parallel applications of the us nrc consolidated code j. gan & t. downar, purdue university j....
TRANSCRIPT

2
Outline
• Code OverviewCode Overview
• Parallel Model (PVM) for TRAC-MParallel Model (PVM) for TRAC-M
• Parallel Model (OpenMP) for Parallel Model (OpenMP) for PARCS PARCS
• ConclusionsConclusions

3
Nuclear Power Plant

4
TRAC-M Overview
• ““TRAC”: The U.S. Nuclear Regulatory TRAC”: The U.S. Nuclear Regulatory Commission Transient Reactor Analysis CodeCommission Transient Reactor Analysis Code
• Advanced best-estimate predictions of postulated accidents Advanced best-estimate predictions of postulated accidents in light-water reactorsin light-water reactors
• Solves the two-fluid mass, energy, and momentum equationsSolves the two-fluid mass, energy, and momentum equations
• A Consolidated Thermal-hydraulic Code for A Consolidated Thermal-hydraulic Code for Nuclear Reactor Safety Analysis, including the Nuclear Reactor Safety Analysis, including the capabilities of older U.S. NRC codes:capabilities of older U.S. NRC codes:
• RELAP and TRAC-P for PWRRELAP and TRAC-P for PWR
• RAMONA and TRAC-B for BWRRAMONA and TRAC-B for BWR

5
Code Features• Objectives: Objectives:
• Readability, Maintainability, Extensibility, and PortabilityReadability, Maintainability, Extensibility, and Portability
• Fortran 90 code, over 150,000 linesFortran 90 code, over 150,000 lines
• Modeling capability:Modeling capability:• 3-D pressure vessel3-D pressure vessel
• Two-fluid nonequilibrium hydrodynamics model with a noncondensable gas Two-fluid nonequilibrium hydrodynamics model with a noncondensable gas field and solute trackingfield and solute tracking
• Flow-regime-dependent constitutive-equation treatmentFlow-regime-dependent constitutive-equation treatment
• Consistent treatment of entire accident sequencesConsistent treatment of entire accident sequences
• The stability-enhancing two-step numerical algorithm is adoptedThe stability-enhancing two-step numerical algorithm is adopted
• Parallel option to extend code functionality and to improve Parallel option to extend code functionality and to improve execution speed:execution speed:
• 3-D neutron kinetics capabilities provided by coupling to an advanced 3-D 3-D neutron kinetics capabilities provided by coupling to an advanced 3-D kinetics code (PARCS)kinetics code (PARCS)

6
TRAC-M Multitask Model
• Using multitask model to extend code functionality and improve execution speed:
TRAC-MSpecial Process
(Steam Generatorsecondary)
TRAC-MSpecial Process
(Steam GeneratorSecondary)
TRAC-MCentral Process
(Reactor Primary)
ReactorContainment
Special Process
Special ProcessFor Reactor Core
3-D kinetics
TRAC-MSpecial Process
(Steam Generatorsecondary)
TRAC-MSpecial Process
(Steam GeneratorSecondary)
TRAC-MCentral Process
(Reactor Primary)
ReactorContainment
Special Process
Special ProcessFor Reactor Core
3-D kinetics
TRAC-MSpecial Process
(Steam Generatorsecondary)
TRAC-MSpecial Process
(Steam GeneratorSecondary)
TRAC-MCentral Process
(Reactor Primary)
ReactorContainment
Special Process
Special ProcessFor Reactor Core
3-D kinetics

7
Exterior Communication Interface
• Interprocess Interprocess communication communication implemented by the ECI implemented by the ECI (Exterior Communications (Exterior Communications Interface)Interface)
• Table driven data transferTable driven data transfer
• Step 2 need an Step 2 need an interprocess message interprocess message passing library – currently passing library – currently using PVMusing PVM

8
Why Choose PVM?
• For modularity we treat each module as a task and For modularity we treat each module as a task and use a central task to control all the modulesuse a central task to control all the modules
• The virtual machine concept makes it possible to The virtual machine concept makes it possible to realize the heterogeneous distributed computingrealize the heterogeneous distributed computing
• Compared with MPI,Compared with MPI,
• PVM provides more flexibility on process controlPVM provides more flexibility on process control
• PVM provides dynamic resource controlPVM provides dynamic resource control
• PVM provides full fault tolerance abilityPVM provides full fault tolerance ability

9
Parallel Applications of TRAC-M
• Sample Problems:Sample Problems:1)1) 2-Pipe Test Problem2-Pipe Test Problem
2)2) AP600 LBLOCAAP600 LBLOCA
3)3) Pressurized Thermal Shock (PTS) ProblemPressurized Thermal Shock (PTS) Problem
• Performance Comparison on Various Platforms:Performance Comparison on Various Platforms:1)1) Xeon PII (dual CPU: 400MHz; Windows 2000);Xeon PII (dual CPU: 400MHz; Windows 2000);
2)2) Xeon PIII (4-CPU: 550MHz; Linux, RedHat);Xeon PIII (4-CPU: 550MHz; Linux, RedHat);
3)3) Xeon PIII (dual CPU: 800MHz; Linux, RedHat);Xeon PIII (dual CPU: 800MHz; Linux, RedHat);
4)4) DEC Alpha 8400 (Digital Unix);DEC Alpha 8400 (Digital Unix);

10
1) Pipe Test Problem
• 2-pipe model:2-pipe model:
pipe 2
pipe 1
TASK B
TASK A

11
Load balance study
• Total 600 cells:Total 600 cells:
1000 time steps running on Dual CPU PC ( 800MHz; Linux)
serial runtime: 63.370 sec
CaseCase TaskTask TcaltTcalt Tcomm_t
Tcomm_t TidleTidle Tot_tTot_t EfficiencyEfficiencySpeedupSpeedup
C(100:500)
C(100:500)
11 12.04012.040 4.0704.070 46.3746.37 16.11016.110
50.7%50.7%22 58.71058.710 3.7703.770 -- 62.48062.480
1.0141.014
B (200:400)
B (200:400)
11 23.64023.640 3.7703.770 22.3822.38 27.41027.410
63.6%63.6%22 46.10046.100 3.6903.690 -- 49.79049.790
1.2731.273
A (300:300)
A (300:300)
11 34.45034.450 4.2504.250 -- 38.70038.700
82.5%82.5%22 34.11034.110 3.9903.990 -- 38.10038.100
1.6501.650

12
Parallel Runtime Analytic Model
• For Task i: Tpi = Tcalt
i + Tcomm_ti + Tidle
i
(1) Calculation time: Tcalt
i
Tcalti = fmytask * Ts
where, fmytask: fraction of total work load
Ts : serial running time
(2) Communication time: Tcomm_ti
Tcomm_ti= ts + tw * m, for each message passed
where, ts: latency
tw: bandwidth
m: message size
(3) Idle time: Tidlei
Tidlei = [max(fitask) - fmytask] * Ts

13
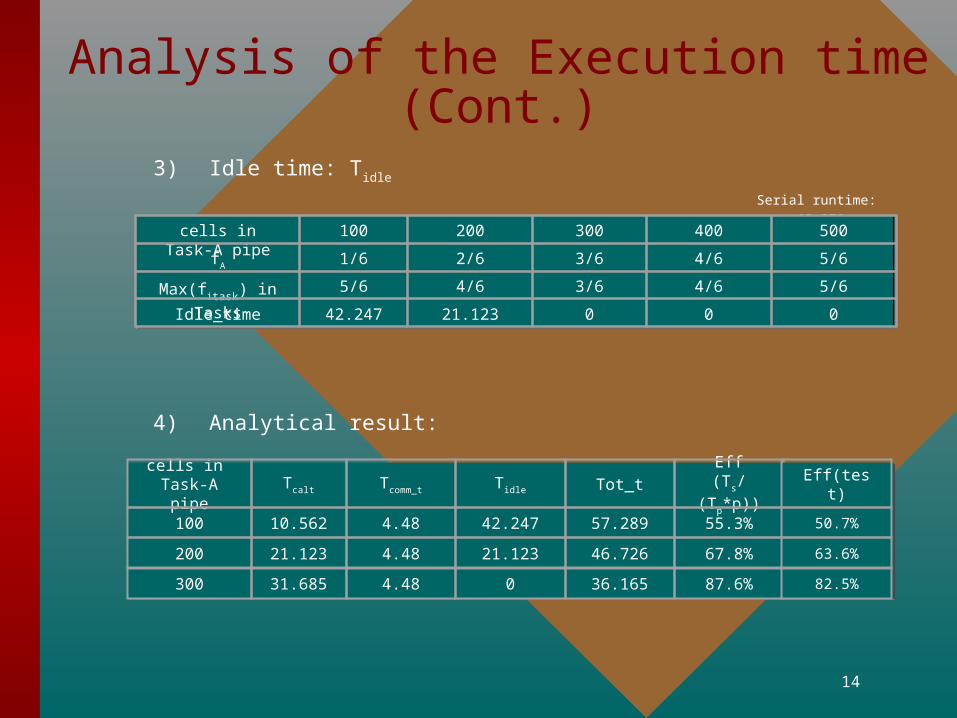
Analysis of the Execution time
1) Calculation time: Tcalt
Serial runtime: 63.370 sec
cells in Task-A 100 200 300 400 500
fraction: fA 1/6 2/6 3/6 4/6 5/6
calt_time 10.562 21.123 31.685 42.247 52.808
2) Communication time: Tcomm_t
• max(m) = 592Bytes, Teach = ts + tw*m 80 s (latency dominated)
• 16 synchronization points, two of them are used only once for initialization.
• message passes twice in each synchronization points: one for data transfer, the other for status check
Tcomm_t 2 * 2 * 14 * 1000 * 80 = 4.48E+6 s = 4.48 secTcomm_t 2 * 2 * 14 * 1000 * 80 = 4.48E+6 s = 4.48 sec
14
Analysis of the Execution time (Cont.)
3) Idle time: Tidle
Serial runtime: 63.370 sec
cells in Task-A pipe 100 200 300 400 500
fA 1/6 2/6 3/6 4/6 5/6
Max(fitask) in Tasks 5/6 4/6 3/6 4/6 5/6
Idle_time 42.247 21.123 0 0 0
4) Analytical result:
cells in Task-A pipe
Tcalt Tcomm_t Tidle Tot_tEff
(Ts/(Tp*p))
100 10.562 4.48 42.247 57.289 55.3%
200 21.123 4.48 21.123 46.726 67.8%
300 31.685 4.48 0 36.165 87.6%
Eff(test)
50.7%
63.6%
82.5%

15
2) Practical Reactor Problem: AP600
• AP600: an advanced light water reactor designed by Westing House
• LBLOCA: a Large Break Loss of Coolant Accident Analysis- Sigificant computational burden in the overall assessment of the reactor plant safety

16
Domain Decompositions
• Three domain decomposistions:
Model A – two tasks model:
(1) reactor vessel
(2) 1D loops
Model B – three tasks model:
(1) core vessel
(2) downcomer vessel
(3) 1D loops
Model C – two tasks model:
(1) core vessel
(2) downcomer vessel + 1D loops
17
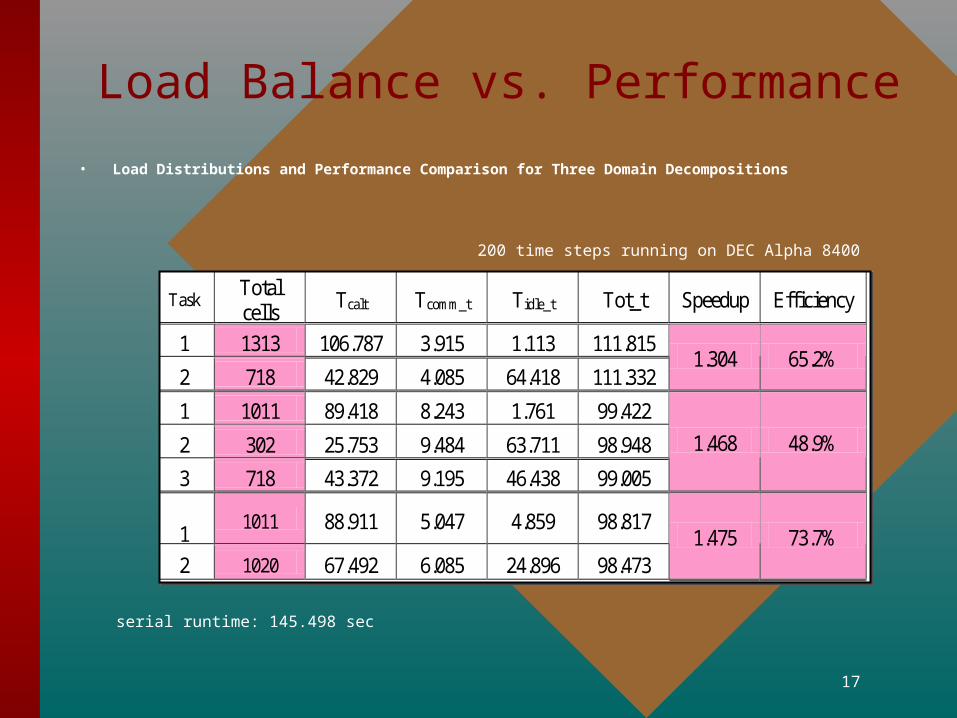
Load Balance vs. Performance
• Load Distributions and Performance Comparison for Three Domain Decompositions
200 time steps running on DEC Alpha 8400
serial runtime: 145.498 sec
Model Task Total cells
Tcalt Tcomm_t Tidle_t Tot_t Speedup Efficiency
1 1313 106.787 3.915 1.113 111.815 A
2 718 42.829 4.085 64.418 111.332 1.304 65.2%
1 1011 89.418 8.243 1.761 99.422
2 302 25.753 9.484 63.711 98.948 B
3 718 43.372 9.195 46.438 99.005
1.468 48.9%
1
1011 88.911 5.047 4.859 98.817 C
2 1020 67.492 6.085 24.896 98.473 1.475 73.7%

18
3) Performance on Various Platforms
• Test Problems: Pressurized Thermal ressurized Thermal
Shock (PTS) with a 3D Shock (PTS) with a 3D
reactor vesselreactor vessel
Only considers Only considers
downcomer (3D vessel) downcomer (3D vessel)
and 4 cold legsand 4 cold legs
• Performance Comparison on Various Platforms:Performance Comparison on Various Platforms: Xeon PII (dual CPU: 400MHz; Windows 2000);Xeon PII (dual CPU: 400MHz; Windows 2000);
Xeon PIII (4-CPU: 550MHz; Linux, RedHat);Xeon PIII (4-CPU: 550MHz; Linux, RedHat);
Xeon PIII (dual CPU: 800MHz; Linux, RedHat);Xeon PIII (dual CPU: 800MHz; Linux, RedHat);
DEC Alpha 8400 (Digital Unix).DEC Alpha 8400 (Digital Unix).

19
Message Passing Library: PVM• PVM Protocols Implemented in TRAC-M
psend & precv for bulk data transfer;
pack/send & recv/unpack for status checking.
pack/send & recv/unpackpack/send & recv/unpack 33.67233.672 304.688304.688 26.66726.667 69.00069.000
Bandwidth on Various Platforms using pack/send and recv/unpack PVM Protocols
0
2
4
6
8
10
12
14
16
18
0 5000 10000 15000 20000 25000 30000 35000 40000
Message Size (Bytes)
Co
mm
un
icti
on
(M
B/s
)
PC (800MHZ, LINUX)
DEC ALPHA 8400
PC (500MHZ, LINUX)
PC (400MHZ, Win2K)
• Latency of PVM Protocols (s):
• Bandwidth:
ProtocolsProtocols DEC AlphaDEC Alpha PC (400Mhz, Win2K)
PC (400Mhz, Win2K)
PC (550Mhz, Linux)
PC (550Mhz, Linux)
PC (800Mhz, Linux)
PC (800Mhz, Linux)
psend & precv
psend & precv
32.15732.157 343.750343.750 51.00051.000 74.87574.875
Bandwidth on Various Platforms using psend and precv PVM Protocols
0
20
40
60
80
100
120
140
160
180
200
0 5000 10000 15000 20000 25000 30000 35000 40000
Message Size (Bytes)
Co
mm
un
icat
ion
(M
B/s
)
PC (550Mhz, Linux)
PC (800Mhz, Linux)
DEC ALPHA 8400
PC (400Mhz, Win2K)

20
Performance Summary
Platform Serial Task Tcalt Tcomm_t Tidle_t Tot_t (CPU)
Speedup Efficiency
Xeon PIIIDual-CPU
Linux80.300
1 46.830 0.270 - 47.100
1.705 85.2%2 38.940 0.330 7.83 39.270
Xeon PIIIFour-CPU
Linux116.79
1 67.350 0.440 - 67.790
1.723 86.1%2 55.850 0.530 11.41 56.380
DEC Alpha UNIX
81.732
1 18.727 1.720 47.886 20.447
1.206 60.3% 2 66.035 1.735 - 67.770
Xeon PIIDual-CPU WIN2000
76.594
1 30.047 17.719 12.968 47.766
1.261 63.1% 2 48.656 12.078 20.547 60.734
• Performance vs platform, which is determined byPerformance vs platform, which is determined by Load balance;Load balance;
Communication cost.Communication cost.

21
Further Developments:
OpenMP Parallel Model for
Neutron Kinetics

22
TRAC-M Functionality Extension
• Another Objective of Parallel OptionAnother Objective of Parallel Option
- Coupling with detailed modeling codes- Coupling with detailed modeling codes
Nuclear Reactor Core

23
Spatial Coupling
Thermal-Hydraulics:Thermal-Hydraulics:
• Computes new Computes new coolant/fuel propertiescoolant/fuel properties
• Sends moderator Sends moderator temp., vapor and temp., vapor and liquid densities, void liquid densities, void fraction, boron conc., fraction, boron conc., and average, and average, centerline, and centerline, and surface fuel temp.surface fuel temp.
• Uses neutronic power Uses neutronic power as heat source for as heat source for conductionconduction
Thermal-Hydraulics:Thermal-Hydraulics:
• Computes new Computes new coolant/fuel propertiescoolant/fuel properties
• Sends moderator Sends moderator temp., vapor and temp., vapor and liquid densities, void liquid densities, void fraction, boron conc., fraction, boron conc., and average, and average, centerline, and centerline, and surface fuel temp.surface fuel temp.
• Uses neutronic power Uses neutronic power as heat source for as heat source for conductionconduction
Neutronics:Neutronics:
• Uses coolant and Uses coolant and fuel properties for fuel properties for local node conditionslocal node conditions
• Updates Updates macroscopic cross macroscopic cross sections based on sections based on local node conditionslocal node conditions
• Computes 3-D fluxComputes 3-D flux
• Sends node-wise Sends node-wise power distributionpower distribution
Neutronics:Neutronics:
• Uses coolant and Uses coolant and fuel properties for fuel properties for local node conditionslocal node conditions
• Updates Updates macroscopic cross macroscopic cross sections based on sections based on local node conditionslocal node conditions
• Computes 3-D fluxComputes 3-D flux
• Sends node-wise Sends node-wise power distributionpower distribution

24
• Equation Solved:Equation Solved:
Time-Dependent Boltzmann Transport EquationTime-Dependent Boltzmann Transport Equation
),,,(),',',()',',(''
),,,(),(),,,(),,,(1
tErStErEErdEd
tErErtErtErt
s
PARCS• ““Purdue Advanced Reactor Core Simulator”Purdue Advanced Reactor Core Simulator”
• U.S. NRC Code for Nuclear Reactor Kinetics AnalysisU.S. NRC Code for Nuclear Reactor Kinetics Analysis
• A Multi-Dimensional Multi-Group Reactor Kinetics Code Based on A Multi-Dimensional Multi-Group Reactor Kinetics Code Based on Nonlinear Nodal MethodNonlinear Nodal Method

25
PARCS Computational Modules
• CMFDCMFD: : Solves the “Global” Coarse Mesh Finite Solves the “Global” Coarse Mesh Finite Difference EquationDifference Equation
• NODALNODAL: : Solves “Local” Higher Order Differenced Solves “Local” Higher Order Differenced EquationsEquations
• XSECXSEC: : Provides Temperature/Fluid Feedback Provides Temperature/Fluid Feedback through Cross Sections (Coefficients of Boltzmann through Cross Sections (Coefficients of Boltzmann Equation)Equation)
• T/HT/H: : Solution of Temperature/Fluid Field EquationsSolution of Temperature/Fluid Field Equations

26
Parallelism in PARCS
• NODAL and XsecNODAL and Xsec Module: Module:– Node by Node CalculationNode by Node Calculation
– Naturally ParallelizableNaturally Parallelizable
• T/HT/H Module: Module:– Channel by Channel CalculationChannel by Channel Calculation
– Naturally ParallelizableNaturally Parallelizable
• CMFDCMFD Module: Module:– Domain Decomposition PreconditioningDomain Decomposition Preconditioning
– Example: Split the Reactor into Two Halves Example: Split the Reactor into Two Halves
– The Number of Iteration Depends on the Number of The Number of Iteration Depends on the Number of DomainsDomains

27
Parallel Application of PARCS• Why Multi-Threaded ProgrammingWhy Multi-Threaded Programming
– Message Passing Message Passing • Large Communication Overhead Large Communication Overhead
– Multi-ThreadingMulti-Threading• Shared Address SpaceShared Address Space
• Negligible Communication Overhead Negligible Communication Overhead
• ImplementationImplementation
– OpenMPOpenMP• FORTRAN, C, C++FORTRAN, C, C++
• Simple Implementation based on DirectivesSimple Implementation based on Directives
– NEACRP Reactor Transient BenchmarkNEACRP Reactor Transient Benchmark• Control Rod Ejection From Hot Zero Power ConditionControl Rod Ejection From Hot Zero Power Condition
• Full 3-Dimensional TransientFull 3-Dimensional Transient
– PlatformPlatform• SGI ORIGIN 2000SGI ORIGIN 2000

28
Parallel Performance (SGI)
8.938.93 2.212.21
3.563.56 2.532.53
8.928.92 2.992.99
1.371.37 3.533.53
22.8 2.64*2)
8.858.85 2.232.23
2.872.87 3.143.14
7.147.14 3.733.73
1.111.11 4.354.35
20.0 3.02*2)
ModuleModuleOpenMPOpenMPOpenMPOpenMP
1 1 *1)*1)1 1 *1)*1) 4444 SpeedupSpeedupSpeedupSpeedup 8888 SpeedupSpeedupSpeedupSpeedupSerialSerialSerialSerial
2222 SpeedupSpeedupSpeedupSpeedup
TimeTime(sec)(sec)TimeTime(sec)(sec)
CMFDCMFDCMFDCMFD 19.319.319.319.3
NodalNodalNodalNodal 9.29.29.29.2
T/HT/HT/HT/H 25.325.325.325.3
XsecXsecXsecXsec 4.44.44.44.4
Total 58.1
19.819.819.819.8
9.09.09.09.0
26.626.626.626.6
4.84.84.84.8
60.2
12.112.112.112.1 1.631.631.631.63
5.85.85.85.8 1.551.551.551.55
12.312.312.312.3 2.172.172.172.17
2.42.42.42.4 2.012.012.012.01
32.6 1.85
*1) Number of Threads *2) Core is divided into 18 planes
Transient Power
050
100150200250300350400450500
0 0.1 0.2 0.3 0.4 0.5
TIME(sec)
Po
wer (
%)
serial
2 threads
4 threads
8 thredsthreads
Transient Power
050
100150200250300350400450500
0 0.1 0.2 0.3 0.4 0.5
TIME(sec)
Po
wer (
%)
serial
2 threads
4 threads
8 thredsthreads

29
CPUCPU
L1 CacheL1 Cache
L2 CacheL2 Cache
MemoryMemory
Memory Access TypeMemory Access Type CyclesCycles
L1 cache hitL1 cache hit 22
L1 cache miss L1 cache miss satisfied by L2 cache satisfied by L2 cache hithit
88
L2 cache miss L2 cache miss satisfied from satisfied from memorymemory
7575
Cache Analysis
Typical Memory Access Cycles Typical Memory Access Cycles (SGI)(SGI)

30
ModuleModuleModuleModule
Cache Miss Ratio (SGI)
OpenMPOpenMPOpenMPOpenMP
CMFDCMFD(BICG)(BICG)
CMFDCMFD(BICG)(BICG)
CacheCacheCacheCache SerialSerialSerialSerial11*1)*1)11*1)*1) 2222
L1L1L1L1 1.001.001.001.00
NodalNodalNodalNodalL1L1L1L1 1.001.001.001.00
L2L2L2L2 1.001.001.001.00
T/HT/H(TRTH)(TRTH)
T/HT/H(TRTH)(TRTH)
L1L1L1L1 1.001.001.001.00
L2L2L2L2 1.001.001.001.00
XSECXSECXSECXSECL1L1L1L1 1.001.001.001.00
L2L2L2L2 1.001.001.001.00
L2L2L2L2 1.001.001.001.00
1.851.851.851.85
1.931.931.931.93
1.601.601.601.60
4.194.194.194.19
0.990.990.990.99
2.092.092.092.09
1.711.711.711.71
1.661.661.661.66
1.001.001.001.00
1.001.001.001.00
0.980.980.980.98
2.732.732.732.73
1.001.001.001.00
1.081.081.081.08
0.990.990.990.99
0.950.950.950.95
Cache Miss Ratio =Cache Miss Ratio =ExecutionParallelofMissesCache
ExecutionSerialofMissesCache
*1) Number of Threads *1) Number of Threads

31
Speedup Estimation Using Cache Misses
where
= Total data access time for serial execution
= Total data access time for 2 threads execution.
thtotal
serialtotal
T
TS
2
serialtotalT
thtotalT 2
•Speedup
where
= Total L2 cache access time = Total memory access time = Number of L1 data cache misses satisfied by L2 cache hit = Number of L2 data cache misses satisfied from main memory = L2 cache access time for 1 word = Main memory access time for 1 word.
MemMemLLmemLtotal tntnTTT 222
2LTmemT
2LnMemn
2LtMemt
•Data Access Time

32
Estimated 2-thread Speedup Based on Data Cache Misses for OpenMP
on SGI
CMFD (BICG)CMFD (BICG)CMFD (BICG)CMFD (BICG) 1.631.631.631.63 1.781.781.781.78
NodalNodalNodalNodal 1.551.551.551.55 1.801.801.801.80
T/H (TRTH)T/H (TRTH)T/H (TRTH)T/H (TRTH) 2.172.172.172.17 2.042.042.042.04
ModuleModuleModuleModuleSpeedupSpeedupSpeedupSpeedup
MeasuredMeasuredMeasuredMeasured PredictedPredictedPredictedPredicted
XSECXSECXSECXSEC 2.012.012.012.01 1.861.861.861.86

33
Conclusions
• ECI provides a flexible and efficient parallel ECI provides a flexible and efficient parallel capability for TRAC-Mcapability for TRAC-M
• Parallel performance is platform dependent and Parallel performance is platform dependent and most stable and efficient on Linux and Unix most stable and efficient on Linux and Unix platformsplatforms
• The Prediction of speedup based on data cache The Prediction of speedup based on data cache misses agrees well with the measured speedupmisses agrees well with the measured speedup
• The key to achieving good parallel performance:The key to achieving good parallel performance:
Balance the load! Balance the load!

34
THANK YOU !