given grammar expensive in general must be fast
to compile a 2000k lines of kernel even for small application code
Theorists have developed specialized kind of grammar which may be parsed efficiently LL(k) and LR(k)

Predictive parsing A.K.A: Recursive descent parsing, top-down
parsing simple to code by hand efficient can parse a large set of grammar
Key idea: one (recursive) function for each nonterminal one clause for each right-hand production rule

Exampledecs -> dec SEMICOLON decs |dec -> VAL ID ASSIGN expexp -> ID | NUM
(* step #1: represent tokens *)datatype token = Val | Id of string | Num of int | Assign | Semicolon | Eof(* step #2: connect with lexer *)token current = ref getToken (); fun advance () = current := getToken ();fun eat (token t) = if !current = t then advance () else error (“want “, t, “but got “, !current)

decs -> dec SEMICOLON decs |dec -> VAL ID ASSIGN expexp -> ID | NUM
(* step #1: represent tokens *)datatype token = Val | Id of string | Num of int | Assign | Semi | Eof(* step #2: connect with lexer *)token current = ref getToken (); fun advance () = current := getToken ();fun eat (token t) = …;(* step #3: build the parser *)fun parseDecs() = case !current of VAL => parseDec (); eat (Semi); parseDecs (); | EOF => () | _ => error (“want VAL or EOF”)fun parseDec () = …fun parseExp () = …

Moral The key point in predicative parsing
is to determine the production rule to use (recursive function to call) must know the “start” symbols of each
rule “start” symbol must not overlap ex: exp -> NUM | ID
This motivates the idea of first and follow sets

MoralS -> w1
-> w2
-> …
-> wn
Current nonterminal is S, and the current input token is t if wk starts with t, then choos
e wk, or if wk derives empty string, an
d the string follow S starts with t
First symbol sets of wi (1<=i<=n) don’t overlap to avoid backtracking

Nullable, First and Follow sets To use predicative parsing, we must compu
te: Nullable: nonterminals that derive empty string First(ω) : set of terminals that can begin any stri
ng derivable from ω Follow(X): set of terminals that can immediately
follow any string derivable from nonterminal X Read Dragon sec 4.4.2 and Tiger sec 3.2
Fixpoint algorithms

Nullable, First and Follow sets Which symbol X, Y and Z
can derive empty string? What terminals may the
string derived from X, Y and Z begin with?
What terminals may follow X, Y and Z?
Z -> d
-> X Y Z
Y -> c
->
X -> Y
-> a

Nullable If X can derive an empty string, iff:
base case: X ->
inductive case: X -> Y1 … Yn
Y1, …, Yn are n nonterminals and may all derive empty strings

Computing NullableNullable <- {};while (Φ still change) for (each production X -> α) switch (α) case : Nullable = {X};∪ break; case Y1 … Yn: if (Y1Nullable && … && YnNullable) Nullable = {X};∪ break;

Example: NullablesZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round
0 1 2
Φ {}

Example: NullablesZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round
0 1 2
Φ {} {Y, X}

Example: NullablesZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round
0 1 2
Φ {} {Y, X} {Y, X}

First(X) Set of terminals that X begins with:
X => a … Rules
base case: X -> a
First (X) ∪= {a} inductive case:
X -> Y1 Y2 … Yn First (X) ∪= First(Y1) if Y1Nullable, First (X) ∪= First(Y2) if Y1,Y2 Nullable, First (X) ∪= First(Y3) …

Computing First// Suppose Nullable has been computedFirst(X) <- {}; // for each Xwhile (First still change) for (each production X -> α) switch (α) case a: First(X) = {a};∪ break; case Y1 … Yn: First(X) = First(Y1);∪ if (Y1\not\in Nullable) break; First(X) = First(Y1);∪ …; // Similar as above

Example: FirstZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round
0 1 2 3
First(Z)
{}
First(Y)
{}
First(X)
{}
Nullable = {X, Y}

Example: FirstZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round
0 1 2 3
First(Z)
{} {d}
First(Y)
{} {c}
First(X)
{} {c, a}
Nullable = {X, Y}

Example: FirstZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round
0 1 2 3
First(Z)
{} {d} {d, c, a}
First(Y)
{} {c} {c}
First(X)
{} {c, a} {c, a}
Nullable = {X, Y}

Example: FirstZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round
0 1 2 3
First(Z)
{} {d} {d, c, a}
{d, c, a}
First(Y)
{} {c} {c} {c}
First(X)
{} {c, a} {c, a} {c, a}
Nullable = {X, Y}

Parsing with FirstZ -> d {d}
-> X Y Z {a, c, d}
Y -> c {c}
-> {}
X -> Y {c}
-> a {a}
First(Z)
{d, c, a}
First(Y)
{c}
First(X)
{c, a}Nullable = {X, Y}
Now consider this string: d
Suppose we choose the production: Z -> X Y Z
But we get stuck at:X -> Y -> aneither can accept d!
Why?

Follow(X) Set of terminals that may follow X:
S => … X a … Rules:
Base case: Follow (X) = {}
inductive case: Y -> ω1 X ω2
Follow(X) ∪= Fisrt(ω2) if ω2 is Nullable, Follow(X) ∪= Follow(Y)

Computing Follow(X)Follow(X) <- {};while (Follow still change) { for (each production Y -> ω1 X ω2 ) Follow(X) = First (∪ ω2); if (ω2 is Nullable) Follow(X) = Follow (Y);∪

Example: FollowZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round 0 1 2 3
First(Z)Follow(Z)
{d, c, a}{}
First(Y)Follow(Y)
{c}{}
First(X)Follow(X)
{c, a}{}
Nullable = {X, Y}

Example: FollowZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round 0 1 2 3
First(Z)Follow(Z)
{d, c, a}{}
{$}
First(Y)Follow(Y)
{c}{} {d, c,
a}
First(X)Follow(X)
{c, a}{} {d, c,
a}
Nullable = {X, Y}

Example: FollowZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round 0 1 2 3
First(Z)Follow(Z)
{d, c, a}{}
{$} {$}
First(Y)Follow(Y)
{c}{} {d, c,
a}{d, c, a}
First(X)Follow(X)
{c, a}{} {d, c,
a}{d, c, a}
Nullable = {X, Y}

Predicative Parsing Table
With Nullables, First(), and Follow(), we can make a parsing table P(N,T) each entry contains a set of productions
t1 t2 t3 t4 … $(EOF)
N1 ri
N2 rk
N3 rj
…

Predicative Parsing Table
For each rule X -> ω for each aFirst(ω), add X -> ω to P(X, a) if X is nullable, add X -> ω to P(X, b) for ea
ch b Follow (X) all other entries are “error”
t1 t2 t3 t4 … $(EOF)
N1 r1
N2 rk
N3 ri
…

Example: Predicative Parsing Table
First(X)Follow(X)
{c, a}{c, d, a}
First(Y)Follow(Y)
{c}{c, d, a}
First(Z)Follow(Z)
{d, c, a}{$}
Z -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Nullable = {X, Y}
a c d
Z Z->X Y Z Z->X Y Z Z->dZ->X Y Z
Y Y-> Y->cY->
Y->
X X->YX->a
X->Y X->Y

Example: Predicative Parsing Table
First(X)Follow(X)
{c, a}{c, d, a}
First(Y)Follow(Y)
{c}{c, d, a}
First(Z)Follow(Z)
{d, c, a}{$}
Z -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Nullable = {X, Y}
a c d
Z Z->X Y Z Z->X Y Z Z->dZ->X Y Z
Y Y-> Y->cY->
Y->
X X->YX->a
X->Y X->Y

LL(1) A context-free grammar is called LL(1) if it can be parsed this way: Left-to-right parsing Leftmost derivation 1 token lookahead
This means that in the predicative parsing table, there is at most one production in every entry

Speeding up set Construction
All these sets (Nullable, First, Follow) can be computed simultaneously see Tiger algorithm 3.13
Order the computation: What’s the optimal order to compute th
ese set?

Example: Speeding up set Construction
Z -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Round
0 1 2 3
First(Z)
{}
First(Y)
{}
First(X)
{}
Nullable = {X, Y}
Q1: What’s reasonable order here?
Q2: How to set this order?
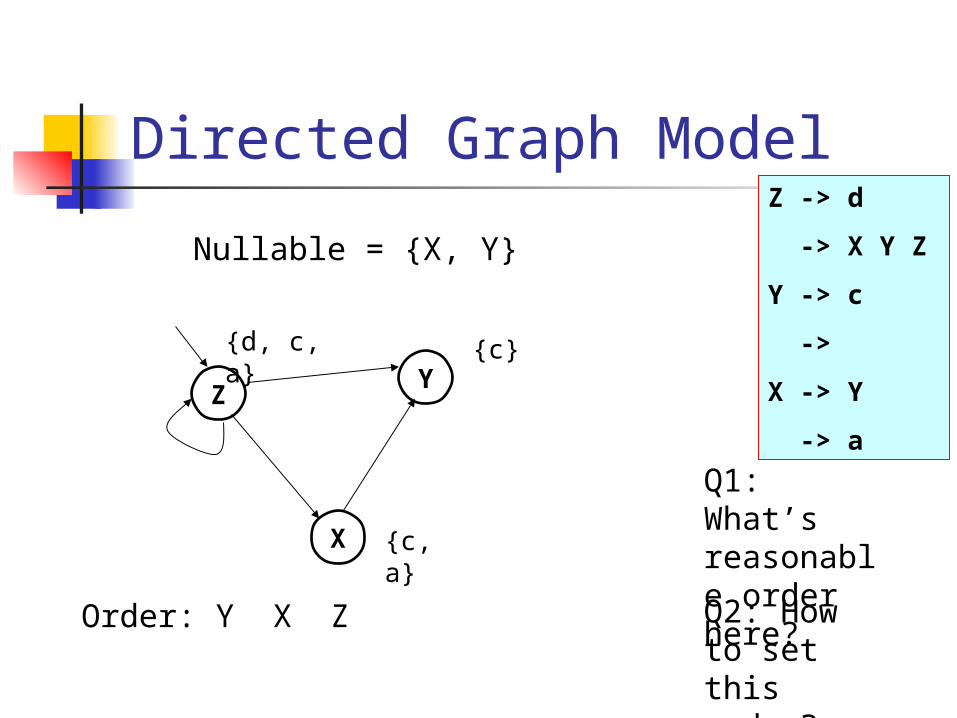
Directed Graph ModelZ -> d
-> X Y Z
Y -> c
->
X -> Y
-> a
Nullable = {X, Y}
Q1: What’s reasonable order here?
Q2: How to set this order?
Z
X
Y{c}
{c, a}
{d, c, a}
Order: Y X Z

Reverse Topological Sort Quasi-topological sort the directed gr
aph Quasi: topo-sort general directed graph i
s impossible also known as reverse depth-first orderin
g Reverse: information (First) flows fro
m successors to predecessors Refer to your favorite algorithm book

Problem
LL(1) can only be used with grammars in which every production rules for a nonterminal start with different terminals
Unfortunately, many grammars don’t have this perfect property

Exampleexp -> num -> id -> exp + exp -> exp * exp
exp -> exp + term -> termterm -> term * factor -> factorfactor -> num -> id
Q: is the right grammar LL(1)? Why or why not?

Solutions
Left-recursion elimination Left-factoring Read:
dragon sec4.3.2, 4.3.3, 4.3.4 tiger sec3.2

Exampleexp -> term exp’exp’ -> + term exp’ -> term -> factor term’term’-> * factor
term’ -> factor -> num -> id
Q: is the right grammar LL(1)? are those two grammars equivalent?
exp -> exp + term -> termterm -> term * factor -> factorfactor -> num -> id

LL(k) LL(1) can be further generalized to LL
(k): Left-to-right parsing Leftmost derivation k token lookahead
Q: table size? other problems with this approach?

Summary Context-free grammar is a math tool for spe
cifying language syntax and others…
Writing parsers for general grammar is hard and costly LL(k) and LR(k)
LL(1) grammars can be implemented efficiently table-driven algorithms (again!)