on-chip pipelined parallel mergesort on the intel...
TRANSCRIPT

Institutionen för datavetenskapDepartment of Computer and Information Science
Final thesis
On-chip Pipelined Parallel Mergesorton the Intel Single-Chip Cloud
Computer
by
Kenan Avdić
LIU-IDA/LITH-EX-A–14/012–SE
October 18, 2014
Linköpings universitetSE-581 83 Linköping, Sweden
Linköpings universitet581 83 Linköping


Linköpings universitetInstitutionen för datavetenskap
Final thesis
On-chip Pipelined Parallel Mergesorton the Intel Single-Chip Cloud
Computer
by
Kenan Avdić
LIU-IDA/LITH-EX-A–14/012–SE
October 18, 2014
Supervisor: Nicolas Melot, Christoph Kessler
Examiner: Christoph Kessler


Abstract
With the advent of mass-market consumer multicore processors, the grow-ing trend in the consumer off-the-shelf general purpose processor industryhas moved away from increasing clock frequency as the classical approachfor achieving higher performance. This is commonly attributed to the well-known problems of power consumption and heat dissipation with high fre-quencies and voltage.
This paradigm shift has prompted research into a relatively new fieldof “many-core” processors, such as the Intel Single-chip Cloud Computer.The SCC is a concept vehicle, an experimental homogenous architectureemploying 48 IA32 cores interconnected by a high-speed communicationnetwork.
As similar multiprocessor systems, such as the Cell Broadband Engine,demonstrate a significantly higher aggregate bandwidth in the interconnectnetwork than in memory, we examine the viability of a pipelined approachto sorting on the Intel SCC. By tailoring an algorithm to the architecture,we investigate whether this is also the case with the SCC and whetheremploying a pipelining technique alleviates the classical memory bottleneckproblem or provides any performance benefits.
For this purpose, we employ and combine different classic algorithms,most significantly, parallel mergesort and samplesort.
iii


Contents
1 Introduction 11.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Previous work . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Contributions of this thesis . . . . . . . . . . . . . . . . . . . 41.4 Organisation of the thesis . . . . . . . . . . . . . . . . . . . . 51.5 Publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 The Intel SCC 6
3 Preliminary Investigation 103.1 Main Memory . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.2 Mesh Interconnect . . . . . . . . . . . . . . . . . . . . . . . . 163.3 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4 Mergesort Algorithm 254.1 Simple approach . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.1.1 Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . 254.1.2 Experimental Evaluation . . . . . . . . . . . . . . . . 27
4.2 Pipelined mergesort . . . . . . . . . . . . . . . . . . . . . . . 324.2.1 Design . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.2.2 Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . 344.2.3 Experimental Evaluation . . . . . . . . . . . . . . . . 39
5 Conclusions and Future Work 42
A Code Listing 48A.1 mem_sat_test.c . . . . . . . . . . . . . . . . . . . . . . . . . 48A.2 mpb_trans.c . . . . . . . . . . . . . . . . . . . . . . . . . . . 52A.3 priv_mem.c . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54A.4 pipelined_merge.h . . . . . . . . . . . . . . . . . . . . . . . . 61A.5 pipelined_merge.c . . . . . . . . . . . . . . . . . . . . . . . . 66
v

CONTENTS CONTENTS
vi

Chapter 1
Introduction
1.1 BackgroundThe increasingly difficult problems of power consumption and heat dissipa-tion have today all but eliminated the classic means of improving processorperformance — increasing its frequency. Instead, to increase performance,technology has moved towards adding more cores to the chip. In combi-nation with redundant processing units and multiple pipelines this allowsvarying degrees of support for thread-level parallelism. In turn, softwaredevelopment in general is being forced to adapt to a parallel paradigm in allareas; desktop, entertainment and recently even embedded applications.
The transition towards hetero- and homogeneous multi- and many-corearchitectures is by no means a simple one. Efficient and effective utilisationof chip resources requiring parallelisation becomes more difficult.
The development of new hardware such as processors and memory sizeshas, until recently, largely been following the well-known Moore’s law. Off-chip memory speeds, however, are lagging behind. As these memories are,in relative terms, orders of magnitude slower than on-chip memory, mainmemory access becomes prominent as one of the major causes of processorstalls. This bottleneck effect is especially pronounced in memory intensiveoperations, such as sorting. In order to lessen the impact of high latenciesof main memory, program behaviour can be altered so as to reduce mainmemory access or avoid accessing main memory altogether. By employ-ing on-chip pipelining, storing intermediate results of sub-tasks in memorycan be avoided. These intermediate results can instead be immediately for-warded onto the next processing unit. In addition, further performance im-provement can be achieved by “parallelising” memory access to either mainmemory or buffers by making it concurrent with computation. This canbe achieved e.g. through asynchronous memory transfers (Direct MemoryAccess) combined with multi-buffering.
We consider implementation of sorting of integers on the Intel Single-
1

CHAPTER 1. INTRODUCTION
Chip Cloud Computer 48-core concept vehicle as an algorithm engineeringproblem. The implementation of such an algorithm involves many variables,most significantly load balancing and memory access and communicationpatterns. A sorting algorithm shares similar requirements with many prac-tical applications, such as image processing, which makes solving such aproblem all the more relevant. As a pipelined variant of parallel mergesort[1] has been shown to achieve higher performance on other architectures [2],we focus on this algorithm primarily, but also look at parallel variations ofsamplesort [3] [4].
Parallel sorting algorithms have been investigated for many years, onmany different platforms. Mergesort in particular originated as an externalsorting algorithm and combined well with the sequential access requirementsof early tape drives. Today, tapes have been replaced by disks or slower off-chip memory, but the sequential nature of mergesort is still highly beneficialdue to good synergy with memory hierarchies available in almost all hard-ware and the locality effects of such memory accesses.
The mergesort algorithm operates recursively using a divide-and-conquerparadigm. The array to be sorted is split recursively into smaller chunks,until chunk size is one. Each chunk is then merged in the correct order,until the sequence is again the complete starting length (Fig. 1.1).
1 2 3 4 5 6 7 8
23
23
2 3
4 6
4 6
4 6
2 3 4 6
234 6
15
15
1 5
78
78
7 8
1 5 7 8
1578
1 2345 678
234 61578
1 2 3 4 5 6 7 8
2 34 61 57 8
2 3 4 61 5 7 8
234 61578
234 61578
234 61578
split
merge
Figure 1.1: The mergesort algorithm [5].
The split operation has negligible cost and is considered trivial. Themerge tasks are independent of each other and can be performed separately.This task independence is a natural recursive decomposition of tasks andallows for their concurrent execution on different processing units, resultingin a parallel mergesort algorithm. The splitting of the sequence results in abinary tree, the depth of which can be used as a variable for modificationof task parallel granularity. That is, tasks are assigned to processing unitsdown to a certain tree level, after which each subtree is locally sorted, i.e.on the mapped processing unit. These lowest level tasks are thus executedsequentially.
The obvious method of transferring sorted subsequences between thetasks is for the tasks to write the results into memory, where they are readby the processing unit that is assigned the next task. This is, however, not
2

CHAPTER 1. INTRODUCTION
always necessary. Subsequent tasks do not need to wait until the previoustask is completed, as each task starts outputting a sorted sequence, it isimmediately input directly into the next. This is pipelined parallel mergesort.In general, memory access cost is traded for a higher communication costinstead. Such an algorithm is also significantly harder to optimise, as thereare many interdependent variables to consider.
1.2 Previous workNo previous work exists in algorithm performance on the Intel Single-ChipCloud Computer, however, a SIMD-enabled and/or pipelined approach hasbeen shown to be very effective in the case of sorting on the Cell BroadbandEngine processor.
The Cell is a heterogeneous PowerPC-based architecture that consists ofa single general purpose core combined with 8 streaming coprocessors [6].The main core, the Power Processing Element (PPE) is a standard 64-bitin-order dual-issue PowerPC core that supports two-way simultaneous mul-tithreading (SMT) and Single-Instruction Multiple-Data (SIMD) instruc-tions1. Being a general purpose core, the PPE runs the operating system,but its main task is controlling the 8 coprocessors, the Synergistic Process-ing Elements (SPE). The SPEs, in turn, are each comprised of a SynergisticProcessing Unit (SPU) and a Memory Flow Controller unit (MFC). TheSPU is an in-order, dual-issue processing unit. It contains a large 128-entry128-bit register file, supports integer and floating-point operations and isSIMD-capable, or rather its processor intrinsics consist of only SIMD in-structions. The SPU has no direct access to system memory. Instead, ituses a local store of 256KiB for both programs and data. The MFC is re-sponsible for translating addresses between the SPUs and the system andperforming DMA transfers to local stores.
At 3.2 GHz clock speed, the PPE theoretically delivers 25.6 GFLOPS2
using single precision operations, while each SPE can reach 25.6 GFLOPS.The PPE, the SPEs, system memory and peripheral input-output interfaceson Cell communicate via a high-speed bus called the Element InterconnectBus (EIB). Typically, separate programs are compiled for the PPE and theSPEs. The PPE controls the SPEs, initialising and running small programsthere. DMA transfers can be initiated by either the PPE or the SPEs.
Regarding sorting work on the Cell processor, recent advances in GPGPU-programming3 [7] were recently considered and applied by Inoue et al. [8].In their work, the authors follow the conclusions made by Furtak et al. [9] onthe benefits of exploiting available SIMD streaming instructions and exam-ine the SIMD capabilities of the Cell; attempting to exploit them in a similarway as previously done on GPUs [7] [10] [11]. The result is Aligned-Access
1AltiVec vector instructions2Billion floating operations per second3General-purpose computing on graphics processing units
3

CHAPTER 1. INTRODUCTION
sort, or AA-sort, which is a combination of an improved SIMD-optimisedcombsort [12], used in-core, and the odd-even merge algorithm [13], used out-of-core, both implemented with SIMD instructions. The relative speedupachieved by AA-sort is 7.87x and 3.33x for the two constituent algorithmsover the same scalar implementation. The algorithm achieves a parallelspeedup of 12.2 with 16 cores when sorting 32-bit integers.
Gedik, Bordawekar and Yu identify similar Cell-specific requirements ofsorting algorithms: SIMD-optimisation of the SPE code, memory transferoptimisation and effective utilisation of the EIB, but substitute the odd-even merge algorithm above with two variations of bitonic sort [14]. ASPE-local sort and two different variations of bitonic sort, distributed in-core and distributed out-of-core sort are produced. The distributed in-coresort uses the local sort algorithm and cross-SPE transfers to internally mergea number of elements up to a size determined by the number of participatingSPEs. For larger sequences, the distributed out-of-core sort is used, whichutilises the in-core algorithm in phases to achieve the final sorted result. Theachieved speedup sorting floats for the in-core and out-of-core sorts, over anIntel Xeon 3.2GHz, is 21x and 4x respectively.
By employing on-chip pipelining on the Cell, Hultén et al. [2] [15] im-prove further upon these results and achieve an additional speedup of 70%for the IBM QS20 and 143% for the PlayStation 3 over the AA-sort im-plementation. This is accomplished by minimising main memory accessthrough on-chip pipelining and asynchronous multi-buffered DMA transfers.A pipelined on-chip version of the parallel mergesort algorithm is appliedusing binary tree task partitioning and subsequently mapped to the SPEs.Task mapping is optimised by expressing it as an integer linear programmingproblem and solving it using an ILP solver.
Scarpazza and Braudaway [16] examine text indexing on the Cell, adapt-ing this specific workload to its hardware. The solution provided affords a 4xperformance advantage over a non-SIMD reference implementation runningon all four cores of a quad-core Intel Q6600 processor.
Haid et al. leverage Kahn process networks [17] to generalise stream-ing applications in general [18] and on Cell specifically [19], by executingtheir model using protothreads [20] (for parallelism) and windowed FIFO(for communication). The parallel speedup achieved here is nearly sevenwhen using seven processors on the PlayStation 3. This is especially inter-esting due to the generic nature of a KPN application compared to otherwiserequired architecture-specific code.
1.3 Contributions of this thesisThe most significant contribution of this thesis is the design and implemen-tation of an on-chip pipelined parallel mergesort algorithm tailored to theunorthodox hardware of the Intel Single-Chip Cloud Computer. Buildingon known work mentioned in the previous section, we attempt to achieve
4

CHAPTER 1. INTRODUCTION
similar results on the SCC as on the Cell [2] [15]. Due to the lack of SIMDinstructions on the SCC hardware, however, no optimisation in that direc-tion is possible, but some other features of the SCC are shown to benefitfrom on-chip pipelining.
Due to there being no previous work on sorting on the SCC, an investi-gation of the memory and mesh interconnect capabilities is performed first.In addition, following the preliminary investigation, a simple naïve imple-mentation is briefly handled and subsequently used for comparison with thefinal pipelined algorithm.
1.4 Organisation of the thesisThe remainder of this thesis is organised as follows. Chapter 2 gives a rela-tively high-level overview of the Intel SCC architecture, with the subsequentchapters each adding more detail to its constituent parts as necessary. Chap-ter 3 deals with preliminary investigation of the architecture details that areidentified to possibly impact the final algorithm design.
Chapter 4 describes the theory behind the mergesort algorithm, a naïveparallel implementation of such an algorithm on the SCC as well as ourfinal design, implementation and results of the pipelined parallel mergesortalgorithm. Chapter 5 offers our conclusions on the results from chapter 4,and future work.
1.5 PublicationsParts of this work have already been published in the following, in chrono-logical order.
• Parallel sorting on Intel Single-Chip Cloud computer [5].
• Investigation of Main Memory Bandwidth on Intel Single-Chip Cloud Computer [21].
• Pipelined Parallel Sorting on the Intel SCC [22].
• Engineering parallel sorting for the Intel SCC [23].
5

Chapter 2
The Intel SCC
00
101
23
45
67
SCC die
DIM
M
R
tiletile
R
tile
R
tile
R
tile
R
tile
RMC MC
DIM
M
tile
R
tile
R
tile
R
tile
R
tile
R
tile
R
tile
R
tile
R
tile
R
tile
R
tile
R
tile
RMC MC
DIM
M
DIM
M
tile
R
tile
R
tile
R
tile
R
tile
R
tile
R
Figure 2.1: Intel SCC Architecture Top View [24].
The Intel Single-Chip Cloud Computer [25] [24] is a chip multiproces-sor. It is comprised of 24 tiles arranged in a 6x4 rectangular grid pattern.The tiles are connected by an on-chip two-dimensional mesh interconnectionnetwork. Each of the 24 tiles contains a pair of second generation Intel Pen-tium IA32 cores (P54C), each in turn with its own L1 and L2 cache. TheL1 cache is 32KiB with 16KiB data and instruction cache. The L2 cache isunified and is of 256KiB size. These caches are write-back, while L1 can beconfigured as write-through.
The two cores on a tile are joined with a mesh interface unit (MIU) (Fig.2.2) that has several responsibilities, but its main task is to provide commu-nication resources between on-tile resources and the on-tile mesh interface,the router. In addition to the two L2 caches and a mesh router, to the MIUis attached a 16KiB message-passing buffer, the MPB. With 24 tiles, thetotal available mesh memory is thus 384KiB. Since the IA32 cores on theSCC use local addresses and are not aware of the global chip configuration,the MIU translates core-local addresses using a look-up table (LUT) into
6

CHAPTER 2. THE INTEL SCC
L2
256 KiB
P54C MPB
16 KiB
P54CL1
32KiB
L2
256 KiB
traffic
gen
mesh
I/F R
L1
32KiB
Figure 2.2: An Intel SCC Tile [5].
non-local accesses, e.g. router, MPB, etc. The MIU is also responsible forthe hardware configuration of the cores, using tile configuration registers.
The architecture supports a special type of data to facilitate message-passing which is new to the P54C Pentium cores, MPBT. This data typebypasses L2 cache entirely and is only cached in L1. In addition, each linein the L1 cache is expanded with a flag, which marks whether the line inquestion holds MPBT-data. The IA32 instruction set is further expandedwith an instruction (CL1INVMB) that invalidates all MPBT-marked datain L1.
Four DDR3 memory controllers are attached evenly to the routers on thetwo shorter sides of the mesh rectangle. Each memory controller supportsDDR3-800 DRAM, up to 16GB per channel, allowing for a total of 64GBmemory capacity. Six tiles are logically grouped in quadrants and eachuse the closest memory controller. The memory variants are core-privatememory and shared memory. Each core has a certain amount of privatememory, which is a reserved area within main memory assigned to that coreonly. This memory is cached in all available caches. The shared memory onthe other hand is evenly distributed over the four main memory controllersand is either only cached in the L1 cache (using the aforementioned MPBTmemory type) or not cached at all.
The SCC provides voltage and clock control with a very high degree ofgranularity and customisation. The voltage regulator controller (VRC) al-lows for voltage adjustment in any of the 6 voltage islands (dashed regions)in Figure 2.3 individually, or the entire mesh collectively. The voltage set-tings can be altered from any core, allowing full application control of thecores’ power state, or the system interface controller (SIF). The SIF is theinterface between the mesh and the external controller located on the systemboard.
Even more granularity is allowed in clock frequency adjustment, as theSCC can control each tile separately. The mesh and its routers, however, allshare a single frequency. Each tile uses the mesh clock as the input with aconfigurable clock divider to arrive at a local clock. The mesh itself can be
7

CHAPTER 2. THE INTEL SCC
System Interface
DDR3 MC
DDR3 MC
DDR3 MC
DDR3 MC
VRC
PLL & JTAG
Figure 2.3: SCC Voltage and clocking islands [24].
considered to reside on its own frequency island.The SCC can be programmed directly, in so called baremetal mode, or
an operating system can be loaded onto each core that subsequently runsprograms. A version of Linux called SCC Linux is provided for the lattermode. A set of tools for management called sccKit is used for externallycontrolling the SCC via the SIF. These tools can be used to configure andmanage the SCC, providing facilities to, e.g., hardware power cycle, resetand reboot the SCC. SccKit is also used for starting the SCC in one ofthe preset frequency profiles. The available frequency profiles are listed inTable 2.1. SCC Linux is available as modified source code for recompilationif kernel modification is necessary. Programs for the SCC Linux are compiledusing standard compilers provided by Intel, such as gcc or icc.
Tile (MHz) Mesh (MHz) Memory (MHz)533 800 800
800 800 8001066
800 1600 8001066
Table 2.1: Available frequency profiles using Intel sccKit
As previously mentioned, an MPI-like API library called RCCE (pro-nounced “rocky”) [26] exists for the SCC. The library provides three APIinterfaces: two for message-passing support (a basic and a gory interface),
8

CHAPTER 2. THE INTEL SCC
and one for power management. The basic message-passing API interfaceis a simple interface with most implementation details (such as synchro-nisation) hidden from the programmer. The gory interface exposes morefunctions and allows for more power and flexibility in implementations.
The programs described in this work are cross-compiled on a manage-ment console following the Intel SCC Programmer’s guide [27], and subse-quently deployed onto the cores for execution and testing. The gory interfaceis used in all algorithm implementations. The input/output control towardsthe processing units is handled by SSH, more specifically, pssh.
9

Chapter 3
Preliminary Investigation
There are several issues to be considered for algorithm design and imple-mentation on the Intel SCC.
First, taking a closer look at the multi-core processor and applying clas-sical multiprocessing paradigms, we see it bears a certain resemblance toa Non-Uniform Memory Access system: there is an interconnect network,its processing units vary in distance to their respective memory controllers,and no cache coherence is provided. Additionally, it is programmed usingan SPMD1 paradigm and there is an MPI-like library that provides collec-tive communication. These variations are very likely to have an effect inthe achieved results, and must be considered. The SCC is flexible in thisregard, as main memory address translation that is performed in hardwarenear the processing units can be configured using the cores’ lookup table.The amount of memory available e.g. can be changed by modifying thistable.
Second, we look at the availability of special SIMD or vector instructions.Unfortunately, no such instructions are available on the Pentium P54C cores.The first Pentium core that features such instructions is the P55C (PentiumMMX).
Third, we consider the capacity and latency of the interconnection meshand memory. Intel specifies its bus width as 16B data plus 2B side band.With a clock of 1600MHz, the mesh should thus be capable of a throughputof 3052 MiB, or 2.98 GiB, per second, with a specified latency of four cycles,including link traversal [24].
3.1 Main MemoryThe memory hierarchy on the SCC from the point of a single tile and core isnot altogether different to a uniprocessor system. As previously mentioned,
1Single Program Multiple Data
10

CHAPTER 3. PRELIMINARY INVESTIGATION
each tile contains two cores, where each core has individual L1 and L2 caches.The L1 caches are 16KiB instruction and 16KiB data each, while the L2caches are 256KiB unified. Each tile has a local memory area intended asa buffer for messaging, the MPB. This buffer is 16KiB per tile, which bydefault is assigned one half per core, so that each core has access to 8KiB ofMPB. Since the SCC consists of 24 tiles, we have a total of 384KiB of MPBmemory.
There are four main memory interface controllers (MICs) attached tothe “east” and “west” corner tiles of the 6-by-4 mesh. The controllers eachsupport a maximum of 16 GB memory, allowing for a total of 64 GB mainmemory. The supported memory type is DDR3-800. This memory is, inthe default configuration, logically divided in a quadrant-wise fashion to thecores on the tiles belonging to the quadrant. Each core in a given quadrant ofthe SCC is assigned a certain amount of exclusive (private) memory, servedby the quadrant-local MIC. This amount naturally depends on the amountof main memory installed, as well as configuration parameters in the cores’lookup tables (LUTs).
A lookup table is a set of configuration registers that are used for memoryaddress translation from core addresses to system addresses. Each core hasa LUT, and each LUT contains 256 entries. On a L2 cache miss, the top 8bits of the core physical address are used as an index into the LUT which forthese 8 bits provides 22 bits of system address information. The remaining24 bits of the core address are finally appended to result in a system addressof 34 bits. Most significantly, this LUT expansion contains a destination IDfor the mesh router where the translated system address is to be forwarded.By configuring each core’s LUT with a certain exclusive address range and aspecific router (where the memory controller is located), cores are providedwith core-private memories. This is the default configuration of the LUTs.
In addition to the aforementioned private memory, a certain amount oftotal system memory is reserved as shared memory. This memory can beindexed by any core (i.e. the cores have overlapping LUT addresses) and isevenly allocated from memory attached to the four memory controllers.
The SCC provides no cache coherence mechanisms. In the case of pri-vate memory, no cache coherence mechanism is even necessary, as memoryis exclusively mapped to a single core. In this case, both L1 and L2 cachesare active. The shared memory, on the other hand, is not cached in L2.Shared memory is either entirely uncached, having all the reads go directlyto memory, or only cached in L1 and marked as MPBT memory. As previ-ously mentioned, an instruction was also added to clear memory flagged withthis flag from the L1 cache. Furthermore, P54C already has the capability toreset the L1 cache completely. Presumably, not caching the shared memoryin L2 by default is due to the fact that the P54C is not equipped with anymeans of clearing or resetting the L2 cache. Activating L2 in combinationwith shared memory makes an implementation of a cache coherence mech-anism a requirement. Ultimately, any cache coherence must be handled by
11

CHAPTER 3. PRELIMINARY INVESTIGATION
the programmer, by e.g. manual cache flushing such as a certain pattern ofaccess. The caches are preconfigured as write-back, while the L1 cache canalso be configured as write-through.
As memory speeds often have a large impact on the performance ofsorting algorithms, we begin by examining the memory performance [21].This is measured in bandwidth, or bandwidth per core, where more thanone core is active. We examine variations in bandwidth with increasingnumber of cores, as well as using different memory access type; read, writeor combined. Since the SCC is capable of clock speed modulation, the effectof core clock on memory bandwidth is also examined. In these tests, memoryand mesh clock speeds are kept constant at 800Mhz, while the core clocksare tested at 533MHz and 800MHZ respectively.
In order to consider the impact of cache, we look at two different memoryaccess strides. Since the cache line width is 32 bytes, reading and writingto memory is performed in two different manners: stride 4 and stride 32bytes. Stride 4 bytes is selected for convenience as it is the size of an integeron this platform, while stride 32 is selected as it is the size of a cacheline (8 integers). Special care is taken to allocate memory with 32-bytealignment, in order to ascertain that the correct part of the cache line isread or written. The mixed pattern denotes a combination of these twostride patterns. A pseudorandom access pattern is also used to attempt tocircumvent any locality optimisations inherent in hardware, whether it iscache effect or memory bank optimisation. This pseudorandom pattern isprovided through a function [28] pi(j) = (a · j) mod S for the index j, alarge, odd constant a and where S is a power of two (see code example inappendix A.1). The random access pattern also applies the previous stridedprinciple to the index j.
In addition to access patterns, we look at read, write and combined accesstypes separately, where combined access refers to simultaneous reading andwriting, as well as the scaling in the amount of cores that are participatingbetween 3 and 12 cores. 12 cores is the maximum default private memorysetup per controller.
The experiment is performed using a fixed data set of 200MiB per eachparticipating core. Time is measured from the point when the cores havestarted up the program, throughout the memory operation and until fin-ished. This is repeated for 100 attempts, after which an average, standarddeviation, minimum and maximum values are collected. The bandwidth percore and the global aggregate bandwidth are measured. There is a numberof core in both measurements which signifies how many cores are active dur-ing the measurement. This was achieved by using variations of the code inappendix A.1.
Figure 3.1 shows the total measured read bandwidth presented as a func-tion of the number of cores. We see no surprises here, the 4-byte/1-int strideaccess achieves the highest throughput for each of the two different clockspeeds respectively. The lowest performance comes from the read random
12

CHAPTER 3. PRELIMINARY INVESTIGATION
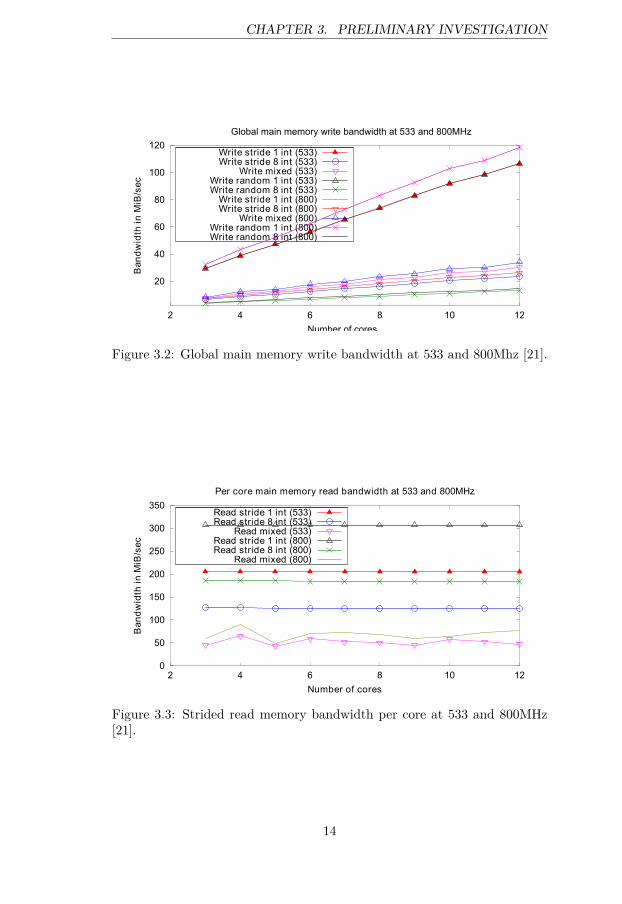
8 int pattern, as this type of access is designed to circumvent caches. Thesame can be said about the results in the diagram for write access in Figure3.2. The highest total throughput of 12-core aggregate, 120MiB per second,is achieved by sequential int writes, which is an excellent example of theeffect of cache. Recall that the L2 cache is write-back on the SCC — it fol-lows that the pattern that results in the fewest cache evictions will achievethe highest performance here. The only patterns that repeatedly write tothe same cache line are the 1-int per write ones and naturally have the high-est performance. We see that 1-int random and sequential access have thesame performance, since they result in the same amount of cache evictions.The weakest performance is shown by 8-int stride random accesses, whichnot only evict a cache line each time, but also are constructed to avoid anymemory optimisations for sequential reading that the memory controller af-fords. This access pattern is likely to be very close to the lowest possiblewrite performance achievable on the SCC. These same results are presentedper core in Figures 3.3 and 3.4.
Since no bandwidth drop with increasing number of cores is evidentand the aggregate memory bandwidth previously shown rises linearly withthe number of cores, this shows that a single memory controller cannot besaturated using a maximum of 12 cores. The slight drop in write bandwidthin Fig. 3.4 is attributed to the L1 cache, which is configured as no-write-allocate. This strategy causes a cache line to not be read into cache on awrite cache miss, i.e. when exclusively writing data, it is likely that the L1is completely bypassed.
0
500
1000
1500
2000
2500
3000
3500
4000
2 4 6 8 10 12
Ban
dw
idth
in
MiB
/sec
Number of cores
Global main memory read bandwidth at 533 and 800MHz
Read stride 1 int (533)Read stride 8 int (533)
Read mixed (533)Read random 1 int (533)Read random 8 int (533)
Read stride 1 int (800)Read stride 8 int (800)
Read mixed (800)Read random 1 int (800)Read random 8 int (800)
Figure 3.1: Global main memory read bandwidth at 533 and 800Mhz [21].
13
CHAPTER 3. PRELIMINARY INVESTIGATION
20
40
60
80
100
120
2 4 6 8 10 12
Ban
dw
idth
in
MiB
/sec
Number of cores
Write stride 1 int (533)Write stride 8 int (533)
Write mixed (533)Write random 1 int (533)Write random 8 int (533)
Write stride 1 int (800)Write stride 8 int (800)
Write mixed (800)Write random 1 int (800)Write random 8 int (800)
Global main memory write bandwidth at 533 and 800MHz
Figure 3.2: Global main memory write bandwidth at 533 and 800Mhz [21].
0
50
100
150
200
250
300
350
2 4 6 8 10 12
Ban
dw
idth
in
MiB
/sec
Number of cores
Per core main memory read bandwidth at 533 and 800MHz
Read stride 1 int (533)Read stride 8 int (533)
Read mixed (533)Read stride 1 int (800)Read stride 8 int (800)
Read mixed (800)
Figure 3.3: Strided read memory bandwidth per core at 533 and 800MHz[21].
14

CHAPTER 3. PRELIMINARY INVESTIGATION
0
2
4
6
8
10
12
2 4 6 8 10 12
Ban
dw
idth
in
MiB
/sec
Number of cores
Per core main memory write bandwidth at 533 and 800MHz
Write stride 1 int (533)Write stride 8 int (533)
Write mixed (533)Write stride 1 int (800)Write stride 8 int (800)
Write mixed (800)
Figure 3.4: Strided write memory bandwidth per core at 533 and 800MHz[21].
Finally, in Figures 3.5 and 3.6, we see that memory locality is a con-sideration, even for random access. Despite the high performance of thememory controllers, they struggle to serve highly irregular access patternsand perform better with sequential access.
1
2
3
4
5
6
2 4 6 8 10 12
Ban
dw
idth
in
MiB
/sec
Number of cores
Bandwidth per core with random access
5 int gap read13 int gap read21 int gap read5 int gap write
13 int gap write21 int gap write
5 int gap combined13 int gap combined21 int gap combined
Figure 3.5: Random pattern read memory bandwidth per core at 533 and800MHz [21].
15

CHAPTER 3. PRELIMINARY INVESTIGATION
2
4
6
8
10
12
14
16
2 4 6 8 10 12
Ban
dw
idth
in
MiB
/sec
Number of cores
Bandwidth per core with random access
5 int gap read13 int gap read21 int gap read5 int gap write
13 int gap write21 int gap write
5 int gap combined13 int gap combined21 int gap combined
Figure 3.6: Random pattern write memory bandwidth per core at 533 and800MHz [21].
3.2 Mesh InterconnectThe speed of the mesh and the message passing buffers is another issue thatinfluences the details in the construction of our algorithm.
The two-dimensional mesh network consists of 24 packet-switched routers,or one per tile (Fig.3.7), organised in the aforementioned 6x4 configuration.The mesh has its own power supply and clock source, in order to improvesupport for dynamic power management. The flow control in the mesh iscredit based. Each core is connected to the router on the tile using the meshinterface unit, which is responsible for, among other things, packetising/de-packetising data and translating local addresses into system addresses. TheMIU has a buffer, MPB, which is 16KiB and divided in half for each core.The MIU communicates directly with the tile router. Each router has eightcredits to give per port and can send a packet to another router only whenit has a credit from that router. Credits are returned to the sender once thepacket has moved on. Error checking is performed primarily through parity.No error correction is performed.
We are interested in the performance of the mesh, routers and the meshinterface unit when under a high load from the processors [5]. This is evalu-ated using a test program (a variation of the listing in appendix A.2). Theevaluation method consists of investigating latency and throughput by hav-ing a single core (core 0) send a specified amount of data to every other corenot sharing the same tile, while monitoring the time taken to perform thetransfer. The variables of the test are core distance in hops (Fig. 3.8) andthe size of the transferred data. Each test is performed 1000 times and theaverage is taken as a sample.
We do not test data sets larger than the size of the L2 cache. Thesesizes would result in frequent main memory access, which in turn generates
16

CHAPTER 3. PRELIMINARY INVESTIGATION
Figure 3.7: SCC Tile Level Diagram [24].
extra mesh traffic and could naturally introduce undesirable variability inour test. By ensuring that data is exchanged from within the L2 cache only,we avoid any impact on timing that main memory access would have.
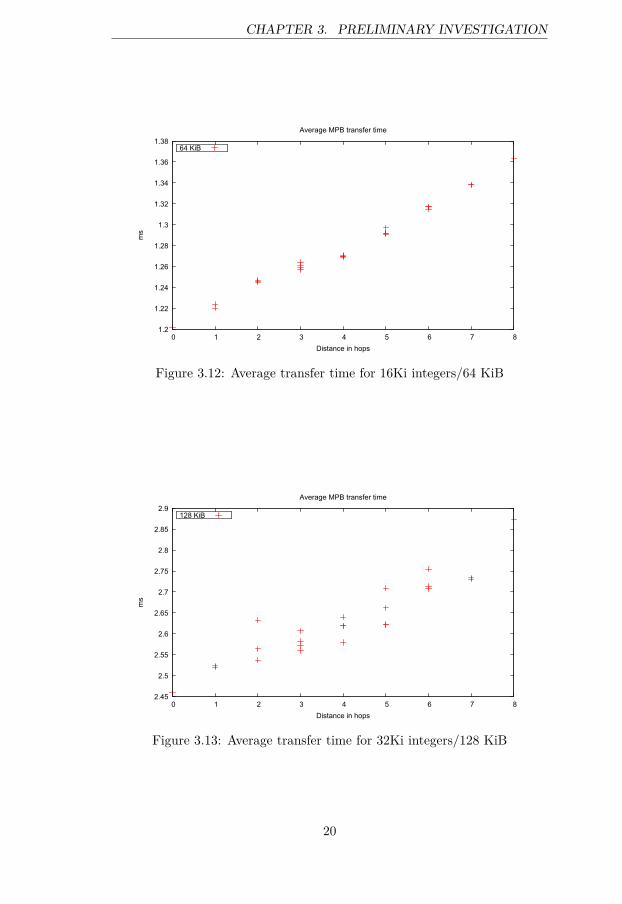
The results of the first round of tests are displayed in Figures 3.9 through3.14 for data sizes of 2, 4, 8, 16, 32 and 64 kibi-integers or 8, 16, 32, 64, 128and 256 kibibytes respectively.
First, in Fig. 3.14 we see the timings for the 64Ki integers are highlyinconsequent. This is attributed to memory access. A data set of thissize is highly unlikely to fit in L2, even if a single program is running onthe processing unit. Other processes along with the operating system areassumed to be intruding on the utilisation of L2. It is evident that there issome private memory access in this case, which is influencing the transfertimings.
Second, for data sets of 2-32 kibi-integers (4-128 KiB), we see that thetimings are roughly doubling with the doubling of the data size. This in-dicates again, as in the case of main memory, that the processing units areunable to saturate the mesh. Another representation of the same data isgiven in Fig. 3.15, where the same numbers can be seen as a function of hopdistance. The marginal timing increase is more prominent in this Figure,along with the cache limit at 256 KiB.
Finally, a second round of testing is performed. This is done in orderto better ascertain the availability of L2 cache, i.e. to find out the amountof data that can safely be cached before memory access starts to have asignificant impact on performance. For this, data sizes of 40, 48 and 56 Ki-
17

CHAPTER 3. PRELIMINARY INVESTIGATION
71
(a) 3 hops between cores.
111
(b) 5 hops between cores.
23
1
(c) 6 hops between cores.
47
1
(d) 8 hops between cores.
Figure 3.8: Four different mappings of core pairs with increasing distance[5].
0.085
0.09
0.095
0.1
0.105
0.11
0 1 2 3 4 5 6 7 8
ms
Distance in hops
Average MPB transfer time
8 KiB
Figure 3.9: Average transfer time for 2Ki integers/8 KiB
18

CHAPTER 3. PRELIMINARY INVESTIGATION
0.28
0.285
0.29
0.295
0.3
0.305
0.31
0.315
0.32
0 1 2 3 4 5 6 7 8
ms
Distance in hops
Average MPB transfer time
16 KiB
Figure 3.10: Average transfer time for 4Ki integers/16 KiB
0.59
0.6
0.61
0.62
0.63
0.64
0.65
0.66
0.67
0.68
0 1 2 3 4 5 6 7 8
ms
Distance in hops
Average MPB transfer time
32 KiB
Figure 3.11: Average transfer time for 8Ki integers/32 KiB
19
CHAPTER 3. PRELIMINARY INVESTIGATION
1.2
1.22
1.24
1.26
1.28
1.3
1.32
1.34
1.36
1.38
0 1 2 3 4 5 6 7 8
ms
Distance in hops
Average MPB transfer time
64 KiB
Figure 3.12: Average transfer time for 16Ki integers/64 KiB
2.45
2.5
2.55
2.6
2.65
2.7
2.75
2.8
2.85
2.9
0 1 2 3 4 5 6 7 8
ms
Distance in hops
Average MPB transfer time
128 KiB
Figure 3.13: Average transfer time for 32Ki integers/128 KiB
20

CHAPTER 3. PRELIMINARY INVESTIGATION
5
5.2
5.4
5.6
5.8
6
6.2
6.4
6.6
6.8
7
7.2
0 1 2 3 4 5 6 7 8
ms
Distance in hops
Average MPB transfer time
256 KiB
Figure 3.14: Average transfer time for 64Ki integers/256 KiB
ints are selected (160, 192 and 224 KiB respectively). The results of theseadditional tests can be seen in Figures 3.16 through 3.18.
From the above we see that main memory access interference beginsto make itself apparent at a data size of 192KiB. 160 KiB, in comparisonwith the lower data set results, looks relatively unaffected. We see thusthat, ideally, to avoid added memory access in mesh communication whendesigning and programming for pipelining (with the current configurationof hardware and software), data sets of 160 KiB should preferably be usedand of definitely no more than 192KiB.
21

CHAPTER 3. PRELIMINARY INVESTIGATION
0
1
2
3
4
5
6
7
0 1 2 3 4 5 6 7 8
Timeinmilliseconds
Hamming distance in hops
Block transfer time and distance between cores
64KiB128KiB256KiB
Figure 3.15: Average time to transfer 64, 128 and 256KiB as a function ofthe distance between cores [5].
2.3
2.35
2.4
2.45
2.5
2.55
2.6
2.65
2.7
2.75
2.8
2.85
0 1 2 3 4 5 6 7 8
ms
Distance in hops
Cached transfers
160 KiB
Figure 3.16: Average transfer time for 40Ki integers/160 KiB
22

CHAPTER 3. PRELIMINARY INVESTIGATION
2.8
2.9
3
3.1
3.2
3.3
3.4
3.5
0 1 2 3 4 5 6 7 8
ms
Distance in hops
Cached transfers
192 KiB
Figure 3.17: Average transfer time for 48Ki integers/192 KiB
3.6
3.8
4
4.2
4.4
4.6
4.8
5
0 1 2 3 4 5 6 7 8
ms
Distance in hops
Cached transfers
224 KiB
Figure 3.18: Average transfer time for 56Ki integers/224 KiB
23

CHAPTER 3. PRELIMINARY INVESTIGATION
3.3 ConclusionsTests were performed on memory and mesh in order to obtain results relevantto our tailored algorithm design. The following are important considerationsto be made during this process:
1. The P54C cores, albeit extended with new features and clocked toa much higher clock than its original stock clock, are not at parperformance-wise with the rest of the hardware in the SCC. The DDR3controllers and the mesh are extremely fast and can only be taxed bythe P54C cores using a heavy write load. This is not entirely unex-pected, as there is limited die area and many cores are provided. Ourtests show that a single memory controller remains at nearly its max-imum performance even when a full quadrant of the SCC is readingfrom it. Furthermore, a single mesh link cannot be significantly sloweddown by communication between any two cores, as long as main mem-ory access is avoided, i.e. for any type of pipelining considerations.
2. Any memory access other than cache will result in added mesh com-munication, since the memory is accessed through the mesh itself. Thepreferred data size to be used for local buffers with pipelining is thus160 KiB, with no more than 192 KiB used at any time. Ideally, theseparameters should be made configurable.
3. Despite the high overall performance of the memory, write bandwidthis comparatively low and the mesh interconnect even faster. Combinedwith the low performance of the processing units, this makes the SCCa good candidate for pipelined sorting.
24

Chapter 4
Mergesort Algorithm
4.1 Simple approachAs an initial implementation, we begin by constructing a naïve parallelmergesort algorithm. Each level of the mergesort tree is mapped to a set ofcores. This simplification means that we may only use a number of coresthat is a power of two, and at maximum, only 32 of the 48 available coresare used. Furthermore, all of these 32 cores are only used in the first round;as the number of sequences to be sorted halves every round, so does thenumber of participating cores. With a large number of cores idle during thesorting, the efficiency of this algorithm should be extremely low.
4.1.1 AlgorithmThe algorithm uses the cores’ private memory to store integer blocks anduncached shared memory as a buffer to transfer these blocks between them.Since uncached shared memory is used, no cache coherence mechanism isrequired. The algorithm is initialised by selecting the number of integersN (the size of data), the number of participating nodes P and setting thenumber of active nodes Pa = P . In step 0, each node pregenerates twopseudorandom nondecreasing sequences of length N/(2P ). These sequencessimulate the output from the initial sequential round of merging.
The algorithm then enters a sequence of rounds, where each round con-sists of two phases, sorting and transfer. In the sorting phase, the activenodes in the current round merge two sequences into one of combined lengthN/Pa. The sorting phase is then completed and the algorithm proceeds tothe transfer phase (Fig. 4.2). In the transfer phase, the number of activenodes is integer-divided by two (using a logical right shift) and the nodesthat are becoming inactive transfer their sorted sequences to the nodes re-maining active. The transfer is performed using buffers in shared memory.During the transfer phase, flags are set in the communicating cores MPBs
25

CHAPTER 4. MERGESORT ALGORITHM
for synchronisation.The round is completed; active nodes (the nodes with their rank less
than Pa) continue on to the next round while the inactive nodes becomeidle.
When the last round completes and the algorithm ends, the root nodehas merged the last two sequences into a single nondecreasing sequence oflength N . Figure 4.1 provides an illustration of this simple algorithm.
core 0 core 2core 1 core 3
Round 1
Round 2
Round 3
merge
communicate
Round 0generate
non-decreasing
Figure 4.1: Naïve Parallel Merge: each round half of the cores becomeinactive after merging and transferring their assigned sequences [5].
Three other variants of the algorithm above are implemented. They usethe same basic algorithm as above, but alter it as follows.
Two of the variants rely on shared instead of private memory exclusively.The shared memory variants of the algorithm do not have a transfer phase;by relying directly on shared memory as storage for input and output blocks,the transfer phase is avoided. That is, there is no copying of data betweenrounds; all that is required is a synchronisation for each subsequent roundto begin. Two cores are assigned a common buffer in shared memory fortheir exclusive use, where one core is the sender and the other the receiver.Flags are set by the cores in their respective MPBs for synchronisation, i.e.when they are allowed to read or write their assigned buffer. The sharedmemory mergesort algorithm is implemented in two variants: one cachedand one uncached.
The uncached shared memory version uses no caches, but accesses mem-ory directly. No cache coherence mechanism is provided or necessary.
In the cached shared memory version of the algorithm, the L1 and L2caches are enabled for caching and an explicit cache flush is added in placeof the transfer phase. As the SCC has no cache coherence, this is requiredto maintain main memory consistency for the next round of computation.
26

CHAPTER 4. MERGESORT ALGORITHM
The final version uses the MPB as a buffer instead of shared memory, andrelies on mesh communication to transfer the data between working cores.Note that this algorithm is still in no way pipelined, the memory blocks aresimply transferred from the private memory range of one set of cores to theprivate memory of another set. This variant should nevertheless reduce theamount of memory access compared to the first version.
core 2 core 0
blocking
blocking
blocking
transfer
transfer
data written
data read
Figure 4.2: A transfer phase of the naïve algorithm variants [5].
4.1.2 Experimental EvaluationThe measurements are performed as follows. Each of the initially activenodes generates two pseudorandom nondecreasing integer sequences thatare to be merged. Once the starting sequences are randomised, timing andthen sorting starts. The sequences local to each core are sorted and therespective algorithm above is followed. When the root task on the root rankprocessing unit completes, the timer is stopped and the resulting sequenceis verified for correctness. Each measurement is performed in excess of 1000runs, and the average of these is sampled. The results of the measurementsare represented in Figures 4.3 through 4.8. One additional test is performedwith constant values for comparison purposes (Fig. 4.9).
The results of the tests show the initial version of the algorithm havingthe weakest performance in all cases except the single node one. This is un-surprising as this version of the algorithm requires the most main memoryaccess. Starting with the 32 node case in Figure 4.8 we see that, for the firstalgorithm that uses private memory with shared memory as a buffer, theadditional phase copying to shared memory and back induces a performancepenalty of over 60% over the same algorithm that instead uses mesh com-munication. Recall that the writing and subsequent reading from sharedmemory between two rounds of the algorithm are replaced here by insteadtransferring the same data between two cores’ private memories using themesh. We see that very similar results are obtained for descending num-bers of cores, the results in Figures 4.8, 4.7 and 4.6 for 32, 16 and 8 coresrespectively are nearly the same. The inefficiency of the base algorithm ishighly apparent in these, since there is no significant speedup in any of the
27

CHAPTER 4. MERGESORT ALGORITHM
Figure 4.3: Merging time using 1 processor [5].
Figure 4.4: Merging time using 2 processors [5].
28

CHAPTER 4. MERGESORT ALGORITHM
Figure 4.5: Merging time using 4 processors [5].
Figure 4.6: Merging time using 8 processors [5].
29

CHAPTER 4. MERGESORT ALGORITHM
Figure 4.7: Merging time using 16 processors [5].
Figure 4.8: Merging time using 32 processors [5].
30

CHAPTER 4. MERGESORT ALGORITHM
variants between 8 and 32 cores, despite the quadrupling of the number ofworking cores. Furthermore, comparing any of the results to its single corecounterpart in Figure 4.3 reveals that there is actually no speedup at all. Inthe case of the shared memory variants in these three Figures, we see thatthe uncached shared memory offers particularly low performance. Despitethe complete lack of a transfer phase here, we still see almost as low perfor-mance as the worst-case variant. Naturally, there is no cache used here, solow performance is expected. The best results are achieved with the cachedshared memory algorithm, which both takes advantage of caching as well asavoids extra copying.
Continuing in the reverse order, we look at the results for 4- and 2-nodetests (Figures 4.5 and 4.4). We see that, as the number of utilised coresdecreases between 8 and 2, the performance of the private memory versionof the algorithm with shared memory buffers improves over the uncachedshared memory one. This is attributed to the fact that these cases are lessparallelised in that there are fewer rounds. As the number of rounds is equalto log2 nodes, each halving of the nodes reduces the number of rounds, andthereby the block transfer operations between rounds, by one.
Ultimately, the results depicted in the Figure for a single processor showbest performance for all variants (Fig. 4.3). That is, our naïve attempt atparallelisation of the mergesort algorithm does not yield any advantage overthe non-parallel version. Both private memory versions of the algorithm inthis special case are the same, and hence perform the same. They performbetter than the cached shared version as the memory required grows, sincethe private memory is always allocated on the closest memory controller.Naturally, uncached shared memory is, lacking cache, again significantlyslower. The single-core results confirm our previous experiments with mem-ory with regards to private and shared memory speeds.
31

CHAPTER 4. MERGESORT ALGORITHM
Figure 4.9: Merging time using 32 processors, using constant values [5].
4.2 Pipelined mergesortThe pipelined parallel mergesort algorithm is a version of the mergesortalgorithm. It shares the same basic features as even the simple parallelmergesort described above, but optimises away as much as possible of thememory access, usually trading it off for a communication cost. By pipelin-ing the steps of the algorithm in a way much similar to how a processorpipelines instructions, one constant stream of sorting can be executed, read-ing, as input, unsorted elements from an external location while writing, asoutput, their sorted sequence. Assuming, again, a tree mapping, the leavesof the tree read the unsorted sequences to be merged, merge a certain buffersize of elements and communicate the subsequence upward in the tree, un-til the stream reaches the root, which writes a fully sorted sequence. Thiscontinues until all the elements are consumed.
There are many variables in designing such an algorithm. A sorting treedepth must be selected that allows for a desired task granularity, but doesnot introduce additional resource strain. The granularity is typically morethan a single task per processing unit. Task assignment must be done ontothe processing units of the underlying hardware in a way that optimisesits usage. Here, a trade-off must be made between the amount of memoryaccess, communication and computation.
32

CHAPTER 4. MERGESORT ALGORITHM
4.2.1 DesignOrdinary sequential merging has a linear computation cost relative to theinput size. Due to this, we know that each full level of the merge tree hasthe same computation cost. Assuming that a root task must be assigned toa single core, one way of partitioning would assume a tree of similar depthas there are nodes. For the SCC in particular, the size of this tree wouldbe infeasible, so the number of tasks must be reduced. Instead of a singlelarge tree, we opt for several smaller ones. Since this will introduce a secondphase of merging, the number of trees must be a power of two to allow abalanced merge phase in the second phase. The number of trees should alsodivide the total core number evenly, in order to efficiently map onto theSCCs 48 cores. The locality of memory controllers on the mesh should alsobe considered.
We opt for a forest of 8 trees with 6 levels each [29] [28], and the top-levelview of the algorithm results in the following phases:
• A local mergesort phase, phase 0, is required to obtain the startingsubsequences. The leaves of the 8 trees each read their assigned blockof input elements to be sorted and merge them in their private mem-ories. After this phase, the pipelined merge phase can begin.
• Phase 1 runs a pipelined parallel merge with 8 6-level trees. Thisresults in 8 sorted subsequences.
• Phase 2 consists of a parallel sample sort algorithm. This is done inorder to achieve a higher core utilisation ratio compared to a solutionsimilar to phase 1.
Phase 2 is required to merge the 8 sorted subsequences produced by phase1. If this phase is mapped to a parallel mergesort in the same manner, therewould be a significant number of idle cores, reducing efficiency. Instead, weopt for a parallel sample sort and use all 48 cores even in the second phase.
The task mapping is modeled to the SCC using an integer linear pro-gramming (ILP) based method [29] [28]. The models allow for optimisationof either the aggregate overall hop distance between tasks, weighted by inter-task communication volumes, or the aggregate overall hop distance of tasksto their memory controller, weighted by the memory access volumes. Themodel balances computational load, in addition to distributing leaf tasksacross cores to reduce the running times of phase 0. The linear combinationis controlled using weight parameters.
An arbitrary manual task map is also produced, the layer map [29]. Thesimple layer map is, as the name implies, based on tree levels. As we knowthat each tree level has the same computation cost, we map each level of atree to a single core. With 12 cores and two 6-level trees, we have exactlyone tree level per core. Since we also know from the previous experimentsthat the distance to the memory is the biggest influence on memory access
33

CHAPTER 4. MERGESORT ALGORITHM
times, we place the first 6-level tree such that the root node (on level one)is on a single core closest to the memory controller, with every subsequenttree level leading away from the MIC in a semi-circular fashion (see Figure4.10). The lowest level leaves are thus mapped on the second-nearest coreto the memory controller. The reverse is done with the second 6-level tree.
MIC
1 2 34 5
6 7
8 9 10 11
12 13 14 1516...3132...63
Figure 4.10: Per-level distribution of the layer map and pipeline data flow.
4.2.2 AlgorithmThe inputs to the algorithm and program are:
• A task map file. This file contains the task mapping to the SCCscores, in a per-quadrant fashion. This mapping is replicated internallyrespective to the local memory controller.
• A data file containing the integer elements to be sorted.
• MPB buffer size to be used in communication.
Initially, the task map file input is parsed in order to generate an internalrepresentation of the task tree. For simplicity, the map file is represented asa 7-level tree, where the root is ignored, i.e. two 6-level trees. The recursivefunction generate_subtree is responsible for the task and tree generation, inaddition to calculating offset sizes (into the unsorted input array) for leaves.Each task is represented by the data structure in Listing 4.1. After the tasktree is generated, each processing unit uses the mapping and the task treeto determine which tasks it is responsible for executing. These tasks arecollected into a local task array.
Listing 4.1: The task data structure representationnumbersepnumbersep numbersep1 struct tasknumbersepnumbersep numbersep2 {numbersepnumbersep numbersep3 unsigned short id;numbersepnumbersep numbersep4 unsigned short local_id;numbersepnumbersep numbersep5 struct task* left_child; /* tree structure */numbersepnumbersep numbersep6 struct task* right_child;
34

CHAPTER 4. MERGESORT ALGORITHM
numbersepnumbersep numbersep7 struct task* parent;numbersepnumbersep numbersep8 unsigned short cpu_id; /* the id of the cpu this task is running on */numbersepnumbersep numbersep9 unsigned short tree_lvl; /* the level of the tree the task is on */numbersepnumbersep numbersep10 t_vcharp buf_start; /* pointer to the start of the buffer in thenumbersepnumbersep numbersep11 * MPB */numbersepnumbersep numbersep12 unsigned short buf_sz; /* the size of the data buffer in 32B linesnumbersepnumbersep numbersep13 * including the header */numbersepnumbersep numbersep14 unsigned size; /* total number of integers that need to benumbersepnumbersep numbersep15 * handled by this task */numbersepnumbersep numbersep16 unsigned progress; /* progress of task, i.e. how much of sizenumbersepnumbersep numbersep17 * has been completed. if equal to sizenumbersepnumbersep numbersep18 * the task is finished. */numbersepnumbersep numbersep19 void (*function)(struct task *task); /* pointer to the function that willnumbersepnumbersep numbersep20 * run this task */numbersepnumbersep numbersep21 leaf_props_t *leaf; /* leaf properties */numbersepnumbersep numbersep22 };numbersepnumbersep numbersep23 typedef struct task task_t;
Based on the processor-local task array, the MPB buffer sizes are calcu-lated and allocated (setup_buffers). Since the leaf nodes all read their inputfrom main memory, they do not need local MPB buffers. Instead, they pushsorted elements upward in the tree. The branches and root, however, eachhave their respective MPB input buffer. The MPB is preallocated and usedproportionally, based on local task weighting as follows:
1. A task weight is assigned to each task and calculated based on the levelof the binary tree the given task is on. Each task has a weight score ofhalf of the task directly above in the task tree, starting with 1 for theroot node, i.e. w = 1/2l, where w is the task weight for a given taskand l = 0, ..., 5 its tree depth, starting with 0 for root. For example,the root task has a score of 1, the branches immediately below theroot have the score of 1/2, and so on. The task weight is proportionalto the computation cost of a task. As it is simple to calculate, it isnot saved in the task structure.
2. Each core gathers its core-local tasks, and calculates the sum of theirweights. The remaining steps are calculated on a core-local basis.
3. The MPB buffer, the size of which to be used is provided as an inputvariable to the program, and no more than 8128 bytes, is assigned toeach task proportionally. The proportion of this buffer that a taskreceives is equal to the proportion of the task weight to the core-localtask weight sum. Given t = 1, ..., n local tasks on the node, Btot asthe constant total per-core buffer size and weight w as in step 1, eachtasks buffer is calculated as follows:
Bt = Btotwt
n∑j=1
wj
As an example, assume an MPB size of 4000 bytes. Assume further thatthe mapping is such that the current core executes 3 tasks, the root of the
35

CHAPTER 4. MERGESORT ALGORITHM
6-level tree and its immediate branches. The MPB buffer size assigned tothe root task would be 4000 · 1/(1 + 1/2 + 1/2) = 2000 bytes.
Next, each node sets up its respective buffers in the MPB. An MPB mem-ory descriptor data type is introduced for keeping track of an MPB buffer(Listing 4.2). This descriptor is used in a similar manner as a protocol headerand contains metadata such as the progress of production/consumption ofdata, etc.
During this process, tasks are also assigned their corresponding taskfunction. There are three types of tasks: root, branch and leaf tasks. Eachof these types of tasks performs the same function, but with a different setof parameters. Therefore, a function is implemented for each: run_root,run_branch and run_leaf. The function type is stored as a function pointerin the task tree structure, so that it can be accessed from there directly.
Listing 4.2: The MPB memory descriptornumbersepnumbersep numbersep1 struct mpb_headernumbersepnumbersep numbersep2 {numbersepnumbersep numbersep3 unsigned long seq; /* the sending tasks counter, equal to progressnumbersepnumbersep numbersep4 * of task. incremented every time the buffernumbersepnumbersep numbersep5 * is written to */numbersepnumbersep numbersep6 unsigned long ack; /* the receiving tasks counter, set equal tonumbersepnumbersep numbersep7 * seq when the buffer has been received */numbersepnumbersep numbersep8 unsigned short start_os; /* the offset to the first valid integernumbersepnumbersep numbersep9 * in buffer (since some may have been consumednumbersepnumbersep numbersep10 * already */numbersepnumbersep numbersep11 unsigned short int_ct; /* number of valid (unconsumed) integersnumbersepnumbersep numbersep12 * currently in data area */numbersepnumbersep numbersep13 unsigned short src_task_id; /* the source task, writes to this buffer */numbersepnumbersep numbersep14 unsigned short dst_task_id; /* the destination task, reads from buffer */numbersepnumbersep numbersep15 } __attribute__((aligned(32)));numbersepnumbersep numbersep16 typedef struct mpb_header mpb_header_t;
Private and cache memory is allocated. The cores that hold leaf orroot tasks allocate private memory for reading or writing as needed. Thecores holding branch tasks allocate small amounts of private memory thatis assumed to remain in cache and is to be used for work. The amount ofcache memory allocated is the minimum required for merging the task athand, depending on the MPB buffer size. Here, a constant is introduced toincrease the amount of cache memory for possible performance tuning. Thisconcludes the setup of the algorithm and sorting can begin.
Phase 0 local merge is initially performed by each leaf task. This isexecuted by the function sequential_merge (see appendix A.5). An inputfile containing the elements to be sorted is read, at a certain offset deter-mined by each leafs position relative to the tree. The elements are copiedto memory and mergesort over the elements is done locally, recursively inplace. Since leaves will continue performing a merge operation even in thenext phase of the algorithm, the elements are sorted locally into two sortedsubsequences, i.e. at the end of phase 0, each leaf has presorted its assignedinput sequence into two sorted subsequences that it will merge further inphase 1. An additional N/2 elements of memory is allocated for each Nelements for sorting performance. This is due to our implementation of the
36

CHAPTER 4. MERGESORT ALGORITHM
mergesort algorithm, which uses this extra memory in order to avoid moremove operations than is necessary1. This lowers the computation cost butincreases memory cost, a beneficial trade-off, given the memory results fromchapter 3.
Phase 1 begins after leaf-containing cores have finished the pre-sortingand all cores have met at a barrier. It proceeds to merge 8 trees in aquadrant-wise fashion, 2 trees per memory controller. The main loop of theprogram steps through the core-local list of tasks and executes each taskbased on its location in the tree in descending priority (breadth-first traver-sal). The loop runs until there are tasks that can run. A task is markedas running until it has no input elements to consume. When a task is exe-cuted, its respective function is called. Each of the three different functionsis based on two supporting functions that control program behaviour:
1. check_and_merge function checks the inbound MPB buffers for newelements. If any are found, they are consumed until either the inputbuffers or output buffer (in cache) has been filled, and the functionreturns. If no new elements are consumed, the function returns. Notethat the sorted elements are not written to the destination yet, butare kept in memory (L2) instead.
2. check_and_push function checks the outbound MPB buffer for emptyspace. If there is empty space in the upstream MPB buffer, sortedelements from memory (L2) are copied into the MPB buffer until eitherit is full or the memory cache is empty.
These two functions update the MPB memory descriptor mentioned ear-lier in order to keep track of buffer and element sizes. Both functions arefully utilised only in branch tasks. The root task does not have an outputbuffer but writes directly to memory and does not need to perform the pushfunction (2). The reverse is valid for the leaf tasks, so they do not checkany inbound buffers (1).
Phase 2 consists of merging the 8 sorted subsequences into a singlecomplete sequence. Sample sort is employed for this purpose. Each of the 8roots in the previous phase begins with calculating pivots on their respectivesubsequence. 47 pivots are computed, that evenly divide the roots sequenceinto 48 equal chunks.
The 47 pivots are communicated by all other roots to a root master,arbitrarily chosen from the 8. The root master calculates medians for thepivots, producing 47 median pivots, which are then distributed back to theroots. The roots use the median pivots to divide their respective sequenceinto 48 chunks each. Finally, the 8 roots copy their data into shared memory,so that each chunk is still bounded by the pivots (Fig. 4.11). That is, afterthe copy operation, the full sequence in shared memory is still divided in 48
1It is possible to perform mergesort entirely in place, when the computation cost isacceptable.
37

CHAPTER 4. MERGESORT ALGORITHM
Root0
(m aster root ) Root 1 Root 2 Root 3all other cores
Calculate
local pivotslocal pivots
local pivots
local pivots
Calculate
global pivotsglobal pivots
global pivots
global pivots
Calculate local
chunks lengthslocal chunks lengths
local chunks lengths
local chunks lengths
all chunks length
all chunks length
all chunks length
all chunks length
Merge chunks
Write chunks
Figure 4.11: Collective communication during pivot calculation and distri-bution [22].
chunks by the pivots, but the chunks bounded by the same pivots are nowconcatenated (see example in Fig. 4.12).
Figure 4.12: Simplified example of samplesort pivot boundaries [22]. Aftersorting, the centre sequence will be completely sorted.
During this synchronisation and copying, all 40 other cores are idle, butnow become active. The 40 remaining cores fetch the calculated chunklengths and together with the 8 roots are each assigned one of the 48 se-quences that were copied to shared memory to sort. As we had 8 roots,there are 8 chunks in each, so an 8-to-1, 3-level, tree is locally merged intoa single subsequence. Since each subsequence is still bounded by the pivots,
38

CHAPTER 4. MERGESORT ALGORITHM
we have arrived at a fully sorted single sequence.
4.2.3 Experimental EvaluationThe program is compiled with the RCCE library version 1.0.13 and theIntel C Compiler. The platform used is the sccKit version 1.3.0. The rele-vant compiler flags used are O3, mcpu=pentium and the program is alwaysstatically compiled. Three different core mappings are tested, a naïve layermap and two ILP-model produced maps, a worst-case and an optimal map2.Each measurement is taken at least 100 times for each of the possible com-binations of variables, in order to reduce any possible interference. Theprogram is run with 48 cores and with varying MPB buffer size: 4096, 6144and 8128 bytes. The input is a file containing unsigned integers generatedusing the pseudorandom function (rand) inherent in the Intel C compiler.Time measurement starts once the pseudorandom sequence to be sorted isloaded into memory, i.e. the time taken to read the file and copy its contentsinto memory is not taken into account.
The results for the three different mappings are represented in Figure4.13. We see that our ILP model provides higher performance than thesimple layer map, especially with higher numbers of integers sorted. Addi-tionally, the worst-case map confirms the impact of ILP optimisation. Usingthe maximum available MPB buffer size affects the measurements positively,with no unexpected behaviour from the three different MPB buffer sizes(Fig. 4.14). In the optimal map case, the difference between 4096- and8128-byte sized MPB amounts to about 2% regardless of the number ofelements sorted.
Table 4.1 shows the overall results for data sizes for 1-16Mi integers.A sequential mergesort was implemented for comparison purposes. Thisalgorithm recursively splits the array of integers given as input into smallerchunks that fit into 1/3 of the L2 cache. Subsequently, a sequential quicksortsorts these chunks, after which they are merged together to attain a fullysorted sequence. Time is measured in the same fashion as in the case of ourprevious algorithms. Measurement starts once the input data is fully loadedin memory, and stops before the sorted array is checked for correctness. Incomparison to this sequential implementation, our best version and mappingof the hybrid algorithm achieved a maximum speedup of 23.7 at an efficiencyof 0.49. Additionally, the comparison to the initial naïve parallel algorithm(private memory with shared memory as buffer) shows a 2.9 speedup whenlarge numbers of elements are sorted.
We are not aware of existing performance results for sorting algorithmson the SCC. Thus we compare the results with the pipelined sorting al-gorithms implemented on the Cell B.E. processor [6]. CellSort [14] uses alocal sort followed by a bitonic sort, which correspond to our phase 0 andphase 1 and 2 respectively, needs 746 ms to sort (distributed out-of-core
2For details concerning the ILP model used, see [22]
39

CHAPTER 4. MERGESORT ALGORITHM
0
5000
10000
15000
20000
25000
1Mi 2Mi 4Mi 8Mi 16Mi 32Mi
ms
Number of integers
Layer mapOptimal map
Worst-case map
Figure 4.13: The hybrid algorithm using three different core mappings.
0
5000
10000
15000
20000
ms
Number of integers
Optimal map, 8128B MPB buffer sizeOptimal map, 4096B MPB buffer size
1Mi 2Mi 4Mi 8Mi 16Mi 32Mi
Figure 4.14: The optimal mapping using two different MPB buffer sizes.
40

CHAPTER 4. MERGESORT ALGORITHM
Data size (Mi) 1 2 4 8 16Sequential 10767 23083 49280 104110 220800
Naïve parallel 1610 3271 6596 13233 26820Best (optimal map) 983 1878 3714 5577 9327
Speedup over sequential 11.0 12.3 13.3 18.7 23.7Speedup over naïve 1.6 1.7 1.77 2.4 2.9Efficiency (naïve) 0.14 0.15 0.16 0.16 0.17Efficiency (best) 0.23 0.26 0.28 0.39 0.49
Table 4.1: Runtime in milliseconds for different data sizes and algorithms.
sort) 32M integers with 16 SPEs, where the time for phase 0 is omitted.While the time taken for our implementation on the SCC is about 15700ms, it must be noted that there is a large disparity between the power ofthe two constituent core types. The frequency of the SCC is lower thanthat of the Cell by a factor of 6, in addition to having significantly weakervector computing capabilities. The vectorised RISC architecture of the Celllends itself much better to these operations, consuming fewer clock cyclesper operation, while utilising four times wider registers. Assuming anotherfactor of 8 speedup due to wider registers (32- against 128-bit), lower CPIand dual issue architecture on the Cell SPEs, we achieve on the SCC a verysimilar result, but with three times more cores.
41

Chapter 5
Conclusions and FutureWork
In this work, we tested the underlying hardware of the SCC in order toimprove our design of a tailored hybrid sorting algorithm. Understandingof the performance of the constituent parts is one of the most importantthings when engineering such an algorithm. We continued to implement anaïve sorting algorithm, in order to achieve a baseline for comparison. Fi-nally, a hybrid sorting algorithm was tailored, using the results of the earlierexperiments, to the hardware of the SCC. The result was a combination ofthe mergesort algorithm, parallelised to a high degree, executed both locallyand in a pipelined configuration, and a version of parallel samplesort basedon merge sorting. We achieved a significant maximum speedup and a satis-factory efficiency in the best case. The engineered algorithm, while not fullyoptimised, is an important stepping stone towards an implementation withimproved efficiency, and can be adapted for similar 2D mesh architectures.
The most immediate optimisation of the algorithm design consists in im-proving phase 2 of the algorithm. First, the communication is not optimised.The only available working primitive with the current RCCE version is abarrier. Barriers are used extensively during calculation and communica-tion of the pivots and sequences. Ideally, a set of collective communicationfunctions should be developed with standard MPI-like functions like scatter,gather, etc. Second, the calculations of pivots and especially the lengths ofsubsequences before phase 2 is suboptimal. Third, phase 2 still containsa memory copy element, which should not be necessary. The copying isdone merely so that the elements are moved into every cores address space.There is a possibility that modifying the cores LUT or using RCCE Pri-vately Owned Public Shared Memory (POPSHM) can be used to map the8 intermediate subsequences into cores’ memory directly, rather than usingthe costly copy-to-shared-memory operation. This would avoid using sharedmemory altogether. Theoretically, many other designs would be possible by
42

CHAPTER 5. CONCLUSIONS AND FUTURE WORK
modifying the cores’ lookup tables so that e.g. their private memory becomeslocated on a different memory controller. If, due to the aforementioned, noimprovement in performance can still be reached, redesigning phase 2 sothat it also runs a pipelined parallel mergesort could produce better results,despite the resultant drop in efficiency due to idle cores.
Other improvements include optimising local tasks. Two tasks runningon the same core do not detect their relationship and still use the MPBfor communication. By having these tasks use private memory, which isL2 cached, to communicate, we free up valuable MPB space, in additionto speeding up memory access. Depending on the degree of the penalty ofMPB access compared to L2 cache, it could become beneficial to put evendeeper branches of the merge tree on a single core to take advantage of this,since available L2 cache is much larger than the MPB.
Additionally, there is a large amount of program optimisation on thecode itself. One example of this is that the memmove function is used tomove the valid remainder of data to the front of the buffer, when cache mem-ory is partially exhausted. A circular queue would be much more efficient.Profiling the code and reviewing or even optimising essential functions usingassembly language would likely yield some benefit.
Ultimately, if cached shared memory with L2 flushes becomes reliable, afull sample sort implementation in shared memory may be viable.
43

Bibliography
[1] Richard Cole. Parallel merge sort. In FOCS, pages 511–516. IEEEComputer Society, 1986.
[2] Rikard Hultén, Christoph W. Kessler, and Jörg Keller. Optimizedon-chip-pipelined mergesort on the Cell/B.E. In Proceedings of the16th international Euro-Par conference on Parallel processing: Part II,Euro-Par’10, pages 187–198, Berlin, Heidelberg, 2010. Springer-Verlag.
[3] W. Donald Frazer and A. C. McKellar. Samplesort: A sampling ap-proach to minimal storage tree sorting. J. ACM, 17(3):496–507, 1970.
[4] Peter Sanders and Sebastian Winkel. Super Scalar Sample Sort. InSusanne Albers and Tomasz Radzik, editors, Algorithms - ESA 2004,volume 3221 of Lecture Notes in Computer Science, pages 784–796.Springer Berlin / Heidelberg, 2004.
[5] Kenan Avdić, Nicolas Melot, Jörg Keller, and Christoph Kessler. Par-allel sorting on Intel Single-Chip Cloud Computer. In Proc. A4MMCworkshop on applications for multi- and many-core processors at ISCA-2011, 2011.
[6] T. Chen, R. Raghavan, J. N. Dale, and E. Iwata. Cell Broadband En-gine Architecture and its first implementation — A performance view.IBM Journal of Research and Development, 51(5):559–572, September2007.
[7] Naga Govindaraju, Jim Gray, Ritesh Kumar, and Dinesh Manocha.Gputerasort: High performance graphics co-processor sorting for largedatabase management. In Proceedings of the 2006 ACM SIGMOD In-ternational Conference on Management of Data, SIGMOD ’06, pages325–336, New York, NY, USA, 2006. ACM.
[8] Hiroshi Inoue, Takao Moriyama, Hideaki Komatsu, and ToshioNakatani. AA-Sort: A New Parallel Sorting Algorithm for Multi-CoreSIMD Processors. In Proceedings of the 16th International Conferenceon Parallel Architecture and Compilation Techniques, PACT ’07, pages189–198, Washington, DC, USA, 2007. IEEE Computer Society.
44

BIBLIOGRAPHY
[9] Timothy Furtak, José Nelson Amaral, and Robert Niewiadomski. UsingSIMD registers and instructions to enable instruction-level parallelismin sorting algorithms. In Proceedings of the nineteenth annual ACMsymposium on Parallel algorithms and architectures, SPAA ’07, pages348–357, New York, NY, USA, 2007. ACM.
[10] Timothy J. Purcell, Craig Donner, Mike Cammarano, Henrik WannJensen, and Pat Hanrahan. Photon mapping on programmable graphicshardware. In Proceedings of the ACM SIGGRAPH/EUROGRAPHICSConference on Graphics Hardware, HWWS ’03, pages 41–50, Aire-la-Ville, Switzerland, Switzerland, 2003. Eurographics Association.
[11] Naga K. Govindaraju, Nikunj Raghuvanshi, and Dinesh Manocha. Fastand approximate stream mining of quantiles and frequencies usinggraphics processors. In Proceedings of the 2005 ACM SIGMOD In-ternational Conference on Management of Data, SIGMOD ’05, pages611–622, New York, NY, USA, 2005. ACM.
[12] Stephen Lacey and Richard Box. A fast, easy sort. BYTE, 16(4):315–ff.,April 1991.
[13] K. E. Batcher. Sorting networks and their applications. In Proceed-ings of the April 30–May 2, 1968, Spring Joint Computer Conference,AFIPS ’68 (Spring), pages 307–314, New York, NY, USA, 1968. ACM.
[14] Bugra Gedik, Rajesh R. Bordawekar, and Philip S. Yu. CellSort: Highperformance sorting on the cell processor. In Proceedings of the 33rdInternational Conference on Very Large Data Bases, VLDB ’07, pages1286–1297. VLDB Endowment, 2007.
[15] Jörg Keller, Christoph W. Kessler, and Rikard Hultén. Optimized on-chip-pipelining for memory-intensive computations on multi-core pro-cessors with explicit memory hierarchy. J. UCS, 18(14):1987–2023,2012.
[16] Daniele Paolo Scarpazza and Gordon W. Braudaway. Workload char-acterization and optimization of high-performance text indexing on thecell broadband engine. 2013 IEEE International Symposium on Work-load Characterization (IISWC), 0:13–23, 2009.
[17] Gilles Kahn. The semantics of a simple language for parallel program-ming. In J. L. Rosenfeld, editor, Information processing, pages 471–475,Stockholm, Sweden, Aug 1974. North Holland, Amsterdam.
[18] Iuliana Bacivarov, Wolfgang Haid, Kai Huang, and Lothar Thiele.Methods and tools for mapping process networks onto multi-processorsystems-on-chip. In Handbook of Signal Processing Systems, volume 2,pages 867–903. New York, 2nd edition, Jun 2013.
45

BIBLIOGRAPHY
[19] W. Haid, Lars Schor, Kai Huang, I. Bacivarov, and L. Thiele. Efficientexecution of kahn process networks on multi-processor systems usingprotothreads and windowed fifos. In Embedded Systems for Real-TimeMultimedia, 2009. ESTIMedia 2009. IEEE/ACM/IFIP 7th Workshopon, pages 35–44, Oct 2009.
[20] Adam Dunkels, Oliver Schmidt, Thiemo Voigt, and Muneeb Ali.Protothreads: Simplifying event-driven programming of memory-constrained embedded systems. In Proceedings of the 4th InternationalConference on Embedded Networked Sensor Systems, SenSys ’06, pages29–42, New York, NY, USA, 2006. ACM.
[21] Nicolas Melot, Kenan Avdić, Jörg Keller, and Christoph W. Kessler.Investigation of main memory bandwidth on intel single-chip cloudcomputer. In Diana Göhringer, Michael Hübner, and Jürgen Becker,editors, MARC Symposium, pages 107–110. KIT Scientific Publishing,Karlsruhe, 2011.
[22] Kenan Avdić, Nicolas Melot, Christoph Kessler, and Jörg Keller.Pipelined parallel sorting on the intel SCC. In Fourth Swedish workshopon Multi-core computing MCC-2011, Linköping, Sweden, 2011.
[23] N. Melot, C. Kessler, K. Avdić, P. Cichowski, and J. Keller. Engineeringparallel sorting for the Intel SCC. In Proceedings of 4th Workshop onusing Emerging Parallel Architectures (WEPA 2012), pages 1–10, 2012.
[24] Intel Corporation. SCC external architecture specification(EAS). https://communities.intel.com/servlet/JiveServlet/downloadBody/5044-102-1-8083/SCC_EAS.pdf, April 2010. Revision0.934, Accessed: 2013-12-30.
[25] J. Howard, S. Dighe, S. Vangal, G. Ruhl, N. Borkar, S. Jain, V. Erra-guntla, M. Konow, M. Riepen, M. Gries, G. Droege, T. Lund-Larsen, S.Steibl, S. Borkar, V. De, and R. Van Der Wijngaart. A 48-Core IA-32message-passing processor in 45nm CMOS using on-die message passingand DVFS for performance and power scaling. IEEE J. of Solid-StateCircuits, 46(1):173–183, January 2011.
[26] Tim Mattson and Rob van der Wijngaart. RCCE: a small library formany-core communication. Technical report, Intel Corporation, 2010.Accessed: 2013-12-30.
[27] Intel Corporation. The SCC programmer’s guide. https://communities.intel.com/servlet/JiveServlet/downloadBody/5684-102-8-22523/SCCProgrammersGuide.pdf, April 2010. Revision1.0, Accessed: 2013-12-30.
[28] Jörg Keller. Personal communication, 2011. FernUniversität in Hagen,Germany.
46

BIBLIOGRAPHY
[29] Christoph Kessler. Personal communication, 2011. Linköpings Univer-sitet, Sweden.
47

Appendix A
Code Listing
A.1 mem_sat_test.cnumbersepnumbersep numbersep1 /*numbersepnumbersep numbersep2 * mem_sat_test.cnumbersepnumbersep numbersep3 * Copyright 2011 Kenan Avdic <[email protected]>numbersepnumbersep numbersep4 * All rights reserved.numbersepnumbersep numbersep5 *numbersepnumbersep numbersep6 * Redistribution and use in source and binary forms, with or withoutnumbersepnumbersep numbersep7 * modification, are permitted provided that the following conditionsnumbersepnumbersep numbersep8 * are met:numbersepnumbersep numbersep9 *numbersepnumbersep numbersep10 * 1. Redistributions of source code must retain the above copyrightnumbersepnumbersep numbersep11 * notice, this list of conditions and the following disclaimer.numbersepnumbersep numbersep12 *numbersepnumbersep numbersep13 * 2. Redistributions in binary form must reproduce the above copyrightnumbersepnumbersep numbersep14 * notice, this list of conditions and the following disclaimer in thenumbersepnumbersep numbersep15 * documentation and/or other materials provided with the distribution.numbersepnumbersep numbersep16 *numbersepnumbersep numbersep17 * 3. Neither the name of the copyright holder nor the names of itsnumbersepnumbersep numbersep18 * contributors may be used to endorse or promote products derived fromnumbersepnumbersep numbersep19 * this software without specific prior written permission.numbersepnumbersep numbersep20 *numbersepnumbersep numbersep21 * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORSnumbersepnumbersep numbersep22 * "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOTnumbersepnumbersep numbersep23 * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESSnumbersepnumbersep numbersep24 * FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THEnumbersepnumbersep numbersep25 * COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,numbersepnumbersep numbersep26 * INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,numbersepnumbersep numbersep27 * BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;numbersepnumbersep numbersep28 * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVERnumbersepnumbersep numbersep29 * CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICTnumbersepnumbersep numbersep30 * LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING INnumbersepnumbersep numbersep31 * ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THEnumbersepnumbersep numbersep32 * POSSIBILITY OF SUCH DAMAGE.numbersepnumbersep numbersep33 *numbersepnumbersep numbersep34 */numbersepnumbersep numbersep35numbersepnumbersep numbersep36 #include <stdio.h>numbersepnumbersep numbersep37 #include <math.h>numbersepnumbersep numbersep38 #include "RCCE.h"numbersepnumbersep numbersep39numbersepnumbersep numbersep40 #define DEBUG 1numbersepnumbersep numbersep41 #define MEMSIZE 32768 /* multiply by 32 to get actual memory used */numbersepnumbersep numbersep42
48

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep43 #define SOME_LARGE_ODD_NUMBER (MEMSIZE + 1)numbersepnumbersep numbersep44numbersepnumbersep numbersep45 typedef struct cache_linenumbersepnumbersep numbersep46 {numbersepnumbersep numbersep47 int a[8] ;numbersepnumbersep numbersep48 } cline __attribute__((aligned(32)));numbersepnumbersep numbersep49numbersepnumbersep numbersep50 intnumbersepnumbersep numbersep51 pi(int N, int i)numbersepnumbersep numbersep52 {numbersepnumbersep numbersep53 return i * SOME_LARGE_ODD_NUMBER % N;numbersepnumbersep numbersep54 }numbersepnumbersep numbersep55numbersepnumbersep numbersep56 int RCCE_APP(int argc, char **argv)numbersepnumbersep numbersep57 {numbersepnumbersep numbersep58 int ID, NP, i, j, N, num_runs, offset, rslt, num_loops, ct;numbersepnumbersep numbersep59 cline *data;numbersepnumbersep numbersep60 //cline tmp __attribute__((aligned(32)));numbersepnumbersep numbersep61 int tmp[16] ;numbersepnumbersep numbersep62 double t, min, max, stddev, sum, sumsq;numbersepnumbersep numbersep63numbersepnumbersep numbersep64 RCCE_init(&argc, &argv);numbersepnumbersep numbersep65 ID = RCCE_ue();numbersepnumbersep numbersep66 NP = RCCE_num_ues();numbersepnumbersep numbersep67numbersepnumbersep numbersep68 if(argc < 4 || (*argv[3] != ’r’ && *argv[3] != ’w’ && *argv[3] != ’c’))numbersepnumbersep numbersep69 {numbersepnumbersep numbersep70 printf("Usage: %s {MB} {repeats} {r/w/c}\n", argv[0]);numbersepnumbersep numbersep71 return 1;numbersepnumbersep numbersep72 }numbersepnumbersep numbersep73numbersepnumbersep numbersep74 /* setup variables, allocate and initialise array */numbersepnumbersep numbersep75 /* N converts MB input to bytes and divides it by struct/cacheline sizenumbersepnumbersep numbersep76 * this is how many of "struct cline" we need to read/write */numbersepnumbersep numbersep77 N = atoi(*++argv) * 1048576 / 32;numbersepnumbersep numbersep78 /* we have a limited number of memory, reuse the allocated memorynumbersepnumbersep numbersep79 * num_loops times */numbersepnumbersep numbersep80 num_loops = N/MEMSIZE;numbersepnumbersep numbersep81 if((num_loops*MEMSIZE) != N)numbersepnumbersep numbersep82 {numbersepnumbersep numbersep83 printf("Num loops not a multiple of MEMSIZE.\n");numbersepnumbersep numbersep84 return 1;numbersepnumbersep numbersep85 }numbersepnumbersep numbersep86 /* rerun everything num_runs times */numbersepnumbersep numbersep87 num_runs = atoi(*++argv);numbersepnumbersep numbersep88 rslt = posix_memalign((void**)&data, 32, 32*MEMSIZE);numbersepnumbersep numbersep89 if(rslt)numbersepnumbersep numbersep90 {numbersepnumbersep numbersep91 printf("Error %d: malloc/align\n", rslt);numbersepnumbersep numbersep92 return 1;numbersepnumbersep numbersep93 }numbersepnumbersep numbersep94 for(i=0; i<MEMSIZE; i++)numbersepnumbersep numbersep95 {numbersepnumbersep numbersep96 for(j=0; j<8; j++)numbersepnumbersep numbersep97 data[i].a[j] = j;numbersepnumbersep numbersep98 }numbersepnumbersep numbersep99 for(i=0; i<16; i++)numbersepnumbersep numbersep100 {numbersepnumbersep numbersep101 tmp[i] = 16-i;numbersepnumbersep numbersep102 }numbersepnumbersep numbersep103numbersepnumbersep numbersep104 min = 99999999999999.9;numbersepnumbersep numbersep105 max = sum = sumsq = stddev = 0;numbersepnumbersep numbersep106numbersepnumbersep numbersep107 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep108 switch(**++argv)numbersepnumbersep numbersep109 {numbersepnumbersep numbersep110 case ’r’: /* read case */
49

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep111 printf("\nBEGIN READ %d UEs: UE %d bytes %d (32x %d mem used), %d runs\n",numbersepnumbersep numbersep112 NP, ID, N*32, MEMSIZE, num_runs);numbersepnumbersep numbersep113 for(i=0; i<num_runs; i++)numbersepnumbersep numbersep114 {numbersepnumbersep numbersep115 ct = num_loops;numbersepnumbersep numbersep116 /* read N values and time it */numbersepnumbersep numbersep117 t = RCCE_wtime();numbersepnumbersep numbersep118 while(ct--)numbersepnumbersep numbersep119 {numbersepnumbersep numbersep120 /* unroll 16 */numbersepnumbersep numbersep121 for(j=0; j<MEMSIZE; j+=16)numbersepnumbersep numbersep122 {numbersepnumbersep numbersep123 tmp[0] = data[pi(N, j)].a[0];numbersepnumbersep numbersep124 tmp[1] = data[pi(N, j+1)].a[0];numbersepnumbersep numbersep125 tmp[2] = data[pi(N, j+2)].a[0];numbersepnumbersep numbersep126 tmp[3] = data[pi(N, j+3)].a[0];numbersepnumbersep numbersep127 tmp[4] = data[pi(N, j+4)].a[0];numbersepnumbersep numbersep128 tmp[5] = data[pi(N, j+5)].a[0];numbersepnumbersep numbersep129 tmp[6] = data[pi(N, j+6)].a[0];numbersepnumbersep numbersep130 tmp[7] = data[pi(N, j+7)].a[0];numbersepnumbersep numbersep131 tmp[8] = data[pi(N, j+8)].a[0];numbersepnumbersep numbersep132 tmp[9] = data[pi(N, j+9)].a[0];numbersepnumbersep numbersep133 tmp[10] = data[pi(N, j+10)].a[0];numbersepnumbersep numbersep134 tmp[11] = data[pi(N, j+11)].a[0];numbersepnumbersep numbersep135 tmp[12] = data[pi(N, j+12)].a[0];numbersepnumbersep numbersep136 tmp[13] = data[pi(N, j+13)].a[0];numbersepnumbersep numbersep137 tmp[14] = data[pi(N, j+14)].a[0];numbersepnumbersep numbersep138 tmp[15] = data[pi(N, j+15)].a[0];numbersepnumbersep numbersep139 }numbersepnumbersep numbersep140 }numbersepnumbersep numbersep141 t = RCCE_wtime() - t;numbersepnumbersep numbersep142 t *= 1000;numbersepnumbersep numbersep143 if(t < min) min = t;numbersepnumbersep numbersep144 if(t > max) max = t;numbersepnumbersep numbersep145 sum += t;numbersepnumbersep numbersep146 sumsq += t*t;numbersepnumbersep numbersep147 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep148 }numbersepnumbersep numbersep149 stddev = sqrt(fabs((sumsq-sum*sum/num_runs)/(num_runs-1)));numbersepnumbersep numbersep150 break;numbersepnumbersep numbersep151 case ’w’: /* write case */numbersepnumbersep numbersep152 printf("\nBEGIN WRITE %d UEs: UE %d bytes %d (32x %d mem used), %d runs\n",numbersepnumbersep numbersep153 NP, ID, N*32, MEMSIZE, num_runs);numbersepnumbersep numbersep154 for(i=0; i<num_runs; i++)numbersepnumbersep numbersep155 {numbersepnumbersep numbersep156 ct = num_loops;numbersepnumbersep numbersep157 /* write N values and time it */numbersepnumbersep numbersep158 t = RCCE_wtime();numbersepnumbersep numbersep159 while(ct--)numbersepnumbersep numbersep160 {numbersepnumbersep numbersep161 for(j=0; j<MEMSIZE; j+=16)numbersepnumbersep numbersep162 {numbersepnumbersep numbersep163 data[pi(N, j)].a[0] = tmp[0];numbersepnumbersep numbersep164 data[pi(N, j+1)].a[0] = tmp[1];numbersepnumbersep numbersep165 data[pi(N, j+2)].a[0] = tmp[2];numbersepnumbersep numbersep166 data[pi(N, j+3)].a[0] = tmp[3];numbersepnumbersep numbersep167 data[pi(N, j+4)].a[0] = tmp[4];numbersepnumbersep numbersep168 data[pi(N, j+5)].a[0] = tmp[5];numbersepnumbersep numbersep169 data[pi(N, j+6)].a[0] = tmp[6];numbersepnumbersep numbersep170 data[pi(N, j+7)].a[0] = tmp[7];numbersepnumbersep numbersep171 data[pi(N, j+8)].a[0] = tmp[8];numbersepnumbersep numbersep172 data[pi(N, j+9)].a[0] = tmp[9];numbersepnumbersep numbersep173 data[pi(N, j+10)].a[0] = tmp[10];numbersepnumbersep numbersep174 data[pi(N, j+11)].a[0] = tmp[11];numbersepnumbersep numbersep175 data[pi(N, j+12)].a[0] = tmp[12];numbersepnumbersep numbersep176 data[pi(N, j+13)].a[0] = tmp[13];numbersepnumbersep numbersep177 data[pi(N, j+14)].a[0] = tmp[14];numbersepnumbersep numbersep178 data[pi(N, j+15)].a[0] = tmp[15];
50

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep179numbersepnumbersep numbersep180 }numbersepnumbersep numbersep181 }numbersepnumbersep numbersep182 t = RCCE_wtime() - t;numbersepnumbersep numbersep183 t *= 1000;numbersepnumbersep numbersep184 if(t < min) min = t;numbersepnumbersep numbersep185 if(t > max) max = t;numbersepnumbersep numbersep186 sum += t;numbersepnumbersep numbersep187 sumsq += t*t;numbersepnumbersep numbersep188 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep189 }numbersepnumbersep numbersep190 stddev = sqrt(fabs((sumsq-sum*sum/num_runs)/(num_runs-1)));numbersepnumbersep numbersep191 break;numbersepnumbersep numbersep192 case ’c’: /* combined read/write case */numbersepnumbersep numbersep193 printf("\nBEGIN COMBINED %d UEs: UE %d bytes %d (32x %d mem used), %d runs\n",numbersepnumbersep numbersep194 NP, ID, N*32, MEMSIZE, num_runs);numbersepnumbersep numbersep195 /* we copy cyclically from middle of data to the start of datanumbersepnumbersep numbersep196 * to avoid caching */numbersepnumbersep numbersep197 offset = N/2;numbersepnumbersep numbersep198 for(i=0; i<num_runs; i++)numbersepnumbersep numbersep199 {numbersepnumbersep numbersep200 ct = num_loops;numbersepnumbersep numbersep201 /* read/write N values and time it */numbersepnumbersep numbersep202 t = RCCE_wtime();numbersepnumbersep numbersep203 while(ct--)numbersepnumbersep numbersep204 {numbersepnumbersep numbersep205 for(j=0; j<MEMSIZE; j+=16)numbersepnumbersep numbersep206 {numbersepnumbersep numbersep207 data[pi(N, j)].a[0] = data[pi(N, offset)].a[0];numbersepnumbersep numbersep208 data[pi(N, j+1)].a[0] = data[pi(N, offset+1)].a[0];numbersepnumbersep numbersep209 data[pi(N, j+2)].a[0] = data[pi(N, offset+2)].a[0];numbersepnumbersep numbersep210 data[pi(N, j+3)].a[0] = data[pi(N, offset+3)].a[0];numbersepnumbersep numbersep211 data[pi(N, j+4)].a[0] = data[pi(N, offset+4)].a[0];numbersepnumbersep numbersep212 data[pi(N, j+5)].a[0] = data[pi(N, offset+5)].a[0];numbersepnumbersep numbersep213 data[pi(N, j+6)].a[0] = data[pi(N, offset+6)].a[0];numbersepnumbersep numbersep214 data[pi(N, j+7)].a[0] = data[pi(N, offset+7)].a[0];numbersepnumbersep numbersep215 data[pi(N, j+8)].a[0] = data[pi(N, offset+8)].a[0];numbersepnumbersep numbersep216 data[pi(N, j+9)].a[0] = data[pi(N, offset+9)].a[0];numbersepnumbersep numbersep217 data[pi(N, j+10)].a[0] = data[pi(N, offset+10)].a[0];numbersepnumbersep numbersep218 data[pi(N, j+11)].a[0] = data[pi(N, offset+11)].a[0];numbersepnumbersep numbersep219 data[pi(N, j+12)].a[0] = data[pi(N, offset+12)].a[0];numbersepnumbersep numbersep220 data[pi(N, j+13)].a[0] = data[pi(N, offset+13)].a[0];numbersepnumbersep numbersep221 data[pi(N, j+14)].a[0] = data[pi(N, offset+14)].a[0];numbersepnumbersep numbersep222 data[pi(N, j+15)].a[0] = data[pi(N, offset+15)].a[0];numbersepnumbersep numbersep223 offset++;numbersepnumbersep numbersep224 if(offset >= MEMSIZE) offset = 0;numbersepnumbersep numbersep225 }numbersepnumbersep numbersep226 }numbersepnumbersep numbersep227 t = RCCE_wtime() - t;numbersepnumbersep numbersep228 t *= 1000;numbersepnumbersep numbersep229 if(t < min) min = t;numbersepnumbersep numbersep230 if(t > max) max = t;numbersepnumbersep numbersep231 sum += t;numbersepnumbersep numbersep232 sumsq += t*t;numbersepnumbersep numbersep233 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep234 }numbersepnumbersep numbersep235 stddev = sqrt(fabs((sumsq-sum*sum/num_runs)/(num_runs-1)));numbersepnumbersep numbersep236 break;numbersepnumbersep numbersep237 default:numbersepnumbersep numbersep238 break;numbersepnumbersep numbersep239 }numbersepnumbersep numbersep240numbersepnumbersep numbersep241 printf("Average Minimum Maximum Stddev\n");numbersepnumbersep numbersep242 printf("%.3f %.3f %.3f %.3f\n",numbersepnumbersep numbersep243 sum/num_runs, min, max, stddev);numbersepnumbersep numbersep244 printf("END %d UEs: UE %d bytes %d (32x %d mem used), %d runs\n",numbersepnumbersep numbersep245 NP, ID, N*32, MEMSIZE, num_runs);numbersepnumbersep numbersep246
51

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep247 free(data);numbersepnumbersep numbersep248 RCCE_finalize();numbersepnumbersep numbersep249 return 0;numbersepnumbersep numbersep250 }
A.2 mpb_trans.c
numbersepnumbersep numbersep1 /*numbersepnumbersep numbersep2 * pingpong.cnumbersepnumbersep numbersep3 * Copyright 2011 Kenan Avdic <[email protected]>numbersepnumbersep numbersep4 * All rights reserved.numbersepnumbersep numbersep5 *numbersepnumbersep numbersep6 * Redistribution and use in source and binary forms, with or withoutnumbersepnumbersep numbersep7 * modification, are permitted provided that the following conditionsnumbersepnumbersep numbersep8 * are met:numbersepnumbersep numbersep9 *numbersepnumbersep numbersep10 * 1. Redistributions of source code must retain the above copyrightnumbersepnumbersep numbersep11 * notice, this list of conditions and the following disclaimer.numbersepnumbersep numbersep12 *numbersepnumbersep numbersep13 * 2. Redistributions in binary form must reproduce the above copyrightnumbersepnumbersep numbersep14 * notice, this list of conditions and the following disclaimer in thenumbersepnumbersep numbersep15 * documentation and/or other materials provided with the distribution.numbersepnumbersep numbersep16 *numbersepnumbersep numbersep17 * 3. Neither the name of the copyright holder nor the names of itsnumbersepnumbersep numbersep18 * contributors may be used to endorse or promote products derived fromnumbersepnumbersep numbersep19 * this software without specific prior written permission.numbersepnumbersep numbersep20 *numbersepnumbersep numbersep21 * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORSnumbersepnumbersep numbersep22 * "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOTnumbersepnumbersep numbersep23 * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESSnumbersepnumbersep numbersep24 * FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THEnumbersepnumbersep numbersep25 * COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,numbersepnumbersep numbersep26 * INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,numbersepnumbersep numbersep27 * BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;numbersepnumbersep numbersep28 * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVERnumbersepnumbersep numbersep29 * CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICTnumbersepnumbersep numbersep30 * LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING INnumbersepnumbersep numbersep31 * ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THEnumbersepnumbersep numbersep32 * POSSIBILITY OF SUCH DAMAGE.numbersepnumbersep numbersep33 *numbersepnumbersep numbersep34 */numbersepnumbersep numbersep35numbersepnumbersep numbersep36 #include <stdio.h>numbersepnumbersep numbersep37 #include <stdlib.h>numbersepnumbersep numbersep38 #include "RCCE.h"numbersepnumbersep numbersep39numbersepnumbersep numbersep40numbersepnumbersep numbersep41 #define DEBUG 0numbersepnumbersep numbersep42 #define MORE_DEBUG 0numbersepnumbersep numbersep43numbersepnumbersep numbersep44 int RCCE_APP(int argc, char **argv)numbersepnumbersep numbersep45 {numbersepnumbersep numbersep46 int ID, ID_friend, NP, N, bufsize, retval, remain, i, repeat, loop, sum;numbersepnumbersep numbersep47 int *buffer, *mpb_p;numbersepnumbersep numbersep48 char *offset;numbersepnumbersep numbersep49 double trecv_start, tsend_start, trecv, tsend, trecv_tot, tsend_tot;numbersepnumbersep numbersep50 RCCE_FLAG f_recv, f_send;numbersepnumbersep numbersep51numbersepnumbersep numbersep52 RCCE_init(&argc, &argv);numbersepnumbersep numbersep53 //RCCE_debug_set(RCCE_DEBUG_ALL);numbersepnumbersep numbersep54numbersepnumbersep numbersep55 ID = RCCE_ue();numbersepnumbersep numbersep56 NP = RCCE_num_ues();numbersepnumbersep numbersep57 ID_friend = NP-1 - ID;numbersepnumbersep numbersep58numbersepnumbersep numbersep59 /* Transfer 1MiB using 4KiB buffer size by default, unless specified
52

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep60 * otherwise on commandline */numbersepnumbersep numbersep61 N = 1*1024;numbersepnumbersep numbersep62 bufsize = 4*1024;numbersepnumbersep numbersep63 repeat = 100;numbersepnumbersep numbersep64 if(argc > 1)numbersepnumbersep numbersep65 N = atoi(*++argv) * 1024;numbersepnumbersep numbersep66 if(argc > 2)numbersepnumbersep numbersep67 bufsize = atoi(*++argv) * 1024;numbersepnumbersep numbersep68 if(argc > 3)numbersepnumbersep numbersep69 repeat = atoi(*++argv);numbersepnumbersep numbersep70numbersepnumbersep numbersep71 /* Allocate memory */numbersepnumbersep numbersep72 buffer = (int*) malloc(N*sizeof(int));numbersepnumbersep numbersep73 mpb_p = (int*) RCCE_malloc(bufsize);numbersepnumbersep numbersep74 /* reset flags */numbersepnumbersep numbersep75 retval = RCCE_flag_alloc(&f_recv);numbersepnumbersep numbersep76 retval &= RCCE_flag_write(&f_recv, RCCE_FLAG_SET, ID);numbersepnumbersep numbersep77 retval &= RCCE_flag_alloc(&f_send);numbersepnumbersep numbersep78 retval &= RCCE_flag_write(&f_send, RCCE_FLAG_UNSET, ID_friend);numbersepnumbersep numbersep79 if(!buffer || !mpb_p || retval!=RCCE_SUCCESS)numbersepnumbersep numbersep80 {numbersepnumbersep numbersep81 printf("Error in setup, alloc+flags\n");numbersepnumbersep numbersep82 return 1;numbersepnumbersep numbersep83 }numbersepnumbersep numbersep84numbersepnumbersep numbersep85 /* Sender sets up data, ascending array */numbersepnumbersep numbersep86 if(ID<ID_friend)numbersepnumbersep numbersep87 {numbersepnumbersep numbersep88 for(i=0; i<N; i++)numbersepnumbersep numbersep89 buffer[i] = i;numbersepnumbersep numbersep90 for(i=0; i<N; i++)numbersepnumbersep numbersep91 sum += buffer[i];numbersepnumbersep numbersep92 }numbersepnumbersep numbersep93numbersepnumbersep numbersep94 tsend_tot = trecv_tot = tsend = trecv = 0;numbersepnumbersep numbersep95 loop = repeat;numbersepnumbersep numbersep96 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep97 while(loop--)numbersepnumbersep numbersep98 {numbersepnumbersep numbersep99 if(ID<ID_friend)numbersepnumbersep numbersep100 {numbersepnumbersep numbersep101 /* sender */numbersepnumbersep numbersep102 remain = N*sizeof(int);numbersepnumbersep numbersep103 offset = (char*)buffer;numbersepnumbersep numbersep104 if(DEBUG)numbersepnumbersep numbersep105 printf("UE %d >>>> UE %d :: %d b buffer size, %d b remaining\n",numbersepnumbersep numbersep106 ID, ID_friend, bufsize, remain);numbersepnumbersep numbersep107 tsend_start = RCCE_wtime();numbersepnumbersep numbersep108 while(remain>0)numbersepnumbersep numbersep109 {numbersepnumbersep numbersep110 /* wait for receive completed signal */numbersepnumbersep numbersep111 RCCE_wait_until(f_recv, RCCE_FLAG_SET);numbersepnumbersep numbersep112 RCCE_flag_write(&f_recv, RCCE_FLAG_UNSET, ID);numbersepnumbersep numbersep113 /* copy data to receivers mpb */numbersepnumbersep numbersep114 RCCE_put((t_vcharp)mpb_p, (t_vcharp)offset, bufsize, ID_friend);numbersepnumbersep numbersep115 if(MORE_DEBUG)numbersepnumbersep numbersep116 printf("UE %d >>>> UE %d :: %d b remaining\n",numbersepnumbersep numbersep117 ID, ID_friend, remain);numbersepnumbersep numbersep118 /* send finished sending signal */numbersepnumbersep numbersep119 RCCE_flag_write(&f_send, RCCE_FLAG_SET, ID_friend);numbersepnumbersep numbersep120 /* modify offset & loop counters */numbersepnumbersep numbersep121 remain -= bufsize;numbersepnumbersep numbersep122 offset += bufsize;numbersepnumbersep numbersep123 }numbersepnumbersep numbersep124 tsend = RCCE_wtime() - tsend_start;numbersepnumbersep numbersep125 if(DEBUG)numbersepnumbersep numbersep126 printf("UE %d >>>> UE %d :: COMPLETE (%d b remaining)\n",numbersepnumbersep numbersep127 ID, ID_friend, remain);
53

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep128 printf("UE %d SEND UE %d %.3f\n", ID, ID_friend, tsend*1000);numbersepnumbersep numbersep129 tsend_tot += tsend;numbersepnumbersep numbersep130 }numbersepnumbersep numbersep131 elsenumbersepnumbersep numbersep132 {numbersepnumbersep numbersep133 /* receiver */numbersepnumbersep numbersep134 remain = N*sizeof(int);numbersepnumbersep numbersep135 offset = (char*)buffer;numbersepnumbersep numbersep136 if(DEBUG)numbersepnumbersep numbersep137 printf("UE %d <<<< UE %d :: %d b buffer size, %d b remaining\n",numbersepnumbersep numbersep138 ID, ID_friend, bufsize, remain);numbersepnumbersep numbersep139numbersepnumbersep numbersep140 trecv_start = RCCE_wtime();numbersepnumbersep numbersep141 while(remain>0)numbersepnumbersep numbersep142 {numbersepnumbersep numbersep143 /* wait for send complete signal */numbersepnumbersep numbersep144 RCCE_wait_until(f_send, RCCE_FLAG_SET);numbersepnumbersep numbersep145 RCCE_flag_write(&f_send, RCCE_FLAG_UNSET, ID);numbersepnumbersep numbersep146 /* copy data from local mpb */numbersepnumbersep numbersep147 RCCE_get((t_vcharp)offset, (t_vcharp)mpb_p, bufsize, ID);numbersepnumbersep numbersep148 if(MORE_DEBUG)numbersepnumbersep numbersep149 printf("UE %d <<<< UE %d :: %d b remaining\n",numbersepnumbersep numbersep150 ID, ID_friend, remain);numbersepnumbersep numbersep151 /* send receive completed signal */numbersepnumbersep numbersep152 RCCE_flag_write(&f_recv, RCCE_FLAG_SET, ID_friend);numbersepnumbersep numbersep153 remain -= bufsize;numbersepnumbersep numbersep154 offset += bufsize;numbersepnumbersep numbersep155 }numbersepnumbersep numbersep156 trecv = RCCE_wtime() - trecv_start;numbersepnumbersep numbersep157numbersepnumbersep numbersep158 if(DEBUG)numbersepnumbersep numbersep159 printf("UE %d <<<< UE %d :: COMPLETE (%d b remaining)\n",numbersepnumbersep numbersep160 ID, ID_friend, remain);numbersepnumbersep numbersep161numbersepnumbersep numbersep162 printf("UE %d RECV UE %d %.3f\n", ID, ID_friend, trecv*1000);numbersepnumbersep numbersep163 trecv_tot += trecv;numbersepnumbersep numbersep164 }numbersepnumbersep numbersep165 }numbersepnumbersep numbersep166 if(ID>ID_friend)numbersepnumbersep numbersep167 printf("TOTAL RECV AVG: %.3f\n", trecv_tot/repeat*1000);numbersepnumbersep numbersep168 elsenumbersepnumbersep numbersep169 printf("TOTAL SEND AVG: %.3f\n", tsend_tot/repeat*1000);numbersepnumbersep numbersep170numbersepnumbersep numbersep171 /* Receiver checks transferred data */numbersepnumbersep numbersep172 if(ID_friend<ID)numbersepnumbersep numbersep173 for(i=0; i<N; i++)numbersepnumbersep numbersep174 if(buffer[i]!=i)numbersepnumbersep numbersep175 printf("Error in transferred data @ %d is: %d\n", i, buffer[i]);numbersepnumbersep numbersep176numbersepnumbersep numbersep177numbersepnumbersep numbersep178 RCCE_flag_free(&f_recv);numbersepnumbersep numbersep179 RCCE_flag_free(&f_send);numbersepnumbersep numbersep180 RCCE_free((t_vcharp)mpb_p);numbersepnumbersep numbersep181 free(buffer);numbersepnumbersep numbersep182 RCCE_finalize();numbersepnumbersep numbersep183 return 0;numbersepnumbersep numbersep184 }
A.3 priv_mem.c
numbersepnumbersep numbersep1 /*numbersepnumbersep numbersep2 * priv_mem_gory.cnumbersepnumbersep numbersep3 * Copyright 2011 Kenan Avdic <[email protected]>numbersepnumbersep numbersep4 * All rights reserved.numbersepnumbersep numbersep5 *numbersepnumbersep numbersep6 * Redistribution and use in source and binary forms, with or without
54

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep7 * modification, are permitted provided that the following conditionsnumbersepnumbersep numbersep8 * are met:numbersepnumbersep numbersep9 *numbersepnumbersep numbersep10 * 1. Redistributions of source code must retain the above copyrightnumbersepnumbersep numbersep11 * notice, this list of conditions and the following disclaimer.numbersepnumbersep numbersep12 *numbersepnumbersep numbersep13 * 2. Redistributions in binary form must reproduce the above copyrightnumbersepnumbersep numbersep14 * notice, this list of conditions and the following disclaimer in thenumbersepnumbersep numbersep15 * documentation and/or other materials provided with the distribution.numbersepnumbersep numbersep16 *numbersepnumbersep numbersep17 * 3. Neither the name of the copyright holder nor the names of itsnumbersepnumbersep numbersep18 * contributors may be used to endorse or promote products derived fromnumbersepnumbersep numbersep19 * this software without specific prior written permission.numbersepnumbersep numbersep20 *numbersepnumbersep numbersep21 * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORSnumbersepnumbersep numbersep22 * "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOTnumbersepnumbersep numbersep23 * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESSnumbersepnumbersep numbersep24 * FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THEnumbersepnumbersep numbersep25 * COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,numbersepnumbersep numbersep26 * INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,numbersepnumbersep numbersep27 * BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;numbersepnumbersep numbersep28 * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVERnumbersepnumbersep numbersep29 * CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICTnumbersepnumbersep numbersep30 * LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING INnumbersepnumbersep numbersep31 * ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THEnumbersepnumbersep numbersep32 * POSSIBILITY OF SUCH DAMAGE.numbersepnumbersep numbersep33 *numbersepnumbersep numbersep34 */numbersepnumbersep numbersep35numbersepnumbersep numbersep36 #include <stdio.h>numbersepnumbersep numbersep37 #include <stdlib.h>numbersepnumbersep numbersep38 #include <time.h>numbersepnumbersep numbersep39 #include "RCCE.h"numbersepnumbersep numbersep40numbersepnumbersep numbersep41 #define DEBUG 0 /* standard debug */numbersepnumbersep numbersep42 #define MORE_DEBUG 0 /* algorithm debug */numbersepnumbersep numbersep43 #define SHOW_ALL 1 /* display results for all UEsnumbersepnumbersep numbersep44 * (normally only UE 0 displays results */numbersepnumbersep numbersep45numbersepnumbersep numbersep46 void mergesort(int l, int r);numbersepnumbersep numbersep47 void merge(int l, int m, int r);numbersepnumbersep numbersep48 int check_sorted(int N);numbersepnumbersep numbersep49numbersepnumbersep numbersep50 int *data, *aux;numbersepnumbersep numbersep51numbersepnumbersep numbersep52 int RCCE_APP(int argc, char **argv)numbersepnumbersep numbersep53 {numbersepnumbersep numbersep54 int ID, NP, i, N, active_cpus, offset, remain, bufsize, chunksize;numbersepnumbersep numbersep55 int priv_memsize, prev, step, rslt, round;numbersepnumbersep numbersep56 int *local_buf, *buffer;numbersepnumbersep numbersep57 double tsync, tcomp, tblock;numbersepnumbersep numbersep58 double tstart, tstart_sync, tstart_comp, tstart_block;numbersepnumbersep numbersep59 double t_tot, tsync_tot, tcomp_tot, tblock_tot;numbersepnumbersep numbersep60 RCCE_FLAG f_recv, f_send;numbersepnumbersep numbersep61numbersepnumbersep numbersep62 RCCE_init(&argc, &argv);numbersepnumbersep numbersep63 //RCCE_debug_set(RCCE_DEBUG_ALL);numbersepnumbersep numbersep64numbersepnumbersep numbersep65 ID = RCCE_ue();numbersepnumbersep numbersep66 NP = RCCE_num_ues();numbersepnumbersep numbersep67numbersepnumbersep numbersep68 if(argc != 2)numbersepnumbersep numbersep69 {numbersepnumbersep numbersep70 if(ID == 0) printf("Please specify data size\n");numbersepnumbersep numbersep71 return 1;numbersepnumbersep numbersep72 }numbersepnumbersep numbersep73numbersepnumbersep numbersep74 N = atoi(*++argv);
55

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep75 chunksize = N / NP;numbersepnumbersep numbersep76numbersepnumbersep numbersep77 if(DEBUG && ID == 0)numbersepnumbersep numbersep78 printf("Starting up: %d elements, %d chunksize on %d UEs, "numbersepnumbersep numbersep79 "%d shmem max\n", N, chunksize, NP, RCCE_SHM_SIZE_MAX);numbersepnumbersep numbersep80numbersepnumbersep numbersep81 /* Allocate all the shared memory as a buffer to use for synchronizationnumbersepnumbersep numbersep82 * between processors. This buffer will later be divided as necessary. */numbersepnumbersep numbersep83 buffer = (int*) RCCE_shmalloc(RCCE_SHM_SIZE_MAX);numbersepnumbersep numbersep84 if (!buffer)numbersepnumbersep numbersep85 {numbersepnumbersep numbersep86 if(ID == 0)numbersepnumbersep numbersep87 printf("Error allocating shared mem\n");numbersepnumbersep numbersep88 return 1;numbersepnumbersep numbersep89 }numbersepnumbersep numbersep90numbersepnumbersep numbersep91 /* Allocate private memory for work. Memory allocated is of different sizenumbersepnumbersep numbersep92 * depending on rank. The data array holds the source and destinationnumbersepnumbersep numbersep93 * values (in-place sort), aux is half the size and used for comparisons.numbersepnumbersep numbersep94 * Minimum required memory for the root node isnumbersepnumbersep numbersep95 * N data + N / 2 comparison vector (aux) */numbersepnumbersep numbersep96 priv_memsize = N * sizeof(int);numbersepnumbersep numbersep97 step = 1;numbersepnumbersep numbersep98 while(step < NP)numbersepnumbersep numbersep99 {numbersepnumbersep numbersep100 if(ID >= step)numbersepnumbersep numbersep101 priv_memsize >>= 1;numbersepnumbersep numbersep102 step <<= 1;numbersepnumbersep numbersep103 }numbersepnumbersep numbersep104 data = (int*)malloc(priv_memsize);numbersepnumbersep numbersep105 aux = (int*)malloc(priv_memsize / 2);numbersepnumbersep numbersep106numbersepnumbersep numbersep107 /* reset flags */numbersepnumbersep numbersep108 rslt = RCCE_flag_alloc(&f_recv);numbersepnumbersep numbersep109 rslt &= RCCE_flag_write(&f_recv, RCCE_FLAG_SET, ID);numbersepnumbersep numbersep110 rslt &= RCCE_flag_alloc(&f_send);numbersepnumbersep numbersep111 rslt &= RCCE_flag_write(&f_send, RCCE_FLAG_UNSET, (ID+(NP>>1))%NP);numbersepnumbersep numbersep112 if(!data || !aux || rslt!=RCCE_SUCCESS)numbersepnumbersep numbersep113 {numbersepnumbersep numbersep114 printf("Error in setup, malloc+flags\n");numbersepnumbersep numbersep115 return 1;numbersepnumbersep numbersep116 }numbersepnumbersep numbersep117 if(DEBUG)numbersepnumbersep numbersep118 printf("UE %d allocated %d bytes private memory for %d int values\n",numbersepnumbersep numbersep119 ID, priv_memsize, priv_memsize / sizeof(int));numbersepnumbersep numbersep120numbersepnumbersep numbersep121 /* Each processor generates 2 semi-random sorted sequences that are to benumbersepnumbersep numbersep122 * merged */numbersepnumbersep numbersep123 srand(time(NULL));numbersepnumbersep numbersep124 step = RAND_MAX / chunksize;numbersepnumbersep numbersep125 prev = 0;numbersepnumbersep numbersep126 for(i = 0; i < chunksize / 2; i++)numbersepnumbersep numbersep127 {numbersepnumbersep numbersep128 data[i] = prev + rand() % step + 1;numbersepnumbersep numbersep129 prev = data[i];numbersepnumbersep numbersep130 //data[i] = i;numbersepnumbersep numbersep131 }numbersepnumbersep numbersep132 prev = 0;numbersepnumbersep numbersep133 for( ; i < chunksize; i++)numbersepnumbersep numbersep134 {numbersepnumbersep numbersep135 data[i] = prev + rand() % step + 1;numbersepnumbersep numbersep136 prev = data[i];numbersepnumbersep numbersep137 //data[i] = i;numbersepnumbersep numbersep138 }numbersepnumbersep numbersep139numbersepnumbersep numbersep140 if(DEBUG && ID == 0)numbersepnumbersep numbersep141 {numbersepnumbersep numbersep142 printf("Starting merge");
56

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep143 }numbersepnumbersep numbersep144numbersepnumbersep numbersep145 printf("\n");numbersepnumbersep numbersep146numbersepnumbersep numbersep147 /* Each node now has data and size; reset timer counters,numbersepnumbersep numbersep148 * set initial barrier */numbersepnumbersep numbersep149 t_tot = tsync_tot = tcomp_tot = tblock_tot = 0;numbersepnumbersep numbersep150 round = 1;numbersepnumbersep numbersep151 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep152 tstart = RCCE_wtime();numbersepnumbersep numbersep153numbersepnumbersep numbersep154 /* first merge the 2 local arrays */numbersepnumbersep numbersep155 merge(0, (chunksize - 1) / 2, chunksize - 1);numbersepnumbersep numbersep156 if(DEBUG)numbersepnumbersep numbersep157 printf("UE %d Calling merge with left = 0, mid = %d, right = %d\n",numbersepnumbersep numbersep158 ID, (chunksize - 1) / 2, chunksize - 1);numbersepnumbersep numbersep159 tcomp = RCCE_wtime() - tstart;numbersepnumbersep numbersep160numbersepnumbersep numbersep161 /* Main loop: in each step the number of active cpus is halved and thenumbersepnumbersep numbersep162 * size of data doubled */numbersepnumbersep numbersep163 active_cpus = NP >> 1;numbersepnumbersep numbersep164 while(active_cpus)numbersepnumbersep numbersep165 {numbersepnumbersep numbersep166 /* one buffer per receiving processor */numbersepnumbersep numbersep167 bufsize = RCCE_SHM_SIZE_MAX / active_cpus / sizeof(int);numbersepnumbersep numbersep168 if(bufsize > chunksize)numbersepnumbersep numbersep169 bufsize = chunksize;numbersepnumbersep numbersep170 local_buf = buffer + ID % active_cpus * bufsize;numbersepnumbersep numbersep171numbersepnumbersep numbersep172 if(DEBUG)numbersepnumbersep numbersep173 printf("UE %d entering main loop active CPUs %d, chunksize %d, "numbersepnumbersep numbersep174 "bufsize %d, local buf offset %d\n",numbersepnumbersep numbersep175 ID, active_cpus, chunksize, bufsize, ID%active_cpus*bufsize);numbersepnumbersep numbersep176numbersepnumbersep numbersep177 /* Sync phase: Fill shared memory buffer, signal receiver to fetch */numbersepnumbersep numbersep178 tstart_sync = RCCE_wtime();numbersepnumbersep numbersep179 if(ID < active_cpus)numbersepnumbersep numbersep180 {numbersepnumbersep numbersep181 /* Receiver */numbersepnumbersep numbersep182 offset = remain = chunksize;numbersepnumbersep numbersep183 if(DEBUG)numbersepnumbersep numbersep184 printf("UE %d <<<< %d values from UE %d\n",numbersepnumbersep numbersep185 ID, remain, ID+active_cpus);numbersepnumbersep numbersep186 while(remain > 0)numbersepnumbersep numbersep187 {numbersepnumbersep numbersep188 /* wait for send complete, append buffer to existing data */numbersepnumbersep numbersep189 tstart_block = RCCE_wtime();numbersepnumbersep numbersep190 if(DEBUG)numbersepnumbersep numbersep191 printf("UE %d <<<< waiting for SEND flag\n", ID);numbersepnumbersep numbersep192 RCCE_wait_until(f_send, RCCE_FLAG_SET);numbersepnumbersep numbersep193 RCCE_flag_write(&f_send, RCCE_FLAG_UNSET, ID);numbersepnumbersep numbersep194 tblock += RCCE_wtime() - tstart_block;numbersepnumbersep numbersep195 RCCE_shflush();numbersepnumbersep numbersep196 /* copy to buffer until either buffer is full or we are outnumbersepnumbersep numbersep197 * of data to copy */numbersepnumbersep numbersep198 for(i = 0; i < bufsize && remain > 0; i++, remain--)numbersepnumbersep numbersep199 {numbersepnumbersep numbersep200 data[offset++] = local_buf[i];numbersepnumbersep numbersep201 /*memcpy(data+offset, local_buf+i, 16*sizeof(int));numbersepnumbersep numbersep202 offset+=16;*/numbersepnumbersep numbersep203 }numbersepnumbersep numbersep204 /* send signal to notify we’re done with buffer */numbersepnumbersep numbersep205 tstart_block = RCCE_wtime();numbersepnumbersep numbersep206 if(DEBUG)numbersepnumbersep numbersep207 printf("UE %d <<<< setting RECV flag of UE %d\n",numbersepnumbersep numbersep208 ID, ID+active_cpus);numbersepnumbersep numbersep209 RCCE_flag_write(&f_recv, RCCE_FLAG_SET, ID+active_cpus);numbersepnumbersep numbersep210 tblock += RCCE_wtime() - tstart_block;
57

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep211 }numbersepnumbersep numbersep212 tsync = RCCE_wtime() - tstart_sync;numbersepnumbersep numbersep213 /* end receive */numbersepnumbersep numbersep214 if(SHOW_ALL)numbersepnumbersep numbersep215 printf("UE %d ROUND %d -- COMP: %.3fms SYNC: %.3fms "numbersepnumbersep numbersep216 "BLCK: %.3fms\n",numbersepnumbersep numbersep217 ID, round, tcomp*1000, tsync*1000, tblock*1000);numbersepnumbersep numbersep218 tcomp_tot += tcomp;numbersepnumbersep numbersep219 tsync_tot += tsync;numbersepnumbersep numbersep220 tblock_tot += tblock;numbersepnumbersep numbersep221numbersepnumbersep numbersep222 /* transfer phase complete, merge new data withnumbersepnumbersep numbersep223 * increased chunksize */numbersepnumbersep numbersep224 chunksize <<= 1;numbersepnumbersep numbersep225 tstart_comp = RCCE_wtime();numbersepnumbersep numbersep226 merge(0, (chunksize - 1) / 2, chunksize - 1);numbersepnumbersep numbersep227 tcomp = RCCE_wtime() - tstart_comp;numbersepnumbersep numbersep228 if(DEBUG)numbersepnumbersep numbersep229 printf("UE %d Calling merge with left = 0, mid = %d, right = %d\n",numbersepnumbersep numbersep230 ID, (chunksize - 1) / 2, chunksize - 1);numbersepnumbersep numbersep231 }numbersepnumbersep numbersep232 else if(ID < (active_cpus<<1))numbersepnumbersep numbersep233 {numbersepnumbersep numbersep234 /* Sender */numbersepnumbersep numbersep235 offset = 0;numbersepnumbersep numbersep236 remain = chunksize;numbersepnumbersep numbersep237 if(DEBUG)numbersepnumbersep numbersep238 printf("UE %d >>>> %d values to UE %d\n",numbersepnumbersep numbersep239 ID, remain, ID - active_cpus);numbersepnumbersep numbersep240 while(remain > 0)numbersepnumbersep numbersep241 {numbersepnumbersep numbersep242 /* fill buffer */numbersepnumbersep numbersep243 if(DEBUG)numbersepnumbersep numbersep244 printf("UE %d >>>> waiting for SEND flag\n", ID);numbersepnumbersep numbersep245 tstart_block = RCCE_wtime();numbersepnumbersep numbersep246 RCCE_wait_until(f_recv, RCCE_FLAG_SET);numbersepnumbersep numbersep247 RCCE_flag_write(&f_recv, RCCE_FLAG_UNSET, ID);numbersepnumbersep numbersep248 tblock += RCCE_wtime() - tstart_block;numbersepnumbersep numbersep249numbersepnumbersep numbersep250 for(i = 0; i < bufsize && remain > 0; i++, remain--)numbersepnumbersep numbersep251 {numbersepnumbersep numbersep252 local_buf[i] = data[offset++];numbersepnumbersep numbersep253 /*memcpy(local_buf+i,data+offset, 16*sizeof(int));numbersepnumbersep numbersep254 offset+=16;*/numbersepnumbersep numbersep255 }numbersepnumbersep numbersep256 /* Signal receiver that the buffer is ready and wait for itnumbersepnumbersep numbersep257 * to finish fetching */numbersepnumbersep numbersep258 RCCE_shflush();numbersepnumbersep numbersep259 tstart_block = RCCE_wtime();numbersepnumbersep numbersep260 if(DEBUG)numbersepnumbersep numbersep261 printf("UE %d <<<< setting SEND flag of UE %d\n",numbersepnumbersep numbersep262 ID, ID-active_cpus);numbersepnumbersep numbersep263 RCCE_flag_write(&f_send, RCCE_FLAG_SET, ID-active_cpus);numbersepnumbersep numbersep264 tblock += RCCE_wtime() - tstart_block;numbersepnumbersep numbersep265 }numbersepnumbersep numbersep266 /* We are done after sending */numbersepnumbersep numbersep267 if(DEBUG)numbersepnumbersep numbersep268 printf("UE %d done sending, going idle.\n", ID);numbersepnumbersep numbersep269 tsync = RCCE_wtime() - tstart_sync;numbersepnumbersep numbersep270 if(SHOW_ALL)numbersepnumbersep numbersep271 printf("UE %d ROUND %d -- COMP: %.3fms SYNC: %.3fms "numbersepnumbersep numbersep272 "BLCK: %.3fms\n",numbersepnumbersep numbersep273 ID, round, tcomp*1000, tsync*1000, tblock*1000);numbersepnumbersep numbersep274 tcomp_tot += tcomp;numbersepnumbersep numbersep275 tsync_tot += tsync;numbersepnumbersep numbersep276 tblock_tot += tblock;numbersepnumbersep numbersep277 }numbersepnumbersep numbersep278
58

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep279 /* phase complete, set new number of active cpus and sync */numbersepnumbersep numbersep280 active_cpus >>= 1;numbersepnumbersep numbersep281 round++;numbersepnumbersep numbersep282 tblock = 0;numbersepnumbersep numbersep283 tstart_block = RCCE_wtime();numbersepnumbersep numbersep284 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep285 tblock += RCCE_wtime() - tstart_block;numbersepnumbersep numbersep286numbersepnumbersep numbersep287 }numbersepnumbersep numbersep288 if(SHOW_ALL && ID == 0)numbersepnumbersep numbersep289 {numbersepnumbersep numbersep290 printf("UE %d ROUND %d -- COMP: %.3fms\n", ID, round, tcomp*1000);numbersepnumbersep numbersep291 tcomp_tot += tcomp;numbersepnumbersep numbersep292 }numbersepnumbersep numbersep293numbersepnumbersep numbersep294 if(DEBUG)numbersepnumbersep numbersep295 printf("UE %d exited main loop\n", ID);numbersepnumbersep numbersep296 t_tot = RCCE_wtime() - tstart;numbersepnumbersep numbersep297numbersepnumbersep numbersep298 if(SHOW_ALL || ID == 0)numbersepnumbersep numbersep299 {numbersepnumbersep numbersep300 printf("UE %d TOTALS -- COMP: %.3fms SYNC: %.3fms BLCK: %.3fms "numbersepnumbersep numbersep301 "TOT: %.3fms\n", ID, tcomp_tot*1000, tsync_tot*1000,numbersepnumbersep numbersep302 tblock_tot*1000, t_tot*1000);numbersepnumbersep numbersep303 printf("UE %d PERCENTS -- COMP: %.2f%% SYNC: %.2f%% BLCK: %.2f%%\n\n",numbersepnumbersep numbersep304 ID, tcomp_tot/t_tot*100, tsync_tot/t_tot*100,numbersepnumbersep numbersep305 tblock_tot/t_tot*100);numbersepnumbersep numbersep306 }numbersepnumbersep numbersep307numbersepnumbersep numbersep308 if(ID == 0)numbersepnumbersep numbersep309 {numbersepnumbersep numbersep310 switch(rslt = check_sorted(N))numbersepnumbersep numbersep311 {numbersepnumbersep numbersep312 case -1:numbersepnumbersep numbersep313 printf("(Warning: first and last values in array are"numbersepnumbersep numbersep314 " equal).\n");numbersepnumbersep numbersep315 case 0:numbersepnumbersep numbersep316 printf("Array sorted OK.\n");numbersepnumbersep numbersep317 break;numbersepnumbersep numbersep318 default:numbersepnumbersep numbersep319 printf("Error sorting array at %d.\n", rslt);numbersepnumbersep numbersep320 }numbersepnumbersep numbersep321 }numbersepnumbersep numbersep322numbersepnumbersep numbersep323 /* Free memory */numbersepnumbersep numbersep324 if(DEBUG) printf("UE %d Freeing memory\n", ID);numbersepnumbersep numbersep325 free(data);numbersepnumbersep numbersep326 free(aux);numbersepnumbersep numbersep327 RCCE_shfree((t_vcharp)buffer);numbersepnumbersep numbersep328 RCCE_finalize();numbersepnumbersep numbersep329numbersepnumbersep numbersep330 return 0;numbersepnumbersep numbersep331 }numbersepnumbersep numbersep332numbersepnumbersep numbersep333 void mergesort(int l, int r)numbersepnumbersep numbersep334 {numbersepnumbersep numbersep335 int m = (l + r) / 2;numbersepnumbersep numbersep336 if (l < r)numbersepnumbersep numbersep337 {numbersepnumbersep numbersep338 mergesort(l, m);numbersepnumbersep numbersep339 mergesort(m + 1, r);numbersepnumbersep numbersep340 if(MORE_DEBUG)numbersepnumbersep numbersep341 printf("In mergesort, merge(left = %d, mid = %d, right = %d)\n",numbersepnumbersep numbersep342 l, m, r);numbersepnumbersep numbersep343 merge(l, m ,r);numbersepnumbersep numbersep344 }numbersepnumbersep numbersep345 }numbersepnumbersep numbersep346
59

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep347 void merge(int l, int m, int r)numbersepnumbersep numbersep348 {numbersepnumbersep numbersep349 // i,j move over left, right halvesnumbersepnumbersep numbersep350 // k moves over whole arraynumbersepnumbersep numbersep351 int i, j, k;numbersepnumbersep numbersep352numbersepnumbersep numbersep353 // Copy lower half to auxnumbersepnumbersep numbersep354 //memcpy(aux, data+l, (m-l+1)*sizeof(int));numbersepnumbersep numbersep355 if(MORE_DEBUG)numbersepnumbersep numbersep356 printf("Copying %d elements to aux from data+%d\n", m-l+1, l);numbersepnumbersep numbersep357 i = 0;numbersepnumbersep numbersep358 j = l;numbersepnumbersep numbersep359 while(i <= (m - l))numbersepnumbersep numbersep360 {numbersepnumbersep numbersep361 if(MORE_DEBUG)numbersepnumbersep numbersep362 printf("Setting aux[%d] = data[%d] = %d\n", i, j, data[j]);numbersepnumbersep numbersep363 aux[i++] = data[j++];numbersepnumbersep numbersep364 }numbersepnumbersep numbersep365numbersepnumbersep numbersep366 /* Merge: copy smaller element:numbersepnumbersep numbersep367 * i iterates over lower half copy (aux)numbersepnumbersep numbersep368 * j iterates over upper half (data)numbersepnumbersep numbersep369 * k iterates over entire array (data) - destination indexnumbersepnumbersep numbersep370 */numbersepnumbersep numbersep371 i = 0;numbersepnumbersep numbersep372 k = l, j = (m + 1);numbersepnumbersep numbersep373 if(MORE_DEBUG)numbersepnumbersep numbersep374 printf("Main mergeloop open k = %d, i = %d, j = %d\n", k, i, j);numbersepnumbersep numbersep375 while(k < j && j <= r)numbersepnumbersep numbersep376 {numbersepnumbersep numbersep377 if(aux[i] <= data[j])numbersepnumbersep numbersep378 {numbersepnumbersep numbersep379 if(MORE_DEBUG)numbersepnumbersep numbersep380 printf("aux[%d] is <= data[%d], setting data[%d] = aux[%d]\n",numbersepnumbersep numbersep381 i, j, k, i);numbersepnumbersep numbersep382 data[k++] = aux[i++];numbersepnumbersep numbersep383 }numbersepnumbersep numbersep384 elsenumbersepnumbersep numbersep385 {numbersepnumbersep numbersep386 if(MORE_DEBUG)numbersepnumbersep numbersep387 printf("aux[%d] is > data[%d], setting data[%d] = data[%d]\n",numbersepnumbersep numbersep388 i, j, k, j);numbersepnumbersep numbersep389 data[k++] = data[j++];numbersepnumbersep numbersep390 }numbersepnumbersep numbersep391 }numbersepnumbersep numbersep392numbersepnumbersep numbersep393 // If something’s left in aux, copy it overnumbersepnumbersep numbersep394 /*if(k < j)numbersepnumbersep numbersep395 {numbersepnumbersep numbersep396 memcpy(data+k, aux+i, (j-k)*sizeof(int));numbersepnumbersep numbersep397 if(MORE_DEBUG)numbersepnumbersep numbersep398 printf("k<j, copying to data+%d from aux+%d ", k, i);numbersepnumbersep numbersep399 }*/numbersepnumbersep numbersep400 while(k < j)numbersepnumbersep numbersep401 {numbersepnumbersep numbersep402 if(MORE_DEBUG)numbersepnumbersep numbersep403 printf("Copying leftovers data[%d] = aux[%d]\n", k, i);numbersepnumbersep numbersep404 data[k++] = aux[i++];numbersepnumbersep numbersep405 }numbersepnumbersep numbersep406 }numbersepnumbersep numbersep407numbersepnumbersep numbersep408 int check_sorted(int N)numbersepnumbersep numbersep409 {numbersepnumbersep numbersep410 int i;numbersepnumbersep numbersep411 for(i = 0; i < N - 1; i++)numbersepnumbersep numbersep412 {numbersepnumbersep numbersep413 if(data[i] > data[i + 1])numbersepnumbersep numbersep414 return i;
60

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep415 }numbersepnumbersep numbersep416 if(data[0] == data[N-1])numbersepnumbersep numbersep417 return -1;numbersepnumbersep numbersep418 return 0;numbersepnumbersep numbersep419 }
A.4 pipelined_merge.h
numbersepnumbersep numbersep1 /*numbersepnumbersep numbersep2 * pipelined_merge.hnumbersepnumbersep numbersep3 * Copyright 2011 Kenan Avdic <[email protected]>numbersepnumbersep numbersep4 * All rights reserved.numbersepnumbersep numbersep5 *numbersepnumbersep numbersep6 * Redistribution and use in source and binary forms, with or withoutnumbersepnumbersep numbersep7 * modification, are permitted provided that the following conditionsnumbersepnumbersep numbersep8 * are met:numbersepnumbersep numbersep9 *numbersepnumbersep numbersep10 * 1. Redistributions of source code must retain the above copyrightnumbersepnumbersep numbersep11 * notice, this list of conditions and the following disclaimer.numbersepnumbersep numbersep12 *numbersepnumbersep numbersep13 * 2. Redistributions in binary form must reproduce the above copyrightnumbersepnumbersep numbersep14 * notice, this list of conditions and the following disclaimer in thenumbersepnumbersep numbersep15 * documentation and/or other materials provided with the distribution.numbersepnumbersep numbersep16 *numbersepnumbersep numbersep17 * 3. Neither the name of the copyright holder nor the names of itsnumbersepnumbersep numbersep18 * contributors may be used to endorse or promote products derived fromnumbersepnumbersep numbersep19 * this software without specific prior written permission.numbersepnumbersep numbersep20 *numbersepnumbersep numbersep21 * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORSnumbersepnumbersep numbersep22 * "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOTnumbersepnumbersep numbersep23 * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESSnumbersepnumbersep numbersep24 * FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THEnumbersepnumbersep numbersep25 * COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,numbersepnumbersep numbersep26 * INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,numbersepnumbersep numbersep27 * BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;numbersepnumbersep numbersep28 * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVERnumbersepnumbersep numbersep29 * CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICTnumbersepnumbersep numbersep30 * LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING INnumbersepnumbersep numbersep31 * ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THEnumbersepnumbersep numbersep32 * POSSIBILITY OF SUCH DAMAGE.numbersepnumbersep numbersep33numbersepnumbersep numbersep34 * Merges a number of integers using parallel pipelined merge.numbersepnumbersep numbersep35 *numbersepnumbersep numbersep36 * Each SCC quadrant with its own memory controller works separately towardsnumbersepnumbersep numbersep37 * its own controller. The tasks are originally mapped as a 7-level tree withnumbersepnumbersep numbersep38 * a 0 weight root node, i.e. 2 6-level binary trees to one quadrant. The codenumbersepnumbersep numbersep39 * will still work even with smaller or larger trees, as long as the "doublenumbersepnumbersep numbersep40 * tree, 0-weight root" principle is followed.numbersepnumbersep numbersep41 *numbersepnumbersep numbersep42 * The mappings look as follows (the mapfile):numbersepnumbersep numbersep43 * 0 1 0 0 0 0 0numbersepnumbersep numbersep44 * 1 1 0 0 0 0 0numbersepnumbersep numbersep45 * 2 0 0 1 0 0 0numbersepnumbersep numbersep46 * 3 0 0 0 0 0 1numbersepnumbersep numbersep47 * ...numbersepnumbersep numbersep48 *numbersepnumbersep numbersep49 * where the first column is task number and the subsequent columns indicatenumbersepnumbersep numbersep50 * tile numbers, i.e. the column number is the tile where the task isnumbersepnumbersep numbersep51 * mapped.numbersepnumbersep numbersep52 *numbersepnumbersep numbersep53 * Task 0 is ignored.numbersepnumbersep numbersep54 * Task 1 is the 0-weight rootnumbersepnumbersep numbersep55 * Task 2 is the root of the left treenumbersepnumbersep numbersep56 * Task 4 is the left child of the left rootnumbersepnumbersep numbersep57 * Task 5 is the right child of the left rootnumbersepnumbersep numbersep58 * Task 3 is the root of the right tree
61

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep59 * Task 6 is the left child of the right rootnumbersepnumbersep numbersep60 * Task 7 is the right child of the right rootnumbersepnumbersep numbersep61 * etc.numbersepnumbersep numbersep62 *numbersepnumbersep numbersep63 * These 2 trees are deduced from the tile mapping.numbersepnumbersep numbersep64 *numbersepnumbersep numbersep65 * It is assumed that in one quadrant, the input tile order is as followsnumbersepnumbersep numbersep66 *numbersepnumbersep numbersep67 * 4 5 6numbersepnumbersep numbersep68 * MC 1 2 3numbersepnumbersep numbersep69 *numbersepnumbersep numbersep70 * and that the host file input to rccerun for every quadrant is innumbersepnumbersep numbersep71 * this order, ienumbersepnumbersep numbersep72 *numbersepnumbersep numbersep73 * 12 14 16numbersepnumbersep numbersep74 * MC 0 2 4numbersepnumbersep numbersep75 *numbersepnumbersep numbersep76 * so that from the application point of view, the cores with ids 0-5, 6-11numbersepnumbersep numbersep77 * belong to the first quadrant, 12-17, 18-23 to the second etc, and the firstnumbersepnumbersep numbersep78 * core in each is the core nearest to the MC.numbersepnumbersep numbersep79 * This is how the data is mapped onto the 8 6-level trees.numbersepnumbersep numbersep80 *numbersepnumbersep numbersep81 *numbersepnumbersep numbersep82 /* ------------------------------------------------------------------------- */numbersepnumbersep numbersep83numbersepnumbersep numbersep84 #pragma oncenumbersepnumbersep numbersep85 #ifndef PIPELINED_MERGE_Hnumbersepnumbersep numbersep86 #define PIPELINED_MERGE_Hnumbersepnumbersep numbersep87numbersepnumbersep numbersep88 #include "RCCE.h"numbersepnumbersep numbersep89numbersepnumbersep numbersep90 /* ---------------------------- DEFINES ------------------------------------ */numbersepnumbersep numbersep91 #define DEBUG 0 /* standard debug */numbersepnumbersep numbersep92 #define MORE_DEBUG 0 /* more debug */numbersepnumbersep numbersep93 #define ALG_DEBUG 0 /* merge algorithm debug */numbersepnumbersep numbersep94 #define MAX_TASKS 127 /* maximum number of tasks allowable */numbersepnumbersep numbersep95 #define HDR_SZ 32 /* size of the mpb header */numbersepnumbersep numbersep96 #define MPB_MAX_BUFF_SIZE (256*32) /* maximum size of the MPB buffer */numbersepnumbersep numbersep97 #define MEM_RATIO 3 /* cache memory size to mpb buffer size rationumbersepnumbersep numbersep98 * (in pow 2: cachemem = buffer << MEM_RATIO) */numbersepnumbersep numbersep99numbersepnumbersep numbersep100 #define max(a, b) ((a)>(b)?(a):(b))numbersepnumbersep numbersep101 #define min(a, b) ((a)<(b)?(a):(b))numbersepnumbersep numbersep102numbersepnumbersep numbersep103 /* ---------------------------- GLOBALS ------------------------------------ */numbersepnumbersep numbersep104 extern int *g_input_p; /* pointer to input memory area location of data */numbersepnumbersep numbersep105 extern int *g_output_p; /* pointer to output memory area */numbersepnumbersep numbersep106 extern t_vcharp g_mpb_buf_p;/* pointer to the start of the MPB buffer */numbersepnumbersep numbersep107 extern unsigned N; /* total number of integers in file per quadrantnumbersepnumbersep numbersep108 * (1/4 of file size) */numbersepnumbersep numbersep109numbersepnumbersep numbersep110 /* ----------------------------- TYPES ------------------------------------- */numbersepnumbersep numbersep111 /* Leaf propertiesnumbersepnumbersep numbersep112 * additional info the leaf tasks need, extends task */numbersepnumbersep numbersep113 struct leaf_propsnumbersepnumbersep numbersep114 {numbersepnumbersep numbersep115 unsigned start; /* initially: byte offset in file, afternumbersepnumbersep numbersep116 * the file is loaded becomes the integernumbersepnumbersep numbersep117 * offset to local memory leaf area */numbersepnumbersep numbersep118 unsigned remain_left; /* number of remaining integers in each */numbersepnumbersep numbersep119 unsigned remain_right; /* subsequence */numbersepnumbersep numbersep120 };numbersepnumbersep numbersep121 typedef struct leaf_props leaf_props_t;numbersepnumbersep numbersep122numbersepnumbersep numbersep123 /* Tasknumbersepnumbersep numbersep124 * holds information about a task */numbersepnumbersep numbersep125 struct tasknumbersepnumbersep numbersep126 {
62

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep127 unsigned short id;numbersepnumbersep numbersep128 unsigned short local_id;numbersepnumbersep numbersep129 struct task* left_child; /* tree structure */numbersepnumbersep numbersep130 struct task* right_child;numbersepnumbersep numbersep131 struct task* parent;numbersepnumbersep numbersep132 unsigned short cpu_id; /* the id of the cpu this task is running on */numbersepnumbersep numbersep133 unsigned short tree_lvl; /* the level of the tree the task is on */numbersepnumbersep numbersep134 t_vcharp buf_start; /* pointer to the start of the buffer in thenumbersepnumbersep numbersep135 * MPB */numbersepnumbersep numbersep136 unsigned short buf_sz; /* the size of the data buffer in 32B linesnumbersepnumbersep numbersep137 * including the header */numbersepnumbersep numbersep138 unsigned size; /* total number of integers that need to benumbersepnumbersep numbersep139 * handled by this task */numbersepnumbersep numbersep140 unsigned progress; /* progress of task, i.e. how much of sizenumbersepnumbersep numbersep141 * has been completed. if equal to sizenumbersepnumbersep numbersep142 * the task is finished. */numbersepnumbersep numbersep143 void (*function)(struct task *task); /* pointer to the function that willnumbersepnumbersep numbersep144 * run this task */numbersepnumbersep numbersep145 leaf_props_t *leaf; /* leaf properties */numbersepnumbersep numbersep146 };numbersepnumbersep numbersep147 typedef struct task task_t;numbersepnumbersep numbersep148numbersepnumbersep numbersep149 /* MPB headernumbersepnumbersep numbersep150 * holds information about the status of a buffer */numbersepnumbersep numbersep151 struct mpb_headernumbersepnumbersep numbersep152 {numbersepnumbersep numbersep153 unsigned long seq; /* the sending tasks counter, equal to progressnumbersepnumbersep numbersep154 * of task. incremented every time the buffernumbersepnumbersep numbersep155 * is written to */numbersepnumbersep numbersep156 unsigned long ack; /* the receiving tasks counter, set equal tonumbersepnumbersep numbersep157 * seq when the buffer has been received */numbersepnumbersep numbersep158 unsigned short start_os; /* the offset to the first valid integernumbersepnumbersep numbersep159 * in buffer (since some may have been consumednumbersepnumbersep numbersep160 * already */numbersepnumbersep numbersep161 unsigned short int_ct; /* number of valid (unconsumed) integersnumbersepnumbersep numbersep162 * currently in data area */numbersepnumbersep numbersep163 unsigned short src_task_id; /* the source task, writes to this buffer */numbersepnumbersep numbersep164 unsigned short dst_task_id; /* the destination task, reads from buffer */numbersepnumbersep numbersep165 } __attribute__((aligned(32)));numbersepnumbersep numbersep166 typedef struct mpb_header mpb_header_t;numbersepnumbersep numbersep167numbersepnumbersep numbersep168 /* Local memory buffer (cache) descriptor */numbersepnumbersep numbersep169 struct mem_buffernumbersepnumbersep numbersep170 {numbersepnumbersep numbersep171 int ct; /* the number of integers currently stored */numbersepnumbersep numbersep172 int max; /* maximum capacity in integers */numbersepnumbersep numbersep173 int *data; /* pointer to data */numbersepnumbersep numbersep174 };numbersepnumbersep numbersep175 typedef struct mem_buffer mem_buffer_t;numbersepnumbersep numbersep176numbersepnumbersep numbersep177 /* Error types */numbersepnumbersep numbersep178 enum err_tnumbersepnumbersep numbersep179 {numbersepnumbersep numbersep180 E_OK, /* No error */numbersepnumbersep numbersep181 E_PARAM, /* Incorrect number of parameters supplied */numbersepnumbersep numbersep182 E_CORENUM, /* Incorrect number of cores */numbersepnumbersep numbersep183 E_TREE, /* Task tree not balanced */numbersepnumbersep numbersep184 E_FILE, /* File error */numbersepnumbersep numbersep185 E_MPB_MEM, /* MPB memory error */numbersepnumbersep numbersep186 E_MEM, /* Memory error */numbersepnumbersep numbersep187 E_SORT /* Subsequence not sorted */numbersepnumbersep numbersep188 };numbersepnumbersep numbersep189numbersepnumbersep numbersep190 /* ----------------------------- FUNCTIONS --------------------------------- */numbersepnumbersep numbersep191numbersepnumbersep numbersep192 /* Recursive function to generate a tree of tasks following the mappingnumbersepnumbersep numbersep193 * described in the mapping array parameter.numbersepnumbersep numbersep194 *
63

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep195 * Uses the globals MPB_BUFF_SIZE and N.numbersepnumbersep numbersep196 * Task id’s are assigned using the parents task id.numbersepnumbersep numbersep197 * Task id assumed 1 for root - the math wont work for arbitrary task ids likenumbersepnumbersep numbersep198 * id 10 for root.numbersepnumbersep numbersep199 *numbersepnumbersep numbersep200 * The mapping array is an int array where index = task id and value = cpu idnumbersepnumbersep numbersep201 * of the task needs to run on.numbersepnumbersep numbersep202 *numbersepnumbersep numbersep203 * 1. Create a root task with task id 1.numbersepnumbersep numbersep204 * 2. Generate the mapping array of task id to cpu idnumbersepnumbersep numbersep205 * 3. Call this function to generate the rest of the treenumbersepnumbersep numbersep206 * (4. Call setup_buffers below to assign buffer sizes to the tasks) */numbersepnumbersep numbersep207 void generate_subtree(task_t *parent, unsigned *mapping, unsigned level,numbersepnumbersep numbersep208 unsigned height);numbersepnumbersep numbersep209numbersepnumbersep numbersep210 /* Calculates sizes for buffers for each task in the tree beginning withnumbersepnumbersep numbersep211 * root. Tasks are directly modified. */numbersepnumbersep numbersep212 void setup_buffers(task_t* root, unsigned num_tasks);numbersepnumbersep numbersep213numbersepnumbersep numbersep214 /* Deletes a subtree including the node, starting from node */numbersepnumbersep numbersep215 void delete_subtree(task_t *node);numbersepnumbersep numbersep216numbersepnumbersep numbersep217 /* Finds (recursively, inorder) in a subtree starting with root the task withnumbersepnumbersep numbersep218 * task_id and returns a pointer to it */numbersepnumbersep numbersep219 task_t* find(const task_t* root, int task_id);numbersepnumbersep numbersep220numbersepnumbersep numbersep221 /* Task functions, called when a task is activated */numbersepnumbersep numbersep222 void run_root(task_t *task);numbersepnumbersep numbersep223 void run_leaf(task_t *task);numbersepnumbersep numbersep224 void run_branch(task_t *task);numbersepnumbersep numbersep225numbersepnumbersep numbersep226 /* Checks the left and right buffers for new data and merges into dst_memnumbersepnumbersep numbersep227 *numbersepnumbersep numbersep228 * dst_mem: location of resultnumbersepnumbersep numbersep229 * dst_ct: number of integers that will fit in dst_memnumbersepnumbersep numbersep230 * mpb_left_hdr_p: pointer to the left childs buffernumbersepnumbersep numbersep231 * mpb_right_hdr_p: pointer to the right childs buffernumbersepnumbersep numbersep232 * task_sz: size of each child tasknumbersepnumbersep numbersep233 *numbersepnumbersep numbersep234 * returns the number of integers that were written to dst_mem */numbersepnumbersep numbersep235 int check_and_merge(int *dst_mem,numbersepnumbersep numbersep236 unsigned dst_ct,numbersepnumbersep numbersep237 t_vcharp mpb_left_hdr_p,numbersepnumbersep numbersep238 t_vcharp mpb_right_hdr_p,numbersepnumbersep numbersep239 unsigned task_sz);numbersepnumbersep numbersep240numbersepnumbersep numbersep241 /* Copies from memory to mpb if the destination buffer is clearnumbersepnumbersep numbersep242 *numbersepnumbersep numbersep243 * dst_hdr_p: pointer to start of destination buffernumbersepnumbersep numbersep244 * src_mem: pointer to start of source memorynumbersepnumbersep numbersep245 * int_ct: the numbers of integers in memorynumbersepnumbersep numbersep246 * dst_cpu: destination cpunumbersepnumbersep numbersep247 * dst_buf_sz: the size of destination buffernumbersepnumbersep numbersep248 *numbersepnumbersep numbersep249 * returns the number of integers that were copied to destination buffer */numbersepnumbersep numbersep250 int check_and_push(t_vcharp dst_hdr_p,numbersepnumbersep numbersep251 int *src_mem,numbersepnumbersep numbersep252 unsigned int_ct,numbersepnumbersep numbersep253 unsigned dst_cpu,numbersepnumbersep numbersep254 unsigned dst_buf_sz);numbersepnumbersep numbersep255numbersepnumbersep numbersep256 /* Executes the sequential mergesort phase: leaf tasks load from file andnumbersepnumbersep numbersep257 * perform sequential merge on their data. Each leaf ends up with 2 equallynumbersepnumbersep numbersep258 * long non-decreasing subsequences.numbersepnumbersep numbersep259 *numbersepnumbersep numbersep260 * integer_offset is the int offset in local input memory (from the globalnumbersepnumbersep numbersep261 * input pointer g_input_p) where the leaf writes its source data from file */numbersepnumbersep numbersep262 void sequential_merge(task_t* leaf_task, const char* filename,
64

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep263 unsigned int_os);numbersepnumbersep numbersep264numbersepnumbersep numbersep265 /* Prints task, header */numbersepnumbersep numbersep266 void print_task(const task_t* task);numbersepnumbersep numbersep267 void print_header(const mpb_header_t* hdr);numbersepnumbersep numbersep268numbersepnumbersep numbersep269 /* Merges count number of integers where:numbersepnumbersep numbersep270 *numbersepnumbersep numbersep271 * dst: pointer to the start of the destination arraynumbersepnumbersep numbersep272 * left: pointer to the start of the left inputnumbersepnumbersep numbersep273 * right: pointer to the start of the right inputnumbersepnumbersep numbersep274 * left_ct: number of integers in left inputnumbersepnumbersep numbersep275 * right_ct: number of integers in right inputnumbersepnumbersep numbersep276 *numbersepnumbersep numbersep277 * returns the number of elements that were written into dest */numbersepnumbersep numbersep278 int merge(int *dst,numbersepnumbersep numbersep279 const int *left,numbersepnumbersep numbersep280 const int *right,numbersepnumbersep numbersep281 unsigned *left_ct,numbersepnumbersep numbersep282 unsigned *right_ct);numbersepnumbersep numbersep283numbersepnumbersep numbersep284 /* Runs the entire mergesort algorithm including a recursive divide phase.numbersepnumbersep numbersep285 * Uses merge_in_place to perform the actual merging in place. After completionnumbersepnumbersep numbersep286 * the data array is non-decreasing between indices l and r.numbersepnumbersep numbersep287 * Before calling, the aux array must be allocated to half the size of data.numbersepnumbersep numbersep288 *numbersepnumbersep numbersep289 * data: start of the array to be sortednumbersepnumbersep numbersep290 * aux: start of the comparison arraynumbersepnumbersep numbersep291 * l: left index of start of sortnumbersepnumbersep numbersep292 * r: right index of end of sort */numbersepnumbersep numbersep293 void mergesort(int *data, int *aux, int l, int r);numbersepnumbersep numbersep294numbersepnumbersep numbersep295 /* Merges in-place 2 nondecreasing sequences into a single non-decreasingnumbersepnumbersep numbersep296 * sequence.numbersepnumbersep numbersep297 *numbersepnumbersep numbersep298 * data is the start of data arraynumbersepnumbersep numbersep299 * aux is the start of the comparison arraynumbersepnumbersep numbersep300 * l is left index (start of sequence 1)numbersepnumbersep numbersep301 * m mid index (start of sequence 2)numbersepnumbersep numbersep302 * r right index (end of sequence 2 -- inclusive!) */numbersepnumbersep numbersep303 void merge_in_place(int *data, int *aux, int l, int m, int r);numbersepnumbersep numbersep304numbersepnumbersep numbersep305 /* makes number evenly divisible by 32 by increasing it */numbersepnumbersep numbersep306 void make_div_by_32(unsigned int* number);numbersepnumbersep numbersep307numbersepnumbersep numbersep308 /* Checks that the sequence in "data" of size "length" is non-decreasingnumbersepnumbersep numbersep309 * returns one of:numbersepnumbersep numbersep310 * positive index of element where the first error is encounterednumbersepnumbersep numbersep311 * 0 if sequence is correctnumbersepnumbersep numbersep312 * -1 if first and last elements are equal */numbersepnumbersep numbersep313 int check_sorted(const int *data, int len);numbersepnumbersep numbersep314numbersepnumbersep numbersep315 /* insertion sort, integers */numbersepnumbersep numbersep316 void isort(int *data, int len);numbersepnumbersep numbersep317numbersepnumbersep numbersep318 /* prefix sum function */numbersepnumbersep numbersep319 int prfx_sum(int* data, int len);numbersepnumbersep numbersep320numbersepnumbersep numbersep321 /* Invalidates lines in L1 that map to MPB lines - invokes the CL1INVMBnumbersepnumbersep numbersep322 * instruction */numbersepnumbersep numbersep323 inline void l1_mpb_invalidate()numbersepnumbersep numbersep324 {numbersepnumbersep numbersep325 asm volatile ( ".byte 0x0f; .byte 0x0a;\n" );numbersepnumbersep numbersep326 }numbersepnumbersep numbersep327numbersepnumbersep numbersep328 /* qsort comparator for integers */numbersepnumbersep numbersep329 inline int comp(const void *val1, const void *val2)numbersepnumbersep numbersep330 {
65

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep331 return *(int*)val1 - *(int*)val2;numbersepnumbersep numbersep332 }numbersepnumbersep numbersep333numbersepnumbersep numbersep334 /* Used for splitting comm with rcce. If the supplied rcce id has a root,numbersepnumbersep numbersep335 * returns 1. */numbersepnumbersep numbersep336 inline int has_root(int id, void *aux)numbersepnumbersep numbersep337 {numbersepnumbersep numbersep338 return ((int*)aux)[2]==(id%12) || ((int*)aux)[3]==(id%12);numbersepnumbersep numbersep339 }numbersepnumbersep numbersep340numbersepnumbersep numbersep341 #endif /* PIPELINED_MERGE_H */
A.5 pipelined_merge.c
numbersepnumbersep numbersep1 /*numbersepnumbersep numbersep2 * pipelined_merge.cnumbersepnumbersep numbersep3 * Copyright 2011 Kenan Avdic <[email protected]>numbersepnumbersep numbersep4 * All rights reserved.numbersepnumbersep numbersep5 *numbersepnumbersep numbersep6 * Redistribution and use in source and binary forms, with or withoutnumbersepnumbersep numbersep7 * modification, are permitted provided that the following conditionsnumbersepnumbersep numbersep8 * are met:numbersepnumbersep numbersep9 *numbersepnumbersep numbersep10 * 1. Redistributions of source code must retain the above copyrightnumbersepnumbersep numbersep11 * notice, this list of conditions and the following disclaimer.numbersepnumbersep numbersep12 *numbersepnumbersep numbersep13 * 2. Redistributions in binary form must reproduce the above copyrightnumbersepnumbersep numbersep14 * notice, this list of conditions and the following disclaimer in thenumbersepnumbersep numbersep15 * documentation and/or other materials provided with the distribution.numbersepnumbersep numbersep16 *numbersepnumbersep numbersep17 * 3. Neither the name of the copyright holder nor the names of itsnumbersepnumbersep numbersep18 * contributors may be used to endorse or promote products derived fromnumbersepnumbersep numbersep19 * this software without specific prior written permission.numbersepnumbersep numbersep20 *numbersepnumbersep numbersep21 * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORSnumbersepnumbersep numbersep22 * "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOTnumbersepnumbersep numbersep23 * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESSnumbersepnumbersep numbersep24 * FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THEnumbersepnumbersep numbersep25 * COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,numbersepnumbersep numbersep26 * INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,numbersepnumbersep numbersep27 * BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;numbersepnumbersep numbersep28 * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVERnumbersepnumbersep numbersep29 * CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICTnumbersepnumbersep numbersep30 * LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING INnumbersepnumbersep numbersep31 * ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THEnumbersepnumbersep numbersep32 * POSSIBILITY OF SUCH DAMAGE.numbersepnumbersep numbersep33numbersepnumbersep numbersep34 * Merges a number of integers using parallel pipelined merge.numbersepnumbersep numbersep35 *numbersepnumbersep numbersep36 * GLOBALS:numbersepnumbersep numbersep37 * The g_input_p memory area is used with the leaves to store input data.numbersepnumbersep numbersep38 * The g_output_p memory area respectively is used with the root tonumbersepnumbersep numbersep39 * store output data. The branches have no need for either memory.numbersepnumbersep numbersep40 *numbersepnumbersep numbersep41 * Each local task has a memory area used for work and as a cachenumbersepnumbersep numbersep42 * buffer. The g_mem_p is a pointer to main memory descriptors thatnumbersepnumbersep numbersep43 * hold the information about the local memory buffers. This memorynumbersepnumbersep numbersep44 * is expected to stay in cachenumbersepnumbersep numbersep45 *numbersepnumbersep numbersep46 * MPB is allocated as a buffer.numbersepnumbersep numbersep47 *numbersepnumbersep numbersep48 * The global variable quad_os signifies the start of each MC-localnumbersepnumbersep numbersep49 * data range and the variable N the number of tasks per tree.numbersepnumbersep numbersep50 *numbersepnumbersep numbersep51 * There are 4 main data structures involved:numbersepnumbersep numbersep52 * mapping, int array - cpu destination for each task
66

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep53 * task_tree, task_t binary tree - the actual task mappingnumbersepnumbersep numbersep54 * tasklist, task_t pointer list - nodes in the tree gathered per-cpu intonumbersepnumbersep numbersep55 * a ptr listnumbersepnumbersep numbersep56 */numbersepnumbersep numbersep57numbersepnumbersep numbersep58 #define _GNU_SOURCEnumbersepnumbersep numbersep59numbersepnumbersep numbersep60 #include <stdio.h>numbersepnumbersep numbersep61 #include "pipelined_merge.h"numbersepnumbersep numbersep62numbersepnumbersep numbersep63 int *g_input_p; /* pointer to input memory area location of data */numbersepnumbersep numbersep64 int *g_output_p; /* pointer to output memory area */numbersepnumbersep numbersep65 t_vcharp g_mpb_buf_p; /* pointer to the start of the MPB transfer buffer */numbersepnumbersep numbersep66 mem_buffer_t *g_mem_p; /* pointer to cache work buffers */numbersepnumbersep numbersep67 unsigned N; /* total number of integers in file per quadrantnumbersepnumbersep numbersep68 * (1/4 of file size) */numbersepnumbersep numbersep69 unsigned quad_os; /* offset to start of input data (in file) fornumbersepnumbersep numbersep70 * MC-local trees, i.e. local quadrant */numbersepnumbersep numbersep71 unsigned rcce_id; /* RCCE ID of local cpu */numbersepnumbersep numbersep72 unsigned rcce_np; /* Number of participating RCCE UEs */numbersepnumbersep numbersep73 unsigned mpb_buff_size; /* size of the mpb buffer */numbersepnumbersep numbersep74numbersepnumbersep numbersep75 /* Timing vars */numbersepnumbersep numbersep76 double t_wait_st = 0, t_comp_st = 0, t_trns_st = 0;numbersepnumbersep numbersep77 double t_wait = 0, t_comp = 0, t_trns = 0, t_start = 0;numbersepnumbersep numbersep78 double t_wait_tot = 0, t_comp_tot = 0, t_trns_tot = 0, t_total = 0;numbersepnumbersep numbersep79numbersepnumbersep numbersep80 int RCCE_APP(int argc, char **argv)numbersepnumbersep numbersep81 {numbersepnumbersep numbersep82 unsigned have_root; /* nonzero if local node has a root task */numbersepnumbersep numbersep83 unsigned number_tasks; /* total number of tasks */numbersepnumbersep numbersep84 unsigned local_tasks; /* number of tasks assigned to the local node */numbersepnumbersep numbersep85 unsigned running_tasks; /* number of remaining tasks in the main loop */numbersepnumbersep numbersep86 unsigned start_task; /* mapping fix task variable */numbersepnumbersep numbersep87 unsigned height; /* the height of the tree */numbersepnumbersep numbersep88 unsigned leaf_task_mem_size;/* memory used by leaf tasks on local node */numbersepnumbersep numbersep89numbersepnumbersep numbersep90 /* Phase 2 variables */numbersepnumbersep numbersep91 unsigned root_mstr; /* root master: 2nd root on first quadrant */numbersepnumbersep numbersep92 unsigned lens[8][48]; /* lengths of roots part of each subsequence */numbersepnumbersep numbersep93 int *shmem_os_p; /* pointer to start of shmem */numbersepnumbersep numbersep94 unsigned roots[8]; /* ranks of roots */numbersepnumbersep numbersep95 unsigned rank; /* rank of local root */numbersepnumbersep numbersep96 unsigned root_mstr_rank; /* rank of root master */numbersepnumbersep numbersep97 unsigned buf_sz;numbersepnumbersep numbersep98 t_vcharp shmem_p;numbersepnumbersep numbersep99 int *buf_p, pivots[47][8], medians[48];numbersepnumbersep numbersep100numbersepnumbersep numbersep101 int i, j, k, tmp;numbersepnumbersep numbersep102 FILE *fp;numbersepnumbersep numbersep103 unsigned input[7], mapping[MAX_TASKS];numbersepnumbersep numbersep104 task_t *task_tree; /* binary tree containing the tasks */numbersepnumbersep numbersep105 task_t **tasklist; /* list of pointers to tasks each cpu runs */numbersepnumbersep numbersep106 task_t *tsk;numbersepnumbersep numbersep107 mpb_header_t mpb_hdr; /* MPB header */numbersepnumbersep numbersep108 RCCE_COMM RCCE_COMM_ROOT;numbersepnumbersep numbersep109numbersepnumbersep numbersep110 RCCE_init(&argc, &argv);numbersepnumbersep numbersep111 rcce_id = RCCE_ue();numbersepnumbersep numbersep112 rcce_np = RCCE_num_ues();numbersepnumbersep numbersep113numbersepnumbersep numbersep114 //RCCE_debug_set(RCCE_DEBUG_ALL);numbersepnumbersep numbersep115 //setvbuf(stdout, NULL, _IONBF, 0);numbersepnumbersep numbersep116numbersepnumbersep numbersep117 if(argc != 4)numbersepnumbersep numbersep118 {numbersepnumbersep numbersep119 if(rcce_id == 0) printf("Usage: %s {mapfile} {datafile} {buff size}\n",numbersepnumbersep numbersep120 argv[0]);
67

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep121 return E_PARAM;numbersepnumbersep numbersep122 }numbersepnumbersep numbersep123 mpb_buff_size = atoi(argv[3]);numbersepnumbersep numbersep124 /*if(rcce_np != 48)numbersepnumbersep numbersep125 {numbersepnumbersep numbersep126 printf("This program needs to run on all 48 cores.\n");numbersepnumbersep numbersep127 return E_CORENUM;numbersepnumbersep numbersep128 }*/numbersepnumbersep numbersep129 printf("\n");numbersepnumbersep numbersep130 /*if(rcce_id == 0)numbersepnumbersep numbersep131 printf("%10s %10s %10s %10s %10s %10s %10s %10s %10s %10s %10s %10s\n",numbersepnumbersep numbersep132 "COMP", "WAIT", "TRANS", "TOTAL", "COMP", "WAIT", "TRANS",numbersepnumbersep numbersep133 "TOTAL", "COMP", "WAIT", "TRANS", "TOTAL");*/numbersepnumbersep numbersep134 t_start = RCCE_wtime();numbersepnumbersep numbersep135numbersepnumbersep numbersep136 /* Parse mapping file, create mapping array where index is task id andnumbersepnumbersep numbersep137 * value is destination tile */numbersepnumbersep numbersep138 /* zero out input array */numbersepnumbersep numbersep139 for(i=0; i<7; i++)numbersepnumbersep numbersep140 input[i] = 0;numbersepnumbersep numbersep141 fp = fopen(argv[1], "r");numbersepnumbersep numbersep142 j = 0;numbersepnumbersep numbersep143 while(fscanf(fp, "%d%d%d%d%d%d%d", &input[0], &input[1], &input[2],numbersepnumbersep numbersep144 &input[3], &input[4], &input[5], &input[6]) != EOF)numbersepnumbersep numbersep145 {numbersepnumbersep numbersep146 for(i=1; i<7; i++)numbersepnumbersep numbersep147 {numbersepnumbersep numbersep148 if(input[i])numbersepnumbersep numbersep149 {numbersepnumbersep numbersep150 mapping[j] = i-1;numbersepnumbersep numbersep151 break; /* not strictly necessary */numbersepnumbersep numbersep152 }numbersepnumbersep numbersep153 }numbersepnumbersep numbersep154 j++;numbersepnumbersep numbersep155 }numbersepnumbersep numbersep156 number_tasks = j;numbersepnumbersep numbersep157 fclose(fp);numbersepnumbersep numbersep158 /* check that the number of tasks corresponds to the maximum for a completenumbersepnumbersep numbersep159 * binary tree + 1 (is a power of two) */numbersepnumbersep numbersep160 if((number_tasks == 0 || number_tasks & (number_tasks-1)) != 0)numbersepnumbersep numbersep161 {numbersepnumbersep numbersep162 printf("Number of tasks in %s not a power of two\n", argv[1]);numbersepnumbersep numbersep163 return E_TREE;numbersepnumbersep numbersep164 }numbersepnumbersep numbersep165 /* calculate height of the tree, log2 */numbersepnumbersep numbersep166 tmp = 1;numbersepnumbersep numbersep167 height = 1;numbersepnumbersep numbersep168 while((tmp<<=1) != number_tasks)numbersepnumbersep numbersep169 height++;numbersepnumbersep numbersep170numbersepnumbersep numbersep171 /* fix the mapping - use 12 cores instead of 6 tilesnumbersepnumbersep numbersep172 * assume left subtree (to root) maps to one half and right subtree to thenumbersepnumbersep numbersep173 * other half of the cores = add 6 to the core ids of right subtree.numbersepnumbersep numbersep174 * Furthermore, we have 4 times this many cores, modify the mapping fornumbersepnumbersep numbersep175 * each quadrant */numbersepnumbersep numbersep176 tmp = 1;numbersepnumbersep numbersep177 start_task = 3;numbersepnumbersep numbersep178 while(start_task<number_tasks)numbersepnumbersep numbersep179 {numbersepnumbersep numbersep180 for(i=0; i<tmp; i++)numbersepnumbersep numbersep181 mapping[start_task+i] += 6;numbersepnumbersep numbersep182 tmp <<= 1;numbersepnumbersep numbersep183 start_task <<= 1;numbersepnumbersep numbersep184 }numbersepnumbersep numbersep185 /* Before we adjust for quadrants, split off the root communicator andnumbersepnumbersep numbersep186 * set root master */numbersepnumbersep numbersep187 /* splitting root comm breaks programme :( */numbersepnumbersep numbersep188 /* RCCE_comm_split(has_root, mapping, &RCCE_COMM_ROOT);*/
68

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep189 root_mstr = mapping[3];numbersepnumbersep numbersep190numbersepnumbersep numbersep191 tmp = rcce_id/12; /* quad index */numbersepnumbersep numbersep192 if(tmp)numbersepnumbersep numbersep193 {numbersepnumbersep numbersep194 /* add 12/24/36 to core ids depending on quad */numbersepnumbersep numbersep195 tmp *= 12;numbersepnumbersep numbersep196 for(i=0; i<number_tasks; i++)numbersepnumbersep numbersep197 mapping[i] += tmp;numbersepnumbersep numbersep198 }numbersepnumbersep numbersep199numbersepnumbersep numbersep200 /* Find the file size, calculate number of integers to sort */numbersepnumbersep numbersep201 fp = fopen(argv[2], "rb");numbersepnumbersep numbersep202 if(!fp)numbersepnumbersep numbersep203 {numbersepnumbersep numbersep204 printf("Error opening file\n");numbersepnumbersep numbersep205 return E_FILE;numbersepnumbersep numbersep206 }numbersepnumbersep numbersep207 fseek(fp, 0L, SEEK_END);numbersepnumbersep numbersep208 /* each 6-l tree handles 1/8 of the file size */numbersepnumbersep numbersep209 N = ftell(fp) / sizeof(int) / 8;numbersepnumbersep numbersep210 /* quadrant offset is 1/4 of file per quadrant */numbersepnumbersep numbersep211 quad_os = (rcce_id/12) * (ftell(fp)/4);numbersepnumbersep numbersep212 fclose(fp);numbersepnumbersep numbersep213numbersepnumbersep numbersep214 /* use the mapping array to create a task tree with task 1 as empty root */numbersepnumbersep numbersep215 task_tree = malloc(sizeof(task_t));numbersepnumbersep numbersep216numbersepnumbersep numbersep217 /* create empty 7-l root */numbersepnumbersep numbersep218 task_tree->id = 1;numbersepnumbersep numbersep219 task_tree->parent = NULL;numbersepnumbersep numbersep220 task_tree->cpu_id = 99;numbersepnumbersep numbersep221 task_tree->tree_lvl = 0;numbersepnumbersep numbersep222 task_tree->buf_start = 0;numbersepnumbersep numbersep223 task_tree->buf_sz = 0;numbersepnumbersep numbersep224 /* multiply N by 2 since the function will halve it */numbersepnumbersep numbersep225 task_tree->size = N<<1;numbersepnumbersep numbersep226 task_tree->progress = task_tree->size;numbersepnumbersep numbersep227numbersepnumbersep numbersep228 /* create the rest of the tree */numbersepnumbersep numbersep229 generate_subtree(task_tree, mapping, 1, height);numbersepnumbersep numbersep230numbersepnumbersep numbersep231 /* count the number of local tasks */numbersepnumbersep numbersep232 local_tasks = 0;numbersepnumbersep numbersep233 for(i=2; i<number_tasks; i++)numbersepnumbersep numbersep234 {numbersepnumbersep numbersep235 local_tasks += (mapping[i] == rcce_id);numbersepnumbersep numbersep236 }numbersepnumbersep numbersep237numbersepnumbersep numbersep238 /* fill local tasklist; assigns tasks in tasktree to cpusnumbersepnumbersep numbersep239 * sorted in priority order: root highest, leaves lowest */numbersepnumbersep numbersep240 tasklist = malloc(sizeof(task_t*) * local_tasks);numbersepnumbersep numbersep241 for(i=2, j=0; i<number_tasks; i++)numbersepnumbersep numbersep242 {numbersepnumbersep numbersep243 if(mapping[i] == rcce_id)numbersepnumbersep numbersep244 {numbersepnumbersep numbersep245 /* find the task with this id and add it to tasklist */numbersepnumbersep numbersep246 tasklist[j] = find(task_tree, i);numbersepnumbersep numbersep247 tasklist[j]->local_id = j;numbersepnumbersep numbersep248 j++;numbersepnumbersep numbersep249 }numbersepnumbersep numbersep250 }numbersepnumbersep numbersep251numbersepnumbersep numbersep252 /* Allocate memory. */numbersepnumbersep numbersep253 /* shared memory */numbersepnumbersep numbersep254 shmem_p = RCCE_shmalloc(N*sizeof(int)*8);numbersepnumbersep numbersep255 if(!shmem_p)numbersepnumbersep numbersep256 {
69

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep257 printf("Error allocating %uB shared memory.\n", N*sizeof(int)*8);numbersepnumbersep numbersep258 return E_MEM;numbersepnumbersep numbersep259 }numbersepnumbersep numbersep260 /* All of mpb */numbersepnumbersep numbersep261 g_mpb_buf_p = RCCE_malloc(mpb_buff_size);numbersepnumbersep numbersep262 if(!g_mpb_buf_p)numbersepnumbersep numbersep263 {numbersepnumbersep numbersep264 printf("Error allocating buffer memory\n");numbersepnumbersep numbersep265 return E_MPB_MEM;numbersepnumbersep numbersep266 }numbersepnumbersep numbersep267numbersepnumbersep numbersep268 g_input_p = NULL;numbersepnumbersep numbersep269 g_output_p = NULL;numbersepnumbersep numbersep270numbersepnumbersep numbersep271 /* set up buffers */numbersepnumbersep numbersep272 setup_buffers(task_tree, number_tasks);numbersepnumbersep numbersep273numbersepnumbersep numbersep274 /* each node goes through its tasklist and sets up headers for buffersnumbersepnumbersep numbersep275 * the node that has root allocates memory for results. */numbersepnumbersep numbersep276 have_root = 0;numbersepnumbersep numbersep277 leaf_task_mem_size = 0;numbersepnumbersep numbersep278 /* prepare the header */numbersepnumbersep numbersep279 mpb_hdr.seq = 0;numbersepnumbersep numbersep280 mpb_hdr.ack = 0;numbersepnumbersep numbersep281 mpb_hdr.start_os = 0;numbersepnumbersep numbersep282 mpb_hdr.int_ct = 0;numbersepnumbersep numbersep283 for(i=0; i<local_tasks; i++)numbersepnumbersep numbersep284 {numbersepnumbersep numbersep285 mpb_hdr.dst_task_id = tasklist[i]->id;numbersepnumbersep numbersep286numbersepnumbersep numbersep287 /* node level-specific setup */numbersepnumbersep numbersep288 if(tasklist[i]->tree_lvl == 1)numbersepnumbersep numbersep289 {numbersepnumbersep numbersep290 /* we have root on node */numbersepnumbersep numbersep291 have_root = 1;numbersepnumbersep numbersep292 /* set root function */numbersepnumbersep numbersep293 tasklist[i]->function = &run_root;numbersepnumbersep numbersep294numbersepnumbersep numbersep295 /* write left childs header to mpb */numbersepnumbersep numbersep296 mpb_hdr.src_task_id = tasklist[i]->left_child->id;numbersepnumbersep numbersep297 RCCE_put(tasklist[i]->left_child->buf_start,numbersepnumbersep numbersep298 (t_vcharp)&mpb_hdr,numbersepnumbersep numbersep299 HDR_SZ,numbersepnumbersep numbersep300 rcce_id);numbersepnumbersep numbersep301numbersepnumbersep numbersep302 /* write right childs header to mpb */numbersepnumbersep numbersep303 mpb_hdr.src_task_id = tasklist[i]->right_child->id;numbersepnumbersep numbersep304 RCCE_put(tasklist[i]->right_child->buf_start,numbersepnumbersep numbersep305 (t_vcharp)&mpb_hdr,numbersepnumbersep numbersep306 HDR_SZ,numbersepnumbersep numbersep307 rcce_id);numbersepnumbersep numbersep308 }numbersepnumbersep numbersep309 else if(tasklist[i]->tree_lvl == (height-1))numbersepnumbersep numbersep310 {numbersepnumbersep numbersep311 /* sum leaf tasks sizes for leaf memory allocation later */numbersepnumbersep numbersep312 leaf_task_mem_size += tasklist[i]->size*sizeof(int);numbersepnumbersep numbersep313 /* set leaf function */numbersepnumbersep numbersep314 tasklist[i]->function = &run_leaf;numbersepnumbersep numbersep315 }numbersepnumbersep numbersep316 elsenumbersepnumbersep numbersep317 {numbersepnumbersep numbersep318 /* set default (branch) function */numbersepnumbersep numbersep319 tasklist[i]->function = &run_branch;numbersepnumbersep numbersep320numbersepnumbersep numbersep321 /* write left childs header to mpb */numbersepnumbersep numbersep322 mpb_hdr.src_task_id = tasklist[i]->left_child->id;numbersepnumbersep numbersep323 RCCE_put(tasklist[i]->left_child->buf_start,numbersepnumbersep numbersep324 (t_vcharp)&mpb_hdr,
70

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep325 HDR_SZ,numbersepnumbersep numbersep326 rcce_id);numbersepnumbersep numbersep327numbersepnumbersep numbersep328 /* write right childs header to mpb */numbersepnumbersep numbersep329 mpb_hdr.src_task_id = tasklist[i]->right_child->id;numbersepnumbersep numbersep330 RCCE_put(tasklist[i]->right_child->buf_start,numbersepnumbersep numbersep331 (t_vcharp)&mpb_hdr,numbersepnumbersep numbersep332 HDR_SZ,numbersepnumbersep numbersep333 rcce_id);numbersepnumbersep numbersep334 }numbersepnumbersep numbersep335 }numbersepnumbersep numbersep336numbersepnumbersep numbersep337 /* allocate memory for root & leaves if any are on local node */numbersepnumbersep numbersep338 if(have_root)numbersepnumbersep numbersep339 {numbersepnumbersep numbersep340 g_output_p = malloc(N*sizeof(int));numbersepnumbersep numbersep341 if(!g_output_p)numbersepnumbersep numbersep342 {numbersepnumbersep numbersep343 printf("Error allocating root memory\n");numbersepnumbersep numbersep344 return E_MEM;numbersepnumbersep numbersep345 }numbersepnumbersep numbersep346 }numbersepnumbersep numbersep347 if(leaf_task_mem_size)numbersepnumbersep numbersep348 {numbersepnumbersep numbersep349 g_input_p = malloc(leaf_task_mem_size);numbersepnumbersep numbersep350 if(!g_input_p)numbersepnumbersep numbersep351 {numbersepnumbersep numbersep352 printf("Error allocating leaf memory\n");numbersepnumbersep numbersep353 return E_MEM;numbersepnumbersep numbersep354 }numbersepnumbersep numbersep355 }numbersepnumbersep numbersep356numbersepnumbersep numbersep357 /* Set up the main memory descriptor array and allocate the cache memorynumbersepnumbersep numbersep358 * used for merging */numbersepnumbersep numbersep359 g_mem_p = malloc(sizeof(mem_buffer_t) * local_tasks);numbersepnumbersep numbersep360 if(!g_mem_p)numbersepnumbersep numbersep361 {numbersepnumbersep numbersep362 printf("Error allocating cache memory.\n");numbersepnumbersep numbersep363 return E_MEM;numbersepnumbersep numbersep364 }numbersepnumbersep numbersep365 for(i=0; i<local_tasks; i++)numbersepnumbersep numbersep366 {numbersepnumbersep numbersep367 /* set buffer empty */numbersepnumbersep numbersep368 g_mem_p[i].ct = 0;numbersepnumbersep numbersep369numbersepnumbersep numbersep370 /* The minimum memory size needed for a task is the largest of:numbersepnumbersep numbersep371 * - twice the destination buffer sizenumbersepnumbersep numbersep372 * - left+right+destination buffer sizesnumbersepnumbersep numbersep373 *numbersepnumbersep numbersep374 * We use left+right+destination*2 for simplicity (since thenumbersepnumbersep numbersep375 * cache memory is much larger in comparison to the mpb buffer)numbersepnumbersep numbersep376 * In addition, we increase it by 2^MEM_RATIO.numbersepnumbersep numbersep377 *numbersepnumbersep numbersep378 * For a root the destination buffer is 0 and we don’t allocate anynumbersepnumbersep numbersep379 * memory, but only use the size during merging. The leavesnumbersepnumbersep numbersep380 * have no input buffers in memory */numbersepnumbersep numbersep381 tmp = 0;numbersepnumbersep numbersep382 if(tasklist[i]->buf_sz > 0) /* branches and leaves */numbersepnumbersep numbersep383 {numbersepnumbersep numbersep384 tmp += (tasklist[i]->buf_sz-1)<<1;numbersepnumbersep numbersep385 }numbersepnumbersep numbersep386 if(tasklist[i]->left_child) /* root & branches */numbersepnumbersep numbersep387 {numbersepnumbersep numbersep388 tmp += tasklist[i]->left_child->buf_sz +numbersepnumbersep numbersep389 tasklist[i]->right_child->buf_sz - 2;numbersepnumbersep numbersep390 }numbersepnumbersep numbersep391numbersepnumbersep numbersep392 /* tmp is in 32B mpb lines, convert */
71

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep393 tmp <<= 5;numbersepnumbersep numbersep394 tmp <<= MEM_RATIO;numbersepnumbersep numbersep395 g_mem_p[i].max = tmp / sizeof(int);numbersepnumbersep numbersep396numbersepnumbersep numbersep397 /* allocate memory for non-root tasks */numbersepnumbersep numbersep398 if(tasklist[i]->tree_lvl != 1)numbersepnumbersep numbersep399 {numbersepnumbersep numbersep400 g_mem_p[i].data = malloc(tmp);numbersepnumbersep numbersep401 if(!g_mem_p[i].data)numbersepnumbersep numbersep402 {numbersepnumbersep numbersep403 printf("Error allocating cache memory.\n");numbersepnumbersep numbersep404 return E_MEM;numbersepnumbersep numbersep405 }numbersepnumbersep numbersep406 /* touch work memory to read it into L2 */numbersepnumbersep numbersep407 for(j=0; j<(tmp/sizeof(int)); j++)numbersepnumbersep numbersep408 g_mem_p[i].data[j] = 41;numbersepnumbersep numbersep409 for(j=0; j<(tmp/sizeof(int)); j++)numbersepnumbersep numbersep410 g_mem_p[i].data[j]++;numbersepnumbersep numbersep411 }numbersepnumbersep numbersep412 elsenumbersepnumbersep numbersep413 {numbersepnumbersep numbersep414 g_mem_p[i].data = NULL;numbersepnumbersep numbersep415 }numbersepnumbersep numbersep416 }numbersepnumbersep numbersep417numbersepnumbersep numbersep418 /* Before the merging, integers must be loaded and sorted intonumbersepnumbersep numbersep419 * subsequences. All the leaves load from file and perform the dividenumbersepnumbersep numbersep420 * & sort part of mergesort before the global merge phase */numbersepnumbersep numbersep421 tmp = 0;numbersepnumbersep numbersep422 t_wait = t_comp = t_trns = 0;numbersepnumbersep numbersep423 for(i=0; i<local_tasks; i++)numbersepnumbersep numbersep424 {numbersepnumbersep numbersep425 if(tasklist[i]->tree_lvl == (height-1))numbersepnumbersep numbersep426 {numbersepnumbersep numbersep427 sequential_merge(tasklist[i], argv[2], tmp);numbersepnumbersep numbersep428 tmp += tasklist[i]->size;numbersepnumbersep numbersep429 }numbersepnumbersep numbersep430 }numbersepnumbersep numbersep431 t_total = RCCE_wtime() - t_start;numbersepnumbersep numbersep432 printf("%.2d %10.3f %10.3f %10.3f %10.3f ", rcce_id, t_comp*1000,numbersepnumbersep numbersep433 t_wait*1000, t_trns*1000, t_total*1000);numbersepnumbersep numbersep434numbersepnumbersep numbersep435 /* File has been loaded, presorting complete.numbersepnumbersep numbersep436 * Ready for global merge phase */numbersepnumbersep numbersep437 /* Barrier between phases not counted! */numbersepnumbersep numbersep438 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep439 t_wait = t_comp = t_trns = 0;numbersepnumbersep numbersep440 t_start = RCCE_wtime();numbersepnumbersep numbersep441numbersepnumbersep numbersep442 running_tasks = 1;numbersepnumbersep numbersep443 while(running_tasks)numbersepnumbersep numbersep444 {numbersepnumbersep numbersep445 running_tasks = 0;numbersepnumbersep numbersep446 for(i=0; i<local_tasks; i++)numbersepnumbersep numbersep447 {numbersepnumbersep numbersep448 if(tasklist[i]->progress < tasklist[i]->size)numbersepnumbersep numbersep449 {numbersepnumbersep numbersep450 tasklist[i]->function(tasklist[i]);numbersepnumbersep numbersep451 running_tasks = 1;numbersepnumbersep numbersep452 }numbersepnumbersep numbersep453 }numbersepnumbersep numbersep454 }numbersepnumbersep numbersep455 t_total = RCCE_wtime() - t_start;numbersepnumbersep numbersep456 printf("%10.3f %10.3f %10.3f %10.3f", t_comp*1000, t_wait*1000,numbersepnumbersep numbersep457 t_trns*1000, t_total*1000);numbersepnumbersep numbersep458numbersepnumbersep numbersep459 /* Barrier between phases not counted! */numbersepnumbersep numbersep460 RCCE_barrier(&RCCE_COMM_WORLD);
72

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep461 t_start = RCCE_wtime();numbersepnumbersep numbersep462 t_wait = t_comp = t_trns = 0;numbersepnumbersep numbersep463numbersepnumbersep numbersep464 /* ===================== Phase 2 sort ===========================numbersepnumbersep numbersep465 * 1. Roots send 47 boundaries each to root masternumbersepnumbersep numbersep466 * 2. Root master calculates actual boundary pivots, broadcastsnumbersepnumbersep numbersep467 * 3. Roots synchronise on numbers of elements in each subsequencenumbersepnumbersep numbersep468 * 4. Roots write to shared memory grouped by subsequence */numbersepnumbersep numbersep469numbersepnumbersep numbersep470 buf_sz = sizeof(int) * rcce_np;numbersepnumbersep numbersep471 make_div_by_32(&buf_sz);numbersepnumbersep numbersep472 /* allocate buffer for mpb values */numbersepnumbersep numbersep473 buf_p = malloc(buf_sz);numbersepnumbersep numbersep474numbersepnumbersep numbersep475 if(have_root)numbersepnumbersep numbersep476 {numbersepnumbersep numbersep477 /* ideally one should be able to find roots by rank using anumbersepnumbersep numbersep478 * communicator e.g.:numbersepnumbersep numbersep479 *numbersepnumbersep numbersep480 * RCCE_comm_rank(RCCE_COMM_ROOT, &rank);numbersepnumbersep numbersep481 *numbersepnumbersep numbersep482 * unfortunately, splitting comms breaks the programme, sonumbersepnumbersep numbersep483 * we find and rank roots manually */numbersepnumbersep numbersep484 for(i=0, j=0; i<8; i+=2, j++)numbersepnumbersep numbersep485 {numbersepnumbersep numbersep486 /* top half root order reversed to bottom half root order */numbersepnumbersep numbersep487 if(i<4)numbersepnumbersep numbersep488 {numbersepnumbersep numbersep489 roots[i] = mapping[3]%12 + j*12;numbersepnumbersep numbersep490 roots[i+1] = mapping[2]%12 + j*12;numbersepnumbersep numbersep491 }numbersepnumbersep numbersep492 elsenumbersepnumbersep numbersep493 {numbersepnumbersep numbersep494 roots[i] = mapping[2]%12 + j*12;numbersepnumbersep numbersep495 roots[i+1] = mapping[3]%12 + j*12;numbersepnumbersep numbersep496 }numbersepnumbersep numbersep497 }numbersepnumbersep numbersep498 /* find the rank of this root (index in roots array) */numbersepnumbersep numbersep499 for(i=0; i<8; i++)numbersepnumbersep numbersep500 {numbersepnumbersep numbersep501 if(roots[i] == rcce_id)numbersepnumbersep numbersep502 rank = i;numbersepnumbersep numbersep503 if(roots[i] == root_mstr)numbersepnumbersep numbersep504 root_mstr_rank = i;numbersepnumbersep numbersep505 }numbersepnumbersep numbersep506numbersepnumbersep numbersep507 /* Find pivots */numbersepnumbersep numbersep508 /* copy pivots to buffer */numbersepnumbersep numbersep509 for(i=0; i<rcce_np-1; i++)numbersepnumbersep numbersep510 buf_p[i] = g_output_p[(i+1)*(N/rcce_np)];numbersepnumbersep numbersep511numbersepnumbersep numbersep512 /* Comm patternnumbersepnumbersep numbersep513 * (done using root masters MPB buffer, global barriers)numbersepnumbersep numbersep514 * !!! INEFFICIENT !!!numbersepnumbersep numbersep515 *numbersepnumbersep numbersep516 * Root master Other rootsnumbersepnumbersep numbersep517 *numbersepnumbersep numbersep518 * <------- pivotsnumbersepnumbersep numbersep519 * ------------------- Barrier -------------------------numbersepnumbersep numbersep520 * compute & write mediansnumbersepnumbersep numbersep521 * ------------------- Barrier -------------------------numbersepnumbersep numbersep522 * median pivots ------->numbersepnumbersep numbersep523 * ------------------- Barrier -------------------------numbersepnumbersep numbersep524 * <--- subsequence lengths --->numbersepnumbersep numbersep525 * ------------------- Barrier -------------------------numbersepnumbersep numbersep526 * ---> subsequence lengths <---numbersepnumbersep numbersep527 *numbersepnumbersep numbersep528 * TODO: if/when comm splitting is fixed, change the barriers to
73

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep529 * roots-only barriers.numbersepnumbersep numbersep530 * TODO (ideally): develop/obtain collective comm functions and usenumbersepnumbersep numbersep531 * instead */numbersepnumbersep numbersep532 if(rcce_id != root_mstr)numbersepnumbersep numbersep533 {numbersepnumbersep numbersep534 /* =================== NON-MASTER ROOTS =================== */numbersepnumbersep numbersep535 /* write pivots to root master mpb, offset by rank */numbersepnumbersep numbersep536 t_trns_st = RCCE_wtime();numbersepnumbersep numbersep537 RCCE_put(g_mpb_buf_p+(buf_sz*rank),numbersepnumbersep numbersep538 (t_vcharp)buf_p,numbersepnumbersep numbersep539 buf_sz,numbersepnumbersep numbersep540 root_mstr);numbersepnumbersep numbersep541 t_trns += RCCE_wtime() - t_trns_st;numbersepnumbersep numbersep542 /* barrier - allow for all data to be put in root master mpbnumbersepnumbersep numbersep543 * before proceeding */numbersepnumbersep numbersep544 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep545 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep546 /* 2nd barrier - wait for root master to finish computations andnumbersepnumbersep numbersep547 * write median pivots */numbersepnumbersep numbersep548 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep549 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep550 /* read median pivots from root master */numbersepnumbersep numbersep551 t_trns_st = RCCE_wtime();numbersepnumbersep numbersep552 RCCE_get((t_vcharp)buf_p,numbersepnumbersep numbersep553 g_mpb_buf_p+(buf_sz*root_mstr_rank),numbersepnumbersep numbersep554 buf_sz,numbersepnumbersep numbersep555 root_mstr);numbersepnumbersep numbersep556 memcpy(medians, buf_p, rcce_np*sizeof(int));numbersepnumbersep numbersep557 t_trns += RCCE_wtime() - t_trns_st;numbersepnumbersep numbersep558 }numbersepnumbersep numbersep559 elsenumbersepnumbersep numbersep560 {numbersepnumbersep numbersep561 /* ===================== ROOT MASTER ====================== */numbersepnumbersep numbersep562 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep563 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep564 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep565 /* have pivots in local mpb after barrier, read them */numbersepnumbersep numbersep566 for(i=0; i<8; i++)numbersepnumbersep numbersep567 {numbersepnumbersep numbersep568 /* no need to access mpb in case of local buffer */numbersepnumbersep numbersep569 if(i == rank)numbersepnumbersep numbersep570 {numbersepnumbersep numbersep571 for(j=0; j<rcce_np-1; j++)numbersepnumbersep numbersep572 pivots[j][i] = *(buf_p+j);numbersepnumbersep numbersep573 }numbersepnumbersep numbersep574 elsenumbersepnumbersep numbersep575 {numbersepnumbersep numbersep576 l1_mpb_invalidate();numbersepnumbersep numbersep577 /* cast to int ptr, copy to pivots array */numbersepnumbersep numbersep578 for(j=0; j<rcce_np-1; j++)numbersepnumbersep numbersep579 pivots[j][i] = ((int*)(g_mpb_buf_p+(buf_sz*i)))[j];numbersepnumbersep numbersep580 }numbersepnumbersep numbersep581 }numbersepnumbersep numbersep582numbersepnumbersep numbersep583 for(i=0; i<rcce_np-1; i++)numbersepnumbersep numbersep584 {numbersepnumbersep numbersep585 /* sort pivots */numbersepnumbersep numbersep586 isort(pivots[i], 8);numbersepnumbersep numbersep587 /* find medians */numbersepnumbersep numbersep588 /* !!! can overflow for negative pivot !!! */numbersepnumbersep numbersep589 medians[i] = pivots[i][3] + (pivots[i][4] - pivots[i][3])/2;numbersepnumbersep numbersep590 }numbersepnumbersep numbersep591 /* write medians to local mpb */numbersepnumbersep numbersep592 t_trns_st = RCCE_wtime();numbersepnumbersep numbersep593 RCCE_put(g_mpb_buf_p+(buf_sz*rank),numbersepnumbersep numbersep594 (t_vcharp)medians,numbersepnumbersep numbersep595 buf_sz,numbersepnumbersep numbersep596 rcce_id);
74

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep597 /* medians written, barrier */numbersepnumbersep numbersep598 t_trns += RCCE_wtime() - t_trns_st;numbersepnumbersep numbersep599 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep600 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep601 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep602 }numbersepnumbersep numbersep603 /* have medians, find lengths of subsequences */numbersepnumbersep numbersep604 for(i=0; i<rcce_np; i++)numbersepnumbersep numbersep605 lens[rank][i] = 0;numbersepnumbersep numbersep606 /* save indices of first value greater than pivot in lens */numbersepnumbersep numbersep607 k = tmp = N/rcce_np;numbersepnumbersep numbersep608 for(i=0; i<rcce_np-1; i++)numbersepnumbersep numbersep609 {numbersepnumbersep numbersep610 if(g_output_p[k]>medians[i])numbersepnumbersep numbersep611 {numbersepnumbersep numbersep612 while(g_output_p[k]>medians[i])numbersepnumbersep numbersep613 k--;numbersepnumbersep numbersep614 lens[rank][i] = k+1;numbersepnumbersep numbersep615 }numbersepnumbersep numbersep616 else if(g_output_p[k]<medians[i])numbersepnumbersep numbersep617 {numbersepnumbersep numbersep618 while(g_output_p[k]<medians[i])numbersepnumbersep numbersep619 k++;numbersepnumbersep numbersep620 lens[rank][i] = k;numbersepnumbersep numbersep621 }numbersepnumbersep numbersep622 elsenumbersepnumbersep numbersep623 lens[rank][i] = k;numbersepnumbersep numbersep624 k += tmp;numbersepnumbersep numbersep625 }numbersepnumbersep numbersep626 lens[rank][rcce_np-1] = N;numbersepnumbersep numbersep627 /* we have indices, not lengths, subtract previous in reverse ordernumbersepnumbersep numbersep628 * (reverse prefix sum) */numbersepnumbersep numbersep629 for(i=rcce_np-1; i>0; i--)numbersepnumbersep numbersep630 lens[rank][i] -= lens[rank][i-1];numbersepnumbersep numbersep631 /* have lengths, all-to-all write */numbersepnumbersep numbersep632 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep633 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep634 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep635 t_trns_st = RCCE_wtime();numbersepnumbersep numbersep636 for(i=0; i<8; i++)numbersepnumbersep numbersep637 {numbersepnumbersep numbersep638 RCCE_put(g_mpb_buf_p+(buf_sz*rank),numbersepnumbersep numbersep639 (t_vcharp)lens[rank],numbersepnumbersep numbersep640 buf_sz,numbersepnumbersep numbersep641 roots[i]);numbersepnumbersep numbersep642 }numbersepnumbersep numbersep643 t_trns += RCCE_wtime() - t_trns_st;numbersepnumbersep numbersep644 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep645 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep646 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep647 /* Read the lengths */numbersepnumbersep numbersep648 t_trns_st = RCCE_wtime();numbersepnumbersep numbersep649 for(i=0; i<8; i++)numbersepnumbersep numbersep650 {numbersepnumbersep numbersep651 if(i==rank) continue;numbersepnumbersep numbersep652 RCCE_get((t_vcharp)buf_p, g_mpb_buf_p+(buf_sz*i), buf_sz, rcce_id);numbersepnumbersep numbersep653 memcpy(lens[i], buf_p, rcce_np*sizeof(int));numbersepnumbersep numbersep654 }numbersepnumbersep numbersep655 /* pivot, median & lengths comp/sync complete */numbersepnumbersep numbersep656numbersepnumbersep numbersep657 /* Copy to shared memory. For each offset, all the lower ranksnumbersepnumbersep numbersep658 * and previous sequences must be summed */numbersepnumbersep numbersep659 shmem_os_p = (int*)shmem_p;numbersepnumbersep numbersep660 for(i=0, j=0;numbersepnumbersep numbersep661 i<rcce_np;numbersepnumbersep numbersep662 j+= lens[rank][i], i++)numbersepnumbersep numbersep663 {numbersepnumbersep numbersep664 /* add rank offset */
75

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep665 for(k=0; k<rank; k++)numbersepnumbersep numbersep666 shmem_os_p += lens[k][i];numbersepnumbersep numbersep667 /* write */numbersepnumbersep numbersep668 memcpy(shmem_os_p, g_output_p+j, lens[rank][i]*sizeof(int));numbersepnumbersep numbersep669 /* add sequence offset */numbersepnumbersep numbersep670 for(k=rank; k<8; k++)numbersepnumbersep numbersep671 shmem_os_p += lens[k][i];numbersepnumbersep numbersep672 }numbersepnumbersep numbersep673 t_trns += RCCE_wtime() - t_trns_st;numbersepnumbersep numbersep674 }numbersepnumbersep numbersep675 elsenumbersepnumbersep numbersep676 {numbersepnumbersep numbersep677 /* ======================== NON-ROOTS ========================== */numbersepnumbersep numbersep678 /* nonroots must converge on all barriers despite being idle */numbersepnumbersep numbersep679 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep680 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep681 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep682 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep683 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep684 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep685 /* find a quad-local root and get lengths from it */numbersepnumbersep numbersep686 tsk = tasklist[0];numbersepnumbersep numbersep687 while(tsk->id != 2 && tsk->id != 3)numbersepnumbersep numbersep688 tsk = tsk->parent;numbersepnumbersep numbersep689 t_trns_st = RCCE_wtime();numbersepnumbersep numbersep690 for(i=0; i<8; i++)numbersepnumbersep numbersep691 {numbersepnumbersep numbersep692 RCCE_get((t_vcharp)buf_p,numbersepnumbersep numbersep693 g_mpb_buf_p+(buf_sz*i),numbersepnumbersep numbersep694 buf_sz,numbersepnumbersep numbersep695 tsk->cpu_id);numbersepnumbersep numbersep696 memcpy(lens[i], buf_p, rcce_np*sizeof(int));numbersepnumbersep numbersep697 }numbersepnumbersep numbersep698 t_trns += RCCE_wtime() - t_trns_st;numbersepnumbersep numbersep699 }numbersepnumbersep numbersep700 free(buf_p);numbersepnumbersep numbersep701numbersepnumbersep numbersep702 /* wait for shm to be written */numbersepnumbersep numbersep703 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep704 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep705 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep706numbersepnumbersep numbersep707 /* find sum */numbersepnumbersep numbersep708 N = 0;numbersepnumbersep numbersep709 for(i=0; i<8; i++)numbersepnumbersep numbersep710 {numbersepnumbersep numbersep711 N += lens[i][rcce_id];numbersepnumbersep numbersep712 }numbersepnumbersep numbersep713 /* save the middle for final merge & allocate aux buffer needed fornumbersepnumbersep numbersep714 * inplace merge */numbersepnumbersep numbersep715 buf_sz = lens[0][rcce_id] + lens[1][rcce_id] + lens[2][rcce_id] +numbersepnumbersep numbersep716 lens[3][rcce_id];numbersepnumbersep numbersep717 buf_p = malloc(buf_sz * sizeof(int));numbersepnumbersep numbersep718numbersepnumbersep numbersep719 /* offset initial pointer */numbersepnumbersep numbersep720 shmem_os_p = (int*)shmem_p;numbersepnumbersep numbersep721 for(i=0; i<rcce_id; i++)numbersepnumbersep numbersep722 for(j=0; j<8; j++)numbersepnumbersep numbersep723 shmem_os_p += lens[j][i];numbersepnumbersep numbersep724numbersepnumbersep numbersep725 /* mergenumbersepnumbersep numbersep726 * ugly & not very generic, can be improved with prefix sum function andnumbersepnumbersep numbersep727 * power of 2 loop (with steps 2,4,8..) */numbersepnumbersep numbersep728 /* 4 merges */numbersepnumbersep numbersep729 t_comp_st = RCCE_wtime();numbersepnumbersep numbersep730 for(i=0, j=0;numbersepnumbersep numbersep731 i<8;numbersepnumbersep numbersep732 j += lens[i][rcce_id]+lens[i+1][rcce_id], i+=2)
76

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep733 {numbersepnumbersep numbersep734 merge_in_place(shmem_os_p,numbersepnumbersep numbersep735 buf_p,numbersepnumbersep numbersep736 j,numbersepnumbersep numbersep737 j + lens[i][rcce_id] - 1,numbersepnumbersep numbersep738 j + lens[i][rcce_id] + lens[i+1][rcce_id] - 1);numbersepnumbersep numbersep739 }numbersepnumbersep numbersep740 /* 2 merges */numbersepnumbersep numbersep741 for(i=0, j=0; i<8; i+=4)numbersepnumbersep numbersep742 {numbersepnumbersep numbersep743 merge_in_place(shmem_os_p,numbersepnumbersep numbersep744 buf_p,numbersepnumbersep numbersep745 j,numbersepnumbersep numbersep746 j + lens[i][rcce_id] + lens[i+1][rcce_id] - 1,numbersepnumbersep numbersep747 j + lens[i][rcce_id] + lens[i+1][rcce_id] +numbersepnumbersep numbersep748 lens[i+2][rcce_id] + lens[i+3][rcce_id] - 1);numbersepnumbersep numbersep749 j += lens[i][rcce_id] + lens[i+1][rcce_id] +numbersepnumbersep numbersep750 lens[i+2][rcce_id] + lens[i+3][rcce_id];numbersepnumbersep numbersep751 }numbersepnumbersep numbersep752 /* final */numbersepnumbersep numbersep753 merge_in_place(shmem_os_p, buf_p, 0, buf_sz-1, N-1);numbersepnumbersep numbersep754 #ifdef SHMADD_CACHEABLEnumbersepnumbersep numbersep755 RCCE_DCMflush();numbersepnumbersep numbersep756 #endifnumbersepnumbersep numbersep757 t_comp += RCCE_wtime() - t_comp_st;numbersepnumbersep numbersep758 RCCE_shflush();numbersepnumbersep numbersep759 RCCE_barrier(&RCCE_COMM_WORLD);numbersepnumbersep numbersep760 t_total += RCCE_wtime() - t_start;numbersepnumbersep numbersep761numbersepnumbersep numbersep762 printf("%10.3f %10.3f %10.3f %10.3f\n", t_comp*1000, t_wait*1000,numbersepnumbersep numbersep763 t_trns*1000, t_total*1000);numbersepnumbersep numbersep764numbersepnumbersep numbersep765 if(rcce_id == 0)numbersepnumbersep numbersep766 {numbersepnumbersep numbersep767 k = 0;numbersepnumbersep numbersep768 for(j=0; j<8; j++)numbersepnumbersep numbersep769 for(i=0; i<rcce_np; i++)numbersepnumbersep numbersep770 k += lens[j][i];numbersepnumbersep numbersep771 shmem_os_p = (int*)shmem_p;numbersepnumbersep numbersep772 tmp = check_sorted(shmem_os_p, k);numbersepnumbersep numbersep773 if(tmp>0)numbersepnumbersep numbersep774 {numbersepnumbersep numbersep775 printf("Error in sort @ %d. Array around error:\n", tmp);numbersepnumbersep numbersep776 for(i=tmp-10; i<tmp+10; i++)numbersepnumbersep numbersep777 printf(" %u", shmem_os_p[i]);numbersepnumbersep numbersep778 printf("\n");numbersepnumbersep numbersep779 //exit(E_SORT);numbersepnumbersep numbersep780 }numbersepnumbersep numbersep781 if(tmp == -1)numbersepnumbersep numbersep782 {numbersepnumbersep numbersep783 printf("Warning, first/last equal: %d %d\n",numbersepnumbersep numbersep784 shmem_os_p[0], shmem_os_p[N-1]);numbersepnumbersep numbersep785 //exit(E_SORT);numbersepnumbersep numbersep786 }numbersepnumbersep numbersep787 }numbersepnumbersep numbersep788numbersepnumbersep numbersep789 /* Free memory */numbersepnumbersep numbersep790 free(buf_p);numbersepnumbersep numbersep791 RCCE_free(g_mpb_buf_p);numbersepnumbersep numbersep792 RCCE_shfree(shmem_p);numbersepnumbersep numbersep793 RCCE_finalize();numbersepnumbersep numbersep794 for(i=0; i<local_tasks; i++)numbersepnumbersep numbersep795 if(g_mem_p[i].data) free(g_mem_p[i].data);numbersepnumbersep numbersep796 free(g_mem_p);numbersepnumbersep numbersep797 free(tasklist);numbersepnumbersep numbersep798 delete_subtree(task_tree);numbersepnumbersep numbersep799 if(g_input_p) free(g_input_p);numbersepnumbersep numbersep800 if(g_output_p) free(g_output_p);
77

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep801 return E_OK;numbersepnumbersep numbersep802 }numbersepnumbersep numbersep803numbersepnumbersep numbersep804 void generate_subtree(task_t *parent, unsigned *mapping, unsigned level,numbersepnumbersep numbersep805 unsigned height)numbersepnumbersep numbersep806 {numbersepnumbersep numbersep807 if(level < height)numbersepnumbersep numbersep808 {numbersepnumbersep numbersep809 task_t *left_child = malloc(sizeof(task_t));numbersepnumbersep numbersep810 task_t *right_child = malloc(sizeof(task_t));numbersepnumbersep numbersep811 static int leaf_offset = 0;numbersepnumbersep numbersep812numbersepnumbersep numbersep813 left_child->id = parent->id<<1;numbersepnumbersep numbersep814 left_child->parent = parent;numbersepnumbersep numbersep815 left_child->cpu_id = mapping[left_child->id];numbersepnumbersep numbersep816 left_child->tree_lvl = level;numbersepnumbersep numbersep817 /* buffer size and start are calculated separately */numbersepnumbersep numbersep818 left_child->buf_start = 0;numbersepnumbersep numbersep819 left_child->buf_sz = 0;numbersepnumbersep numbersep820 left_child->size = parent->size>>1;numbersepnumbersep numbersep821 left_child->progress = 0;numbersepnumbersep numbersep822numbersepnumbersep numbersep823 right_child->id = left_child->id+1;numbersepnumbersep numbersep824 right_child->parent = parent;numbersepnumbersep numbersep825 right_child->cpu_id = mapping[right_child->id];numbersepnumbersep numbersep826 right_child->tree_lvl = level;numbersepnumbersep numbersep827 right_child->buf_start = 0;numbersepnumbersep numbersep828 right_child->buf_sz = 0;numbersepnumbersep numbersep829 right_child->size = left_child->size;numbersepnumbersep numbersep830 right_child->progress = 0;numbersepnumbersep numbersep831numbersepnumbersep numbersep832 parent->left_child = left_child;numbersepnumbersep numbersep833 parent->right_child = right_child;numbersepnumbersep numbersep834numbersepnumbersep numbersep835 /* set leaf specific data using static variablenumbersepnumbersep numbersep836 * ->> recursive inorder(symmetric) traversal */numbersepnumbersep numbersep837 if((level+1) == height)numbersepnumbersep numbersep838 {numbersepnumbersep numbersep839 left_child->leaf = malloc(sizeof(leaf_props_t));numbersepnumbersep numbersep840 left_child->leaf->start = leaf_offset;numbersepnumbersep numbersep841 left_child->leaf->remain_left = left_child->size/2;numbersepnumbersep numbersep842 left_child->leaf->remain_right = left_child->size/2;numbersepnumbersep numbersep843 leaf_offset += left_child->size*sizeof(int);numbersepnumbersep numbersep844 right_child->leaf = malloc(sizeof(leaf_props_t));numbersepnumbersep numbersep845 right_child->leaf->start = leaf_offset;numbersepnumbersep numbersep846 right_child->leaf->remain_left = right_child->size/2;numbersepnumbersep numbersep847 right_child->leaf->remain_right = right_child->size/2;numbersepnumbersep numbersep848 leaf_offset += left_child->size*sizeof(int);numbersepnumbersep numbersep849 }numbersepnumbersep numbersep850 elsenumbersepnumbersep numbersep851 {numbersepnumbersep numbersep852 left_child->leaf = right_child->leaf = NULL;numbersepnumbersep numbersep853 }numbersepnumbersep numbersep854numbersepnumbersep numbersep855 generate_subtree(left_child, mapping, level+1, height);numbersepnumbersep numbersep856 generate_subtree(right_child, mapping, level+1, height);numbersepnumbersep numbersep857 }numbersepnumbersep numbersep858 }numbersepnumbersep numbersep859numbersepnumbersep numbersep860 void setup_buffers(task_t* root, unsigned num_tasks)numbersepnumbersep numbersep861 {numbersepnumbersep numbersep862 int offset[48];numbersepnumbersep numbersep863 double sum[48];numbersepnumbersep numbersep864 int i, j;numbersepnumbersep numbersep865 task_t *tsk;numbersepnumbersep numbersep866numbersepnumbersep numbersep867 /* reset count arrays */numbersepnumbersep numbersep868 for(i=0; i<48; i++)
78

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep869 {numbersepnumbersep numbersep870 offset[i] = 0;numbersepnumbersep numbersep871 sum[i] = 0;numbersepnumbersep numbersep872 }numbersepnumbersep numbersep873numbersepnumbersep numbersep874 /* task weights are calculated as 1/(2^(level))numbersepnumbersep numbersep875 * i.e. each tasks weight is half of the task above in the treenumbersepnumbersep numbersep876 *numbersepnumbersep numbersep877 * total weights are summed per node and the size of buffers is thennumbersepnumbersep numbersep878 * computed based on the weights */numbersepnumbersep numbersep879numbersepnumbersep numbersep880 /* NOTE: buffers are allocated on the parent of the task, since data isnumbersepnumbersep numbersep881 * pushed upwards after merge, e.g. leaf tasks push results to buffer innumbersepnumbersep numbersep882 * parent */numbersepnumbersep numbersep883numbersepnumbersep numbersep884 /* task 1 is empty 7-l root, 2 & 3 are 6-level roots and don’t use a buffernumbersepnumbersep numbersep885 * -> start at task 4 */numbersepnumbersep numbersep886 for(i=4; i<num_tasks; i++)numbersepnumbersep numbersep887 {numbersepnumbersep numbersep888 tsk = find(root, i);numbersepnumbersep numbersep889 sum[tsk->parent->cpu_id] += 1.0/(1<<tsk->tree_lvl);numbersepnumbersep numbersep890 }numbersepnumbersep numbersep891 /* with sum computed, we can assign the buffer sizes proportionally, i.e.numbersepnumbersep numbersep892 * the proportion is weight / weight sum */numbersepnumbersep numbersep893 for(i=4; i<num_tasks; i++)numbersepnumbersep numbersep894 {numbersepnumbersep numbersep895 tsk = find(root, i);numbersepnumbersep numbersep896numbersepnumbersep numbersep897 tsk->buf_start = g_mpb_buf_p + offset[tsk->parent->cpu_id];numbersepnumbersep numbersep898 tsk->buf_sz = 1.0/(1<<tsk->tree_lvl) /numbersepnumbersep numbersep899 sum[tsk->parent->cpu_id] * (mpb_buff_size>>5);numbersepnumbersep numbersep900 if(tsk->buf_sz < 2)numbersepnumbersep numbersep901 {numbersepnumbersep numbersep902 printf("Error setting up buffers, use larger buffer size\n");numbersepnumbersep numbersep903 exit(E_MPB_MEM);numbersepnumbersep numbersep904 }numbersepnumbersep numbersep905 offset[tsk->parent->cpu_id] += tsk->buf_sz << 5;numbersepnumbersep numbersep906 }numbersepnumbersep numbersep907 }numbersepnumbersep numbersep908numbersepnumbersep numbersep909 void delete_subtree(task_t *node)numbersepnumbersep numbersep910 {numbersepnumbersep numbersep911 if(node != NULL)numbersepnumbersep numbersep912 {numbersepnumbersep numbersep913 delete_subtree(node->left_child);numbersepnumbersep numbersep914 delete_subtree(node->right_child);numbersepnumbersep numbersep915 free(node->leaf);numbersepnumbersep numbersep916 free(node);numbersepnumbersep numbersep917 }numbersepnumbersep numbersep918 }numbersepnumbersep numbersep919numbersepnumbersep numbersep920 task_t* find(const task_t* task, int task_id)numbersepnumbersep numbersep921 {numbersepnumbersep numbersep922 if(task)numbersepnumbersep numbersep923 {numbersepnumbersep numbersep924 task_t *retval;numbersepnumbersep numbersep925 if(task->id == task_id)numbersepnumbersep numbersep926 return (task_t*)task;numbersepnumbersep numbersep927 if(retval = find(task->left_child, task_id))numbersepnumbersep numbersep928 return retval;numbersepnumbersep numbersep929 if(retval = find(task->right_child, task_id))numbersepnumbersep numbersep930 return retval;numbersepnumbersep numbersep931 }numbersepnumbersep numbersep932 return NULL;numbersepnumbersep numbersep933 }numbersepnumbersep numbersep934numbersepnumbersep numbersep935 void run_root(task_t *task)numbersepnumbersep numbersep936 {
79

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep937 unsigned wrote_ct;numbersepnumbersep numbersep938numbersepnumbersep numbersep939 /* There is no buffer for root task, merge directly to memory */numbersepnumbersep numbersep940 wrote_ct = check_and_merge(g_output_p + task->progress,numbersepnumbersep numbersep941 g_mem_p[task->local_id].max,numbersepnumbersep numbersep942 task->left_child->buf_start,numbersepnumbersep numbersep943 task->right_child->buf_start,numbersepnumbersep numbersep944 task->left_child->size);numbersepnumbersep numbersep945numbersepnumbersep numbersep946 task->progress += wrote_ct;numbersepnumbersep numbersep947 }numbersepnumbersep numbersep948numbersepnumbersep numbersep949 void run_leaf(task_t *task)numbersepnumbersep numbersep950 {numbersepnumbersep numbersep951 unsigned dst_ct, left_ct, right_ct, init_left_ct, init_right_ct;numbersepnumbersep numbersep952 unsigned consm_ct = 0;numbersepnumbersep numbersep953 int *dst_p, *left_p, *right_p;numbersepnumbersep numbersep954numbersepnumbersep numbersep955 /* compute the number of integers that can fit in destination buffer */numbersepnumbersep numbersep956 unsigned buf_ct = ((task->buf_sz-1) << 5) / sizeof(int);numbersepnumbersep numbersep957numbersepnumbersep numbersep958 /* if there is space in work buffer and the task is not finished, merge */numbersepnumbersep numbersep959 if(g_mem_p[task->local_id].ct < buf_ct &&numbersepnumbersep numbersep960 (task->leaf->remain_left > 0 || task->leaf->remain_right > 0))numbersepnumbersep numbersep961 {numbersepnumbersep numbersep962 /* dst_ct is the remaining number of integers before the memory buffernumbersepnumbersep numbersep963 * is full */numbersepnumbersep numbersep964 dst_ct = buf_ct - g_mem_p[task->local_id].ct;numbersepnumbersep numbersep965 dst_p = g_mem_p[task->local_id].data + g_mem_p[task->local_id].ct;numbersepnumbersep numbersep966 /* set pointers to start of sequences */numbersepnumbersep numbersep967 left_p = g_input_p + task->leaf->start + task->size/2 -numbersepnumbersep numbersep968 task->leaf->remain_left;numbersepnumbersep numbersep969 right_p = g_input_p + task->leaf->start + task->size -numbersepnumbersep numbersep970 task->leaf->remain_right;numbersepnumbersep numbersep971 /* leaf has 2 subsequences and 2 progresses */numbersepnumbersep numbersep972 left_ct = task->leaf->remain_left;numbersepnumbersep numbersep973 right_ct = task->leaf->remain_right;numbersepnumbersep numbersep974numbersepnumbersep numbersep975 /* but we can only merge a maximum of dst_ct elements each run */numbersepnumbersep numbersep976 if(left_ct > dst_ct)numbersepnumbersep numbersep977 left_ct = dst_ct;numbersepnumbersep numbersep978 if(right_ct > dst_ct)numbersepnumbersep numbersep979 right_ct = dst_ct;numbersepnumbersep numbersep980numbersepnumbersep numbersep981 consm_ct = 0;numbersepnumbersep numbersep982 if(left_ct > 0 && right_ct > 0)numbersepnumbersep numbersep983 {numbersepnumbersep numbersep984 /* both sequences have integers for merge, merge normally */numbersepnumbersep numbersep985 /* since we don’t know how many integers merge will consume fromnumbersepnumbersep numbersep986 * either sequence, we save the left and right count vars */numbersepnumbersep numbersep987 init_left_ct = left_ct;numbersepnumbersep numbersep988 init_right_ct = right_ct;numbersepnumbersep numbersep989 t_comp_st = RCCE_wtime();numbersepnumbersep numbersep990 consm_ct = merge(dst_p,numbersepnumbersep numbersep991 left_p,numbersepnumbersep numbersep992 right_p,numbersepnumbersep numbersep993 &left_ct,numbersepnumbersep numbersep994 &right_ct);numbersepnumbersep numbersep995 t_comp += RCCE_wtime() - t_comp_st;numbersepnumbersep numbersep996 task->leaf->remain_left -= init_left_ct - left_ct;numbersepnumbersep numbersep997 task->leaf->remain_right -= init_right_ct - right_ct;numbersepnumbersep numbersep998 /* update remaining buffer count and mem pointer */numbersepnumbersep numbersep999 dst_ct -= consm_ct;numbersepnumbersep numbersep1000 dst_p += consm_ct;numbersepnumbersep numbersep1001 /* increment left/right sequence pointers */numbersepnumbersep numbersep1002 left_p += init_left_ct - left_ct;numbersepnumbersep numbersep1003 right_p += init_right_ct - right_ct;numbersepnumbersep numbersep1004 }
80

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep1005 /* if left or right sequences are spent but there is still space innumbersepnumbersep numbersep1006 * work buffer, copy data */numbersepnumbersep numbersep1007 if(dst_ct > 0)numbersepnumbersep numbersep1008 {numbersepnumbersep numbersep1009 if(left_ct == 0 && right_ct == 0)numbersepnumbersep numbersep1010 {numbersepnumbersep numbersep1011 /* both sequences spent, do nothing */numbersepnumbersep numbersep1012 printf("Both sequences spent but entered leaf merge anyway\n");numbersepnumbersep numbersep1013 dst_ct = 0;numbersepnumbersep numbersep1014 }numbersepnumbersep numbersep1015 else if(left_ct == 0 && task->leaf->remain_left == 0)numbersepnumbersep numbersep1016 {numbersepnumbersep numbersep1017 /* copy from right sequence, but make sure not to copy morenumbersepnumbersep numbersep1018 * integers than we have */numbersepnumbersep numbersep1019 if(dst_ct > right_ct)numbersepnumbersep numbersep1020 dst_ct = right_ct;numbersepnumbersep numbersep1021 t_comp_st = RCCE_wtime();numbersepnumbersep numbersep1022 memcpy(dst_p, right_p, dst_ct*sizeof(int));numbersepnumbersep numbersep1023 t_comp += RCCE_wtime() - t_comp_st;numbersepnumbersep numbersep1024 consm_ct += dst_ct;numbersepnumbersep numbersep1025 task->leaf->remain_right -= dst_ct;numbersepnumbersep numbersep1026 }numbersepnumbersep numbersep1027 else if(right_ct == 0 && task->leaf->remain_right == 0)numbersepnumbersep numbersep1028 {numbersepnumbersep numbersep1029 /* copy from left sequence, but make sure not to copy morenumbersepnumbersep numbersep1030 * integers than we have */numbersepnumbersep numbersep1031 if(dst_ct > left_ct)numbersepnumbersep numbersep1032 dst_ct = left_ct;numbersepnumbersep numbersep1033 t_comp_st = RCCE_wtime();numbersepnumbersep numbersep1034 memcpy(dst_p, left_p, dst_ct*sizeof(int));numbersepnumbersep numbersep1035 t_comp += RCCE_wtime() - t_comp_st;numbersepnumbersep numbersep1036 consm_ct += dst_ct;numbersepnumbersep numbersep1037 task->leaf->remain_left -= dst_ct;numbersepnumbersep numbersep1038 }numbersepnumbersep numbersep1039 }numbersepnumbersep numbersep1040numbersepnumbersep numbersep1041 /* increment the cache memory used counter */numbersepnumbersep numbersep1042 g_mem_p[task->local_id].ct += consm_ct;numbersepnumbersep numbersep1043 }numbersepnumbersep numbersep1044numbersepnumbersep numbersep1045 /* try to push existing data if any */numbersepnumbersep numbersep1046 if(g_mem_p[task->local_id].ct >= buf_ct ||numbersepnumbersep numbersep1047 task->progress+g_mem_p[task->local_id].ct >= task->size)numbersepnumbersep numbersep1048 {numbersepnumbersep numbersep1049 consm_ct = check_and_push(task->buf_start,numbersepnumbersep numbersep1050 g_mem_p[task->local_id].data,numbersepnumbersep numbersep1051 g_mem_p[task->local_id].ct,numbersepnumbersep numbersep1052 task->parent->cpu_id,numbersepnumbersep numbersep1053 (task->buf_sz-1)<<5);numbersepnumbersep numbersep1054numbersepnumbersep numbersep1055 /* update task progress and work buffer count */numbersepnumbersep numbersep1056 if(consm_ct > 0)numbersepnumbersep numbersep1057 {numbersepnumbersep numbersep1058 task->progress += consm_ct;numbersepnumbersep numbersep1059 g_mem_p[task->local_id].ct -= consm_ct;numbersepnumbersep numbersep1060 /* If there is still some integers in buffer, move them to thenumbersepnumbersep numbersep1061 * front */numbersepnumbersep numbersep1062 if(g_mem_p[task->local_id].ct > 0)numbersepnumbersep numbersep1063 {numbersepnumbersep numbersep1064 memmove(g_mem_p[task->local_id].data,numbersepnumbersep numbersep1065 g_mem_p[task->local_id].data+consm_ct,numbersepnumbersep numbersep1066 g_mem_p[task->local_id].ct*sizeof(int));numbersepnumbersep numbersep1067 }numbersepnumbersep numbersep1068 }numbersepnumbersep numbersep1069 }numbersepnumbersep numbersep1070 }numbersepnumbersep numbersep1071numbersepnumbersep numbersep1072 void run_branch(task_t *task)
81

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep1073 {numbersepnumbersep numbersep1074 unsigned consm_ct;numbersepnumbersep numbersep1075numbersepnumbersep numbersep1076 /* compute the number of integers that can fit in destination buffer */numbersepnumbersep numbersep1077 unsigned buf_ct = ((task->buf_sz-1) << 5) / sizeof(int);numbersepnumbersep numbersep1078numbersepnumbersep numbersep1079 /* if there is space in work buffer and the task is not finished, merge */numbersepnumbersep numbersep1080 if(g_mem_p[task->local_id].ct < buf_ct &&numbersepnumbersep numbersep1081 task->progress+g_mem_p[task->local_id].ct < task->size)numbersepnumbersep numbersep1082 {numbersepnumbersep numbersep1083 /* save how many were merged */numbersepnumbersep numbersep1084 g_mem_p[task->local_id].ct +=numbersepnumbersep numbersep1085 check_and_merge(g_mem_p[task->local_id].data +numbersepnumbersep numbersep1086 g_mem_p[task->local_id].ct,numbersepnumbersep numbersep1087 g_mem_p[task->local_id].max -numbersepnumbersep numbersep1088 g_mem_p[task->local_id].ct,numbersepnumbersep numbersep1089 task->left_child->buf_start,numbersepnumbersep numbersep1090 task->right_child->buf_start,numbersepnumbersep numbersep1091 task->left_child->size);numbersepnumbersep numbersep1092 }numbersepnumbersep numbersep1093numbersepnumbersep numbersep1094 /* try to push existing data if any */numbersepnumbersep numbersep1095 if(g_mem_p[task->local_id].ct >= buf_ct ||numbersepnumbersep numbersep1096 task->progress+g_mem_p[task->local_id].ct >= task->size)numbersepnumbersep numbersep1097 {numbersepnumbersep numbersep1098 consm_ct = check_and_push(task->buf_start,numbersepnumbersep numbersep1099 g_mem_p[task->local_id].data,numbersepnumbersep numbersep1100 g_mem_p[task->local_id].ct,numbersepnumbersep numbersep1101 task->parent->cpu_id,numbersepnumbersep numbersep1102 (task->buf_sz-1)<<5);numbersepnumbersep numbersep1103numbersepnumbersep numbersep1104 if(consm_ct > 0)numbersepnumbersep numbersep1105 {numbersepnumbersep numbersep1106 task->progress += consm_ct;numbersepnumbersep numbersep1107 g_mem_p[task->local_id].ct -= consm_ct;numbersepnumbersep numbersep1108numbersepnumbersep numbersep1109 /* if we werent able to copy all the data from cache, move thenumbersepnumbersep numbersep1110 * remainder in front */numbersepnumbersep numbersep1111 if(g_mem_p[task->local_id].ct > 0)numbersepnumbersep numbersep1112 {numbersepnumbersep numbersep1113 memmove(g_mem_p[task->local_id].data,numbersepnumbersep numbersep1114 g_mem_p[task->local_id].data+consm_ct,numbersepnumbersep numbersep1115 g_mem_p[task->local_id].ct*sizeof(int));numbersepnumbersep numbersep1116 }numbersepnumbersep numbersep1117 }numbersepnumbersep numbersep1118 }numbersepnumbersep numbersep1119 }numbersepnumbersep numbersep1120numbersepnumbersep numbersep1121 int check_and_merge(int *dst_mem,numbersepnumbersep numbersep1122 unsigned dst_ct,numbersepnumbersep numbersep1123 t_vcharp mpb_left_hdr_p,numbersepnumbersep numbersep1124 t_vcharp mpb_right_hdr_p,numbersepnumbersep numbersep1125 unsigned task_sz)numbersepnumbersep numbersep1126 {numbersepnumbersep numbersep1127 t_vcharp mpb_left_buf_p, mpb_right_buf_p;numbersepnumbersep numbersep1128 mpb_header_t left_hdr, right_hdr;numbersepnumbersep numbersep1129 unsigned left_ct, right_ct;numbersepnumbersep numbersep1130 unsigned wrote_ct = 0;numbersepnumbersep numbersep1131numbersepnumbersep numbersep1132 /* fetch the child headers (local) and check for new data */numbersepnumbersep numbersep1133 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep1134 RCCE_get((t_vcharp)&left_hdr, mpb_left_hdr_p, HDR_SZ, rcce_id);numbersepnumbersep numbersep1135 RCCE_get((t_vcharp)&right_hdr, mpb_right_hdr_p, HDR_SZ, rcce_id);numbersepnumbersep numbersep1136 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep1137numbersepnumbersep numbersep1138 /* first, if neither buffer changed, yield */numbersepnumbersep numbersep1139 if(left_hdr.seq == left_hdr.ack && left_hdr.seq < task_sz ||numbersepnumbersep numbersep1140 right_hdr.seq == right_hdr.ack && right_hdr.seq < task_sz)
82

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep1141 {numbersepnumbersep numbersep1142 return 0;numbersepnumbersep numbersep1143 }numbersepnumbersep numbersep1144numbersepnumbersep numbersep1145 /* move the buffer pointers to where the integers we want are located */numbersepnumbersep numbersep1146 /* Note that MPB buffers must be 32-byte aligned in RCCE due to L1 caching.numbersepnumbersep numbersep1147 * however, here we are working with local mpb buffer which the core cannumbersepnumbersep numbersep1148 * address, and the result is uploaded to a remote buffer using a differentnumbersepnumbersep numbersep1149 * function */numbersepnumbersep numbersep1150 mpb_left_buf_p = mpb_left_hdr_p + HDR_SZ + left_hdr.start_os;numbersepnumbersep numbersep1151 mpb_right_buf_p = mpb_right_hdr_p + HDR_SZ + right_hdr.start_os;numbersepnumbersep numbersep1152numbersepnumbersep numbersep1153 left_ct = left_hdr.int_ct;numbersepnumbersep numbersep1154 right_ct = right_hdr.int_ct;numbersepnumbersep numbersep1155numbersepnumbersep numbersep1156 /* if both buffers have some data to merge, merge normally */numbersepnumbersep numbersep1157 if(left_ct > 0 && right_ct > 0)numbersepnumbersep numbersep1158 {numbersepnumbersep numbersep1159 /* still receiving input in both buffers */numbersepnumbersep numbersep1160 /* invalidate L1 before directly accessing MPB */numbersepnumbersep numbersep1161 l1_mpb_invalidate();numbersepnumbersep numbersep1162 t_comp_st = RCCE_wtime();numbersepnumbersep numbersep1163 wrote_ct = merge(dst_mem,numbersepnumbersep numbersep1164 (int*)mpb_left_buf_p,numbersepnumbersep numbersep1165 (int*)mpb_right_buf_p,numbersepnumbersep numbersep1166 &left_ct,numbersepnumbersep numbersep1167 &right_ct);numbersepnumbersep numbersep1168 t_comp += RCCE_wtime() - t_comp_st;numbersepnumbersep numbersep1169 /* decrease remaining space in memory and move memory ptr forward */numbersepnumbersep numbersep1170 dst_ct -= wrote_ct;numbersepnumbersep numbersep1171 dst_mem += wrote_ct;numbersepnumbersep numbersep1172 /* move mpb buffer ptrs forward by how many integers were consumed */numbersepnumbersep numbersep1173 mpb_left_buf_p += (left_hdr.int_ct - left_ct) * sizeof(int);numbersepnumbersep numbersep1174 mpb_right_buf_p += (right_hdr.int_ct - right_ct) * sizeof(int);numbersepnumbersep numbersep1175 }numbersepnumbersep numbersep1176 /* if there is more space in destination buffer and we are at the end ofnumbersepnumbersep numbersep1177 * data for either child, copy from other child instead */numbersepnumbersep numbersep1178 if(dst_ct > 0)numbersepnumbersep numbersep1179 {numbersepnumbersep numbersep1180 if(right_ct == 0 && left_ct == 0)numbersepnumbersep numbersep1181 {numbersepnumbersep numbersep1182 /* both sequences spent at the same time, do nothing */numbersepnumbersep numbersep1183 dst_ct = 0;numbersepnumbersep numbersep1184 }numbersepnumbersep numbersep1185 else if(left_ct == 0 &&numbersepnumbersep numbersep1186 left_hdr.seq >= task_sz)numbersepnumbersep numbersep1187 {numbersepnumbersep numbersep1188 /* left input exhausted, copy from right sequence, but make surenumbersepnumbersep numbersep1189 * not to copy more integers than are available */numbersepnumbersep numbersep1190 if(dst_ct > right_ct)numbersepnumbersep numbersep1191 dst_ct = right_ct;numbersepnumbersep numbersep1192 /* invalidate L1 before directly accessing MPB */numbersepnumbersep numbersep1193 t_comp_st = RCCE_wtime();numbersepnumbersep numbersep1194 l1_mpb_invalidate();numbersepnumbersep numbersep1195 memcpy(dst_mem, (void*)mpb_right_buf_p, dst_ct*sizeof(int));numbersepnumbersep numbersep1196 t_comp += RCCE_wtime() - t_comp_st;numbersepnumbersep numbersep1197 wrote_ct += dst_ct;numbersepnumbersep numbersep1198 right_ct -= dst_ct;numbersepnumbersep numbersep1199 }numbersepnumbersep numbersep1200 else if(right_ct == 0 &&numbersepnumbersep numbersep1201 right_hdr.seq >= task_sz)numbersepnumbersep numbersep1202 {numbersepnumbersep numbersep1203 /* left input exhausted, copy from right sequence, but make surenumbersepnumbersep numbersep1204 * not to copy more integers than are available */numbersepnumbersep numbersep1205 if(dst_ct > left_ct)numbersepnumbersep numbersep1206 dst_ct = left_ct;numbersepnumbersep numbersep1207 /* invalidate L1 before directly accessing MPB */numbersepnumbersep numbersep1208 t_comp_st = RCCE_wtime();
83

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep1209 l1_mpb_invalidate();numbersepnumbersep numbersep1210 memcpy(dst_mem, (void*)mpb_left_buf_p, dst_ct*sizeof(int));numbersepnumbersep numbersep1211 t_comp += RCCE_wtime() - t_comp_st;numbersepnumbersep numbersep1212 wrote_ct += dst_ct;numbersepnumbersep numbersep1213 left_ct -= dst_ct;numbersepnumbersep numbersep1214 }numbersepnumbersep numbersep1215 }numbersepnumbersep numbersep1216numbersepnumbersep numbersep1217 /* check if any data from buffers has been consumed and update the headersnumbersepnumbersep numbersep1218 * accordingly */numbersepnumbersep numbersep1219 if(left_hdr.int_ct != left_ct)numbersepnumbersep numbersep1220 {numbersepnumbersep numbersep1221 /* left buffer has changed */numbersepnumbersep numbersep1222 if(left_ct == 0)numbersepnumbersep numbersep1223 {numbersepnumbersep numbersep1224 left_hdr.ack = left_hdr.seq;numbersepnumbersep numbersep1225 left_hdr.start_os = 0;numbersepnumbersep numbersep1226 }numbersepnumbersep numbersep1227 elsenumbersepnumbersep numbersep1228 {numbersepnumbersep numbersep1229 left_hdr.start_os += (left_hdr.int_ct - left_ct) * sizeof(int);numbersepnumbersep numbersep1230 }numbersepnumbersep numbersep1231 left_hdr.int_ct = left_ct;numbersepnumbersep numbersep1232numbersepnumbersep numbersep1233 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep1234 RCCE_put(mpb_left_hdr_p, (t_vcharp)&left_hdr, HDR_SZ, rcce_id);numbersepnumbersep numbersep1235 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep1236 }numbersepnumbersep numbersep1237 if(right_hdr.int_ct != right_ct)numbersepnumbersep numbersep1238 {numbersepnumbersep numbersep1239 /* right buffer has changed */numbersepnumbersep numbersep1240 if(right_ct == 0)numbersepnumbersep numbersep1241 {numbersepnumbersep numbersep1242 right_hdr.ack = right_hdr.seq;numbersepnumbersep numbersep1243 right_hdr.start_os = 0;numbersepnumbersep numbersep1244 }numbersepnumbersep numbersep1245 elsenumbersepnumbersep numbersep1246 {numbersepnumbersep numbersep1247 right_hdr.start_os += (right_hdr.int_ct - right_ct) * sizeof(int);numbersepnumbersep numbersep1248 }numbersepnumbersep numbersep1249 right_hdr.int_ct = right_ct;numbersepnumbersep numbersep1250numbersepnumbersep numbersep1251 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep1252 RCCE_put(mpb_right_hdr_p, (t_vcharp)&right_hdr, HDR_SZ, rcce_id);numbersepnumbersep numbersep1253 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep1254 }numbersepnumbersep numbersep1255 return wrote_ct;numbersepnumbersep numbersep1256 }numbersepnumbersep numbersep1257numbersepnumbersep numbersep1258 int check_and_push(t_vcharp dst_hdr_p,numbersepnumbersep numbersep1259 int *src_mem,numbersepnumbersep numbersep1260 unsigned int_ct,numbersepnumbersep numbersep1261 unsigned dst_cpu,numbersepnumbersep numbersep1262 unsigned dst_buf_sz)numbersepnumbersep numbersep1263 {numbersepnumbersep numbersep1264 mpb_header_t hdr;numbersepnumbersep numbersep1265 unsigned buf_sz;numbersepnumbersep numbersep1266numbersepnumbersep numbersep1267 /* check if destination mpb buffer is available and copy */numbersepnumbersep numbersep1268 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep1269 RCCE_get((t_vcharp)&hdr, dst_hdr_p, HDR_SZ, dst_cpu);numbersepnumbersep numbersep1270 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep1271 if(hdr.seq != hdr.ack) return 0;numbersepnumbersep numbersep1272numbersepnumbersep numbersep1273 /* desired buffer size is for all the integers to fit ... */numbersepnumbersep numbersep1274 buf_sz = int_ct * sizeof(int);numbersepnumbersep numbersep1275 make_div_by_32(&buf_sz);numbersepnumbersep numbersep1276 /* ... but it might be too large for the destination buffer */
84

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep1277 if(buf_sz > dst_buf_sz)numbersepnumbersep numbersep1278 {numbersepnumbersep numbersep1279 buf_sz = dst_buf_sz;numbersepnumbersep numbersep1280 int_ct = buf_sz / sizeof(int);numbersepnumbersep numbersep1281 }numbersepnumbersep numbersep1282numbersepnumbersep numbersep1283 t_trns_st = RCCE_wtime();numbersepnumbersep numbersep1284 RCCE_put(dst_hdr_p+HDR_SZ, (t_vcharp)src_mem, buf_sz, dst_cpu);numbersepnumbersep numbersep1285 t_trns += RCCE_wtime() - t_trns_st;numbersepnumbersep numbersep1286numbersepnumbersep numbersep1287 /* update the counters, header */numbersepnumbersep numbersep1288 hdr.seq += int_ct;numbersepnumbersep numbersep1289 hdr.start_os = 0;numbersepnumbersep numbersep1290 hdr.int_ct = int_ct;numbersepnumbersep numbersep1291numbersepnumbersep numbersep1292 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep1293 RCCE_put(dst_hdr_p, (t_vcharp)&hdr, HDR_SZ, dst_cpu);numbersepnumbersep numbersep1294 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep1295numbersepnumbersep numbersep1296 return int_ct;numbersepnumbersep numbersep1297 }numbersepnumbersep numbersep1298numbersepnumbersep numbersep1299 void sequential_merge(task_t* leaf_task, const char* filename,numbersepnumbersep numbersep1300 unsigned int_os)numbersepnumbersep numbersep1301 {numbersepnumbersep numbersep1302 /* load from file, mergesort & create a sorted subsequence */numbersepnumbersep numbersep1303 FILE* fp;numbersepnumbersep numbersep1304 int task_sz = leaf_task->size;numbersepnumbersep numbersep1305 int *write_at = g_input_p + int_os;numbersepnumbersep numbersep1306 int *aux_p;numbersepnumbersep numbersep1307numbersepnumbersep numbersep1308 /* open file */numbersepnumbersep numbersep1309 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep1310 fp = fopen(filename, "rb");numbersepnumbersep numbersep1311 if(!fp)numbersepnumbersep numbersep1312 {numbersepnumbersep numbersep1313 printf("Could not open file %s\n", filename);numbersepnumbersep numbersep1314 exit(E_FILE);numbersepnumbersep numbersep1315 }numbersepnumbersep numbersep1316 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep1317numbersepnumbersep numbersep1318 /* seek to offset in task and copy to memory.numbersepnumbersep numbersep1319 * quadrant offset must be taken into account when seeking in file */numbersepnumbersep numbersep1320 t_trns_st = RCCE_wtime();numbersepnumbersep numbersep1321 fseek(fp, quad_os+leaf_task->leaf->start, SEEK_SET);numbersepnumbersep numbersep1322 fread(write_at, sizeof(int), task_sz, fp);numbersepnumbersep numbersep1323 t_trns += RCCE_wtime() - t_trns_st;numbersepnumbersep numbersep1324 t_wait_st = RCCE_wtime();numbersepnumbersep numbersep1325 fclose(fp);numbersepnumbersep numbersep1326 t_wait += RCCE_wtime() - t_wait_st;numbersepnumbersep numbersep1327numbersepnumbersep numbersep1328 /* after sequential_merge completes, the leaf data is in memory - filenumbersepnumbersep numbersep1329 * offset is no longer necessary. the leaf_start property of the leafnumbersepnumbersep numbersep1330 * task is changed to instead be the integer offset to the leafs datanumbersepnumbersep numbersep1331 * in memory */numbersepnumbersep numbersep1332 leaf_task->leaf->start = int_os;numbersepnumbersep numbersep1333numbersepnumbersep numbersep1334 /* mergesort in place sequentially */numbersepnumbersep numbersep1335 /* allocate the comparison array */numbersepnumbersep numbersep1336 aux_p = malloc((task_sz/2+1)/2*sizeof(int));numbersepnumbersep numbersep1337 /* setup start time the first time we’re called */numbersepnumbersep numbersep1338 t_comp_st = RCCE_wtime();numbersepnumbersep numbersep1339 mergesort(write_at, aux_p, 0, task_sz/2-1);numbersepnumbersep numbersep1340 mergesort(write_at, aux_p, task_sz/2, task_sz-1);numbersepnumbersep numbersep1341 t_comp += RCCE_wtime() - t_comp_st;numbersepnumbersep numbersep1342 /* free the comparison array */numbersepnumbersep numbersep1343 free(aux_p);numbersepnumbersep numbersep1344 }
85

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep1345numbersepnumbersep numbersep1346 void print_task(const task_t* task)numbersepnumbersep numbersep1347 {numbersepnumbersep numbersep1348 printf("TASK: %u, CPU %u", task->id, task->cpu_id);numbersepnumbersep numbersep1349 if(task->parent)numbersepnumbersep numbersep1350 printf(", parent %u", task->parent->id);numbersepnumbersep numbersep1351 if(task->left_child)numbersepnumbersep numbersep1352 printf(", left %u, right %u",numbersepnumbersep numbersep1353 task->left_child->id, task->right_child->id);numbersepnumbersep numbersep1354 printf("\n\ton level %u, at buffer offset %p, size %u",numbersepnumbersep numbersep1355 task->tree_lvl, task->buf_start, task->buf_sz);numbersepnumbersep numbersep1356 if(task->leaf)numbersepnumbersep numbersep1357 printf(", leaf remain left %u, right %u\n",numbersepnumbersep numbersep1358 task->leaf->remain_left, task->leaf->remain_right);numbersepnumbersep numbersep1359 printf("\ttask size %u\n", task->size);numbersepnumbersep numbersep1360 }numbersepnumbersep numbersep1361numbersepnumbersep numbersep1362 void print_header(const mpb_header_t* hdr)numbersepnumbersep numbersep1363 {numbersepnumbersep numbersep1364 printf("HEADER for task %u, reader task %u\n", hdr->src_task_id,numbersepnumbersep numbersep1365 hdr->dst_task_id);numbersepnumbersep numbersep1366 printf("\tseq: %u, ack: %u :: int start %u, int count %u\n", hdr->seq,numbersepnumbersep numbersep1367 hdr->ack, hdr->start_os, hdr->int_ct);numbersepnumbersep numbersep1368 }numbersepnumbersep numbersep1369numbersepnumbersep numbersep1370 int merge(int *dst,numbersepnumbersep numbersep1371 const int *left,numbersepnumbersep numbersep1372 const int *right,numbersepnumbersep numbersep1373 unsigned *left_ct,numbersepnumbersep numbersep1374 unsigned *right_ct)numbersepnumbersep numbersep1375 {numbersepnumbersep numbersep1376 int *start = dst;numbersepnumbersep numbersep1377 while(*left_ct && *right_ct)numbersepnumbersep numbersep1378 {numbersepnumbersep numbersep1379 if(*left == *right)numbersepnumbersep numbersep1380 {numbersepnumbersep numbersep1381 if(*left_ct >= *right_ct)numbersepnumbersep numbersep1382 {numbersepnumbersep numbersep1383 *dst++ = *left++;numbersepnumbersep numbersep1384 (*left_ct)--;numbersepnumbersep numbersep1385 }numbersepnumbersep numbersep1386 elsenumbersepnumbersep numbersep1387 {numbersepnumbersep numbersep1388 *dst++ = *right++;numbersepnumbersep numbersep1389 (*right_ct)--;numbersepnumbersep numbersep1390 }numbersepnumbersep numbersep1391 }numbersepnumbersep numbersep1392 else if(*left < *right)numbersepnumbersep numbersep1393 {numbersepnumbersep numbersep1394 *dst++ = *left++;numbersepnumbersep numbersep1395 (*left_ct)--;numbersepnumbersep numbersep1396 }numbersepnumbersep numbersep1397 elsenumbersepnumbersep numbersep1398 {numbersepnumbersep numbersep1399 *dst++ = *right++;numbersepnumbersep numbersep1400 (*right_ct)--;numbersepnumbersep numbersep1401 }numbersepnumbersep numbersep1402 }numbersepnumbersep numbersep1403 return (dst - start);numbersepnumbersep numbersep1404 }numbersepnumbersep numbersep1405numbersepnumbersep numbersep1406 void mergesort(int *data, int *aux, int l, int r)numbersepnumbersep numbersep1407 {numbersepnumbersep numbersep1408 int m = (l + r) / 2;numbersepnumbersep numbersep1409 if (l < r)numbersepnumbersep numbersep1410 {numbersepnumbersep numbersep1411 mergesort(data, aux, l, m);numbersepnumbersep numbersep1412 mergesort(data, aux, m+1, r);
86

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep1413 merge_in_place(data, aux, l, m ,r);numbersepnumbersep numbersep1414 }numbersepnumbersep numbersep1415 }numbersepnumbersep numbersep1416numbersepnumbersep numbersep1417 void merge_in_place(int *data, int *aux, int l, int m, int r)numbersepnumbersep numbersep1418 {numbersepnumbersep numbersep1419 /* i,j move over left, right halvesnumbersepnumbersep numbersep1420 * k moves over entire array */numbersepnumbersep numbersep1421 int i, j, k;numbersepnumbersep numbersep1422numbersepnumbersep numbersep1423 /* Copy lower half to aux */numbersepnumbersep numbersep1424 /* memcpy version */numbersepnumbersep numbersep1425 /* memcpy(aux, data+l, (m-l+1)*sizeof(int));*/numbersepnumbersep numbersep1426 /* non memcpy version is faster with uncached shmem */numbersepnumbersep numbersep1427 i = 0;numbersepnumbersep numbersep1428 j = l;numbersepnumbersep numbersep1429 while(i <= (m - l))numbersepnumbersep numbersep1430 {numbersepnumbersep numbersep1431 aux[i++] = data[j++];numbersepnumbersep numbersep1432 }numbersepnumbersep numbersep1433numbersepnumbersep numbersep1434 /* Merge: copy smaller element:numbersepnumbersep numbersep1435 * i iterates over lower half copy (aux)numbersepnumbersep numbersep1436 * j iterates over upper half (data)numbersepnumbersep numbersep1437 * k iterates over entire array (data) - destination indexnumbersepnumbersep numbersep1438 */numbersepnumbersep numbersep1439 i = 0;numbersepnumbersep numbersep1440 k = l, j = m+1;numbersepnumbersep numbersep1441 while(k < j && j <= r)numbersepnumbersep numbersep1442 {numbersepnumbersep numbersep1443 if(aux[i] < data[j])numbersepnumbersep numbersep1444 {numbersepnumbersep numbersep1445 data[k++] = aux[i++];numbersepnumbersep numbersep1446 }numbersepnumbersep numbersep1447 elsenumbersepnumbersep numbersep1448 {numbersepnumbersep numbersep1449 data[k++] = data[j++];numbersepnumbersep numbersep1450 }numbersepnumbersep numbersep1451 }numbersepnumbersep numbersep1452numbersepnumbersep numbersep1453 /* If something’s left in aux, copy it over */numbersepnumbersep numbersep1454 /* memcpy version */numbersepnumbersep numbersep1455 /*if(k < j)numbersepnumbersep numbersep1456 {numbersepnumbersep numbersep1457 memcpy(data+k, aux+i, (j-k)*sizeof(int));numbersepnumbersep numbersep1458 if(ALG_DEBUG)numbersepnumbersep numbersep1459 printf("Copying %d left starting with data[%d] = aux[%d]\n",numbersepnumbersep numbersep1460 (j-k), k, i);numbersepnumbersep numbersep1461 }*/numbersepnumbersep numbersep1462 /* non-memcpy version - faster with uncached shmem */numbersepnumbersep numbersep1463 while(k < j)numbersepnumbersep numbersep1464 {numbersepnumbersep numbersep1465 data[k++] = aux[i++];numbersepnumbersep numbersep1466 }numbersepnumbersep numbersep1467 }numbersepnumbersep numbersep1468numbersepnumbersep numbersep1469 void make_div_by_32(unsigned int* number)numbersepnumbersep numbersep1470 {numbersepnumbersep numbersep1471 /* number is divisible by 32 if lowest 5 bits are 0 */numbersepnumbersep numbersep1472 if((*number)&0x1F)numbersepnumbersep numbersep1473 {numbersepnumbersep numbersep1474 /* zero out lowest 5 bits & add 32 */numbersepnumbersep numbersep1475 *number &= 0xFFFFFFE0;numbersepnumbersep numbersep1476 *number += 32;numbersepnumbersep numbersep1477 }numbersepnumbersep numbersep1478 }numbersepnumbersep numbersep1479numbersepnumbersep numbersep1480 int check_sorted(const int *data, int len)
87

APPENDIX A. CODE LISTING
numbersepnumbersep numbersep1481 {numbersepnumbersep numbersep1482 int i;numbersepnumbersep numbersep1483 for(i = 0; i < len-1; i++)numbersepnumbersep numbersep1484 {numbersepnumbersep numbersep1485 if(data[i] > data[i+1])numbersepnumbersep numbersep1486 return i;numbersepnumbersep numbersep1487 }numbersepnumbersep numbersep1488 if(data[0] == data[len-1])numbersepnumbersep numbersep1489 return -1;numbersepnumbersep numbersep1490 return 0;numbersepnumbersep numbersep1491 }numbersepnumbersep numbersep1492numbersepnumbersep numbersep1493 void isort(int *data, int len)numbersepnumbersep numbersep1494 {numbersepnumbersep numbersep1495 int i, j, t;numbersepnumbersep numbersep1496 for(i=1; i<len; i++)numbersepnumbersep numbersep1497 {numbersepnumbersep numbersep1498 t = data[i];numbersepnumbersep numbersep1499 for(j=i-1; j>=0 && data[j]>t; j--)numbersepnumbersep numbersep1500 data[j+1] = data[j];numbersepnumbersep numbersep1501 data[j+1] = t;numbersepnumbersep numbersep1502 }numbersepnumbersep numbersep1503 }numbersepnumbersep numbersep1504numbersepnumbersep numbersep1505 int prfx_sum(int* data, int len)numbersepnumbersep numbersep1506 {numbersepnumbersep numbersep1507 int i, rs = 0;numbersepnumbersep numbersep1508 for(i=0; i<len; i++)numbersepnumbersep numbersep1509 {numbersepnumbersep numbersep1510 rs += data[i];numbersepnumbersep numbersep1511 }numbersepnumbersep numbersep1512 return rs;numbersepnumbersep numbersep1513 }
88

På svenskaDetta dokument hålls tillgängligt på Internet – eller dess framtida ersättare– under en längre tid från publiceringsdatum under förutsättning att ingaextra-ordinära omständigheter uppstår.
Tillgång till dokumentet innebär tillstånd för var och en att läsa, laddaner, skriva ut enstaka kopior för enskilt bruk och att använda det oförändratför ickekommersiell forskning och för undervisning. Överföring av upphovs-rätten vid en senare tidpunkt kan inte upphäva detta tillstånd. All annananvändning av dokumentet kräver upphovsmannens medgivande. För attgarantera äktheten, säkerheten och tillgängligheten finns det lösningar avteknisk och administrativ art.
Upphovsmannens ideella rätt innefattar rätt att bli nämnd som upphovs-man i den omfattning som god sed kräver vid användning av dokumentet påovan beskrivna sätt samt skydd mot att dokumentet ändras eller presenterasi sådan form eller i sådant sammanhang som är kränkande för upphovsman-nens litterära eller konstnärliga anseende eller egenart.
För ytterligare information om Linköping University Electronic Press seförlagets hemsida http://www.ep.liu.se/
In EnglishThe publishers will keep this document online on the Internet – or its possiblereplacement – for a considerable time from the date of publication barringexceptional circumstances.
The online availability of the document implies a permanent permissionfor anyone to read, to download, to print out single copies for your own useand to use it unchanged for any non-commercial research and educationalpurpose. Subsequent transfers of copyright cannot revoke this permission.All other uses of the document are conditional on the consent of the copy-right owner. The publisher has taken technical and administrative measuresto assure authenticity, security and accessibility.
According to intellectual property law the author has the right to bementioned when his/her work is accessed as described above and to be pro-tected against infringement.
For additional information about the Linköping University ElectronicPress and its procedures for publication and for assurance of document in-tegrity, please refer to its WWW home page: http://www.ep.liu.se/
© Kenan Avdić