other factors multiprocessors -...
TRANSCRIPT

1
Multiprocessors
Adapted from UCB cs252 Sp 2007 lectures
CprE 581 Computer SystemsArchitecture
(Chapter 5 of Hennessy-Patterson. 5th edition text)
2
Uniprocessor Performance (SPECint)
• VAX : 25%/year 1978 to 1986• RISC + x86: 52%/year 1986 to 2002• RISC + x86: 22%/year 2002 to present
11/29/2016 3
Déjà vu all over again?“… today’s processors … are nearing an impasse as technologies approach the
speed of light..”David Mitchell, The Transputer: The Time Is Now (1989)
Transputer had bad timing (Uniprocessor performance) Procrastination rewarded: 2X seq. perf. / 1.5 years
“We are dedicating all of our future product development to multicore designs. … This is a sea change in computing”
Paul Otellini, President, Intel (2005) All microprocessor companies switch to MP (2X CPUs / 2 yrs)
Procrastination penalized: 2X sequential perf. / 5 yrs
Manufacturer/Year AMD/’11 Intel/’11 IBM/’10 Sun/’10
Processors/chip 8 4 8 8Threads/Processor 1 2 4 8
Threads/chip 8 8 32 64
4
Other Factors MultiprocessorsGrowth in data-intensive applications Data bases, file servers, …
Growing interest in servers, server perf.Increasing desktop perf. less important Outside of graphics
Improved understanding in how to use multiprocessors effectively Especially server where significant natural TLP
Advantage of leveraging design investment by replication Rather than unique design
5
Flynn’s TaxonomyFlynn classified by data and control streams in 1966
SIMD Data-Level ParallelismMIMD Thread-Level ParallelismMIMD popular because Flexible: N programs or 1 multithreaded program Cost-effective: same MPU in desktop & MIMD machine
Single Instruction, Single Data (SISD)
(Uniprocessor)
Single Instruction, Multiple Data SIMD
(single PC: Vector, CM-2)
Multiple Instruction, Single Data (MISD)
Multiple Instruction, Multiple Data MIMD
(Clusters, SMP servers)
M.J. Flynn, "Very High-Speed Computers", Proc. of the IEEE, V 54, 1900-1909, Dec. 1966.
6
Back to Basics“A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast.”Parallel Architecture = Computer Architecture + Communication Architecture

2
7
Two Models for Communication and Memory Architecture1. Communication occurs by explicitly passing messages among the
processors: message-passing multiprocessors (aka multicomputers)• Modern cluster systems contain multiple stand-alone computers
communicating via messages2. Communication occurs through a shared address space (via
loads and stores): shared-memory multiprocessors either• UMA (Uniform Memory Access time) for shared address,
centralized memory MP• NUMA (Non-Uniform Memory Access time multiprocessor)
for shared address, distributed memory MPIn past, confusion whether “sharing” means sharing physical memory (Symmetric MP) or sharing address space
8
Centralized vs. Distributed Memory
P1
$
Inter-connection network
$
Pn
Mem Mem
P1
$
Inter-connection network
$
Pn
Mem Mem
Centralized Memory Distributed Memory
Scale
9
Centralized Memory Multiprocessor Also called symmetric multiprocessors (SMPs)
because single main memory has a symmetric relationship to all processors
Large caches single memory can satisfy memory demands of small number of processors
Can scale to a few dozen processors by using a switch and by using many memory banks
Although scaling beyond that is technically conceivable, it becomes less attractive as the number of processors sharing centralized memory increases
10
Distributed Memory Multiprocessor
Pro: Cost-effective way to scale memory bandwidth If most accesses are to local memory
Pro: Reduces latency of local memory accesses
Con: Communicating data between processors more complex
Con: Software must be aware of data placement to take advantage of increased memory BW
Programming model (pro or con?)
11
Challenges of Parallel ProcessingBig challenge is % of program that is inherently sequential What does it mean to be inherently sequential?
Suppose 80X speedup from 100 processors. What fraction of original program can be sequential?a. 10%b. 5%c. 1%d. <1%
12
Amdahl’s Law Answers
%75.992.79/79Fraction
Fraction8.0Fraction8079
1)100
Fraction Fraction 1(80
100
Fraction Fraction 1
1 08
Speedup
Fraction Fraction 1
1 Speedup
parallel
parallelparallel
parallelparallel
parallelparallel
parallel
parallelenhanced
overall

3
13
Challenges of Parallel Processing
Second challenge is long latency to remote memorySuppose 32 CPU MP, 2GHz, 200 ns remote memory, all local accesses hit memory hierarchy and base CPI is 0.5. (Remote access = 200/0.5 = 400 clock cycles.) What is performance impact if 0.2% instructions that involve remote access?a. 1.5Xb. 2.0Xc. 2.5X
14
CPI Equation CPI = Base CPI +
Remote request rate x Remote request cost
CPI = 0.5 + 0.2% x 400 = 0.5 + 0.8 = 1.3No communication is 1.3/0.5 or 2.6 faster than 0.2% instructions involve local access
15
Communication and SynchronizationParallel processes must co-operate to complete a single task fasterRequires distributed communication and synchronization Communication is for data values, or “what” Synchronization is for control, or “when” Communication and synchronization are often inter-related
i.e., “what” depends on “when”Message-passing bundles data and control Message arrival encodes “what” and “when”
In shared-memory machines, communication usually via coherent caches & synchronization via atomic memory operations Due to advent of single-chip multiprocessors, it is likely
cache-coherent shared memory systems will be the dominant form of multiprocessor
16
symmetric• All memory is equally far away from all processors
• Any processor can do any I/O(set up a DMA transfer)
Symmetric Multiprocessors
MemoryI/O controller
Graphicsoutput
CPU-Memory bus
bridge
Processor
I/O controller I/O controller
I/O bus
Networks
Processor
17
SynchronizationThe need for synchronization arises whenever there are concurrent processes in a system
(even in a uniprocessor system)
Forks and Joins: In parallel programming, a parallel process may want to wait until several events have occurred
Producer-Consumer: A consumer process must wait until the producer process has produced data
Exclusive use of a resource: Operating system has to ensure that only one process uses a resource at a given time
producer
consumer
fork
join
P1 P2
18
A Producer-Consumer Example
The program is written assuming instructions are executed in order.
Producer posting Item x:Load Rtail, (tail)Store (Rtail), xRtail=Rtail+1Store (tail), Rtail
Consumer:Load Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinLoad R, (Rhead)Rhead=Rhead+1Store (head), Rheadprocess(R)
Producer Consumertail head
Rtail Rtail Rhead R
Problems?

4
19
A Producer-Consumer Example continued
Producer posting Item x:Load Rtail, (tail)Store (Rtail), xRtail=Rtail+1Store (tail), Rtail
Consumer:Load Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinLoad R, (Rhead)Rhead=Rhead+1Store (head), Rheadprocess(R)
Can the tail pointer get updatedbefore the item x is stored?
Programmer assumes that if 3 happens after 2, then 4happens after 1.
Problem sequences are:2, 3, 4, 14, 1, 2, 3
1
2
3
4
20
Sequential ConsistencyA Memory Model
“ A system is sequentially consistent if the result ofany execution is the same as if the operations of allthe processors were executed in some sequential order, and the operations of each individual processorappear in the order specified by the program”
Leslie Lamport
Sequential Consistency = arbitrary order-preserving interleavingof memory references of sequential programs
M
P P P P P P
21
Sequential ConsistencySequential concurrent tasks: T1, T2Shared variables: X, Y (initially X = 0, Y = 10)
T1: T2:Store (X), 1 (X = 1) Load R1, (Y) Store (Y), 11 (Y = 11) Store (Y’), R1 (Y’= Y)
Load R2, (X) Store (X’), R2 (X’= X)
what are the legitimate answers for X’ and Y’ ?
(X’,Y’) {(1,11), (0,10), (1,10), (0,11)} ?
If y is 11 then x cannot be 0
22
Sequential ConsistencySequential consistency imposes more memory ordering constraints than those imposed by uniprocessor program dependencies ( )
What are these in our example ?
T1: T2:Store (X), 1 (X = 1) Load R1, (Y) Store (Y), 11 (Y = 11) Store (Y’), R1 (Y’= Y)
Load R2, (X) Store (X’), R2 (X’= X)additional SC requirements
Does (can) a system with caches or out-of-order execution capability provide a sequentially consistentview of the memory ?
23
Multiple Consumer Example
Producer posting Item x:Load Rtail, (tail)Store (Rtail), xRtail=Rtail+1Store (tail), Rtail
Consumer:Load Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinLoad R, (Rhead)Rhead=Rhead+1Store (head), Rheadprocess(R)
What is wrong with this code?
Critical section:Needs to be executed atomically by one consumer locks
tail headProducer
Rtail
Consumer1
R Rhead
Rtail
Consumer2
R Rhead
Rtail
24
Locks or SemaphoresE. W. Dijkstra, 1965
A semaphore is a non-negative integer, with thefollowing operations:
P(s): if s>0, decrement s by 1, otherwise wait
V(s): increment s by 1 and wake up one of the waiting processes
P’s and V’s must be executed atomically, i.e., without• interruptions or• interleaved accesses to s by other processors
initial value of s determines the maximum no. of processesin the critical section
Process iP(s)
<critical section>V(s)

5
25
Implementation of SemaphoresSemaphores (mutual exclusion) can be implemented using ordinary Load and Store instructions in the Sequential Consistency memory model. However, protocols for mutual exclusion are difficult to design...
Simpler solution:atomic read-modify-write instructions
Test&Set (m), R: R M[m];if R==0 then
M[m] 1;
Swap (m), R:Rt M[m];M[m] R;R Rt;
Fetch&Add (m), RV, R:R M[m];M[m] R + RV;
Examples: m is a memory location, R is a register
26
CriticalSection
P: Test&Set (mutex),Rtempif (Rtemp!=0) goto PLoad Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinLoad R, (Rhead)Rhead=Rhead+1Store (head), Rhead
V: Store (mutex),0process(R)
Multiple Consumers Example using the Test&Set Instruction
Other atomic read-modify-write instructions (Swap, Fetch&Add, etc.) can also implement P’s and V’s
What if the process stops or is swapped out while in the critical section?
27
Nonblocking SynchronizationCompare&Swap(m), Rt, Rs:if (Rt==M[m])
then M[m]=Rs;Rs=Rt ;status success;
else status fail;
try: Load Rhead, (head)spin: Load Rtail, (tail)
if Rhead==Rtail goto spinLoad R, (Rhead)Rnewhead = Rhead+1Compare&Swap(head), Rhead, Rnewheadif (status==fail) goto tryprocess(R)
status is animplicit argument
28
Load-reserve & Store-conditionalSpecial register(s) to hold reservation flag and address, and the outcome of store-conditional
try: Load-reserve Rhead, (head)spin: Load Rtail, (tail)
if Rhead==Rtail goto spinLoad R, (Rhead)Rhead = Rhead + 1Store-conditional (head), Rheadif (status==fail) goto tryprocess(R)
Load-reserve R, (m):<flag, adr> <1, m>; R M[m];
Store-conditional (m), R:if <flag, adr> == <1, m> then cancel other procs’
reservation on m;M[m] R; status succeed;
else status fail;
29
Performance of LocksBlocking atomic read-modify-write instructions
e.g., Test&Set, Fetch&Add, Swapvs
Non-blocking atomic read-modify-write instructionse.g., Compare&Swap,
Load-reserve/Store-conditionalvs
Protocols based on ordinary Loads and Stores
Performance depends on several interacting factors:degree of contention, caches, out-of-order execution of Loads and Stores
30
Issues in Implementing Sequential Consistency
Implementation of SC is complicated by two issues
• Out-of-order execution capabilityLoad(a); Load(b) yesLoad(a); Store(b) yes if a bStore(a); Load(b) yes if a bStore(a); Store(b) yes if a b
• CachesCaches can prevent the effect of a store from being seen by other processors
M
P P P P P P

6
31
Memory FencesInstructions to sequentialize memory accesses
Processors with relaxed or weak memory models (i.e.,permit Loads and Stores to different addresses to be reordered) need to provide memory fence instructions to force the serialization of memory accesses
Examples of processors with relaxed memory models:Sparc V8 (TSO,PSO): Membar Sparc V9 (RMO):
Membar #LoadLoad, Membar #LoadStoreMembar #StoreLoad, Membar #StoreStore
PowerPC (WO): Sync, EIEIO
Memory fences are expensive operations, however, one pays the cost of serialization only when it is required
32
Using Memory Fences
Producer posting Item x:Load Rtail, (tail)Store (Rtail), xMembarSSRtail=Rtail+1Store (tail), Rtail
Consumer:Load Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinMembarLLLoad R, (Rhead)Rhead=Rhead+1Store (head), Rheadprocess(R)
Producer Consumertail head
Rtail Rtail Rhead R
ensures that tail ptris not updated before x has been stored
ensures that R isnot loaded before x has been stored
33
Data-Race Free Programs a.k.a. Properly Synchronized Programs
Process 1...Acquire(mutex);< critical section>
Release(mutex);
Process 2...Acquire(mutex);< critical section>
Release(mutex);
Synchronization variables (e.g. mutex) are disjointfrom data variables
Accesses to writable shared data variables are protected in critical regions
no data races except for locks(Formal definition is elusive)
In general, it cannot be proven if a program is data-race free.
34
Fences in Data-Race Free Programs
Process 1...Acquire(mutex);membar;
< critical section>membar;Release(mutex);
Process 2...Acquire(mutex);membar;
< critical section>membar;Release(mutex);
• Relaxed memory model allows reordering of instructions by the compiler or the processor as long as the reordering is not done across a fence
• The processor also should not speculate or prefetch across fences
35
Mutual Exclusion Using Load/Store A protocol based on two shared variables c1 and c2. Initially, both c1 and c2 are 0 (not busy)
What is wrong?
Process 1...c1=1;
L: if c2=1 then go to L< critical section>
c1=0;
Process 2...c2=1;
L: if c1=1 then go to L< critical section>
c2=0;
Deadlock!
36
Mutual Exclusion: second attempt
To avoid deadlock, let a process give up the reservation (i.e. Process 1 sets c1 to 0) while waiting.
• Deadlock is not possible but with a low probability a livelock may occur.
• An unlucky process may never get to enter the critical section starvation
Process 1...
L: c1=1;if c2=1 then
{ c1=0; go to L}< critical section>
c1=0
Process 2...
L: c2=1;if c1=1 then
{ c2=0; go to L}< critical section>
c2=0

7
37
A Protocol for Mutual ExclusionT. Dekker, 1966
Process 1...c1=1;turn = 1;
L: if c2=1 & turn=1 then go to L
< critical section>c1=0;
A protocol based on 3 shared variables c1, c2 and turn. Initially, both c1 and c2 are 0 (not busy)
• turn = i ensures that only process i can wait • variables c1 and c2 ensure mutual exclusion
Solution for n processes was given by Dijkstra and is quite tricky!
Process 2...c2=1;turn = 2;
L: if c1=1 & turn=2 then go to L
< critical section>c2=0;
38
Analysis of Dekker’s Algorithm... Process 1c1=1;turn = 1;
L: if c2=1 & turn=1 then go to L
< critical section>c1=0;
... Process 2c2=1;turn = 2;
L: if c1=1 & turn=2 then go to L
< critical section>c2=0;
Sce
nario
1
... Process 1c1=1;turn = 1;
L: if c2=1 & turn=1 then go to L
< critical section>c1=0;
... Process 2c2=1;turn = 2;
L: if c1=1 & turn=2 then go to L
< critical section>c2=0;
Sce
nario
2
39
N-process Mutual ExclusionLamport’s Bakery Algorithm
Process i
choosing[i] = 1;num[i] = max(num[0], …, num[N-1]) + 1;choosing[i] = 0;
for(j = 0; j < N; j++) {while( choosing[j] );while( num[j] &&
( ( num[j] < num[i] ) ||( num[j] == num[i] && j < i ) ) );
}
num[i] = 0;
Initially num[j] = 0, for all jEntry Code
Exit Code
40
Memory Consistency in SMPs
Suppose CPU-1 updates A to 200. write-back: memory and cache-2 have stale valueswrite-through: cache-2 has a stale value
Do these stale values matter?What is the view of shared memory for programming?
cache-1A 100
CPU-Memory bus
CPU-1 CPU-2
cache-2A 100
memoryA 100
41
Write-back Caches & SC
• T1 is executed
prog T2LD Y, R1ST Y’, R1LD X, R2ST X’,R2
prog T1ST X, 1ST Y,11
cache-2cache-1 memoryX = 0Y =10X’=Y’=
X= 1Y=11
Y =Y’= X = X’=
• cache-1 writes back Y X = 0Y =11X’=Y’=
X= 1Y=11
Y =Y’= X =
X’=
X = 1Y =11X’=Y’=
X= 1Y=11
Y = 11Y’= 11X = 0X’= 0
• cache-1 writes back X
X = 0Y =11X’=Y’=
X= 1Y=11
Y = 11Y’= 11X = 0X’= 0
• T2 executed
X = 1Y =11X’= 0Y’=11
X= 1Y=11
Y =11Y’=11 X = 0X’= 0
• cache-2 writes backX’ & Y’
42
Write-through Caches & SCcache-2
Y = Y’= X = 0X’=
memory
X = 0Y =10X’=Y’=
cache-1
X= 0Y=10
prog T2LD Y, R1ST Y’, R1LD X, R2ST X’,R2
prog T1ST X, 1ST Y,11
Write-through caches don’t preserve sequential consistency either
• T1 executedY = Y’= X = 0X’=
X = 1Y =11X’=Y’=
X= 1Y=11
• T2 executed Y = 11Y’= 11X = 0X’= 0
X = 1Y =11X’= 0Y’=11
X= 1Y=11
8
43
Maintaining Sequential ConsistencySC is sufficient for correct producer-consumerand mutual exclusion code (e.g., Dekker)
Multiple copies of a location in various cachescan cause SC to break down.
Hardware support is required such that• only one processor at a time has write
permission for a location• no processor can load a stale copy of
the location after a write
cache coherence protocols
44
Cache Coherence Protocols for SC
write request:the address is invalidated (updated) in all othercaches before (after) the write is performed
read request:if a dirty copy is found in some cache, a write-back is performed before the memory is read
We will focus on Invalidation protocolsas opposed to Update protocols
45
Warmup: Parallel I/O
(DMA stands for Direct Memory Access)
Either Cache or DMA canbe the Bus Master andeffect transfers
DISKDMA
PhysicalMemory
Proc.
R/W
Data (D) Cache
Address (A)
AD
R/W
Page transfersoccur while theProcessor is running
MemoryBus
46
Problems with Parallel I/O
Memory Disk: Physical memory may bestale if Cache copy is dirty
Disk Memory: Cache may hold state data and not see memory writes
DISK
DMA
PhysicalMemory
Proc.Cache
MemoryBus
Cached portionsof page
DMA transfers
47
Snoopy Cache Goodman 1983Idea: Have cache watch (or snoop upon) DMA transfers, and then “do the right thing”Snoopy cache tags are dual-ported
Proc.
Cache
Snoopy read portattached to MemoryBus
Data(lines)
Tags andState
A
D
R/W
Used to drive Memory Buswhen Cache is Bus Master
AR/W
48
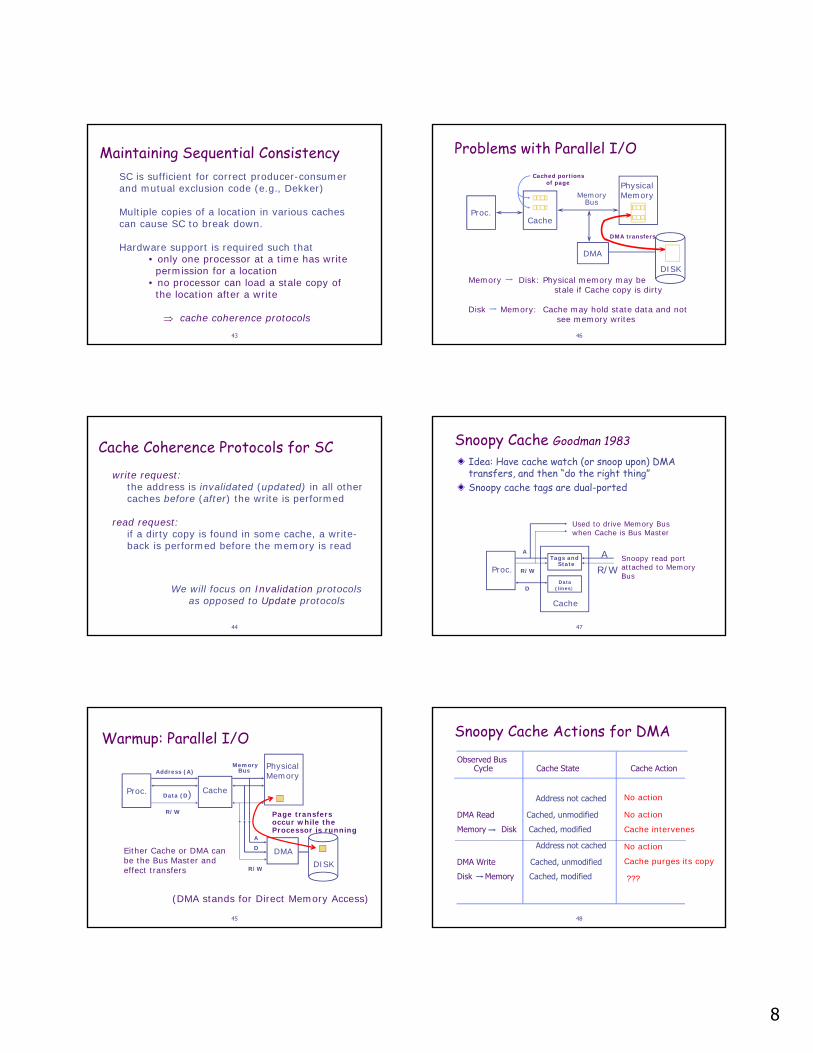
Snoopy Cache Actions for DMA
Observed Bus Cycle Cache State Cache Action
Address not cached
DMA Read Cached, unmodifiedMemory Disk Cached, modified
Address not cached
DMA Write Cached, unmodifiedDisk Memory Cached, modified
No action
No action
No action
Cache intervenes
Cache purges its copy
???

9
49
Shared Memory Multiprocessor
Use snoopy mechanism to keep all processors’ view of memory coherent
M1
M2
M3
SnoopyCache
DMA
PhysicalMemory
MemoryBus
SnoopyCache
SnoopyCache DISKS
Copyright © 2012, Elsevier Inc. All rights reserved.
Cache CoherenceProcessors may see different values through their caches:
Centralized S
hared-Mem
ory Architectures
51
Example Cache Coherence Problem
Processors see different values for u after event 3 With write back caches, value written back to memory depends
on happenstance of which cache flushes or writes back value when Processes accessing main memory may see very stale value
Unacceptable for programming, and its frequent!
I/O devices
Memory
P1
$ $ $
P2 P3
5
u = ?4
u = ?
u :51
u :5
2
u :5
3
u= 7
52
Example
Intuition not guaranteed by coherenceexpect memory to respect order between accesses to different locations issued by a given process to preserve orders among accesses to same location by
different processesCoherence is not enough! pertains only to single location
P1 P2/*Assume initial value of A and flag is 0*/
A = 1; while (flag == 0); /*spin idly*/flag = 1; print A;
Mem
P1Pn
Conceptual Picture
53
P
DiskMemory
L2L1
100:34
100:35
100:67
Intuitive Memory Model
Too vague and simplistic; 2 issues1. Coherence defines values returned by a read2. Consistency determines when a written value will
be returned by a readCoherence defines behavior to same location, Consistency defines behavior w.r.t other locations
• Reading an address should return the last value written to that address– Easy in uniprocessors,
except for I/O
Copyright © 2012, Elsevier Inc. All rights reserved.
Cache CoherenceCoherence All reads by any processor must return the most
recently written value Writes to the same location by any two
processors are seen in the same order by all processors
Consistency When a written value will be returned by a read If a processor writes location A followed by
location B, any processor that sees the new value of B must also see the new value of A
Centralized S
hared-Mem
ory Architectures

10
55
Defining Coherent Memory System1. Preserve Program Order: A read by processor P to
location X that follows a write by P to X, with no writes of X by another processor occurring between the write and the read by P, always returns the value written by P
2. Coherent view of memory: Read by a processor to location X that follows a write by anotherprocessor to X returns the written value if the read and write are sufficiently separated in timewhen no other writes to X occur between the two accesses
3. Write serialization: 2 writes to same location by any 2 processors are seen in the same order by all processors
56
Write Consistency
For now assume1. A write does not complete (and allow the next
write to occur) until all processors have seen the effect of that write
2. The processor does not change the order of any write with respect to any other memory access
if a processor writes location A followed by location B, any processor that sees the new value of B must also see the new value of A
These restrictions allow the processor to reorder reads, but forces the processor to finish writes in program order
57
Basic Schemes for Enforcing CoherenceProgram on multiple processors will normally have copies of the same data in several caches Unlike I/O, where its rare
Rather than trying to avoid sharing in SW, SMPs use a HW protocol to maintain coherent caches Migration and Replication key to performance of shared data
Migration - data can be moved to a local cache and used there in a transparent fashion Reduces both latency to access shared data that is allocated
remotely and bandwidth demand on the shared memoryReplication – for shared data being simultaneously read, since caches make a copy of data in local cache Reduces both latency of access and contention for read
shared data
58
2 Classes of Cache Coherence Protocols
1. Directory based — Sharing status of a block of physical memory is kept in just one location, the directory
2. Snooping — Every cache with a copy of data also has a copy of sharing status of block, but no centralized state is kept• All caches are accessible via some broadcast
medium (a bus or switch) • All cache controllers monitor or snoop on the
medium to determine whether or not they have a copy of a block that is requested on a bus or switch access
Copyright © 2012, Elsevier Inc. All rights reserved.
Snoopy Coherence Protocols
Write invalidate On write, invalidate all other copies Use bus itself to serialize
Write cannot complete until bus access is obtained
Write update On write, update all copies
Centralized S
hared-Mem
ory Architectures
60
Snoopy Cache-Coherence Protocols
Cache Controller “snoops” all transactions on the shared medium (bus or switch) relevant transaction if for a block it contains take action to ensure coherence
invalidate, update, or supply value depends on state of the block and the protocol
Either get exclusive access before write via write invalidate or update all copies on write
StateAddressData
I/O devicesMem
P1
$
Bus snoop
$
Pn
Cache-memorytransaction

11
61
Example: Write-through Invalidate
Must invalidate before step 3Write update uses more broadcast medium BW all recent MPUs use write invalidate
I/O devices
Memory
P1
$ $ $
P2 P3
5
u = ?4
u = ?
u :51
u :5
2
u :5
3
u= 7
u = 7
62
Architectural Building BlocksCache block state transition diagram FSM specifying how disposition of block changes
invalid, valid, dirtyBroadcast Medium Transactions (e.g., bus) Fundamental system design abstraction Logically single set of wires connect several devices Protocol: arbitration, command/addr, data Every core observes every transaction
Broadcast medium enforces serialization of read or write accesses Write serialization 1st processor to get medium invalidates others copies Implies cannot complete write until it obtains bus All coherence schemes require serializing accesses to same
cache blockAlso need to find up-to-date copy of cache block
63
Locate up-to-date copy of dataWrite-through: get up-to-date copy from memory Write through simpler if enough memory BWWrite-back harder Most recent copy can be in a cacheCan use same snooping mechanism1. Snoop every address placed on the bus2. If a processor has dirty copy of requested cache block, it
provides it in response to a read request and aborts the memoryaccess
Complexity from retrieving cache block from a processorcache, which can take longer than retrieving it frommemory
Write-back needs lower memory bandwidth Support larger numbers of faster processors Most multiprocessors use write-back
64
Cache Resources for WB SnoopingNormal cache tags can be used for snoopingValid bit per block makes invalidation easyRead misses easy since rely on snoopingWrites Need to know if any other copies of theblock are cached No other copies No need to place write on bus
for WB Other copies Need to place invalidate on bus
65
Cache Resources for WB Snooping
To track whether a cache block isshared, add extra state bit associatedwith each cache block, like valid bitand dirty bit Write to Shared block Need to place invalidate on bus
and mark cache block as private (if an option) No further invalidations will be sent for that block This processor called owner of cache block Owner then changes state from shared to unshared (or
exclusive)
66
Cache behavior in response to busEvery bus transaction must check the cache-address tags could potentially interfere with processor cache accesses
A way to reduce interference is to duplicate tags One set for caches access, one set for bus accesses
Another way to reduce interference is to use L2 tags Since L2 less heavily used than L1 Every entry in L1 cache must be present in the L2 cache, called
the inclusion property If Snoop gets a hit in L2 cache, then it must arbitrate for the
L1 cache to update the state and possibly retrieve the data, which usually requires a stall of the processor

12
67
Example Protocol
Snooping coherence protocol is usually implemented by incorporating a finite-state controller in each nodeLogically, think of a separate controller associated with each cache block That is, snooping operations or cache requests for
different blocks can proceed independentlyIn implementations, a single controller allows multiple operations to distinct blocks to proceed in interleaved fashion that is, one operation may be initiated before another is
completed, even through only one cache access or one bus access is allowed at time
68
Ordering
Writes establish a partial orderDoesn’t constrain ordering of reads, though shared-medium (bus) will order read misses too any order among reads between writes is fine,
as long as in program order
R W
R
R R
R R
RR R W
R
R
R R
RR
R
P0:
P1:
P2:
69
Example Write Back Snoopy Protocol
Invalidation protocol, write-back cache Snoops every address on bus If it has a dirty copy of requested block, provides that block in
response to the read request and aborts the memory accessEach memory block is in one state: Clean in all caches and up-to-date in memory (Shared) OR Dirty in exactly one cache (Exclusive) OR Not in any caches
Each cache block is in one state (track these): Shared : block can be read OR Exclusive : cache has only copy, its writeable, and dirty OR Invalid : block contains no data (in uniprocessor cache too)
Read misses: cause all caches to snoop busWrites to clean blocks are treated as misses
Copyright © 2012, Elsevier Inc. All rights reserved.
Snoopy Coherence ProtocolsLocating an item when a read miss occurs In write-back cache, the updated value
must be sent to the requesting processor
Cache lines marked as shared or exclusive/modified Only writes to shared lines need an
invalidate broadcastAfter this, the line is marked as exclusive
Centralized S
hared-Mem
ory A
rchitectures
Copyright © 2012, Elsevier Inc. All rights reserved.
Snoopy Coherence Protocols
Centralized S
hared-Mem
ory Architectures
Copyright © 2012, Elsevier Inc. All rights reserved.
Snoopy Coherence Protocols
Centralized S
hared-Mem
ory Architectures

13
73
Cache State Transition DiagramThe MSI protocol
M
S I
M: ModifiedS: SharedI: Invalid
Each cache line has a tag
Address tagstatebits
Write miss
Other processorintent to write
Readmiss
Other processorintent to write
Read by anyprocessor
P1 readsor writes
Cache state in processor P1
Other processor readsP1 writes back
Permitted States for a pair of caches
M S I
M X X
S X
I
74
[edit]
75
Two Processor Example(Reading and writing the same cache line)
M
S I
Write miss
Readmiss
P2 intent to write
P2 reads,P1 writes back
P1 readsor writes
P2 intent to write
P1
M
S I
Write miss
Readmiss
P1 intent to write
P1 reads,P2 writes back
P2 readsor writes
P1 intent to write
P2
P1 reads
P1 writes
P2 readsP2 writes
P1 writesP2 writes
P1 reads
P1 writes
76
Observation
If a line is in the M state then no other cache can have a copy of the line! Memory stays coherent, multiple differing copies
cannot exist
M
S I
Write miss
Other processorintent to write
Readmiss
Other processorintent to write
Read by anyprocessor
P1 readsor writesOther processor reads
P1 writes back
Copyright © 2012, Elsevier Inc. All rights reserved.
Snoopy Coherence ProtocolsComplications for the basic MSI protocol: Operations are not atomic
E.g. detect miss, acquire bus, receive a response Creates possibility of deadlock and races One solution: processor that sends invalidate can hold
bus until other processors receive the invalidate
Extensions: Add exclusive state to indicate clean
block in only one cache (MESI protocol) Prevents needing to write invalidate on a write
Owned state
Centralized S
hared-Mem
ory Architectures
10/16/2007 78
MESI: An Enhanced MSI protocolincreased performance for private data
M E
S I
M: Modified ExclusiveE: Exclusive, unmodifiedS: SharedI: Invalid
Each cache line has a tag
Address tagstatebits
Write missOther processorintent to write
Read miss,shared
Other processorintent to write
P1 write
Read by anyprocessor
Other processor readsP1 writes back
P1 readP1 writeor read
Cache state in processor P1
Read miss, not shared

14
79
Snooper Snooper Snooper Snooper
Optimized Snoop with Level-2 Caches
• Processors often have two-level caches• small L1, large L2 (usually both on chip now)
• Inclusion property: entries in L1 must be in L2invalidation in L2 invalidation in L1
• Snooping on L2 does not affect CPU-L1 bandwidth
What problem could occur?
CPU
L1 $
L2 $
CPU
L1 $
L2 $
CPU
L1 $
L2 $
CPU
L1 $
L2 $
80
Intervention
When a read-miss for A occurs in cache-2, a read request for A is placed on the bus
• Cache-1 needs to supply & change its state to shared• The memory may respond to the request also!
Does memory know it has stale data?
Cache-1 needs to intervene through memory controller to supply correct data to cache-2
cache-1A 200
CPU-Memory bus
CPU-1 CPU-2
cache-2
memory (stale data)A 100
81
False Sharing
state blk addr data0 data1 ... dataN
A cache block contains more than one word
Cache-coherence is done at the block-level and not word-level
Suppose M1 writes wordi and M2 writes wordk andboth words have the same block address.
What can happen?
82
Synchronization and Caches:Performance Issues
Cache-coherence protocols will cause mutex to ping-pongbetween P1’s and P2’s caches.
Ping-ponging can be reduced by first reading the mutexlocation (non-atomically) and executing a swap only if it is found to be zero.
cache
Processor 1R 1
L: swap (mutex), R;if <R> then goto L; <critical section>
M[mutex] 0;
Processor 2R 1
L: swap (mutex), R;if <R> then goto L; <critical section>
M[mutex] 0;
Processor 3R 1
L: swap (mutex), R;if <R> then goto L; <critical section>
M[mutex] 0;
CPU-Memory Bus
mutex=1cache cache
83
Performance Related to Bus OccupancyIn general, a read-modify-write instruction requires two memory (bus) operations without intervening memory operations by other processors
In a multiprocessor setting, bus needs to be locked for the entire duration of the atomic read and write operation
expensive for simple busesvery expensive for split-transaction buses
modern ISAs useload-reserve store-conditional
10/16/2007 84
Load-reserve & Store-conditional
If the snooper sees a store transaction to the addressin the reserve register, the reserve bit is set to 0
• Several processors may reserve ‘a’ simultaneously• These instructions are like ordinary loads and storeswith respect to the bus traffic
Can implement reservation by using cache hit/miss, no additional hardware required (problems?)
Special register(s) to hold reservation flag and address, and the outcome of store-conditionalLoad-reserve R, (a):
<flag, adr> <1, a>; R M[a];
Store-conditional (a), R:if <flag, adr> == <1, a> then cancel other procs’
reservation on a;M[a] <R>; status succeed;
else status fail;

15
85
Performance: Load-reserve & Store-conditional
The total number of memory (bus) transactions is not necessarily reduced, but splitting an atomic instruction into load-reserve & store-conditional:
• increases bus utilization (and reducesprocessor stall time), especially in split-transaction buses
• reduces cache ping-pong effect because processors trying to acquire a semaphore donot have to perform a store each time
86
Blocking cachesOne request at a time + CC SC
Non-blocking cachesMultiple requests (different addresses) concurrently + CC
Relaxed memory modelsCC ensures that all processors observe the same order of loads and stores to an address
Out-of-Order Loads/Stores & CC
CacheMemorypushout (Wb-rep)
load/storebuffers
CPU
(S-req, E-req)
(S-rep, E-rep)
Wb-req, Inv-req, Inv-repsnooper
(I/S/E)
CPU/MemoryInterface
87
Performance of Symmetric Shared-Memory Multiprocessors
Cache performance is combination of 1. Uniprocessor cache miss traffic2. Traffic caused by communication
Results in invalidations and subsequent cache misses
4th C: coherence miss Joins Compulsory, Capacity, Conflict
88
Coherency Misses1. True sharing misses arise from the communication of data
through the cache coherence mechanism• Invalidates due to 1st write to shared block• Reads by another CPU of modified block in different cache• Miss would still occur if block size were 1 word
2. False sharing misses when a block is invalidated because some word in the block, other than the one being read, is written into• Invalidation does not cause a new value to be
communicated, but only causes an extra cache miss• Block is shared, but no word in block is actually shared
miss would not occur if block size were 1 word
89
Example: True v. False Sharing v. Hit?
Time P1 P2 True, False, Hit? Why?
1 Write x1
2 Read x2
3 Write x1
4 Write x2
5 Read x2
• Assume x1 and x2 in same cache block. P1 and P2 both read x1 and x2 before.
True miss; invalidate x1 in P2
False miss; x1 irrelevant to P2
False miss; x1 irrelevant to P2
False miss; x1 irrelevant to P2
True miss; invalidate x2 in P1
90
MP Performance 4 Processor Commercial Workload: OLTP, Decision Support (Database), Search Engine
0
0.25
0.5
0.75
1
1.25
1.5
1.75
2
2.25
2.5
2.75
3
3.25
1 MB 2 MB 4 MB 8 MB
Cache size
InstructionCapacity/ConflictColdFalse SharingTrue Sharing
• True sharing and false sharing unchanged going from 1 MB to 8 MB (L3 cache)
• Uniprocessor cache missesimprove withcache size increase (Instruction, Capacity/Conflict,Compulsory)

16
91
MP Performance 2MB Cache Commercial Workload: OLTP, Decision Support (Database), Search Engine
• True sharing,false sharing increase going from 1 to 8 CPUs
0
0.5
1
1.5
2
2.5
3
1 2 4 6 8
Processor count
InstructionConflict/CapacityColdFalse SharingTrue Sharing
92
Synchronization and Caches:Performance Issues
Cache-coherence protocols will cause mutex to ping-pongbetween P1’s and P2’s caches.
Ping-ponging can be reduced by first reading the mutexlocation (non-atomically) and executing a swap only if it is found to be zero.
cache
Processor 1R 1
L: swap (mutex), R;if <R> then goto L; <critical section>
M[mutex] 0;
Processor 2R 1
L: swap (mutex), R;if <R> then goto L; <critical section>
M[mutex] 0;
Processor 3R 1
L: swap (mutex), R;if <R> then goto L; <critical section>
M[mutex] 0;
CPU-Memory Bus
mutex=1cache cache
93
Performance Related to Bus OccupancyIn general, a read-modify-write instruction requires two memory (bus) operations without intervening memory operations by other processors
In a multiprocessor setting, bus needs to be locked for the entire duration of the atomic read and write operation
expensive for simple busesvery expensive for split-transaction buses
modern ISAs useload-reserve store-conditional
94
Load-reserve & Store-conditional
If the snooper sees a store transaction to the addressin the reserve register, the reserve bit is set to 0
• Several processors may reserve ‘a’ simultaneously• These instructions are like ordinary loads and storeswith respect to the bus traffic
Can implement reservation by using cache hit/miss, no additional hardware required (problems?)
Special register(s) to hold reservation flag and address, and the outcome of store-conditionalLoad-reserve R, (a):
<flag, adr> <1, a>; R M[a];
Store-conditional (a), R:if <flag, adr> == <1, a> then cancel other procs’
reservation on a;M[a] <R>; status succeed;
else status fail;
95
Performance: Load-reserve & Store-conditional
The total number of memory (bus) transactions is not necessarily reduced, but splitting an atomic instruction into load-reserve & store-conditional:
• increases bus utilization (and reducesprocessor stall time), especially in split-transaction buses
• reduces cache ping-pong effect because processors trying to acquire a semaphore donot have to perform a store each time
96
A Cache Coherent System Must:Provide set of states, state transition diagram, and actionsManage coherence protocol (0) Determine when to invoke coherence protocol (a) Find info about state of block in other caches to
determine action whether need to communicate with other cached copies
(b) Locate the other copies (c) Communicate with those copies (invalidate/update)
(0) is done the same way on all systems state of the line is maintained in the cache protocol is invoked if an “access fault” occurs on the line
Different approaches distinguished by (a) to (c)

17
97
Bus-based CoherenceAll of (a), (b), (c) done through broadcast on bus faulting processor sends out a “search” others respond to the search probe and take necessary
actionCould do it in scalable network too broadcast to all processors, and let them respond
Conceptually simple, but broadcast doesn’t scale with p on bus, bus bandwidth doesn’t scale on scalable network, every fault leads to at least p network
transactionsScalable coherence: can have same cache states and state transition diagram different mechanisms to manage protocol
98
Scalable Approach: Directories
Every memory block has associated directory information keeps track of copies of cached blocks and their
states on a miss, find directory entry, look it up, and
communicate only with the nodes that have copies if necessary
in scalable networks, communication with directory and copies is through network transactions
Many alternatives for organizing directory information
Copyright © 2012, Elsevier Inc. All rights reserved.
Directory ProtocolsDirectory keeps track of every block Which caches have each block Dirty status of each block
Implement in shared L3 cache Keep bit vector of size = # cores for each block in L3 Not scalable beyond shared L3
Implement in a distributed fashion:
Distributed S
hared Mem
ory and Directory-B
ased Coherence
100
Basic Operation of Directory
• k processors. • With each cache-block in memory:
k presence-bits, 1 dirty-bit• With each cache-block in cache:
1 valid bit, and 1 dirty (owner) bit• ••
P P
Cache Cache
Memory Directory
presence bits dirty bit
Interconnection Network
• Read from main memory by processor i:• If dirty-bit OFF then { read from main memory; turn p[i] ON; }• if dirty-bit ON then { recall line from dirty proc (cache state
to shared); update memory; turn dirty-bit OFF; turn p[i] ON; supply recalled data to i;}
• Write to main memory by processor i:• If dirty-bit OFF then {send invalidations to all caches that have
the block; turn dirty-bit ON; supply data to i; turn p[i] ON; ... }
101
Directory ProtocolSimilar to Snoopy Protocol: Three states Shared: ≥ 1 processors have data, memory up-to-date Uncached (no processor has it; not valid in any cache) Exclusive: 1 processor (owner) has data;
memory out-of-dateIn addition to cache state, must track which processors have data when in the shared state (usually bit vector, 1 if processor has copy)Keep it simple(r): Writes to non-exclusive data
write miss Processor blocks until access completes Assume messages received and acted upon in order sent
102
Directory ProtocolNo bus and don’t want to broadcast: interconnect no longer single arbitration point all messages have explicit responses
Terms: typically 3 agents involved Local node (processor+cache) where a request originates Home node (directory controller) where the memory
location of an address resides Remote node (processor+cache) has a copy of a cache
block, whether exclusive or sharedExample messages on next slide: P = processor number, A = address

18
10/18/2007 103
Directory Protocol Messages (Fig 4.22)
Message type Source Destination Msg ContentRead miss Local cache Home directory P, A
Processor P reads data at address A; make P a read sharer and request data
Write miss Local cache Home directory P, A Processor P has a write miss at address A;
make P the exclusive owner and request dataInvalidate Home directory Remote caches A
Invalidate a shared copy at address AFetch Home directory Remote cache A
Fetch the block at address A and send it to its home directory;change the state of A in the remote cache to shared
Fetch/Invalidate Home directory Remote cache A Fetch the block at address A and send it to its home directory;
invalidate the block in the cacheData value reply Home directory Local cache Data
Return a data value from the home memory (read miss response)Data write back Remote cache Home directory A, Data
Write back a data value for address A (invalidate response)
104
State Transition Diagram for One Cache Block in Directory-Based System
States identical to snoopy case; transactions very similarTransitions caused by read misses, write misses, invalidates, data fetch requestsGenerates read miss & write miss message to home directoryWrite misses that were broadcast on the bus for snooping explicit invalidate & data fetch requestsNote: on a write, a cache block is bigger, so need to read the full cache block
105
CPU -Cache State MachineState machinefor CPU requestsfor each memory blockInvalid stateif in memory
Fetch/Invalidatesend Data Write Back message
to home directory
Invalidate
Invalid
Exclusive(read/write)
CPU Read
CPU Read hit
Send Read Missmessage
CPU Write:Send Write Miss msg to homedirectory
CPU Write: Send Write Miss messageto home directory
CPU read hitCPU write hit
Fetch: send Data Write Back message to home directory
CPU read miss:Send Read Miss
CPU write miss:send Data Write Back message and Write Miss to home directory
CPU read miss: send Data Write Back message and read miss to home directory
Shared(read/only)
106
State Transition Diagram for Directory
Same states & structure as the transition diagram for an individual cache2 actions: update of directory state & send messages to satisfy requests Tracks all copies of memory blockAlso indicates an action that updates the sharing set, Sharers, as well as sending a message
107
Directory State MachineState machinefor Directory requests for each memory blockUncached stateif in memory
Data Write Back:Sharers = {}
(Write back block)
UncachedShared(read only)
Exclusive(read/write)
Read miss:Sharers = {P}send Data Value Reply
Write Miss: send Invalidate to Sharers;then Sharers = {P};send Data Value Reply msg
Write Miss:Sharers = {P}; send Data Value Replymsg
Read miss:Sharers += {P}; send Fetch;send Data Value Replymsg to remote cache(Write back block)
Read miss: Sharers += {P};send Data Value Reply
Write Miss:Sharers = {P}; send Fetch/Invalidate;send Data Value Replymsg to remote cache
108
Example Directory ProtocolMessage sent to directory causes two actions: Update the directory More messages to satisfy request
Block is in Uncached state: the copy in memory is the current value; only possible requests for that block are: Read miss: requesting processor sent data from memory &requestor
made only sharing node; state of block made Shared. Write miss: requesting processor is sent the value & becomes the
Sharing node. The block is made Exclusive to indicate that the only valid copy is cached. Sharers indicates the identity of the owner.
Block is Shared the memory value is up-to-date: Read miss: requesting processor is sent back the data from memory
& requesting processor is added to the sharing set. Write miss: requesting processor is sent the value. All processors in
the set Sharers are sent invalidate messages, & Sharers is set to identity of requesting processor. The state of the block is made Exclusive.

19
109
Example Directory ProtocolBlock is Exclusive: current value of the block is held in the cache of the processor identified by the set Sharers (the owner) three possible directory requests: Read miss: owner processor is sent data fetch message, causing state of
block in owner’s cache to transition to Shared and causes owner to send data to directory, where it is written to memory & sent back to requesting processor. Identity of requesting processor is added to set Sharers, which still contains the identity of the processor that was the owner (since it still has a readable copy). State is shared.
Data write-back: owner processor is replacing the block and hence must write it back, making memory copy up-to-date (the home directory essentially becomes the owner), the block is now Uncached, and the Sharer set is empty.
Write miss: block has a new owner. A message is sent to old owner causing the cache to send the value of the block to the directory from which it is sent to the requesting processor, which becomes the new owner. Sharers is set to identity of new owner, and state of block is made Exclusive.
110
Example
P1 P2 Bus Directory Memorystep State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value
P1: Write 10 to A1
P1: Read A1P2: Read A1
P2: Write 40 to A2
P2: Write 20 to A1
A1 and A2 map to the same cache block
Processor 1 Processor 2 Interconnect MemoryDirectory
111
Example
P1 P2 Bus Directory Memorystep State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value
P1: Write 10 to A1 WrMs P1 A1 A1 Ex {P1}Excl. A1 10 DaRp P1 A1 0
P1: Read A1P2: Read A1
P2: Write 40 to A2
P2: Write 20 to A1
A1 and A2 map to the same cache block
Processor 1 Processor 2 Interconnect MemoryDirectory
112
Example
P1 P2 Bus Directory Memorystep State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value
P1: Write 10 to A1 WrMs P1 A1 A1 Ex {P1}Excl. A1 10 DaRp P1 A1 0
P1: Read A1 Excl. A1 10P2: Read A1
P2: Write 40 to A2
P2: Write 20 to A1
A1 and A2 map to the same cache block
Processor 1 Processor 2 Interconnect MemoryDirectory
113
Example
P2: Write 20 to A1
A1 and A2 map to the same cache block
P1 P2 Bus Directory Memorystep State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value
P1: Write 10 to A1 WrMs P1 A1 A1 Ex {P1}Excl. A1 10 DaRp P1 A1 0
P1: Read A1 Excl. A1 10P2: Read A1 Shar. A1 RdMs P2 A1
Shar. A1 10 Ftch P1 A1 10 10Shar. A1 10 DaRp P2 A1 10 A1 Shar. P1,P2} 10
1010
P2: Write 40 to A2 10
Processor 1 Processor 2 Interconnect MemoryDirectory
A1
Write BackWrite Back
A1
114
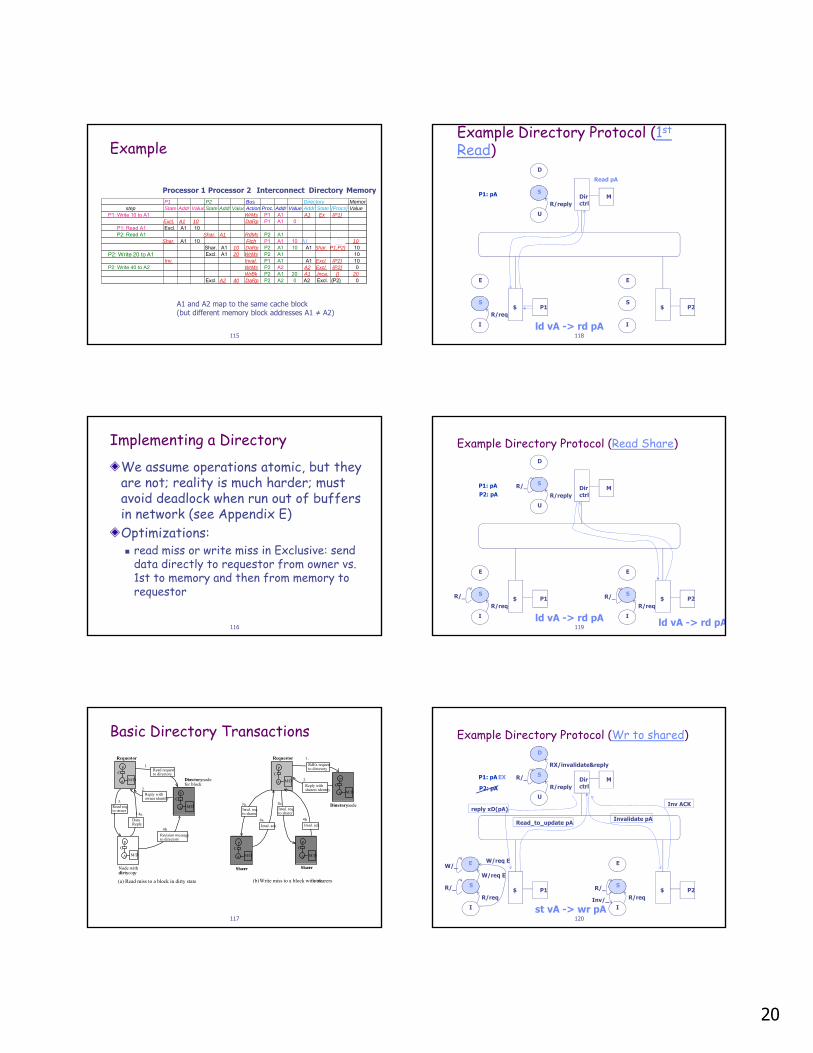
Example
P2: Write 20 to A1
A1 and A2 map to the same cache block
P1 P2 Bus Directory Memorystep State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value
P1: Write 10 to A1 WrMs P1 A1 A1 Ex {P1}Excl. A1 10 DaRp P1 A1 0
P1: Read A1 Excl. A1 10P2: Read A1 Shar. A1 RdMs P2 A1
Shar. A1 10 Ftch P1 A1 10 10Shar. A1 10 DaRp P2 A1 10 A1 Shar. P1,P2} 10Excl. A1 20 WrMs P2 A1 10
Inv. Inval. P1 A1 A1 Excl. {P2} 10P2: Write 40 to A2 10
Processor 1 Processor 2 Interconnect MemoryDirectory
A1A1
20
115
Example
P2: Write 20 to A1
A1 and A2 map to the same cache block (but different memory block addresses A1 ≠ A2)
P1 P2 Bus Directory Memorystep State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value
P1: Write 10 to A1 WrMs P1 A1 A1 Ex {P1}Excl. A1 10 DaRp P1 A1 0
P1: Read A1 Excl. A1 10P2: Read A1 Shar. A1 RdMs P2 A1
Shar. A1 10 Ftch P1 A1 10 10Shar. A1 10 DaRp P2 A1 10 A1 Shar. P1,P2} 10Excl. A1 20 WrMs P2 A1 10
Inv. Inval. P1 A1 A1 Excl. {P2} 10P2: Write 40 to A2 WrMs P2 A2 A2 Excl. {P2} 0
WrBk P2 A1 20 A1 Unca. {} 20Excl. A2 40 DaRp P2 A2 0 A2 Excl. {P2} 0
Processor 1 Processor 2 Interconnect MemoryDirectory
A1A1
116
Implementing a Directory
We assume operations atomic, but they are not; reality is much harder; must avoid deadlock when run out of buffers in network (see Appendix E)Optimizations: read miss or write miss in Exclusive: send
data directly to requestor from owner vs. 1st to memory and then from memory to requestor
117
Basic Directory Transactions
P
A M/D
C
P
A M/D
C
P
A M/D
C
Read requestto directory
Reply withowner identity
Read req.to owner
DataReply
Revision messageto directory
1.
2.
3.
4a.
4b.
P
A M/D
CP
A M/D
C
P
A M/D
C
RdEx requestto directory
Reply withsharers identity
Inval. req.to sharer
1.
2.
P
A M/D
C
Inval. req.to sharer
Inval. ack
Inval. ack
3a. 3b.
4a. 4b.
Requestor
Node withdirty copy
Directory nodefor block
Requestor
Directory node
Sharer Sharer
(a) Read miss to a block in dirty state (b) Write miss to a block with two sharers
118
Example Directory Protocol (1st
Read)
E
S
I
P1$
E
S
I
P2$
D
S
U
MDirctrl
ld vA -> rd pA
Read pA
R/reply
R/req
P1: pA
S
S
119
Example Directory Protocol (Read Share)
E
S
I
P1$
E
S
I
P2$
D
S
U
MDirctrl
ld vA -> rd pA
R/reply
R/req
P1: pA
ld vA -> rd pA
P2: pA
R/reqR/_
R/_
R/_S
S
S
120
Example Directory Protocol (Wr to shared)
E
S
I
P1$
E
S
I
P2$
D
S
U
MDirctrl
st vA -> wr pA
R/reply
R/req
P1: pA
P2: pA
R/req
W/req E
R/_
R/_
R/_
Invalidate pARead_to_update pA
Inv ACK
RX/invalidate&reply
S
S
S
D
E
reply xD(pA)
W/req EW/_
Inv/_
EX

21
10/18/2007 121
Example Directory Protocol (Wr to Ex)
E
S
I
P1$
E
S
I
P2$
D
S
U
MDirctrlR/reply
R/req
P1: pA
st vA -> wr pAR/req
W/req E
R/_
R/_
R/_
Reply xD(pA)Write_back pA
Read_toUpdate pA
RX/invalidate&reply
D
E
Inv pA
W/req EW/_
Inv/_ Inv/_
W/req EW/_
I
E
W/req E
RU/_
122
A Popular Middle Ground
Two-level “hierarchy”Individual nodes are multiprocessors, connected non-hiearchically e.g. mesh of SMPs
Coherence across nodes is directory-based directory keeps track of nodes, not individual
processorsCoherence within nodes is snooping or directory orthogonal, but needs a good interface of
functionalitySMP on a chip directory + snoop?