parallel computing using mpi
DESCRIPTION
Parallel Computing Using MPI. AnCAD, Inc. 逸奇科技. Main sources of the Material. - PowerPoint PPT PresentationTRANSCRIPT

Parallel Computing Using MPI
AnCAD, Inc. 逸奇科技

Main sources of the Material
• MacDonald, N., Minty, E., Harding, T. and Brown, S. “Writing Message-Passing Parallel Programs with MPI,” Edinburgh Parallel Computing Centre, Germany. (Available at http://www.lrz-muenchen.de/services/software/parallel/mpi/epcc-course/)
• “MPICH-A Portable MPI Implementation,” Web page available at http://www-unix.mcs.anl.gov/mpi/mpich/, Argonne National Laboratory, USA.
• “Message Passing Interface (MPI) Forum,” Web page available at http://www.mpi-forum.org/, Message Passing Interface Forum.
• Group, W., Lusk, E. and Skjellum, A. (1999). Using MPI Portable Parallel Programming with the Message-Passing Interface, MIT Press, England.
• Grama, A., Gupta, A., Karypis, G. and Kumar, V. (2003). Introduction to Parallel Computing 2nd Edition, Addison Wesley, USA.

Computational Science
• Computer– A stimulation of growth
of science
• Computational Science– A branch of science
between
Theoretical Science and
Experimental Science
A supercomputer system (ASCI Red)
A nuclear surface test

Trends of Computing (1)
• Requirements never stop• Scientific computing
– Fluid dynamics– Structural analysis– Electromagnetic analysis– Optimization of design– Bio-informatics– Astrophysics
• Commercial applications– Network security– Web and database data mining– Optimizing business and market
decisions
F-117 fighter (2D analysis in 1970s)
B-2 bomber (3D analysis in 1980s)
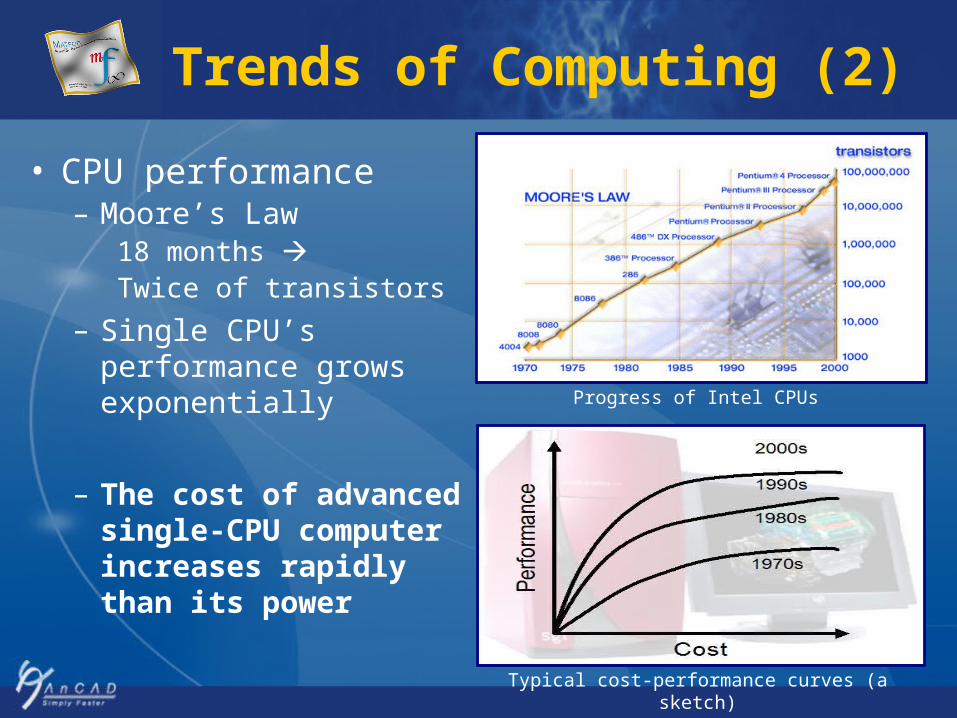
Trends of Computing (2)
• CPU performance– Moore’s Law
18 months Twice of transistors
– Single CPU’s performance grows exponentially
– The cost of advanced single-CPU computer increases rapidly than its power
Progress of Intel CPUs
Typical cost-performance curves (a sketch)

Trends of Computing (3)
• Solutions– A bigger supercomputer, or
– A cluster of small computers
• Today’s supercomputers– Also use multiple processors– Needs parallel computing skills to
exploit their performance
• A cluster of small computers– Less budget– More flexibility– Needs more knowledge on parallel
computing
Avalon (http://www.lanl.gov)

Parallel Computer Architectures
• Shared-memory architecture – Typical SMP (Symmetric Multi-
Processing)– Programmers use threads or O
penMP
• Distributed-memory architecture– Needs message passing amon
g processors– Programmers use MPI (Messa
ge Passing Interface) or PVM (Parallel Virtual Machine)
Shared-memory architecture
Distributed-memory architecture

Distributed Shared-Memory Computers
• Assemblages of shared-memory parallel computers
• Constellations:– Np < Nn*Nn
• Clusters or MPP:– Np >= Nn*Nn
A Constellation
Np: # of processors (CPUs)Nn: # of nodes (shared- mem. computers)MPP: Massively Parallel Processors
A Cluster or MPP
ASCI Q (http://www.lanl.gov)

Trend of Parallel Architectures
• Clusters get popular rapidly.– Clusters get in TOP500 list
since 1997.
– More than 40% of TOP500 are clusters in Nov, 2003.
– 170 are Intel-based clusters.
• More than 70% of TOP500 are message-passing based.
• All TOP500 supercomputers requires message passing to exploit their performance.
Trend of Top500 supercomputers’ architectures(http://www.top500.org)

Top 3 of the TOP500 (Nov. 2003)
• Earth Simulator – 35.86-Tera Flops – Earth Simulator Center (Japan)
• ASCI Q– 13.88-Tera Flops– Los Alamos Nat’l Lab. (USA)
• Virginia Tech’s X– 10.28-Tera Flops– Virginia Tech (USA)
(http://www.top500.org)

Earth Simulator
• For climate simulation• Massively Parallel Processor
s• 640 computing nodes• Each node:
– 8 NEC vector CPUs– 16 GB shared memory
• Network– 16 GB/s inter-node bandwidth
• Parallel tools:– Automatic vectorizing in CPU– OpenMP in each node– MPI or HPF across nodes
Earth Simulator site
Earth Simulator interconnection
(http://www.es.jamstec.go.jp/)

ASCI Q
• For numerical nuclear testing• Cluster
– Each node has independent operating system
• 2048 computing nodes– An option: adding to 3072
• Each node:– 4 HP Alpha processors– 10 GB memory
• Network– 250 MB/s of bandwidth– ~5 µs of latency time
ASCI Q site
ASCI Q
(http://www.lanl.gov/asci)

Virginia Tech’s X
• Scientific computing• Cluster• 1100 computing nodes• Each node:
– 2 2GHz-PowerPC CPUs– 4 GB memory– Mac OS X
• Network– 1.25 GB/s of bandwidth– 4.5 µs of latency time
• Parallel Tools– MPI
(http://www.eng.vt.edu/tcf/)

MPI is a …
• Library– Not a language– Functions or subroutines for
Fortran and C/C++ programmers
• Specification– Not a particular implementation– Computer vendors may provide
specific implementations.– Free and open source code may
be available. (http://www.mpi-forum.org/)
MPI_Init()
MPI_Comm_rank()
MPI_Comm_size()
MPI_Send()
MPI_Recv()
MPI_Finalize()

Six-Function Version of MPI
• MPI_Init– Initialize MPI– A must-do function at the beginning
• MPI_Comm_size– Number of processors (Np)
• MPI_Comm_rank– “This” processor’s ID
• MPI_Send– Sending data to a (specific) processor
• MPI_Recv– Receiving data from a (specific) processor
• MPI_Finalize– Terminate MPI– A must-do function at the end

Message-Passing Programming Paradigm
MPI on message-passing architecture(Edinburgh Parallel Computing Centre)

Message-Passing Programming Paradigm
MPI on shared-memory architecture(Edinburgh Parallel Computing Centre)

Single Program Multiple Data
• Single program– The same program runs on each processor.– Single program eases compilation and maintenance.
• Local variables– All variables are local. No shared data.
• Different at MPI_Comm_rank – Each processor gets different response from MPI_Comm_rank.
• Using sequential language– Programmers writes in Fortran / C / C++.
• Message passing– Message passing can be the only way to communicate.

Single Program Multiple Data
Processor 0
Processor 1
Processor 2
Processor 3

Hello World!
void main(int argc, char ** argv){ MPI_Init(&argc,&argv); printf("Hello world.\n"); MPI_Finalize();}
An MPI program
Output of the program

Emulating General Message Passing with SPMD
void main(int argc, char ** argv){ int Size, Rank; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD, &Size); MPI_Comm_rank(MPI_COMM_WORLD, &Rank); if (Rank==0) { Controller (argc, argv); } else { Workers (argc, argv); }
MPI_Finalize();}
(Edinburgh Parallel Computing Centre)
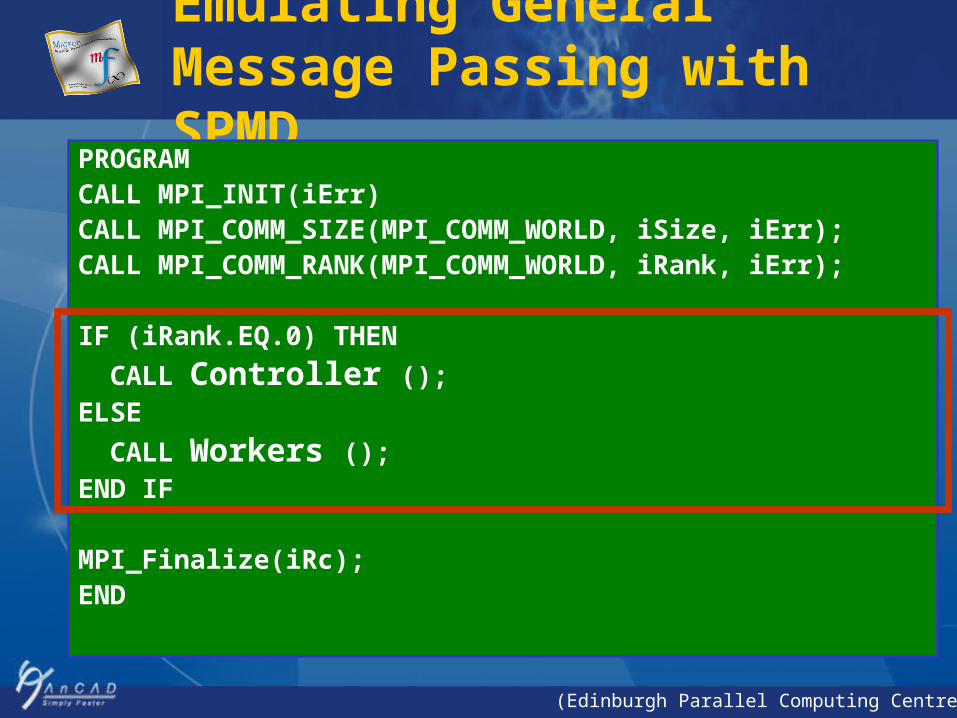
Emulating General Message Passing with SPMD
PROGRAM CALL MPI_INIT(iErr)CALL MPI_COMM_SIZE(MPI_COMM_WORLD, iSize, iErr);CALL MPI_COMM_RANK(MPI_COMM_WORLD, iRank, iErr);
IF (iRank.EQ.0) THEN
CALL Controller ();ELSE
CALL Workers ();END IF
MPI_Finalize(iRc);END
(Edinburgh Parallel Computing Centre)

MPI Messages
• Messages are packets of data moving between processors
• The message passing system has to be told the following information:– Sending processor– Location of data in sending processor– Data type– Data length– Receiving processor(s)– Destination location in receiving processor(s)– Destination size

Message Sending Modes
• How do we communicate?– Phone
Information is supposed to be synchronized.
When you are talking, you may need to be concentrated.
– FaxInformation is supposed to be synchronized.
When faxing, you can do some other works.
After making sure the fax completes, you can leave.
– MailAfter sending mail, you have no idea about the
completion.

Synchronous/Asynchronous Sends
• Synchronous Sends– Completion implies a
receipt
• Asynchronous Sends– Only knows when the
message has left.
(Edinburgh Parallel Computing Centre)
An asynchronous send
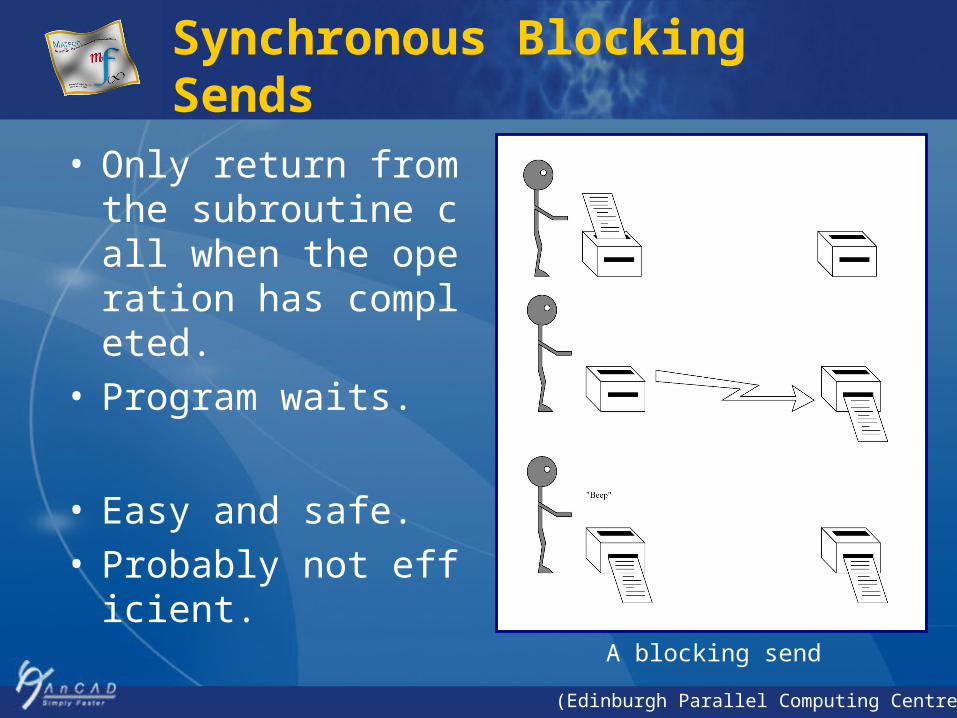
Synchronous Blocking Sends
• Only return from the subroutine call when the operation has completed.
• Program waits.
• Easy and safe.• Probably not efficient.
A blocking send
(Edinburgh Parallel Computing Centre)

Synchronous Non-Blocking Sends
• Return straight away.• Allow program to
continue to perform other work.
• Program can test or wait.
• More flexible.• Probably more efficient.• Programmers should be
careful.A non-blocking send
(Edinburgh Parallel Computing Centre)

Non-Blocking Sends w/o wait
• All non-blocking sends should have matching wait operations.
• Do not modify or release the sending data until completion.
Non-blocking send without test and wait
(Edinburgh Parallel Computing Centre)

Collective Communications
• Collective communication routines are higher level routines involving several processes at a time.
• Can be built out of point-to-point communications.
Broadcasting: a popular collective communication
(Edinburgh Parallel Computing Centre)

Collective Communications
Broadcasting
BarrierReduction (e.g., summation)
(Edinburgh Parallel Computing Centre)

Writing MPI Programs
Most of the following original MPI training materials were developed under the Joint Information Systems Committee (JISC) New Technologies Initiative by the Training and Education Centre at Edinburgh Parallel Computing Centre (EPCC-TEC), University of Edinburgh, United Kingdom.

MPI in C and FORTRAN
C/C++ FORTRAN
Header file #include <mpi.h> include ‘mpif.h’
Function calls
Ierr= MPI_Xxx(…); CALL MPI_XXX(…, IERROR)
(Edinburgh Parallel Computing Centre)

Initialization of MPI
• In Cint MPI_Init (int argc, char** argv);
• In FORTRANMPI_INIT(IERROR)
• Must be the first routine called
(Edinburgh Parallel Computing Centre)

MPI Communicator
• A required argument for all
MPI communication calls
• Processes can communicate
only if they share the same c
ommunicator(s).
• MPI_COMM_WORLD is avai
lable
• Programmer-defined commu
nicators are allowed.
(Edinburgh Parallel Computing Centre)

Size and Rank
• SizeQ: How many processors are contained in a co
mmunicator?
A: MPI_Comm_size(MPI_Comm, int *);
• Rank Q: How do I identify different processes in my M
PI program?
A: MPI_Comm_rank(MPI_Comm, int *);
(Edinburgh Parallel Computing Centre)

Exiting MPI
• In Cint MPI_Finalize ();
• In FORTRANMPI_FINALIZE(IERROR)
• Must be the last MPI routine called
(Edinburgh Parallel Computing Centre)

Contents of Typical MPI Messages
• Data to send
• Data length
• Data type
• Destination process
• Tag
• Communicator
(Edinburgh Parallel Computing Centre)

Data Types
(Edinburgh Parallel Computing Centre)

Why is Data Type Needed ?
• For heterogeneous parallel architecture
3.1416
…011001001001100101… …011001001001100101…
@#$%?
Binary datamessage passing
(Edinburgh Parallel Computing Centre)

Point-to-Point Communication
• Communication between two processes.
• Source process sends message to destination process.
• Communication takes place within a communicator.
• Destination process is identified by its rank in communicator.
(Edinburgh Parallel Computing Centre)

P2P Communication Modes
(Edinburgh Parallel Computing Centre)

MPI Communication Modes
(Edinburgh Parallel Computing Centre)
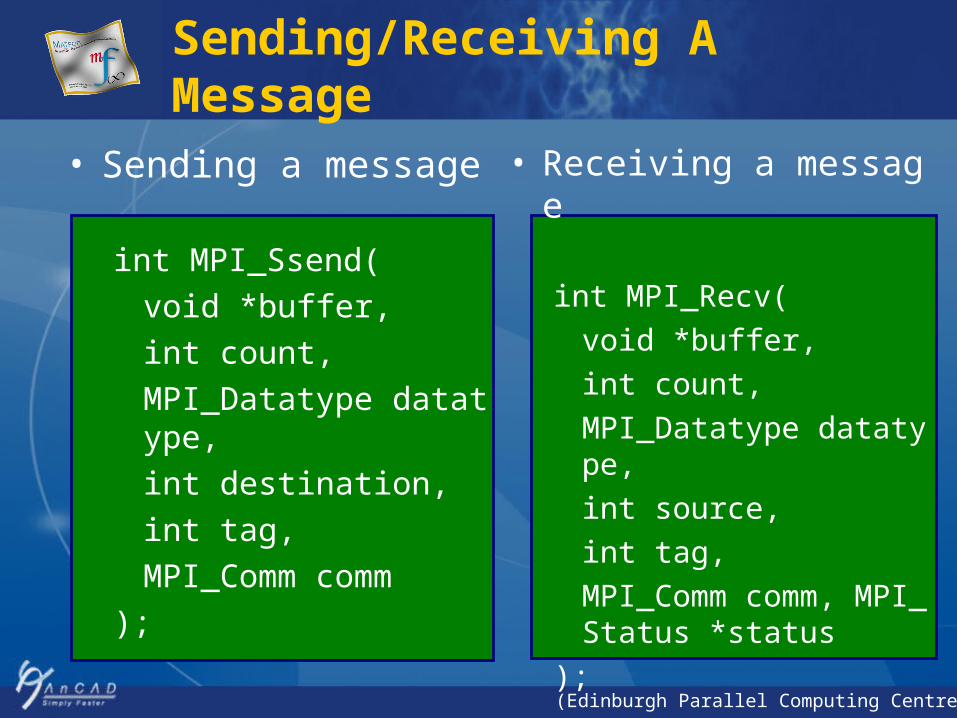
Sending/Receiving A Message
• Sending a message
int MPI_Ssend(
void *buffer,
int count,
MPI_Datatype datatype,
int destination,
int tag,
MPI_Comm comm
);
• Receiving a message
int MPI_Recv(
void *buffer,
int count,
MPI_Datatype datatype,
int source,
int tag,
MPI_Comm comm, MPI_Status *status
);
(Edinburgh Parallel Computing Centre)

Wildcarding
• Receiver can wildcard– From any source (MPI_ANY_SOURCE)– With any tag (MPI_ANY_TAG)
• Actual source and tag are returned in receiver’s status parameter.
• Sender can not use any wildcard– Destination (receiver) must be specified.– Tag must be specified.
(Edinburgh Parallel Computing Centre)

Message Order Preservation
• Messages do not overtake each other.
• This is true even for non-synchronous sends.
(Edinburgh Parallel Computing Centre)

Blocking/Non-Blocking Sends
• Blocking send– Returns after
completion.
• Non-blocking send– Returns immediately.– Allows test and wait.
A non-blocking send
(Edinburgh Parallel Computing Centre)

Synchronous? Blocking?
• Synchronous/Asynchronous sends– Synchronous sends:
Completion implies the receive is completed.
– Asynchronous sends:Completion means the buffer can be re-used,
irrespective of whether the receive is completed.
• Blocking/Non-blocking sends– Blocking sends
Return only after completion.
– Non-blocking sendsReturn immediately.
(Edinburgh Parallel Computing Centre)

MPI Sending Commands
Synchronous
send
Asynchronous
sendReceive
Blocking MPI_SsendMPI_Bsend
MPI_RsendMPI_Recv
Non-blocking
MPI_IssendMPI_Ibsend
MPI_IrsendMPI_Irecv
(Edinburgh Parallel Computing Centre)

Non-Blocking Sends
• Avoids deadlock
• May Improve efficiency
Deadlock
(Edinburgh Parallel Computing Centre)

Non-Blocking Communications
• Step 1:– Initiate non-blocking communication.– E.g., MPI_Isend or MPI_Irecv
• Step 2:– Do other work.
• Step 3:– Wait for non-blocking communication to compl
ete.– E.g., MPI_Wait
(Edinburgh Parallel Computing Centre)

MPI Non-Blocking Commands
• Sending a message
int MPI_Isend( void *buffer,
int count,
MPI_Datatype datatype,
int destination,
int tag,
MPI_Comm comm,
MPI_Request * request );
int MPI_Wait(
MPI_Request request,
MPI_Status * status );
• Receiving a message
int MPI_Irecv( void *buffer,
int count,
MPI_Datatype datatype,
int source,
int tag,
MPI_Comm comm,
MPI_Request * request );
int MPI_Wait(
MPI_Request request,
MPI_Status * status );
(Edinburgh Parallel Computing Centre)

Blocking and Non-Blocking
• A blocking send can be used with a non-blocking receive, and vice versa.
(Edinburgh Parallel Computing Centre)

Derived Data Type
• Construct new data typeMPI_Type_vector (…)
MPI_Type_struct (…)
…
• Commit new data typeMPI_Type_commit (…)
• Release a data type MPI_Type_free (…)
(Edinburgh Parallel Computing Centre)

MPI Collective Communications
• Communications involving a group of processes.
• Called by all processes in a communicator.
• Blocking communications.
• Examples:– Barrier synchronization– Broadcast, scatter, gather.– Global summation, global maximum, etc.
(Edinburgh Parallel Computing Centre)

MPI Barrier Synchronization
int MPI_Barrier (MPI_Comm comm);
(Edinburgh Parallel Computing Centre)

MPI Broadcast
int MPI_Bcast ( buffer, count, datatype,
root, comm );
(Edinburgh Parallel Computing Centre)

MPI Scatter
int MPI_Scatterv ( sendbuf, sendcount, datatype, recvbuf, recvcount, recvtype, root, comm ) ;
(Edinburgh Parallel Computing Centre)

MPI Gather
int MPI_Gather ( sendbuf, sendcount, datatype, recvbuf, recvcount, recvtype, root, comm ) ;
(Edinburgh Parallel Computing Centre)

MPI Reduction Operations
int MPI_Reduce ( sendbuf, recvbuf, count, datatype, OP, root, comm ) ;
The OP can be – MPI_MAX– MPI_MIN– MPI_SUM, etc.– User defined OP.
(Edinburgh Parallel Computing Centre)

Installation of MPI
• MPICH– Probably the most popular MPI
implementation – Provides both Unix and
Windows versions– Freely available (Try
http://www-unix.mcs.anl.gov/mpi/)
• In Windows– Execute the installation file
and follow the instructions
• In most Unix– “configure” and “make”
Windows MPICH Installation
Unix MPICH Installation

Logging and GUI Timeline
• MPE – MPI Parallel Environment
– A library with a set of functions
– Generates a logging file
• Jumpshot – A GUI program– Shows timeline figures
• MPE and Jumpshot are included in MPICH
MPE_Init_log() MPE_Describe_stateMPE_Log_eventMPE_Finish_log
Four-function version of MPE
Example of Jumpshot-4(http://www-unix.mcs.anl.gov/perfvis/)

just do it