optimization of sequence queries in database systems
DESCRIPTION
Optimization of Sequence Queries in Database Systems. Reza Sadri Carlo Zaniolo [email protected] [email protected] [email protected] Amir Zarkesh Jafar Adibi [email protected] [email protected]. - PowerPoint PPT PresentationTRANSCRIPT

Optimization of Sequence Queries in Database Systems
Reza Sadri Carlo [email protected] [email protected]
Amir Zarkesh Jafar Adibi [email protected] [email protected]

Time series Analysis Many Applications:
Querying purchase patterns for marketing Stock market analysis Studying meteorological data
What’s needed: Expressive query language for finding
complex patterns in database sequences Efficient and scalable implementation:
Query Optimization

SQL-TS A query language for finding
complex patterns in sequences Minimal extension of SQL—only the
from clause affected A new Query optimization technique
based on extensions of the Knuth, Morris & Pratt (KMP) string-search algorithm

Text Search Optimization
Boyer and Moore Precomputed shift functions for each character and sub-
pattern Dependent to the alphabet size Works best for non-repeating patterns O(mn) worst case time
Knuth, Morris and Pratt (KMP) Independent of the alphabet size Most efficient in general: O(m+n) time
Karp and Rabin Prefix Hashing Dependent to the alphabet size O(mn) worst case time

Optimized string search:KMP
Consider text array text and pattern array p:
i 1 2 3 4 5 6 7 8 9 10 11 text[i] a b a b a b c a b c aj 1 2 3 4 5 6pattern[j] a b a b c a
After failing, use the information acquired so to: - backtrack to shift(j), rather than i+1, and - only check pattern values after next(j)But in SQL-TS we have general predicates & star patterns

shift and next Success for first j-1 elements of pattern. Failure
for jth element (when input is at i) Any shift less than shift(j) is guaranteed to lead
to failure, Match elements in the pattern starting at next(j)
Shifted Pattern
i – j + 1
1
1
i – j + shift(j) + 1 i - j + shift(j) + next(j)
shift(j) + 1 shift(j) + next(j)
i
j
next(j) j - shift(j)
Input
Pattern
shift(j)

Equality Predicates: KMP suffices
Find companies whose closing stock price inthree consecutive days was 10, 11, and 15.
SELECT X.name FROM quote CLUSTER BY name
SEQUENCE BY date AS (X, Y, Z)
WHERE X.price =10 AND Y.price=11
AND Z.price=15
But in SQL-TS we have general predicates
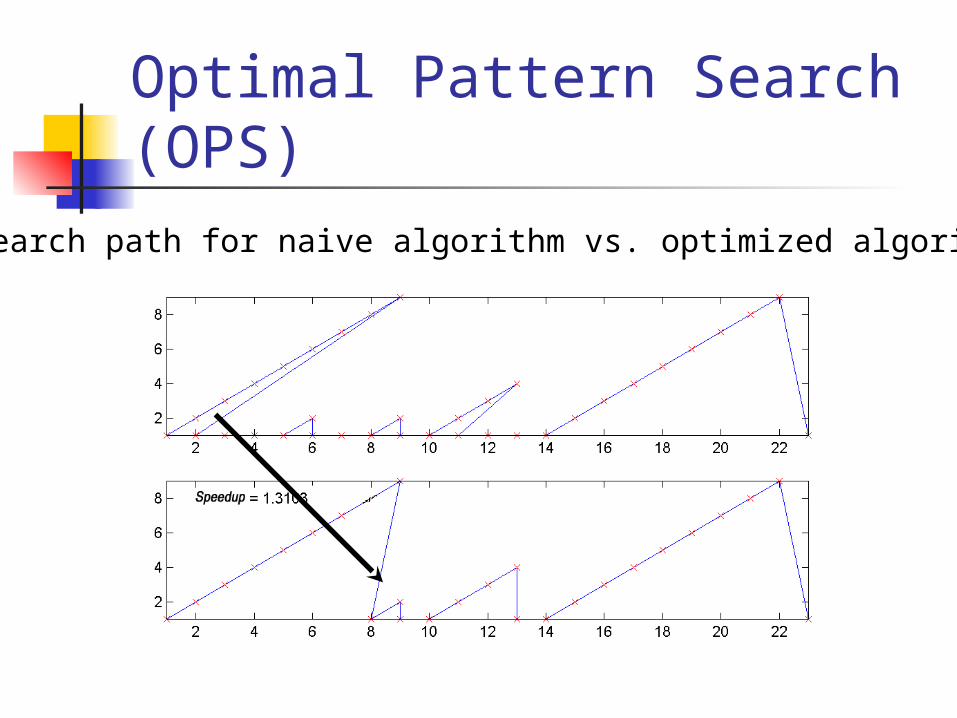
Optimal Pattern Search (OPS)
Search path for naive algorithm vs. optimized algorithm:

Beyond KMP: General PredicatesFor IBM stock prices, find all instances where the pattern of two successive
drops followed by two successive increases, and the drops take the price to a value between 40 and 50, and the first increase doesn't move the price beyond 52.
SELECT X.date AS start_date, X.price U.date AS end_date, U.price FROM quote CLUSTER BY name SEQUENCE BY date AS (X, Y, Z, T, U) WHERE X.name='IBM' AND Y.price < X.price AND Z.price < Y.price AND 40 < Z.price < 50 AND Z.price < T.price AND T.price < 52 AND T.price < U.price

*Z(less than 2% change)
*U(less than 2% change)
*W(less than 2% change)
*Y *R
*V*T
Beyond KMP: Star Patterns
Relaxed Double Bottom: Only considering increases and decreases
that are more than 2%
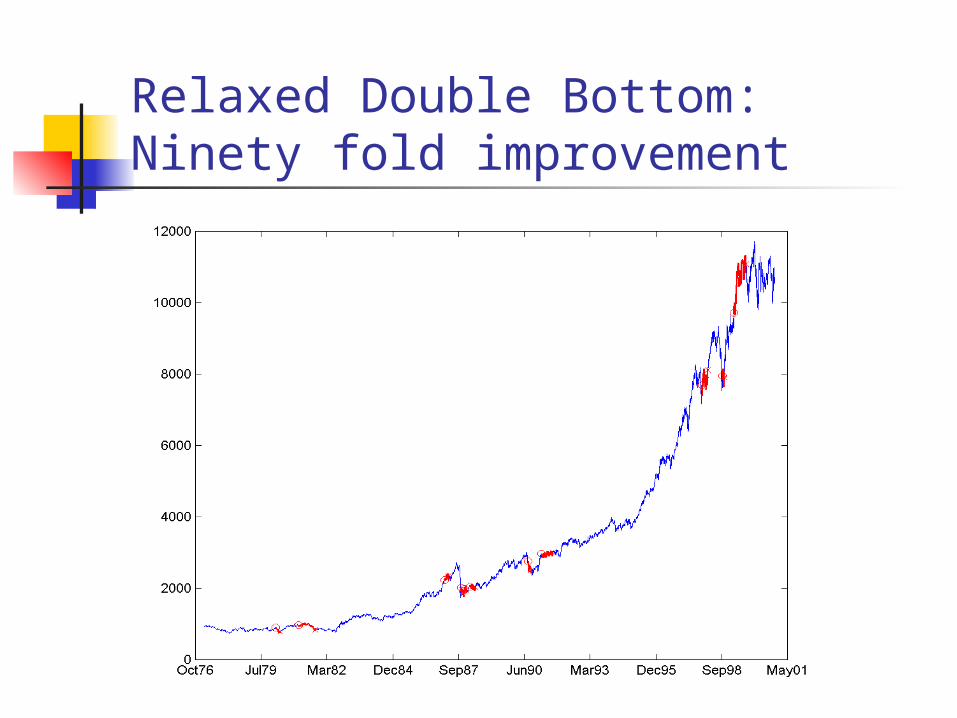
Relaxed Double Bottom: Ninety fold improvement
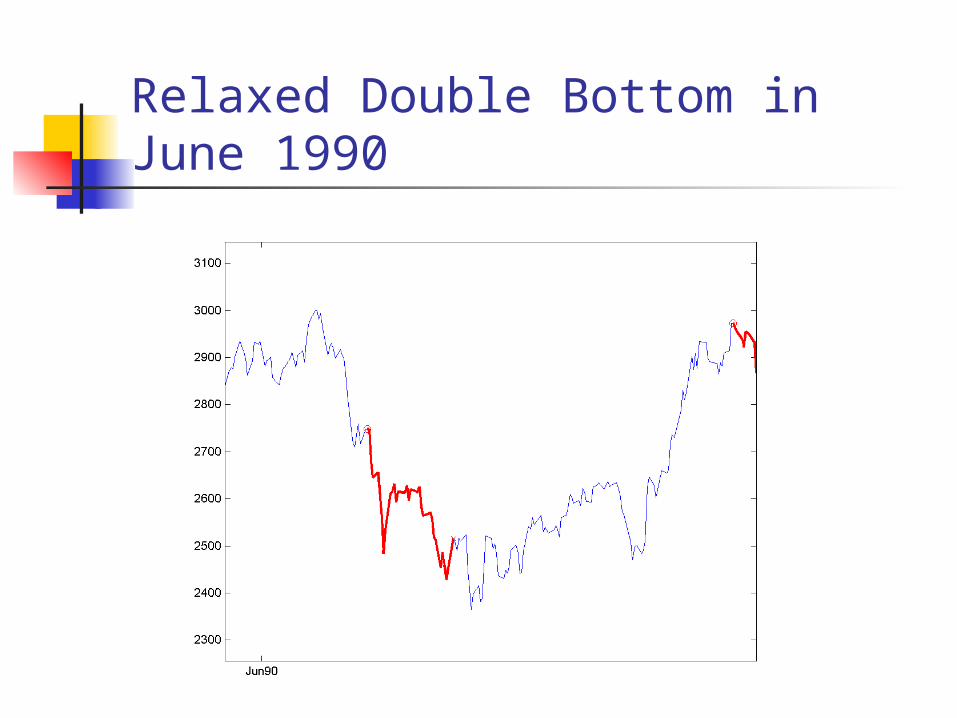
Relaxed Double Bottom in June 1990

Conclusion
Significant speedups—from 6 to 900 times faster
Queries, partial ordered domains, aggregates also treated in this approach
Many other optimization opportunities: e.g., parallel search for multiple patterns

shift and next Success for first j-1 elements of pattern. Failure
for jth element (when input is at i) Any shift less than shift(j) is guaranteed to lead
to failure, Match elements in the pattern starting at next(j)
Shifted Pattern
i – j + 1
1
1
i – j + shift(j) + 1 i - j + shift(j) + next(j)
shift(j) + 1 shift(j) + next(j)
i
j
next(j) j - shift(j)
Input
Pattern
shift(j)

General Predicates--Contp1(t) = (t.price < t.previous.price)
p2(t) = (t.price < t.previous.price) (40<t.price<50)
p3(t) = (t.price > t.previous.price) (t.price<52)
p4(t) = (t.price > t.previous.price)
And we need to find the implication between this pattern elements

Matrices and : Input tested on pj is now tested against pk
otherwiseU
ppif
Falsepandppif
kj
jkj
kj 0
1
otherwiseU
ppif
Truepandppif
kj
jkj
kj 0
1
Combing values of these lower triangular matrices ( j k),We derive the values of next(j) and shift (j)
pj succeeded:
pj failed:

Example
00
0
0
010
0
0
UUUU
UUUU
UUU
U
5,2,5021,20,10,95
:
654321
xxxxxx
pppppp
patternfollowingtheConsider
10100
10100
1010
1
10
1
U
UU

STAR PatternsSELECT X.NEXT.date, X.NEXT.price, S.previous.date, S.previous.priceFROM quote CLUSTER BY name, SEQUENCE BY date AS (*X, Y, *Z, *T, U, *V, S)WHERE X.name='IBM‘ AND X.price > X.previous.price AND 30 < Y.price AND Y.price < 40 AND Z.price < Z.previous.price AND T.price >
T.previous.price AND 35 < U.price AND U.price < 40 AND V.price < V.previous.price AND S.price < 30

Same input, Transitions on Original Pattern vs. Transitions on Pattern after the index set back j-k21
31 32
41 42 43
Example: Elements j and k are star predicates and jk is U: U j,k+1
j+1,k j+1,k+1
Handling Star Patterns

Possible Transitions Elements j and k are star predicates and jk is U: U j,k+1
j+1,k j+1,k+1
Elements j and k are star predicates and jk is 1:
1 j,k+1
j+1,k j+1,k+1
Elements j and k are not star predicates: j,k j,k+1
j+1,k j+1,k+1
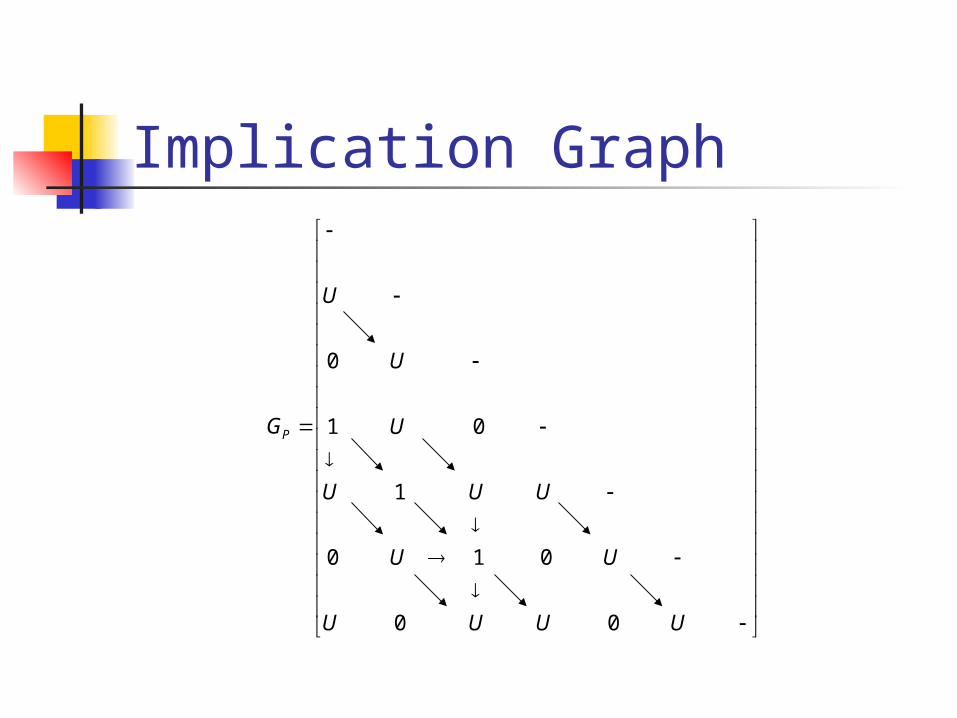
Implication Graph
UUUU
UU
UUU
U
U
U
GP
00
010
1
01
0