numerical methods and benchmarking across
TRANSCRIPT

New Directions in Numerical Linear Algebra and High Performance Computing:Celebrating the 70th Birthday of Jack Dongarra , July 7-8, 2021
Numerical methods and benchmarking across scales, precisions, and hardware platforms
Piotr Luszczek
July 7, 2021
University of Tennessee

2 / 23
Motivation for Kernel Benchmarks

3 / 23
If at first you don’t succeed...
[…] the problem with simulations is that they are doomed to succeed […]
Rodney Brooks

4 / 23
Whimsical Non-Sequitur
[…] the problem with simulations is that they are doomed to succeed […]
Anonymous
benchmarks

5 / 23
Measurement as a Tool for Science
I often say that when you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot measure it, when you cannot express it in numbers, your knowledge is of a meagre and unsatisfactory kind; it may be the beginning of knowledge, but you have scarcely in your thoughts advanced to the state of Science, whatever the matter may be.
Lord Kelvin, PLA Vol.1 Electrical Units of Measure
If you can't measure it, you can't improve it.
Peter Drucker, Management

6 / 23
Measurement as a Tool for Science
I often say that when you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot measure it, when you cannot express it in numbers, your knowledge is of a meagre and unsatisfactory kind; it may be the beginning of knowledge, but you have scarcely in your thoughts advanced to the state of Science, whatever the matter may be.
Lord Kelvin, PLA Vol.1 Electrical Units of Measure
If you can't measure it, you can't improve it.
Peter Drucker, Management

7 / 23
Scientific Code before the Disco Era subroutine dgefa(a,lda,n,ipvt,info) integer lda,n,ipvt(1),info double precision a(lda,1) double precision t integer idamax,j,k,kp1,l,nm1 nfo = 0 nm1 = n - 1 if (nm1 .lt. 1) go to 70 do 60 k = 1, nm1 kp1 = k + 1 l = idamax(n-k+1,a(k,k),1) + k - 1 ipvt(k) = l if (a(l,k) .eq. 0.0d0) go to 40 if (l .eq. k) go to 10 t = a(l,k) a(l,k) = a(k,k) a(k,k) = t 10 continue t = -1.0d0/a(k,k) call dscal(n-k,t,a(k+1,k),1) do 30 j = kp1, n t = a(l,j) if (l .eq. k) go to 20 a(l,j) = a(k,j) a(k,j) = t 20 continue call daxpy(n-k,t,a(k+1,k),1,a(k+1,j),1) 30 continue go to 50 40 continue info = k 50 continue 60 continue 70 continue ipvt(n) = n if (a(n,n) .eq. 0.0d0) info = n return end
c********************************************c*** KERNEL 5 TRI-DIAGONAL ELIMINATION, BELOW DIAGONAL (NO VECTORS)c********************************************cdir$ novector 1005 DO 5 i = 2,n 5 X(i)= Z(i) * (Y(i) – X(i-1))cdir$ vectorc********************************************c*** KERNEL 7 EQUATION OF STATE FRAGMENTc********************************************cdir$ ivdep 1007 DO 7 k= 1,n X(k)= U(k ) + R*( Z(k ) + R*Y(k )) + 1 T*( U(k+3) +R*(U(k+2)+ R*U(k+1)) + 2 T*( U(k+6) + Q*( U(k+5) + Q*U(k+4)))) 7 CONTINUEc********************************************c*** KERNEL 21 MATRIX*MATRIX PRODUCTc******************************************** 1021 DO 21 k= 1,25 DO 21 i= 1,25 DO 21 j= 1,n PX(i,j)= PX(i,j) +VY(i,k) * CX(k,j) 21 CONTINUEc********************************************c*** KERNEL 23 2-D IMPLICIT HYDRODYNAMICSc******************************************** fw= 0.17500d0 1023 DO 23 j= 2,6 DO 23 k= 2,n QA= ZA(k,j+1)*ZR(k,j)+ZA(k,j-1)*ZB(k,j)+ ZA(k+1,j)*ZU(k,j)+ZA(k-1,j)*ZV(k,j) +ZZ(k,j) 23 ZA(k,j)= ZA(k,j) +fw*(QA -ZA(k,j))

8 / 23
Where did 100 come from?

9 / 23
Conditioning of Random Matrices after WWII● With probability ≈ 1, κ < 10N
– [von Neumann and Goldstine 1947]● For a “random matrix” of order N the expectation [of κ] value
has been shown to be about N.– [von Neumann 1963, p. 14]
● […] we choose two different values of κ, namely N and N√10– [von Neumann 1963, p. 477]
● Von Neumann’s goal was to pick test matrices with “rules of thumb”
● Modern random matrix theory– [Edelman and Sutton 2004] [Azaïs and Wschebor 2004]
[Viswanath and Trefethen 1998] [Yeung and Chan 1997] [Trefethen and Schreiber 1990]

10 / 23
HPL, Rmax, Nmax, N½
R∞

11 / 23
Dangers of Single Value of Merit
Any observed statistical regularity will tend to collapse oncepressure is placed upon it for control purposes.
Charles Goodhart
When a measure becomes a target, it ceases to be a good measure.
Marilyn Strathern
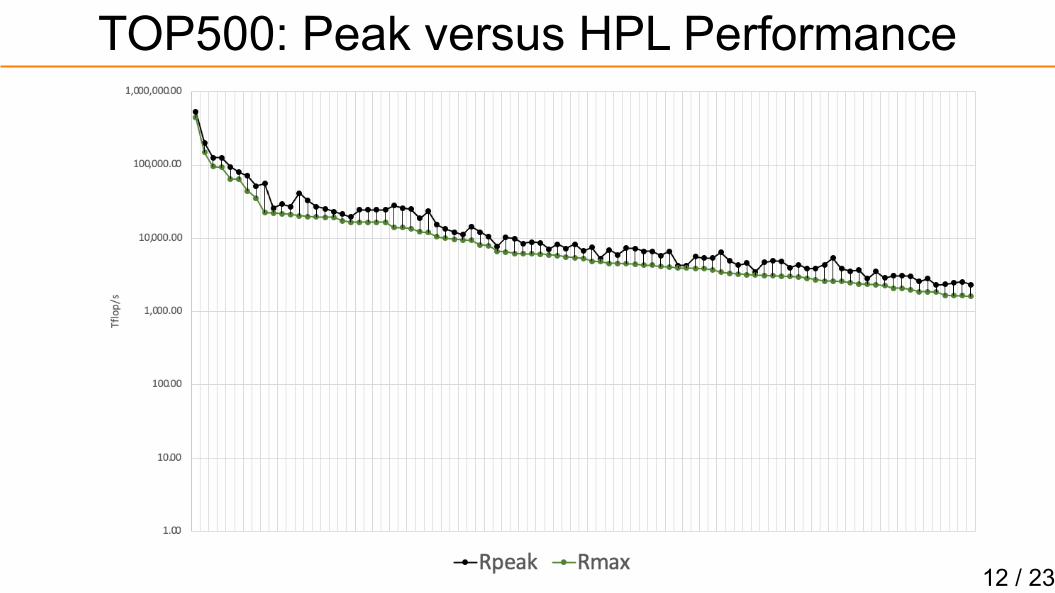
12 / 23
TOP500: Peak versus HPL Performance

13 / 23
HPLFFT
STREAMRandomAccess
HPCC

14 / 23
High Performance Conjugate Gradients
Multigrid
L [u ]≡∇2 u= f
Sparse matrix based on 27-point stencil
A u= f
Multigrid and Gauss-Seidel

15 / 23
HPCG Iterations
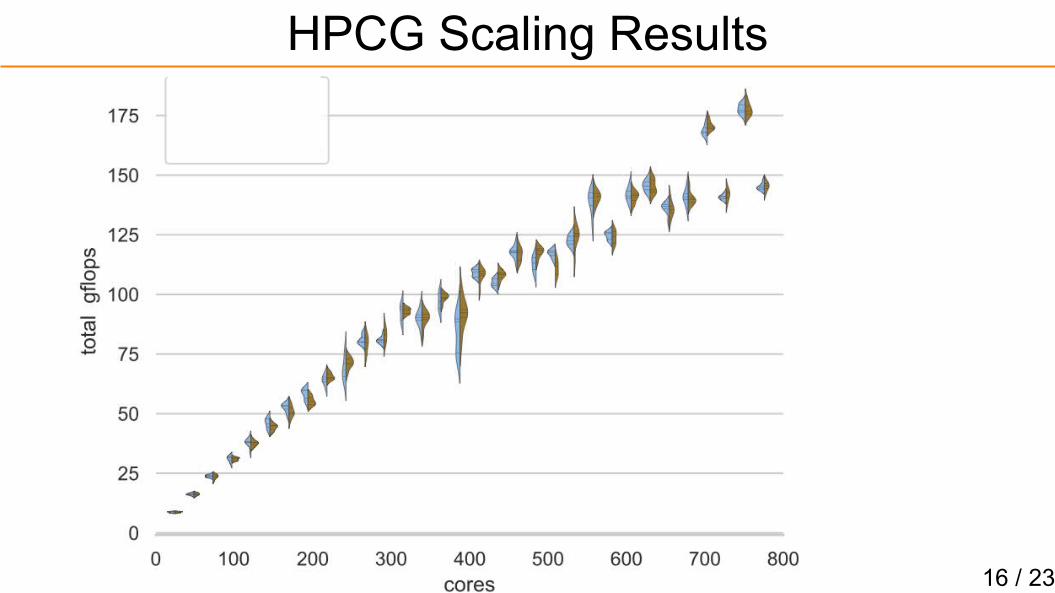
16 / 23
HPCG Scaling Results

17 / 23
TOP500: Peak vs. HPL vs. HPCG Performance

18 / 23
Modern Hardware dominatedby
ML, DL, and AI workloads

19 / 23
NVIDIA Ampere A100 Highlights
INT32 FP32 FP64INT32 FP32
FP32 FP64FP32
FP32 FP64FP32
FP32 FP64FP32
FP32 FP64FP32
FP32 FP64FP32
FP32 FP64FP32
FP32 FP64FP32
Tensor Core
LD/STSFU
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
LD/ST
Register File (16,384x32 bits)
Dispatch Unit (32 threads/clock)Warp Scheduler (32 threads/clock)
L0 Instruction Cache
238
108
105
78
5211FP64
FP32
TF32
FP16
BF16
Precision Width Exponent bits
Mantissa bits Epsilon Max
Quadruple 128 15 112 O(10-34) 1.2x104932
Extended 80 15 64 O(10-19)
Double 64 11 52 O(10-16) 1.8x10308
Single 32 8 23 O(10-7) 3.4x1038
Half* 16 5 10 O(10-3) 65504
*Only storage format is specified
BFloat 16 8 7 O(10-2) 3.4x1038
IEEE 754 2018 standard update includes 16-bit for computing
Graphics, gaming
Science ML, AI
INT32 INT32
INT32 INT32
INT32 INT32
INT32 INT32
INT32 INT32
INT32 INT32
INT32 INT32

20 / 23
The Landscape of Mixed-Precision Hardware● Mixed-Precision Startup
Hardware– GraphCore
● Colossus– Habana
● Labs Gaudi– Cerebras
● Wafer Scale Chip– Blaize
● Graph Streaming Processor– Groq
● Tensor Streaming Processor – SambaNova
● Cardinal– Tenstorrent
● Grayskull
● NVIDIA Mixed-Precision Hardware– Pascal
● FP16 units only– Volta
● Tensor Cores and FP16– Turing
● Tensor Cores and FP16– Ampere
● Tensor Cores for FP16 and FP64

21 / 23
HPL-AI Benchmark OverviewGMRES𝑟𝑒𝑠( , 𝑨 𝒙𝟎, ,𝒃 𝑴−1)
for =0, 1, 2,…𝑘𝒓𝒌 ← −𝒃 𝑨𝒙𝒌𝒛 𝒌← 𝑴−1 𝒓𝒌 ← ‖𝛽 𝒛𝒌 ‖2
𝑽:,0 ← 𝒛𝒌 ∕ 𝛽 ← 𝐬 [ , 0, 0, …, 0]𝛽 𝑇
for j=0, 1, 2, …←𝒘 𝑴−1 𝑨𝑽:,𝑗
𝒘,𝑯:,𝑗 ← ( , 𝑜𝑟𝑡ℎ𝑜𝑔𝑜𝑛𝑎𝑙𝑖𝑧𝑒 𝒘 𝑽:,𝑗 )𝑯𝑗+1,𝑗 ← ‖ ‖𝒘 2
𝑽:, +1𝑗 ← ∕ ‖ ‖𝒘 𝒘 2 𝑯:, 𝑗 ← 𝑮𝟎 𝑮𝟏…𝑮 −𝒋 𝟏 𝑯:,𝑗𝑮𝒋 ← 𝑟𝑜𝑡𝑎𝑡𝑖𝑜𝑛_ (𝑚𝑎𝑡𝑟𝑖𝑥 𝑯:,𝑗)𝑯:, 𝑗 ← 𝑮𝒋 𝑯:,𝑗 ← 𝒔 𝑮𝒋 𝒔
𝒖𝒌 ← 𝑽𝑯−1 𝒔𝒙𝒌+𝟏 ← 𝒙 𝒌+ 𝒖𝒌
16-bit preconditioning with dense LU factorization
● Half-Precision LINPACK for Accelerator Introspection
● Exploits low-precision hardware to take advantage of performance– FP16, BF16, TF32
● Uses Carson-Higham 3-precision iterative refinement– Dense LU in lowest
precision: A16 = L16 U16 – GMRES preconditioned
with L16 and U16 factors in 64-bit precision

22 / 23
HPL-AI vs. Peak vs. HPL vs. HPCG Performance

23 / 23
More Information
● www.top500.org/ ● hpcchallenge.org/● hpcg-benchmark.org/ ● icl.bitbucket.io/hpl-ai/