pabio590b – week 1 microarrays overview design & hybridization data analysis
TRANSCRIPT

Pabio590B – week 1
Microarrays
Overview
Design & hybridization
Data analysis

Overview
Affix/synthesize probes of known sequence to chip
Hybridize with labeled sample
Quantify level of hybridization to each probe
Normalization
Statistics
Clustering & more

Experiments you might do
Measure RNA expression
Changes in gene expression over time / lifecycle
Compare differences between tissues/cell types
Comparisons between species/strains/conditions
Whole genome transcript mapping (tiling arrays)
Measure DNA contentPresence or absence of region
Copy number via Comparative Genomic Hybridization
SNP Genotyping/Re-sequencing
OtherChIP on chip arrays
RIP on chip

Microarray Design
Affix/synthesize probes of known sequence to chip
Hybridize with labeled sample
Quantify level of hybridization to each probe
Normalization
Statistics
Clustering & more

RNA Expression Chip Designs
Expression Array:- N number of probes per gene of interest- Trade-off between accuracy and number of features
Tiling array:- Place probe of X nt every Y bases - Biased vs unbiased
50 nt 50 nt
70 nt tiling window
20 nt

Probe considerations
Number of probes per region of
interest
Specificity of probes
Distance between probes (tiling)
Mismatch probes (Affymetrix)

Hybridization
Affix/synthesize probes of known sequence to chip
Hybridize with labeled sample
Quantify level of hybridization to each probe
Normalization
Statistics
Clustering & more

Two-color vs One-color
Two-color • Two samples one each slide• cy3 - green - 532nm• cy5 - red - 635nm
One-color• One sample per slide• cy3
No significant difference in accuracy or reproducibility

Designs for Two-color Array
Experiment Replicatescy3 cy5WT MuWT MuWT Mu
cy3 cy5WT1 Mu1WT2 Mu2WT3 Mu3
Biological Replicates
Dye Swapscy3 cy5WT MuMu WTWT MuMu WT
cy3 cy5ref Aref Bref Cref Dref Eref F
Common Reference
cy3 cy5A BB CC DD EE FF A
Round Robin

Data Normalization
Affix/synthesize probes of known sequence to chip
Hybridize with labeled sample
Quantify level of hybridization to each probe
Normalization
Statistics
Clustering & more

Within-Array Normalization
Lowess Normalization
Before After
Signal intensity
Cy3
/Cy5

Between-Array Normalization
RNA Spike-in Random Probes Median Scaling Quantile Scaling
Median and quantile normalization are predicated upon the arrays in question having the same distribution. That is to say, if you can safely assume that the bulk of genes have the same expression across the arrays, only then you can use those methods.

Quantile Normalization
Before After

Statistical Analysis
Affix/synthesize probes of known sequence to chip
Hybridize with labeled sample
Quantify level of hybridization to each probe
Normalization
Statistics
Clustering & more

Some Advice About Statistics
Don’t get too hung up on p-values [or any other stat].
Ultimately what matters is biological relevance and external knowledge and other heterogeneous measures (related functions, pathways, other data types) that are not easily measured by statistics alone.
P-values should help you evaluate the strength of the evidence, rather than being used as an absolute yardstick of significance.
Statistical significance is not necessarily the same as biological relevance and vice-versa.
John Quackenbush
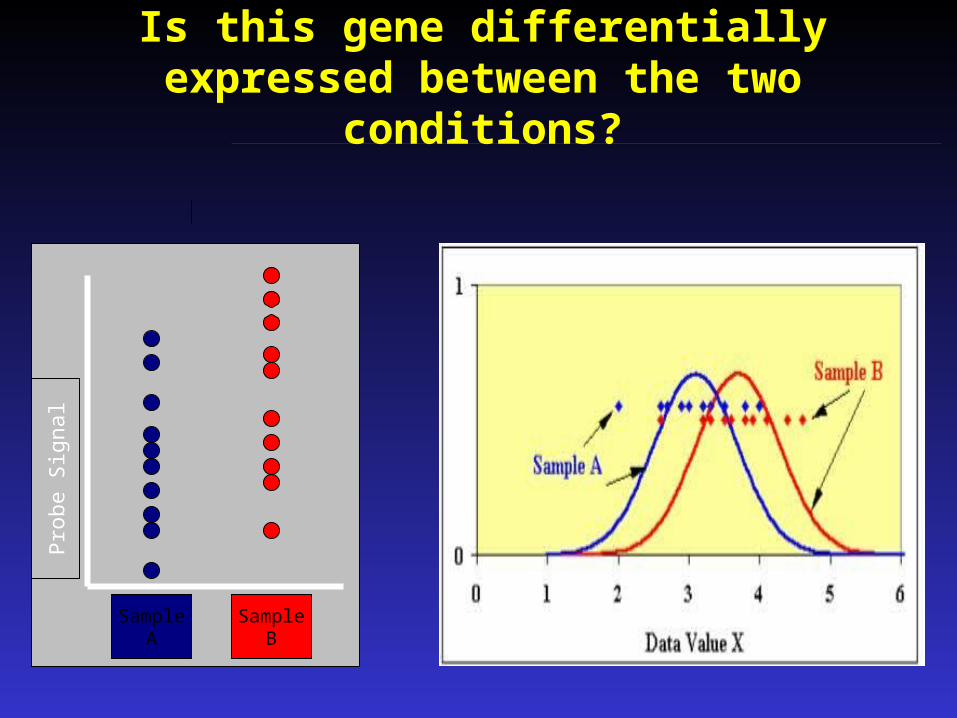
Is this gene differentially expressed between the two conditions?
SampleA
SampleB
Pro
be S
igna
l

To rephrase the question
Is the mean probe value different between Samples A & B• Null Hypothesis = H0 = means are the same• Alternate Hypothesis = Ha = means are different

What affects our ability to test the hypothesis?
Difference in means Number of sample points Standard deviations of sample

The T-statistic
Directly proportional to difference in means Inversely proportional to standard deviation Directly proportional to sample size
The T-test calculates how likely the T-statistic is, given the null hypothesis that the means are actually the same.

T-statistic and P-values
P-values can be determined from theoretical distributions or permutation testing
• Theoretical distributions rely on a set of assumptions that array experiments do not necessarily follow
• Permutation tests do not rely on any assumptions

Permutation Testing
GeneA
GeneB
Pro
be S
igna
l
Original
Group1
Group2
Pro
be S
igna
l
Permutation 2
Group1
Group2
Pro
be S
igna
l
Permutation 1
1) Permute n times by random shuffling
2) Calculate T-statistic for each permutation
3) Calculate probability of original T-statistic

Interpreting P-values
T-test tests the null hypothesis that sample means are equal
Gene X has p-value of 5% from T-test 95% chance it is differentially expressed 5% chance that is NOT differentially
expressed
= False Positive Rate = 5%

T-Test Refinements
Equal vs unequal variance of samples
Equal vs unequal sample size Dependant vs independent
samples
CAVEAT:
As sample sizes get smaller, the validity of p-values calculated via permutation diminishes. Microarrays typically have few probes per gene, so sample size is smallish.

Multiple Testing Problem
If there is a 5% chance of false positives in one experiment, what happens when we are testing 10,000 genes. • The majority of those genes are not
differentially expressed, but• a 5% p-value means we will have 500
false-positives.

Family-Wise Error Rate (FWER)
One comparison: FWER = p-value
10,000 comparisons: FWER ~ 1.0
That means that when making 10,000 comparisons you are sure to make at least one error.
FWER is the probability of making one or more false discoveries (type I errors) among all the hypotheses when performing multiple pair-wise tests.

Bonferroni Correction
What if you want to keep the FWER at 5%
• 0.05 / 10,000 = 0.000005 = 5e-6
• Only those genes with T-test p-value of < 5xe-6 are called differentially expressed
• Leads to experiment-wide of 0.05
The Standard Bonferroni correction is considered very conservative

Adjusted Bonferroni
Rank all genes by ascending order of p-value
Assign gene with smallest p-value a corrected p-value of / N (0.5/10,000)
Assign gene with second smallest p-value a corrected p-value of / N-1
Etc…The Adjusted Bonferroni correction is less conservative

False Discovery Rate
Measures the likely number of false positives amongst “discovered” genes
Factors affecting FDR:• Proportion of actual differentially
expressed genes• Distribution of the true differences• Measurement variability• Sample size

Analysis of Variance (ANOVA)
Microarray testing across ≥ 3 conditions
Is a gene expressed equally across all conditions?
F-ratio for given gene X:(variability within conditions) / (variability across
conditions)
Calculate p-value• Look up probability of F-ratio• Determine probability by permutation testing

Significance Analysis of Microarrays (SAM)
Gene-specific T-tests Computes statistic (dj) for each gene j
• measures the relationship between gene expression and a response variable
• describes and groups the data based on experimental conditions
• uses non-parametric statistics
• repeated permutations are used to determine FDR
Accounts for correlations in genes and avoids parametric assumptions about the (normal vs non-normal) distribution of individual genes

Clustering
Affix/synthesize probes of known sequence to chip
Hybridize with labeled sample
Quantify level of hybridization to each probe
Normalization
Statistics
Clustering & more

Why do clustering?
Identify groups of possibly co-regulated genes (e.g. so you can look for common sequence motifs)
Identify typical temporal or spatial gene expression patterns (e.g. cell-cycle data)
Arrange a set of genes in a linear order that is at least not totally meaningless

Can also cluster experiments
Quality control• detect bad/outlying experiments
Identify or categorize classes of biological samples • sorting by tumor sub-type

How you cluster?
Define a distance measure Group genes (or experiments)
based on that measure
Objects are placed into groups. Objects within a group are more similar to each other than objects across groups.
In some cases groups are hierarchically organized based on the intra-group similarity

Distance Metrics
Correlation (X,Y) = 1 Distance (X,Y) = 4
Correlation (X,Z) = -1 Distance (X,Z) = 2.83
Correlation (X,W) = 1 Distance (X,W) = 1.41
Correlation Euclidean

Clustering considerations
Euclidean clustering• Magnitude & direction• ≥ 2 conditions
Correlation clustering • Direction only• ≥ 3 conditions
Array data is noisy, so you probably need multiple data points per condition
Clustering methods• Hierarchical• Partitional• Other

Hierarchical clustering
Initial state - each item is a cluster
Iterate- join two most similar cluster
Stop- when number of clusters reaches user-defined value
Agglomerative, bottom-up method

Linkage methods
Single Link:Similarity of two most similar members
Complete Link:Similarity of two most similar members
Average Link:Average similarity of all members
Ways to determine cluster similarity
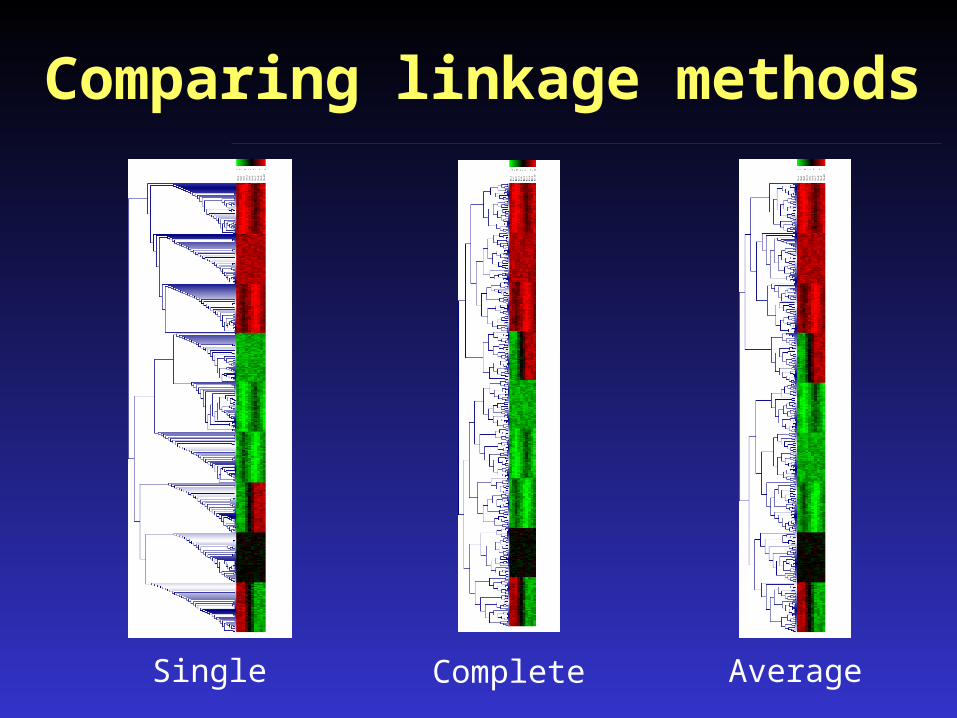
Comparing linkage methods
Single AverageComplete

Partitional (K-means) clustering
Partition data into K random clusters
Assign each point to nearest cluster
Calculate centroid of each cluster
GOTO step 2
Divisive, top-down method

Other methods
Support Vector Machines (SVM) K-nearest Neighbor (KNN) Self Organizing Maps (SOM) Self Organizing Tree Algorithm (SOTA) Cluster Affinity Search Technique
(CAST) QT Cluster (QTC) Discriminant Analysis Classifier (DAM) Principal Component Analysis (PCA) Etc.

Warnings and Limitations
Clusters are like statisticsIdeally they mirror reality, but they should only be taken seriously in conjunction with confirmatory data from other sources.
Clustering software clusters thingsIf you tell it to find 4 clusters, it will find 4 clusters in anything!
Garbage In, Garbage OutClustering typically relies on a set of input parameters that can be hard to evaluate except for empirically evaluating the outputs for a given set of input parameters.

Clusters Interpretation - EASE
(Expression Analysis Systematic Explorer)
Population Size: 40 genesCluster size: 12 genes
10 genes, shown in green, have a common biological theme and 8 occur within the cluster

Microarray Analysis Software
TIGR MEVLimmaSAMEDGE
• These software packages are free and open-source
• Each has different strengths/weaknesses and makes different assumptions about your data

$$ Analysis Platforms
Gene Sifter
Rosetta Resolver
Bio Discovery

Microarray Data Sources
Gene Expression Omnibus
(NCBI)
ArrayExpress (EBI)
Stanford Microarray Database
Yale Microarray Database

Microarray Data Standards
Microarray Gene Expression Data Society (MGED)• MIAME• MAGE - OM• MAGE ML
RNA Abundance Database (RAD)• Integrating data from various types of
expression experiments