nosql
DESCRIPTION
TRANSCRIPT

NOSQL, NO?
Introductory presentation

SQL
Relational algebra
Tables, Columns, Rows
Metadata separate
from data
Normalized data
Optimized storage
RELATIONAL
ACID
Optimal for ad-hoc
queries
Sharding can be
difficult

MySQL
SQL Server
Oracle
Postgres
DB2
Interbase, Firebird
POPULAR RDBMS
Informix
Progress
Pervasive
Sybase
Access
…

SQL
Unified language to create and query both data
and metadata
Similar to English
Verbose(!)
Can get complex for non-trivial queries
Does not expose execution plan – you say what you
want it to return, not how

SQL EXAMPLES
If you can say what you mean, you can query the existing data
Results are near-instant when querying based on primary keyselect * from valute where id=1 and sid=42
Results are fast when querying based on non-unique indexselect valuta from valute where ((id=1 and sid=42)) and (valute.firma_id=123 and
valute.firma__sid=1)
Very readable for trivial queriesselect r.customer,sum(rs.iznos) sveukupno from racuni r
join racuni_stavke rs on r.id=rs.racun_id
where r.id=5
order by rs.ordinal

SQL EXAMPLES
Not so readable for non-trivial queriesselect "MP" tip_prometa, mprac.broj broj_racuna, mprac_stavke.kolicina kolicina,
(mprac.tecaj*mprac_stavke.kolicina*mprac_stavke.rabat_iznos) rabat_iznos, (round(mprac_stavke.cijena - mprac_stavke.rabat_iznos -
mprac_stavke.rabat2_iznos - mprac_stavke.rabat3_iznos - mprac_stavke.porez1 - mprac_stavke.porez2 -
mprac_stavke.porez_potrosnja,6)*mprac_stavke.kolicina) iznos, (mprac_stavke.kolicina* ifnull((select sum(pn_cijena*kolicina)/sum(kolicina)
from mprac_skl left join skl_stavke on mprac_skl.skl_id=skl_stavke.skl_id and mprac_skl.skl__sid=skl_stavke.skl__sid where
mprac_skl.mprac_id=mprac.id and mprac_skl.mprac__sid=mprac.sid and skl_stavke.artikl_id=mprac_stavke.artikl_id and
skl_stavke.artikl__sid=mprac_stavke.artikl__sid ),0) ) iznos_nabavno, ifnull( (select sum(mprac_stavke.kolicina*ambalaze.naknada_kom) from
artikli_ambalaze left join ambalaze on ambalaze.id=artikli_ambalaze.ambalaza_id and ambalaze.sid=artikli_ambalaze.ambalaza__sid where
artikli_ambalaze.artikl_id=artikli.id and artikli_ambalaze.artikl__sid=artikli.sid and ambalaze.kalkulacija="N" ),0) naknada,
radnici_komercijalisti.ime racun_komercijalist_ime, (select naziv from skladista where skladista.tip_skladista="M" and pj_id=mprac.pj_id limit
1) skladiste_naziv , pj.naziv pj_naziv, mprac.datum, cast(concat("(",if(DayOfWeek(mprac.datum)=1,7,DayOfWeek(mprac.datum)-1),") ",
if(DayOfWeek(mprac.datum)=1,"1 Nedjelja", if(DayOfWeek(mprac.datum)=2,"2 Ponedjeljak", if(DayOfWeek(mprac.datum)=3,"3 Utorak",
if(DayOfWeek(mprac.datum)=4,"4 Srijeda", if(DayOfWeek(mprac.datum)=5,"5 Èetvratk", if(DayOfWeek(mprac.datum)=6,"6 Petak",
if(DayOfWeek(mprac.datum)=7,"7 Subota","")))))))) as char(15)) dan_u_tjednu, cast(month(mprac.datum) as unsigned) mjesec,
cast(week(mprac.datum) as unsigned) tjedan, cast(quarter(mprac.datum) as unsigned) kvartal, cast(year(mprac.datum) as unsigned) godina,
cast(if(tipovi_komitenata.tip="F",trim(concat(partneri.ime," ",partneri.prezime)),partneri.naziv) as char(200)) kupac_naziv,
partneri_mjesta.postanski_broj kupac_mjesto, partneri_mjesta.mjesto kupac_mjesto_naziv, partneri_grupe_mjesta.naziv …

RDBMS SCALING
Vertical scaling• Better CPU, more CPUs• More RAM• More disks• SAN
Partitioning
Sharding

PARTITIONING
With many rows and heavy usage, partitioning is a
must
What to partition• Tables• Indexes• Views
Typical cases• Monthly data• Alphabetical keys

RDBMS SHARDING
Sharding means using several databases where
each represents part of data (500 clients on one
server, another 500 on another)
Requires changing application codeconnect(calculate_server_from(sharding_key))
Impossible to join data from different databases, so
choose your sharding key wisely
Very difficult to repartition your databases based
on a new key

RDBMS METADATA
Metadata: data describing other data
RDBMS structures are explicitly defined, and each
data type is optimized for storage
Lots of constraints
Can get slow with lot of data

NOSQL
“Not SQL”, “Not only SQL”
Core NoSQL databases invented mostly because
RDBMS made life very hard for huge and heavy
traffic web databases
NoSQL databases are the ones significantly
different from relational databases

NOSQL TYPES
Wide Column Store / Column Families
Document Store
Key Value / Tuple Store
Graph Databases
Object Databases
XML Databases
Multivalue Databases

4 MAIN DATA MODELS
Key-Value Stores
BigTable Clones (aka "ColumnFamily")
Document Databases
Graph DatabasesSource:
http://blogs.neotechnology.com/emil/2009/11/nosql-scaling-to-size-and-scaling-to-complexity.htm
l

KEY/VALUE STORES
Lineage: Amazon's Dynamo paper and Distributed
HashTables.
Data model: A global collection of key-value pairs.
Example: Voldemort, Dynomite, Tokyo CabinetSource:
http://blogs.neotechnology.com/emil/2009/11/nosql-scaling-to-size-and-scaling-to-complexity.htm
l

BIGTABLE CLONES
Lineage: Google's BigTable paper.
Data model: Column family, i.e. a tabular model
where each row at least in theory can have an
individual configuration of columns.
Example: HBase, Hypertable, CassandraSource:
http://blogs.neotechnology.com/emil/2009/11/nosql-scaling-to-size-and-scaling-to-complexity.htm
l

DOCUMENT DATABASES
Lineage: Inspired by Lotus Notes.
Data model: Collections of documents, which
contain key-value collections (called "documents").
Example: CouchDB, MongoDB, RiakSource: http://
blogs.neotechnology.com/emil/2009/11/nosql-scaling-to-size-and-scaling-to-complexity.html

GRAPH DATABASES
Lineage: Draws from Euler and graph theory.
Data model: Nodes & relationships, both which can
hold key-value pairs
Example: AllegroGraph, InfoGrid, Neo4jSource: http://
blogs.neotechnology.com/emil/2009/11/nosql-scaling-to-size-and-scaling-to-complexity.html

Hadoop / Hbase
Cassandra
Amazon SimpleDB
MongoDB
CouchDB
Redis
POPULAR NOSQL
MemcacheDB
Voldemort
Hypertable
Cloudata
IBM Lotus/Domino

NOSQL CHARACTERISTICTS
Almost infinite horizontal scaling
Very fast
Performance doesn’t deteriorate with growth (much)
No fixed table schemas
No join operations
Ad-hoc queries difficult or impossible
Structured storage
Almost everything happens in RAM

REAL-WORLD USE
Cassandra • Facebook (original developer, used it till late 2010)• Twitter• Digg• Reddit• Rackspace• Cisco
BigTable• Google (open-source version is HBase)
MongoDB• Foursquare• Craigslist• Bit.ly• SourceForge• GitHub

WHY NOSQL?
Handles huge databases (I know, I said it before)
Redundancy, data is pretty safe on commodity
hardware
Super flexible queries using map/reduce
Rapid development (no fixed schema, yeah!)
Very fast for common use cases

PERFORMANCE
RDBMS uses buffer to ensure ACID properties
NoSQL does not guarantee ACID and is therefore
much faster
We don’t need ACID everywhere!
I used MySQL and switched to MongDB for my
analytics app• Data processing (every minute) is 4x faster with
MongoDB, despite being a lot more detailed (due to much simple development)

SCALING
Simple web application with not much traffic• Application server, database server all on one
machine
SCALING
More traffic comes in• Application server• Database server

SCALING
Even more traffic comes in• Load balancer• Application server x2• Database server

SCALING
Even more traffic comes in• Load balancer x N
• easy
• Application server x N• easy
• Database server xN• hard for SQL databases

SQL SLOWDOWN
Not linear!
http://www.slideshare.net/
rightscale/scaling-sql-and-
nosql-databases-in-the-clo
ud

NOSQL SCALING
Need more storage?• Add more servers!
Need higher performance?• Add more servers!
Need better reliability?• Add more servers!

SCALING SUMMARY
You can scale SQL databases (Oracle, MySQL, SQL
Server…)• This will cost you dearly• If you don’t have a lot of money, you will reach limits
quickly
You can scale NoSQL databases• Very easy horizontal scaling• Lots of open-source solutions• Scaling is one of the basic incentives for design, so it
is well handled• Scaling is the cause of trade-offs causing you to have
to use map/reduce

RAM
Why map/reduce? I just need some simple queries.
Tomorrow I will need some other queries….
SQL databases are optimized for very efficient disk
access, but for significant scaling need RAM caching
(MySQL+memcached)
NoSQL databases are designed to keep whole
working set in RAM

WORKING SET
In real-world use working set is much less than
complete database• For analytics 99% of queries will be regarding last
30 days
As you need RAM only for working set, you can use
commodity servers, VPS, and just add more as your
app becomes more popular

WORKING SET WOES
Foursquare has millions of users and working set the same as the
database
They used a single 66GB Amazon EC2 High-Memory Quadruple
Extra Large Instance (with cheese) for millions of users
When their RAM usage was 65GB, they decided to shard
Too late, they started to have disk swaps
Disk is much slower than RAM - 100x slowdown
Server could not keep up due to swapping
11 hours outage (ouch!)

MAP/REDUCE
Google’s framework for processing highly
distributable problems across huge datasets
using a large number of computers
Let’s define large number of computers• Cluster if all of them have same hardware• Grid unless Cluster (if !Cluster for old-style
programmers)

MAP/REDUCE
Process split into two phases• Map
• Take the input, partition it delegate to other machines• Other machines can repeat the process, leading to tree structure• Each machine returns results to the machine who gave it the task
• Reduce• collect results from machines you gave the tasks• combine results and return it to requester
• Slower than sequential data processing, but massively parallel• Sort petabyte of data in a few hours• Input, Map, Shuffle, Reduce, Output

MAP/REDUCE EXAMPLE
You need to write two functions
Count different words in a set of documents

MONGODB
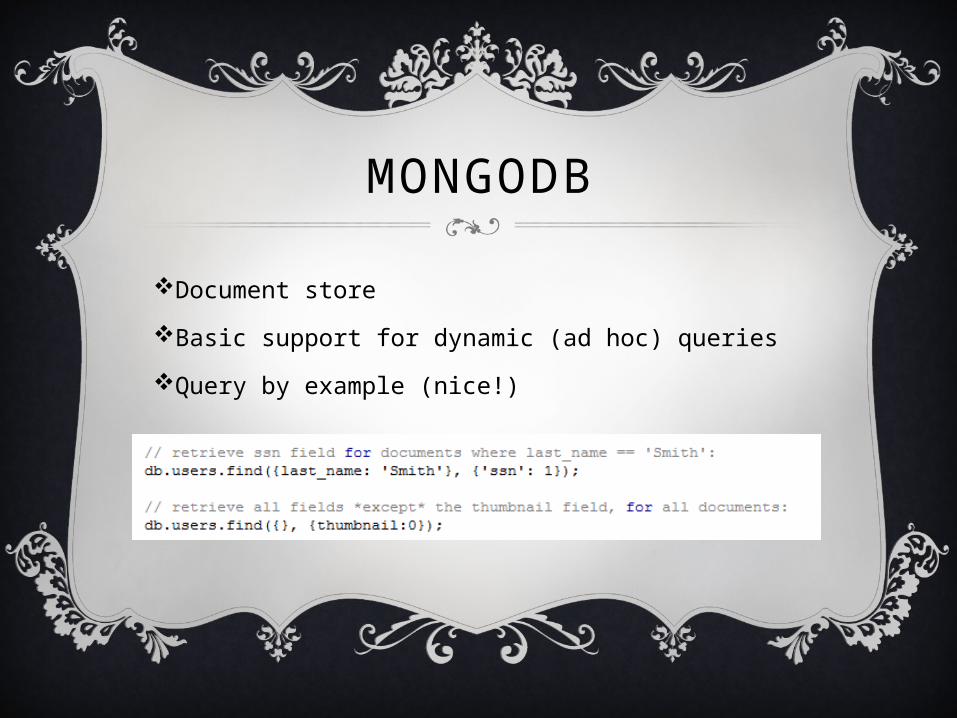
Document store
Basic support for dynamic (ad hoc) queries
Query by example (nice!)

MONGODB
Conditional Operators• <, <=, >, >=• $all, $exists, $mod, $ne, $in, $nin, $nor, $or, $and,
$size, $type
Regular expressions

MONGODB
Data is stored as BSON (binary JSON)• Makes it very well suited for languages with native JSON support
Map/Reduce written in Javascript• Slow! There is one single thread of execution in Javascript
Master/slave replication (auto failover with replica sets)
Sharding built-in
Uses memory mapped files for data storage
Performance over features
On 32bit systems, limited to ~2.5Gb
An empty database takes up 192Mb
GridFS to store big data + metadata (not actually an FS)
Source: http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis

CASSANDRA
Written in: Java
Protocol: Custom, binary (Thrift)
Tunable trade-offs for distribution and replication (N, R, W)
Querying by column, range of keys
BigTable-like features: columns, column families
Writes are much faster than reads (!)• Constant write time regardless of database size
Map/reduce possible with Apache HadoopSource: http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis

HBASE
Written in: Java
Main point: Billions of rows X millions of columns
Modeled after BigTable
Map/reduce with Hadoop
Query predicate push down via server side scan and get filters
Optimizations for real time queries
A high performance Thrift gateway
HTTP supports XML, Protobuf, and binary
Cascading, hive, and pig source and sink modules
No single point of failure
While Hadoop streams data efficiently, it has overhead for starting map/reduce jobs. HBase is column oriented
key/value store and allows for low latency read and writes.
Random access performance is like MySQL
Source: http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis

REDIS
Written in: C/C++
Main point: Blazing fast
Disk-backed in-memory database,
Master-slave replication
Simple values or hash tables by keys,
Has sets (also union/diff/inter)
Has lists (also a queue; blocking pop)
Has hashes (objects of multiple fields)
Sorted sets (high score table, good for range queries)
Has transactions (!)
Values can be set to expire (as in a cache)
Pub/Sub lets one implement messaging (!)
Source: http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis

COUCHDB
Written in: Erlang
Main point: DB consistency, ease of use
Bi-directional (!) replication, continuous or ad-hoc, with conflict detection, thus, master-master replication. (!)
MVCC - write operations do not block reads
Previous versions of documents are available
Crash-only (reliable) design
Needs compacting from time to time
Views: embedded map/reduce
Formatting views: lists & shows
Server-side document validation possible
Authentication possible
Real-time updates via _changes (!)
Attachment handling
CouchApps (standalone JS apps)
Source: http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis

HADOOP
Apache project
A framework that allows for the distributed
processing of large data sets across clusters of
computers
Designed to scale up from single servers to
thousands of machines
Designed to detect and handle failures at the
application layer, instead of relying on hardware for
it

HADOOP
Created by Doug Cutting, who named it after his son's toy elephant
Hadoop subprojects• Cassandra• HBase• Pig
Hive was a Hadoop subproject, but is now a top-level Apache project
Used by many large & famous organizations• http://wiki.apache.org/hadoop/PoweredBy
Scales to hundreds or thousands of computers, each with several processor cores
Designed to efficiently distribute large amounts of work across a set of machines
Hundreds of gigabytes of data constitute the low end of Hadoop-scale
Built to process "web-scale" data on the order of hundreds of gigabytes to terabytes or
petabytes

HADOOP
See http://
www.slideshare.net/hadoop/practical-problem-solvin
g-with-apache-hadoop-pig
Uses Java, but allows streaming so other languages
can easily send and accept data items to/from
Hadoop

HADOOP
Uses distributed file system (HDFS)• Designed to hold very large amounts of data (terabytes or
even petabytes)• Files are stored in a redundant fashion across multiple
machines to ensure their durability to failure and high availability to very parallel applications
• Data organized into directories and files• Files are divided into block (64MB by default) and
distributed across nodes
Design of HDFS is based on the design of the Google File
System

HIVE
A petabyte-scale data warehouse system for
Hadoop
Easy data summarization, ad-hoc queries
Query the data using a SQL-like language called
HiveQL
Hive compiler generates map-reduce jobs for most
queries

PIG
Platform for analyzing large data sets
High-level language for expressing data analysis
programs
Compiler produces sequences of Map-Reduce
programs
Textual language called Pig Latin• Ease of programming• System optimizes task execution automatically• Users can create their own functions

PIG LATIN
Pig Latin – high level Map/Reduce programming
Equivalent to SQL for RDBMS systems.
Pig Latin can be extended using Java User Defined
Functions
“Word Count” script in Pig Latin

MY MONGODB

MY MONGODB

SUMMARY
NoSQL is a great problem solver if you need it
Choose your NoSQL platform carefully as each is
designed for specific purpose
Get used to Map/Reduce
It’s not a sin to use NoSQL alongside (yes)SQL
database
I am really happy to work with MongoDB instead
of MySQL