multicore compiler for low power high performance ... compiler for low power high performance...
TRANSCRIPT

Multicore Compiler for Low pPower High Performance
Embedded ComputingHironori Kasahara
Professor Department of Computer ScienceProfessor, Department of Computer ScienceDirector, Advanced Chip-Multiprocessor
Research InstitutesResearch Institutes Waseda University
Tokyo JapanTokyo, Japanhttp://www.kasahara.cs.waseda.ac.jp
April 18, 2008, 9:30-10:20, IEEE Cool Chips XI

Hironori Kasahara<Personal History>B.S. (1980,Waseda), M.S.(1982,Waseda), Ph.D.(1985,EE, Waseda). Res.Assoc. (1983,Waseda),Special Research Fellow JSPS (1985) ,Visiting Scholar (1985.Univ.California at Berkeley), .Assist. Prof. (1986.Waseda), Assoc. Prof.(1988,Waseda), Visiting Research Scholar(1989-1990. Center for Supercomputing R&D, Univ.of Illinois at Urbana-Champaign), Prof.(1997-,Dept. CS, Waseda). , IFAC World Congress Young Author Prize (1987), IPSJ Sakai Memorial Special Award (1997), STARC Industry-Academia Cooperative Research Award (2004)( ) y p ( )
<Activities for Societies>IPSJ:Sig. Computer Architecture(Chair), Trans of IPSJ Editorial Board (HG Chair),
Journal of IPSJ Editorial Board (HWG Chair), 2001 Journal of IPSJ Special Issue on Parallel Processing(Chair of Editorial Board: Guest Editor, JSPP2000 (Program Chair) etc.Processing(Chair of Editorial Board: Guest Editor, JSPP2000 (Program Chair) etc. ACM :International Conference on Supercomputing(ICS)(Program Committee)
Int’l conf. on Supercomputing (PC, esp. ‘96 ENIAC 50th Anniversary Co-Prog. Chair). IEEE: Computer Society Japan Chapter Chair, Tokyo Section Board Member, SC07 PCOTHER: PCs of many conferences on Supercomputing and Parallel Processing.
<Activities for Governments>METI:IT Policy Proposal Forum(Architecture/HPC WG Chair),
Super Advanced Electronic Basis Technology Investigation CommitteeSuper Advanced Electronic Basis Technology Investigation CommitteeNEDO:Millennium Project IT21 “Advanced Parallelizing Compiler”( Project Leader),Computer Strategy WG (Chair).Multicore for Realtime Consumer Electronics Project Leader etc.MEXT:Earth Simulator project evaluation committee, 10PFLOPS Supercomputer evaluat. comm.JAERI: Research accomplishment evaluation committee, CCSE 1st class invited researcher.JAERI: Research accomplishment evaluation committee, CCSE 1st class invited researcher. JST: Scientific Research Fund Sub Committee, COINS Steering Committee ,
Precursory Research for Embryonic Science and Technology (Research Area Adviser)Cabinet Office: CSTP Expert Panel on Basic Policy, Information & Communication Field
Promotion Strategy R&D Infrastructure WG Software & Security WGPromotion Strategy , R&D Infrastructure WG, Software & Security WG <Papers>Papers 164(IEEE Trans. Computer, IPSJ Trans., ISSCC, Cool Chips, Supercomputing, ACM
ICS) , Invited Talks 66, Tech. Reports 115, Symposium 25, News Papers/TV/Web News/Magazine 173, etc.

Multi-core EverywhereMulti-core from embedded to supercomputers
Consumer Electronics (Embedded)Mobile Phone, Game, Digital TV, Car Navigation,
DVD CDVD, Camera, IBM/ Sony/ Toshiba Cell, Fuijtsu FR1000, NEC/ARMMPCore&MP211, Panasonic Uniphier, Renesas SH multi-core(4 core RP1 8 core RP2)Renesas SH multi core(4 core RP1, 8 core RP2)Tilera Tile64, SPI Storm-1(16 VLIW cores)
PCs, ServersIntel Quad Xeon, Core 2 Quad, Montvale, Tukwila, 80 coreAMD Quad Core Opteron, Phenom
WSs, Deskside & Highend ServersIBM Power4,5,5+,6 Sun Niagara(SparcT1,T2), Rock
S tIBM BlueGene/L
Lawrence Livermore National Laboratory2005/04稼動予定
OSCAR Type Multi-core Chip by Renesas in METI/NEDO Multicore for Real-time Consumer Electronics Project (Leader: Prof.Kasahara)
SupercomputersEarth Simulator:40TFLOPS, 2002, 5120 vector proc.IBM Blue Gene/L: 360TFLOPS, 2005, Low power CMP
based 128K processor chips, BG/P 2008
Lawrence Livermore National Laboratory2005/04稼動予定
低消費電力チップマルチプロセッサをベースとしたスパコン
High quality application software, Productivity, Costperformance, Low power consumption are important
Ex, Mobile phones, GamesC il t d lti
65,536-プロセッサチップ(128Kプロセッサ
360TFLOPS Compiler cooperated multi-core processors are promising to realize the above futures
=毎秒360兆回の 浮動小数点計算)
キャビネットあたり1024プロセッサチップ
1プロセッサチップ上に2プロセッサ集積

Roadmap of compiler cooperative multicore project02 03 04 05 06 07 0800 01 09 10
Apply for Supercomputer CompilersCompiler development of
Millennium Project IT21NEDO Advanced Parallelizing Compiler Apply for Supercomputer Compilers
Multiprocessor ServersParallelizing Compiler
(Waseda Univ. Fujitsu,Hitachi,JIPDEC,AIST)
STARC Compiler Cooperative Practical ResarchBasic resrach STARC:
Semiconductor Technology Academic
Research Center Fujitsu,Toshiba,NEC,
STARC:Semiconductor
Technology Academic Research Center
Fujitsu,Toshiba,NEC,
(Waseda・Toshiba・Fujitsu・Panasonic・Sony)
(Waseda・Fujitsu・NEC・Toshiba)
p pChip Multiprocessor( Waseda Univ., Fujitsu, NEC,Toshiba, Panasonic,Sony) Waseda Univ Hitachi Renesas
Arch. % CompilR&D
Plan Practical Use
Renesas,Panasonic, Sony etc.
Renesas,Panasonic, Sony etc.
y
NEDO (2004.07-2007.06)Heterogeneous Multiprocessor(Waseda Univ., Hitachi)
Waseda Univ., Hitachi, Renesas,
Soft realtime
PlanMulticore Arch. Compiler
Practical Use
( , )
NEDO (2005.06-2008.03)Multicore Technology for Realtime Consumer Electronics Plan
API R&DPractical Use
Waseda Univ., Hitachi, Renesas,Fujitsu, NEC, Toshiba, PanasonicPower Saving Multicore
Architecture,P ll li i C il API H t M lti A h
Mar. Oct.
Parallelizing Compiler,APINEDO (2007.02- 2010.03)
Heterogeneous Multicore for Consumer Electronics Waseda U i Hit hi R T k I t f T h
Mar.Mar.
PlanHetero Multicore Arch.
& Compiler R&D

METI/NEDO National Project Multi core for Real time Consumer ElectronicsMulti-core for Real-time Consumer Electronics
<Goal> R&D of compiler cooperative multi-core processor technology for consumer (2005.7~2008.3)**core processor technology for consumer electronics like Mobile phones, Games, DVD, Digital TV, Car CMP m
(マルチコア・チ プ )
PC0(プロセッサコア0) PC
CMP 0 (マルチコアチップ0)
CSM j
CPU(プロセッサ)
I/O DevicesI/O
(入出力装置)CMP m(マルチコア・チ プ )
PC0(プロセッサコア0) PC
CMP 0 (マルチコアチップ0)
CSM j
CPU(プロセッサ)
I/O DevicesI/O
(入出力装置)
新マルチコアプロセッサ
•高性能
低消費電力
新マルチコアプロセッサ
•高性能
低消費電力
CMP m(マルチコア・チ プ )
PC0(プロセッサコア0) PC
CMP 0 (マルチコアチップ0)
CSM j
CPU(プロセッサ)
I/O DevicesI/O
(入出力装置)CMP m(マルチコア・チ プ )
PC0(プロセッサコア0) PC
CMP 0 (マルチコアチップ0)
CSM j
CPU(プロセッサ)
I/O DevicesI/O
(入出力装置)
新マルチコアプロセッサ
•高性能
低消費電力
新マルチコアプロセッサ
•高性能
低消費電力
( )
navigation systems. <Period> From July 2005 to March 2008
チップm)
(プロセッサ
コアn)
) PC1(プロ
セッサコア1)
PC n
DSM(分散共有メモリ)
LDM/D-cache
(ローカルデータメモリ/L1データ
キャッシュ)
LPM/I-Cache
(ローカルプログラムメモリ/
命令キャッシュ)
j
CSM(集中共有
メモリ)
I/O
CSP k
(入出力用マルチコア・チップ)
NI(ネットワークインターフェイス)
DTC(データ
転送コントローラ)
チップm)
(プロセッサ
コアn)
) PC1(プロ
セッサコア1)
PC n
DSM(分散共有メモリ)
LDM/D-cache
(ローカルデータメモリ/L1データ
キャッシュ)
LPM/I-Cache
(ローカルプログラムメモリ/
命令キャッシュ)
j
CSM(集中共有
メモリ)
I/O
CSP k
(入出力用マルチコア・チップ)
NI(ネットワークインターフェイス)
DTC(データ
転送コントローラ)
•低消費電力
•短HW/SW開発期間
•各チップ間でアプリケーション
•低消費電力
•短HW/SW開発期間
•各チップ間でアプリケーション
チップm)
(プロセッサ
コアn)
) PC1(プロ
セッサコア1)
PC n
DSM(分散共有メモリ)
LDM/D-cache
(ローカルデータメモリ/L1データ
キャッシュ)
LPM/I-Cache
(ローカルプログラムメモリ/
命令キャッシュ)
j
CSM(集中共有
メモリ)
I/O
CSP k
(入出力用マルチコア・チップ)
NI(ネットワークインターフェイス)
DTC(データ
転送コントローラ)
チップm)
(プロセッサ
コアn)
) PC1(プロ
セッサコア1)
PC n
DSM(分散共有メモリ)
LDM/D-cache
(ローカルデータメモリ/L1データ
キャッシュ)
LPM/I-Cache
(ローカルプログラムメモリ/
命令キャッシュ)
j
CSM(集中共有
メモリ)
I/O
CSP k
(入出力用マルチコア・チップ)
NI(ネットワークインターフェイス)
DTC(データ
転送コントローラ)
•低消費電力
•短HW/SW開発期間
•各チップ間でアプリケーション
•低消費電力
•短HW/SW開発期間
•各チップ間でアプリケーション
<Features> ・Good cost performance・Short hardware and software development periods
CSM / L2 Cache(集中共有メモリあるいはL2キャッシュ )
IntraCCN (チップ内結合網: 複数バス、クロスバー等 )
InterCCN (チップ間結合網: 複数バス、クロスバー、多段ネットワーク等 )
CSM / L2 Cache(集中共有メモリあるいはL2キャッシュ )
IntraCCN (チップ内結合網: 複数バス、クロスバー等 )
InterCCN (チップ間結合網: 複数バス、クロスバー、多段ネットワーク等 )
プリケ ション共用可
•高信頼性
•半導体集積度と共に性能向上
プリケ ション共用可
•高信頼性
•半導体集積度と共に性能向上
マルチコア統合ECU
,,
CSM / L2 Cache(集中共有メモリあるいはL2キャッシュ )
IntraCCN (チップ内結合網: 複数バス、クロスバー等 )
InterCCN (チップ間結合網: 複数バス、クロスバー、多段ネットワーク等 )
CSM / L2 Cache(集中共有メモリあるいはL2キャッシュ )
IntraCCN (チップ内結合網: 複数バス、クロスバー等 )
InterCCN (チップ間結合網: 複数バス、クロスバー、多段ネットワーク等 )
プリケ ション共用可
•高信頼性
•半導体集積度と共に性能向上
プリケ ション共用可
•高信頼性
•半導体集積度と共に性能向上
マルチコア統合ECU
,,development periods・Low power consumption・Scalable performance improvement
開発マルチコアチップは情報家電へ開発マルチコアチップは情報家電へ開発マルチコアチップは情報家電へ開発マルチコアチップは情報家電へ開発マルチコアチップは情報家電へ開発マルチコアチップは情報家電へ
p pwith the advancement of semiconductor ・Use of the same parallelizing compiler for multi-cores from different vendors using newly developed API
**Hitachi, Renesas, Fujitsu,
Toshiba, Panasonic, NEC

NEDOMulticore Technology for Realtime Consumer Electronics R&D Organization(2005.7-2008.3 )
Integrated R&D Steering CommitteeChair : Hironori Kasahara (Waseda Univ.), Project LeaderSub-chair : Kunio Uchiyama (Hitachi), Project Sub-leader
Grant: Multicore Architecture and CompilerResearch and Development
Subsidy: Evaluation Environment for MulticoreTechnologyResearch and Development
Project Leader :Prof. Hironori Kasahara, Waseda Univ.
TechnologyProject Sub-leader :
Dr. Kunio Uchiyama, Chief Researcher, Hitachi
R&D Steering ComitteeT t Chi E l ti S t
Standard MulticoreArchitecture & APIC i
Architecture & CompilerR&D Group.Group Leader :
gTest Chip Development Group.Group Leader : Renesas Technology
Evaluation Sytem Development GroupGroup Leader : Hitachi
CommitteeChair : Prof. HironoriKasahara, Waseda Univ.
Group Leader :Associate Prof. KeijiKimura, Waseda Univ.(Outsourcing : Fujitsu)
gy
Hitachi, Fujitsu, Toshiba, NEC, Panasonic Renesas Technologyanasonic, Renesas Technology

METI/NEDO Advanced Parallelizing Compiler Technology ProjectBackground and Problems①Adoption of parallel processing as a core
Millenium Project IT21 2000.9.8 –2003.3.31W d U i F jit Hit hi AIST ①Adoption of parallel processing as a core
technology on PC to HPC ② Increase of importance of software on IT③ Need for improvement of cost-performance
and usability
Performance
1T
Waseda Univ., Fujitsu, Hitachi, AIST
Contents of Research and Development① R & D of advanced parallelizing compiler
and usabilityHardware Peak performance
Multigrain, Data localization, Overhead hiding② R & D of Performance evaluation technology
for parallelizing compilers<Purpose>
Proj
ect
Improvement of① Effective performance
Goal: Double the effective performance
Ripple EffectA
PC P① Effective performance
②Cost-performance③ Ease of use
Slow down
pp① Development of competitive next
generation PC and HPC② Putting the innovative automatic
parallelizing compiler technology Effective Performance
1980 20001990
p g p gyto practical use
③ Development and market acquisitionof future single-chip multiprocessors
④ Boosting R&D in the following many fields:year1G
IT, Bio-tech., Device, Earth environment, Next-generation VLSI design, Financial engineering, Weather forecast, New clean energy, Space development, Automobile, Electric Commerce, etc
④ g g y
Theoretical maximum performance vs.Effective performance of HPC
y

Performance of APC Compiler on IBM pSeries690 16 Processors High-end Server
• IBM XL Fortran for AIX Version 8.1– Sequential execution : -O5 -qarch=pwr4– Automatic loop parallelization : -O5 -qsmp=auto -qarch=pwr4– OSCAR compiler : -O5 -qsmp=noauto -qarch=pwr4
(su2cor: -O4 -qstrict)12.0
XL Fortran(max)3.4s 3.1s 3.5s3 5 ti d
10.0
XL Fortran(max)
APC(max)3.0s
38.5s
28.8s3.5 times speedup in average
6.0
8.0
dup
ratio
3.8s
38.5s
4.0Spee
16.7s7.1s
16 4s 13 0s115.2s 107.4s 105.0s
28.9s
0.0
2.0
23 1s
19.2s
16.7s
38 3s
21.5s21.0s
16.4s
23.2s
13.0s
37.4s
39 5s27 8s35 1s30 3s21 5s 126 5s 307 6s 291 2s 279 1s
126.5s 184.8s
22 5s 85 8s 18 8s
22.5s 85.8s 18.8s
282 4s 321 4s
282.4s 321.4s
tomcatvswim
su2corhydro 2d
mgridappluturb3d aps i
fppppwave5
wupwiseswim2kmgrid
2kapplu2ks ixt r
ackaps i2k
23.1s 38.3s 39.5s27.8s35.1s30.3s21.5s 126.5s 307.6s 291.2s 279.1s22.5s 85.8s 18.8s 282.4s 321.4s

Performance of Multigrain Parallel Processing for 102.swim on IBM pSeries690
16 00
14.00
16.00XLF(AUTO)
OSCAR
10.00
12.00
p ra
tio
6.00
8.00
Spee
d up
2.00
4.00S
0.001 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Processors
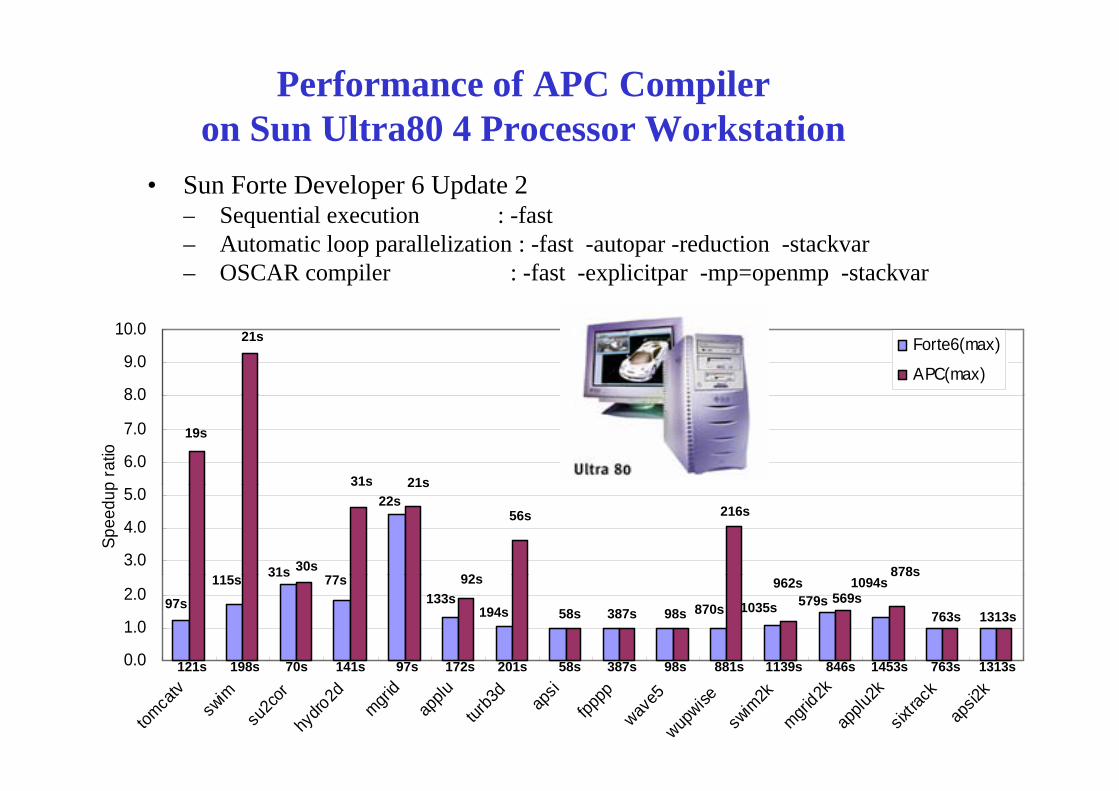
Performance of APC Compileron Sun Ultra80 4 Processor Workstation
• Sun Forte Developer 6 Update 2Sequential execution : fast
on Sun Ultra80 4 Processor Workstation
– Sequential execution : -fast– Automatic loop parallelization : -fast -autopar -reduction -stackvar– OSCAR compiler : -fast -explicitpar -mp=openmp -stackvar
8 0
9.0
10.0Forte6(max)
APC(max)
21s
6.0
7.0
8.0
p ra
tio
19s
31s 21s
3.0
4.0
5.0
Spee
dup
115 31s 30s77
31s22s
21s
92
56s 216s
878s
0.0
1.0
2.0
121s 198s 70s 141s 97s 172s 201s
97s
115s 31s 77s133s
92s
194s
881s 1139s 846s 1453s
870s 1035s
962s579s 569s
1094s878s
58s 387s 98s
58s 387s 98s
763s 1313s
763s 1313s
0.0
tomca
tv
swim
su2c
orhy
dro2d
mgrid
applu
turb3
d
apsi
fpppp
wave5
wupwise
swim
2kmgri
d2kap
plu2k
sixtra
ckap
si2k
121s 198s 70s 141s 97s 172s 201s 881s 1139s 846s 1453s58s 387s 98s 763s 1313s

OSCAR Parallelizing Compiler• Improve effective performance, cost-performance
and productivity and reduce consumed power– Multigrain Parallelization
• Exploitation of parallelism from the whole program by use ofcoarse-grain parallelism among loops and subroutines,coarse grain parallelism among loops and subroutines, near fine grain parallelism among statements in addition to loop parallelism
Data Localization– Data Localization• Automatic data distribution for distributed shared memory, cache
and local memory on multiprocessor systems.– Data Transfer Overlapping
• Data transfer overhead hiding by overlapping task execution anddata transfer using DMA or data pre-fetchingdata transfer using DMA or data pre fetching
– Power Reduction• Reduction of consumed power by compiler control of
frequency, voltage and power shut down with hardware supports.
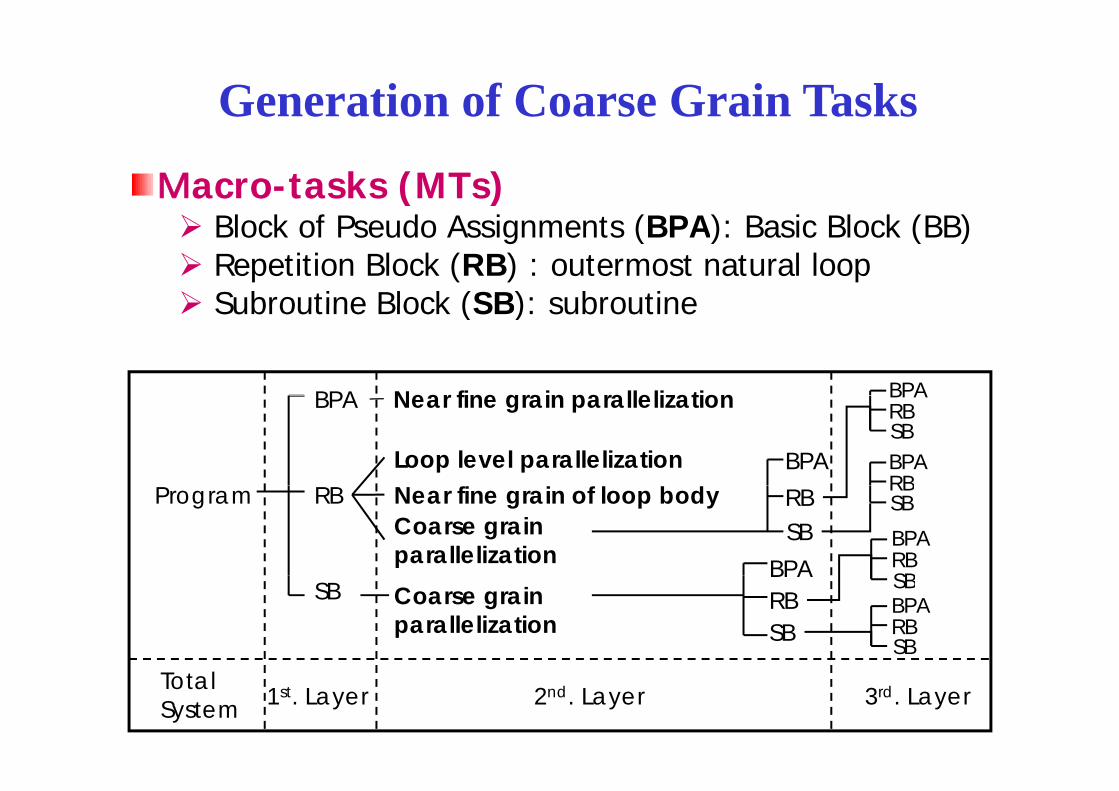
Generation of Coarse Grain Tasks
Macro-tasks (MTs)Bl k f P d A i t (BPA) B i Bl k (BB)Block of Pseudo Assignments (BPA): Basic Block (BB)Repetition Block (RB) : outermost natural loop Subroutine Block (SB): subroutineSubroutine Block (SB): subroutine
BPA Near fine grain parallelization BPABPA Near fine grain parallelization
Loop level parallelization BPA
BPARBSBBPARBProgram RB Near fine grain of loop body
Coarse grainparallelization
RBSB
BPA
RBSBBPARBSBSB Coarse grain
parallelization
BPARBSB
SBBPARBSB
1st. Layer 2nd. Layer 3rd. LayerTotalSystem

Earliest Executable Condition Analysis for coarse grain tasks (Macro-tasks)
1 BPABPA
Data Dependency
Control flow
Conditional branch
Block of Psuedo
1
3 BPA2 BPA
4 BPA
BPA
RB Repetition Block
RB
Block of PsuedoAssignment Statements
7
2 3
4 8BPA
5 BPA
6 RB
7 RB15 BPA
RB
RB
RB
BPA
7
11
4
5 6
8
9 10
6
BPA8 BPA
9 BPA 10 RB
11 BPA
RB 1115 7
12
13
Data dependency
Extended control dependency11 BPA
12 BPA
13 RB14
13Extended control dependencyConditional branch
ORAND
Original control flowA Macro Flow Graph14 RB
ENDA Macro Task Graph
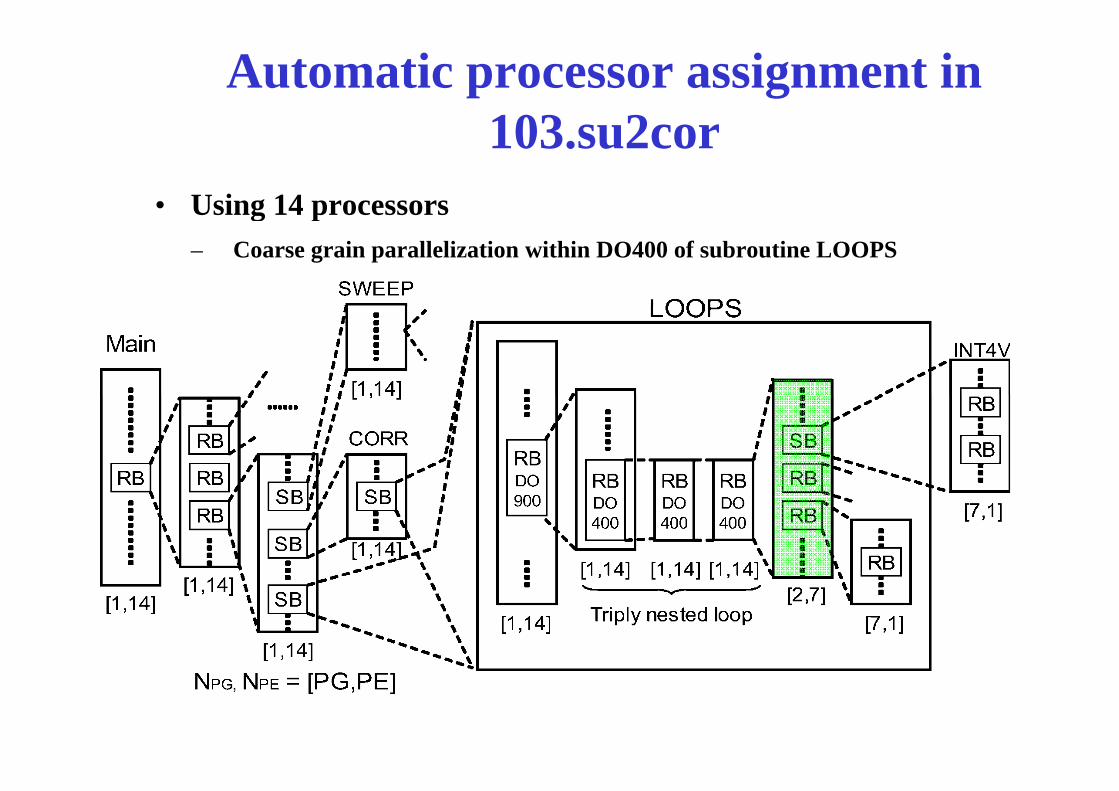
Automatic processor assignment in 103 su2cor103.su2cor
• Using 14 processorsg p– Coarse grain parallelization within DO400 of subroutine LOOPS

MTG of Su2cor-LOOPS-DO400MTG of Su2cor-LOOPS-DO400Coarse grain parallelism PARA_ALD = 4.3
DOALL Sequential LOOP BBSB
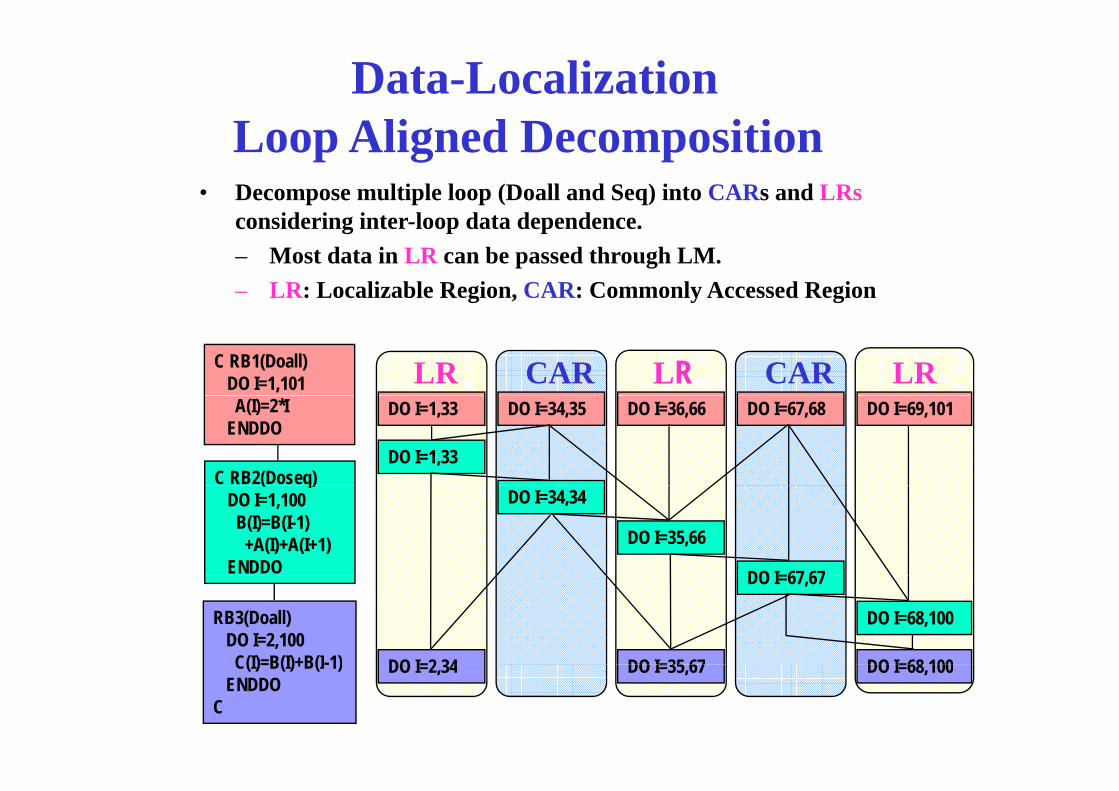
Data-Localization L Ali d D itiLoop Aligned Decomposition
• Decompose multiple loop (Doall and Seq) into CARs and LRs id i i t l d t d dconsidering inter-loop data dependence.
– Most data in LR can be passed through LM.– LR: Localizable Region, CAR: Commonly Accessed Region
LR CAR CARLR LRC RB1(Doall)DO I=1,101
DO I=69,101DO I=67,68DO I=36,66DO I=34,35DO I=1,33
DO I=1,33C RB2(Doseq)
A(I)=2*IENDDO
DO I=67 67
DO I=35,66
DO I=34,34( q)
DO I=1,100B(I)=B(I-1)
+A(I)+A(I+1)ENDDO
DO I=2 34
DO I=68,100
DO I=67,67
DO I=68 100DO I=35 67
RB3(Doall)DO I=2,100
C(I)=B(I)+B(I-1) DO I=2,34 DO I=68,100DO I=35,67C(I)=B(I)+B(I-1)ENDDO
C

Data Localization11
2
1
32
PE0 PE1
12 1
3 4 56
23 45
6 7 8910 1112
3
4
2
6 7
8
14
18
7
6 7 8910 1112
1314 15 16
5
8
9
11
15
18
19
25
8 9 101718 19 2021 22
10
11
13 16
25
29
112324 25 26
dlg0dlg3dlg1 dlg2
17 20
21
22 26
30
12 1314
15
2728 29 3031 32
33Data Localization Group
dlg023 24
27 28
32
MTG MTG after Division A schedule for two processors
15 33Data Localization Group31

An Example of Data Localization for Spec95 SwimDO 200 J=1 N cache sizeDO 200 J=1 N cache sizeDO 200 J=1,NDO 200 I=1,M
UNEW(I+1,J) = UOLD(I+1,J)+1 TDTS8*(Z(I+1,J+1)+Z(I+1,J))*(CV(I+1,J+1)+CV(I,J+1)+CV(I,J)2 +CV(I+1 J)) TDTSDX*(H(I+1 J) H(I J))
UN
0 1 2 3 4MBcache sizeDO 200 J=1,N
DO 200 I=1,MUNEW(I+1,J) = UOLD(I+1,J)+
1 TDTS8*(Z(I+1,J+1)+Z(I+1,J))*(CV(I+1,J+1)+CV(I,J+1)+CV(I,J)2 +CV(I+1 J)) TDTSDX*(H(I+1 J) H(I J))
UN
0 1 2 3 4MBcache size
2 +CV(I+1,J))-TDTSDX*(H(I+1,J)-H(I,J))VNEW(I,J+1) = VOLD(I,J+1)-TDTS8*(Z(I+1,J+1)+Z(I,J+1))
1 *(CU(I+1,J+1)+CU(I,J+1)+CU(I,J)+CU(I+1,J))2 -TDTSDY*(H(I,J+1)-H(I,J))
VOZ
PNVN UOPO CVCUH
2 +CV(I+1,J))-TDTSDX*(H(I+1,J)-H(I,J))VNEW(I,J+1) = VOLD(I,J+1)-TDTS8*(Z(I+1,J+1)+Z(I,J+1))
1 *(CU(I+1,J+1)+CU(I,J+1)+CU(I,J)+CU(I+1,J))2 -TDTSDY*(H(I,J+1)-H(I,J))
VOZ
PNVN UOPO CVCUHPNEW(I,J) = POLD(I,J)-TDTSDX*(CU(I+1,J)-CU(I,J))
1 -TDTSDY*(CV(I,J+1)-CV(I,J))200 CONTINUE
H
UNPNVN
PNEW(I,J) = POLD(I,J)-TDTSDX*(CU(I+1,J)-CU(I,J))1 -TDTSDY*(CV(I,J+1)-CV(I,J))
200 CONTINUE
H
UNPNVN
DO 210 J=1,NUNEW(1,J) = UNEW(M+1,J)VNEW(M+1,J+1) = VNEW(1,J+1)PNEW(M+1 J) = PNEW(1 J)
UNVOPNVN UO
U PV
DO 210 J=1,NUNEW(1,J) = UNEW(M+1,J)VNEW(M+1,J+1) = VNEW(1,J+1)PNEW(M+1 J) = PNEW(1 J)
UNVOPNVN UO
U PV
DO 300 J=1,N
PNEW(M+1,J) = PNEW(1,J)210 CONTINUE
VOPNVN UOPO
C h li fli tDO 300 J=1,N
PNEW(M+1,J) = PNEW(1,J)210 CONTINUE
VOPNVN UOPO
C h li fli tDO 300 I=1,MUOLD(I,J) = U(I,J)+ALPHA*(UNEW(I,J)-2.*U(I,J)+UOLD(I,J))VOLD(I,J) = V(I,J)+ALPHA*(VNEW(I,J)-2.*V(I,J)+VOLD(I,J))POLD(I,J) = P(I,J)+ALPHA*(PNEW(I,J)-2.*P(I,J)+POLD(I,J)) (b) Image of alignment of arrays on
Cache line conflicts occurs among arrays which share the same location on cache
DO 300 I=1,MUOLD(I,J) = U(I,J)+ALPHA*(UNEW(I,J)-2.*U(I,J)+UOLD(I,J))VOLD(I,J) = V(I,J)+ALPHA*(VNEW(I,J)-2.*V(I,J)+VOLD(I,J))POLD(I,J) = P(I,J)+ALPHA*(PNEW(I,J)-2.*P(I,J)+POLD(I,J)) (b) Image of alignment of arrays on
Cache line conflicts occurs among arrays which share the same location on cache
( , ) ( , ) ( ( , ) ( , ) ( , ))300 CONTINUE
(a) An example of target loop group for data localization
(b) Image of alignment of arrays on cache accessed by target loops
( , ) ( , ) ( ( , ) ( , ) ( , ))300 CONTINUE
(a) An example of target loop group for data localization
(b) Image of alignment of arrays on cache accessed by target loops

Data Layout for Removing Line Conflict Misses by Array Dimension Paddingby Array Dimension Padding
Declaration part of arrays in spec95 swim
PARAMETER (N1=513, N2=513) PARAMETER (N1=513, N2=544)
before padding after padding
COMMON U(N1,N2), V(N1,N2), P(N1,N2),* UNEW(N1,N2), VNEW(N1,N2),1 PNEW(N1,N2), UOLD(N1,N2),
COMMON U(N1,N2), V(N1,N2), P(N1,N2),* UNEW(N1,N2), VNEW(N1,N2),1 PNEW(N1,N2), UOLD(N1,N2),
* VOLD(N1,N2), POLD(N1,N2),2 CU(N1,N2), CV(N1,N2),* Z(N1,N2), H(N1,N2)
* VOLD(N1,N2), POLD(N1,N2),2 CU(N1,N2), CV(N1,N2),* Z(N1,N2), H(N1,N2)
4MB 4MB
padding
Box: Access range of DLG0

Power Reduction by Power Supply, Clock Frequencyand Voltage Control by OSCAR Compiler
• Shortest execution time mode
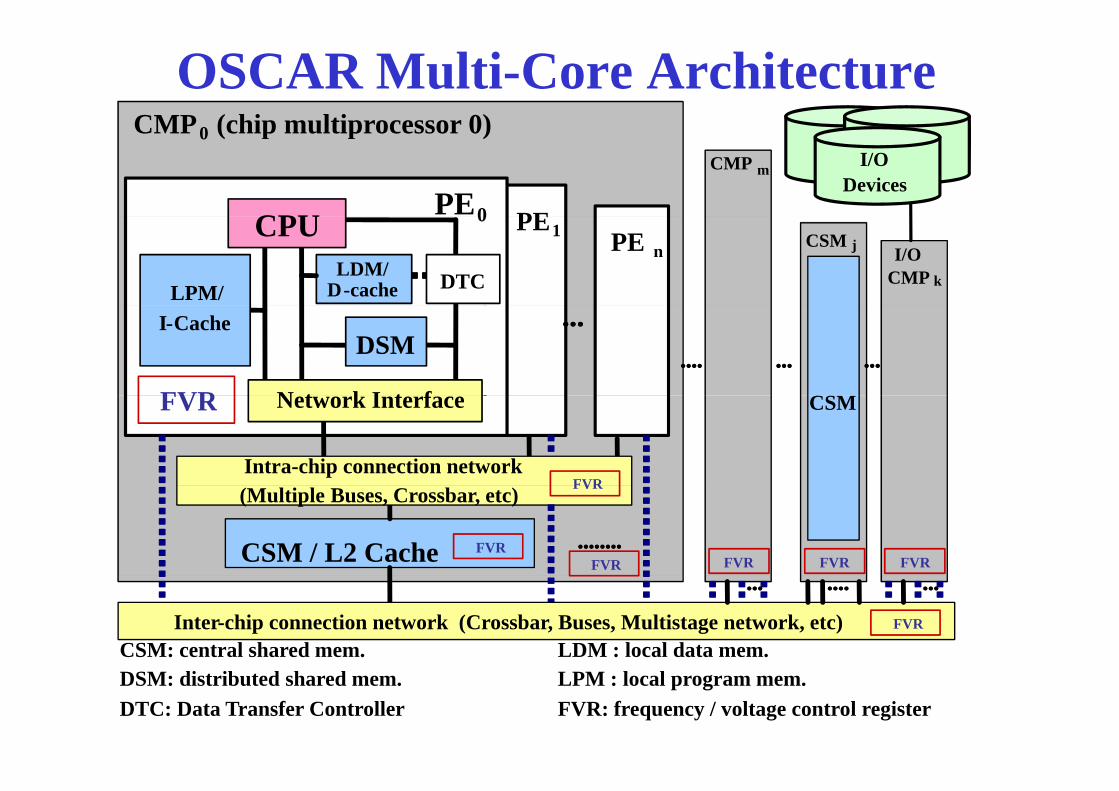
OSCAR Multi-Core ArchitectureCMP (chip multiprocessor 0)
CMP m
PE0 PE
CMP (chip multiprocessor 0)0
CPU
I/ODevicesI/O
Devices0 PE1 PE n
LDM/D-cacheLPM/
CSM j I/OCMP k
CPUDTC
DSMI-Cache
CSN t k I t fFVR
Intra-chip connection network
CSMNetwork InterfaceFVR
FVR
CSM / L2 Cache
(Multiple Buses, Crossbar, etc) FVR
FVRFVR FVR FVR FVR
Inter-chip connection network (Crossbar, Buses, Multistage network, etc)CSM: central shared mem. LDM : local data mem.
FVR
DSM: distributed shared mem.DTC: Data Transfer Controller
LPM : local program mem.FVR: frequency / voltage control register
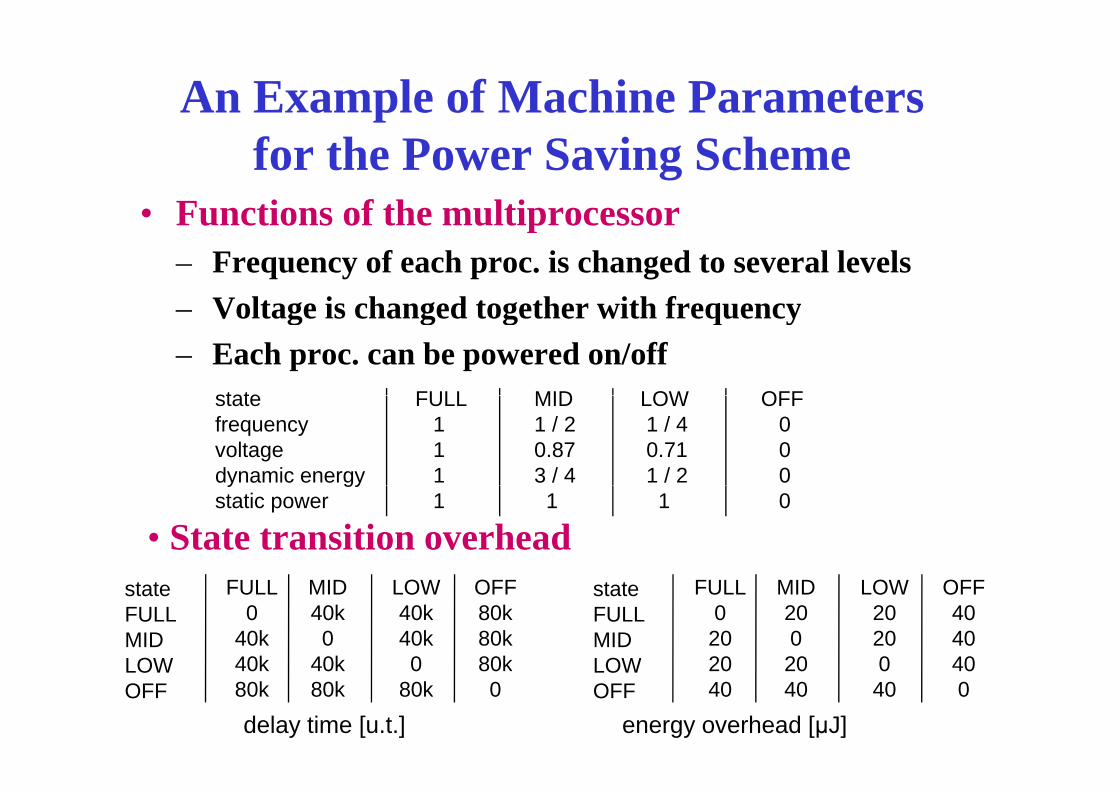
An Example of Machine Parameters for the Power Saving Scheme
• Functions of the multiprocessor• Functions of the multiprocessor– Frequency of each proc. is changed to several levels
Voltage is changed together with frequency– Voltage is changed together with frequency– Each proc. can be powered on/off
state FULL MID LOW OFFstatefrequencyvoltagedynamic energy
FULL111
MID1 / 20.873 / 4
LOW1 / 40.711 / 2
OFF000y gy
static power 1 1 1 0
• State transition overheadstateFULLMIDLOW
FULL0
40k40k
MID40k0
40k
LOW40k40k0
OFF80k80k80k
stateFULLMIDLOW
FULL02020
MID20020
LOW20200
OFF404040LOW
OFF40k80k
40k80k
080k
80k0
LOWOFF
2040
2040
040
400
delay time [u.t.] energy overhead [μJ]
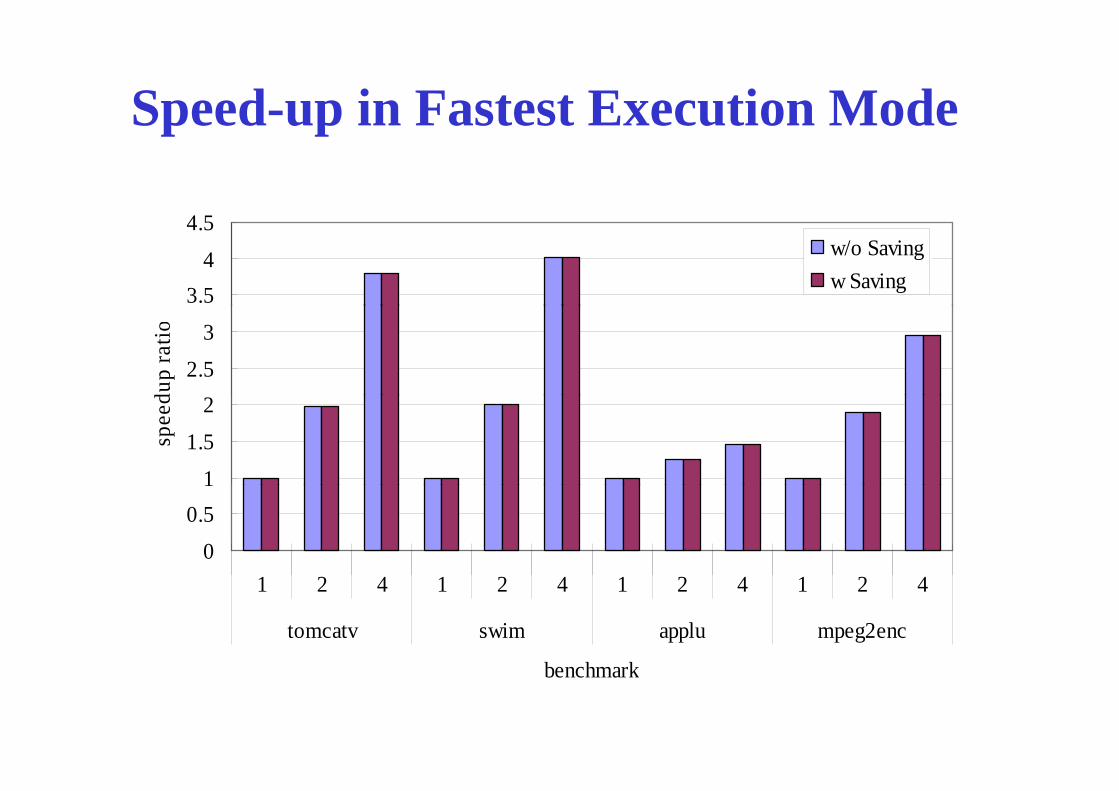
Speed-up in Fastest Execution Modep p
4 5
3.54
4.5w/o Savingw Saving
2.5
3
dup
ratio
1
1.5
2
spee
d
0
0.51
1 2 4 1 2 4 1 2 4 1 2 4
tomcatv swim applu mpeg2enc
b h kbenchmark

Consumed Energy in Fastest Execution Mode
200 1600
140160
180
200
w/o Savingw Saving 1200
14001600
J)
80
100
120
140
ener
gy(J
)
600800
1000
nerg
y(m
J
20
4060
200400600en
01 2 4 1 2 4 1 2 4
tomcatv swim applu
01 2 4
b fbenchmark
mpeg2 encode
number of proc.
mpeg2_encode
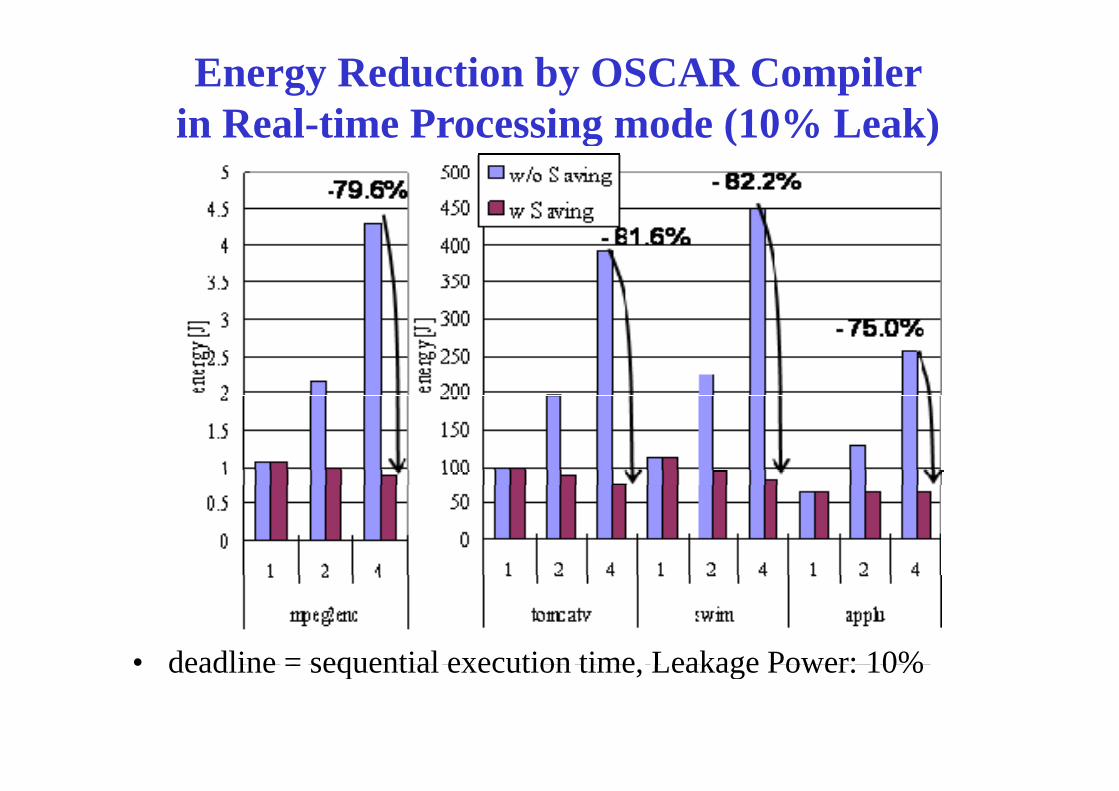
Energy Reduction by OSCAR Compiler in Real-time Processing mode (10% Leak)in Real-time Processing mode (10% Leak)
• deadline = sequential execution time Leakage Power: 10%• deadline = sequential execution time, Leakage Power: 10%
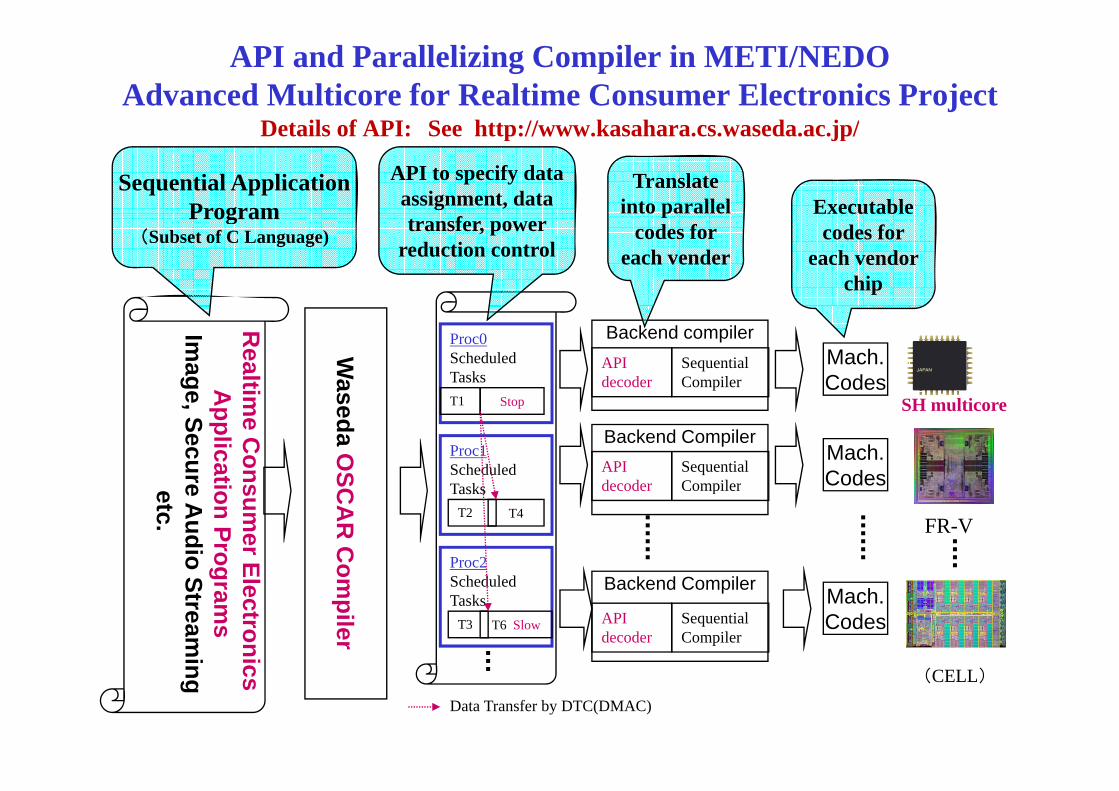
API and Parallelizing Compiler in METI/NEDOAdvanced Multicore for Realtime Consumer Electronics Project
Details of API: See http://www kasahara cs waseda ac jp/Details of API: See http://www.kasahara.cs.waseda.ac.jp/
ExecutableTranslate
into parallel API to specify data assignment, data
Sequential Application Program
codes for each vendor
chip
pcodes for
each vendertransfer, power
reduction control
Program(Subset of C Language)
RealtiA
Image
Was
Backend compilerMach. Codes
Proc0ScheduledTasks
APIdecoder
Sequential Compilerm
e Cons
Applicati
e, Secure
seda OS
Backend Compiler
T1 Stop
Proc1ScheduledT k
SH multicore
Mach.CodesAPI
decoderSequential Compilersum
er Eion Proge A
udio etc.
SCA
R C
o
FR-V
TasksT2 T4
Proc2
Codesdecoder Compiler
Electronigram
sStream
i
ompiler
Backend CompilerScheduledTasks
T3 T6 Slow
Mach.CodesSequential
CompilerAPIdecoder
csng (CELL)
Data Transfer by DTC(DMAC)

Fujitsu FR-1000Multicore ProcessorFR550 VLIW Processor
I-cacheInteger Operation UnitFR-V Multi-core Processor
Inst 0
FR550 core
FR550 core
GR32KBInst. 0Inst. 1Inst. 2Inst. 3
DMA-E
Local BUS IF
Mem. Cont. Mem. Cont.
Memory
Memory Crossbar Switch
DMA-I FR
Media Operation Unit
D-cache32KB
Inst. 4Inst. 5Inst. 6Inst. 7
FR550 core
FR550 core
IO
Media Operation Unit
C 1 C 2IO Chip
Core1 Core2
×
Core1 Core2
Switch SwitchFast I/O Bus
Memory Memory Memory Memory
Crossbar
Fast I/O Bus
•Memory Bus: 64bit x 2ch / 266MHz•System Bus: 64bit / 178MHz
Bus Crossbar(FR1000)
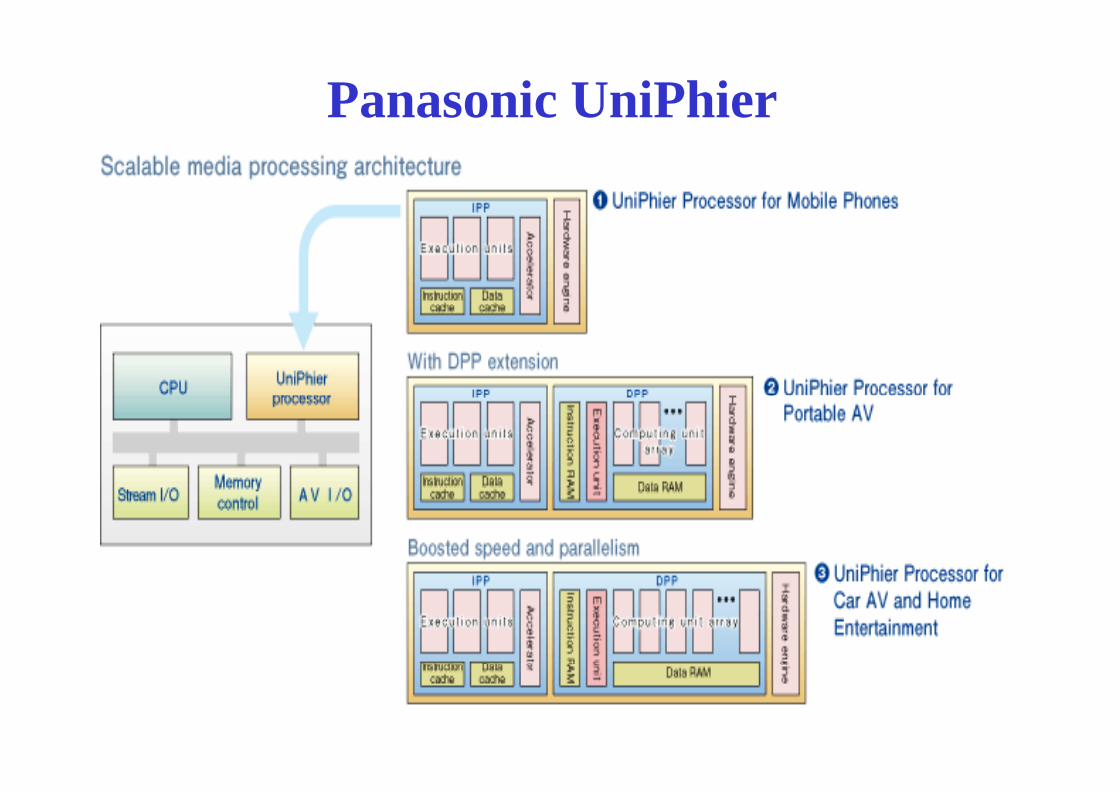
Panasonic UniPhier
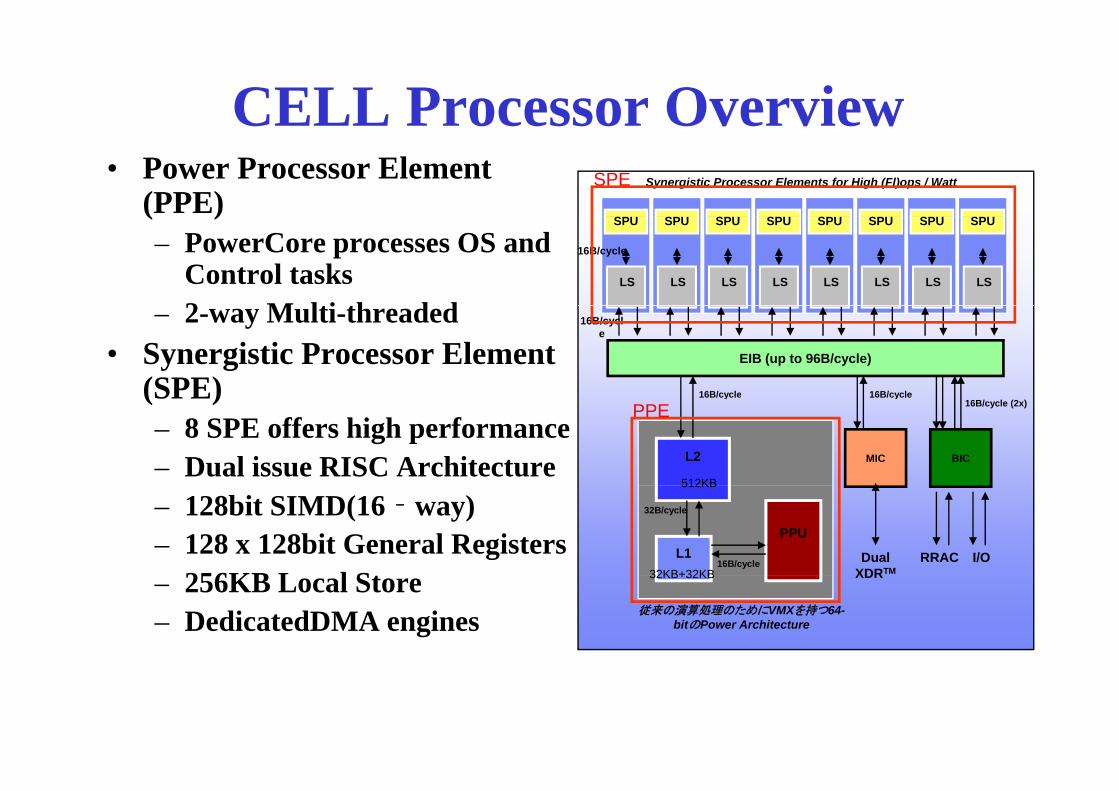
CELL Processor OverviewC ocesso Ove v ew• Power Processor Element
(PPE)Synergistic Processor Elements for High (Fl)ops / WattSPE
( )– PowerCore processes OS and
Control tasks2 M lti th d d
SPU
LS
SPU
LS
SPU
LS
SPU
LS
SPU
LS
SPU
LS
SPU
LS
SPU
LS
16B/cycle
– 2-way Multi-threaded• Synergistic Processor Element
(SPE) 16B/cycle16B/cycle
EIB (up to 96B/cycle)
16B/cycle
(SPE)– 8 SPE offers high performance– Dual issue RISC Architecture
16B/cycle (2x)16B/cycle
BICMIC
16B/cycle
L2
512KB
PPE
– 128bit SIMD(16‐way)– 128 x 128bit General Registers
256KB L l StRRAC I/ODual
XDRTM
PPUL1
32B/cycle
16B/cycle
512KB
32KB+32KB– 256KB Local Store– DedicatedDMA engines
XDR
従来の演算処理のためにVMXを持つ64-bitのPower Architecture
32KB+32KB

1987 OSCAR(Optimally SSccheduled Advanced Multiprocessor)
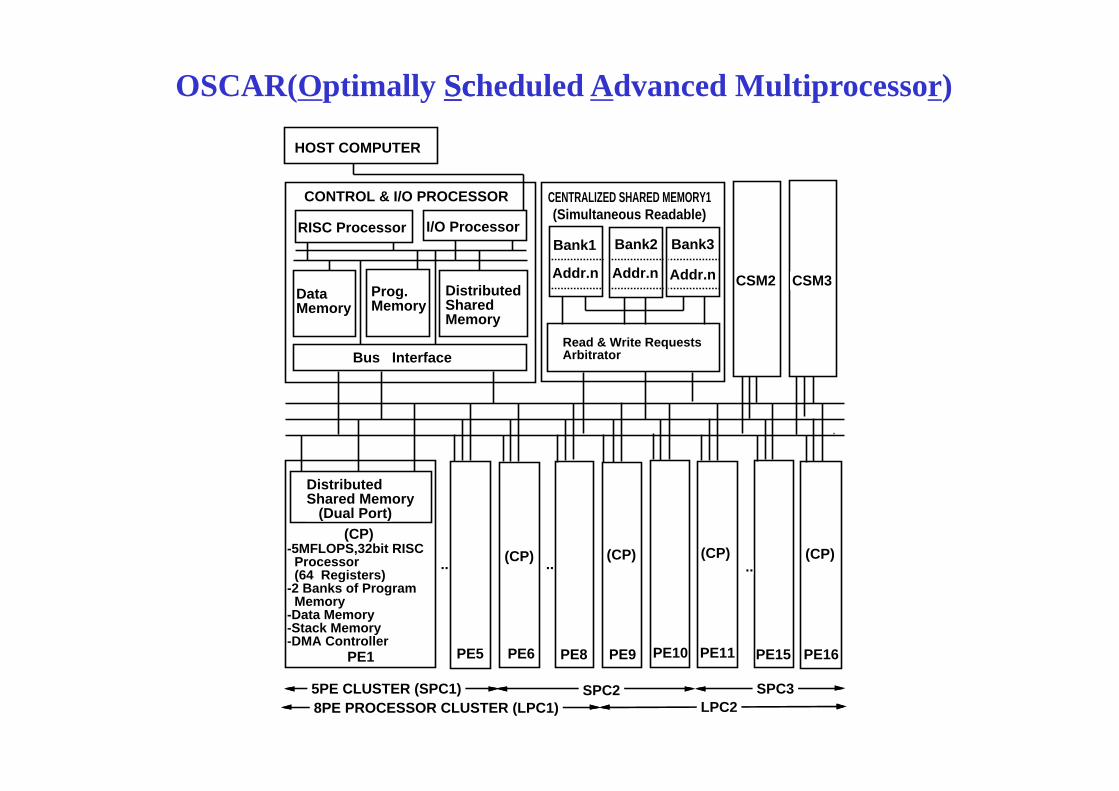
OSCAR(Optimally SSccheduled Advanced Multiprocessor)
HOST COMPUTER
CONTROL & I/O PROCESSOR(Simultaneous Readable)
CENTRALIZED SHARED MEMORY1
RISC Processor I/O Processor
DataMemory
Prog.Memory
Bank1
Addr.n
Bank2
Addr.n
Bank3
Addr.nDistributedShared
(Simultaneous Readable)
CSM2 CSM3
Read & Write RequestsArbitrator
Memory Memory
Bus Interface
SharedMemory
Distributed
(CP)(CP)
(CP) (CP) (CP).. ..
DistributedShared Memory (Dual Port)
-5MFLOPS,32bit RISC Processor (64 Registers)
..
PE1 PE5 PE6 PE10 PE11 PE15PE8 PE9 PE16
(64 Registers)-2 Banks of Program Memory-Data Memory-Stack Memory-DMA Controller
5PE CLUSTER (SPC1) SPC2 SPC3 LPC2 8PE PROCESSOR CLUSTER (LPC1)

SYSTEM BUS
OSCAR PE (Processor Element)SYSTEM BUS
BUS INTERFACE
D S MLOCAL BUS 2LOCAL BUS 1
D M A L P M L S M L D M IPU FPU
R E GI N S C
R E G
D M A L D M
INSTRUCTION BUS DP
: DMA CONTROLLER : LOCAL DATA MEMORYD M AL P M
I N S C
D S M
L D M
D PI P U
F P U
: DMA CONTROLLER: LOCAL PROGRAM MEMORY (128KW * 2BANK): INSTRUCTION CONTROL UNIT
: LOCAL DATA MEMORY (256KW): DATA PATH: INTEGER PROCESSING UNIT: FLOATING: DISTRIBUTEDD S M
L S M
F P U
R E G: LOCAL STACK MEMORY (4KW)
: FLOATING PROCESSING UNIT: REGISTER FILE (64 REGISTERS)
: DISTRIBUTED SHARED MEMORY (2KW)

1987 OSCAR PE Board
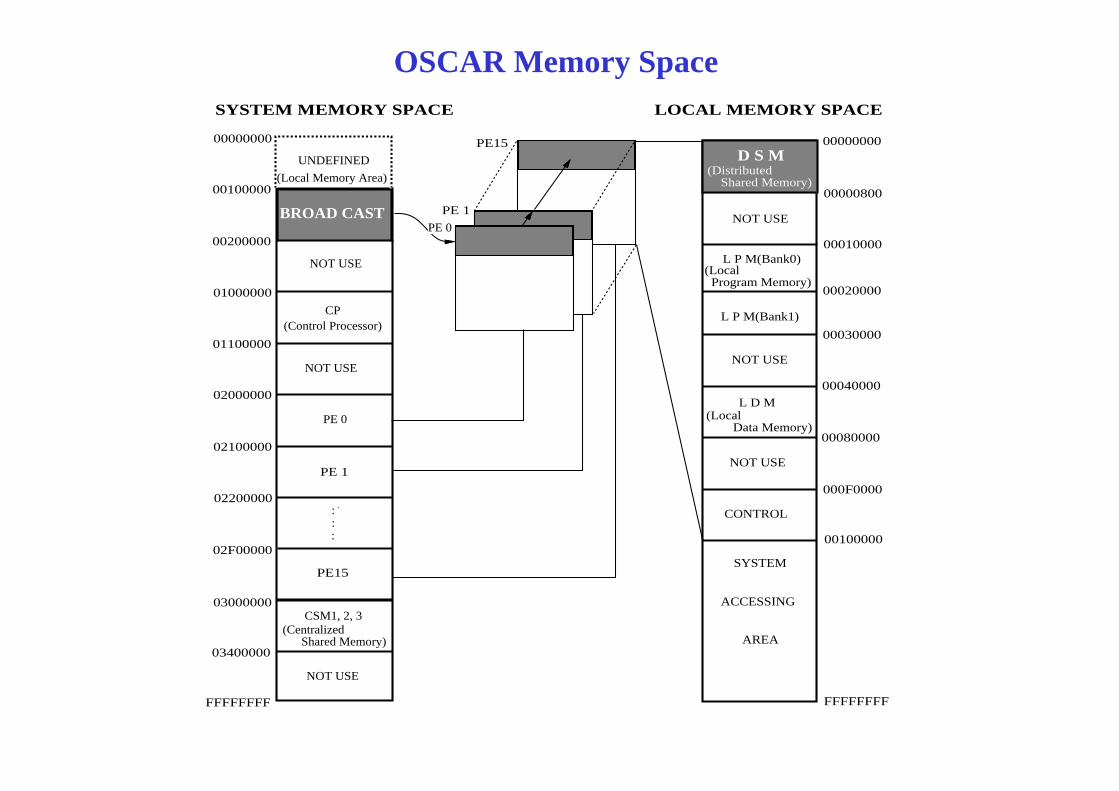
LOCAL MEMORY SPACESYSTEM MEMORY SPACE
OSCAR Memory Space
00000000
00100000
UNDEFINED
00000000
00000800
D S M
NOT USE
(Distributed Shared Memory)
PE 1
PE15
(Local Memory Area)
BROAD CAST
00200000
01000000
CP
NOT USE
00010000
NOT USE
L P M(Bank0)(Local Program Memory)
PE 0
PE 1
00020000
BROAD CAST
01100000
02000000
NOT USE
CP
00030000
00040000
NOT USE
(Control Processor)L P M(Bank1)
02000000
02100000
PE 0
00080000
000F0000
L D M
NOT USEPE 1
(Local Data Memory)
02200000
02F00000
:::
000F0000
00100000
CONTROL
SYSTEMPE15
03000000
03400000
CSM1, 2, 3ACCESSING
AREA
PE15
(Centralized Shared Memory)
FFFFFFFF
NOT USE
FFFFFFFF

OSCAR Multi-Core ArchitectureCMP (chip multiprocessor 0)
CMP m
PE0 PE
CMP (chip multiprocessor 0)0
CPU
I/ODevicesI/O
Devices0 PE1 PE n
LDM/D-cacheLPM/
CSM j I/OCMP k
CPUDTC
DSMI-Cache
CSN t k I t fFVR
Intra-chip connection network
CSMNetwork InterfaceFVR
FVR
CSM / L2 Cache
(Multiple Buses, Crossbar, etc) FVR
FVRFVR FVR FVR FVR
Inter-chip connection network (Crossbar, Buses, Multistage network, etc)CSM: central shared mem. LDM : local data mem.
FVR
DSM: distributed shared mem.DTC: Data Transfer Controller
LPM : local program mem.FVR: frequency / voltage control register

Image of Generated Multigrain Parallelized Code using the developed Multicore API
Centralized scheduling codeCode using the developed Multicore API
(The API is compatible with OpenMP)code
SECTIONSSECTION SECTION1st layer
Distributed scheduling
d
T0 T1 T2 T3
MT1_1
T4 T5 T6 T7MT1_1
1st layer
code SYNC SENDMT1_2
SYNC RECVMT1_3SB
MT1_2DOALL
MT1 4MT1-3
1_4_11_4_11_3_2
1_3_3
1_3_1
1_3_2
1_3_3
1_3_1
1_3_2
1_3_3
1_3_1MT1_4RB MT1-4
1_4_2
1_4_4
1_4_3
1_4_2
1_4_4
1_4_31_3_4
1 3 6
1_3_5
1_3_4
1 3 6
1_3_5
1_3_4
1 3 6
1_3_5
1_3_1
1_3_2 1_3_3 1_3_41_4_11_3_6 1_3_6 1_3_6
END SECTIONS2nd layer
1_3_5 1_3_6
1_4_21_4_3 1_4_4
Thread group0
Thread group1
2nd layer
2nd layer
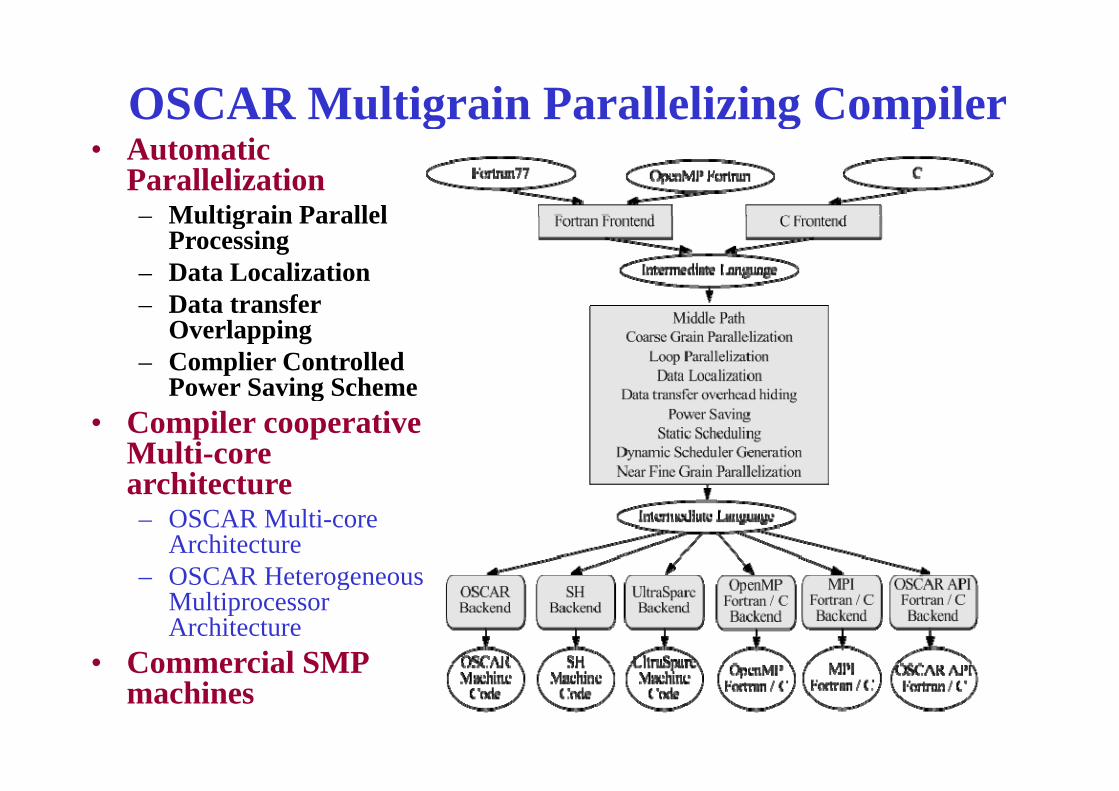
OSCAR Multigrain Parallelizing Compilerg g p• Automatic
ParallelizationMultigrain Parallel– Multigrain Parallel Processing
– Data LocalizationData transfer– Data transfer Overlapping
– Complier Controlled Power Saving SchemePower Saving Scheme
• Compiler cooperative Multi-core architecturearchitecture– OSCAR Multi-core
ArchitectureOSCAR Heterogeneous– OSCAR Heterogeneous Multiprocessor Architecture
• Commercial SMP• Commercial SMP machines

Performance of OSCAR Compiler Using the
9 Intel Ver.10.1
Multicore API on Intel Quad-core Xeon
678
o
OSCAR
456
eedu
p ra
tio
123sp
e
0
mca
tv
swim
u2co
r
dro2
d
mgr
id
appl
u
urb3
d
apsi
fppp
p
wav
e5
swim
mgr
id
appl
u
apsi
tom su
hyd m tu f w m
SPEC95 SPEC2000
• OSCAR Compiler gives us 2.09 times speedup on the average against Intel Compiler ver.10.1
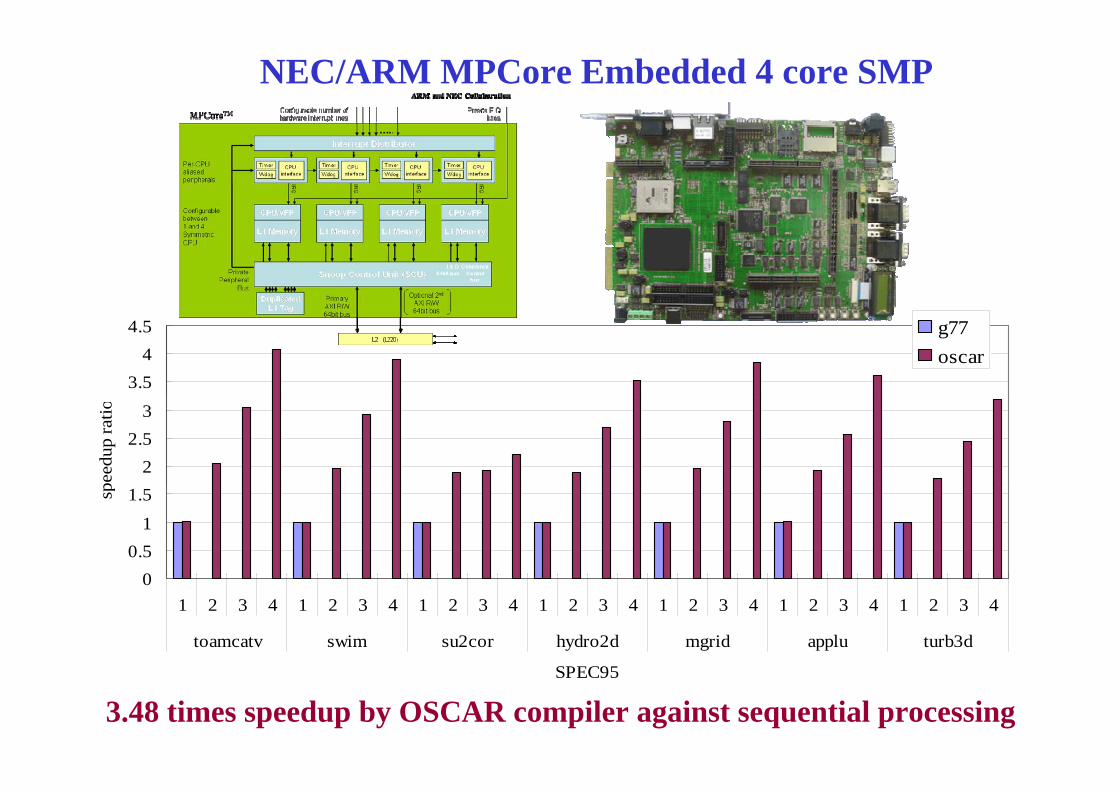
NEC/ARM MPCore Embedded 4 core SMP
3.54
4.5 g77oscar
22.5
3
peed
up ra
tio
00.5
1
1.5sp
01 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
toamcatv swim su2cor hydro2d mgrid applu turb3d
SPEC95
3.48 times speedup by OSCAR compiler against sequential processing
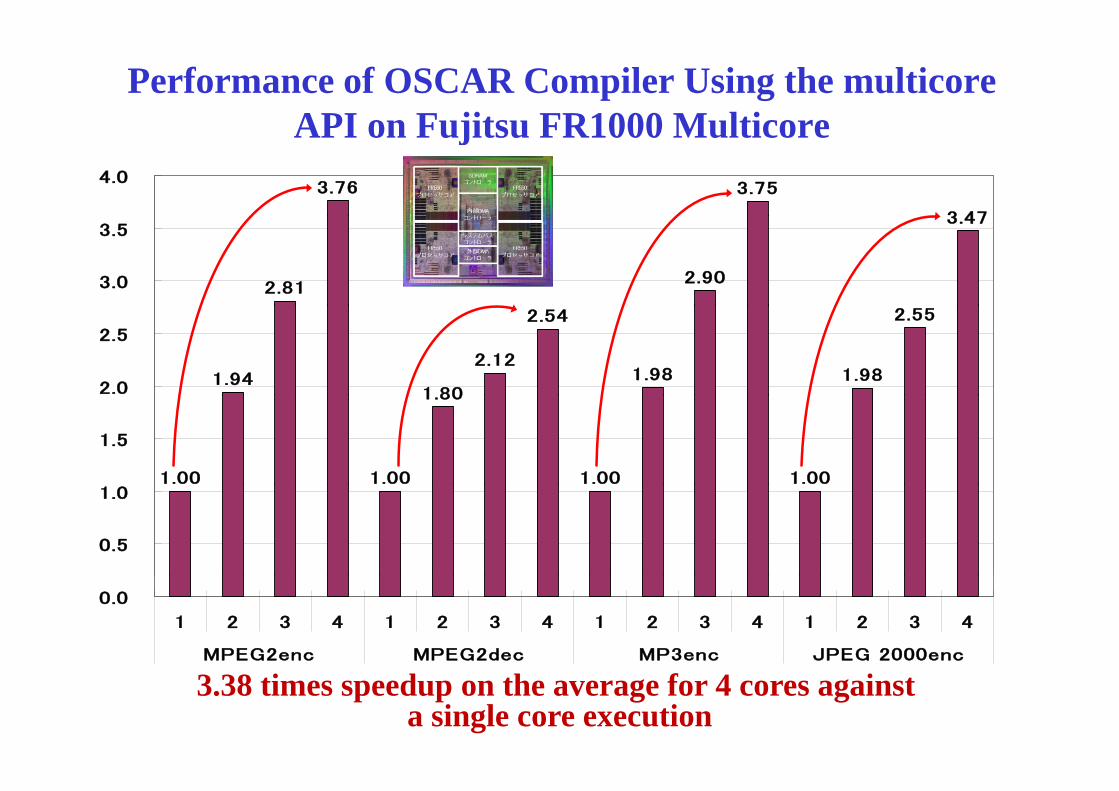
Performance of OSCAR Compiler Using the multicoreAPI on Fujitsu FR1000 MulticoreAPI on Fujitsu FR1000 Multicore
3.76 3.75
3 47
4.0
2.812.90
3.47
3.0
3.5
1.941 80
2.12
2.54
1.98 1.98
2.55
2.0
2.5
1.00 1.00
1.80
1.00 1.00
1.5
0.5
1.0
0.0
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
MPEG2enc MPEG2dec MP3enc JPEG 2000enc
3.38 times speedup on the average for 4 cores againsta single core execution

Performance of OSCAR Compiler Using the Developed API 4 (SH4A) OSCAR T M ltiAPI on 4 core (SH4A) OSCAR Type Multicore
4.0
3.353.24
3.50
3.173.5
4.0
2.57 2.532.71
2 07
2.5
3.0
1.781.86 1.88 1.83
2.07
1.5
2.0
1.00 1.00 1.00 1.00
0.5
1.0
0.0
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
MPEG2enc MPEG2dec MP3enc JPEG 2000enc
3.31 times speedup on the average for 4cores against 1core

Performance OSCAR Multigrain Parallelizing Compiler on a IBM p550q 8core Deskside Server
2.7 times speedup against loop parallelizing compiler on 8 cores
Loop parallelizationMultigrain parallelizition
7
8
9
5
6
7
dup
ratio
2
3
4
spee
d
0
1
2
t t i 2 h d 2d id l t b3d i f 5 i id l itomcatvswim su2corhydro2dmgrid applu turb3d apsi fpppp wave5 swim mgrid applu apsispec95 spec2000
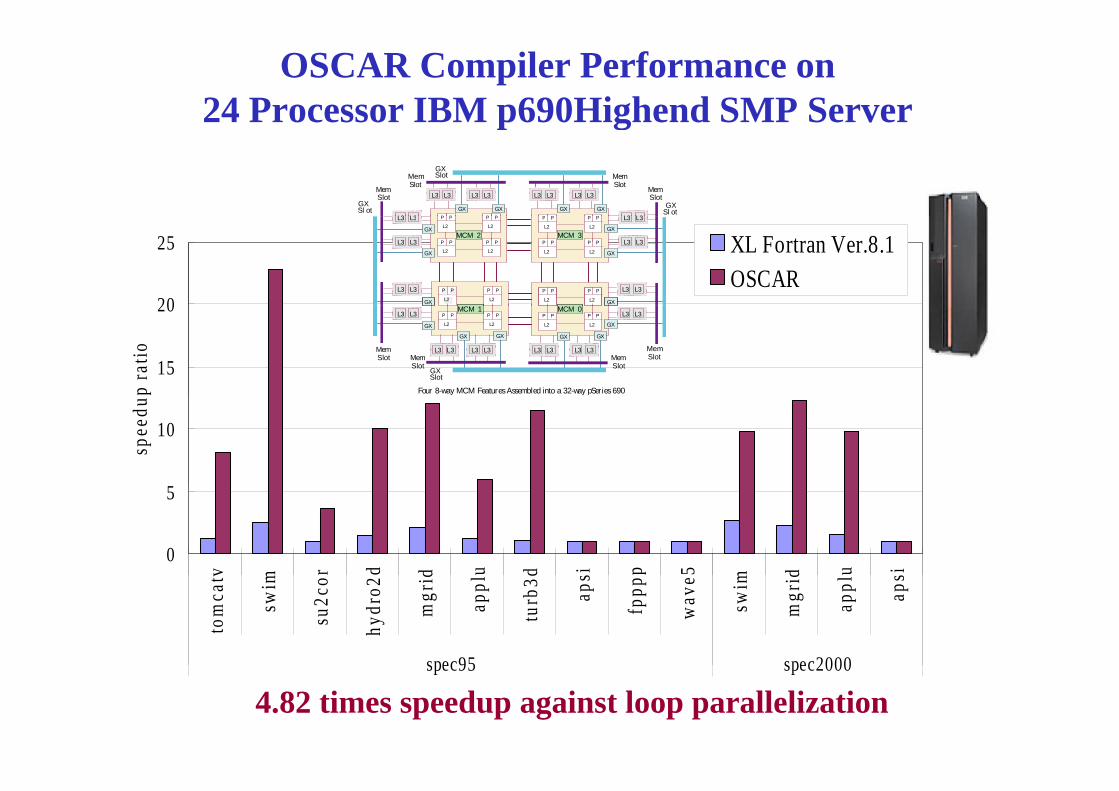
OSCAR Compiler Performance on 24 Processor IBM p690Highend SMP Serverp g
GXGXP P P P
GXP P P P
GX
MemSlot
GX Sl ot
L3 L3 L3 L3L3 L3 L3 L3
L3 L3 L3 L3
GX SlotMem
SlotMemSlot
MemSlot
GX Sl ot
20
25 XL Fortran Ver.8.1OSCAR
P
L2
P P
L2
P
P
L2
PP
L2
P
P
L2
P P
L2
P
GX
P
L2
PP
L2
P
P
L2
P P
L2
P
GX
GX
GX
P
L2
P P
L2
P
GXGX
L3 L3
L3 L3
L3 L3
L3 L3
L3 L3
L3 L3
MCM 3MCM 2
15
20
p ra
tio
GXGX
P
L2
PP
L2
P
GX
P
L2
PP
L2
P
GX
GXGX
L3 L3 L3 L3L3 L3L3 L3
L3 L3 L3 L3MCM 1 MCM 0
MemSlot
MemSlot
MemSlot
MemSlot
GX Slot
Four 8-way MCM Features Assembled into a 32-way pSeries 690
10
spee
du
0
5
v m r d d u d i p 5 m d u i
tom
catv
swim
su2c
o
hydr
o2
mgr
i d
appl
turb
3d
aps
fppp
p
wav
e
swi m
mgr
id
appl ap
s
spec95 spec2000
4.82 times speedup against loop parallelization spec95 spec2000
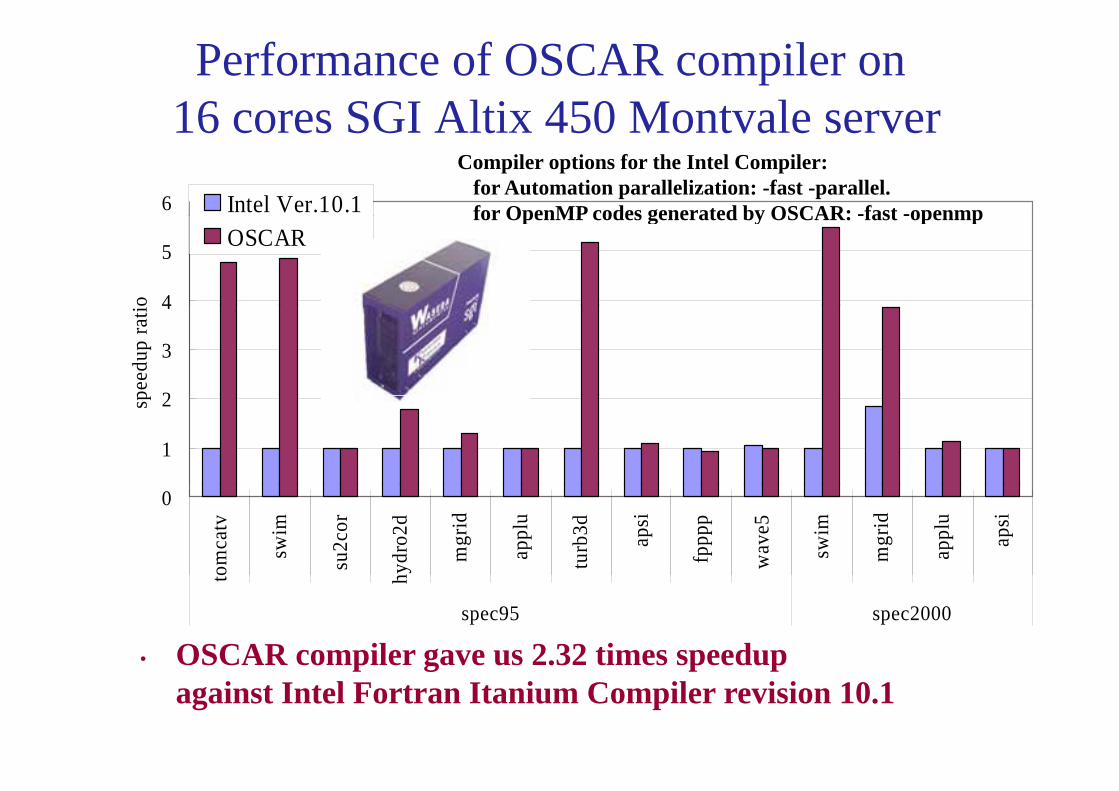
Performance of OSCAR compiler on16 cores SGI Altix 450 Montvale server16 cores SGI Altix 450 Montvale server
6 Intel Ver.10.1
Compiler options for the Intel Compiler:for Automation parallelization: -fast -parallel.for OpenMP codes generated by OSCAR: -fast -openmp
4
5
o
OSCAR for OpenMP codes generated by OSCAR: -fast -openmp
2
3
4
peed
up ra
ti
1
2sp
0
omca
tv
swim
su2c
or
hydr
o2d
mgr
id
appl
u
turb
3d apsi
fppp
p
wav
e5
swim
mgr
id
appl
u
apsi
• OSCAR compiler gave us 2.32 times speedup
to h
spec95 spec2000
OSC co p e gave us .3 t es speedupagainst Intel Fortran Itanium Compiler revision 10.1

Processor Block DiagramProcessor Block DiagramCCN:Cache controllerIL DL I t ti /D t
Core #3CPU FPUCore #2
600MHzIL, DL: Instruction/Data
local memory
I$32K
D$32K
IL DL
CPU FPU
CCNI$32K
D$32K
CPU FPUCore #1
$ $CPU FPUCore #0
CPU FPU rolle
r
URAM: User RAMGCPG: Global clock pulse generator
IL8K
DL16K
CCN
URAM 128K
32K 32KIL8K
DL16K
CCNI$32K
D$32K
IL8K
DL16K
CCNI$32K
D$32K
CPU FPU
CCN
p co
ntr
LCPGgLCPG: Local CPG for each coreLBSC: SRAM controller
URAM 128K8K 16KURAM 128K
IL8K
DL16K
URAM 128K Snoo
p(S
NC
)LCPG0-3LCPG0-3LCPG
0-3LCPG0-3
On-chip system bus (SHwy)
LBSC: SRAM controllerDBSC: DDR2 controller
300MHzS (0 3
DBSC PCIExp
HWGCPGIPLBSC
4 laneDDR232bit
SRAM32bit

Chip OverviewProcess Technology
90nm, 8-layer, triple-Vth, CMOS
Chip Size 97 6mm2 (9 88mm x 9 88mm)Core Core Chip Size 97.6mm (9.88mm x 9.88mm)
Supply Voltage 1.0V (internal), 1.8/3.3V (I/O)
Power Consumption
0.6 mW/MHz/CPU @ 600MHz (90nm G)
#0 PeripheralsCore
#1
Consumption 600MHz (90nm G)
Clock Frequency 600MHz
CPU Performance 4320 MIPS (Dhrystone 2.1)
SNC
Core Core
#3FPU Performance 16.8 GFLOPS
I/D Cache 32KB 4way set-associative (each)
#2#3
( )
ILRAM/OLRAM 8KB/16KB (each CPU)
URAM 128KB (each CPU)
P k FCBGA 554 i 29SH4A Multicore SoC Chip Package FCBGA 554pin, 29mm x 29mm
ISSCC07 Paper No.5.3, Y. Yoshida, et al., “A 4320MIPS Four-Processor Core SMP/AMP with pIndividually Managed Clock Frequency for Low Power Consumption”
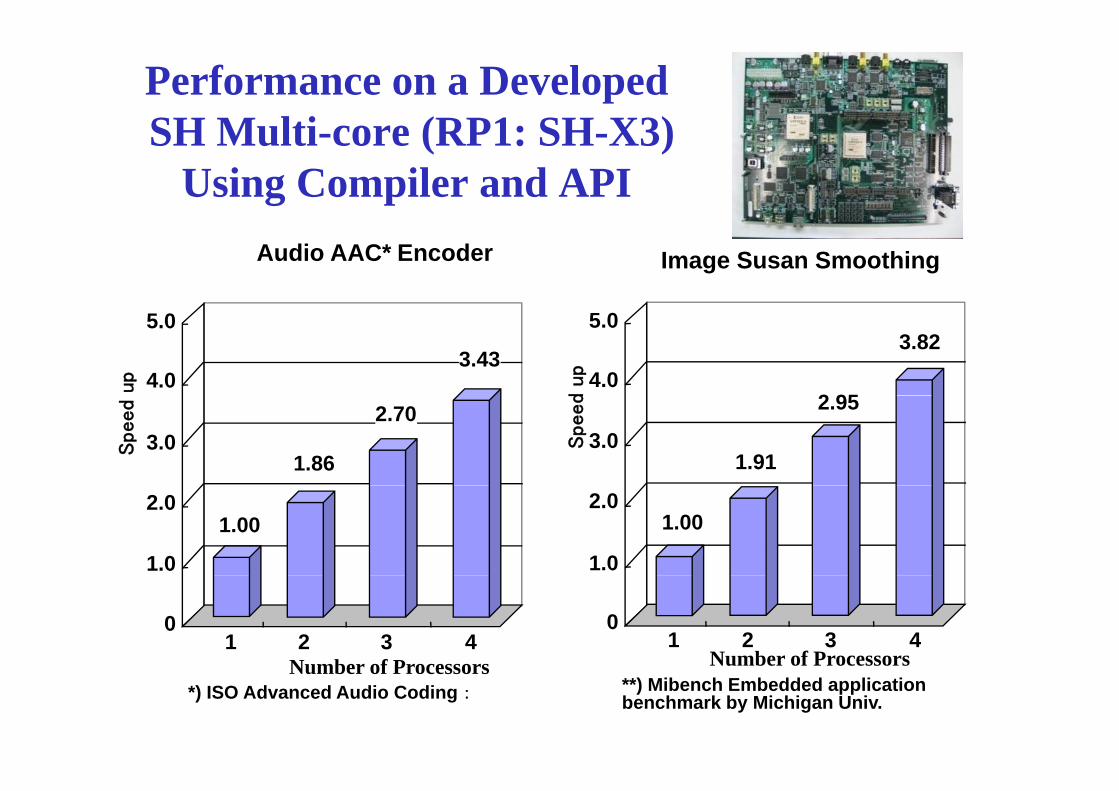
Performance on a DevelopedSH Multi core (RP1: SH X3)SH Multi-core (RP1: SH-X3)
Using Compiler and APIAudio AAC* Encoder Image Susan Smoothing
up
5.0
4.02 95
3.825.0
4.03.43
d u
p
Speed
3.01.91
2.95
3.01.86
2.70
Speed
2.0
1.0
1.002.0
1.0
1.00
Number of Processors1 2 3 4
01 2 3 4
0Number of ProcessorsNumber of Processors
**) Mibench Embedded application benchmark by Michigan Univ.*) ISO Advanced Audio Coding:
Number of Processors

RP2 Chip Photo and Specifications
Process 90nm 8-layer triple-ILRAM I$ Process Technology
90nm, 8-layer, triple-Vth, CMOS
Chip Size 104 8mm2
Core#1
C0
LB
SC
URAMDLRAM
Core#0ILRAM
D$
I$
Chip Size 104.8mm(10.61mm x 9.88mm)
CPU Core 6.6mm2
Core#2 Core#3SN
SHWY CPU Core Size
6.6mm(3.36mm x 1.96mm)
Supply 1.0V–1.4V (internal), Core#6 Core#7
SNC
1
SHWY VSWC
pp yVoltage
( ),1.8/3.3V (I/O)
Power 17 (8 CPUs, Core#4 Core#5
SC
SM
Domains(
8 URAMs, common)DBSC
DDRPADGCPG
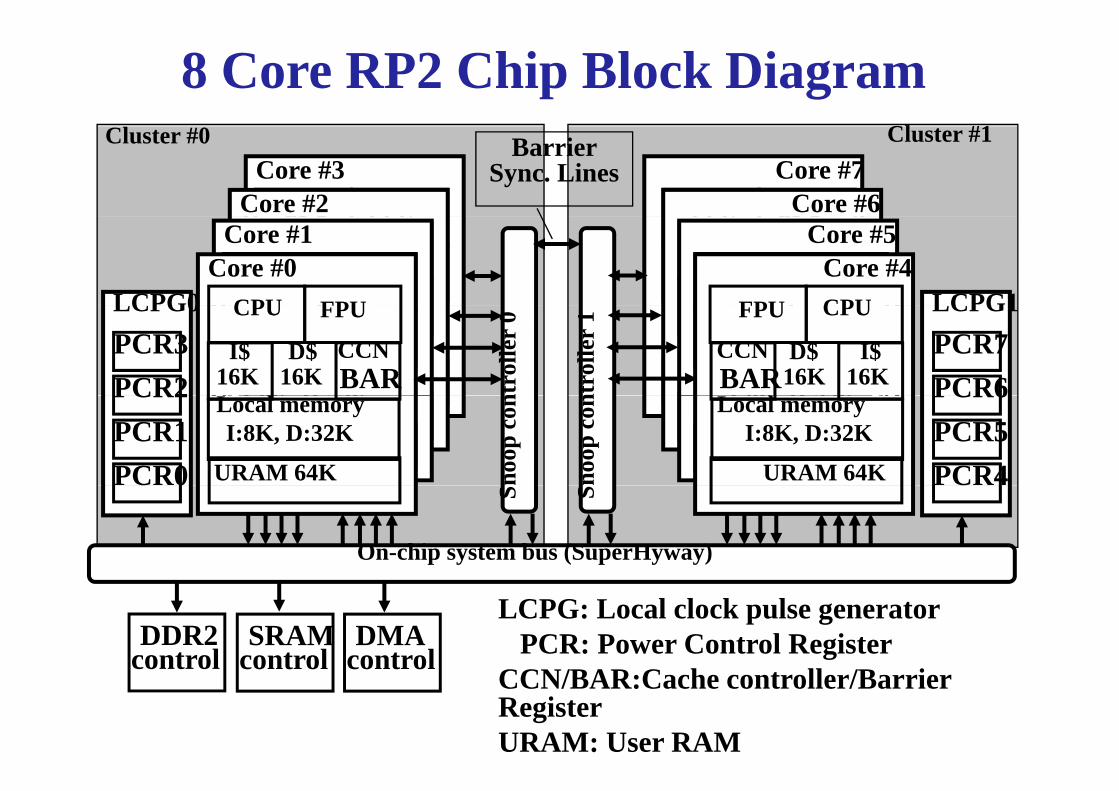
8 Core RP2 Chip Block DiagramCl #1
Core #3CPU FPUCore #2
Cluster #0 Cluster #1Core #7CPUFPU Core #6
Barrier Sync. Lines
I$16K
D$16K
CPU FPU
Local memoryI$
16KD$
16K
CPU FPUCore #1CPU FPUCore #0
CPU FPULCPG0 LCPG1
I$16K
D$16K
CPUFPU
I$16K
D$16K
CPUFPU Core #5CPUFPU Core #4
CPUFPU
User RAM 64K
Local memoryI:8K, D:32K
16K 16KLocal memoryI:8K, D:32K
I$16K
D$16K
Local memoryI 8K D 32K
I$16K
D$16K
CPU FPU
CCNBAR
ntro
ller
1
ntro
ller
0LCPG0PCR3PCR2
LCPG1PCR7PCR6User RAM 64K
I:8K, D:32K16K16K
I:8K, D:32K
I$16K
D$16K
I 8K D 32K
I$16K
D$16K
CPUFPU
CCNBAR
User RAM 64KUser RAM 64K
I:8K, D:32K
URAM 64K
Local memoryI:8K, D:32K
noop
con
noop
con
PCR2PCR1PCR0
PCR6PCR5PCR4
User RAM 64KUser RAM 64K
I:8K, D:32K
URAM 64K
Local memoryI:8K, D:32K
On-chip system bus (SuperHyway)SSC 0 C
DDR2LCPG: Local clock pulse generator
PCR: Power Control RegistercontrolSRAM
controlDMA
controlCCN/BAR:Cache controller/Barrier RegisterURAM: User RAM
control control control
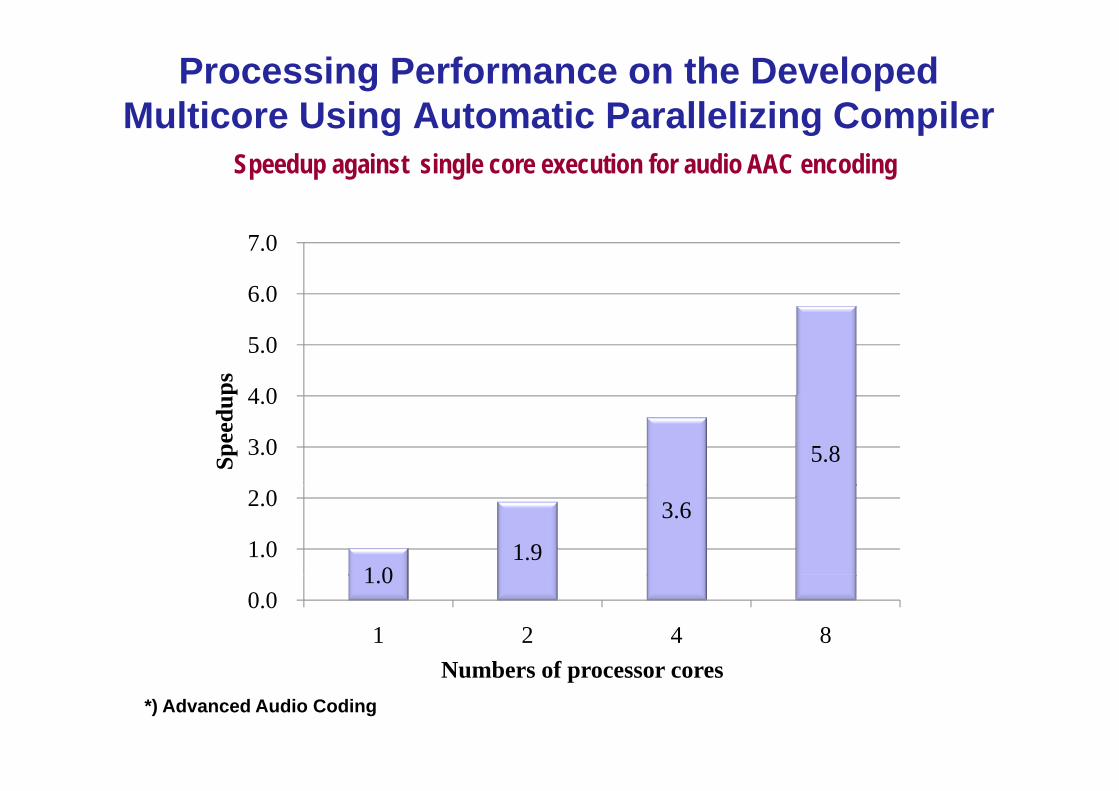
Processing Performance on the Developed Multicore Using Automatic Parallelizing CompilerMulticore Using Automatic Parallelizing Compiler
Speedup against single core execution for audio AAC encoding
6.0
7.0
4 0
5.0
ps
5.8 3.0
4.0
Spee
du
1 01.9
3.6 1.0
2.0
1.0 0.0
1 2 4 8N b f
*) Advanced Audio Coding
Numbers of processor cores
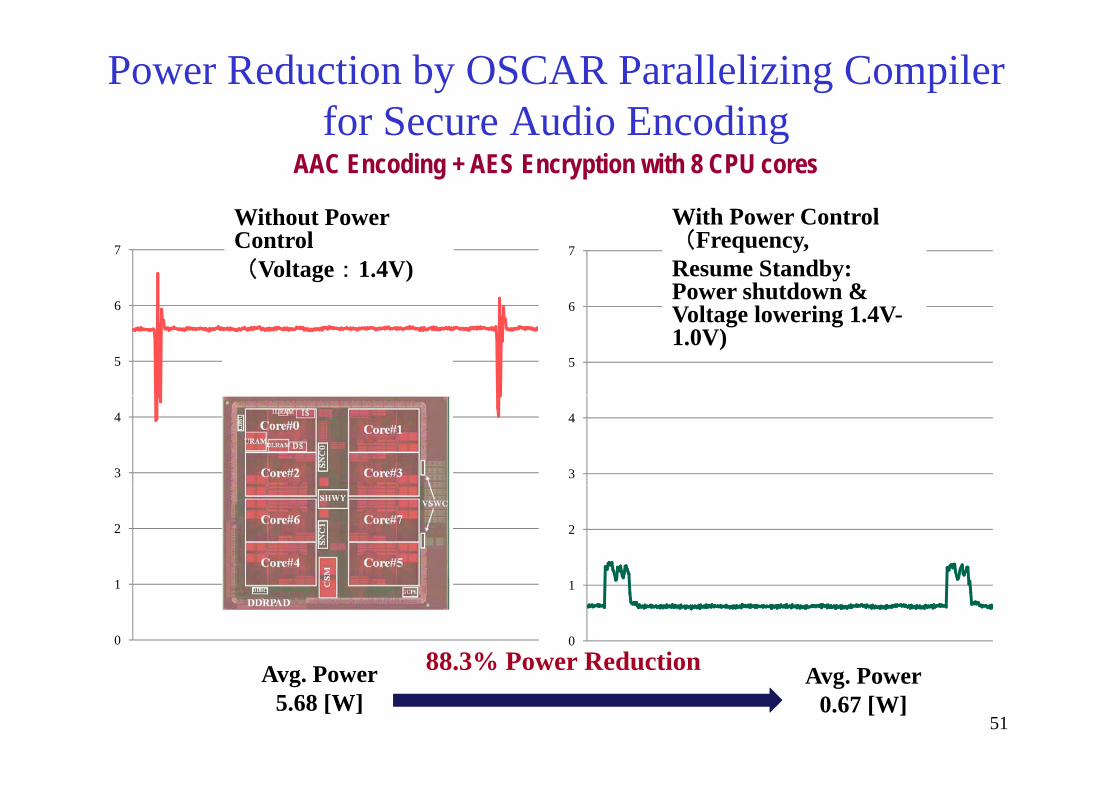
Power Reduction by OSCAR Parallelizing Compiler for Secure Audio Encodingfor Secure Audio Encoding
AAC Encoding + AES Encryption with 8 CPU cores
Without Power With Power Control
6
7
Without Power Control(Voltage:1.4V)
6
7
With Power Control (Frequency, Resume Standby: Power shutdown &
5
6
5
6 Voltage lowering 1.4V-1.0V)
3
4
3
4
2 2
88 3% Power Reduction0
1
0
1
Avg. Power5.68 [W]
Avg. Power0.67 [W]
88.3% Power Reduction
51

Power Reduction by OSCAR Parallelizing Compiler for MPEG2 Decodingfor MPEG2 DecodingMPEG2 Decoding with 8 CPU cores
Without Power C l With Power Control
6
7
6
7Control(Voltage:1.4V)
W owe Co o(Frequency, Resume Standby: Power shutdown & Voltage lowering 1 4V
5 5
6 Voltage lowering 1.4V-1.0V)
3
4
3
4
1
2 2
73 5% Power Reduction0
1
0
1
Avg. Power5.73 [W]
Avg. Power1.52 [W]
73.5% Power Reduction
52
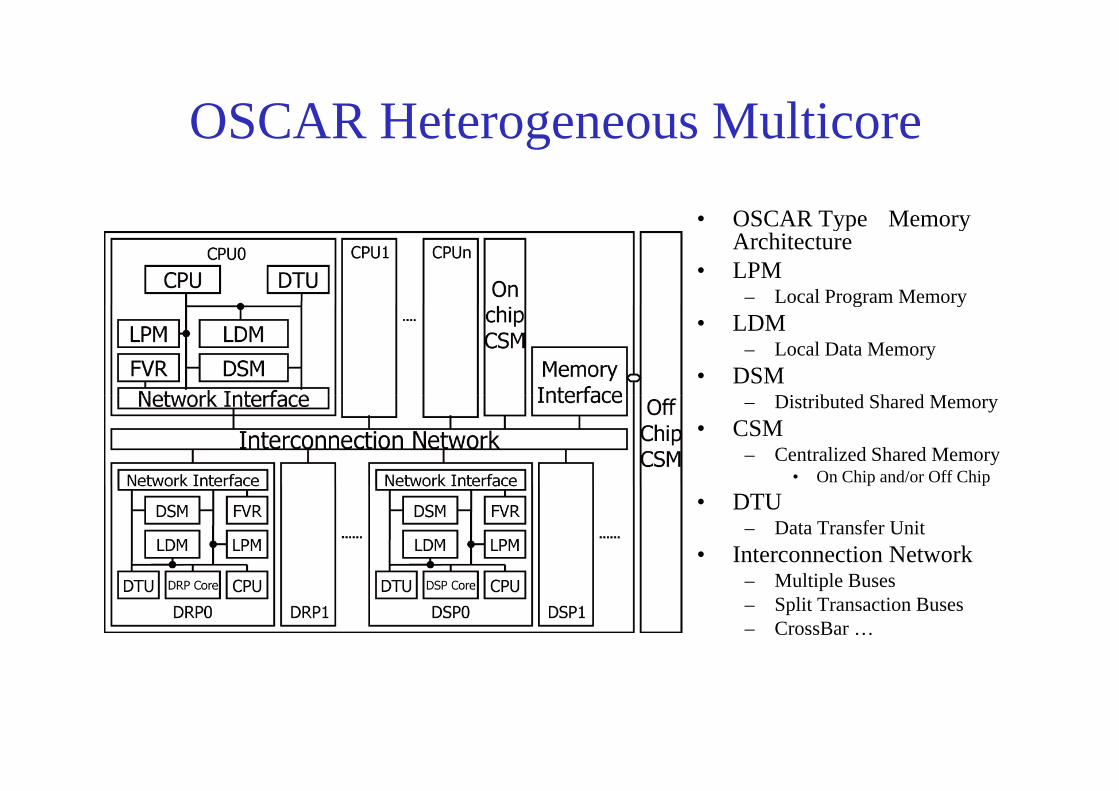
OSCAR Heterogeneous MulticoreOSCAR Heterogeneous Multicore
• OSCAR Type Memory• OSCAR Type Memory Architecture
• LPM– Local Program Memoryg y
• LDM– Local Data Memory
• DSMDi ib d Sh d M– Distributed Shared Memory
• CSM– Centralized Shared Memory
• On Chip and/or Off Chipp p• DTU
– Data Transfer Unit• Interconnection Network
M lti l B– Multiple Buses– Split Transaction Buses– CrossBar …

Static Scheduling of Coarse Grain Tasks for a Heterogeneous Multi-core
MT1for CPU
MT2for CPU
MT3for CPU
MT6for CPU
MT5for DRP
MT4for DRP
MT7 MT10MT9MT8MT7for DRP
MT10for DRP
MT9for DRP
MT8for CPU
MT13f DRP
MT12f DRP
MT11f CPU for DRPfor DRPfor CPU
EMT

An Image of Static Schedule for Heterogeneous Multi-core with Data Transfer Overlapping and Power Controlpp g
TIM
EE
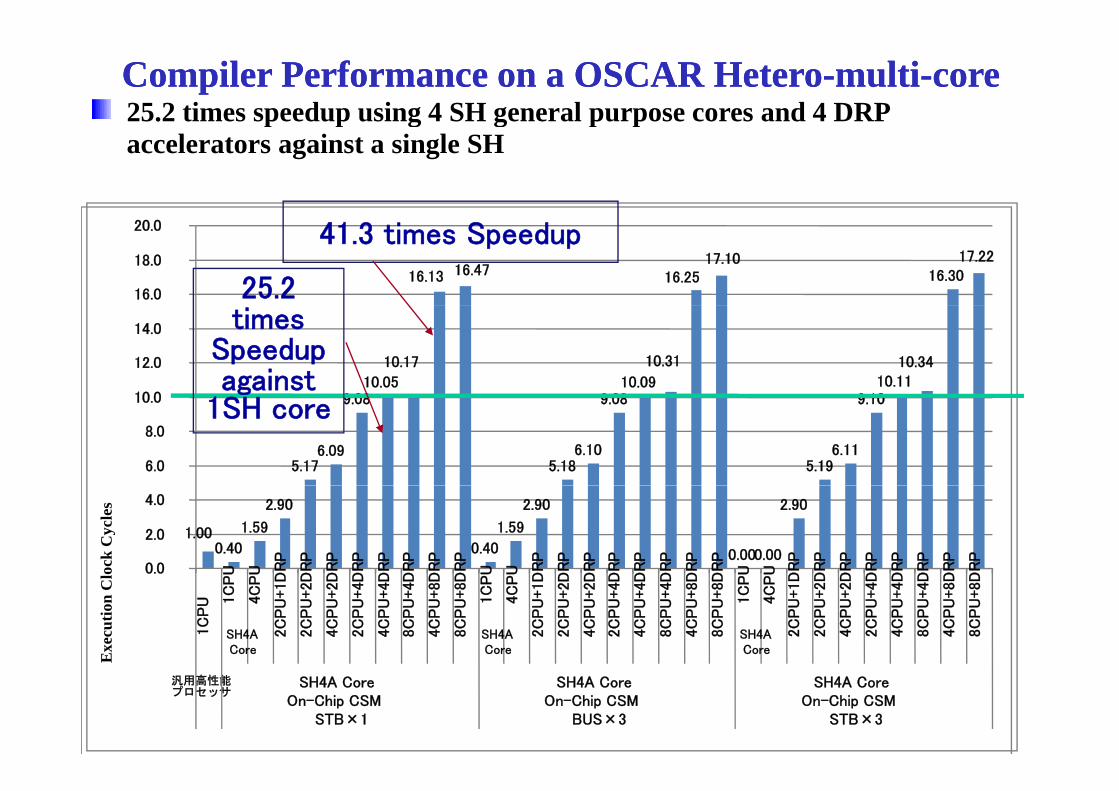
Compiler Performance on a OSCAR HeteroCompiler Performance on a OSCAR Hetero--multimulti--corecore25.2 times speedup using 4 SH general purpose cores and 4 DRP p p g g p paccelerators against a single SH
16.3016.25
17.2217.1016.13 16.47
16.0
18.0
20.0
25.2
41.3 times Speedup
9 0810.05
9 0810.09
9 1010.11
10.3410.3110.17
10 0
12.0
14.0 times Speedup against
5.176.09
9.08
5.186.10
9.08
5.196.11
9.10
6.0
8.0
10.01SH core
0.40
1.59
2.90
0.40
1.59
2.90
0.000.00
2.90
1.00
0.0
2.0
4.0
U U DR
P
DR
P
DR
P
DR
P
DR
P
DR
P
DR
P
DR
P
U U DR
P
DR
P
DR
P
DR
P
DR
P
DR
P
DR
P
DR
P
U U DR
P
DR
P
DR
P
DR
P
DR
P
DR
P
DR
P
DR
P
lock
Cyc
les
1C
PU 1
CP
4C
P
2C
PU
+1D
2C
PU
+2D
4C
PU
+2D
2C
PU
+4D
4C
PU
+4D
8C
PU
+4D
4C
PU
+8D
8C
PU
+8D
1C
P
4C
P
2C
PU
+1D
2C
PU
+2D
4C
PU
+2D
2C
PU
+4D
4C
PU
+4D
8C
PU
+4D
4C
PU
+8D
8C
PU
+8D
1C
P
4C
P
2C
PU
+1D
2C
PU
+2D
4C
PU
+2D
2C
PU
+4D
4C
PU
+4D
8C
PU
+4D
4C
PU
+8D
8C
PU
+8D
Exe
cutio
n C
l
SH4ACore
SH4ACore
SH4ACore
汎用高性能プロセッサ
SH4A CoreOn-Chip CSM
STB×1
SH4A CoreOn-Chip CSM
BUS×3
SH4A CoreOn-Chip CSM
STB×3
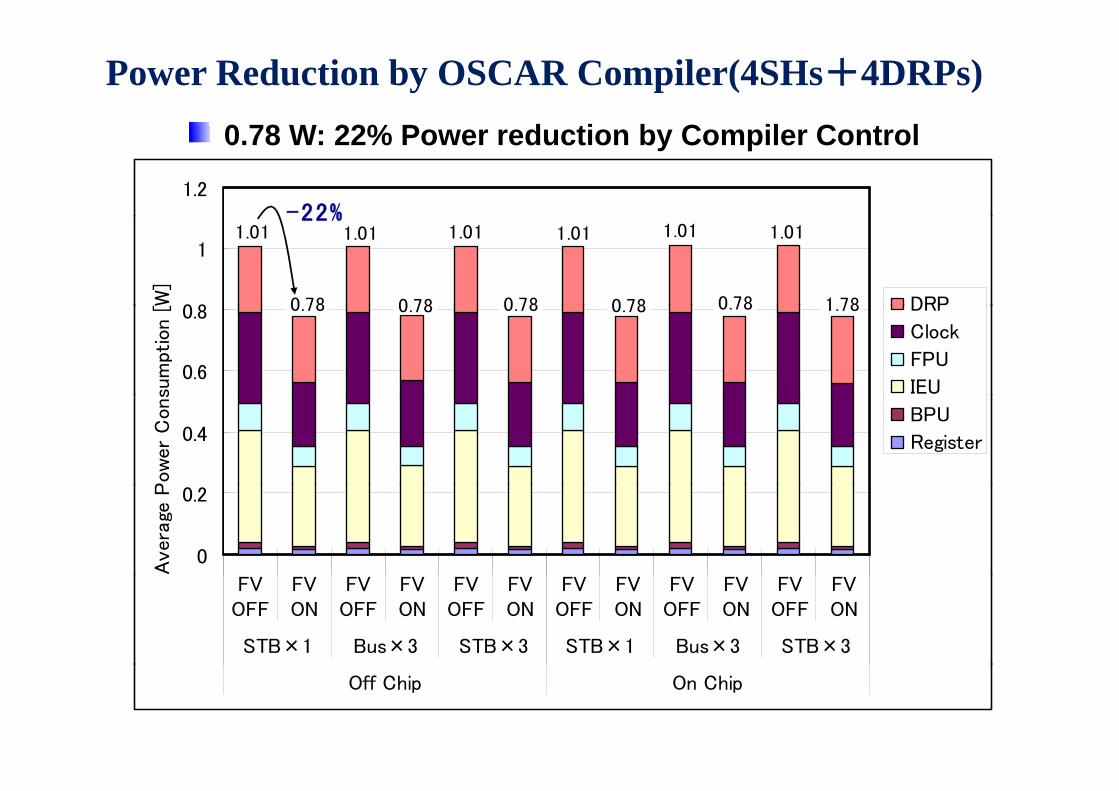
Power Reduction by OSCAR Compiler(4SHs+4DRPs)0 78 W 22% P d ti b C il C t l0.78 W: 22% Power reduction by Compiler Control
1.2-22%
0 8
1
[W]
DRP
1.01
0 78
1.01
0 78
1.01
0 78
1.01
0 78
1.01
0 78
1.01
1 78
22%
0.6
0.8
sum
ptio
n [ DRP
Clock
FPU
IEU
0.78 0.78 0.78 0.78 0.78 1.78
0.4
Pow
er
Cons
BPU
Register
0
0.2
Avera
ge P
FVOFF
FVON
FVOFF
FVON
FVOFF
FVON
FVOFF
FVON
FVOFF
FVON
FVOFF
FVON
STB×1 Bus×3 STB×3 STB×1 Bus×3 STB×3
Off Chip On Chip

Compiler cooperative low power high effectiveConclusions
Compiler cooperative low power, high effective performance, short software development period multi-core processors will be more important in wide range ofcore processors will be more important in wide range of information systems from embedded applications like games, mobile phones, digital TVs and automobiles to g p gpeta-scale supercomputers. Automatically generated parallel programs using the y g p p g gdeveloped multicore API by OSCAR compiler give us the following performances:
3.31 times speedup on 4core (SH4A) OSCAR type multicore3.38 times speedup on 4 core FR1000 against 1 core88% power reduction by the compiler power control on the developed 8 core (SH4A) multicore for realtime secure AAC encodingAAC encoding 70% power reduction on the multicore for MPEG2 decoding