my query is slow, now what?
TRANSCRIPT

Gianluca SartoriOwnersqlconsulting.it
My query is slow, now what?

2
Gianluca Sartori
• Independent SQL Server consultant
• Working with SQL Server since version 7
• MCTS, MCITP, MCT
• DBA @ Formula 1 team
Blog: spaghettidba.com
Twitter: @spaghettidba

3
Agenda
My query is slow!
The performance tuning pyramid
Schema design
Code optimization
Indexing

The performance tuningpyramid

5

Schema design

7
Schema Design
Normalization
1NF:Must have a key, atomic attributes only
2NF:Each attribute depends on the whole key
3NF:Each attribute depends only on the key
«The key, the whole key and nothing but the key, so help me Codd»

8
Schema Design
Denormalization clues
• Data repeated redundancy
• Inconsistent data anomalies
• Data separated by «,»
eg: [email protected], [email protected]
• Structured data in «notes» columns
• Column names with a numeric suffix
eg: Area1, Area2 , Area3…

9
Schema Design Worst PracticesNo Primary Key or surrogate keys only«Id» is not the only possible key!
No Foreign KeysThey’re «difficult» to deal with
No CHECK constraintThe application will enforce consistency…
Wrong data typesVAT number, Telephone number
Dates stored as strings
Use of NULL where inappropriate
Use of «dummy» values (eg: ‘.’ , 0)

Query Optimization

11
Query optimization
RBAR
Code Re-Use
Sort / DISTINCT
A query to rule them all
Redundant subqueries

12
Query optimization
• Row By Agonizing Row
• Cursors
• WHILE loops
• App-side cursors
• Scalar and multi-statement functions
http://www.sqlservercentral.com/Authors/Articles/Jeff_Moden/80567/
Jeff Moden

13
RBAR - Cursors
• Procedural code
• Fixed execution strategy doesn’t scale!
• Use lots of memory and CPU
• Use lots of tempdb space
• Execute a huge amount of statements
• Can (almost) always be replaced with set-based code

14
RBAR

15
Code Reuse
• Stored procedures, functions and views encapsulate the complexity
• Code reuse works as far as it doesn’t hurt performance
• What to avoid:• Stored procedure invoked inside cursor loops
• Scalar functions with data access
• Multi-statement table-valued functions
• Views on views on views…

16
Code ReuseStored procedures encapsulate complex logic• Different from OO• No inheritance, polymorfism etc…
Impossible to combine with other constructs
• Require cursors to be applied on a set• App-side cursors are no better!• The same applies to ORMs
If no data modification happens, better use a function (ITVF if possible)

17
Code Reuse – Cursors and stored procedures

18
Functions
Scalar functions work well for complex calculations with NO data access
• Invoked for each row in the input set
• «hidden» RBAR
Better use inline table-valued functions
• Multi-statement table-valued functions return table variables estimated cardinality = 1
• Merged in the outer execution plan

19
Code Reuse – Scalar functions

Might look like a brilliant idea at first
• You can end up losing control
• Unneeded multiple accesses to the same tables
• Unnecessary JOINs
Views on views on views…

21
Code Reuse – Views on views on views…

22
SORT / DISTINCTIf not necessary, don’t sort results
DISTINCT is the refugium peccatorum for missed JOIN predicates
EXISTS often helps avoiding CROSS JOINs for filter predicates
UNION is always DISTINCT
Use UNION ALL whenever possible

One query to rule them all• Set-based is ok, everything in one query is too much
• The optimizer is good, not perfect
• Too complex: where do we start from?
• Divide et impera• Break the code into pieces• CTEs• Temporary tables• Table Variables• Functions
• Identify redundant pieces• Re-assemble
• http://spaghettidba.com/2012/03/15/how-to-eat-a-sql-elephant/

24
Divide et imperaRedundant Subqueries

Indexing

26
Indexing
SARGAbility
Deciding which indexes to create?
Common mistakes
Included columns
Execution plan analysis
How to read an execution plan
What to look for

27
SARGAbility
SARGABLE = Search ARGument ABLE
A predicate is «sargable» when it can be evaluated by means of an index
• Non-Sargable in general is every predicate that requirestransforming the column before evaluation
eg: functions
WHERE YEAR(order_date) = YEAR(GETDATE())

28
SARGabilty - examplesWHERE YEAR(SellStartDate) = YEAR(GETDATE())
WHERE SellStartDate >= DATEADD(yy, DATEDIFF(yy,0,getdate()), 0)AND SellStartDate < DATEADD(yy, DATEDIFF(yy,0,getdate())+1, 0)
WHERE ISNULL(ProductLine,'M') = 'M'
WHERE ProductLine = 'M' OR ProductLine IS NULL
WHERE LEFT(ProductNumber,2) = 'BK'
WHERE ProductNumber LIKE 'BK%'

29
Deciding which indexes to createCreate indexes to support the following predicates• WHERE• JOIN• GROUP BY• ORDER BY
Indexes are used effectively when the leading column appears in the predicate
Execution plans suggest missing indexes• Watch out from overly «aggressive» suggestions

30
Common mistakes• One index for each column• Missing indexes on Foreign Keys• Accepting all suggestions from the DB Tuning Advisor• Duplicate Indexes• Sub-optimal clustered index• Unique• Small• Invariable• Ever-increasing• Not testing on the whole workload

31
Included columnsColumns not present in filter predicates but only in the SELECT list can be included
Included columns are not for free
• Present at leaf level in the B-tree
• Contribute to index size
Clustered index always includes all columns
Nonclustered indexes always include the clustering key

32
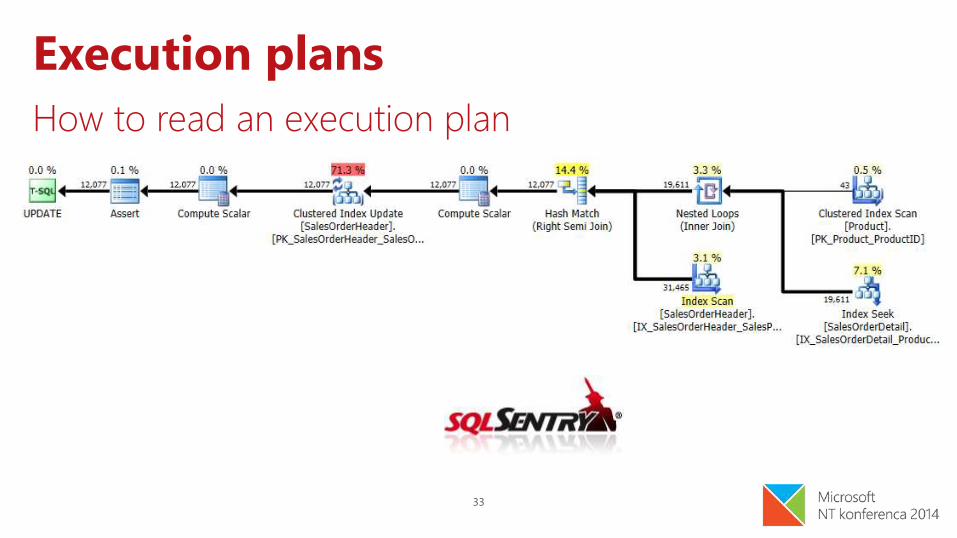
Execution plans
Output of the query optimizer
T-SQL
statement
Parser Algebrizer
Algebrizer
TreeOptimizer
Statistics
Execution Plan
33
Execution plans
How to read an execution plan

34
Execution plans
What to look for: Implicit conversions
Scans
Missing JOIN predicate alerts
Spools
Sorts
Parallelism
Wrong cardinality estimates

35
RecapSimplify codeRBAR is the root of all evilRemove redundant accessesDivide et impera
Execution plansAdding indexes may helpUnused indexes?SARGability Included columns
Schema design mistakes?

Q&A.
