mỘt sỐ kỸ thuẬt tÌm kiẾm thỰc thỂ dỰa trÊn quan hỆ …
TRANSCRIPT

BỘ GIÁO DỤC VÀ ĐÀO TẠO VIỆN HÀN LÂM KHOA HỌC
VÀ CÔNG NGHỆ VIỆT NAM
HỌC VIỆN KHOA HỌC VÀ CÔNG NGHỆ
-----------------------------
Trần Lâm Quân
MỘT SỐ KỸ THUẬT TÌM KIẾM THỰC THỂ DỰA TRÊN
QUAN HỆ NGỮ NGHĨA ẨN VÀ GỢI Ý TRUY VẤN HƯỚNG
NGỮ CẢNH
LUẬN ÁN TIẾN SĨ TOÁN HỌC
Hà Nội – 2020

BỘ GIÁO DỤC VÀ ĐÀO TẠO VIỆN HÀN LÂM KHOA HỌC
VÀ CÔNG NGHỆ VIỆT NAM
HỌC VIỆN KHOA HỌC VÀ CÔNG NGHỆ
-----------------------------
Trần Lâm Quân
MỘT SỐ KỸ THUẬT TÌM KIẾM THỰC THỂ DỰA TRÊN
QUAN HỆ NGỮ NGHĨA ẨN VÀ GỢI Ý TRUY VẤN HƯỚNG
NGỮ CẢNH
Chuyên ngành: Cơ sở toán học cho tin học
Mã số: 9.46.01.10
LUẬN ÁN TIẾN SĨ TOÁN HỌC
NGƯỜI HƯỚNG DẪN KHOA HỌC:
TS. Vũ Tất Thắng
Hà Nội – 2020

i
LỜI CAM ĐOAN
Tôi xin cam đoan đây là công trình nghiên cứu của riêng tôi, được hoàn thành
dưới sự hướng dẫn của TS Vũ Tất Thắng. Các kết quả nêu trong luận án là trung thực
và chưa từng được công bố trong bất kỳ công trình nào khác.
Tôi xin chịu trách nhiệm về những lời cam đoan của mình.
Hà nội, tháng 12 năm 2020
Tác giả
Trần Lâm Quân

ii
LỜI CẢM ƠN
Luận án này được hoàn thành với sự nỗ lực không ngừng của tác giả và sự giúp
đỡ hết mình từ thầy hướng dẫn, gia đình, bạn bè và đồng nghiệp.
Đầu tiên, tác giả xin bày tỏ lời tri ân tới TS Vũ Tất Thắng, Thầy đã tận tình
hướng dẫn tác giả hoàn thành luận án này, Thày đã kiên trì và đặc biệt, đã định hướng
cho nghiên cứu sinh suốt quá trình nghiên cứu.
Tác giả xin gửi lời cảm ơn tới các Thầy, Cô và cán bộ của Viện Công nghệ thông
tin, Học viện Khoa học và Công nghệ (Viện Hàn lâm Khoa học và Công nghệ Việt Nam)
đã nhiệt tình giúp đỡ và tạo ra môi trường nghiên cứu tốt để tác giả hoàn thành công
trình nghiên cứu; đã có những góp ý chính xác để tác giả có được những công bố như
ngày hôm nay.
Tác giả xin cảm ơn tới Ban Lãnh đạo Tổng công ty Hàng không Việt Nam
(Vietnam Airlines), Trung tâm Nghiên cứu Ứng dụng và các đồng nghiệp nơi tác giả
công tác đã ủng hộ để luận án được hoàn thành.
Cuối cùng, xin gửi lời cảm ơn đến tất cả các thành viên trong gia đình, các bạn
bè đã luôn ủng hộ, chia sẻ, động viên và khích lệ tôi học tập, nghiên cứu
Hà Nội, tháng 12 năm 2020
Trần Lâm Quân

iii
MỤC LỤC
Trang phụ bìa
Lời cam đoan i
Lời cảm ơn ii
Mục lục iii
Danh mục các ký hiệu, các chữ viết tắt v
Danh mục các bảng vii
Danh mục các hình vẽ, đồ thị viii
MỞ ĐẦU 01
CHƯƠNG 1: TỔNG QUAN
1.1. Bài toán tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn 05
1.2. Các nghiên cứu liên quan đến tìm kiếm thực thể dựa trên ngữ nghĩa ẩn 07
1.2.1. Lý thuyết ánh xạ cấu trúc (Structure Mapping Theory – SMT) 07
1.2.2. Mô hình không gian vector (Vector Space Model - VSM) 08
1.2.3. Phân tích quan hệ tiềm ẩn (Latent Relational Analysis - LRA) 09
1.2.4. Ánh xạ quan hệ tiềm ẩn (Latent Relational Mapping Engine - LRME) 09
1.2.5. Quan hệ ngữ nghĩa tiềm ẩn (Latent Semantic Relation – LSR) 11
1.2.6. Tương đồng quan hệ dựa trên Wordnet 11
1.2.7. Mô hình học biểu diễn vector từ Word2Vec 12
1.3. Phương pháp tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn với các nghiên cứu
liên quan 14
1.4. Bài toán gợi ý truy vấn hướng ngữ cảnh 14
1.5. Các nghiên cứu liên quan đến gợi ý truy vấn 15
1.5.1. Kỹ thuật gợi ý truy vấn dựa trên phiên (Session-based) 15
1.5.2. Kỹ thuật gợi ý truy vấn dựa trên cụm (Cluster-based) 18
1.6. Phương pháp gợi ý truy vấn dựa trên hướng ngữ cảnh với các nghiên cứu liên
quan 22
1.7. Các kết quả đạt được của luận án 24
CHƯƠNG 2: TÌM KIẾM THỰC THỂ DỰA TRÊN QUAN HỆ NGỮ NGHĨA ẨN
2.1. Bài toán 25
2.2. Phương pháp tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn 27

iv
2.2.1. Kiến trúc – Mô hình 27
2.2.2. Thành phần rút trích quan hệ ngữ nghĩa 30
2.2.3. Thành phần gom cụm các quan hệ ngữ nghĩa 32
2.2.4. Thành phần tính toán độ tương đồng quan hệ giữa 2 cặp thực thể 39
2.3. Kết quả thực nghiệm - Đánh giá 43
2.3.1. Dataset 44
2.3.2. Kiểm thử - Điều chỉnh tham số 45
2.3.3. Đánh giá với độ đo MRR 46
2.3.4. Hệ thống thực nghiệm 46
2.4. Kết luận chương 49
CHƯƠNG 3: GỢI Ý TRUY VẤN HƯỚNG NGỮ CẢNH
3.1. Bài toán 50
3.2. Phương pháp hướng ngữ cảnh 52
3.2.1. Định nghĩa – Thuật ngữ 52
3.2.2. Đề dẫn – Ví dụ minh họa 53
3.2.3. Kiến trúc – Mô hình 55
3.2.4. Offline phase 55
3.2.5. Online phase – Giải thuật gợi ý truy vấn 63
3.2.6. Phân tích ưu nhược điểm 64
3.2.7. Các đề xuất kỹ thuật 66
3.2.8. Kỹ thuật phân lớp kết quả tìm kiếm dựa trên dàn khái niệm 73
3.3. Kết quả thực nghiệm - Đánh giá 84
3.3.1. Dataset 85
3.3.2. Đánh giá, so sánh 85
3.3.3. Hệ thống thực nghiệm 88
3.4. Kết luận chương 92
CHƯƠNG 4: KẾT LUẬN VÀ KIẾN NGHỊ
4.1. Kết luận 94
4.2. Kiến nghị 95
DANH MỤC CÔNG TRÌNH CỦA TÁC GIẢ 96
TÀI LIỆU THAM KHẢO 97

v
DANH MỤC CÁC KÝ HIỆU, CÁC CHỮ VIẾT TẮT
Ký hiệu Tên tiếng Anh Tên tiếng Việt
CBOW Continous Bag-Of-Words Mô hình Túi từ liên tục áp dụng trong
Word2Vec
C Cluster, Clustering Cụm, Phân cụm
CL Concept Lattice Dàn khái niệm
Dataset Data-set Tập dữ liệu mẫu
FCA Formal Concept Analysis Phân tích khái niệm hình thức
Fe Filter-Entities Hàm lọc tìm các cặp thực thể ứng viên
FC Formal Context Khái niệm hình thức
IRES Implicit Relational Entity
Search
Tìm kiếm thực thể dựa trên quan hệ ẩn;
IR Information Retrieval Tìm kiếm thông tin
IRS Implicit Relational Search Tìm kiếm dựa trên quan hệ ẩn
LM Language Model Mô hình ngôn ngữ
LRME Latent Relation Mapping
Engine
Ánh xạ quan hệ tiềm ẩn
LRA Latent Relational Analysis Phân tích quan hệ tiềm ẩn
LSR Latent Semantic Relation Quan hệ ngữ nghĩa tiềm ẩn
MRR Mean Reciprocal Rank Trung bình của RR (Reciprocal Rank) tập
truy vấn
NE Named Entity Thực thể có tên
PMI Pointwise Mutual
Information
Độ đo thông tin tương hỗ
q Query Câu truy vấn
QLogs Query Log Tập truy vấn trong quá khứ
Q-suggest Query suggestion Gợi ý truy vấn; Đề xuất truy vấn
Re Rank-Entities Hàm xếp hạng các thực thể trong tập ứng
viên
RelSim Relational Similarity Tương đồng quan hệ

vi
RR Reciprocal Rank Thứ hạng phù hợp của một đối tượng (truy
vấn)
SE Search Engine Máy tìm kiếm
SL Semantic relation Quan hệ ngữ nghĩa
Session Session Phiên tìm kiếm
SR Similarity relation Quan hệ tương đồng
SMT Structure Mapping Theory Lý thuyết ánh xạ cấu trúc
term Term(s) Từ, cụm từ, thuật ngữ
mining Text mining Khai phá dữ liệu văn bản
VS Voice search Tìm kiếm bằng giọng nói
VSM Vector Space Model Mô hình không gian vector
Word2Vec Word to Vector Mô hình học biểu diễn từ thành vector

vii
DANH MỤC CÁC BẢNG
Bảng 1.1: Tìm tương quan giữa các thuật ngữ trong 2 danh sách 9
Bảng 1.2: Kết quả tương quan giữa các thuật ngữ trong 2 danh sách 10
Bảng 2.1: Kết quả giải thuật rút trích quan hệ ngữ nghĩa 31
Bảng 2.2: Các phân lớp NER (Location, Organization, Personal, Time) 44
Bảng 2.3: Các ví dụ kết quả thực nghiệm với input q = {A, B, C} và output D 48
Bảng 3.1: Cấu trúc rút gọn của phiên tìm kiếm 53
Bảng 3.2: Bảng ngữ cảnh 1 75
Bảng 3.3: Bảng so sánh tìm kiếm hướng ngữ cảnh và Lucene-Nutch 86

viii
DANH MỤC CÁC HÌNH VẼ, ĐỒ THỊ
Hình 1.1: Danh sách trả về từ Keyword-SE ứng với query: “Việt Nam”, “Hà Nội”,
“Pháp” 1
Hình 1.2: Danh sách trả về từ Keyword-SE ứng với q1, q2 3
Hình 1.3: Input: “Cuba”, “José Marti”, “Ấn Độ” (ngữ nghĩa ẩn: “anh hùng dân tộc”) 5
Hình 1.4: Tìm kiếm dựa trên quan hệ ngữ nghĩa với truy vấn đầu vào gồm 3 thực thể 6
Hình 1.5: Ánh xạ cấu trúc SMT 8
Hình 1.6: Quan hệ giữa từ mục tiêu và ngữ cảnh trong mô hình Word2Vec 12
Hình 1.7: Word2Vec “học” quan hệ “ẩn” giữa từ mục tiêu và ngữ cảnh của từ 13
Hình 1.8: QFG sử dụng trọng số 17
Hình 1.9: Các phương pháp phân cụm 18
Hình 1.10: Các đối tượng Core, Border, Noise phân cụm DBSCAN 21
Hình 1.11: Khả năng Directly Density-reachable và Density-reachable 21
Hình 1.12: Gợi ý truy vấn bằng các kỹ thuật truyền thống 22
Hình 1.13: Ngữ cảnh truy vấn 23
Hình 1.14: Minh họa truy vấn “tiger” 23
Hình 2.1: Tìm kiếm dựa trên quan hệ ngữ nghĩa với đầu vào gồm 3 thực thể 27
Hình 2.2: Kiến trúc tổng quát mô hình tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa
ẩn 29
Hình 2.3: Giá trị F-Score tương ứng với mỗi giá trị thay đổi của α, θ1 45
Hình 2.4: So sánh PMI với f: tần suất (số lần đồng hiện) dựa trên MRR 46
Hình 2.5: Thực nghiệm IRS với nhãn thực thể B-PER 47
Hình 2.6: Thực nghiệm IRS với thực thể kiểu thời gian 47
Hình 3.1: Ngữ cảnh truy vấn 53
Hình 3.2: Ví dụ minh họa với truy vấn “gladiator” 54
Hình 3.3: Ví dụ minh họa với truy vấn “tiger” 54
Hình 3.4: Mô hình của tiếp cận gợi ý truy vấn hướng ngữ cảnh 55
Hình 3.5: Đồ thị 2 phía (tập đỉnh Q – tập đỉnh U) 56
Hình 3.6: Sử dụng cấu trúc dữ liệu mảng để phân cụm 59
Hình 3.7: Mô phỏng trực quan tiến trình dựng cây hậu tố 62
Hình 3.8: Phase online: Tiến trình gợi ý truy vấn 63

ix
Hình 3.9: Áp dụng random walk cải thiện vấn đề dữ liệu thưa 69
Hình 3.10: Dựng dàn khái niệm từ bảng ngữ cảnh 1 75
Hình 3.11: Tìm kiếm và phân lớp kết quả với truy vấn “jaguar” 76
Hình 3.12: Tìm kiếm trên dàn 83
Hình 3.13: Mô hình hệ thống thực nghiệm kỹ thuật tìm kiếm hướng ngữ cảnh 84
Hình 3.14: (a): Độ đo tính đa dạng; 14 (b): Độ đo tính thích đáng 87
Hình 3.15: Silverlight đề nghị truy xuất camera, microphone trên máy client 88
Hình 3.16: ARS Server thực hiện speech to text 89
Hình 3.17: Tìm kiếm hướng ngữ cảnh tương tác giọng nói 89
Hình 3.18: Gợi ý truy vấn (gõ không dấu) 90
Hình 3.19: Tìm kiếm áp dụng phương pháp hướng ngữ cảnh 90
Hình 3.20: Gợi ý nhanh 91
Hình 3.21: Phân loại kết quả 91

1
MỞ ĐẦU
1. Tính cấp thiết của luận án
Trong kỷ nguyên big-data, trên không gian Internet, lượng dữ liệu mới sinh ra
không ngừng, Search Engine là cốt lõi để đáp ứng nhu cầu tìm kiếm thông tin của
người sử dụng. Đồng thời, nhu cầu tìm kiếm thông tin với yêu cầu cao ngày càng cấp
bách. Cơ chế tìm kiếm dựa vào từ khóa ít có khả năng suy diễn thông tin chưa biết.
Ngoài ra, câu truy vấn người dùng đưa vào trên thực tế thường ngắn, mơ hồ và đa
nghĩa [1 – 6]. Do đó, cần thiết phải tập trung nghiên cứu cách thức cải tiến để đưa ra
các gợi ý truy vấn hiệu quả hơn, hoặc hình thái tìm kiếm mới như tìm ra tên các thực
thể dựa trên ngữ nghĩa ẩn.
Theo thống kê, xấp xỉ 71% câu tìm kiếm trên web có chứa tên thực thể [7],
[8]. Khi xét truy vấn chỉ gồm tên thực thể: “Việt Nam”, “Hà Nội”, “Pháp”, về trực
quan, ta thấy ngữ nghĩa tiềm ẩn sau truy vấn này. Nói cách khác, tiềm ẩn một quan
hệ tương tự giữa cặp tên thực thể “Việt Nam”:“Hà Nội” và cặp tên thực thể
“Pháp”:“?”. Nếu chỉ xét trực quan, đây là một trong những khả năng “tự nhiên” của
con người - khả năng suy ra thông tin/tri thức chưa biết bằng suy diễn tương tự. Với
truy vấn trên, con người có khả năng đưa ra đáp án tức thời, nhưng máy tìm kiếm
Search Engine (SE) chỉ tìm được những tài liệu chứa các từ khóa nói trên, SE không
đưa ngay ra được câu trả lời “Paris”.
Hình 1.1: Danh sách trả về từ Keyword-SE ứng với query=”Việt Nam”, “Hà
Nội”, “Pháp”.

2
Cũng như vậy, thế giới thực tồn tại những câu hỏi dạng: “nếu Fansipan cao
nhất Việt Nam, thì đâu là đỉnh của Tây Tạng?”, “biết Elizabeth là nữ hoàng Anh thì
quốc vương Nhật Bản là ai?”, .v.v. Đối với những truy vấn tồn tại quan hệ tương đồng
như trên, cơ chế tìm kiếm theo từ khóa khó khăn trong việc đưa ra đáp án, trong khi
con người có thể dễ dàng suy luận tương tự. Nghiên cứu, mô phỏng khả năng tự nhiên
của con người khi suy diễn từ một miền ngữ nghĩa quen thuộc (“Việt Nam”, “Hà
Nội”) sang một miền ngữ nghĩa không quen thuộc (“Pháp”, “?”) - là mục đích của
bài toán thứ nhất.
Bài toán thứ 2 về gợi ý truy vấn. Trong các phiên tìm kiếm, lượng kết quả trả
về nhiều nhưng phần lớn không thích hợp với ý định tìm kiếm của người sử dụng1.
Từ đó, có nhiều hướng nghiên cứu đặt ra nhằm cải thiện kết quả, hỗ trợ người tìm
kiếm. Các hướng nghiên cứu này bao gồm: gợi ý truy vấn (query suggestion), viết lại
truy vấn (rewriting query), mở rộng truy vấn (query expansion), cá nhân hóa
(personalized recommendations), phân hạng kết quả (ranking/re-ranking search
results), .v.v.
Hướng nghiên cứu về gợi ý truy vấn thường áp dụng các kỹ thuật truyền thống
như gom cụm, đo độ tương đồng, .v.v. của các truy vấn [9], [10]. Tuy nhiên, các kỹ
thuật truyền thống có ba nhược điểm: Thứ nhất, chỉ đưa ra được các câu gợi ý tương
tự hoặc có liên quan với truy vấn vừa nhập - mà chất lượng chưa chắc đã tốt hơn truy
vấn vừa nhập. Thứ hai, không đưa ra được xu hướng mà tri thức số đông thường hỏi
sau truy vấn hiện hành. Thứ ba, những cách tiếp cận này không xét chuỗi truy vấn
một cách liền mạch từ người sử dụng để nắm bắt ý định tìm kiếm của người dùng.
Chẳng hạn, trên các Search Engine (SE) thông dụng, gõ 2 truy vấn liên tiếp q1: “Joe
Biden là ai”, q2: “Ông ấy bao nhiêu tuổi”, rõ ràng q1, q2 có liên quan ngữ nghĩa. Tuy
nhiên kết quả trả về của q1, q2 là 2 tập kết quả rất khác nhau. Điều này cho thấy
nhược điểm của cơ chế tìm kiếm theo từ khóa.
Nắm bắt chuỗi truy vấn liền mạch, nói cách khác, nắm bắt được ngữ cảnh tìm
kiếm, SE sẽ “hiểu” được ý định tìm kiếm của người sử dụng. Hơn nữa, nắm bắt chuỗi
truy vấn, SE có thể gợi ý truy vấn theo chuỗi, chuỗi gợi ý này là tri thức số đông,
cộng đồng thường hỏi sau q1, q2. Đây là mục đích của bài toán thứ hai.
1
https://static.googleusercontent.com/media/guidelines.raterhub.com/en//searchqualityevaluatorguidelines.pdf

3
Hình 1.2: Danh sách trả về từ SE ứng với q1, q2.
2. Mục tiêu của luận án
Mục tiêu tổng quát của luận án là tập trung nghiên cứu, xác định và thực
nghiệm các phương pháp, các nguyên lý nhằm giải quyết 2 bài toán nêu trên. Cài đặt
thực nghiệm các phương pháp và áp dụng các đề xuất cải thiện kỹ thuật. Phân tích,
đánh giá kết quả sau thực nghiệm. So sánh với các kỹ thuật khác.
3. Đóng góp của luận án
Luận án nghiên cứu giải quyết vấn đề tìm kiếm thực thể dựa trên quan hệ ngữ
nghĩa và gợi ý truy vấn hướng ngữ cảnh. Đóng góp chính của luận án gồm:
1) Xây dựng kỹ thuật tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn sử
dụng phương pháp phân cụm nhằm nâng cao hiệu quả tìm kiếm.
2) Đề xuất độ đo tương đồng tổ hợp trong bài toán gợi ý truy vấn theo
ngữ cảnh nhằm nâng cao chất lượng gợi ý.
3) Ứng dụng kỹ thuật hướng ngữ cảnh, xây dựng máy tìm kiếm chuyên sâu
áp dụng hướng ngữ cảnh trong miền cơ sở tri thức riêng (dữ liệu hàng
không).
4. Đối tượng nghiên cứu
Thuộc lớp bài toán khai phá dữ liệu, khai phá ngữ nghĩa và xử lý ngôn ngữ tự
nhiên, đối tượng nghiên cứu trong luận án gồm:
- Phương pháp tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn.
- Phương pháp gợi ý truy vấn hướng ngữ cảnh.

4
5. Phạm vi của luận án
Với phương pháp tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn, bộ dữ liệu
thử nghiệm là các tập data-set trích rút từ Viwiki, Vn-news, dữ liệu ngành hàng không
(Vietnam Airlines). Miền ngôn ngữ tiếng Việt.
Với phương pháp gợi ý truy vấn hướng ngữ cảnh, đặt trọng tâm vào phương
pháp hướng ngữ cảnh nên các kỹ thuật chỉnh sửa, viết lại truy vấn không được đề cập
trong khuôn khổ luận án.
6. Phương pháp luận
Luận án giải quyết các vấn đề nghiên cứu đặt ra theo cách tiếp cận sau:
- Khảo sát các kết quả nghiên cứu của một số tác giả đã công bố.
- Phân tích, đề xuất giải pháp cho từng vấn đề.
- Công bố, trao đổi, thảo luận và báo cáo tại các buổi seminar, hội thảo, hội nghị
khoa học, .v.v.
- Sử dụng phương pháp nghiên cứu lý thuyết, xây dựng và kiểm thử các mô hình
đề xuất trên dữ liệu đã được công bố và dữ liệu tự thu thập.
- Kết quả được báo cáo dưới dạng số liệu hoặc trực quan hóa để thuận tiện cho
việc đánh giá, kiểm chứng.
7. Cấu trúc luận án
Ngoài phần mở đầu, luận án được tổ chức thành 4 chương có bố cục như sau:
Chương 1 giới thiệu tổng quan vấn đề nghiên cứu trong luận án, trình bày và phân
tích các vấn đề còn tồn tại trong các nghiên cứu liên quan để làm rõ câu hỏi nghiên
cứu. Khắc phục các vấn đề còn tồn tại trong các nghiên cứu liên quan, chương 2: Tìm
kiếm thực thể dựa trên quan hệ ngữ nghĩa, mục đích giải quyết bài toán thứ nhất.
Chương 3: Gợi ý truy vấn hướng ngữ cảnh trong bài toán tìm kiếm, mục đích giải
quyết bài toán thứ hai. So sánh đánh giá, kết quả thực nghiệm, kết quả nghiên cứu
của luận án được nêu ở cuối mỗi chương. Chương 4 kết luận, nêu ưu nhược điểm,
hướng phát triển của luận án và tài liệu tham khảo.

5
CHƯƠNG 1: TỔNG QUAN
1.1. Bài toán tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn
Luận án đặt mục tiêu nghiên cứu về tìm kiếm thực thể dựa trên quan hệ ngữ
nghĩa ẩn (Implicit Relational Search) mô phỏng khả năng suy ra thông tin/tri thức
chưa biết bằng suy diễn tương tự, như một khả năng “tự nhiên” của con người.
Xét truy vấn gồm các thực thể: “Kinh Qur’an”:“Đạo Hồi”, “sách Phúc
Âm”:”?”, con người có khả năng suy diễn tức thời cho dấu “?”, nhưng máy tìm kiếm
chỉ đưa ra kết quả là những tài liệu có chứa các từ khóa trên, không đưa ngay được
câu trả lời “Kitô giáo”. Do chỉ tìm thực thể, các kỹ thuật như mở rộng truy vấn hoặc
viết lại truy vấn không áp dụng với dạng quan hệ có ngữ nghĩa ẩn trong cặp thực thể.
Từ đó, một hình thái tìm kiếm mới được nghiên cứu, motive của câu truy vấn tìm
kiếm có dạng: {(A, B), (C, ?)}, trong đó (A, B) là cặp thực thể nguồn, (C, ?) là cặp
thực thể đích. Đồng thời, hai cặp (A, B), (C, ?) có quan hệ tương đồng về ngữ nghĩa.
Cụ thể, khi người sử dụng nhập vào truy vấn gồm 3 thực thể {(A, B), (C, ?)}, máy
tìm kiếm có nhiệm vụ liệt kê, tìm kiếm trong danh sách ứng viên các thực thể D (thực
thể dấu ?), mỗi thực thể D thỏa điều kiện có quan hệ ngữ nghĩa với C, đồng thời cặp
(C, D) có quan hệ tương đồng với cặp (A, B). Quan hệ ngữ nghĩa - theo nghĩa hẹp và
dưới góc nhìn từ vựng - được biểu diễn bởi ngữ cảnh gồm các từ/cụm từ
(terms/patterns/context) xung quanh (trước, giữa và sau) cặp thực thể đã biết. Vì quan
hệ ngữ nghĩa, quan hệ tương đồng không nêu tường minh trong truy vấn (câu truy
vấn chỉ gồm 3 thực thể: A, B, C), nên hình thái tìm kiếm theo motive được gọi là mô
hình tìm kiếm thực thể dựa trên ngữ nghĩa ẩn (Implicit Relational Entity Search hay
Implicit Relational Search, ngắn gọn: IRS).
Hình 1.3: Truy vấn: ”Cuba”, “José Marti”, “Ấn Độ” (ngữ nghĩa ẩn: “anh hùng dân
tộc”).

6
Tương tự, xét truy vấn chỉ gồm 3 thực thể query q = “Truyện Kiều”:“Nguyễn
Du”, “?”:“Victor Hugo”, truy vấn q không mô tả quan hệ ngữ nghĩa (“là kiệt tác”,
“tác phẩm nổi tiếng”, “sáng tác bởi” hay “di sản văn hóa”, .v.v.). Mô hình tìm kiếm
thực thể dựa trên ngữ nghĩa có nhiệm vụ tìm ra thực thể “?”, thỏa điều kiện có quan
hệ ngữ nghĩa với thực thể “Victor Hugo”, đồng thời cặp “?”:“Victor Hugo” tương
đồng với cặp “Truyện Kiều”:“Nguyễn Du”.
Hình 1.4: Tìm kiếm dựa trên quan hệ ngữ nghĩa ẩn với truy vấn đầu vào chỉ gồm
3 thực thể.
Tìm/tính toán độ tương đồng quan hệ giữa 2 cặp thực thể là một bài toán khó,
khó vì: Thứ nhất, độ tương đồng quan hệ biến đổi theo thời gian, xét 2 cặp thực thể
(Joe Biden, tổng thống Mỹ) và (Elizabeth, nữ hoàng Anh), độ tương đồng quan hệ
biến đổi theo nhiệm kỳ. Thứ hai, do yếu tố thời gian, 2 cặp thực thể có thể không chia
sẻ hoặc chia sẻ rất ít ngữ cảnh xung quanh cặp thực thể, như: Apple:iPod (vào 2010s)
và Sony:Walkman (vào 1980s), dẫn đến kết quả 2 cặp thực thể không tương đồng.
Thứ ba, trong một cặp thực thể, có thể có nhiều quan hệ ngữ nghĩa khác nhau, như:
“Ổ dịch Corona khởi phát từ Vũ Hán”; “Corona cô lập thành phố Vũ Hán”; “Số ca
lây nhiễm Corona giảm dần ở Vũ Hán”; .v.v. Thứ tư, cặp thực thể chỉ có một quan
hệ ngữ nghĩa nhưng có hơn một cách biểu đạt: “X was acquired by Y” và “X buys
Y”. Thứ năm, khó do nội tại thực thể có tên (tên cá nhân, tổ chức, địa danh, ..) vốn
(Victor Hugo, ?)
Truyện Kiều là kiệt tác của
Nguyễn Du
Notre-Dame de Paris là tác
phẩm nổi tiếng của Victor
Hugo
Text Corpus
(Nguyễn Du, Truyện Kiều) Implicit
Relational
Search Engine
(IRS)
? =
Notr
e-D
ame
de
Par
is
output input

7
không phải các từ thông dụng hoặc có trong từ điển. Và cuối cùng, khó do thực thể
D chưa biết, thực thể D đang trong tiến trình tìm kiếm.
Một trường hợp khác, câu truy vấn theo motive: q = {(A, B), (C, ?)}, nhưng
thực tế quan hệ của cặp thực thể (A, B) không chỉ là đơn nghĩa mà có thể là đa nghĩa,
lúc này sẽ có nhiều quan hệ ngữ nghĩa khác nhau trong cùng một cặp thực thể. Ví dụ
cặp thực thể (Notre Dame:Paris) sẽ có các quan hệ ngữ nghĩa như “vụ cháy”, “biểu
tượng”, “tác phẩm văn học”, “chuyện tình thằng gù”, “vương miện gai”, .v.v.
Mô hình IRS có nhiệm vụ giải bài toán tìm kiếm như vậy. Mô hình IRS là mô
hình sử dụng quan hệ tương đồng từ miền ngữ nghĩa quen thuộc, từ đó suy luận, tìm
kiếm thông tin/tri thức trong một miền ngữ nghĩa không quen thuộc.
1.2. Các nghiên cứu liên quan đến tìm kiếm thực thể dựa trên ngữ nghĩa ẩn
Motive tìm kiếm của câu truy vấn có dạng: q = {(A, B), (C, ?)}, trong đó (A,
B) là cặp thực thể nguồn, (C, ?) là cặp thực thể đích, câu truy vấn chỉ gồm 3 thực thể:
A, B, C. Quan hệ ngữ nghĩa, quan hệ tương đồng không được nêu tường minh trong
truy vấn. Mô hình tìm kiếm thực thể dựa trên ngữ nghĩa ẩn IRS có nhiệm vụ tìm kiếm
thực thể D (thực thể dấu hỏi chấm) chưa biết.
Xác định mối quan hệ tương đồng giữa cặp thực thể (A, B), (C, ?) là điều kiện
cần để xác định thực thể cần tìm. Thuộc lớp bài toán xử lý ngôn ngữ tự nhiên, độ
tương đồng quan hệ là một trong những tác vụ quan trọng nhất của tìm kiếm dựa trên
ngữ nghĩa. Do đó, luận án liệt kê các hướng nghiên cứu chính về độ tương đồng quan
hệ.
1.2.1. Lý thuyết ánh xạ cấu trúc (Structure Mapping Theory – SMT)
Nghiên cứu trong [11] viết: AI và Khoa học nhận thức (Cognitive scientists)
cho rằng tương tự là cốt lõi của nhận thức. Nguyên lý có ảnh hưởng nhất đến mô hình
tính toán của lập luận tương tự là Lý thuyết ánh xạ cấu trúc (SMT).
SMT [12] coi độ tương đồng là ánh xạ “tri thức” (mapping of knowledge) từ
miền nguồn vào miền đích, theo luật ánh xạ: Loại bỏ các thuộc tính của đối tượng
nhưng vẫn duy trì được ánh xạ quan hệ giữa các đối tượng từ miền nguồn vào miền
đích.
Luật ánh xạ (Mapping rules): M: si ti; (trong đó s: source, t: target).
Loại bỏ thuộc tính: HOT(si) ↛HOT(ti); MASSIVE(si) ↛MASSIVE(ti); ...

8
Duy trì ánh xạ quan hệ: Revolves(Planet, Sun) Revolves(Electron,
Nucleus).
Hình 1.5: Ánh xạ cấu trúc SMT.
Hình 1.5 cho thấy do cùng các cấu trúc s (subject), o (object), nên SMT xét
các cặp: (Planet, Sun) và (Electron, Nucleus) là tương đồng quan hệ, dù cặp đối tượng
nguồn và đích - Sun và Nucleus, Planet và Electron rất khác nhau về thuộc tính, như
HOT, MASSIVE, …
Phân tích:
Tham chiếu với mục tiêu nghiên cứu, nếu câu truy vấn là: ((Planet, Sun),
(Electron, ?)), SMT sẽ kết xuất câu trả lời chính xác: “Nucleus”. Tuy nhiên, SMT
không khả thi với các cấu trúc bậc thấp (thiếu quan hệ). Vì vậy, SMT không khả thi
với bài toán tìm kiếm thực thể dựa vào quan hệ ngữ nghĩa ẩn.
1.2.2. Mô hình không gian vector (Vector Space Model - VSM)
Áp dụng mô hình không gian vector, Turney [13] đưa ra khái niệm vector mẫu
– tần suất, trong đó mỗi vector được tạo thành bởi mẫu (pattern) chứa cặp thực thể
(A, B) và tần suất xuất hiện của mẫu. Mô hình không gian vector thực hiện phép đo
độ tương đồng quan hệ như sau: Các mẫu được tạo thủ công, query đến Search Engine
(SE), số kết quả trả về từ SE là tần suất xuất hiện của mẫu. Từ đó, độ tương đồng
quan hệ của 2 cặp thực thể được tính bởi Cosine giữa 2 vector. Ví dụ, xét cặp (traffic,
street) và cặp (water, riverbed), 2 cặp này nhiều khả năng cùng xuất hiện trong câu,

9
như: “traffic in the street” và “water in the riverbed”. Độ đo Cosine giữa 2 vector
(traffic, street) và (water, riverbed) sẽ quyết định 2 vector có tương đồng hay không.
1.2.3. Phân tích quan hệ tiềm ẩn (Latent Relational Analysis - LRA)
Mở rộng VSM, Turney lai ghép VSM với LRA để xác định mức tương đồng
quan hệ [14], [15], [16]. Như VSM, LRA sử dụng vector được tạo thành bởi mẫu
(pattern/context) chứa cặp thực thể (A, B) và tần suất của mẫu, mẫu được xét theo n-
grams. Nói cách khác, phương pháp LRA xác định các n-grams thường xuyên nhất
để gắn mẫu với cặp thực thể (A, B). Đồng thời, LRA áp dụng thêm từ điển đồng nghĩa
để mở rộng các biến thể như: A bought B, A acquired B; X headquarters in Y, X
offices in Y,... Sau đó, LRA xây dựng ma trận mẫu - cặp thực thể, với mỗi phần tử
của ma trận biểu diễn tần suất xuất hiện cặp (A, B) thuộc mẫu. Tiến trình LRA thực
hiện tương tự với cặp (C, D). Nhằm giảm chiều ma trận, LRA áp dụng SVD (Singular
Value Decomposition) để giảm số cột. Cuối cùng, LRA áp dụng phép đo Cosine trên
các dòng của ma trận (row vectors) chứa các cặp (A, B) và (C, D) để tính độ tương
đồng quan hệ giữa 2 cặp thực thể.
Phân tích:
Tuy là cách tiếp cận hiệu quả để xác định độ tương đồng quan hệ, LRA đòi
hỏi thời gian tính toán, xử lý khá dài, tham khảo trong [17] cho biết với 374 SAT
analogy questions (các câu hỏi loại suy của kỳ thi đánh giá năng lực SAT – Scholastic
Aptitude Test), kỹ thuật LRA cần 8 ngày để thực hiện. Điều này không khả thi với
một hệ tìm kiếm đáp ứng thời gian thực.
1.2.4. Ánh xạ quan hệ tiềm ẩn (Latent Relation Mapping Engine – LRME)
Để cải thiện việc dựng các luật ánh xạ, các cấu trúc s (subject), o (object) một
cách thủ công trong SMT, Turney áp dụng phép ánh xạ quan hệ tiềm ẩn LRME [11],
bằng cách kết hợp SMT và LRA. Mục đích: Tìm mối quan hệ giữa 2 terms A, B (xét
terms như là thực thể). Với đầu vào (bảng 1.1) là 2 danh sách các terms từ 2 miền
(nguồn và đích), đầu ra (bảng 1.2) là kết quả ánh xạ 2 danh sách:
Bảng 1.1: Tìm tương quan giữa các thuật ngữ (terms) trong 2 danh sách
Miền nguồn Miền đích
planet revolves
attracts atom
revolves attracts

10
sun electromagnetism
gravity neucleus
solar system charge
mass electron
Bảng 1.2: Kết quả tương quan giữa các terms trong 2 danh sách
Miền nguồn Ánh xạ M Miền đích
solar system → atom
sun → neucleus
planet → electron
mass → charge
attracts → attracts
revolves → revolves
gravity → electromagnetism
Từ tập dữ liệu (corpus), đầu vào của LRME là 2 danh sách các terms được rút
trích từ corpus, sau đó xây dựng ánh xạ (song ánh) giữa 2 tập terms: A và B, các terms
có thứ tự tùy ý. Các terms ai, bj thuộc danh sách (A, B) có thể là một từ đơn (planet),
có thể là một cụm từ (solar system).
Do tính chất song ánh, A và B có cùng số term:
A = {a1, a2, …, am};
B = {b1, b2, …, bm};
Đầu ra (O) của LRME là song ánh M từ A đến B:
O = {M: A → B} (1.1)
M(ai) ϵ B M(A) = {M(a1), M(a2), …, M(am)} = B (1.2)
Do danh sách B có m phần tử m! hoán vị m! song ánh từ AB;
Ký hiệu P(A, B) là tập m! song ánh (A, B). Kết hợp độ đo tương đồng (simr)
trong LRA, đầu ra của LRME là hàm mục tiêu:
𝑀 = argmax𝑀∈𝑃(𝐴,𝐵)
∑ ∑ sim𝑟(𝑎𝑖: 𝑎𝑗 , 𝑀(𝑎𝑖): 𝑀(𝑎𝑗))𝑚𝑗=𝑖+1
𝑚𝑖=1 (1.3)

11
Phân tích:
Đầu vào LRME là 2 dãy chứa terms, đầu vào của IRS là 1 cặp thực thể, có thể
nói IRS khó hơn LRME theo nghĩa ít thông tin đầu vào hơn.
Có m! hoán vị nên LRME phải vét cạn m! trường hợp. Mô hình tìm kiếm thực
thể dựa vào ngữ nghĩa ẩn IRS không áp dụng hoán vị để xác định mối quan hệ tương
đồng.
1.2.5. Quan hệ ngữ nghĩa tiềm ẩn (Latent Semantic Relation – LSR)
Bollegala, Duc. et al. [17], [18], Kato [19] sử dụng giả thuyết phân phối
(Distributional hypothesis) ở mức context: Trong corpus, nếu 2 context pi, pj khác
nhau nhưng thường đồng hiện với các cặp thực thể wm, wn thì 2 context pi, pj tương
tự về ngữ nghĩa. Khi pi, pj tương tự về ngữ nghĩa, các cặp thực thể wm, wn tương đồng
về quan hệ.
Phân tích:
Giả thuyết phân phối đòi hỏi các cặp thực thể phải luôn “đồng hiện” với các
context, đồng thời giải thuật gom cụm Bollega đề xuất ở mức context (mức câu, theo
nghĩa câu thường đồng hiện với cặp thực thể) chứ không thực hiện gom cụm ở mức
terms trong câu. Độ tương đồng chỉ dựa trên giả thuyết phân phối mà không dựa trên
tương đồng về term sẽ ảnh hưởng không nhỏ đến chất lượng của kỹ thuật gom cụm,
từ đó ảnh hưởng đến chất lượng của hệ tìm kiếm.
Ngoài ra, các tác giả của [17], [18], [19] không xét số quan hệ của cặp thực thể
nguồn và đích là không chắc chắn, theo nghĩa ánh xạ quan hệ. Ví dụ, ta có quan hệ
1-1 khi xét cặp thực thể (Mặt trăng, Trái đất). Xét cặp thực thể (Mặt trời, Vệ tinh), ta
có quan hệ 1-nhiều. Xét cặp thực thể (Nhà sản xuất-Công ty) ta có quan hệ nhiều-
nhiều. Nếu áp dụng 3 loại ánh xạ quan hệ vào tìm kiếm thực thể, xét thêm yếu tố thời
gian, kết quả tìm kiếm sẽ chính xác và cập nhật hơn.
1.2.6. Tương đồng quan hệ dựa trên hệ thống phân loại tương đồng Wordnet
Cao [20] và Agirre [21] đề xuất độ đo tương đồng quan hệ dựa trên hệ phân
loại tương đồng trong Wordnet, tuy nhiên như các phương pháp trên, Wordnet không
chứa thực thể có tên (Named Entity), vì vậy Wordnet không thích hợp với mô hình
tìm kiếm thực thể.

12
1.2.7. Mô hình học biểu diễn vector từ Word2Vec
Mô hình Word2Vec do Mikolov và các đồng sự đề xuất [22], là mô hình học
biểu diễn mỗi từ thành một vector (ánh xạ một từ thành một one-hot vector), mô hình
có mục đích diễn tả mối quan hệ (xác suất) giữa từ với ngữ cảnh của từ. Mô hình
Word2Vec có 2 kiến trúc mạng nơ-ron đơn giản: Continous Bag-Of-Words (CBOW)
và Skip-gram. Áp dụng với Skip-gram, ở mỗi bước huấn luyện, mô hình Word2Vec
dự đoán các ngữ cảnh trong vòng skip-gram nhất định. Khi các mô hình vector từ như
Count vector hay TF-IDF chỉ xét đến tần số xuất hiện của một từ hay cụm từ mà
không quan tâm đến ngữ cảnh, ưu điểm của Skip-gram là duy trì mối quan hệ ngữ
nghĩa giữa các từ trong một cửa sổ trượt (context window). Giả sử từ huấn luyện input
là “banking”, với cửa sổ trượt skip = m = 2, output ngữ cảnh trái sẽ kết xuất là “turning
into”, output ngữ cảnh phải là “crises as”:
Hình 1.6: Quan hệ giữa từ mục tiêu và ngữ cảnh trong mô hình Word2Vec.
Để dự đoán, hàm mục tiêu trong Skip-gram thực hiện tối đa hóa xác suất. Với
một chuỗi từ huấn luyện w1, w2, …, wT, Skip-gram áp dụng Maximum Likelihood:
𝐽(𝜃) =1
𝑇∑ ∑ log 𝑝(𝑤𝑡+𝑗|𝑤𝑡)−𝑚≤𝑗≤𝑚,𝑗≠0
𝑇𝑡=1 (1.4)
trong đó T: số lượng từ có trong data-set; t: từ được huấn luyện;
m: window-side (skip); 𝜃: vector biểu diễn;
Quá trình huấn luyện áp dụng giải thuật lan truyền ngược (back-propagation);
Xác suất đầu ra p(wt+j|wt) xác định bởi hàm kích hoạt softmax:
𝑝(𝑜|𝑐) =exp (𝑢𝑜
𝑇 𝑣𝑐)
∑ exp (𝑢𝑤𝑇 𝑣𝑐)𝑊
𝑤−1 (1.5)
trong đó
W: Vocabulary;
c: từ được huấn luyện (input/center); o: output của c;
u: Vector biểu diễn của o; v: Vector biểu diễn của c;

13
Trong thực nghiệm, Mikolov et al. [22], [23], [24], [25] xử lý cụm từ như một
từ đơn, loại bỏ các từ lặp lại thường xuyên, sử dụng hàm Negative Sampling loss
function chọn ngẫu nhiên n từ để xử lý tính toán thay vì toàn bộ các từ trong data-set,
giúp cho thuật toán huấn luyện nhanh hơn so với hàm softmax nói trên.
Hình 1.7: Word2Vec “học” quan hệ “ẩn” giữa từ mục tiêu và ngữ cảnh của từ 1.
Phân tích:
Khi huấn luyện trên mạng neural với lượng dữ liệu text đủ lớn, các vector từ
được điều chỉnh càng chính xác. Các phép cộng trừ vector, như:
vector(“king”) - vector(“man”) ≈ vector(“queen”) - vector(“woman”)
cho thấy mô hình Word2Vec và các biến thể của Word2Vec [26], [27], [28]
phù hợp với dạng truy vấn “A:B :: C:?”, nói cách khác, mô hình Word2Vec khá gần
với hướng nghiên cứu trong luận án. Khác biệt ở điểm: đầu vào của Word2Vec (theo
mô hình Skip-gram) là một từ, đầu ra là một ngữ cảnh. Đầu vào của mô hình tìm kiếm
thực thể dựa trên ngữ nghĩa là 3 thực thể (A:B :: C:?), đầu ra là thực thể cần tìm kiếm
(D). Một cách hình thức, nếu coi cặp thực thể A:B là một vector, mô hình tìm kiếm
thực thể dựa trên ngữ nghĩa cần tìm vector (C, D), song song với vector (A, B) đã
biết.
1 https://cs224d.stanford.edu/lectures/CS224d-Lecture2.pdf

14
1.3. Phương pháp tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn với các
nghiên cứu liên quan
Về tìm kiếm thực thể dựa trên ngữ nghĩa, từ các vấn đề còn tồn tại, để tiệm
cận đến một “trí thông minh nhân tạo” trong máy tìm kiếm, luận án nghiên cứu, áp
dụng các kỹ thuật mô phỏng khả năng tự nhiên của con người: khả năng suy ra thông
tin/tri thức không xác định bằng suy diễn tương tự. Trong luận án, chương 2 nghiên
cứu mô hình tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa, kết hợp độ đo Cosine ở
mức terms để cải thiện giải thuật gom cụm, mở rộng nghiên cứu bằng cách hiện thực
mô hình tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa, miền ngôn ngữ tiếng Việt.
1.4. Bài toán gợi ý truy vấn hướng ngữ cảnh
Trong bài toán, động lực nghiên cứu là kỹ thuật gợi ý truy vấn dựa trên hướng
ngữ cảnh.
Đối với cơ chế tìm kiếm theo từ khóa, thống kê [29] cho thấy các thuật ngữ
(keywords/terms) trong truy vấn người dùng đưa vào và các thuật ngữ trong tài liệu
thường rất khác nhau, khác cả về từ vựng và ngữ nghĩa. Do đó, hiệu quả của tìm kiếm
thông tin phụ thuộc đồng thời vào khả năng biểu đạt các mô tả nhu cầu tìm kiếm của
con người, khả năng “hiểu” truy vấn và khả năng xếp hạng kết quả của máy tìm kiếm.
Đối với SE, khả năng “hiểu” ý định tìm kiếm trong câu truy vấn của người sử
dụng là một thách thức. Các tiếp cận truyền thống để hiểu truy vấn trong IR
(Information Retrieval) tập trung vào các kỹ thuật: Phản hồi rõ (explicit feedback
[30], [31], [32]); Phản hổi ẩn (implicit feedback [33], [34], [35], [36]); User profile
[37], [38], [39]; Từ điển đồng nghĩa (thesaurus [40], [41], [42]); Trích đoạn snippets,
anchor texts [43]. Bên cạnh đó, khi dữ liệu trên Internet tăng không ngừng, để tận
dụng trí khôn của cộng đồng (“the wisdom of crowds”), nhằm hỗ trợ người tìm kiếm
và cải thiện kết quả, các kỹ thuật khai phá dữ liệu được áp dụng. Tập dữ liệu được sử
dụng để khai phá là Query Log (nhật ký truy vấn, viết tắt: QLogs). Tập truy vấn trong
quá khứ QLogs ghi lại các truy vấn và “tương tác” của người dùng với công cụ tìm
kiếm, do vậy QLogs chứa các thông tin giá trị về nội dung truy vấn, mục đích, hành
vi, thói quen, sở thích cũng như các phản hồi ngầm (implicit feedback) của người sử
dụng trên tập kết quả mà SE trả về. Khai phá tập dữ liệu QLogs có ích trong nhiều

15
ứng dụng, như: Phân tích truy vấn, quảng cáo, xu hướng, cá nhân hóa, gợi ý truy vấn,
.v.v.
Dựa trên lịch sử tìm kiếm của cộng đồng, gợi ý truy vấn là kỹ thuật nhằm cải
thiện hiệu quả của tìm kiếm, bằng cách đề xuất đến người sử dụng kinh nghiệm của
các phiên tìm kiếm trước, đề xuất các lựa chọn thay thế cho truy vấn ban đầu của
người dùng [44]. Nói cách khác, gợi ý truy vấn tìm cách tận dụng “tri thức” trong các
phiên tìm kiếm trước – nhằm đưa ra các đề xuất thay thế, gợi ý, để giới thiệu đến
người dùng những truy vấn tốt hơn so với câu truy vấn vừa nhập, đặc biệt với những
truy vấn ngắn.
1.5. Các nghiên cứu liên quan đến gợi ý truy vấn
Xoay quanh hạt nhân là Query-Logs (Qlogs), có thể nói việc gợi ý truy vấn
theo các kỹ thuật truyền thống thực hiện 2 chức năng chính:
- Đưa ra câu truy vấn gợi ý có liên quan với truy vấn gốc (dẫn đến các kết
quả tìm kiếm khác có liên quan với kết quả tìm kiếm của truy vấn gốc).
- Đưa ra câu truy vấn gợi ý “tốt hơn” câu truy vấn gốc (truy vấn gợi ý và
truy vấn gốc có cùng ý định tìm kiếm).
Miền xác định là Qlogs, lĩnh vực gợi ý truy vấn (query suggestion) có 2 lớp kỹ
thuật chính: Dựa trên phiên (session-based) và Dựa trên cụm (cluster-based).
Kỹ thuật dựa trên phiên với phiên tìm kiếm là một chuỗi liên tục các câu truy
vấn (đề cập trong mục 1.5.1). Kỹ thuật dựa trên cụm áp dụng phép đo độ tương đồng
nhằm gom các truy vấn tương tự nhau thành từng cụm (nhóm, đề cập trong mục
1.5.2).
1.5.1. Kỹ thuật gợi ý truy vấn dựa trên phiên (Session-based)
a) Dựa vào các câu truy vấn đồng hiện (co-occurrence) hay liền kề (adjacency)
Trong cách tiếp cận dựa trên Session, các cặp truy vấn liền kề (adjacency) hoặc
đồng hiện (co-occurrence) thuộc cùng một phiên đóng vai trò danh sách ứng viên cho
đề xuất truy vấn:
- Nếu qi và qj thường xuyên đồng xuất hiện trong cùng 1 session, thì 2 query
có thể gợi ý lẫn nhau.
- Nếu qj thường xuyên đứng ngay sau qi trong cùng 1 session, thì qj có thể
gợi ý cho qi.

16
Theo cách tiếp cận dựa trên truy vấn đồng hiện hay liền kề, các nghiên cứu
trong [45], [46], [47], [48] khai phá các cặp truy vấn kết hợp từ dữ liệu Session và
xếp hạng các ứng viên dựa trên tần suất xuất hiện cùng với các truy vấn đầu vào. Để
giải quyết vấn đề dữ liệu thưa, các tiếp cận này đề xuất truy vấn ở mức từ/cụm từ thay
vì cả câu truy vấn.
b) Dựa vào đồ thị (Query Flow Graph - QFG)
Trên đồ thị QFG, 2 truy vấn qi, qj cùng thuộc ý đồ tìm kiếm (search mission)
được biểu diễn như một cạnh có hướng từ qi tới qj. Mỗi node trên đồ thị tương ứng
với một truy vấn, bất kỳ cạnh nào trên đồ thị cũng được xem như 1 hành vi tìm kiếm
(searching behavior) [49].
Cấu trúc tổng quát phiên trong CFG được biểu diễn: QLog = <q, u, t, V, C>;
trong đó:
q: câu truy vấn; u: Định danh user submit câu truy vấn;
t: nhãn thời gian (timestamp); V: tập kết quả SE trả về;
C: Tập tài liệu được người dùng chọn đọc (URL Clicked)
Boldi et al. [50], [51] sử dụng cấu trúc phiên rút gọn QLog = <q, u, t> để thực
hiện gợi ý truy vấn, theo một dãy các bước:
Xây dựng đồ thị QFG với đầu vào là tập các phiên trong Query
Logs.
Hai truy vấn qi và qj được nối với nhau nếu tồn tại ít nhất một
phiên mà qi, qj xuất hiện liên tiếp.
Tính trọng số w(qi, qj) trên mỗi cạnh:
w(qi, qj) = {
𝑓(𝑞𝑖, 𝑞𝑗)
𝑑(𝑞𝑖), 𝑖𝑓 (𝑤(𝑞𝑖 , 𝑞𝑗) > 𝜃) ∨ (𝑞𝑖 = 𝑠) ∨ (𝑞𝑖 = 𝑡)
0, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒 (1.6)
trong đó:
f(𝑞𝑖, 𝑞𝑗): số lần xuất hiện qj ngay sau qi trong phiên;
d(qi): số lần xuất hiện qi trong QLogs;
𝜃: threshold (giá trị độ tin cậy trong kiểm định thống kê, 𝜃 = 0.9);
s, t: 2 node trạng thái bắt đầu, kết thúc của chuỗi truy vấn trong phiên;
Xác định các chuỗi thỏa điều kiện (1.6) để phân tích ý đồ của
người dùng.

17
Khi một truy vấn mới đưa vào, dựa vào đồ thị, QFG đưa ra các
gợi ý truy vấn lần lượt có trọng số cạnh lớn nhất.
Hình 1.8: QFG sử dụng trọng số.
Phân tích:
Kỹ thuật gợi ý truy vấn dựa vào QFG không thực sự hiệu quả, với mỗi node là
1 query, tập QLogs vốn có kích thước rất lớn (hàng triệu queries) sẽ ảnh hưởng đến
chi phí tính toán, thời gian xử lý. Ngoài ra, QFG có khả năng dư thừa thông tin, nói
cách khác, các đề xuất truy vấn có thể khá giống nhau. Trong hình 1.8, nối kết với
truy vấn qi=“barcelona fc” là các truy vấn qj1=“barcelona fc website” và
qj2=“barcelona fc fixtures”, đều có tiền tố là “barcelona fc”, có trọng số cạnh gần xấp
xỉ bằng (0.043 và 0.031); Một mặt, trường hợp có nhiều truy vấn qj2 và qj2,…, qjk
tương tự nhau được đề xuất, cảm nhận của người dùng và kết quả trả về thực tế sẽ dư
thừa. Mặt khác, QFG chỉ xét <q, u, t>, không xét V - tập danh sách trả về; và C - tập
Url clicked, tập hành vi người dùng chọn kết quả. Để khai phá hành vi, một vài hướng

18
nghiên cứu mở rộng QFG, mô tả trong [52], [53], tận dụng tập C – Url clicked để bổ
sung (qi, qj) vào ý đồ tìm kiếm, nếu như qi, qj cùng chia sẻ chung các Url clicked. Tuy
nhiên các kỹ thuật dựa trên QFG nói riêng cũng như Session-based nói chung đều
dựa trên cặp truy vấn (qi, qj) đồng hiện hay liền kề, mà không xét như một ngữ cảnh,
nên các kỹ thuật này không giải quyết được vấn đề dữ liệu thưa.
1.5.2. Kỹ thuật gợi ý truy vấn dựa trên cụm (Cluster-based)
Trong cách tiếp cận dựa trên Cluster, QLogs sẽ được xử lý, tính toán và phân
thành các cụm (Clustering). Khi máy tìm kiếm (SE) nhận truy vấn đầu vào, SE thực
hiện so khớp (maximum matching) với các cụm, câu truy vấn đầu vào “gần” cụm nào
nhất, các truy vấn thuộc cụm đó sẽ được xét như ứng viên để gợi ý truy vấn.
Hình 1.9: Các phương pháp phân cụm ([54]).
Tổng quát, các phương pháp phân cụm [55], [56], [57] được chia thành:
Phân cụm phân hoạch (Partitioning): các phân hoạch được tạo ra và
đánh giá theo một tiêu chí nhất định. Thuật toán tiêu biểu là K-means.
Phương pháp này kết xuất các cụm rời nhau.
Phân cụm phân cấp (Hierarchical): phân rã tập dữ liệu/đối tượng có thứ
tự phân cấp theo một tiêu chí nhất định. Phương pháp tiêu biểu là AHC
(Agglomerative Hierarchical Clustering). Kết xuất của thuật toán này
có thể tạo thành các cụm giao nhau (overlapping).
Dựa trên mật độ (Density-based): dựa trên phân tích các điểm nối kết
và hàm mật độ (connectivity and density functions). Phương pháp tiêu

19
biểu là DB-SCAN (Density-Based Spatial Clustering of Applications
with Noise).
Và các phương pháp gom cụm dữ liệu khác, như: Gom cụm dựa trên
lưới (grid-based); Gom cụm dựa trên mô hình (model-based); Gom cụm
dựa trên cây hậu tố (Suffix tree); Gom cụm dựa trên phân tích ma
trận,…
Các nghiên cứu trong [58], [59], [60] áp dụng k-means và biến thể của k-means
để trích xuất các truy vấn tương tự, nhưng k-means vốn có “lỗi bẩm sinh”: khó định
trước k, nên khó xác định được độ hội tụ của thuật toán.
Các nghiên cứu trong [61], [62] ứng dụng phân cụm phân cấp AHC để gom
cụm truy vấn. Wu et al. [63], [64] tiếp cận theo hướng đồ thị 2 phía (bipartite graph),
phía câu truy vấn – phía click-through URL và thuật toán DB-SCAN để gom cụm.
Các cách tiếp cận này đều tỏ ra hiệu quả trong việc gom các truy vấn tương tự thành
nhóm. Tuy nhiên các cách tiếp cận này đều có chi phí tính toán cao và khó mở rộng
khi quy mô dữ liệu QLogs lớn.
a) Thuật toán phân cụm K-means:
Đầu vào: QLogs gồm N câu truy vấn.
Đầu ra: k cụm (k cần xác định trước). Các đối tượng trong cụm là “tương tự”
về tính chất.
Bước 1: Biểu diễn tập câu truy vấn bằng cách sử dụng mô hình không gian
vector (VSM – Vector Space Model) mỗi truy vấn được biểu diễn bởi 1
vector trong không gian đa chiều:
�⃗� ∶= [𝑤𝑡0, 𝑤𝑡1, … , 𝑤𝑡Ω]
trong đó:
t0, t1, .., tΩ : tập các terms trong q.
wti: trọng số của term ti trong q.
Bước 2: Chọn ngẫu nhiên k điểm làm trọng tâm, xác định k cụm từ các trọng
tâm (tâm cụm).
Bước 3: Tính khoảng cách E giữa các điểm (x) trong tập dữ liệu với từng trọng
tâm, điểm nào gần trọng tâm j nhất (khoảng cách E nhỏ nhất) sẽ thuộc cụm j.
E = ∑ ∑ (||𝑥𝑖 − 𝐶𝑗||)2𝑥𝑖𝜖𝐶𝑗
𝑘𝑖=1 (1.7)

20
Bước 4: “Trộn” lại mỗi cụm, tính lại trọng tâm mới (trung bình cộng của các
điểm thuộc cụm).
Lặp lại Bước 3, Bước 4 cho tới khi trọng tâm các cụm không đổi.
Phân tích:
Ưu điểm: dễ cài đặt.
Nhược điểm:
Phương pháp K-means phù hợp với các dữ liệu dạng số.
Phải truyền vào tham số k ngẫu nhiên khó xác định k trọng tâm ban
đầu, khó xác định độ hội tụ của thuật toán.
Độ phức tạp tính toán: O(kNt); trong đó t là số lần lặp.
b) Thuật toán phân cụm Hierarchical (kết tụ theo hướng bottom-up)
Đầu vào: N câu truy vấn (N phần tử) trong QLogs.
Đầu ra: Tập cụm, các đối tượng trong mỗi cụm “tương tự” về tính chất.
Bước 1: Xét mỗi phần tử là một cụm. N phần tử tương ứng tổng số N cụm
được khởi tạo. Tính ma trận khoảng cách N*N giữa các cụm theo một trong
ba loại khoảng cách sau:
Khoảng cách lớn nhất giữa các phần tử (x, y) thuộc 2 cụm (A, B).
max{d(x, y): x thuộc A, y thuộc B} (1.8)
Khoảng cách nhỏ nhất giữa các phần tử của 2 cụm.
min{d(x, y): x thuộc A, y thuộc B} (1.9)
Khoảng cách trung bình các phần tử của 2 cụm.
1
|𝐴|∙|𝐵|∑ ∑ 𝑑(𝑥, 𝑦)𝑦∈𝐵𝑥∈𝐴 (1.10)
Bước 2: Tìm cặp cụm có khoảng cách nhỏ nhất, trộn hợp thành một cụm mới.
Lúc này tổng số cụm đã giảm đi 1.
Bước 3: Tính khoảng cách từ cụm mới đến các cụm còn lại.
Bước 4: Lặp lại bước 2, 3 cho đến khi chỉ còn lại một số cụm đủ nhỏ hoặc
khoảng cách giữa các cụm vượt quá một ngưỡng cho trước.
Phân tích:
Ưu điểm: Dễ cài đặt. Là thuật toán phân cụm không giám sát (không cần biết
trước số cụm cần phân)
Nhược điểm:
Mỗi lần trộn chỉ trộn 2 cụm gần nhất.

21
Độ phức tạp tính toán: O(n2); AHC không quay lui ở mỗi bước trộn.
c) Thuật toán phân cụm DB-SCAN
Ý tưởng cơ bản của phân cụm dựa trên mật độ như sau: Kết hợp những
đối tượng có mật độ thỏa một ngưỡng cho trước vào trong một cụm. Nói cách
khác, một cụm được định nghĩa như là một tập các điểm có kết nối dựa trên
mật độ. Do đó, cụm có hình dạng tùy ý.
Các khái niệm:
Đối với mỗi đối tượng của một cụm, lân cận trong một bán kính
cho trước (ε) (gọi là ε-neighborhoods) phải chứa ít nhất một số lượng tối
thiểu các đối tượng (ký hiệu số lượng tối thiểu các đối tượng: MinPts).
Nếu đối tượng có ε-neighborhood với MinPts thì đối tượng này
được gọi là đối tượng lõi (core object/core point). Các đối tượng khác ngoài
đối tượng lõi được xem là nhiễu hoặc đối tượng biên (noise/outlier/border
point).
Hình 1.10: Các đối tượng Core, Border, Noise trong phân cụm DBSCAN.
Direct density-reachable (khả năng đạt được trực tiếp): p1 có thể đạt được
trực tiếp từ q nếu p1 trong vùng láng giềng ε-neighborhood của q và q phải
là core object.
Hình 1.11: Khả năng Direct Density-reachable và Density-reachable.

22
Density-reachable (khả năng đạt được): Cho trước tập đối tượng D, bán
kính ε và MinPts: Đối tượng q là density-reachable từ đối tượng p nếu:
chuỗi các đối tượng: p1, ..., pn D, với p1 = p và pn = q sao cho pi+1 direct
density-reachable từ pi theo ε và MinPts, 1 ≤ i ≤ n.
Density-connected (kết nối dựa trên mật độ): Cho trước tập các đối tượng
D, ε và MinPts với p, q D;
q là density-connected với p nếu: o D sao cho cả q và p đều density-
reachable từ o theo các thông số ε và MinPts.
Đầu vào: N truy vấn trong Qlogs, tập đối tượng D, bán kính ε, ngưỡng
MinPts.
Đầu ra: Density-based clusters (và noise/outliers, border)
Bước 1: Xác định ε-neighborhood của mỗi đối tượng p D.
Bước 2: Nếu p là core object, tạo được một cluster.
Bước 3: Từ bất kì core object p, tìm tất cả các đối tượng density-reachable
và đưa các đối tượng này (hoặc các cluster) vào cluster ứng với p.
3.1. Trộn hợp các cluster đạt được (density-reachable cluster).
3.2. Dừng khi không có đối tượng mới nào được thêm vào.
Phân tích:
Ưu điểm: Khi một truy vấn thêm vào cụm chỉ tác động ε láng giềng nhất định.
Nhược điểm: Yêu cầu trị cho thông số nhập ε và MinPts (các biến toàn cục).
Độ phức tạp tính toán: O(NlogN).
1.6. Phương pháp gợi ý truy vấn dựa trên hướng ngữ cảnh với các nghiên cứu
liên quan
Đối với gợi ý truy vấn, các kỹ
thuật truyền thống như
Implicit/Explicit Feedback,
Thesaurus, User profile, … chỉ đưa ra
các gợi ý tương tự với truy vấn nhập
vào của người dùng.
Hình 1.12: Gợi ý truy vấn bằng các kỹ
thuật truyền thống

23
So với các phương pháp gợi ý truy vấn trình bày trên, gợi ý truy vấn dựa trên
hướng ngữ cảnh (Context-aware Query Suggestion) có các điểm khác biệt (ưu điểm)
mới, gồm: Context-aware xét các truy vấn đứng ngay trước truy vấn hiện hành như
một ngữ cảnh tìm kiếm, nhằm “nắm bắt” ý định tìm kiếm của người dùng, mục đích
“hiểu” được câu truy vấn, để đưa ra các gợi ý xác đáng. Rõ ràng, lớp truy vấn đứng
ngay trước có mối liên hệ ngữ nghĩa với truy vấn hiện hành, phản ảnh liền mạch ý
định tìm kiếm của người sử dụng. Kế tiếp, thực hiện khai phá các truy vấn đứng ngay
sau truy vấn hiện hành - như một danh sách gợi ý. Có thể nói, đây là ưu điểm riêng
của cách tiếp cận này so với cách tiếp cận chỉ gợi ý những truy vấn tương tự với truy
vấn hiện hành. Lớp truy vấn đứng ngay sau truy vấn hiện hành, một cách hình thức,
phản ánh những vấn đề mà người dùng thường hỏi sau câu truy vấn hiện hành. Đồng
thời, lớp truy vấn ngay sau truy vấn hiện hành thường gồm những câu truy vấn (chuỗi
truy vấn) tốt hơn, phản ánh rõ hơn ý đồ tìm kiếm.
Lớp queries trước của qcurrent ↔ ngữ cảnh) .. qcurrent .. (Lớp queries sau)
Hình 1.13: Ngữ cảnh truy vấn.
Xét truy vấn: “tiger”, ý đồ tìm kiếm trong trường hợp này sẽ là: Một loài động
vật? Một hãng hàng không? Một vận động viên? Một hệ điều hành? Việc không xác
định được ngữ cảnh tìm kiếm sẽ gây khó khăn khi đưa ra gợi ý phù hợp. Nếu biết truy
vấn ngay trước đó là “Woods” hoặc “golf”, thì gần như chắc chắn người sử dụng
đang tìm kiếm thông tin về một vận động viên. Tương tự với truy vấn “Jordan”, nếu
biết lớp truy vấn ngay trước là “NBA” hoặc “basketball”, một cách tự nhiên, ta biết
ý định tìm kiếm của người sử dụng về “Michel Jordan”. Do đó dưới góc nhìn của hệ
thống, ý đồ tìm kiếm đã hiển thị rõ ràng hơn.
Hình 1.14: Minh họa truy vấn “tiger”.

24
Chi tiết phương pháp gợi ý truy vấn dựa trên hướng ngữ cảnh được trình bày
trong Chương 3. Một cách hình thức, gợi ý truy vấn hướng ngữ cảnh là khả năng đưa
ra được xu hướng mà tri thức cộng đồng thường hỏi sau truy vấn hiện hành, tận dụng
được sức mạnh của tri thức số đông.
1.7. Các kết quả đạt được
Kết quả chính của luận án gồm:
Với phương pháp Tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn, nhằm giải
quyết bài toán thứ nhất:
- Xây dựng kỹ thuật tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn sử
dụng phương pháp phân cụm nhằm nâng cao hiệu quả tìm kiếm.
Với phương pháp Gợi ý truy vấn Hướng ngữ cảnh, mục đích giải quyết bài
toán thứ hai:
- Ứng dụng kỹ thuật hướng ngữ cảnh, xây dựng máy tìm kiếm chuyên sâu
áp dụng hướng ngữ cảnh trong miền cơ sở tri thức riêng (dữ liệu hàng
không).
- Đề xuất độ đo tương đồng tổ hợp trong bài toán gợi ý truy vấn theo ngữ
cảnh nhằm nâng cao chất lượng gợi ý.

25
CHƯƠNG 2: TÌM KIẾM THỰC THỂ DỰA TRÊN QUAN HỆ NGỮ NGHĨA
ẨN
Chương này trình bày kiến trúc tổng quát của mô hình Tìm kiếm thực thể dựa
trên quan hệ ngữ nghĩa ẩn. Mô hình gồm 3 thành phần chính: Rút trích quan hệ ngữ
nghĩa; Gom cụm quan hệ ngữ nghĩa và Tính toán quan hệ tương đồng giữa 2 cặp
thực thể. Từ việc phân tích ưu nhược điểm của các thành phần, luận án đề xuất độ đo
tương đồng kết hợp - theo terms và theo giả thuyết phân phối, mục đích cải tiến chất
lượng cụm, nâng cao hiệu quả tìm kiếm So sánh đánh giá, kết quả thực nghiệm,
hướng phát triển, trình bày ở cuối chương.
2.1. Bài toán
Trong tự nhiên, tồn tại mối quan hệ giữa 2 thực thể, như: Khuê Văn các – Văn
miếu; Stephen Hawking - Nhà vật lý; Thích Ca - phái Đại thừa; Apple - iPhone; .v.v.
Mở rộng hơn, tồn tại mối quan hệ tương đồng giữa 2 cặp thực thể (entity pair),
ví dụ cặp Nguyễn Du – truyện Kiều và cặp Đoàn thị Điểm – Chinh phụ ngâm, 2 cặp
thực thể này tương đồng quan hệ ngữ nghĩa: “là tác giả”; cặp Hà Nội – Việt Nam và
cặp Paris – Pháp tương đồng quan hệ ngữ nghĩa: “là thủ đô”; Kinh Qur’an – Đạo Hồi
và sách Phúc Âm – Kitô giáo tương đồng quan hệ ngữ nghĩa: “là kinh thánh”; Cốm
– làng Vòng và Chả mực – Hạ Long tương đồng quan hệ ngữ nghĩa: “là đặc sản”;
.v.v. Mỗi quan hệ tương đồng ẩn dưới một ngữ nghĩa riêng.
Trong thế giới thực, tồn tại những câu hỏi dạng: “biết Fansipan là ngọn núi
cao nhất Việt Nam thì ngọn núi nào cao nhất Ấn Độ?”, “nếu Biden là tổng thống đắc
cử Hoa Kỳ thì ai là người quyền lực nhất Thụy Điển?”, .v.v.
Trong cơ chế tìm kiếm theo từ khóa, theo thống kê, các truy vấn thường ngắn,
mơ hồ và đa nghĩa [1], [3], [5]. Cũng theo thống kê, xấp xỉ 71% câu tìm kiếm trên
web có chứa tên thực thể [7], [8]. Nếu người sử dụng nhập vào các thực thể: “Việt
Nam”, “Hà Nội”, “Pháp” thì máy tìm kiếm chỉ đưa ra được kết quả là những tài liệu
có chứa các từ khóa trên, chứ không đưa ngay được câu trả lời “Paris”. Do chỉ tìm
thực thể, các kỹ thuật mở rộng, viết lại câu truy vấn không áp dụng với dạng quan hệ
có ngữ nghĩa ẩn trong cặp thực thể. Từ đó, một hình thái tìm kiếm mới được nghiên
cứu, motive của truy vấn tìm kiếm có dạng: {(A, B), (C, ?)}, trong đó (A, B) là cặp

26
thực thể nguồn, (C, ?) là cặp thực thể đích. Đồng thời, hai cặp (A, B), (C, ?) có quan
hệ tương đồng về ngữ nghĩa. Nói cách khác, khi người sử dụng nhập vào truy vấn
{(A, B), (C, ?)}, máy tìm kiếm có nhiệm vụ liệt kê danh sách các thực thể D, mỗi
thực thể D thỏa điều kiện có quan hệ ngữ nghĩa với C, đồng thời cặp (C, D) có quan
hệ tương đồng với cặp (A, B). Quan hệ ngữ nghĩa - theo nghĩa hẹp và dưới góc nhìn
từ vựng - được biểu diễn bởi ngữ cảnh gồm các từ/cụm từ (terms/patterns/context)
xung quanh (trước, giữa và sau) cặp thực thể đã biết1. Với đầu vào chỉ gồm 3 thực
thể: “Việt Nam”, “Hà Nội”, “Pháp”, quan hệ ngữ nghĩa “là thủ đô” không được chỉ
ra trong câu truy vấn.
Hình thái tìm kiếm theo motive được gọi là tìm kiếm thực thể dựa trên quan
hệ ngữ nghĩa ẩn (Implicit Relational Entity Search hay Implicit Relational Search,
ngắn gọn: IRS). Khả năng suy ra thông tin/tri thức không xác định bằng suy diễn
tương tự là một trong những khả năng tự nhiên của con người. Chương 2 đặt mục tiêu
nghiên cứu, mô phỏng khả năng trên. Mô hình IRS tìm kiếm thông tin/tri thức từ một
miền ngữ nghĩa không quen thuộc bằng cách sử dụng quan hệ tương đồng từ miền
quen thuộc. Vì quan hệ ngữ nghĩa, quan hệ tương đồng không được nêu tường minh
trong truy vấn (câu truy vấn chỉ gồm 3 thực thể: A, B, C), nên mô hình IRS được gọi
là mô hình tìm kiếm thực thể dựa trên ngữ nghĩa ẩn. Đóng góp chính của chương 2
là: Xây dựng kỹ thuật tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn sử dụng
phương pháp phân cụm nhằm nâng cao hiệu quả tìm kiếm.
Đồng thời, luận án đề xuất độ đo tương đồng kết hợp - theo terms và theo giả
thuyết phân phối; Từ độ đo đề xuất, đồng thời áp dụng heuristic vào giải thuật gom
cụm để cải thiện chất lượng cụm.
Chương 2 theo bố cục sau: Phần 2.1 đặt vấn đề. Phần 2.2 nghiên cứu về mô
hình tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa, trình bày các kỹ thuật rút trích,
gom cụm, xếp hạng và mô hình tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa, trên
miền ngôn ngữ tiếng Việt. Trong phần này, luận án trình bày hai giải thuật chính: i)
Giải thuật gom cụm kết hợp và ii) Giải thuật Ranking theo độ tương đồng quan hệ
RelSim (Relational Similarity). Đề xuất giải pháp kết hợp độ đo tương đồng theo Giả
thiết phân phối và theo term. Phần 2.3 lựa chọn tập dữ liệu mẫu, hiện thực hệ thống
1 Birger Hjorland. Link: http://vnlp.net.

27
tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa, kết quả thực nghiệm, các độ đo, phép
tinh chỉnh tham số và đánh giá. Phần 2.4 kết luận chương và nêu hướng đi kế tiếp.
2.2. Phương pháp tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn
2.2.1. Kiến trúc – Mô hình
Khái niệm tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn là phân biệt rõ
nhất đối với cơ chế tìm kiếm theo từ khóa. Hình 2.1 mô phỏng câu truy vấn chỉ gồm
3 thực thể, query = {(Việt Nam, Mê Kông), (Trung Quốc, ?)}, viết quy ước: q = {(A,
B), (C, ?)}. Trong đó (Việt Nam, Mê Kông) là cặp thực thể nguồn, (Trung Quốc, ?)
là cặp thực thể đích. Máy tìm kiếm có nhiệm vụ tìm ra thực thể (“?”) có quan hệ ngữ
nghĩa với thực thể “Trung Quốc”, đồng thời cặp thực thể (Trung Quốc, ?) phải tương
đồng quan hệ với cặp thực thể (Việt Nam, Mê Kông). Lưu ý rằng câu truy vấn trên
không chứa một cách tường minh quan hệ ngữ nghĩa giữa 2 thực thể. Việc không
tường minh quan hệ ngữ nghĩa bởi trên thực tế - quan hệ ngữ nghĩa được biểu đạt
dưới nhiều cách khác nhau xung quanh cặp thực thể (Việt Nam, Mê Kông), ví dụ như
“sông dài nhất”, “sông lớn nhất”, “lưu vực rộng nhất”, …
Do câu truy vấn chỉ gồm 3 thực thể không bao gồm quan hệ ngữ nghĩa, nên
mô hình được gọi là mô hình tìm kiếm thực thể dựa trên ngữ nghĩa ẩn.
Hình 2.1: Tìm kiếm dựa trên quan hệ ngữ nghĩa với đầu vào gồm 3 thực thể
input
Mê Kông dài nhất
Việt Nam
Trường Giang lớn nhất Trung
Quốc
Text
Corpus
Implicit Relational
Search Engine
(IRS)
(Việt Nam, Mê Kông)
(Trung Quốc, ?) ? =
Trư
ờn
g G
ian
g
output

28
Hình thái tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn phải xác định được
quan hệ ngữ nghĩa giữa 2 thực thể, đồng thời tính toán được độ tương đồng của 2 cặp
thực thể. Từ đó, đưa ra câu trả lời cho thực thể chưa biết (thực thể ?).
Trên một kho dữ liệu cụ thể, về tổng quan - mô hình tìm kiếm thực thể dựa
trên quan hệ ngữ nghĩa ẩn (IRS) gồm 3 thành phần chính: i) Thành phần rút trích quan
hệ ngữ nghĩa từ kho dữ liệu; ii) Thành phần gom cụm các quan hệ ngữ nghĩa (chính
xác hơn, thành phần gom cụm các câu context chứa cặp thực thể); và iii) Thành phần
tính toán độ tương đồng quan hệ giữa 2 cặp thực thể. Về thực hiện, mô hình IRS gồm
2 phases: phase online: đáp ứng tìm kiếm thời gian thực, phase off-line: xử lý, tính
toán, lưu trữ quan hệ ngữ nghĩa, quan hệ tương đồng. Trong đó, thành phần rút trích
và thành phần gom cụm các quan hệ ngữ nghĩa thuộc phase off-line của mô hình IRS.
Thành phần rút trích quan hệ ngữ nghĩa: Từ kho dữ liệu, thành phần rút trích
quan hệ ngữ nghĩa sẽ rút trích các mẫu (câu gốc chứa cặp thực thể và context), như
minh họa trên, rút trích mẫu: A sông dài nhất B, với A, B là 2 tên thực thể (Named
Entity). Tập mẫu thu được sẽ gồm: các mẫu thực sự khác nhau, các mẫu giống nhau,
các mẫu có độ dài và terms khác nhau nhưng biểu đạt cùng ngữ nghĩa, chẳng hạn: A
là sông lớn nhất của B, A là sông thuộc B có lưu vực rộng nhất, hay B có sông dài
nhất là A, .v.v.
Thành phần gom cụm các quan hệ ngữ nghĩa: Từ tập mẫu thu được, thực hiện
gom cụm để xác định các cụm chứa các câu context (mẫu đã loại đi cặp thực thể A,
B), trong đó mỗi context thuộc cùng cụm có quan hệ tương đồng về ngữ nghĩa. Lập
chỉ mục các context và cặp thực thể tương ứng.
Thành phần tính toán quan hệ tương đồng giữa 2 cặp thực thể: Thuộc phase
online của mô hình IRS. Đón truy vấn q = {(A, B), (C, ?)}, IRS tìm kiếm trong bảng
chỉ mục cặp thực thể (A, B) và tập quan hệ ngữ nghĩa (mẫu) tương ứng. Từ tập quan
hệ ngữ nghĩa thu được, thực hiện tìm các cặp thực thể (C, Di) gắn với quan hệ. Áp
dụng độ đo Cosine tính toán, xếp hạng mức tương đồng giữa (A, B) và (C, Di), đưa
ra danh sách các thực thể Di đã xếp hạng để trả lời truy vấn.

29
Hình 2.2: Kiến trúc tổng quát mô hình tìm kiếm thực thể dựa trên quan hệ ngữ
nghĩa ẩn.
Giả sử query q = {(Việt Nam, Mê Kông), (Trung Quốc, ?)}, IRS tìm được cụm
chứa cặp thực thể (Việt Nam, Mê Kông) và câu context chứa quan hệ ngữ nghĩa tương
ứng: “sông dài nhất” (từ câu gốc: “Mê Kông là sông dài nhất Việt Nam”). Cụm này
đồng thời chứa một quan hệ ngữ nghĩa tương tự: “sông lớn nhất”, trong đó quan hệ
“sông lớn nhất” gắn với gặp thực thể (Trung Quốc, Trường Giang) (từ câu gốc:
“Trường Giang là sông lớn nhất Trung Quốc”). IRS đưa “Trường Giang” vào danh
sách ứng viên, xếp hạng quan hệ ngữ nghĩa theo phép đo độ tương đồng, trả kết quả
về người tìm kiếm.
Vậy, một cách hình thức, IRS tìm kiếm thông tin dựa vào mối quan hệ tương
đồng ngữ nghĩa giữa 2 cặp thực thể, trong khi tìm kiếm theo từ khóa thực hiện tìm
kiếm theo terms trong câu truy vấn. Trong trường hợp IRS không tìm thấy A, B hoặc
C, IRS áp dụng cơ chế tìm kiếm theo từ khóa.
Nhận truy vấn đầu vào q = {(A, B), (C, ?}, kiến trúc tổng quát của IRS được
mô hình hóa:
Cặp thực thể -
Quan hệ ngữ
nghĩa
Kho ngữ liệu
(Corpus)
Chỉ mục đảo (Inverted
Index for IRS)
Rút trích quan hệ
ngữ nghĩa
Gom cụm quan hệ
ngữ nghĩa
Tính độ tương đồng
quan hệ (RelSim)
Tập kết quả ứng viên
(Candidate answers)
Tập kết quả trả về
được phân hạng
(Ranked answers)
Quer
y:
{(V
iệt
Nam
, M
ê K
ông
), (
Tru
ng Q
uố
c, ?
)}

30
Hàm Filter-Entities (Fe) lọc/tìm tập ứng viên S chứa các cặp thực thể (C, Di);
trong đó (C, Di) có quan hệ tương đồng với cặp thực thể đầu vào (A, B):
Fe(q, D) = Fe({(A, B), (C, ?)}, D) = {1, 𝑖𝑓 𝑅𝑒𝑙𝑒𝑣𝑎𝑛𝑡(𝑞, 𝐷)0, 𝑒𝑙𝑠𝑒
(2.1)
Hàm Rank-Entities (Re) tính RelSim, xếp hạng các thực thể Di, Dj trong tập
ứng viên S theo phép đo RelSim (Relational Similarity), thực thể nào có
RelSim cao hơn được xếp thứ tự thấp hơn (theo nghĩa gần top hơn, hay rank
cao hơn):
∀ Di, Dj ∊ S, nếu:
RelSim((A, B),(C, Di)) > RelSim((A, B),(C, Dj)) : Re(q, Di) < Re(q, Dj)
(2.2)
Danh sách kết quả L kết hợp từ Fe và Re:
List L = Fe × Re (2.3)
Độ đo tương đồng Cosine (với x, y là các vector n chiều):
Cosine(x, y) = ∑ 𝑥𝑖
𝑛𝑖=1 ∙𝑦𝑖
√∑ 𝑥𝑖2𝑛
𝑖=12
√∑ 𝑦𝑖2𝑛
𝑖=12
(2.4)
2.2.2. Thành phần rút trích quan hệ ngữ nghĩa
Một cách hình thức, thành phần rút trích quan hệ ngữ nghĩa thực hiện việc rút
trích ra ngữ cảnh gồm các từ/cụm từ (terms/patterns) xung quanh (trước, giữa và sau)
của cặp thực thể. Ngữ cảnh (context) biểu diễn quan hệ ngữ nghĩa của cặp thực thể.
Xét câu: a1 a2 ... ai A w1 w2 ... wj B b1 b2 ... bk.
Với A, B là 2 thực thể, ta có chuỗi biểu diễn ngữ cảnh p (context p):
p = a1a2 ..ai w1 w2 .. wj b1 b2 .. bk (2.5)
Giải thuật rút trích quan hệ ngữ nghĩa thực hiện theo các bước:
Bước 1: Đặt điều kiện và ngưỡng:
- Câu context phải chứa ít nhất 2 thực thể A, B.
- Context phải chứa ít nhất 2 terms có tần suất xuất hiện >= 10 trong toàn
Corpus. Mục đích đặt ra điều kiện này để cô gọn không gian xử lý, tìm kiếm
của bài toán.
Bước 2: Tách từ, loại từ dừng:
- Do yêu cầu tìm kiếm, tức thời trả lại kết quả cho người sử dụng, luận án xây
dựng module tách từ bằng phương pháp so khớp từ dài nhất (Longest-

31
matching) và từ điển (72721 terms).
- Sử dụng từ điển Stopword (2462 terms) để loại từ dừng.
Bước 3: Nhận dạng NER, tách thực thể, tách mẫu context, tính TF, IDF, trọng
số TF.IDF
- Nhận dạng NER theo: 9 nhãn tổng quát, Proper (ký tự đầu viết hoa), các
hàm xác định ngày tháng, kiểu số, các rules mà thực thể có tên thường kết
hợp: Mr., Ms., GS., TS., UBND, TCT, TNHH, .v.v.
- Sau khi tách các NER, câu còn lại context mô tả ngữ nghĩa các NER.
- Tính TF (Term Frequency), IDF (Inverted Document Frequency), trọng số
TF.IDF của các terms. Tiến trình tính trọng số TFIDF của term nhằm loại
bỏ đi các terms trong context có trọng số quá thấp (noise, un-grammar) hoặc
các terms có trọng số quá cao (quá thông dụng). Mục đích để thu hẹp không
gian tìm kiếm, thời gian xử lý và tính Cosine.
Kết quả của giải thuật rút trích cặp thực thể và quan hệ ngữ nghĩa tương ứng
sẽ lưu vào database, minh họa trong Bảng 2.1: Với 2 câu: “Mỹ - Hàn phóng hàng loạt
tên lửa dằn mặt Triều Tiên”; “Hiện nay xã Tân Tiến là một xã nông thôn mới tiêu
biểu toàn tỉnh Hậu Giang”.
Bảng 2.1: Kết quả giải thuật rút trích quan hệ ngữ nghĩa
NER Context TF TF.IDF
Mỹ - Hàn_Triều
Tiên
phóng_hàng loạt_tên lửa_dằn
mặt
0.25|0.25|0.25|
0.25
2.8|5.31|3.77|5.
61
Tân Tiến_Hậu
Giang
xã_nông thôn_mới_tiêu
biểu_toàn_tỉnh
0.17|0.17|0.17|
0.17|0.17|0.17
2.28|5.61|3.32|5
.61|2.87|3.22
Bước 4: Sinh các sub-string theo n-grams (quy ước chọn n = 3, mỗi gram là
một term/token).
Tiến trình sinh substring để phục vụ việc so sánh độ tương tự 2 câu, áp dụng
trong giải thuật gom cụm. Giải thuật gom cụm - về bản chất là giải thuật kết hợp giữa
độ đo tương tự theo term và độ đo tương tự theo Giả thuyết phân phối. Xét độ đo
tương tự theo term, với 2 câu s1: “Trần Quốc Tuấn nhà quân sự kiệt xuất thời Trần”
và s2: “Gia Cát Lượng từ khi bước chân ra khỏi lều tranh trở thành nhà quân sự kiệt

32
xuất thời Tam Quốc”. Về ngữ nghĩa, s1 và s2 là tương tự, nhưng s1, s2 có độ dài khác
nhau khi so sánh câu. Vì vậy, để đạt hiệu quả trong việc so sánh độ tương đồng 2 câu,
các câu s1, s2 sẽ được chia thành các sub-string giữ thứ tự từ, mỗi sub-string có độ
dài n (n = 3), mỗi sub-string được xem như một context.
Trong Bảng 2.1, câu “Mỹ-Hàn phóng hàng loạt tên lửa để dằn mặt Triều Tiên”
sẽ được chia thành các sub-string: “Mỹ-Hàn_phóng_hàng loạt_tên lửa_Triều Tiên”;
“Mỹ-Hàn_phóng_hàng loạt_dằn mặt_Triều Tiên”; “Mỹ-Hàn_phóng_tên lửa_dằn
mặt Triều Tiên”; “Mỹ-Hàn_hàng loạt_tên lửa_dằn mặt_Triều Tiên”. Với n = 3 và bảo
toàn thứ tự từ, số sub-string được tạo sẽ là tổ hợp chập 3 của tổng các tokens (terms).
Việc chia các sub-string được thực hiện bằng các hàm thao tác trên xâu ký tự.
2.2.3. Thành phần gom cụm các quan hệ ngữ nghĩa
Tiến trình gom cụm thực hiện gom các phần tử “tương tự” nhau vào thành
cụm. Trong mô hình tìm kiếm thực thể dựa trên ngữ nghĩa, các phần tử trong cụm là
các câu context tương đồng về ngữ nghĩa. Độ tương đồng là một đại lượng dùng để
so sánh 2 hay nhiều phần tử với nhau, phản ánh mối tương quan giữa 2 phần tử. Do
đó, luận án khái quát các phép đo độ tương đồng về terms, độ tương đồng dựa trên
không gian vector, độ tương đồng ngữ nghĩa – của 2 context.
2.2.3.1. Các phép đo độ tương đồng giữa 2 context
a) Độ tương đồng về terms
Các hàm thống kê dựa trên từ vựng (terms) để tính toán độ tương đồng giữa
các câu là Zaro, Constrast model và Jaccard.
o Hàm Zaro: Do Winkler đề xuất1. Khoảng cách Zaro tính độ tương đồng
giữa 2 xâu ký tự a, b:
SimZaro(a,b) = {0, 𝑖𝑓 𝑚 = 01
3(
𝑚
|𝑎|+
𝑚
|𝑏|+
𝑚−𝑠𝑘𝑖𝑝
𝑚) 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
(2.6)
Trong đó m: số terms chung của a, b; skip: ½ số bước chuyển.
Số bước chuyển skip được thực hiện khi 2 terms chung trong a, b có khoảng
cách không lớn hơn giá trị:
⌊max (|𝑎|,|𝑏|)
2⌋ - 1 (2.7)
1 https://en.wikipedia.org/wiki/Jaro-Winkler_distance

33
o Constrast model: Do Tversky đề xuất (“Features of similarity”,
Psychological Review, 1977)1, áp dụng mô hình tương phản để tính độ
tương đồng giữa 2 câu a, b:
Sim(a,b) = α*f(a∩b) − 𝛽*f(a-b) − γ*f(b−a) (2.8)
Trong đó: f(a∩ 𝑏) biểu diễn các terms chung của a, b;
f(ai−𝑏j) biểu diễn các terms riêng của ai;
Các hệ số α, 𝛽, γ là các số thực dương, được xác định trong quá trình thử
nghiệm.
o Hệ số Jaccard (Paul Jaccard, “Etude comparative de la distribution
orale dans une portion des Alpes et des Jura”. In Bulletin del la Socit
Vaudoise des Sciences Naturelles, volume 37, pages 547-579). Hệ số
Jaccard đo độ tương đồng của 2 câu a, b được tính đơn giản như sau:
Sim(a, b) = |𝑎∩𝑏|
|𝑎∪𝑏| (2.9)
b) Độ tương đồng dựa trên không gian vector
Trong phương pháp không gian vector, câu được biểu diễn như một vector đặc
trưng, không gian hay số chiều của vector tương ứng với số terms trong câu: 𝑣𝑎⃗⃗⃗⃗⃗ = {a1,
a2,.., an}. Trong đó, mỗi ai được gán giá trị trọng số thông qua cách tính trọng số câu,
ký hiệu <ai, wi> hay 𝑤𝑖𝑎.
Lúc này 𝑣𝑎⃗⃗⃗⃗⃗ được biểu diễn:
𝑣𝑎⃗⃗⃗⃗⃗ = {< 𝑤1𝑎>, < 𝑤2
𝑎>. …, < 𝑤𝑛𝑎>} (2.10)
o Euclidean: Khoảng cách Euclide của 2 vector 𝑣𝑎⃗⃗⃗⃗⃗ , 𝑣𝑏⃗⃗⃗⃗⃗ được định nghĩa:
Euclide-Dist(𝑣𝑎⃗⃗⃗⃗⃗ , 𝑣𝑏⃗⃗⃗⃗⃗) = √∑ (𝑤𝑖𝑎 − 𝑤𝑖
𝑏)2𝑛𝑖=1 (2.11)
Mức tương đồng giữa 2 vector được tính bởi công thức:
Sim(𝑣𝑎⃗⃗⃗⃗⃗ , 𝑣𝑏⃗⃗⃗⃗⃗ ) = 1 −Euclide−Dist(𝑣𝑎⃗⃗ ⃗⃗ ⃗ ,𝑣𝑏⃗⃗ ⃗⃗ ⃗)
𝑛 (2.12)
o Manhattan: Khoảng cách Manhattan của 2 vector 𝑣𝑎⃗⃗⃗⃗⃗ , 𝑣𝑏⃗⃗⃗⃗⃗:
Manhattan-Dist(𝑣𝑎⃗⃗⃗⃗⃗ , 𝑣𝑏⃗⃗⃗⃗⃗) = ∑ |𝑤𝑖𝑎 − 𝑤𝑖
𝑏|𝑛𝑖=1 (2.13)
Mức tương đồng giữa 2 vector được tính tương tự:
Sim(𝑣𝑎⃗⃗⃗⃗⃗ , 𝑣𝑏⃗⃗⃗⃗⃗ ) = 1 −Manhattan−Dist(𝑣𝑎⃗⃗ ⃗⃗ ⃗ ,𝑣𝑏⃗⃗ ⃗⃗ ⃗)
𝑛 (2.14)
1 http://www.cogsci.ucsd.edu/~coulson/203/tversky-features.pdf

34
o Cosine: Độ tương đồng Cosine là góc giữa 2 vector:
Sim(𝑣𝑎⃗⃗⃗⃗⃗ , 𝑣𝑏⃗⃗⃗⃗⃗ ) = ∑ 𝑤𝑖
𝑎𝑤𝑖𝑏𝑛
𝑖=1
√∑ (𝑤𝑖𝑎)2𝑛
𝑖=1 √∑ (𝑤𝑖𝑏)2𝑛
𝑖=1
(2.15)
c) Độ tương đồng ngữ nghĩa
Có khá nhiều lý thuyết về tương đồng ngữ nghĩa [65] cũng như các độ đo mức
tương đồng ngữ nghĩa được mô tả trong [66], [67]. Phạm vi luận án đề cập và áp dụng
Giả thuyết phân phối [17]: Các từ xảy ra trong cùng ngữ cảnh thì có xu hướng tương
đồng ngữ nghĩa. Do tiếng Việt chưa có hệ thống Vietwordnet để tính toán độ tương
đồng ngữ nghĩa giữa 2 terms, luận án sử dụng độ tương hỗ PMI để đo, đánh giá độ
tương đồng ngữ nghĩa giữa 2 câu (context).
o PMI (Pointwise Mutual Information – Độ đo thông tin tương hỗ):
Phương pháp PMI được đề xuất bởi Church and Hanks [1990]. Dựa vào
xác suất đồng xảy ra giữa 2 terms t1, t2 trong kho ngữ liệu, độ tương
hỗ t1, t2 được xác định bởi:
PMI(t1, t2) = log2(𝑃(𝑡1,𝑡2)
𝑃(𝑡1).𝑃(𝑡2)) (2.16)
Trong đó:
- P(t1, t2): Xác suất xuất hiện đồng thời của t1 và t2 trong tập văn bản huấn
luyện;
- P(ti): Xác suất xuất hiện term ti trong tập văn bản huấn luyện;
Từ đó, độ tương đồng ngữ nghĩa giữa 2 context a, b được xác định:
Sim(a, b) = ∑ 𝑃𝑀𝐼(𝑤𝑖𝑎 , 𝑤𝑗
𝑏)𝑛𝑖=1,𝑗=1 (2.17)
Trong đó:
- Sim(a, b): Độ tương đồng ngữ nghĩa của 2 context a, b;
- 𝑤𝑖𝑎: Trọng số của term thứ i trong câu a;
Ưu điểm của PMI: Nếu chỉ đơn thuần tính số lần xuất hiện đồng thời của t1 và
t2 thì phép đo độ tương đồng ngữ nghĩa sẽ thiếu chính xác đối với các terms có tần
số xuất hiện nhiều. Chẳng hạn, xét 3 terms: “the”, “car” và “drive” trong corpus. Rõ
ràng, 2 terms “drive” và “car” có tương quan ngữ nghĩa mạnh hơn so với “the” và
“car”. Tuy nhiên nếu xét theo tần suất xuất hiện, “car” sẽ có tương quan ngữ nghĩa
với “the” mạnh hơn so với “drive”. Độ đo PMI được áp dụng để khắc phục nhược
điểm này. Ví dụ, kho ngữ liệu có 10000 terms, đếm được tần suất xuất hiện của “the”

35
là 1000 lần, “car” xuất hiện 20 lần, “drive” xuất hiện 10 lần; Số lần đồng hiện trong
câu context của “the” và “car”, “car” và “drive” lần lượt là 10 và 5. Áp công thức
(2.16) để tính PMI, ta có:
PMI(t1, t2) = log2(𝑃(𝑡1,𝑡2)
𝑃(𝑡1).𝑃(𝑡2))= log2(
𝐶(𝑡1,𝑡2)
𝑁𝐶(𝑡1)
𝑁.𝐶(𝑡2)
𝑁
)= log2(𝐶(𝑡1,𝑡2).𝑁
𝐶(𝑡1).𝐶(𝑡2))
Với N = 10000; C(“the”) = 1000; C(“car”) = 20; C(“drive”) = 10; C(“the”,
“car”) = 10; C(“car”, “drive”) = 5, ta có:
PMI(“the”, “car”) = log2 (10,10000
1000.20) ≈ 2.32
PMI(“car”, “drive”) = log2 (5,10000
20.10) ≈ 7.96
Hai terms càng tương đồng ngữ nghĩa khi giá trị PMI càng cao, PMI(“car”,
“drive”) lớn hơn PMI(“the”, “car”), nên độ tương đồng ngữ nghĩa của của “car” và
“drive” mạnh hơn “the” và “car”. Vấn đề độ lệch tương đồng ngữ nghĩa với các terms
có tần số xuất hiện nhiều được loại bỏ.
Ngoài ra, để tránh độ lệch ngữ nghĩa giữa t1 và t2 trong các terms có tần suất
xuất hiện không thường xuyên, đồng thời tránh trường hợp log2 = -∞ (xác suất đồng
xảy ra giữa 2 terms t1, t2 bằng 0), Paltel et al. cải tiến độ đo PMI:
PMI(t1, t2) = (𝐶(𝑡1,𝑡2)
𝐶(𝑡1,𝑡2)+1×
min (𝐶(𝑡1),𝐶(𝑡2))
min (𝐶(𝑡1),𝐶(𝑡2))+1)log2(
𝐶(𝑡1,𝑡2)
𝑁𝐶(𝑡1)
𝑁.𝐶(𝑡2)
𝑁
) (2.18)
Luận án áp dụng độ đo PMI này để cải thiện cho độ đo dựa trên tần suất trong
các xử lý tương đồng ngữ nghĩa giữa 2 câu áp dụng Giả thuyết phân phối trình bày
trong phần 2.3.2.
2.2.3.2. Gom cụm các quan hệ ngữ nghĩa
Mặc định, khi 2 cặp thực thể tương đồng quan hệ, thì context của 2 cặp thực
thể sẽ có các terms chung. Tuy nhiên, do tính biểu đạt tự nhiên của ngôn ngữ, 2
context dù không có terms chung vẫn có thể tương tự ngữ nghĩa. Ví dụ xét 2 context:
“Hoa Đà, thầy thuốc người Trung Hoa” và “Tôn Thất Tùng, vị bác sĩ Việt Nam”, hay
2 context khác: “Lady Gaga, nữ ca sĩ người Mỹ” và “Khánh Ly, người hát nhạc Việt”.
Rõ ràng các context này không có terms chung nhưng vẫn tương đồng về ngữ nghĩa.
Vì vậy, để nhận dạng quan hệ tương đồng ngữ nghĩa giữa 2 context không có terms
chung, luận án áp dụng Giả thuyết phân phối (Distributional hypothesis).
Giả thuyết phân phối phát biểu rằng: Các từ xảy ra trong cùng ngữ cảnh thì có
xu hướng tương đồng ngữ nghĩa. Có nghĩa, nếu trong một tập mẫu mà term t1 thường

36
đồng hiện với term t2 trong mỗi mẫu thì t1 và t2 có xác suất tương đồng ngữ nghĩa cao
[17].
Mở rộng giả thuyết phân phối ở mức context: Trong corpus, nếu 2 context p1,
p2 thường đồng hiện với cặp thực thể (X, Y) thì 2 context p1, p2 là tương đồng ngữ
nghĩa. Trong [17] nêu ví dụ về 2 context: “X was acquired by Y” và “X buys Y”
thường đồng hiện với cặp thực thể (Google, Youtube) và/hoặc (Adobe Systems,
Macromedia), vì vậy 2 context nói trên “was acquired by” và “buys” sẽ tương đồng
ngữ nghĩa. Khi p1, p2 tương đồng ngữ nghĩa thì các cặp thực thể (Google, Youtube)
và (Adobe Systems, Macromedia) tương đồng về quan hệ. Về cơ sở toán học, giả
thuyết mở rộng này tương tự với mô hình không gian vector, nếu xem mỗi context
như một vector có trọng số thì 2 context đồng hiện trong càng nhiều cặp thực thể, độ
tương đồng Cosine giữa 2 vector càng cao.
Kỹ thuật mở rộng giả thuyết phân phối đã được ứng dụng thành công trong
các nghiên cứu nhận dạng mẫu tương đồng ngữ nghĩa, hoặc cải thiện độ chính xác
trong giải thuật đo độ tương đồng ngữ nghĩa [17]. Nghiên cứu trong [17], [18] toán
học hóa việc mở rộng giả thuyết phân phối theo các công thức:
Ký hiệu cặp thực thể (A, B) là w, xét trong toàn corpus, ta có P(w) là tập các
context mà w đồng hiện:
P(w) = {p1, p2, …, pn} (2.19)
Tương tự, W(p) là tập các cặp thực thể mà context p đồng hiện:
W(p) = {w1, w2, …, wm} (2.20)
Gọi số lần đồng hiện của wi và pj trong cùng một câu context là f(wi, pj). Gọi
vector tần suất các cặp thực thể mà context p đồng hiện là ɸ(p); ɸ(p) được định
nghĩa:
ɸ(p) = (f(w1, p), f(w2, p), .., f(wm, p))T (2.21)
Tương tự, ɸ(w) là vector tần suất tập context đồng hiện với cặp thực thể w:
ɸ(w) = (f(w, p1), f(w, p2), .., f(w, pn))T (2.22)
Độ đo tương đồng theo giả thuyết phân phối của 2 context p, q:
SimDH(p,q) = Cosine(ɸ(p),ɸ(q)) = ∑ (𝑓(𝑤𝑖,𝑝)∙𝑓(𝑤𝑖,𝑞))𝑖
||𝑓(𝑤𝑖,𝑝)||||𝑓(𝑤𝑖,𝑞)|| (2.23)
Với ||f(wi, p)|| là dạng chuẩn L2:
||𝑓(𝑤𝑖 , 𝑝)|| = √∑ 𝑓2(𝑤𝑖 , 𝑝)𝑖2
(2.24)

37
Áp dụng PMI để cải tiến độ đo tương đồng theo giả thuyết phân phối:
SimDH(p,q) = Cosine(PMI(p, q)) = ∑ (𝑃𝑀𝐼(𝑤𝑖,𝑝)∙𝑃𝑀𝐼(𝑤𝑖,𝑞))𝑖
||𝑃𝑀𝐼(𝑤𝑖,𝑝)||||𝑃𝑀𝐼(𝑤𝑖,𝑞)|| (2.25)
Tuy nhiên một nhược điểm của giả thuyết phân phối là đòi hỏi các cặp thực
thể chung phải luôn “đồng hiện” với các context. Độ đo tương đồng chỉ dựa trên giả
thuyết phân phối mà không dựa trên tương đồng về term sẽ ảnh hưởng không nhỏ
đến chất lượng của kỹ thuật gom cụm. Do đó trong giải thuật gom cụm, luận án đề
xuất kết hợp giải thuyết phân phối và độ đo Cosine. Kết hợp được mô tả:
Độ tương đồng theo terms của 2 context p, q:
Simterm(p, q) = ∑ (weighti(p)∙weighti(q))n
i=1
||weight(p)|| ||weight(q)|| (2.26)
Độ đo tương đồng kết hợp:
Sim(p,q) = Max(SimDH(p, q),Simterm(p, q)) (2.27)
Mỗi cụm C gồm 1 tập các context tương đồng pi, tâm cụm được vector hóa:
Centroid C⃗⃗ = norm(∑ pi⃗⃗⃗⃗⃗pi∈C
|C|) (2.28)
2.2.3.3. Giải thuật gom cụm
Là một trong hai giải thuật chính của Chương, giải thuật gom cụm được cải
tiến từ [17], [18], trong đó:
Đầu vào:
- Tập P = {p1, p2, …, pn}; Ngưỡng phân cụm θ1, ngưỡng heuristic θ2; Dmax;
- Kết quả hàm đo độ tương đồng kết hợp, áp dụng theo công thức (2.27)
Đầu ra:
- Tập cụm kết quả Cset (chứa ClusterID, context, trọng số mỗi context và cặp
thực thể tương ứng).
- Mỗi cụm chứa các context tương đồng về ngữ nghĩa.
Giải thuật:
Program Clustering_algorithm
// Khởi tạo tập cụm kết quả bằng rỗng.
01. Cset = {}; iCount=0;
02. for each context pi ∈ P do
03. Dmax = 0; c* = NULL;
04. for each cluster cj ∈ Cset do
05. Sim_cp=Sim(pi,Centroid(cj))
06. if (Sim_cp > Dmax) then

38
07. Dmax = Sim_cp; c* ← cj;
08. end if
09. end for
10. if (Dmax > θ1) then
11. c*.append(pi)
12. else
13. Cset ∪= new cluster{c*}
14. end if
15. if (iCount > θ2) then
16. iCount++;
17. exit Current_Proc_Cluster_Alg();
18. end if
19. end for
20. Return Cset;
@CallMerge_Cset_from_OtherNodes()
End.
Diễn giải giải thuật:
Nhận vào tập context P, ngưỡng phân cụm θ1 ∊ [0, 1]. Ngưỡng θ2 từ dòng 15-
19 là một heuristic để các nodes khác thực hiện song song khi thực hiện gom cụm với
số context lớn (hơn 400000). Mảng toàn cục Cset được sử dụng để so sánh, trộn hợp,
khử trùng lặp các Cluster_ID kết quả.
Trong giải thuật, hàm Sim(pi, Centroid(cj)) áp dụng độ đo tương đồng kết hợp
mà luận án đề xuất. Thân vòng lặp, từ dòng 5-8, lặp tìm cụm cj tương đồng nhất với
context pi đang xét. Nếu giá trị hàm đo lớn hơn ngưỡng phân cụm θ1, bổ sung context
pi vào cluster hiện hành cj, nếu không, một cụm mới chỉ chứa pi được tạo ra (dãy câu
lệnh 10-14). Các phép tính độ tương đồng, tâm cụm áp dụng theo các công thức từ
(2.23) - (2.28).
Độ phức tạp tính toán:
Giải thuật có độ phức tạp tính toán O(N.C), với N là số context cần gom cụm,
C là tổng số cụm gom được (N >> C). Áp dụng heuristic tính song song, giải thuật có
thể gom cụm trong thời gian tương đối ngắn, thậm chí khi tập context có kích thước
rất lớn.
Áp dụng Giả thuyết phân phối khắc phục được nhược điểm 2 context dù không
có terms chung vẫn có thể tương đồng ngữ nghĩa. Áp dụng độ đo tương đồng theo

39
terms không đòi hỏi các cặp thực thể chung phải luôn “đồng hiện” với các context.
Do đó, nghiên cứu kết hợp hàm đo độ tương đồng theo terms và theo Giả thuyết phân
phối trong bước phân cụm. Thực nghiệm cho thấy chất lượng cụm được cải thiện
đáng kể khi áp dụng kết hợp nói trên.
2.2.4. Thành phần tính toán độ tương đồng giữa 2 cặp thực thể
Thuộc phase online của mô hình IRS. Tính toán độ tương đồng quan hệ giữa
2 cặp thực thể là một bài toán khó, khó vì: Thứ nhất, độ tương đồng quan hệ biến đổi
theo giai đoạn, xét 2 cặp thực thể (Biden, tổng thống Mỹ) và (Elizabeth, nữ hoàng
Anh), độ tương đồng quan hệ biến đổi theo nhiệm kỳ. Thứ hai, do yếu tố thời gian, 2
cặp thực thể có thể không chia sẻ hoặc chia sẻ rất ít ngữ cảnh xung quanh cặp thực
thể, như: Apple:iPod (vào 2010s) và Sony:Walkman (vào 1980s), dẫn đến kết quả 2
cặp thực thể không tương đồng. Thứ ba, trong một cặp thực thể, có thể có nhiều quan
hệ ngữ nghĩa khác nhau, như: “Ổ dịch Corona khởi phát từ Vũ Hán”; “Corona cô lập
thành phố Vũ Hán”; “Số ca lây nhiễm Corona giảm dần ở Vũ Hán”; .v.v. Thứ tư,
trong cặp thực thể chỉ có một quan hệ tương đồng ngữ nghĩa nhưng có hơn một cách
biểu đạt: “X was acquired by Y” và “X buys Y”. Thứ năm, khó do nội tại thực thể có
tên (tên cá nhân, tổ chức, địa danh, ..) vốn không phải các từ thông dụng hoặc có
trong từ điển. Và cuối cùng, khó do thực thể D chưa biết, thực thể D đang trong tiến
trình tìm kiếm.
Thành phần tính toán độ tương đồng quan hệ giữa 2 cặp thực thể thực hiện 2
tác vụ: Lọc (tìm) và Phân hạng. Như mô tả trong phần 2.2.1, nhận vào truy vấn q={(A,
B), (C, ?)}, thông qua bảng chỉ mục (inverted index), IRS gọi hàm Filter-Entities Fe
đặt lọc (tìm) tập ứng viên chứa các cặp thực thể (C, Di) và quan hệ ngữ nghĩa (context)
tương ứng, với điều kiện context (C, Di) tương đồng với context (A, B) – được rút
trích từ Cset. Kế tiếp, gọi hàm Rank-Entities Re để xếp hạng các thực thể Di, Dj trong
tập ứng viên theo phép đo RelSim (Relational Similarity), trả về danh sách các {Di}
đã xếp hạng.
a) Giải thuật Filter-Entities
Đầu vào:
- Query q = (A, B)(C, ?);
- Ký hiệu hình thức: P(w), W(p) nêu trong (2.19), (2.20);
Đầu ra:

40
- Tập ứng viên S (gồm các thực thể Di và context tương ứng).
Giải thuật:
Program Filter_entities
01. S = {};
02. P(w) = EntPair_from_Cset.Context();
03. for each context pi ∈ P(w) do
04. W(p) = Context(pi).EntPairs();
05. if (W(p) contains (C:Di)) then S ∪= W(p);
06. end for
07. return S
End.
Diễn giải giải thuật:
Biến P(w) nhận giá trị trả về từ hàm EntPair_from_Cset.Context() gồm các
context p* chứa cặp thực thể (A, B) và các context thuộc cùng cụm với p*. Vòng lặp
for (dòng lệnh 03-06) lọc tìm các context ràng buộc với cặp thực thể (C, Di), trong đó
thực thể C đã biết. Như vậy, S chứa toàn bộ các context gắn với cặp thực thể (C, Di)
và tương đồng với context (A, B).
Mặc dù Filter-Entities lọc ra được tập ứng viên S chứa câu trả lời, không đảm
bảo rằng các thực thể ứng viên Di trong cặp thực thể đích (C, Di) chính xác và nhất
quán ngữ nghĩa với cặp thực thể nguồn (A, B). Lấy ví dụ, truy vấn query q = {(Lý
Thường Kiệt, Như Nguyệt), (Napoléon, ?)}, nếu quan hệ ngữ nghĩa là: “trận đánh nổi
tiếng” thì đáp án đúng là “Waterloo”. Tuy nhiên trong corpus, quan hệ ngữ nghĩa giữa
cặp thực thể (Lý Thường Kiệt, Như Nguyệt) có thể có các mẫu như: “phòng tuyến”,
“chiến dịch”, … Khi xét riêng ngữ nghĩa “chiến dịch” thì Napoléon có khoảng 7 chiến
dịch liên minh, IRS sẽ không biết trả về kết quả nào thích hợp nhất. Vì vậy mô hình
IRS thực hiện phép đo RelSim (một biến thể của Cosine) để xếp hạng các thực thể
Di, Dj trong tập ứng viên, trả kết quả về người tìm kiếm là danh sách các {Di} được
xếp hạng. Phép đo RelSim là giá trị trả về của giải thuật Rank_Entities.
Độ phức tạp tính toán:
Tiến trình rút trích quan hệ ngữ nghĩa thực hiện với điều kiện giới hạn: Context
chứa ít nhất 2 thực thể, ngoài ra chứa ít nhất 2 terms, mỗi term có tần suất xuất hiện
>= 10 trong toàn Corpus. Điều kiện giới hạn này cô gọn đáng kể không gian tìm kiếm.
Tập cụm kết quả Cset bao gồm: ClusterID, context, trọng số mỗi context và
cặp thực thể tương ứng - được lưu theo dạng chỉ mục đảo (inverted index). Hàm lọc

41
tìm các cặp thực thể ứng viên Filter-Entities (câu lệnh 02) thực chất chỉ là một phép
liệt kê context và entities thỏa điều kiện thuộc (A, B) đã biết, Filter-Entities không
đòi hỏi bất cứ phép tính toán tương đồng nào, do đó phép liệt kê này thực chất là thao
tác tra cứu, tìm kiếm trên bảng băm, có thời gian tính toán là O(1).
Do đó, thời gian tính của giải thuật Filter-Entities nằm ở vòng lặp for (dòng
lệnh 03-06). Vòng lặp for chỉ thực hiện trên tập con rất nhỏ số context đồng hiện với
cặp (A, B) trong query đưa vào. Vì thực chất số lượng context đồng hiện với cặp (A,
B) bị giới hạn bởi một hằng số, không phụ thuộc kích thước tập dữ liệu mẫu. Vì vậy,
thời gian tính của hàm Filter-Entities là hằng số, đáp ứng tìm kiếm thời gian thực.
Sau thực thi Filter-Entities, thu được tập con gồm các thực thể Di và context
tương ứng. Tiến trình RelSim chỉ thực hiện xử lý, tính toán trên tập con rất nhỏ này,
đồng thời áp dụng ngưỡng α để loại bớt các thực thể Di có giá trị RelSim thấp. Vì vậy,
sau tiến trình Filter-Entities, mô hình trong (2.1) được biến đổi:
Với: Fe(q,D) = Fe({(A, B),(C,?)}, D):
𝐹𝑒(𝑞, 𝐷𝑖) = {1, 𝑖𝑓 𝑅𝑒𝑙𝑆𝑖𝑚((𝐴, 𝐵), (𝐶, 𝐷𝑖)) > α0, 𝑒𝑙𝑠𝑒
(2.29)
b) Giải thuật Rank-Entities
Là một trong hai giải thuật chính, giải thuật Rank-Entities có nhiệm vụ tính
RelSim:
Đầu vào:
- Tập ứng viên từ giải thuật Filter-Entities.
- Cặp thực thể nguồn (A, B), ký hiệu s;
- Các thực thể ứng viên (C, Di), ký hiệu c;
- Các context tương ứng với s, c;
- Cset: Tập cụm thu được từ giải thuật Clustering_algorithm;
- Với các thực thể A, B, C đã biết tập cụm tương ứng chứa A, B, C được
xác định;
- Ngưỡng α (so giá trị RelSim); Ngưỡng α được đặt ra trong quá trình kiểm
thử chương trình.
- Khởi tạo tích vô hướng (β); tập used-context (γ);
Đầu ra:
- Danh sách câu trả lời (danh sách thực thể được xếp hạng) Di;

42
Các ký hiệu hình thức:
- P(s), P(c) được nêu trong công thức (2.19), (2.20);
- f(s, pi), f(c, pi), ɸ(s), ɸ(c) nêu trong (2.21), (2.22);
- γ: Biến (dạng tập hợp) giữ các context đã xét;
- q: Biến trung gian (Context);
- Ω: Cụm;
Giải thuật:
Program Rank_Entities
01. for each context pi ∈ P(c) do
02. if (pi ∈ P(s)) then
03. β ← β + f(s, pi)·f(c, pi)
04. γ ← γ ∪ {pi}
05. else
06. Ω ← cluster contains pi
07. max_co-occurs = 0;
08. q ← NULL;
09. for each context pj ∈ (P(s)\P(c)\γ) do
10. if (pj ∈ Ω) & (f(s, pj) > max_co-occurs)
11. max_co-occurs ← f(s, pj);
12. q ← pj;
13. end if
14. end for
15. if (max_co-occurs > 0) then
16. β ← β + f(s, q)·f(c, pi)
17. γ ← γ ∪ {q}
18. end if
19. end if
20. end for
21. RelSim ← β/L2-norm(ɸ(s), ɸ(c))
22. if (RelSim ≥ α) then return RelSim
End.
Diễn giải giải thuật:
Trường hợp 2 cặp thực thể nguồn và đích cùng một quan hệ ngữ nghĩa (cùng
chia sẻ chung một context, câu lệnh 1-2): pi ∊ P(s) ∩ P(c), tính tích vô hướng tương
tự như công thức Cosine tính độ tương đồng.

43
Trường hợp pi ∊ P(c) nhưng pi ∉ P(s), giải thuật tìm context pj (hay biến trung
gian q, dòng 12), trong đó pi, pj thuộc cùng một cụm đã biết. Thân vòng lặp (từ lệnh
10-13) chọn ra context pj có số lần đồng hiện (co-occurs) với s lớn nhất. Nói cách
khác, tìm context có ngữ nghĩa phổ biến nhất với s. Theo giả thuyết phân phối, 2
context pi, pj đồng hiện trong càng nhiều cặp thực thể, độ tương đồng Cosine giữa 2
vector càng cao. Khi giá trị Cosine càng cao, pi, pj càng tương tự. Kết thúc giải thuật,
cặp thực thể đích (C, Di) được xếp hạng theo ngưỡng RelSim, đạt độ chính xác và
nhất quán ngữ nghĩa với cặp thực thể nguồn (A, B).
Dãy câu lệnh từ 15-18 tính tích vô hướng. Các câu lệnh 21-22 tính giá trị
RelSim. Từ tập RelSim thu được, sắp xếp để thực thể Di nào có RelSim cao hơn được
xếp thứ tự thấp hơn (theo nghĩa gần top hơn, hay rank cao hơn). Tập kết quả Di là
danh sách câu trả lời cho truy vấn mà người dùng muốn tìm.
Độ phức tạp tính toán:
Giải thuật gồm 2 vòng lặp for lồng nhau, trong thân vòng lặp có câu lệnh so
sánh. Vì vậy, đánh giá cận trên độ phức tạp tính toán của giải thuật là O(n2), với n là
số lần đồng hiện của wi và pj trong cùng một câu context f(wi, pj), như công thức
(2.21) đã nêu.
Tuy nhiên, như đã phân tích trong giải thuật Filter-Entities lượng context đồng
hiện với cặp (A, B) đã biết bị giới hạn bởi hằng số, như vậy, n là hằng số và rất nhỏ
so với kích thước toàn bộ data-set. Nói cách khác, thời gian tính của giải thuật Rank-
Entities là hằng số, tăng chậm khi kích thước dữ liệu mẫu (corpus) tăng. Giải thuật
Rank-Entities đảm bảo được tốc độ tính toán RelSim, phân hạng kết quả Di là danh
sách câu trả lời tức thời cho truy vấn mà người dùng muốn tìm.
2.3. Kết quả thực nghiệm - Đánh giá
Mục đích kiểm thử, đánh giá để tìm ra giá trị phù hợp của các tham số như:
Ngưỡng θ1 trong giải thuật Phân cụm, ngưỡng α trong giải thuật Rank_Entities.
Từ tập dữ liệu mẫu trong thực nghiệm, luận án xây dựng dataset, tập mẫu này
gồm các thực thể và kiểu quan hệ ngữ nghĩa trong cặp thực thể. Áp dụng các độ đo
Precision, Recall, F-Score trên train-set và test-set để điều chỉnh tham số, nhằm tìm
ra giá trị tối ưu cho θ1 và α.
Để so sánh, đánh giá giữa tần suất (số lần đồng hiện) và độ tương hỗ PMI trong

44
tính toán độ tương đồng ngữ nghĩa của 2 context, luận án sử dụng độ đo MRR (Mean
Reciprocal Rank), độ đo MRR được biết là độ đo phản ánh cả đặc tính recall và
precision, thường dùng cho các kỹ thuật tìm kiếm có độ chính xác cao [68].
2.3.1. Dataset
Tập dataset được xây dựng từ tập dữ liệu mẫu trong thực nghiệm, dựa vào 4
phân lớp thực thể có tên: PER; ORG; LOC và TIME; Các phân lớp này thường được
sử dụng để đánh giá trong các hệ thống trích xuất quan hệ [69], [70], các thuật giải
đo lường độ tương đồng quan hệ [71], [72], các hệ tìm kiếm quan hệ ẩn [19]. Mỗi
phân lớp gồm 50 truy vấn, theo [73], [74] một bộ 50 truy vấn được coi là đủ lớn để
đánh giá một hệ thống truy xuất thông tin. Các truy vấn được rút trích ngẫu nhiên, có
dạng q={(Trung Quốc:Đôn Hoàng),(Nara:?)}. Các truy vấn có thể duy nhất 1 câu trả
lời chính xác, ví dụ q={(Vietnam:2/9):(Hong Kong:?)}, cũng có thể có nhiều câu trả
lời chính xác, ví dụ với context=“văn hào”, thực thể có tên “Hemingway” có thể ghép
cặp với nhiều thực thể khác như: “Chuông nguyện hồn ai”, “Ông già và biển cả”,
“Giã từ vũ khí”, .v.v.
Các phân lớp này và các cặp thực thể gắn context tương ứng với mỗi phân lớp
được minh họa trong Bảng 2.2:
Bảng 2.2: Các phân lớp NER (Location, Organization, Personal, Time)
Stt Phân
lớp
NER
Context Entity-pair Example
1
LOC
bích họa
Phật
giáo
Đôn Hoàng:Trung
Quốc
Bích họa Phật giáo Đôn Hoàng ở
Trung Quốc.
Nara:Nhật Bản Bích họa Phật giáo Nara tại Nhật
Bản.
2 ORG đặt trụ
sở tại
WHO:Geneva WHO đặt trụ sở tại Geneva.
Unesco:Paris Unesco đặt trụ sở tại Paris.
3
PER
tác
phẩm
kinh
điển
Don Quixote
:
Cervantes
Don Quixote là tác phẩm kinh
điển của Cervantes.
Oliver Twist
:
Oliver Twist là tác phẩm kinh
điển của Charles Dickens.

45
Charles Dickens
4
TIME
Ngày
Quốc
khánh
Hong Kong:1/7 Ngày Quốc khánh Hong Kong là
1/7.
Macedonia:8/9 Ngày Quốc khánh Macedonia là
8/9.
2.3.2. Kiểm thử - Điều chỉnh tham số
Để đánh giá hiệu quả của thuật toán phân cụm và thuật toán xếp hạng ứng viên
Rank_Entities, Chương 2 thực hiện thay đổi các giá trị θ1 và α, sau đó đo độ Precision,
Recall, F-Score tương ứng với mỗi giá trị thay đổi của θ1.
Precision(Q) = Số truy vấn có ít nhất 1 câu trả lời đúng
Tổng số truy vấn (2.30)
Recall(Q) = Số truy vấn có ít nhất 1 câu trả lời đúng
Tổng số truy vấn có ít nhất một câu trả lời (2.31)
F-Score(Q) = 2⨉Precision(Q)⨉Recall(Q)
Precision(Q)+Recall(Q) (2.32)
Kết quả thực nghiệm tại Hình 2.3 cho thấy tại α = 0.5, θ1 = 0.4, điểm F-Score
đạt giá trị cao nhất.
Hình 2.3: Giá trị F-Score tương ứng với mỗi giá trị thay đổi của α, θ1.
Giải thuật Rank_Entities dòng 22 (if (RelSim ≥ α) return RelSim) cho
thấy, khi α quá nhỏ thì số lượng ứng viên tăng, có thể có nhiễu, đồng thời thời gian
xử lý real-time tốn chi phí thời gian do hệ thống xử lý nhiều truy vấn ứng viên. Ngược

46
lại khi α lớn thì giá trị Recall rất nhỏ, kéo theo F-Score giảm đáng kể.
2.3.3. Đánh giá với độ đo MRR (Mean Reciprocal Rank)
Đối với bộ truy vấn Q, nếu thứ hạng câu trả lời đúng đầu tiên trong truy vấn q
∈ Q là rq, thì độ đo MRR của bộ truy vấn Q được tính:
MRR(Q) = 1
|𝑄|∑
1
𝑟𝑞𝑞∈𝑄 (2.33)
Trong thực nghiệm, với mục đích so sánh, giải thuật Rank_Entities (dòng lệnh
03, 16) tính tích vô hướng của f(s,p)·f(c,p) và tích vô hướng của PMI(s,p)·PMI(c,p).
Với 4 phân lớp thực thể: PER; ORG; LOC và TIME; phương pháp dựa trên tần suất
đồng hiện (f) đạt giá trị trung bình MRR(f) ≈ 0.69; trong khi đó, phương pháp dựa
trên PMI đạt MRR(PMI) ≈ 0,86. Điều này cho thấy PMI giúp cải thiện độ chính xác
tốt hơn tần suất đồng hiện.
.
Hình 2.4: So sánh PMI với f: tần suất (số lần đồng hiện) dựa trên MRR.
2.3.4. Hệ thống thực nghiệm
Tập dữ liệu mẫu trong thực nghiệm được download từ các nguồn Viwiki (7877
files) và Vn-news (35440 files). Mục đích chọn nguồn Viwiki và Vn-news vì các
dataset này gồm các mẫu chứa các thực thể có tên (Named Entity). Tiến trình đọc,
lấy nội dung file, tách đoạn, tách câu (main-sentences, sub-sentences), thu được
1572616 câu.
Việc phân lớp các thực thể có tên NER (Named Entity Recognition), thực
nghiệm chọn phân lớp ở mức tổng quát, với 9 nhãn: B-LOC; B-MISC; B-ORG; B-

47
PER; I-LOC; I-MISC; I-ORG; I-PER và O, trong đó tiếp đầu ngữ B- Begin và I- Inner
tương ứng vị trí bắt đầu và bên trong tên thực thể.
Các nhãn tổng quát của NER: PER: Tên người; ORG: Tên tổ chức; LOC: Địa
danh; TIME: Kiểu thời gian; NUM: Kiểu số; CUR: Kiểu tiền tệ; PCT: Kiểu phần
trăm; MISC: Kiểu thực thể khác; O: Không phải thực thể.
Giải thuật rút trích patterns lưu vào database, sau khi thực hiện các bước xử lý
và các điều kiện giới hạn, Database còn lại 404507 câu context. Từ tập context này,
giải thuật gom cụm các quan hệ ngữ nghĩa gom được 124805 cụm.
Theo hiện biết, với tiếng Việt, chưa có một mô hình tìm kiếm thực thể dựa trên
quan hệ ngữ nghĩa ẩn. Do đó, luận án chưa có điều kiện để so sánh, kiểm thử với các
phương pháp khác.
Hình 2.5: Thực nghiệm IRS với nhãn thực thể B-PER.
Hình 2.6: Thực nghiệm IRS với thực thể kiểu thời gian.
Để đánh giá độ chính xác, thực nghiệm thực hiện 500 queries để kiểm thử, kết
quả cho thấy độ chính xác đạt khoảng 92%.

48
Bảng 2.3: Các ví dụ kết quả thực nghiệm với input q = {A, B, C} và output D
ID A B C D
.. German
Angela
Merkel
Israel Benjamin Netanyahu
.. Harry Kane Tottenham Messi Barca
.. Chí Anh Khánh Thi Khắc Việt Tuấn Hưng
.. … … … …
.. Hà Nội Kim Quy Hoàn
Kiếm
Gươm Thần Kim Quy
(Magical sword – Golden
Turtle)
.. Hoàng Công
Lương
Hòa Bình Thiên Sơn RO
Một vài ngoại lệ cần giải quyết trong phạm vi nghiên cứu, khi người dùng đưa
vào câu truy vấn ngẫu nhiên, tùy ý, không theo motive q = {(A, B), (C, ?)}. Trong
câu truy vấn, mối quan hệ ngữ nghĩa của cặp thực thể đầu vào (A, B) bằng 0, nói cách
khác trong corpus không tồn tại quan hệ ngữ nghĩa (A, B) hoặc thậm chí không tồn
tại cặp thực thể (A, B), mô hình IRS sẽ biến đổi thành cơ chế tìm kiếm theo từ khóa
và áp dụng hướng ngữ cảnh.
Trong trường hợp, câu truy vấn theo motive: q = {(A, B), (C, ?)}, nhưng thực
tế quan hệ của cặp thực thể (A, B) không chỉ là đơn nghĩa mà có thể là đa nghĩa, lúc
này sẽ có nhiều quan hệ ngữ nghĩa khác nhau trong cùng một cặp thực thể. Ví dụ cặp
thực thể (Notre Dame:Paris) sẽ có các quan hệ ngữ nghĩa như “vụ cháy”, “biểu
tượng”, “tác phẩm văn học”, “chuyện tình thằng gù”, “vương miện gai”, .v.v. Với
ràng buộc là thực thể C đã biết, giải thuật Rank-Entities tìm kiếm các cụm ứng viên,
trả về kết quả là danh sách các thực thể {Di} được tối đa hóa tương đồng với ngữ
nghĩa của cặp quan hệ (A, B).
Nói cách khác, về bản chất, IRS dựa vào tương đồng ngữ nghĩa cặp thực thể
(A, B) + thực thể ràng buộc C. Nếu ngữ nghĩa trong truy vấn (A, B) là đa nghĩa
(A, B) thuộc nhiều cụm (ngữ nghĩa) khác nhau kết quả trả về có tính đa dạng, phủ
các khía cạnh ngữ nghĩa khác nhau (với điều kiện thỏa ràng buộc C).

49
Ngoài ra, để tường minh về mặt ngữ nghĩa trong danh sách kết quả này, câu
context gắn kèm Di được kết xuất dưới dạng snippet.
2.4. Kết luận chương
Khả năng suy ra thông tin/tri thức không xác định bằng suy diễn tương tự là
một trong những khả năng tự nhiên của con người. Chương 2 trình bày mô hình tìm
kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn (IRS) nhằm mô phỏng khả năng trên.
Mô hình IRS tìm kiếm thông tin/tri thức từ một miền không quen thuộc và không cần
biết trước từ khóa, bằng cách sử dụng ví dụ tương tự (quan hệ tương đồng) từ một
miền quen thuộc. Đóng góp chính của Chương 2: Xây dựng kỹ thuật tìm kiếm thực
thể dựa trên quan hệ ngữ nghĩa ẩn sử dụng phương pháp phân cụm nhằm nâng cao
hiệu quả tìm kiếm. Đồng thời, luận án đề xuất độ đo tương đồng kết hợp - theo terms
và theo giả thuyết phân phối; Từ độ đo đề xuất, đồng thời áp dụng heuristic vào giải
thuật gom cụm để cải thiện chất lượng cụm.
Bên cạnh khả năng tìm kiếm thông tin/tri thức bằng cách sử dụng quan hệ
tương đồng, mô hình IRS còn có khả năng ánh xạ cơ sở tri thức từ miền ngữ nghĩa
quen thuộc vào một miền ngữ nghĩa không quen thuộc để khai phá và thu thập tri
thức.
Hướng phát triển của đề tài, một mặt - xét thêm các loại ánh xạ quan hệ, thêm
yếu tố thời gian để kết quả tìm kiếm được cập nhật và chính xác. Mặt khác, có thể
mở rộng tìm kiếm thực thể với truy vấn đầu vào chỉ gồm một thực thể, ví dụ: “Sông
nào dài nhất Trung Quốc?”, mô hình tìm kiếm thực thể dựa trên ngữ nghĩa ẩn sẽ đưa
ra được câu trả lời chính xác: “Trường Giang”, dù Corpus chỉ có câu gốc “Trường
Giang là sông lớn nhất Trung Quốc”.

50
CHƯƠNG 3: GỢI Ý TRUY VẤN HƯỚNG NGỮ CẢNH
Khắc phục các vấn đề còn tồn tại trong các nghiên cứu liên quan về gợi ý truy
vấn, chương này trình bày hướng nghiên cứu về phương pháp hướng ngữ cảnh trong
gợi ý truy vấn. Phân tích các ưu nhược điểm của phương pháp hướng ngữ cảnh, đưa
ra các đề xuất kỹ thuật khắc phục nhược điểm, đề xuất phương pháp cải tiến và công
thức tổ hợp mới. Thực nghiệm trên một máy tìm kiếm tiếng Việt chuyên ngành hàng
không. Cải thiện tiến trình hậu xử lý (nghiên cứu, hiện thực cấu trúc Dàn khái niệm
để phân lớp kết quả tìm kiếm.). Thực hiện tích hợp tổng hợp, nhận dạng tiếng nói như
một tùy chọn trong máy tìm kiếm hướng ngữ cảnh. So sánh đánh giá, kết quả thực
nghiệm, hướng phát triển được trình bày ở cuối chương.
3.1. Bài toán
Trong lĩnh vực gợi ý truy vấn (query suggestion), các tiếp cận truyền thống
như session-based, document-click based, .v.v. thực hiện khai phá tập truy vấn trong
quá khứ (Query Logs) để kết xuất gợi ý. Cách tiếp cận truyền thống thường áp dụng
các kỹ thuật như gom cụm, đo độ tương đồng, .v.v. của truy vấn [9], [10]. Tuy nhiên,
các tiếp cận truyền thống có ba nhược điểm: Thứ nhất, chỉ đưa ra được các gợi ý
tương tự hoặc có liên quan với truy vấn vừa nhập - mà chất lượng chưa chắc đã tốt
hơn truy vấn vừa nhập. Thứ hai, không đưa ra được xu hướng mà tri thức số đông
thường hỏi sau truy vấn hiện hành. Thứ ba, những cách tiếp cận này không xét chuỗi
truy vấn liên tiếp từ người sử dụng như một ngữ cảnh tìm kiếm, trong khi việc nắm
bắt ngữ cảnh tìm kiếm phản ánh việc nắm bắt ý đồ tìm kiếm của người sử dụng.
Cách tiếp cận “Gợi ý truy vấn hướng ngữ cảnh bởi khai phá dữ liệu phiên và
các tài liệu chọn đọc” (gọi ngắn gọn: “cách tiếp cận hướng ngữ cảnh” của Huanhuan
Cao cùng cộng sự [9], [10]) là một hướng đi mới - hướng này xét các truy vấn đứng
ngay trước truy vấn vừa đưa vào (truy vấn hiện hành) như một ngữ cảnh tìm kiếm,
để “nắm bắt” ý định tìm kiếm của người dùng, nhằm đưa ra các gợi ý xác đáng hơn.
Rõ ràng, lớp truy vấn đứng ngay trước có mối liên hệ ngữ nghĩa với truy vấn hiện
hành. Kế tiếp, thực hiện khai phá các truy vấn đứng ngay sau truy vấn hiện hành -
như một danh sách gợi ý. Có thể nói, đây là ưu điểm riêng của cách tiếp cận này so
với cách tiếp cận chỉ gợi ý những truy vấn tương tự với truy vấn hiện hành. Lớp truy

51
vấn đứng ngay sau truy vấn hiện hành, một cách hình thức, phản ánh những vấn đề
mà người dùng thường hỏi sau câu truy vấn hiện hành. Đồng thời, lớp truy vấn ngay
sau truy vấn hiện hành thường gồm những câu truy vấn tốt hơn, phản ánh rõ hơn ý
đồ tìm kiếm. Rõ ràng, nắm bắt được ngữ cảnh tìm kiếm, sẽ hiểu được ý định tìm
kiếm, cô gọn được tập kết quả trả về, hiển thị những kết quả thích đáng với mối quan
tâm tìm kiếm của người sử dụng.
Tuy nhiên, cách tiếp cận hướng ngữ cảnh cũng có một vài nhược điểm: khi
người sử dụng đưa vào một hoặc một chuỗi truy vấn mà không thuộc bất cứ một ngữ
cảnh tìm kiếm nào đã có trong quá khứ, phương pháp này không đưa ra được gợi ý.
Kỹ thuật gom cụm trong tiếp cận hướng ngữ cảnh chỉ đơn thuần dựa trên các URLs
click (các tài liệu người dùng chọn đọc) mà không xét đến tính tương đồng của từ,
cụm từ (terms) trong các câu truy vấn mà người dùng đưa vào. Đây là vấn đề ảnh
hưởng đến chất lượng khi gom cụm, chất lượng cụm không tốt sẽ ảnh hưởng đến chất
lượng câu gợi ý không tốt, đặc biệt với những ngôn ngữ bản địa như tiếng Việt. Một
vấn đề khác: Khi kích thước dữ liệu tăng cao, việc tổ chức, lưu trữ trên cây hậu tố sao
cho đáp ứng tức thời việc gợi ý truy vấn. Mỗi câu truy vấn đa nghĩa chỉ thuộc duy
nhất một cụm cũng không thực sự chính xác.
Do đó, Chương 3 đặt mục đích nghiên cứu và ứng dụng phương pháp hướng
ngữ cảnh, xác định các ưu nhược điểm, nêu các đề xuất cải thiện kỹ thuật, cũng như
bước đầu đưa ra các phân tích, chứng minh bằng thực nghiệm. Đặt trọng tâm vào
phương pháp hướng ngữ cảnh nên các kỹ thuật chỉnh sửa, viết lại truy vấn không
được đề cập trong khuôn khổ luận án.
Bên cạnh phương pháp hướng ngữ cảnh, Chương 3 nghiên cứu các phương
pháp thống kê ứng dụng trong nhận dạng và tổng hợp tiếng nói để tương tác với người
sử dụng qua ngôn ngữ tự nhiên, qua tiếng nói. Như một tùy chọn cho máy tìm kiếm,
luận án trình bày quá trình tích hợp kỹ thuật nhận dạng và tổng hợp tiếng nói tiếng
Việt vào máy tìm kiếm [75], [76], tạo thành một máy tìm kiếm có tương tác giọng
nói. Với mục đích tương tác hai chiều với người dùng, chức năng nhận dạng (Speech
To Text) cung cấp khả năng truy vấn bằng tiếng nói, chức năng tổng hợp (Text To
Speech) trả lời bằng giọng nói với độ chính xác cao.
Đóng góp chính của chương 3 bao gồm:
1) Ứng dụng kỹ thuật hướng ngữ cảnh, xây dựng máy tìm kiếm chuyên

52
sâu áp dụng hướng ngữ cảnh trong miền cơ sở tri thức riêng (dữ liệu hàng
không).
2) Đề xuất độ đo tương đồng tổ hợp trong bài toán gợi ý truy vấn theo
ngữ cảnh nhằm nâng cao chất lượng gợi ý.
Ngoài ra, chương 3 cũng có các đóng góp bổ sung trong thực nghiệm: i) Tích
hợp nhận dạng và tổng hợp tiếng nói tiếng Việt như một tùy chọn vào máy tìm kiếm
để tạo thành một hệ tìm kiếm có tương tác tiếng nói. ii) Áp dụng cấu trúc dàn khái
niệm để phân lớp tập kết quả trả về.
Bố cục chương 3 gồm: Phần 3.1 đặt vấn đề. Phần 3.2 trình bày phương pháp
gợi ý truy vấn hướng ngữ cảnh. Nêu các ưu nhược điểm của phương pháp hướng ngữ
cảnh, các đề xuất kỹ thuật khắc phục nhược điểm, thực nghiệm trên một máy tìm
kiếm tiếng Việt, đề xuất tiến trình hậu xử lý (phân nhóm kết quả sau tìm kiếm), giới
thiệu phương pháp cải thiện và công thức tổ hợp mới. Thực hiện tích hợp tổng hợp,
nhận dạng tiếng nói như một tùy chọn trong máy tìm kiếm hướng ngữ cảnh. Nghiên
cứu, hiện thực cấu trúc Dàn khái niệm để phân lớp kết quả tìm kiếm. Phần 3.3 thực
nghiệm, đánh giá trên một máy tìm kiếm tiếng Việt phụ thuộc lĩnh vực (hàng không).
Kết luận và hướng đi kế tiếp trình bày trong phần 3.4.
3.2. Phương pháp hướng ngữ cảnh
3.2.1. Định nghĩa – Thuật ngữ
Phiên tìm kiếm: Là chuỗi liên tục các câu truy vấn. Chuỗi truy vấn được biểu
diễn với thứ tự thời gian. Mỗi phiên tương ứng với một người dùng.
Cấu trúc phiên tổng quát: {sessionID; queryText; queryTime; URL_clicked}
trong đó:
- Session ID: Định danh của phiên tìm kiếm (mã tự sinh từ Web-server);
- queryTime: Nhãn thời gian (thời gian khi truy vấn được gửi đi);
- queryText: câu truy vấn;
- URL_clicked: ID của các URL được nhấn từ người sử dụng;
Ngoài ra, phiên có thể có thêm các thuộc tính khác như: Result-List (tập kết
quả mà SE đáp ứng q), Location, Regions, Search device, User_ID, .v.v.

53
Bảng 3.2: Cấu trúc (dạng rút gọn) của phiên tìm kiếm
sessionID queryText queryTime URL_clicked
User 1 khủng bố 2011-05-15 10:47 1491|
User 2 Vietnam Airlines 2011-05-15 10:48 2096|19730
User 1 Bin Laden bị tiêu diệt 2011-05-15 10:50 58896|337
Ý đồ tìm kiếm: Là chuỗi con của phiên. Các truy vấn trong một ý đồ sẽ liên
tiếp về thời gian, liên quan về ý nghĩa, được phát ra từ cùng một người dùng.
Xét trong tầm vực Gợi ý truy vấn hướng ngữ cảnh, ý đồ tìm kiếm được phản
ánh bởi một hoặc một nhóm các truy vấn đại diện.
Ngữ cảnh (context): Thuật ngữ ngữ cảnh đặc tả chuỗi lân cận trước truy vấn
hiện hành. Trong phiên tìm kiếm của một người dùng, ngữ cảnh là chuỗi truy
vấn đứng ngay trước truy vấn vừa nhập.
Lớp queries trước của qcurrent ↔ ngữ cảnh) .. qcurrent .. (Lớp queries sau)
Hình 3.1: Ngữ cảnh truy vấn.
Khái niệm (concept): Khi gom cụm, mỗi cụm là một nhóm các truy vấn tương
tự nhau. Trong tiếp cận gợi ý truy vấn hướng ngữ cảnh, mỗi cụm được thuật
ngữ hóa bởi khái niệm.
Timeout: Ngưỡng thời gian phân biệt giữa hai phiên tìm kiếm. Ngưỡng là một
tham số được sử dụng trong tiến trình khai phá Query Logs, được đặc tả trong
mã nguồn, thời gian mặc định bằng 30 phút.
3.2.2. Đề dẫn - Ví dụ minh họa
Ví dụ 1: Xét truy vấn đầu vào: “gladiator”, rất khó để đưa ra gợi ý với câu truy
vấn này (Lịch sử đấu sĩ? Một đấu sĩ nổi tiếng? Tiêu đề một bộ phim?). Nếu
tìm được truy vấn ngay trước đó: “beautiful mind”, thì gần như chắc chắn
người sử dụng đang tìm kiếm một bộ phim, dẫn đến việc gợi ý truy vấn hiệu
quả hơn.

54
Hình 3.2: Ví dụ minh họa với truy vấn “gladiator”.
Ví dụ 2: Với truy vấn: “tiger”, ý đồ tìm kiếm trong trường hợp này sẽ là: Một
loài động vật? Một hãng hàng không? Một vận động viên? Một hệ điều hành?
Việc không xác định được ngữ cảnh tìm kiếm sẽ gây khó khăn khi đưa ra gợi
ý xác đáng. Nếu biết truy vấn ngay trước đó là “Woods” hoặc “golf”, thì gần
như chắc chắn người sử dụng đang tìm kiếm thông tin về một vận động viên.
Tương tự với truy vấn “Jordan”, nếu biết lớp truy vấn ngay trước là “NBA”
hoặc “basketball”, một cách tự nhiên, ta biết ý định tìm kiếm của người sử
dụng về “Michel Jordan”. Do đó dưới góc nhìn của hệ thống, ý đồ tìm kiếm
đã hiển thị rõ ràng hơn.
Hình 3.3: Ví dụ minh họa với truy vấn “tiger”.
Trên đây là hai ví dụ dẫn để minh họa cho tiếp cận hướng ngữ cảnh, trong thực
tế có rất nhiều ví dụ tương tự. Phần tiếp theo, luận án trình bày motivation, mô hình
và chi tiết của tiếp cận hướng ngữ cảnh.

55
3.2.3. Kiến trúc – Mô hình
Phương pháp hướng ngữ cảnh dựa trên hai phases: online và offline, khái quát:
Hình 3.4: Mô hình của tiếp cận gợi ý truy vấn hướng ngữ cảnh.
Trong một phiên tìm kiếm (online phase), tiếp cận gợi ý truy vấn hướng ngữ
cảnh đón câu truy vấn hiện hành và xét chuỗi truy vấn đứng ngay trước truy vấn hiện
hành như một ngữ cảnh. Chính xác hơn, diễn dịch chuỗi truy vấn đứng trước current
query thành chuỗi khái niệm - chuỗi khái niệm này biểu đạt ý định tìm kiếm của người
sử dụng.
Khi có được ngữ cảnh tìm kiếm, hệ thống thực hiện so khớp với tập ngữ cảnh
dựng sẵn (phase offline, tập ngữ cảnh dựng sẵn được xử lý tính toán sẵn trên tập truy
vấn trong quá khứ - Query Logs. Về cấu trúc dữ liệu và lưu trữ, tập ngữ cảnh dựng
sẵn được lưu trên cấu trúc dữ liệu cây hậu tố). Tiến trình so khớp (maximum
matching) kết xuất danh sách ứng viên, danh sách này gồm các vấn đề mà đa số người
dùng thường hỏi sau truy vấn vừa nhập. Sau bước ranking, danh sách ứng viên trở
thành danh sách gợi ý.
3.2.4. Phase Offline
Pha offline có mục đích xây dựng cây hậu tố từ tập dữ liệu mẫu (Query Logs,
ký hiệu Q). Pha offline thực hiện tuần tự các bước: Xây dựng đồ thị 2 phía (bipartite
graph); Gom cụm trên đồ thị 2 phía; Xây dựng tập chuỗi khái niệm, rút trích tập chuỗi

56
khái niệm thành tập chuỗi khái niệm thường xuyên (ngắn gọn: chuỗi thường xuyên);
Dựng cây hậu tố. Trong đó gom cụm và dựng cây hậu tố là hai thành phần quan trọng
nhất của pha offline.
a) Đồ thị 2 phía – Gom cụm trên đồ thị 2 phía
Theo lý thuyết đồ thị, một đồ thị vô hướng G:=(V, E) được gọi là 2 phía nếu
tồn tại một phân hoạch của tập đỉnh V=V1∪V2 sao cho V1 và V2 là các tập độc lập
(không giao nhau, thỏa điều kiện không có cạnh nối giữa 2 đỉnh bất kỳ thuộc cùng
một tập). Nếu |V1|=|V2| thì G là đồ thị 2 phía cân bằng.
Một đồ thị 2 phía đầy đủ (biclique) là một đồ thị 2 phía đặc biệt, trong đó mỗi
đỉnh của tập thứ nhất nối với mọi đỉnh của tập thứ hai.
Như đã biết, khi người dùng đưa ra câu truy vấn, máy tìm kiếm sẽ đáp ứng
bằng một tập các URLs kết quả. Trong đó URLs click là những urls mà người dùng
click chọn đọc trên tập kết quả trả về, URLs click phản ánh mối quan tâm của người
dùng trên một tài liệu cụ thể.
Tham chiếu với lý thuyết, đồ thị 2 phía trong tiếp cận hướng ngữ cảnh được
xây dựng với Q và U là 2 tập đỉnh, E là tập cạnh. Cụ thể, mỗi node truy vấn trong tập
đỉnh Q tương ứng với một query, mỗi node URL trong tập đỉnh U tương ứng một url
được click. Cạnh eij nối qi với uj nếu uj được click bởi qi. Trọng số trên cạnh eij (ký
hiệu wij) là tổng số lần uj được click bởi qi, trọng số này được tính trên toàn Query
Logs.
Xuất phát từ ý tưởng căn bản: Trong Query Logs Q, nếu 2 truy vấn chia sẻ
chung các URLs click (thuộc tập U) thì 2 truy vấn đó được xét là tương đồng [63],
[64]. Một cách hình thức, 2 truy vấn – đặc biệt là 2 truy vấn tương đồng về ngữ nghĩa
có thể không có term(s) chung, nhưng chúng chia sẻ chung các thuật ngữ trong các
tài liệu (URLs click) mà người tìm kiếm chọn đọc.
Hình 3.5: Đồ thị 2 phía (tập đỉnh Q – tập đỉnh U)

57
Trên đồ thị 2 phía, mỗi query q có thể nối với một hoặc nhiều urlClicks, ngược
lại, mỗi urlClick có thể nối với một hoặc một vài queries. Khi tiến hành gom
cụm, mỗi query qi (qi ∈ Q) được xét như một vector, mỗi chiều của vector qi
tương ứng với một url uj trên tập U (uj ∈ U, U là tập các urlClicks). Theo [77],
chiều thứ j của qi được tính bởi công thức:
𝑞𝑖⃗⃗⃗ ⃗[j] = norm(wij) = wij
√∑ wij′2
uj′∈U2
(3.1)
trong đó:
- wij: tổng số lần uj được click bởi qi;
- uj’: các urls khác uj, được click bởi qi. (các chiều còn lại của vector qi)
Khoảng cách giữa 2 truy vấn qi và qj được đo bằng khoảng cách Euclide (theo
urlClicks) giữa 2 vector qi, qj:
distance(qi, qj) = √∑ (𝑞𝑖⃗⃗⃗ ⃗[k] − 𝑞𝑗⃗⃗⃗⃗ [k])2𝑢𝑘∈𝑈
2 (3.2)
Mỗi cụm C gồm một tập các câu truy vấn, tâm cụm được vector hóa:
C⃗⃗ = norm(∑ qi⃗⃗⃗⃗⃗qi∈C
|C|) (3.3)
với |C| là số queries chứa trong C.
Theo (3.2), ta có khoảng cách giữa truy vấn q và tâm cụm C:
distance(q, C) = √∑ (�⃑�[k] − 𝐶[k])2𝑢𝑘∈𝑈
2 (3.4)
Đường kính (D, diameter) của một cụm được tính bởi công thức:
D = √∑ ∑ (�⃗⃑�[i] − �⃑⃗�[j])2|𝐶|
𝑗=1|𝐶|𝑖=1
|𝐶|(|𝐶|−1)
2
(3.5)
Giải thuật gom cụm sử dụng tham số Dmax như một ngưỡng để kiểm soát, sao
cho với mỗi cụm có đường kính D, D luôn nhỏ hơn hoặc bằng Dmax.
b) Giải thuật Gom cụm
Ý tưởng của giải thuật gom cụm: Giải thuật quét toàn bộ các queries trong
Query Logs một lần, các cụm sẽ được tạo ra trong tiến trình quét. Ban đầu, mỗi cụm
được khởi tạo bằng một truy vấn, rồi mở rộng dần bởi các truy vấn tương tự. Quá
trình mở rộng dừng khi đường kính cụm vượt ngưỡng Dmax. Do mỗi cụm (cluster)

58
được xem như một khái niệm (concept), nên tập cụm là tập khái niệm.
Đầu vào:
- Tập Query Logs Q, ngưỡng Dmax;
Đầu ra:
- Tập cụm Cset;
Giải thuật:
program Context_Aware_Clustering_alg
// Khởi tạo mảng dim_array[d] = Ø, ∀d (d: click-document).
// Mảng dim_array chứa số chiều các vectors.
// Giải thuật Context_Aware_Clustering_alg thực hiện thêm dần
// các query trong QLogs vào tập cụm Cset;
01. for each query qi ∈ Q do
02. θ = Ø;
03. for each nonZeroDimension d of 𝑞𝑖⃗⃗⃗⃗ do {
04. θ ∪= dim_array[d];
}
05. C = arg-minC’∈θdistance(qi, C’);
06. if (diameter(C ∪ {qi}) ≤ Dmax) {
07. C ∪= qi; cập nhật lại đường kính và tâm cụm C;
}
08. else {
C = new cluster({qi}); Cset ∪= C;
}
09. for each nonZeroDimension d of 𝑞𝑖⃗⃗⃗⃗ do {
10. if (C ∉ dim_array[d])
dim_array[d] ∪= C;
}
end for
11. return Cset;
end.
Diễn giải giải thuật:
Với mỗi truy vấn qi ∈ Q, trước tiên giải thuật tìm cụm C gần với qi nhất, kiểm
tra đường kính C∪{qi}: nếu không lớn hơn Dmax thì qi được thêm vào C, nếu không,
một cụm mới chỉ chứa qi được tạo ra (dãy câu lệnh 01 - 08). Các phép tính toán tâm
cụm, đường kính, khoảng cách áp dụng theo các công thức từ (3.1) - (3.5).

59
Có thể thấy phép toán quan trọng trong giải thuật là tìm ra cụm C gần với qi
nhất (lệnh 05). Thuật toán gom cụm sử dụng mảng dim_array[d] để lưu trữ số chiều
của các vectors và tìm cụm C gần nhất. Mỗi phần tử thuộc mảng tương ứng với một
chiều của vector và liên kết với tập cụm Cset. Trong đó mỗi cluster C ∈ θ sẽ chứa ít
nhất một truy vấn qi sao cho vector qi[j] ≠ 0. Để minh họa, giả sử nhận vào truy vấn
q, q có 3 URLclicks tương ứng với các phần tử d3, d6, d9 thuộc mảng dim_array. Để
tìm cụm gần nhất với q đang xét, thực hiện phép hợp θ3, θ6 và θ9 tương ứng của d3,
d6, d9. Một cách hình thức, cụm C (thuộc tập cụm Cset) gần nhất với q, nếu tồn tại,
sẽ chứa những document được click chung với {d3, d6, d9}.
Hình 3.6: Sử dụng cấu trúc dữ liệu mảng để phân cụm.
Các phần tử (queries) trong cụm phải tương đồng “gần” nhau về khoảng cách,
để thỏa điều kiện đường kính cụm không vượt quá Dmax. Giả thiết θ3 chứa cluster C2,
θ6 chứa cluster C5, θ9 chứa cluster C10. Giả sử q có thể cập nhật vào C5, C10, tuy
nhiên khoảng cách giữa q và tâm cụm C10 nhỏ hơn khoảng cách giữa q và tâm cụm
C5, giải thuật thực hiện chèn q vào C10.
Độ phức tạp tính toán:
Một cách tổng quát, có thể thấy chi phí tính toán trên mỗi query là không đổi
và trên thực tế, số chiều của mỗi query không lớn, giải thuật có độ phức tạp tính toán
là O(Nq), với Nq là số queries trong Query Logs.
c) Dựng cây hậu tố
Như trình bày trong mục 3.2.4, để ánh xạ từ tập Query Logs thành tập chuỗi
khái niệm, phương pháp tiếp cận hướng ngữ cảnh thực hiện khai phá dữ liệu trên mỗi

60
phiên truy vấn.
Bước đầu tiên - tiến trình tách phiên, việc tách mỗi phiên được áp dụng theo
nguyên tắc: Trên cùng một sessionID, 2 truy vấn được chia vào 2 phiên nếu khoảng
thời gian giữa chúng nhiều hơn 30 phút [78], [79], cấu trúc QLogs lưu trường
queryTime. Mỗi phiên sau khi tách sẽ gồm một chuỗi các câu truy vấn (query
sequences), có dạng:
Query Session QS = q1q2.…qm
Bước kế tiếp, với tập khái niệm thu được ở giải thuật gom cụm, tập chuỗi truy
vấn sẽ được ánh xạ thành tập chuỗi khái niệm (cs - concept sequences), sao cho thỏa
điều kiện: qi ∈ Ci, trong đó Ci thu được ở bước gom cụm. Quá trình ánh xạ được thực
hiện dễ dàng bởi so khớp query.
Concept Sequence cs = c1c2.…cn
Các truy vấn trong cùng một phiên thường cùng một ý định tìm kiếm. Tuy
nhiên ở mỗi truy vấn, người sử dụng thường hiệu chỉnh truy vấn để mô tả chính xác
hơn ý đồ tìm kiếm. Việc khai phá dữ liệu trên từng truy vấn đơn không có nhiều ý
nghĩa trong việc xác định ý đồ tìm kiếm. Do đó, để khai phá chuỗi truy vấn, nói cách
khác, khai phá trên tập chuỗi khái niệm thu được, tiếp cận hướng ngữ cảnh tiến hành
xác định tập chuỗi thường xuyên. Khuôn khổ luận án sẽ không trình bày các giải thuật
chuyên xác định chuỗi thường xuyên như SPG (Sequential Pattern Generator) [80],
PrefixSpan [81], tuy nhiên ý tưởng căn bản xác định chuỗi thường xuyên trong tiếp
cận hướng ngữ cảnh là rõ ràng, ví dụ, nhận vào 3 chuỗi khái niệm c2c3, c1c2c3 và
c2c3c4 thì chuỗi thường xuyên thu được sẽ là c2c3. Có thể thấy tập chuỗi thường
xuyên là tập chuỗi khái niệm được cô gọn, độ dài chuỗi thường xuyên nằm trong
khoảng [2, maxLength(concept sequences)].
Từ tập chuỗi thường xuyên, tiếp cận hướng ngữ cảnh áp dụng giải thuật dựng
cây. Theo tính chất của cây hậu tố và nhằm gợi ý truy vấn (sử dụng lớp truy vấn sau
câu truy vấn hiện hành để gợi ý), tương ứng với mỗi chuỗi thường xuyên cs = c1 .. cl,
tiếp cận hướng ngữ cảnh sử dụng cl là khải niệm ứng viên cho cs’ = c1..cl-1. Mỗi node
trên cây hậu tố gắn với một danh sách xếp hạng các truy vấn (theo quy ước, truy vấn
có lượng click nhiều hơn được xếp hạng cao hơn).

61
d) Giải thuật dựng cây hậu tố
Đầu vào:
- Tập chuỗi thường xuyên cs; ngưỡng K ứng viên;
Đầu ra:
- Cây hậu tố T;
Giải thuật:
Program Suffix_Tree_alg
// Khởi tạo T.root = Ø;
01. for each frequent concept sequence cs = c1..cl do
02. cn = FindNode(c1..cl-1, T)
03. minc = arg minc∈cn.candListc.freq;
04. if (cs.freq > minc.freq) or (|cn.candList| < K)
05. add cl into cn.candList;
cl.freq = cs.freq;
06. if (|cn.candList| > K)
remove minc from cn.candList;
07. return T;
End.
Method FindNode(cs = c1..cl, T)
01. if (|cs|=0) then return T.root;
02. cs’ = c2..cl;
pn = findNode(cs’, T);
cn = pn.childList[c1];
03. if (cn == null)
04. cn = new node(cs);
cn.candList = Ø;
pn.childList[c1] = cn;
05.return cn;
Diễn giải giải thuật:
Do giải thuật dựng cây áp dụng đệ qui, nên luận án sử dụng hình vẽ để mô
phỏng trực quan từng bước tiến trình dựng cây:
Giả thiết, đầu vào gồm 4 chuỗi thường xuyên:
(1) c1, c2
(2) c2, c3

62
(3) c1, c3, c2
(4) c2, c3, c1, c4
Các ký hiệu:
{c2}: khái niệm ứng viên;
Như vậy, các queries trong khái niệm ứng viên sẽ đóng vai trò như các
gợi ý truy vấn.
Hình 3.7: Mô phỏng trực quan tiến trình dựng cây hậu tố.
Trên cây hậu tố, nếu đầu vào là {c1}, sẽ có 2 hậu tố {c2} và {c4} – chính xác
hơn là các queries trong {c2} và {c4} được xét như các gợi ý truy vấn, nếu đầu vào
là {c3c1}, các queries trong {c4} được xét như các gợi ý truy vấn.
Độ phức tạp tính toán:
Trong giải thuật dựng cây hậu tố, chi phí chính thuộc hàm đệ qui findNode.
Từ lời gọi chương trình có thể thấy hàm thực hiện đệ qui ở l-1 mức. Tại mỗi mức,
hàm findNode xác định thứ bậc cha con của các nút trên cây hậu tố (parent node pn,
child node cn) (dòng 02-04, findNode method). Theo giả thiết (dữ liệu đầu vào), mỗi

63
node trên cây hậu tố có không quá Nc node con, với Nc là số khái niệm (number of
concepts). Do đó độ phức tạp tính toán của hàm đệ qui là O(logNc), vậy, độ phức tạp
tính toán của toàn giải thuật dựng cây là O(Ncs.logNc), với Ncs là số lượng chuỗi
thường xuyên (number of frequent concept sequences).
Từ cây hậu tố xây dựng được, phương pháp tiếp cận hướng ngữ cảnh thực hiện
quá trình gợi ý truy vấn - phase online.
3.2.5. Phase Online – Giải thuật gợi ý truy vấn
a) Phase Online
Ý tưởng của pha online: Với q là truy vấn vừa nhập, giả sử chuỗi truy vấn ngay
trước q là q1q2q3 (ký hiệu qs), chuỗi truy vấn này sẽ được diễn dịch thành chuỗi khái
niệm (bằng so khớp query). Ví dụ, tương ứng với q1q2q3 đã nêu, chuỗi khái niệm thu
được sau phép diễn dịch là c9c2c5 (ký hiệu cs, concept sequence). Thực hiện phép so
khớp (maximum matching) c9c2c5 trên cây hậu tố chuỗi khái niệm, như sau: đầu tiên
tìm c5, nếu tìm được, tìm tiếp c2c5 bằng cách kiểm tra các nodes con của c5. Cứ lan
truyền như vậy trên cây hậu tố cho đến node ứng viên, danh sách xếp hạng queries
gắn kết trên node ứng viên (ví dụ q5q9q20) trở thành danh sách gợi ý.
Hình 3.8: Phase online: Tiến trình gợi ý truy vấn.
b) Giải thuật gợi ý truy vấn
Đầu vào:
- Cây hậu tố T và tập chuỗi truy vấn qs vừa nhập từ người dùng;
Đầu ra:
- Tập kết quả S-Set: tập truy vấn gợi ý ;

64
Giải thuật:
Program QuerySuggestion_alg
// Khởi tạo S-Set = Ø; Con trỏ CurN = T.root;
01. map qs into cs;
02. curC = the last concept in cs;
03. while true do
04. chN = curN’s child node whose first concept is curC;
05. if (chN == null) then break;
06. curN = chN;
07. curC = the previous concept of curC in cs;
08. if (curC == null) then break;
09. if (curN != T.root) then
10. S-Set = curN’s candidate query suggestions;
11. return S-Set
End
Diễn giải giải thuật - Độ phức tạp tính toán:
Một cách hình thức, quá trình diễn dịch từ chuỗi truy vấn qs thành chuỗi khái
niệm cs có chi phí O(|qs|) (dòng 01 của thuật toán online). Vòng lặp while (dòng 03-
08) có mục đích tìm ra node ứng viên phù hợp (đạt nhiều hậu tố nhất của cs). Khi xét
vòng lặp while, như đã trình bày trong giải thuật tạo cây hậu tố, chi phí của vòng lặp
là O(logNc), tuy nhiên do cây đã xác định, các nodes con của cây có thể lưu trữ trong
một cấu trúc mảng tĩnh (static array), do đó chi phí có thể giảm đến O(1). Tổng hợp,
chi phí của giải thuật gợi ý truy vấn online là O(|qs|), chi phí này đáp ứng yêu cầu của
tiến trình gợi ý truy vấn online.
3.2.6. Phân tích ưu nhược điểm
Ưu điểm:
Về lý thuyết, với bài toán gợi ý truy vấn - đây là cách tiếp cận mới. Thực hiện
gợi ý truy vấn, các tiếp cận kinh điển cũ thường lấy các truy vấn đã có trong Query
Logs để đề xuất. Các đề xuất này chỉ tương tự hoặc có liên quan với truy vấn hiện
hành, chứ không đưa ra được xu hướng mà tri thức số đông thường hỏi sau câu truy
vấn hiện hành. Cũng như vậy, chưa có một tiếp cận nào đặt chuỗi truy vấn ngay trước
truy vấn hiện hành vào một ngữ cảnh tìm kiếm - như một thể hiện liền mạch ý đồ tìm
kiếm của người sử dụng.
Về thực nghiệm, tiếp cận gợi ý truy vấn hướng ngữ cảnh đưa ra các giải thuật
mới trong các thuật toán gom cụm, dựng cây hậu tố, gợi ý truy vấn. Các giải thuật

65
này được thử nghiệm trên tập dữ liệu mẫu rất lớn (1,812,563,301 truy vấn;
2,554,683,191 URLs clicked; 840,356,624 phiên tìm kiếm [9], [10]).
Phương pháp hướng ngữ cảnh, trên hết là ý tưởng gợi ý bằng những vấn đề mà
người dùng thường hỏi sau truy vấn hiện hành, là một điểm độc đáo, hiệu quả, là “nét
thông minh” trong lĩnh vực gợi ý truy vấn.
Nhược điểm:
Tuy nhiên tiếp cận hướng ngữ cảnh cũng có một số hạn chế nhất định, luận án
liệt kê một vài nhược điểm của phương pháp hướng ngữ cảnh.
Khi người dùng đưa vào một hay một vài truy vấn là mới hoặc thậm chí không
mới - theo nghĩa không có mặt trong chuỗi khái niệm thường xuyên (chẳng
hạn, trong tập dữ liệu mẫu, với 2 chuỗi khái niệm c2c3 và c1c2c3, giải thuật
xác định chuỗi thường xuyên thu được là c2c3, trong trường hợp này - người
sử dụng đưa vào c1). Tiếp cận hướng ngữ cảnh không đưa ra được gợi ý dù c1
đã có trong quá khứ (đã tồn tại trong QLogs).
Với truy vấn đầu tiên: ngữ cảnh tìm kiếm trong tình huống này chưa có, phép
diễn dịch chuỗi truy vấn thành chuỗi khái niệm không xảy ra, không có khả
năng tìm kiếm trên cây hậu tố, xét thuần về lý thuyết thì tiếp cận hướng ngữ
cảnh không đưa ra được gợi ý.
Cùng một ý định tìm kiếm, những người dùng khác nhau có thể đưa ra những
truy vấn khác nhau. Ví dụ, hai truy vấn: “tôi là học trò” và “học trò là tôi” là
hai câu tìm kiếm khác nhau về thứ tự từ, giống nhau về ngữ nghĩa, cùng một
ý đồ tìm kiếm, tuy nhiên tập kết quả trả về khác nhau dẫn đến các URLs click
khác nhau. Hơn nữa, trên thực tế, rất nhiều truy vấn tương tự nhau nhưng
không có URL click chung, thậm chí không có URL click. Phép gom cụm dựa
trên click-through sẽ không hiệu quả trong trường hợp này.
Mỗi cụm (khái niệm) gồm một nhóm các truy vấn tương đồng. Độ đo tương
đồng chỉ dựa trên URL click mà không dựa trên tương đồng về term, điều này
có thể ảnh hưởng không nhỏ đến chất lượng của kỹ thuật gom cụm.
Ràng buộc mỗi truy vấn chỉ thuộc một cụm (khái niệm): quan điểm này không
hợp lý và không tự nhiên đối với câu truy vấn đa nghĩa như “tiger” hoặc
“gladitor”, hay rất nhiều từ đa nghĩa khác trong tiếng Việt, .v.v.

66
Chỉ xét đến gợi ý truy vấn (query suggestion) mà không xét đến gợi ý tài liệu
(gợi ý URL - URL recommendation). Đồng thời, định hướng “click-through”
nhưng không sử dụng các thông tin clicked Urls trong ngữ cảnh tìm kiếm (khi
tìm kiếm trên cây hậu tố, Concept sequence đầu vào chỉ gồm các queries).
Trên đồ thị 2 phía, phía tập đỉnh Q các vector khá thưa (số chiều thấp), phía
tập đỉnh URLs click cũng gặp phải vấn đề dữ liệu thưa (URL click thưa), khi
các vectors thưa, chất lượng gom cụm sẽ bị ảnh hưởng.
Trong thuật giải gom cụm, khi Query Logs lớn, hoặc số chiều của mỗi vector
lớn, mảng dim_array[d] sẽ có kích thước rất lớn, đòi hỏi cấp phát một lượng
bộ nhớ lớn khi thực thi.
Trong tiến trình gợi ý truy vấn online, thực tế còn một bước tìm kiếm, so sánh
queries để ánh xạ/diễn dịch từ chuỗi truy vấn thành chuỗi khái niệm. Khi so
khớp trên cây hậu tố, việc lưu trữ các nodes con của cây bằng cấu trúc mảng
yêu cầu một dung lượng bộ nhớ đáng kể.
Thực tế, trong một phiên tìm kiếm bất kỳ, người sử dụng nhập vào một hoặc
khá nhiều truy vấn, cũng như vậy, người sử dụng có thể không hoặc click rất
nhiều URL kết quả, trong đó mặc nhiên có những URL click không như ý,
được xem như nhiễu (noise). Phương pháp hướng ngữ cảnh cần có chuỗi truy
vấn liên tiếp mới hình thành ngữ cảnh không phản ảnh thực tế, khi người dùng
chỉ nhập vào 1 truy vấn. Tuy nhiên, việc phụ thuộc vào URL click và không
xét đến tính tương đồng term là nhược điểm rõ nhất của phương pháp này.
3.2.7. Các đề xuất kỹ thuật
Theo góc nhìn bản địa hóa (máy tìm kiếm tiếng Việt), sau khi nghiên cứu, tìm
hiểu về tiếp cận gợi ý truy vấn hướng ngữ cảnh, chúng tôi nêu một vài đề xuất kỹ
thuật đóng góp cho tiếp cận hướng ngữ cảnh. Phần đề xuất chủ yếu đề cập đến các
bước: cải thiện bước gom cụm, lưu trữ cấu trúc dữ liệu và thực hiện tức thời gợi ý
truy vấn. Nhằm đơn giản cho quá trình phân tích, luận án nêu đề xuất như một dãy
các bước.
Bước 1: Tiền xử lý QueryLogs: Query Logs là nơi lưu trữ lịch sử và hành vi
tìm kiếm của người sử dụng. Bộ thu thập Query Logs có thể tự xây dựng, cũng có thể
là một nguồn dữ liệu các câu truy vấn mẫu đã được kiểm định trên Internet (Query
KDD, Query Trec, Query Logs của AOL, …).

67
Quá trình tiền xử lý Query Logs sẽ loại các queries không có kết quả trả về,
các queries có text giống nhau, các queries tương tự nhau trong một phiên tìm
kiếm, trộn hợp các URLs click của các queries đã loại bỏ để khắc phục vấn đề
URLs click thưa.
Việc loại bỏ từ dừng trên máy tìm kiếm có thể cần cân nhắc khi người dùng
muốn tìm kiếm nguyên văn, tuy nhiên việc loại bỏ từ dừng trên Query Logs là
cần thiết để so khớp query, gợi ý truy vấn.
Thực hiện tách từ các truy vấn trong Query Logs để chính xác khi so khớp và
gợi ý. Khác với từ tiếng Anh phân cách bằng khoảng trắng, tách từ tiếng Việt
nhằm đảm bảo từ được đủ nghĩa. Do tính chất của tìm kiếm online yêu cầu tức
thời trả lại kết quả cho người dùng, luận án tự xây dựng module tách từ bằng
phương pháp so khớp Longest-matching và từ điển (72721 terms).
Lưu trữ vào Query Logs, tiền xử lý để tận dụng nội dung trong tập kết quả của
2 yếu tố: titles và topK snippets: Với lợi điểm của title - mang yếu tố ngữ nghĩa
từ người tạo file; Lợi điểm của topK snippets - trích đoạn chứa tập các câu
hoàn chỉnh, thành câu, đầy đủ ngữ nghĩa và đã được tính điểm để xếp hạng,
trích chọn từ giải thuật ranking của máy tìm kiếm.
Bước 2: Gom cụm: Về khía cạnh gợi ý truy vấn, tuy chung một triết lý với
nhóm nghiên cứu hướng ngữ cảnh trong [9], [10]: “đưa ra gợi ý mà số đông người
dùng thường hỏi sau truy vấn hiện hành”, nhưng hướng tiếp cận, cách thực hiện, tổ
hợp công thức, chi tiết cấu trúc dữ liệu, thiết kế, giải thuật, mã nguồn, .v.v. trong máy
tìm kiếm của luận án là hoàn toàn khác. Khai phá Query Logs, bước gom cụm trong
ứng dụng của luận án không đơn thuần dựa vào click-through mà tập trung vào ba
thành phần cố định và chắc chắn, gồm: Câu truy vấn; Top N kết quả trả về; Tập URLs
click. Đây là ba thành phần quan trọng nhất của tác vụ khai phá dữ liệu, với các tiền
đề:
Nếu giao các từ khóa (terms) trong hai truy vấn đạt một tỷ lệ nhất định thì hai
truy vấn đó tương đồng.
Nếu giao trong top N kết quả của hai truy vấn đạt một tỷ lệ nhất định thì hai
truy vấn đó tương đồng.
Nếu giao trong tập các URLs click của hai truy vấn vượt ngưỡng tương đồng
thì hai truy vấn đó tương đồng.

68
Phương pháp gợi ý hướng ngữ cảnh trong [9], [10] chỉ đề cập đến các phép đo
độ tương đồng theo URLs click, không xét đến vai trò của độ đo tương đồng theo tập
URLs kết quả và tương đồng theo từ khóa (terms). Một cách hình thức, ý định tìm
kiếm ánh xạ tư duy của người sử dụng, tư duy được phản ánh bởi tiếng nói và chữ
viết, đặc biệt chữ viết (terms) trong kỹ thuật gợi ý truy vấn. Vì vậy, việc xét đồng thời
tổ hợp các tiền đề nêu trên, kết hợp với các ngưỡng rút ra từ thực nghiệm, đảm bảo
độ đo tương đồng chính xác, đảm bảo yếu tố hội tụ nhanh (fast convergence). Luận
án đề xuất tập công thức mới, tổ hợp các độ đo tương đồng để giải quyết bài toán gợi
ý truy vấn (các công thức 3.10, 3.11, 3.12). Thực tế, ứng dụng chỉ thực hiện 2 vòng
lặp để gom cụm các câu truy vấn tương đồng. Nghiên cứu liệt kê các công thức sau:
Tần suất xuất hiện TF (Term Frequency) của term ti trong query qj:
TFij = nij
∑ nkjk (3.6)
trong đó:
- nij: số lần xuất hiện ti trong qj;
- nkj: tổng số terms của qj;
Mô phỏng theo IDF, tần suất nghịch đảo truy vấn IQF (Inverted Query
Frequency) của term ti trong query qj được viết lại:
IQFi = log|Q|
1+|{q:ti∈Q}| (3.7)
trong đó:
- Q: tổng số queries trong Query Logs;
- q: ti∈Q: tổng số queries chứa ti;
Trọng số (weight) term ti trong query qj được tính bởi TFIQF:
TFIQFi = wi = TFij × IQFi (3.8)
Từ đó, trọng số truy vấn qj bằng tổng trọng số các terms thuộc qj.
Độ tương đồng (Similarity) theo từ khóa của 2 truy vấn p, q:
Simkeywords(p, q) = ∑ w(ki(p))+w(ki(q))n
i=1
2×MAX(kn(p),kn(q)) (3.9)
trong công thức trên:
- kn(.): tổng trọng số các terms trong p, trong q;
- w(ki(.)): trọng số term chung thứ i của p và q;
Độ tương đồng theo top50 URL kết quả của 2 truy vấn p, q:

69
Simtop50URL(p, q) = ∧(topUp,top Uq)
2×MAX(kn(p),kn(q)) (3.10)
ký hiệu:
- (topUp, topUq): phần giao trong top50URL kết quả của p và q;
Độ tương đồng theo clickedUrls của 2 truy vấn p, q:
SimURLsClicked(p, q) = ∧(U_click_p,U_click_q)
2×MAX(kn(p),kn(q)) (3.11)
ký hiệu:
- (U_Clickp, U_Clickq): số URLs click chung của p và q;
- U_Clickp: số URL clicked trong 1 query;
Từ (3.9), (3.10), (3.11), ta có đẳng thức tính độ tương đồng tổ hợp:
Sim(p, q) =𝑐𝑜𝑚𝑏𝑖𝑛𝑎𝑡𝑖𝑜𝑛
α. Sim(p, q) +keywords
β. Sim(p, q) +𝑡𝑜𝑝50𝑈𝑅𝐿
γ. Sim(p, q) URLsclicked
(3.12)
Với α + β + γ = 1; α, β, γ là các tham số ngưỡng rút ra trong quá trình thực
nghiệm. Trong ứng dụng máy tìm kiếm, α = 0,4; β = 0,4; γ = 0,2.
Bước 3: Cải thiện vấn đề dữ liệu thưa:
Để cải thiện vấn đề dữ liệu thưa trên đồ thị 2 phía, có thể áp dụng kỹ thuật
bước ngẫu nhiên (random walk) để tăng cường mật độ URLs click:
Hình 3.9: Áp dụng random walk cải thiện vấn đề dữ liệu thưa.
Kỹ thuật bước ngẫu nhiên của mô hình Markov [82], [83], [84] có thể khái
quát như sau: Trước khi thực hiện bước ngẫu nhiên, d3 chỉ nối kết với q2, sau bước
ngẫu nhiên, d3 được nối với q1 nếu U(q1) ⊆ U(q2).

70
Bước 4: Cấu trúc dữ liệu:
Trong các phương thức gom cụm, dựng cây hậu tố và gợi ý online, nghiên cứu
trong luận án sử dụng cấu trúc bảng để thực hiện lưu trữ. Việc sử dụng bảng có các
lợi điểm như:
Nhất quán với Query Logs (vốn là một cấu trúc bảng).
Các thao tác sẽ thực hiện trên bảng chứ không phải thao tác trên vector, do đó,
không cần xét đến việc phải giảm chiều vector. Tận dụng được sức mạnh tìm
kiếm tức thời của các hệ quản trị dữ liệu như Oracle hoặc SQL.
Bước 5: Gợi ý truy vấn:
Với truy vấn đầu tiên: Việc xác định câu truy vấn đầu tiên dựa vào sessionID,
IP Address và nhãn thời gian. Trong một phiên tìm kiếm, câu truy vấn đầu tiên mặc
nhiên sẽ chưa có lớp truy vấn nào đứng ngay trước, chưa có ngữ cảnh vì vậy chưa
đưa ra được gợi ý. Để thực hiện gợi ý truy vấn trong trường hợp này có thể xét các
đề xuất sau.
Xem truy vấn đầu tiên chính là một ngữ cảnh tìm kiếm. Thực hiện tìm kiếm
trên cây hậu tố và kết xuất danh sách gợi ý.
Nếu không tìm thấy, thay vì sử dụng cả câu query có thể áp dụng chuỗi con
trong câu truy vấn (tách từ). Tìm kiếm trên từng từ/cụm từ được tách (đã loại
bỏ từ dừng), nếu ít nhất 2 từ/cụm từ được tìm thấy (có chứa) trong chuỗi
thường xuyên của cây hậu tố, thực hiện kết xuất danh sách gợi ý.
Nếu không tìm thấy, thực hiện gợi ý truy vấn (bằng các câu truy vấn tương tự,
có liên quan) như các kỹ thuật truyền thống.
Bên cạnh việc gợi ý bằng những đoạn text (query recommendation), đồng thời
gợi ý tài liệu (URL recommendation), là những URLs click được chọn lọc - có trọng
số điểm cao hoặc số lần click cao. Cụ thể, với một query q, đưa ra top-K tài liệu
thường được click đọc, hoặc ngược lại với một url u, đưa ra top-K truy vấn thường
xuyên click trên u.
Bước 6: Thực hiện gợi ý tức thời.
Khi người sử dụng gửi đi câu truy vấn, nếu phải đợi đến nửa phút hệ thống
mới xử lý xong và xuất kết quả gợi ý thì … gần như không có một người dùng nào
sẽ ở lại với hệ thống. Việc đáp ứng tức thời trở thành một yêu cầu mặc định đối với
hệ thống gợi ý truy vấn. Nếu Query Logs và cấu trúc cây hậu tố được lưu trữ dưới

71
dạng bảng, có thể tận dụng khả năng tìm kiếm nhanh (giây, milli-giây) bằng mệnh đề
contains trong các dịch vụ của các hệ quản trị cơ sở dữ liệu quan hệ như Oracle
Fulltext index, SQL Fulltext search, .v.v. điều này đảm bảo cho việc so khớp, tìm
kiếm và kết xuất kết quả được thực hiện tức thời ở pha online.
Sau khi thu được tập gợi ý, hệ thống sử dụng phương thức lọc để khử các gợi
ý có hàm lượng thông tin tương tự nhau. Ví dụ, các gợi ý như “CNN TV” và “CNN
Television”, “Yamaha motors” và “Yamaha motorcycle”, hay“Solar systems” và
“the Solar system” thực chất là tương tự [85], [86], [87], [75]. Việc cung cấp gợi ý sẽ
có ý nghĩa nếu thỏa yêu cầu gợi ý thích đáng lẫn yêu cầu gợi ý đa dạng. Mục tiêu của
phương thức lọc nhằm giảm dư thừa và có thể bao phủ hầu hết các ý đồ tìm kiếm.
Bước 7: Hậu xử lý: tổ chức, sắp xếp tập kết quả trả về.
Phương pháp gợi ý truy vấn là bài toán con trong lớp bài toán cần giải quyết
của máy tìm kiếm áp dụng các kỹ thuật phát hiện tri thức. Khai phá tập dữ liệu mẫu
trong quá khứ của một Search Engine thuộc tiến trình tiền xử lý. Tiến trình hậu xử lý
thực hiện việc phân nhóm tập kết quả trả về theo các chủ đề - là một dạng của bài
toán gợi ý: gợi ý theo chủ đề.
Sau câu truy vấn, Search Engine trả về một danh sách tài liệu dài và đa chủ đề.
Mặc dù áp dụng thuật toán xếp hạng kết quả (ranking), nếu người sử dụng muốn tìm
kiếm chuyên sâu trong một phạm vi, lĩnh vực cụ thể, người sử dụng sẽ phải tự xử lý
lượng dữ liệu lớn để tìm ra thông tin mà họ cần. Nếu có thể phân loại, thu gọn kết
quả tìm kiếm thành các chủ đề cụ thể, nhằm hạn chế việc thông tin bị vùi lấp bởi một
danh sách quá dài, người dùng sẽ tiện lợi trong tìm kiếm, dễ quan sát tập kết quả, dễ
đưa ra quyết định tài liệu nào thích hợp. Từ nhu cầu thực tế này, các phương pháp tổ
chức, sắp xếp lại kết quả trả về được nghiên cứu, áp dụng. Về bản chất, phương pháp
này có hai kỹ thuật chính:
Phân loại kết quả sau tìm kiếm.
Phân loại kết quả trước tìm kiếm.
Phân loại kết quả sau tìm kiếm: Đầu vào của thủ tục gom cụm là 3 thành phần
chính tương ứng với mỗi tài liệu kết quả: tiêu đề, URL và đoạn snippet được rút trích
trong tài liệu. Đây là kỹ thuật được thực hiện online. Vì yếu tố thời gian, gần như
không khả thi nếu download về toàn bộ tài liệu kết quả, sau đó tiến hành gom cụm
trên tập tài liệu toàn văn. Vì vậy, kỹ thuật gom cụm kết quả sau tìm kiếm dựa vào text

72
trong tiêu đề, text trong snippet để tiến hành phân cụm. Cũng vì ngưỡng thời gian, kỹ
thuật này chỉ lấy top k kết quả trả về để thực thi. Có thể thấy - kỹ thuật gom cụm kết
quả sau tìm kiếm thường được áp dụng trên máy tìm kiếm tổng quát, điển hình thực
nghiệm ở các trang Vivisimo, Credo, EigenCluster, SnakeT, Clusty, Grouper, .v.v.
Tuy nhiên kỹ thuật này đối mặt với những trở ngại khó vượt qua: Chất lượng
cụm sẽ không hoàn toàn tối ưu khi chỉ dựa vào snippets. Snippet chỉ là đoạn trích
ngắn, không đầy đủ thông tin để có thể đại diện cho một tài liệu toàn văn. Trở ngại
về thời gian - thuật toán gom cụm online phải đủ nhanh để trả lại kết quả cho người
dùng trực tuyến. Một trở ngại khác, rất đáng kể mà bài toán gom cụm sau tìm kiếm
phải giải quyết trong thời gian thực - là gán nhãn cụm (nhãn chủ đề), nhãn cụm phải
được mô tả đủ ngữ nghĩa, dễ hiểu để người dùng có thể lựa chọn. Do đó, nghiên cứu
không áp dụng hướng gom cụm kết quả sau tìm kiếm.
Phân loại kết quả trước tìm kiếm: Kỹ thuật phân loại kế quả trước tìm kiếm
không phù hợp với các Search Engines tìm kiếm tổng quát, có kho dữ liệu thu thập
từ không gian Internet: nơi lượng dữ liệu là khổng lồ, đa ngôn ngữ, đa chủ đề, các
phần tử (document) rất khác nhau về kích thước, định dạng, cấu trúc, .v.v. Tuy nhiên,
kỹ thuật này khả thi với tìm kiếm chuyên sâu, miền tìm kiếm được thực hiện trên một
lĩnh vực cụ thể, lượng tài liệu đã biết. Trên thực tế có những miền dữ liệu chuyên
ngành đặc thù, phục vụ cho tác nghiệp hàng ngày của một doanh nghiệp, một hãng,
một tập đoàn, một tổ chức, .v.v. và hoàn toàn “vắng mặt” trên Internet. Trong trường
hợp tìm kiếm chuyên sâu trên một miền dữ liệu được xác định và được giới hạn,
nhược điểm của gom cụm kết quả sau tìm kiếm lại là ưu điểm của phân loại kết quả
trước tìm kiếm. Đặc biệt, kỹ thuật này thực hiện offline, với những chủ đề, lĩnh vực
được xác định trước. Nói cách khác, khi tiến trình Crawler của bộ thu thập dữ liệu kết
thúc, các tài liệu thuộc cùng một chủ đề đã thuộc về một thư mục xác định, có tên mô
tả ngữ nghĩa, tính chất tài liệu. Đặc biệt với các tài liệu trong data-set phụ thuộc miền
(ví dụ lĩnh vực hàng không), trong đó tên tài liệu và các tag meta mô tả tài liệu có thể
được thu thập, ứng dụng trong các bài toán phân lớp hoặc áp dụng trong các kỹ thuật
phân lớp như dàn khái niệm. Các nhãn được phân lớp có thể được như tham chiếu
như tên chủ đề. So với phân loại kết quả sau tìm kiếm, kỹ thuật phân loại kết quả
trước tìm kiếm này có những lợi điểm:

73
Rõ ràng, từ khi hình thành, mỗi tài liệu vốn đã thuộc về một lĩnh vực, nói cách
khác, đã được phân loại sẵn một cách tự nhiên. Ngữ nghĩa của mỗi lĩnh vực
(mỗi nhãn) hoặc ngữ nghĩa của mỗi chủ đề con trong lĩnh vực được mặc định
đúng, đủ tổng quát và dễ hiểu.
Do thực hiện offline, nên tập nhãn thu được (sau các thủ tục như dựng dàn,
duyệt dàn) sẽ kết hợp với việc duyệt lại một cách thủ công (có thêm yếu tố xử
lý của con người), nên dưới góc nhìn ngữ nghĩa, tập nhãn thu được là tối ưu.
Do thực hiện offline nên gần như không tốn tài nguyên khi xử lý online: thời
gian tính, các phép toán, bộ nhớ, băng thông, .v.v., chỉ bằng một thủ tục so
khớp ID của URL kết quả với tên thư mục hay nhãn chủ đề mà ID này thuộc
về, có thể phân loại tập kết quả và hiển thị kết quả cho người sử dụng tức thời.
Trong thực nghiệm máy tìm kiếm hướng ngữ cảnh, các thủ tục tạo dàn và
duyệt dàn được áp dụng trong việc phân lớp kết quả tìm kiếm.
3.2.8. Kỹ thuật phân lớp kết quả tìm kiếm dựa trên Dàn khái niệm
Cấu trúc dàn và kỹ thuật FCA (Formal Concept Analysis - Phân tích khái niệm
hình thức) có khả năng tự động phân nhóm tập kết quả trả về từ máy tìm kiếm. Việc
phân nhóm tập kết quả vào các chủ đề giúp người sử dụng dễ dàng quan sát, đưa ra
quyết định tài liệu nào thích hợp, hạn chế việc thông tin phù hợp bị vùi lấp bởi một
danh sách quá dài. Với dữ liệu chuyên ngành hàng không, luận án sử dụng dàn để
phân lớp tập kết quả trả về theo chủ đề định sẵn.
Từ những năm 1980, Dàn khái niệm (Concept lattice) được nghiên cứu và áp
dụng cho các lớp bài toán về phân tích dữ liệu, khai phá văn bản, tìm tập phổ biến,
phân lớp kết quả tìm kiếm thành các chủ đề, .v.v. Trong cấu trúc dàn, FCA được ứng
dụng để khảo sát dữ liệu - bằng cách lập bảng với các dòng mô tả đối tượng và các
cột mô tả thuộc tính, từ đó xây dựng cấu trúc dàn [88].
Trong tìm kiếm thông tin, FCA xét tương quan đối tượng - thuộc tính như
tương quan tài liệu - thuật ngữ. Trong tiến trình tạo dàn, FCA quy ước mỗi nút trong
dàn là một khái niệm. Thuật toán dựng dàn cài đặt vào mỗi khái niệm một cặp đôi
gồm: tập tài liệu có chung các thuật ngữ, và tập thuật ngữ cùng xuất hiện trong các
tài liệu. Mở rộng, có thể xem mỗi khái niệm (mỗi nút trong dàn) như một cặp câu hỏi,
câu trả lời. Phép duyệt top-down hoặc bottom-up trên dàn sẽ duyệt lên hoặc duyệt

74
xuống để đi đến khái niệm tổng quát hoặc khái niệm chi tiết. Tương ứng với khái
niệm tổng quát sẽ là số lượng tài liệu kết quả nhiều hơn, và ngược lại khái niệm chi
tiết sẽ có số tài liệu tìm kiếm ít hơn. Đặc biệt, tập phủ trên của tập tài liệu có chung
thuật ngữ được xác định là các chủ đề được sinh trong tiến trình dựng và duyệt dàn.
Xuất phát từ dàn khái niệm, phương pháp FCA được đưa ra vào đầu những
năm 1980, từ đó có trên 10.000 ấn phẩm khoa học và một loạt các công cụ triển khai
trong thực tiễn [88], bao gồm các ứng dụng phân tích dữ liệu, tổ chức phân lớp các
kết quả tìm kiếm trên web theo các khái niệm - dựa trên các chủ đề chung [89], dịch
vụ web ngữ nghĩa [90], [91], tìm tập phổ biến, phân tích, nhận biết và sửa lỗi mã
nguồn phần mềm, trong các ứng dụng mạng như phân tích và tổ chức tập văn bản,
phân loại thư điện tử và nhiều ứng dụng phân tích dữ liệu khác1.
Các khái niệm, một cách hình thức, thể hiện các khái niệm trong tự nhiên như:
“sinh vật sống dưới nước”, “ô tô có hệ thống điều dẫn các bánh xe”, “mọi số chia hết
cho 3 và 4 thì chia hết cho 6”. Trường hợp tập văn bản cụ thể, sau khi trích lọc tập
các khái niệm hình thức (tập văn bản - tập thuật ngữ), giữa chúng sẽ có mối liên hệ
nhất định vì các khái niệm chia sẻ các thuộc tính (terms), đây là cơ sở tạo nên dàn
khái niệm.
Để có được dàn khái niệm, cần sử dụng quá trình phân tích khái niệm hình
thức. Tiến trình dựng dàn khái niệm gồm hai giai đoạn: Giai đoạn một - trích lọc từ
tập văn bản ra tập khái niệm. Giai đoạn hai - sử dụng tập khái niệm thu được để thực
hiện việc tạo và duyệt dàn. Câu truy vấn được người sử dụng đưa vào sẽ so khớp với
các khái niệm trên dàn, nếu tương đồng, tập văn bản trong khái niệm và trong các lớp
cha của khái niệm sẽ là tập kết quả cần tìm.
a) Bài toán minh họa
Để nhìn trực quan về dàn khái niệm, luận án trình bày bài toán (ví dụ) minh
họa trong tự nhiên về dàn khái niệm (tập đối tượng, tập thuộc tính):
1 https://rulemlrr19.inf.unibz.it/rw2019/downloads/RW2019-Rudolph-FCA.pdf

75
Bảng 3.2: Bảng ngữ cảnh 1
Tập thuộc
tính
M
Tập
đối
tượng
G Th
ở d
ướ
i n
ướ
c
Bay
đư
ợc
Có
mỏ
Có
bà
n t
ay
Có
kh
un
g x
ươ
ng
Có
cá
nh
Số
ng d
ướ
i n
ướ
c
Đẻ c
on
Ph
át
sán
g
Dơi x x x x
Đại bàng x x x x
Khỉ x x x
Cá vẹt x x x x
Chim cánh cụt x x x x
Cá mập x x x
Cá lân tinh x x x x
Từ bảng ngữ cảnh trên, dàn khái niệm được hình thành một cách trực quan bởi
lược đồ Hasse:
Hình 3.10: Dựng dàn khái niệm từ bảng ngữ cảnh 1.
Tương ứng với truy vấn “hãy cho biết, loài nào có cánh, bay được và đẻ con?”,
phép duyệt và tìm kiếm trên dàn sẽ trả về kết quả là một khái niệm C={G,
M}=({Dơi}, {Bay được, Có cánh, Đẻ con}). Tuy nhiên, đặc điểm của kỹ thuật FCA
nằm ở phân lớp tập kết quả tìm kiếm. Nếu truy vấn đưa vào là “dơi”, tập kết quả thu
được sẽ được phân lớp vào các chủ để: loài động vật “bay được”, “có cánh”, “đẻ con”,

76
… Tương tự, nếu truy vấn đưa vào là “jaguar”, tập kết quả thu được sẽ được phân
thành các chủ đề: “car”, “big cat”, “MAC OS”, ...
Hình 3.11: Tìm kiếm và phân lớp kết quả với truy vấn “jaguar”.
Có thể thấy, việc phân hạng của thuật toán dựa trên đặc trưng của cấu trúc dàn,
tập khái niệm cha chứa nhiều đối tượng (tài liệu) hơn, tập khái niệm con chứa nhiều
thuộc tính (terms) hơn. Khi kết xuất kết quả, đặc biệt trường hợp câu truy vấn có chứa
cụm từ, những kết quả đầu chứa tất cả các terms cần tìm, các kết quả sau chứa một
phần các terms trong câu truy vấn, theo số lượng giảm dần. Hình 3.11 minh họa việc
tìm kiếm và phân lớp tập kết quả trả trên cấu trúc dàn [92], [93]
(http://credo.fub.it/cgi-bin/credo/search?query=jaguar). Về phân lớp kết quả tìm
kiếm, trong quá trình duyệt dàn, tập phủ trên (biến upper cover của hàm
Locate_Pivot) chứa các nhãn, các nhãn này mô tả chủ đề các phân lớp.
b) Cấu trúc Dàn trong toán học
Tập thứ tự (L, ≤) được gọi là một dàn nếu với mọi cặp phần tử (a, b) L đều
tồn tại cận trên đúng (cận trên nhỏ nhất) và cận dưới đúng (cận dưới lớn nhất) [94].
Trong tập được sắp (A, ≤) cận trên đúng, cận dưới đúng của tập con B A
nếu tồn tại, được ký hiệu bởi Sup(B), Inf(B). Trường hợp B = {b1, b2, …, bn} ta viết
Sup{b1, b2, …, bn}, Inf{b1, b2, …, bn} hoặc Sup(b1, b2, …, bn), Inf(b1, b2, …, bn).

77
Trong dàn L, đặt ab = Sup(a,b), ab = Inf(a, b), a, b L. Tập được sắp (L, ≤)
được gọi là một dàn đầy đủ nếu SL, SØ đều tồn tại Sup(S), Inf(S).
c) Nguyên lý Dàn khái niệm trong FCA
Từ giả thiết mối quan hệ objects - attributes (G - M) được xét như mối quan
hệ documents - terms, các định nghĩa dưới đây được nêu dưới góc độ của FCA [95].
Định nghĩa 1: (định nghĩa về ngữ cảnh hình thức - Formal Context): Một ngữ
cảnh hình thức là một bộ ba ngôi K(G, M, I) trong đó G là tập đối tượng, M là
tập thuộc tính và I là mối quan hệ nhị phân giữa G và M (I G x M). Ký hiệu
gIm hay (g,m)I được đọc là đối tượng g có thuộc tính m.
Nếu quy chiếu vào bài toán tìm kiếm trong thực nghiệm, G gồm các văn bản
(docs) trong tập dữ liệu mẫu, M gồm các thuật ngữ (terms) tương ứng trong
các files: G = {doc1, doc2, …, docn}; M = {term1, term2, …, termk}.
Định nghĩa 2 (định nghĩa về quan hệ thứ tự): Trên một ngữ cảnh (G, M, I),
một khái niệm X=(A, B) được gọi là nhỏ hơn hoặc bằng một khái niệm Y=(C,
D) nếu A⊆C hoặc D⊆B, được ký hiệu X ≤ Y.
Định nghĩa 3 (định nghĩa về Hasse diagram): Cấu trúc của dàn khái niệm được
biểu diễn bởi đồ thị có hướng Hasse. Các nút trên đồ thị là các khái niệm và
các cung đóng vai trò như các tương quan giữa các khái niệm. Nếu quan hệ X
- Y là quan hệ khái niệm cha - khái niệm con:
X≺Y Z : X ≤ Z ≤ Y.
thì có một cung được định hướng giữa X và Y trên Hasse diagram.
Từ các định nghĩa trên, phát biểu định nghĩa về dàn khái niệm:
Định nghĩa 4 (định nghĩa về dàn khái niệm): Gọi L là tập gồm tất cả các khái
niệm của ngữ cảnh K(G, M, I), trong L tồn tại quan hệ thứ tự (≤). Một dàn dựa
trên các đặc tính này (L, ≤) được gọi là dàn khái niệm.
d) Phép tạo và duyệt dàn
Tạo dàn
Từ mô hình toán học (1982) [96], nhiều giải thuật về tạo dàn được đưa ra [88].
Luận án trình bày giải thuật AddIntent - là phiên bản cải tiến của giải thuật tạo dàn
AddAtom [97]. Trong các giải thuật tạo dàn, AddIntent là kỹ thuật thêm dần các khái
niệm vào dàn, nói cách khác, giả sử tập dữ liệu mẫu có N tài liệu, AddIntent sẽ thêm
dần các tài liệu 1, 2, …i, i+1, …, N vào dàn Li, Li+1, … L.

78
Thủ tục tạo dàn CreateLatticeIncrementall
Đầu vào:
- Tập dữ liệu mẫu (G, M, I);
Đầu ra:
- Dàn L;
Giải thuật:
Program CreateLatticeIncrementally_alg
01: CreateLatticeIncrementally(G, M, I)
02: BottomConcept := (Ø, M)
03: L := {BottomConcept}
04: For each g in G
05: ObjConcept = AddIntent(g’, BottomConcept, L)
06: Add g to the extent of ObjConcept and all concepts above
07: End For
End
Diễn giải giải thuật:
Thủ tục CreateLatticeIncrementally(G, M, I) nhận vào toàn bộ tập dữ liệu mẫu
(tập đối tượng G gồm các files, tập thuộc tính M gồm các terms trong files, và tương
quan I thuộc G, M). AddIntent là giải thuật theo hướng Bottom-Up, được khởi gán
bằng {0, M}. Nói cách khác, khái niệm BottomConcept chứa toàn bộ terms của dàn
L (dòng 02). Tiến trình bắt đầu với việc cập nhật khái niệm BottomConcept vào đáy
của dàn (dòng 03).
Với mỗi đối tượng g thuộc tập đối tượng G (với mỗi file thuộc tập files), thủ
tục gọi hàm AddIntent để thêm dần các khái niệm vào dàn khái niệm, truyền vào
AddIntent ba tham biến: g’ (intent, tập terms trong một file), khái niệm
BottomConcept (tập terms trong các files) và dàn L (dòng 04, 05). Trong thân thủ
tục, hàm AddIntent tạo khái niệm (và các nối kết ràng buộc với khái niệm khác), vòng
lặp For .. End For của thủ tục lần lượt lấy từng khái niệm của tập khái niệm được tạo
- để cập nhật vào Extent, dòng 06. Thủ tục kết thúc là dàn được tạo xong.
Độ phức tạp tính toán:
Thực tế, khi các concepts trong dàn tăng lên với tốc độ của hàm mũ, đòi hỏi
thời gian tính của CPU, các giải thuật tạo dàn đều cố gắng tiệm cận đến độ phức tạp
tính toán có thời gian đa thức. Với giải thuật AddIntent, thời gian của giải thuật được

79
tính toán trong trường hợp tốt nhất được đánh giá bằng O(|L||G|2max(|g’|)). Trong đó
L là dàn khái niệm, G là tập đối tượng của L, max(g’) là số thuộc tính lớn nhất của
một concept trong L.
Duyệt dàn
Từ định nghĩa về khái niệm hình thức, FCA xét mỗi khái niệm trong dàn là
một cặp (câu trả lời, truy vấn). Câu truy vấn tương ứng với intent, câu trả lời tương
ứng extent của khái niệm. Mở rộng, mối quan hệ giữa các truy vấn có thể xem như
mối quan hệ giữa các khái niệm trên dàn. Khi tìm kiếm, hệ thống sẽ phân tích câu
truy vấn, tìm ra các khái niệm hình thức (terms), duyệt dàn và so khớp với các khái
niệm thuộc dàn. Cốt lõi của việc duyệt dàn trên thực tế nằm ở hàm AddIntent. Có thể
nói AddIntent là hàm “xương sống” của hai tiến trình tạo dàn và tìm kiếm trên dàn.
Tư tưởng của giải thuật duyệt và tìm kiểm trên dàn (BR-Explorer [95]) như
sau: Sử dụng hàm AddIntent để đưa câu truy vấn (intent) vào dàn (nhằm thỏa quan
hệ thứ tự ≤). Tiến hành tìm khái niệm trụ (Locate_Pivot) ứng với intent của câu truy
vấn. Cuối cùng tập kết quả gồm các tài liệu trong khái niệm trụ và các tài liệu trong
các khái niệm cha của khái niệm trụ là tập kết quả cần tìm. Kết quả tìm được sẽ được
xếp hạng, những kết quả đầu chứa tất cả các thuật ngữ cần tìm, các kết quả phía sau
chứa một phần các thuật ngữ trong yêu cầu tìm kiếm, theo số lượng giảm dần.
Hàm BR-Explorer
01: Insert Q into B(G, M, I) via AddIntent function.
02: P = ({x}″,{x}′) := Locate Pivot(B(GQ,MQ,IQ),Q)
03: n := 1 /* n is the level in B(GQ,MQ,IQ) from P */
04: SUBSn-1 := {P}
05: rank := 1
06: if {x}″ ≠ {x}′ then
07: Rrank := {x}″ \ {x}′
08: Robjects := (rank,Rrank)
09: rank := rank + 1
10: end if
11: while SUBSn-1 ≠ Ø do
12: SUBSn := upper-covers(SUBSn-1)
13: Rrank := Ø
14: for all C = (A,B) ∈ SUBSn such that B ≠ Ø do
15: Rrank := Rrank ∪ A
16: end for

80
17: EmergingObjects := Rrank \ ({x}∪R1,R2,...,Rrank-1)
18: Robjects := Robjects ∪ (rank, EmergingObjects)
19: n := n + 1
20: rank := rank + 1
21: end while
Diễn giải giải thuật:
Dòng đầu tiên của giải thuật (dòng 01) thực hiện việc đưa truy vấn Q (yêu cầu
từ phía người dùng) vào dàn nhằm so khớp khái niệm. Dàn biến đổi thành “dàn mới”,
ký hiệu là B(GQ,MQ,IQ). Dàn này được tạo thành từ dàn ban đầu hợp thêm truy vấn
Q. Sau khi gọi hàm Locate_Pivot, kết quả trả về là một khái niệm, khái niệm này hoặc
thuộc tập phủ trên upper-covers (tìm thấy) hoặc thuộc BottomConcept (không tìm
thấy).
Nếu tìm thấy, giải thuật thực hiện phân hạng kết quả trả về, biến Robjects lưu
việc phân hạng (dòng 8-18). Việc phân hạng kết quả thực hiện xét tập SUBS, khởi
gán SUBS0={P} (dòng 4), Tại bước này nếu {x}″≠ {x}′ thì tập đối tượng trong
{x}″\{x}′ được thêm vào Robjects với thứ hạng tương ứng (dòng 6-10). Giải thuật thực
hiện vòng lặp các bước kế tiếp, SUBS1=upper-cover(SUBS0), SUBS2=upper-
cover(SUBS1),… đến SUBSn. Tại bước thứ i, nếu khái niệm ⊤ xuất hiện trong SUBSi
và nếu intent của ⊤ là rỗng thì các đối tượng trong extent của ⊤ được bỏ qua. Trong
trong quá trình duyệt dàn và tìm tập phủ trên, cặp (rank, set of objects) được lưu vào
biến kết quả Robjects.
Trong giải thuật BR-Explorer, đoạn giả mã (hàm Locate_Pivot) xác định tập
phủ trên (tập chủ đề):
Hàm Locate_Pivot
Đầu vào:
- Dàn L; khái niệm biểu diễn cho truy vấn
Đầu ra:
- Locate_Pivot chứa các upper-cover
Giải thuật:
Program Locate_Pivot_alg
01: found := false
/* ⊥ is the BottomConcept in B(Gq,Mq,Iq) */
02: SUBS := {⊥}
03: while !found do

81
04: for each C = (A,B) ∈ SUBS do
05: if x’ = B then
06: Pivot P := C
07: found := true
08: break
09: else if x′ ⊂ B then
10: SUBS := upper-cover(SUBS)
11: break
12: end if
13: end for
14: end while
End
Diễn giải giải thuật:
Tương ứng với truy vấn q (câu truy vấn được đưa vào từ phía người dùng, hàm
Locate_Pivot sẽ:
Trả về BottomConcept nếu không tìm thấy.
Trả về một khái niệm (khái niệm này nằm trong tập phủ trên upper-cover của
các khái niệm có intent (tập terms) chứa hoặc bằng tập terms của truy vấn q
(dòng 04-13).
Quá trình duyệt dàn, tập phủ trên (biến upper cover của hàm Locate_Pivot) chứa
các nhãn, các nhãn này mô tả chủ đề các phân lớp thuộc tập kết quả tìm kiếm.
Độ phức tạp tính toán:
Thực chất, hàm BR-Explorer thực hiện duyệt, tìm kiếm trên dàn bằng cách hợp
câu truy vấn vào dàn, lúc này dàn biến đổi thành một dàn “mới”, 2 vòng lặp while và
for cho biết cận trên độ phức tạp tính toán của thủ tục duyệt dàn là O(n2).
e) Phân tích
Lĩnh vực khai phá dữ liệu đã có nhiều kỹ thuật được nghiên cứu và ứng dụng,
dàn khái niệm và FCA là một trong những kỹ thuật như vậy, áp dụng trong phân tích
dữ liệu văn bản. Phần đánh giá, thảo luận này trình bày ưu nhược điểm của dàn khái
niệm.
Ưu điểm:
Hình minh họa 3.11 cho thấy dàn khái niệm thích hợp với kỹ thuật gom cụm
(theo các chủ đề), phân lớp các khái niệm.

82
Mối quan hệ khái niệm cha - khái niệm con của cấu trúc dàn thỏa quan hệ thứ
tự ≺ , người tìm kiếm có thể khai thác thông tin tại các node lân cận thuộc dàn
mà không mất thời gian tìm kiếm lại trên toàn tập cơ sở dữ liệu văn bản lớn.
Nhược điểm:
Trong ứng dụng tìm kiếm thông tin, khi câu truy vấn được đưa vào dàn, phải
gọi lớp hàm như AddIntent. AddIntent thực hiện đệ qui, dẫn đến tăng đáng kể
thời gian tìm kiếm. Ngoài việc duyệt dàn để tìm ra các khái niệm, các hàm tìm
kiếm trên dàn như BR-Explorer có nhược điểm về thời gian tính, nội hàm gọi
các hàm khác (để tính toán lan truyền trên dàn) và phải đệ qui (khi thêm câu
truy vấn vào dàn thông qua AddIntent).
Trên thực tế, các áp dụng trong lĩnh vực tìm kiếm thông tin của dàn khái niệm
(http://intoweb.loria.fr/CreChainDo/index.php, http://credo.fub.it,
http://vivisimo.com,) được biết đến và như chính các trang này nhìn nhận [92],
[93], là những ứng dụng Meta - Search Engine chỉ lấy về khoảng 10 trang đầu
kết quả của máy tìm kiếm khác (Yahoo, Bing. Google), những kết quả này là
những xâu ký tự, những đoạn trích sơ lược có chứa từ khóa (snippets). Dựa
trên tập kết quả sơ lược này, thực hiện dựng dàn và xuất lại kết quả theo định
dạng dàn. Các áp dụng này không hẳn là một Search Engine truyền thống và
toàn văn, có thể đáp ứng việc tìm kiếm.
Các khái niệm trên dàn mang theo tập thuộc tính intent (tập terms), trường hợp
tập dữ liệu mẫu là lớn dẫn đến tập khái niệm cũng rất lớn [94], [95], [97].
Trong một thực nghiệm khác, khi khảo sát giải thuật tạo dàn chỉ với 30 tài liệu,
mỗi tài liệu khoảng 20 Kbytes, thực nghiệm gặp 885541 concepts. Để giảm số
khái niệm, có thể dựng những dàn cục bộ thay vì dàn đầy đủ, tuy nhiên cách
thức này làm mất đi mối liên hệ giữa các khái niệm trong dàn, hay phải ứng
dụng trên một môi trường tính toán hiệu năng cao với nhiều nodes xử lý cấu
hình mạnh.
Khi cài đặt thực nghiệm trên dữ liệu mẫu là các tài liệu về chuyến bay [98],
[99], tập dữ liệu mẫu gồm 118 văn bản, mỗi tài liệu lấy 50 từ/cụm từ xuất hiện nhiều
nhất (loại bỏ từ dừng), tập khái niệm thu được xấp xỉ 250000 khái niệm. Việc xây
dựng dàn được tính toán offline, vì thế khi tìm kiếm sẽ không cần phải dựng lại dàn.
Việc dựng dàn được thực hiện không thường xuyên.

83
Hình 3.12: Tìm kiếm trên dàn.
Chương trình demo viết bằng C# trên nền ASP.NET, sử dụng hệ SQL Server
để lưu trữ cấu trúc dàn. Hình 3.12 minh họa việc duyệt và tìm kiếm trên dàn tương
ứng với câu truy vấn “Hãng hàng không (HK) nào bay đến US, Europe, Canada,
Mexico và Carribean ?”.
Trong thực nghiệm máy tìm kiếm hướng ngữ cảnh (một tập mẫu khác, mục
3.4.1), các thủ tục tạo dàn và duyệt dàn được áp dụng: Trên tập dữ liệu mẫu phụ thuộc
miền (hàng không), tên và các tag meta mô tả tài liệu được thu thập, thực nghiệm ứng
dụng phương pháp dàn khái niệm để phân lớp các kết quả tìm kiếm. Trên tập mẫu
khá nhỏ này, việc dựng dàn và duyệt dàn được thực hiện offline, mục đích nhận được
tập chứa các nhãn (biến upper cover), các nhãn này mô tả chủ đề các phân lớp của
các tài liệu chuyên ngành.
Dàn có một nền tảng toán học, các nguyên lý đa dạng, là một cấu trúc đẹp. Để
cung cấp một góc nhìn nghiên cứu, luận án trình bày về lý thuyết dàn: cách tạo, duyệt
và phân loại, hiển thị kết quả tìm kiếm trên dàn, phân tích ưu nhược điểm của cấu
trúc dàn. Tuy nhiên thực nghiệm cho thấy dàn thích hợp với khai phá, phân lớp và
gom cụm dữ liệu thuộc bước hậu xử lý của quá trình tìm kiếm, không hoàn toàn thích
hợp trong ứng dụng như một máy tìm kiếm hướng tổng quát hoặc chuyên sâu.
Ngoài ra, cấu trúc dàn thích hợp với các kỹ thuật làm mịn truy vấn (query
refinement) [92], [93]. Ở một cách tiếp cận, cấu trúc dàn có thể xếp hạng kết quả từ

84
cao xuống thấp theo độ tương thích. Do đó, ngoài khả năng phân lớp theo chủ đề tập
kết quả tìm kiếm khi kết hợp cấu trúc dàn với kỹ thuật hướng ngữ cảnh, có thể áp
dụng cấu trúc dàn trong các bài toán gợi ý, như gợi ý tài liệu.
Tóm lại, về gợi ý truy vấn, xoay quanh hạt nhân là Qlogs, mục các nghiên cứu
liên quan trong đã khái quát các kỹ thuật chủ yếu áp dụng trong Query Suggestion.
Lý thuyết liên quan đến Gợi ý truy vấn chia thành 2 lớp kỹ thuật chính: Session-based
và Cluster-based. Kỹ thuật dựa trên Session (Phiên tìm kiếm) khai phá chuỗi liên tục
các câu truy vấn để tìm các truy vấn luôn đồng hiện. Kỹ thuật dựa trên cluster nhằm
gom các truy vấn tương tự nhau (theo độ đo tương đồng), từ đó đưa ra gợi ý truy vấn.
Các kỹ thuật khác xoay quanh câu truy vấn có thể kể đến như: Kỹ thuật Mở rộng truy
vấn Query Expansion (vdụ: NY Times New York Times) sử dụng các phương
thức: thesaury, luật kết hợp, Query Relation Graph, .v.v.; Kỹ thuật Làm mịn/sàng lọc,
thay thế truy vấn, Viết lại truy vấn Query Refinement, Query Substitution, Rewriting
Query (vdụ: machin learn machine learning), thực hiện stemming, acronym, sử
dụng các phương thức: Maximum Entropy Model, .v.v. không đề cập trong khuôn
khổ Chương 3.
3.3. Kết quả thực nghiệm - Đánh giá
Hình 3.13: Mô hình hệ thống thực nghiệm kỹ thuật tìm kiếm hướng ngữ cảnh

85
Từ những phân tích trên, Chương 3 nghiên cứu và ứng dụng để xây dựng một
máy tìm kiếm hướng ngữ cảnh. Đồng thời nghiên cứu, tích hợp vào máy tìm kiếm
hướng ngữ cảnh các tùy chọn truy vấn và trả lời bằng tiếng nói để hình thành một
Voice search.
3.3.1. Data-set
Thế giới số là một không gian rất rộng, gần như không có bộ máy tìm kiếm
nào đủ phổ quát, vạn năng để đáp ứng mọi yêu cầu tìm kiếm. Vì vậy, thay vì xây
dựng máy tìm kiếm tổng quát, luận án hướng đến việc xây dựng máy tìm kiếm chuyên
sâu, khai phá sâu hơn về dữ liệu cũng như hành vi tìm kiếm của người dùng [76].
Ứng dụng máy tìm kiếm chuyên sâu khác với máy tìm kiếm tổng quát ở 3
điểm: Dữ liệu đầu vào là dữ liệu chuyên ngành, gợi ý truy vấn với các kỹ thuật riêng
(hệ công thức riêng) trên Query Logs đặc thù, cũng như phân nhóm kết quả trả về,
hình thành nên một máy tìm kiếm khác với các máy tìm kiếm tổng quát. Việc bổ sung
thêm nhận dạng, tổng hợp tiếng nói vào máy tìm kiếm hình thành nên một máy tìm
kiếm hướng ngữ cảnh có tương tác giọng nói [34], [76].
Tập dữ liệu mẫu áp dụng trong thử nghiệm được thực hiện trên một phần của
tập dữ liệu gốc với khoảng 20000 tài liệu lĩnh vực Hàng không, thuộc các định dạng
phổ biến: html, pdf, doc, xls, txt, .v.v, mỗi tài liệu có độ dài biến đổi từ 1 đến 4500
trang A4.
Trong khuôn khổ Chương 3, nghiên cứu trích chọn 50 truy vấn từ Query Logs
làm dữ liệu thử nghiệm (test cases), theo [73], [74], một bộ 50 truy vấn được coi là
đủ lớn để đánh giá một hệ thống truy xuất, tìm kiếm thông tin. Việc trích chọn nhằm
tránh những câu truy vấn quá phổ biến (không hữu ích) như “hàng không”, “máy
bay”, .v.v. Trích xuất ngẫu nhiên 400 phiên tìm kiếm làm dữ liệu huấn luyện - đây là
những phiên tìm kiếm từ người dùng thực trong hoạt động tác nghiệp hàng ngày.
3.3.2. Đánh giá, so sánh
Các phương pháp so sánh: Để đánh giá hiệu quả của phương pháp hướng
ngữ cảnh, luận án lập bảng đối sánh giữa máy tìm kiếm áp dụng hướng ngữ
cảnh và máy tìm kiếm thông dụng Lucene (Nutch), đồng thời so sánh kỹ thuật
gợi ý truy vấn với hai phương pháp baselines: Adjacency và N-Gram. Tiêu chí
so sánh dựa vào:
o Tính thích đáng (quality - độ đo chất lượng) và

86
o Tính đa dạng (coverage - độ phủ) của tập gợi ý truy vấn.
Bảng so sánh
Bảng 3.3: Bảng so sánh tìm kiếm hướng ngữ cảnh và Lucene-Nutch
Lucene - Nutch SE hướng ngữ cảnh
Tập dữ liệu mẫu Chung tập dữ liệu
Thời gian tìm kiếm milliseconds milliseconds, thực nghiệm sử dụng hàm
Datediff tính khoảng cách giữa 2 thời
điểm t1: câu truy vấn gửi đi và t2: SE trả
về tập kết quả)
Xếp hạng kết quả
(ranking)
Có Có
Tính thực tiễn Thông dụng Áp dụng trên mạng Hàng không VN
Khả năng gợi ý
nhanh
Không Có
Phân loại tập kết quả
trả về
Không Có
Gợi ý truy vấn Không Có
Tiêu chí so sánh
Độ đo chất lượng phản ánh đúng đắn nhu cầu thông tin đồng thời giúp người
sử dụng tìm được những gì họ quan tâm. Độ phủ phản ánh tính đa dạng, bao phủ
nhiều khía cạnh tìm kiếm khác nhau. Để thực hiện đánh giá, luận án so sánh kỹ thuật
gợi ý hướng ngữ cảnh với 2 phương pháp baselines: Adjacency và N-Gram.
Phương pháp Adjacency khái quát như sau: nhận vào chuỗi truy vấn q1, q2, ..,
qi - trên tất cả các phiên tìm kiếm - Adjacency xếp hạng theo tần suất xuất hiện các
truy vấn ngay sau một truy vấn qi. Sau đó kết xuất topN (N = 5) truy vấn có tần suất
xuất hiện cao nhất như danh sách gợi ý.
Tương tự, phương pháp N-Gram nhận đầu vào là chuỗi query sequence qs =
q1, q2, .., qi. Trên các phiên tìm kiếm, N-Gram thực hiện xếp hạng theo tần suất xuất
hiện các truy vấn ngay sau chuỗi qs, trả về topN truy vấn có tần suất xuất hiện cao
nhất như danh sách gợi ý.

87
Hình 3.14: (a): Độ đo tính đa dạng; (b): Độ đo tính thích đáng.
Độ phủ được đo bằng tỷ lệ số test cases có khả năng đưa ra gợi ý truy vấn trên
tổng số test cases. Hình a minh họa kết quả phép đo độ phủ của 3 phương pháp. Như
giả thiết đặt ra, khi nhận vào test case qs = q1, q2, .., qi, phương pháp N-Gram chỉ đưa
ra được danh sách gợi ý nếu tồn tại trong dữ liệu huấn luyện phiên tìm kiếm dạng
qs1= q1, q2, .., qi, qi+1, .., qj. Rõ ràng, phương pháp Adjacency có tỷ lệ đa dạng vượt
trội so với phương pháp N-gram, vì chỉ cần tồn tại chuỗi dạng qs2= .., qi, qi+1, .., qj
thuộc dữ liệu huấn luyện. Nói cách khác, qs1 là một trường hợp đặc biệt của qs2. Tuy
nhiên, xét theo trình tự thời gian trong một phiên tìm kiếm, phương pháp N-Gram có
ưu điểm - khi gợi ý, sẽ gợi ý thành chuỗi (cả chuỗi gợi ý). So với 2 phương pháp N-
Gram và Adjacency, trường hợp “vắng mặt” cả qs1 lẫn qs2, phương pháp hướng ngữ
cảnh chứng minh tính hiệu quả trội hơn 2 phương pháp trên, bởi chỉ cần chuỗi truy
vấn dạng qs2’= .., qi’, qi+1, .., qj mà qi và qi’ tương đồng (thuộc cùng một cụm), kỹ
thuật hướng ngữ cảnh vẫn thực hiện cung cấp danh sách gợi ý.
Độ đo chất lượng được tính điểm bằng cách lấy ý kiến chuyên gia (con người).
Đối chiếu với truy vấn hiện hành, nếu câu gợi ý trong danh sách được đánh giá là
thích đáng, phương pháp được cộng 1 điểm. Nếu danh sách gợi ý có hai hoặc nhiều
hơn các câu gợi ý gần trùng lặp, phương pháp chỉ được cộng 1 điểm. Nếu test case
không đưa ra được gợi ý, thử nghiệm không đếm test case này. Tổng điểm của một
phương pháp ứng với một test case cụ thể bằng tổng điểm cộng được chia cho tổng
số câu gợi ý truy vấn. Điểm trung bình của mỗi phương pháp bằng thương số giữa
tổng điểm và tổng số test cases đếm được.
Trên tất cả các mẫu thử nghiệm, trên cả 2 phép đo về tính thích đáng và tính
đa dạng, thang điểm đánh giá của 3 phương pháp được minh họa trong hình b, cho
0
10
20
30
40
50
60
Adjacency N-Gram Hướng ngữ cảnh
0.7
0.8
0.9
1
Adjacency N-Gram Hướng ngữ cảnh

88
thấy gợi ý hướng ngữ cảnh tối ưu so với 2 phương pháp baselines. Thay vì gợi ý ở
mức truy vấn đơn lẻ, phương pháp hướng ngữ cảnh xác định ý đồ tìm kiếm của người
sử dụng ở mức cụm (mức khái niệm).
3.3.3. Hệ thống thực nghiệm
Để diễn giải, Chương 3 nêu quá trình demo thực nghiệm như một dãy các
bước:
Bước 1: Truy cập máy tìm kiếm hướng ngữ cảnh có tương tác giọng nói.
Bước 2: Tìm kiếm bằng giọng nói là một tùy chọn của máy tìm kiếm. Thực
nghiệm sử dụng công nghệ Silverlight của Microsoft để có thể truy xuất, ghi
âm thanh trên máy client và thực hiện lưu file (định dạng .wav) về máy Server.
Hình 3.15: Silverlight đề nghị truy xuất camera, microphone trên máy client.
Bước 3 (chạy nền background): Server tìm kiếm hướng ngữ cảnh sử dụng
websocket kết nối đến ASR Server (Automatic Speech Recognition, máy chủ
phần mềm tự động nhận dạng giọng nói), chuyển file âm thanh dạng wav nói
trên cho ASR Server nhận dạng speech to text (chuyển lời nói thành văn bản
text).
Bước 4: Sử dụng kỹ thuật lập trình socket, ASR Server chuyển lại câu text đã
được nhận dạng cho Server máy tìm kiếm hướng ngữ cảnh.

89
Hình 3.16: ARS Server thực hiện speech to text.
Bước 5: Server máy tìm kiếm hướng ngữ cảnh nhận câu text này như một
query đầu vào, thực hiện tìm kiếm, thực hiện lưu câu truy vấn vào Query Logs,
áp dụng các kỹ thuật khai phá dữ liệu (hướng ngữ cảnh) để trả kết quả, phân
loại kết quả và kết xuất gợi ý truy vấn về người sử dụng.
Hình 3.17: Tìm kiếm hướng ngữ cảnh tương tác giọng nói.
Như hình minh họa: Khung trái được hiện thực bằng kỹ thuật phân lớp chủ đề
(áp dụng dàn khái niệm); Khung giữa màn hình là tập kết quả trả về của máy tìm
kiếm, biểu tượng micro và loa để thực hiện chức năng voice-search (Speech To Text
và Text To Speech); Khung phải thực hiện kỹ thuật context-aware hướng ngữ cảnh
để gợi ý truy vấn.
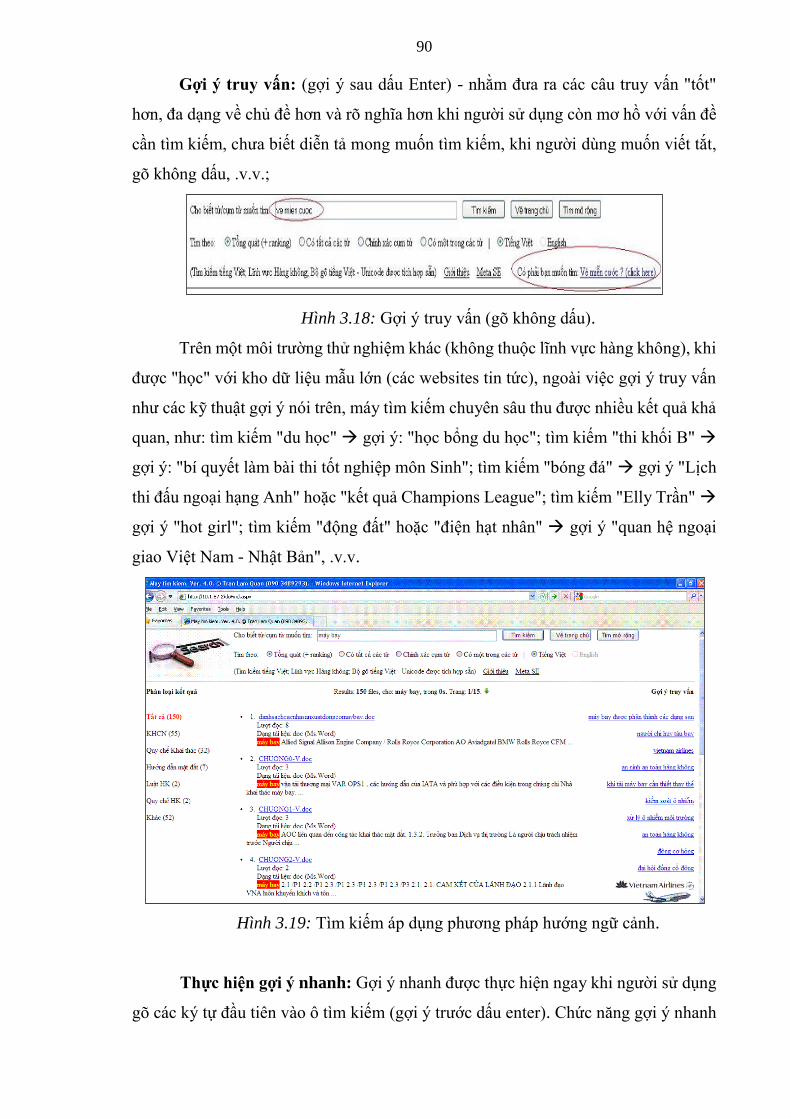
90
Gợi ý truy vấn: (gợi ý sau dấu Enter) - nhằm đưa ra các câu truy vấn "tốt"
hơn, đa dạng về chủ đề hơn và rõ nghĩa hơn khi người sử dụng còn mơ hồ với vấn đề
cần tìm kiếm, chưa biết diễn tả mong muốn tìm kiếm, khi người dùng muốn viết tắt,
gõ không dấu, .v.v.;
Hình 3.18: Gợi ý truy vấn (gõ không dấu).
Trên một môi trường thử nghiệm khác (không thuộc lĩnh vực hàng không), khi
được "học" với kho dữ liệu mẫu lớn (các websites tin tức), ngoài việc gợi ý truy vấn
như các kỹ thuật gợi ý nói trên, máy tìm kiếm chuyên sâu thu được nhiều kết quả khả
quan, như: tìm kiếm "du học" gợi ý: "học bổng du học"; tìm kiếm "thi khối B"
gợi ý: "bí quyết làm bài thi tốt nghiệp môn Sinh"; tìm kiếm "bóng đá" gợi ý "Lịch
thi đấu ngoại hạng Anh" hoặc "kết quả Champions League"; tìm kiếm "Elly Trần"
gợi ý "hot girl"; tìm kiếm "động đất" hoặc "điện hạt nhân" gợi ý "quan hệ ngoại
giao Việt Nam - Nhật Bản", .v.v.
Hình 3.19: Tìm kiếm áp dụng phương pháp hướng ngữ cảnh.
Thực hiện gợi ý nhanh: Gợi ý nhanh được thực hiện ngay khi người sử dụng
gõ các ký tự đầu tiên vào ô tìm kiếm (gợi ý trước dấu enter). Chức năng gợi ý nhanh

91
trong thực nghiệm sử dụng kỹ thuật AJAX (Asynchronous Javascript And XML) để
gửi, xử lý và nhận chuỗi ký tự trong tương tác client - server mà không cần tải lại
toàn trang. Để tiện lợi cho việc tìm kiếm, tiết kiệm thời gian cho người sử dụng, các
câu tìm kiếm (câu truy vấn) phổ biến nhất hoặc có tổ hợp trọng số cao nhất (highest
score) được gợi ý ngay khi người sử dụng gõ vào một phần câu truy vấn:
Hình 3.20: Gợi ý nhanh.
Phân loại kết quả (áp dụng dàn khái niệm): Sau câu truy vấn, các Máy tìm
kiếm (như Google, Bing, Yahoo! Search, Ask, .v.v.) thường trả về một danh sách dài
(hàng triệu kết quả) và đa chủ đề. Nếu người dùng muốn tìm kiếm chuyên sâu trong
một lĩnh vực cụ thể, người dùng sẽ phải tự xử lý lượng dữ liệu lớn để tìm ra thông tin
mà họ cần. Phân loại, gom tập tài liệu kết quả vào các lĩnh vực cụ thể sẽ hạn chế việc
thông tin bị vùi lấp bởi một danh sách quá dài, giúp người sử dụng dễ dàng quan sát
tập kết quả, đưa ra quyết định tài liệu nào thích hợp.
Hình 3.21: Phân loại kết quả.

92
Các máy tìm kiếm tổng quát nói trên thu thập dữ liệu từ không gian Internet -
nơi kho dữ liệu là khổng lồ, đa ngôn ngữ, nhiều lĩnh vực, đa cấu trúc, định dạng, .v.v.
Kỹ thuật phân loại kết quả sau tìm kiếm là một kỹ thuật online. Vì yếu tố thời gian -
phải trả kết quả tức thời cho người sử dụng - nên gần như không khả thi khi thực hiện
phân loại tài liệu trên những Máy tìm kiếm tổng quát. Một trở ngại khác, rất đáng kể
mà bài toán phân loại online phải vượt qua, đó là gán nhãn (đặt tiêu đề cho mỗi chủ
đề tương ứng). Tiêu đề phải mô tả đủ ngữ nghĩa và dễ hiểu để người dùng có thể lựa
chọn. Máy tìm kiếm của luận án thực hiện tìm kiếm chuyên sâu, trên một miền dữ
liệu cụ thể (dữ liệu tác nghiệp Hàng không, "vắng mặt" trên Internet), lượng tài liệu
là biết trước, áp dụng giải thuật dựng dàn được thực hiện off-line, kết hợp với việc
duyệt lại tập nhãn một cách thủ công (thêm yếu tố xử lý của con người), vì vậy thích
hợp cho kỹ thuật phân loại kết quả trước tìm kiếm.
3.4. Kết chương
Dưới góc nhìn lý thuyết, Chương 3 trình bày một cách tường minh về phương
pháp hướng ngữ cảnh: tư tưởng, nguyên lý, mô hình, các công thức và các thuật toán,
.v.v. cũng như nêu lên các đề xuất cải thiện kỹ thuật. Dưới góc nhìn thực nghiệm,
việc cài đặt (các biến, cấu trúc dữ liệu, thuật toán, đáp ứng tức thời gợi ý truy vấn, ...)
trở nên hoàn toàn khả thi. Kết quả của thực nghiệm đưa ra 3 dạng gợi ý: Gợi ý truy
vấn, gợi ý tài liệu và gợi ý chủ đề.
Đóng góp chính của chương 3 bao gồm:
1) Ứng dụng kỹ thuật hướng ngữ cảnh, xây dựng máy tìm kiếm chuyên
sâu áp dụng hướng ngữ cảnh trong miền cơ sở tri thức riêng (dữ liệu hàng
không).
2) Đề xuất độ đo tương đồng tổ hợp trong bài toán gợi ý truy vấn theo
ngữ cảnh nhằm nâng cao chất lượng gợi ý.
Ngoài ra, chương 3 cũng có các đóng góp bổ sung trong thực nghiệm: i) Tích
hợp nhận dạng và tổng hợp tiếng nói tiếng Việt như một tùy chọn vào máy tìm kiếm
để tạo thành một hệ tìm kiếm có tương tác tiếng nói. ii) Áp dụng cấu trúc dàn khái
niệm để phân lớp tập kết quả trả về.
Phương pháp gợi ý truy vấn hướng ngữ cảnh là một nhánh trong bài toán về
máy tìm kiếm, tuy nhiên đây là một vấn đề thiết thực, thu hút sự quan tâm nghiên cứu

93
và rõ ràng là một bài toán khó. Nắm vững nguyên lý, cài đặt hiệu quả phương pháp
hướng ngữ cảnh, là một giải pháp tốt hỗ trợ người sử dụng trong quá trình tìm kiếm
thông tin. Máy tìm kiếm tiếng Việt áp dụng phương pháp hướng ngữ cảnh hứa hẹn
đem đến những kết quả đột biến, thú vị và hiệu quả trong lĩnh vực gợi ý truy vấn.
Việc phát hiện tri thức tiếp tục đặt ra nhiều vấn đề mới vì nội tại Query Logs còn
chứa nhiều tri thức tiềm ẩn, ví dụ như dữ liệu về {IP, query}: phản ánh lịch sử người
dùng (user’s history) có thể khai phá để tìm kiếm cá nhân hóa (personalized search)
hay gợi ý truy vấn cá nhân hóa (personalized query suggestion); Hay như khai phá
dữ liệu cặp {URL, title} để tìm các kết quả liên quan. Hoặc khai phá đồ thị 2 phía để
tìm ra mối quan hệ tài liệu – truy vấn dù tập tài liệu (tập đỉnh U), tập truy vấn (tập
đỉnh Q) không có terms chung: Nếu tập tài liệu D’ thường xuyên được click đọc bởi
tập queries Q’, thì các terms trong Q’ liên quan mạnh đến các terms trong D’. Cũng
như vậy, gợi ý truy vấn và phân loại tập kết quả thực chất là 2 tiến trình riêng biệt,
cần nghiên cứu áp dụng tính toán song song.

94
CHƯƠNG 4: KẾT LUẬN VÀ KIẾN NGHỊ
Trong phần kết luận, tác giả tóm lược lại các kết quả chính và những đóng góp
của luận án. Ngoài ra, tác giả trình bày một số hạn chế của luận án và thảo luận về
hướng phát triển của các nghiên cứu tiếp theo trong tương lai.
4.1. Kết luận
Áp dụng phân tích khái niệm hình thức (FCA – Formal Concept Analysis) và
cấu trúc dàn khái niệm để khai phá và tìm kiếm dữ liệu văn bản. Dàn là một cấu trúc
đẹp về mặt toán học, thích hợp với khai phá, phân tích và gom cụm dữ liệu, nhưng
dàn không hoàn toàn thích hợp trong lĩnh vực tìm kiếm. Do đó, luận án chuyên sâu
hai hướng nghiên cứu chính: i) Tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa, nhằm
mô phỏng khả năng suy ra thông tin/tri thức chưa biết bằng suy diễn tương tự, như
một khả năng “tự nhiên” của con người; và ii) Gợi ý truy vấn hướng ngữ cảnh - xét
chuỗi truy vấn liền mạch nhằm nắm bắt ý định tìm kiếm, sau đó đưa ra xu hướng mà
tri thức số đông thường hỏi sau truy vấn hiện hành.
Đóng góp của luận án gồm:
Với phương pháp Tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn, nhằm giải
quyết bài toán thứ nhất:
- Luận án nghiên cứu, xây dựng kỹ thuật tìm kiếm thực thể dựa
trên quan hệ ngữ nghĩa ẩn sử dụng phương pháp phân cụm nhằm nâng
cao hiệu quả tìm kiếm.
Với phương pháp Gợi ý truy vấn Hướng ngữ cảnh, mục đích giải quyết bài
toán thứ hai:
- Ứng dụng kỹ thuật hướng ngữ cảnh, xây dựng máy tìm kiếm
chuyên sâu áp dụng hướng ngữ cảnh trong miền cơ sở tri thức riêng (dữ
liệu hàng không).

95
- Đề xuất độ đo tương đồng tổ hợp trong bài toán gợi ý truy vấn
theo ngữ cảnh nhằm nâng cao chất lượng gợi ý.
4.2. Kiến nghị
Với hướng nghiên cứu Tìm kiếm thực thể dựa trên quan hệ ngữ nghĩa ẩn, có
thể nhận thấy mô hình tìm kiếm bị cứng hóa bởi 3 thực thể đầu vào, đây là một nhược
điểm. Để khắc phục nhược điểm, một mặt - xét thêm các loại ánh xạ quan hệ, thêm
yếu tố thời gian để kết quả tìm kiếm được cập nhật và chính xác. Mặt khác, có thể
mở rộng tìm kiếm thực thể với truy vấn đầu vào chỉ gồm một thực thể, ví dụ: “Sông
nào dài nhất Trung Quốc?”, mô hình tìm kiếm thực thể dựa trên ngữ nghĩa ẩn sẽ đưa
ra được câu trả lời chính xác: “Trường Giang”, dù Corpus chỉ có câu gốc “Trường
Giang là sông lớn nhất Trung Quốc”.
Với hướng nghiên cứu Gợi ý truy vấn dựa trên kỹ thuật hướng ngữ cảnh, một
mặt, nghiên cứu này còn một vài thiếu sót thậm chí là khuyết điểm, như lọc nhiễu âm
thanh đầu vào để cải thiện chất lượng nhận dạng, áp dụng học máy để tối ưu các tham
số α, β, γ trong cách tính độ tương đồng tổ hợp của phương pháp tìm kiếm hướng ngữ
cảnh. Mặt khác, nghiên cứu các biến thể của tương đồng quan hệ RelSim (Relational
Similarity) [100], nghiên cứu các phương pháp kết hợp như Word2Vec, Doc2Vec,
Word embeddings [101] … cho máy tìm kiếm. Hướng phát triển, luận án tập trung
vào nghiên cứu các áp dụng các thuật toán thích nghi, các mô hình thống kê, là thành
phần cốt lõi nhất của các hệ thống xử lý ngôn ngữ tự nhiên hiện nay.

96
DANH MỤC CÔNG TRÌNH CỦA TÁC GIẢ
1. Trần Lâm Quân - Vũ Tất Thắng. “Tìm kiếm thực thể dựa trên quan hệ ngữ
nghĩa ẩn”. Hội thảo Quốc gia lần thứ XXI: Một số vấn đề chọn lọc của Công
nghệ Thông tin và Truyền thông. (27-28/07.2018).
2. Trần Lâm Quân - Vũ Tất Thắng. “Search for entities based on the Implicit
Semantic Relations”. Tạp chí Tin học và Điều khiển 2019 (Volume 35,
Number 3. 2019).
3. Trần Lâm Quân - Đỗ Quốc Trường - Phan Đăng Hưng - Đinh Anh Tuấn - Phi
Tùng Lâm - Vũ Tất Thắng - Lương Chi Mai. “A study of applying Vietnamese
voice interaction for a context-based Aviation search engine”. The IEEE RIVF
2013 International Conference on Computing and Communication
Technologies. 10-13.11.2013.
4. Trần Lâm Quân – Vũ Tất Thắng. “Context-aware and voice interactive
search”. (the SoCPaR 2013 special issue). Journal of Network and Innovative
Computing. ISSN 2160-2174 Volume 2, pages 233-239, 2014.
5. Trần Lâm Quân - Phan Đăng Hưng - Vũ Tất Thắng. “Tìm kiếm bằng giọng
nói với kĩ thuật hướng ngữ cảnh”. Tạp chí Khoa học và Công nghệ - Viện Hàn
lâm Khoa học và Công nghệ Việt Nam. ISSN: 0886 768X. Số 52 (1B),
29.06.2014.
6. Trần Lâm Quân - Lê Đức Hiếu - Lê Ngọc Thế - Vũ Tất Thắng. “Một cách tiếp
cận sử dụng cấu trúc dàn khái niệm để khai phá và tìm kiếm dữ liệu văn bản”.
Hội thảo Quốc gia lần thứ XVII: Một số vấn đề chọn lọc của Công nghệ Thông
tin và Truyền thông. 30-31.10.2014.

97
TÀI LIỆU THAM KHẢO
[1]. Christoph Kofler, Martha Larson, Alan Hanjalic, User Intent in Multimedia
Search: A Survey of the State of the Art and Future Challenges. ACM Journals.
Computing Surveys, Vol. 49, No. 2, August 2016.
[2]. R. Song, Z. Luo, J.-Y. Nie, Y. Yu and H.-W. Hon, Identification of ambiguous
queries in web search. Information Processing & Management, 45(2), pages 216–
229, 2009.
[3]. W. Song, Y. Liu, L. Liu et al., Semantic composition of distributed
representations for query subtopic mining. Frontiers Inf Technol Electronic Eng 19,
2018.
[4]. J. Xu, F. Ye, Query Recommendation Using Hybrid Query Relevance. Future
Internet, 2018.
[5]. S. Gaou, A. Bekkari, The Optimization of Search Engines to Improve the Ranking
to Detect User’s Intent. In Advanced Information Technology, Services and Systems.
(AIT2S) 2017.
[6]. Dirk Lewandowski, Jessica Drechsler, Sonja von Mach, Deriving query intents
from web search engine queries. Journal of the American Society for Information
Science and Technology, September 2012.
[7]. Imrattanatrai, Wiradee & Kato, Makoto & Tanaka, Katsumi & Yoshikawa,
Masatoshi, Entity Ranking for Queries with Modifiers Based on Knowledge Bases
and Web Search Results. In IEICE Transactions on Information and Systems, 2018.
[8]. Li, Jing & Sun, Aixin & Han, Ray & Li, Chenliang, A Survey on Deep Learning
for Named Entity Recognition. In IEEE Transactions on Knowledge and Data
Engineering, 2020.
[9]. H. Cao, D. Jiang, J. Pei, Q. He, Z. Liao, E. Chen and H. Li, Towards context-
aware search by learning a very large variable length hidden markov model from
search logs. In Proceedings of the 18th international conference on World wide web,
pages 191–200, April 2009.
[10]. H. Cao, D. Jiang, J. Pei, Q. He, Z. Liao, E. Chen, E and H. Li, Context-aware
query suggestion by mining click-through and session data. In Proceedings of KDD,
pages 875-883, 2008.

98
[11]. Peter D. Turney, The latent relation mapping engine: Algorithm and
experiments. Journal of Artificial Intelligence Research (JAIR), 33, pages 615-655,
2008.
[12]. Dedre Gentner, Structure-mapping: A Theoretical Framework for Analogy.
Elsevier. Cognitive Science, Volume 7, Issue 2, pages 155-170, April–June 1983.
[13]. Peter D. Turney, M.L. Littman, Corpus-based Learning of Analogies and
Semantic Relations. Machine Learning, 60(1–3), pages 251–278, 2005.
[14]. Peter D. Turney, Distributional semantics beyond words: Supervised learning
of analogy and paraphrase. Transactions of the Association for Computational
Linguistics (TACL), 1, pages 353-366, 2013.
[15]. Peter D. Turney and P. Pantel, From frequency to meaning: Vector space models
of semantics. Journal of Artificial Intelligence Research (JAIR), 37, pages 141-188,
2010.
[16]. Peter D. Turney, Similarity of semantic relations. Computational Linguistics,
32(3), 2006.
[17]. Bollegala, Danushka & Matsuo, Yutaka & Ishizuka, Mitsuru, Measuring the
Similarity between Implicit Semantic Relations from the Web. Proceedings of WWW,
pages 651-660, 2009.
[18]. Duc, N., Bollegala et al., Cross-Language Latent Relational Search: Mapping
Knowledge across Languages. In Association for the Advancement of AI, 2011.
[19]. Kato et al., Query by analogical example: relational search using web search
engine indices. In Proceedings of the 18th ACM conference on Information and
knowledge management. ACM, 2009.
[20]. Y.J. Cao et al., Relational Similarity Measure: An Approach Combining
Wikipedia and WordNet. Journal of Applied Mechanics and Materials, 2011.
[21]. E. Agirre, E. Alfonseca, K. Hall, J. Kravalova, M. Pasca and A. Soroa, A study
on similarity and relatedness using distributional and wordnet-based approaches. In
NAACL ’09 Proceedings of Human Language Technologies: The 2009 Annual
Conference of the North American Chapter of the Association for Computational
Linguistics, pages 19–27, 2009.
[22]. Mikolov et al., Distributed Representations of Words and Phrases and their
Compositionality. In Advances in Neural Information Processing Systems 26 (NIPS),

99
2013.
[23]. Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov,
Enriching Word Vectors with Subword Information. Transactions of the Association
for Computational Linguistics, Vol. 5, pages 135-146, 2017.
[24]. Edouard Grave, Piotr Bojanowski, Prakhar Gupta, Armand Joulin, Tomas
Mikolov. Learning Word Vectors for 157 Languages. In LREC (Language Resources
and Evaluation). Feb 19, 2018.
[25]. Tomas Mikolov et al., Efficient Estimation of Word Representations in Vector
Space. In ICLR (Workshop Poster), 2013.
[26]. Kata Gábor, Haïfa Zargayouna, Isabelle Tellier, Davide Buscaldi, Thierry
Charnois, Exploring Vector Spaces for Semantic Relations. In Proceedings of the
2017 Conference on Empirical Methods in Natural Language Processing, pages
1814–1823, 2017.
[27]. Hugo Caselles-Dupré, Florian Lesaint, Jimena Royo-Letelier, Word2vec
applied to recommendation: hyperparameters matter. In Proceedings of the 12th
ACM Conference on Recommender Systems, pages 352–356, September 2018.
[28]. S. Yilmaz, S. Toklu, A deep learning analysis on question classification task
using Word2vec representations. Neural Comput & Applic 32, pages 2909–2928,
2020.
[29]. Prajakta Shinde, Pranjali Joshi, Survey of various query suggestion system,
International Journal of Engineering And Computer Science. ISSN:2319-7242;
Volume 3 Issue 12, pages 9576-9580, December 2014.
[30]. Susan Dumais, Personalized search: potential and pitfalls, In Proceedings of
the 25th ACM International on Conference on Information and Knowledge
Management, October 2016.
[31]. Jinyoung Kim, Jaime Teevan, Nick Craswell, Explicit In Situ User Feedback
for Web Search Results. SIGIR '16: Proceedings of the 39th International ACM
SIGIR conference on Research and Development in Information Retrieval, pages
829–832, July 2016.
[32]. Sørig, Esben; Collignon, Fiebrink and Kando, Evaluation of Rich and Explicit
Feedback for Exploratory Search. In Second Workshop on Evaluation of
Personalisation in Information Retrieval (WEPIR), March, 2019.

100
[33]. Thorsten Joachims et al., Accurately Interpreting Clickthrough Data as Implicit
Feedback. SIGIR, Volume 51, Issue 1, June 2017.
[34]. Edward Rolando Núñez-Valdéz et al., Implicit feedback techniques on
recommender systems applied to electronic books. Computers in Human Behavior.
Volume 28, Issue 4, ScienceDirect, 2012.
[35]. Gai Li and Qiang Che, Exploiting Explicit and Implicit Feedback for
Personalized Ranking. Hindawi Publishing Corporation - Mathematical Problems in
Engineering, Article ID 2535329, 11 pages, 2016.
[36]. Keping Bi, Choon Hui Teo, Yesh Dattatreya, Vijai Mohan, W. Bruce Croft.
Leverage Implicit Feedback for Context-aware Product Search. In SIGIR 2019
eCom, Paris, France, July 2019.
[37]. W. Chen, F. Cai, H. Chen, M. De Rijke, Personalized query suggestion
diversification. In Proceedings of the 40th International ACM SIGIR Conference on
Research and Development in Information Retrieval, pages 817–820, 2017.
[38]. W. Chen, F. Cai, H. Chen et al., Personalized query suggestion diversification
in information retrieval. Springer Link, Front. Comput. Sci. 14, 143602, 19
December 2019.
[39]. C. Bouhini, M. Géry and C. Largeron, Personalized information retrieval
models integrating the user's profile. IEEE Tenth International Conference on
Research Challenges in Information Science (RCIS), Grenoble, pages 1-9, 2016.
[40]. Hiteshwar Kumar Azad, Akshay Deepak, A new approach for query expansion
using Wikipedia and WordNet. Elsevier, Information Sciences. Volume 492, pages
147-163, August 2019.
[41]. Hiteshwar Kumar Azad, Akshay Deepak. Query expansion techniques for
information retrieval: A survey. Elsevier. Information Processing & Management.
Volume 56, Issue 5, pages 1698-1735, September 2019.
[42]. Claveau, Vincent, Kijak, Ewa, Distributional thesauri for information retrieval
and vice versa. In Language and Resource Conference, LREC, 2016.
[43]. Q. Chen, L. Yao and J. Yang, Short text classification based on LDA topic
model. International Conference on Audio, Language and Image Processing
(ICALIP), Shanghai, pages 749-753, 2016.
[44]. J. Xu, F. Ye, Query Recommendation Using Hybrid Query Relevance. Future

101
Internet Journals. Volume 10, Issue 11, 2018.
[45]. Wanyu Chen, Fei Cai, Honghui Chen, Maarten de Rijke, Personalized Query
Suggestion Diversification. In Proceedings of the 40th International ACM SIGIR
Conference on Research and Development in Information Retrieval, pages 817–820,
August 2017.
[46]. Choudhary, Durga & Chandra, Subhash, Adaptive Query Recommendation
Techniques for Log Files Mining to Analysis User’s Session Pattern. In International
Journal of Computer Applications, 2016.
[47]. J. Guo, X. Zhu, Y. Lan et al., Modeling users’ search sessions for high utility
query recommendation. Information Retrieval Journal 20, 2017.
[48]. Lingling Meng, A Survey on Query Suggestion. International Journal of Hybrid
Information Technology. Vol. 7, No. 6, 2014.
[49]. Bai, Lu, Jiafeng Guo, Xueqi Cheng, Xiubo Geng and Pan Du, Exploring the
Query-Flow Graph with a Mixture Model for Query Recommendation. SIGIR
Workshop on Query Representation and Understanding, July 2011.
[50]. P. Boldi, F. Bonchi, C. Castillo, D. Donato, A. Gionis and S. Vigna, The query-
flow graph: model and applications. In Proceeding of the 17th ACM conference on
Information and knowledge management (CIKM’08), pages 609–618, 2008.
[51]. P. Boldi, F. Bonchi, C. Castillo, D. Donato, A. Gionis and S. Vigna, Query
Suggestions Using Query-Flow Graphs. In Proceedings of the 2009 workshop on
Web Search Click Data (WSCD ’09), pages 56–63, Feb 9, 2009.
[52]. Xinbao Shao, Qingshan Li, Yishuai Lin, Boyu Zhou, A meta-search group
recommendation mechanism based on user intent identification. In Proceedings of
the 6th International Conference on Software and Computer Applications (ICSCA
'17), pages 102–106, February 2017.
[53]. E. Sadikov, J. Madhavan, L.Wang and A. Halevy, Clustering query refinements
by user intent. In Proceedings of the International World Wide Web Conference
(WWW’10), pages 841–850, 2010.
[54]. Saxena et al., A Review of Clustering Techniques and Developments. Article in
Neurocomputing, July 2017.
[55]. T. Sajana, C. M. Sheela Rani and K. V. Narayana, A Survey on Clustering
Techniques for Big Data Mining. Indian Journal of Science and Technology, Vol

102
9(3), January 2016.
[56]. Parth Ritin Saraiya et al., Study of Clustering Techniques in the Data Mining
Domain. In International Journal of Computer Science and Mobile Computing, Vol.7
Issue.11, pages 31-37, November 2018.
[57]. K. Sathiyakumari, G. Manimekalai, V. Preamsudha and M. P. Scholar, A survey
on various approaches in document clustering. Int. J. Comput. Technol, pages 1534–
1539, 2011.
[58]. Manpreet Kaur, Usvir Kaur, A Survey on Clustering Principles with K-means
Clustering Algorithm Using Different Methods in Detail. IJCSMC, Vol. 2, Issue. 5,
pages 327 – 331, May 2013.
[59]. Gursharan Saini, Harpreet Kaur, K-Mean Clustering and PSO: A Review.
International Journal of Engineering and Advanced Technology (IJEAT). ISSN: 2249
– 8958, Volume-3, Issue-5, June 2014.
[60]. Hamada M. Zahera, Gamal F. El Hady, F. Waiel, Abd El-Wahed, Query
Recommendation for Improving Search Engine Results. In Proceedings of the World
Congress on Engineering and Computer Science (WCECS), October 20-22, 2010.
[61]. Naeem, Arshia; Rehman, Mariam; Anjum, Maria; Asif, Muhammad,
Development of an efficient hierarchical clustering analysis using an agglomerative
clustering algorithm. Current Science (00113891), Vol. 117 Issue 6, pages 1045-
1053, 9/25/2019.
[62]. Dhiliphanrajkumar Thambidurai, Suruliandi Aandavar and Selvaperumal
Prakasam. Query Recommendation by Coupling Personalization with Clustering for
Search Engine. I.J. Information Technology and Computer Science, pages 82-91,
11/2016.
[63]. W. Wu, H. Li, and J. Xu, Learning query and document similarities from click-
through bipartite graph with metadata. In Proceedings of the Sixth ACM
International Conference on Web Search and Data Mining, 2013.
[64]. L. Noce, I. Gallo and Zamberletti, A. Query and Product Suggestion for Price
Comparison Search Engines based on Query-product Click-through Bipartite
Graphs. In Proceedings of the 12th International Conference on Web Information
Systems and Technologies (WEBIST 2016) - Volume 1, pages 17-24, 2016.

103
[65]. Sébastien Harispe, Sylvie Ranwez, Stefan Janaqi, and Jacky Montmain,
Semantic Similarity from Natural Language and Ontology Analysis. Synthesis
Lectures on Human Language Technologies, Vol. 8, No. 1. (Arxiv, 167 pages), May
2015.
[66]. Slimani, Thabet, Description and Evaluation of Semantic Similarity Measures
Approaches. International Journal of Computer Applications. Vol 80. 25-33.
10.5120/13897-1851, 2013.
[67]. Christoph Lofi, Measuring Semantic Similarity and Relatedness with
Distributional and Knowledge-based Approaches. Information and Media
Technologies, Volume 10, Issue 3. Online ISSN 1881-0896, pages 493-501,
September 15, 2015.
[68]. N. Craswell, Mean Reciprocal Rank. In Encyclopedia of Database Systems.
Springer, Boston, MA, 2009.
[69]. Yao, Yuan et al., DocRED: A Large-Scale Document-Level Relation Extraction
Dataset. ACL (Association for Computational Linguistics), 2019.
[70]. Michele Banko and Oren Etzioni, The Tradeoffs Between Open and Traditional
Relation Extraction. In Proceedings of the 46th Annual Meeting of the Association
for Computational Linguistics, ACL 2008, Columbus, Ohio, USA, pages 28-36,
2008.
[71]. Yun Liu, Mingxin Li, Hui Liu, Junjun Cheng, Yanping Fu, Research of
Unsupervised Entity Relation Extraction. Journal of Computers Vol. 30 No. 1, pages
31-41, 2019.
[72]. Bollegala et al., Relational Duality: Unsupervised Extraction of Semantic
Relations between Entities on the Web. In Proceedings of the 19th International
Conference on World Wide Web, WWW 2010, pages 151-160, Raleigh, North
Carolina, USA, 2010.
[73]. Parapar, Javier & Losada, David & Presedo-Quindimil, Manuel & Barreiro,
Alvaro. Using score distributions to compare statistical significance tests for
information retrieval evaluation. Journal of the Association for Information Science
and Technology. 71. (10.1002/asi.24203), 2019.
[74]. Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schutze,
Introduction to Information Retrieval. Cambridge University Press, 2008.

104
[75]. W. Chen, F. Cai, H. Chen et al., Personalized query suggestion diversification
in information retrieval. Front. Comput. Sci. 14, 143602, 2020.
[76]. Trần Lâm Quân, Vũ Tất Thắng, Kỹ thuật gợi ý truy vấn hướng ngữ cảnh trong
bài toán tìm kiếm. Hội thảo Quốc gia lần thứ XV: Một số vấn đề chọn lọc của Công
nghệ Thông tin và Truyền thông, 03-04.12.2012.
[77]. Z. Liao, D. Jiang, E. Chen, P. Pei, H. Cao, H. Li, Mining Concept Sequences
from Large-Scale Search Logs for Context-Aware Query Suggestion. ACM Trans.
Intell. Syst. Technol. 9, 4, Article 87, 40 pages, 2011.
[78]. T. Ruotsalo, G. Jacucci & S. Kaski, Interactive faceted query suggestion for
exploratory search: Whole-session effectiveness and interaction engagement. Journal
of the Association for Information Science and Technology, 2019.
[79]. Souvick Ghosh, Chirag Shah, Session-based Search Behavior in Naturalistic
Settings for Learning-related Tasks. In CIKM '19: Proceedings of the 28th ACM
International Conference on Information and Knowledge Management, pages 2449–
2452, November 2019.
[80]. Sowmya Yalamanchili (IBM), Log mining in Query recommendation.
International Journal of Information Technology & Systems, Vol. 4; No. 1: ISSN:
2277-9825, 2015.
[81]. X. Fei, S. Zheng, L. Yan and C. Fan, A improved sequential pattern mining
algorithm based on PrefixSpan. World Automation Congress (WAC), Rio Grande,
2016.
[82]. Zhengshen Jiang, Hongzhi Liu, Bin Fu, Zhonghai Wu, Tao Zhang,
Recommendation in Heterogeneous Information Networks based on Generalized
Random Walk Model and Bayesian Personalized Ranking. In Proceedings of the
Eleventh ACM International Conference on Web Search and Data Mining (WSDM
'18), pages 288–296, February 2018.
[83]. Gao, J., et al., Smoothing clickthrough data for web search ranking. SIGIR'09,
pages 355-362, 2009.
[84]. C Rasell and M. Szummer, Random walks on the click graph. In Proceedings of
the 30th annual international ACM SIGIR conference on Research and development
in information retrieval(SIGIR’07), pages 239-246, 2007.
[85]. M. Shajalal, M. Z. Ullah, A. N. Chy and M. Aono, Query subtopic

105
diversification based on cluster ranking and semantic features. International
Conference On Advanced Informatics: Concepts, Theory And Application
(ICAICTA), George Town, pages 1-6, 2016.
[86]. Xiaofei, Zhu., et al., A unified framework for recommending diverse and
relevant queries. In Proceedings of the 20th international conference on World wide
web (WWW '11), pages 37–46, March 2011.
[87]. Wanyu Chen, Fei Cai, Honghui Chen, Maarten de Rijke, Personalized Query
Suggestion Diversification. In Proceedings of the 40th International ACM SIGIR
Conference on Research and Development in Information Retrieval (SIGIR '17),
pages 817–820, August 2017.
[88]. Claudio Carpineto, Sergei O. Kuznetsov, Amedeo Napoli, Formal Concept
Analysis Meets Information Retrieval. Workshop co-located with the 35th European
Conference on Information Retrieval (ECIR), 2013.
[89]. Frano Škopljanac-Mačina, Bruno Blašković, Formal Concept Analysis –
Overview and Applications, ScienceDirect, 24th DAAAM International Symposium
on Intelligent Manufacturing and Automation, 2013.
[90]. Larry González, Aidan Hogan, Modelling Dynamics in Semantic Web
Knowledge Graphs with Formal Concept Analysis. In Proceedings of the 2018 World
Wide Web Conference (WWW '18), pages 1175–1184, April 2018.
[91]. A. Abid, M. Rouached & N. Messai, Semantic web service composition using
semantic similarity measures and formal concept analysis. Multimed Tools Appl 79,
6569–6597, Dec 2019.
[92]. Claudio Carpineto and Giovanni Romano, Using Concept Lattices for Text
Retrieval and Mining. In Formal Concept Analysis, pages 161-179, 2005.
[93]. Singh, Prem & Cherukuri, Aswani Kumar, Concept lattice reduction using
different subset of attributes as information granules. In Granular Computing.
Springer International Publishing Switzerland. 2016.
[94]. Bernhard Ganter, Sebastian Rudolph, Gerd Stumme, Explaining Data with
Formal Concept Analysis, Springer International Publishing, 2019.
[95]. Nizar Messai, Marie-Dominique Devignes, Amedeo Napoli, and Malika Smail-
Tabbone, BR-Explorer: An FCA-based algorithm for Information Retrieval. Fourth
International Conference, CLA, 2006.

106
[96]. Ganter, Wille, Formal Concept Analysis: Mathematical Foundations. Springer-
Verlag, Berlin Heidelberg New York, 1999.
[97]. D.G. Kourie, S. Obiedkov, B.W. Watson, D. Van der Merwe, An incremental
algorithm to construct a lattice of set intersections. Sci. Comput. Programm 74, pages
128–142, 2009.
[98]. Trần Lâm Quân, Tìm kiếm thế hệ mới: Tìm kiếm thông minh lai. Chuyên san
ngành Hàng không Việt Nam, 2011.
[99]. Trần Lâm Quân, Vũ Tất Thắng, An Approach Using Concept Lattice Structure
for Data Mining and Information Retrieval. Journal of Science and Technology: Issue
on Information and Communication Technology, Vol. 1, No.1, August 2015.
http://ict.jst.udn.vn/index.php/jst/article/view/4
[100]. Wang, Chenguang et al., RelSim: Relation Similarity Search in Schema-Rich
Heterogeneous Information Networks. In Proceedings of the 2016 SIAM
International Conference on Data Mining (SDM), 2016.
[101]. Kata Gábor, Haïfa Zargayouna, Isabelle Tellier, Davide Buscaldi, Thierry
Charnois, Exploring Vector Spaces for Semantic Relations. In Proceedings of the
2017 Conference on Empirical Methods in Natural Language Processing, pages
1814–1823, September 7–11, 2017.