neural networks and machine learning research at the …€¦ · · 2017-05-09neural networks and...
TRANSCRIPT

Neural Networks and Machine Learning research at the Laboratory of
Computer and Information Science, Helsinki University of Technology
Erkki Oja
Department of Computer Science
Aalto University, Finland
AIHelsinki Seminar, April 28, 2017

CIS lab: the pre-history

CIS Lab
• Established first in 1965 as the electronics lab at Dept. of Technical Physics, HUT
• Changed names many times
• Chair 1965 – 1993: Teuvo Kohonen, 1993 – 2009: Erkki Oja. Then restructured
• Now part of the big CS Department at Aalto.

Neural networks

Neural networks
• Teuvo Kohonen started research into neural networks in early 1970’s (associative memories, subspace classifiers, speech recognition); then the Self-Organizing Map (SOM) from early 1980’s
• Teuvo will give a presentation in AIHelsinki later this spring
• E. Oja completed his PhD in 1977 with Teuvo.

Kohonen-Oja paper
Part of my PhD Thesis

Cooper et al
One of my Postdoc papers

Subspace book

Neural networks and AI
• 1970’s and 1980’s was the time of deep contradictions between neural computation (connectionism) and ”true AI”
• True AI was symbolic, the mainstream was expert (knowledge-based) systems, search, logic, frames, semantic nets, Lisp, Prolog etc.
• In late 1980’s, probabilistic (Bayesian) reasoning and neural networks slowly sneaked into AI.
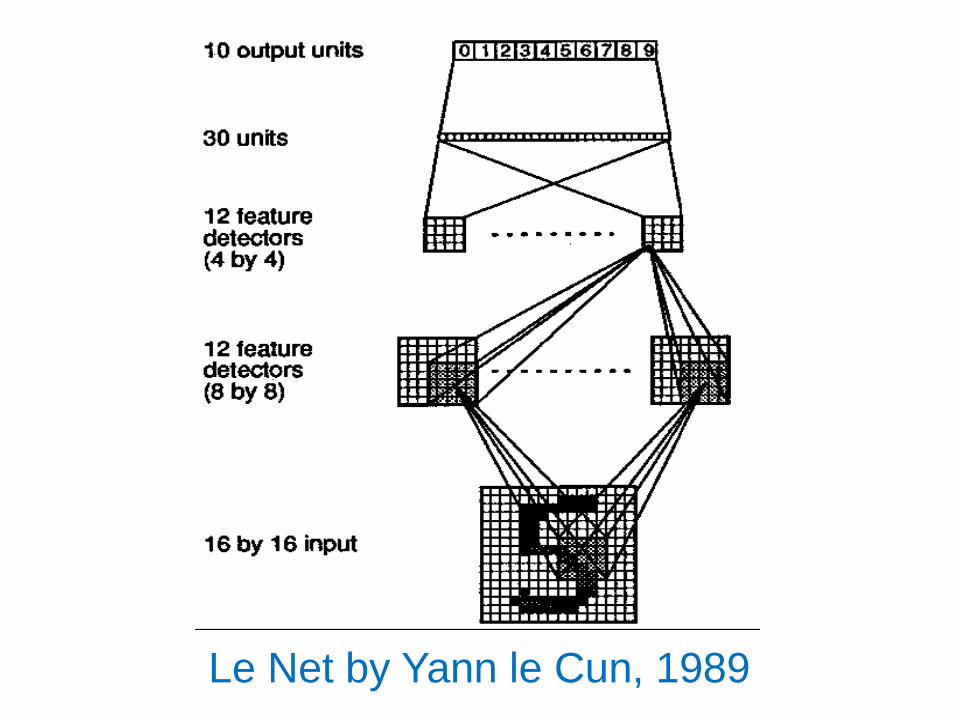
Le Net by Yann le Cun, 1989

The first ICANN ever, in 1991

• My problem at that time: what is nonlinear Principal Component Analysis (PCA)?
• My solution: a novel neural network, deep auto-encoder
• E. Oja: Data compression, feature extraction, and auto-association in feedforward neural networks. Proc. ICANN 1991, pp. 737-745.

Deep auto-encoder (from the paper)

• The trick is that a data vector x is both the input and the desired output.
• This was one of the first papers on multilayer (deep) auto-encoders, which today are quite popular.
• In those days, this was quite difficult to train.
• Newer results: Hinton and Zemel (1994), Bengio (2009), and many others.

CIS lab: the past 25 years

The research was structured by 4 consequent Centers of Excellence financed by the Academy of Finland
• Neural Networks Research Centre NNRC, 1994 – 1999
• Continuation, 2000 – 2005
• Adaptive Informatics Research Centre AIRC, 2006 – 2011
• Computational Inference Research Centre COIN, 2012 - 2017
DEPARTMENT OF INFORMATION
AND COMPUTER SCIENCE
ADAPTIVE INFORMATICS
RESEARCH CENTRE

COIN Centre of Excellence in
Computational Inference:
Introduction
Erkki Oja, Director of COIN

Data analysis,
Machine learning
(Oja, Kaski,
Laaksonen)
Computational
logic,
Intelligent systems
(Niemelä,
Myllymäki) Computational
statistics,
Computational
biology
(Corander, Aurell)
Added Value
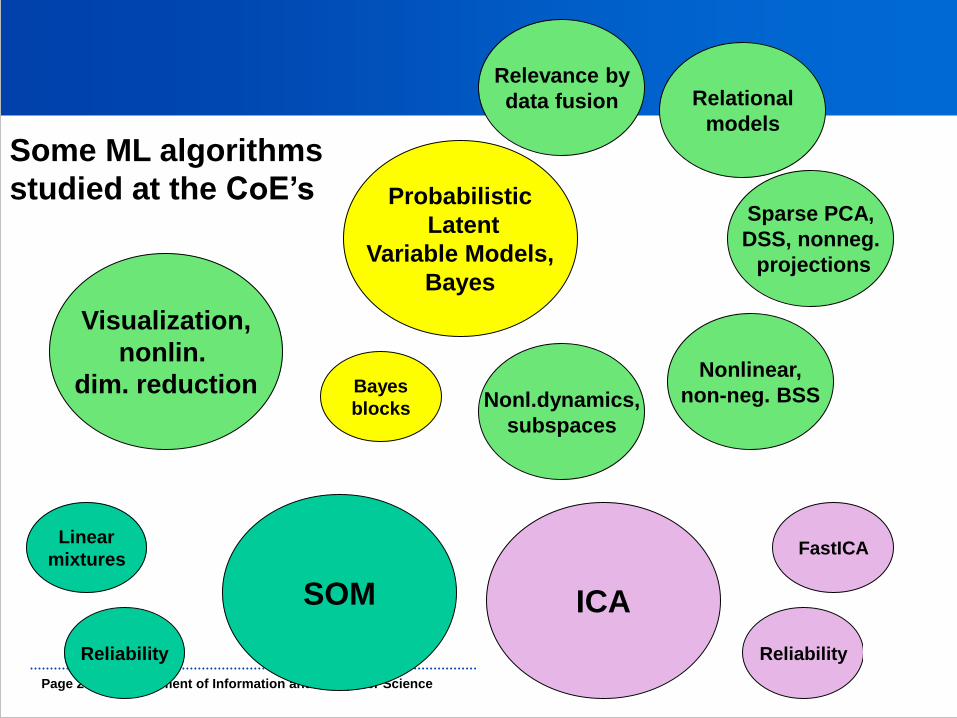
Department of Information and Computer Science Page 20
SOM ICA
Probabilistic
Latent
Variable Models,
Bayes
Reliability Reliability
Linear
mixtures FastICA
Visualization,
nonlin.
dim. reduction Bayes
blocks Nonl.dynamics,
subspaces
Nonlinear,
non-neg. BSS
Sparse PCA,
DSS, nonneg.
projections
Relational
models
Relevance by
data fusion
Some ML algorithms
studied at the CoE’s

Demonstration of Independent Component Analysis (ICA): Original 9 “independent” images

9 mixtures with random mixing; this is the only available data we have

Estimated original images, found by an ICA algorithm


My own present research topic:
matrix factorizations for data analysis

Department of Information and Computer Science Page 26
SOM ICA
Probabilistic
Latent
Variable Models,
Bayes
Reliability Reliability
Linear
mixtures FastICA
Visualization,
nonlin.
dim. reduction Bayes
blocks Nonl.dynamics,
subspaces
Nonlinear,
non-neg. BSS
Sparse PCA,
DSS, nonneg.
projections
Relational
models
Relevance by
data fusion
Some ML algorithms
studied at the CoE’s


Example: spatio-temporal data
• Graphically, the situation may be like this:
space
space
time
time
X W
H

Global daily temperature (10.512 points x 20.440 days)

E.g. global warming component
One row of matrix H
Corresponding column of matrix W


A successful example: the Netflix competition

Non-negative matrix factorization

• NMF and its extensions is today quite an active research topic
– Tensor factorizations (Cichocki et al, 2009)
– Low-rank approximation (LRA) (Markovsky, 2012)
– Missing data (Koren et al, 2009)
– Robust and sparse PCA (Candés et al, 2011)
– Symmetric NMF and clustering (Ding et al, 2012)

NMF and clustering
• Clustering is a very classical problem, in which n vectors (data items) must be partitioned into r clusters.
• The clustering result can be shown by the nxr cluster indicator matrix H
• It is a binary matrix whose element if and only if the i-th data vector belongs to the j-th cluster
1ijh





• The k-means algorithm is minimizing the cost function:
• If the indicator matrix is suitably normalized then this becomes equal to (Ding et al, 2012)
• Notice the similarity to NMF and PCA! (“Binary PCA”)
2
1
r
j Cx
ji
ji
cxJ
2TXHHXJ

• Actually, minimizing this (for H) is
mathematically equivalent to maximizing
which immediately allows the “kernel trick” of replacing with kernel , extending k-means to any data structures (Yang and Oja, IEEE Tr-Neural Networks, 2010).
)( TT XHHXtr
XX T ),( ji xxk

A novel clustering method: DCD
• Starting again from the binary cluster indicator matrix H, we can define another binary matrix called cluster incidence matrix defined as
• Its ij-th element is equal to one if the i-th and the j-th data item are in the same cluster, zero otherwise.
THHM

• It is customary to normalize it so that the row sums (and column sums, because it is symmetric) are equal to 1 (Shi and Malik, 2000). Call the normalized matrix also M.
• Assume a suitable similarity measure between every i-th and j-th data items (for example a kernel). Then a nice criterion is:
ijS
MSJ

• This is an example of symmetrical NMF because both the similarity matrix and the incidence matrix are symmetrical, and both are naturally nonnegative.
• S is full rank, but the rank of M is r.
• Contrary to the usual NMF, there are two extra constraints: the row sums of M are equal to 1, and M is a (scaled) binary matrix.
• The solution: probabilistic relaxation to smooth the constraints (Yang, Corander and Oja,
JMLR, 2016)

Data-cluster-data (DCD) random walk

Clustering results for large datasets
DCD k-means Ncut
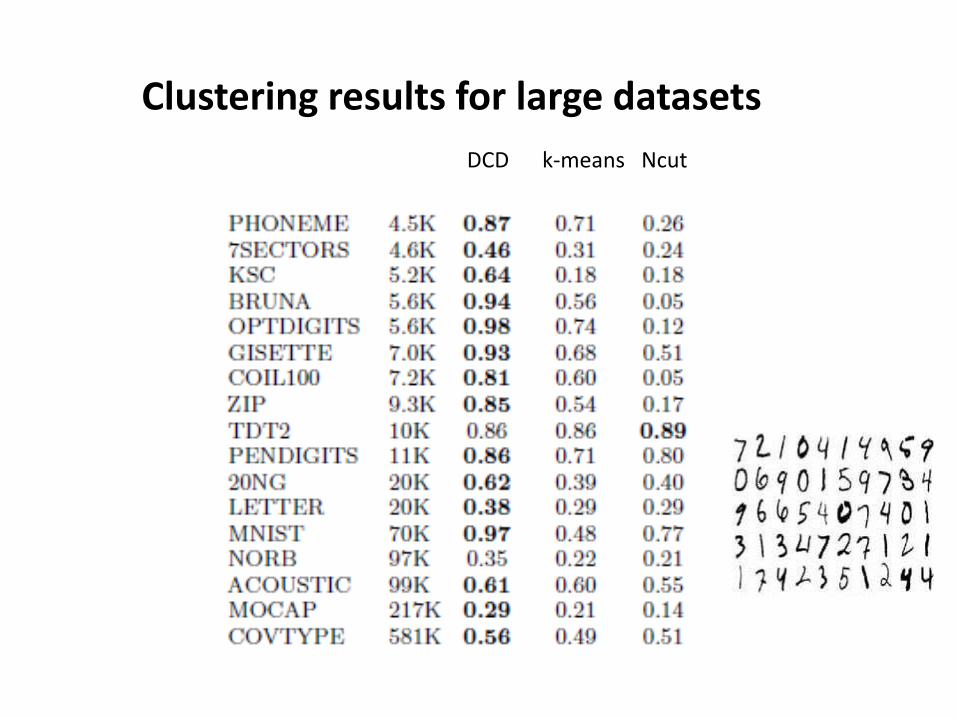
Clustering results for large datasets
DCD k-means Ncut

”CIS lab”: the future
• Now part of the CS department at Aalto School of Science
• Less isolated, much partnerships (other CS groups, HIIT, Helsinki University etc.)
• Talented researchers, increasingly international
• Strong impact on Machine Learning in Finland and in the world, in research and teaching
• Example: our M.Sc. Program Macadamia (Machine Learning and Data Mining; Mannila & Oja 2008)

Macadamia was the 3rd most popular M.Sc. Program in Aalto School of Science in 2017

THANK YOU FOR YOUR ATTENTION!