modeling heterogeneous networks for information ranking...
TRANSCRIPT

MODELING HETEROGENEOUS NETWORKS FORINFORMATION RANKING, ENRICHMENT AND RESOLUTION
ON MICROBLOGS
By
Hongzhao Huang
A Dissertation Submitted to the Graduate
Faculty of Rensselaer Polytechnic Institute
in Partial Fulfillment of the
Requirements for the Degree of
DOCTOR OF PHILOSOPHY
Major Subject: COMPUTER SCIENCE
Examining Committee:
Heng Ji, Dissertation Adviser
Peter Fox, Member
Jim Hendler, Member
Chin-Yew Lin, Member
Yizhou Sun, Member
Rensselaer Polytechnic InstituteTroy, New York
April 2015(For Graduation May 2015)

c� Copyright 2015
by
Hongzhao Huang
All Rights Reserved
ii

CONTENTS
LIST OF TABLES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vi
LIST OF FIGURES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . viii
ACKNOWLEDGMENT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . x
ABSTRACT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xii
1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 Motivations of Research in Microblogging . . . . . . . . . . . . . . . . . 1
1.2 Overall Problem: Enhancing Natural Language Understanding for Mi-croblogs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Insights of the Thesis: Leveraging and Modeling Heterogeneous Infor-mation Networks for Natural Language Processing . . . . . . . . . . . . 61.3.1 Microblog Ranking . . . . . . . . . . . . . . . . . . . . . . . . . 81.3.2 Microblog Wikification . . . . . . . . . . . . . . . . . . . . . . . 91.3.3 Morph Decoding . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.4 Contributions of the Thesis . . . . . . . . . . . . . . . . . . . . . . . . . 14
2. Background and Relevant Literature . . . . . . . . . . . . . . . . . . . . . . . 16
2.1 Homogeneous and Heterogeneous Information Networks . . . . . . . . . 16
2.2 Graph-based Approaches . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2.1 Ranking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2.2 Similarity Measurement . . . . . . . . . . . . . . . . . . . . . . 212.2.3 Semi-supervised Learning . . . . . . . . . . . . . . . . . . . . . 23
2.3 Related Work to the Thesis Topic . . . . . . . . . . . . . . . . . . . . . . 242.3.1 Ranking in Microblogging . . . . . . . . . . . . . . . . . . . . . 242.3.2 Microblog Wikification . . . . . . . . . . . . . . . . . . . . . . . 252.3.3 Morph Decoding . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3. Microblog Ranking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.1 Motivations and Hypotheses . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2 Our Proposed Approach: Tri-HITS . . . . . . . . . . . . . . . . . . . . . 283.2.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.2.2 Filtering non-informative Tweets . . . . . . . . . . . . . . . . . . 29
iii

3.2.3 Initializing Ranking Scores . . . . . . . . . . . . . . . . . . . . . 303.2.4 Constructing Heterogeneous Networks . . . . . . . . . . . . . . 323.2.5 Iterative Propagation . . . . . . . . . . . . . . . . . . . . . . . . 323.2.6 Redundancy Removal . . . . . . . . . . . . . . . . . . . . . . . 34
3.3 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.3.1 Data and Evaluation Metric . . . . . . . . . . . . . . . . . . . . 353.3.2 Effect of Parameters . . . . . . . . . . . . . . . . . . . . . . . . 373.3.3 Performance and Analysis . . . . . . . . . . . . . . . . . . . . . 383.3.4 Remaining Challenges . . . . . . . . . . . . . . . . . . . . . . . 41
3.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4. Microblog Wikification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.1 Preliminaries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.2 Principles and Approach Overview . . . . . . . . . . . . . . . . . . . . . 444.2.1 Principles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.2.2 Approach Overview . . . . . . . . . . . . . . . . . . . . . . . . 45
4.3 A Deep Semantic Relatedness Model . . . . . . . . . . . . . . . . . . . . 464.3.1 The DSRM Architecture . . . . . . . . . . . . . . . . . . . . . . 464.3.2 Learning the DSRM . . . . . . . . . . . . . . . . . . . . . . . . 49
4.4 Relational Graph Construction . . . . . . . . . . . . . . . . . . . . . . . 504.4.1 Local Compatibility . . . . . . . . . . . . . . . . . . . . . . . . 514.4.2 Meta Path . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524.4.3 Coreference . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.4.4 Semantic Relatedness . . . . . . . . . . . . . . . . . . . . . . . . 544.4.5 The Combined Relational Graph . . . . . . . . . . . . . . . . . . 54
4.5 Semi-supervised Graph Regularization . . . . . . . . . . . . . . . . . . . 55
4.6 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564.6.1 Data and Scoring Metric . . . . . . . . . . . . . . . . . . . . . . 574.6.2 End-to-End Wikification . . . . . . . . . . . . . . . . . . . . . . 584.6.3 Quality of Semantic Relatedness Measurement . . . . . . . . . . 614.6.4 Concept Disambiguation . . . . . . . . . . . . . . . . . . . . . . 634.6.5 Discussions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 654.6.6 Remaining Challenges . . . . . . . . . . . . . . . . . . . . . . . 66
4.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
iv

5. Morph Decoding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.1 Approach Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.2 Morph Detection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
5.3 Morph Resolution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 715.3.1 Target Candidate Identification . . . . . . . . . . . . . . . . . . . 715.3.2 Target Candidate Ranking . . . . . . . . . . . . . . . . . . . . . 72
5.3.2.1 Surface Features . . . . . . . . . . . . . . . . . . . . . 725.3.2.2 Semantic Features . . . . . . . . . . . . . . . . . . . . 725.3.2.3 Social Features . . . . . . . . . . . . . . . . . . . . . . 775.3.2.4 Learning-to-Rank . . . . . . . . . . . . . . . . . . . . 78
5.4 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 785.4.1 Data and Evaluation Metric . . . . . . . . . . . . . . . . . . . . 795.4.2 Morph Detection Performance . . . . . . . . . . . . . . . . . . . 795.4.3 Morph Resolution Performance . . . . . . . . . . . . . . . . . . 805.4.4 Remaining Challenges . . . . . . . . . . . . . . . . . . . . . . . 83
5.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
6. Conclusions and Future Directions . . . . . . . . . . . . . . . . . . . . . . . . 86
6.1 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
6.2 Future Directions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
REFERENCES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
v

LIST OF TABLES
1.1 Distributions of morph examples. . . . . . . . . . . . . . . . . . . . . . . . 13
2.1 Meta paths in DBLP bibliographic network. . . . . . . . . . . . . . . . . . 19
3.1 Description of methods (method with ⇤ make use of the Bayesian approachto initialize user credibility scores. . . . . . . . . . . . . . . . . . . . . . . 36
3.2 Tweet distribution by grade. . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.3 Grade distributions for filtered tweets. . . . . . . . . . . . . . . . . . . . . 40
4.1 Description of wikification methods. . . . . . . . . . . . . . . . . . . . . . 57
4.2 Statistics of Freebase KG. . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.3 Overall performance. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.4 The performance of systems without using concatenated meta paths. . . . . 60
4.5 Overall performance of concept semantic relatedness methods. . . . . . . . 62
4.6 Examples of relatedness scores between a sample of concepts and the con-cept “National Basketball Association”. . . . . . . . . . . . . . . . . . . . 62
4.7 Examples of relatedness scores between a sample of concepts and the con-cept “National Football League”. . . . . . . . . . . . . . . . . . . . . . . 63
4.8 Examples of relatedness scores between a sample of concepts and the con-cept “Apple Inc.”. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.9 Overall disambiguation performance on AIDA dataset. . . . . . . . . . . . . 65
4.10 Overall disambiguation performance on tweet set. . . . . . . . . . . . . . . 65
4.11 Impact of semantic KGs and DNN on concept semantic relatedness. . . . . 66
4.12 Impact of semantic KGs and DNN on concept disambiguation. . . . . . . . 66
5.1 Description of feature sets. ⇤ Glob only uses the same set of similarity mea-sures when combined with other semantic features. . . . . . . . . . . . . . 78
5.2 Data statistics. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.3 Performance of morph detection. . . . . . . . . . . . . . . . . . . . . . . . 80
5.4 The system performance based on each single feature set. . . . . . . . . . . 81
vi

5.5 The system performance based on combinations of surface and semanticfeatures. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5.6 The system performance of integrating cross source and cross genre infor-mation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.7 The effects of social features. . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.8 The effects of temporal constraint. . . . . . . . . . . . . . . . . . . . . . . 83
5.9 Accuracy of target candidate detection. . . . . . . . . . . . . . . . . . . . . 83
5.10 Performance of two categories. . . . . . . . . . . . . . . . . . . . . . . . . 84
5.11 Effects of popularity of morphs. . . . . . . . . . . . . . . . . . . . . . . . . 85
vii

LIST OF FIGURES
1.1 A sample of tweets related to hurricane irene in 2011. . . . . . . . . . . . . 2
1.2 A sample of tweets with informal and implicit information. . . . . . . . . . 3
1.3 An illustration of wikification task for tweets. Concept mentions detectedin tweets are marked as bold, and correctly linked concepts are underlined.The concept candidates are ranked by their prior popularity which will beexplained in section 4.4.1, and only top 2 ranked concepts are listed. . . . . 4
1.4 A heterogeneous information network example. . . . . . . . . . . . . . . . 6
1.5 An example of Freebase. Nodes represent concepts such as “Miami Heat”,and edges represent semantic relations such as “Coach” and “Location”.Each concept is also provided with textual description and concept types. . . 8
1.6 An illustration of topical coherence for a text. . . . . . . . . . . . . . . . . 11
1.7 Cross-source comparable data example (each morph and target pair is shownin the same color). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1 (a) Heterogeneous DBLP biobiographic network, (b) Homogeneous co-authornetwork. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2 Schema of the heterogeneous DBLP biobiographic network. . . . . . . . . . 17
3.1 Web-Tweet-User heterogeneous networks. . . . . . . . . . . . . . . . . . . 29
3.2 Overview of Tri-HITS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.3 Annotation guideline for tweet ranking. . . . . . . . . . . . . . . . . . . . . 36
3.4 Effect of parameters: (a) �td and �dt for Web-Tweet networks, (b) �td forWeb-Tweet networks, (c) �dt for Web-Tweet-User networks. . . . . . . . . . 38
3.5 Performance comparison of ranking methods. . . . . . . . . . . . . . . . . 39
3.6 (a) Explicit vs inferred implicit Tweet-User relations to construct Tweet-User networks; (b) TextRank vs one-step propagation on explicit Tweet-User networks using bayesian approach and retweet/reply/user mention re-lations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.7 Co-HITS vs Tri-HITS on (a) Web-Tweet networks, (b) Tweet-User networks. 41
4.1 Approach overview. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
viii

4.2 The DSRM architecture. . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3 Schema of the Twitter network. . . . . . . . . . . . . . . . . . . . . . . . . 52
4.4 A example of the relational graph constructed for the example tweets inFigure 1.3. Each node represents a pair of hm, ci, separated by a comma.The edge weight is obtained from the linear combination of the weights ofthe three proposed relations. Not all mentions are included due to the spacelimitations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.5 The effect of labeled tweet size. . . . . . . . . . . . . . . . . . . . . . . . . 60
4.6 The effect of parameter µ. . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.7 Error distributions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
5.1 Overview of morph decoding. . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.2 Network Schema of Morph-Related Heterogeneous Information Network . . 73
5.3 Example of morph-related heterogeneous information network. . . . . . . . 74
ix

ACKNOWLEDGMENT
First of all, I would like to express my sincere gratitude and appreciation to my advisor
Prof. Heng Ji. When I first joined her group, I had very limited research experience. It
was her tremendous guidance, support, enthusiasm and encouragement that led me into
the scientific research world and introduced me the attractive fields of natural language
processing. Prof. Ji is always willing to accept new ideas and provide me full supports
to pursue my research goals. In addition, she is always ready to offer help to all of my
personal issues beyond research. It is my great honor to have her as my supervisor.
I would also like to thank my other doctoral committee members Prof. Peter Fox,
Prof. Jim Hendler, Dr. Chin-Yew Lin, and Prof. Yizhou Sun for the great efforts they
have put on supervising this thesis. During the writing of this thesis, they have provided
me a lot of insightful comments and suggestions that guide me to always think bigger and
capture the whole picture, which are not only critical and valuable to this thesis but also
benefit my whole future careers. Specific thanks to Dr. Chin-Yew Lin who provided me
a great summer internship opportunity at his group at Microsoft Research Asia. And the
academic work of Prof. Sun has greatly inspired this thesis.
I also owe my gratitude to many collaborators who contributed a lot to this thesis
and provided me tremendous guidance. The exciting discussions with Dr. Hongbo Deng
sparked the idea of Tri-HITS, and the joint work with Dr. Zhen Wen led to the exciting
morph work. Dr. Yunbo Cao, Dr. Xiaojiang Huang, and Dr. Shuming Shi provided
me great guidance during my first internship at Microsoft Research Asia. And I was
very fortunate to have Dr. Larry Heck as my supervisor during my second internship at
Microsoft Research. Dr. Heck introduced me the fascinating deep learning techniques
and provided me a lot of suggestions and tremendous help for my future careers.
I wish to thank all members and visitors from Blender lab at both CUNY and RPI. It
is my extremely fortunate to spend the past four years with them. I appreciate all of their
tremendous help on both research projects and daily life. Specially thanks to Dr. Haibo
Li and Dr. Arkaitz Zubiaga who we worked together on the tweet ranking project, Dr.
Taylor Cassidy on the joint work of the tweet wikification project, Prof. Sujian Li, Dian
x

Yu, Boliang Zhang, Xiaoman Pan on the teamwork of morph projects, and Prof. Hong Yu
on providing me many constructive comments on my thesis work.
I would also like to thank my parents, my sister, and my wife. Their selfless love
and encouragement helped me go through all those difficult times and kept me moving
forward. In particular, I would like to thank my wife for her sacrifice and full understand-
ing. It was very difficult for her in the past two years because we need to be separated
after I moved to RPI. Finally, I am the most grateful for my beloved grandmother for her
love and caring. I feel very guilty for not being able to accompany her during her most
difficult time at the end of her life. This thesis is dedicated to her.
xi

ABSTRACT
Microblogging, a new type of online information sharing platform through short mes-
sages of up to 140 characters, has grown up quickly and received increasing attentions in
recent years. A microblogging platform (e.g., Twitter) enables both individuals and or-
ganizations to disseminate information, from current affairs to breaking news in a timely
fashion, which makes it a valuable knowledge source with super-fresh information. For
example, during Hurricane Irene in 2011, updates from users living in New York City
and transportation/evacuation posts from the government are very useful information for
people to keep track of the disaster. Therefore, conducting related Natural Language Pro-
cessing (NLP) research on this new genre is demanded to assist knowledge mining and
discovery.
Different from the semi-structured knowledge bases (e.g., Wikipedia) and the tra-
ditional news, the informal microblogs tend to be noisy, short, and informal. And the
phenomenon of information implicitness is more prominent and pervasive in microblog-
ging. These characteristics bring unique challenges to people’s reading and understand-
ing of the informal microblogs, as well as many knowledge mining and discovery tasks.
Thus, in order to alleviate these problems, in this thesis we propose to filter noisy and un-
informative information, enrich the short microblogs with background knowledge from
knowledge bases such as Wikipedia, and resolve the informal and implicit information to
their regular referents.
To achieve our goals, we propose to leverage and model heterogeneous information
networks (HINs), in contrast to most existing NLP approaches on traditional genres (e.g.,
news) that only explored single type of information (e.g., texts). Microblogging contains
heterogeneous types of information from social network structures to cross-genre link-
ages, forming rich HINs. By designing effective approaches to model both unstructured
texts and structured HINs, we can incorporate additional evidence from HIN structures
beyond texts. In this thesis, we present different approaches to construct HINs from cross-
genre, cross-source, and cross-type information by incorporating the existing clean social
relations, as well as performing deep content analysis with some of the well-developed
xii

NLP approaches. We also present various effective approaches including unsupervised
propagation, semi-supervised graph regularization, supervised learning-to-rank and deep
neural networks to model HINs for ranking, classification, and similarity measurement.
Our experimental results demonstrate that heterogeneous information network analysis
approaches are also powerful in the field of NLP.
xiii

CHAPTER 1Introduction
1.1 Motivations of Research in MicrobloggingMicroblogging, a new type of online information sharing platform through short
messages of up to 140 characters, has grown up quickly and received increasing atten-
tions in recent years. A microblogging platform (e.g., Twitter [1] and Sina Weibo [2])
enables both individuals and organizations to seek and disseminate information, from cur-
rent affairs, breaking news, personal updates to nearby events in a timely fashion [3], [4].
The study in [4] further revealed that a retweeted microblog post could reach 1,000 users
on average and it would be disseminated instantly after the first retweet. In addition,
microblogging platforms generate a frequently updated set of trending topics by summa-
rizing a large amount of messages that reflect the hot topics being discussed at a given mo-
ment [5]. All these properties make microblogging a valuable knowledge source and fast
information diffusion platform with super-fresh information. Figure1.1 shows a sample
of Twitter messages (tweets) during Hurricane Irene in 2011. We can obtain very useful
information such as the detailed evacuation zones and the close of transportation sys-
tems to keep track of the disaster. Thus it is crucial to conduct related Natural Language
Processing (NLP) research to assist knowledge mining and discovery from microblogs.
Different from the semi-structured knowledge bases (e.g., Wikipedia [6]) and the
traditional news, microblogging serves as a unique information source with real-time and
detailed information from diverse resources. It has its own unique characteristics: (i)
Portions of this chapter previously appeared as: H. Huang, A. Zubiaga, H. Ji, H. Deng, D. Wang, H.Le, T. Abdelzaher, J. Han, A. Leung, J. Hancock, and C. Voss, “Tweet ranking based on heterogeneousnetworks,” in Proc. of the 24th Int. Conf. on Comput. Linguist., Mumbai, India, 2012, pp. 1239–1256.
H. Huang, Y. Cao, X. Huang, H. Ji, and C.-Y. Lin, “Collective tweet wikification based on semi-supervised graph regularization,” in Proc. of the 52nd Annu. Meeting of the Assoc. for Comput. Linguist.,Baltimore, Maryland, 2014, pp. 380–390.
H. Huang, Z. Wen, D. Yu, H. Ji, Y. Sun, J. Han, and H. Li, “Resolving entity morphs in censoreddata,” in Proc. of the 51st Annu. Meeting of the Assoc. for Comput. Linguist., Sofia, Bulgaria, 2013, pp.1083–1093.
1

2
across the street is an evacuation zone, but my side of the street isn't. here's to the hurricane coloring in the lines... #irene
NYC evacuation order covers 370,000 people who must relocate by tomorrow at 5 pm. Nearly 30 m people under Hurricane Warning on East Coast.
Good morning hurricane Irene hit my side at 5:30am .... as she passing her way to upstate NY Hurricane Irene Prompts Mandatory Emergency Evacuation of New York City http://t.co/
r2ZEokx No subway, no Broadway in New York: America's biggest subway system was ordered shut down
as Hurricane Irene bor... http://t.co/BuGSvsc
Figure 1.1: A sample of tweets related to hurricane irene in 2011.
Noiseness, microblog posts from diverse sources tend to contain uninformative noise such
as subjective comments and conversations. For instance, during Hurricane Irene, there are
many informative tweets such as New Yorkers, find your exact evacuation zone by your
address here: http://t.co/9NhiGKG /via @user #Irene #hurricane #NY. However, the ma-
jority of tweets are babbles such as Me, Myself, and Hurricane Irene. and I’m ready For
hurricane Irene.. The Pear Analytics (2009) report [7] on 2000 sample tweets demon-
strated that 40.55% of the tweets are pointless babble, 37.55% are conversations, and
only 8.7% have pass-along value. (ii) Shortness, the maximum length of 140 characters
results in the lack of information within a single post. The lack of information not only
makes it difficult for people to understand a single post, but also brings unique challenges
for many NLP tasks such as entity linking and text classification which rely extensively
on the richness of contextual and topical clues. (iii) Informality and Implicitness, the
free usage of languages has resulted in many misspellings, informal writings, and the
use of alias/morphs. People also tend to create their own languages to achieve their own
communication goals such as avoiding active censorship, expressing positive or negative
sentiments, and making their descriptions more vivid. Thus, information implicitness is
more prominent and pervasive in microblogs. For example, in Chinese microblogging,
Internet users tend to use morphs such as “Conquer West King” or “Governor Bo” to refer
to the former politician“Bo Xilai”. Figure 1.2 gives more examples to demonstrate the
phenomenon of information informality and implicitness in microblogging. The infor-
mal terms “KD” and “LBJ” and the morph “King” are used to refer to basketball players
“Kevin Durant” and “LeBron James”.

3
Alice: “Will KD and LeBron burn out? @Bob takes a look at the fatigue factor entering the playoffs.”
Bob: “@Alice KD hasn’t had any rest at all. King will be good he used to these moments and he’s had some rest #Heat”
Alice: “@Bob LBJ will perform much better in the playoffs, heat has a difficult regular season...”
Figure 1.2: A sample of tweets with informal and implicit information.
1.2 Overall Problem: Enhancing Natural Language Understanding
for MicroblogsDue to the above unique characteristics of the microblog genre data, it is crucial to
develop automatic tools to process microblogs and provide more background knowledge
to assist people’s reading and understanding on these noisy, short, and informal texts,
as well as to assist downstreaming knowledge mining and discovery tasks. This moti-
vates the overall problem of this thesis: enhancing natural language understanding for
microblogs. We propose to resolve three important sub-problems corresponding to the
above unique characteristics to achieve this goal.
Sub-problem 1: Identification of salient information. Automatic detection of im-
portant information and filtering of uninformative information solves the noiseness prob-
lem. That is particularly useful in emerging situations. This is because eyewitnesses
might be live-tweeting about anything happening at ongoing events [8] such as natural
disasters.
To assist in these situations, we propose to develop a ranking system that organizes
microblog posts by informativeness, so that informative posts are readily identified, while
pointless and speculative observations are filtered out. However, the definition of infor-
mativeness might vary for different points of view. Microblogging users can produce
diverse content ranging from news and events, to conversations and personal status up-
dates. While personal updates and conversations might be relevant to a specific group of
people, we aim to find messages on topics that are informative to a general audience, such
as breaking news and real-time coverage of on-going events. For example, during Hur-
ricane Irene in 2011, updates from a user living in New York City about her own safety
might be very informative to her friends and relatives, but not so informative to others.
To produce rankings that are as relevant to as many people as possible, we define infor-

4
Stay up Hawk Fans. We are going through a slump now, but we have to stay positive. Go Hawks!
Congrats to UCONN and Kemba Walker. 5 wins in 5 days, very impressive...
Just getting to the Arena, we play the Bucks tonight. Let's get it!
Fan (person); Mechanical fan
Slump (geology); Slump (sports)
Atlanta Hawks; Hawks (film)
University of Connecticut; Connecticut Huskies
Kemba Walker
Arena; Arena (magazine); Arena (TV series)
Bucks County, Pennsylvania; Milwaukee Bucks
Tweets Concept CandidatesGo Gators!!! Florida Gators football; Florida Gators men's basketballt1
t2
t3
t4
Figure 1.3: An illustration of wikification task for tweets. Concept mentions de-tected in tweets are marked as bold, and correctly linked concepts areunderlined. The concept candidates are ranked by their prior popularitywhich will be explained in section 4.4.1, and only top 2 ranked conceptsare listed.
mativeness as the extent to which a message meets the general interest of people involved
with or tracking the event. For example, during disasters such as Hurricane, general au-
diences are concerned about the causes and impacts of disasters. They would like to be
informed about whether they need to evacuate or whether the transportation systems are
affected or not. And during sports-related events such as World Cup, the latest sports
results meets the general interest of people.
Sub-problem 2: Information enrichment from a knowledge base with rich and
clean knowledge. Information ranking alleviates the information noiseness problem, but
it fails to solve the information brevity problem. Therefore, information enrichment is
crucial to automatically obtain topically-related background knowledge for the short mes-
sages. Fortunately, web-scale knowledge bases (KBs) (e.g., Wikipedia, DBpedia [9],
and Freebase [10]) with rich and clean information have been emerging. These knowl-
edge bases include rich knowledge about concepts including textual descriptions and
facts. This motivates us to study the popular Wikification (Disambiguation to Wikipedia)
task [11], which aims to automatically identify each concept mention in a microblog post,
and link it to a concept referent in a KB (e.g., Wikipedia). For example, as shown in Fig-
ure 1.3, Hawks in t2
is an identified mention, and its correct referent concept in Wikipedia
is Atlanta Hawks. An end-to-end wikification system needs to resolve two sub-problems:
(i) concept mention detection, (ii) concept mention disambiguation.

5
Automatic information linking to these KBs relieve the information brevity prob-
lem. It allows a reader to easily grasp the related topics and enriched information from
a KB. From a system-to-system perspective, it has been demonstrated its usefulness in a
variety of applications, including coreference resolution [12], classification [13], and user
interest discovery [14], [15].
Sub-problem 3: Identification and resolution of informal and implicit information.
Due to the free usage of languages, there exists a huge amount of informal and implicit
information in microblog posts. In particular, there exists one particular language evo-
lution that creates new ways to communicate sensitive subjects because of the existence
of internet information censorship. We call this phenomenon information morph. For
example, when Chinese online users talk about the former politician “Bo Xilai”, they use
a morph “Conquer West King” instead, a historical figure four hundreds years ago who
governed the same region as Bo. A morph can be either a regular term with new meaning
or a newly created term and it can be considered as a special case of alias used for hiding
true entities in malicious environment [16],[17]. However, social network plays an impor-
tant role in generating morphs. Usually morphs are generated by harvesting the collective
wisdom of the crowd to achieve certain communication goals. Aside from the purpose of
avoiding censorship, other motivations for using morph include expressing sarcasm/irony,
positive/negative sentiment or making descriptions more vivid towards some entities or
events.
The tweet ranking and wikification tasks fail to detect and link such implicit infor-
mation to a KB for two main reasons: (i) unsuccessful identification of candidate entries
in a KB. This is because informal languages are rarely used in a KB with formal texts,
thus there do not exist explicit linkages between a morph mention and its concept referent.
For instance, the anchor text “Conquer West King” is always linked to its original king
“Wu Sangui” in Wikipedia, while none is linked to the former politician “Bo Xilai”. (ii)
The creation and usage of morphs is usually triggered by a certain ongoing event. And
such up-to-date information may not be updated in KBs in a timely fashion. For example,
the usage of “Conquer West King” to refer to “Bo Xilai” was because Bo went out of
power and he shared many common characteristics with the ancient king “Wu Sangui”.
To correctly resolve morphs, it is crucial to explore and leverage background knowledge

6
from comparable data sources such as news.
To address these limitations, we propose a new task “morph decoding” that aims
to detect implicit morphs and resolve them to Web entities. We believe that success-
ful discovery and resolution of morphs is a crucial step for automated understanding of
the fast evolving social media language, which is important to solve the informality and
implicitness problem. Another application is to help common users without enough back-
ground/cultural knowledge to understand internet language for their daily use.
We believe that solving these three important issues are crucial steps to advance
natural language understanding in the informal microblog data. By detecting salient in-
formation, linking mentions to a KB with rich background knowledge, identifying and
resolving implicit morphs, it can benefit down-streaming natural language understanding
systems such as semantic parsing, question answering, and relation extraction.
1.3 Insights of the Thesis: Leveraging and Modeling Heterogeneous
Information Networks for Natural Language Processing
follow
follow
retweet
replyreply
follow
follow
follow
Semantic Relatedness
Coreference
Semantic Relationship
Semantic Relationship
Semantic Relationship
Web Documents
Concept Mentions
Concepts in Knowledge Base
Microblog Posts Social User Community
Social User Community
Figure 1.4: A heterogeneous information network example.
Many of the state-of-the-art NLP systems only relied on the content of a single mi-
croblog post and performed much worse than those designed for traditional formal genre
due to the informal writing style, noiseness, and the lack of context and labeled data in
microblogs. However, different from traditional formal genres such as news, microblog-

7
ging platforms contain heterogeneous types of inter-connected objects, including social
network structures, cross-genre and cross-type linkages. As shown in Figure 1.4, we can
see that multiple types of objects in microblogging are connected with each other through
multiple types of linked relations. For example, microblog posts have direct linkages
to other posts through retweeting and replying relations, microblogs are also connected
to social users through the authorship relation, users are connected to other users via
follower-followee relation, and users also form communities. In addition, some of the
tweets also have cross-genre linkages to the formal genre web documents via the em-
bedded urls or topically-related relations. Furthermore, concept mentions with different
relationships such as coreference and semantic relatedness can be extracted from both
tweets and web documents, with linkages to concepts in a KB. Finally, the concepts in a
KB also form a large-scaled network with different types of concepts and semantic rela-
tions. Figure 1.5 shows an example of Freebase in sports domain. These networks with
multiple types of objects or multiple types of linked relations are defined as Heteroge-
neous Information Networks (HINs), in contrasts to Homogeneous Information Networks
which contain one single type of object and one single type of relation.
HINs have achieved remarkable success over various tasks in the field of data min-
ing, including ranking [18], [19], classification [20], [21], clustering [19], [22], and simi-
larity search and link analysis [23], [24]. HINs have also shown advantages over homo-
geneous networks in the above tasks. This is because the latter is an information loss
projection of the former [25], and modeling HINs directly can incorporate evidence from
multi-typed networks and differentiate different types of objects and relations.
In the field of NLP, homogeneous networks have been applied successfully in var-
ious tasks, including document summarization [26], [27], entity linking [28], word sense
disambiguation [29], and relation extraction [30]. However, HINs have not received many
attentions by the researchers in the NLP field. We then can come up with a very natural
question: can we leverage heterogeneous networks to enhance the state-of-the-art NLP
approaches, especially on microblogs? HINs provide more feasible ways to incorporate
and combine evidence from both unstructured texts and structured networks, and to cap-
ture discrepancies between multi-typed nodes and linkages. This motivates the general
solution of this thesis: leveraging and modeling heterogeneous information networks to

8
Titanic Roster
Member
National Basketball Association
Miami
Erik Spoelstra
Miami Heat
Coach Dwyane
Wade Location
1988 Founded
Description
Professional Sports Team
Type
The Miami Heat are an American professional basketball team based in Miami, Florida. The team is a member of the Southeast Division in the Eastern Conference of the National Basketball Association. They play their home games at the American Airlines Arena in Downtown Miami. The team owner is Micky Arison, who also owns cruise-ship giant Carnival Corporation.
Figure 1.5: An example of Freebase. Nodes represent concepts such as “MiamiHeat”, and edges represent semantic relations such as “Coach” and “Lo-cation”. Each concept is also provided with textual description and con-cept types.
enhance NLP for microblogs. In the following subsections, we introduce our motivations
of our proposed approaches based on HINs to tackle the above discussed issues in this
thesis.
1.3.1 Microblog Ranking
The challenges for this task is that microblogs are from very diverse sources and
noisy. The previous research on microblog ranking has relied on either the text of mi-
croblogs or explicit features of social network such as retweets, replies, and follower-
followee relationships, we believe that such networks can be enhanced by integrating
information from a formal genre. On one hand, tweets from different sources tend to
contain non-informative noise such as subjective comments and conversations. Therefore
it is challenging to identify salient information from microblog content alone. On the
other hand, events of general interest such as natural disasters or political elections are
the topics of microblogs sent by many users from multiple communities which are not
connected to each other. In these situations, users are likely to be unaware of each other.

9
As a result, they fail to connect with many others on topics of mutual interest. This lack of
social interaction produces networks with few explicit linkages between users, and there-
fore between microblogs and users. The sparsity of linkages would limit the effectiveness
of features extracted from social networks.
To address these limitations, we propose to rank microblogs based on a heteroge-
neous network which consists of microblogs, social users, and web documents. We es-
tablish cross-genre linkages between microblogs and web documents, and infer implicit
tweet-user relations beyond the explicit ones, so that networks are enriched by connecting
users that are sharing similar contents. To model cross-genre and cross-type linkages and
capture strong social signals from social networks, we then propose an effective propaga-
tion model to refine the ranking scores of the above three types of objects simultaneously.
The detailed approach will be introduced in Chapter 3.
1.3.2 Microblog Wikification
Motivations of a semi-supervised collective inference model. Measuring context
similarity is a crucial evidence for this task. Context similarity measurement normally
requires to leverage the surrounding contexts of a concept mention and the describing ar-
ticle of a concept in a KB. However, the lack of rich contextual information in a microblog
post has made it challenging to compute context similarity accurately. For instance, if we
only rely on the context of each single microblog to compute context similarity for the
mentions in Figure 1.3, we can only achieve 25% disambiguation accuracy. We can see
that the context of a single microblog usually cannot provide enough information for sim-
ilarity computation for disambiguation. However, we can see that those four microblogs
in Figure 1.3 are topically-relevant and they are posted by the same author within a short
time. If we perform collective inference over them, we can reliably link ambiguous men-
tions such as “Gators”, “Hawks”, and “Bucks” to basketball teams instead of other con-
cepts such as the county “Bucks County”. This motivates us to leverage social network
relations to expand each single microblog with more topically-relevant information, and
design a collective inference model that jointly resolve multiple mentions over multiple
microblogs simultaneously.
For more accurate prominent mention detection and disambiguation, it is also cru-

10
cial to use a set of labeled seeds as guidance for model learning. Sufficient labeled data
is crucial for supervised models. However, manual wikification annotation for short doc-
uments is challenging and time-consuming [31]. The challenges are: (i) unlinkability, a
valid concept may not exist in the KB. (ii) ambiguity, it is impossible to determine the
correct concept due to the dearth of information within a single tweet or there is more
than one correct answer. For instance, it would be difficult to determine the correct ref-
erent concept for “Gators” in t1
in Figure 1.3. Linking “UCONN” in t3
to University
of Connecticut may also be acceptable since Connecticut Huskies is the athletic team
of the university. (iii) prominence, it is challenging to select a set of linkable mentions
that are important and relevant. It is not tricky to select “Fans”, “slump”, and “Hawks” as
linkable mentions, but other mentions such as “stay up” and “stay positive” are not promi-
nent. Therefore, it is challenging to create sufficient high quality labeled microblogs for
supervised models and worth considering semi-supervised learning with the exploration
of unlabeled data. Besides the discussed annotation issues, it is also challenging to incor-
porate into the supervised models multi-dimensional global evidences, which will make
the problem untractable and impossible to find optimal solutions [32].
In order to address these unique challenges for wikification for the short microblogs,
we employ graph-based semi-supervised learning algorithms [33]–[37] for collective in-
ference by exploiting the manifold (cluster) structure in both unlabeled and labeled data.
Different from unsupervised methods, semi-supervised learning approaches can leverage
a small set of labeled seeds to guide model learning, which is crucial for salient and link-
able mention detection. And in contrast to supervised learning models, a large amount
of unlabeled data can be used by semi-supervised learning algorithms to help discover
real data distributions. In order to construct a semantic-rich relational graph capturing
the similarity between mentions and concepts for the model, we introduce three novel
fine-grained relations based on a set of local features and HINs.
Motivations of better concept semantic relatedness approaches. Beyond context
expansion, another crucial evidence for this task is topical coherence which assumes that
information from the same context tends to belong to the same topic. For instance, the
text in Figure 1.6 is on a specific topic NBA basketball, and we can see that the mentions
from this text are also linked to concepts related to this topic. Modeling topical coherence

11
normally requires to define a measure to capture semantic relatedness between candidate
concepts of the mentions from the same context. The standard relatedness measure widely
adopted in existing wikification or entity linking systems leveraged Wikipedia anchor
links with Normalized Google Distance [38], which can be formulated as:
SRmw(ci, cj) = 1� logmax(|Ci|, |Cj|)� log |Ci \ Cj|
log(|C|)� logmin(|Ci|, |Cj|),
where |C| is the total number of concepts in Wikipedia, and Ci and Cj are the set of
concepts that have links to ci and cj , respectively. Our analysis reveals that it gener-
ates unreliable relatedness scores in many cases and tends to be biased towards popular
concepts. For instance, it predicts that “NBA” is more semantically-related to the city
“Chicago” than its basketball team “Chicago Bulls” 1. This is because popular concepts
such as “Chicago” tend to share more common incoming links with other concepts in
Wikipedia. Also, an underling assumption of this method is that semantically-related
concepts must share common anchor links, which is too strong.
NBA basketball - Friday 's results : Detroit 93 Cleveland 81 New York 103 Miami 85 Phoenix 101 Sacramento 95. Miami is going through a slump now.
National Basketball Association
Detroit Pistons New York Knicks
Miami HeatSacramento Kings
Cleveland Cavaliers
Phoenix Suns Slump (sports)
Figure 1.6: An illustration of topical coherence for a text.
To address these limitations, we propose a novel deep semantic relatedness model
(DSRM) that leverages semantic knowledge graphs (KGs) and deep neural networks
(DNN). In the past decade, tremendous efforts have been made to construct many large-
scale structured and linked KGs (e.g., Freebase and DBpedia), which stores a huge amount
of clean and important knowledge about concepts from contextual and typed information
to structured facts. Each fact is represented as a triple connecting a pair of concepts by a
certain relationship and of the form {leftconcept, relation, rightconcept}. An example1The relatedness score generated by [38] between “NBA” and “Chicago Bulls” is 0.59, while the score
between “NBA” and “Chicago” is 0.83.

12
about the concept “Miami Heat” in Freebase is as shown in Figure 1.5. These semantic
KGs are valuable resources to enhance relatedness measurement and deep understanding
of concepts.
Low dimensional representations (i.e., distributed representations) of objects (e.g.,
words, documents, and entities) have shown remarkable success in the fields of NLP and
information retrieval due to their ability to capture the latent semantics of objects [39],
[40]. Deep learning techniques have been applied successfully to learn distributed repre-
sentations since they can extract hidden semantic features with hierarchical architectures
and map objects into a latent space (e.g., [39]–[43]). Motivated by the previous work,
we propose to learn latent semantic entity representations with deep learning techniques
to enhance entity relatedness measurement. We directly encode heterogeneous types of
semantic knowledge from KGs including structured knowledge (i.e., concept facts and
concept types) and textual knowledge (i.e., concept descriptions) into DNN. Therefore,
compared to the standard approach proposed by [38], our proposed DSRM is in nature a
deep semantic model that can capture the latent semantics of concepts. Another advan-
tage is that it can capture more semantically-related relations between concepts which do
not share any common anchor links. We will present the detailed approach in Chapter 4.
1.3.3 Morph Decoding
An end-to-end morph decoding system needs to resolve two sub-problems: (1)
morph detection, (2) morph resolution. Morph detection is difficult for the following
aspects: (i) Large-scope candidates, all terms may serve as morph candidates, but only
a very small percentage of them are used as morphs. As we annotate a sample of 4, 668
tweets, only 450 out of 19, 704 unique terms are morphs. (ii) Informality, many morphs
are informal terms (e.g., “m|| (rice and cake)” and “�ö (not thick)”), compared to
the regular entities.
Morph resolution is also challenging due to the following reasons. First, the sen-
sitive real targets that exist in the same data source under active censorship are often
automatically filtered. Table 1.1 presents the distributions of some examples of morphs
and their targets in English Twitter and Chinese Sina Weibo. For example, the target
“Chen Guangcheng” only appears once in Weibo. Thus, the co-occurrence of a morph

13
and its target is quite low in the vast amount of information in social media. Second, most
morphs were not created based on pronunciations, spellings or other encryptions of their
original targets. Instead, they were created according to semantically related entities in
historical and cultural narratives (e.g. “Conquer West King” as morph of “Bo Xilai”) and
thus very difficult to capture based on typical lexical features. Third, tweets from Twit-
ter/Chinese Weibo are short (only up to 140 characters) and noisy, resulting in difficult
extraction of rich and accurate evidences due to the lack of enough contexts.
Table 1.1: Distributions of morph examples.
Frequency in Twitter
Frequency in Weibo
Morph Target
Morph Target Morph Target Hu Ji Hu Jintao 1 3,864 2,611 71 Blind Man
Chen Guangcheng
18 2,743 20,941 1
Baby Wen Jiabao 2238 2021 26,279 8
Although a morph and its target may have very different orthographic forms, they
tend to be embedded in similar semantic contexts which involve similar topics and events.
Figure 1.7 presents some example messages under censorship (Weibo) and not under cen-
sorship (Twitter and Chinese Daily). We can see that they include similar topics, events
(e.g., “fell from power”, “gang crackdown”, “sing red songs”), and semantic relations
(e.g., family relations with “Bo Guagua”). Therefore if we can automatically extract and
exploit these indicative semantic contexts, we can narrow down the real targets effectively.
In order to tackle these challenges, we propose a HIN-based approach to effectively
model the contexts of a morph and its target. We first construct HINs from multiple
sources, such as Twitter, Sina Weibo and web documents in formal genre (e.g. news)
because a morph and its target tend to appear in similar contexts. The previous work on
alias detection [16] have utilized homogeneous networks to model the unstructured texts.
In order to capture the discrepant contributions of different neighbor sets, we explore and
propose various meta path-based similarity measures to extract effective semantic features
for morph resolution. We will describe this approach in detail in Chapter 5.
In this thesis, two notions of “semantics” are used. First, there exist specific seman-
tic relationships between many concepts or objects in the world. For instance, as shown in

14
� Peace West King from Chongqingfell from power, still need to sing red songs?
� There is no difference between that guy’s plagiarism and Buhou’s gang crackdown.
� Remember that Buhou said that his family was not rich at the press conference a few days before he fell from power. His son Bo Guagua is supported by his scholarship.
� Bo Xilai: ten thousand letters of accusation have been received during Chongqing gang crackdown.
� The webpage of “Tianze Economic Study Institute” owned by the liberal party has been closed. This is the first affected website of the liberal party after Bo Xilai fell from power.
� Bo Xilai gave an explanation about the source of his son, Bo Guagua’s tuition.
� Bo Xilai led Chongqing city leaders and 40 district and county party and government leaders to sing red songs.
Weibo (censored) Twitter and Chinese News (uncensored)
Figure 1.7: Cross-source comparable data example (each morph and target pair isshown in the same color).
Figure 1.5, a “Coach” relationship exist between the person “Erik Spoelstra” and the bas-
ketball team “Miami Heat”, and a “Location” relationship exists between “Miami Heat”
and the city “Miami”. These relationships vary accross domains. For instance, some im-
portant relationships in sports domain include “Coach”, “Founder”, and “Roster”. While
in movie domain, popular relationships include “Director”, “Actor”, and “Genre”. By
defining these relationships and schemas, many web-scale semantic knowledge graphs
such as Freebase and DBpedia have been constructed. On the other hand, many objects
are conceptually-related, but there do not exist explicit and direct relationships between
them. In other words, their relationships are latent. For instance, these three concepts
“Atlanta Hawks”, “Miami Heat”, and “Slump (sports)” are all related to the sports do-
main. Even though there do not exist specific relationships between them, but capturing
the latent semantics are also crucial for many NLP tasks.
1.4 Contributions of the ThesisAfter identifying the unique characteristics of the informal microblog genre data,
we have proposed to tackle three crucial issues to enhance natural language understanding
in microblogs. Our general solution is to leverage and model heterogeneous information
networks to enhance current the-state-of-the-art approaches for the studied sub-problems.
We summarize our key contributions as follows:

15
• The most important contribution of this thesis is that we have introduced a new
and unique angle to improve current NLP approaches in microblogging: conduct-
ing heterogeneous information network analysis for NLP. Through our three case
studies, we show that heterogeneous information network analysis is also powerful
for many NLP tasks. This is crucial since the previous success achieved by HIN-
based approaches in data mining field were mostly based on existing clean and rich
HINs (e.g., DBLP [44]). In this thesis, we explore and construct HINs which are
involved with unstructured texts and tend to include a lot of noise. Thus this thesis
demonstrates the potential application of HIN-based approaches in the field of NLP,
especially on microblogs.
• Another important contribution is that we have enhanced natural language under-
standing in microblogging for both humans and machines. It helps users identify
salient information, provides users rich background knowledge, and resolves the
morphed entities to their regular referents that are easy to understand. Our work
can also benefit many down-streaming NLP and knowledge mining tasks such as
information extraction and text classification.
• We propose, explore, and adapt various approaches including unsupervised propa-
gation, semi-supervised graph regularization, supervised learning-to-rank and deep
neural networks to model HINs for ranking, classification, and similarity measure-
ment. We achieved the state-of-the-art performance in several NLP tasks. For
instance, we advanced the standard concept relatedness method which is adopted
in many existing wikification and entity link systems.
• We propose methods to construct HINs directly from the noisy raw texts with both
existing social network relations and well-developed NLP approaches. We also
explore cross-genre, cross-platform, and cross-type information to construct HINs.
• We propose a brand-new task: morph decoding, which is crucial to study the fast
evolution language in social media.

CHAPTER 2Background and Relevant Literature
In this chapter, we introduce the necessary background knowledge and review the rel-
evant literature. We first formally define homogeneous and heterogeneous information
networks and introduce their applications. Next, we survey the graph-based approaches
for ranking, similarity measurement, and classification that have broad applications in the
field of data mining and NLP. In this thesis, we also extend and exploit these approaches
to resolve our problems. Finally, we review the related research to our overall thesis topic
with an emphasis on the informal microblog genre data.
2.1 Homogeneous and Heterogeneous Information NetworksTwo core concepts for this thesis are homogeneous and heterogeneous information
networks. Formally, an information network can be defined as a directed graph G =
(V , E) with an object type mapping function ⌧ : V ! A and a link type mapping function
� : E ! R, where each object v 2 V belongs to one particular object type ⌧(v) 2 A,
each link e 2 E belongs to a particular relation �(e) 2 R. If two links belong to the
same relation type, then they share the same starting object type as well as the same
ending object type. An information network is homogeneous if and only if there is only
one type for both objects and links, and an information network is heterogeneous when
the objects are from multiple distinct types or there exist more than one type of links.
Figure 2.1(a) shows an example of heterogeneous DBLP bibliographic network, which
includes three types of objects: venues, papers, and authors. The links between papers
and venues indicate “publishing or “published by” relationship, the links between papers
Portions of this chapter previously appeared as: H. Huang, A. Zubiaga, H. Ji, H. Deng, D. Wang, H.Le, T. Abdelzaher, J. Han, A. Leung, J. Hancock, and C. Voss, “Tweet ranking based on heterogeneousnetworks,” in Proc. of the 24th Int. Conf. on Comput. Linguist., Mumbai, India, 2012, pp. 1239–1256.
H. Huang, Y. Cao, X. Huang, H. Ji, and C.-Y. Lin, “Collective tweet wikification based on semi-supervised graph regularization,” in Proc. of the 52nd Annu. Meeting of the Assoc. for Comput. Linguist.,Baltimore, Maryland, 2014, pp. 380–390.
H. Huang, Z. Wen, D. Yu, H. Ji, Y. Sun, J. Han, and H. Li, “Resolving entity morphs in censoreddata,” in Proc. of the 51st Annu. Meeting of the Assoc. for Comput. Linguist., Sofia, Bulgaria, 2013, pp.1083–1093.
16

17
and authors indicate “writing” or “written by” relationship, and the links between papers
and papers indicate “citing” or “cited by” relationship. Figure 2.1(b) shows an example
of homogeneous co-author network, there exists only one type of objects (e.g., authors)
and one type of relation (e.g., co-author relationship).
ACL
COLING
MorphRes
TweetRank
Wikifcation
(a) (b)
Figure 2.1: (a) Heterogeneous DBLP biobiographic network, (b) Homogeneous co-author network.
Topic
Venue
Paper Authorwrite-1
write
mention-1
mention
publish Publish-1
contain/contain-1
Figure 2.2: Schema of the heterogeneous DBLP biobiographic network.
There has been extensive previous work on homogeneous information networks in
various tasks such as ranking, classification, clustering, link analysis and prediction [26],
[45]–[52]. In recent years, mining directly over heterogeneous information networks
(HINs) has been received increasing attentions, and has demonstrated advantages over
the approaches relying on homogeneous networks in the field of data mining. This is
mainly because the later is an information loss projection of the former. For example,

18
the co-author network only contains the co-author relationship, while other information
regarding papers and venues is missing.
One specific type of HINs is the web-scale knowledge graphs (KGs) such as DBpe-
dia and Freebase with an example shown in Figure 1.5. Semantic KGs contain millions
of concepts and store a huge amount of knowledge from structured facts, concept types,
to textual descriptions. Each fact is represented as a triple connecting a pair of concepts
by a certain relationship and of the form {left concept, relation, right concept}. For
instance, {Miami Heat, Founded, 1988} indicates the fact that the basketball team Miami
Heat was founded in 1988. Semantic KGs have been demonstrated to be useful resources
for external knowledge mining for entity and relation extraction [53], [54] and corefer-
ence and entity linking [55], [56]. Some recent work learned distributed representations
for concepts directly from KGs for semantic parsing [57], link prediction [42], [43], [58],
and question answering [59], [60]. By learning the distributed representations such that
the existing relationships between entities are preserved, new relationships can be inferred
to complete the KGs.
An important concept defined over HINs is meta path, which is a path defined over
a network and composed of a sequence of relations between different object types [24].
For example, Table 2.1 shows a set of meta paths extracted from the DBLP bibliographic
network with the network schema as shown in Figure 2.1 [23]. Each meta path normally
has its own semantic meaning. For instance, the path “A - P - A” indicates that two author
ai and aj are co-authors. The meta path concept has been successfully applied to enhance
various tasks, including link prediction [23], similarity search [24], clustering [22], and
classification [21]. The advantages of meta path-based approaches are that they have
better ability to capture the different semantic meanings of each type of path.
2.2 Graph-based Approaches2.2.1 Ranking
Link-based ranking approaches are an important class of ranking algorithms that
utilize link structures to determine the authority or importance of a node in a network. We
survey several popular link-based ranking algorithms based on homogeneous or hetero-
geneous networks.

19
Table 2.1: Meta paths in DBLP bibliographic network.
Meta Path Semantic Meaning of the PathA - P - A ai and aj are co-authorsA - P! P - A ai cites ajA - P P - A ai is cited by ajA - P - V - P - A ai and aj publish in the same venuesA - P - A - P - A ai and aj are co-authors of the same authorA - P - T - P - A ai and aj write papers on the same topicA - P! P! P - A ai cites papers that cite ajA - P! P P - A ai and aj cites the same paperA - P P! P - A ai and aj are cited by the same paper
PageRank. The first important link-based ranking algorithm is PageRank [45],
which is a random-walk based weight propagation algorithm. The underlying assump-
tion of the PageRank algorithm is that both the number of nodes pointing to a node and
the quality of these nodes are important for object ranking. High-quality nodes should
have higher contributions. Given a graph G = (V,E), where V is a set of nodes and E as
a set of edges. The PageRank can be formulated as:
ri = (1� d) + d ⇤X
vj
2In(vi
)
rj|Out(vj)|
.
where vi is a vertex with ri as the ranking score, In(vi) is the set of nodes that have
links to vi, and Out(vi) is the set of nodes that have links from vi, |Out(vj)| is the size of
of the set Out(vi). d is a damping factor, which controls that probability that the random
walk from the current node continues.
Many variant versions of PageRank have been proposed to handle weighted or undi-
rected graphs. For example, TextRank [26] was proposed rank sentences in a weighted
and undirected sentence graphs for document summarization, which can be formulated as
follows:
ri = (1� d) + d ⇤X
vj
2In(vi
)
wjirjX
vk
2Out(vj
)
wjk
.
Another variant is Personalized PageRank [47] by including the personalization
evidence r0(vi) for each node vi, which can be formulated as:

20
ri = (1� d)r0i + d ⇤X
vj
2In(vi
)
rj|Out(vj)|
.
HITS. HITS [46] is another popular link-based ranking algorithm. Its main differ-
ence with PageRank is that a specific type of nodes called Hubs is created and used. The
authors claimed that good authorities are not necessary to point to other good authorities,
but good authorities should be linked by many good hubs. A good hub points to many
good authorities. In HITS, each node vi has two scores: authority score ai and hub score
hi. It can be formally presented as:
ai =
X
vj
2In(vi
)
hj,
hj =
X
vi
2Out(vj
)
ai.
Co-HITS. Co-HITs [18] is another link analysis algorithm designed over a bipartite
graph with content from two types of objects. The intuition behind the score propagation
is the mutual reinforcement to boost co-linked objects.
Given a bipartite graph G = (U [ V,E), where U and V are two disjoint set of
vertices. We use wuvij (or wvu
ji ) to denote the weight for the edge between ui and vj .
To put all the weights between sets U and V together, we can use W uv 2 R|U |⇥|V | (or
W vu 2 R|V |⇥|U |) to denote the weight matrix between U and V . Note that W uv 2 R|U |⇥|V |
is the transpose of W vu 2 R|V |⇥|U | as we have wuvij = wvu
ji . For each ui 2 U , a transition
probability puvij is defined as the probability that vertex ui in U reaches vertex vj in V
at the next step. Formally, it is defined as a normalized weight puvij =
wuv
ijPk
wuv
ik
, such
thatP
j2V puvij = 1. Similarly, we obtain the transition probability pvuji =
wvu
jiPk
wvu
jk
andP
i2U pvuji = 1 for each vj 2 V .
Then the iterative framework of Co-HITS can be formulated as:
r(ui) = (1� �u)r0
(ui) + �u
X
j2V
pvuji r(vj),
r(vj) = (1� �v)r0
(vj) + �v
X
i2U
puvij r(ui).

21
Where �u 2 [0, 1] and �v 2 [0, 1] are personalized parameters, r0(ui) and r0(vj)
are initial ranking scores for ui and vj , and r(ui) and r(vj) denote updated ranking scores
of vertices ui and vj . When both �u and �v are set to be 1, then it becomes the HITs
algorithm. And when one of the parameters �u or �v is set to be 1, then it becomes to the
personalized PageRank.
2.2.2 Similarity Measurement
Similarity measurement is crucial in this thesis since it is directly related to the
microblog wikification and morph resolution tasks. Accurate similarity measurement
approaches also enable us to construct cleaner networks. We review several commonly
used graph-based similarity measures for link prediction [48]. Given a graph G = (V,E),
where V is a set of nodes, and E is the set of existing links. Then the following measures
can be used to predict the probability of linkage between two nodes x and y. Each of
them provides different angles to measure the similarity between two nodes. When there
is labeled data available, supervised approaches such as learning to rank algorithms can
be leveraged to combine them [16], [23].
Common Neighbors. It measures the size of the common neighbor set between x
and y. In other words, sim(x, y) = |�(x)\�(y)|, where �(x) and �(x) are neighbor sets
for x and y, and |.| is the size of a set.
Jaccards coefficient It is a commonly used similarity measures, which can be for-
mulated as: sim(x, y) = |�(x)\�(y)||�(x)[�(y)| .
Adamic/Adar. It aims to capture the importance of each common neighbor. It re-
fines simple counting of common neighbors by putting lower weights on more frequent
neighbors, which can be formulated as: sim(x, y) =P
z2|�(x)\�(y)|1
log(|�(z))| .
The above measures are based on neighbor sets, and the following are path-based
measures.
Path Count. It measures the number of path instances between x and y.
Random Walk. It measures the probability of a random walk that starts from x and
ends at y.
SimRank. SimRank [49] is also a random walk based approach with the assumption

22
that two similar node should share many similar neighbors, which can be formulated as:
sim(x, y) = �
Pa2�(x)
Pb2�(y) sim(a, b)
|�(x)||�(y)| .
Normalized Google Distance (NGD). NGD [61] was originally invented to measure
the similarity between words and phrases based on their co-occurrence in large-scale
documents. Formally, it can presented as:
NGD(x, y) =logmax(|f(x)|, |f(y)|)� log |f(x) \ f(y)|
log(N)� logmin(|f(x)|, |f(y)|) ,
where x and y are two words/phrases, f(x) is the set of documents that contain x, and
N is a normalizing factor. Intuitively, if two words co-occur in many documents, they
tend to more related to each other. NGD has been combined with Wikipedia anchor
links to measure relatedness of concepts [38], which has been widely adopted in many
wikification and entity linking systems.
The above measures have also been adapted to heterogeneous information networks
with the usage of meta path concept [23], [24]. Let P be a specific type of meta path
between two objects x and y, we summarize some of the similarity measures based on P .
Different from above measures, meta path-based methods only leverage one type of path
each time to compute a specific feature, thus they can capture the unique contributions of
each path.
Path Count. It measures the number of path instances of P between x and y. Specif-
ically, sim(x, y) = |p 2 P|.Random walk. It measures the probability of the random walk that starts from x and
ends at y following meta path P . Namely, sim(x, y) =P
p2P prob(p), where P is the set
of all path instances starting with x and ends with y.
Pairwise random walk. For a meta path P that can be decomposed into two shorter
meta paths with the same length P = (P1
P2
), pairwise random walk s(x, y) measures
the probability of the pairwise random walk that starts from both x and y that reaches the
same mediate object: sim(x, y) =
P(p1p2)2(P1P2)
prob(p1
)prob(p�1
2
), where p�1
2
is the
inverse of p2
.
PathSim. PathSim [24] is proposed to measure similarity between peer objects.

23
Given a symmetric meta path P , the similarity between a two x and y can be defined as
sim(x, y) =2⇥ |{px y : px y 2 P}|
|{px y : px y 2 P}|+ |{px y : px y 2 P}| ,
where pm e is a path instance between m and e that follows the defined meta path P ,
pm m is that between m and m, and pe e is that between e and e.
2.2.3 Semi-supervised Learning
Another important family of graph-based algorithms is the graph-based semi-supervised
or transductive learning algorithms, which exploit the manifold (cluster) structure in both
unlabeled and labeled data [33]–[37]. These approaches normally assume label smooth-
ness over a defined graph, where the nodes represent a set of labeled and unlabeled in-
stances, and the weighted edges reflect the closeness of each pair of instances. The goal
of these approaches are two fold: (i) the refined labels should be close to the annotated la-
bels, (ii) the refined labels should be smooth over the whole defined graph. We summarize
two popular approaches.
Experimental Setting. Denoting a dataset with n instances as X = {x1
, ..., xl, ..., xn},
the label vector as F = {f1
, ..., fl, ..., fn}, where each fi belongs to a label set L, the first
l instances are labeled seeds with labeled vector as Fl, and the remaining n � l ones are
unlabeled instances. Then the goal of these transductive algorithms is to infer labels Fu
for the remaining unlabeled instances based on the defined graph structure constructed
over both labeled and unlabeled data.
Weight matrix computation. Normally, transductive learning relies on a n⇥ n sym-
metric weight matrix W that reveals of the similarity of each pair of instances. Suppose
x 2 Rm and each xi is represented as a m-dimensional feature vector: xi = hxi1, ..., ximi,then a common way to compute W is:
Wij = exp(�mX
d=1
(xid � xjd)2
�2
d
).
Label Propagation. One of the earliest transductive learning algorithm is label
propagation (LP) [33]. It aims to minimize the following objective function to ensure
that unlabeled data instances that are strongly connected in the graph should have similar

24
labels:
⌦(F ) =
1
2
nX
i,j=1
wij(Fi � Fj)2.
LLGC. Another popular transductive learning approach is learning with local and
global consistency (LLGC) [36]. It aims to minimize the following objective function:
⌦(F ) =
1
2
nX
i,j=1
Wij
�����FipDii
� FjpDjj
�����
2
+ µnX
i=1
��Fi � F 0
i
��2 .
There also exist both closed-form and iterative form solutions for LP and LLGC
since their objective functions are convex [33],[36]. In practice, the closed-form solutions
have problems due to scalability and efficiency issues, thus iterative form solutions are
more suitable for practical applications on large-scale datasets. The assumptions of both
LP and LLGC are similar, and the difference mainly lies in the selection of loss function
and regularizer.
2.3 Related Work to the Thesis TopicIn this section, we summarize the previous work related to this thesis.
2.3.1 Ranking in Microblogging
Previous research on microblog ranking has relied on the analysis of content [62],
user credibility [63]–[66] and URL availability, or combinations of them [67], [68]. In
addition, Huang et al.[68] also exploited content similarity to propagate evidence within
the microblog genre. Most work has been based on supervised learning models such
as RankSVM, Naive-Bayes classifier, and Linear Regression. Inouye and Kalita [69]
compared various unsupervised methods to rank microblogs for summarization purposes,
but only used lexical-level content analysis features.
In analyzing the information credibility of microblogs, Castillo et al. [70] relied on
various levels of features (i.e., message-based, user-based, topic-based and propagation-
based features) and supervised learning models for information credibility assessment in
Twitter, which Gupta et.al [71] extended by capturing relations among events, tweets,
and users. A Bayesian model was proposed in [72], [73] to assess microblog credibility.

25
However, it remains as a preliminary approach due to the linear assumption made in the
iterative algorithm of the basic fact-finding scheme. Intensive research has also been
conducted on information credibility analysis (cf. [74]).
In identifying influential users in microblogging services, TwitterRank [75] used a
variant of PageRank algorithm with both content information and link structure to mea-
sure user influence. Pal and Counts [76] leveraged a clustering approach to avoid bias to
highly visible users. Romero et al. [77] analyzed the information forwarding activity of
users and they proved that user popularity did not indicate influence.
2.3.2 Microblog Wikification
The task of linking concept mentions has received increased attentions over the past
several years, from the linking of concept mentions in a single text [11], to the linking
of a cluster of coreferent named entity mentions spread throughout different documents
(Entity Linking) [78], [79].
Building such a linking system requires the solving of two sub-problems: mention
detection and mention disambiguation. A significant portion of recent work considers the
two sub-problems separately and focus on the latter by first defining candidate concepts
for a deemed mention based on anchor links. Mention disambiguation is then formu-
lated as a ranking problem, either by resolving one mention at each time (non-collective
approaches), or by disambiguating a set of relevant mentions simultaneously (collective
approaches). Non-collective methods usually rely on prior popularity and context simi-
larity with supervised models [11],[80],[81], while collective approaches further leverage
the global coherence between concepts normally through supervised or graph-based re-
ranking models [28], [31], [32], [80]–[91]. Especially note that when applying the collec-
tive methods to short messages from social media, evidence from other messages usually
needs to be considered [31], [90], [91].
[92], [93] proposed to perform joint detection and disambiguation of mentions for
tweets. [92] studied several supervised machine learning models, but without considering
any global evidence either from a single tweet or other relevant tweets. [93] explored sec-
ond order entity-to-entity relations but did not incorporate evidence from multiple tweets.

26
2.3.3 Morph Decoding
We propose the brand-new task morph decoding to detect and resolve informal and
implicit morphs to their true targeted entities.
Many of the morphs are created to avoid active censorship. Bamman et al. [94] au-
tomatically discovered politically sensitive terms from Chinese tweets based on message
deletion analysis to analyze social user behavior under active censorship. In contrast, our
work goes beyond target idendification by resolving implicit morphs to their real targets.
Some recent work attempted to detect and normalize Chinese informal words into
formal words [95]–[100]. Information morph discovery also belongs to the category of
anomalous text detection. However, morphs are created and used by social user inten-
tionally to achieve certain communication goals. Not all anomalous texts are used as
morphs (e.g., “Ÿõ(geliable)” to replace “à“(awesome)). In addition, many morphs
are regular terms (e.g., “Conquer West King” and “King”).
Our morph resolution work is closely related to alias detection [16], [17], [101],
[102]. [16], [17] proposed to detect aliases in malicious environments by modeling the
behaviors of the entities with semantic models and information theoretic approach. [101]
studied alias detection problem in the Web with lexical patterns-based and co-occurrence-
based models. However, sensitive morphs rarely co-occur with their real targets, which
fails the pattern-based methods. [102] detected email alias by modeling the collocation
of two email addresses to web pages.

CHAPTER 3Microblog Ranking
In this chapter, we introduce Tri-HITS, a novel propagation model that leverages global
information iteratively computed across heterogeneous networks constructed from web
documents, microblogs, and users, to rank microblogs on a topic by informativeness. We
propose three high-level hypotheses that motivate the presented methods of construct-
ing heterogeneous networks of microblogs, users, and web documents. The proposed
model, Tri-HITS, operates iteratively over all networks incorporating the semantics and
importance of different linkages. By ranking microblogs about the Hurricane Irene, we
demonstrate that incorporating a formal genre such as web documents, inferring implicit
social networks and performing effective ranking score propagation with the proposed
model can significantly improve the ranking quality.
3.1 Motivations and HypothesesNext, we describe the motivational aspects and hypotheses in this work, which we
aim to prove.
Hypothesis 1: Informative tweets are more likely to be posted by credible users;
and vice versa (credible users are more likely to post informative tweets). [67], [68] con-
sider that users who have more followers, mentions, and retweets, and are listed more,
are more likely to be authoritative. They used retweet, reply, user mention and follower
counts to to compute the degree of authoritativeness of users; and showed that user ac-
count authority is a helpful feature for tweet ranking. However, for events of general in-
terest involving multiple communities, users are more likely to be unaware of each other,
and rarely interact. This makes it insufficient to rely on user-user networks constructed
from retweet and reply interactions to compute user credibility scores. To overcome this
problem, we apply a Bayesian approach to compute the credibility of users by incorpo-
rating the contents shared by them.
This chapter previously appeared as: H. Huang, A. Zubiaga, H. Ji, H. Deng, D. Wang, H. Le, T.Abdelzaher, J. Han, A. Leung, J. Hancock, and C. Voss, “Tweet ranking based on heterogeneous networks,”in Proc. of the 24th Int. Conf. on Comput. Linguist., Mumbai, India, 2012, pp. 1239–1256.
27

28
Hypothesis 2: Tweets involving many users are more likely to be informative. Hav-
ing many users share similar tweets at the same time helps identify informative tweets.
For example, in the context of Hurricane Irene, users were likely to share information
about the Evacuation Zone when they found relevant news or events. The synchronization
of information within groups has been successfully harnessed in other fields like financial
trading, autonomous swarms of exploratory robots, and flocks of communicating software
agents [103]. This idea has also been successfully exploited for event summarization from
tweets [104].
Hypothesis 3: Tweets aligned with contents of web documents are more likely to
be informative. Tweets come from diverse sources, and can diverse content ranging from
news and events, to conversations and personal status updates. Therefore, informative
tweets tend to be interspersed with noisy and non-informative tweets. This differs from
formal genres such as web documents, which tend to be cleaner. In the case of current
events such as natural disasters or political elections, there are tight correlations between
social media and web documents. Important information shared in social media tends
to be posted in web documents. For example, the following informative tweets would
rank highly because they are linked to informative web documents: ” New Yorkers, find
your exact evacuation zone by your address here: http://t.co/9NhiGKG /via @user #Irene
#hurricane #NY” and ”Details of Aer Lingus flights affected by Hurricane Irene can be
found at http://t.co/PCqE74V201d”. As far as we know, this is the first work to integrate
information from a formal genre such as web documents to enhance tweet ranking.
3.2 Our Proposed Approach: Tri-HITSBased on the formulated hypotheses, we describe how Tri-HITS works. Tri-HITS
is developed over the heterogeneous networks that include web documents, tweets, and
users, as shown in Figure 3.1.
3.2.1 Overview
Figure 3.2 depicts how Tri-HITS works. For a set of tweets on a specific topic,
a rule-based filtering component is first applied to filter out a subset of non-informative
tweets. For the remaining tweets, we define queries based on top terms in tweets, and use

29
U1
U2
U3
T1
T2
T3
T4
D1
D2
D3
Web-Tweet Networks Tweet-User Networks
Web-Tweet-User Networks
Figure 3.1: Web-Tweet-User heterogeneous networks.
Bing Search API [105] to retrieve the titles 2 of the top m web documents for those queries
(m = 2 for these experiments). Then we apply TextRank and a Bayesian approach that
initialize ranking scores for tweets, web documents, and users. Finally, we iteratively
propagate ranking scores for web documents, tweets, and users across the networks to
refine the tweet ranking.
3.2.2 Filtering non-informative Tweets
Tweets are more likely to be shortened or informally written than texts from a for-
mal genre such as web documents. Thus, a prior filtering step would clean up the set
of tweets and improve the ranking quality. We observed that numerous non-informative
tweets have some common characteristics, which help infer patterns to clean up the set of
tweets. In our filtering method, we define several patterns to capture the characteristics
of a non-informative tweet, i.e., very short tweets without a complementary URL, tweets
with first personal pronouns, or informal tweets containing slang words [106]. These fea-
tures have been shown to be effective in previous work on tweet ranking and information
credibility [66], [67], [70]. Our filtering component accurately filters out non-informative
tweets, achieving 96.59% at precision.2We rely on page titles, but it could be extended to the whole content of web documents straightfor-
wardly.

30
Tweets T
Query Construction And Retrieval of Web Documents D
Ranked Tweets Based on
Informativeness
Iterative Propagation
Heterogeneous Networks
Heterogeneous Networks Construction
Infer Implicit U-T Links
Noisy Tweet Filtering
Users U
Initialize Ranking Scores
Align T-D
Figure 3.2: Overview of Tri-HITS.
3.2.3 Initializing Ranking Scores
Initializing scores for tweets and web documents. For a set of tweets T , we first
construct an undirected and weighted graph G = (V,E). After removing stopwords and
punctuations, the bag-of-words of each tweet ti is represented as a vertex vi 2 V , and the
weight for the edge between tweets is the cosine similarity using TF-IDF representations.
Then, we use TextRank to compute initial scores. The same approach is used to initialize
ranking scores for web documents.
Initializing user credibility scores. Based on Hypothesis 1, we define two ap-
proaches to compute initial user credibility scores. First, we construct a user network
based on retweets, replies and user mentions as in [67]. This results in a directed and
weighted graph Gd = (V,E), where V is the set of users and E is the set of directed
edges. A directed edge exists from ui to uj if user ui interacts with uj (i.e., mentions,
retweets, or replies to uj). The weight of the edge is defined as Nij , according to the

31
number of interactions. In this case, we use TextRank to compute initial user credibility
scores.
In addition, we also use the Bayesian ranking approach [72], [73] that considers
the credibility scores of tweets and users simultaneously based on Tweet-User networks.
Given a set of users U = {u1
, u2
, ..., um}, and a set of claims C = {c1
, c2
, ..., cn} the
users make (each claim corresponds to a cluster of tweets in this paper). We also define
matrix W cu where wcuji = 1 if user ui makes claim cj , and is zero otherwise. Let ut
i
denote the proposition that ’user ui speaks the truth’. Let ctj denote the proposition that
’claim cj is true’. Also, let P (uti) and P (ut
i|W cu) be the prior and posterior probability
that user ui speaks the truth. Similarly, P (cti) and P (cti|W cu) are the prior and posterior
probability that claim ci is true. We define the credibility rank of a claim Rank(cj) as the
increase in the posterior probability that a claim is true, normalized by prior probability
P (cti). Similarly, the credibility rank of a user Rank(ui) is defined as the increase in the
posterior probability that a user is credible, normalized by prior probability P (uti). In
other words, we can get:
Rank(cj) =
P (ctj|W cu)� P (ctj)
P (ctj)(3.1)
Rank(ui) =
P (uti|W cu
)� P (uti)
P (uti)
(3.2)
In our previous work, we showed that the following relations hold true regarding
the credibility rank of a claim Rank(cj) and a user Rank(ui):
Rank(cj) =
X
k2Usersj
Rank(uk) (3.3)
Rank(ui) =
X
k2Claimsi
Rank(ck) (3.4)
where Usersj is the set of users makes claim cj , and Claimsi is the set of claims
the user ui makes. From the above, the credibility of sources and claims can be derived

32
as:
P (ctj|W cu) = pta(Rank(cj) + 1) (3.5)
P (uti|W cu
) = pts(Rank(ui) + 1) (3.6)
where pta and pts are initialization constants, which are the ratio of true claims to the total
claims, and the ratio of credible users to the total users.
Then, Equation 3.6 is used to compute initial user credibility scores as our second
approach.
3.2.4 Constructing Heterogeneous Networks
Next, we describe the two types of networks we build as constituent parts of het-
erogeneous networks:
Tweet-User networks. Based on Hypothesis 2, we expand the Tweet-User net-
works by inferring implicit tweet-user relations. If a user ui posted a set of tweets Ti
during a period of time, we say an implicit relation exists between ui and a tweet tj if the
maximum cosine similarity between tj and ti 2 Ti exceeds or equals a threshold �tu.
Web-Tweet networks. Given a set of tweets T and a set of associated web docu-
ments D, we build a bipartite graph G = T [D,E, where an undirected edge with weight
wtdij is added when the cosine similarity between ti 2 T and dj 2 D exceeds or equals
�td. This approach creates cross-genre linkages between tweets and web documents on
similar events (e.g., evacuation events).
In subsection 4.6, we will discuss the effects of parameters �td and �tu.
3.2.5 Iterative Propagation
We introduce a novel algorithm to incorporate both initial ranking scores and global
evidence from heterogeneous networks. It propagates ranking scores across heteroge-
neous networks iteratively. Our algorithm is an extension of Co-HITS [18], which we
introduced in detail in Chapter 2.
The problem with Co-HITS in our experimental settings is the transition probabil-
ity. As mentioned before, we choose cosine similarity as the weight for the edge between
two vertices, and a similarity matrix W is obtained to denote the weight matrix where

33
each entry wij is the similarity between vertex ui and vertex vj . Although the transition
probability is a natural normalization for the weight between two vertices, it may not be
suitable for similarity matrix. The reason is that the original similarity between different
objects has already been normalized, so a further normalization from the similarity matrix
to transition matrix may weaken or damage inherent meanings of the original similarity.
For example, if a tweet ui is aligned with one and only one document vj with relatively
low similarity weight, the transition probability wuvij will be increased to 1 after normal-
ization. Similarly, some higher similarity weights may be normalized to small transition
probabilities.
By extending and adapting Co-HITS, we develop Tri-HITS to handle heteroge-
neous networks with three types of objects: users, tweets and web documents. Given the
similarity matrices W dt (between documents and tweets) and W tu (between tweets and
users), and initial ranking scores of s0(d), s0(t) and s0(u), we aim to refine the initial
ranking scores and obtain the final ranking scores s(d), s(t) and s(u). Starting from doc-
ument s(d), the update process considers both the initial score s0(d) and the propagation
from connected tweets s(t), which can be expressed as:
s(di) =
X
j2T
wtdjis(tj),
s(di) = (1� �td)s0
(di) + �tds(di)Pi s(di)
, (3.7)
where W td is the transpose of W dt, and �td 2 [0, 1] is the parameter to balance between
initial and propagated ranking scores. Tri-HITS normalizes the propagated ranking scores
s(di), while Co-HITS propagates normalized ranking scores by using the transition matrix
instead of the original similarity matrix, potentially weakening or damaging the inherent
meanings of the original similarity. Similarly, we define the propagation from tweets to
users as:
s(uk) =
X
j2T
wtujks(tj),
s(uk) = (1� �tu)s0
(uk) + �tus(uk)Pk s(uk)
, (3.8)

34
Each tweet s(tj) may be influenced by the propagation from both documents and users:
sd(tj) =
X
i2D
wdtij s(di),
su(tj) =
X
k2U
wutkjs(uk),
s(tj) = (1� �dt � �ut)s0
(tj) (3.9)
+�dtsd(tj)Pj sd(tj)
+ �utsu(tj)Pj su(tj)
.
where W ut is the transpose of W tu, �dt and �ut are parameters to balance between initial
and propagated ranking scores. The � variables define the networks being considered: (i)
when �dt is set to 0, only Tweet-User networks are considered (Method 3 in Table 3.1);
(ii) when �ut is set to 0, only Web-Tweet networks are considered (Method 4); (iii) when
both �dt and �ut are different from 0, the entire heterogeneous Web-Tweet-User network
is considered (Method 5). For methods relying on bipartite graphs, we define as one-step
propagation when the propagation is performed in a single direction, while we call it
two-step propagation when it is performed in both directions. The selection of one-step
propagation and two-step propagation is controlled by � parameters.
Model Convergence Proof: From Equation (3.7), and assuming �td > 0 (the rank-
ing scores s(d) for web documents would not change if �td = 0), we get:
s(di) =1
�td
[s(di)� (1� �td)s0
(di)] =s(di)Pi s(di)
. (3.10)
s(d), the normalized score of s(d), is similar to the normalized authority or hub scores
defined in HITS [46], the difference being only the function to select vector norms. Klein-
berg proved that s(di) converges as the iterative procedure continues, from which the
convergence of the ranking scores s(d) for web documents is guaranteed. The same as-
sumption proves the convergence of ranking scores for tweets and users.
Algorithm 1 summarizes Tri-HITS.
3.2.6 Redundancy Removal
Since a list of top-ranked tweets might contain redundant information, diversity is
an important factor to be considered. Diversity has been previously considered, not only

35
Input: A set of tweets (T ), and users (U ) on a given topic.Output: Ranking scores (St) for T .
1: Use rule-based method to filter out noisy tweets (remaining T posted by users U );2: Retrieve relevant web documents D for T ;3: Use TextRank and Bayesian Ranking to compute initial ranking scores S0
t for T , S0d for D
and initial credibility scores S0u for U ;
4: Construct heterogeneous networks across T , U and D;5: k 0, diff 10e6;6: while k < MaxIteration and diff > MinThreshold do7: Use Eq. (3.9) to compute Sk+1
t ;8: Use Eq. (3.8) to compute Sk+1
u ;9: Use Eq. (3.7) to compute Sk+1
d ;10: Normalize Sk+1
t ,Sk+1d , and Sk+1
u ;11: diff
P(|Sk+1
t � Skt |);
12: k k + 113: end while
Algorithm 1: Tri-HITS: Tweet ranking using heterogeneous networks
for information retrieval [107], but also for multi-document summarization [108]. Since
users on Twitter can be tweeting similar information obliviously, and retweet and reply
others’ tweets, redundancy has been shown to be a pervasive phenomenon [109]. This
issue has not been considered in previous works on tweet ranking [67], [68]. In this work,
we perform a redundancy removal step to diversify top ranked tweets. To do so, we adopt
the widely used greedy procedure [107], [108] to apply redundancy removal on top of
Tri-HITS. Based on the initial ranking of each approach, tweet ti in position i is pruned
when the cosine similarity with tj 2 [t1
, ti�1
] in upper ranked positions exceeds or equals
a predefined threshold �red3
3.3 ExperimentsNext, we present the experiment settings and analyze the methods shown in Ta-
ble 3.1.
3.3.1 Data and Evaluation Metric
We use tweets on the Hurricane Irene from August 26 to September 2, 2011 for our
experiments. Using the query terms hurricane or irene to monitor tweets, we collected3We choose �red = 0.6 as a threshold, obtained from our empirical studies with values from 0.1 to 1.0
in the development set.

36
Table 3.1: Description of methods (method with ⇤ make use of the Bayesian ap-proach to initialize user credibility scores.
Methods Descriptions Hypotheses1. Baseline TextRank based on tweet-tweet networks.2. 1+Filtering Baseline with filtering included.3. 2+Tweet-User⇤ Propagation on explicit and implicit Tweet-User
networks.1 and 2
4. 2+Web-Tweet Propagation on Web-Tweet networks. 35. 3+4 Web-Tweet-User⇤
Propagation on Web-Tweet-User networks. all
176,014 tweets posted by 139,136 users within that timeframe. For evaluation purposes,
we segment the tweets into 153 hours with an average of 1,150 tweets in each hour.
! The$quality$of$a$tweet$was$judged$to$a$54star$likert$scale,$according$to$informa;veness$and$readability$of$the$content.$Tweets$with$grade$5$are$the$most$informa;ve,$while$tweets$with$label$1$are$the$least$informa;ve.$Two$basic$criteria$that$judge$the$informa;veness$of$a$tweet$are:$(1)$Whether$the$tweet$is$likely$to$be$news?$(2)$Does$the$tweet$include$informa;on$that$a$general$audience$will$be$concerned$about$during$an$event?$
! Tweets$with$label$5$are$very$informa;ve$and$have$good$readability.$They$can$be$used$as$news$;tles$directly.$o AP)$44$NYC$Mayor$Michael$Bloomberg$has$ordered$mandatory$
evacua;ons$for$residents$in$low4lying$coastal$areas$ahead$of$Hurricane$Irene.$
! Tweets$with$label$4$are$informa;ve$and$have$good$readbility.$o Patch$Storm$Tracker:$Follow$the$track$of$Hurricane$Irene$here.$hSp://
t.co/iSI8kzL$! Tweets$with$label$3$are$informa;ve$but$readability$is$not$good.$
o 'Prayer$for$the$US$RT$@etharkamal:$RT$@guardiannews:$Hurricane$Irene$hits$New$York$\u2013$live$updates$hSp://t.co/t0ZHFqB$
! Tweets$with$label$2$can$provide$some$limited$informa;on.$o About$to$leave$for$school$and$hurricane$Irene$decides$to$hit$
#whaShefuck$! Tweets$with$label$1$can$not$provide$any$useful$informa;on.$
o Me,$Myself,$and$Hurricane$Irene.$
Figure 3.3: Annotation guideline for tweet ranking.
We randomly chose tweets from three hours to be manually annotated as our ref-
erence. This subset contains 3,460 tweets posted on different days: August 27, 2011,
August 28, 2011 and September 1, 2011. Following the annotation guidelines defined by
[68], two annotators parallelly assigned each tweet a grade in a 5-star likert scale. The

37
Table 3.2: Tweet distribution by grade.
Grade 5 4 3 2 1Hour 1 65 48 93 119 847Hour 2 135 159 255 164 458Hour 3 129 102 162 123 602
annotation guideline is as shown in Figure 3.3. Tweets with grade 5 are the most infor-
mative, while tweets with label 1 are the least informative. When the label difference
between annotators was 1, the lower grade was selected. When the label difference was
greater than 1, those tweets were re-annotated until the label difference did not exceed 1.
Table 3.2 shows the distributions of all grades for each of the three hours of tweets.
To evaluate tweet ranking, we rely on three-fold cross validation using nDCG as a
measure [110], which considers both the informativeness, and the position of a tweet:
nDCG(�, k) =1
|�|
|�|X
i=1
DCGik
IDCGik
,
DCGik =
kX
j=1
2
relij � 1
log(1 + j),
where � is the set of documents in the test set, each document corresponding to
an hour of tweets in our case, relij is the human-annotated label for the tweet j in the
document i, and IDCGik is the DCG score for the ideal ranking. The average nDCG
score for the top k tweets is: Avg@k =
Pki=1
nDCG(�, i)/k. To favor diversity of top
ranked tweets, redundant tweets are penalized to lower down the final score.
3.3.2 Effect of Parameters
We study the impact of different parameters on the training set. We present the
most representative figures to show the effect, due to the lack of space. For TextRank, we
explore �tt values from 0 to 1. For the enhanced approaches, we firstly perform one-step
propagation of ranking scores from web documents to tweets by considering all pairs of
�td and �dt from 0 to 1 with a step of 0.1. For each �td, the corresponding �dt and the
best average nDCG scores for top 10 and 100 tweets are shown in Figure 3.4(a). We no-
tice that when both initial tweet ranking scores and propagated ranking scores from web

38
documents are considered (i.e., �td is set from 0 to 0.9 and �dt > 0), the ranking quality
outperforms that by simply considering initial ranking scores of tweets (i.e. �td = 1).
Secondly, for the ranking performance of double-step ranking scores propagation, we
choose to set �td = 0.1, �dt = 0.4 and test �td from 0 to 1. Figure 3.4(b) shows an
encouraging improvement in the ranking quality, and more stable over the baseline and
one-step propagation. This suggests that two-step propagation provides mutual improve-
ment in the ranking quality. The reason is that the ranking of web documents may also be
refined using tweet and user evidence thanks to the large volume and synchrony of tweet-
ing [109]. Here, �td = 0.2 yields the best performance. The aforementioned process is
followed for Tweet-User networks, finding the best performance for �tu = 0.1, �ut = 0.2,
and �tu = 0.6.
When validating on the test set, Method 4 based on Web-Tweet networks outper-
forms Method 3 relying on Tweet-User networks. Therefore, for Web-Tweet-User net-
works, we keep the above values, and explore �ut values from 0 to 0.6 (e.g., 1 � �dt).
Figure 3.4(c) shows that integrating web documents, tweets and users, the ranking qual-
ity improves over both Web-Tweet networks and Tweet-User networks.
0.0 0.2 0.4 0.6 0.8 1.00.60
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
0.0 0.2 0.4 0.6 0.8 1.00.60
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
0.0 0.2 0.4 0.60.60
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
λut λtd
Ave
rage
nD
CG
0.3
0.10.1
0.10.1
0.1
0.2
0.30.4
0.6
Ave
rage
nD
CG
λdt=0.2
Avg@10 Avg@100
(a) (b)δtd=0.1, λdt=0.4
Avg@10 Avg@100
(c)δtu=0.1, δtd=0.1, λtu=0.6, λdt=0.4, λtd=0.2
Avg@10 Avg@100
Ave
rage
nD
CG
δtd
Figure 3.4: Effect of parameters: (a) �td and �dt for Web-Tweet networks, (b) �td forWeb-Tweet networks, (c) �dt for Web-Tweet-User networks.
3.3.3 Performance and Analysis
Figure 3.5 shows the performance of ranking methods. The performance gain from
Method 1 to Method 2 shows the need of filtering short and informal tweets. In this case,
filtering reduced from 3,460 to 1,765 tweets (⇠ 49% reduction). Table 3.3 shows the
distribution of labels for filtered tweets: a great majority of 91.75% had been annotated

39
1 2 3 4 5 6 7 8 9 100.50
0.55
0.60
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
nDCG@n
n
1. TextRank 2. 1+Filtering 3. 2+Tweet-User 4. 2+Web-Tweet 5. 3+4Web-Tweet-User
1
2
3
4
5
Figure 3.5: Performance comparison of ranking methods.
as 1, while only 0.11% had been annotated as 5.
Methods 3, 4 and 5, which integrate heterogeneous networks after filtering, out-
perform the baseline TextRank. When tweets are aligned with web documents (Method
4), the ranking quality improves significantly, proving that web documents can help infer
informative tweets adding support from a formal genre. The fact that tweets with low ini-
tial ranking scores are aligned with web documents helps improve their ranking positions
(Hypothesis 3). For example, the ranking of the tweet “Hurricane Irene: City by City
Forecasts http://t.co/x1t122A” is improved compared to TextRank, helped by the fact that
10 retrieved web documents are about this topic.
Integrating users (Method 5) further improves performance. This indicates that
Web-Tweet and Tweet-User networks may complement each other in improving rank-
ing. For example, the tweet “A social-media guide to dealing with Hurricane Irene
http://t.co/0XBEnEJ” is not top-ranked when only using Web-Tweet networks, since none
of the retrieved web documents is related to it. However, similar tweets appear with high
frequency in the tweet set. Hence, inferring implicit tweet-user relations and propagating
information through the tweet-user network also improves the ranking.
Figure 3.6(a) shows that inferring implicit tweet-user relationships outperforms the
only use of explicit tweet-user relations, especially for top positions. Looking into lower

40
Table 3.3: Grade distributions for filtered tweets.
Grade 5 4 3 2 1Percentage 0.11% 0.17% 3.13% 4.84% 91.75%
1 2 3 4 5 6 7 8 9 10
0.60
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
1 2 3 4 5 6 7 8 9 10
0.60
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
nn
Explicit+Implicit Tweet-User Networks Explicit Tweet-User Networks
nDCG@n
(a)
TextRank+FilteringRetweet/Reply/User-
Mention RelationsBayesian Approach
nDCG@n
(b)
Figure 3.6: (a) Explicit vs inferred implicit Tweet-User relations to construct Tweet-User networks; (b) TextRank vs one-step propagation on explicit Tweet-User networks using bayesian approach and retweet/reply/user mentionrelations.
positions, we find that the redundancy removal performs better for the only use of explicit
relations. However, both approaches can still perform similarly in positions 5 ⇠ 10. This
corroborates the synchronous behavior of users as an indicator of informative contents
(Hypothesis 2). Since it is likely that a large set of users only tweet once within a short
timeframe, limiting to explicit tweet-user relations results in sparse links, and ranking
quality cannot be bootstrapped. Interestingly, inferring implicit tweet-user relations can
capture synchronous behavior of users, which indicates subjects that users are concerned
about.
Figure 3.6(b) shows that initializing user credibility scores with the Bayesian ap-
proach and performing one-step ranking score propagation from users to tweets based
on the explicit tweet-user networks also outperforms TextRank. This corroborates our
hypothesis that credible users are more likely to post informative tweets (Hypothesis 1).
In addition, using only retweets, replies, and user mentions to compute initial user rank-
ing scores, the performance does not improve over TextRank. The reason is that for an
event of general interest like the Hurricane Irene, users from different communities rarely
interact with each other.
Finally, Figure 3.7 shows that Tri-HITS significantly outperforms Co-HITS over
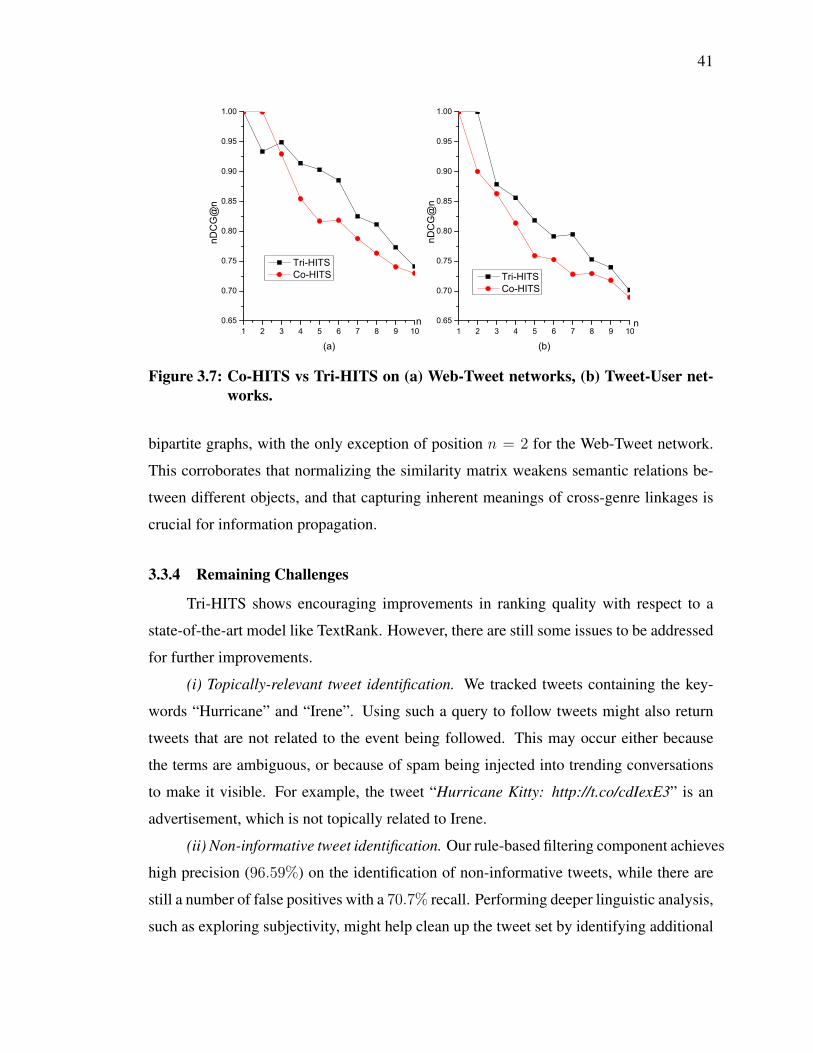
41
1 2 3 4 5 6 7 8 9 100.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
1 2 3 4 5 6 7 8 9 100.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
Tri-HITS Co-HITS
n
nDCG@n
(a)
n
nDCG@n
Tri-HITS Co-HITS
(b)
Figure 3.7: Co-HITS vs Tri-HITS on (a) Web-Tweet networks, (b) Tweet-User net-works.
bipartite graphs, with the only exception of position n = 2 for the Web-Tweet network.
This corroborates that normalizing the similarity matrix weakens semantic relations be-
tween different objects, and that capturing inherent meanings of cross-genre linkages is
crucial for information propagation.
3.3.4 Remaining Challenges
Tri-HITS shows encouraging improvements in ranking quality with respect to a
state-of-the-art model like TextRank. However, there are still some issues to be addressed
for further improvements.
(i) Topically-relevant tweet identification. We tracked tweets containing the key-
words “Hurricane” and “Irene”. Using such a query to follow tweets might also return
tweets that are not related to the event being followed. This may occur either because
the terms are ambiguous, or because of spam being injected into trending conversations
to make it visible. For example, the tweet “Hurricane Kitty: http://t.co/cdIexE3” is an
advertisement, which is not topically related to Irene.
(ii) Non-informative tweet identification. Our rule-based filtering component achieves
high precision (96.59%) on the identification of non-informative tweets, while there are
still a number of false positives with a 70.7% recall. Performing deeper linguistic analysis,
such as exploring subjectivity, might help clean up the tweet set by identifying additional

42
non-informative tweets. For example, an analysis of writing styles would help identify
the tweet “Hurricane names hurricane names http://t.co/iisc7UY ;)” as informal because
it contains repeated phrases. And the tweet “My favorite parts of Hurricane coverage is
when the weathercasters stand in those 100 MPH winds right on the beach. Good stuff.”
is clearly subjective commentary that may entertain but will not meet the general interest
of people involved with or tracking the event.
(iii) Deep semantic analysis of the content. Users may rely on distinct terms to
refer to the same concept. More extensive semantic analyses of text could help iden-
tify those terms, possibly enhancing the propagation process. For example, information
extraction tools can be used to extract entities and events, and their coreferential rela-
tions, such as “NYC” and “New York City”, or “MTA closed” and “subway shutting
down”. Likewise, existing dictionaries such as WordNet [111] can be utilized to mine
synonym/hypernym/hyponym relations, and Brown clusters [112] can be explored to
mine other types of relations.
3.4 SummaryIn this chapter,
(1) We have introduced Tri-HITS, a novel propagation model that makes use of het-
erogeneous networks composed of tweets, users, and web documents to rank tweets based
on informativeness. This approach can help filter noisy and uninformative information for
end users, and alleviate the “information noiseness” problem in microblogging.
(2) We have conducted cross-genre information analysis between the formal genre
of web documents and the informal genre micrblogs.
(3) We have inferred more social network relations in order to capture the collective
wisdom of the crowd and extract more effective evidence from social networks.
(4) We have studied the integration of different genres to capture the discrepancy of
“tweet - user” and “tweet - web” networks.

CHAPTER 4Microblog Wikification
In Chapter 3, we have proposed to identify informative microblogs to alleviate the “in-
formation noiseness” problem. However, effective information filtering fails to enrich the
short microblogs with rich and clean background knowledge. In this chapter, we intro-
duce our collective inference Wikification approach and deep semantic relatedness model
to enhance microblog wikification so that we can enrich the short microblogs with back-
ground knowledge from a knowledge base. Our designed collective inference model is
based on semi-supervised graph regularization that leverages both a small amount of la-
beled microblogs and a large amount of unlabeled microblogs. And the deep semantic
relatedness model is designed to enhance concept semantic relatedness measurement for
topical coherence modeling.
4.1 PreliminariesConcept and Concept Mention: We define a concept c as a Wikipedia article
(e.g., Atlanta Hawks), and a concept mention m as an n-gram from a specific tweet.
Each concept has a set of textual representation fields [92], including title (the title of the
article), sentence (the first sentence of the article), paragraph (the first paragraph of the
article), content (the entire content of the article), and anchor (the set of all anchor texts
with incoming links to the article).
Wikipedia Lexicon Construction: We first construct an offline lexicon with each
entry as hm, {c1
, ..., ck}i, where {c1
, ..., ck} is the set of possible referent concepts for
the mention m. Following the previous work [82], [113], [114], we extract the possible
mentions for a given concept c using the following resources: the title of c; the aliases
appearing in the introduction and infoboxes of c (e.g., The Evergreen State is an alias
of Washington state); the titles of pages redirecting to c (e.g., State of Washington is a
Portions of this chapter previously appeared as: H. Huang, Y. Cao, X. Huang, H. Ji, and C.-Y. Lin,“Collective tweet wikification based on semi-supervised graph regularization,” in Proc. of the 52nd Annu.Meeting of the Assoc. for Comput. Linguist., Baltimore, MD, USA, 2014, pp. 380–390.
43

44
redirecting page of Washington (state)); the titles of the disambiguation pages containing
c; and all the anchor texts appearing in at least 5 pages with hyperlinks to c (e.g., WA
is a mention for the concept Washington (state) in the text “401 5th Ave N [[Seattle]],
[[Washington (state)—WA]] 98109 USA”. We also propose three heuristic rules to extract
mentions (i.e., different combinations of the family name and given name for a person,
the headquarters of an organization, and the city name for a sports team).
Concept Mention Extraction: Based on the constructed lexicon, we then consider
all n-grams of size n (n=7 in this paper) as concept mention candidates if their entries
in the lexicon are not empty. We first segment @usernames and #hashtags into regular
tokens (e.g., @amandapalmer is segmented as amanda palmer and #WorldWaterDay is
split as World Water Day) using the approach proposed by [115]. Segmentation assists
finding concept candidates for these non-regular mentions.
4.2 Principles and Approach Overview
Relational Graph Construction
Knowledge Base (Wikipedia)
Labeled and Unlabeled Tweets
Wikipedia Lexicon ConstructionConcept Mention and
Concept Candidate Extraction
Local Compatibility(local features, cosine similarity)
Coreference(meta path,
mention similarity)
Semantic Relatedness(meta path, concept semantic relatedness)
Semi-Supervised Graph Regularization
<Mention, Concept>Pairs
Figure 4.1: Approach overview.

45
4.2.1 Principles
A single tweet may not provide enough evidence to identify prominent mentions
and infer their correct referent concepts due to the lack of contextual information. To
tackle this problem, we propose incorporating global evidence from multiple tweets and
performing collective inference for both mention identification and disambiguation. We
first introduce the following three principles that our approach relies on.
Principle 1 (Local compatibility): Two pairs of hm, ci with strong local compat-
ibility tend to have similar labels. Mentions and their correct referent concepts usually
tend to share a set of characteristics such as string similarity between m and c (e.g.,
hChicago, Chicagoi and hFacebook, Facebooki). We define the local compatibility to
model such set of characteristics.
Principle 2 (Coreference): Two coreferential mentions should be linked to the
same concept. For example, if we know “nc” and “North Carolina” are coreferential,
then they should both be linked to North Carolina.
Principle 3 (Semantic Relatedness): Two highly semantically-related mentions
are more likely to be linked to two highly semantically-related concepts. For instance,
when “Sweet 16” and “Hawks” often appear together within relevant contexts, they can
be reliably linked to two baseketball-related concepts NCAA Men’s Division I Basketball
Championship and Atlanta Hawks, respectively.
4.2.2 Approach Overview
Given a set of tweets ht1
, ..., t|T |i, our system first generates a set of candidate con-
cept mentions, and then extracts a set of candidate concept referents for each mention
based on the Wikipedia lexicon. Given a pair of mention and its candidate referent con-
cept hm, ci, the remaining task of wikification is to assign either a positive label if m
should be selected as a prominently linkable mention and c is its correct referent concept,
or otherwise a negative label. The label assignment is obtained by our semi-supervised
graph regularization framework based on a relational graph, which is constructed from
local compatibility, coreference, and semantic relatedness relations. The overview of our
approach is as illustrated in Figure 4.1.

46
4.3 A Deep Semantic Relatedness ModelIn order to construct the relational graph, we first introduce our newly proposed
deep semantic relatedness model (DSRM) for more accurate concept relatedness mea-
surement and more effective topical coherence modeling. In order to learn low dimen-
sional representations (i.e., distributed representations) that capture latent semantics of
concepts, we directly encode heterogeneous types of semantic knowledge from semantic
knowledge graphs (KGs) including structured knowledge (i.e., concept facts and con-
cept types) and textual knowledge (i.e., concept descriptions) into deep neural networks
(DNN). By automatically mining a large amount of training instances from KGs and
Wikipedia, we then train the neural network models discriminatively in a supervised fash-
ion such that the distances between semantically-related concepts are minimized in a la-
tent space. In this way, the neural networks can be optimized directly for the concept
relatedness task and capture semantics in this dimension.
Our proposed DSRM is relevant to the work in [40]. We extend their work to large-
scale semantic KGs by leveraging both structured and contextual knowledge for semantic
representation learning of concepts. Then we apply the approach to model topical coher-
ence for concept disambiguation, as opposed to Web search. He at al. [116] first explored
deep learning techniques to measure local context similarity for concept disambiguation.
Our work complements theirs since we aim to measure entity relatedness for global topi-
cal coherence modeling.
4.3.1 The DSRM Architecture
The architecture of DSRM is as shown in Figure 4.2. In oder to compute the se-
mantic relatedness scores between a given pair of concepts ci and cj (e.g., “Miami Heat”
and “National Basketball Association”), the DSRM first maps each concept into a low-
dimensional numerical feature vector (i.e., distributed representations) through a hierar-
chical architecture. The hierarchical architecture consists of (1) a feature vector layer that
represents a concept with heterogeneous types of knowledge from semantic KGs, (2) A
word hashing layer that transforms a feature vector with high dimension (e.g., 5m) into
a vector with relative small dimension (e.g., 105k), (3) Multiple semantic layers that ex-
tract hidden semantic features through non-linear projections. After obtaining distributed

47
Feature Vector
Word Hashing
Multi-layer non-linear projections
Semantic Layer
1m
105k (50k + 3.2k + 1.6k + 50k)
300
300
300
x
l1
l2
l3
y
{W2 , b2}
W1
{W3 , b3}
{W4 , b4}
Di
4m 3.2k 1.6k Ci Ri CTi
300
300
300
Dj Cj CTj Rj
Semantic relatedness (cosine similarity)
SR(ci , cj)
1m
105k (50k + 3.2k + 1.6k + 50k)
4m 3.2k 1.6k
Figure 4.2: The DSRM architecture.
representations yi and yj for both ci and cj , we use them to measure concept semantic
relatedness.
Feature Vector Layer: The knowledge representations of a concept from KGs
are shown in the bottom layer (Feature Vector). In particular, we leverage four types of
knowledge from KGs to represent each concept c, which is described in details as follows:
• Connected Concepts C: the set of connected concepts of c. For instance, as shown
in Figure 1.5, C = {“Erik Spoelstra”, “Miami”, “NBA”, “Dwyane Wade”} for “Miami
Heat”.
• Relations R: the set of relations that c holds. For example, R = {“Coach”, “Location”,
“Founded”, “Member”, “Roster”} for “Miami Heat” in Figure 1.5.
• Concept Types CT : the set of attached concept types for c. CT = {“professional
sports team”} for “Miami Heat”.
• Concept Description D: the textual description of a concept. The description provides
a concise summary of salient information of c. For instance, from the description of
“Miami Heat”, we can learn about its important information such as role, location, and
founder.
Word Hashing Layer: Following [40], we adopt the letter-n-gram based word

48
hashing technique to reduce the dimensionality of the bag-of-word term vectors. This is
because the vocabulary size of the large-scale KGs is often very large (e.g., more than 4
million concepts and 1 million bag-of-words exist in Wikipedia), which makes the “one-
hot” vector representation very expensive. However, the word hashing techniques can
dramatically reduce the vector dimensionality to a constant small size (e.g., 50k). It also
can handle the out-of-vocabulary words and newly created concepts. The specific ap-
proach we use is based on letter tri-grams. For instance, the word “cat” can be split into
letter tri-grams (#ca, cat, at#) by first adding start- and end- marks to the word (e.g.,
#cat#). We then use a vector of letter tri-grams to represent the word.
For each concept, we generate its surface form and represent it as bag-of-words.
And then the word hashing layer transforms each word into a letter tri-gram vector. Sim-
ilarly, we represent the concept description of a concept as bag-of-words, which are then
transformed by the word hashing layer into letter tri-gram vectors.
We do not adopt word hashing techniques to break down relations and concept
types because their sizes are relatively small (i.e., 3.2k relations and 1.6k concept types).
Thus each relation or concept type is represented as a binary “one-hot” vector (e.g..,
[0, ..., 0, 1, 0, ..., 0]).
Semantic Layers: On top of the word hashing layer, we have multiple hidden
layers to perform non-linear transformations, which allow the DNN to extract hidden
semantic features by performing back propagation with respect to an objective function
designed for the concept relatedness task. Finally, we can obtain the semantic representa-
tion y for c from the top layer. Denoting l1
as the output vector of the word hashing layer,
y as the output semantic vector of c, N as the number of layers, li, i = 2, ..., N � 1 as the
output vectors of the intermediate hidden layers, Wi and bi as the weight matrix and bias
term of the i-th layer respectively, we then can formally present the DSRM as:
li = f(Wili�1
+ bi), i = 2, ..., N � 1
y = f(WN lN�1
+ bN)
where we use the tanh as the activation function at the output layer and the intermediate
hidden layers. Specifically, f(x) = tanh(x) = 1�e�2x
1+e�2x .

49
Concept Semantic Relatedness Measurement: After we obtain the semantic rep-
resentations for concept ci and cj , we use cosine similarity to measure their relatedness as
SRDSRM(ci, cj) =
yTc
i
yc
j
||yc
i
||||yc
j
|| , where yci
and ycj
are the semantic representations of ci and
cj , respectively.
4.3.2 Learning the DSRM
Training Data Mining: In order to train the DSRM which can capture semantics
specific to the concept relatedness task, we first automatically mine training data based on
KGs and Wikipedia anchor links. Beyond using linked concept pairs from KGs as positive
training instances, we also mine more training data (especially negative instances) from
Wikipedia. Suppose ti is an anchor text from a Wikipedia article, and it is linked to a
concept ci. And tj is an anchor text within � = 150 character window of ti, and cj is
its linked concept. Then we consider hci, cji as a positive training instance. To obtain
negative training instances for ci, we randomly sample 5 other candidate concepts of tj(denoted as ˆCj), and consider each hci, c0ji as a negative training instance for each c0j 2 ˆCj .
Similarly, we obtain negative training instances for cj . In this way, we finally obtain about
20 million positive training pairs and 200 million negative training pairs. By mining the
training instances automatically, we can train the DSRM in an unsupervised way and save
tremendous human annotation efforts. The disadvantages are that we can not provide
more fine-grained annotations for more accurate model learning and there exists noise in
the training data.
Model Training: Following [39], [40], [117], we formulate a loss function as:
L(^) = � log
Y
(c,c+)
P (c+|c),
where ^ denotes the set of parameters of the DSRM, and c+ is a semantically-related
concept of c. P (cj|ci) is the posterior probability of concept cj given ci through the
softmax function:
P (cj|ci) =exp(�SRDSRM
(ci, cj))Pc02C
i
exp(�SRDSRM(ci, c0))
,
where � is the smoothing parameter which is determined based on a held-out set,
and Ci is the set of related or non-related concepts of ci in the training data.

50
To obtain the optimal solution, we need to minimize the above loss function. The
idea of the loss function is to ensure that the posterior probabilities of positive training
instances are higher than the negative ones. The model is trained using mini-batch based
stochastic gradient descent (SGD) [39],[40], and the training normally converges after 20
epochs in our experiments.
Implementation Details: In order to avoid over-fitting, we determine model pa-
rameters with cross validation by randomly splitting the mined concept pairs into two
sets: training and validation sets. We set the number of hidden layers as 2 and the number
of units in each hidden layer and output layer as 300. Further gains have been observed
by increasing the number of hidden layers to 2 or 3 in DNN for many tasks such as
Web Search [40] and digit recognition [118]. But adding too many hidden layers (e.g.,
� 4) can worsen the generalization performance since over-fitting is more likely to oc-
cur [118]. Following [40], we initialize each weight matrix Wi, i = 2, ..., N � 1 with a
uniform distribution:
Wi ⇠"�
s6
(|li�1
|+ |li|,
s6
(|li�1
|+ |li|
#,
where|l| is the size of the vector l.
During SGD optimization, we set mini-batch size of training instances as 1024.
And it takes roughly 72 hours to finish the model training on an NVidia Tesla K20 GPU
machine.
4.4 Relational Graph ConstructionWe first construct the relational graph G = hV,Ei, where V = {v
1
, ..., vn} is a
set of nodes and E = {e1
, ..., em} is a set of edges. Each vi = hmi, cii represents a
tuple of mention mi and its referent concept candidate ci. An edge is added between two
nodes vi and vj if there is a proposed relation based on the three principles described in
section 4.2.1.

51
4.4.1 Local Compatibility
We first compute local compatibility (Principle 1) by considering a set of novel local
features to capture the importance and relevance of a mention m to a tweet t, as well as
the correctness of its linkage to a concept c. We have designed a number of features which
are similar to those commonly used in wikification and entity linking work [11],[92],[93].
Mention Features We define the following features based on information from
mentions.
• IDFf (m) = log(
|C|df(m)
), where |C| is the total number of concepts in Wikipedia
and df(m) is the total number of concepts in which m occurs, and f indicates the
field property, including title, content, and anchor.
• Keyphraseness(m) =
|Ca
(m)|df(m)
to measure how likely m is used as an anchor in
Wikipedia, where Ca(m) is the set of concepts where m appears as an anchor.
• LinkProb(m) =
Pc2C
a
(m) count(m,c)P
c2C
count(m,c), where count(m, c) indicates the number of
occurrence of m in c.
• SNIL(m) and SNCL(m) to count the number of concepts that are equal to or
contain a sub-n-gram of m, respectively [92].
Concept Features The concept features are solely based on Wikipedia, including
the number of incoming and outgoing links for c, and the number of words and characters
in c.
Mention + Concept Features This set of features considers information from both
mention and concept:
• prior popularity prior(m, c) =
count(m,c)Pc
0 count(m,c0) , where count(m, c) measures the
frequency of the anchor links from m to c in Wikipedia.
• TFf (m, c) =count
f
(m,c)
|f | to measure the relative frequency of m in each field repre-
sentation f of c, normalized by the length of f . The fields include title, sentence,
paragraph, content and anchor.
• NCT (m, c), TCN(m, c), and TEN(m, c) to measure whether m contains the title
of c, whether the title of c contains m, and whether m is equal to the title of c,
respectively.

52
Context Features This set of features include (i) Context Capitalization features,
which indicate whether the current mention, the token before, and the token after are
capitalized. (ii) tf-idf based features, which include the dot product of two word vectors
vc and vt, and the average tf-idf value of common items in vc and vt, where vc and vt are
the top 100 tf-idf word vectors in c and t.
Local Compatibility Computation For each node vi = hmi, cii, we collect its
local features as a feature vector Fi = hf1, f2, ..., fdi. To avoid features with large nu-
merical values that dominate other features, the values of each feature are re-scaled using
feature standardization approach. The cosine similarity is then adopted to compute the
local compatibility of two nodes and construct a k nearest neighbor (kNN) graph, where
each node is connected to its k nearest neighboring nodes. We compute the weight matrix
that represents the local compatibility relation as:
W locij =
8<
:cosine(Fi, Fj) j 2 kNN(i)
0 Otherwise
4.4.2 Meta Path
Mention
Hashtag
Tweet Userpost-1
post
contain-1
contain
contain-1 contain
Figure 4.3: Schema of the Twitter network.
In this subsection, we introduce the meta paths we will use to detect coreference
(section 4.4.3) and semantic relatedness relations (section 4.4.4).
Recall that in the chapter 2, we introduce the concept of meta path, which is a path
defined over a network and composed of a sequence of relations between different object
types [24]. In our experimental setting, we can construct a natural Twitter network sum-
marized by the network schema in Figure 4.3. The network contains four types of objects:

53
Mention (M), Tweet (T), User (U), and Hashtag (H). Tweets and mentions are connected
by links “contain” and “contained by” (denoted as “contain�1”); users and tweets are
connected by links “post” and “posted by” (denoted as “post�1”); and tweets and #hash-
tags are connected by links “contain” and “contained by” (denoted as “contain�1”).
We then define the following five types of meta paths to connect two mentions as:
• “M - T - M”,
• “M - T - U - T - M”,
• “M - T - H - T - M”,
• “M - T - U - T - M - T - H - T - M”,
• “M - T - H - T - M - T - U - T - M”.
Each meta path represents one particular semantic relation. For instance, the first three
paths express the explicit relations that two mentions are from the same tweet, posted by
the same user, and share the same #hashtag, respectively. The last two paths are con-
structed by concatenating the first three simple paths to express the implicit relations that
two mentions co-occur with a third mention sharing either the same authorship or #hash-
tag. Such complicated paths can be exploited to detect more semantically-related men-
tions from richer contexts. For example, the relational link between “narita airport” and
“Japan” would be missed without using the path “narita airport - t1
- u1
- t2
- american -
t3
- h1
- t4
- Japan” since they don’t directly share any authorship or #hashtag.
4.4.3 Coreference
A coreference (Principle 2) usually occurs across multiple tweets due to the highly
redundant information in Twitter. To ensure high precision, we propose a simple yet
effective approach utilizing the rich social network relations in Twitter.
We consider two mentions mi and mj coreferential if either mi and mj share the
same surface form or one mention is an abbreviation of the other, and at least one meta
path exists between mi and mj . Then we define the weight matrix representing the coref-

54
erential relation as:
W corefij =
8>><
>>:
1.0 if mi and mj are coreferential,
and ci = cj
0 Otherwise
4.4.4 Semantic Relatedness
Ensuring topical coherence (Principle 3) has been beneficial for wikification on
formal texts (e.g., News) by linking a set of semantically-related mentions to a set of
semantically-related concepts simultaneously [28], [32], [119]. However, the shortness of
a single tweet means that it may not provide enough topical clues. Therefore, it is im-
portant to extend this evidence to capture semantic relatedness information from multiple
tweets.
We define the semantic relatedness score between two mentions as SR(mi,mj) =
1.0 if at least one meta path exists between mi and mj , otherwise SR(mi,mj) = 0. Then
we compute a weight matrix representing the semantic relatedness relation as:
W relij =
8<
:SR(Ni, Nj) if SR(Ni, Nj) � �
0 Otherwise
where SR(Ni, Nj) = SR(mi,mj) ⇥ SR(ci, cj), SR(ci, cj) is a semantic relatedness
model, and � = 0.3, which is optimized from a development set.
4.4.5 The Combined Relational Graph
Based on the above three weight matrices W loc, W coref , and W rel, we obtain the
combined graph G with weight matrix W , where Wij = ↵W locij + �W coref
ij + �W relij . ↵,
�, and � are three coefficients between 0 and 1 with the constraint that ↵ + � + � =
1. They control the contributions of these three relations in our semi-supervised graph
regularization model. An example graph of G is shown in Figure 4.4. Compared to the
referent graph which considers each mention or concept as a node in previous graph-based
re-ranking approaches [28], [90], our novel graph representation has two advantages: (i)
It can easily incorporate more features related to both mentions and concepts. (ii) It is
more appropriate for our graph-based semi-supervised model since it is difficult to assign

55
hawks, Atlanta Hawks
uconn, Connecticut
Huskies
bucks, Milwaukee
Bucks
kemba walker, Kemba Walker
0.404
gators, Florida Gators
men's basketballnow, Now
days, Day
tonight, Tonight
0.932
0.7640.665
0.467
0.5630.538
0.447
Figure 4.4: A example of the relational graph constructed for the example tweets inFigure 1.3. Each node represents a pair of hm, ci, separated by a comma.The edge weight is obtained from the linear combination of the weightsof the three proposed relations. Not all mentions are included due to thespace limitations.
labels to a pair of mention and concept in the referent graph.
4.5 Semi-supervised Graph RegularizationGiven the constructed relational graph with the weighted matrix W and the label
vector Y of all nodes, we assume the first l nodes are labeled as Yl and the remaining u
nodes (u = n� l) are initialized with labels Y 0
u . Then our goal is to refine Y 0
u and obtain
the final label vector Yu.
Intuitively, if two nodes are strongly connected, they tend to hold the same label.
We propose a novel semi-supervised graph regularization framework based on the graph-
based semi-supervised learning algorithm [33]:
Q(Y) = µnX
i=l+1
(yi � y0i )2
+
1
2
X
i,j
Wij(yi � yj)2.
The first term is a loss function that incorporates the initial labels of unlabeled examples
into the model. In our method, we adopt prior popularity (section 4.4.1) to initialize the
labels of the unlabeled examples. The second term is a regularizer that smoothes the
refined labels over the constructed graph. µ is a regularization parameter that controls the
trade-off between initial labels and the consistency of labels on the graph. The goal of the

56
proposed framework is to ensure that the refined labels of unlabeled nodes are consistent
with their strongly connected nodes, as well as not too far away from their initial labels.
The above optimization problem can be solved directly since Q(Y) is convex [33],
[36]. Let I be an identity matrix and DW be a diagonal matrix with entries Dii =P
j Wij .
We can split the weighted matrix W into four blocks as W =
2
4Wll Wlu
Wul Wuu
3
5, where Wmn
is an m ⇥ n matrix. Dw is split similarly. We assume that the vector of the labeled
examples Yl is fixed, so we only need to infer the refined label vector of the unlabeled
examples Yu. In order to minimize Q(Y), we need to find Y ⇤u such that
@Q
@Yu
����Yu
=Y ⇤u
= (Duu + µIuu)Yu �WuuYu �
WulYl � µY 0
u = 0.
Therefore, a closed form solution can be derived as Y ⇤u = (Duu+µIuu�Wuu)
�1
(WulYl+
µY 0
u ).
However, for practical application to a large-scale data set, an iterative solution
would be more efficient to solve the optimization problem. Let Y tu be the refined labels
after the tth iteration, the iterative solution can be derived as:
Y t+1
u = (Duu + µIuu)�1
(WuuYtu +WulYl + µY 0
u ).
The iterative solution is more efficient since (Duu + µIuu) is a diagonal matrix and its
inverse is very easy to compute.
4.6 ExperimentsIn this section, we compare our proposed collective tweet wikification approach
with state-of-the-art methods as shown in Table 4.1. We then study the quality of various
concept relatedness measurement approaches and their impact on wikification.

57
Table 4.1: Description of wikification methods.
Methods DescriptionsTagMe The same approach that is described in [86], which aims to annotate short texts based on prior
popularity and semantic relatedness of concepts. It is basically an unsupervised approach,except that it needs a development set to tune the probability threshold for linkable mentions.
Meij A state-of-the-art system described in [92], which is a supervised approach based on therandom forest model. It performs mention detection and disambiguation jointly, and it istrained from 400 labeled tweets.
SSRegu1 Our proposed model based on Principle 1, using 200 labeled tweets.SSRegu12 Our proposed model based on Principle 1 and 2, using 200 labeled tweets.SSRegu13 Our proposed model based on Principle 1 and 3, using 200 labeled tweets.SSRegu123 Our proposed full model based on Principle 1, 2 and 3, using 200 labeled tweets.
Table 4.2: Statistics of Freebase KG.
Knowledge Graph Element Size# Concepts 4.12m# Relations 3.17k# Concept Types 1.57k
4.6.1 Data and Scoring Metric
For our experiments, we use a Wikipedia dump on May 3, 2013 as our knowledge
base, which includes 30 million pages. To reduce noise, we remove the entities which
have fewer than 5 incoming anchor links and obtain 4 millions entities. And we use
a portion of Freebase limited to Wikipedia concepts as the semantic KG with detailed
statistics shown in Table 5.2.
For our experiments we use a public data set [92] including 502 tweets posted by
28 verified users. The data set was annotated by two annotators. We randomly sample
102 tweets for development and the remaining for evaluation. For computational effi-
ciency, we also filter some mention candidates by applying the preprocessing approach
proposed in [86], and remove all the concepts with prior popularity less than 2% from an
mention’s concept set for each mention, similar to [93]. For concept disambiguation, we
compute both standard micro (aggregates over all mentions) and macro (aggregates over
all documents) precision scores over the top ranked candidate concepts. And for end-to-
end wikification, we use the standard precision, recall and F1 measures. A mention and
concept pair hm, ci is judged as correct if and only if m is linkable and c is the correct
referent concept for m.
To evaluate the quality of concept relatedness, we use a benchmark test set cre-

58
Table 4.3: Overall performance.
Methods Precision Recall F1TagMe 0.329 0.423 0.370Meij 0.393 0.598 0.475SSRegu
1
0.538 0.435 0.481SSRegu
12
0.638 0.438 0.520SSRegu
13
0.541 0.457 0.495SSRegu
123
0.650 0.441 0.525
ated by [120] from CoNLL 2003 data. It includes 3, 314 concepts as testing queries and
each query has 91 candidate concepts in average to measure relatedness. After obtaining
the ranked orders of candidate concepts for these queries, we compute the nDCG [110]
and mean average precision (MAP) [121] scores to evaluate the relatedness measurement
quality.
4.6.2 End-to-End Wikification
Overall Performance The overall performance of various approaches is shown in
Table 4.3. The results of the supervised method proposed by [92] are obtained from 5-
fold cross validation. For our semi-supervised setting, we experimentally sample 200
tweets for training and use the remaining set as unlabeled and testing sets. In our semi-
supervised regularization model, the matrix W loc is constructed by a kNN graph (k = 20).
The regularization parameter µ is empirically set to 0.1, and the coefficients ↵, �, and �
are learnt from the development set by considering all the combinations of values from
0 to 1 at 0.1 intervals. In order to randomize the experiments and make the comparison
fair, we conduct 20 test runs for each method and report the average scores across the 20
trials.
The relatively low performance of the baseline system TagMe demonstrates that
only relying on prior popularity and topical information within a single tweet is not
enough for an end-to-end wikification system for the short tweets. As an example, it is
difficult to obtain topical clues in order to link the mention “Clinton” to Hillary Rodham
Clinton by relying on the single tweet “wolfblitzercnn: Behind the scenes on Clinton’s
Mideast trip #cnn”. Therefore, the system mistakenly links it to the most popular concept
Bill Clinton.

59
In comparision with the supervised baseline proposed by [92], our model SSRegu1
relying on local compatibility already achieves comparable performance with 50% of la-
beled data. This is because that our model performs collective inference by making use of
the manifold (cluster) structure of both labeled and unlabeled data, and that the local com-
patibility relation is detected with high precision4 (89.4%). For example, the following
three pairs of mentions and concepts hpelosi, Nancy Pelosii, hobama, Barack Obamai,and hgaddafi, Muammar Gaddafii have strong local compatibility with each other since
they share many similar characteristics captured by the local features such as string sim-
ilarity between the mention and the concept. Suppose the first pair is labeled, then its
positive label will be propagated to other unlabeled nodes through the local compatibility
relation, and correctly predict the labels of other nodes.
Incorporating coreferential or semantic relatedness relation into SSRegu1
provides
further gains, demonstrating the effectiveness of these two relations. For instance, “wh” is
correctly linked to White House by incorporating evidence from its coreferential mention
“white house”. The coreferential relation (Principle 2) is demonstrated to be more bene-
ficial than the semantic relatedness relation (Principle 3) because the former is detected
with much higher precision (99.7%) than the latter (65.4%).
Our full model SSRegu123
achieves significant improvement over the supervised
baseline (5% absolute F1 gain with 95.0% confidence level by the Wilcoxon Matched-
Pairs Signed-Ranks Test), showing that incorporating global evidence from multiple tweets
with fine-grained relations is beneficial. For instance, the supervised baseline fails to link
“UCONN” and “Bucks” in our examples to Connecticut Huskies and Milwaukee Bucks,
respectively. Our full model corrects these two wrong links by propagating evidence
through the semantic links as shown in Figure 4.4 to obtain mutual ranking improvement.
The best performance of our full model also illustrates that the three relations complement
each other.
Effect of Concatenated Meta Paths In this chapter, we propose a unified frame-
work utilizing meta path-based semantic relations to explore richer relevant context. Be-
yond the straightforward meta paths, we introduce more complicated ones by concate-
nating the simple ones. The performance of the system without using the concatenating4Here we define precision as the percentage of links that holds the same label.

60
Table 4.4: The performance of systems without using concatenated meta paths.
Methods Precision Recall F1SSRegu
12
0.644 0.423 0.510SSRegu
13
0.543 0.441 0.486SSRegu
123
0.657 0.419 0.512
meta paths is shown in Table 4.4. In comparison with the system based on all defined meta
paths, we can clearly see that the systems using concatenated meta paths significantly out-
perform those relying on the simple ones. This is because the concatenated meta paths
can incorporate more relevant information with implicit relations into the models by in-
creasing 1.6% coreference links and 9.3% semantic relatedness links. For example, the
mention “narita airport” is correctly disambiguated to the concept “Narita International
Airport” with higher confidence since its semantic relatedness relation with “Japan” is
detected with the concatenated meta path as described in section 4.4.2.
50 100 150 200 250 300 350 4000.30
0.35
0.40
0.45
0.50
0.55
0.60
F1
Labeled Tweet Size
SSRegu123 Meij
Figure 4.5: The effect of labeled tweet size.
Effect of Labeled Data Size In previous experiments, we experimentally set the
number of labeled tweets to be 200 for overall performance comparision with the base-
lines. In this subsection, we study the effect of labeled data size on our full model. We
randomly sample 100 tweets as testing data, and randomly select 50, 100, 150, 200, 250,
and 300 tweets as labeled data. 20 test runs are conducted and the average results are
reported across the 20 trials, as shown in Figure 4.5. We find that as the size of the
labeled data increases, our proposed model achieves better performance, demonstrating

61
that our proposed relational graph can capture the semantic relations between mentions
and concepts effectively. It is encouraging to see that our approach, with only 31.3%
labeled tweets (125 out of 400), already achieves a performance that is comparable to the
state-of-the-art supervised model trained from 100% (400) labeled tweets.
0.1 0.5 1 2 5 10 20 30 40 500.30
0.35
0.40
0.45
0.50
0.55
0.60
F1
Regularization Parameter µ
SSRegu123
Figure 4.6: The effect of parameter µ.
Parameter Analysis In previous experiments, we empirically set the parameter
µ = 0.1. µ is the regularization parameter that controls the trade-off between initial
labels and the consistency of labels on the graph. When µ increases, the model tends to
trust more in the initial labels. Figure 4.6 shows the performance of our models by varying
µ from 0.02 to 50. We can easily see that the system performce is stable when µ < 0.4.
However, when µ � 0.4, the system performance dramatically decreases, showing that
prior popularity is not enough for an end-to-end wikification system.
4.6.3 Quality of Semantic Relatedness Measurement
In this subsection, we evaluate the relatedness measurement quality of various re-
latedness methods: (i) M&W, the Wikipedia anchor link-based method proposed by [38].
(ii) DSRM1
, our proposed DSRM based on connected concepts. (iii) DSRM12
, DSRM
based on connected concepts and relations. (iii) DSRM123
, DSRM based on connected
concepts, relations, and concept types. (iv) DSRM1234
, DSRM based on all four types of
knowledge.
The overall performance of various relatedness methods are shown in Table 4.5.
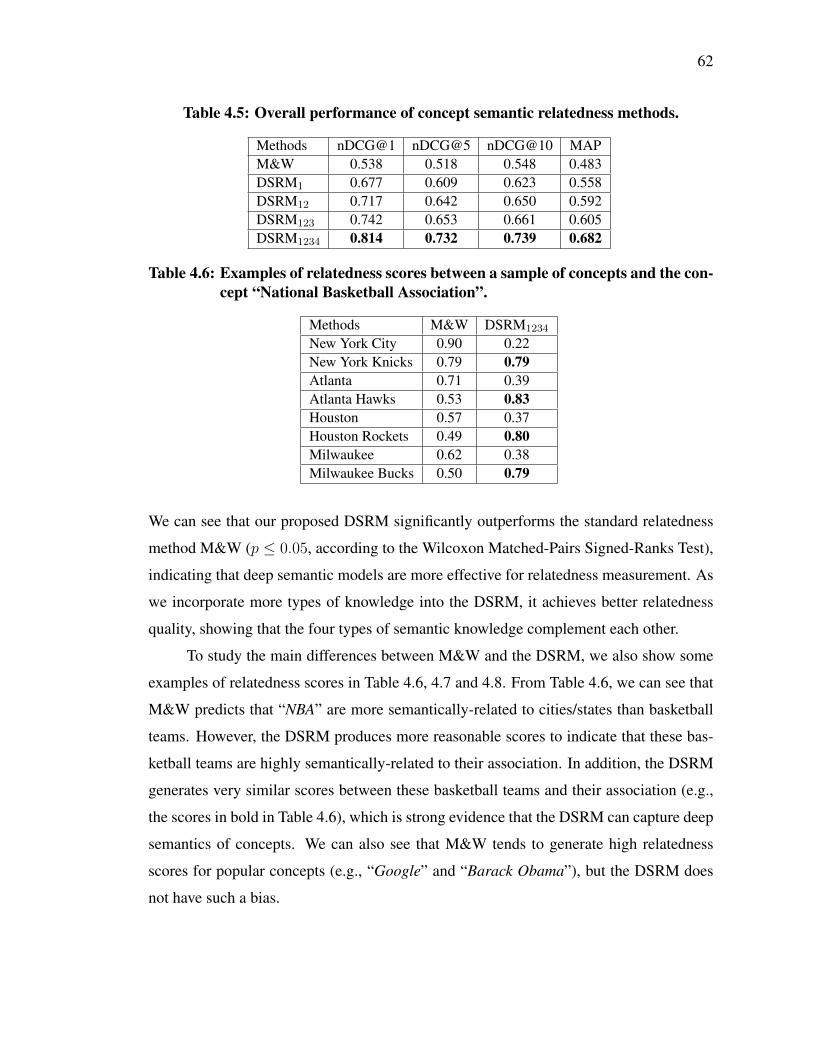
62
Table 4.5: Overall performance of concept semantic relatedness methods.
Methods nDCG@1 nDCG@5 nDCG@10 MAPM&W 0.538 0.518 0.548 0.483DSRM
1
0.677 0.609 0.623 0.558DSRM
12
0.717 0.642 0.650 0.592DSRM
123
0.742 0.653 0.661 0.605DSRM
1234
0.814 0.732 0.739 0.682
Table 4.6: Examples of relatedness scores between a sample of concepts and the con-cept “National Basketball Association”.
Methods M&W DSRM1234
New York City 0.90 0.22New York Knicks 0.79 0.79Atlanta 0.71 0.39Atlanta Hawks 0.53 0.83Houston 0.57 0.37Houston Rockets 0.49 0.80Milwaukee 0.62 0.38Milwaukee Bucks 0.50 0.79
We can see that our proposed DSRM significantly outperforms the standard relatedness
method M&W (p 0.05, according to the Wilcoxon Matched-Pairs Signed-Ranks Test),
indicating that deep semantic models are more effective for relatedness measurement. As
we incorporate more types of knowledge into the DSRM, it achieves better relatedness
quality, showing that the four types of semantic knowledge complement each other.
To study the main differences between M&W and the DSRM, we also show some
examples of relatedness scores in Table 4.6, 4.7 and 4.8. From Table 4.6, we can see that
M&W predicts that “NBA” are more semantically-related to cities/states than basketball
teams. However, the DSRM produces more reasonable scores to indicate that these bas-
ketball teams are highly semantically-related to their association. In addition, the DSRM
generates very similar scores between these basketball teams and their association (e.g.,
the scores in bold in Table 4.6), which is strong evidence that the DSRM can capture deep
semantics of concepts. We can also see that M&W tends to generate high relatedness
scores for popular concepts (e.g., “Google” and “Barack Obama”), but the DSRM does
not have such a bias.

63
Table 4.7: Examples of relatedness scores between a sample of concepts and the con-cept “National Football League”.
Methods M&W DSRM1234
New York City 0.89 0.09New York Jets 0.92 0.63Boston 0.92 0.19Boston Bruins 0.62 0.38Dallas 0.87 0.34Dallas Cowboys 0.72 0.68Philadelphia 0.93 0.19Philadelphia Eagles 0.79 0.65Miami 0.54 0.27Miami Dolphins 0.92 0.69
Table 4.8: Examples of relatedness scores between a sample of concepts and the con-cept “Apple Inc.”.
Methods M&W DSRM1234
Apple 0.32 0.27Google 0.98 0.81Microsoft 0.86 0.86Samsung 0.49 0.69Facebook 0.83 0.65Twitter 0.83 0.60The New York Times 0.78 0.38The Wall Street Journal 0.78 0.49Steve Jobs 0.78 0.74Bill Gates 0.79 0.68Barack Obama 0.71 0.36
4.6.4 Concept Disambiguation
It will be also interesting to study the performance of our proposed collective infer-
ence based on graph regularization on news dataset to demonstrate its effectiveness. Thus
we also use a benchmark news dataset (AIDA) based on CoNLL 2003 data [122]. It in-
cludes 131 documents and 4,485 non-NIL mentions. We compare our methods with two
state-of-art approaches on news dataset: (i) Shirak, this approach utilizes a probabilistic
taxonomy with the Naive Bayes model [123]. (ii) AIDA, it is a graph-based collective
approach which finds a dense subgraph for joint disambiguation [122].
Topical coherence modeling is mainly used to enhance disambiguation instead of
mention detection, thus to better study the impact of various semantic relatedness meth-

64
ods, we focus on concept disambiguation in this subsection. For concept disambiguation,
many existing approaches are unsupervised. To compare with these state-of-the-art meth-
ods, we also develop an unsupervised graph regularization framework (GraphRegu) for
concept disambiguation, which makes our model more robust to unseen and new data. We
only leverage the semantic relatedness relation to construct the relational graph to study
the impact of relatedness measurement approaches on disambiguation.
We initialize the ranking score of each node based on a sub-system of AIDA [122],
which relies on the linear combination of prior popularity and context similarity. The
context similarity proposed in AIDA is computed based on the extracted keyphrases (e.g.,
Wikipedia anchor texts) of an entity and all of their partial matches in the text of a men-
tion. We also adopt two heuristics to mine a set of labeled seed nodes for the graph
regularization model: (i) If a node v = hm, ei contains unambiguous mention, then v is
selected as a seed node and it has an initial ranking score 1.0. (ii) For a mention m with
the top ranked candidate entity by prior popularity as e, if the prior popularity p(e|m) of
e satisfies p(e|m) � 0.95 and e is also the top ranked entity by context similarity, then
all nodes related to m are selected as labeled seeds. The node v = hm, ei will be as-
signed a ranking score 1.0, and other nodes will be assigned a ranking score 0. During the
graph regularization process, the ranking scores of these labeled seed nodes will remain
unchanged.
The overall disambiguation performance is shown in Table 4.9 and 4.10 for the
AIDA dataset and the tweet set, respectively. Compared with other strong baseline ap-
proaches, our developed unsupervised approach GraphRegu + M&W achieves very com-
petitive performance for both datasets, illustrating that our proposed collective inference
approach is effective to model topical coherence for concept disambiguation.
Our best system based on the DSRM with all four types of knowledge (denoted
as DSRM1234
) significantly outperforms various strong baseline competitors for both
datasets (all with p 0.05). Specially compared with the standard method M&W,
DSRM1234
obtains 4.4% and 6.8% absolute micro precision gains in disambiguation for
news and tweets, respectively. For instance, GraphRegu + M&W fails to disambiguate
the mention “Middlesbrough” to the football club “Middlesbrough F.C.” in the text “Lee
Bowyer was expected to play against Middlesbrough on Saturday.”. This is because

65
M&W generates the same semantic relatedness score (0.39) between h“Middlesbrough
F.C.”, “Lee Bowyer”i and h“Middlesbrough” and “Lee Bowyer”i. However, DSRM1234
computes the relatedness score for the former pair as 0.68, much higher than the score
0.33 of the latter one, thus GraphRegu + DSRM1234
correctly disambiguates the mention.
Table 4.9: Overall disambiguation performance on AIDA dataset.
Baseline Approaches Our MethodsShirak AIDA GraphRegu +
M&W DSRM1 DSRM12 DSRM123 DSRM1234
micro [email protected] 0.814 0.823 0.822 0.842 0.853 0.849 0.866macro [email protected] 0.835 0.820 0.811 0.833 0.839 0.836 0.855
Table 4.10: Overall disambiguation performance on tweet set.
Baseline Approaches Our MethodsTagMe Meij GraphRegu +
M&W DSRM1 DSRM12 DSRM123 DSRM1234
micro [email protected] 0.610 0.683 0.651 0.692 0.702 0.715 0.719macro [email protected] 0.605 0.692 0.662 0.690 0.696 0.709 0.717
4.6.5 Discussions
In this subsection, we aim to answer two questions: (i) Are semantic KGs better
resources than Wikipedia anchor links for relatedness measurement? (ii) Is the DNN
a better choice than Normalized Google Distance (NGD) [61] and Vector Space Model
(VSP) [124] for relatedness measurement?
In order to answer these two questions, we directly apply NGD and VSP with the
tf-idf representations on the same KG that we use to learn the DSRM. Then we combine
them with the graph regularization model and study their impact on concept disambigua-
tion. Table 4.11 and 4.12 show the relatedness quality and disambiguation performance,
respectively. As shown in the first three rows of both tables, we can clearly see that
NGD and VSP based on KGs significantly outperform their variants with Wikipedia an-
chor links (p 0.05), which confirms that semantic KGs are better resources than the
Wikipedia anchor links for relatedness measurement. This is because KGs contain cleaner
semantic knowledge about concepts than Wikipedia anchor links. For instance, “Apple
Inc.” and “Barack Obama” share many noisy incoming links (e.g., “Austin, Texas” and
“2010s”) that are not helpful to capture their relatedness.

66
Table 4.11: Impact of semantic KGs and DNN on concept semantic relatedness.
Methods nDCG@1 nDCG@5 nDCG@10 MAPM&W 0.538 0.518 0.548 0.483M&W
1234
0.692 0.578 0.576 0.514VSP
1234
0.680 0.579 0.583 0.520DSRM
1234
0.814 0.732 0.737 0.682
Table 4.12: Impact of semantic KGs and DNN on concept disambiguation.
Methods AIDA dataset Tweet setmicro macro micro [email protected] [email protected] [email protected] [email protected]
M&W 0.822 0.811 0.651 0.662M&W
1234
0.846 0.838 0.682 0.692VSP
1234
0.848 0.835 0.694 0.702DSRM
1234
0.867 0.855 0.719 0.717
From the last three rows of Table 4.11 and 4.12, we can see that the DSRM based
on DNN significantly outperform NGD and VSP for both relatedness measurement and
concept disambiguation (p 0.05), illustrating that the DNN are indeed more effec-
tive to measure concept relatedness. By extracting useful semantic features layer by
layer with nonlinear functions and transforming sparse binary “one-hot” vectors into low-
dimensional feature vectors in a latent space, the DNN has better ability to represent con-
cepts semantically.
4.6.6 Remaining Challenges
Figure 4.7 demonstrates the distributions of errors from our best system. We can
easily see that a large portion (69.2%) of mistakes are directly caused by mention de-
tection, showing that mention detection performance bottleneck of a tweet wikification
system. This is consistent with the conclusion obtained in [93]. Even though our joint
model has successfully identified 68.4% mentions which are not linkable and salient, de-
tecting linkable mentions remains a very challenging problem. 15.8% of errors are related
to mention disambiguation, showing that disambiguation is relatively easy in microblog
messages. Among the disambiguation errors, 69% of them are on commonly used terms
such as “coverage” and “record”, instead of named entities. Some most challenging men-
tions for disambiguation in both news and microblogs include city and country names

67
(e.g., “Chicago”) which actually refer to sports teams (e.g., “Chicago Bulls”). This is
because our proposed DSRM produce accurate relatedness scores between these sports
teams, as well as between cities and countries. And the system will be biased towards
the popular cities and countries. One possible solution is to design a joint model to per-
form mention disambiguation and to discover document interest simultaneously. Concept
candidate extraction is also more challenging in microblogs due to the informal usage of
languages. In this work, we have segmented the @usernames and #hashtags into reg-
ular tokens for more accurate candidate extraction. Further normalization of typos and
abbreviation into regular tokens can help improve the candidate extraction performance.
6.9%
8.1%
3.1%
12.7%25.4%
43.8%
1. Mention Detection (False Positives) 2. Mention Detection (False Negatives) 3. Mixture of Mention Detection and
Disambiguation 4. Mention Disambiguation 5. Concept Candidate Extraction 6. Annotation
Figure 4.7: Error distributions.
4.7 SummaryIn this chapter,
(1) We have introduced a novel semi-supervised graph regularization framework for
wikification to simultaneously tackle the unique challenges of annotation and information
brevity in short tweets. To the best of our knowledge, this is the first work to explore the
semi-supervised collective inference model for the wikification task.
(2) We have extracted various semantic meta paths from HINs to expand the con-
texts of short tweets, which was proved to be an effective method to incorporate more
topically-relevant information for collective inference.
(3) We have constructed a relational graph with three types of fine-grained relations
including local compatibility based on a set of local features, coreference, and semantic
relatedness. We have also studied the impact of each relation and showed that these

68
relations can complement each other for the wikification task.
(4) We have introduced a deep semantic relatedness model (DSRM) based on deep
neural networks and semantic knowledge graphs. The DSRM maps each concept into a
low-dimensinoal vector that capture its latent semantics. We have compared the impact of
semantic KGs and Wikipedia anchor links, as well as the DNN and some classic similarity
measures that do not use semantics on relatedness measurement. We proved that both
semantic KGs and DNN are better choices for relatedness measurement.
(5) By studying three novel fine-grained relations to construct the relational graph,
detecting semantically-related information with semantic meta paths, and exploiting the
data manifolds in both unlabeled and labeled data for collective inference, our work can
dramatically save annotation cost and achieve better performance.

CHAPTER 5Morph Decoding
In previous chapters, we have introduced our methods to rank microblogs and enrich mi-
croblogs with background knowledge from knowledge bases. Thus we can alleviate the
information noiseness and information brevity problems. However, the wikification sys-
tems have failed to detect and resolve morphs which tend to be informal terms conveying
more implicit information. In this chapter, we propose novel approaches to tackle the
newly proposed morph decoding problem.
5.1 Approach Overview
Comparable Data Acquisition
Target Candidate Ranking
Target
Learning to Rank
Semantic Features
Semantic Annotation, Morph Detection, and
Target Candidate Identification
Surface Features Social Features
Censored Data
Uncensored Data
Figure 5.1: Overview of morph decoding.
Portions of this chapter previously appeared as: H. Huang, Z. Wen, D. Yu, H. Ji, Y. Sun, J. Han, andH. Li, “Resolving entity morphs in censored data,” in Proc. of the 51st Annu. Meeting of the Assoc. forComput. Linguist., Sofia, Bulgaria, 2013, pp. 1083–1093.
69

70
Given a set of Weibo tweet messages W = {w1
, w2
, ..., wn}, the goal of morph
decoding is to find a set of morph M = {m1
,m2
, ...,mp}, and then resolve each mi to
its real targets. Figure 5.1 depicts the general procedure of our approach. First, relevant
comparable data sets that include m are retrieved. In this paper we collect comparable
censored data from Weibo and uncensored data from Twitter and Web documents such
as news articles. We then apply various annotations such as word segmentation, part-of-
speech tagging, noun phrase chunking, name tagging to these data sets to obtain a set of
unique terms, entities, and events. It consists of three main steps.
• Morph Detection: To detect morphs, we propose a set of novel features to capture
the common characteristics of morphs.
• Target Candidate Identification: For each m, identify a list of target candidates
E = {e1
, e2
, ..., eN}. We make use of temporal distribution constraints to identify
target candidates.
• Target Candidate Ranking: Rank the target candidates in E. We explore various
features including surface, semantic and social features, and incorporate them into
a learning to rank framework. Finally, the top ranked candidate is produced as the
resolved target.
5.2 Morph DetectionWe first introduce the first step of our approach – morph detection. This step takes
advantage of the common characteristics shared among morphs and identifies the po-
tential morphs using a supervised method, since it is relatively easy to collect a certain
number of corpus-level morphs as training data. Through formulating this task as a bi-
nary classification problem, we adopt the Support Vector Machines (SVMs) [125] as the
learning model. We propose the following four categories of features.
Basic: (i) character unigram, bigram, trigram, and surface form; (ii) part-of-speech
tags; (iii) the number of characters; (iv) whether some characters are identical. These
basic features will help identify several common characteristics of morph candidates (e.g.,
they are very likely to be nouns, and very unlikely to contain single characters).

71
Dictionary: Many morphs are non-regular names derived from proper names while
retaining some characteristics. For example, the morphs “Ñc (Governor Bo)” and “⇤
� (Gourmand Province)” are derived from their target entity names “Ñôe (Bo Xilai)”
and “�⌧� (Guandong Province)”, respectively. Therefore, we adopt a dictionary of
proper names [126] and propose the following features: (i) Whether a term occurs in
the dictionary. (ii) Whether a term starts with a commonly used last name, and includes
uncommonly used characters as its first name. (iii) Whether a term ends with a geo-
political entity or organization suffix word, but it’s not in the dictionary.
Phonetic: Many morphs are created based on phonetic (Chinese pinyin in our case)
modifications. For instance, the morph “m|| (Rice Cake)” has the same phonetic
transcription as its target entity “⇤∞∞ (Fan Bingbing)”. To extract phonetic-based
features, we compile a dictionary composed of hphonetic transcription, termi pairs from
the Chinese Gigaword corpus. Then for each term, we check whether it has the same
phonetic transcription as any entry in the dictionary but they include different characters.
Language Modeling: Many morphs rarely appear in a general news corpus (e.g.,
“‡| (Bother Octopus), referring to an octopus in Germany, famous for soccer game
prediction”). Therefore, we propose to use the character-based language models trained
from Gigaword to calculate the occurrence probabilities of each term, and use n-gram
probabilities (n 2 [1 : 5]) as features.
5.3 Morph Resolution5.3.1 Target Candidate Identification
The general goal of the first step is to identify a list of target candidates for each
morph query from the comparable corpora including Sina Weibo, Chinese News websites
and English Twitter. However, obviously we cannot consider all of the named entities
in these sources as target candidates due to the sheer volume of information. In addition,
morphs are not limited to named entity forms. In order to narrow down the scope of target
candidates, we propose a Temporal Distribution Assumption as follows. The intuition is
that a morph m and its real target e should have similar temporal distributions in terms of
their occurrences. Suppose the data sets are separated into Z temporal slots (e.g. by day),
the assumption can be stated as:

72
Let Tm = {tm1
, tm2
, ..., tmZm
} be the set of temporal slots each morph m occurs,
and Te = {te1, te2, ..., teZe
} be the set of slots a target candidate e occurs. Then e is
considered as a target candidate of m if and only if, for each tmi 2 Tm (i = 1, 2, ..., Zm),
there exist a j 2 {1, 2, ..., Ze} such that tmi � tej �, where � is a threshold value (in
this paper we set the threshold to 7 days, which is optimized from a development set).
For comparison we also attempted topic modeling approach to detect target candidates,
as shown in section 5.4.
5.3.2 Target Candidate Ranking
Next, we propose a learning-to-rank framework to rank target candidates based on
various levels of novel features based on surface, semantic and social analysis.
5.3.2.1 Surface Features
We first extract surface features between the morph and the candidate based on mea-
suring orthographic similarity measures which were commonly used in entity coreference
resolution (e.g. [16], [127]).
String edit distance: The minimum number of insertions, deletions, and substitu-
tions required to transform one string into the other.
Normalized string edit distance: normalize string edit distance by the maximum
length of the two strings [128].
Longest common subsequence: find the longest subsequence common to both of the
two strings [129]. These measures can be effective when the morph keeps some characters
from the target, for example, “T.; (Qiao Boss)” refers to “T⇤Ø (Steve Jobs).”
5.3.2.2 Semantic Features
Information Network Construction: In order to construct the information net-
works for morphs, we apply the Standford Chinese word segmenter with Chinese Penn
Treebank segmentation standard [130] and Stanford part-of-speech tagger [131] to pro-
cess each sentence in the comparable data sets. Then we apply a hierarchical Hidden
Markov Model (HMM) based Chinese lexical analyzer ICTCLAS [132] to extract named
entities, noun phrases and events.

73
We have also attempted using the results from Dependency Parsing, Relation Ex-
traction and Event Extraction tools [133] to enrich the link types. Unfortunately the state-
of-the-art techniques for these tasks still perform poorly on social media in terms of both
accuracy and coverage of important information, these sophisticated semantic links all
produced negative impact on the target ranking performance. Therefore we limited the
types of vertices into: Morph (M), Entity(E), which includes target candidates, Event
(EV), and Non-Entity Noun Phrases (NP); and used co-occurrence as the edge type. We
extract entities, events, and non-entity noun phrases that occur in more than one tweet as
neighbors. And for two vertices xi and xj , the weight wij of their edge is the frequency
they co-occur together within the tweets. A network schema of such networks is shown
in Figure 5.2. Figure 5.3 presents an example of a heterogeneous information network
M E
NPEV
Figure 5.2: Network Schema of Morph-Related Heterogeneous Information Net-work
from the motivation examples following the above network schema, which connects the
morphs “Peace West King”, “Buhou” and their corresponding target “Bo Xilai”.
Meta-Path-Based Semantic Similarity Measurements: Given the constructed
network, a straightforward solution for finding the target for a morph is to use link-based
similarity search. However, now objects are linked to different types of neighbors, if all
neighbors are treated as the same, it may cause information loss problems. For example,
the entity “ÕÜ (Chongqing)” is a very important aspect characterizing the politician
“Ñôe(Bo Xilai)” since he governed it, and if a morph m which is also highly cor-
related with “ÕÜ (Chongqing)”, it is very likely that “Bo Xilai” is the real target of
m. Therefore, the semantic features generated from neighbors such as the entity “ÕÜ
(Chongqing)” should be treated differently from other types of neighbors such as “∫
M(talented people)” .

74
Gang Crackdown
Fell From Power
Chongqing
Sing Red Songs
Buhou
Peace West King
Bo Xilai
Bo Guagua
Entity
Entity
Entity
Event
Event
Event
Morph
Morph
Figure 5.3: Example of morph-related heterogeneous information network.
In this work, we propose to measure the similarity of two nodes over heterogeneous
networks as shown in Figure 5.2, by distinguishing neighbors into three types according
to the network schema (i.e. entities, events, non-entity noun phrases). We then adopt
meta-path-based similarity measures [23], [24], which are defined over heterogeneous
networks to extract semantic features. A meta-path is a path defined over a network,
and composed of a sequence of relations between different object types. For example, as
shown in Figure 5.2, a morph and its target candidate can be connected by three meta-
paths, including “M - E - E”, “M - EV - E”, and “M - NP - E”. Intuitively, each meta-path
provides a unique angle to measure how similar two objects are.
For the determined meta-paths, we extract semantic features using the similarity
measures proposed in [16], [23]. We denote the neighbor sets of certain type for a morph
m and a target candidate e as �(m) and �(e), and a meta-path as P . We now list several
meta-path-based similarity measures below.
Common neighbors (CN). It measures the number of common neighbors that m and
e share as |�(m) \ �(e)|.Path count (PC). It measures the number of path instances between m and e fol-
lowing meta-path P .
Pairwise random walk (PRW). For a meta-path P that can be decomposed into two

75
shorter meta-paths with the same length P = (P1
P2
), pairwise random walk measures
the probability of the pairwise random walk starting from both m and e and reaching the
same middle object. More formally, it is computed asP
(p1p2)2(P1P2)prob(p
1
)prob(p�1
2
),
where p�1
2
is the inverse of p2
.
Kullback-Leibler distance (KLD). For m and e, the pairwise random walk probabil-
ity of their neighbors can be represented as two probability vectors hpm(x1
), ..., pm(xN)iand hpe(x1
), ..., pe(xN)i. Then Kullback-Leibler distance [16] can be computed as
NX
i=1
pm(xi) logpm(xi)
pe(xi)+ pe(xi) log
pe(xi)
pm(xi)
Beyond the above similarity measures, we also propose to use cosine-similarity-
style normalization method to modify common neighbor and pairwise random walk mea-
sures so that we can ensure the morph node and the target candidate node are strongly
connected and also have similar popularity. The modified algorithms penalize features
involved with the highly popular objects, since they are more likely to have accidental
interactions with each other.
Normalized common neighbors (NCN). Normalized common neighbors can be
measured as sim(m, e) =
|�(m)\�(e)|p|�(m)|
p|�(e)|
. It refines the simple counting of common
neighbors by avoiding bias to highly visible or concentrated objects.
Pairwise random walk/cosine (PRW/cosine). Pairwise random walk measures
linkage weights disproportionately with their visibility to their neighbors, which may be
too strong. Instead, we propose to use a tamer normalization method as:
X
(p1p2)2(P1P2)
f(p1
)f(p�1
2
),
where
f(p1
) =
count(m, x)pPx2⌦ count(m, x)
,
f(p2
) =
count(e, x)pPx2⌦ count(e, x)
,
and ⌦ is the set of middle objects connecting the decomposed meta-paths p1
and p�1
2
,

76
count(y, x) is the total number of paths between y and the middle object x, y could be m
or e.
The above similarity measures can also be applied to homogeneous networks that
do not differentiate the neighbor types.
Global Semantic Feafure Generation: A morph tends to have higher temporal
correlation with its real target, and share more similar topics compared to other irrele-
vant targets. Therefore, we propose to incorporate temporal information into similarity
measures to generate global semantic features.
Let T = t1
[ t2
[ ... [ tN be a set of temporal slots (i.e. by day), E be the set of
target candidates for each morph m. Then for each ti 2 T , and each e 2 E, the local
semantic features simti
(m, e) is extracted based only on the information posted within
ti using one of the similarity measures introduced in Section 5.3.2.2. Then we propose
two approaches to generate global semantic features. The first approach is adding the
similarity score between m and e in each temporal slot to attain the first set of global
features:
simglobal sum(m, e) =X
ti
2T
simti
(m, e).
The second method first normalizes the similarity score in each temporal slot ti, them
sum the normalized scores to generate the second set of global features, which can be
calculated as
simglobal norm(m, e) =X
ti
2T
normti
(m, e).
where normti
(m, e) =sim
t
i
(m,e)Pe2E
simt
i
(m,e).
Integrate Cross Source/Cross Genre Information: Due to internet information
censorship or surveillance, users may need to use morphs to post sensitive information.
For example, the Chinese Weibo message “˝€ªÜ,ÿÅ!@�ö⌫ (Already put in
prison, still need to serve Buhou?” include a morph �ö (Buhou). In contrast, users
are less restricted in some other uncensored social media such as Twitter. For example,
the tweet from Twitter “...äÑôe\“s�ã”�⇧“�ö”... (...call Bo Xilai“peace
west king” or “buhou”...)” contains both the morph and the real targetÑôe (Bo Xilai).
Therefore, we propose to integrate information from another source (e.g. Twitter) to help
resolution of sensitive morphs in Weibo.

77
Another difficulty from morph resolution in micro-blogging is that tweets are only
allowed to contain maximum 140 characters with a lot of noise and diverse topics. The
shortness and diversity of tweets may limit the power of content analysis for semantic
feature extraction. However, formal genres such as web documents are cleaner and con-
tain richer contexts, thus can provide more topically related information. In this work,
we also exploit the background web documents from the embedded URLs in tweets to
enrich information network construction. After applying the same annotation techniques
as tweets for uncensored data sets, sentence-level co-occurrence relations are extracted
and integrated into the network as shown in Figure 5.2.
5.3.2.3 Social Features
It has been shown that there exist correlation between neighbors in social networks
[134], [135]. Because of such social correlation, close social neighbors in social media
such as Twitter and Weibo may post similar information, or share similar opinion. There-
fore, we can utilize social correlation to assist in resolving morphs.
As social correlation can be defined as a function of social distance between a pair
of users, we use social distance as a proxy to social correlation in our approach. The social
distance between user i and j is defined by considering the degree of separation in their
interaction (e.g. retweeting and mentioning) and the amount of the interaction. Similar
definition has been shown effective in characterizing social distance in social networks
extracted from communication data [135], [136]. Specifically, it is
dist(i, j) =K�1X
k=1
1
strength(vk, vk+1
)
.
where v1
, ..., vk are the nodes on the shortest path from user i to user j, and strength(vk, vk+1
)
measures the strength of interactions between vk and vk+1
as:
strength(i, j) =log(Xij)
maxj log(Xij).
where Xij is the total interactions between user i and j, including both retweeting and
mentioning (If Xij < 10, we set strength(i, j) = 0).
We integrate social correlation and temporal information to define our social fea-

78
tures. The intuition is that when a morph is used by an user, the real target may also in
the posts by the user or his/her close friends within a certain time period. Let T be the set
of temporal slots a morph m occurs, Ut be the set of users whose posts include m in slot
t where t 2 T , and Uc be the set of close friends (i.e., social distance < 0.5) for Ut. The
social features are defined as
s(m, e) =
Pt2T f(e, t, Ut, Uc)
|T | .
where f(e, t, Ut, Uc) is a indicator function which return 1 if one of the users in Ut or Uc
posts tweets include the target candidate e within 7 days before t.
5.3.2.4 Learning-to-Rank
Similar to [16], [23], we then model the probability of linkage prediction between a
morph m and its target candidate e as a function incorporating the surface, semantic and
social features. Given a training pair hm, ei, we choose the standard logistic regression
model to learn weights for the features defined above. The learnt model is used to predict
the probability of linking an unseen morph and its target candidate. Based on the de-
scending ranking order of the probability, we select top k candidates as the final answers
based on the answer size k.
5.4 ExperimentsNext, we present the experiment under various settings shown in Table 5.1, and the
impacts of cross source and cross genre information.
Table 5.1: Description of feature sets. ⇤ Glob only uses the same set of similaritymeasures when combined with other semantic features.
Feature sets DescriptionsSurf Surface featuresHomB Semantic features extracted from homogeneous CN, PC, PRW, and KLDHomE HomB + semantic features extracted from homogeneous NCN and PRW/cosineHetB Semantic features extracted from heterogeneous CN, PC, PRW and KLDHetE HetB + semantic features extracted from heterogeneous NCN and PRW/cosineGlob⇤ Global semantic featuresSocial Social network features

79
Table 5.2: Data statistics.
Data Training Development Testing# Tweets 1,500 500 2,688# Unique Terms 10,098 4, 848 15,108# Morphs 250 110 341
5.4.1 Data and Evaluation Metric
We collected 1, 553, 347 tweets from Chinese Sina Weibo from May 1 to June 30 to
construct the censored data set, and retrieved 66, 559 web documents from the embedded
URLs in tweets as the initial uncensored data set. Retweets and redundant web docu-
ments are filtered to ensure more reliable frequency counting of co-occurrence relations.
We then randomly sampled 4, 688 non-redundant tweets and asked two Chinese native
speakers to manually annotate morph in these tweets. The annotated dataset is randomly
split into training, development, and testing sets, with detailed statistics shown in Ta-
ble 5.2. In addition, we used 23 sensitive morphs and the entities that appear in the tweets
as queries and retrieved 25, 128 Chinese tweets from 10% Twitter feeds within the same
time period, as well as 7, 473 web documents from the embedded URLs and added them
into the uncensored data set. For morph resolution, we are more interested in resolving
popular morphs that tend to have more social impacts. Thus we filtered the manually
annotated morphs which appeared fewer than 5 days and obtained a test set consisted of
107 morph entities (81 persons and 26 locations) and their real targets as our references.
To evaluate the system performance, we use leave-one-out cross validation by com-
puting accuracy as Acc@k =
Ck
Q, where Ck is the total number of correctly resolved
morphs at top k ranked answers, and Q is the total number of morph queries. We con-
sider a morph as correctly resolved at the top k answers if the top k answer set contains
the real target of the morph.
5.4.2 Morph Detection Performance
Table 5.3 shows the performance of morph detection using different feature sets.
We can see that the recall values keep increasing as we use more features, while the
precision values keep relatively stable. With all features, our approach newly discovers
888 potential morphs in the test data (9.3% of all the terms in the testing data), indicating
that this step can effectively narrow down the scope of morphs. The basic features greatly

80
Table 5.3: Performance of morph detection.
Features Precision Recall F1
1. Basic 0.270 0.702 0.3902. 1 + Dictionary 0.230 0.780 0.3563. 2 + Phonetic 0.235 0.786 0.3624. 3 + LM 0.245 0.801 0.376
narrow down the scope of candidates by filtering those terms which are easily judged
to be non-morphs (e.g., regular names with part-of-speech tag NR or terms with only
one character). Dictionary and phonetic-based features can further help to improve the
recall values by detecting the irregular terms which are derived from regular names. For
example, the dictionary features can help to identify the commonly used characters (e.g.,
“� (province)”) in entities from the irregular mentions (e.g., “1� (Singing Province)”).
The phonetic features can detect some irregular terms (e.g., “�&⇤ (Charred Cloth)”)
with the same phonetics as regular names (e.g., “�§Ë (Ministry of Foreign Affairs)”).
LM-based features further detect informal terms such as “meŒ (Six Step Man)” and
“‡| (Octopus Brother)” which are rarely used in the standard corpus. However, our
approach fail to detect some potential morphs such as “Ûã(Boxing Champion)”, “�∫
(Great People)”, “§Î��Nursing Supervisor)”. We find that these missed morphs are
general terms, and deeper understanding of their true targets are crucial to discover them.
5.4.3 Morph Resolution Performance
Single Genre Information: We first study the contributions of each set of surface
and semantic features, as shown in the first five rows in Table 5.4. The poor performance
based on surface features shows that morph resolution task is very challenging since 70%
of morphs are not orthographically similar to their real targets. Thus, capturing a morph’s
semantic meaning is crucial. Overall, the results demonstrate the effectiveness of our pro-
posed methods. Specifically, comparing “HomB” and “HetB”, “HomE” and “HetE”, we
can see that the semantic features based on heterogeneous networks have advantages over
those based on homogeneous networks. This corroborates that different neighbor sets
contribute differently, and such discrepancies should be captured. And comparisions of
“HomB” and “HomE”, “HetB” and “HetE”demonstrate the effectiveness of our two new
proposed measures. To evaluate the importance of each similarity measures, we delete

81
the semantic features obtained from each measure in “HetE” and re-evaluate the system.
We find that NCN is the most effective measure, while KLD is the least important one.
Further adding the global semantic features significantly improves the performance. This
indicates that capturing both temporal correlations and semantics of morphing simultane-
ously are important for morph resolution.
Table 5.5 shows that combination of surface and semantic features further improves
the performance, showing that they are complementary. For example, using only surface
features, the real target “T⇤Ø �Steve Jobs ” of the morph “T.; (Qiao Boss)”
is not top ranked since some other candidates such as “Tª (George)” are more ortho-
graphically similar. However, “Steve Jobs” is ranked top when combined with semantic
features.
Table 5.4: The system performance based on each single feature set.
Features Surf HomB HomE HetB HetEAcc@1 0.028 0.201 0.192 0.224 0.252Acc@5 0.159 0.313 0.369 0.393 0.421Acc@10 0.243 0.346 0.407 0.439 0.467Acc@20 0.313 0.411 0.467 0.50 0.523Features + Glob + Glob + Glob + GlobAcc@1 0.230 0.285 0.257 0.285Acc@5 0.402 0.407 0.449 0.458Acc@10 0.435 0.458 0.50 0.495Acc@20 0.486 0.523 0.565 0.542
Table 5.5: The system performance based on combinations of surface and semanticfeatures.
Features Surf + HomB Surf + HomE Surf + HetB Surf + HetEAcc@1 0.234 0.238 0.262 0.276Acc@5 0.416 0.444 0.481 0.519Acc@10 0.477 0.505 0.533 0.570Acc@20 0.519 0.561 0.565 0.598Features + Glob + Glob + Glob + GlobAcc@1 0.290 0.341 0.322 0.346Acc@5 0.505 0.495 0.528 0.533Acc@10 0.551 0.551 0.579 0.584Acc@20 0.594 0.603 0.636 0.631
Impact of Cross Source and Cross Genre Information: We integrate the cross
source information from Twitter, and the cross genre information from web documents
into Weibo tweets for information network construction, and extract a new set of semantic

82
features. Table 5.6 shows that further gains can be achieved. Notice that integrating tweets
from Twitter mainly improves the ranking for top k where k > 1. This is because Weibo
dominates our dataset, and in Weibo many of these sensitive morphs are mostly used with
their traditional meanings instead of the morph senses. Further performance improvement
is achieved by integrating information from background formal web documents which can
provide richer context and relations.
Table 5.6: The system performance of integrating cross source and cross genre in-formation.
Features Surf + HomB + Glob Surf + HomE + Glob Surf + HetB + Glob Surf + HetE + GlobAcc@1 0.290 0.341 0.322 0.346Acc@5 0.505 0.495 0.528 0.533Acc@10 0.551 0.551 0.579 0.584Acc@20 0.594 0.603 0.636 0.631Features + Twitter + Twitter + Twitter + TwitterAcc@1 0.308 0.336 0.336 0.346Acc@5 0.514 0.519 0.547 0.565Acc@10 0.579 0.594 0.594 0.636Acc@20 0.631 0.640 0.668 0.668Features + Web + Web + Web + WebAcc@1 0.327 0.360 0.341 0.379Acc@5 0.528 0.519 0.565 0.575Acc@10 0.594 0.589 0.622 0.645Acc@20 0.631 0.650 0.678 0.678
Effects of Social Features: Table 5.7 shows that adding social features can im-
prove the best performance achieved so far. This is because a group of people with close
relationships may share similar opinion. As an example, two tweets “...of course the
reputation of Buhou is a little too high! //@User1: //@User2: Chongqing event tells
us...)” and “...do not follow Bo Xilai...@User1...) are from two users in the same social
group.One includes a morph “Buhou” and the other includes its target “Bo Xilai”.
Effects of Candidate Detection: The performance with and without candidate
detection step (using all features) is shown in Table 5.8. The gain is small since the com-
bination of all features in the learning to rank framework can already well capture the
relationship between a morph and a target candidate. Nevertheless, the temporal distribu-
tion assumption is effective. It helps to filter out 80% of unrelated targets and speed up
the system 5 times, while retain 98.5% of the morph candidates that can be detected.
We also attempted using topic modeling approach to detect target candidates. Due
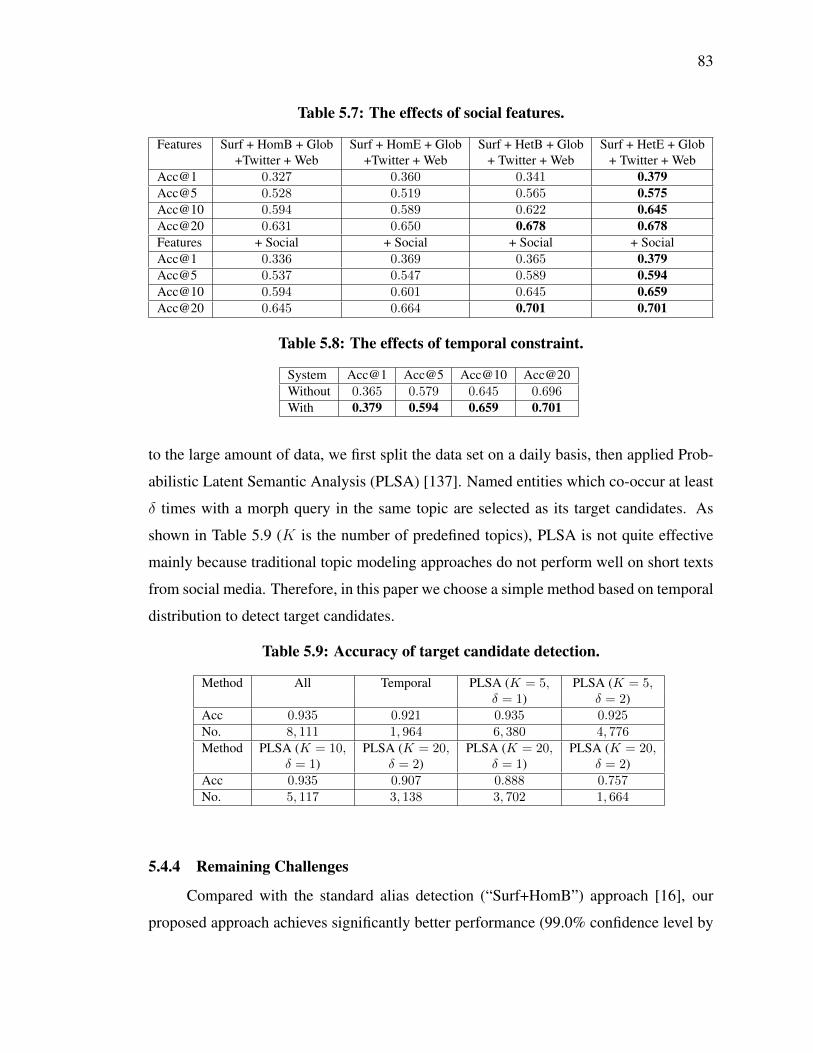
83
Table 5.7: The effects of social features.
Features Surf + HomB + Glob Surf + HomE + Glob Surf + HetB + Glob Surf + HetE + Glob+Twitter + Web +Twitter + Web + Twitter + Web + Twitter + Web
Acc@1 0.327 0.360 0.341 0.379Acc@5 0.528 0.519 0.565 0.575Acc@10 0.594 0.589 0.622 0.645Acc@20 0.631 0.650 0.678 0.678Features + Social + Social + Social + SocialAcc@1 0.336 0.369 0.365 0.379Acc@5 0.537 0.547 0.589 0.594Acc@10 0.594 0.601 0.645 0.659Acc@20 0.645 0.664 0.701 0.701
Table 5.8: The effects of temporal constraint.
System Acc@1 Acc@5 Acc@10 Acc@20Without 0.365 0.579 0.645 0.696With 0.379 0.594 0.659 0.701
to the large amount of data, we first split the data set on a daily basis, then applied Prob-
abilistic Latent Semantic Analysis (PLSA) [137]. Named entities which co-occur at least
� times with a morph query in the same topic are selected as its target candidates. As
shown in Table 5.9 (K is the number of predefined topics), PLSA is not quite effective
mainly because traditional topic modeling approaches do not perform well on short texts
from social media. Therefore, in this paper we choose a simple method based on temporal
distribution to detect target candidates.
Table 5.9: Accuracy of target candidate detection.
Method All Temporal PLSA (K = 5, PLSA (K = 5,� = 1) � = 2)
Acc 0.935 0.921 0.935 0.925No. 8, 111 1, 964 6, 380 4, 776Method PLSA (K = 10, PLSA (K = 20, PLSA (K = 20, PLSA (K = 20,
� = 1) � = 2) � = 1) � = 2)Acc 0.935 0.907 0.888 0.757No. 5, 117 3, 138 3, 702 1, 664
5.4.4 Remaining Challenges
Compared with the standard alias detection (“Surf+HomB”) approach [16], our
proposed approach achieves significantly better performance (99.0% confidence level by

84
the Wilcoxon Matched-Pairs Signed-Ranks Test for Acc@1). We further explore several
types of factors which may affect the system performance as follows.
One important aspect affecting the resolution performance is the morph & non-
morph ambiguity. We categorize a morph query as “Unique” if the string is mainly used
as a morph when it occurs, such as “Ñc (Governor Bo)” which is used to refer to
“Bo Xilai”; otherwise as “Common” (e.g. “ùù (Baby)” ,“!� (President)” ). Table
5.10 presents the separate scores for these two categories. We can see that the morphs
in “Unique” category have much better resolution performance than those in “Common”
category. This is because morphs in the “Common” category are also used with its original
meanings, which introduces a lot of noise to heterogeneous network construction. This
can be avoided if we perform context-aware morph resolution by determining whether a
term is used as a morph in a specific microblog post and only leveraging the posts that a
term is used as morphs to construct the network.
Table 5.10: Performance of two categories.
Category Number Acc@1 Acc@5 Acc@10 Acc@20Unique 72 0.479 0.715 0.771 0.819Common 35 0.171 0.343 0.40 0.429
Our resolution system has successfully identified the true targets for 70% morph
queries in the top 20 ranked candidates. Our analysis reveals that deeper profile under-
standing of both morphs and target entities is required to select the true targets for many
morph queries. For instance, the morphs for these three politicians “—Â⇣�Kim Il-
sung)”,“—c (Kim Jong-il)”, and “—ci (Kim Jong-un)” are “—'÷ (Kim Big
Fat)”, “—å÷ (Kin Second Fat)”, and “— ÷ (Kim Third Fat)” respectively. These
morphs and their true targets are very similar, thus it is crucial conduct deeper inference
to capture their family relationships. And detecting the types of both morphs and target
candidates can help filtering candidates that have inconsistent types with morph queries.
We also investigate the effects of popularity of morphs on the resolution perfor-
mance. We split the queries into 5 bins with equal size based on the non-descending
frequency, and evaluate Acc@1 separately. As shown in Table 5.11, we can see that the
popularity is not highly correlated with the performance.

85
Table 5.11: Effects of popularity of morphs.
Rank 0 ⇠ 20% 20% ⇠ 40% 40% ⇠ 60% 60% ⇠ 80% 80% ⇠ 100%All 0.333 0.476 0.341 0.429 0.318Unique 0.321 0.679 0.379 0.571 0.483Common 0.214 0.214 0.071 0.071 0.286
5.5 SummaryIn this chapter,
(1) We have studied the brand-new “morph decoding” task.
(2) We have proposed a set of novel features to capture common characteristics of
morphs and learnt a supervised morph detection model that can greatly narrow down the
scope of morph candidates.
(3) We have proposed to detect target candidates by exploiting the dynamics of the
social media to extract temporal distribution of entities, based on the assumption that the
popularity of an individual is correlated between censored and uncensored text within a
certain time window.
(4) We have built and analyzed heterogeneous information networks from multiple
sources, such as Twitter, Sina Weibo and web documents in formal genre (e.g. news) with
some well-devleloped NLP approaches because a morph and its target tend to appear in
similar contexts.
(5) We have proposed two new similarity measures, as well as integrating temporal
information into the similarity measures to generate global semantic features.
(6) We have modeled social user behaviors and used social correlation to assist in
measuring semantic similarities because the users who posted a morph and its correspond-
ing target tend to share similar interests and opinions.
(7) We have adopted a supervised learning-to-rank framework to combine various
features, including surface features, semantic features extracted from HINs, and social
features.
(8) We have compared various methods based on heterogeneous networks and ho-
mogeneous networks for morph resolution, and showed that HIN-based methods substan-
tially outperform those based on homogeneous networks.

CHAPTER 6Conclusions and Future Directions
6.1 ConclusionsIn this thesis, we have aimed to enhance natural language understanding in the infor-
mal microblogs for both humans and machines by studying three important issues related
to information ranking, enrichment, and resolution. By identifying salient and informative
information, enriching the short microblog posts with rich and clean background knowl-
edge from knowledge bases, and detecting and resolving informal and implicit morphs to
their regular referents, this thesis can assist people’s reading and understanding for mi-
croblogs and can benefit many down-streaming knowledge mining and discovery tasks.
We have introduced a series of approaches based on heterogeneous information networks
(HINs) to achieve our goals. We have showed that mining and modeling HINs is also
powerful in the field of NLP. Thus this thesis sheds lights on many other NLP tasks that
can explore and leverage HINs. Some recent work has also demonstrated that modeling
HINs is effective in other NLP tasks. For example, Yu et al. [138] adopted a similar idea
of our tweet ranking framework and achieved the state-of-the-art slot filling validation
performance. The work in [139] directly modeled HINs with both content information
and social networks to enhance information recommendation. We have mainly conducted
experiments for microblog posts. However, many of the approaches proposed in this the-
sis can also be easily applied and adapted to other genre data, especially the data from
social media. This is because there also exist heterogeneous types of information (e.g.,
social networks, retweeting and replying relations, or thread information) in many other
social media platforms such as Facebook and discussion forums. And our approaches are
also able to construct HINs directly from the unstructured texts (e.g., our morph resolution
and wikification systems). Our findings can be summarized as follows:
• For information ranking, directly modeling heterogeneous networks is more ef-
fective than homogeneous networks. Performing cross-genre information analysis
between the formal genre web documents and informal genre micloblogs improves
identification of informative posts such as news. And leveraging both explicit and
86

87
inferred implicit social network relations help detect informative tweets that meet
the general interest of social users. Cross-genre information analysis and social
user behavior analysis provide complementary evidence to enhance information
ranking.
• Information brevity in each single microblog post brings unique challenges for
the tweet wikification tasks. It is crucial to expand microblog contexts with more
topically-related information. We showed that extracting semantic meta paths from
HINs is an effective way for context expansion. We also demonstrated that leverag-
ing heterogeneous types of relations including local compatibility based on a set of
local features, coreference and semantic relatedness relations enhance tweet wikifi-
cation. In addition, graph-based semi-supervised learning algorithms that perform
collective inference and make use of a large amount of unlabeled data save tremen-
dous annotation costs for this challenging task.
• Modeling topical coherence is crucial for the wikification task and it requires accu-
rate semantic relatedness measurement between concepts. We showed that seman-
tic knowledge graphs are better resources than Wikiepdia anchor links for related-
ness measurement since the latter contains more noisy links. And the deep semantic
models based on deep neural networks (DNN) are also better choices than simi-
larity measures (e.g., Normalized Google Distance and Vector Space Model) that
do not use semantics. This is because DNN exploits hierarchical structures with
non-linear functions to extract useful hidden semantic features and it can represent
concepts with low-dimensional representations that captures the latent semantics
of concepts. We further showed that encoding heterogeneous types of knowledge
including structured facts, concept types, and textual descriptions into deep neural
networks advance relatedness measurement.
• In morph decoding, we showed that heterogeneous networks provide a more effec-
tive way to model unstructured texts than homogeneous networks. By categorizing
the surrounding contexts of morphs and target entities into entities, events, and
other non-entity noun phrases, and capturing their discrepant contributions with
meta path-based heterogeneous information analysis approaches, we substantially

88
enhance morph resolution performance.
6.2 Future DirectionsInformation Freshness Measurement In tweet ranking, we proposed to rank tweets
based on informativeness after applying temporal and spatial constraints to obtain an ini-
tial set of tweets on a topic. From the view of end users, information freshness is also a
crucial factor to judge ranking quality. Our current approach has not taken this factor into
consideration, even though we have removed redundant tweets and penalized redundant
tweets during ranking quality evaluation. Thus the first natural extension is to incorporate
information freshness into the ranking model. One approach is to measure information
freshness based on temporal information and select informative tweets which are not re-
dundant with all informative tweets selected before.
NIL entity recognition and clustering in microblogs In tweet wikification, we
only focused on detecting salient mentions which are linkable to Wikipedia, which have
some limitations. A knowledge base such as Wikipedia is usually constructed manu-
ally and is not updated in a timely fashion, thus many important concepts and facts are
still missing in it. However, new information emerges quickly, especially in microblog-
ging where information is directly from millions of individuals and organizations. This
makes NIL entity recognition and clustering necessary since NIL entities can also be
salient information in their specific contexts. NIL entity recognition and clustering has
been introduced in the Knowledge Base Population (KBP) track at TAC 2011, and exist-
ing successful approaches mainly leveraged unsupervised clustering algorithms and topic
modeling, supervised approach, string matching, and within-document coreference [79].
Thus another natural extension is to adapt and enhance these existing approaches to mi-
croblogs by incorporating additional evidence (e.g., semantic meta paths) mined from
HINs.
Richer and Cleaner Heterogeneous Information Network Construction To fully
leverage the power of heterogeneous network structures, it is crucial to construct HINs
with rich and clean information. And one significant distinction between the field of data
mining and NLP is that we focus more on processing unstructured texts in NLP. In many
cases we need to construct HINs directly from unstructured texts. Thus one natural ex-

89
tension is to enhance the current approaches for HIN construction. In this thesis, we have
leveraged well-developed NLP approaches, explored and proposed computational lin-
guistic features, and leveraged existing HINs to detect more types of nodes and relations
for HIN construction. We can further improve these approaches in several directions: (i)
Leveraging existing web-scaled semantic knowledge graphs (KGs). These semantics KGs
such as Freebase and DBpedia have contained a huge amount of entities, relations, and
facts from various domains. In this thesis, we have showed that semantic KGs are valu-
able resources to measure concept semantic relatedness relations. Some recent work has
successfully leveraged deep learning techniques to jointly model these KGs with unstruc-
tured texts for entity fact extraction [58]. These approaches aim to learn latent semantic
representations of words, concepts, and relations such that the relationships between con-
cepts are preserved in the KGs. We can leverage and extend these approaches to extract
more types of nodes and relations directly from texts. Another direction is to use distant
supervision approaches with these KGs to develop web-scaled extraction models. (ii) So-
cial network relations inferring. During events of general interest such as natural disasters
or political elections, social networks evolve and new communities form quickly [140].
During our study of tweet ranking, we also found that microblog information of these
events of general interest tend to be posted by users from diverse communities and there
exist few explicit social network linkages. In order to construct HINs with rich informa-
tion, it is crucial to infer more implicit social relations by automatically discovering social
communities and identifying social leaders and influencers.
Better Modeling and Mining Approaches In this thesis, we have encoded sepa-
rately heterogeneous types of knowledge from semantic KGs into DNN by putting each
type of knowledge into different dimensions of input feature vector. It is interesting to
directly encode semantic meta paths or even a subgraph into neural networks in order to
capture semantics more effectively. Some possible solutions include leveraging differ-
ent types of neural networks such as convolutional neural networks and recursive neural
networks. In addition, linguistic knowledge and features are crucial for many NLP tasks.
Thus, another interesting extension is to design a unified framework to automatically learn
weights associated with both linguistic features and HIN structures. Inspired by the work
on clustering and topic modeling with network structures [141], [142], we can explore

90
probabilistic models with a joint objective function regarding both linguistic features and
the regularization from HIN structures.

REFERENCES
[1] Twitter Inc., “Twitter.” [Online]. Available: https://twitter.com/, (Date LastAccessed March 7, 2015).
[2] Sina Corp., “Sina weibo.” [Online]. Available: http://weibo.com/, (Date LastAccessed March 7, 2015).
[3] A. Java, X. Song, T. Finin, and B. Tseng, “Why we twitter: Understandingmicroblogging usage and communities,” in Proc. of the 9th WebKDD and 1stSNA-KDD 2007 Workshop on Web Mining and Social Network Anal., New York,NY, USA, 2007, pp. 56–65.
[4] H. Kwak, C. Lee, H. Park, and S. Moon, “What is twitter, a social network or anews media?” in Proc. of the 19th Int. Conf. on WWW, New York, NY, USA,2010, pp. 591–600.
[5] A. Zubiaga, D. Spina, V. Fresno, and R. Martınez, “Classifying trending topics: Atypology of conversation triggers on twitter,” in Proc. of the 20th ACM Int. Conf.on Inform. and Knowl. Manage., New York, NY, USA, 2011, pp. 2461–2464.
[6] Wikipedia, “Wikipedia.” [Online]. Available: http://www.wikipedia.org/, (DateLast Accessed March 7, 2015).
[7] Pear Analytics, “Pear analytics twitter study,” 2009. [Online]. Available: http://pearanalytics.com/wp-content/uploads/2012/12/Twitter-Study-August-2009.pdf,(Date Last Accessed March 12, 2015).
[8] N. Diakopoulos, M. De Choudhury, and M. Naaman, “Finding and assessingsocial media information sources in the context of journalism,” in Proc. of theSIGCHI Conf. on Human Factors in Computing Syst., New York, NY, USA, 2012,pp. 2451–2460.
[9] DBpedia, “Dbpedia.” [Online]. Available: http://dbpedia.org/, (Date LastAccessed March 7, 2015).
[10] Freebase, “Freebase.” [Online]. Available: https://www.freebase.com/, (Date LastAccessed March 7, 2015).
[11] R. Mihalcea and A. Csomai, “Wikify!: Linking documents to encyclopedicknowledge,” in Proc. of the 16th ACM Conf. on Inform. and Knowl. Manage.,New York, NY, USA, 2007, pp. 233–242.
91

92
[12] L. Ratinov and D. Roth, “Learning-based multi-sieve co-reference resolution withknowledge,” in Proc. of the 2012 Joint Conf. on Empirical Methods in NaturalLanguage Process. and Comput. Natural Language Learn., Jeju Island, Korea,2012, pp. 1234–1244.
[13] D. Vitale, P. Ferragina, and U. Scaiella, “Classification of short texts by deployingtopical annotations,” in Proc. of the 34th European Conf. on Advances in Inform.Retrieval, Berlin, Heidelberg, 2012, pp. 376–387.
[14] M. Michelson and S. A. Macskassy, “Discovering users’ topics of interest ontwitter: A first look,” in Proc. of the 4th Workshop on Analytics for NoisyUnstructured Text Data, New York, NY, USA, 2010, pp. 73–80.
[15] Z. Xu, L. Ru, L. Xiang, and Q. Yang, “Discovering user interest on twitter with amodified author-topic model,” in Proc. of the 2011 IEEE/WIC/ACM Int. Conf. onWeb Intell. and Intelligent Agent Technology, Washington, DC, USA, 2011, pp.422–429.
[16] P. Hsiung, A. Moore, D. Neill, and J. Schneider, “Alias detection in link data sets,”in Proc. of the Int. Conf. on Intell. Anal., McLean, VA, USA, 2005, pp. 1–6.
[17] P. Pantel, “Alias detection in malicious environments,” in AAAI Fall Symp. onCapturing and Using Patterns for Evidence Detection, Menlo Park, CA, USA,2006, pp. 14–20.
[18] H. Deng, M. R. Lyu, and I. King, “A generalized co-hits algorithm and itsapplication to bipartite graphs,” in Proc. of the 15th ACM SIGKDD Int. Conf. onKnowl. Discovery and Data Mining, New York, NY, USA, 2009, pp. 239–248.
[19] Y. Sun, Y. Yu, and J. Han, “Ranking-based clustering of heterogeneousinformation networks with star network schema,” in Proc. of the 15th ACMSIGKDD Int. Conf. on Knowl. Discovery and Data Mining, New York, NY, USA,2009, pp. 797–806.
[20] M. Ji, Y. Sun, M. Danilevsky, J. Han, and J. Gao, “Graph regularized transductiveclassification on heterogeneous information networks,” in Proc. of the 2010European Conf. on Mach. Learning and Knowl. Discovery in Databases, Berlin,Heidelberg, 2010, pp. 570–586.
[21] X. Kong, P. S. Yu, Y. Ding, and D. J. Wild, “Meta path-based collectiveclassification in heterogeneous information networks,” in Proc. of the 21st ACMInt. Conf. on Inform. and Knowl. Manage, New York, NY, USA, 2012, pp.1567–1571.
[22] Y. Sun, B. Norick, J. Han, X. Yan, P. S. Yu, and X. Yu, “Pathselclus: Integratingmeta-path selection with user-guided object clustering in heterogeneousinformation networks,” ACM Trans. Knowl. Discov. Data, vol. 7, no. 3, pp.11:1–11:23, Sep. 2013.

93
[23] Y. Sun, R. Barber, M. Gupta, C. Aggarwal, and J. Han, “Co-author relationshipprediction in heterogeneous bibliographic networks,” in Proc. of the 2011 Int.Conf. on Advances in Social Networks Anal. and Mining, Washington, DC, USA,2011, pp. 121–128.
[24] Y. Sun, J. Han, X. Yan, P. Yu, and T. Wu, “Pathsim: Meta path-based top-ksimilarity search in heterogeneous information networks,” The Proc. of the VLDBEndow., vol. 4, no. 11, pp. 992–1003, Aug. 2011.
[25] Y. Sun and J. Han, “Mining heterogeneous information networks: A structuralanalysis approach,” SIGKDD Explor. Newsl., vol. 14, no. 2, pp. 20–28, Apr. 2013.
[26] R. Mihalcea and P. Tarau, “Textrank: Bringing order into texts,” in Proc. of the2014 Conf. on Empirical Methods in Natural Language Process., Barcelona,Spain, 2004, pp. 404–411.
[27] G. Erkan and D. R. Radev, “Lexrank: Graph-based lexical centrality as salience intext summarization,” J. Artif. Int. Res., vol. 22, no. 1, pp. 457–479, Dec. 2004.
[28] X. Han, L. Sun, and J. Zhao, “Collective entity linking in web text: A graph-basedmethod,” in Proc. of the 34th Int. ACM SIGIR Conf. on Res. and Development inInform. Retrieval, New York, NY, USA, 2011, pp. 765–774.
[29] Z.-Y. Niu, D.-H. Ji, and C. L. Tan, “Word sense disambiguation using labelpropagation based semi-supervised learning,” in Proc. of the 43rd Annu. Meetingof the Assoc. for Comput. Linguist., Ann Arbor, Michigan, 2005, pp. 395–402.
[30] J. Chen, D. Ji, C. L. Tan, and Z. Niu, “Relation extraction using label propagationbased semi-supervised learning,” in Proc. of the 21st Int. Conf. on Computat.Linguist. and 44th Annu. Meeting of the Assoc. for Comput. Linguist., Sydney,Australia, 2006, pp. 129–136.
[31] T. Cassidy, H. Ji, L.-A. Ratinov, A. Zubiaga, and H. Huang, “Analysis andenhancement of wikification for microblogs with context expansion,” in Proc. ofthe 24th Int. Conf. on Comput. Linguist., Mumbai, India, 2012, pp. 441–456.
[32] L. Ratinov, D. Roth, D. Downey, and M. Anderson, “Local and global algorithmsfor disambiguation to wikipedia,” in Proc. of the 49th Annu. Meeting of the Assoc.for Comput. Linguist.: Human Language Technologies, Portland, OR, USA, 2011,pp. 1375–1384.
[33] X. Zhu, Z. Ghahramani, and J. Lafferty, “Semi-supervised learning using gaussianfields and harmonic functions,” in Proc. of the 20th Int. Conf. on Mach. Learn.,Washington, DC, USA, 2003, pp. 912–919.
[34] A. J. Smola and I. R. Kondor, “Kernels and regularization on graphs.” in Proc. ofthe Annu. Conf. on Comput. Learn. Theory, Washington, DC, USA, 2003, pp.144–158.

94
[35] A. Blum, J. Lafferty, M. R. Rwebangira, and R. Reddy, “Semi-supervised learningusing randomized mincuts,” in Proc. of the 21st Int. Conf. on Mach. Learn., NewYork, NY, USA, 2004, pp. 13–20.
[36] D. Zhou, O. Bousquet, T. N. Lal, J. Weston, and B. Scholkopf, “Learning withlocal and global consistency,” in Advances in Neural Inform. Process. Syst. 16,Vancouver, Canada, 2004, pp. 321–328.
[37] P. P. Talukdar and K. Crammer, “New regularized algorithms for transductivelearning,” in Proc. of the European Conf. on Mach. Learn. and Knowl. Discoveryin Databases, Berlin, Heidelberg, 2009, pp. 442–457.
[38] D. Milne and I. Witten, “An effective, low-cost measure of semantic relatednessobtained from wikipedia links,” in Prof. of the 23th Conf. on Artif. Intell.,Chicago, IL, USA, 2008, pp. 25–30.
[39] R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. Kuksa,“Natural language processing (almost) from scratch,” J. Mach. Learn. Res.,vol. 12, pp. 2493–2537, Nov. 2011.
[40] P.-S. Huang, X. He, J. Gao, L. Deng, A. Acero, and L. Heck, “Learning deepstructured semantic models for web search using clickthrough data,” in Proc. ofthe 22nd ACM Int. Conf. on Inform. and Knowl. Manage., New York, NY, USA,2013, pp. 2333–2338.
[41] Y. Bengio, R. Ducharme, P. Vincent, and C. Janvin, “A neural probabilisticlanguage model,” J. Mach. Learn. Res., vol. 3, pp. 1137–1155, Mar. 2003.
[42] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko,“Translating embeddings for modeling multi-relational data,” in Advances inNeural Inform. Process. Syst. 26, Lake Tahoe, NV, USA, 2013, pp. 2787–2795.
[43] R. Socher, D. Chen, C. Manning, and A. Ng, “Reasoning with neural tensornetworks for knowledge base completion,” in Advances in Neural Inform.Process. Syst. 26, Lake Tahoe, NV, USA, 2013, pp. 926–934.
[44] DBLP, “Dblp.” [Online]. Available: http://dblp.uni-trier.de/, (Date Last AccessedMarch 8, 2015).
[45] L. Page, S. Brin, R. Motwani, and T. Winograd, “The pagerank citation ranking:Bringing order to the web,” in Proc. the 7th Int. Conf. on WWW, Brisbane,Australia, 1998, pp. 161–172.
[46] J. M. Kleinberg, “Authoritative sources in a hyperlinked environment,” J. ACM,vol. 46, no. 5, pp. 604–632, Sep. 1999.

95
[47] T. Haveliwala, S. Kamvar, and G. Jeh, “An analytical comparison of approachesto personalizing pagerank,” Stanford InfoLab, Menlo Park, CA, USA, Tech. Rep.2003-35, June 2003.
[48] D. Liben-Nowell and J. Kleinberg, “The link prediction problem for socialnetworks,” in Proc. of the 20th Int. Conf. on Inform. and Knowl. Manage., NewYork, NY, USA, 2003, pp. 556–559.
[49] G. Jeh and J. Widom, “Simrank: A measure of structural-context similarity,” inProc. of the 8th ACM SIGKDD Int. Conf. on Knowl. Discovery and Data Mining,New York, NY, USA, 2002, pp. 538–543.
[50] J. Shi and J. Malik, “Normalized cuts and image segmentation,” IEEE Trans.Pattern Anal. Mach. Intell., vol. 22, no. 8, pp. 888–905, Aug. 2000.
[51] P. Sen, G. M. Namata, M. Bilgic, L. Getoor, B. Gallagher, and T. Eliassi-Rad,“Collective classification in network data,” AI Mag., vol. 29, no. 3, pp. 93–106,Sep. 2008.
[52] Y. Duan, F. Wei, M. Zhou, and H.-Y. Shum, “Graph-based collective classificationfor tweets,” in Proc. of the 21st ACM Int. Conf. on Inform. and Knowl. Manage.,New York, NY, USA, 2012, pp. 2323–2326.
[53] D. Hakkani-Tur, L. Heck, and G. Tur, “Using a knowledge graph and query clicklogs for unsupervised learning of relation detection,” in Proc. of the 2013 IEEEInt. Conf. on Acoust., Speech and Signal Process., Vancouver, BC, Canada, 2013,pp. 8327–8331.
[54] L. Heck, D. Hakkani-Tur, and G. Tur, “Leveraging knowledge graphs forweb-scale unsupervised semantic parsing,” in Proc. of Conf. of the Int. SpeechCommun. Assoc., Lyon, France, 2013, pp. 1594–1598.
[55] H. Hajishirzi, L. Zilles, D. Weld, and L. S. Zettlemoyer, “Joint coreferenceresolution and named-entity linking with multi-pass sieves,” in Proc. of the 2013Conf. on Empirical Methods in Natural Language Process, Seattle, WA, USA,2013, pp. 289–299.
[56] S. Dutta and G. Weikum, “Cross-document co-reference resolution usingsample-based clustering with knowledge enrichment,” Trans. of the Assoc. forComput. Linguist., vol. 3, no. 1, pp. 15–28, Jan. 2015.
[57] A. Bordes, X. Glorot, J. Weston, and Y. Bengio, “Joint learning of words andmeaning representations for open-text semantic parsing,” in Proc. of the 15th Int.Conf. on Artif. Intell. and Stat., La Palma, Spain, 2012, pp. 127–135.
[58] Z. Wang, J. Zhang, J. Feng, and Z. Chen, “Knowledge graph and text jointlyembedding,” in Proc. of the 2014 Conf. on Empirical Methods in NaturalLanguage Process., Doha, Qatar, 2014, pp. 1591–1601.

96
[59] A. Bordes, S. Chopra, and J. Weston, “Question answering with subgraphembeddings,” in Proc. of the 2014 Conf. on Empirical Methods in NaturalLanguage Process., Doha, Qatar, 2014, pp. 615–620.
[60] M. Yang, N. Duan, M. Zhou, and H. Rim, “Joint relational embeddings forknowledge-based question answering,” in Proc. of the 2014 Conf. on EmpiricalMethods in Natural Language Process, Doha, Qatar, 2014, pp. 645–650.
[61] R. L. Cilibrasi and P. M. B. Vitanyi, “The google similarity distance,” IEEE Trans.on Knowl. and Data Eng., vol. 19, no. 3, pp. 370–383, Mar. 2007.
[62] J. Sankaranarayanan, H. Samet, B. E. Teitler, M. D. Lieberman, and J. Sperling,“Twitterstand: News in tweets,” in Proc. of the 17th ACM SIGSPATIAL Int. Conf.on Advances in Geographic Inform. Syst., New York, NY, USA, 2009, pp. 42–51.
[63] S. A. Golder, A. Marwick, and S. Yardi, “A structural approach to contactrecommendations in online social networks,” in Proc. SIGIR2009 Workshop onSearch in Social Media, Boston, MA, USA, 2009, pp. 1–4.
[64] Y. Yamaguchi, T. Takahashi, T. Amagasa, and H. Kitagawa, “Turank: Twitter userranking based on user-tweet graph analysis,” in Proc. of the 11th Int. Conf. onWeb Inform. Syst. Eng., Berlin, Heidelberg, 2010, pp. 240–253.
[65] J. Hannon, M. Bennett, and B. Smyth, “Recommending twitter users to followusing content and collaborative filtering approaches,” in Proc. of the 4th ACMConf. on Recommender Syst., New York, NY, USA, 2010, pp. 199–206.
[66] I. Uysal and W. B. Croft, “User oriented tweet ranking: A filtering approach tomicroblogs,” in Proc. of the 20th ACM Int. Conf. on Inform. and Knowl. Manage.,New York, NY, USA, 2011, pp. 2261–2264.
[67] Y. Duan, L. Jiang, T. Qin, M. Zhou, and H.-Y. Shum, “An empirical study onlearning to rank of tweets,” in Proc. of the 23rd Int. Conf. on Comput. Linguist.,Stroudsburg, PA, USA, 2010, pp. 295–303.
[68] M. Huang, Y. Yang, and X. Zhu, “Quality-biased ranking of short texts inmicroblogging services,” in Proc. of 5th Int. Joint Conf. on Natural LanguageProcess., Chiang Mai, Thailand, 2011, pp. 373–382.
[69] D. Inouye and J. K. Kalita, “Comparing twitter summarization algorithms,” inProc. of the 2011 IEEE 3rd Int. Conf. on Social Computing, Boston, MA, USA,2011, pp. 298–306.
[70] C. Castillo, M. Mendoza, and B. Poblete, “Information credibility on twitter,” inProc. of the 20th Int. Conf. on WWW. New York, NY, USA: ACM, 2011, pp.675–684.

97
[71] M. Gupta, P. Zhao, and J. Han, “Evaluating event credibility on twitter,” in Proc.of the Twelfth SIAM Int. Conf. on Data Mining, Anaheim, CA, USA, 2012, pp.153–164.
[72] D. Wang, T. Abdelzaher, H. Ahmadi, J. Pasternack, D. Roth, M. Gupta, J. Han,O. Fatemieh, H. Le, and C. Aggrawal, “On bayesian interpretation of fact-findingin information networks,” in Proc. of the 14th Int. Conf. on Inform. Fusion,Chicago, IL, USA, 2011, pp. 1–8.
[73] D. Wang, L. Kaplan, H. Le, and T. Abdelzaher, “On truth discovery in socialsensing: A maximum likelihood estimation approach,” in Proc. of the 11th Int.Conf. on Inform. Process. in Sensor Networks, New York, NY, USA, 2012, pp.233–244.
[74] M. Gupta and J. Han, “Heterogeneous network-based trust analysis: a survey,”SIGKDD Explor. Newsl., vol. 13, no. 1, pp. 54–71, Aug. 2011.
[75] J. Weng, E.-P. Lim, J. Jiang, and Q. He, “Twitterrank: Finding topic-sensitiveinfluential twitterers,” in Proc. of the 3rd ACM Int. Conf. on Web Search and DataMining, New York, NY, USA, 2010, pp. 261–270.
[76] A. Pal and S. Counts, “Identifying topical authorities in microblogs,” in Proc. ofthe 4th ACM Int. Conf. on Web Search and Data Mining, New York, NY, USA,2011, pp. 45–54.
[77] D. M. Romero, W. Galuba, S. Asur, and B. A. Huberman, “Influence and passivityin social media,” in Proc. of the 20th Int. Conf. Companion on WWW, New York,NY, USA, 2011, pp. 113–114.
[78] H. Ji, R. Grishman, H. Dang, K. Griffitt, and J. Ellis, “Overview of the tac 2010knowledge base population track,” in Text Anal. Conf., Gaithersburg, MD, USA,2010, pp. 1–25.
[79] H. Ji, R. Grishman, and H. Dang, “Overview of the tac 2011 knowledge basepopulation track,” in Text Anal. Conf., Gaithersburg, MD, USA, 2011, pp. 1–33.
[80] D. Milne and I. H. Witten, “Learning to link with wikipedia,” in Proc. of the 17thACM Conf. on Inform. and Knowl. Manage., New York, NY, USA, 2008, pp.509–518.
[81] X. Han and L. Sun, “A generative entity-mention model for linking entities withknowledge base,” in Proc. of the 49th Annu. Meeting of the Assoc. for Comput.Linguist.: Human Language Technologies, Portland, OR, USA, 2011, pp.945–954.
[82] S. Cucerzan, “Large-scale named entity disambiguation based on Wikipediadata,” in Proc. of the 2007 Joint Conf. on Empirical Methods in Natural Language

98
Process. and Comput. Natural Language Learn., Prague, Czech Republic, 2007,pp. 708–716.
[83] X. Han and J. Zhao, “Named entity disambiguation by leveraging wikipediasemantic knowledge,” in Proc. of the 18th ACM Conf. on Inform. and Knowl.Manage., New York, NY, USA, 2009, pp. 215–224.
[84] S. Kulkarni, A. Singh, G. Ramakrishnan, and S. Chakrabarti, “Collectiveannotation of wikipedia entities in web text,” in Proc. of the 15th ACM SIGKDDInt. Conf. on Knowl. Discovery and Data Mining, New York, NY, USA, 2009, pp.457–466.
[85] M. Pennacchiotti and P. Pantel, “Entity extraction via ensemble semantics,” inProc. of the 2009 Conf. on Empirical Methods in Natural Language Process.,Singapore, 2009, pp. 238–247.
[86] P. Ferragina and U. Scaiella, “Tagme: On-the-fly annotation of short textfragments (by wikipedia entities),” in Proc. of the 19th ACM Int. Conf. on Inform.and Knowl. Manage., New York, NY, USA, 2010, pp. 1625–1628.
[87] Y. Guo, W. Che, T. Liu, and S. Li, “A graph-based method for entity linking,” inProc. of 5th Int. Joint Conf. on Natural Language Process., Chiang Mai, Thailand,2011, pp. 1010–1018.
[88] Z. Chen and H. Ji, “Collaborative ranking: A case study on entity linking,” inProc. of the 2011 Conf. on Empirical Methods in Natural Language Process.,Edinburgh, Scotland, UK., 2011, pp. 771–781.
[89] Z. Kozareva, K. Voevodski, and S. Teng, “Class label enhancement via relatedinstances,” in Proc. of the 2011 Conf. on Empirical Methods in Natural LanguageProcess., Edinburgh, Scotland, UK., 2011, pp. 118–128.
[90] W. Shen, J. Wang, P. Luo, and M. Wang, “Linking named entities in tweets withknowledge base via user interest modeling,” in Proc. of the 19th ACM SIGKDDInt. Conf. on Knowl. Discovery and Data Mining, New York, NY, USA, 2013, pp.68–76.
[91] X. Liu, Y. Li, H. Wu, M. Zhou, F. Wei, and Y. Lu, “Entity linking for tweets,” inProc. of the 51st Annu. Meeting of the Assoc. for Comput. Linguist., Sofia,Bulgaria, 2013, pp. 1304–1311.
[92] E. Meij, W. Weerkamp, and M. de Rijke, “Adding semantics to microblog posts,”in Proc. of the 5th ACM Int. Conf. on Web Search and Data Mining, New York,NY, USA, 2012, pp. 563–572.
[93] S. Guo, M.-W. Chang, and E. Kiciman, “To link or not to link? a study onend-to-end tweet entity linking,” in Proc. of the 2013 Conf. of the North Amer.

99
Chapter of the Assoc. for Comput. Linguist.: Human Language Technologies,Atlanta, GA, USA, 2013, pp. 1020–1030.
[94] D. Bamman, B. O’Connor, and N. A. Smith, “Censorship and deletion practices inchinese social media,” First Monday, vol. 17, no. 3, pp. 1–21, Mar. 2012.
[95] Y. Xia, K.-F. Wong, and W. Gao, “Nil is not nothing: Recognition of chinesenetwork informal language expressions,” in Proc. of the 4th SIGHAN Workshopon Chinese Language Process., Jeju Island, Korea, 2005, pp. 95–102.
[96] Y. Xia and K.-F. Wong, “Anomaly detecting within dynamic chinese chat text,” inProc. Workshop On New Text Wikis And Blogs And Other Dynamic Text Sources,Trento, Italy, 2006, pp. 48–55.
[97] Y. Xia, K.-F. Wong, and W. Li, “A phonetic-based approach to chinese chat textnormalization,” in Proc. of the 21st Int. Conf. on Comput. Linguist. and 44thAnnu. Meeting of the Assoc. for Comput. Linguist., Sydney, Australia, 2006, pp.993–1000.
[98] Z. Li and D. Yarowsky, “Mining and modeling relations between formal andinformal chinese phrases from web corpora,” in Proc. of the Conf. on EmpiricalMethods in Natural Language Process., Stroudsburg, PA, USA, 2008, pp.1031–1040.
[99] A. Wang, M.-Y. Kan, D. Andrade, T. Onishi, and K. Ishikawa, “Chinese informalword normalization: an experimental study,” in Proc. of the 6th Int. Joint Conf. onNatural Language Process., Nagoya, Japan, 2013, pp. 127–135.
[100] A. Wang and M.-Y. Kan, “Mining informal language from chinese microtext:Joint word recognition and segmentation,” in Proc. of the 51st Annu. Meeting ofthe Assoc. for Comput. Linguist., Sofia, Bulgaria, 2013, pp. 731–741.
[101] D. Bollegala, Y. Matsuo, and M. Ishizuka, “Automatic discovery of personal namealiases from the web,” IEEE Trans. Knowl. Data Eng., vol. 23, no. 6, pp. 831–844,Apr. 2011.
[102] R. Holzer, B. Malin, and L. Sweeney, “Email alias detection using social networkanalysis,” in Proc. of the 3rd Int. Workshop on Link Discovery, New York, NY,USA, 2005, pp. 52–57.
[103] I. Couzin, “Collective minds,” Nature, vol. 445, no. 7129, p. 715, Feb. 2007.
[104] A. Zubiaga, D. Spina, E. Amigo, and J. Gonzalo, “Towards real-timesummarization of scheduled events from Twitter streams,” in Proc. of the 23rdACM Conf. on Hypertext and social media, New York, NY, USA, 2012, pp.319–320.

100
[105] Microsoft Corp., “Bing search api.” [Online]. Available:http://www.bing.com/toolbox/bingdeveloper/, (Date Last Accessed March 15,2015).
[106] M. Hunter, “Twitter slang words.” [Online]. Available:http://www.mltcreative.com/blog/bid/54272/Social-Media-Minute-Big-A-List-of-Twitter-Slang-and-Definition, (Date LastAccessed March 15, 2015).
[107] B. Carterette and P. Chandar, “Probabilistic models of ranking novel documentsfor faceted topic retrieval,” in Proc. of the 18th ACM Conf. on Inf. and Knowl.Manage., New York, NY, USA, 2009, pp. 1287–1296.
[108] R. McDonald, “A study of global inference algorithms in multi-documentsummarization,” in Proc. of the 29th European Conf. on IR Res., Berlin,Heidelberg, 2007, pp. 557–564.
[109] F. M. Zanzotto, M. Pennacchiotti, and K. Tsioutsiouliklis, “Linguistic redundancyin twitter,” in Proc. of the Conf. on Empirical Methods in Natural LanguageProcess., Stroudsburg, PA, USA, 2011, pp. 659–669.
[110] K. Jarvelin and J. Kekalainen, “Cumulated gain-based evaluation of irtechniques,” ACM Trans. Inf. Syst., vol. 20, no. 4, pp. 422–446, Oct. 2002.
[111] G. A. Miller, “Wordnet: A lexical database for english,” Commun. ACM, vol. 38,no. 11, pp. 39–41, Nov. 1995.
[112] P. F. Brown, P. V. deSouza, R. L. Mercer, V. J. D. Pietra, and J. C. Lai,“Class-based n-gram models of natural language,” Comput. Linguist., vol. 18,no. 4, pp. 467–479, Dec. 1992.
[113] R. Bunescu, “Using encyclopedic knowledge for named entity disambiguation,”in Proc. of the 11st Conf. of the European Chapter of the Assoc. for Comput.Linguist., Trento, Italy, 2006, pp. 9–16.
[114] B. Hachey, W. Radford, J. Nothman, M. Honnibal, and J. R. Curran, “Evaluatingentity linking with wikipedia,” Artif. Intell., vol. 194, pp. 130–150, Jan. 2013.
[115] K. Wang, C. Thrasher, and B.-J. P. Hsu, “Web scale nlp: A case study on url wordbreaking,” in Proc. of the 20th Int. Conf. on WWW, New York, NY, USA, 2011,pp. 357–366.
[116] Z. He, S. Liu, M. Li, M. Zhou, L. Zhang, and H. Wang, “Learning entityrepresentation for entity disambiguation,” in Proc. of the 51st Annu. Meeting ofthe Assoc. for Comput. Linguist., Sofia, Bulgaria, 2013, pp. 30–34.

101
[117] Y. Shen, X. He, J. Gao, L. Deng, and G. Mesnil, “Learning semanticrepresentations using convolutional neural networks for web search,” in Proc. ofthe Companion Publication of the 23rd Int. Conf. on WWW Companion, Republicand Canton of Geneva, Switzerland, 2014, pp. 373–374.
[118] H. Larochelle, Y. Bengio, J. Louradour, and P. Lamblin, “Exploring strategies fortraining deep neural networks,” J. Mach. Learn. Res., vol. 10, no. 1, pp. 1–40, Jun.2009.
[119] X. Cheng and D. Roth, “Relational inference for wikification,” in Proc. of the2013 Conf. on Empirical Methods in Natural Language Process., Seattle, WA,USA, 2013, pp. 1787–1796.
[120] D. Ceccarelli, C. Lucchese, S. Orlando, R. Perego, and S. Trani, “Learningrelatedness measures for entity linking,” in Proc. of the 22nd ACM Int. Conf. onInform. and Knowl. Manage., New York, NY, USA, 2013, pp. 139–148.
[121] C. D. Manning, P. Raghavan, and H. Schutze, Introduction to InformationRetrieval, 1st ed. New York, NY, USA: Cambridge University Press, 2008.
[122] J. Hoffart, M. Yosef, I. Bordino, H. Furstenau, M. Pinkal, M. Spaniol, B. Taneva,S. Thater, and G. Weikum, “Robust disambiguation of named entities in text,” inProc. of the 2011 Conf. on Empirical Methods in Natural Language Process.,Edinburgh, Scotland, UK., 2011, pp. 782–792.
[123] M. Shirakawa, H. Wang, Y. Song, Z. Wang, K. Nakayama, T. Hara, and S. Nishio,“Entity disambiguation based on a probabilistic taxonomy,” Microsoft Research,Seattle, WA, USA, Tech. Rep. MSR-TR-2011-125, 2011.
[124] G. Salton, A. Wong, and C. S. Yang, “A vector space model for automaticindexing,” Commun. ACM, vol. 18, no. 11, pp. 613–620, Nov. 1975.
[125] C. Cortes and V. Vapnik, “Support-vector networks,” Mach. Learn., vol. 20, no. 3,pp. 273–297, Sep. 1995.
[126] Q. Li, H. Li, H. Ji, W. Wang, J. Zheng, and F. Huang, “Joint bilingual nametagging for parallel corpora,” in Proc. of the 21st ACM Int. Conf. on Inform. andKnowl. Manage., New York, NY, USA, 2012, pp. 1727–1731.
[127] V. Ng, “Supervised noun phrase coreference research: The first fifteen years,” inProc. of the 48th Annu. Meeting of the Assoc. for Comput. Linguist., Uppsala,Sweden, 2010, pp. 1396–1411.
[128] R. A. Wagner and M. J. Fischer, “The string-to-string correction problem,” J.ACM, vol. 21, no. 1, pp. 168–173, Jan. 1974.
[129] D. S. Hirschberg, “Algorithms for the longest common subsequence problem,” J.ACM, vol. 24, no. 4, pp. 664–675, Oct. 1977.

102
[130] P.-C. Chang, M. Galley, and C. D. Manning, “Optimizing chinese wordsegmentation for machine translation performance,” in Proc. of the 3rd Workshopon Statistical Mach. Translation, Columbus, OH, USA, 2008, pp. 224–232.
[131] K. Toutanova, D. Klein, C. D. Manning, and Y. Singer, “Feature-richpart-of-speech tagging with a cyclic dependency network,” in Proc. of the 2003Conf. of the North Amer. Chapter of the Assoc. for Comput. Linguist. on HumanLanguage Technology, Edmonton, Alberta, Canada, 2003, pp. 173–180.
[132] H.-P. Zhang, H.-K. Yu, D.-Y. Xiong, and Q. Liu, “Hhmm-based chinese lexicalanalyzer ictclas,” in Proc. of the second SIGHAN workshop on Chinese languageprocess., Stroudsburg, PA, USA, 2003, pp. 184–187.
[133] H. Ji and R. Grishman, “Refining event extraction through cross-documentinference,” in Proc. of the 46st Annu. Meeting of the Assoc. for Comput. Linguist.,Columbus, OH, USA, 2008, pp. 254–262.
[134] A. Anagnostopoulos, R. Kumar, and M. Mahdian, “Influence and correlation insocial networks,” in Proc. of the 14th ACM SIGKDD Int. Conf. on Knowl.Discovery and Data Mining, New York, NY, USA, 2008, pp. 7–15.
[135] Z. Wen and C.-Y. Lin, “On the quality of inferring interests from socialneighbors,” in Proc. of the 16th ACM SIGKDD Int. Conf. on Knowl. Discoveryand Data Mining, New York, NY, USA, 2010, pp. 373–382.
[136] C. Lin, L. Wu, Z. Wen, H. Tong, V. Griffiths-Fisher, L. Shi, and D. Lubensky,“Social network analysis in enterprise,” Proc. of the IEEE, vol. 100, no. 9, pp.2759–2776, Jul. 2012.
[137] T. Hofmann, “Probabilistic latent semantic indexing,” in Proc. of the 22nd Annu.Int. ACM SIGIR Conf. on Res. and Development in Inform. Retrieval, New York,NY, USA, 1999, pp. 50–57.
[138] D. Yu, H. Huang, T. Cassidy, H. Ji, C. Wang, S. Zhi, J. Han, C. Voss, andM. Magdon-Ismail, “The wisdom of minority: Unsupervised slot filling validationbased on multi-dimensional truth-finding,” in Proc. of the 25th Int. Conf. onComput. Linguist., Dublin, Ireland, 2014, pp. 1567–1578.
[139] Q. Zhang and H. Wang, “Collaborative topic regression with multiple graphsfactorization for recommendation in social media,” in Proc. of the 25th Int. Conf.on Comput. Linguist., Dublin, Ireland, 2014, pp. 233–244.
[140] Y. Tyshchuk, H. Li, H. Ji, and W. A. Wallace, “Evolution of communities ontwitter and the role of their leaders during emergencies,” in Proc. of the 2013IEEE/ACM Int. Conf. on Advances in Social Networks Analysis and Mining, NewYork, NY, USA, 2013, pp. 727–733.

103
[141] Q. Mei, D. Cai, D. Zhang, and C. Zhai, “Topic modeling with networkregularization,” in Proc. of the 17th Int. Conf. on WWW, New York, NY, USA,2008, pp. 101–110.
[142] Y. Sun, C. C. Aggarwal, and J. Han, “Relation strength-aware clustering ofheterogeneous information networks with incomplete attributes,” Proc. VLDBEndow., vol. 5, no. 5, pp. 394–405, Jan. 2012.