mus-rover - bnl.gov · the student starts as a tabula rasa that picks pitches uniformly at random...
TRANSCRIPT

MUS-ROVERAn Automatic Music Theorist and Pedagogue
Haizi Yu, Lav R. Varshney
University of Illinois at Urbana-Champaign
Supported in part by C3SR

A Music Story

A Music Story
BWV 124

A Music Story
?
BWV 124

What makes music music?


Gradus ad Parnassum

Gradus ad Parnassum
“The path towards Mount Parnassus”

Gradus ad Parnassum
“The path towards Mount Parnassus”
the home of the muses

Gradus ad Parnassum
“The path towards Mount Parnassus”
the home of the muses

Gradus ad Parnassum
“The path towards Mount Parnassus”
the home of the muses

A New Learning ProblemAutomatic Concept Learning
Input Output
ConceptsRulesLaws…

A New Learning Paradigm
New Concept RepresentationNew Learning Algorithm

Data space: (X, pX) (X, p)or for short
Representation: Data Space

Data space: (X, pX) (X, p)or for short
Assume a data point x 2 X is an i.i.d. sampledrawn from a probability distribution p .
Representation: Data Space

Data space: (X, pX) (X, p)or for short
Assume a data point x 2 X is an i.i.d. sampledrawn from a probability distribution p .
However, the data distribution , or an estimation of it, is known.
p
The goal here is not to estimate but to explain it.p
Representation: Data Space

Representation: Chord SpaceConsidering chords from Bach’s four-part chorales recorded in sheet music.Here, a chord is any collection of four simultaneously sounding pitches.
Chord space: X = Z4
chord: x =
2
664
x1
x2
x3
x4
3
775 2 X
pitch:
voice:
xi 2 Z
i 2 {1, 2, 3, 4}S A T B
(C4 ! 60)
C3
B[3
48
58
67
76E5
G4 !
!
!
!
2
66666666664
3
77777777775
2
66666666664
3
77777777775

Representation: Abstraction
An abstraction is a partition of the data space . A X

Representation: Abstraction
An abstraction is a partition of the data space . A X
X = {x1, x2, x3, x4, x5, x6}A = {{x1, x6}, {x3}, {x2, x4, x5}}

Representation: Abstraction
An abstraction is a partition of the data space . A X
X = {x1, x2, x3, x4, x5, x6}A = {{x1, x6}, {x3}, {x2, x4, x5}}
cells (or less formally, clusters)

Representation: Abstraction
An abstraction is a partition of the data space . A X
X = {x1, x2, x3, x4, x5, x6}A = {{x1, x6}, {x3}, {x2, x4, x5}}
cells (or less formally, clusters)
An concept is a partition cell.

Representation: Abstraction
An abstraction is a partition of the data space . A X
X = {x1, x2, x3, x4, x5, x6}A = {{x1, x6}, {x3}, {x2, x4, x5}}
cells (or less formally, clusters)
An concept is a partition cell.
A partition matrix is a concise way of representing an abstraction .A
A

Representation: Abstraction
An abstraction is a partition of the data space . A X
X = {x1, x2, x3, x4, x5, x6}A = {{x1, x6}, {x3}, {x2, x4, x5}}
cells (or less formally, clusters)
An concept is a partition cell.
A partition matrix is a concise way of representing an abstraction .A
A
A =
2
41 0 0 0 0 10 0 1 0 0 00 1 0 1 1 0
3
5

Representation: Abstraction
An abstraction is a partition of the data space . A X
X = {x1, x2, x3, x4, x5, x6}A = {{x1, x6}, {x3}, {x2, x4, x5}}
cells (or less formally, clusters)
An concept is a partition cell.
A partition matrix is a concise way of representing an abstraction .A
A
A =
2
41 0 0 0 0 10 0 1 0 0 00 1 0 1 1 0
3
5
x6x5x4x3x2x1
1st cell2nd cell3rd cell

Representation: Probabilistic RulesA probabilistic rule is a pair:
(A, pA)
where is an abstraction (partition);Ais a probability distribution over the abstracted concepts (cells).
pA
0.50.4
0.1X = {x1, x2, x3, x4, x5, x6}A = {{x1, x6}, {x3}, {x2, x4, x5}}

Representation Summary
Abstraction:
Concept:
Probabilistic rule:
a partition
a partition cell (cluster)
abstraction & distribution

Representation Summary
Automatic concept learning: ?
Abstraction:
Concept:
Probabilistic rule:
a partition
a partition cell (cluster)
abstraction & distribution

Automatic Concept Learningis
the process of learning probabilistic rules
But how?
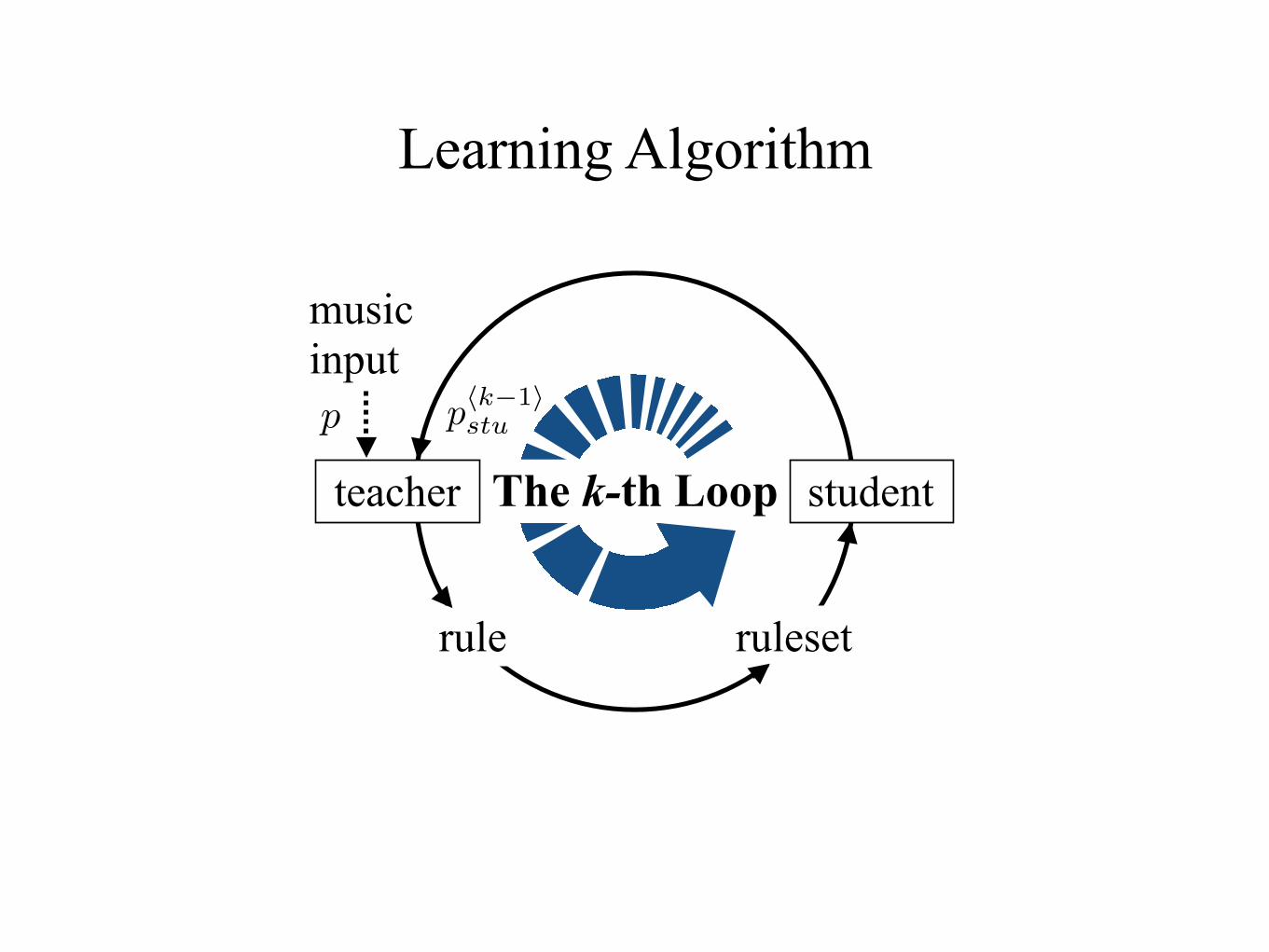
Learning AlgorithmPublished as a conference paper at ICLR 2017
The k-th Loop student teacher
rule ruleset
music input
�k
{�i
}k
i=1
p̂ phk�1istu
phkistu
�
The teacher solves:
maximize D⇣
phk�1i�,stu
|| p̂�
⌘
subject to � 2 �\�hk�1i
(discrete optimization)
The student solves:
maximize Sq
⇣
phkistu
⌘
subject to phkistu
2 �1
· · ·
phkistu
2 �k
(linear least-squares)
Figure 1: MUS-ROVER’s self-learning loop (the kth iteration). The teacher (discriminator) takesas inputs the student’s latest style p
hk�1istu
and the input style p̂, and identifies a feature � throughwhich the two styles manifest the largest gap D(·||·). The identified feature is then made into a rule(a constraint set �
k
), and augments the ruleset {�i
}k
i=1. The student (generator) takes as input theaugmented ruleset to update its writing style into p
hkistu
, and favors creativity, i.e. more possibilities,by maximizing the Tsallis entropy S
q
subject to the rule constraints. In short, the teacher extractsrules while the student applies rules; both perform their tasks by solving optimization problems.
We compare the paths taken by this improved automatic theorist to paths taken by human theorists(say Fux), studying similarities as well as pros and cons of each. So advantages from both can bejointly taken to maximize the utility in music education and research. In this paper in particular,we highlight the concept hierarchy that one would not get from our prior work, as well as enhancedsyllabus personalization that one would not typically get from traditional pedagogy.
2 MUS-ROVER OVERVIEW
As the first algorithmic pathfinder in music, MUS-ROVER I introduced a “teacher ⌦ student” modelto extract compositional rules for writing 4-part chorales (Yu et al., 2016a;b). The model is im-plemented by a self-learning loop between a generative component (student) and a discriminativecomponent (teacher), where both entities cooperate to iterate through the rule-learning process (Fig-ure 1). The student starts as a tabula rasa that picks pitches uniformly at random to form sonorities(a generic term for chord) and sonority progressions. The teacher compares the student’s writingstyle (represented by a probabilistic model) with the input style (represented by empirical statistics),identifying one feature per iteration that best reveals the gap between the two styles, and making ita rule for the student to update its probabilistic model. As a result, the student becomes less andless random by obeying more and more rules, and thus, approaches the input style. Collecting fromits rule-learning traces, MUS-ROVER I successfully recovered many known rules, such as “Parallelperfect octaves/fifths are rare” and “Tritons are often resolved either inwardly or outwardly”.
What is Inherited from MUS-ROVER I MUS-ROVER II targets the same goal of learning in-terpretable music concepts. It inherits the self-learning loop, as well as the following design choices.
(Dataset and Data Representation) We use the same dataset that comprises 370 C scores of Bach’s4-part chorales. We include only pitches and their durations in a piece’s raw representation, notatedas a MIDI matrix whose elements are MIDI numbers for pitches. The matrix preserves the two-dimensional chorale texture, with rows corresponding to melodies, and columns to harmonies.
(Rule Representation) We use the same representation for high-level concepts in terms of rules,unrelated to rules in propositional logic. A (compositional) rule is represented by a feature and itsdistribution: r = (�, p
�
), which describes likelihoods of feature values. It can also be transformedto a linear equality constraint (A
�
pstu
= p�
) in the student’s optimization problem (�’s in Figure 1).
(Student’s Probabilistic Model) We still use n-gram models to represent the student’s style/belief,with words being sonority features, and keep the student’s optimization problem as it was. Toreiterate the distinctions to many music n-grams, we never run n-grams in the raw feature space, butonly collectively in the high-level feature spaces to prevent overfitting. So, rules are expressed asprobabilistic laws that describe either (vertical) sonority features or their (horizontal) progressions.
2
p

Learning AlgorithmPublished as a conference paper at ICLR 2017
The k-th Loop student teacher
rule ruleset
music input
�k
{�i
}k
i=1
p̂ phk�1istu
phkistu
�
The teacher solves:
maximize D⇣
phk�1i�,stu
|| p̂�
⌘
subject to � 2 �\�hk�1i
(discrete optimization)
The student solves:
maximize Sq
⇣
phkistu
⌘
subject to phkistu
2 �1
· · ·
phkistu
2 �k
(linear least-squares)
Figure 1: MUS-ROVER’s self-learning loop (the kth iteration). The teacher (discriminator) takesas inputs the student’s latest style p
hk�1istu
and the input style p̂, and identifies a feature � throughwhich the two styles manifest the largest gap D(·||·). The identified feature is then made into a rule(a constraint set �
k
), and augments the ruleset {�i
}k
i=1. The student (generator) takes as input theaugmented ruleset to update its writing style into p
hkistu
, and favors creativity, i.e. more possibilities,by maximizing the Tsallis entropy S
q
subject to the rule constraints. In short, the teacher extractsrules while the student applies rules; both perform their tasks by solving optimization problems.
We compare the paths taken by this improved automatic theorist to paths taken by human theorists(say Fux), studying similarities as well as pros and cons of each. So advantages from both can bejointly taken to maximize the utility in music education and research. In this paper in particular,we highlight the concept hierarchy that one would not get from our prior work, as well as enhancedsyllabus personalization that one would not typically get from traditional pedagogy.
2 MUS-ROVER OVERVIEW
As the first algorithmic pathfinder in music, MUS-ROVER I introduced a “teacher ⌦ student” modelto extract compositional rules for writing 4-part chorales (Yu et al., 2016a;b). The model is im-plemented by a self-learning loop between a generative component (student) and a discriminativecomponent (teacher), where both entities cooperate to iterate through the rule-learning process (Fig-ure 1). The student starts as a tabula rasa that picks pitches uniformly at random to form sonorities(a generic term for chord) and sonority progressions. The teacher compares the student’s writingstyle (represented by a probabilistic model) with the input style (represented by empirical statistics),identifying one feature per iteration that best reveals the gap between the two styles, and making ita rule for the student to update its probabilistic model. As a result, the student becomes less andless random by obeying more and more rules, and thus, approaches the input style. Collecting fromits rule-learning traces, MUS-ROVER I successfully recovered many known rules, such as “Parallelperfect octaves/fifths are rare” and “Tritons are often resolved either inwardly or outwardly”.
What is Inherited from MUS-ROVER I MUS-ROVER II targets the same goal of learning in-terpretable music concepts. It inherits the self-learning loop, as well as the following design choices.
(Dataset and Data Representation) We use the same dataset that comprises 370 C scores of Bach’s4-part chorales. We include only pitches and their durations in a piece’s raw representation, notatedas a MIDI matrix whose elements are MIDI numbers for pitches. The matrix preserves the two-dimensional chorale texture, with rows corresponding to melodies, and columns to harmonies.
(Rule Representation) We use the same representation for high-level concepts in terms of rules,unrelated to rules in propositional logic. A (compositional) rule is represented by a feature and itsdistribution: r = (�, p
�
), which describes likelihoods of feature values. It can also be transformedto a linear equality constraint (A
�
pstu
= p�
) in the student’s optimization problem (�’s in Figure 1).
(Student’s Probabilistic Model) We still use n-gram models to represent the student’s style/belief,with words being sonority features, and keep the student’s optimization problem as it was. Toreiterate the distinctions to many music n-grams, we never run n-grams in the raw feature space, butonly collectively in the high-level feature spaces to prevent overfitting. So, rules are expressed asprobabilistic laws that describe either (vertical) sonority features or their (horizontal) progressions.
2
p
A(k)

Learning AlgorithmPublished as a conference paper at ICLR 2017
The k-th Loop student teacher
rule ruleset
music input
�k
{�i
}k
i=1
p̂ phk�1istu
phkistu
�
The teacher solves:
maximize D⇣
phk�1i�,stu
|| p̂�
⌘
subject to � 2 �\�hk�1i
(discrete optimization)
The student solves:
maximize Sq
⇣
phkistu
⌘
subject to phkistu
2 �1
· · ·
phkistu
2 �k
(linear least-squares)
Figure 1: MUS-ROVER’s self-learning loop (the kth iteration). The teacher (discriminator) takesas inputs the student’s latest style p
hk�1istu
and the input style p̂, and identifies a feature � throughwhich the two styles manifest the largest gap D(·||·). The identified feature is then made into a rule(a constraint set �
k
), and augments the ruleset {�i
}k
i=1. The student (generator) takes as input theaugmented ruleset to update its writing style into p
hkistu
, and favors creativity, i.e. more possibilities,by maximizing the Tsallis entropy S
q
subject to the rule constraints. In short, the teacher extractsrules while the student applies rules; both perform their tasks by solving optimization problems.
We compare the paths taken by this improved automatic theorist to paths taken by human theorists(say Fux), studying similarities as well as pros and cons of each. So advantages from both can bejointly taken to maximize the utility in music education and research. In this paper in particular,we highlight the concept hierarchy that one would not get from our prior work, as well as enhancedsyllabus personalization that one would not typically get from traditional pedagogy.
2 MUS-ROVER OVERVIEW
As the first algorithmic pathfinder in music, MUS-ROVER I introduced a “teacher ⌦ student” modelto extract compositional rules for writing 4-part chorales (Yu et al., 2016a;b). The model is im-plemented by a self-learning loop between a generative component (student) and a discriminativecomponent (teacher), where both entities cooperate to iterate through the rule-learning process (Fig-ure 1). The student starts as a tabula rasa that picks pitches uniformly at random to form sonorities(a generic term for chord) and sonority progressions. The teacher compares the student’s writingstyle (represented by a probabilistic model) with the input style (represented by empirical statistics),identifying one feature per iteration that best reveals the gap between the two styles, and making ita rule for the student to update its probabilistic model. As a result, the student becomes less andless random by obeying more and more rules, and thus, approaches the input style. Collecting fromits rule-learning traces, MUS-ROVER I successfully recovered many known rules, such as “Parallelperfect octaves/fifths are rare” and “Tritons are often resolved either inwardly or outwardly”.
What is Inherited from MUS-ROVER I MUS-ROVER II targets the same goal of learning in-terpretable music concepts. It inherits the self-learning loop, as well as the following design choices.
(Dataset and Data Representation) We use the same dataset that comprises 370 C scores of Bach’s4-part chorales. We include only pitches and their durations in a piece’s raw representation, notatedas a MIDI matrix whose elements are MIDI numbers for pitches. The matrix preserves the two-dimensional chorale texture, with rows corresponding to melodies, and columns to harmonies.
(Rule Representation) We use the same representation for high-level concepts in terms of rules,unrelated to rules in propositional logic. A (compositional) rule is represented by a feature and itsdistribution: r = (�, p
�
), which describes likelihoods of feature values. It can also be transformedto a linear equality constraint (A
�
pstu
= p�
) in the student’s optimization problem (�’s in Figure 1).
(Student’s Probabilistic Model) We still use n-gram models to represent the student’s style/belief,with words being sonority features, and keep the student’s optimization problem as it was. Toreiterate the distinctions to many music n-grams, we never run n-grams in the raw feature space, butonly collectively in the high-level feature spaces to prevent overfitting. So, rules are expressed asprobabilistic laws that describe either (vertical) sonority features or their (horizontal) progressions.
2
p
A(k)
(A(k), pA(k))

Learning AlgorithmPublished as a conference paper at ICLR 2017
The k-th Loop student teacher
rule ruleset
music input
�k
{�i
}k
i=1
p̂ phk�1istu
phkistu
�
The teacher solves:
maximize D⇣
phk�1i�,stu
|| p̂�
⌘
subject to � 2 �\�hk�1i
(discrete optimization)
The student solves:
maximize Sq
⇣
phkistu
⌘
subject to phkistu
2 �1
· · ·
phkistu
2 �k
(linear least-squares)
Figure 1: MUS-ROVER’s self-learning loop (the kth iteration). The teacher (discriminator) takesas inputs the student’s latest style p
hk�1istu
and the input style p̂, and identifies a feature � throughwhich the two styles manifest the largest gap D(·||·). The identified feature is then made into a rule(a constraint set �
k
), and augments the ruleset {�i
}k
i=1. The student (generator) takes as input theaugmented ruleset to update its writing style into p
hkistu
, and favors creativity, i.e. more possibilities,by maximizing the Tsallis entropy S
q
subject to the rule constraints. In short, the teacher extractsrules while the student applies rules; both perform their tasks by solving optimization problems.
We compare the paths taken by this improved automatic theorist to paths taken by human theorists(say Fux), studying similarities as well as pros and cons of each. So advantages from both can bejointly taken to maximize the utility in music education and research. In this paper in particular,we highlight the concept hierarchy that one would not get from our prior work, as well as enhancedsyllabus personalization that one would not typically get from traditional pedagogy.
2 MUS-ROVER OVERVIEW
As the first algorithmic pathfinder in music, MUS-ROVER I introduced a “teacher ⌦ student” modelto extract compositional rules for writing 4-part chorales (Yu et al., 2016a;b). The model is im-plemented by a self-learning loop between a generative component (student) and a discriminativecomponent (teacher), where both entities cooperate to iterate through the rule-learning process (Fig-ure 1). The student starts as a tabula rasa that picks pitches uniformly at random to form sonorities(a generic term for chord) and sonority progressions. The teacher compares the student’s writingstyle (represented by a probabilistic model) with the input style (represented by empirical statistics),identifying one feature per iteration that best reveals the gap between the two styles, and making ita rule for the student to update its probabilistic model. As a result, the student becomes less andless random by obeying more and more rules, and thus, approaches the input style. Collecting fromits rule-learning traces, MUS-ROVER I successfully recovered many known rules, such as “Parallelperfect octaves/fifths are rare” and “Tritons are often resolved either inwardly or outwardly”.
What is Inherited from MUS-ROVER I MUS-ROVER II targets the same goal of learning in-terpretable music concepts. It inherits the self-learning loop, as well as the following design choices.
(Dataset and Data Representation) We use the same dataset that comprises 370 C scores of Bach’s4-part chorales. We include only pitches and their durations in a piece’s raw representation, notatedas a MIDI matrix whose elements are MIDI numbers for pitches. The matrix preserves the two-dimensional chorale texture, with rows corresponding to melodies, and columns to harmonies.
(Rule Representation) We use the same representation for high-level concepts in terms of rules,unrelated to rules in propositional logic. A (compositional) rule is represented by a feature and itsdistribution: r = (�, p
�
), which describes likelihoods of feature values. It can also be transformedto a linear equality constraint (A
�
pstu
= p�
) in the student’s optimization problem (�’s in Figure 1).
(Student’s Probabilistic Model) We still use n-gram models to represent the student’s style/belief,with words being sonority features, and keep the student’s optimization problem as it was. Toreiterate the distinctions to many music n-grams, we never run n-grams in the raw feature space, butonly collectively in the high-level feature spaces to prevent overfitting. So, rules are expressed asprobabilistic laws that describe either (vertical) sonority features or their (horizontal) progressions.
2
p
A(k)
(A(k), pA(k))n
(A(i), pA(i))ok
i=1

Learning AlgorithmPublished as a conference paper at ICLR 2017
The k-th Loop student teacher
rule ruleset
music input
�k
{�i
}k
i=1
p̂ phk�1istu
phkistu
�
The teacher solves:
maximize D⇣
phk�1i�,stu
|| p̂�
⌘
subject to � 2 �\�hk�1i
(discrete optimization)
The student solves:
maximize Sq
⇣
phkistu
⌘
subject to phkistu
2 �1
· · ·
phkistu
2 �k
(linear least-squares)
Figure 1: MUS-ROVER’s self-learning loop (the kth iteration). The teacher (discriminator) takesas inputs the student’s latest style p
hk�1istu
and the input style p̂, and identifies a feature � throughwhich the two styles manifest the largest gap D(·||·). The identified feature is then made into a rule(a constraint set �
k
), and augments the ruleset {�i
}k
i=1. The student (generator) takes as input theaugmented ruleset to update its writing style into p
hkistu
, and favors creativity, i.e. more possibilities,by maximizing the Tsallis entropy S
q
subject to the rule constraints. In short, the teacher extractsrules while the student applies rules; both perform their tasks by solving optimization problems.
We compare the paths taken by this improved automatic theorist to paths taken by human theorists(say Fux), studying similarities as well as pros and cons of each. So advantages from both can bejointly taken to maximize the utility in music education and research. In this paper in particular,we highlight the concept hierarchy that one would not get from our prior work, as well as enhancedsyllabus personalization that one would not typically get from traditional pedagogy.
2 MUS-ROVER OVERVIEW
As the first algorithmic pathfinder in music, MUS-ROVER I introduced a “teacher ⌦ student” modelto extract compositional rules for writing 4-part chorales (Yu et al., 2016a;b). The model is im-plemented by a self-learning loop between a generative component (student) and a discriminativecomponent (teacher), where both entities cooperate to iterate through the rule-learning process (Fig-ure 1). The student starts as a tabula rasa that picks pitches uniformly at random to form sonorities(a generic term for chord) and sonority progressions. The teacher compares the student’s writingstyle (represented by a probabilistic model) with the input style (represented by empirical statistics),identifying one feature per iteration that best reveals the gap between the two styles, and making ita rule for the student to update its probabilistic model. As a result, the student becomes less andless random by obeying more and more rules, and thus, approaches the input style. Collecting fromits rule-learning traces, MUS-ROVER I successfully recovered many known rules, such as “Parallelperfect octaves/fifths are rare” and “Tritons are often resolved either inwardly or outwardly”.
What is Inherited from MUS-ROVER I MUS-ROVER II targets the same goal of learning in-terpretable music concepts. It inherits the self-learning loop, as well as the following design choices.
(Dataset and Data Representation) We use the same dataset that comprises 370 C scores of Bach’s4-part chorales. We include only pitches and their durations in a piece’s raw representation, notatedas a MIDI matrix whose elements are MIDI numbers for pitches. The matrix preserves the two-dimensional chorale texture, with rows corresponding to melodies, and columns to harmonies.
(Rule Representation) We use the same representation for high-level concepts in terms of rules,unrelated to rules in propositional logic. A (compositional) rule is represented by a feature and itsdistribution: r = (�, p
�
), which describes likelihoods of feature values. It can also be transformedto a linear equality constraint (A
�
pstu
= p�
) in the student’s optimization problem (�’s in Figure 1).
(Student’s Probabilistic Model) We still use n-gram models to represent the student’s style/belief,with words being sonority features, and keep the student’s optimization problem as it was. Toreiterate the distinctions to many music n-grams, we never run n-grams in the raw feature space, butonly collectively in the high-level feature spaces to prevent overfitting. So, rules are expressed asprobabilistic laws that describe either (vertical) sonority features or their (horizontal) progressions.
2
p
A(k)
(A(k), pA(k))n
(A(i), pA(i))ok
i=1
phkistu

Teacher: a Discriminative Model
Want to find the abstraction which exhibits the largest statistical difference between the student and the input data.

Teacher: a Discriminative ModelThe teacher solves an optimization problem:
maximize
A2PX
DKL
⇣phk�1iA,stu
�� pA⌘
subject to the abstraction A satisfying
the memorability condition
the hierarchy condition
. . .

Teacher: a Discriminative ModelThe teacher solves an optimization problem:
maximize
A2PX
DKL
⇣phk�1iA,stu
�� pA⌘
subject to the abstraction A satisfying
the memorability condition
the hierarchy condition
. . .
What does come from?PX

Teacher: a Discriminative Model
PX : abstraction universe

Teacher: a Discriminative Model
PX : abstraction universe
Mathematically, a partition lattice, which is a special type of partially ordered set

Teacher: a Discriminative Model
PX : abstraction universe
Mathematically, a partition lattice, which is a special type of partially ordered setPictorially, a directed acyclic graph (vertex: partition; edge: coarser than)

Teacher: a Discriminative Model
PX : abstraction universe
Mathematically, a partition lattice, which is a special type of partially ordered setPictorially, a directed acyclic graph (vertex: partition; edge: coarser than)
coarser
finer
(more general)
(more specific)

Teacher: a Discriminative Model
How to construct A 2 PX (abstraction universe) ?

Teacher: a Discriminative Model
• Feature-Induced Partition • Symmetry-Generated Partition
How to construct A 2 PX (abstraction universe) ?

Teacher: a Discriminative Model
• Feature-Induced Partition • Symmetry-Generated Partition
How to construct A 2 PX (abstraction universe) ?
In both cases, the underlying mechanism that generates the partition is human-interpretable.
We do not consider arbitrary partitions.

Teacher: a Discriminative Model
• Feature-Induced Partition • Symmetry-Generated Partition
How to construct A 2 PX (abstraction universe) ?
In both cases, the underlying mechanism that generates the partition is human-interpretable.
We do not consider arbitrary partitions.

Teacher: a Discriminative Model
• Feature-Induced Partition
How to construct A 2 PX (abstraction universe) ?
A� =���1({y}) | y 2 �(X)
How to construct � 2 � (feature universe) ?
� = d � w
d 2 D (discriptors) and w 2 W (windows) ?How to constructd = bk � · · · � b1, bi 2 B
w = wI , I ✓ {1, 2, 3, 4}

Teacher: a Discriminative Model
• Feature-Induced Partition
How to construct A 2 PX (abstraction universe) ?
For example: d = mod12 � diff, w = w{1,4}
A� =���1({y}) | y 2 �(X)
How to construct � 2 � (feature universe) ?
� = d � w
d 2 D (discriptors) and w 2 W (windows) ?How to constructd = bk � · · · � b1, bi 2 B
w = wI , I ✓ {1, 2, 3, 4}

Teacher: a Discriminative ModelThe teacher solves an optimization problem:
maximize
A2PX
DKL
⇣phk�1iA,stu
�� pA⌘
subject to the abstraction A satisfying
the memorability condition
the hierarchy condition
. . .

Teacher: a Discriminative ModelThe teacher solves an optimization problem:
given , computing is easy:p pANote that:
x1 x2 x3 x5 x6x4
0.1 0.1 0.10.2 0.2
0.3
{x1, x6} {x3} {x2, x4, x5}? ? ?
maximize
A2PX
DKL
⇣phk�1iA,stu
�� pA⌘
subject to the abstraction A satisfying
the memorability condition
the hierarchy condition
. . .

Teacher: a Discriminative ModelThe teacher solves an optimization problem:
given , computing is easy:p pANote that:
x1 x2 x3 x5 x6x4 {x1, x6} {x3} {x2, x4, x5}
0.1 0.1 0.10.2 0.2
0.3
? ? ?
maximize
A2PX
DKL
⇣phk�1iA,stu
�� pA⌘
subject to the abstraction A satisfying
the memorability condition
the hierarchy condition
. . .

Teacher: a Discriminative ModelThe teacher solves an optimization problem:
given , computing is easy:p pANote that:
{x1, x6} {x3} {x2, x4, x5}x1 x2 x3 x5 x6x4
0.1 0.1 0.10.2 0.2
0.3 0.30.30.4
maximize
A2PX
DKL
⇣phk�1iA,stu
�� pA⌘
subject to the abstraction A satisfying
the memorability condition
the hierarchy condition
. . .

Student: a Generative Model
Apply probabilistic rules, which is known as the rule realization problem.
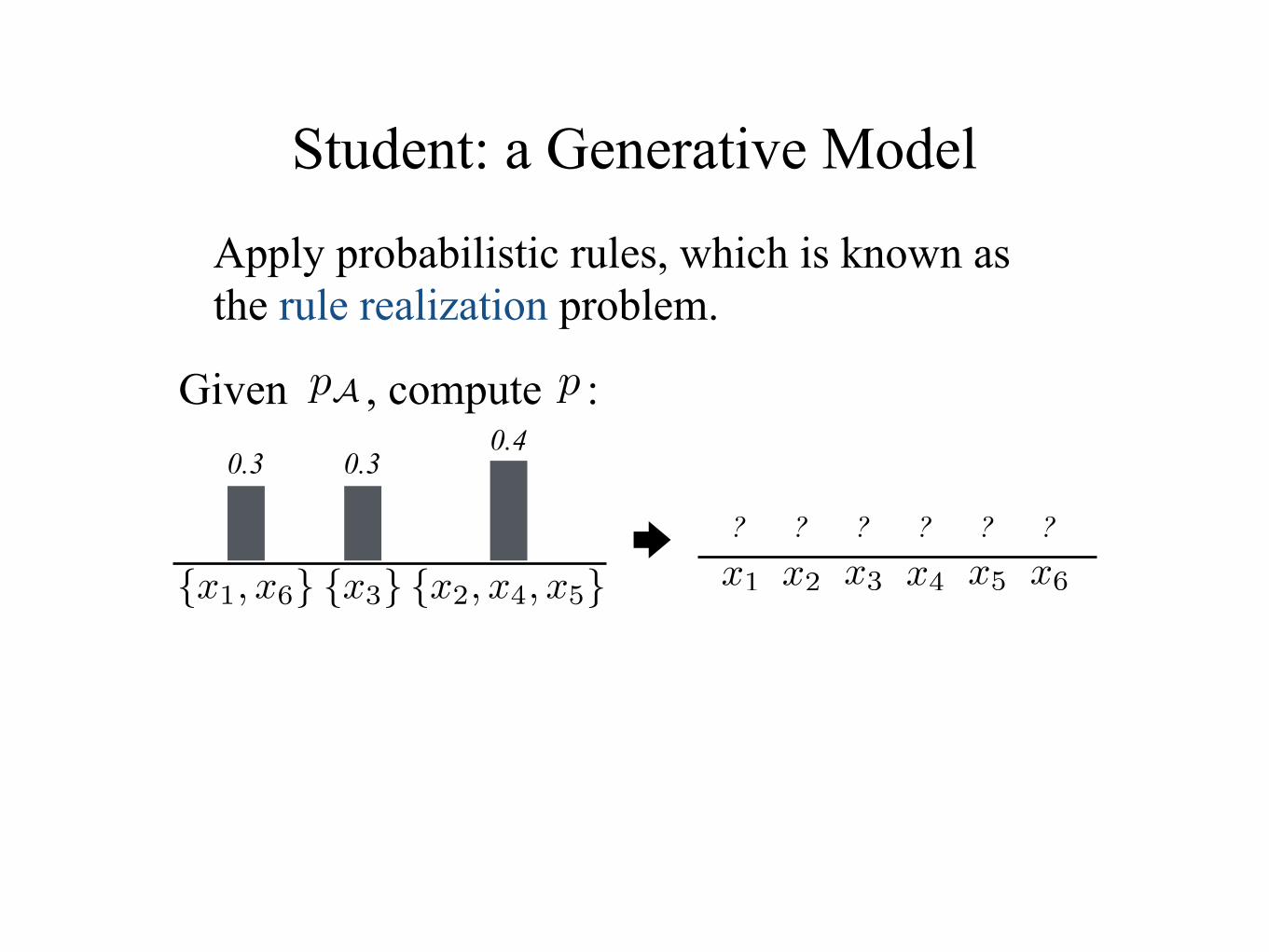
Student: a Generative Model
Apply probabilistic rules, which is known as the rule realization problem.
Given , compute :ppA
x1 x2 x3 x5 x6x4{x1, x6} {x3} {x2, x4, x5}
0.30.30.4
? ? ? ? ? ?
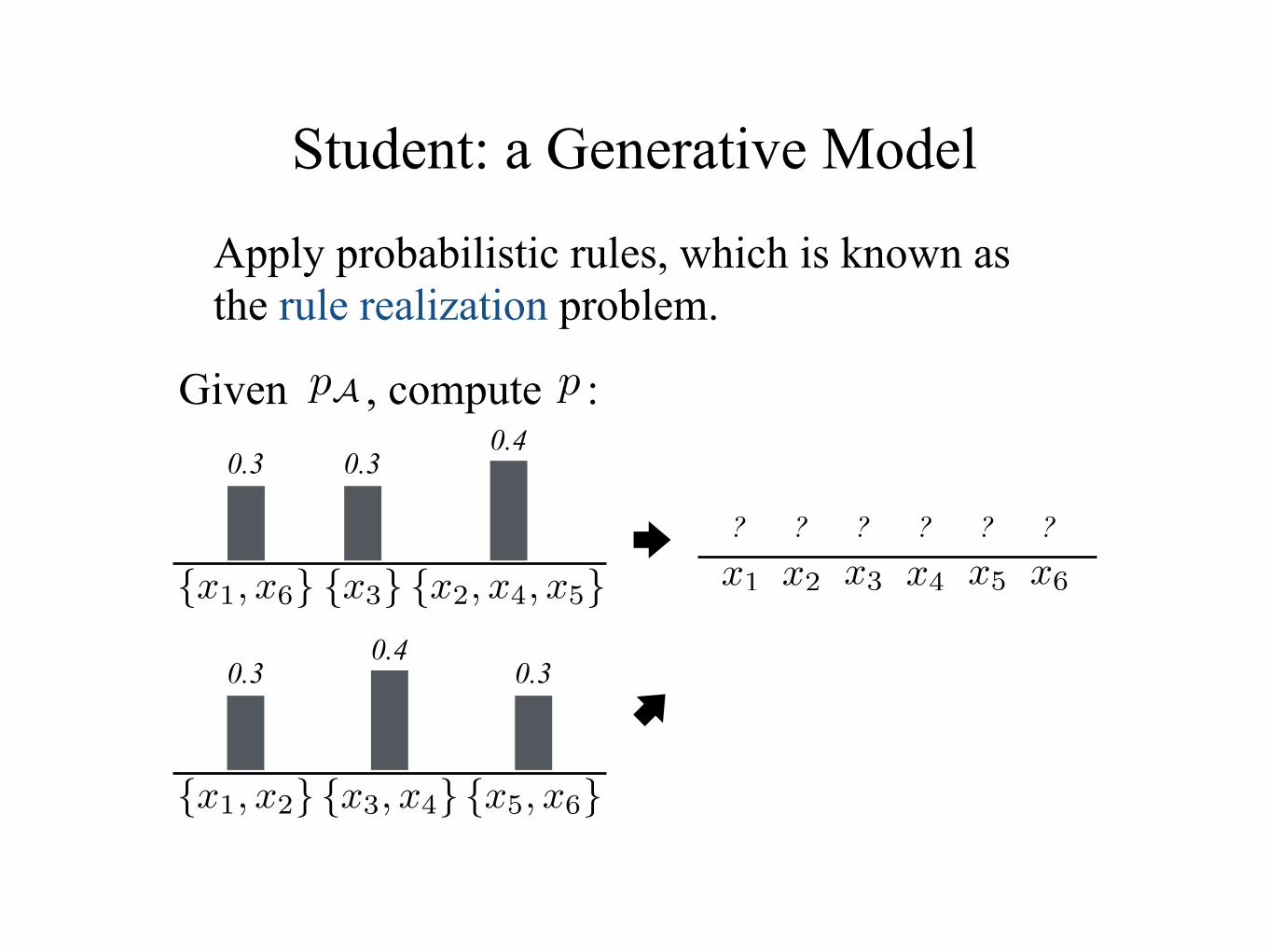
Student: a Generative Model
Apply probabilistic rules, which is known as the rule realization problem.
Given , compute :ppA
x1 x2 x3 x5 x6x4{x1, x6} {x3} {x2, x4, x5}
0.30.30.4
? ? ? ? ? ?
0.30.30.4
{x1, x2} {x3, x4} {x5, x6}

Student: a Generative Model
Apply probabilistic rules, which is known as the rule realization problem.
Given , compute :ppA
x1 x2 x3 x5 x6x4{x1, x6} {x3} {x2, x4, x5}
0.30.30.4
? ? ? ? ? ?
0.30.30.4
{x1, x2} {x3, x4} {x5, x6}
…

Student: a Generative Model
Apply probabilistic rules, which is known as the rule realization problem.
Given , compute :ppA
x1 x2 x3 x5 x6x4{x1, x6} {x3} {x2, x4, x5}
0.30.30.4
? ? ? ? ? ?
0.30.30.4
{x1, x2} {x3, x4} {x5, x6}
…
not necessarily uniquewhich one do we prefer?

Want to find the probabilistic model which enables novelty while at the same time satisfies all the rules.
Student: a Generative Model

Student: a Generative ModelThe student solves another optimization problem:
maximize
phkistu2�|X|
Sq(phkistu) := (q � 1)
�1⇣1� kphkistukqq
⌘
subject to A(i)phkistu = pA(i) , i = 1, . . . , k

Student: a Generative ModelThe student solves another optimization problem:
maximize
phkistu2�|X|
Sq(phkistu) := (q � 1)
�1⇣1� kphkistukqq
⌘
subject to A(i)phkistu = pA(i) , i = 1, . . . , k
Tsallis entropy: measures randomness

Student: a Generative ModelThe student solves another optimization problem:
maximize
phkistu2�|X|
Sq(phkistu) := (q � 1)
�1⇣1� kphkistukqq
⌘
subject to A(i)phkistu = pA(i) , i = 1, . . . , k
Tsallis entropy: measures randomness
partition matrix: represents abstraction

linear equality constraint
Student: a Generative ModelThe student solves another optimization problem:
maximize
phkistu2�|X|
Sq(phkistu) := (q � 1)
�1⇣1� kphkistukqq
⌘
subject to A(i)phkistu = pA(i) , i = 1, . . . , k
Tsallis entropy: measures randomness
partition matrix: represents abstraction

linear equality constraint
Student: a Generative ModelThe student solves another optimization problem:
maximize
phkistu2�|X|
Sq(phkistu) := (q � 1)
�1⇣1� kphkistukqq
⌘
subject to A(i)phkistu = pA(i) , i = 1, . . . , k
Tsallis entropy: measures randomness
partition matrix: represents abstraction
gini impurity function q = 2 :

linear equality constraint
Student: a Generative ModelThe student solves another optimization problem:
maximize
phkistu2�|X|
Sq(phkistu) := (q � 1)
�1⇣1� kphkistukqq
⌘
subject to A(i)phkistu = pA(i) , i = 1, . . . , k
Tsallis entropy: measures randomness
partition matrix: represents abstraction
gini impurity function q = 2 :
Linear Least-Squares Problem!

How MUS-ROVER Self-Evolves?

Context-Free Rules (1-gram)
Rules and Outcomes

Student 0
Fundamentals (1-gram)

Fundamentals (1-gram)
Rule 1:order � w1,2,3,4

Fundamentals (1-gram)
Rule 1:order � w1,2,3,4
(Spacing) Almost always, the soprano pitch is above the alto, alto above tenor, and tenor above bass.

Fundamentals (1-gram)
Student 1

Fundamentals (1-gram)
Rule 2:mod12 � w1
11970 52 41 3 1086

Fundamentals (1-gram)
(Scale) The soprano voice is drawn from a diatonic scale with high probability.
Rule 2:mod12 � w1
11970 52 41 3 1086

Fundamentals (1-gram)
Student 2

Fundamentals (1-gram)
Student 22

Fundamentals (1-gram)
Student 22

Context-Specific Rules (n-gram)
Bach’s Music Brain
Loop 0
Part Writing (n-gram): 14th Chord unlearned1-gram

Loop 1
Part Writing (n-gram): 14th Chord unlearned1-gram3-gram

Loop 2unlearned1-gram3-gram10-gram
Part Writing (n-gram): 14th Chord

Loop 3unlearned1-gram3-gram10-gram6-gram
Part Writing (n-gram): 14th Chord

Loop 4unlearned1-gram3-gram10-gram6-gram7-gram
Part Writing (n-gram): 14th Chord

Loop 5unlearned1-gram3-gram10-gram6-gram7-gram
Part Writing (n-gram): 14th Chord

Loop 6unlearned1-gram3-gram10-gram6-gram7-gram
Part Writing (n-gram): 14th Chord
Loop 7unlearned1-gram3-gram10-gram6-gram7-gram4-gram
Part Writing (n-gram): 14th Chord

Loop 8unlearned1-gram3-gram10-gram6-gram7-gram4-gram
Part Writing (n-gram): 14th Chord

Loop 9unlearned1-gram3-gram10-gram6-gram7-gram4-gram
Part Writing (n-gram): 14th Chord

Loop 10unlearned1-gram3-gram10-gram6-gram7-gram4-gram
Part Writing (n-gram): 14th Chord
unlearned1-gram3-gram10-gram6-gram7-gram4-gram
End of Loop 10
Part Writing (n-gram): 14th Chord

Generalizing to Other Topic Domains
• Physics • Cancer biology • and more

References• Haizi Yu, Igor Mineyev, and Lav R. Varshney. A Group-Theoretic
Approach to Abstraction: Hierarchical, Interpretable, and Task-Free Clustering. arXiv:1807.11167v1 [cs.LG], 2018.
• Haizi Yu, Tianxi Li, and Lav R. Varshney. Probabilistic rule realization and selection. In Proceedings of NIPS 2017.
• Haizi Yu, and Lav R. Varshney. Towards deep interpretability (MUS-ROVER II): learning hierarchical representations of tonal music. In Proceedings of ICLR 2017.
• Haizi Yu, Lav R. Varshney, Guy E. Garnett, and Ranjitha Kumar. MUS-ROVER: A self-learning system for musical compositional rules. In Proceedings of MUME 2016.
• Haizi Yu, Lav R. Varshney, Guy E. Garnett, and Ranjitha Kumar. Learning interpretable musical compositional rules and traces. In ICML 2016 Workshop on Human Interpretability in Machine Learning.