msc thesis business informatics
TRANSCRIPT

1
Ontwerp van data warehouses: opslag van data en integratie van constraints
Ferry Kemperman Huissen / Nijmegen
Februar i – December 2000
Afstudeerscriptie nr. 475 Bedrijfsgerichte Informatica
Faculteit der Natuurwetenschappen, Wiskunde en Informatica Katholieke Universiteit Nijmegen

2

3
VOORWOORD.............................................................................................................................................. 5
1 CONTEXTBEPALING ............................................................................................................................... 6
1.1 WAT IS EEN DATA WAREHOUSE EN WAT KUN JE ER MEE DOEN? .................................................................. 6 1.2 DE DATA WAREHOUSE ARCHITECTUUR ..................................................................................................... 8
1.2.1 De operationele systemen ................................................................................................................. 9 1.2.2 De extractietools: Wrapper en Monitor............................................................................................. 9 1.2.3 De Integrator.................................................................................................................................. 10 1.2.4 De data warehouse gezien als database .......................................................................................... 10 1.2.5 De metadata ................................................................................................................................... 10 1.2.6 De data mart .................................................................................................................................. 10 1.2.7 De multidimensionale database....................................................................................................... 11 1.2.8 De Molap/Rolap server................................................................................................................... 11 1.2.9 De front end tools of OLAP tools .................................................................................................... 11
1.3 PROBLEMATIEK OMTRENT DE OPSLAG VAN DATA EN INTEGRATIE VAN CONSTRAINTS ............................... 11 1.3.1 Iets over data opslag in data warehouses ........................................................................................ 12
2 CONSTRAINTS IN EEN DATA WAREHOUSE, EEN VERKENNING VIA PSM ............................... 14
2.1 KORTE INTRODUCTIE VAN HET DIMENSIONALE MODEL ............................................................................ 14 2.1.1 Een case uitwerking........................................................................................................................ 14
2.1.1.1 Introductie van de case ..............................................................................................................................14 2.1.1.2 De case wordt in het dimensionale model gegoten .....................................................................................15 2.1.1.3 Case invulling van het geschetste model van Down Under..........................................................................17
2.2 CONSTRAINTS IN HET DIMENSIONALE MODEL, EEN BENADERING VIA HET RELATIONELE MODEL ................ 19 2.2.1 Introductie van PSM....................................................................................................................... 20 2.2.2 Populaties in PSM .......................................................................................................................... 23
2.2.2.1 Universe of instances gedefinieerd.............................................................................................................23 2.2.2.2 Populaties gedefinieerd..............................................................................................................................24
2.2.3 Constraints in PSM......................................................................................................................... 27 2.2.3.1 Relationele algebra....................................................................................................................................27
2.2.3.1.1 Schema gedefinieerd ..........................................................................................................................28 2.2.3.1.2 Val gedefinieerd.................................................................................................................................28 2.2.3.1.3 Meer relationele operaties...................................................................................................................30
2.2.3.2 Constraints onder de loep ..........................................................................................................................33 2.2.3.2.1 Total role constraint ...........................................................................................................................33 2.2.3.2.2 Uniqueness constraint.........................................................................................................................36
2.2.3.2.2.1 Uniqueness constraint applied to one facttype ..............................................................................37 2.2.3.2.2.2 Uniqueness constraint applied to more facttypes...........................................................................39 2.2.3.2.2.3 Uniqueness constraint applied to objectification ...........................................................................42
2.2.3.2.3 Occurrence frequency constraint.........................................................................................................49 2.2.3.2.4 Set constraints....................................................................................................................................50 2.2.3.2.5 Enumeration constraint.......................................................................................................................50 2.2.3.2.6 Power type constraints........................................................................................................................50 2.2.3.2.7 Specialisation constraints....................................................................................................................51 2.2.3.2.8 Subtype defining rules........................................................................................................................51 2.2.3.2.9 Schema type constraints .....................................................................................................................52 2.2.3.2.10 Constraint definities .........................................................................................................................52
3 HET DIMENSIONALE MODEL UITGEDIEPT..................................................................................... 53
3.1 EEN VERDERE VERKENNING VAN CONSTRAINTS IN HET DIMENSIONALE MODEL......................................... 53 3.2 FUNCTIES VAN DE CONSTRAINTS IN HET DIMENSIONALE MODEL............................................................... 54 3.3 EEN VERKENNING VAN DE CONSTRAINTS IN DE DATA CUBE VIA EEN VOORBEELD ...................................... 54
3.3.1 De data cube geanalyseerd ............................................................................................................. 54 3.3.1.1 Perspectieven van dimensies: de rotate-functie ...........................................................................................56 3.3.1.2 Aggregatie van data: Drill Up/Down en Roll Up ........................................................................................56 3.3.1.3 Begrippenkader.........................................................................................................................................57
3.3.2 De presentatie van gegevens in data cube jargon ............................................................................ 58 3.3.2.1 Enkelvoudige cel.......................................................................................................................................58 3.3.2.2 Tweedimensionale slice.............................................................................................................................58 3.3.2.3 Multidimensionale sub cube ......................................................................................................................59
3.4 DE CASE DOWN UNDER IN HET DATA CUB E CONCEPT .............................................................................. 60 3.4.1 De intra-cube constraints................................................................................................................ 62 3.4.2 De inter-cube constraints............................................................................................................... 63

4
3.5 CONSTRAINTS BENADERD VANUIT HET DIMENSIONALE MODEL VIA STAR JOIN SCHEMA ............................. 64 3.6 VOORBEELD VAN HET GEBRUIK VAN DE JOIN EN APPLICATION CONSTRAINT ............................................. 64
3.6.1 De dimensie geografische ligging en de application constraint........................................................ 66 3.6.2 SQL en de join constraint................................................................................................................ 67
4 RELATIONEEL EN DIMENSIONAAL: EEN VERGELIJKEND ONDERZOEK MET BETREKKING TOT CONSTRAINTS EN MEER................................................................................................................ 69
4.1 INTRODUCTIE VAN NESTED DATA CUBES ............................................................................................... 69 4.2 NESTED DATA CUBES OPGEBOUWD ........................................................................................................ 69 4.3 NESTED DATA CUBES: EEN EERSTE VERKENNING VIA DOWN UNDER ....................................................... 71 4.4 KLASSIEKE DATASTRUCTUREN IN NDC .................................................................................................. 72 4.5 NDC ALGEBRA ...................................................................................................................................... 73
4.5.1 De bagify operator ......................................................................................................................... 73 4.5.2 De extend operator ......................................................................................................................... 74 4.5.3 De nest operator............................................................................................................................. 75 4.5.4 De unnest operator ......................................................................................................................... 77 4.5.5 De duplicate operator..................................................................................................................... 77 4.5.6 De select operator .......................................................................................................................... 78 4.5.7 De rename operator........................................................................................................................ 79 4.5.8 De aggregate operator.................................................................................................................... 79
4.6 MODELLERING VAN RELATIONELE OPERATOREN IN HET NDC MODEL ...................................................... 80 4.7 NDC ALGEBRA TOEPASBAAR OP ELKE DIEPTE IN EEN NDC ..................................................................... 84 4.8 EEN INFORMELE MAPPING VAN RELATIONEEL OP DIMENSIONAAL EN VICE VERSA...................................... 84 4.9 DOWN UNDER IN PSM: EEN VERGELIJKING MET HET NDC MODEL .......................................................... 86 4.10 OPSLAG VAN AGGREGATIES IN EEN DATA WAREHOUSE .......................................................................... 93 4.11 MULTIDIMENSIONALE BENADERING VAN AGGREGATIES IN PSM GEMODELLEERD .................................. 93 4.12 EEN AANZET TOT DE BESCHRIJVING VAN DE SEMANTIEK VAN CONSTRAINTS IN HET DIMENSIONALE MODEL
................................................................................................................................................................... 97 4.13 EEN INTERMEZZO OVER VIEW MAINTENANCE ...................................................................................... 100
5 CONCLUSIES EN VERDER ONDERZOEK ........................................................................................ 102
5.1 SAMENVATTING................................................................................................................................... 102 5.2 ALGEMENE CONCLUSIES ...................................................................................................................... 103 5.3 VERDER ONDERZOEK ........................................................................................................................... 104 5.4 TERUGBLIK ......................................................................................................................................... 105
BIBLIOGRAFIE ........................................................................................................................................ 106
BRONVERMELDING FIGUREN EN TABELLEN................................................................................. 108
INDEX ........................................................................................................................................................ 109
FIGURENINDEX....................................................................................................................................... 111
TABELLENINDEX.................................................................................................................................... 111

5
Voorwoord Voor u ligt mijn afstudeerscriptie “Ontwerp van data warehouses: opslag van data en integratie van constraints” , de kroon op mijn studie Bedrijfsgerichte Informatica. Deze scriptie heeft mij veel tijd en moeite gekost, evenals mijn studie. Moeizame periodes wisselden zich tijdens mijn studietijd af met momenten van goede motivatie. Sommige vakken vond ik zeer interessant (vooral die uit de specialisatierichting en de leerzame GiP-reeks) en gingen me dan ook redelij k goed af, maar andere bezorgden me hoofdbrekens. Met name P4, W4 en W6 vielen me erg zwaar en hebben me de nodige moeite gekost te halen. Na 8 jaar middelbare school en 6½ jaar universiteit vind ik het mooi geweest. Ik wil iedereen bedanken die mij gedurende mijn gehele studietijd en scriptie heeft geholpen, op welke wijze dan ook. Mensen die ik in dit verband bij name wil noemen zijn: mijn ouders en mijn broer Mark, mijn goede vrienden Ernest Neijenhuis en Jaap Penders met wie ik zeer veel heb samengewerkt in het verleden, mijn goede vriend en studiegenoot Dennis Noy voor een perfecte samenwerking gedurende de gehele studie aan de KUN. We vulden elkaar perfect aan. Verder mijn afstudeerbegeleider Patrick van Bommel voor de goede begeleiding en de (bijna) wekelijkse nuttige bijeenkomsten. Verder heb ik gedurende mijn studie prettig samengewerkt met mijn goede vriend Sander van Woerkom en Richard Arts. Zij hebben mij geholpen bij vakken die me moeilij k vielen. Zonder hen was ik hier nooit gekomen! Bedankt allemaal! Ferry Kemperman 22 december 2000 Een tweetal opmerkingen vooraf: Dit werk is in de wij-vorm geschreven. Ik heb hier bewust voor gekozen. De definitie van Val wordt in de li teratuur beschreven met een ruimteli jk haakje. Door printerproblemen is in dit werk het een gewoon haakje ( [ en ] ) geworden. Informatie over de auteur: Ferry Remon Kemperman werd op 16 januari 1974 geboren in Huissen. Na de HAVO (1986-1991) aan het Nederrijn College in Arnhem vervolgde hij op dezelfde school met het VWO (1991-1994). In september 1994 begon hij met de opleiding Informatica aan de Katholieke Universiteit Nijmegen. In de periode december 2000 rondde hij i n de specialisatierichting Bedrijfsgerichte Informatica deze studie af met het voor u liggende werk. Het afstudeerpraatje werd gehouden op 12 januari 2001 om 14.00 uur in colloquiumkamer A2041.

6
They say it's always the same, two steps forward one step back Whatever he arranges, we must do the best we can Your pain is mine, my blood is yours, can you hear me, I 'm calli ng you You have the power over me, I 'm rendered helpless, you've got me on my knees You have the power over me, nothing is certain, I wait for recovery Power Over Me, Mr.Mister
1 Contextbepaling In dit eerste hoofdstuk zal een kader worden geschept voor de probleemstelling die wordt behandeld in deze scriptie. Als eerste zal worden ingegaan op de vraag wat een data warehouse nu precies inhoudt en wat je ermee kan doen. Vervolgens zal een introductie worden gegeven over hoe een data warehouse technisch gezien eruit ziet en wat voor specifieke problemen er kunnen optreden bij het opzetten van zo’n data warehouse. Als laatste zal dit hoofdstuk worden afgesloten met een uiteenzetting naar de specifieke probleemstell ing van deze scriptie, namelij k de opslag van data in data warehouses voor OLAP-toepassingen en de integratie van constraints. Hier zullen ook de verschill ende problemen aan bod komen. 1.1 Wat is een data warehouse en wat kun je er mee doen? De term data warehouse komt al geruime tijd voor in wetenschappelij ke en technische vakbladen, maar ook in magazines en tijdschriften van specifieke maatschappelij ke en commerciële sectoren. Een voorbeeld van zo’n sector is het bankwezen. Hieronder zien we een artikel dat door NCR banken uit Noorwegen op het WWW is gezet als persbericht [WWW03]. In dit persbericht wordt een mooie toepassing geschetst van een data warehouse, in het Nederlands ook wel gegevenspakhuis genoemd.
De toekomst volgens NCR en Sparebanken NOR Amsterdam, 7 augustus 1998 - Volgens NCR Corporation en Sparebanken NOR (Noorwegen) wordt bankieren gemakkelijker, sneller en leuker voor de consument, leidt het tot minder kosten voor de banken en tot minder papierwerk voor iedereen. De twee bedrijven hebben tezamen het bankfiliaal van morgen bedacht, ontworpen en ingevoerd. Zodra een klant een filiaal van Sparebanken NOR binnenloopt, voert hij zijn bankcard in. Met een speciaal genummerd kaartje wordt hij geïdentificeerd door het gegevenspakhuis, dat een bericht terugstuurt met de klantgegevens. Een videoscherm boven de baliemedewerker toont op de klant gerichte advertenties en de baliemedewerker zelf heeft alle relevante gegevens onmiddellijk bij de hand, zoals welke folders naar deze klant zijn gestuurd en welke diensten verder kunnen worden aangeboden. Klanten bekrachtigen hun opdrachten elektronisch, zodat geen papier nodig is. Dit concept maakt ook de omvangrijke procedureboeken en de dagelijkse papieren administratie van het bankkantoor overbodig. Iedere week worden vijf filialen van Sparebanken NOR herbouwd en uitgerust, en worden de medewerkers omgeschoold. Inmiddels zijn meer dan 140 nieuwe filialen omgevormd. Volgens plan zullen medio 1999 alle 350 kantoren in het netwerk van Sparebanken NOR en zijn partners volgens dit concept zijn aangepast. In dit artikel wordt de indruk gewekt dat de data warehouse een soort grote database is met een grote mate van flexibiliteit m.b.t. tot het vinden van informatie en verbanden in die informatie. Dit laatste is onder meer te halen uit de zin “Een videoscherm boven de baliemedewerker toont op de klant gerichte

7
advertenties en de baliemedewerker zelf heeft alle relevante gegevens onmiddellij k bij de hand”. Nu er een gedachte is gecreëerd omtrent het begrip data warehouse kunnen we een definitie aangeven op een hoog abstractieniveau. “ Een data warehouse is een concept dat is opgebouwd uit hard- en software elementen dat het mogelij k maakt om zeer grote hoeveelheden gegevens te analyseren om zodoende managers in staat te stellen om betere bedr ijfsbeslissingen te nemen op strategisch en tactisch niveau” Een kanttekening die hier geplaatst dient te worden is het volgende. Een data warehouse is op vele abstractieniveaus te definiëren, van zeer abstracte naar technisch zeer gedetailleerde definities. Tevens is er een groot aantal definities in omloop, waarbij een ieder zijn eigen interpretatie aan dit begrip geeft. In dit document zullen we de bovenstaande definitie aanhouden wanneer we praten op het niveau van het gebruik van data warehouses (dus de meer algemene definitie) en de definitie die wordt gegeven in de volgende paragraaf in het geval er op technisch niveau over data warehouses wordt gesproken. Dan is er ook nog een derde interpretatie die in dit document voorkomt, namelijk de data warehouse beschouwende als een database. Deze interpretatie zal uitsluitend voorkomen bij het gebruik in figuren en bespreking van deze figuren. Wanneer we de definitie onder de loep nemen, vallen geli jk aan aantal zaken op. Een data warehouse is een concept en geen nieuwe technologie. Een data warehouse moet men dus beschouwen als een vernieuwd inzicht opgebouwd uit al reeds bekende zaken. Een van die zaken zijn de zogenaamde legacy-systemen, bestaande uit een informatiesysteem en een database die er zijn voor operationele doeleinden. Een intuïtieve definitie die men van een data warehouse zou kunnen geven is een grote verzameling gegevens (een soort super database) die geanalyseerd kan worden om bepaalde verbanden en trends te vinden om zo een betere bedrij fsvoering er op na te kunnen houden. Vragen die hierbij rijzen zijn natuurli jk: Hoe kom je aan zo’n grote verzameling gegevens? Welke gegevens komen er in die super database en op welke wijze? Welke eisen dienen er gesteld te worden aan die gegevens? Welke analyses moeten er met de gegevens gemaakt kunnen worden? Hoe pak je die analyses aan? Etcetera Een antwoord op enkele van deze vragen zal in de loop van deze scriptie worden gegeven. Een andere vraag die gesteld kan worden is de vraag naar de noodzaak van zo’n data warehouse. Zijn operationele systemen (ook wel OLTP of legacy-systeem genoemd) niet in staat de gevraagde analyses te plegen? Een ontkennend antwoord moet hier worden gegeven. Een dergelij ke analyse vereist een aantal belangrij ke aspecten van het systeem en de gegevens. Operationele systemen konden dit niet aan vanwege [Hobo97]: • Gebrek aan historische data • Inconsistentie en verandering van gegevens • Gegevens die nodig zijn voor een analyse zitten vaak in verschil lende operationele systemen • Query uitvoeringen duren extreem lang (zeer complexe query’s, slechte retrievaltijd) De belangrij ke verschillen tussen een operationeel systeem en een data warehouse kunnen hieruit direct worden afgeleid (gedeeltelij k afgeleid uit [Hobo97]). • Tijdsfactor
In een data warehouse is het van groot belang dat de historie van gegevens wordt vastgehouden. Er wordt dus een historie opgeslagen van de gegevens. Er worden geen updates van de gegevens gemaakt en de gegevens zijn in principe read-only in een data warehouse. In een operationeel systeem is een historie niet aanwezig. De tijdsdimensie van gegevens is een zeer belangrijk aspect bij een data warehouse.

8
• Onderwerp georiënteerde kijk In een data warehouse gaat het erom de eindgebruiker als referentiepunt te zien in het presenteren van de gegevens. In een operationeel systeem zijn de gegevens vaak georganiseerd naar het perspectief van een applicatie.
• Grote hoeveelheid gegevens Bij een data warehouse gaat het om beheer van zeer grote aantallen gegevens. Dit komt mede door het feit dat er historische gegevens dienen te worden opgeslagen (in principe wordt er in een data warehouse niets verwijderd vanuit historisch perspectief). In tegenstelling tot een operationeel systeem, waarbij vaak historische gegevens worden geüpdate, is het hier dus van essentieel belang deze juist te bewaren.
• Samenvattingen en geaggregeerde gegevens In operationele databases is er vaak een zeer grote mate van detail aanwezig in de gegevens. Een data warehouse zal samenvattingen en aggregatie van gegevens moeten toepassen om tot goed gebruik te komen van de data warehouse. Dit is een noodzaak om informatie te kunnen extraheren die voor beslissingsondersteunde doeleinden worden gebruikt.
• Integratie en associatie van gegevens uit verschill ende bronnen De data warehouse “voedt” zichzelf via vaak al bestaande (operationele) systemen en verschill ende applicaties. Deze verschillende bronnen gebruiken vaak verschill ende manieren waarop hun gegevens worden opgeslagen en worden beheerd. Voor opname in de data warehouse dienen de gegevens consistent te zijn en moeten bepaalde zaken geconverteerd worden. Dit alles om een bruikbare data warehouse te verkrijgen.
• Multidimensionaliteit van gegevens Gegevens die in een data warehouse worden opgeslagen kunnen vanuit meerdere dimensies worden opgeslagen. Dit om er voor te zorgen dat de gegevens vanuit elk gewenst perspectief bekeken en geraadpleegd kunnen worden. Een toepassing hiervan is de presentatie van gegevens in een kubus i.p.v. de traditionele 2-dimensionale tabellen.
Nu we een beeld hebben gevormd van een data warehouse en zijn doelen kunnen we in de volgende paragraaf doorgaan met het conceptidee achter een data warehouse. We doen dit door aan de hand van een meer technisch perspectief naar een data warehouse te kij ken. 1.2 De data warehouse architectuur Het begrip data warehouses passeert vaak de revue in de vakli teratuur over databases. In deze li teratuur worden allerlei verschill ende technische definities gebruikt voor een data warehouse. Om een goed kader te geven aan het begrip data warehouse in technische zin is het noodzakelij k in te zien dat we een data warehouse moeten beschouwen als een architectuur van deels al reeds bestaande systemen en technieken. Een data warehouse is eigenlijk een architectuur voor het genereren van informatie die kan ondersteunen bij bedrijfsbeslissingen op het tactisch en strategisch managementniveau. Nu zullen we een bespreking geven van de algemene architectuur van een data warehouse. Wanneer het technische kader rond een data warehouse is geschept, kunnen we ons toespitsen op de problematiek omtrent gegevensopslag in de volgende paragraaf. In onderstaande figuur (figuur 1) zien we een algemene structuur van een data warehouse. Het figuur is ontleend aan [SMKK98].

9
Figuur 1: De data warehouse architectuur
We zullen de verschillende onderdelen van de architectuur afzonderlij k bespreken in de nu volgende paragrafen. Dit draagt bij aan het creëren van een goed inzicht in de architectuur van een data warehouse, hetgeen weer belangrij k is als fundament voor het inzicht in de opslag van data in een data warehouse. 1.2.1 De operationele systemen Onder operationele systemen worden die systemen verstaan die in een bedrijf als dagelij ks gebruik dienen. Deze systemen zorgen voor de dagelij kse informatievoorziening van het bedrijf en bevatten gegevens van alledag. Een operationeel systeem is vaak een eenvoudige database met relatief weinig (complexe) informatie en een onderliggend informatiesysteem. We hebben reeds gezien wat de kenmerken van dergelij ke systemen zijn (paragraaf 1.1). Een belangrijk kenmerk van operationele systemen is het ontbreken van een historie. De gegevens in een operationeel systeem zijn bedoeld voor dag tot dag beslissingen. [Hobo97] spreekt over gegevens voor het draaiende houden van de onderneming. Een belangrijk inzicht bij operationele systemen is dat ze van heel verschillende aard kunnen zijn. De systemen kunnen zeer uiteenlopend zijn qua gegevensopslag, soort database, soort informatie, manier van beheer, manier van retrieval van informatie (en daarmee samenhangend de responsietijden). Voorbeelden zijn een Relational Database Management Systemen (RDBMS) of andere, bijvoorbeeld, heterogene informatiesystemen. De bedoeling is nu om gegevens uit deze operationele systemen als bron te gebruiken voor de data warehouse data. Om deze gegevens in een data warehouse te kunnen opnemen is het noodzakelij k de gegevens te bewerken. Dit wordt gedaan door de zogenaamde extractietools als de wrapper en de monitor. Deze worden in de volgende paragraaf besproken. 1.2.2 De extractietools: Wrapper en Monitor De wrapper is een stuk software dat er voor zorgt dat de informatie afkomstig uit de operationele gegevenbronnen wordt geanalyseerd voor opname in de data warehouse. De gegevens dienen te worden geselecteerd, getransformeerd en te worden opgeschoond alvorens ze worden doorgegeven

10
aan de zogenaamde integrator. De integrator zal in de volgende paragraaf worden besproken. De wrapper gaat bijvoorbeeld kijken of de gegevensmodellen van de operationele gegevensbronnen aansluiten bij het gegevensmodel van de data warehouse. Wanneer dit niet het geval is, zal de wrapper een transformatie moeten maken van de presentatie van deze gegevens. Een voorbeeld van zo’n transformatie is de presentatie van flat files in de vorm van een relationeel gegevensmodel (wanneer de data warehouse gebruikt maakt van het relationele gegevensmodel). De monitor heeft hetzelfde doel als de wrapper, maar focust op een ander punt. De monitor, zoals de naam als suggereert, “monitort” op veranderingen in de operationele gegevensbronnen. Wanneer er zich een wijziging voordoet in de operationele systemen, zal er een update moeten plaatsvinden van de data warehouse. De monitor spaart veranderingen in de bronnen op en zal deze op gezette tijden doorgeven aan de integrator. Dit is uiterst belangrij k, daar de data warehouse up-to-date dient te blij ven in vrijwel alle gevallen. De monitor bekijkt bijvoorbeeld veranderingen van bepaalde waarden en formaten van de operationele systemen. Wanneer de data warehouse continu online moet zijn, zal de monitor de veranderingen direct moeten doorgeven aan de integrator. Wanneer de data warehouse af en toe offline kan zijn (denk aan ’s nachts of in het w eekend) is het mogelij k om op gezette tijden de data warehouse te updaten (in deze offline tijd). Echter, in deze tijd, waar handel over de hele wereld en dus in verschill ende tijdzones plaatsvindt, is het zeer wenselij k de data warehouse continu online te laten. Dit brengt met zich mee dat het maken van een update in de data warehouse niet zo gemakkelij k meer is. Een probleem dat optreedt is het geval dat er concurrent gebruikt wordt gemaakt van bepaalde updates en query-vragen. Dit probleem zal later nog aan de orde komen. 1.2.3 De Integrator De integrator is een tool dat de data, na aanlevering door de wrapper /monitor, opmaakt voor opslag in de data warehouse. Denk hierbij aan data die inconsistent is uit verschill ende bronnen en data die conflicten kunnen opleveren. Het uiteindelij ke doel is het creëren van een data warehouse dat direct kan inspelen op de vraag naar managementinformatie die nodig wordt geacht. De integrator is voornamelijk bedoeld om de data klaar te zetten voor tools die het vervolgens in de data warehouse laden. 1.2.4 De data warehouse gezien als database De feitelijke database die als data warehouse wordt beschouwd kan op meerdere manieren worden uitgelegd. In de data warehouse worden gegevens opgeslagen uit de externe bronnen. Dit kunnen gegevens zijn die een afbeelding zijn van de externe bron (lees een view) of de feitelij ke data. Deze gegevens kunnen ook geaggregeerd zijn, d.w.z. dat ze zijn voorbewerkt door een eerdere aanvraag. Op deze wijze ontstaat redundantie in de database. De wijze waarop de data warehouse is opgebouwd hangt af van de gebruikte architectuur, relationeel of multidimensionaal. 1.2.5 De metadata De metadata is een speciaal soort data in de data warehouse. Metadata laat zich het best uitleggen als data over data. Hiermee wordt bedoeld data die wordt opgeslagen over de feitelij ke data in de data warehouse. Denk aan gegevens die iets vertellen over wanneer bepaalde data in de warehouse is opgeslagen, wanneer er voor het laatst geüpdate is vanuit een bepaalde externe bron, etc. Ook gegevens die iets zeggen over de creatie van gegevens in een data warehouse en het gebruik van deze gegevens in een data warehouse vallen onder metadata. 1.2.6 De data mart Een data mart is een verkleind data warehouse. Een data mart richt zich op speciale afdelingen van een bedrijf en is dus ook bedoeld voor analyses t.b.v. 1 soort divisie. Aangezien de data mart niet binnen de scope van deze scriptie valt, zal ik hier volstaan met een verwijzing naar een recent artikel over data marts. Zie hiervoor het artikel van Rob Arntz voor de NSCCS 2000 [Arntz00].

11
1.2.7 De multidimensionale database De multidimensionale database bevat, naast de gewone data warehouse, gegevens die worden gepresenteerd in multidimensionale vorm. Dit zijn vaak geaggregeerde gegevens, die reeds zijn voorbewerkt door de OLAP-server (uit eerdere query’s) en voor een snelle retrievaltijd van een nieuwe query stand-by blij ven. Wanneer nu een query wordt gelanceerd die de geaggregeerde gegevens direct kan gebruiken, zonder ze eerst te hoeven berekenen uit de gewone data, kan deze binnen een veel snellere retrievaltijd worden beantwoord. De data warehouse hoeft echter niet een aparte database voor dit soort query’s te hebben. Het is goed mogeli jk dat de data warehouse zelf een multidimensionale gegevensopslag gebruikt. De multidimensionale database vormt een belangrij k onderdeel van deze scriptie. 1.2.8 De Molap/Rolap server De MOLAP-architectuur en ROLAP-architectuur zijn de twee verschillende architecturen die gebruikt worden voor het uitvoeren van de analyses door de OLAP tools. De MOLAP architectuur is een architectuur die zich baseert op het multidimensionale model. De geaggregeerde gegevens worden bij deze architectuur in een aparte database opgeslagen naast de data warehouse. Deze database slaat de gegevens multidimensionaal op. In dit geval is het niet nodig geaggregeerde gegevens op te slaan in de feitelij ke data warehouse. De server heeft voornamelij k tot doel de gebruikersvragen om te zetten in complexe query’s (extended SQL ) die geschikt zijn om informatie te halen uit de data warehouse en deze vervolgens in de vorm van een multidimensionale presentatie aan te bieden aan de OLAP tools. De ROLAP architectuur is een architectuur waarbij de data warehouse wordt opgebouwd volgens het relationele model. Hierbij dienen de OLAP tools de relationele structuur van de data warehouse te benaderen. Multidimensionale aspecten van de gegevens dienen in een relationeel model te worden opgeslagen. Dit is zeer wel mogelijk. [Hobo97] spreekt over een mythe die ontkracht wordt door Sjoerd Hobo: “gegevens dienen multidimensionaal te worden opgeslagen indien men ze multidimensionaal wilt benaderen.” Dit is pertinent onwaar. 1.2.9 De front end tools of OLAP tools De front end tools zijn de gebruikersprogramma’s waarmee de eindgebruikers van de data warehouse, bijv. de manager die een analyse maakt, de data warehouse aanspreekt voor het uitvoeren van een analyse. De front end tool lanceert de query, bijvoorbeeld geformuleerd in de vorm van een extended SQL-query (hier komen we later op terug), en presenteert na acceptabele retrievaltijd het antwoord in een duidelij ke en overzichtelijke tabel of tabellen. Zo’n front end tool kan zijn een spreadsheet, een data mining tool of andersoortige analyseprogramma’s zijn. [Hobo97] omschrijft OLAP tools als “gereedschappen die gebruikt worden om gegevens te analyseren, de resultaten te visualiseren en die mogelij kheden bieden informatie samen te stellen als resultaat van die analyse.” Deze definitie dekt de drie belangrijke functies van deze tools. Analyse, presentatie en samenstelling van informatie vormen de hoofdtaken van een OLAP tool. 1.3 Problematiek omtrent de opslag van data en integratie van constraints In deze scriptie zullen we verschillende kanten van de data warehouse belichten. Het uitgangspunt hierbij is de verschill ende problemen die spelen bij de opslag en benadering van data in een data warehouse in kaart te brengen. We zullen hiervoor het gebruik van constraints in een data warehouse als rode draad nemen. Het gebruik van constraints in data warehouses is namelij k een ondergeschoven kindje in het huidige onderzoek naar data warehouses. We laten de importantie van een goede constraint set aan het licht komen. We benaderen het gebruik van constraints in een data warehouse op twee verschill ende manieren: vanuit het concept van de data cube en het star join schema. Het dimensionale model, waarop data warehouses worden gemodelleerd, wordt krachtig geïntroduceerd en diep geanalyseerd. Aan de hand van een case zullen we de werking van de verschill ende concepten in dit model demonstreren. Een link met het relationele model is onontbeerlijk: veel inzichten van dit model kunnen we doortrekken naar het dimensionale model.

12
We bekijken hiertoe de manier waarop constraints worden gedefinieerd in het relationele model. Dit doen we uitgebreid aan de hand van de modelleringstechniek PSM. Na introductie van een modelleringstechniek voor het dimensionale model, het zogenaamde Nested Data Cube model (NDC), proberen we de lijn van deze constraints door te trekken naar dit model. Ons uiteindelij ke doel is het aanreiken van mogelij kheden en inzichten om constraints in het dimensionale model te beschrijven in de NDC algebra of soortgelij ke algebra’s. Dit doen we ondermeer door de verschillende problemen uit de beide modellen te vergeli jken (o.a. het modelleren van de belangrij ke aggregatiemogelij kheden uit het dimensionale model in het relationele model). Het belang van een goede en formele beschrijving van constraints in een data warehouse is zeer groot. Dit wordt duidelijk gemaakt aan de hand van verschillende invalshoeken. We zullen ter verduidelij king de inhoud van deze scriptie even kort bespreken. Hoofdstuk 1 geeft de contextbepaling weer. We bespreken het concept data warehouse op verschillende manieren en geven de problemen weer van het huidige onderzoek naar data warehouses. Tevens bakenen we het probleemgebied van deze scriptie af. Hoofdstuk 2 introduceert het dimensionale model aan de hand van een casebeschrij ving. Tevens kijken we naar PSM en de benadering van constraints in dit model. Hoofdstuk 3 diept het dimensionale model helemaal uit met een beschrijv ing van de data cube en de problematiek omtrent constraints in een data warehouse wordt hierin uitgemeten. Hoofdstuk 4 introduceert het NDC model en diens algebra en maakt een vergelij king tussen het dimensionale model en het relationele model. Verschillende problemen binnen data warehouses komen hier aanbod, zoals view maintenance, de uitdrukkingskracht van de NDC algebra, de modellering van relationele operatoren in de NDC algebra, de benadering van aggregaties en de modellering hiervan in het relationele model. Tenslotte geven we een handreiking naar de mogelij kheid om de constraints in het dimensionale model te beschrijven op een manier waarop dit binnen PSM is gedaan. De “taal” hiervoor zou de NDC algebra kunnen zijn. Als laatste in deze paragraaf een kleine technische sectie ter verduidelij king van de manier waarop data wordt opgeslagen in een data warehouse. 1.3.1 Iets over data opslag in data warehouses Het uiteindelijke doel van een data warehouse is het direct kunnen inspelen op de vraag naar managementinformatie die nodig wordt geacht. Hierdoor dient de data warehouse een zeer flexibele “houding” aan te nemen. Deze “houding” moet het mogelijk maken om bepaalde complexe en zeer uiteenlopende vragen (lees: zeer complexe query’s, gesteld via bijvoorbeeld een spreadsheet -achtige applicatie) zeer snel te kunnen verwerken. Het format van een data warehouse kan zeer uiteenlopen. Er zijn drie manieren om de warehouse data op te bouwen: top-down, bottom-up en een hybride manier, die de twee eerste combineert. Bij de top-down manier gaat het erom dat de bronnen direct worden aangesproken om de warehouse data te creëren. Dit gaat op basis van de bestaande data warehouse applicaties. Eenvoudige, vaak gebruikte en bekende query’s zijn reeds uitgevoerd en opgeslagen in de data warehouse. Al het voorwerk is dus reeds gedaan. Bij bottom-up worden de acties pas uitgevoerd, zodra er een vraag wordt gesteld aan de data warehouse. De gecombineerde, hybride versie maakt gebruikt van sommige reeds bewerkte data uit de data warehouse en sommige onbewerkte data rechtstreeks uit de bronnen. Een manier om de data warehouse met deze grote mate van flexibil iteit te laten werken kan gedaan worden door de data warehouse op te laten bouwen volgens het multidimensionale datamodel. Het idee hierachter is dat data op zo een manier wordt opgeslagen dat alle mogelij kheden van interpretatie van de data nog mogelij k zijn. De noodzaak van deze benadering is dat data warehouses niet kunnen worden ontworpen met traditionele methoden. In legacy systemen (operationele systemen) worden vaak eenvoudige query’s uitgevoerd. Bij data warehouses moeten zeer ingewikkelde query’s kunnen worden uitgevoerd. Dit vraagt om een zeer flexibele opslag van gegevens (zoals we al zeiden: alle mogelij ke interpretaties moeten nog open liggen). Een voorbeeld hiervan is het gebruik van vele join-operaties op de opgeslagen gegevens (dit blij kt vaak voor te komen bij data warehouses).

13
Het multidimensionale datamodel maakt gebruik van zogenaamde feiten en dimensies. Feiten bevatten de eigenlijke data en dimensies geven een interpretatie van deze gegevens. Hierdoor ontstaan redundantie, maar dit is juist de bedoeling. Een voorbeeld van een multidimensionaal datamodel is de zogenaamde data cube.

14
2 Constraints in een data warehouse, een verkenning via PSM In dit tweede hoofdstuk zullen we beginnen met een korte introductie van het dimensionale model, waarbij we dit model demonstreren aan de hand van een case. Vervolgens verleggen we het accent naar de modelleringstechniek PSM. PSM zal worden geformaliseerd en als basis dienen voor de beschrij ving van constraints in het dimensionale model. De semantiek van PSM die in deze exercitie wordt beschreven zal als eerste in een reeks van twee formalisaties (waarbij de NDC’s uit hoofdstuk 4 de tweede vormen) dienen als uitgangspositie voor een beschrij ving van constraints in een data warehouse. 2.1 Korte introductie van het dimensionale model Ten grondslag aan een data warehouse ligt het dimensionale model. [Kim96] spreekt over het dimensionale model en [SMKK98] heeft het over het multidimensionale model. De heren Kimball en Samtani c.s. spreken naar mijn mening over hetzelfde model. Op exact dezelfde wijze wordt het model opgebouwd en met precies dezelfde vocabulaire. Het conceptuele idee wordt echter op een iets andere manier benaderd. Waar Kimball het heeft over het Star-join schema spreekt Samtani c.s. over de data cube. Beide benaderingen zullen worden gebruikt om zo een verschillende toenadering te maken naar het gebruik van constraints in dit model. Aangezien een bespreking van dit model later uitgebreid wordt beschreven, is een korte introductie hier noodzakelijk voor een goed begrip van de problematiek rond constraints. In dit model hebben we te maken met een feitentabel en dimensietabellen. De feitentabel bevat alle, veelal numerieke en optelbare gegevens (bijvoorbeeld totale verkopen, totaal aantal verkochte eenheden) over elke mogelijke combinatie van de dimensies. Deze tabel is dus vergeleken met de dimensietabellen zeer groot. De dimensietabellen hebben een dimensie als uitgangspunt. Een dimensie moet opgevat worden in dit verband als een variabel gegeven waarin informatie uit de feitentabel worden opgeslagen. Voorbeelden van zulke dimensies zijn tijd (denk aan jaren, kwartalen, maanden, weken, etc.) soort product (soort product, beschrij ving, merk, etc.) en geografische ligging (Europa, Azië, Australië, USA, etc.). De dimensietabellen bevatten naast een dimensie-key (de unieke sleutel voor elk record in de dimensietabel) een reeks attributen die de dimensie verder beschrij ven. Deze attributen zijn dan ook vaak van tekstuele aard. De attributen van de dimensietabel worden voornamelijk gebruikt om bij query-aanvragen (lees extended SQL, want daar hebben we het over bij data warehouses) te dienen als bron voor het kunnen gebruiken van constraints en “row headers”. Dit laatste geeft aan dat dit het hoofdattribuut wordt in het antwoord op de gestelde query-vraag van het systeem naar de eindgebruiker (de SQL gebruiker). Ter verduidelij king van dit model volgt in de volgende paragraaf een uitwerking van een voorbeeld. 2.1.1 Een case uitwerking In deze paragraaf zal een case worden beschreven die verder als voorbeeld zal dienen bij de verduideli jking van zo’n dimensionaal model. Als eerste zal er een korte introductie plaatsvinden waarin de case beschreven wordt. Vervolgens zullen de gegevens uit deze case worden geplaatst in het dimensionale model. Aan de hand van de invulling in dit model zal het model verder worden uitgediept. 2.1.1.1 Introductie van de case Een E-commerce bedrijf, genaamd Down Under, gevestigd in Sydney, Australië verkoopt CD’s aan de consument via het Internet. Het bedrijf biedt deze CD’s aan via een interactieve website waarop de consument zijn bestell ing kan plaatsen. We spreken hier dus over een B2C (Business 2 Consumer) bedrijf en laten de B2B-tak (Business 2 Business) hier dus helemaal weg. Op deze website bevinden zich allerlei opties om het voor de consument makkelijk te maken om kiezen. Men kan zoeken in de online database op auteur, titel, jaar van verschijnen, genre etc. Van de in de database aanwezige en

15
dus leverbare CD’s is het mogelij k om een track listing op te vragen. Wanneer een bestelli ng is geplaatst kan de wijze van betaling worden opgegeven. Dit kan op drie manieren. Allereerst kan online de creditcard gedebiteerd worden, ten tweede kan een factuur in de vorm van een acceptgiro worden meegestuurd met de bestelli ng (waarmee men achteraf kan betalen) en als laatste is er nog de mogelij kheid om de bestelling zelf af te halen en contant te betalen. Voor de distributie van de CD’s gebruikt men regionale centra om de vervoers- en transactiekosten zo laag mogelij k te houden. Het bedrijf zorgt zelf voor de levering van de goederen, zodat men vanuit deze regionale centra distribueert naar de consument. Deze centra houden er dus zelf een magazijn op na. De centra zijn gevestigd in Darwin voor verspreiding in Northern Territory, Perth voor verspreiding in West Australia, Brisbane voor verspreiding in Queensland en Sydney voor verspreiding in New South Wales, South Australia, Victoria en Tasmanië. Er zijn dus vier van deze regionale centra, waarbij het hoofdkantoor in Sydney een groot deel voor haar rekening neemt. Down Under levert dus alleen aan consumenten binnen Australië. Sinds kort heeft Down Under het plan opgevat om ook te gaan leveren in Nieuw Zeeland. De levering gebeurt vanuit het kantoor in Sydney, maar door de hoge transportkosten en lange levertijd is het bedrijf een distributiepunt gestart in Auckland, Nieuw Zeeland. Het loopt goed, dus het distributiepunt blijft bestaan. De levering gebeurt eens per maand met kleine vans vanuit de distributiepunten die de bestellingen gaan afleveren. Een voordeel van deze manier is dat wanneer een CD niet op voorraad is, men deze tijdig kan bestellen en als nog binnen het gestelde termijn kan leveren. Voor de case gaan we er even vanuit dat het bedrijf dus geen gebruik maakt van de bestaande postdiensten (in Australië is dit in de dunbevolkte delen toch een lastig vraagstuk, daar hier zeer zelden de posterijen de consument aandoen en dan nog per vliegtuig). Omdat het bedrijf zich inzicht wil verschaffen in de verschillende verkopen en een nauwkeurige analyse wil maken van de historische cijfers m.b.t. de invloed van seizoenen, levertijd, genreverkopen, etc. etc. is het noodzakelij k dat er een data warehouse wordt aangelegd om deze analyses mogelij k te maken. Met dit hulpmiddel (de data warehouse) en de daaraan gekoppelde analyses kan men de strategie voor de toekomst bepalen en zo ook beter inspelen op de commerciële problematiek. Beslissingen op tactisch en strategisch niveau kunnen beter worden onderbouwd. Een opmerking die op deze plaats gemaakt dient te worden is, dat vanwege de eenvoud van het voorbeeld slechts 1 feitentabel wordt gedefinieerd. In een data warehouse heeft men altijd te maken met zeer veel feitentabellen met allen, soms verschillende dimensies. 2.1.1.2 De case wordt in het dimensionale model gegoten Als eerste moeten we bepalen wat de belangrij ke structuur vormt voor de data warehouse. Hiermee wordt bedoeld welke gegevens interessant zijn om opgenomen te worden in de data warehouse. Dit is een eerste stap in het bepalen van de dimensies. In onze case is het product, de CD, een aparte dimensie. Men wil precies weten welke CD wat waar doet. Ten tweede is er natuurl ijk de bijna standaard aanwezige tijddimensie en als derde is er de geografische dimensie. Deze dimensies zijn bijna zo goed als standaard in een productiebedrijf en een handelsbedrijf. In ons geval moet de vraag worden gesteld of er nog een extra dimensie dient te worden toegevoegd. Gemakshalve doen we dat hier niet, om de eenvoud van het voorbeeld te behouden. Een dimensie die [Kim96] aanhaalt is ook een vaak voorkomende, namelijk de promotiedimensie. Hierbij gaat het erom of de verkoop van bepaalde producten afhangt van bepaalde promotionele activiteiten, zoals bonnen, aanbiedingen of reclamedrukwerk. Nu we de dimensies Tijd, Geografie en Product hebben afgeleid dient de opmerking te worden gemaakt dat in de feitentabel het betalingsverkeer wordt opgenomen. De wijze van betaling, creditcard, acceptgiro of cash, wordt aangegeven in de vorm van omzet per soort betaling in de feitentabel. Nu we de basisconstructie voor het dimensionale model hebben afgeleid, kunnen we dit in een eerste schema zetten. Zie hiervoor figuur 2. We zien de feitentabel in het midden van de figuur. Deze bevat de specifieke gegevens over de verkoop en afzet van de CD’s. Aangezien dit een in principe onuitputtelij ke li jst is, geven we een aantal voorbeelden van zulke cijfers. Het aantal verkochte eenheden is een voorbeeld van zo’n cijfer. Als men nadenkt over de betekenis van dit veld zie je vanzelf dat het een combinatie is van de reeds gedefinieerde dimensies. Ook de wijze waarop de

16
betaling plaatsvindt kan men definiëren in de feitentabel. Denk hierbij aan het feit dat de betalingswijze nergens is opgenomen binnen de gedefinieerde dimensies!
Figuur 2: Het dimensionale model voor Down Under, de Verkoop feitentabel
De sleutels die genoemd staan in de feitentabel komen altijd voort uit de reeds gedefinieerde dimensies. Een unieke combinatie van Tijd, Plaats en Product leveren de records op voor de feitentabel. De echte analytische gegevens staan dus in de feitentabel, terwij l de beschrij vende gegevens in de dimensietabellen staan! Nu we het basisidee te pakken hebben, is de volgende stap in onze casebeschrijving de invulli ng van de dimensieattributen die de dimensies moeten beschrij ven. Zoals we zullen zien spelen deze dimensieattributen een belangrijke rol in het gebruik van constraints. Hierover later meer in dit hoofdstuk en hoofdstuk 3. De dimensie Tijd heeft een verdeling in jaren, maanden, dagen etc. Dit zijn sowieso attributen die moeten worden opgenomen, maar ook vakanties, weekends, uitverkoopdagen dienen te worden opgenomen in de dimensie Tijd. In de productdimensie worden zaken opgenomen titel, artiest, genre, jaar van verschijnen, een attribuut dan aangeeft of het een single of cd betreft, platenmaatschappij etc. etc. Let erop dat dit niet altijd zaken zijn die hiërarchisch of causaal een relatie met elkaar onderhouden. We zullen later zien dat dit geen problemen oplevert met SQL-aanvragen. In de geografische dimensie worden zaken opgenomen als verkocht in Australië of Nieuw Zeeland, geleverd uit welke stad, verkocht in welke regio of stad (uit welke gedeelten van het land of welke steden worden de CD’s gekocht) etc. Wanneer we dit in een schema pl aatsen komen we uit bij figuur 3. De attributen die de dimensies bevat geven aan de SQL-vragensteller de mogelij kheid om binnen de dimensies afbakeningen te regelen. Dit gebeurt in de vorm van beperken van velden binnen deze dimensies. Binnen de dimensie “Tijd” kan bijvoorbeeld worden beperkt op een bepaald jaar of bepaalde maand. Om nu een concrete uitwerking van zo’n vraagstelling te geven, volgt nu een invulli ng van het dimensionale model van Down Under m.b.t. tot de verkooptabel. In de vorm van vier invulli ngen van de feitentabel en de drie dimensietabellen zal worden geprobeerd het principe van een aanvraag te verduidelij ken.

17
Figuur 3: De dimensies met de dimensieattributen van de Down Under verkooptabel
We zullen dit doen in de volgende paragraaf. 2.1.1.3 Case invulling van het geschetste model van Down Under Allereerst maken we een invulling van de drie dimensietabellen met daarin alle in figuur 3 genoemde dimensieattributen. We moeten wel realiseren dat dit een zeer klein fragment is van de werkelijke grootte van de tabel. In het echt zijn dit vele malen grotere tabellen. Voor de doeleinden die we hier echter willen demonstreren, is een tabel van deze grootte uitermate geschikt. Plaatssleutel Distributiecentrum State/Department Plaats Land 1 Darwin Northern Territory Katherine Aus 2 Darwin Northern Territory Darwin Aus 3 Perth Western Australia Perth Aus 4 Perth Western Australia Broome Aus 5 Perth Western Australia Hyden Aus 6 Auckland n/a Wellington NZ 7 Sydney New South Wales Tamworth Aus
Tabel 1: Invulling van de geografische dimensietabel
Productsleutel Artiest Titel Platenmy jaar Genre Single 1 Springsteen, Bruce Greatest Hits Columbia 1995 Rock nee 2 Springsteen, Bruce Nebraska Columbia 1982 Rock nee 3 Police, The Outlandos d'Amour A&M 1978 Pop nee 4 Lauper, Cyndi Hat Full Of Stars Epic 1993 Pop nee 5 Foreigner 4 Atlantic 1981 Rock nee
Tabel 2: Invulling van de productdimensietabel
18
Tijdsleutel Maand Maandnr Weekend Schoolvak. Dagnummer Opruimingsdag Kwartaal Jaar 1 Jan 1 Nee Nee 18 nee 1 2000 2 Jan 1 Nee Nee 19 ja 1 2000 3 Mrt 3 Nee Nee 55 nee 1 2000 4 Mrt 3 Nee Nee 56 nee 1 2000 5 Mei 5 Nee Nee 131 nee 2 2000 6 Mei 5 Nee Nee 133 nee 2 2000 7 Dec 12 Nee Ja 350 nee 4 2000
Tabel 3: Invulling van de tijddimensietabel
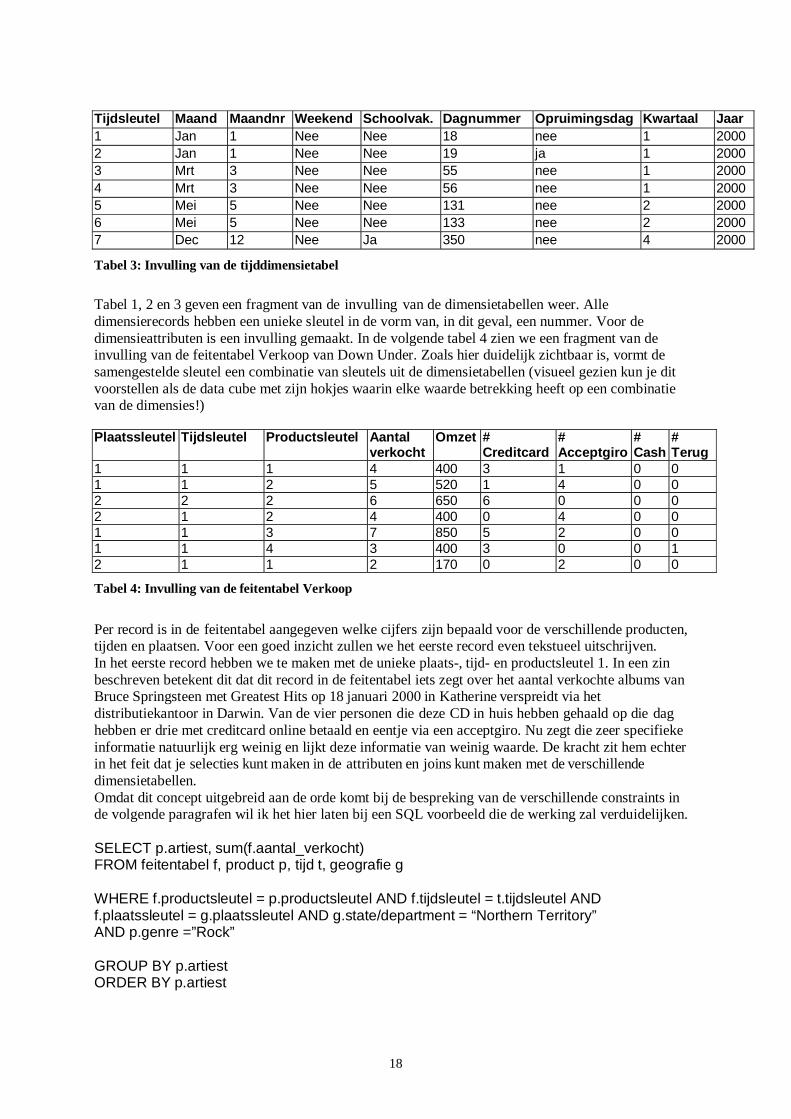
Tabel 1, 2 en 3 geven een fragment van de invulling van de dimensietabellen weer. Alle dimensierecords hebben een unieke sleutel in de vorm van, in dit geval, een nummer. Voor de dimensieattributen is een invulling gemaakt. In de volgende tabel 4 zien we een fragment van de invulling van de feitentabel Verkoop van Down Under. Zoals hier duidelijk zichtbaar is, vormt de samengestelde sleutel een combinatie van sleutels uit de dimensietabellen (visueel gezien kun je dit voorstellen als de data cube met zijn hokjes waarin elke waarde betrekking heeft op een combinatie van de dimensies!) Plaatssleutel Tijdsleutel Productsleutel Aantal
verkocht Omzet #
Creditcard # Acceptgiro
# Cash
# Terug
1 1 1 4 400 3 1 0 0 1 1 2 5 520 1 4 0 0 2 2 2 6 650 6 0 0 0 2 1 2 4 400 0 4 0 0 1 1 3 7 850 5 2 0 0 1 1 4 3 400 3 0 0 1 2 1 1 2 170 0 2 0 0
Tabel 4: Invulling van de feitentabel Verkoop
Per record is in de feitentabel aangegeven welke cijfers zijn bepaald voor de verschillende producten, tijden en plaatsen. Voor een goed inzicht zullen we het eerste record even tekstueel uitschrijven. In het eerste record hebben we te maken met de unieke plaats-, tijd- en productsleutel 1. In een zin beschreven betekent dit dat dit record in de feitentabel iets zegt over het aantal verkochte albums van Bruce Springsteen met Greatest Hits op 18 januari 2000 in Katherine verspreidt via het distributiekantoor in Darwin. Van de vier personen die deze CD in huis hebben gehaald op die dag hebben er drie met creditcard online betaald en eentje via een acceptgiro. Nu zegt die zeer specifieke informatie natuurlijk erg weinig en lijkt deze informatie van weinig waarde. De kracht zit hem echter in het feit dat je selecties kunt maken in de attributen en joins kunt maken met de verschillende dimensietabellen. Omdat dit concept uitgebreid aan de orde komt bij de bespreking van de verschillende constraints in de volgende paragrafen wil ik het hier laten bij een SQL voorbeeld die de werking zal verduidelijken. SELECT p.artiest, sum(f.aantal_verkocht) FROM feitentabel f, product p, tijd t, geografie g WHERE f.productsleutel = p.productsleutel AND f.tijdsleutel = t.tijdsleutel AND f.plaatssleutel = g.plaatssleutel AND g.state/department = “Northern Territory” AND p.genre =”Rock” GROUP BY p.artiest ORDER BY p.artiest

19
Bovenstaand stukje SQL is een eenvoudig voorbeeld over een mogelij ke query die gesteld kan worden aan ons systeem, beschreven in de case. Door middel van de joins tussen de dimensietabellen en de feitentabel (de sleutel matching) is het mogelij k om attributen uit de verschillende dimensies op te nemen in het antwoord. De matching van de attributen uit de dimensietabellen zorgt ervoor dat het antwoord wordt afgebakend op precies die informatie die je wil t hebben. Hier gaat het dus om artiesten uit het rockgenre en CD’s die verspreidt zijn in het Northern Territory. Wanneer deze query wordt losgelaten zal het volgende antwoord worden gegenereerd. Zie tabel 5. Artiest SUM(aantal_verkocht) Foreigner 0 Springsteen, Bruce 21
Tabel 5: Gegenereerd antwoord
Tot zover de uitwerking van deze case. Het dimensionale model heeft hiermee een duidelij k voorbeeld gekregen in de vorm van een reële uitwerking. Nu is de basis gelegd voor een verdere analyse naar het gebruik van constraints toe in dit model. 2.2 Constraints in het dimensionale model, een benadering via het relationele model Nu dit model is geschetst is de basis gelegd voor een introductie van de constraints die een rol spelen in dit model. Als eerste kijken we naar de benadering die gemaakt wordt door [SMKK98]. Vanuit het perspectief van relationele databases wordt geprobeerd de lij n door te trekken naar het dimensionale model als basis voor een data warehouse. Bij het ontwerpen van relationele databases wordt in de conceptuele gegevensmodelleringsfase al rekening gehouden met het gebruik van constraints. Constraints worden gebruikt om bepaalde zaken te verplichten dan wel te verbieden bij het maken van bijvoorbeeld een voorbeeldpopulatie van het gegevensmodel (wat natuurli jk een afbeelding van de werkelij kheid is! Denk hierbij aan het Universe of Discourse). Dit komt reeds tot uiting in de conceptuele fase. Constraints die hierbij optreden zijn als volgt te categoriseren. • Key constraints • Referential integrity constraints • Not Null constraints • Relation-based check constraints • Attribute-based constraints • General assertions Voordat we verderop ingaan op de wijze waarop de tweedeling van constraints van [SMKK98] tot stand komt vanuit dit relationele perspectief, is het op zijn plaats hier een link te leggen naar de gegevensmodellering met behulp van PSM (Predicator Set Model, zie voor een uitgebreide beschrij ving van PSM [Hof94]). In [Hof94] wordt nameli jk een goede en uitgebreide beschrij ving gegeven van de constraints zoals die hierboven door [SMKK98] zijn gecategoriseerd. We zullen nu een korte informele beschrijving geven van één van deze constraints. Een key constraint is in de wereld van PSM een zogenaamde uniqueness constraint. Deze constraint zorgt ervoor dat een populatie in een gedeelte van het feittype (een tabel in het relationele model) maar 1 keer mag voorkomen. Dit gedeelte kan slaan op slechts 1 veld, maar ook op meerdere velden. Het gedeelte van het feittype dat hieraan moet voldoen wordt de sleutel genoemd, vandaar ook de term key constraint. Ook kan een uniqueness constraint over meerdere feittypes gaan en zelfs over nog meer gecompliceerde structuren. Dit zullen we hier buiten beschouwing laten. In PSM wordt gebruikt gemaakt van een relationele algebra om de semantiek van verschill ende constraints te kunnen beschrij ven. Sommige constraints, waaronder ook de uniqueness constraint, hebben ook een grafische notatie in PSM-schema’s. We zullen nu aan de hand van de formele definities van de verschill ende soorten constraints een basis creëren voor de constraints die later in het dimensionale mode kunnen worden beschreven. We zullen voortborduren op het reeds aangehaalde PSM. In de volgende subparagraaf wordt als eerste een

20
introductie gegeven van PSM en vervolgens zullen, verderop, de verschillende constraints worden besproken. Deze uitstap naar PSM vormt een belangrijke basis voor de latere formalisering van constraints in het dimensionale model. We kiezen PSM als uitgangspunt voor zo’n formalisering. 2.2.1 Introductie van PSM Aangezien er vele informatiemodelleringmethoden zijn (Bijv. ER-diagrammen), is het weinig zinvol hier een algemeen betoog te houden over deze verschillende methoden. Voor het doel, het construeren van constraints in het dimensionale model, beperken we ons hier tot NIAM en PSM. NIAM is een informatiemodelleringstechniek die gebruikt wordt als basis voor de constructen van PSM. Je kunt NIAM als een soort voorloper beschouwen. In [Hof94] wordt op basis van een introductie van NIAM verder gebouwd aan de constructies die mogelijk zijn in PSM. De manier waarop we de constructies en constraints in PSM introduceren en bespreken zal gaan aan de hand van een aantal figuren uit [Hof93] en [Hof94]. [Hof93] is het proefschrift waarop het collegedictaat [Hof94] is gebaseerd. Het eerste figuur (figuur 4) staat echter alleen in [Hof93], met daarbij een interessante sectie over constraints, waar later nog kort gebruik van wordt gemaakt. Aan de hand van dit figuur maken we een analyse van de voorkomende constructen. We bekijken figuur 4.
Figuur 4: PSM schema inzake Amerikaanse presidenten
In dit figuur zien we de verschillende (niet alle) constructen in de modelleringtechniek PSM. De belangrijkste en opvallende grafische notaties zijn de bollen, blokjes en de relaties hiertussen. We zullen eerst een korte informele bespreking geven van de verschillende onderdelen uit het figuur. De bollen stellen de objecttypes voor, die weer onderverdeeld kunnen worden in labeltypes en entiteittypes. Labeltypes worden in dit schema aangegeven met de haakjes ( ). De rest van de bollen zijn entiteittypes. Tussen de bollen, de entiteiten, geven de blokjes relaties aan tussen deze entiteiten. Zo’n relatie (1,2 of meer blokjes) wordt een feittype genoemd. De namen bij de blokjes worden

21
predicatoren genoemd. De pijl tjes in het schema hebben betrekking op constraints. Hier gaan we later op in. We zullen nu een consistente en formele notatie invoeren voor zo’n PSM schema als figuur 4. Figuur 4 wordt, zonder de constraints te beschrij ven, een informatiestructuur genoemd. Een informatiestructuur bestaat uit een vijftiental onderdelen. De verzameling van deze onderdelen vormen samen een informatiestructuur, aangeduid met het symbool I. De vijftiental onderdelen worden hieronder beschreven. 1. Een eindige verzameling van predicatoren, genoteerd met P 2. Een niet lege, eindige verzameling van objecttypes, genoteerd met O 3. Een verzameling labeltypes, genoteerd met L, waarbij geldt L⊆O
4. Een verzameling entiteiten (of entiteittypes), genoteerd met �, waarbij geldt
�⊆O
5. Een partitie F van de verzameling van predicatoren P. F is een verzameling van feittypes. Een predicator speelt een rol in een feittype. De functie Fact: P � F geeft bij elke predicator het
feittype waarin deze voorkomt. De definitie van deze functie is Fact(p) = f � p � f. Er geldt tevens F ⊆O
6. Een verzameling G van powertypes. Er geldt G⊆O 7. Een verzameling S van sequentietypes. Er geldt S⊆O 8. Een verzameling C van schematypes. Er geldt C⊆O 9. Een functie die een predicator verbindt aan zijn basis uit de verzameling objecttypes. De definitie
is Base: P � O 10. Een functie die het elementtype van een powertype of sequentietype oplevert. De definitie is Elt:
G � S � O
11. Een relatie die de elementen van een schematype verbindt met het schematype. De definitie is � ⊆
C � O 12. Een binaire relatie Spec op objecttypes, die specialisatie vastlegt 13. Een binaire relatie Gen op objecttypes, die generalisatie vastlegt 14. Een algebra D die opgebouwd wordt uit de verzameling D van concrete domeinen (bijv. strings,
int, natno, long int, etc) en de verzameling F van operatoren (bijv. +, -, *, etc). Definitie D = <D,F>
15. Een functie Dom: L � D. Deze functie verbindt alle labeltypes aan een concreet domein uit D. De instanties van labeltypes (denk bijv. aan een naam) komen uit een dezer domeinen.
Deze 15 onderdelen vormen samen dus I. De notatie voor zo’n informatiestructuur ziet er als volgt uit:
I = <P, O, L, �
, F, G, S, C, Base, Elt, ��� Spec, Gen, D, Dom> Een informatiestructuur I moet voldoen aan een reeks voorwaarden die in [Hof94] uitgebreid wordt besproken. Het is niet erg zinvol om deze hier te beschrijven. Vandaar een verwijzing op deze plek naar [Hof94], de voorwaarden PSM1 t/m PSM11 over de regels m.b.t. de constructie van PSM-schema’s, de type-gerelateerdheid van objecten zijn vastgelegd in de regels T1 t/m T8. Deze zijn te vinden op blz.46 t/m 52 van [Hof94]. Een derde soort voorwaarden, voor ons de interessantste, gaat over de toegestane populaties in de informatiestructuren. Toegestane populaties leggen de semantiek van een data model vast, in dit geval een PSM schema. Hieruit is direct de link te leggen met constraints, die immers bepaalde populaties toestaan dan wel uitsluiten. Voor we echter verder gaan met populaties in PSM schema’s, schrijven we eerst het genoemde voorbeeld uit in de zojuist geïntroduceerde notatie. Hiertoe zullen we de verzamelingen definiëren. P = { headed-by, being-president-of, having-as-vice-president, being-vice-president-of, inaugurated-in, being-inauguration-year-of, resulting-from, resulting-in, being-spouse-of, having-spouse-as, p1, p2, p3, won-by, winning, having-as, of, being-member-of, having-as-member, born-in, being-birthstate-of, serving, being-served-by, dying-at, being-age-at-death-of}

22
O = {Administration, Adm-nr, Person, Person-name, Nr-of-votes, Nr, Election, Elec-Id, Nr-of-children, Politician, President, Year, Year-nr, Age, Nr-of-years, State, State-name, Party, Party-name, Hobby, Hobby-name, Marriage, Admin-pres, {having-as-vice-president, being-vice-president-of}, Election-results, {won-by, winning}, {inaugurated-in, being-inauguration-year-of}, Family-size, Birthyear, {having-as, of}, {being-member-of, having-as-member}, Birthstate, {serving, being-served-by}, {dying-at, being-age-at-death-of}} L = {Adm-nr, Person-name, Nr, Elec-Id, Year-nr, Hobby-name, Party-name, State-name}
� = {Administration, Person, Nr-of-votes, Election, Year, Age, Nr-of-years, State, Party, Hobby,
President, Politician, Nr-of-children} F = {Admin-pres, {having-as-vice-president, being-vice-president-of}, {won-by, winning}, {inaugurated-in, being-inauguration-year-of}, {having-as, of}, {being-member-of, having-as-member}, Birthstate, {serving, being-served-by}, {dying-at, being-age-at-death-of}, Election-results, Family-size, Marriage, Birthyear}
G = �
S = �
C = � Verder geven de gedefinieerde functies en relaties de volgende (gedeeltelijke) invulling: President Spec Politician Politician Spec Person Fact(headed-by) = Admin-pres Fact(won-by) = {won-by, winning} etcetera Base(being-served-by) = Nr-of-years Base(of) = Hobby etcetera Dom(Hobby-name) = string Dom(Year-nr) = integer etcetera De overige functies en relaties zijn hier niet gedefinieerd, omdat sommige constructies (zoals powertypes) ontbreken in het voorbeeld PSM schema. Een eerste opmerking die hier dient te worden gemaakt m.b.t figuur 4 betreft het feit dat feittypes op twee manieren kunnen worden weergegeven. Ten eerste is een naamgeving aan het construct feittype mogelijk, zoals we zien bij Admin-pres. Een andere mogelijkheid is het feittype aan te duiden als een verzameling van zijn rollen (of predicatoren). Het feittype {having-as, of} is zo’n voorbeeld. Een tweede opmerking betreft het construct Marriage uit figuur 4. Het gaat hier om een zogenaamd geobjectificeerd feittype. Dit is een feittype dat door middel van objectificatie (grafisch gezien als een bol over het feittype) wordt getransformeerd tot een entiteit die zelf weer rollen kan spelen in feittypes. Hoe zo’n geobjectificeerd feittype dient te worden behandeld, zal worden be sproken bij de beschrijving van populaties in PSM.

23
2.2.2 Populaties in PSM In een PSM schema, met constraints nog buiten beschouwing latend, kunnen populaties worden gedefinieerd. Een populatie moet men zien als een invulling van een informatiestructuur I aan de hand van de gedefinieerde objecten (objecttypen). Zo’n invulling is een eindige verzameling van instanties die aan de objecttypes uit O worden toegewezen. Uiteraard moet de invulli ng voldoen aan de regels van de informatiestructuur I. Deze zullen we definiëren in een volgende subparagraaf. Als eerste moeten we definiëren wat nu precies een populatie is. [Hof94] definieert een expressie (predikaat) IsPop(I,Pop). Dit predikaat geeft de waarde TRUE als een populatie Pop op I kan worden toegepast. Anders gezegd: I heeft een geldige populatie in Pop.
Wanneer Pop een populatie is van I, dan is Pop een afbeelding van alle objecttypes uit O op ����� � ( � ). Deze laatste verzameling bestaat uit alle eindige deelverzamelingen van de universe of instances.
De universe of instances � bevat alle mogelij ke instanties die in een informatiestructuur kunnen optreden. Deze universe of instances wordt in de volgende subparagraaf inductief gedefinieerd.
Belangrijk is te zien dat � een zeer algemene verzameling is die voor ALLE (geldige) informatiestructuren een basis vormt voor een geldige populatie. Anders gezegd: Een populatie voor een informatiestructuur I is een invulli ng van objecttypes in eindige verzamelingen van deelverzamelingen van de universe of instances. 2.2.2.1 Universe of instances gedefinieerd
Voordat we � kunnen definiëren kijken we eerst naar de instanties van labeltypes en entiteiten. Labeltypes worden geïnstancieerd door hun concrete domein die gedefinieerd is d.m.v. de functie Dom, die aan ieder labeltype een concreet domein toevoegt. We hebben in het voorbeeld gezien dat dit bijvoorbeeld het labeltype Year-nr verbindt aan het concrete domein integer. De instanties van
entiteiten komen uit een speciaal domein � , dat bestaat uit ongestructureerde waarden.
De universe of instances � wordt door de volgende regels vastgelegd. � is een kleinste verzameling die voldoet aan:
1. � D ⊆ �
2. � ⊆ �
3. X1,….,Xn �� P1,….,Pn P’ � { P1 : X1,….,Pn : Xn} � , met P’ de verzameling van alle mogelij ke predicatoren die kunnen voortkomen in een informatiestructuur
4. X1,….,Xn ���� X1,….,Xn} �
5. X1,….,Xn ��� <X1,….,Xn> �
6. Y1,…,Yn ⊆ �� O1,….,On O’ � { O1 : Y1,…., On :Yn } ��� met O’ de verzameling van alle mogelij ke objecttypes die kunnen voortkomen in een informatiestructuur
Wanneer we kijken naar deze zes regels vallen een aantal zaken op met betrekking tot de constructie van populaties. De universe of instances bestaat uit twee gedefinieerde domeinen (regel 1 en 2) en vier geconstrueerde verzamelingen (regels 4 t/m 6). Bij regel drie wordt een verzameling gedefinieerd die dient ter invull ing van een feittype. De predicatoren uit een feittype krijgen een element uit de universe of instances toegewezen. De toegewezen verzameling is dan zelf weer een element van de universe of instances. Dit dient om een zinvolle invulli ng te geven aan feittypes. Regel 4 en 5 zorgen ervoor dat respectievelij k het powertype en sequentietype gepopuleerd kunnen worden. Regel 4 construeert een verzameling van elementen uit de universe of instances en regel 5 geeft een li jst (sequentie, verzameling met volgordeafhankelij kheid) van elementen uit de universe of instances. Tenslotte geeft regel 6 aan hoe schematypes gepopuleerd worden. Schematypes bevatten elementen uit de verzameling van objecttypes (een schematype kan dus ook een schematype bevatten!). De verzameling van objecttypes die in een schematype voorkomen kunnen door middel van een

24
toewijzing van de objecten aan hun populaties (de Y’s in regel 6) in een verzameling weer een element van de universe of instances opleveren. Met deze regels is de opbouw van mogelijke instanties van PSM-schema’s vastgelegd. 2.2.2.2 Populaties gedefinieerd In [Hof94] volgt een veertiental regels met betrekking tot deze instanties. Deze populatieregels leggen beperkingen op aan de mogelijke populaties met betrekking tot de semantiek van de PSM constructies. We zullen deze regels hier opschrijven met daaronder een korte beschrijving van de werking van de regel. Dit is van belang bij het introduceren van de constraints in PSM.
[P1] x � y �
x,y � L � Pop(x) � Pop(y) = � Deze regel geeft aan dat wanneer twee objecttypes x en y niet type-gerelateerd zijn en geen van beiden labeltypes zijn, er geen gemeenschappelijke instanties in hun populatie kunnen zitten. De term type-
gerelateerdheid (symbool x � y, x is type-gerelateerd met y) geeft aan dat instanties van een objecttype ook kunnen voorkomen in hun type-gerelateerde objecttypes. Denk hierbij bijvoorbeeld aan als x Gen y geldt, er dan altijd geldt dat elke mogelijke instantie uit de populatie van y ook een instantie is van x.
[P2] x � L � Pop(x) ⊆ Dom(x) Deze elementaire regel was in principe al afleidbaar bij de constructie van de universe of instances. De populatie van een labeltype komt uit zijn concrete domein.
[P3] Root(x) � Pop(x) ⊆ � , met Root(x) = x � ��� gen(x) ���
spec(x) De definitie Root geeft aan dat het gaat om zogenaamde root entity types, hetgeen entiteittypes zijn die niet gegeneraliseerd zijn of een subtype zijn. P3 geeft dus aan dat wanneer x een root entity type is,
dan moet de populatie van x uit het abstracte domein � komen.
[P4] x � F �
y � Pop(x) � y : x � ��� p � x [y(p) � Pop(Base(p))] Deze regel zorgt ervoor dat de populatie van een feittype, tupels, wordt opgebouwd uit een toewijzing van elementen uit de universe of instances aan de predicatoren voorkomende in dat feittype. Een tweede eis is dat de toegewezen elementen aan de predicatoren uit het feittype elementen zijn die ook voorkomen in de basis van deze predicatoren.
[P5] x � G �
y � Pop(x) � y ��� (Pop(Elt(x)))\{ � }
De populaties van powertypes worden opgebouwd uit deelverzamelingen van de populaties uit hun elementtypes. Dit wordt in P5 precies weergegeven. De powerset van de populatie van het elementtype (van de powertype in kwestie) met het element lege verzameling daaruit weggelaten.
[P6] x � G � Pop( � x) = {{ � px : u, � e
x : v} � u � Pop(x) �
v � u}
In deze regel wordt de populatie van het impliciete feittype � x ,dat de relatie beschrijft tussen een elementtype en zijn powertype, gedefinieerd. De twee predicatoren van dit impliciete feittype, met hun toewijzing uit respectievelijk de populatie van x en u (hetgeen weer een element is uit de populatie van
het elementtype van x). Dit tupel wordt genoteerd met { � px : u, � e
x : v}, met de eerste predicator die als basis het powertype heeft, en de tweede predicator die als basis het elementtype heeft. Het impliciete feittype, dat bij ieder powertype kan worden gedefinieerd, wordt meestal niet grafisch

25
weergegeven, tenzij er speciale eisen worden gesteld aan de invulling van dit feittype, zoals constraints. Hierover later meer.
[P7] x � S � y � Pop(x) � y � Pop(Elt(x))+ Wanneer de populatie van een sequentietype aan de orde komt, is het noodzaak dat er een volgorde afhankelijkheid wordt vastgelegd. P7 geeft aan dat y als instantie van een sequentietype een lijst is van elementen afkomstig uit het elementtype van het sequentietype.
[P8] Pop(I) = { n ��� \{0} ��� s � S � u � Pop(s) [|u| n] } Wanneer een sequentietype voorkomt in een PSM-schema worden er automatisch 2 feittypes gedefinieerd. De eerste is, net als bij het powertype, het impliciete feittype die een brug slaat tussen
het elementtype en het sequentietype. Deze wordt genoteerd met � x = { � sx , � e
x }. Het tweede impliciete feittype dat bij sequentietypes wordt gemaakt, is degene die de elementen in de sequentie indexeert. Dit is van belang, omdat hier de volgorde er wel toe doet. Dit gebeurt op de volgende wijze.
Figuur 5: Impliciete feittypes voor een sequentietype

26
We kijken naar figuur 5. We zien het sequentietype playlist. Een playlist is een li jst met songs met volgordeafhankelij kheid. Gemakshalve hebben we hier de identificatie voor playlist weggelaten. Het labeltype Index zorgt voor de indexering van de elementen uit de playlist. Dit gebeurt via het impliciete feittype @playlist. Dit feittype bestaat uit 2 predicatoren, n.l. @s
playlist en @iplayl ist. De tweede
heeft als basis het labeltype Index. Hierbij geldt dat Dom(Index) = � . Op deze wijze wordt een index bijgehouden van de elementen in de elementen van het sequentietype. De volgende 2 regels zijn van toepassing op deze twee impliciete feittypes.
[P9] x � S � Pop( � x) = { { � sx: u , � e
x: v } � u � Pop(x) ��� i � Pop(I) [u<i> = v] } Deze regel geeft aan hoe de populatie van het eerste impliciete feittype wordt opgebouwd. Men ziet dat de tweede predicator (met als basis het elementtype van x) een toewijzing v krijgt (uit de populatie van dit elementtype dus) die moet voldoen aan het bestaan van een geïndexeerd element.
[P10] x � S � Pop( � x) = { { � sx: u , � i
x: v } � u � Pop( � x) � u( � sx)<v> = u( � e
x) } De populatie van het impliciete feittype dat voor de indexering zorgt is wat ingewikkelder.
Het eerste lid van een tupel uit de populatie van � x , de predicator die als basis het geobjectificeerde
feittype � x heeft, wordt bij de toewijzing bij zo’n element uit Pop( � x) een verplichting opgelegd die staat beschreven in het tweede deel van P10. De index v die wordt toegevoegd door I, moet
overeenkomen met het geïndexeerde element toegevoegd aan de predicator � ex.
[P11] x � C � y � Pop(x) � IsPop(Ix, y) Deze regel zegt dat de populatie van een schematype wordt bepaald door de populaties van de onderliggende informatiestructuur. Anders gezegd: de populatie van de onderdelen uit een schematype zijn de basis van de populatie van het schematype. Ix is de denotatie van de informatiestructuur in een schematype en voldoet aan alle eisen van een gewone informatiestructuur.
[P12] x y � Pop( � x,y) = { { �� x,y: u, ��� x,y: v} � u � Pop(x) � v � u(y) } Ook schematypes hebben impliciete feittypes tussen de objecten in het schematype en het schematype
zelf. Zo’n impliciet feittype wordt aangeduid met � x,y , waarbij x het schematype is en y het object in de decompositie. De predicatoren in dit impliciete feittype worden aangeduid met een klein c’tje in de bovenhoek voor de predicator met de basis het schematype en een klein d’tje voor de predicator met als basis het gedecomposeerde objecttype. De populatie van dit feittype bestaat uit tupels met als eerste element een toewijzing uit de elementen van het schematype. Het tweede lid van de tupel is een element dat voorkomt in de populatie van y, maar tevens “zitting heeft” in het geselecteerde element uit de populatie van het schematype (u).
[P13] x Spec y � Pop(x) ⊆ Pop(y) Deze regel spreekt voor zich. Immers de populatie van een specialisatie is een deelverzameling van zijn bovenliggende pater famil ias. Denk bijvoorbeeld aan een object Zoogdieren met subtypes Mensen en Apen. Een mens is een zoogdier, maar een zoogdier is niet altijd een mens. Een simpele regel laat de waarheid van P13 zien.
[P14] gen(x) � Pop(x) = �� Pop(y) � x Gen y} Wanneer x een generalisatie is van een stelletje objecten, dan is de populatie van x een vereniging van de populaties van zijn onderliggende objecten.

27
Met de in deze paragraaf vastgelegde regels met betrekking tot populaties, is het mogeli jk om nu in te gaan op de verschill ende constraints binnen PSM. 2.2.3 Constraints in PSM Alvorens we in gaan op de wijze waarop in PSM met constraints wordt omgegaan, is het eerst noodzakelij k een categorisatie te maken van de constraints zoals deze in PSM voorkomen. In [Hof94] wordt als eerste gesproken over een tweedeling in constraints, namelij k als eerste constraints die grafisch worden aangeduid in PSM-schema’s. Voorbeelden daarvan zijn we al tegengekomen, zoals de pij ltjes boven feittypes en de bollen aan de objecttypes. De tweede soort constraints zijn degene die beschreven worden aan de hand van een relationele algebra. Naast deze tweedeling spreekt men ook over het verschil tussen statische en dynamische constraints. Een statische constraint is een constraint die populaties uitsluit die niet geldig zijn. Niet geldig zijn is het niet overeenkomen met een toestand in het Universe of Discourse. Het Universe of Discourse is het model van een gedeelte van de werkelij kheid dat gemodelleerd dient te worden. Dynamische constraints verbieden bepaalde transities/verschuivingen tussen populaties. Statische constraints zijn de constraints waar wij voorlopig op zullen focussen. PSM gebruikt voor de beschrijving van de semantiek van statische constraints een relationele algebra. Een relationele algebra is geïntroduceerd in het relationele gegevensmodel met als doel het maken van een retrieval mogelijkheid. Dit hoofddoel zal later ook nog aan bod komen, maar als eerste gaan we kijken naar de beschrij ving van constraints met behulp van deze relationele algebra.
Als eerste definiëren we een PSM schema � als een combinatie van een informatiestructuur I en een verzameling van constraints R. Een populatie van een PSM schema wordt gedefinieerd als een populatie van zijn informatiestructuur en de geldigheid van de gedefinieerde constraints in deze structuur. Formeel:
IsPop( � ,Pop) = IsPop(I,Pop) ��� r � R [Pop � r] De “voor alle” expressie geeft aan dat de populatie alle constraints in het schema waar moet maken. Nu we weten wat een PSM schema precies inhoudt, rij st de vraag hoe we de verzameling constraints R kunnen beschrijven en definiëren. We zullen hiertoe de relationele algebra introduceren. 2.2.3.1 Relationele algebra Een relationele algebra voor PSM gebruikt als bouwstenen zogenaamde relationele expressies. Relationele expressies worden als volgt geconstrueerd. Ze zijn of een feittype of een relationele operatie toegepast op één of meer relationele expressies. Relationele operaties zullen we hier niet uitgebreid bespreken. Voor een uitgebreide beschrijving van relationele operaties verwijzen we naar [Weide]. In [Weide] wordt het relationele gegevensmodel vanaf scratch opgebouwd. Voor een goede opbouw van de theorie die hierna volgt, is het noodzakeli jk dat we hier de relationele operatoren kort noemen. In [Weide] worden de volgende 4 voor ons interessante relationele operaties genoemd.
1. De projectie operatie, genoteerd met � . De projectie operatie wordt gebruikt om een beperking mogelij k te maken in de kolommen (attributen, predicatoren) van een tabel in het relationele gegevensmodel.
2. De selectie operatie, genoteerd met � . De selectie operatie maakt het mogelijk beperkingen uit te voeren in de tupels van een tabel. Alleen de gewenste tupels worden zo geselecteerd.
3. De join operatie, genoteerd met � . Deze operatie maakt het mogelij k twee tabellen te koppelen tot een nieuwe tabel, waarbij de attributen uit de afzonderlij ke tabellen worden gekoppeld met gemengde tupels in het resultaat van een join operatie.

28
4. De hernoem operatie, genoteerd met � . Deze operator hernoemt een attribuut in een relationele expressie.
Deze vier operaties spelen een grote rol in de opbouw en werking van de relationele algebra van PSM. Uiteraard bestaan naast deze wat meer geavanceerde operaties, de standaardoperaties zoals vereniging en verschil. Deze komen, waar nodig, aan bod. We zullen nu verder gaan met de opbouw van relationele expressies. Een relationele expressie is eigenlij k een beschrijving van een afgeleid feittype. Zo’n afgeleid feittype (afgeleid, omdat er dus via relationele operatoren kan worden gerekend met feittypes) heeft twee kenmerken, namelij k een type en een populatie. Dit geheel in overstemming met PSM-schema’s. Twee operaties op relationele expressies geven de mogeli jkheid om deze twee kenmerken te genereren. Het zijn de operaties Schema voor de generatie van het type en Val voor de generatie van de bijbehorende populatie. Deze zijn als volgt gedefinieerd.
2.2.3.1.1 Schema gedefinieerd Als relationele expressie een enkel feittype f is dan: Schema (f) = f (= de verzameling van predicatoren uit f) Anders is Schema gedefinieerd naar de opbouw van de relationele expressies. Schema is altijd te schrij ven als een verzameling van predicatoren. Dit gaat als volgt. Laat r en s relationele expressies zijn. Dan geldt:
Schema (r � s) = Schema (r) � Schema (s) Laat r een relationele expressie zijn, q1,…q n (allen verschillend) en p1,…pn (uit Schema (r))
predicatoren, dan is de projectie � q1:p1,…,qn:pn (r) een relationele expressie met de volgende definitie:
Schema ( � q1:p1,…,qn:pn (r)) = { q1,…q n} Wanneer we kijken naar de selectie operatie, dan kunnen voor wat betreft de schemadefinitie kort zijn. Een relationele expressie r, waarbij een selectie operatie op wordt toegepast heeft geen directe invloed op het resultaat van het type van het afgeleide feittype. We noemen F een will ekeurige selectie. Dan
geldt voor de selectie � F(r) (ook een relationele expressie):
Schema ( � F(r)) = Schema (r)
2.2.3.1.2 Val gedefinieerd De operatie Val geeft bij elke relationele expressie een populatie op basis van een informatiestructuur en een voorbeeldpopulatie. We zullen Val ook definiëren aan de hand van de opbouw van relationele expressies via relationele operaties. Als eerste hebben we de basisdefinitie van de populatie van een feittype f. Dit is eigenlij k triviaal, maar dient als basis voor de opbouw van de operatie Val. Val [ f ] (Pop) = Pop(f) Voor de definitie van Val is het interessant om als eerste te kij ken naar de standaardoperaties vereniging en verschil. Wanneer we 2 relationele expressies r en s bekijken, met bijvoorbeeld Schema

29
(r) = Schema (s), dan zijn de vereniging r � s en het verschil r � s gedefinieerd als relationele expressies met de volgende populaties.
Val [ r � s ] (Pop) = Val [ r ] (Pop) � Val [ s ] (Pop)
Val [ r � s ] (Pop) = Val [ r ] (Pop) � Val [ s ] (Pop) Wanneer we kijken naar twee relationele expressies r en s, kunnen we de join tussen deze twee als volgt populeren. Dit gebeurt middels de volgende definitie van Val.
Val [ r � s ] (Pop) = { t � t[Schema (r)] � Val [ r ] (Pop) � t[Schema (s)] � Val [ s ] (Pop) } In deze definitie zien we dat alle tupels die gevormd worden uit het cartesisch product van de populaties van de relationele expressies r en s worden verwerkt in de populatie van hun join. Ook de andere operaties, projectie en selectie, hebben een dergelij ke definitie. Hieronder komen ze voorbij . Voor de definitie van Val met betrekking tot de projectie operatie, gaan we uit van dezelfde voorwaarden als bij de definitie van de projectie bij Schema.
Val [ � q1:p1,…,qn:pn (r) ] (Pop) = { t ��� s Val [ r ] (Pop) 1 � i � n [t (qi) = s (pi)] } Deze ingewikkelde definitie verdient een nadere verklaring. Deze definitie geeft aan dat wanneer een tupel (met een geprojecteerde predicator) voorkomt in de populatie van de projectie, deze ook moet voorkomen in de populatie van de relationele expressie, zoals die voor de projectie bestaat. Merk op dat de projectie operatie tevens kan dienen voor het hernoemen van predicatoren. Voor we een Val definitie voor de selectie operatie kunnen opstellen, is het noodzakelij k eerst een definitie te geven van de mogelij ke selectieformules. Hiertoe geven we eerst de definitie van de
verzameling � , de selectieformules. � is de kleinste verzameling die voldoet aan: (met P’ alle mogelij ke predicatoren uit een informatiestructuur en D de verzameling van concrete domeinen)
1. p, q � P’ p = q � �
2. p � P’, c ��� D p = c � �
3. f, g � � f � g � �
4. f � � �� f � � Voor de definitie van Val met betrekking tot de selectie operatie is verder nodig te weten wanneer een tupel uit de populatie van de relationele expressie met een selectie operatie voldoet aan een
selectieformule uit � . We schrij ven het volgende, met tupel t voldoet aan de selectieformule f uit ���
t � f, met t een partiële functie van P’ naar � en f uit � , dan en slechts dan als
t(p) = t(q) en � k �� [t(p) = k] en � k �� [t(q) = k], met f van de vorm p = q
t(p) = c en � k �� [t(p) = k], met f van de vorm p = c
t � x en t � y, met f van de vorm x � y
t ��� x, met f van de vorm � x

30
Nu we de betekenis van “t � f” hebben vastgelegd, kunnen we de definitie van Val voor de selectie operatie vastleggen.
Wanneer r een relationele expressie is, f een selectieformule, dan is de selectie � f (r) een ook een relationele expressie met de volgende populatie.
Val [ � f (r) ] (Pop) = { t � Val [ r ] (Pop)�t � f }
Nu het voorwerk van deze definitie is gedaan, is de uitleg van deze Val niet meer moeilij k. Alle tupels uit de populatie van relationele expressie r worden overgenomen, indien ze voldoen aan de selectieformule f. Nu voor de definities voor Schema en Val zijn opgebouwd aan de hand van de opbouw van de relationele expressies, is het fundament gelegd voor een verdere uitbreiding van de relationele algebra voor PSM-schema’s. In de volgende subparagraaf introduceren we nog meer relationele operaties, waarmee de relationele algebra wordt uitgebreid. Hierbij worden voor iedere operatie de definities van Schema en Val bijgewerkt.
2.2.3.1.3 Meer relationele operaties In deze paragraaf breiden we het aantal relationele operaties op relationele expressies uit.
Als eerste introduceren we de extensie operatie � . Deze operatie breidt een relationele expressie r uit met een nieuwe predicator a. Deze predicator telt het aantal tupels met een gelij ke waarde voor een
verzameling van predicatoren uit Schema (r). Deze verzameling wordt gedefinieerd als � . We definiëren:
Schema ( � (r, � , a)) = Schema (r) � { a}
Val [ � (r, � , a) ] (Pop) =
{ t �t[Schema (r)] � Val [ r ] (Pop) � t(a) = | { s � Val [ r ] (Pop)
�t( � ) = s( � ) } | }
Deze definities zijn verder duidelij k. Als tweede introduceren we de “unnest ” operatie. Deze operatie wordt gebruikt om geneste feittypes te “unnesten”. Dit “unnesten” is feitelij k het elimineren van een extra laag in een hiërarchische geneste structuur. We zullen dit nu formaliseren. Laat g een relationele expressie zijn, p een predicator uit Schema (g), f een feittype zodat geldt Base
(p) is type-gerelateerd met f.. We definiëren vervolgens S = Schema (g) \ { p} . We kunnen dan � pf (g)
als relationele expressie definiëren. We zullen nu het bijbehorende figuur uit [Hof94] ter verduideli jking opnemen. Zie figuur 6. Het feittype f wordt als het ware geëlimineerd en diens predicatoren komen bij het feittype g te zitten. De bijbehorende definitie voor Schema en Val zijn als volgt.
Schema ( � pf (g)) = f � S
Val [ � pf (g) ] (Pop) = { t � s[S]
�t � Val [ f ] (Pop) � s � Val [ g ] (Pop) � s(p) = t }
De definitie van Schema spreekt voor zich, daar de verzameling S de predicatoren uit het feittype f er bij krijgt. De definitie van Val relateert hier duidelij k aan. De populatie uit het feittype f wordt gekoppeld aan die uit g, met dien verstande dat de populatie toegewezen aan predicator p vervangen wordt door de reeks uit f.

31
Figuur 6: Werking van de unnest operatie
In een speciaal geval van unnesten kan er bij de definitie van de unnest operatie een probleem optreden. Dit is het geval wanneer de doorsnede van de verzameling S en Schema (f) niet leeg is. Dit betekent dat er 1 of meer gemeenschappelijke predicatoren zijn tussen g en f. Het probleem dat dan
optreed is, dat de waardenverzameling van Val [ � pf (g) ] (Pop) dan kan bestaan uit relaties in plaats
van functies. In dit geval is deze Val niet gedefinieerd. Om dit te ondervangen is een sterke versie van de unnest operatie nodig. Deze introduceren we als “strong unnest ”. Deze operatie werkt als volgt. W e nemen een relationele expressie g, een predicator p uit Schema (g), en f een feittype zodat Base (p)
type-gerelateerd is met f. Nu is S = Schema (g) \ {p} en T = f � S. T geeft dus de verzameling van predicatoren die de feittypes f en g gemeenschappelijk hebben, met daaruit weggelaten p. De strong
unnest operatie � pf (g), werkend op g, is een relationele expressie met de volgende definities.
Schema ( � pf (g)) = f � S
Val [ � pf (g) ] (Pop) =
{ t � s[S] � t � Val [ f ] (Pop) � s � Val [ g ] (Pop) � s(p) = t � s[T] = s(p)[T] } De strong unnest operatie gedraagt zich op dezelfde wijze als de gewone unnest operatie, in het geval de verzameling T leeg is. [Hof94] bespreekt nog enkele boolean operaties, waarvan we de volgenden even aanstippen. Wanneer b een boolean expressie is, schrijven we het volgende wanneer een populatie voldoet aan deze boolean expressie.
Pop � b Een voorbeeld hiervan is de test IsEmpty (r), waarbij de relationele expressie getest wordt op het feit of deze een lege populatie heeft. Dit wordt genoteerd als:
Pop � IsEmpty (r) � Val [ r ] (Pop) =

32
Een belangrijke boolean expressie is degene die functionele afhankelijkheid vastlegt binnen een relationele expressie. Wanneer we 2 deelverzamelingen uit Schema (l), met l een relationele expressie
en de deelverzamelingen � , � ⊆ Schema (l) nemen, dan noteren we de volgende boolean expressie.
� l � �
Deze boolean expressie is waar in een populatie, wanneer een populatie voldoet aan de volgende
eigenschap. De populatie moet voor elke instantie uit de predicatorenverzameling � rechtstreeks dat
gedeelte afleiden uit het � -gedeelte van deze betreffende instantie. Formeel opgeschreven ziet dit er als volgt uit.
Pop ��� l � � � � x,y � Val [ l ] (Pop) [x[ � ] = y[ � ] x[ � ] = y[ � ]]
De boolean expressie � l � � is waar in populatie Pop dan en slechts dan als voor alle
instanties uit Val [ l ] (Pop) geldt dat wanneer de instanties voor een bepaalde predicatorenverzameling hetzelfde zijn, dan dit ook voor een andere, willekeurige predicatorenverzameling uit het relationele schema waar moet zijn. Vergelijkingsoperaties tussen relationele expressies bestaan, maar ze zijn alleen nuttig in het geval van verschillende relationele schema’s van relationele expressies. We zullen drie vergelijkingsoperaties kort introduceren. r en s zijn hierin relationele expressies met verschillende relationele schema’s. De subset operatie: Pop � r ⊆ s � � t � Val [ r ] (Pop) � u � Val [ s ] (Pop) � p � Schema (r) [t(p) = u( � (p))] , waarbij geldt dat � :
Schema (r) Schema (s) , met � p � Schema (r) [p ~ � (p)] De gelijkheidsoperatie: Pop � r = � s � r ⊆ � s � s ⊆ ����� r , met de subset operatie gedefinieerd zoals hierboven. De exclusie operatie: Pop � r ��� s � � t � Val [ r ] (Pop) � u � Val [ s ] (Pop) � p � Schema (r) [t(p) = u( � (p))] Als laatste categorie operaties, voeren we hier nog een tweetal speciale operaties aan.
De eerste is de zogenaamde range operatie, genoteerd met � p (r). Deze operatie genereert de waardenverzameling behorende bij 1 predicator (p) uit een bepaalde relationele expressie r. Deze waardenverzameling kan een populatie zijn, maar kan ook een objectenverzameling zijn uit bijvoorbeeld entiteiten. Hiervoor kan deze operatie geen algebraïsche operatie worden genoemd. De definiëring voor Schema en Val zien er als volgt uit voor deze operatie.
Schema ( � p (r) ) = {p}
Val [ � p (r) ] (Pop) = { t(p) � t � Val [ r ] (Pop) } De omgekeerde versie van de range operatie, is de lift operatie. Deze operatie kan als invoer een objecttype hebben of een relationele expressie. De definities van Val en Schema zien er als volgt uit.

33
Schema ( � p (r) ) = {p}
Val [ � p (r) ] (Pop) = { t � t(p) � Val [ r ] (Pop) } Een klein nuanceverschil in de definitie met de range operatie, maar de populatieverzameling van de lift operatie is totaal verschillend. Bij de range operator worden alleen de elementen uit de universe of instances m.b.t. de geselecteerde predicator gegenereerd, terwijl de lift operatie tot gevolg heeft dat de volledige tupels (dus predicator met toewijzing uit de universe of instances) worden gegenereerd. De predicator hoeft dus niet per se een onderdeel te zijn van een relationele expressie. Bij een objecttype als invoer van de lift operatie worden de elementen van dit objecttype toegevoegd aan de predicator die door de lift operatie wordt gebruikt. Het is natuurlijk wel noodzakelijk dat dit objecttype de basis is van zo’n predicator. Hierbij eindigt de beschrijving van de relationele algebra voor PSM. Vanuit deze relationele algebra zullen we een beschrijving gaan geven van de verschillende soorten constraints in PSM. 2.2.3.2 Constraints onder de loep We zullen als eerste een categorisatie maken van de voorkomende constraints in PSM. Na deze categorisatie zal een bespreking plaatsvinden van de total role constraint en de uniqueness constraints samengaand met een voorbeeld, bestaande uit een PSM schema en een voorbeeldpopulatie. Deze constraints vormen de basis van alle constraints. Ook het doel van deze constraints wordt uitgelegd. Vervolgens zal de formalisering van de constraints plaatsvinden. Deze formalisering wordt, zoals reeds gezegd, opgeschreven in de besproken theorie m.b.t. PSM en diens relationele algebra. De formalisering van de overige constraints zal in vogelvlucht gaan, daar de basis wordt gelegd bij de twee genoemde soorten constraints. We hebben in PSM de volgende (soorten) constraints (gebaseerd op [Hof94]). Gezien de naamgeving van de constraints in het Engels is, zullen we deze niet trachten te vertalen naar een krom Nederlands construct. • Total role constraint • Uniqueness constraint applied to one facttype • Uniqueness constraint applied to more facttypes • Uniqueness constraint applied to objectification • Occurrence frequency constraint • Set constraints • Enumeration constraint • Power exclusion constraint • Cover constraint • Set cardinality constraint • Membership constraint • Specialisation constraints • Subtype constraints (subtype defining rules) • Schema type constraints De belangrijkste constraints, dat wil zeggen vaak voorkomend, hebben een grafische notatie binnen PSM. Onder deze vallen o.a. de total tole constraint, de verschillende uniqueness constraints (met verreweg de moeilijkste semantiek), occurence frequency constraints en set constraints. We zullen beginnen met deze grafische constraints.
2.2.3.2.1 Total role constraint
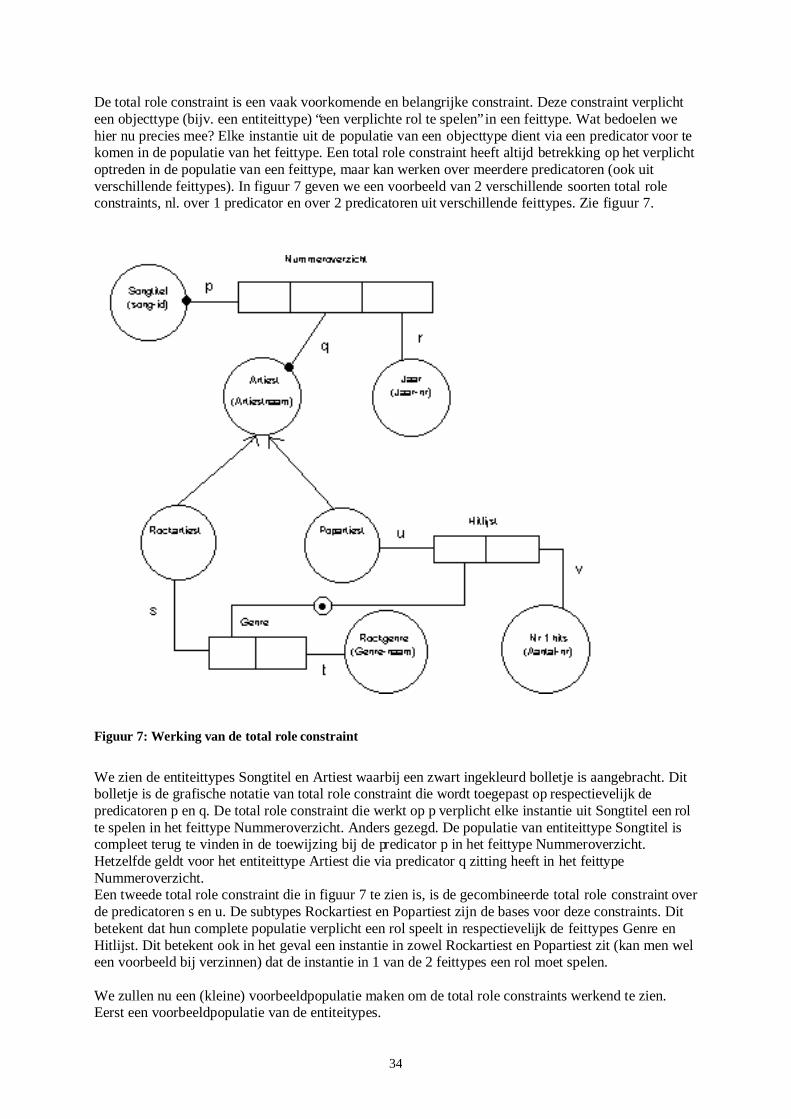
34
De total role constraint is een vaak voorkomende en belangrijke constraint. Deze constraint verplicht een objecttype (bijv. een entiteittype) “een verplichte rol te spelen” in een feittype. Wat bedoelen we hier nu precies mee? Elke instantie uit de populatie van een objecttype dient via een predicator voor te komen in de populatie van het feittype. Een total role constraint heeft altijd betrekking op het verplicht optreden in de populatie van een feittype, maar kan werken over meerdere predicatoren (ook uit verschillende feittypes). In figuur 7 geven we een voorbeeld van 2 verschillende soorten total role constraints, nl. over 1 predicator en over 2 predicatoren uit verschillende feittypes. Zie figuur 7.
Figuur 7: Werking van de total role constraint
We zien de entiteittypes Songtitel en Artiest waarbij een zwart ingekleurd bolletje is aangebracht. Dit bolletje is de grafische notatie van total role constraint die wordt toegepast op respectievelijk de predicatoren p en q. De total role constraint die werkt op p verplicht elke instantie uit Songtitel een rol te spelen in het feittype Nummeroverzicht. Anders gezegd. De populatie van entiteittype Songtitel is compleet terug te vinden in de toewijzing bij de predicator p in het feittype Nummeroverzicht. Hetzelfde geldt voor het entiteittype Artiest die via predicator q zitting heeft in het feittype Nummeroverzicht. Een tweede total role constraint die in figuur 7 te zien is, is de gecombineerde total role constraint over de predicatoren s en u. De subtypes Rockartiest en Popartiest zijn de bases voor deze constraints. Dit betekent dat hun complete populatie verplicht een rol speelt in respectievelijk de feittypes Genre en Hitlijst. Dit betekent ook in het geval een instantie in zowel Rockartiest en Popartiest zit (kan men wel een voorbeeld bij verzinnen) dat de instantie in 1 van de 2 feittypes een rol moet spelen. We zullen nu een (kleine) voorbeeldpopulatie maken om de total role constraints werkend te zien. Eerst een voorbeeldpopulatie van de entiteitypes.

35
Pop(Songtitel) = { Glory Days, Nobody’s Wife, The River, Head Games, Hero, Kyrie, Rovianne} Pop(Artiest) = { Bruce Springsteen, Anouk, Foreigner, Mariah Carey, Mr.Mister, Sahara Snow} Pop(Jaar) = { 1960,…,2000} Pop(Rockartiest) = { Bruce Springsteen, Anouk, Foreigner, Mr.Mister, Sahara Snow} Pop(Popartiest) = { Anouk, Mariah Carey} Pop(Rockgenre) = { AOR, Classic Rock, Hardrock, Softrock, Metal} Pop(Nr 1 hits) = { 1,..,20} Nu volgt een populatie van de feittypes die voldoet aan de gestelde total role constraints. Pop(Nummeroverzicht) = {{ p : Glory Days, q : Bruce Springsteen, r : 1984} , {p : Nobody’s Wife, q : Anouk, r : 1997} , {p : The River, q : Bruce Springsteen, r : 1979} , {p : Head Games, q : Foreigner, r : 1979} , {p : Hero, q : Mariah Carey, r : 1993} , {p : Kyrie, q : Mr.Mister, r : 1985} , {p : Rovianne, q : Sahara Snow, r : 1997}} Pop(Genre) = {{ s : Bruce Springsteen, t : Softrock} , {s : Anouk, t : Hardrock} , {s : Bruce Springsteen, t : Classic Rock} , {s : Foreigner, t : AOR} , {s : Mr.Mister, t : AOR} , { s : Sahara Snow, t : AOR}} Pop(Hitlijst) = {{ u : Mariah Carey, v: 3}} Deze populatie voldoet aan de total role constraints. Dit is als volgt in te zien. Alle instanties van Pop(Songtitel) komen terug in het feittype Nummeroverzicht. Ook alle artiesten, de instanties van Pop(Artiest), komen terug in het feittype Nummeroverzicht. De total role constraint over de twee predicatoren s en u is ook geldig in deze populatie. De vereniging van de instanties uit Rockartiest en Popartiest spelen tenminste allemaal 1 rol in òf het feittype Genre òf het feittype Hitlij st. Een populatie die niet aan deze laatst genoemde constraint had voldaan zou de volgende kunnen zijn. In het geval dat in de populatie van het feittype Genre de instantie { s: Anouk, t: Hardrock} was weggelaten en de rest hetzelfde als hierboven. Aan de total role constraint zou dan niet voldaan zijn, omdat de instantie Anouk op geen enkele wijze een rol speelde in één der twee feittypes (Genre of Hitli jst). Anouk maakt immers deel uit van de beide subtypes. Nu we de werking hebben gezien van de total role constraint, kunnen we met behulp van de relationele algebra de semantiek vastleggen. Definitie Total Role Constraint
Een total role constraint is een verzameling predicatoren genoteerd met � . Deze is als volgt gedefinieerd.
� ⊆P waarvoor geldt ��� �����p,q � [p ~ q]
Een populatie Pop die voldoet aan een total role constraint � maakt het volgende predikaat waar.
�Pop(Base(q)) =
�Val [ � q ( q (Fact(q))) ] (Pop) (Regel TRC)
q �� q ��
We noemen dit predikaat TRC, naar Total Role Constraint. TRC is de eerste in een serie regels die we als basis kunnen gebruiken voor de omzetting naar constraints in het dimensionale model.Nu volgen nog enkele notaties met betrekking tot de total role constraint.

36
We noteren Pop � total ( � ), wanneer de populatie Pop voldoet aan de total role constraint � . Wanneer we teruggaan naar de reeds gedefinieerde verzameling R, kunnen we de total role constraint
� als volgt toevoegen aan de verzameling R. total ( � ) � R is geldig wanneer � een geldige total role
constraint is in het PSM schema � . Als laatste in deze subparagraaf halen we nog een keer de voorbeeldpopulatie aan van figuur 7. We zullen TRC uitschrijven aan de hand van de total role constraint over de predicatoren s en u. Op deze wijze kunnen we de werking van TRC duidelijk maken. De correctheid van de total role constraint die werkt over de predicatoren s en u en het voldoen van de gegeven voorbeeldpopulatie kunnen we als volgt inzien.
Als eerste is de bedoelde total role constraint gedefinieerd als � = {s,u}. Deze is correct gedefinieerd, daar s en u voorkomen in de predicatorenverzameling van de informatiestructuur van figuur 7 en er geldt dat s ~ u. Dit laatste is in te zien door het feit dat Base(s) ~ Base(u), met Base(s) = Rockartiest en Base(u) = Popartiest. Popartiest en Rockartiest hebben dezelfde pater familias, namelijk Artiest en zijn dus type-gerelateerd. De total role constraint is dus een zinvolle. Wanneer we nu gaan kijken naar of de gegeven voorbeeldpopulatie voldoet aan deze total role constraint, moeten we beide leden van TRC uitschrijven. We beginnen met het linkerlid (die voor het gelijkheidsteken). �
Pop(Base(q)) = Pop(Base(s)) �
Pop(Base(u)) = Pop(Rockartiest) �
Pop(Popartiest) = q ��� {Bruce Springsteen, Anouk, Foreigner, Mr.Mister, Sahara Snow}
� {Anouk, Mariah Carey} =
{Bruce Springsteen, Anouk, Foreigner, Mariah Carey, Mr.Mister, Sahara Snow} Dit is de verzameling voorkomende uit het linkerlid van TRC. Het rechterlid is lastiger: �
Val [ � q ( q (Fact(q))) ] (Pop) = Val [ � u ( u (Fact(u))) ] (Pop) �
Val [ � s ( s (Fact(s))) ] (Pop) = q ��� Val [ � u ( u (Hitlijst)) ] (Pop)
�Val [ � s ( s (Genre)) ] (Pop) =
{ t(u) t � Val [ u (Hitlijst)] (Pop)} �
{ t(s) t � Val [ s (Genre)] (Pop)} =
{ t(u) t � {{u : Mariah Carey}}} ���
t(s) t � {{s : Bruce Springsteen}, {s : Anouk}, {s : Foreigner}, {s : Mr.Mister}, {s : Sahara Snow}}} =
{Mariah Carey} �
{Bruce Springsteen, Anouk, Foreigner, Mr.Mister, Sahara Snow} = {Bruce Springsteen, Anouk, Foreigner, Mariah Carey, Mr.Mister, Sahara Snow} De conclusie hieruit is dat het linkerlid gelijk is aan het rechtlid en dus TRC voor deze voorbeeldpopulatie geldig is. Dit houdt in dat de total role constraint {s,u} van de voorbeeldpopulatie een geldige maakt. Nu kunnen we ook eenvoudig inzien dat bij het ontbreken van de tupel {s: Anouk, t: Hardrock} in de populatie van Genre TRC voor die voorbeeldpopulatie ongeldig zou maken. Het rechterlid van TRC zou dan niet het element Anouk opleveren, terwijl het linkerlid dit wel doet. Tot zover de bespreking van de total role constraint in PSM. We vervolgen met een ander belangrijke constraint, nl. de uniqueness constraint.
2.2.3.2.2 Uniqueness constraint

37
De uniqueness constraint komt, zoals gezegd, in drie vormen voor. We zullen deze, gezien hun importantie en complexiteit, in afzonderlij ke subparagrafen bespreken. Allereerst iets over het algemene doel van een uniqueness constraint. Dit constraint beperkt het aantal dezelfde instanties van predicatoren of bepaalde verzamelingen van predicatoren tot 1. Hiermee wordt deze instantie voor die predicator of verzameling van predicatoren uniek, vandaar de naam uniqueness constraint. Het algemene belang van de uniqueness constraint in de informatiemodellering is zeer vergaand. Een voorbeeld. We hebben in data warehouses al te maken gehad met indexeringen en indexvelden. Denk aan de sleutels die gebruikt worden in de dimensietabellen. Deze berusten op uniqueness constraints. Twee algemene belangen in de databasemodelleringswereld zijn ten eerste het waarborgen van de integriteit van het model en de mogelijkheden voor het maken van efficiënte toegangsalgoritmes (met gebruikmaking van sleutels en indexen). We zullen in de volgende drie subparagrafen deze soorten uniqueness constraints de revue laten passeren. • Uniqueness constraint applied to one facttype • Uniqueness constraint applied to more facttypes • Uniqueness constraint applied to objectification Dit zijn de drie soorten uniqueness constraints die voorkomen in PSM. Nadat deze de revue zijn gepasseerd, volgt een beschrij ving van een algoritme waarmee de semantiek voor een uniqueness constraint in het algemeen kan worden afgeleid.
2.2.3.2.2.1 Uniqueness constraint applied to one facttype De uniqueness constraint die werkt binnen 1 enkel feittype is de eenvoudigste. Deze vorm zorgt ervoor dat binnen de populatie van 1 feittype instanties van 1 of meerdere predicatoren slechts 1 keer voor mogen komen. We noemen de predicatorverzameling waar de uniqueness constraint op van toepassing
is de sleutel of key. Een sleutel is dus een verzameling predicatoren, genaamd � , waarvan een bepaalde instantie slechts eenmaal mag voorkomen in diens populatie. We zullen dit aan de hand van een klein voorbeeld demonstreren. Zie figuur 8.
Figuur 8: Werking van de uniqueness constraint binnen 1 feittype

38
In figuur 8 zien we de grafische notatie van de uniqueness constraint binnen 1 feittype. Deze wordt aangegeven met een pijl boven de rollen van de predicatoren die zitting hebben in de uniqueness
constraint. In figuur 8 is dus sprake van 2 uniqueness constraints, namelijk � = {q,r} en � = {u}. We gaan nu kijken hoe deze werken aan de hand van een kleine voorbeeldpopulatie die voldoet aan figuur 8 en de gedefinieerde uniqueness constraints. Pop(Jaar) = {1900,…,2000} Pop(Artiest) = {Men At Work, Little River Band, Crowded House, Split Enz} Pop(Songtitel) = {Down Under, Home On Monday, Weather With You, Message To My Girl, Who Can It Be Now?} Pop(Top 40 positie) = {1,..,40} Pop(Oprichting) = {{s : 1979, u : Men At Work}, {s : 1975, u : Little River Band}, {s : 1985, u : Crowded House}, {s : 1972, u : Split Enz}} Pop(Notering) = {{r : Men At Work, q : Down Under, p : 2}, {r : Little River Band, q : Home On Monday, p : 12}, {r : Crowded House, q : Weather With You, p : 13}, {r : Split Enz, q : Message To My Girl, p : 28}, {r : Men At Work, q : Who Can It Be Now?, p : 6}} Dat deze populatie voldoet aan de uniqueness constraints is als volgt in te zien. De uniqueness
constraint � = {u} is correct toegepast in bovenstaande populatie, omdat de instanties van de basis van predicator u, allen maximaal 1 keer voorkomen in de populatie van het feittype Oprichting. Deze uniqueness constraint gaat over slechts 1 predicator, terwijl de tweede gedefinieerde over twee gaat,
nl. � = {q,r}. Aan deze uniqueness constraint is ook voldaan door de voorbeeldpopulatie. De predicatoren q en r krijgen gezamenlijk een unieke toevoeging van hun basis in het feittype Notering. Dit betekent per tupel een unieke combinatie van Artiest en Songtitel. Wanneer we kijken naar de populatie van Notering dan zien we de band Men At Work wel 2 keer voorkomen, maar telkens met een ander nummer. Aan de constraint is dus voldaan. Wat in strijd zou zijn met de uniqueness constraint {q,r} zou het geval geweest zijn dat Men At Work met Down Under twee keer zou voorkomen in Notering. Een laatste opmerking over de uniqueness constraint binnen 1 feittype betreft het feit dat wanneer een feittype geen uniqueness constraint heeft (dus geen pijl boven de rollen) er geldt dat er over het gehele feittype f een uniqueness constraint moet worden gedacht. Deze wordt echter niet genoteerd, omdat een feittype op zichzelf geen dubbele tupels in zijn populatie toelaat. We zullen de uniqueness constraint binnen 1 feittype nu formaliseren aan de hand van de relationele algebra. Definitie Uniqueness constraint applied to one facttype
Een uniqueness constraint binnen 1 feittype is een verzameling predicatoren � binnen feittype f, als volgt gedefinieerd.
� ⊆f waarvoor geldt ��������
( � ) = f �
f ⊆P
met de functie �
( � ) die onderdeel is van de semantiek van een uniqueness constraint. Deze wordt bij de uniqueness constraint toegepast op meerdere feittypes gedefinieerd. Voor dit type constraint geldt
echter de eenvoudige gelijkheid �
( � ) = f.

39
Verder introduceren we hier de definitie die de volledige semantiek van een uniqueness constraint
beschrijft. Laat r een relationele expressie zijn en � een verzameling predicatoren uit Schema (r).
We definiëren dan: Pop � identifier (r, � ) dan en slechts dan als Pop � � r � Schema (r).
De boolean expressie identifier (r, � ) legt de semantiek van een uniqueness constraint vast. Dit zien
we later. We introduceren nu eerst unique ( � ), met � de verzameling predicatoren die in de uniqueness constraint zitting hebben. Daarvoor wordt de volgende notatie ingevoerd (analoog aan de reeds gedefinieerde total role constraint):
Een uniqueness constraint is een verzameling predicatoren � ( ������� ⊆P). Een populatie Pop
voldoet aan een uniqueness constraint � , genoteerd als Pop � unique ( � ), dan en slechts dan als
Pop � identifier (� ( � ), � ). De functie � ( � ) wordt in de volgende paragraaf gedefinieerd.
2.2.3.2.2.2 Uniqueness constraint applied to more facttypes Deze soort uniqueness constraint is semantisch gezien een stuk moeilij ker dan zijn hiervoor besproken voorganger. Bij een uniqueness constraint waarbij predicatoren uit verschill ende feittypes betrokken zijn, is het van belang dat de predicatoren een onderlinge “equivalentie” vertonen. Hiermee wordt bedoeld dat niet ieder paar will ekeurige predicatoren uit verschillende feittypes een uniqueness constraint kan zijn. Deze equivalentie wordt belichaamd door de volgende definitie. Wanneer predicatoren uit een aantal feittypes samen zitting hebben in een uniqueness constraint is het noodzakelij k dat deze feittypes “ joinable via common object types” zijn. Dit is als volgt recursief gedefinieerd.
Jn( � ) = |Facts ( � ) | > 1 � f, g � Facts ( � ), f � g [ f \ � ~ g \ ��� Jn( � \ f) ] met
� de verzameling predicatoren in de uniqueness constraint,
Facts ( � ) = { Fact (p) � p ����� en
twee verzamelingen predicatoren a en b zijn type gerelateerd, a ~ b, wanneer geldt p � a q � b[p ~ q]. Deze definitie geeft het volgende aan. Wanneer er meerdere feittypes betrokken zijn bij de uniqueness constraint, dan zijn deze feittypes joinable via common object types als geldt dat er twee feittypes f en g zijn, waarvan de predicator of predicatoren een rol speelt of spelen in de uniqueness constraint, waarvan hun restverzameling predicatoren type-gerelateerd zijn. Met restverzameling wordt de verzameling predicatoren uit een feittype bedoeld die geen zitting heeft in de uniqueness constraint. Een tweede eis is dat de feittypes uit de predicatorenverzameling met daaruit weggelaten de predicatoren uit het feittype f ook joinable via common object types zijn. We kunnen nu de semantiek van een uniqueness constraint toegepast op meerdere feittypes volledig
maken door de beloofde definitie van � ( � ). We zullen dan een uitgebreid voorbeeld geven om de geïntroduceerde theorie in praktijk te brengen. Definitie Uniqueness constraint applied to more facttypes
Een uniqueness constraint toegepast op meerdere feittypes is een verzameling predicatoren � , met de volgende definitie.

40
� ⊆P waarvoor geldt ������� Jn( � )
Verder wordt voor dit type constraint een afgeleid feittype � ( � ) gedefinieerd, waarvan � de sleutel is.
� ( � ) = � C( ) f � Facts ( ) f met
C( � ) = �� �� p = q p,q �� Facts (� ) \ � , p~q
We kunnen nu voor dit type uniqueness constraint het volgende definiëren.
Pop � unique ( � ) � Pop � identifier ( � C( ) f � Facts ( ) f, � )
De conditie unique ( � ) verplicht dat de verzameling � een sleutel is over het afgeleide feittype � ( � ). We zullen dit nu in de praktijk brengen via een voorbeeld. We kijken naar figuur 9.
Figuur 9: Werking van de uniqueness constraint over meerdere feittypes
We zien in figuur 9 een uniqueness constraint over meerdere feittypes, nl. Bandinfo, Frequentieoverzicht en DJ/VJ overzicht. Alvorens we gaan kijken of dit een uniqueness constraint is dat voldoet aan de gestelde eisen, geven we nu eerst een populatie van de entiteittypes uit figuur 9.

41
Pop(Frequentie) = { 60.0 FM,….,120.0 FM} Pop(Muziekstation) = { TMF, MTV Europe, Radio 3, Radio 538, Skyradio} Pop(Radiostation) = { Radio 3, Radio 538, Skyradio} Pop(Medewerker) = { Erik de Zwart, Henk Westbroek, Edwin Evers, Rob Stenders, Jeroen van Inkel, Katja Schuurman, Jeroen Post} Pop(Artiest) = {Toto, Foreigner, Madonna, Bon Jovi, Richard Marx, U2, The Corrs} Pop(Opgericht) = { 1900,…,2000} Pop(Hits) = { Pamela, Stop Loving You, Africa, Rosanna, I Want To Know What Love Is, That Was Yesterday, Juke Box Hero, Women, Always, Bed Of Roses, Livin’ On A Prayer, Dry County, Papa Don’t Preach, Holiday, Frozen, Cherish, Right Here Waiting, Angelia, Satisfied, Hazard, Where The Streets Have No Name, Pride (In The Name Of Love), One, Sunday Bloody Sunday, Breathless, Runaway, Radio, Dreams} Pop(Genre) = { Softrock, Pop, Folk, Hardrock} Als eerste moeten we gaan kijken of de uniqueness constraint over meerdere feittypes “joi nable via
common object types” is. We definiëren hiervoor � = { r,s,w,x} en bekijken de definitie voor Jn( � ).
Jn( � ) = |Facts ( � ) | > 1 � �
f, g � Facts ( � ), f � g [ f \ � ~ g \ ��� Jn( � \ f) ] Het aantal feittypes waar de uniqueness constraint zitting in heeft met 1 of meerdere predicatoren,
gedefinieerd met het aantal elementen in de waardenverzameling van de functie Facts ( � ), is drie. Aan de als-voorwaarde in definitie is dus voldaan. Vervolgens kiezen we twee feittypes uit deze
verzameling Facts ( � ), zeg Frequentieoverzicht en DJ/VJ overzicht, en kijken we of hun restverzameling van predicatoren met elkaar type-gerelateerd zijn. We substitueren en krijgen:
Frequentieoverzicht \ � = { v}
DJ/VJ overzicht \ � = { y} met { v} ~ { y} is waar, vanwege v ~ y en Muziekstations ~ Radiostations
Vervolgens komen we bij Jn( � \ Frequentieoverzicht) en ook hier is het aantal elementen in Facts ( � ) nog steeds groter dan 1. We kiezen weer 2 feittypes uit Facts ( � ), hetgeen er nu nog maar 2 zijn. We substitueren en krijgen:
DJ/VJ overzicht \ � = { y}
Bandinfo \ � = { p, q, u, t} met { y} ~ { p, q, u, t} is waar, vanwege y ~ u en Muziekstations ~ Radiostations
Vervolgens hebben we nog over Jn( � \ { Frequentieoverzicht,DJ/VJ overzicht} ), maar dit is altijd waar. Dit komt door het feit dat de als-voorwaarde in de bewering niet waar is (er is nog maar 1 feittype, nl. Bandinfo) en dus de als-dan-bewering wel waar.
Conclusie: aan de eis Jn( � ) is voldaan, waarmee deze uniqueness constraint dus goed gedefinieerd is. We kunnen nu de semantiek van deze uniqueness constraint gaan vastleggen.
Als eerste zullen we het afgeleide feittype � ( � ) definiëren door de relationele expressie voor dit specifieke geval uit te schrijven. De definitie staat hieronder nog een keer.
� ( � ) = C( � ) f � Facts ( � ) f met
C( � ) = �� �� p = q p,q �� Facts (� ) \ � , p~q

42
We schrij ven de selectieformule C( � ) uit. We definiëren
C({ w, x, r, s} ) = y = u � v = y � u = v
Vervolgens kunnen we �
( � ) definiëren. �
( � ) = � y = u � v = y � u = v (Frequentieoverzicht � DJ/VJ overzicht � Bandinfo) De semantiek van deze uniqueness constraint wordt dus:
identifier ( � y = u � v = y � u = v (Frequentieoverzicht � DJ/VJ overzicht � Bandinfo), { w, x, r, s} ) We kunnen hiermee een voorbeeldpopulatie van de feittypes geven die aan deze uniqueness constraint voldoet. Pop(Frequentieoverzicht) = {{ w : 89.0 FM, v : Radio 538} , {w : 98.6 FM, v : Radio 3}, {w : 100.7 FM, v : Skyradio} , {w : 100.4 FM, v : Skyradio}} Pop(DJ/VJ overzicht) = {{ x : Erik de Zwart, y : TMF} , {x : Erik de Zwart, y : Radio 538} , {x : Henk Westbroek, y : Radio 3} , {x : Edwin Evers, y : Radio 538} , {x : Rob Stenders, y : Radio 3} , {x : Jeroen van Inkel, y : Radio 538} , {x : Katja Schuurman, y : MTV Europe} , {x : Jeroen Post, y : TMF}} Pop(Bandinfo) = {{ p : Toto, q : 1978, r : Africa, s : Rosanna, u : Radio 538, t : Softrock} , {p : Foreigner, q : 1976, r : I Want To Know What Love Is, s : Tha t Was Yesterday, u : Skyradio, t : Hardrock} , {p : Madonna, q : 1983, r : Papa Don’t Preach, s : Frozen, u : Skyradio, t : Pop} , {p : Richard Marx, q : 1987, r : Right Here Waiting, s : Angelia, u : Skyradio, t : Softrock} , {p : Bon Jovi, q : 1983, r : Always, s : Bed Of Roses, u : Radio 3, t : Hardrock} , {p : U2 , q : 1976, r : Pride (In The Name Of Love), s : Sunday Bloody Sunday, u : Radio 3, t : Softrock} , {p : The Corrs, q : 1991, r : Radio, s : Breathless, u : Skyradio, t : Folk}} Het is aan zo’n populatie eenvoudig te zien dat hij voldoet. De predicatoren w, x, r en s moeten met hun toewijzing gezamenlij k uniek zijn. In de populatie van DJ/VJ overzicht komt weliswaar tweemaal Erik de Zwart voor, maar voor de andere predicatoren uit de uniqueness constraint is geen enkele instantie dubbel. Een voorbeeld van een populatie die niet voldoet zou de volgende zijn. Men neemt bovenstaande populatie met de volgende toevoeging. Aan Pop(Frequentieoverzicht) wordt de tupel { w : 100.7 FM, v : Radio 3} toegevoegd en aan Pop(Bandinfo) wordt toegevoegd { p: The Corrs, q : 1991, r : Radio, s : Breathless, u : Radio 538, t : Folk} . Het probleem dat nu optreedt is dat tweemaal in deze populatie de “predicatortoewijzing” w : 100.7 FM, x : Erik de Zwart, r : R adio, s : Breathless voorkomt. Dit is in strijd met de gedefinieerde uniqueness constraint. We gaan nu verder met de uniqueness constraint die werkt over objectif icatie.
2.2.3.2.2.3 Uniqueness constraint applied to objectification Een uniqueness constraint die mede werkt op een predicator die zich bevindt in een geobjectif iceerd feittype is weer een fractie complexer dan de hiervoor besproken variant. We zullen de theorie omtrent deze constraint opbouwen na introductie van een figuur. We bekijken figuur 10. In dit figuur gaat het over dammatches uit het verleden.

43
Figuur 10: Werking van de uniqueness constraint met objectificatie
We zien een feittype Match dat is geobjectificeerd. Dit is te herkennen aan de bol die rond het feittype is getekend. Match speelt via de predicator t een rol in het feittype Matchoverzicht, hetgeen een overzicht geeft van de historische dammatches. De uniqueness constraint die is gedefinieerd in dit figuur betreft twee predicatoren, waarvan er één in het geobjectificeerde feittype zit. We beginnen met een populatie van de entiteittypes. Pop(Speler) = { Roozenburg, Deslauriers, Koeperman, Sjtsjogoljew, Baba Sy, Andreiko, Sijbrands, Wiersma, Gantwarg, Van der Wal, Dibman, Tsjizjow, Valneris, Schwarzman, Wirny, Clerc, Van Dijk, Huisman, Keller} Pop(Land) = { Rusland, Nederland, Canada, Senegal, Letland} Pop(Jaar) = { 1948,…,2000}
Pop(Resultaat) = { a+,b=,c- � a,b,c ��� }
Bij een uniqueness constraint zoals deze, met een predicator in � die onderdeel is van een geobjectificeerd feittype, is meer aan de hand dan bij een gewone uniqueness constraint waarbij meerdere feittypes een rol spelen. De eis die in de vorige paragraaf werd gesteld naar aanleiding van het joinable zijn, is hier nog steeds van kracht. Het verschil zit hem echter in het feit dat bij een geobjectificeerd feittype vaak nog een extra unnestoperatie moet worden toegepast om deze join mogelij k te maken. Om grip te krijgen op de semantiek die bij dit soort uniqueness constraint hoort,

44
zullen we nu een algemene methode invoeren om die semantiek af te leiden. We hebben hiervoor nog wel extra instrumentarium nodig. In [Hof94] wordt een alternatieve schrijfwijze geïntroduceerd voor (delen van) PSM-schema’s om complexe constraints en door complexe operaties ontstane afgeleide feittypes duidelij k in beeld te brengen. Dit heeft tot doel om het inzicht in de werking van deze materie te vergemakkelij ken, hetgeen een noodzakelij ke stap is. We zullen deze techniek hier kort introduceren en toepassen bij het uitwerken van het geïntroduceerde voorbeeld. Het betreft de zogenaamde Object Interpretation Structures of kortweg OIS. Definitie Object Interpretation Structure (OIS) Een OIS is een verzameling van objecten uit een informatiestructuur en relationele expressies (die bijvoorbeeld constraints vastleggen) die daarop kunnen worden toegepast. Formeel is een OIS te
definiëren als een verzameling N ⊆ O � R(I). Een OIS wordt gepresenteerd aan de hand van een Object Interpretation Graph. Een Object Interpretation Graph is een gerichte graaf, met elementen van N als nodes en predicatoren uit P als pijlen tussen deze nodes. De restrictie bij dit is dat pijlen altijd vertrekken uit een objecttype dat geen feittype is en aankomen in een feittype. Nu volgen enkele functies en predikaten die betrekking hebben op een OIS. Hierbij geldt dat N is een
OIS binnen een informatiestructuur I en n � N.
children(N, n) = { x � N ���
p � Schema(n) [ Base(p) ~ x ]}
leaf(N, n) � children(N, n) = � depth(N, n) = if leaf (N, n) then 0
else 1 + max x � children(N, n) depth (N , x) endif
top(N, n) � � x � N [n � children(N, x)]
superfluous(N, n) = top(N, n) ( �
x � N [ Schema(n) Schema(x) ] � leaf(N, n))
reduce(N) = N \ { n � N �
superfluous(N, n) }
path(x, y) = x ~ y � �
p � P [Base(p) ~ x path(Fact(p),y)]
N[x � n] = { x} � N \ { n} Wanneer we een gedeelte van een informatiestructuur willen afbeelden in een Object Interpretation Graph maken we gebruik van een Relevant Object Interpretation Structure (ROIS). We definiëren een
ROIS als volgt. Een ROIS schrijven we als OIS(I, ) met I een informatiestructuur en een deelverzameling van P. Deze is als volgt inductief gedefinieerd als de kleinste verzameling die voldoet aan:
1. p � �� Base(p) � OIS(I, ) Fact(p) � OIS(I, ) 2. Fact(p) � OIS(I, ) � q � Fact(p) [Base(q) � OIS(I, )] � Base(p) � OIS(I, )] 3. x, y � OIS(I, ) path(x, z) path(z, y) � z � OIS(I, )
Tot zover dit intermezzo over de Object Interpretation Structure. De semantiek voor een uniqueness constraint wordt vastgelegd aan de hand van de definitie van het
afgeleide feittype � ( ). We kunnen nu voor een uniqueness constraint in het algemeen de semantiek
(de definitie van � ( )) afleiden via het volgende algoritme.

45
Definitie The Uniquest Algorithm
De semantiek van een uniqueness constraint, � ( � ), wordt berekend aan de hand van de definitie
� ( ��� OIS(I, � )). Het algoritme ziet er als volgt uit.
� ( � , N) =
if exists n � N such that � ⊆ Schema(n) � depth(N, n) = 1 then return n
elif exists n � N, p � Schema(n) \ � , f � N � F such that top(N, n) � f ~ Base(p) ��� leaf(N, f)
then if exists g � N � F such that g f � g ~ Base(p) �� leaf(N, g) then error: ambiguous with respect to unnesting
else return � ( � , reduce(N [ � pf (n) � n]))
endif elif n � N [depth(N, n) � 1] � Jn(N, � ) then return � C(N, � ) ( � n � N, Schema (n) ������� n) else error: no joinable descendants endif waarbij
Jn(N, � ) = |Facts (N, � ) | > 1 � � f, g � Facts (N,� ), f � g [ Schema(f) \ � ~ Schema(g) \ ��� Jn(N\{ f} , � ) ]
Facts (N, � ) = { x � N ��� leaf(N, x) � Schema(x) � �� �"!
C(N, � ) = ## ## p = q
p,q �%$ (N, � ) , p~q
&(N, � ) = { p � P \ �'� � n � N [ p � Schema(n) ] }
Tot zover de definitie van het Uniquest Algorithm. Het algoritme zullen we demonstreren aan de hand van het geïntroduceerde voorbeeld (figuur 10). De eerste stap die we zullen nemen is het tekenen van de Object Interpretation Graph behorende bij de Relevant Object Interpretation Structure van de informatiestructuur uit figuur 10 en de daarin
gedefinieerde uniqueness contraint. We definiëren, met I de informatiestructuur uit figuur 10 en � = { u,s} :
OIS(I, � ) (Base(s) = Speler, Base(u) = Jaar, Fact(s) = Match, Fact(u) = Matchoverzicht, volgens regel 1.
Resultaat volgens regel 2, want Matchoverzicht (Fact(u)) is een element van OIS(I, � ) en er is
predicator t uit Matchoverzicht waarvoor geldt dat de basis (Match) ook in OIS(I, � ) zit. Hierdoor is de
basis van de predicator v ook een element van OIS(I, � ). Volgens regel 3 behoort Herkomst ook tot OIS( I, � ), omdat men voor zowel x en y neemt Match. Dan is path(x, z), met z = Herkomst, gelij k aan path(Match, Herkomst). Dit is waar, omdat Match ~ Herkomst (immers: Match = { s,r} en Herkomst = { p,q} en q ~ s omdat Base(q) = Base(s)). Ook geldt

46
path(z,y) = path(Herkomst, Match), vanwege Herkomst ~ Match. Dus geldt ook dat z = Herkomst
een element is van OIS(I, � ).
Omdat ook Herkomst element is van OIS(I, � ), is Land dit ook. Regel 2 zegt immers, wanneer
Herkomst een element is van OIS(I, � ), en een andere predicator uit Herkomst (q) als basis ook een
element is uit OIS(I, � ), dan is de basis van de eerste predicator ook een element. Dus Land is ook een
element uit OIS(I, � ).
Dit betekent dat de hele informatiestructuur I uit figuur 10 gelij k is aan OIS(I, � ). Dit hoeft echter niet altijd zo te zijn. We gaan nu de bijbehorende Object Interpretation Graph weergeven. Zie figuur 11.
Figuur 11: Object Interpretation Graph van dammatches
Aan de hand van de Object Interpretation Graph zullen we visueel bijhouden wat het algoritme doet.
We berekenen �
( ��� OIS(I, � )) aan de hand van het algoritme. We definiëren vooraf formeel:
OIS(I, � ) = { Land, Speler, Match, Jaar, Resultaat, Herkomst, Matchoverzicht} .
De eerste test controleert of er een element in OIS(I, � ) zit waarvan de hele uniqueness constraint in diens predicatorverzameling zit. Dit is hier niet het geval. De uniqueness constraint { u,s} is verdeeld over twee feittypes, namelij k Match en Matchoverzicht.
De tweede test vraagt of er drie elementen bestaan, een object n uit OIS(I, � ), een predicator p uit het
schema van n zonder de constraint predicatoren en een object f uit OIS(I, � ), zijnde een feittype, zodat geldt dat n een topnode is, node f type-gerelateerd is met de basis van predicator p en dat f geen blad is. Een object n met een gedefinieerd schema kunnen alleen de feittypes zijn, dus Herkomst, Match en Matchoverzicht. De predicator p is dan wel te vinden en f ook als zijnde ook Herkomst, Match of Matchoverzicht. Bij de volgende keuze van deze drie is voldaan aan de gestelde voorwaarde. Men ziet: n = Matchoverzicht, p = t, f = Match Matchoverzicht is een topnode. Ook geldt Match ~ Base(t), want Match ~ Match. Verder is in te zien dat Match geen blad is, getuige het volgende:

47
� leaf (OIS(I, � ), Match) � children(OIS(I, � ), Match) � �
children(OIS(I, � ), Match) � � � { x � OIS(I, � ) ��� p Schema(Match) [ Base(p) ~ x ]} �
�
{ x � OIS(I, � ) �� p Schema(Match) [ Base(p) ~ x ]} � � � { Speler} �
�
In de then-statement wordt vervolgens getest of er nog een object is uit OIS( I, � ), zijnde een feittype en ongelij k aan de gedefinieerde f (= Match) waarvoor geldt dat het ook type -gerelateerd is met de basis van de gekozen predicator t en geen blad is. Het is eenvoudig in te zien dat zo’n el ement in ons voorbeeld niet bestaat. De twee overgebleven kandidaten, Matchoverzicht en Herkomst, voldoen beide niet. De basis van t is Speler en zowel Matchoverzicht als Herkomst zijn niet type-gerelateerd met Speler. Er is immers geen type gerelateerdheidsfunctie tussen entiteittypes en feittypes. Er is hier dus geen sprake van een ambigue situatie met betrekking tot unnesten. Na deze check wordt het volgende teruggeleverd door het algoritme:
� ( � , reduce(OIS(I, � ) [ � tMatch (Matchoverzicht) Matchoverzicht])).
We komen door dit resultaat in een incarnatiestap van het algoritme terecht. We schrij ven het bovenstaande uit.
� ( � , reduce(OIS(I, � ) [ � tMatch (Matchoverzicht) Matchoverzicht])) =
� ( � , reduce({ � tMatch (Matchoverzicht), Match, Speler, Jaar, Resultaat, Herkomst, Land} )
De reduce functie haalt alle overbodige (superfluous) nodes eruit. Hierbij wordt de overbodige node Match geëlimineerd.
Wanneer we kijken naar het schema van de relationele expressie � tMatch (Matchoverzicht), zien we het
volgende.
Schema ( � tMatch (Matchoverzicht)) = Match � Schema (Matchoverzicht) \ { t} = {s, r, v, u, w}
We kunnen nu een tweede Object Interpretation Graph tekenen, met het resultaat van de strong unnest. Men ziet dan de predicatorverzameling van deze relationele expressie visueel mooi terugkomen. Zie figuur 12.
Figuur 12: Object Interpretation Graph van dammatches na de unnesting van Matchoverzicht
Aan deze Object Interpretation Graph is goed te zien dat de Uniquest Algorithm bij de eerste test gelijk resultaat levert. Dit blij kt uit de volgende redenering. We hebben:

48
�( � , reduce({ � t
Match (Matchoverzicht), Match, Speler, Jaar, Resultaat, Herkomst, Land}) = �( ������� t
Match (Matchoverzicht), Speler, Jaar, Resultaat, Herkomst, Land}) =
� tMatch (Matchoverzicht)
De laatste stap is in te zien door het feit dat de eerste test slaagt van de Uniquest Algorithm. Men ziet:
� ⊆ � tMatch (Matchoverzicht) en depth( ��� t
Match (Matchoverzicht), Speler, Jaar, Resultaat, Herkomst,
Land}, � tMatch (Matchoverzicht)) = 1
De semantiek voor de uniqueness constraint wordt dus:
identifier ( � tMatch (Matchoverzicht), {s,u})
Als laatste sectie in de paragraaf gaan we terug naar de gegeven voorbeeldpopulatie en vervolgen we hieronder met een populatie van de feittypes die voldoet aan de constraint. (Geen rekening gehouden met uitdager/verdediger verhouding). Pop(Herkomst) = {{q : Roozenburg, p : Nederland}, {q : Keller, p : Nederland}, {q : Huisman, p : Nederland}, {q : Van Dijk, p : Nederland}, {q : Deslauriers, p : Canada}, {q : Koeperman, p : Rusland}, {q : Sjtsjogoljew, p : Rusland}, {q : Andreiko, p : Rusland}, {q : Sijbrands, p : Nederland}, {q : Wiersma, p : Nederland}, {q : Gantwarg, p : Rusland}, {q : Baba Sy, p : Senegal}, {q : Van der Wal, p : Nederland}, {q : Dibman, p : Rusland}, {q : Wirny, p : Rusland}, {q : Clerc, p : Nederland}, {q : Tsjizjow, p : Rusland}, {q : Valneris, p : Letland}, {q : Schwarzman, p : Rusland}} Pop(Match) = {{s : Roozenburg, r : Keller}, {s : Roozenburg, r : Huisman}, {s : Koeperman, r : Deslauriers}, {s : Koeperman, r : Van Dijk}, {s : Koeperman, r : Sjtsjogoljew}, {s : Koeperman, r : Baba Sy}, {s : Koeperman, r : Andreiko}, {s : Sijbrands, r : Andreiko}, {s : Sijbrands, r : Koeperman}, {s : Wiersma, r : Gantwarg}, {s : Wiersma, r : Wirny}, {s : Wiersma, r : Van der Wal}, {s : Gantwarg, r : Clerc}, {s : Dybman, r : Gantwarg}, {s : Tsjizjow, r : Sijbrands}, {s : Tsjizjow, r : Valneris}, {s : Tsjizjow, r : Wiersma}, {s : Schwarzman, r : Tsjizjow}} Pop(Matchoverzicht) = {{u : 1951, t : {s : Roozenburg, r : Keller}, v : 2+ 15= 1-, w : Roozenburg}, {u : 1954, t : {s : Roozenburg, r : Huisman}, v : 4+ 8= 0-, w : Roozenburg},

49
{u : 1958, t : { s : Koeperman, r : Deslauriers} , v : 4+ 14= 2-, w : Koeperman} , {u : 1959, t : { s : Koeperman, r : Van Dijk} , v : 7+ 13= 2-, w : Koeperman} , {u : 1961, t : { s : Koeperman, r : Sjtsjogoljew} , v : 2+ 18= 0-, w : Koeperman} , {u : 1963, t : { s : Koeperman, r : Baba Sy} , v : 0+ 0= 0-, w : Koeperman} , {u : 1965, t : { s : Koeperman, r : Sjtsjogoljew} , v : 7+ 12= 1-, w : Koeperman} , {u : 1967, t : { s : Koeperman, r : Andreiko} , v : 2+ 18= 0-, w : Koeperman} , {u : 1969, t : { s : Koeperman, r : Andreiko} , v : 0+ 17= 3-, w : Andreiko} , {u : 1971, t : { s : Koeperman, r : Andreiko} , v : 0+ 20= 0-, w : Andreiko} , {u : 1973, t : { s : Sijbrands, r : Andreiko} , v : 2+ 18= 0-, w : Sijbrands} , {u : 1974, t : { s : Sijbrands, r : Koeperman} , v : 0+ 0= 0-, w : Koeperman} , {u : 1979, t : { s : Wiersma, r : Gantwarg} , v : 0+ 0= 0-, w : Wiersma} , {u : 1981, t : { s : Wiersma, r : Gantwarg} , v : 2+ 18= 0-, w : Wiersma} , {u : 1983, t : { s : Wiersma, r : Van der Wal} , v : 1+ 19= 0-, w : Wiersma} , {u : 1984, t : { s : Wiersma, r : Wirny} , v : 1+ 18= 1-, w : Wiersma} , {u : 1985, t : { s : Gantwarg, r : Clerc} , v : 2+ 17= 1-, w : Gantwarg} , {u : 1987, t : { s : Dybman, r : Gantwarg} , v : 0+ 20= 0-, w : Dybman} , {u : 1989, t : { s : Tsjizjow, r : Sijbrands} , v : 1+ 18= 1-, w : Tsjizjow} , {u : 1991, t : { s : Tsjizjow, r : Valneris} , v : 6+ 10= 0-, w : Tsji zjow} , {u : 1993, t : { s : Tsjizjow, r : Wiersma} , v : 2+ 15= 1-, w : Tsjizjow} , {u : 1995, t : { s : Tsjizjow, r : Valneris} , v : 3+ 2= 1-, w : Tsjizjow} , {u : 1998, t : { s : Schwarzman, r : Tsjizjow} , v : 2+ 0= 1-, w : Schwarzman}} In 1963 kon door omstandigheden de geplande match tussen Iser Koeperman en Baba Sy geen doorgang vinden. In 1986 werd de wereldtitel van 1963 gedeeld toegekend aan Koeperman en postuum aan Baba Sy. Hij kwam in de jaren 70 door een auto-ongeluk om het leven. Door de uniqueness constraint kan dit niet worden weergegeven. Er zou dan een tupel moeten worden toegevoegd met { u : 1963, t : { s : Koeperman, r : Baba Sy} , v : 0+ 0= 0-, w : Baba Sy} aan de populatie van Matchoverzicht, maar door het dubbel voorkomen van s : Koeperman en u : 1963 is dit verboden. Tot zover de uniqueness constraints. Met de in deze paragrafen geïntroduceerde theorie is het mogelij k de overige constraints te formaliseren. We presenteren ze in de volgende paragrafen in vogelvlucht.
2.2.3.2.3 Occurrence frequency constraint De occurrence frequency constraint is een generalisatie van de uniqueness constraint. Zoals de naam als zegt zorgt deze constraint ervoor dat in een populatie van een bepaalde toewijzing aan een verzameling van predicatoren slechts een aantal malen mag voorkomen. Bij de uniqueness constraint is dit aantal precies één. We kunnen dit als volgt formaliseren.
Een predicatorverzameling � uit P heeft minimaal n en maximaal m toewijzingen van een bepaalde instantiecombinatie. We schrij ven:
frequency( � , n, m) De definitie hiervan is:
Pop � frequency( � , n, m) d.e.s.d.a.
Pop � IsEmpty (� ( � )) � Val [ min( � (� ( � ), � , a), a) ] (Pop) � n
Val [ max( � (� ( � ), � , a), a) ] (Pop) � m De semantiek van deze constraint ligt hiermee vast. We zullen dit hier niet verder uitdiepen. De grafische notatie wordt op dezelfde wijze aangegeven als een uniqueness constraint, maar in plaats van het u-tekentje, staat hier de afbakening n … m.

50
2.2.3.2.4 Set constraints Set constraints zijn constraints die bepaalde combinaties van instanties in de toewijzing aan predicatoren verplichten dan wel verbieden. In de categorie hebben we de subset constraint, de equal constraint en de exclusion constraint. De semantiek voor deze drie constraints ziet er als volgt uit.
Laat � en � predicatorverzamelingen zijn en � een match tussen deze twee verzamelingen. De match
� is een serie semantisch correcte toewijzingen van predicatoren uit � naar predicatoren uit � . Het semantisch correct zijn is vaak eenvoudig uit het PSM schema af te lezen. De bases van de aan elkaar toegewezen predicatoren moeten hetzelfde zijn. Wanneer dit alles correct gedefinieerd is, dan kunnen de volgende constraints worden gedefinieerd.
Pop � subset � ( � , � ) � Pop ���� ( ( � )) ⊆ � ��� ( ( � ))
Pop � equal � ( � , � ) � Pop � �� ( ( � )) = � ��� ( ( � ))
Pop � exclusion � ( � , � ) � Pop ����� ( ( � )) ��� ��� ( ( � )) Hiermee ligt de semantiek van set constraints vast.
2.2.3.2.5 Enumeration constraint Een enumeration constraint beperkt het aantal waarden in de populatie van een labeltype. Het woord enumeration, vrij vertaald opsomming, geeft aan dat het om een door de werkelijkheid afgebakend domein gaat. Een voorbeeld hiervan is een labeltype geslachtscode, waarvan de enige 2 waarden “man” en “vrouw” kunnen zijn, geheel in overstemming met de werkelijkheid. Formeel gedefinieerd ziet de enumeration constraint er als volgt uit. Hierin is l een labeltype en V een verzameling van waarden.
Pop � enumeration (l, V) � Pop(l) ⊆ V
2.2.3.2.6 Power type constraints Power type constraints zijn constraints die iets vastleggen of verbieden in de populaties van het desbetreffende powertype en diens elementtype. We onderscheiden vier soorten power type constraints, t.w. 1. Power exclusion constraint 2. Cover constraint 3. Set cardinality constraint 4. Membership constraint We zullen deze vier constraints kort formaliseren. Een power exclusion constraint werkt op een
objecttype g, met � (g) � G. De functie � geeft voor ieder objecttype zijn unieke pater familias. Hier wordt dus verplicht dat de unieke pater familias van het objecttype g een powertype is. Een populatie Pop voldoet aan de power exclusion constraint pow_exclusion (g), als de volgende voorwaarde stand houdt.
Pop � pow_exclusion (g) � � x,y � Pop(g) [ x � y ����� x = y ] De tweede constraint, de cover constraint, geeft aan dat elke instantie van een objecttype moet voorkomen in een instantie van een powertype. Formeel, met g hetzelfde als hierboven:

51
Pop � cover (g) � � Pop(g) = Pop(Elt( � ))) De set cardinality constraint geeft aan dat de instanties van een powertype op zijn minst een bepaald aantal elementen heeft, evenals een maximum aantal elementen. Formeel genoteerd wordt dit (met g hetzelfde als hierboven en n, m natuurli jke getallen):
Pop � cardinality (g, n, m) � � x, � Pop(g) [ n ��� x �� m ] Als laatste komt hier de membership constraint aan bod. Dit constraint verplicht instanties element te zijn van andere instanties. Een eenvoudige gedachtegang ter verduidelij king is het volgende. Wanneer Edwin van der Sar de keeper is van het Nederlands elftal, dan zal hij ook moeten voorkomen in de selectie van het Nederlands elftal. Formeel: Edwin van der Sar is in de rol van keeper een lid van het Nederlands elftal. De membership constraint ziet er formeel gedefinieerd als volgt uit, met p en q predicatoren uit P.
Pop � member (p, q) � Pop � t Val [ � ({ p, q} ) ] (Pop) � t(p) t(q)
2.2.3.2.7 Specialisation constraints Er zijn twee specialisatie constraints. De eerste is de subtype exclusion constraint, de tweede de total subtype constraint. Voor we de semantiek van deze constraints kunnen geven, moeten we eerst een definitie geven van “een familie van entiteittypes”. In deze famili e van entiteittypes kunnen we dan de laagste gemeenschappelijke voorvader definiëren.
Een familie van entiteittypes, genoteerd met , wordt als volgt gedefinieerd.
⊆ � , met ���� en � x,y ��� [ � (x) = � (y)]
We kunnen hierin de laagste gemeenschappelijke voorvader, genoteerd als � ( ), als volgt definiëren.
� x ��� [ x Spec+ � ( )] � � x ��� [ x Spec+ y ] � � ( ) Spec* y De definities van Spec+ en Spec* zijn terug te vinden in [Hof94]. Een subtype exclusion constraint,
gedefinieerd over een famili e van entiteittypes , verplicht de populaties van de entiteittypes in deze familie disjunct te zijn. Formeel wordt dit als volgt vastgelegd:
Pop � sub_exclusion ( ) � � x,y ��� [x � y � Pop(x) � Pop(y) = � ] De total subtype constraint over een familie van entiteittypes verplicht dat de vereniging van de populaties van de entiteittypes van deze familie overeenkomt met de populatie van de laagste gemeenschappelijke voorvader van die famili e. Formeel:
Pop � sub_total ( ) � Pop( � ( )) = � Pop(x) x ���
2.2.3.2.8 Subtype defining rules Subtype defining rules zijn regels die het mogelijk maken om op basis van een selectiecriterium (de regel) te bepalen of een instantie van de pater familias ook een instantie is van het gegeven subtype. Een subtype defining rule wordt benaderd als zijnde een constraint. We definiëren:

52
SubRule (s, r) � Pop(s) = � Pop(t) � Val [�
p (r) ] (Pop) t,s Spec t
Met s een subtype, r een relationele expressie met schema { p} , waarbij geldt s Spec+ Base(p). Elk subtype heeft precies één subtype defining rule. Er worden bepaalde voorwaarden gesteld aan het opstellen van subtype defining rules, waarbij enkele nieuwe operaties en relaties worden geïntroduceerd in [Hof94]. Wij zullen deze hier niet introduceren, daar de relevantie voor ons onderzoek ontbreekt. Als laatste introduceren we kort de schema type constraints.
2.2.3.2.9 Schema type constraints Een schema type constraint ziet er als volgt uit. Een schematype c, en een constraint r die gedefinieerd is voor de informatiestructuur binnen het schematype c zijn de twee argumenten bij de definitie van zo’n schema type constraint. Formeel:
Pop � schema_constr (c, r) � � x � Pop(c) [x � r] Eigenlij k is dit dus geen nieuw soort constraint, maar word er een generalisatie gemaakt voor alle soorten constraints die gedefinieerd zijn binnen de informatiestructuur van het schematype.
2.2.3.2.10 Constraint definities Tot zover de beschrij ving van de constraints in PSM. We zullen de beschreven technieken in hoofdstuk 4 laten terugkomen, waarbij wordt getracht een match te maken met constraints in het dimensionale model. We gaan nu eerst terug naar de beschrijv ing van en het onderzoek naar de constraints in het dimensionale model. De genoemde tweedeling in constraints in het dimensionale model zal verder worden uitgewerkt. Dit zal worden gedaan in het volgende hoofdstuk.

53
3 Het dimensionale model uitgediept In dit hoofdstuk zullen we verder gaan met het uitdiepen van het dimensionale model. Hierbij zal de toenadering met betrekking tot constraints de leidraad vormen. In hoofdstuk 2 zijn we gestart met de case “Down Under”, om de werking van het dimensionale model te demonstreren. We zullen beginnen met de benadering van constraints vanuit het data cube model en vervolgens zullen we verder gaan met de benadering van Kimball uit [Kim96] met betrekking tot zijn visie op constraints in het dimensionale model. 3.1 Een verdere verkenning van constraints in het dimensionale model W gaan terug naar de match van de beschreven constraints van het relationele model naar het dimensionale model. Het dimensionale model kan men visueel interpreteren als een data cube. In een data cube worden gegevens opgeslagen in arrays van de dimensies. Om dit goed in te zien kan men denken aan het wiskundige concept van een 3-dimensionaal assenstelsel met de assen x, y en z. De assen stellen nu echter de dimensies voor, dus bijvoorbeeld tijd, plaats en winkel. We bekijken figuur 13 (ontleend aan [Kim96]) voor een goed beeld van deze data cube. Elke cel in deze kubus bevat gegevens voor die combinatie van de drie dimensies.
Figuur 13: De data cube: elke cel bevat informatie die betrekking heeft op de unieke combinatie van tijd, markt en product
Op basis van dit model worden door [SMKK98] een tweedeling gemaak t in zogenaamde intra-cube constraints en inter-cube constraints. Hierbij wordt de data cube als object gebruikt voor het onderscheid tussen de beide soorten constraints. Intra-cube constraints zijn constraints die betrekking hebben op de gegevens in de data cube. Deze constraints hebben iets te maken met de relaties tussen de attributen in de data cube. Voorbeelden van dit type zijn constraints die iets vastleggen over de relatie tussen de verschillende dimensies in de data cube, de relaties tussen de measure-attributen (die attributen die meetbare feiten zijn, dus de attributen uit de feitentabel) en de verschillende dimensies, de hiërarchie van de dimensies en andere cel karakteristieken van de data cube. Het is noodzaak deze verzameling van verschillende soorten intra-cube constraints te onderzoeken en te formaliseren. De inter-cube constraints zeggen niets over relaties tussen attributen binnen 1 data cube maar tussen meerdere data cubes. Er zijn voor dit type constraints verschill ende benaderingen mogelij k. Er kunnen constraints zijn die iets zeggen (vastleggen, verplichten) over de relatie tussen de dimensies van de ene en de andere data cube. Een andere invalshoek is te kijken naar de measure-attributen van twee data cubes en de relaties daartussen. Een derde mogelij kheid is constraints te construeren die iets zeggen

54
over de relatie tussen dimensies uit de ene data cube en de measure-attributen uit de andere data cube. Tenslotte kun je ook nog constraints maken die iets zeggen over de relaties tussen data cubes onderling in het algemeen. Twee data cubes kunnen onderling samengevoegd worden tot een nieuwe data cube, een data cube kan een onderdeel zijn van een grotere data cube. Wat je in dit geval dus eigenlijk doet is constraints construeren die zich richten op de data cube als bouwsteen, waarbij dus niet gelij k gerefereerd wordt aan de dimensies en de attributen die de data cube bezit. 3.2 Functies van de constraints in het dimensionale model Een aantal belangrijke functies van deze constraints in het dimensionale model, en in multidimensionale databases, zijn van uiteenlopende aard. Ten eerste zijn de cube constraints een belangrij k instrument in de conceptuele modellering van een data warehouse. Het geeft de mogelij kheid om met triggers te werken in het multidimensionale model. De triggers zijn een belangrij k instrument voor relationele databases om de robuustheid van het systeem te garanderen. Denk hierbij aan triggers als een update, insert of delete transactie op een database. Bij een goede definitie van de constraints in de conceptuele fase is bij de implementatie de werking van deze constraints uiterst nuttig. Bij het dimensionale model wordt de aandacht nu gefocused op deze triggers. Helaas is in het huidige onderzoek naar het dimensionale model nog niet altijd goed omgegaan met de invloed (en de importantie) van deze constraints voor o.a. het robuust krijgen van het systeem. De verschill ende algoritmes die ontwikkeld zijn t.b.v. het onderhoud aan een data warehouse hebben nog niet het gewenste resultaat opgeleverd met betrekking tot de view maintenance concepten. View maintenance is een belangrij k concept in de data warehouse ontwikkeling. Later zal in deze scriptie nog gesproken worden over view maintenance (Zie paragraaf 4.13). Een grote rol voor de constraints is hierin weggelegd. Een tweede zeer belangrijke functie van constraints is het kunnen definiëren van een object algebra voor het dimensionale model. Deze object algebra maakt het dan mogelij k om allerlei, formele en consistente definities te formuleren ten aanzien van deze constraints om zodoende een consistente en correcte modelleringstechniek voor het dimensionale model te introduceren. Ook hier kan de link weer worden gelegd met het relationele model. De relationele algebra in bijvoorbeeld PSM draagt voor een groot gedeelte bij aan de formalisatie van deze modelleringstechniek. Een derde functie betreft de mogelijkheid om via constraints nieuwe attributen voor het dimensionale model te ontwikkelen. Daarbij hangt natuurli jk een hoop af van het feit hoe de constraints te gebruiken zijn voor deze nieuwe attributen. Als laatste kan de ontwikkeling van de constraints ook een ingang openen naar nieuwe implementatietechnieken voor het dimensionale model, met daarbij in het achterhoofd houdende dat de multidimensionaliteit van de gegevens bli jft gehandhaafd. 3.3 Een verkenning van de constraints in de data cube via een voorbeeld In deze paragraaf gaan we aan de hand van een uitgewerkt voorbeeld de constraints die op een data cube kunnen worden gedefinieerd analyseren. Aangezien op dit gebied nog erg weinig is gedaan zal een gedeelte van deze paragraaf naar eigen inzicht van de auteur worden verkregen. We kijken we naar de mogelij kheden voor het gebruik van deze constraints in de data cube. Om dit allemaal te kunnen realiseren moeten we eerst het concept data cube analyseren. Dit doen we aan de hand van het opbouwen van een invulling van de data cube. Verschill ende voorbeelden en inzichten zullen hierbij worden aangehaald. 3.3.1 De data cube geanalyseerd Om te beginnen plaatsen we hier een figuur uit een sheetsreeks van een presentatie van Joachim Hammer over data warehousing en multidimensionale analyse [Hammer]. Zie figuur 14.
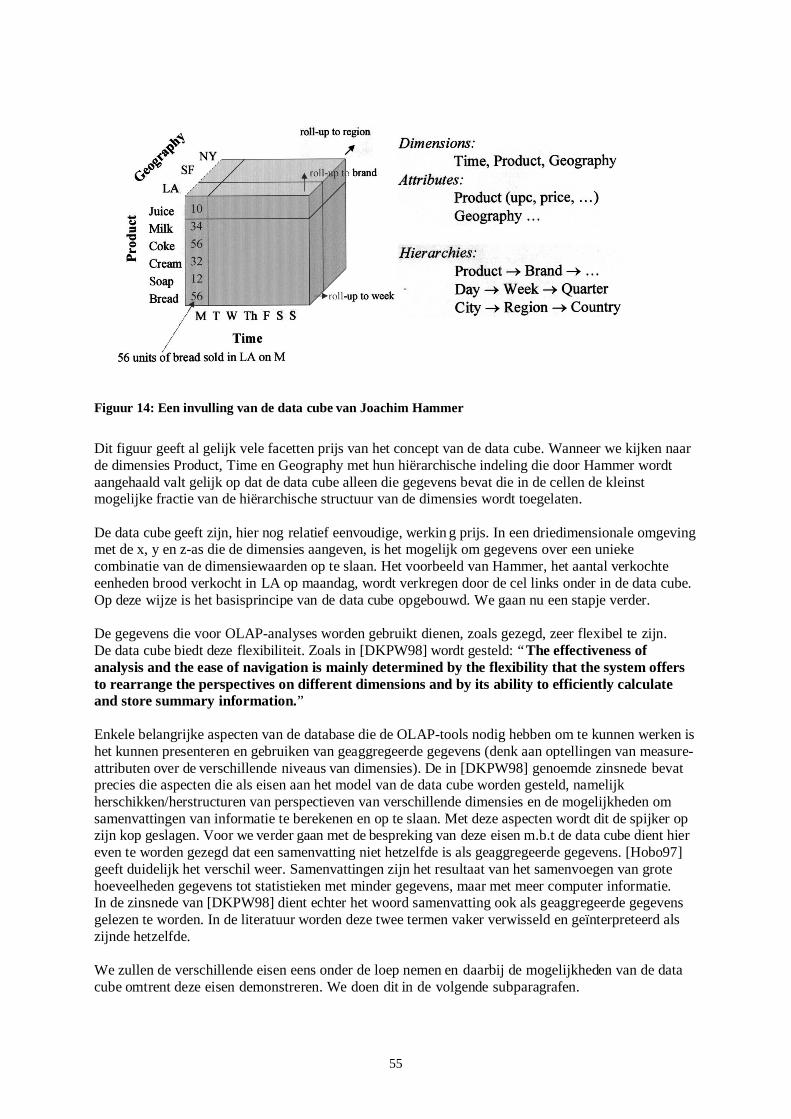
55
Figuur 14: Een invulling van de data cube van Joachim Hammer
Dit figuur geeft al gelijk vele facetten prijs van het concept van de data cube. Wanneer we kijken naar de dimensies Product, Time en Geography met hun hiërarchische indeling die door Hammer wordt aangehaald valt gelij k op dat de data cube alleen die gegevens bevat die in de cellen de kleinst mogelij ke fractie van de hiërarchische structuur van de dimensies wordt toegelaten. De data cube geeft zijn, hier nog relatief eenvoudige, werking prijs. In een driedimensionale omgeving met de x, y en z-as die de dimensies aangeven, is het mogelijk om gegevens over een unieke combinatie van de dimensiewaarden op te slaan. Het voorbeeld van Hammer, het aantal verkochte eenheden brood verkocht in LA op maandag, wordt verkregen door de cel links onder in de data cube. Op deze wijze is het basisprincipe van de data cube opgebouwd. We gaan nu een stapje verder. De gegevens die voor OLAP-analyses worden gebruikt dienen, zoals gezegd, zeer flexibel te zijn. De data cube biedt deze flexibil i teit. Zoals in [DKPW98] wordt gesteld: “ The effectiveness of analysis and the ease of navigation is mainly determined by the flexibility that the system offers to rearrange the perspectives on different dimensions and by its ability to efficiently calculate and store summary information.” Enkele belangrijke aspecten van de database die de OLAP-tools nodig hebben om te kunnen werken is het kunnen presenteren en gebruiken van geaggregeerde gegevens (denk aan optelli ngen van measure-attributen over de verschil lende niveaus van dimensies). De in [DKPW98] genoemde zinsnede bevat precies die aspecten die als eisen aan het model van de data cube worden gesteld, namelij k herschikken/herstructuren van perspectieven van verschillende dimensies en de mogelij kheden om samenvattingen van informatie te berekenen en op te slaan. Met deze aspecten wordt dit de spijker op zijn kop geslagen. Voor we verder gaan met de bespreking van deze eisen m.b.t de data cube dient hier even te worden gezegd dat een samenvatting niet hetzelfde is als geaggregeerde gegevens. [Hobo97] geeft duidelij k het verschil weer. Samenvattingen zijn het resultaat van het samenvoegen van grote hoeveelheden gegevens tot statistieken met minder gegevens, maar met meer computer informatie. In de zinsnede van [DKPW98] dient echter het woord samenvatting ook als geaggregeerde gegevens gelezen te worden. In de literatuur worden deze twee termen vaker verwisseld en geïnterpreteerd als zijnde hetzelfde. We zullen de verschillende eisen eens onder de loep nemen en daarbij de mogeli jkheden van de data cube omtrent deze eisen demonstreren. We doen dit in de volgende subparagrafen.

56
3.3.1.1 Perspectieven van dimensies: de rotate-functie Als eerste eis hebben we in de vorige paragraaf gezien dat het noodzakelij k is om dimensies in de data cube in een ander perspectief te kunnen zien. Dit is noodzakelij k om de data in de cube op een andere wijze te kunnen bekijken voor het uitvoeren van verschillende analyses. Wanneer we recht tegen een data cube aankijken (zie bijvoorbeeld figuur 14) zien we 2 dimensies (in dit geval Tijd en Product) als een plat vlak aan de voorkant. Dit is de view waarop dit moment tegenaan wordt gekeken. Voor een andersoortige analyse zal een andere view mogelij k moeten zijn, bijvoorbeeld die van Geografie en Product. Hiertoe moet de data cube kunnen roteren. Een formele definitie van het toepassen van het roteren kan zijn het wijzigen van de dimensionale oriëntatie van een rapport en of een beeldschermdisplay. Nu onderscheiden we van deze functie drie soorten (afgeleid van [WWW05]). Met de rotatie van een data cube kan als eerste worden gedoeld op het verwisselen van rijen en kolommen. Een voorbeeld hiervan is wanneer in een rapport de dimensie Tijd in de rij en de dimensie Product in de kolom wordt verwisseld. Hier komt het dus gewoon neer op het verwisselen van twee dimensies in een rapport of beeldschermpresentatie door middel van het verwisselen van de rij- en de kolomdimensie. Een tweede soort rotatie is er eentje van een complexere aard. Wanneer een rijdimensie wordt omgezet in een kolomdimensie naast andere bestaande dimensies spreken van deze tweede soort. Een voorbeeld hiervan is als een dimensie Tijd en Geografie in de rij worden afgezet tegen een dimensie Product in de kolom. In dit geval hebben we te maken met geneste dimensies. Hier komen we later op terug. Nu wijzigen we de dimensie Geografie van een rijdimensie in een kolomdimensie. Een derde soort is wanneer een dimensie die helemaal niet gepresenteerd staat in het rapport (volgens [WWW05] een zogenaamde “off -spreadsheet dimension”) wordt geïntroduceerd i.p.v. van een wel getoonde dimensie (in een rij of kolom). Denk hierbij aan de wijziging van een Tijd/Product dimensietabel in een Tijd/Geografie dimensietabel. De flexibele houding van gegevens, waarin in hoofdstuk 1 al over gesproken is, maakt de data cube met betrekking tot de eerste eis een geschikt concept voor OLAP-toepassingen. De tweede eis met betrekking tot het berekenen en opslaan van samenvattingen en aggregaties van data wordt gehaald met in de volgende subparagraaf geïntroduceerde technieken. 3.3.1.2 Aggregatie van data: Drill Up/Down en Roll Up In het model van de data cube zijn de dimensies onderverdeeld in verschillende levels. Deze levels zorgen ervoor dat de dimensie een hiërarchische structuur heeft. Een dimensie geogafische ligging heeft bijvoorbeeld de levels land, departement en stad. Wanneer we nog even kijken naar het voorbeeld van Hammer (figuur 14) zien we bij de dimensie Geography in de data cube een onderverdeling in de steden (is de laagste level!) LA, San Francisco en New York. Voor elk van deze steden is het aantal verkochte eenheden vastgelegd. Wanneer we nu naar een level hoger gaan (bijvoorbeeld region zoals Hammer aangeeft) zullen de gegevens uit de data cube geaggregeerd worden met betrekking tot de dimensie Geography naar een hogere level, nl. region. Men kan zich nu een andere data cube voorstellen als resultaat met wederom drie dimensies Product, Time en Geography, maar nu met een indeling naar producten, weekdagen en regio’s. Deze data cube bevat dus geaggregeerde gegevens. Men spreekt wel van een Roll Up functie. Uiteraard kan dit met meerdere dimensies en levels tegelij k gebeuren. Hierdoor ontstaat redundantie in de database, maar zoals we al eerder hebben opgemerkt zijn geaggregeerde gegevens zeer welkom bij het uitvoeren van complexe query’s. Naast de term Roll Up wordt ook wel eens consolidatie gebruikt. Elke relatie tussen data (of dat nu hiërarchische zijn of niet) kan in principe via zo’n Roll Up voorgecalculeerd worden. Vaak zijn dit natuurli jk optelli ngen (zie het voorbeeld), maar het is zeer wel goed mogelij k dat er andersoortige berekenbare functies kunnen worden gebruikt. Denk bijvoorbeeld aan gemiddelden en statistische waarden.

57
Een andere techniek is het navigeren (dus niet het echte bouwen van geaggregeerde gegevens zoals bij Roll-Up. [Hobo97] benadert die m.i. niet goed) in de verschill ende hiërarchieën van de dimensies. Wanneer geaggregeerde gegevens worden opgeslagen in een database of kunnen worden berekend aan de hand van de bestaande gegevens (dus op detailniveau, zoals de data cube in figuur 14) is het mogelij k om te navigeren in deze gegevens op basis van de hiërarchie in de dimensies. Dit wordt Drill Down en Drill Up genoemd. Wanneer bij een analyse bijvoorbeeld wordt gevraagd naar gegevens omtrent bepaalde verkopen in LA, is mogelijk om een Drill Down operatie te doen in de Geography dimensie van bijvoorbeeld USA (landenlevel) naar California (Region level) naar LA (stedenlevel, het laagste level met het meeste detail). Een Drill Up operatie gaat vanzelfsprekend in tegengestelde richting. Om bovenstaande termen visueel te verduidelijken kijken we naar figuur 15.
Figuur 15: Roll Up, Drill Down en Drill Up functies
In figuur 15 zien we een fragment uit de hiërarchische structuur van een dimensie Geografische ligging. Er zijn vier levels gedefinieerd, t.w. wereldeel, land, stad en wijk. Wanneer een aggregatie van gegevens plaatsvindt zal de Roll Up functie vanuit de laagste levels de opbouw verzorgen. De Drill Up functie, met als voorbeeld een Drilli ng Up Path, zal vanuit gegevens over bijvoorbeeld verkopen in Christchurch een analyse maken naar boven, de verkopen in Nieuw Zeeland en vervolgens in heel Oceanië. In tegengestelde richting gaat het Dril ling Down Path via de verschillende levels van Oceanië naar Doubleview, een wijk in Perth. 3.3.1.3 Begrippenkader Om het belangrijke begrippenkader compleet te maken is hier de introductie van de termen “sli ce” en “slice and dice” op zijn plaats. Met een “slice” wo rdt bedoeld: een “plakje” of gedeelte van een data cube , zeg sub cube, die verkregen is naar aanleiding van een selectie op 1 of meerdere dimensies. Wanneer we weer kijken naar figuur 14 en we bijvoorbeeld een selectie maken op de dimensie Geography met als afbakening

58
alleen de stad LA houden we alleen dat “plakje” van de data cube over waarvoor de gegevens over LA gaan. Formeel gedefinieerd is een slice een onderverzameling van een multidimensionale structuur die overeenkomt met een enkele waarde die is gedefinieerd voor 1 of meerdere leden van de dimensies die niet in die onderverzameling zitten. Je bakent dus als ware een of meerdere dimensies af met als antwoord een slice. Merk op dat een slice dus wordt verkregen door een Drill Down! Met de term “slice and dice” wordt een door de eindgebruiker geïnitieerd proces bedoeld waarbij hij /zij vraagt om een presentatie van de gegevens door een specificatie te geven. Dit proces vindt dan plaats via rotaties van de data cube en Drill Down en Drill Up functies. Het gaat hier dus om een navigatieproces. Het resultaat van zo’n slice and dice-opdracht voor een data cube is of informatie uit een specifieke cel van die data cube, een 2 dimensionale slice of een multidimensionale sub cube. Andere begrippen zullen we in de volgende paragraaf behandelen. Deze begrippen hebben betrekking op de presentatie van de gegevens. Dit is eveneens een belangrij k onderdeel in het inzicht in het concept data cube. We zullen daarna aan de hand van een vervolg op de case de data cube verder analyseren. Wanneer we dan tot een reële vraagstuk zijn gekomen gaan we kijken naar de wijze waarop constraints kunnen worden geformuleerd. Daarbij zal als eerste gefocused gaan worden op de intra-cube constraints. 3.3.2 De presentatie van gegevens in data cube jargon
De presentatie van gegevens naar aanleiding van een query die gelanceerd is op een data cube vereist een apart inzicht in de materie. Met het opgebouwde begrippenkader in de vorige paragrafen is het mogelij k hierin duidelij k te scheppen. Zoals reeds is gesteld is de uitkomst van een multidimensionale query (een slice and dice-opdracht) op een data cube een van de volgende alternatieven. • Een enkelvoudige cel van de data cube • Een tweedimensionale slice van de data cube • Een multidimensionale sub cube van de data cube We zullen deze drie alternatieven presenteren in de vorm van een rapport of beeldschermdisplay. Dit doen we in de volgende subparagrafen. 3.3.2.1 Enkelvoudige cel In het geval het antwoord op een query informatie is die uit een enkelvoudige cel van de data cube is verkregen, spreken van we van celinformatie of informatie afkomstig uit een member combination. Deze term, afkomstig uit [WWW05], geeft aan dat een combinatie van members, een unieke combinatie vormt tussen allen dimensies. Een member is dus een waarde van 1 van de dimensies uit de data cube. Een voorbeeld hiervan is bij een dimensie tijd de members Herfst, Maandag of 2003. Bij het tonen van het resultaat volstaat in principe een volzin met deze informatie, daar geen enkele dimensie volledig hoeft te worden gepresenteerd. Er is immers op alle gebruikte dimensies een selectie gemaakt. Een selectie wordt ook wel eens een fil ter of conditie genoemd. Het presenteren van informatie afkomstig uit een enkelvoudige cel heeft, door het feit dat er geen dimensies worden gepresenteerd, niet veel om handen. 3.3.2.2 Tweedimensionale slice Lastiger wordt het wanneer het resultaat een tweedimensionale slice is. Zo’n tweedimensionale slice bevat in het antwoord dus twee dimensies die volledig worden afgebeeld in het antwoord, met meerdere members (wel uit 1 level van dimensie!) uitgesplitst. Zo’n tweedimensionale slice kan opgeleverd worden wanneer in 1 van de 3 dimensies in de data cube (of natuurlij k 2 van de 4, etc.)

59
wordt afgebakend op een bepaalde member. Wanneer er bijvoorbeeld een Drill Down plaatsvindt naar een zeer laag level in de hiërarchie van de geografische dimensie uit figuur 15 (naar bijvoorbeeld Doubleview) dan kunnen we deze member afspli tsen in het antwoord t.o.v. de andere twee dimensies, zeg Tijd en Product. Laten we als meetbaar feit de verkopen nemen. In het resultaat wordt dan een tweedimensionale voorstell ing gemaakt van een rijdimensie Tijd tegen kolomdimensie Product. Er worden dan de verkopen weergegeven in bijvoorbeeld bepaalde maanden en de verschillende automerken als producten. De tabel betreft dan wel alleen de verkopen in Doubleview, de member die is geselecteerd uit de geografische dimensie. In dit voorbeeld wordt de geografische dimensie de zogenaamde page dimension genoemd. Hiermee wordt die dimensie bedoeld waarvoor in het antwoord een member is geselecteerd. De pagina (page) gaat dan alleen over informatie omtrent de geselecteerde member. De presentatie van een multidimensionale query in het platte vlak (2 of meerdimensionaal) wordt de page display genoemd. Deze page display maakt gebruikt van een tabelvorm met 1 of meerdere rijdimensies en 1 of meerdere kolomdimensies. Verder is dus de gegevens die worden afgebeeld in de tabel afhankelij k van het geselecteerde member uit de page dimension. Hoe dit visueel wordt uitgewerkt zien we in de volgende subparagraaf. 3.3.2.3 Multidimensionale sub cube Wanneer het antwoord op een query uit 3 of meerdere dimensies bestaat die niet zijn beteugeld op een member spreken we van een multidimensionale sub cube. Dit houdt in dat er in het antwoord op de query een rapport (of spreadsheet) moet worden gecreëerd met 2 of meerdere rij - of kolomdimensies. Dit vereist een speciale techniek die we nesting noemen. Nesting is een techniek die het mogeli jk maakt om bij de presentatie van de gegevens 1 of meerdere dimensies te nesten in de rijen of kolommen. De beste manier om hierin een goed inzicht te verschaffen is via een voorbeeld uitgewerkt in een visueel beeld. We zullen hiervoor hetzelfde soort voorbeeld pakken als we eerder hebben gedaan. We nemen nu vijf dimensies, t.w. Tijd, Geografie, Product, Distributiekanaal en Vervoer. Tijd, Geografie en Product hebben we reeds eerder gezien. Voor de dimensie Distributiekanaal nemen we voor het voorbeeld slechts 1 level, t.w. een onderverdeling in Groothandel, Consument, Tussenhandel. Bij de dimensie Vervoer gaat het over het transport per boot, vliegtuig, auto (Deze dimensie zou je weer kunnen onderverdelen in vliegtuigmaatschappijen, verschillende bootdiensten en transporteurs etc, maar voor het gemak van het voorbeeld doen we dit hier niet). Wanneer een query is gelanceerd op dit voorbeeld met als enige selectie het product Ford Sierra. Hierbij wordt dus de member “Ford Sierra” gekozen uit de product dimensie. Deze dimensie wordt de page dimension in dit voorbeeld. Voor de page display wordt nu een voorbeeld gemaakt waarin de overige vier dimensies worden gepresenteerd in rijdimensies en kolomdimensies. We kiezen in deze opmaak voor Tijd en Geografie als rijdimensies en Distributiekanaal en Vervoer als kolomdimensies. Als cel informatie nemen we hier de verkopen in guldens. Het resultaat valt te aanschouwen in tabel 6. Dit is een fragment uit de hele tabel, maar het gaat erom het inzicht te verschaffen in de nesting techniek en het presenteren van een multidimensionale sub cube. Uiteraard is het mogelij k om andere levels, dimensie etc. in de tabel te plaatsen. We hebben gezien dat dit kan d.m.v. de rotate-functie.

60
Verkopen in gld Vervoer dimensie Vliegtuig Schip
Ford Sierra Distributie dimensie Groothandel Consument Tussenhandel Groothandel Consument Tussenhandel
x fl 1000,--
Tijddimensie Geografie dimensie
Januari Australië 250 200 500 0 300 300
Europa 300 300 400 0 300 0
Noord Amerika 200 400 250 0 300 0
Februari Australië 100 100 400 0 200 100
Europa 0 100 300 0 250 250
Noord Amerika 0 200 300 0 300 250
Maart Australië 0 0 450 0 300 250
Europa 100 0 600 100 0 400
Noord Amerika 150 0 0 0 0 450
April Australië 250 0 0 0 0 0
Europa 300 0 100 0 0 0
Noord Amerika 140 100 0 0 0 400
Mei Australië 100 0 0 0 0 900
Europa 100 0 0 0 0 850
Noord Amerika 100 200 100 0 700 600
Juni Australië 250 0 100 250 1000 750
Europa 900 0 100 0 1500 700
Noord Amerika 950 0 150 0 200 700
Juli Australië 400 0 200 0 2000 600
Europa 300 500 0 0 150 650
Noord Amerika 200 300 0 0 150 350
Augustus Australië 450 450 0 0 100 150
Europa 1000 300 200 0 100 0
Noord Amerika 900 400 200 0 250 0
September Australië 100 400 200 0 300 100
Europa 0 450 0 100 100 150
Noord Amerika 150 100 100 100 100 400
Tabel 6: Geneste dimensies in zowel de rij- als kolomdimensies
We zien in deze tabel duidelijk de nesting van bijvoorbeeld de rijdimensies Tijd en Geografie. De maand januari heeft drie afzetplaatsen, en zo ook februari, maart etc. De page dimension, Product, kan bijvoorbeeld in een spreadsheet direct worden veranderd in een ander member i.p.v. Ford Sierra. Je kunt bijvoorbeeld de verkopen van een Opel Omega op het scherm toveren met dezelfde structuur als in de page display. Ook is het mogelijk om vanuit deze situatie Drill Up te doen naar alle Fordmerken. Wanneer je dit doet, krijg je alle verkopen van Fordmerken (bijv. die van de Escort, Sierra en Fiesta bij elkaar) (een hoger level in de dimensie product) te zien. Ook de rotate-functie kan hier uitstekend worden toegepast. Wanneer je bijvoorbeeld rij- en kolomdimensies wilt verwisselen roteer je de data cube. Dit is direct zichtbaar in een spreadsheet. Nu alle vormen van antwoord op een multidimensionale query zijn toegelicht en uitgewerkt, zullen we aan de hand van de case toewerken naar de data cube constraints, t.w. de intra cube constraints. 3.4 De case Down Under in het data cube concept In de Down Under case hebben we te maken met drie dimensies: geografie-, tijd- en productdimensie. Wanneer we deze dimensies, met allen hun eigen sleutel voor elke mogelijke combinatie van zijn members, visueel voorstellen als de assen van de data cube krijgen we een duidelijk beeld. Voor de eenvoud gebruiken we dus voorlopig 1 data cube. Deze data cube bevat dus de detailgegevens omtrent de dimensies. In deze cube is dus nog niets geaggregeerd.

61
Er komt nu een extra probleem om de hoek kijken wanneer we naar de invulling kijken van de data cube. Vanwege het feit dat elke cel (member combination), gegevens kan bevatten, zijn er een hoop lege cellen. Dit komt omdat niet elke combinatie van de dimensies zinvolle informatie zal bevatten. Hierdoor zal er sprake zijn van een zogenaamde schaarse multidimensionale database ofwel de database is sparse. In een multidimensionale database waarin dit relatief weinig voorkomt spreken we over een database die dense is. Aangezien de afbeelding van de case op het model van [Kim96] al is geschiedt, trekken we hier de lijn door naar de data cube. De dimensies met hun unieke sleutel vormen de basiselementen voor de opbouw van de gegevens in data cube. We zullen nu een afbeelding maken van deze data cube.
Figuur 16: De data cube toegepast op Down Under
In figuur 16 zien we de data cube toegepast op Down Under. De n/a geeft aan dat in deze cel geen informatie is opgeslagen. Wanneer er veel van deze n/a cellen spreken we van een data cube die sparse is. Een mogelijke invulling van de data cube (zeg driedimensionale database) zou het volgende kunnen zijn. De notatie die we hierbij gebruiken is afkomstig van [DKPW98]. In dit artikel worden multidimensionale databases duidelijk en constructief opgebouwd, samen met een visueel aspect. Dit aspect gebruiken we hier. Later zal [DKPW98] een belangrijke rol gaan spelen in de constructie van constraints. Plaatssleutel Productsleutel Tijdsleutel Omzet 1 1 1 >>> 200 1 2 2 >>> 300 2 2 2 >>> 400 3 3 2 >>> 500 3 4 2 >>> 600
Tabel 7: Een fragment van de invulling van de data cube van Down Under
We zien de drie velden (in dit geval de sleutels van de dimensies) die de unieke combinatie garanderen voor een cel en de measure-gegevens die bij het dimensionale model volgens Kimball in de feitentabel staan. In het concept van de data cube staan deze gegevens dus in de cellen, hetgeen in dit voorbeeld de omzet is (andere velden, zoals de betalingsmethoden kunnen hier natuurlijk ook in staan)!

62
Het >>>-symbool is een verwijzing van de member combinatie naar de cell gegevens (measure gegevens) Deze data cube is de basis van de case. Na het toepassen van allerlei technieken is het evenwel goed mogelij k dat er veel meer data cubes ontstaan, bijvoorbeeld op een hoger niveau. Hier komen we later uitgebreid op terug. We gaan nu in op de intra-cube constraints in de volgende paragraaf. 3.4.1 De intra-cube constraints Nu we het idee duideli jk hebben inzake de case in het data cube concept, grijpen we even terug naar de mogelij ke soorten van intra-cube constraints. Dit zijn constraints die iets zeggen of vastleggen over de volgende soorten relaties. • Relatie tussen de dimensies binnen een data cube • Relatie tussen de measure gegevens uit de cellen in de data cube en de dimensies • Relaties als gevolg van de dimensie hiërarchieën • Overige cel karakteristieken Deze categorisering is een goede basis om verder na denken over intra-cube constraints. De vraag die hierbij als eerste opduikt is de volgende. Wat willen we per se niet bij de invulli ng van de data cube? Als we hierover beginnen na te denken komen we als eerste uit bij enkele praktische zaken die we uit willen sluiten bij een invulling van zo’n data cube (of multidimensionale database). Aan de hand van de categorisering lopen we de verschillende problemen af. We beginnen daarom bij de dimensies en de relaties tussen de dimensies. Ten eerste willen we niet dat members van een dimensie het NULL of de lege status kunnen krijgen. Wanneer we bijvoorbeeld naar de Producttabel kijken van onze case mag het niet voorkomen dat een productsleutel (die zorgt voor een unieke combinatie van attributen (ook members!)) een veld bevat dat leeg is. Zie tabel 8 hieronder. Productsleutel Artiest Titel Platenmy jaar Genre Single 1 Springsteen, Bruce Greatest Hits 1995 Rock nee 2 Springsteen, Bruce Nebraska Columbia 1982 Rock nee 3 Police, The Outlandos d'Amour A&M Pop nee 4 Lauper, Cyndi Hat Full Of Stars Epic 1993 Pop nee 5 Foreigner 4 Atlantic 1981 nee
Tabel 8: Een dimensietabel met NULL waarden
Dat dit niet kan spreekt voor zich. Wanneer er in een Roll Up functie wordt gelanceerd naar bijvoorbeeld Genre en er een veld leeg is, zorgt dit voor een foutmelding. Ook een sorteerfunctie op jaar wordt in de war geschopt bij een NULL-waarde veld. De eerste constatering is dus dat een member geen lege waarde mag kennen. We weten dat in een data cube een groot deel van de velden leeg zijn door het feit dat niet elke combinatie van members uit dimensies iets zinvols betekent. Het is echter de vraag, zoals wordt gesteld in [WWW05], of in een data cube ALLE mogelijke combinaties van members moeten voorkomen in de dimensies. Hiermee bedoelen we dat ELKE combinatie van de members in een dimensie (ongeacht hiërarchie) kan worden gebruikt in een data cube. Wanneer we dit projecteren op onze case zou bijvoorbeeld bij de Productdimensie de volgende situatie kunnen ontstaan. Zie onderstaande tabel.

63
Productsleutel Artiest Titel Platenmy jaar Genre Single 1 Springsteen, Bruce Greatest Hits Columbia 1995 Rock nee 2 Springsteen, Bruce Greatest Hits Columbia 1995 Rock ja 3 Springsteen, Bruce Greatest Hits Columbia 1996 Rock nee 4 Springsteen, Bruce Greatest Hits Columbia 1995 Pop ja
Tabel 9: Ongewenste inconsistentie bij members binnen een dimensie
Dit is iets wat niet gewenst is. Tussen de verschill ende members van de dimensies moet er een bepaalde afbakening worden gedefinieerd met betrekking tot de onderliggende relatie van de members. In dit voorbeeld zien we dat de CD Greatest Hits van Bruce Springsteen uitgegeven is in meerdere jaren, zowel een single als CD is en ook nog van verschillende genres. Bij de definiëring van de members zullen dus bepaalde mogelij kheden moeten worden uitgesloten binnen 1 dimensie. Een tweede constatering is dan ook dat we afhankelij ke members of de relaties tussen de members moeten kunnen afbakenen. Dit kunnen we doortrekken naar meerdere dimensies. Wanneer we meerdere dimensies hebben, is het van groot belang dat de onderlinge samenhang van de dimensies consistent is. Daarmee bedoelen we dat bijvoorbeeld members van verschillende dimensies niet met elkaar in tegenstrijd mogen zijn. Zo mogen er natuurlijk geen members dubbel voorkomen binnen dimensies. Wanneer er binnen twee dimensies allebei een soort geografische member voorkomt (bijvoorbeeld een plaats of land) kan er een conflict ontstaan. Een eis is dus dat bij de definitie van dimensies een set van members wordt gedefinieerd die binnen 1 dimensie consistent is, zodat een conflict met members uit een andere dimensie kan worden vermeden. Ook [Kim96] benadrukt het feit dat bij de definitie van dimensies goed moet worden nagedacht over de impact van deze dimensies op het geheel. Iets wat ook wenselij k is, is het feit dat het aantal dimensies gebruikt binnen 1 data cube wordt beperkt tot een minimum. Hierbij handhaaf je dan het overzicht van de data. De brainstorm die we tot nu toe in deze paragraaf hebben gedaan levert een paar interessante punten op. Het bestaan van een zogenaamde “lege member”, een NULL -waarde, is best mogelij k, maar moet dan wel in de definitie van een hiërarchie worden meegenomen. We verwijzen naar het NDC model uit hoofdstuk 4 voor de omgang met dit probleem. De NULL-waarde moet een eigen member zijn van de hiërarchie binnen de dimensie, wat dus wil zeggen dat hij eigenlij k niet als leeg veld moet worden beschouwd. Ook de verbanden tussen de dimensies zullen nauwkeurig moeten worden beschreven. Members moeten onderling consistent zijn: een voorwaarde voor een goed fundament van een data warehouse is een goede definitie van de dimensies, attributen en de onderlinge hiërarchie. De genoemde soorten van intra-cube constraints in een data cube zullen moeten worden geformaliseerd in de toekomst. We zullen later zien dat het NDC model uitkomst zou kunnen bieden. In de volgende paragraaf zeggen we kort nog even wat over de inter-cube constraints. 3.4.2 De inter-cube constraints De inter-cube constraints zijn grofweg als volgt te categoriseren als constraints die iets zeggen over: • Relaties tussen dimensies uit verschillende data cubes • Relaties tussen de measure-attributen uit de verschillende data cubes • Relaties tussen dimensies uit de ene data cube en de measure-attributen uit de andere data cube • Andersoortige relaties tussen data cubes We zullen demonstreren wat voor een soort constraints inter-cube constraints nu precies zijn, aan de hand van de volgende gedachtegang.

64
We hebben een op basis level niveau gedefinieerde data cube met in zijn cellen 1 measure-attribuut. We nemen de dimensies tijd, geografie, product en het measure-attribuut omzet. We maken een aggregatie naar een hoger level in de geografiedimensie, wat een tweede data cube creëert. Dit levert de volgende uitgangspositie: Data cube 1: Omzet per CD, Dag en Plaats Data cube 2: Omzet per CD, Dag en Land We kijken naar de verbanden tussen deze twee data cubes. Als eerste geven we hier de opmerking die [Kim96] maakt over geaggregeerde data, namelij k dat de dimensie die op een hoger level wordt getild nieuwe dimensieattributen introduceert of dimensieattributen kan laten vallen die niet relevant zijn op dit level. Ook worden er voor de geaggregeerde dimensietabellen nieuwe sleutels aangemaakt. Dit zijn allemaal zaken die moeten worden vastgelegd en consistent worden gemaakt door definities van goede inter-cube constraints. 3.5 Constraints benaderd vanuit het dimensionale model via star join schema Wanneer we kijken naar het dimensionale model en de manier waarop [Kim96] dit benadert zien we enkele verschill en in het concept van de data cube. In een star join schema, zoals Kimball dit noemt, hebben we te maken met een grafische afbeelding van de feitentabel en daarom heen liggen de dimensietabellen. Elke dimensietabel bevat de dimensie-sleutel en een stel dimensieattributen. Deze attributen zijn, zoals reeds gezegd, beschrij vende velden behorende bij die specifieke dimensie. In de feitentabel bevindt zich de eigenlij ke data. Deze benadering levert ook een andere invalshoek op voor de beschrijving van constraints. Er wordt in eerste instantie gesproken over zogenaamde join constraints en application constraints. De join constraints zorgen ervoor dat bij een query alleen die records uit de dimensietabel worden opgehaald die ook in de feitentabel voorkomen. Daarbij vindt een match plaats op de dimensiesleutel uit de feitentabel en de desbetreffende dimensiesleutels uit de dimensietabel. Dit verklaart ook de naam join constraint, daar er een join plaatsvindt tussen de dimensietabel(len) en de feitentabel. Deze join constraint is een belangrij k constraint om de attributen op te halen van de desbetreffende dimensie uit de dimensietabel. Zie het casevoorbeeld. De application constraint is een heel ander type constraint. Deze maakt gebruikt van de tekstuele en numerieke eigenschappen van de attributen van de dimensietabel. Bij een application constraint wordt gematched op een attribuut uit de dimensietabel om zodoende alleen die records te selecteren die van toepassing zijn voor het antwoord. Denk bijvoorbeeld bij een dimensie “geografische ligging” aan alle winkels in Australië. Het basisidee achter dit concept is dat de beperkingen aan het antwoord op een query worden opgelegd via de verschill ende dimensies. Hiertoe dient de application constraint in een belangrij k opzicht. Een goed voorbeeld waarbij het inzicht in dit concept kan worden verbeterd is het volgende. Bij een query aanvraag wordt het antwoord in twee fases verkregen. Allereerst zullen de application constraints hun werk doen door de dimensietabellen waarop de constraints van toepassing zijn door te lopen. Hierbij kan de gebruiker kij ken of de gewenste informatie uit de dimensietabellen worden opgenomen in het antwoord. Wanneer dit is voltooid zal via een zogenaamde multiple join (join constraint) het antwoord worden geconstrueerd uit de feitentabel en de dimensietabellen. Daarbij zal de opteleigenschap van de feiten in de feitentabel een belangrij ke rol spelen (denk bijvoorbeeld aan de totaal gemaakte kosten voor een bepaald product). Via detail informatie uit de feitentabel kan het totaal worden afgeleid voor het antwoord op de query. Een reëel voorbeeld zal dit verhaal verder verduideli jken. 3.6 Voorbeeld van het gebruik van de join en application constraint In dit voorbeeld zullen we aan de hand van een case de werking van de genoemde constraints vastleggen. Hiertoe maken we eerste een reële uitwerking van een praktijksituatie.

65
We nemen de volgende structuur van een (gedeelte van een) data warehouse op in een dimensionaal model, uitgewerkt als star join schema. Zie figuur 17.
Figuur 17: Dimensionaal schema voor de afzet van bepaalde producten
In het dimensionale schema zien we een feitentabel en drie dimensietabellen. De feitentabel bevat alle sleutels uit de dimensietabellen. De zogenaamde “foreign keys”, dat wil zeggen die sleutels die voorkomen in de feitentabel uit de dimensietabellen, vormen samen de “composite key ”. Deze samengestelde sleutel (uit de “foreign keys”) zorgt ervoor dat iedere record in de feitentabel uniek is door een unieke combinatie van deze “foreign keys”. Alvorens het voorbeeld te bespreken is de volgende opmerking op zijn plaats. Dit voorbeeld is een zeer sterk vereenvoudigde weergave van een werkelij k dimensionaal schema. De initiële gedachte hierachter is dan ook het concept te verduidelij ken zonder daarbij storende elementen veroorzaakt door de complexiteit van de praktijksituatie te hebben. De dimensietabellen bevatten naast hun sleutel van de desbetreffende dimensie een aantal attributen. De attributen van bijvoorbeeld de geografische dimensie zijn werelddeel, land en plaats. Op deze manier kan de dimensie een hiërarchische structuur beschrij ven die van groot belang is bij het maken van analyses als het gaat om geografische spreiding van de afzet van producten. Let erop dat de dimensie niet de feitelijke gegevens bevat over de afzet: deze zitten in de feitentabel! Op dezelfde manier kunnen de andere dimensies worden uitgewerkt in attributen. De tijddimensie heeft bijvoorbeeld een onderverdeling in de attributen maand, jaar, maandnummer en het seizoen. Het seizoenveld geeft aan of het zomer, winter, herfst of lente betreft. Dit kan van belang zi jn bij sommige producten (denk aan seizoensinvloeden). De tijddimensie zal in het echt nog veel meer attributen bevatten, maar die laten we in dit voorbeeld gemakshalve achterwege. De productdimensie bevat in ons voorbeeld de attributen merk, gewicht en de bederf-flag. De bederf-flag geeft aan of een product aan bederf onderhevig is of niet. Dit wordt in een record ingevoerd als J of N. De flag wordt vaak gebruikt in databases om een soort boolean waarde te simuleren. Bijvoorbeeld de tijddimensie zou ook een flagwaarde kunnen hebben in de vorm van een vakantieperiode, weekend of bepaalde dag in het jaar. De feitentabel bevat alle informatie met betrekking tot de numerieke, additieve gegevens zoals afzet en kosten per unieke gecombineerde sleutel. Voor de eenvoudigheid is het bij deze twee velden gelaten.

66
Nu we de context hebben geschetst waarin het voorbeeld plaatsvindt, gaan we aan de hand van de dimensie geografische ligging een invulling geven aan de manier waarop de application constraint wordt toegepast. 3.6.1 De dimensie geografische ligging en de application constraint Aan de hand van de reeds genoemde manier van het doorlopen van een dimensietabel voor het aangeven van application constraints met betrekking tot de attributen van de dimensie. Een makkelij ke manier om deze constraints aan te geven in een dimensietabel is door een speciale browser te gebruiken [Kim96]. Deze browser maakt het mogelij k om zeer snel, zonder tussenkomst van SQL, constraints aan te geven die betrekking hebben op de beperking van een dimensie. Wanneer we kijken naar figuur 18 zien we de dimensie geografische ligging, met al zijn verschillende attributen en veldwaarden, geopend in zo’n browser. In dit figuur hebben we de beginsituatie aangegeven van waaruit application constraints kunnen worden opgelegd voor deze dimensie. Tussen de verschill ende attributen is er in dit geval een hiërarchisch verband. Een werelddeel bestaat uit landen en landen bevatten plaatsen. Dit verband kan in een andere dimensie ook causaal zijn en niet perse hiërarchisch. De bedoeling is nu om door te klikken op een van de veldwaarden van een attribuut een restrictie op te leggen aan de dimensie. De browser zal bij het aanklikken van een veldwaarde deze toevoegen in de constrainttabel onder de veldnaam. Nu zullen automatisch de andere attributen worden aangepast in hun waarden. Wanneer we een constraint willen opleggen op bijvoorbeeld “Wer elddeel” kunnen we klikken op Oceanië. Nu zal het attribuut “Land” alleen landen als Australië, Nieuw Zeeland weergegeven daar deze zich in het werelddeel Oceanië bevinden. Op deze manier is een application constraint op de dimensie geografische ligging vastgelegd. Je kunt nu nog een stapje verder gaan door in de landentabel Australië aan te klikken. De dimensie geografische ligging wordt nu, bij query uitvoering, beperkt tot de afzet en kosten in alleen Australi ë.
Figuur 18: De dimensie geografische ligging in de browser voor toepassing van de application constraint

67
Figuur 19: De dimensie geografische ligging in de browser na toepassing van de application constraint
Wanneer we dit uitvoeren is het resultaat in figuur 19 te zien. Figuur 19 laat zien dat de application constraint Werelddeel = “Oceanië” verder is aangescherpt met de application constraint Land = “Austral ië”. In veldwaarden van het attribuut plaats staan nu de steden die voldoen aan de application constraint, t.w. plaatsen in Australië. [Kim96] geeft bij de bespreking van deze “browsertechniek ” een belangrij k fenomeen aan voor data warehouses in het algemeen. De application constraints die op deze wijze worden toegevoegd aan de dimensietabellen zijn gerealiseerd via de zogenaamde “Select Distinct ” opdracht. Op het moment dat er in de dimensietabel op een waarde van een veld wordt geklikt (in de browser) om deze te markeren als constraint wordt er een “Select Distinct” opdracht gelanceerd om de andere velden te updaten aan de hand van de gegeven constraint. In ons voorbeeld is dit het moment dat we op bijvoorbeeld Oceanië hebben geklikt en vervolgens zal het veld “Land” automatisch alleen die landen geven die een relatie hebben met het werelddeel Oceanië, t.w. Australië, Nieuw Zeeland etc. Hier staat bewust een relatie hebben, omdat het in dit geval een hiërarchische is, maar dit zeker niet altijd het geval is. Er kan immers ook sprake zijn van een andersoortige relatie. Een voorbeeld hiervan is een ongecorreleerde relatie. Denk bijvoorbeeld aan relaties die op het eerste gezicht niet duidelij k zijn, maar die door een ander verband wel gerelateerd zijn. Ook deze relaties worden door de “Select Distinct” opdracht onderscheiden. Op deze manier is de browsertechniek een zeer waardevolle manier om application constraints te benoemen voor de verschillende dimensies in een data warehouse omgeving. 3.6.2 SQL en de join constraint De join constraint zullen we kort demonstreren, daar de werking al duidelij k is uit de gegeven uitleg. We herhalen het stukje SQL uit paragraaf 2.1.1.3. De vergelij kingen tussen sleutels uit de dimensietabellen en die uit de feitentabel, zoals f.productsleutel met p.productsleutel, zijn in feite de werking van de join constraint. Er worden alleen die records geselecteerd die in de feitentabel voorkomen. De joins tussen de dimensietabellen en de feitentabel beperken het aantal records tot degene die nodig zijn voor generatie van het antwoord. Deze beperking wordt uitgevoerd door de join constraint.

68
SELECT p.artiest, sum(f.aantal_verkocht) FROM feitentabel f, product p, tijd t, geografie g WHERE f.productsleutel = p.productsleutel AND f.tijdsleutel = t.tijdsleutel AND f.plaatssleutel = g.plaatssleutel AND g.state/department = “Northern Territory” AND p.genre =”Rock” GROUP BY p.artiest ORDER BY p.artiest

69
4 Relationeel en dimensionaal: een vergelij kend onderzoek met betrekking tot constraints en meer In dit hoofdstuk wordt naar aanleiding van de verkenning van de constraints in het dimensionale model uit hoofdstuk 3 een aanzet tot een formalisatie gemaakt van deze constraints. Aan de hand van de in PSM gedefinieerde semantiek van de diverse constraints uit het relationele model zullen we trachten een aanzet te geven tot het maken van een soortgelij ke semantiek voor constraints in een data warehouse. Hiertoe zullen we eerst op onderzoek uit moeten gaan met betrekking tot de beide benaderingen en specifieke modellen uit beide werelden moeten vergelij ken. De algebra waar deze te ontwikkelen semantiek in beschreven kan worden is de algebra geïntroduceerd in [DKPW98]. In dit bewuste artikel wordt een model geïntroduceerd dat gebaseerd is op het concept van de data cube. Dit model wordt Nested Data Cube (kortweg NDC) genoemd. We zullen dit model en diens algebra introduceren in de volgende paragrafen. 4.1 Introductie van Nested Data Cubes Het door Dekeyser, Kuijpers, Paredaens en Wijsen geïntroduceerde model van de Nested Data Cube heeft tot doel OLAP analyses uit te voeren op multidimensionale databases. De besproken methoden zoals navigatie, Drill Up/Down, Roll Up en rotatie worden door dit model ondersteund. Het model heeft tot doel een flexibele omgang met de multidimensionale data in een data cube te creëren, zodat OLAP analyses vlot kunnen worden uitgevoerd. We hebben het belang van flexibili teit, bijvoorbeeld het vlot kunnen wijzigen van verschillende perspectieven op de data, via rotatie van dimensies, al uitvoerig besproken. Nested Data Cubes zijn een veralgemening van twee andere OLAP modellen, namelijk f-tables en hypercubes. F-tables zijn een door Cabibbo e.a. geïntroduceerde techniek om OLAP analyses uit te voeren, waarbij feitelij ke gegevens (de feiten in het dimensionale model) functioneel afhankelijk worden opgeslagen van de dimensies. Hypercubes zijn een onder meer door Agrawal aangehaald model, waarbij Agrawal een algebra heeft ontwikkeld op basis van deze hypercubes waarvan een eenvoudige vertaling naar SQL mogelijk is. Verder komen in het NDC model ook eenvoudige data structuren voor als bags, verzamelingen en relaties. We zullen het model en diens algebra niet verder informeel beschrij ven, maar formeel introduceren. Als basis gebruiken we hiervoor het (uitgebreidere) technische rapport [NDCtr98], waarop het artikel [DKPW98] is gebaseerd. We doen dit in de volgende paragraaf. 4.2 Nested Data Cubes opgebouwd Alvorens we de term Nested Data Cube (vanaf nu NDC) kunnen definiëren, zullen we eerst een aantal verzamelingen, functies en schrijfwijzen moeten introduceren. We beginnen met de introductie van een standaard datastructuur, namelij k de bag. Deze wordt in de theorie van NDC als volgt genoteerd: { |a,b,c|} , als zijnde de elementen a, b en c in de bag. We definiëren twee verzamelingen: A als de verzameling van attributen L als de verzameling van levels Zoals we reeds gezien hebben zijn levels een onderverdeling van een dimensie in verschill ende hiërarchische lagen. Men denkt bijvoorbeeld aan de dimensie geografie, met als levels land, regio en stad. We kunnen nu voor een level de volgende functie definiëren. Laat w een level zijn, dan definiëren we dom(w) als de verzameling van concrete waarden die binnen deze level valt. De verzameling dom is gedefinieerd als de verzameling van alle concrete waarden:

70
dom = � { dom(l) � l � L }
Verder definiëren we een roll-up functie R-UPwv, waarbij (v, w) � L � L . Deze functie is voor
bepaalde paren v, w gedefinieerd en projecteert ieder element van v op een element van w. We spreken van een coördinaat type als een verzameling { A1 : l1, …., A n : ln} , met alle A’s als verschill ende attributen en alle l’s als levels. Een coördinaat van het coördinaat type
{ A1 : l1, …., A n : ln} is een verzameling { A1 : v1, …., A n : vn} , met vi � dom(li) voor alle i uit [1, n].
De functie dom is ook gedefinieerd met als invoer een coördinaat type. We schrij ven dan dom( � ), met
� een coördinaat type, hetgeen resulteert in de verzameling van al zijn mogelij ke coördinaten. Verder is er nog een functie die alle attributen oplevert van de invoer zijnde een coördinaat type of coördinaat. We definiëren: att({ A1 : l1, …., A n : ln} ) = { A1,…, A n} att({ A1 : v1, …., A n: vn} ) = { A1,…, A n} We kunnen nu een Nested Data Cube schema introduceren. We zeggen dat een NDC schema een
formulering � is met de volgende syntax.
� = [ ��� � ] | � � = l | { |� |}
waarbij � een coördinaat type is en l een level. Verder geeft het symbool | aan dat het één der twee alternatieven kan voorstellen. De functie dom is ook gedefinieerd voor NDC schema’s en wel als volgt:
dom([ �� � ]) = {{ v1 � w1,…, v m � wm} | m 0} , waarbij de v’s paarsgewijs verschill ende
coördinaten zijn uit dom( � ) en de w’s afkomstig zijn uit dom( � ).
dom({ |� |} ) = {{ |v1,…,v m|} | m 1} , waarbij de v’s afkomstig zijn uit dom( � ). We kunnen nu een definitie van een Nested Data Cube geven. Definitie Nested Data Cube
Een Nested Data Cube, kortweg NDC, over een NDC schema � is een element van dom( � ). Let hierbij op de belangrijke parallel bij relationele databases en in het bijzonder PSM, waarbij we het steeds hadden over het Schema als zijnde de onderliggende structuur van een relationele expressie. Als afsluiting van deze paragraaf nog twee definities. Aangezien we met een recursieve definitie te maken hebben van een NDC schema, is het mogelij k om een functie depth te definiëren.
De diepte van een NDC schema � , genoteerd als depth( � ), is als volgt gedefinieerd:
depth([ ��� � ]) = 1 + depth( � )
depth( � ) = 0

71
We spreken over de diepte van een NDC op dezelfde wijze als de diepte van een NDC schema. Dus wanneer Q een NDC over een NDC schema met diepte n is, dan zeggen we Q heeft diepte n.
Als laatste nog de definitie van een subschema. Laat � een NDC schema zijn en n een natuurlij k getal
tussen 1 en depth( � ). We definiëren dan een subschema van � op diepte n als volgt:
subscheme([ ���
� ], n) = subscheme( � , n-1) als n � 2
subscheme( � , 1) = � We zullen nu aan de hand van een voorbeeld het NDC model introduceren. Vervolgens zal de algebra aan bod komen. 4.3 Nested Data Cubes: een eerste verkenning via Down Under We zullen ter demonstratie van de theorie in paragraaf 4.2 een klein voorbeeld uitwerken. We gaan hiervoor terug naar de geïntroduceerde Down Under case. We hadden hier de volgende dimensies en attributen. De geografische dimensie met de attributen Plaatssleutel, Distributiecentrum, State/Department, Plaats en Land. Als tweede hebben we de tijddimensie met de attributen Tijdssleutel, Maand, Maandnummer, Weekend-flag, Schoolvakantie-flag, Dagnummer in jaar, Opruimingsdag-flag, Kwartaal en Jaar. Als laatste de productdimensie met de attributen Artiest, Titel, Platenmaatschappij , Jaar van verschijnen, Genre en Single-flag. De feitentabel bevat o.a. de sleutels, het aantal verkochte eenheden, omzet, etc. Laten we beginnen met een voorbeeld van een NDC schema. We nemen de attributen Plaats, Maand en Artiest. We kiezen deze ook direct als level. Dit is natuurli jk mogelij k, omdat levels ook onderdeel zijn van de attributen van een dimensie. We krijgen bijvoorbeeld:
� = [{ Plaats: Plaats, Maand: Maand} �
[{ Artiest: Artiest} �
nummer} ]] We zien als eerste binnen de blokhaakjes een coördinaat type, waarbij er twee attributen worden toegewezen aan twee levels, namelij k Plaats aan Plaats en Maand aan Maand. Vervolgens zien we na de toewijzingspijl (eigenlijk een soort nestpij l, omdat het gaat over nesting) wederom een coördinaat type met een toewijzing van het attribuut Artiest aan het level Artiest. Na de pijl volgt hier een veld met het measure-attribuut omzet (hier beschreven als het type nummer). Men moet hieraan wel toevoegen dat dom(nummer) = { 1, 2, 3,…}
We kunnen nu een NDC geven over het NDC schema � . Zie figuur 20.

72
Figuur 20: Een NDC voor Down Under
Natuurli jk is dit ook maar weer fragment van een reële situatie. We zien in deze NDC een drietal instanties van Plaats, namelij k Katherine, Broome en Tamworth. Voor elk van deze drie plaatsen wordt gekeken naar de omzet van de CD’s van Foreigner en Toto in januari. We zullen nu wat van de geïntroduceerde functies uitschrijven en il lustreren. Het instrumentarium om NDC’s te manipuleren, is pas voorhanden na de introductie van de NDC algebra. Als eerste kijken we naar de diepte van de NDC uit figuur 20. We schrij ven:
depth( � ) = depth([{ Plaats: Plaats, Maand: Maand} � [{ Artiest: Artiest} � nummer ]]) =
1 + depth([{ Artiest: Artiest} � nummer ]) = 1 + (1 + depth(nummer)) = 1 + 1 + 0 = 2
Verder kunnen we een subschema definiëren van � op bijvoorbeeld diepte 2. We berekenen:
subscheme([{ Plaats: Plaats, Maand: Maand} � [{ Artiest: Artiest} � nummer ]] , 2) =
subscheme([{ Artiest: Artiest} � nummer ], 1) = [{ Artiest: Artiest} � nummer ] Het definiëren van de dom functies is hier triviaal, zodat we dit hier weglaten. We zullen dit voorbeeld later doortrekken na de introductie van de NDC algebra. In de volgende paragraaf worden enkele klassieke datastructuren gemodelleerd in de theorie van de NDC. 4.4 Klassieke datastructuren in NDC Klassieke datastructuren kunnen gemodelleerd worden binnen de theorie van de NDC. We definiëren hier een viertal van deze structuren op basis van een NDC schema.
• Bag : Een NDC over een NDC schema van de vorm { |�|}
• Verzameling : Een NDC over een NDC schema van de vorm [{ A : l} ��� ] • Relatie : Een NDC over een NDC schema van de vorm [ ����� ] • F-table : Een NDC over een NDC schema van de vorm [ ��� l]

73
Hierbij wordt het symbool � geïntroduceerd als een basislevel met dom( � ) = { � } . We kunnen dit level
zien als een NULL level met de � -waarde als enige concrete waarde. De modellering van een bag in de NDC theorie is eenvoudig, daar dit dataconstruct zelf een NDC kan zijn. Een verzameling kan in de wereld van de NDC worden gemodelleerd als een NDC over een schema met slechts 1 element in het coördinaat type. De toewijzing van dit coördinaat type is “leeg”, als zijnde
het level � . Men kan vervolgens inzien dat dit construct overeenkomt met een verzameling, daar een coördinaat van dit coördinaat type een NDC is met slechts de invull ing van 1 attribuut. Men krijgt dus een opsomming van elementen van dit ene attribuut op 1 level.
Een relatie is gemodelleerd als zijnde een NDC over schema van de vorm [ ����� ]. Men kan inzien dat een coördinaat type met meerdere attributen toegewezen aan bepaalde levels een relatie definieert tussen deze attributen. De toewijzing na de pijl i s in dit schema wederom leeg. De NDC over zo’n schema beschrijft dan een relatie tussen deze attributen.
Als laatste is het ook mogelijk om een F-table te modelleren. We zien een schema van de vorm [ ���l], waarbij het verschil met de relatie hem zit in het toegewezen level. Je krijgt dus een verzameling van attributen die wordt toegewezen aan een concreet domein. De waarden uit dit domein komen uit dom(l). We vervolgen nu met de introductie van de NDC algebra. 4.5 NDC algebra De NDC algebra omvat een aantal operators waarmee NDC’s gemanipuleerd kunnen worden. Daar de importantie van deze operators erg groot is, zullen we deze uitgebreid introduceren en bespreken. We hebben de volgende operators binnen de NDC algebra: 1. bagify 2. extend 3. nest 4. unnest 5. duplicate 6. select 7. rename 8. aggregate We zullen ze in de volgende subparagrafen de revue laten passeren. 4.5.1 De bagify operator De bagify operator “verzamelt” gegevens binnen een NDC en zet ze in een bag in een nieuwe NDC. De naam van de operator verraadt de werking al een beetje. Bagify is goed te vergelijken met de projectieoperator binnen de relationele algebra. We zullen een recursieve definitie geven van bagify op NDC schema’s, waarbij moet worden gezegd dat bagify ook gedefinieerd is op NDC’s. Dit gebeurt op een geheel parallelle wijze als bij een NDC schema. We zullen dit later demonstreren aan de hand van een voorbeeld. Een operator bagify heeft als invoer een NDC met diepte groter dan 0. Bij de definities zullen we, wanneer we praten over een NDC schema als invoer wel alle (r elevante) alternatieven opschrij ven, vanwege de volledigheid van de functie.
bagify([ � 1 � [ � 2 ��� ]]) = [ � 1 � bagify([ � 2 ��� ])] bagify([ � �� ]) = { | � |}
bagify( � ) = niet gedefinieerd

74
Wanneer we kijken naar deze definitie zien we dat er attributen worden geëlimineerd uit de NDC waarop de bagify wordt toegepast. Dit komt geheel overeen met de projectieoperator uit de relationele algebra, waarbij ook attributen (in PSM: predicatoren) kunnen worden verwijderd. Laten we een bagify operator loslaten op ons NDC schema uit paragraaf 4.3. We zien dan:
bagify([{ Plaats: Plaats, Maand: Maand} � [{ Artiest: Artiest} � nummer ]]) =
[{ Plaats: Plaats, Maand: Maand} � bagify[{ Artiest: Artiest} � nummer ]] =
[{ Plaats: Plaats, Maand: Maand} � { |nummer|} ] We kunnen deze bagify operator ook loslaten op de NDC gedefinieerd in figuur 20. Het resultaat zien we in figuur 21.
Figuur 21: De NDC na de bagify operatie
De attributen van de binnenste NDC zijn verwijderd en de numerieke gegevens zijn samengevoegd in een bag. Hier zien we gelij k al een demonstratie van de kracht van NDC’s, namelij k het samenrapen van gegevens in een bag voor aggregatiedoeleinden. Hierover later meer. De bagify operator kan ook voor een vreemde situatie zorgen, wanneer het volgende gebeurd. Laten we de NDC in figuur 21 “Down Under NDC” noemen. We kunnen dan definiëren: bagify (Down Under NDC) = { |{ |300, 400|} , { |400, 300|} , { |350, 400|} |} . Het resultaat is een bag van bags. We kunnen vervolgens ook eenvoudig inzien dat het geen zin heeft een bagify operator te definiëren op een level of een bag, daar een level zelf al een gedefinieerd domein heeft in de vorm van een verzameling en een bag in een bag natuurlij k totaal zinloos is. We gaan verder met de operator extend. 4.5.2 De extend operator De extend operator breidt een NDC uit met een extra attribuut in de buitenste NDC. Gezien de complexiteit van deze operator is het wijselij k hier het tweetal definities voor de extend operator formeel te geven. De eerste definieert een extend operator op een NDC schema, de tweede op een NDC.
De extend operator heeft als invoer 4 argumenten, t.w. een NDC schema van de vorm [ �
��� ], een
attribuut A zijnde geen attribuut uit att(�), een level l en een relatie R als zijnde een deelverzameling
van het cartesisch product tussen de domeinen van �
en l. We definiëren formeel:

75
extend([ � ��� ], A, l, R) = [ ��� { A : l } ��� ] Voor de definitie van de extend operator werkend op een NDC genaamd C, zien we het volgende:
extend(C, A, l, R) is gedefinieerd als de kleinste NDC die v � { A : c } � w bevat waarbij geldt:
C bevat v � w en (v, c) � R. De definitie van extend werkend op een NDC schema is semantisch gezien duideli jk: aan het NDC schema wordt het attribuut A met level l toegevoegd. Wanneer we echter naar de tweede definitie kijken, wordt het een stuk moeilij ker. We gaan deze definitie eerst uitschrij ven met een voorbeeld, zodat we een beter inzicht krijgen in de werking van de extend operator. We nemen de NDC uit figuur 20. We noemen deze NDC K. We nemen als invoer K, een attribuut Platenmaatschappij, een level Platenmaatschappij en een verzameling R. R bestaat uit paren die er uitzien als het voorbeeld ({ Plaats:
Katherine, Maand: Januari} , Atlantic). Het eerste element is een coördinaat van het coördinaat type � en het tweede element komt uit dom(Platenmaatschappij). De relatie R is een moeilij k te definiëren verzameling. In [NDCtr98] wordt echter een methode aangereikt om voor een NDC zo’n relatie R te definiëren. We zien:
Laat C een NDC zijn over het NDC schema [ � � l ]. We definiëren dan “ relation induced by C “,
genoteerd met rel(C), als zijnde de kleinste verzameling dom( � ) � dom(l) die (v, c) bevat, met de
voorwaarde dat C v � c bevat. Deze verzameling is ook gedefinieerd op het schema [ � � { |l|} ], met
het verschil dat c een element moet zijn van w en v � w moet voorkomen in C. Voor ons voorbeeld definiëren we:
R = rel([{ Plaats: Plaats, Maand: Maand} � Platenmaatschappij]) = { ({ Plaats: Katherine, Maand: Januari} , Atlantic), ({ Plaats: Broome, Maand: Januari} , Atlantic), ({ Plaats: Tamworth, Maand: Januari} , Atlantic)} Deze verzameling is kunstmatig gemaakt, daar de bijhorende NDC niet is gedefinieerd in ons voorbeeld. Voor de demonstratie van de extend operator voldoet hij echter. We zullen later het nut van deze definitie zien terugkomen. We kunnen nu invullen: extend(K, Platenmaatschappij, Platenmaatschappij , R) =
{{ Plaats: Katherine, Maand: Januari, Platenmaatschappij: Atlantic} �� Artiest: Foreigner} � 300,
{ Plaats: Katherine, Maand: Januari, Platenmaatschappij: Atlantic} �� Artiest: Toto} � 400,
{ Plaats: Broome, Maand: Januari, Platenmaatschappij: Atlantic} �� Artiest: Foreigner} � 400,
{ Plaats: Broome, Maand: Januari, Platenmaatschappij: Atlantic} �� Artiest: Toto} � 300,
{ Plaats: Tamworth, Maand: Januari, Platenmaatschappij: Atlantic} �� Artiest: Foreigner} � 350,
{ Plaats: Tamworth, Maand: Januari, Platenmaatschappij: Atlantic} �� Artiest: Toto} � 400} De NDC K is uitgebreid met een attribuut Platenmaatschappij. We zien bij deze definitie meteen de tweedimensionale schrijfwijze voor een NDC. De operator extend is een belangrijk instrument inzake het manipuleren van NDC’s. We zullen dit later zien. We gaan verder met de nest operator. 4.5.3 De nest operator

76
De nest operator is een operator die er voor kan zorgen dat een bepaald gedeelte in een NDC als een aparte NDC wordt opgenomen binnen die NDC. Als eerste kijken we naar een nest operator op een
NDC schema, met als invoer een schema [ � ��� ] en een verzameling X die een deelverzameling is
van att( � ). We definiëren:
C is een NDC over een NDC schema [ � ��� ], X � att( � ), Y = att( � ) \ X. Laat verder � = � [X] en �= � [Y], dan is
nest([ � ��� ], X) = [ � � [ � ��� ]] De operatie nest is verder gedefinieerd op een NDC. We definiëren het volgende: Laat C een NDC zijn en X hetzelfde als hierboven. Verder gelden alle andere hierboven gegevens definities. We zien dan: nest(C, X) is als volgt gedefinieerd:
Laat V = { v[X] | v � w C} , dan voor elke x uit V geldt dat
nest(C, X) bevat x � C’ waarbij C’ een NDC is over het schema [ � ��� ] die voldoet aan
C’ = { v[Y] � w | v � w C en v[X] = x} We zullen de werking van nest illustreren aan de hand van een voorbeeld uit [NDCtr98]. Zie figuur 22 en 23.
Figuur 22: De NDC voor de nest operatie
In figuur 22, afkomstig uit [NDCtr98], zien we een NDC die we gebruiken als uitgangssituatie van een nestoperatie. De nestoperatie die we loslaten op deze NDC, genaamd C, is nest(C,{ Area} ). Hierbij i s de verzameling attributen { Area} dus de in de definitie gebruikte X. Wanneer we de operatie

77
uitvoeren, zien we in figuur 23 het resultaat. In dit voorbeeld is mooi te zien dat er een nest plaatsvindt op het attribuut “ area”. We zien in figuur 23 een opdeling van de NDC in de “area’s” Italië en België. De onderliggende NDC’s geven precies die informatie die voor die area’s gelden. De NDC bevat niet meer of minder informatie dan die uit figuur 22.
Figuur 23: De NDC na de nest operatie
We gaan nu door met de tegenhanger van de nest operator, nl. de unnest operator. 4.5.4 De unnest operator De unnest operator is de inverse van de nest operator. We zullen hier dan ook volstaan met het geven van de formele definitie, daar de werking na het vorige voorbeeld wel duidelijk is. De unnest operator heeft maar 1 argument, namelij k een schema of een NDC. We definiëren:
C is een NDC over het schema [ � 1 � [ � 2 ��� ]] , met de voorwaarde att( � 1) � att( � 2) = � . We zien:
unnest([ � 1 � [ � 2 ��� ]]) = [ � 1 � � 2 ��� ]
unnest(C) is de kleinste NDC die a � b � w bevat, waarbij geldt dat C a � C’ bevat en er geldt dat
b � w een element is van C’. 4.5.5 De duplicate operator De duplicate operator maakt het mogelijk om in een NDC waardes van attributen te dupliceren en in de meest rechtse toewijzing in een NDC te plaatsen. Formeel ziet dit er als volgt uit. Een duplicate operator heeft 2 argumenten, een schema of een NDC en een attribuut A.
Laat C een NDC zijn over een schema [ � ��� ] en A : l � � . We schrij ven dan:

78
duplicate([ � ��� ], A) = [ � � l ]
duplicate(C, A) is de kleinste NDC over [ � � l ] waarvoor geldt dat deze v � c bevat als geldt dat
v � C’ een element is van C en v(A) = c (C’ is een NDC over � ) De duplicate operator demonstreren we aan de hand van de case Down Under. Als uitgangspositie kijken we weer naar de NDC in figuur 20. We noemen deze gemakshalve weer K. We definiëren het volgende: duplicate(K, Maand). Het uitschrij ven van deze operator levert het volgende op:
duplicate(K, Maand) levert een NDC op over het schema [{ Plaats: Plaats, Maand: Maand} �Maand]. De NDC zelf wordt gedefinieerd aan de hand van de op te nemen toewijzingen. Deze
toewijzingen moet voldoen aan v � c, waarbij v de coördinaten moeten zijn uit de oude NDC. De waarde c bestaat in dit geval alleen uit de concrete waarde “Januari” u it het domein van Maand. Wanneer we dit alles visueel presenteren ontstaat de NDC in figuur 24.
Figuur 24: De NDC na het toepassen van duplicate
We vervolgen met de operator select. 4.5.6 De select operator De select operator heeft als invoer drie argumenten. Het eerste argument is een NDC schema of een NDC, het tweede een attribuut A en het derde een attribuut B of een concrete waarde c uit een domein
van een level. We vooronderstellen een NDC C over een schema [ � ��� ], A : l � � , B � att( � ), c �dom(l). We definiëren dan:
select([ � ��� ], A, c) = [ � ��� ] select([ � ��� ], A, B) = [ � ��� ]
select(C, A, c) is de kleinste NDC over het schema [ � ��� ] die v � w bevat, wanneer geldt dat
v � w ook in C zit en v(A) = c.

79
select(C, A, B) is de kleinste NDC over het schema [ � ��� ] die v � w bevat, wanneer geldt dat
v � w ook in C zit en v(A) = v(B). We zullen de select operator niet verder demonstreren. Later zal de toepassing van deze operator uitgebreid aan bod komen. De werking van de select operator is aan de hand van de definitie vrij goed in te zien. We vervolgens met de rename operator. 4.5.7 De rename operator De rename operator heeft tot doel het hernoemen van attributen. Formeel ziet de rename operator er zo uit:
Laat C een NDC zijn over een NDC schema [ � ��� ], A � att( � ), en B een attribuut waarbij B �
att( � ). We zien dan:
rename([ � ��� ], A, B) = [ ��� �� ], waarbij ��� het coördinaat type is waarin A vervangen is door B.
rename(C, A, B) is de kleinste NDC over [ ��� ��� ] die v { B : c} � w bevat, wanneer geldt dat C
v { A : c} � w bevat. We zullen deze operator ook niet visueel verduidelij ken. De laatste definitie laat de werking duidelijk zien. Een attribuut B wordt geïntroduceerd en daarbij vervangt deze A in de nieuwe NDC. Alle toegewezen waarden blijven precies hetzelfde onder B, getuige de c in de definitie. Het gaat dus louter om een naam van een attribuut. Als laatste kij ken we naar de aggregate operator. 4.5.8 De aggregate operator De aggregate operator is in staat functies toe te passen op de rechtse waarden in een NDC. Denk hierbij aan aggregaties, maar ook andersoortige functies (bijv. statistische functies). We definiëren
eerst een functie ground, die bij een NDC schema de meest rechtse level of bag oplevert ( � ). We definiëren eenvoudig:
ground([ � ��� ]) = ground( � )
ground( � ) = �
We kunnen nu de aggregate operator definiëren. Aggregate heeft twee argumenten als invoer, nameli jk een NDC of een NDC schema en een functie f. We beginnen met de definitie van aggregate op een
NDC schema. Laat C een NDC zijn over het schema � met ground( � ) = � en laat f een volledige
functie zijn van dom( � ) naar dom( � ), waarbij � een NDC schema is dat gelij kvormig is met � (de functie f moet een goed gedefinieerde zijn). We zien:
aggregate([ � ��� ], f ) = [ � � aggregate ( � , f)] aggregate( � , f ) = �
Een aggregate operator op een NDC, genaamd C, en een functie f is als volgt gedefinieerd.

80
aggregate(C, f) = { v1 � aggregate (w1, f), …., v n � aggregate (wn, f)} , wanneer C een NDC over
[ �
��� ], met de toewijzingen v naar w.
aggregate(C, f) = f(c), wanneer C een NDC is over � , met de syntax C = c 4.6 Modellering van relationele operatoren in het NDC model In deze paragraaf gaan we een belangrij k aspect van het NDC model aan het licht brengen. We zullen de relationele operatoren projectie, selectie, join en rename gaan modelleren in het NDC model. Hiermee wordt de basis gelegd tussen voor de match van de beschreven semantiek voor constraints in PSM naar constraints in het dimensionale model (data warehouses). In [NDCtr98] wordt gerefereerd naar de SPJR algebra (Selection-Projection-Join-Rename algebra) met de volgende stelling: The NDC algebra expresses the SPJR algebra De SPJR algebra is niets anders dan de relationele algebra, beschreven met de genoemde relationele operatoren. [NDCtr98] verwijst voor deze algebra naar een standaardwerk over de basisprincipes in databases. Wij verwijzen hier naar het inhoudelijk gelij kwaardige [Weide]. In [NDCtr98] wordt een bewijs gegeven voor de hierboven geponeerde stelling. We zullen dit bewijs hier weergeven, doorspekt met verhelderende voorbeelden. De importantie van dit bewijs is dusdanig groot voor het verdere onderzoek, dat we hier uitgebreid te werk zullen gaan. We beginnen met de invoering van een notatie. We schrijven cube(R) als zijnde de NDC voortgebracht door R. Hierin is R een relatie over een verzameling attributen X. Dit houdt het volgende in: X is een verzameling van attributen en een tupel over X is een totale functie van X naar dom(l), waarin l een verwant level is van de attributen. We noemen een eindige verzameling tupels
over een verzameling attributen X een relatie over X. Laat att(�) = X en
�(A) = l voor alle A uit X.
We kunnen nu definiëren:
cube(R) is de kleinste NDC over het NDC schema [�
��� ] waarvan v ��� een element is als v een element is van R. We kunnen met deze definitie projectie, selectie, join en rename uitdrukken in de NDC algebra. Dit gaat als volgt. Laat R en S relaties zijn over respectievelijk X en Y. We schrijven het volgende op:
Een projectieoperatie toegepast op R, genoteerd met cube( � XR), is te berekenen uit cube(R).
Een selectieoperatie toegepast op R, genoteerd met cube( A=a R) of cube( A=B R), is te berekenen uit cube(R).
Een join tussen R en S, genoteerd met cube(R S), is te berekenen uit cube(R) en cube(S).
Een renameoperatie, genoteerd met cube(�
A � B R), is te berekenen uit cube(R). Deze vier beweringen zullen we bewijzen aan de hand van het geven van een beschrij ving in de NDC algebra, waarmee een directe vertaalstap van de uitgangscube naar de toegepaste cube wordt gemaakt. De projectieoperatie. De beginsituatie is een NDC genaamd C = cube(R). Laat R een relatie zijn over
XY en f een functie van dom({ |� |} ) naar dom( � ). De NDC cube( � XR) is dan als volgt gedefinieerd:
cube( � XR) = aggregate(bagify(nest(C, X)), f) We zullen dit demonstreren aan de hand van een voorbeeld. We nemen voor XY de verzameling attributen A1, A2, A3 en A4. We nemen level l = level5, met dom(level5) = { d1, d2, d3, d4, d5,…,d100} . Vervolgens definiëren we R = {{ A1:d1, A2:d2, A3:d3, A4:d4} ,{ A1:d2, A2:d3, A3:d1, A4: d4}} . We kiezen X = { A1, A2} We kunnen dan definiëren:

81
cube(R) =
{{ A1:d1, A2:d2, A3:d3, A4:d4} � � , { A1:d2, A2:d3, A3:d1, A4:d4} � � }
Deze cube(R) is het uitgangspunt voor de berekening van cube( � XR). We substitueren:
cube( � XR) = aggregate(bagify(nest(C, X)), f) We berekenen eerst nest(C, X). nest(C, X) = nest (C, {A1, A2} ). De NDC die deze operator oplevert is de volgende:
nest (C, { A1, A2} ) = {{ A1:d1, A2:d2} ��� A3:d3, A4:d4} � � , { A1:d2, A2:d3} ��� A3:d1, A4:d4}
� � } . Vervolgens passen we op deze NDC de bagify operator toe. Dit levert:
bagify({ { A1:d1, A2:d2} ��� A3:d3, A4:d4} � � , { A1:d2, A2:d3} ��� A3:d1, A4:d4} � � } =
{{ A1:d1, A2:d2} � bagify� A3:d3, A4:d4} � � , { A1:d2, A2:d3} � bagify� A3:d1, A4:d4} � � } =
{{ A1:d1, A2:d2} � { |�
|} , { A1:d2, A2:d3} � { |�
|} } Als laatste de aggregate operator. We substitueren:
aggregate({ { A1:d1, A2:d2} � { |�
|} , { A1:d2, A2:d3} � { |�
|}} , f) =
{{ A1:d1, A2:d2} � aggregate({ |�
|} , f), { A1:d2, A2:d3} � aggregate({ |�
|} , f)} =
{{ A1:d1, A2:d2} � � , { A1:d2, A2:d3} � � } We zien dat de resulterende NDC precies die attributen bevat waarop was geprojecteerd, namelij k die uit de verzameling X. De selectieoperatie. De selectieoperator werkt recht toe recht aan. We nemen weer als beginsituatie de NDC C = cube(R). We definiëren dan:
cube( � A=a R) = select(C, A, a)
cube( � A=B R) = select(C, A, B) Voor de uitwerking van een voorbeeld van de selectieoperatie nemen we dezelfde situatie als hiervoor, met dezelfde verzamelingen. We definiëren dus wederom R als een relatie op XY, waarbij R = {{ A1:d1, A2:d2, A3:d3, A4:d4} ,{ A1:d2, A2:d3, A3:d1, A4: d4}} . We zien wederom cube(R) =
{{ A1:d1, A2:d2, A3:d3, A4:d4} � � , { A1:d2, A2:d3, A3:d1, A4:d4} � � }
We berekenen nu cube( � A2=d2 R) en cube( � A1=A2 R).
cube( � A2=d2 R) = select(C, A2, d2) = {{ A1:d1, A2:d2, A3:d3, A4:d4} � � }
cube( � A1=A2 R) = select(C, A1, A2) = {}

82
We schrij ven dit niet uit, omdat de selectieoperator uit de NDC algebra al besproken is. De werking is rechtlij nig met de normale relationele selectieoperator. De laatste levert een lege NDC op, omdat er geen match is tussen A1 en A2. Tot zover de selectieoperatie. We gaan door met de moeil ijke join operatie. De joinoperatie. De join operatie is moeilij k te simuleren in de NDC algebra. Het is wel mogelij k, maar er dient dan een onderscheid gemaakt te worden tussen 2 verschillende soorten joins. Deze 2 soorten onderscheiden we als volgt. We definiëren eerst twee relaties R en S over respectievelij k XY en YZA. Dan kunnen we schrij ven:
R � S = (R ��� YA S) � S De twee type joins die we moeten onderscheiden zijn dan: 1. R is een relatie over XY en S een relatie over YA, waarbij A niet in XY zit. 2. R is een relatie over XY en S is een relatie over Y. De join van type 1 wordt als volgt gesimuleerd in de NDC algebra. We nemen als uitgangssituatie de
relaties R over XY en S over YA, waar X � Y = � en A � XY. Laat vervolgens C = cube(R) en D = cube(S). We kunnen dan definiëren:
cube(R � S) = unnest(extend(nest(C, Y), A, l, rel(bagify(nest(duplicate(D,A), Y))))) Dit is een zeer ingewikkelde definitie die we na introductie van het tweede type join zullen demonstreren.
Join type 2 is als volgt te simuleren. We nemen R en S als relaties over XY en Y, waarbij X � Y = � . Laat wederom C = cube(R) en D = cube(S) zijn. We kunnen dan schrij ven:
cube(R � S) = aggregate(bagify(nest(unnest(extend(nest(C, Y), A, � , rel(D))), XY)), f) We zullen een voorbeeld uitwerken van de eerste definitie. We nemen aan dat dit ook de tweede definitie verduidelij k, met veelal dezelfde soort operatoren. We definiëren hiervoor de volgende zaken: X = { A1, A2} Y = { A3, A4} Een attribuut A zijnde geen element uit X of Y. Een level l, met dom(l) = { d1,..d100} R = {{ A1:d1, A2:d2, A3:d3, A4:d4} ,{ A1:d1, A2:d3, A3: d4, A4:d7}} S = {{ A3:d3, A4:d4, A:d10} , { A3:d8, A4:d9, A:d11} } We kunnen vervolgens noteren:
C = cube(R) = {{ A1:d1, A2:d2, A3:d3, A4:d4} �� , {A1:d1, A2:d3, A3: d4, A4:d7} �� }
D = cube(S) = {{ A3:d3, A4:d4, A:d10} �� , { A3:d8, A4:d9, A:d11} �� } We substitueren de gegevens in de definitie.
cube(R � S) = unnest(extend(nest(C, Y), A, l, rel(bagify(nest(duplicate(D,A), Y))))) = unnest(extend(nest(C, { A3, A4} ), A, l, rel(bagify(nest(duplicate(D, A), { A3, A4} ))))) We berekenen nu:
duplicate (D, A) = {{ A3:d3, A4:d4, A:d10} � d10 , {A3:d8, A4:d9, A:d11} � d11}

83
Vervolgens:
nest({ { A3:d3, A4:d4, A:d10} � d10 , { A3:d8, A4:d9, A:d11} � d11} , { A3, A4} ) =
{{ A3:d3, A4:d4} � { A:d10} � d10, { A3:d8, A4:d9} � { A:d11} � d11} Op deze NDC wordt volgens de definitie een bagify losgelaten. Dit gaat zo:
bagify({ { A3:d3, A4:d4} � { A:d10} � d10, { A3:d8, A4:d9} � { A:d11} � d11} ) =
{{ A3:d3, A4:d4} � { |d10|} , { A3:d8, A4:d9} � { |d11|}} Vervolgens wordt van deze NDC (we noemen hem J) de “relation induced by J” berekend. We schrij ven:
rel({{ A3:d3, A4:d4} � { |d10|} , { A3:d8, A4:d9} � { |d11|}} ) = { ({ A3:d3, A4:d4} , d10), ({ A3:d8, A4:d9} , d11)} We vervolgen met de uitwerking van nest(C, { A3, A4} ). nest(C, { A3, A4} ) =
nest({ { A1:d1, A2:d2, A3:d3, A4:d4} � � , { A1:d1, A2:d3, A3:d4, A4:d7} � � } , { A3, A4} ) =
{{ A3:d3, A4:d4} ��� A1:d1, A2:d2} � � , { A3:d4, A4:d7} � { A1:d1, A2:d3} � � } We kunnen nu de extend operator substitueren:
extend({ { A3:d3, A4:d4} ��� A1:d1, A2:d2} � � , { A3:d4, A4:d7} � { A1:d1, A2:d3} � � } , A, l, { ({ A3:d3, A4:d4} , d10), ({ A3:d8, A4:d9} , d11)} ) =
{{ A3:d3, A4:d4, A:d10} ��� A1:d1, A2:d2} � � } We zien dat het tweede paar uit “relation induced by J” niet terug komt in het resultaat van de extend operator. Dit komt omdat het coördinaat type niet voorkomt in de input NDC van de extend operator. We gaan verder met de laatste operator, n.l. unnest.
unnest({ { A3:d3, A4:d4, A:d10} ��� A1:d1, A2:d2} � � } =
{{ A3:d3, A4:d4, A:d10, A1:d1, A2:d2} � � } Alles samengevat krijgen we dus:
cube(R � S) = cube({{ A1:d1, A2:d2, A3:d3, A4:d4} ,{ A1:d1, A2:d3, A3: d4, A4:d7}} � {{ A3:d3, A4:d4, A:d10} , { A3:d8, A4:d9, A:d11}} ) =
{{ A3:d3, A4:d4, A:d10, A1:d1, A2:d2} � � } Je ziet hier zeer fraai hoe de join de overeenkomende elementen bij elkaar heeft gezocht. { A3:d3, A4:d4} zijn twee overeenkomende elementen uit het “coördinaat type” in R en S. Deze zorgen er voor dat de join de gemeenschappelij ke elementen samenvoegt in de resulterende NDC, n.l. A:d10, A1:d1 en A2:d2. Tot zover de join operatie. We kijken als laatste in deze paragraaf naar de rename operator. De renameoperatie. Voor het simuleren van de relationele rename, kunnen we gebruik maken van zijn naamgenoot uit de NDC algebra. We nemen als beginsituatie wederom de NDC C = cube(R). We definiëren nu:
cube( � A � B R) = rename(C, A, B)

84
We zullen dit niet demonstreren, daar het inzichtelijk duidelijk is hoe deze operator werkt. In de volgende paragraaf zullen we de uitdrukkingskracht van de NDC algebra verder demonstreren door invoering van de operatoren op een bepaalde diepte in een NDC. 4.7 NDC algebra toepasbaar op elke diepte in een NDC Een tweede belangrijk aspect van het NDC model is het kunnen toepassen van de operatoren uit de NDC algebra op elke gewenste sub-NDC in een NDC op een bepaalde diepte. Deze mogelijkheid is te danken aan het recursieve karakter van de NDC. De definitie van een NDC schema is gemaakt op basis van zogenaamde staartrecursie. Deze staartrecursie zorgt ervoor dat door middel van toewijzing van een bepaalde diepte in een NDC de operator kan worden toegepast op precies die sub NDC die zich op die diepte bevindt. We zullen dit nu formaliseren.
Laat C een NDC zijn over het NDC schema � . Laat d een diepte zijn tussen 0 en depth( � ). We
schrijven op(C, a1,…,a n) als zijnde een van de operatoren van de NDC algebra. Laat � ’ = subscheme
( � , d). opd(C, a1,…,a n) geeft de operatie op aan die wordt toegepast op de NDC op diepte d van de
NDC C. Deze operatie is gedefinieerd als op( � ’,a 1,…,a n) ook gedefinieerd is. De operatie op een bepaalde diepte d is als volgt gedefinieerd. Eerst op schema’s, daarna op NDC’s. We onderscheiden 3 gevallen.
1. d = 0, dan op0( � , a1,…,a n) = op( � , a1,…,a n), mits de operator gedefinieerd is op �
2. d = 1, dan op1( � , a1,…,a n) = op( � , a1,…,a n)
3. d > 1, dan opd([ � � � ], a1,…,a n) = [ � � opd-1( � , a1,…,a n)] 1. d = 0, dan op0(C, a1,…,a n) = op(C, a1,…,a n), mits de operator gedefinieerd is op een concrete waarde of een bag. 2. d = 1, dan op1(C, a1,…,a n) = op(C, a1,…,a n)
3. d > 1 en C = {v1 � w1,.., vn � wn} dan opd(C, a1,…,a n) = {v1 � opd-1(w1, a1,…,a n), …,
vn � opd-1(wn, a1,…,a n)} Een laatste opmerking die we hier maken is het feit dat operatoren op een diepte groter dan 1 afleidbaar zijn uit bestaande operatoren op een mindere diepte. We zullen dit hier niet bewijzen. Zie voor dit bewijs de appendix in [NDCtr98]. 4.8 Een informele mapping van relationeel op dimensionaal en vice versa In deze paragraaf willen we een eerste voorzichtige stap gaan maken naar de overeenkomsten tussen het relationele model en het dimensionale model. We zullen hiervoor de verschillende termen uit de modellen naast elkaar leggen in een tabel. Vervolgens zullen we de verschillende aspecten bespreken en precies kijken hoe deze matchen. Als uitgangsmodel nemen we in de tabel het dimensionale model, daar we toewerken naar een semantiek van constraints in dit model op basis van de relationele algebra in PSM. In de tabel zullen toewerken van meer algemene termen van beide modellen, naar specifieke termen uit het NDC model en PSM.
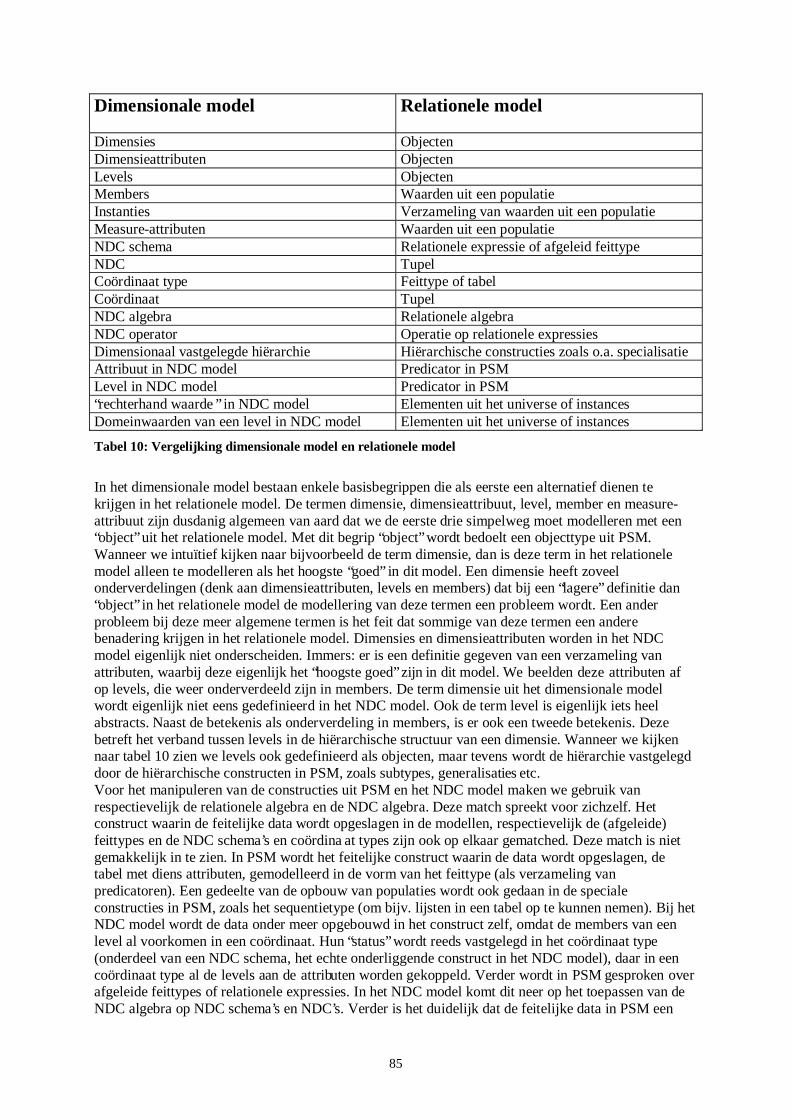
85
Dimensionale model
Relationele model
Dimensies Objecten Dimensieattributen Objecten Levels Objecten Members Waarden uit een populatie Instanties Verzameling van waarden uit een populatie Measure-attributen Waarden uit een populatie NDC schema Relationele expressie of afgeleid feittype NDC Tupel Coördinaat type Feittype of tabel Coördinaat Tupel NDC algebra Relationele algebra NDC operator Operatie op relationele expressies Dimensionaal vastgelegde hiërarchie Hiërarchische constructies zoals o.a. specialisatie Attribuut in NDC model Predicator in PSM Level in NDC model Predicator in PSM “rechterhand waarde” in NDC model Elementen uit het universe of instances Domeinwaarden van een level in NDC model Elementen uit het universe of instances
Tabel 10: Vergelijking dimensionale model en relationele model
In het dimensionale model bestaan enkele basisbegrippen die als eerste een alternatief dienen te krijgen in het relationele model. De termen dimensie, dimensieattribuut, level, member en measure-attribuut zijn dusdanig algemeen van aard dat we de eerste drie simpelweg moet modelleren met een “object” uit het relationele model. Met dit begrip “object” wordt bedoelt een objecttype uit PSM. Wanneer we intuïtief kij ken naar bijvoorbeeld de term dimensie, dan is deze term in het relationele model alleen te modelleren als het hoogste “goed” in dit model. Een dimensie heeft zoveel onderverdelingen (denk aan dimensieattributen, levels en members) dat bij een “lagere” definitie dan “object” in het relationele model de modellering van deze termen een probleem wordt. Een ander probleem bij deze meer algemene termen is het feit dat sommige van deze termen een andere benadering krijgen in het relationele model. Dimensies en dimensieattributen worden in het NDC model eigenlijk niet onderscheiden. Immers: er is een definitie gegeven van een verzameling van attributen, waarbij deze eigenlij k het “hoogste goed” zijn in dit model. We beelden deze attributen af op levels, die weer onderverdeeld zijn in members. De term dimensie uit het dimensionale model wordt eigenlij k niet eens gedefinieerd in het NDC model. Ook de term level is eigenlijk iets heel abstracts. Naast de betekenis als onderverdeling in members, is er ook een tweede betekenis. Deze betreft het verband tussen levels in de hiërarchische structuur van een dimensie. Wanneer we kijken naar tabel 10 zien we levels ook gedefinieerd als objecten, maar tevens wordt de hiërarchie vastgelegd door de hiërarchische constructen in PSM, zoals subtypes, generalisaties etc. Voor het manipuleren van de constructies uit PSM en het NDC model maken we gebruik van respectievelij k de relationele algebra en de NDC algebra. Deze match spreekt voor zichzelf. Het construct waarin de feitelij ke data wordt opgeslagen in de modellen, respectievelijk de (afgeleide) feittypes en de NDC schema’s en coördinaat types zijn ook op elkaar gematched. Deze match is niet gemakkelij k in te zien. In PSM wordt het feitelij ke construct waarin de data wordt opgeslagen, de tabel met diens attributen, gemodelleerd in de vorm van het feittype (als verzameling van predicatoren). Een gedeelte van de opbouw van populaties wordt ook gedaan in de speciale constructies in PSM, zoals het sequentietype (om bijv. lijsten in een tabel op te kunnen nemen). Bij het NDC model wordt de data onder meer opgebouwd in het construct zelf, omdat de members van een level al voorkomen in een coördinaat. Hun “status” wordt reeds vastgelegd in het coördinaat type (onderdeel van een NDC schema, het echte onderliggende construct in het NDC model), daar in een coördinaat type al de levels aan de attributen worden gekoppeld. Verder wordt in PSM gesproken over afgeleide feittypes of relationele expressies. In het NDC model komt dit neer op het toepassen van de NDC algebra op NDC schema’s en NDC’s. Verder is het duideli jk dat de feitelij ke data in PSM een

86
populatie is van de gedefinieerde constructen. In het NDC model is dit de definitie van een coördinaat of NDC. Tenslotte worden de feitelijke data in PSM gevisualiseerd door elementen uit het universe of instances, zoals gedefinieerd. In het NDC model zijn dit de domeinen van de levels en de “rechterhand waarden” in een NDC. Een attribuut en een level in het NDC model kunnen in PSM worden gemodelleerd als zijnde een predicator (tabelattribuut in algemene zin). Uit deze intuïtieve uiteenzetting over een mogelij ke match tussen de twee modellen dienen enkele conclusies te worden getrokken. De eerste is het verschil in benadering in de opbouw van de data constructies. Het NDC model werkt recursief. Dit betekent dat in het dataconstruct, de NDC zelf dus, alle informatie ligt opgeslagen. We kunnen dit op een andere wijze benaderen door te zeggen dat een NDC in een NDC een op zichzelf staand construct is. Eigenlij k is dit ook zo, wanneer we de perceptie nemen vanuit de NDC algebra. Deze is immers ook gedefinieerd ten aanzien van bepaalde NDC’s binnen een NDC. Denk hierbij vooral aan de operatoren die op een bepaalde diepte kunnen opereren. Tegenover deze recursieve benadering van het NDC model, vinden we in het PSM model geen recursieve data constructen terug. Het tweede grote verschil tussen het NDC model en PSM is vooralsnog het grote verschil op conceptueel niveau. In PSM wordt bijvoorbeeld al rekening gehouden met constraints op conceptueel niveau. In het NDC model moet dit nog worden ingevoerd, hetgeen deze scriptie o.a. beoogd. We zullen nu wat concreter gaan kijken naar de werking van beide modellen in relatie tot elkaar. Hiervoor zullen we de case Down Under voor een gedeelte gaan beschrij ven in PSM. 4.9 Down Under in PSM: een vergeli jking met het NDC model Als eerste gaan we de Down Under case voor een gedeelte in PSM modelleren. We zullen hiervoor gebruik maken van de casebeschrijving uit paragraaf 2.1 In figuur 25 zien we een gedeelte van de beschreven case gemodelleerd in een PSM schema. Gemakshalve hebben we enkele attributen weggelaten en de tabellen consistent gehouden met het dimensionale model. In figuur 25 zien we een PSM schema, waarbij opgemerkt dient te worden dat dit slechts een gedeelte is van een volledig schema voor Down Under.

87
Figuur 25: Down Under in een PSM schema

88
We hebben in het schema enkele constraints aangegeven, zoals de uniqueness constraint over de dimensietabellen en een total role constraint bij het entiteittype “Plaats”. Laten we beginnen met een voorbeeldpopulatie van het PSM schema uit figuur 25. Dit is een niet complete invulling in vergelijking met de werkelijkheid. De entiteittypes hebben de volgende populatie: Pop(Dimensie id) = { G1,…GN,T1,…,TN,P1,…,PN} , waarbij N z eer groot is. Pop(Distributiecentrum) = { Perth, Darwin, Auckland, Sydney} Pop(Plaats) = { Katherine, Darwin, Perth, Auckland, Sydney, Port Douglas, Mossman, Hamilton Island, Airlie Beach, Tamworth, Threeways, Broome, Welli ngton, Christchurch, Brisbane, Cairns, Coogee} Pop(Land) = { Australië, Nieuw Zeeland} Pop(State) = { n/a, Northern Territory, Western Australia, New South Wales, Queensland} Pop(Maand) = { Januari, Februari,…,December} Pop(Maandnummer) = { 1,..,12} Pop(Kwartaal) = { 1,2,3,4} Pop(Artiest) = { Foreigner, Toto, Elton John, Anouk, U2, Yes, Queen, Chesney Hawkes, Krezip} Pop(Titel) = { 4, Double Vision, Love Songs, Urban Soli tude, War, The Miracle, The One And Only, I Would Stay, The Seventh One, The Very Best Of Yes} Pop(Genre) = { Pop, Hardrock, Folk, Rock} Pop(Jaar) = { 1980,…,2000}
Pop(Aantal Eenheden) = �
Pop(Omzet) = � De feittypes zijn als volgt gepopuleerd: Pop(Geografietabel) = {{ a: G1, b: Darwin, c: Katherine, d: Northern Territory, e: Australië} , { a: G2, b: Darwin, c: Threeways, d: Northern Territory, e: Australië} , { a: G3, b: Darwin, c: Darwin, d: Northern Territory, e: Australië} , { a: G4, b: Brisbane, c: Port Douglas, d: Queensland, e: Australië} , { a: G5, b: Brisbane, c: Mossman, d: Queensland, e: Australië} , { a: G6, b: Brisbane, c: Hamilton Island, d: Queensland, e: Australië} , { a: G7: b: Sydney, c: Tamworth, d: New South Wales, e: Australië} , { a: G8: b: Sydney, c: Coogee, d: New South Wales, e: Australië} , { a: G9, b: Auckland, c: Christchurch, d: n/a, e: Nieuw Zeeland} , { a: G10, b: Auckland, c: Well ington, d: n/a, e: Nieuw Zeeland}} Pop(Tijdstabel) = {{ f: T1, g: Januari, h: 1, i: 1, j: 1998} , { f: T2, g: Februari, h: 2, i: 1, j: 1998} , { f: T3, g: Februari, h: 2, i: 1, j: 2000} , { f: T4, g: April, h: 4, i: 2, j: 2000} , { f: T5, g: Augustus, h: 8, i: 3, 1999} , { f: T6, g: Augustus, h: 8, i: 3, 2000} , { f: T7, g: December, h: 12, i: 4, 2000}} Pop(Producttabel) = {{ k: P1, l: Foreigner, m: 4, n: Rock} , {k: P2, l: Foreigner, m: Double Vision, n: Rock} , {k: P3, l: Toto, m: The Seventh One, n: Rock} , {k: P4, l: Elton John, m: Love Songs, n: Pop} , {k: P5, l: Anouk, m: Urban Soli tude, n: Hardrock} , {k: P6, l: U2, m: War, n: Rock} , {k: P7, l: Yes, m: The Very Best Of Yes, n: Rock} , {k: P8, l: Queen, m: The Miracle, n: Rock} , {k: P9, l: Chesney Hawkes, m: The One And Only, n: Pop} , {k: P10, l: Krezip, m: I Would Stay, n: Pop}}

89
Pop(Verkooptabel) = {{ q: T1, r: G1, s: P1, t: 2, u: 200} , {q: T2, r: G1, s: P1, t: 3, u: 300} , {q: T2, r: G2, s: P2, t: 1, u: 200} , {q: T2, r: G2, s: P3, t: 1, u: 100} , {q: T2, r: G3, s: P4, t: 2, u: 300}} Pop(Plaats/Land tabel) = {{ o: Katherine, p: Australië} , {o: Darwin, p: Australië} . {o: Perth, p: Australië} , {o: Auckland, p: Nieuw Zeeland} , {o: Sydney, p: Australië} , {o: Port Douglas, p: Australië} , {o: Mossman, p: Australië} , {o: Hamilton Island, p: Australië} , {o: Airlie Beach, p: Australië} , {o: Tamworth, p: Australië} , {o: Threeways, p: Australië} , {o: Broome, p: Australië} , {o: Well ington, p: Nieuw Zeeland} , {o: Christchurch, p: Nieuw Zeeland} , { o: Brisbane, p: Australië} , {o: Cairns: p: Australië} {o: Coogee, p: Australië}} Wat meteen opvalt tussen de casebeschrijvi ng in het dimensionale model en die in PSM is het feit dat de hiërarchie binnen de dimensies anders wordt benaderd. In het PSM schema uit figuur 25 is ter illustratie van dit feit het feittype Plaats/Land tabel opgenomen. Hierin wordt een bepaalde hiërarchie in de “dimensionale” dimensie vastgelegd. In het NDC model zit deze hiërarchie er “ingebakken” door het feit dat er verschillende Roll Up functies tussen de levels zijn gedefinieerd. We brengen in herinnering:
De roll-up functie R-UPwv, waarbij (v, w) � L � L , is gedefinieerd voor bepaalde paren v, w en
projecteert ieder element van v op een element van w. Hierin speelt het woord “bepaalde” een sleutelrol. Er moet een hiërarchisch of causaal verband bestaan tussen deze levels wil zo’n roll up functie gedefinieerd zijn. We zullen deze functie demonstreren aan de hand van de case. We kijken naar de populatie van het feittype Plaats/Land tabel. In deze populatie zijn twee entiteittypes (Land en Plaats) verbonden door een geografisch bepaalde hiërarchie. Elke plaats ligt maar in 1 land is hierbij de (door de empirie) opgelegde beperking. In PSM simuleren we deze beperking door de aangegeven uniqueness constraint. In het NDC is hiervoor geen constraint nodig, maar wordt de empirie gemodelleerd door het al dan niet bestaan van een roll up functie. We kunnen voor het NDC model het genoemde feittype als volgt vastleggen: We definiëren: R-UPLand
Plaats waarbij gedefinieerd wordt: R-UPLand
Plaats(Katherine) = Australië R-UPLand
Plaats(Welli ngton) = Nieuw Zeeland R-UPLand
Plaats(Tamworth) = Australië Enzovoort. De roll up functie zorgt er dus voor dat ieder element van een lager in de hiërarchie liggend level een match heeft naar een hoger gelegen level. Hiërarchieën zijn niet altijd even duidelij k zichtbaar en er kunnen ook meerdere soorten hiërarchische structuren binnen 1 dimensie lopen. We kunnen bijvoorbeeld bij de tijdsdimensie een opdeling maken in de levels dag – week – jaar en anderzijds dag – maand – kwartaal – jaar. Ook bijvoorbeeld een dimensie product kan meerdere hiërarchische structuren herbergen. Je kunt bijvoorbeeld een product onderverdelen in categorieën (denk aan speelgoed of etenswaar) en merken. Je krijgt dan, in een schema, bijvoorbeeld een volgende, uitgebreidere structuur voor bepaalde dimensies. We kijken hiervoor naar figuur 26.

90
Figuur 26: Verschillende hiërarchieën in dimensies
We zien in dit figuur verschillende richtingen binnen een dimensie. In de tijdsdimensie kunnen we in dit model een roll up functie uitvoeren van dag naar jaar via twee paden. Het is niet mogelijk om van deze twee paden 1 pad te maken door het feit dat een maand niet precies uit een bepaald aantal weken bestaat. Dit houdt in dat het pad dag – week – maand – kwartaal – jaar niet mogelij k is. Een measure-attribuut dat op het laagste level is gedefinieerd, dag, kan geaggregeerd worden naar week (7 dagen in 1 week), en verder naar jaar. Aggregatie van week naar maand is onmogelij k door het feit dat er niet precies een aantal weken in een maand zitten. Maand naar kwartaal is wel mogelijk en ook kwartaal naar jaar. In [CabTor] wordt ingegaan op het gebruik van roll up functies is het dimensionale model, waarbij voor het net genoemde verband tussen levels wordt besproken. [CabTor] demonstreert ook een algemene benadering van de roll up functie, waarin wordt vastgelegd hoe de levels onderling gerelateerd zijn. Een verzameling R-UP, zijnde een verzameling van roll up functies, is als volgt gedefinieerd. De verzameling R-UP moet voldoen aan:
1. Voor ieder paar van levels 1 en k, waarbij geldt l � k (“ l rolls up to k”), bestaat de roll up functie R-UPk
l op de beschreven manier. 2. Een roll up functie werkt op basis van compositie. Dit houdt in dat, wanneer een hiërarchie bestaat
tussen de levels l, k en m, gedefinieerd met l � k � m, de functie R-UPml gelij k is aan
R-UPkl � R-UPm
k . Dit houdt in dat alle roll up functies onafhankelijk zijn van het gekozen aggregatiepad. We zullen dit laatste demonstreren. We nemen uit figuur 26 de tijdsdimensie en zullen nu kijken naar de paden dag – week – jaar en dag – maand – kwartaal – jaar.
We kunnen definiëren dag � week � jaar en dag � maand � kwartaal � jaar. Wanneer we elementen uit de domeinen loslaten op de roll up functies zoals beschreven in (1) krijgen we het volgende te zien. Eerst enkele invullingen van de roll up functies. R-UP week
dag (1 januari 2000) = Week 1, 2000 R-UP week
dag (2 januari 2000) = Week 1, 2000

91
R-UP jaarweek (Week 1, 2000) = 2000
R-UP maanddag (1 januari 2000) = januari 2000
R-UP kwartaalmaand (januari 2000) = 1e kwartaal 2000
R-UP jaarkwartaal (1
e kwartaal 2000) = 2000 Men zegt in deze schrijfwijze ook wel: “Week 1, 2000 rolls up to 2000” of “2000 drill s down to Week 1, 2000”. Dit laatste zullen we echter niet gebruiken, daar we de term drill down in een andere context gebruiken dan roll up (zie hoofdstuk 3). Nu kunnen we beide aggregatiepaden aflopen van dag naar jaar. Door compositie van de roll up functies leveren ze exact hetzelfde op. Deze consistentie tussen de levels is er altijd. We zien:
R-UP jaardag (1 januari 2000) = R-UP jaar
week � R-UP weekdag (1 januari 2000) = 2000
R-UP jaardag (1 januari 2000) = R-UP jaar
kwartaal � R-UP kwartaalmaand � R-UP maand
dag (1 januari 2000) = 2000 Nu we de hiërarchie zoals die gebruikt wordt in het dimensionale model en specif iek in het NDC model begrijpen, gaan we proberen een match te maken van een NDC naar een PSM schema en de daarbij afgeleide zaken. We hebben in het PSM schema voor Down Under al gezien dat een feittype gebruikt kan worden voor hiërarchische vastlegging. We nemen nu als uitgangspositie de volgende NDC. Zie figuur 27.
Figuur 27: Een NDC binnen Down Under
Deze NDC gaan we “vertalen” naar een PSM schema. De attributen Plaats, Dag en Artiest worden in PSM entiteittypes. We gaan in PSM uit van de “laagste levels” van de dimensies. In een feitentabel in het dimensionale model staan namelijk ook measure-attributen gedefinieerd op het laagste level. We zullen voor de eenvoud de in de NDC genoemde levels als laagste level beschouwen. Het attribuut Artiest komt uit de dimensie product en zal niet verder geaggregeerd worden in ons voorbeeld; we beperken ons nu tot de geografische dimensie en de tijdsdimensie. Voor hen geldt dus nu respectievelij k Plaats en Dag als laagste level. De getallen in de NDC zijn de measure-attributen. Deze zullen in PSM waarden uit de universe of instances zijn, evenals de domeinwaarden van de levels (bijv “Tamworth” en “8 Jan 2000”). Zie hiervoor tabel 10. Een eerste gedachte is een PSM schema te maken met vier entiteittypes (Plaats, Dag, Artiest en Omzet). Deze laatste is het measure-attribuut (“rechterhand waarde” in de NDC). Vervolgens maken we een feittype waarin alle drie de dimensies en het measure-attribuut vertegenwoordigd zijn. Dit li jkt
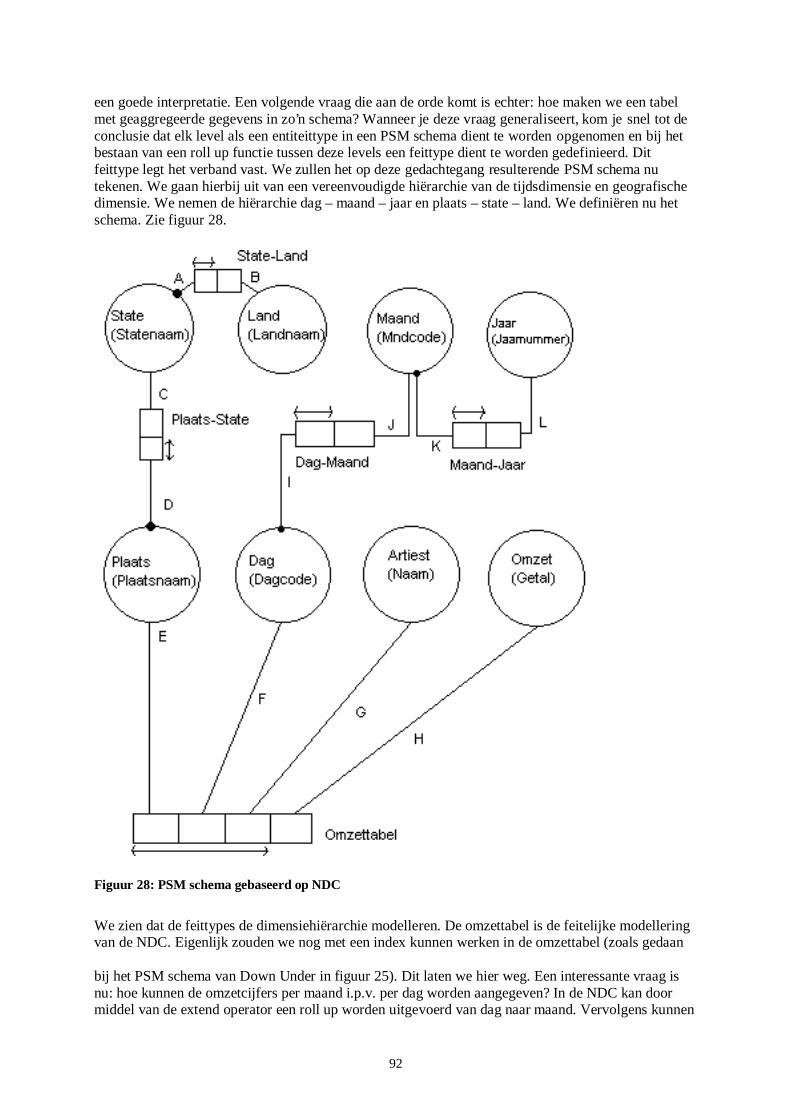
92
een goede interpretatie. Een volgende vraag die aan de orde komt is echter: hoe maken we een tabel met geaggregeerde gegevens in zo’n schema? Wanneer je deze vraag generali seert, kom je snel tot de conclusie dat elk level als een entiteittype in een PSM schema dient te worden opgenomen en bij het bestaan van een roll up functie tussen deze levels een feittype dient te worden gedefinieerd. Dit feittype legt het verband vast. We zullen het op deze gedachtegang resulterende PSM schema nu tekenen. We gaan hierbij uit van een vereenvoudigde hiërarchie van de tijdsdimensie en geografische dimensie. We nemen de hiërarchie dag – maand – jaar en plaats – state – land. We definiëren nu het schema. Zie figuur 28.
Figuur 28: PSM schema gebaseerd op NDC
We zien dat de feittypes de dimensiehiërarchie modelleren. De omzettabel is de feitelij ke modellering van de NDC. Eigenlij k zouden we nog met een index kunnen werken in de omzettabel (zoals gedaan bij het PSM schema van Down Under in figuur 25). Dit laten we hier weg. Een interessante vraag is nu: hoe kunnen de omzetcijfers per maand i.p.v. per dag worden aangegeven? In de NDC kan door middel van de extend operator een roll up worden uitgevoerd van dag naar maand. Vervolgens kunnen

93
de aggregate en bagify operator de NDC terugbrengen in de huidige vorm. We zullen dit hier niet demonstreren. In de NDC algebra zijn al enkele voorbeelden behandeld. De vraag die nu dient te worden beantwoord is: hoe moeten we dit aanpakken in PSM? Anders gezegd: hoe kunnen we de roll up functie “modelleren” in PSM en hoe pakken we de aggregatie van het measure-attribuut aan? Voor beantwoording van deze vraag zullen we eerst een link maken naar het boek van Kimball, [Kim96], waarin hij bespreekt hoe aggregatietabellen worden gecreëerd in het Star-join schema. Dit doen we in de volgende paragraaf. 4.10 Opslag van aggregaties in een data warehouse In een data warehouse worden aggregaties opgeslagen in aparte feitentabellen. In een feitentabel, zoals die gedefinieerd is in het dimensionale model, worden additieve gegevens opgeslagen op de zogenaamde base level. Dit houdt in dat alle dimensies die een rol spelen in die feitentabel op het laagste level zijn gedefinieerd. Aggregatie van gegevens houdt in dat een of meerdere dimensies naar een hoger level worden getild. [Kim96] onderscheidt drie soorten aggregaties voor een feitentabel met daarin drie dimensies die een rol spelen. Men spreekt over zogenaamde one-way aggregate, two-way aggregate en three-way aggregate. Een one-way aggregatie houdt simpelweg in dat een der dimensies naar een hoger level wordt getild (vergelij kbaar met de roll up functie). Bij een two-way aggregate zijn dit twee dimensies, enzovoort. Elke soort aggregatie levert een nieuwe afgeleide feitentabel. Een afgeleide feitentabel van bijvoorbeeld een one-way aggregatie bevat de geaggregeerde measure-attributen van de base level feitentabel en de sleutels van de bijbehorende dimensies. De dimensie die geaggregeerd is naar een hoger level, krijgt automatisch een nieuwe afgeleide dimensietabel met die dimensieattributen die op dat level geldig zijn. Tevens wordt er voor deze afgeleide dimensietabel nieuwe sleutels gedefinieerd (zogenaamde “artificial keys”). Wanneer er een join tussen de afgeleide feitentabel en diens dimensietabellen plaatsvindt, moet er altijd rekening gehouden met de desbetreffende afgeleide dimensietabellen en diens artificial keys. Met een terugkoppeling naar de NDC uit figuur 25, kunnen we deze theorie demonstreren. Stel we hebben een feitentabel met de omzet van CD’s. Deze feitentabel bevatten de sleutels uit de dimensietabellen Tijd, Geografie en Product. De laagste levels zijn respectievelij k Dag, Plaats en CD. De dimensietabellen hebben verschillende dimensieattributen, die allen relevant zijn op het laagste level. Nu will en we een two-way aggregatie maken naar Maand en State (respectievelij k de twee opvolgende levels van Dag en Plaats). We moeten hiervoor een nieuwe feitentabel creëren, met de sleutel van de Product dimensie, het measure-attribuut dat geaggregeerd is op Maand en State-niveau en de nieuwe artificiële sleutels van de afgeleide Tijd- en Geografiedimensie op respectievelijke Maand en State-niveau. Ook de eventuele attributen die in deze dimensies zinvol waren op alleen base level niveau verdwijnen. Denk hierbij bijvoorbeeld aan een attribuut “aantal inwoners in stad” op stad -niveau in de Geografiedimensie. Kimball benadert de creatie van nieuwe dimensietabellen op een hoger level iets anders dan wij. Hij spreekt bij een nieuwe level (bijv. Maand) ook weer over een dimensie. Om verwarring te voorkomen doen wij dit hier niet. Een dimensie is bij ons een begrip dat onderverdeeld is in levels. Dimensie is het “hoogste goed”. Na deze belangrij ke exercitie gaan we terug naar de gestelde vraag uit paragraaf 4.9. We doen dit in de volgende paragraaf. 4.11 Multidimensionale benadering van aggregaties in PSM gemodelleerd We willen in het PSM schema van figuur 28 een roll up functie loslaten op Dag. We zullen, analoog aan het in de vorige paragraaf gehouden betoog, een feittype moeten creëren dat de afgeleide feitentabel modelleert. In dit feittype spelen sowieso de entiteittypes Plaats, Artiest, Maand en Omzet een rol. Laten we eens gaan kijken hoe de begintabel (Omzettabel) en de afgeleide tabel (Omzettabel na aggregatie) zich verhouden.

94
Plaats Dag Artiest Omzet Sydney 1-jan-00 Toto 200 Sydney 2-jan-00 Toto 400 Sydney 4-feb-00 Toto 500 Brisbane 1-jan-00 Scorpions 600 Brisbane 2-jan-00 Scorpions 100 Brisbane 2-feb-00 Scorpions 200 Perth 2-feb-00 Scorpions 100 Perth 5-feb-00 Scorpions 200 Perth 10-feb-00 Toto 200 Plaats Maand Artiest Omzet Sydney jan-00 Toto 600 Brisbane jan-00 Scorpions 700 Perth feb-00 Scorpions 300 Perth feb-00 Toto 200 Brisbane feb-00 Scorpions 200 Sydney feb-00 Toto 500
Tabel 11: Invulling van de omzettabel en de roll up naar Maand
In tabel 11 zien we bovenaan een invulli ng van de omzettabel. In de onderste tabel staat de corresponderende invulli ng van deze tabel na aggregatie van de omzetgegevens n.a.v. de roll up van Dag naar Maand. We gaan deze afgeleide tabel proberen te verkrij gen door toepassing van SQL, en expliciet de taal B-RIDL uit [Falk94]. Voor we dit doen weiden we eerst even uit over de verhoudingen en plaatsing van SQL, relationele algebra en meer. B-RIDL (Basic Reference and IDea Language) is een SQL-taal waarmee eenvoudige query’s kunnen worden uitgevoerd. B-RIDL gebruikt zoveel mogelij k natuurli jke taal voor het opstellen van deze query’s. De relationele algebra die in deze scriptie is geïntroduceerd wordt in [Hof 93] verder geformaliseerd en uitgebreid naar het gebruik van natuurli jke taal toe. Via definities in multisets (bags) en padexpressies (weer gedefinieerd op basis van bags) wordt de taal LISA -D (Language for Information Structure and Access Descriptions) opgebouwd. LISA-D, dat meer uitdrukkingskracht heeft dan de relationele algebra, maakt het mogelij k complexere constraints te beschrijven. Daar LISA-D semantisch gezien is opgebouwd via padexpressies (die meer uitdrukkingskracht hebben dan de relationele algebra) is er bijna een 1 op 1 vertaling mogelij k met de constructies en termen uit PSM. LISA-D bevat tevens enkele eenvoudige constructen voor modellering van transacties binnen processen (de dynamische aspecten van informatiemodellering). Een complete informatiemodelleringstechniek die hieruit is ontwikkeld is Hydra. Voor meer informatie over padexpressies, LISA-D en Hydra verwijzen we naar [Hof93]. De afgeleide tabel uit tabel 11 zou als volgt kunnen worden opgevraagd in SQL. SELECT O.Plaats, O.Artiest, D.Maand, SUM(O.Omzet) FROM Omzettabel O, Dag-Maand D WHERE O.Dag = D.Dag GROUP BY O.Plaats, O.Artiest, D.Maand We zien dat vooral in het maken van aggregaties de GROUP BY-clausule in SQL van groot belang is. GROUP BY zorgt er in dit geval onder meer voor dat de rekenkundige functie SUM op O.Omzet

95
wordt losgelaten op iedere mogelijke combinatie van de attributen genoemd bij GROUP BY. Voor elke combinatie die in de begintabel voorkomt tussen Plaats, Artiest en Maand (uit de Dag-Maand tabel) wordt de omzet in de tabel berekend. Het feitttype Dag-Maand zorgt dat er een join mogelijk is met de gesimuleerde feitentabel “Omzettabel”. De total -role constraint en uniqueness constraint zijn van belang bij de werking, daar er gematched wordt op dag (die eenmaal voorkomt en moet voorkomen in de populatie dit feittype). Het stukje SQL wat we hierboven hebben geformuleerd is te vertalen naar relationele algebra. We gebruiken hiervoor in beginsel een vertaalschema uit [CG85]. Dit artikel bespreekt een directe vertaling van in SQL gestelde query’s naar de concepten en operaties uit de relati onele algebra. De operaties uit de relationele algebra die in het artikel worden gebruikt, worden als volgt gedenoteerd. PJ[A], als een projectieoperatie over een verzameling attributen A. SL[p], als een selectieoperatie op tupels die aan het predikaat p voldoen. Verder nog CP (cartesisch product), UN (vereniging), DF (verschil), IN (doorsnijding) en JN[jp] (een joinoperatie met predikaat jp). Een door [CG85] gedefinieerde extra basisoperatie is de zogenaamde functie evaluatie operatie, genoteerd met FN. Deze heeft tot doel aggregatiefuncties te kunnen toepassen in de relationele algebra. We schrijven de operatie FN op een relatie R (te lezen als tabel) als volgt op: FN[F1(B1), F2(B2), …., F N(BN); A] R Deze operatie breidt het attributenschema R uit met nieuwe attributen F1(B1), F2(B2), …., F N(BN), waarbij deze functies (de F’s) zijn toegepast op deelverzamelingen van tupels van R met dezelfde waarden van de attributen uit A. Formeel is de operatie als volgt volledig gedefinieerd:
1. FN[�
;�
] R = R
2. FN[F(B); �
] R = R CP RF(B)
3. FN[F(B); A] R = � t � R FN[F(B); �
] (SL[A = t.A] R), waarbij t een tupel is uit R
4. FN[�
; A] = R 5. FN[F1(B1), F2(B2), …., F N(BN); A] R = FN[F1(B1); A] (…FN[F N(BN); A] R )) Deze operatie is een zeer belangrijk concept bij het maken van een vertaling SQL query’s naar
relationele algebra. We kunnen FN vergelijken met de extensie operatie � uit de relationele algebra van PSM. FN is een veralgemenisering van deze operatie. FN maakt het mogelijk GROUP BY-clausules uit SQL te vertalen naar de relationele algebra. In [CG85] wordt een translatie voor het volgende SQL statement aangeleverd. We hebben dit iets veralgemeniseerd, daar [CG85] een voorbeeld gebruikt. SELECT <(functies op) attributen> FROM <relaties> WHERE <predikaat> GROUP BY <attributen> Dit statement is als volgt te vertalen in de relationele algebra: PJ[attributen] FN[functies;attributen in group by] <SL [predikaat] of JN[predikaat]> Dit levert voor het gegeven stukje SQL van ons op:

96
PJ[O.Plaats, O.Artiest, D.Maand, SUM(O.Omzet)] FN[SUM(O.Omzet);{O.Plaats, O.Artiest, D.Maand}] (O JN[O.Dag = D.Dag] D) We zullen bewijzen dat dit een goede definitie is in de relationele algebra. Hiervoor moeten we voornamelijk kijken naar de FN operatie. We zien:
FN[F(B); A] R = � t � R FN[F(B); � ] (SL[A = t.A] R), waarbij t een tupel is uit R (volgens definitie). We substitueren: FN[SUM(O.Omzet);{O.Plaats, O.Artiest, D.Maand}] (O JN[O.Dag = D.Dag] D) =
� t � (O JN[O.Dag = D.Dag] D) FN[SUM(O.Omzet), � ] (SL[O.Plaats = t.O.Plaats AND O.Artiest = t.O.Artiest AND D.Maand = t.D.Maand] (O JN[O.Dag = D.Dag] D)) De uitdrukking O JN[O.Dag = D.Dag] D levert de tabel op met alle attributen uit O en D, waarbij de tupels gejoined zijn door het predikaat O.Dag = D.Dag. Alle tupels uit deze tabel worden toegepast op de selectie operatie. We kunnen dit verder uitwerken:
� t � (O JN[O.Dag = D.Dag] D) (SL[O.Plaats = t.O.Plaats AND O.Artiest = t.O.Artiest AND D.Maand = t.D.Maand] (O JN[O.Dag = D.Dag] D)) CP (SL[O.Plaats = t.O.Plaats AND O.Artiest = t.O.Artiest AND D.Maand = t.D.Maand] (O JN[O.Dag = D.Dag] D)) SUM(O.Omzet)
Deze vereniging van cartesische producten demonstreren we aan de hand van ons voorbeeld. Allereerst de invulling van (O JN[O.Dag = D.Dag] D). Zie tabel 12 hieronder. Plaats Maand Dag Artiest Omzet Sydney Jan-00 1-jan-00 Toto 200 Sydney Jan-00 2-jan-00 Toto 400 Sydney Feb-00 4-feb-00 Toto 500 Brisbane Jan-00 1-jan-00 Scorpions 600 Brisbane Jan-00 2-jan-00 Scorpions 100 Brisbane Feb-00 2-feb-00 Scorpions 200 Perth Feb-00 2-feb-00 Scorpions 100 Perth Feb-00 5-feb-00 Scorpions 200 Perth Feb-00 10-feb-00 Toto 200
Tabel 12: Resultaat van (O JN[O.Dag = D.Dag] D)
Vervolgens moeten we invulling geven aan de selectie operatie SL[O.Plaats = t.O.Plaats AND O.Artiest = t.O.Artiest AND D.Maand = t.D.Maand] (O JN[O.Dag = D.Dag] D), waarbij t een tupel is uit tabel 12. Wanneer kijken naar het eerste tupel en tweede tupel uit tabel 12, zien we dat voor de drie selectieattributen Plaats, Maand en Artiest dezelfde waarden worden aangenomen. Voor deze 2 tupels wordt de omzet geaggregeerd naar Maand-niveau: 200 + 400 = 600. Het cartesisch product zorgt ervoor dat de tabel achter iedere tupel een attribuut SUM(O.Omzet) krijgt met diens geaggregeerde waarden. Dubbele tupels worden er daarna door de vereniging uitgevist. Hierna wordt de projectieoperatie losgelaten op de tabel, hetgeen resulteert in de onderste tabel uit tabel 11. Een laatste opmerking die we hier plaatsen is dat de attributen dezelfde naam hebben behouden als in de inputtabellen (zoals O.Omzet, vandaar die ietwat vreemde namen als t.O.Artiest). We zullen hiermee de PSM modellering van aggregaties uit het dimensionale model eindigen. Het is mogelijk om deze aggregaties te berekenen in de relationele algebra, maar voor een PSM invalshoek zal een uitbreiding moeten worden gemaakt via padexpressies. De operaties uit de relationele algebra, zoals die beschreven zijn in deze scriptie, lijken niet krachtig genoeg. De werking van de FN operatie bijvoorbeeld, heeft geen gelijke in de relationele algebra van PSM. Een werking op tupels is hier

97
namelijk niet mogelij k met de gedefinieerde extensie operatie. Een verwijzing voor verder onderzoek naar het berekenen van aggregaties op het niveau van relationele algebra geven we naar [GBLP95]. In de volgende paragraaf gaan we toe naar waar het allemaal om begonnen is: de constraints in het dimensionale model. 4.12 Een aanzet tot de beschrijving van de semantiek van constraints in het dimensionale model In de literatuur over data warehousing wordt nog maar weinig gesproken over het formaliseren van constraints. Nu hebben we, zoals gezien, vele soorten constraints en wordt er ook zeer uiteenlopend geschreven over het begrip constraints binnen data warehouses. In de Oracle Data Warehousing Guide is een sectie te vinden over constraints, [WWW04]. In deze sectie worden twee belangrij ke doelen van constraints in specifiek data warehouses uit de doeken gedaan: • Data cleanliness: Constraints can be used to verify that the data in the data warehouse conforms
to basic level of data consistency and correctness. Thus, constraints are often used in a data warehouse to prevent the introduction of dirty data.
• Supporting query optimization: The Oracle database will util ize constraints when optimizing SQL queries. Although constraints can be useful in many aspects of query optimization, constraints are particularly important for query-rewrite of materialized views.
Het eerste doel is voor ons de belangrijkste, daar dit gaat om constraints die er voor moeten zorgen dat er geen “dirty data” in de data warehouse verschijnt. Naar mijn mening gaat het hier om constraints die in de conceptuele fase van de modellering moeten worden geïntroduceerd. Wanneer er een modificatie op de data plaatsvindt moet deze modificatie gecheckt worden op het voldoen aan de gedefinieerde constraints. Analoog aan wat we gezien hebben bij de introductie van de PSM constraints, gaat het bij deze constraints ook om bepaalde, niet gewilde, populaties uit te sluiten. Het tweede doel van constraints in een data warehouse is niet minder belangrijk, maar belicht een ander aspect van de data warehouse omgeving. Hierbij gaat het om de reeds aangehaalde view maintenance. Voor een uitgebreide sectie over view maintenance zie paragraaf 4.13. Het formeel beschrij ven van constraints in een data warehouse vereist nog een specifiek onderzoek naar de exacte werking van constraints in bijvoorbeeld een data cube. We zullen hieronder een aanzet gaan geven over hoe mogelijke constraints beschreven kunnen worden in een algebra zoals de NDC algebra. Hierbij wordt opgemerkt dat het slechts een aanzet betreft en dus geen volledige uitwerking. Dit vereist veel meer onderzoek. We gebruiken hiervoor de gewonnen inzichten in manier waarop in PSM constraints worden aangepakt en de manier waarop het dimensionale model (specifiek: NDC model) in elkaar steekt. De semantiek van een uniqueness constraint kan in PSM worden afgeleid met The Uniquest Algorithm. We hebben gezien: �
( � , N) =
if exists n � N such that � ⊆ Schema(n) � depth(N, n) = 1 then return n
elif exists n � N, p � Schema(n) \ � , f � N � F such that top(N, n) � f ~ Base(p) ��� leaf(N, f)
then if exists g � N � F such that g � f � g ~ Base(p) ��� leaf(N, g) then error: ambiguous with respect to unnesting
else return
�( � , reduce(N [ p
f (n) n])) endif
elif � n � N [depth(N, n) 1] � Jn(N, � ) then return � C(N, � ) ( � n � N, Schema (n) ������� n) else error: no joinable descendants endif

98
waarbij
Jn(N, � ) = |Facts (N, � ) | > 1 � �
f, g � Facts (N,� ), f � g [ Schema(f) \ � ~ Schema(g) \ ��� Jn(N\{f}, � ) ]
Facts (N, � ) = { x � N � leaf(N, x) � Schema(x) � �������
C(N, � ) = �� �� p = q
p,q ��� (N, � ) , p~q
�(N, � ) = { p � P \ �� � n � N [ p � Schema(n) ] }
Voor een zoveel mogelijk parallelle vertaling van dit algoritme naar de NDC algebra zijn enkele
aannames noodzakelijk. Een uniqueness constraint werkt in PSM over predicatoren. � ( � , N) geeft de
semantiek weer van de uniqueness constraint � . In paragraaf 4.6 hebben we de notatie cube(R) als zijnde de NDC voortgebracht door de relatie R ingevoerd. We nemen aan dat de relatie R overeenkomt met een tabel (met populatie) in PSM. Uit [Hof94] nemen we de volgende figuur. Zie figuur 29.
Figuur 29: Uniqueness constraint over objectificatie
In dit figuur zien we een uniqueness constraint over, onder meer, een geobjectificeerd feittype. Met behulp van The Uniquest Algorithm kunnen we de semantiek berekenen van deze constraint. Deze is
identifier (� ( � ), {p, s, u}) = identifier ( � r (g) � � t (h), {p, s, u}) De nu volgende sectie is geheel naar eigen inzicht van de auteur. Deze geeft een gedachtegang weer van de auteur en zal verder moeten worden onderzocht eer er een goede formalisatie kan plaatsvinden van constraints. Het is een mogelijke ingang naar een nieuw onderzoeksterrein. Laten we proberen de lijn door te trekken naar NDC’s. De feittypes g, h en f (en diens populatie) gaan we modelleren als de NDC’s voortgebracht door de relaties G, H en F (w aarbij G de relatie is die ontstaat door toewijzing van de attributen uit het feittype g naar elementen uit het universe of instances). De entiteittypes beschouwen we als attributen uit een dimensie, oftewel elementen uit de verzameling der attributen uit het NDC model. Met deze basisovereenkomsten gaan we aan de slag. Een opmerking vooraf: de standaardlevel die bij de definitie van cube gebruikt wordt, laten we los en interpreteren we als de elementen uit de populatie van de entiteittypes. Tevens gaan we proberen de

99
objectificatie zoals die voorkomt in het schema uit te drukken in een NDC. De interpretatie van cube is hieronder dus iets anders. Derhalve zullen we de aangepaste definitie van cube kubus noemen. We definiëren:
kubus(G) = {{ C: c1} � { A: a1, B: b1} � �,
{C: c2} � { A: a1, B: b2} � �,
{C: c3} � { A: a1, B: b3} � �}
kubus(F) = {{ A: a1, B: b1} � �,
{A: a1, B: b2} � �,
{ A: a1, B: b3} � ���
kubus(H) = {{ D: d1} � { A: a1, B: b1} � �,
{D: d1} � { A: a1, B: b2} � �,
{D: d1} � { A: a1, B: b3} � �}
Deze gewijzigde definitie laat een aantal zaken anders zien. De modellering van het geobjectificeerde feittype f als de NDC kubus(F) voldoet aan de standaard van cube. Wat wij nu getracht hebben te doen, is de objectificatie van f door te voeren in de recursief gedefinieerde NDC’s. De definitie van de NDC kubus(H) houdt rekening met kubus(F), waarbij deze volledig terugkomt in kubus(H). We trekken nu een parallel met de beschrij ving van de genoemde uniqueness constraint. Wat moet gelden in deze NDC verzameling wil de uniqueness constraint gelden? Laten we de drie gevallen uit The Uniquest Algorithm onderscheiden. Als één of meerdere attributen uit één NDC met diepte 1 een unieke toewijzing moeten krijgen, kunnen we eenvoudig de NDC terugleveren waarin de uniqueness constraint moet gelden. Met krijgt dan bijvoorbeeld (stel we
hebben een uniqueness constraint over A en B uit kubus(F)( � )) het volgende:
identifier (kubus(F), { kubus(F)A, kubus(F)B} ) (Geval 1: � valt binnen 1 NDC op diepte 1) Dit betekent dus letterlij k dat de attributen kubus(F)A en kubus(F)B (de schrijfwijze geeft aan dat dit attributen zijn uit kubus(F); dit is noodzakelij k omdat we hier geen predicatoren gebruiken bij de toewijzingen) een identifier vormen voor kubus(F). Let wel dat dit een zeer sterk constraint is: we beletten een attribuut meerdere waarden te hebben, dus kan het voorkomen dat een eventuele operatie uit de NDC algebra uitgesloten wordt door zo’n constraint. Zie ondermeer de nestoperatie die gedemonstreerd wordt in de figuren 22 en 23. Een tweede mogelij kheid die voor een uniqueness constraint binnen 1 NDC bestaat is het feit dat deze zich op een grotere diepte bevindt dan 1. Het idee is dan om deze naar “de oppervlakte van de NDC” te halen. Hiermee bedoelen we het volgende: als de attributen uit de uniqueness constraint voorkomen op een diepte groter dan 1, dan kun je ze selecteren met de functie subscheme. Vervolgens kun je deze terugleveren. Nog moeilij ker wordt het geval wanneer de uniqueness constraint binnen 1 NDC valt, maar op attributen op verschillende dieptes. Dan zul je de attributen naar 1 niveau moeten tillen met de operatoren zoals nest en unnest. Dit alles zou tot het volgende begin kunnen leiden van The Uniquest Algorithm voor het herleiden van de semantiek voor uniqueness constraints in NDC’s. Laat NDC de
verzameling NDC’s zijn die voorkomt bij een modellering van een case. De verzamel ing � is de verzameling van attributen die zitting hebben in de uniqueness constraint. We gebruiken een pseudo-code voor de beschrij ving van het algoritme.
identifier (� ( � ), � ) =

100
if exists n � NDC such that � ⊆ att(n(�)) � depth([n]) = 1 { bestaat er één NDC die de attributen uit
de uniqueness constraint bevat op zijn hoogste niveau?}
then return identifier (n, � ) { Zo ja, lever deze NDC terug in de semantiek}
elif exists n � NDC such that � ⊆ att(n(subscheme([n], k)) voor een k waarvoor geldt 2 < k < depth([n]) { bestaat er één NDC die de attributen uit de uniqueness constraint bevat op een diepte groter dan 1?}
then return identifier (n(subscheme([n], k), � ) (Zo ja, lever de NDC terug die op de diepte k zat waarop de attributen uit de uniqueness constraint zitten)
elif exists n � NDC such that � ⊆ att(n(subscheme([n], k)) voor meerdere k’s waarvoor geldt 2 < k < depth([n]) { bestaat er één NDC die de attributen van de uniqueness constraints op meerdere dieptes in zich heeft?}
then return identifier (K, � ) waarbij K de NDC is waarbij door meerdere unnest operaties de gewenste attributen (uit de uniqueness constraint) naar diepte 1 worden gehaald. K is dus een NDC met diepte 1 en de “lege member” als toewijzing. Enzovoort Waarbij de volgende definities worden ingevoerd: [n], waarbij n een NDC is, geeft het onderliggende schema van de NDC aan. Dit kun je beschouwen als de Schema functie uit PSM. n([]), is de inverse van bovenstaande functie. De input NDC wordt via een schema definitie “uitgekleed” en daarna weer gepopuleerd. De functie att op een NDC van diepte 1 levert de attributen uit diens coördinaat type. Op deze wijze is het mogelij k een algoritme te construeren. De gedachtegang is duidelij k en uit verder onderzoek zal moeten blij ken of de ingeslagen weg kan worden vervolgd. Hiermee sluiten we deze sectie af. 4.13 Een intermezzo over view maintenance In deze paragraaf bespreken we een ander belangrij k fenomeen binnen data warehouses, namelij k view maintenance. In een data warehouse wordt informatie opgeslagen die uit verschil lende, zeer uiteenlopende bronnen komt. Dit gebeurt in zogenaamde “materialized views”, een kopie of pointer (of binnen een bewerking) naar de brondata. Wanneer de data in de bron veranderd moeten de materialized views ook geüpdate worden voor de data warehouse. Dit brengt ons gelij k bij de introductie van de term view maintenance. Zoals [SMKK98] de definitie aanreikt, dekt naar mijn mening precies de inhoud. [SMKK98] definieert view maintenance als volgt: “The process of updating a materialized view in response to the changes in the underlying source data is called view maintenance” View maintenance is een belangrij k aandachtsgebied bij het succes van een data warehouse omgeving. Vanwege de enorme omvang van data warehouse omgevingen (denk aan alleen al aan het aantal bronnen) is view maintenance (lees: onderhoud van materialized views) niet zo makkelij k gezegd als gedaan binnen data warehouses. Het probleem zit hem naast de omvang ook in de dynamiek van zo’n omgeving. Een standaard protocol dat gebruikt wordt voor view maintenance binnen data warehouses is het volgende: 1. Trigger de data warehouse omgeving zodra in de bronnen een verandering binnen de data optreed (bijvoorbeeld een update, uitbreiding, wijziging etc.). 2. Maak direct een kopie van de status van de data uit deze bronnen op het moment van de trigger. 3. Bereken de view updates op basis van de verworven kopie bij 2 en de veranderingen. 4. Bewaar de view updates in de data warehouse in tijdsvolgorde.

101
Dit protocol zou prima werken in een relatief stabiele, kleine omgeving. Data warehouse omgevingen zijn dit meestal niet. Door het random karakter van de veranderingen en het grote aantal bronnen van een data warehouse gebeurt meestal het volgende. Wanneer bovenstaand protocol wordt gebruikt is het probleem dat wanneer een view update wordt berekend naar aanleiding van veranderingen er een tweede verandering binnen die tijd kan optreden, waardoor de oorspronkelij ke status van de bronnen wijzigt. Dit veroorzaakt inconsistenties binnen de materialized views. Om dit probleem te ondervangen zijn er verschillende oplossingen aan te dragen. Een eerste constatering is dat het berekenen van view updates tijd nodig heeft. Deze tijd wordt binnen het aangegeven protocol niet gegund aan de data warehouse. Deze tijd is niet terug te dringen, getuige het volgende voorbeeld uit [SMKK98]. Een materialized view MV is gedefinieerd over een verzameling relaties R (={ A,B,C} , bijvoorbeeld) uit de bronnen. De MV slaat een voorberekende query op in de data warehouse. Wanneer nu een verandering wordt gemaakt in een relatie uit zo’n bron, zeg B, is het mogelij k dat dit van invloed is op MV. De data warehouse zou de update zelf moeten kunnen berekenen uit de huidige status (MV zelf dus) en de aangegeven verandering uit de bron. De data warehouse kan echter meer informatie nodig hebben over andere relaties uit de bron(nen) om deze update te kunnen berekenen. Daar de data warehouse los staat van zijn bronnen, heeft berekentijd nodig. Hier ligt dus geen weg open voor oplossing. Een idee om dit probleem te omzeilen is door naar de bronnen te kij ken. Het blijkt dat niet elke verandering in de bron reden is om een view update te berekenen, daar sommige updates bepaalde views helemaal niet beïnvloeden. Een idee om elke verandering in de bron te fil teren om het effect te berekenen voor de data warehouse (geen effect of de noodzaak van een view update berekening) krijgt gestalte in de vorm van update fil tering. Update filtering draagt in dit geval bij aan het reduceren van tijd die gespendeerd wordt aan onderhoud van de data warehouse. Er hoeven immers minder onderhoudstransacties met de data warehouse te worden uitgevoerd. Een bijkomend effect van deze methode is echter dat de bronnen en de extractie tools “intelli genter” moet worden gemaakt. Om een beoordeling van het effect te kunnen maken moeten de bronnen en de extractie tools weten welke rol ze spelen in de data warehouse en de nodige kennis hebben van de configuratie van de data warehouse. Immers: een update zal tegen de gedefinieerde constraints (in de data warehouse) moeten worden aangehouden voordat een uitspraak kan worden gedaan over de al dan niet mogelij ke impact van zo’n update voor de data warehouse. Vanwege dit feit is het dan niet meer mogeli jk de bronnen en de data warehouse los van elkaar te zien. Dit impliceert weer andere problemen, zoals configuratieproblemen. Wanneer alle bronnen en de data warehouse “gekoppeld” zijn en er zich maar 1 verandering voor doet in 1 enkel schema, dan zullen alle schakels in de keten moeten worden geüpdate met betrekking tot de gedefinieerde constraints. Dit benadrukt wederom het feit van een goede definitie van constraints in een data warehouse. Als laatste zullen we in deze paragraaf nog iets zeggen over de wijze waarop view maintenance kan worden gerealiseerd binnen de data warehouse omgeving. Er zijn hiervoor twee benaderingen mogelij k. De eerste is de zogenaamde incrementele manier, waarbij de veranderingen in de bronnen direct worden doorgegeven aan de data warehouse. De tweede manier is de batch benadering: een groot aantal updates worden klaargezet om op een bepaald tijdstip in één keer te worden doorgegeven aan de data warehouse. Bij deze benadering worden gedurende de zogenaamde maintenance transaction (de transactie die de batchoperatie uitvoert) nieuwe view updates berekent en doorgevoerd in de data warehouse omgeving. Gedurende deze transactie moet de data warehouse omgeving offline zijn. Gezien het huidige belang van “twentyfour -seven” (denk aan Internet, 24-uurs-economie, transacties over verschill ende tijdzones) kan een data warehouse nooit offline zijn. De incrementele manier zou dus de oplossing kunnen zijn. Echter: het kostenaspect en de beschreven gevaren van updates (vorige alinea) zorgen ervoor dat dit nog in de kinderschoenen van de ontwikkeling staat. Een vraagstuk ligt hier dus nog open. Tot zover dit intermezzo. View maintenance is een belangrijk aspect van een data warehouse met nog enkele moeilij ke openstaande vraagstukken.

102
5 Conclusies en verder onderzoek In dit laatste hoofdstuk zullen we de conclusies van dit werk presenteren en aanbevelingen doen voor verder onderzoek. We beginnen met een samenvatting van het gevolgde pad in dit werk in de volgende paragraaf (5.1). In de paragrafen daarna zullen we integraal de conclusies (5.2) en verdere onderzoeksingangen (5.3) presenteren. We sluiten af met een paragraaf waarin we kort terugblikken op dit werk. 5.1 Samenvatting Deze paragraaf beschrijft kort en krachtig de behandelde onderwerpen en poogt een totaalbeeld te schetsen van deze onderwerpen in een samenhangende structuur. In hoofdstuk 1 hebben we gekeken naar het concept data warehouses op twee niveaus. De eerste beschrij ving vindt plaats op een hoog abstractieniveau en geeft een analyse van de doelen van zo’n data warehouse en maakt een vergelijking met operationele systemen. Het gewonnen inzicht is hier dat voor de analyses die met een data warehouse moeten worden gemaakt geen operationele systemen als losstaande onderdelen kunnen worden gebruikt. Naar aanleiding van dit inzicht wordt een beschrijvi ng gegeven van de data warehouse architectuur op een lager, meer technisch niveau. We beschrijven in paragraaf 1.2 de verschill ende onderdelen van deze architectuur. De samenhang van de onderdelen wordt besproken en samengebracht in een schema. Na deze sectie over het concept gaan we in hoofdstuk 1 door met de probleemstelli ng van de scriptie en de verwante, behandelde onderwerpen . Het ultieme doel hierbij i s het aanreiken van inzichten die kunnen bijdragen aan het beschrij ven van data warehouse constraints in een formele algebra. We zullen hier niet verder over uitweiden op deze plaats, daar dit verderop uitgebreid aan bod komt. Hoofdstuk 1 sluit af met een kleine sectie over de data opslag in data warehouses. In hoofdstuk twee introduceren we het dimensionale model, het model waarop data warehouses zijn gebaseerd. Aan de hand van een case (Down Under) demonstreren we de werking van dit model. We laten gedurende deze bespreking zien hoe het dimensionale model dient te worden “gevuld” en hoe de werkingen van de onderlinge constructies binnen dit model moeten worden gebruikt. Vervolgens verleggen we het accent naar constraints en gaan naar aanleiding van een gemaakte constraint- indeling door naar de opbouw van de informatiemodelleringstechniek PSM. PSM wordt vanaf scratch opgebouwd. Het doel van de PSM-beschrij ving is de formele definiëring van constraints in het relationele model. Vanuit deze perceptie wordt de beschrij ving ook opgebouwd: na de gebruikelij ke introductie van de constructies in het model verleggen we het accent naar de wijze waarop in PSM populaties worden beschreven. Aan de hand van de opgestelde regels bouwen we een zeer formele en strakke definitie op van een geldige populatie binnen een PSM schema. Voor de formalisering van constraints gebruikt PSM een relationele algebra. Enkele constraints worden ook grafisch weergegeven. We introduceren de relationele algebra en bespreken de relationele operaties. In de relationele algebra is het feittype (en afgeleide feittype) in principe de bal in het voetbal. Dit zijn de objecten waarmee “gespeeld” wordt. Afgeleide feittypes, ook wel relationele expressies genoemd, ontstaan door toepassing van operaties op feittypes of andere relationele expressies. Een relationele expressie heeft twee belangrijke kenmerken: Val (beschrij ving van een populatie) en Schema (het “type” van de relationele expressie, ook wel het onderliggende schema genoemd). Voor elke relationele expressie zijn deze kenmerken te definiëren. Aan de hand een categorisering van de constraints in PSM beschrijven we de formele semantiek. We leggen de functie en werking van de constraints uit en demonstreren daar een groot aantal van middels een voorbeeld. Speciale technieken worden aangehaald om de semantiek te kunnen afleiden. Technieken die we in dit verband kunnen noemen zijn de nest/unnest methode en Object Interpretation Structures. We behandelen en demonstreren deze uitgebreid. De semantiek van de uniqueness constraint kan afgeleid worden met een integratie van deze technieken, resulterende in The Uniquest Algorithm. Dit algoritme dient als basis voor de beschrijving van de semantiek van meer geavanceerde constraints. In hoofdstuk 3 gaan we verder met het beschrij ven van het dimensionale model. We starten dit hoofdstuk met een verkenning van constraints in het dimensionale model. We kijken vanuit een tweetal percepties naar constraints in het dimensionale model: vanuit de data cube en het star join

103
schema van Kimball. Voor we een uitgebreide bespreking maken van het model van de data cube, geven we eerst enkele belangrij ke functies van constraints binnen het dimensionale model. De analyse van het data cube model geeft een scala aan inzichten weer die belangrijk zijn in het dimensionale model. Flexibil iteit van de gegevens binnen de data cube is hierin het sleutelwoord. De revue passeren de rotate-functie, Drill Up en Down, Roll Up en de presentatievormen van gegevens in data cube jargon. We creëren op deze wijze een begrippenkader die de functies van het data cube model goed laat beschrij ven. Verder laat de analyse van de data cube de verschillende inzichten in het dimensionale model goed zien. We besteden na deze analyse aandacht aan de opdeling in inter-cube constraints en intra-cube constraints. Als laatste demonstreren we aan de hand van de case de constraints in het dimensionale model volgens Kimball. Via zijn benadering bekijken we de werking van de constraints die hij definieert: join en application constraints. In hoofdstuk 4 introduceren we een modelleringstechniek voor het dimensionale model. Dit model is gebaseerd op de data cube. Deze techniek, Nested Data Cubes genaamd, wordt vanaf scratch opgebouwd. We definiëren, net als bij PSM, de constructies in dit model. Na de introductie van dit model laten we zien dat klassieke datastructeren kunnen worden gemodelleerd in het NDC model. Vervolgens bouwen we de NCC algebra, waarmee de NDC’s gemanipuleerd kunnen worden, op. De NDC operatoren demonstreren we aan de hand van verschillende voorbeelden. Een belangrijk aspect is het kunnen toepassen van de relationele operaties selectie, projectie, join en rename in het NDC model. Via een op sommige punten ingewikkelde benadering modelleren we deze operaties in de NDC algebra (vooral de join operatie blij kt lastig). Een uitgewerkt voorbeeld verheldert de werking van ondermeer de ingewikkelde join modellering. We laten kort zien dat de NDC algebra, door het recursieve karakter van de NDC, toepasbaar is op verschillende dieptes in een NDC. Incarnaties die door de recursieve definitie ontstaan, zijn dus apart te manipuleren binnen het NDC model. Vanaf paragraaf 4.8 komt een geheel eigen inzicht van de auteur naar boven door middel van een vergelij king tussen het dimensionale en relationele model. We mappen de beide modellen op elkaar en gaan daarbij de constructies uit beide modellen vergelij ken. Vervolgens maken we een invulling van Down Under in PSM. We werken hierbij toe naar het toepassen van aggregaties in het dimensionale model (volgens Kimball één van de twee belangrij kste en krachtigste middelen van het dimensionale model). We demonstreren de werking van de roll up functie en kijken hoe hiërarchieën binnen dimensies worden gebruikt. Een voorbeeld NDC wordt vertaald naar een PSM schema via de gemaakte mapping van de modellen. Het uitgangspunt is hierbij een vertaalslag te maken van de manier waarop aggregaties binnen het NDC model worden gebruikt naar een manier om deze aggregaties in PSM te modelleren. We doen dit door middel van het introduceren van feittypes die de hiërarchie van een dimensie simuleren. Analoog aan de wijze waarop we aggregaties in het dimensionale model berekenen, gaan we in PSM zo’n aggregatie proberen te berekenen. We gebruiken hiervoor aanvankelij k SQL. Het is echter noodzakeli jk om deze aggregaties op het niveau van relationele algebra te kunnen berekenen, daar de semantiek van constraints op dit niveau gedefinieerd dient te worden. De relationele algebra uit PSM schiet echter te kort qua uitdrukkingkracht. We vinden de oplossing door een GROUP BY construct uit SQL te vertalen naar een primitieve relationele operatie, FN genaamd. We onderzoeken dit en formaliseren zo’n vertaalslag van SQL naar de (primitieve) relationele algebra waar deze operatie onderdeel van uit maakt. Verder nemen we in hoofdstuk 4 nog een sectie op over view maintenance en de problematiek die hierin een rol speelt. In paragraaf 4.12 geven we een aanzet om constraints in data warehouses formeel te beschrij ven in een algebra als de NDC algebra. We doen hierbij een poging alvast enkele zaken op elkaar te matchen. Een gedeelte van The Uniquest Algorithm wordt omgezet naar een analoge benadering in het NDC model. We gebruiken hierbij een PSM schema met een uniqueness constraint als voorbeeld. We projecteren de inhoud van dit schema op een NDC die wordt gegenereerd op een bijna geli jke wijze als de eerder gedefinieerde NDC cube. Dit levert een gedachtegang op die verder kan worden uitgediept. Hoofdstuk 5 tenslotte geeft een samenvatting van de besproken onderwerpen en geeft de conclusies van het gemaakte werk. 5.2 Algemene conclusies

104
In deze paragraaf geven we korte en algemene conclusies van dit werk weer. Op basis hiervan geven we in de volgende paragraaf ingangen voor verder onderzoek. Een eerste conclusie die getrokken kan worden uit dit werk, is het feit dat het concept data warehouses nog verder geformaliseerd dient te worden. Hiermee bedoelen we dat de huidige literatuur over data warehouses nog teveel verdeeld is over de precieze betekenis van een data warehouse. Er moet een integraal beeld ontstaan van wat een data warehouse precies inhoudt en welke onderdelen wel en geen onderdeel van een data warehouse architectuur zijn. Het begrip is nog teveel een containerbegrip. Een tweede conclusie en belangrij kste conclusie uit dit werk, is het feit dat het formaliseren van een consistente constraint verzameling binnen het data warehouse model een absolute must is. De onderzoekswereld heeft tot nu toe constraints binnen een data warehouse niet als volwaardig onderzoekgebied beschouwd. Dit is naar de mening van de auteur een pertinente inschattingsfout geweest. De werking van een data warehouse valt of staat bij de definiëring van constraints. We verwijzen hiervoor naar de beschreven functies van constraints in paragraaf 3.2 en de motivatie gegeven in paragraaf 4.13 over view maintenance. Als verlengde van deze conclusie is het dus een noodzaak een goede formalisatie van de data warehouse constraints te maken op een gelij ksoortige wijze waarop in deze scriptie een handreiking is gedaan. Met als mogeli jk uitgangspunt de formalisatie van constraints in PSM is het nodig de lijn door te trekken naar constraints in een data warehouse. Een derde conclusie die we kunnen trekken uit dit werk, is dat op het terrein van view maintenance nog een belangrij k onderzoeksterrein open ligt. In de volgende paragraaf verwijzen we naar de geconstateerde problemen. Een vierde en laatste conclusie die we hier trekken, is dat de theorie van het NDC model en diens algebra een goed onderliggend model is voor verdere formalisatie van een informatiemodelleringstechniek voor data warehouses. De expressieve kracht van het model is in deze scriptie tot uitdrukking gekomen. Alle eisen omtrent flexibele data opslag die in deze scriptie aan bod zijn gekomen komen in het model terug. Tevens is het model eenvoudig te implementeren in een reële situatie. Deze implementatietechniek is niet besproken, daar het buiten de scope van het onderzoek viel. We geven hiervoor een verwijzing naar [NDCtr98]. Tot zover de conclusies. We gaan nu door met het geven van suggesties voor verder onderzoek. 5.3 Verder onderzoek Deze scriptie geeft diverse ingangen aan voor verder onderzoek. Uiteraard noemen we hier als eerste het belang van het formaliseren van de consistente set van constraints voor data warehouses. We hebben in paragraaf 4.12 een aanzet gegeven over hoe constraints in het relationele model (in de vorm van PSM) doorgetrokken kunnen worden naar een data warehouse model zoals het NDC model. Er zal echter nog veel onderzocht moeten worden. Allereerst zal een inventarisatie moeten worden gemaakt van constraints in de data cube. Men zal een onderzoek kunnen doen naar de verschillende soorten relaties binnen een data cube, resulterende in een overzicht met precies die relaties waarop een eventuele intra-cube constraints kunnen worden gedefinieerd. Deze intra-cube constraints kunnen dan verder geformaliseerd worden via de genoemde methode. De auteur is van mening dat de definitie van intra-cube constraints niet gemakkelij k zal zijn. Het is dermate lastig om van te voren de relaties aan te geven, dat het naar de mening van de auteur noodzakelij k is eerst een formele modelleringstechniek voor data warehouses moet worden ontworpen waarbij constraints geïntegreerd zijn. Via het model van Kimball is het misschien te doen, maar de auteur vindt dit model toch nog te abstract op sommige punten. Ook het formaliseren van de inter-cube constraints is een onderzoek waard. Een tweede ingang voor verder onderzoek zijn de verschillende open vragen op het gebied van view maintenance. We verwijzen hiervoor naar paragraaf 4.13, waar verschillende vragen worden opgeworpen.

105
Van kleinere aard zijn verder een onderzoek naar de expressieve kracht van relationele operatoren met betrekking tot aggregaties. Er zijn allerlei generalisaties van operatoren gemaakt, waarbij aggregaties het uitgangspunt zijn. [GBLP95] geeft een dergelijke analyse. Op dit terrein kan nog verder onderzoek worden verricht. Van een andere orde is een onderzoek naar het concept data warehouse. Het zou voor de onderzoeksgemeenschap handig zijn als er een soort standaardwerk was dat alle bestaande definities en inzichten van en over data warehouses integreert en bij elkaar brengt. Naar de mening van de auteur is het belang van zo’n werk groot. Als laatste kan men nog verder onderzoek verrichten naar het NDC model op het gebied van diens algebra, uitdrukkingskracht, integratie met andere concepten, uitbreiding met geavanceerde constructen (met gedefinieerde semantiek). Een en al analoog aan PSM. Van algemeen belang tenslotte, zou een verdere analyse van overeenkomsten tussen het relationele model en dimensionale model kunnen zijn. Nieuwe inzichten kunnen hieruit ontstaan. Tot zover de ingangen voor verder onderzoek. 5.4 Terugblik De importantie van een goed gedefinieerde en geformaliseerde constraint verzameling voor data warehouses is evident. De auteur heeft geprobeerd verschillende ideeën en inzichten bij elkaar te brengen, zodat de bestaande twijfels over de stelli ng in de vorige zin zijn weggenomen. Dit werk is hopelijk een aanzet tot nieuwe onderzoeken. Enkele ingangen zijn hierbij aangeboden. Data warehouses zijn een hot item en zullen nog veel onderzoeken vergen. Hopelij k heeft dit werk daar iets aan bijgedragen.

106
Bibliografie [Weide] Th.P. van der Weide, Dictaat P3, Katholieke Universiteit Nijmegen, 1995, Nijmegen [Hof94] A.H.M. ter Hofstede, Dictaat IS1, Katholieke Universiteit Nijmegen, 1994, Nijmegen [Hof93] A.H.M. ter Hofstede, Information Modelling in Data Intensive Domains, 1993, Proefschrift KUN, Nijmegen [Hobo97] S. Hobo, Richtlijnen voor een succesvol Datawarehouse, Katholieke Universiteit Nijmegen, Maart 1997, Nijmegen [Arntz00] R. Arntz, Data marts als componenten van data warehouses, Katholieke Universiteit Nijmegen, 2000, Nijmegen (NL), in: Proceedings Nijmegen Student Conference Computer Science 2000 (blz. 115-129) [Kim96] R. Kimball, The Data Warehouse Toolkit, 1996, New York [DKPW98] S. Dekeyser, B. Kuijpers, J. Paredaens en J. Wijsen, Nested Data Cubes for OLAP (extended abstract), Universiteit van Antwerpen, 1998, Antwerpen, in: Lecture Notes in Computer Science: Advances in Database Technologies (deel 1552) (blz. 129-140) [NDCtr98] ] S. Dekeyser, B. Kuijpers, J. Paredaens en J. Wijsen, Nested Data Cubes for OLAP, Technical Report 9804, Universiteit van Antwerpen, 1998, Antwerpen, ftp://wins.uia.ac.be/pub/olap/ndc.ps [SMKK98] S. Samtani, M. Mohania, V.Kumar en Y. Kambayashi, Recent Advances and Research Problems in Data Warehousing, Universiteiten van Missouri-Kansas City, South-Australia en Kyoto, 1998, in: Lecture Notes in Computer Science: Advances in Database Technologies (deel 1552) (blz. 81-91) [GBLP95] J. Gray, A. Bosworth, A. Layman, H. Pirahesh, Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals, Microsoft Technical Report MSR-TR-95-22, Februari 1995, Redmond (USA) [Falk94] E.D. Falkenberg, Lecture Notes 1994 Part B (Dictaat S&O, gegeven in 1994), Katholieke Universiteit Nijmegen, 1994, Nijmegen [Hammer] J. Hammer, Data Warehousing / Multidimensional Analysis (presentatie sheets), http://www.cise.ufl.edu/~jhammer/classes/wh-seminar/MDDB/index.htm [CabTor] L. Cabibbo, R. Torlone, Querying Multidimensional Databases, Universiteit van Rome, 1997, Rome, in: Lecture Notes in Computer Science: Database Programming Languages (deel 1369) (blz. 319-335) [CG85] S. Ceri, G.Gottlob, Translating SQL Into Relational Algebra: Optimization, Semantics, and Equivalence of SQL Queries, 1985, Milaan, in: IEEE Transactions on Software Engineering (Vol SE-11, nr 4, April 1985), (blz. 324-345) [WWW03] NCR Corporation, Persbericht 1998, http://www.ncr.nl/perscentrum/perb_1998/pers_070898.htm [WWW04] Oracle, Oracle8i Data Warehousing Guide Release 2 Chapter 7 Constraints, http://quake.emsphone.com/oracle/server.816/a76994/constrai.htm

107
[WWW05] OLAP council online, OlAP AND OLAP Server Definitions, http://www.olapcouncil.org

108
Bronvermelding figuren en tabellen De figuur op de voorpagina is gemaakt door de auteur. De figuur op pagina 2 is een bewerking van een figuur afkomstig van http://www.msigroup.com/images/dataware.jpg Figuur 1: Afkomstig uit [SMKK98] Figuur 2: Eigen figuur, © Ferry Kemperman, 2000 Figuur 3: Eigen figuur, © Ferry Kemperman, 2000 Figuur 4: Afkomstig uit [Hof93] Figuur 5: Eigen bewerking van figuur afkomstig uit [Hof94], © Ferry Kemperman, 2000 Figuur 6: Afkomstig uit [Hof94] Figuur 7: Eigen figuur, © Ferry Kemperman, 2000 Figuur 8: Eigen figuur, © Ferry Kemperman, 2000 Figuur 9: Eigen figuur, © Ferry Kemperman, 2000 Figuur 10: Eigen figuur, © Ferry Kemperman, 2000 Figuur 11: Eigen figuur, © Ferry Kemperman, 2000 Figuur 12: Eigen figuur, © Ferry Kemperman, 2000 Figuur 13: Afkomstig uit [Kim96] Figuur 14: Afkomstig uit de presentatie [Hammer] Figuur 15: Eigen figuur, © Ferry Kemperman, 2000 Figuur 16: Eigen bewerking van figuur afkomstig uit [Kim96], © Ferry Kemperman, 2000 Figuur 17: Eigen figuur, © Ferry Kemperman, 2000 Figuur 18: Eigen figuur, © Ferry Kemperman, 2000 Figuur 19: Eigen figuur, © Ferry Kemperman, 2000 Figuur 20: Eigen figuur, © Ferry Kemperman, 2000 Figuur 21: Eigen figuur, © Ferry Kemperman, 2000 Figuur 22: Figuur afkomstig uit [NDCtr98] Figuur 23: Figuur afkomstig uit [NDCtr98] Figuur 24: Eigen figuur, © Ferry Kemperman, 2000 Figuur 25: Eigen figuur, © Ferry Kemperman, 2000 Figuur 26: Eigen figuur, © Ferry Kemperman, 2000 Figuur 27: Eigen figuur, © Ferry Kemperman, 2000 Figuur 28: Eigen figuur, © Ferry Kemperman, 2000 Figuur 29: Figuur afkomstig uit [Hof94] Tabel 1: Eigen tabel, © Ferry Kemperman, 2000 Tabel 2: Eigen tabel, © Ferry Kemperman, 2000 Tabel 3: Eigen tabel, © Ferry Kemperman, 2000 Tabel 4: Eigen tabel, © Ferry Kemperman, 2000 Tabel 5: Eigen tabel, © Ferry Kemperman, 2000 Tabel 6: Eigen tabel, © Ferry Kemperman, 2000 Tabel 7: Eigen tabel, © Ferry Kemperman, 2000 Tabel 8: Eigen tabel, © Ferry Kemperman, 2000 Tabel 9: Eigen tabel, © Ferry Kemperman, 2000 Tabel 10: Eigen tabel, © Ferry Kemperman, 2000 Tabel 11: Eigen tabel, © Ferry Kemperman, 2000 Tabel 12: Eigen tabel, © Ferry Kemperman, 2000

109
Index
A
aggregatie, 56 application constraint, 64, 66, 67 attribute-based constraints, 19
B
bag, 69 bedrijfsbeslissingen, 7, 8; op tactisch managementniveau,
8 bottom-up methode, 12 B-RIDL, 94 browsertechniek, 67 Business 2 Business, 14 Business 2 Consumer, 14
C
composite key, 65 constraints, 14, 19, 64, 106 coördinaat, 70 coördinaat type, 70 cover constraint, 50
D
data cube, 13, 14, 18, 53, 54, 55, 56, 57, 58, 60, 61, 62, 63, 64
data mart, 10 data mining tool, 11 data warehouse, 6, 7, 8, 9, 10, 11, 12, 14, 15, 19, 54, 65,
67 dimensieattributen, 16, 17, 18, 64 dimensietabel, 14, 17, 56, 64, 66, 67 dimensionale model, 14, 15, 16, 19, 20, 53, 54, 61, 64 dirty data, 97 Drill Down, 57, 58, 59 Drill Up, 56, 57, 58, 60
E
enkelvoudige cel, 58 entiteiten, 20, 21 entiteittypes, 20, 21 enumeration constraint, 50 extended SQL, 11, 14
F
famil ie van entiteittypes, 51 feitentabel, 14, 15, 16, 18, 19, 53, 61, 64, 65, 68 foreign keys, 65 front end tool, 11 f-tables, 69 functie evaluatie operatie, 95
G
geaggregeerde gegevens, 8, 11, 55, 56, 57 general assertions, 19 geneste dimensies, 56 geobjectificeerd feittype, 22 GROUP BY, 18, 68, 94, 95 GROUP BY-clausule, 94
H
historie, 7, 9 hybride methode, 12 Hydra, 94 hypercubes, 69
I
informatiestructuur, 21 integrator, 10 inter-cube constraints, 53 intra-cube constraints, 53, 58, 62
J
join constraint, 64, 67 joinable via common object types, 39
K
key constraints, 19
L
laagste gemeenschappelijke voorvader, 51 labeltypes, 20, 21 legacy systemen, 12 LISA-D, 94
M
materialized views, 97 measure-attributen, 53, 55 member combination, 58, 61 membership constraint, 51 metadata, 10 MOLAP-architectuur, 11 monitor, 9, 10 multidimensionale database, 11, 61, 62 multidimensionale datamodel, 12, 13 multidimensionale sub cube, 58, 59 multiple join, 64 mythe, 11
N
navigeren, 57 NDC, 69

110
NDC algebra, 72, 73; aggregate, 73; bagify, 73, 74; duplicate, 73; extend, 73, 74; nest, 73; rename, 73; select, 73; unnest, 30, 31, 47, 73
Nested Data Cube, 69 NIAM, 20 not null constraints, 19
O
Object Interpretation Graph, 44 Object Interpretation Structures, 44, 102 objecttypes, 20, 21 OIS, 44 OLAP, 1, 6, 11, 55, 56, 106, 107 one-way aggregate, 93 operationeel systeem, 7, 8, 9
P
padexpressies, 94 pater familias, 26, 36, 50 persbericht, 6 power exclusion constraint, 50 powertypes, 21, 22 predicatoren, 21 PSM, 19, 20, 54
Q
query, 7, 10, 11, 12, 14, 19, 56, 58, 59, 60, 64, 66
R
RDBMS, 9 rechterhand waarde, 85, 91 referential integrity constraints, 19 relation-based check constraints, 19 Relevant Object Interpretation Structure, 44 ROIS, 44 ROLAP-architectuur, 11 Roll Up, 56, 57, 62 rotate-functie, 56, 59, 60
S
samengestelde sleutel, 18, 65 samenvattingen, 8, 55, 56 schema type constraint, 52 schematypes, 21 Select Distinct, 67 sequentietypes, 21 slice and dice, 57, 58 SPJR algebra, 80 SQL, 14, 16, 18, 19, 66, 67, 69, 94, 95, 106 Star-join schema, 14, 93 subtype exclusion constraint, 51
T
three-way aggregate, 93 top-down methode, 12 total role constraint, 34, 35 total subtype constraint, 51 tweedimensionale slice, 58 two-way aggregate, 93
U
uniqueness constraint, 19 Uniquest Algorithm, 45, 47, 48, 97, 98, 99 Universe of Discourse, 19 universe of instances, 23, 24, 33, 85, 86, 91
V
view maintenance, 54, 100
W
wrapper, 9, 10
�
�, 23

111
Figurenindex Figuur 1: De data warehouse architectuur..........................................................................................................9 Figuur 2: Het dimensionale model voor Down Under, de Verkoop feitentabel .................................................16 Figuur 3: De dimensies met de dimensieattributen van de Down Under verkooptabel.......................................17 Figuur 4: PSM schema inzake Amerikaanse presidenten..................................................................................20 Figuur 5: Impliciete feittypes voor een sequentietype......................................................................................25 Figuur 6: Werking van de unnest operatie .......................................................................................................31 Figuur 7: Werking van de total role constraint ................................................................................................. 34 Figuur 8: Werking van de uniqueness constraint binnen 1 feittype ................................................................... 37 Figuur 9: Werking van de uniqueness constraint over meerdere feittypes .........................................................40 Figuur 10: Werking van de uniqueness constraint met objectif icatie................................................................. 43 Figuur 11: Object Interpretation Graph van dammatches.................................................................................46 Figuur 12: Object Interpretation Graph van dammatches na de unnesting van Matchoverzicht..........................47 Figuur 13: De data cube: elke cel bevat informatie die betrekking heeft op de unieke combinatie van tijd, markt
en product...............................................................................................................................................53 Figuur 14: Een invulling van de data cube van Joachim Hammer.....................................................................55 Figuur 15: Roll Up, Drill Down en Drill Up functies.......................................................................................57 Figuur 16: De data cube toegepast op Down Under .........................................................................................61 Figuur 17: Dimensionaal schema voor de afzet van bepaalde producten...........................................................65 Figuur 18: De dimensie geografische ligging in de browser voor toepassing van de appl ication constraint........66 Figuur 19: De dimensie geografische ligging in de browser na toepassing van de application constraint ...........67 Figuur 20: Een NDC voor Down Under ..........................................................................................................72 Figuur 21: De NDC na de bagify operatie........................................................................................................74 Figuur 22: De NDC voor de nest operatie........................................................................................................76 Figuur 23: De NDC na de nest operatie...........................................................................................................77 Figuur 24: De NDC na het toepassen van duplicate.........................................................................................78 Figuur 25: Down Under in een PSM schema................................................................................................... 87 Figuur 26: Verschillende hiërarchieën in dimensies.........................................................................................90 Figuur 27: Een NDC binnen Down Under .......................................................................................................91 Figuur 28: PSM schema gebaseerd op NDC....................................................................................................92 Figuur 29: Uniqueness constraint over objectificatie........................................................................................98
Tabellenindex Tabel 1: Invulling van de geografische dimensietabel ......................................................................................17 Tabel 2: Invulling van de productdimensietabel ...............................................................................................17 Tabel 3: Invulling van de tijddimensietabel .....................................................................................................18 Tabel 4: Invulling van de feitentabel Verkoop................................................................................................. 18 Tabel 5: Gegenereerd antwoord ......................................................................................................................19 Tabel 6: Geneste dimensies in zowel de rij- als kolomdimensies......................................................................60 Tabel 7: Een fragment van de invulling van de data cube van Down Under......................................................61 Tabel 8: Een dimensietabel met NULL waarden..............................................................................................62 Tabel 9: Ongewenste inconsistentie bij members binnen een dimensie.............................................................63 Tabel 10: Vergeli jking dimensionale model en relationele model.....................................................................85 Tabel 11: Invulling van de omzettabel en de roll up naar Maand......................................................................94 Tabel 12: Resultaat van (O JN[O.Dag = D.Dag] D) .........................................................................................96