network inference, with an application to yeast systems biology center for genomic sciences...
Post on 22-Dec-2015
216 views
TRANSCRIPT

Network Inference, With an Application to Yeast Systems Biology
Center for Genomic SciencesCuernavaca, MexicoSeptember 25, 2006
Reinhard Laubenbacher
Virginia Bioinformatics Institute
And
Department of Mathematics
Virginia Tech
http://polymath.vbi.vt.edu

Contributors and Collaborators
Applied Discrete Mathematics Group
(http://polymath.vbi.vt.edu)
• Miguel Colòn-Velez
• Elena Dimitrova (now at Clemson U)
• Luis Garcia (now at Texas A&M)
• Abdul Jarrah
• John McGee (now at Radford U)
• Brandy Stigler (now at MBI)
• Paola Vera-Licona
Collaborators• Diogo Camacho (VBI)• Ana Martins (VBI)• Pedro Mendes (VBI)• Wei Shah (VBI)• Vladimir Shulaev (VBI)• Michael Stillman (Cornell)• Bernd Sturmfels (UC
Berkeley)
Funding: NIH, NSF, Commonwealth of VA

“All processes in organisms,
from the interaction of molecules to the complex
functions of the brain and other whole organs,
strictly obey […] physical laws.
“Where organisms differ from inanimate matter is
in the organization of their systems and especially
in the possession of coded information.”
E. Mayr, 1988

Genome
Molecularnetworks
Organism
Environment
Increasingcomplexity
A multiscale system

Discrete models
“[The] transcriptional control of a gene can be described by a discrete-valued function of several discrete-valued variables.”
“A regulatory network, consisting of many interacting genes and transcription factors, can be described as a collection of interrelated discrete functionsand depicted by a wiring diagram similar to the diagram of a digital logic circuit.”
Karp, 2002

Model Types
Ideker, Lauffenburger, Trends in Biotech 21, 2003

Biochemical Networks
Brazhnik, P., de la Fuente, A. and Mendes, P. Trends in Biotechnology 20, 2002
Gene space
Protein space
Metabolic space
M etabo lite 1 M etabo lite 2
P ro te in 1
P ro te in 2
P ro te in 3
P ro te in 4 C om p lex 3 :4
G ene 1
G ene 2
G ene 3
G ene 4

• Oxidative Stress is a general term used to describe the steady state level of oxidative damage in a cell, tissue, or organ, caused by the species with high oxidative potential.
Introduction to oxidative stress and CHP
+ X + oxidized X
Cumene hydroperoxide (CHP)
Cumyl alcohol (COH)
C CH3CH3
O
O
H
C CH3CH3
O
H
• Cumene hydroperoxide (CHP) is an organic peroxide, thus has high oxidative potential. CHP is very reactive and can easily oxidize molecules such as lipids, proteins and DNA.
• Oxidation by CHP
Courtesy of Wei Sha

Glutathione-glutaredoxin antioxidant defense system
glutathione peroxidase (GPX1, GPX2, GPX3)
GSSG + ROH
(alcohol or water)
Glu + Cys
-GluCys
-glutamylcysteine synthetase (GSH1)
glutathione synthetase (GSH2) + Gly
Feedback inhibition
glutathione S-transferase (GTT1, GTT2)
+
RX
HX + R-SG
glutaredoxin (GRX1, GRX2)
GSHROOH
(peroxides)
+
NADPHNADP+
thioredoxin reductase (TRR1)glutathion oxidoreductase (GLR1)
Courtesy of Wei Sha

Saccharomyces cerevisiae systems biology at VBI Experimentation
Samples for metabolites,
RNA and proteins
Freeze-dry
Metaboliteextraction
GC-MS
Separate cells from the media
DataAnalysis
Quench metabolism in cold buffered methanol
Cell growth in controlled batch (in fermentors)
Experimental treatment(i.e. oxidative stress)
Break cells with high frequency
sound waves
LC-MS CE-MS
RNAextraction
Proteinextraction
AffymetrixGeneChipTM
2D PAGE,MALDI-MS
Sample Prep
Modeling
Courtesy V. Shulaev

CHP treated Samples
Control Samples
Experimental design
Affymetrix Yeast Genome S98 array
0 min 3 min 6 min 12 min 20 min 40 min 70 min 120 min
Cumene hydroperoxide (CHP)
12
3
Wild type yeast cultureWild type yeast culture
Wild type yeast culture
0 min 3 min 6 min 12 min 20 min 40 min 70 min 120 min
Buffer (EtOH)
12
3
Fermentor that contains yeast cell culture
Wild type yeast cultureWild type yeast culture
Wild type yeast culture
Courtesy W. Sha

Comparisons Significantly changed genes (p<0.01)
Up-regulated genes
Down-regulated genes
Cont_3min vs. Cont_0min
1 0 1
Cont_6min vs. Cont_0min
4 2 2
Cont_12min vs. Cont_0min
2 1 1
Cont_20min vs. Cont_0min
18 12 6
Cont_40min vs. Cont_0min
1054 571 483
Cont_70min vs. Cont_0min
2709 1343 1366
Cont_120min vs. Cont_0min
2829 1344 1485
Why is it important to use control samples?
Comparisons Significantly changed genes (p<0.01)
Up-regulated genes
Down-regulated genes
CHP_3min vs. CHP_0min
26 25 1
CHP_6min vs. CHP_0min
235 170 65
CHP_12min vs. CHP_0min
1093 512 581
CHP_20min vs. CHP_0min
1646 867 779
CHP_40min vs. CHP_0min
1643 932 711
CHP_70min vs. CHP_0min
1800 1067 733
CHP_120min vs. CHP_0min
2465 1344 1121
Control samples CHP treated samples
Courtesy W. Sha

Cumene hydroperoxide (CHP) and cumyl alcohol (COH) progress curves
0
50
100
150
200
250
0 20 40 60 80 100 120
Time (min)
Con
cent
ratio
n (
M)
CHP
COH
0
20
40
60
80
100
0 10 20 30 40 50
Time (h)C
on
cen
tra
tion
(m M
)
CHP
COH
In yeast cell culture In medium
Courtesy W. Sha

Pathways induced by oxidative stress were identified
GO term 3min 6min 12min 20min
Response_to_stress >0.1 0.016645 0 0
Carbohydrate_metabolism >0.1 >0.1 0 0
Sporulation >0.1 >0.1 0.02106 0.000644
Protein_catabolism >0.1 >0.1 0.030576 0
Signal_transduction >0.1 >0.1 0.032308 0.000449
KEGG term 3min 6min 12min 20min
Glutathione metabolism >0.1 0.002443 0.013898 5.4E-05
Glycerolipid metabolism >0.1 0.01106 0.00064 0.020554
Starch and sucrose metabolism >0.1 >0.1 0.000485 0.000364
Fructose and mannose metabolism >0.1 >0.1 0.006715 0.028673
Proteasome >0.1 >0.1 >0.1 8.81E-15
Ubiquitin mediated proteolysis >0.1 >0.1 >0.1 0.004418
Courtesy W. Sha

Pathways repressed by oxidative stress were identified
GO term 3min 6min 12min 20min
Nuclear_organization_and_biogenesis >0.1 0.022552 0.000632 0.036472
Ribosome_biogenesis_and_assembly >0.1 0.093905 0 0
Organelle_organization_and_biogenesis >0.1 >0.1 0 0
RNA_metabolism >0.1 >0.1 0 0
Cell_cycle >0.1 >0.1 0.00014 0.036506
Cytokinesis >0.1 >0.1 0 0
Electron_transport >0.1 >0.1 >0.1 0
KEGG term 3min 6min 12min 20min
cell cycle >0.1 0.006487 1.232E-07 0.001035
purine metabolism >0.1 0.009725 5.656E-10 1.133E-09
RNA polymerase >0.1 >0.1 5.396E-13 2.423E-09
pyrimidine metabolism >0.1 >0.1 8.983E-11 6.318E-09
Courtesy W. Sha

k-means clustering analysis result
1 2 3
54
Courtesy W. Sha
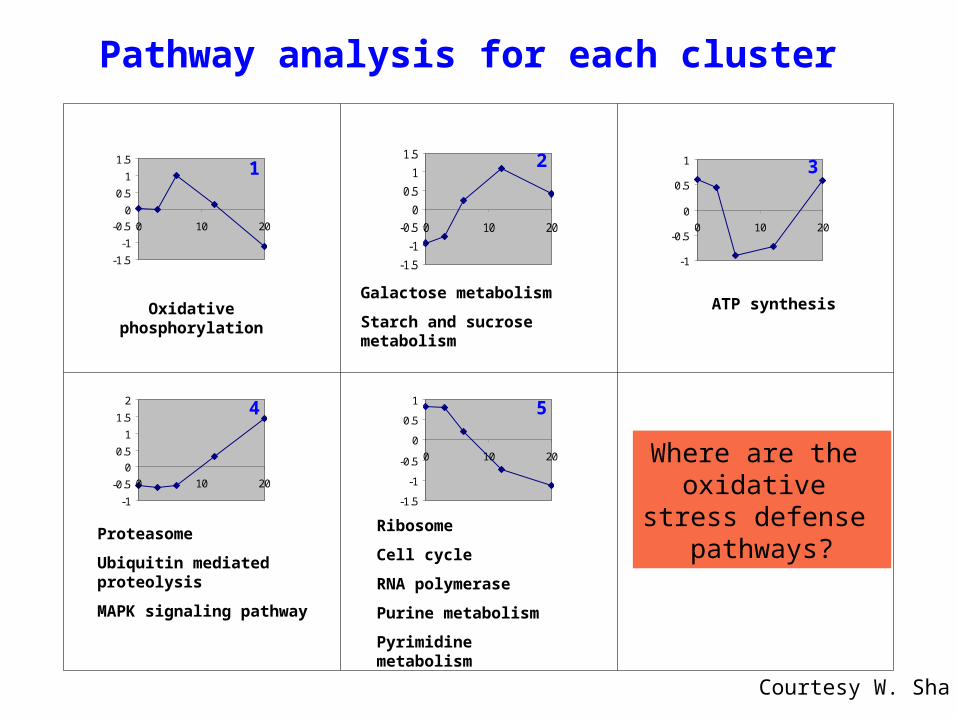
Pathway analysis for each cluster
Ribosome
Cell cycle
RNA polymerase
Purine metabolism
Pyrimidine metabolism
Oxidative phosphorylationGalactose metabolism
Starch and sucrose metabolism
-1.5
-1
-0.5
0
0.5
1
1.5
0 10 20
2
-1.5
-1
-0.5
0
0.5
1
1.5
0 10 20
1
ATP synthesis
-1
-0.5
0
0.5
1
0 10 20
3
-1
-0.5
0
0.5
1
1.5
2
0 10 20
4
Proteasome
Ubiquitin mediated proteolysis
MAPK signaling pathway
-1.5
-1
-0.5
0
0.5
1
0 10 20
5
Where are the oxidative
stress defense pathways?
Courtesy W. Sha

YAP1 was successfully knocked out in yap1 mutant yeast
The transformation of CHP to COH
0
50
100
150
200
250
0 20 40 60 80 100 120
Time (min)
Con
cent
ratio
n (
M)
CHP
COH
in wild type
in yap1 mutant
020406080
100120140160
0 4 8 12 16 20
Time (min)
Ex
pre
ss
ion
le
ve
l
Time series of YAP1 gene expression level in
wild type control sample
wild type CHP treated sample
yap1 mutant Control sample
yap1 mutant CHP treated sample
Genotype Phenotype
0
50
100
150
200
250
0 20 40 60 80 100 120
Time (min)
Con
cent
ratio
n (m
M)
CHP
COH
Courtesy W. Sha

Claytor Lake Network
M1 M2
M23
Courtesy P. Mendes

“Bottom-up modeling:” Model individual pathways and aggregate to system-level models
“Top-down modeling:” Develop network inference methods for system-level phenomenological models

Courtesy P. Mendes

Genetic Regulation
Courtesy P. Mendes

I = lac repressor
= protein which regulates transcription of lac mRNA (genes in blue)
Z = beta-galactosidase
= protein which cleaves lactose to produce glucose, galactose, and allolactose
Y = Lactose permease
= protein which transports lactose into the cell
http://web.mit.edu/esgbio/www/pge/lac.html

Discrete Model for lac Operon
fM = A
fB = M
fA = A (L B)
fL = P (L B)
fP = MModel assumptions
• Transcription/translation require 1 time unit
• mRNA/protein degradation require 1 time unit
• Extracellular lactose always available
M = mRNA for lac genes: LacZ, LacY, LacAB = beta-galactosidaseA = allolactose
= isomer of lactose (inducer)L = lactose (intracellular)P = lactose permease

Discrete Model with Dynamics
(M, B, A, L, P)

Variables x1, … , xn with values in a finite set X.(s1, t1), … , (sr, tr) state transition observations with sj, tj
ε Xn.
Goal: Identify a collection of “best” dynamical systems f=(f1, … ,fn): Xn → Xn
such that f(sj)=tj.
(1) Wiring diagram(2) Dynamics

R. Laubenbacher and B. Stigler, A computational algebra approach to the reverse-engineering of gene regulatory networks, J. Theor. Biol. 229 (2004)
A. Jarrah, R. Laubenbacher, B. Stigler, and M. Stillman, Reverse-engineering of polynomial dynamical systems, Adv. in Appl. Math. (2006) in press

Pandapas network• 10 genes, 3 external biochemicals• 17 interactions
Time course data: 9 time points• Generated 8 time series for wildtype, knockouts G1, G2, G5 • 192 data points• G6, G9 constant
Data discretization• 5 states per node• 95 data points
– 49% reduction – < 0.00001% of 513 total states
Method Validation:Simulated gene network
Courtesy B. Stigler

Method Validation:Simulated gene network
Minimal Sets Algorithm
• 77% interactions• Identified targets of P2, P3 (x12, x13)• 11 false positives, 4 false negatives
Pandapas Reverse engineeredCourtesy B. Stigler

Example: Gene Regulatory Networks
)()(01.0
)(1
)(01.0
)(1
)()(01.0
01.0
)())(01.0))((01.0))((01.0(
10
)()(01.0
)(01.0
)(101.0
)()(01.0
)(01.0
)(101.0
53
3
1
15
43
4
3531
63
23
1
1
2
13
1
1
1
tGtG
tG
tG
tG
dt
dG
tGtGdt
dG
tGtGtGtGdt
dG
tGtG
tG
tG
dt
dG
tGtG
tG
tG
dt
dG
Stable steady states: (1.99006, 1.99006, 0.000024814, 0.997525, 1.99994)
(-0.00493694, -0.00493694, -0.0604538, -0.198201, 0.0547545)

Data (discretized to 5 states)
Algorithm input: 7 such time courses, 60 state transitions
1 1 1 1 1
0.203145 0.203145 0.135339 0.169883 3.469657
0.415507 0.415507 0.018334 0.220206 3.478608
1.192199 1.192199 0.002502 0.600941 2.773302
1.760581 1.760581 0.00036 0.883442 2.223943
1.941092 1.941092 7E-05 0.973211 2.047744
1.980977 1.980977 3.09E-05 0.993022 2.008786
1.988499 1.988499 2.56E-05 0.996752 2.001455
1.989805 1.989805 2.49E-05 0.997398 2.000187
1.990021 1.990021 2.48E-05 0.997505 1.999978
1.990056 1.990056 2.48E-05 0.997522 1.999944
3 1 2 2 1
1 0 1 1 2
1 0 0 1 4
3 0 0 1 3
3 1 0 1 2
4 2 0 1 2
4 2 0 2 2
4 2 0 2 2
4 2 0 2 2
4 2 0 2 2
4 2 0 2 2

A model for 1 wildtype time series
f1 = – x4+1f2 = 1f3 = x4+1f4 = 1f5 = – x5
3 – 2x52+2x4 – 2x5 – 2
var1 = {4}
var2 = {}
var3 = {4}
var4 = {}
var5 = {4, 5}
G1
G2 G5G4
G3

G1
G2 G5G4
G3
G1
G2 G5G4
G3
G1
G2 G5G4
G3
Adding another wildtype time series
G1
G2 G5G4
G3
Adding a knockout time series
All time series

Using 10 random variable orders
G1
G2 G5G4
G3

Wiring diagram missing two (20%) edges; includes 5 indirect interactions.
Network has 55 = 3125 possible state transitions. Input: 60 ( = approx. 2%) state transitions.

Dynamics
Stable steady state:
(1.99006, 1.99006, 0.000024814, 0.997525, 1.99994)
Wild type time series 1
-1
-0.5
0
0.5
1
1.5
2
2.5
3
3.5
4
1 2 3 4 5 6 7 8 9 10 11
Time
Gen
e ex
pre
ssio
n
G1, G2
G3
G4
G5
DiscretizationFixed point: (4, 4, 2, 4,
2)

Dynamics
f1 = 3x3x53+x5
4+4x33+x1
2x5+4x3x52+2x1
2+3x32+4x1x5+x5
2+4x3+4x5+3
f2 = 4x3x54+4x3x5
3+4x54+x3
3+4x12x5+2x3x5
2+4x53+2x1
2+2x1x3+3x32+2x3x5+4x5
2+4x1+4x5+1
f3 = x13x4+4x1x4
3+3x12x4+4x1x4
2+x43+x1
2+x1x4+x42+x1+x4+4
f4 = x3x54+2x3x5
3+3x54+4x3
3+x12x5+3x3
2x5+2x3x52+2x1x3+2x3
2+x52+4x1+x3+4x5+4
f5 = 4x3x54+3x3x5
3+2x53+x1
2+2x1x3+2x32+4x3+4x5+4
Phase space: There are 4 components and 4 fixed point(s) Components Size Cycle Length 1 2200 1 2 890 1 3 10 1 4 25 1
TOTAL: 3125 = 55 nodes
Printing fixed point(s)... [ 0 1 2 1 0 ] lies in a component of size 25. [ 2 2 4 2 3 ] lies in a component of size 10. [ 4 4 2 2 3 ] lies in a component of size 890. [ 4 4 2 4 2 ] lies in a component of size 2200.

Summary
• To use “omics” data set to their full potential network inference methods are useful.
• Cellular processes are dynamical systems, so we need methods for the inference of dynamical systems models.
• Special data requirements.
• Models are useful to generate new hypotheses.
• Validation of modeling technologies is crucial.