miskolci egyetem gépészmérnöki és informatikai kar
TRANSCRIPT

Általános Informatikai Intézeti Tanszék
Az adattárolási modell és a modell osztályok
kidolgozása elektronikus kézirat feltöltő
rendszerhez
Szakdolgozat
Miskolci Egyetem Gépészmérnöki és Informatikai Kar
Mérnökinformatikus Szak (Bsc)
Készítette: Burai Gergő
NEPTUN kód: FGPRDE
Tervezésvezető: Dr. Baksáné dr. Varga Erika

I
Tartalomjegyzék
1. Bevezetés ......................................................................................................... 1
2. Felhasznált technológiák .................................................................................. 3
2.1 Spring és Spring MVC ............................................................................................................. 3
2.2 Maven ....................................................................................................................................... 6
2.3 MySQL ..................................................................................................................................... 6
2.4 ORM rendszerek és a MyBatis ................................................................................................. 7
2.5 JUnit ....................................................................................................................................... 10
2.6 SVN ........................................................................................................................................ 10
3. Specifikáció .................................................................................................... 13
3.1 Általános követelmények ....................................................................................................... 13
3.2 Részletes specifikáció ............................................................................................................ 13
3.3 Rendszerkövetelmények ......................................................................................................... 18
4. Tervezés ......................................................................................................... 19
4.1 Modulok ................................................................................................................................. 19
4.2 Adatbázis tervezés .................................................................................................................. 21
4.2.1 Felhasználó ......................................................................................................................... 23
4.2.2 Cikk .................................................................................................................................... 23
4.2.3 További egyedek ................................................................................................................ 24
4.2.4 Felhasználó és cikk közötti kapcsolatok ............................................................................ 24
4.3 Java osztályok tervezése ......................................................................................................... 25
4.4 Adathozzáférési interfészek ................................................................................................... 28
4.4.1 ConfigDAO ........................................................................................................................ 29
4.4.2 UserDAO ............................................................................................................................. 29
4.4.3 SubmissionDAO................................................................................................................. 30
4.4.4 HistoryDAO ....................................................................................................................... 33
5. Implementáció ................................................................................................ 34
5.1 Az adatbázis ................................................................................................................................. 34
5.2 Az adathozzáférési osztályok ....................................................................................................... 36
5.2.1 Modul felépítése ........................................................................................................................ 36
5.2.2 MyBatis konfiguráció ................................................................................................................ 37

II
5.2.3 MyBatis implementáció ............................................................................................................ 38
6. Tesztelés ......................................................................................................... 45
7. Összegzés ....................................................................................................... 48
8. Summary ........................................................................................................ 49
9. Irodalomjegyzék............................................................................................. 50

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
1
1. Bevezetés
A szakdolgozatom témája egy elektronikus kéziratfeltöltő rendszer adattárolási modelljének
kidolgozása, valamint az adathozzáférési réteg megtervezése és implementálása.
Csoportmunkában dolgoztunk hárman, Károlyi Máté, Fogt Tamás és jómagam. A feladatunk
célja a Miskolci Egyetem PSAIE (Production Systems and Information Engineering)
folyóiratához a webes felület kidolgozása és a mögötte lévő üzleti logikát, valamint az
adattárolást megvalósító kéziratkezelő rendszer létrehozása volt. Az én részem a feladatban a
rendszer legalsó rétegének, az adattárolási rétegnek a megtervezése és implementálása volt. Ez
magában foglalja az adattárolási modell osztályainak megtervezését, a relációs adatbázis
táblaszerkezeteinek kidolgozását, az adathozzáférési interfészek létrehozását, valamint az
ezeket megvalósító osztályok implementálását, ezáltal a különböző táblamódosítási és
lekérdezési adatbázis-műveletek megírását.
A PSAIE folyóirat célja magas színvonalú kutatási anyagok publikálása a termelési rendszerek
és a mérnök informatika területén. A tudományos folyóiratok általános célja a tudományos
témájú publikációk széleskörű terjesztése. Az elektronikus formában publikált kutatási
eredmények díjmentes rendelkezésre bocsátása a közzétett információt jobban láthatóvá és
könnyebben elérhetővé teszi, ezáltal gyorsabban hivatkozhatnak rájuk. A magas hivatkozási
arány megnöveli a folyóirat elismertségét is.
A cikkek általános publikációs fázisai:
preprint: a kiadóhoz megjelentetésre beküldött kézirat,
postprint: lektorálás utáni, a bírálók észrevételeinek, korrekciós kéréseinek
megfelelően kialakított verzió,
kiadói változat: korrektúrázott, tördelőszerkesztett, nyomdakész publikáció.
A megírt kéziratot a szerző először beküldi egy tudományos folyóirathoz. A tudományos
cikkek minőségét a bírálók ítélik meg. A tudományos folyóiratnál szakmai bírálatnak vetik alá
a beérkezett cikkeket, erről készül el a szakmai bírálat (review). A kéziratot elismert kutatók

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
2
bírálata alapján ítélhetnek publikálásra érdemesnek. Majd ha az elbírálás pozitív kimenetelű
volt, a cikket továbbküldik nyelvi lektorálásra. Ezután következik a nyomdai szerkesztés,
amely során nyomdakész állapotba kerül a cikk, készen a megjelentetésre. Végül bekerül a
folyóirat következő kiadványába és annak kiadásakor fog megjelenni.
A kéziratkezelő rendszer (manuscript handler system) egy szoftver, amelynek célja a
tudományos cikkek publikálási folyamatának megvalósítása és leegyszerűsítése. Magasszintű
környezetet és kezelőfelületet biztosít a felhasználók számára. Legfontosabb feladata a
különböző szerepkörök elkülönítése, ezek általában a következők: szerző, szerkesztő,
főszerkesztő, bíráló. A rendszer felel az ezekhez tartozó különböző funkciók és szolgáltatások
biztosításáért és a szerepkörök együttműködésének megvalósításáért a publikációs folyamat
során. Ezenkívül fontos még a könnyű adattárolás és adatelérés biztosítása és a hozzáférések
szerepkör szerinti szabályozása. Egyéb funkciókat is nyújthat a rendszer, például kimutatások
összeállítása, automatikus e-mail üzenetek küldése, események naplózása, stb.
A rendszer alapvetően a Miskolci Egyetem PSAIE tudományos folyóiratához készült, de
általános alkalmazást fejlesztettünk (ún. white-labeled product), ami azt jelenti, hogy bármely
hasonló folyóirat működtetéséhez fel lehet használni. A rendszer moduláris felépítése lehetővé
teszi, hogy a struktúra megváltozása nélkül le lehessen cserélni az egyes implementációkat,
ezáltal testreszabni az alkalmazást. Ezeket a pontokat a rendszerben testreszabási pontoknak
nevezik (customization point).
A szakdolgozatban először a feladat megoldása során felhasznált technológiákat ismertetem és
részletezem. Ezután a specifikáció értelmezését követő tervezési folyamatról és magáról a
specifikációról írok hosszabban. Ezt követően az implementációs folyamat részletezése
következik. Végül a szakdolgozatot egy magyar, valamint egy angol nyelvű összegzés zárja.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
3
2. Felhasznált technológiák
A feladat elkészítésénél használt különböző kész komponensek és technológiák felsorolása
következik:
A rendszert az Eclipse nevű nyílt forráskódú, platformfüggetlen szoftverkeretrendszer
segítségével fejlesztettük, Java programozási nyelven.
A projektet az Apache Maven [3] plugin segítségével hoztuk létre különböző
modulokká felosztva, és a Maven segítségével épül fel az alkalmazás.
A webalkalmazást a Spring Web MVC (model-view-controller) [1] keretrendszer
használatával fejlesztettük.
Adattárolásra MySQL relációs adatbázist használtam.
Az adatbázis-kezelést a MyBatis [4] ORM keretrendszer használatával valósítottam
meg.
A webalkalmazást Apache Tomcat 8.0 szerveren fejlesztettük, teszteltük.
A webes felület a Bootstrap front-end keretrendszer és az Angular JS Javascript
keretrendszer segítségével készült el.
A teszteket a JUnit keretrendszer használatával írtam meg.
A közös munka során az SVN [2] verziókövető rendszert használtuk.
2.1 Spring és Spring MVC
A Spring MVC [1] a Spring keretrendszer része. Ez egy nyílt forráskódú alkalmazás-
keretrendszer és az IOC (Inversion of Control, fordított vezérlés) tervezési mintát valósítja
meg Java platformon. A rendszer alapvető funkcióit bármely Java alkalmazás felhasználhatja,
azonban készültek különböző modulok és bővítmények, amelyek webalkalmazások
fejlesztésében segítenek Java EE platformon. A Spring tulajdonképpen egy IOC konténer, az
IOC tervezési mintát a Dependency Injection (függőség injektálás) segítségével valósítja meg.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
4
Szoftverfejlesztés során az egyes elemek működése gyakran függ más elemek által nyújtott
szolgáltatásoktól. Általában tudniuk kell, hogy mely komponensekkel kommunikáljanak, hogy
azok hol találhatóak, és hogy miként kommunikáljanak velük. Ha egy ilyen szolgáltatás
valamilyen módon megváltozik, akkor azt valószínűleg elég sok helyen át kell írni.
A hagyományos módszer a kód struktúrálására az, hogy a szolgáltatások elérésének módját az
alapvető logika részeként implementáljuk. Egy másik módszer, hogy elkerüljük az előzővel
járó nehézségeket, hogy csak függőségeket deklarálunk a szükséges szolgáltatásokhoz, és
valamilyen módon egy külső kódrészlet felel majd ezek megtalálásáért és inicializálásáért. Ez
lehetővé teszi, hogy a szolgáltatások megváltozása esetén az ezeket használó kódrészleteket ne
kelljen megváltoztatni. Ezt a fajta módszert hívjuk Dependency Injection-nek és a kódrészlet,
ami a függőségek feloldásáért felel, általában egy, a módszert megvalósító keretrendszer,
esetünkben a Spring.
A Spring MVC kérés (request) alapú keretrendszer és szorosan kapcsolódik a Servlet API-hoz.
A különböző HTTP kérések először egy diszpécser szervlethez érkeznek be
(DispatcherServlet), ami front controller-ként működik. Ez azt jelenti, hogy ennek az
osztálynak a felelőssége, hogy a kéréseket a megfelelő interfészekhez delegálja. Ezek közül a
legfontosabbak:
Controller: Az adattárolási modell (Model) és a felület (View) közötti réteg az MVC
struktúrában, feladata a bejövő kérések kezelése és a megfelelő válaszok
visszaküldése.
HandlerInterceptor: Opcionális elem, a bejövő kéréseken hajthatunk végre egyéb
műveleteket. Működése hasonló a szervlet filter működéséhez.
HandlerMapping: Kiválasztja a megfelelő objektumokat a kérések lekezelésére
valamilyen paraméter, vagy feltétel alapján.
LocaleResolver: Visszaadja az egyedi felhasználóhoz tartozó lokalizációs adatokat.
MultipartResolver: Fájlfeltöltést segítő funkciót ellátó interfész.
View: A kliensnek küldött válasz általában. Ez egy felület a Model rétegből lekérdezett
megfelelő adatokkal kitöltve.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
5
ViewResolver: Visszaadja a felületet a neve alapján, amit aztán vissza lehet küldeni a
kliensnek válaszként.
Az 1. ábra jól mutatja a kérés kiszolgálásának folyamatát.
1. ábra: Kérés kiszolgálása Spring keretrendszerben [1]
A kéréseket lekezelő kontrollereket a @Controller annotációval kell ellátni. A kezelő
metódusokat pedig hozzárendelhetjük URL címekhez a @RequestMapping annotáció
segítségével. A Spring 3.0 verziótól kezdve a kontrollerekkel RESTful webalkalmazásokat is
készíthetünk. Mi is ezt az elvet követtük az alkalmazás fejlesztésekor, ennek jelentése az, hogy
a kliens és a szerver elkülönül egymástól, egyiket se érdekli a másik implementációja, a
kommunikáció az interfészeken keresztül zajlik, valamint hogy állapotmentes a
kommunikáció, tehát nem tárolhatunk semmilyen információt a klienstől a kérések között, a
kéréseknek minden szükséges adatot tartalmaznia kell. Ennek megvalósítására használható
például a @PathVariable annotáció, amellyel a kérés URL címének paramétereiből nyerhetjük
ki az adatokat, vagy a @RequestBody és @ResponseBody annotációk a JSON-alapú
kommunikációhoz. Mindkét módszert alkalmazzuk a rendszerünkben.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
6
2.2 Maven
Az Apache Maven egy automatizált projekt buildelő eszköz Java projektekhez. A Maven
egyrészt leírja, hogy hogyan épül fel a projekt, másrészt meghatározza a projekt függőségeit
más moduloktól, vagy külső függvénykönyvtáraktól, amely csomagokat a build folyamat
során automatikusan le is tölt. Ezen információk egy xml fájlban vannak eltárolva, melynek
neve pom.xml. A Maven a külső csomagokat dinamikusan tölti le egy, vagy több repository-
ból, ez általában a központi Maven repository. A letöltött csomagokat a Maven helyi
gyorsítótárban tárolja.
A korábban említett pom.xml fájl (pom = Project Object Model) minden olyan információt
tartalmaz, ami szükséges egy projekt buildeléséhez. Ez általában magában foglalja a projekt
nevét, tulajdonosát és a függőségek listáját. A nagyobb projekteket általában szétszedik
különálló modulokká, ahol minden modulhoz külön tartozik egy pom fájl. Ekkor annak a
projektnek a pom fájlja, ami összefogja a modulokat, lesz a gyökere az alkalmazásnak, ennek
segítségével egyszerűen lehet buildelni az összes modult. Mi is ezt a moduláris felosztást
használtuk.
2.3 MySQL
A MySQL egy nyílt-forráskódú relációs adatbázis-kezelő rendszer (RDBMS). A relációs
adatbázis az adatokat táblákba szervezi, amelyek felépítése a következőképp néz ki: az adatok
azonos felépítésű sorokként kerülnek be egy táblába, ez a rekord. A felépítést, azaz a tárolandó
adatokat az oszlopok határozzák meg, ez pedig a mező. A tábla így egy egyedtípust
reprezentál. Ha egy mezőt elsődleges kulcsnak jelölünk ki, akkor annak értéke egyértelműen
meghatározza a rekordot, nem ismétlődhet. Ezt kihasználva megadhatjuk ezt a mezőt egy

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
7
másik táblában idegen kulcsnak jelölve, majd lekérdezéseknél egyesíthetjük a táblákat a
kulcsértékek alapján.
Minden relációs adatbázis-kezelő rendszer, így a MySQL is az SQL (Structured Query
Language, azaz struktúrált lekérdező nyelv) nyelvet használja az adatbázis létrehozására,
módosítására és az adatok lekérdezésére.
A MySQL nem biztosít grafikus felületet az adatbázisok kezelésére, kivéve a Windows
rendszereket. Helyette a parancssoros eszközöket használhatjuk, vagy egy külön program, a
MySQL Workbench letöltésével érhetjük ezt el. Én a munkám során parancssort és a
phpMyAdmin-t használtam, ami egy MySQL adatbázisok kezelésére PHP nyelven írt grafikus
felületet biztosító eszköz.
2.4 ORM rendszerek és a MyBatis
Az ORM (Object-Relational Mapping) keretrendszerek célja az adatbázisban tárolt adatok
átalakítása objektum-orientált programozási nyelvek által feldolgozható objektumokká.
Számos ingyenes és fizetős ORM rendszer áll a fejlesztők rendelkezésére, egyik
legnépszerűbb a MyBatis [4] (korábban iBatis). Munkám során ezt a keretrendszert használtam
az adatbázis kezelésére és az adatok lekérdezésére.
Az adatok a relációs adatbázisban táblákba vannak szervezve, ebben a tárolandó adatokat a
mezők határozzák meg, a komplex adatokat pedig külön táblában kell tárolni, idegen kulccsal
hivatkozva a fő táblára. Objektum-orientált nyelveknél az adatok objektumokban tárolódnak,
amelyek összetett adatokat reprezentálnak és a különböző adattagoknak megfelelő értékek
különböző táblákban helyezkedhetnek el. Ennek feloldását oldja meg az ORM keretrendszer.
Az objektumokat egyszerű skaláris adatok csoportjaira bontja fel az adatbázis számára.
Ugyanígy lekérdezéseknél a bejövő adatokat objektumokká szervezi. A nehézség az
objektumok logikai szerkezetének adatbázisban tárolható formára alakításának automatizálása,

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
8
megtartva az objektum tulajdonságait és ezek kapcsolatait, hogy igény szerinti vissza lehessen
az adatokat alakítani. Ha implementáltuk a letárolási és lekérdezési funkcionalitást, akkor az
objektumaink perzisztensek lesznek.
A hagyományos adathozzáférési technikákhoz viszonyítva (pl. JDBC) az ORM rendszerek
jelentősen lecsökkentik a szükséges kód mennyiségét.
Az ORM keretrendszerek hátránya abban nyilvánul meg, hogy magas absztrakciós szintű
eszközök, ezáltal nehézkesebben lehet az általánostól eltérő, összetett funkciókat
megvalósítani, mint például a JDBC technológiát alkalmazva. Ezenkívül az ORM szoftverre
való támaszkodás gyakran vezet gyenge tervezésű adatbázisok létrehozásához.
A MyBatis egy Java alapú ORM keretrendszer, ami az objektumokat tárolt eljárásokkal köti
össze vagy annotációk használatával, vagy külön XML dokumentumok segítségével (mapper).
Ez egy ingyenes szoftver, ami az Apache szoftvercsaládhoz tartozik. Eredetileg iBatis néven
indult, majd az iBatis 3.0-tól kezdődött a MyBatis, amelyet részben az iBatis eredeti alkotói
üzemeltetnek. A legtöbb ORM rendszerrel ellentétben a MyBatis nem az objektumokat képezi
le az adatbázis tábláira, hanem metódusokat képez le SQL utasításokra.
A MyBatis segítségével az adatbázis-kezelő rendszerek teljes funkcionalitása elérhető,
bonyolult lekérdezések, tárolt eljárások, nézetek (view). A JDBC-hez képest jelentősen
leegyszerűsíti a kódot, az SQL utasítások egy metódushívással végrehajthatóak. A MyBatis
képes egy lekérdezés eredményéül kapott rekordhalmazt automatikusan a hozzákötött
objektumot tároló kollekcióvá alakítani, ami lehet bármilyen Collection interfészt megvalósító
gyűjtemény osztály.
A MyBatis könnyen beépül a Spring keretrendszerbe. Ezt kihasználva felépíthetjük úgy a
kódunkat, hogy az üzleti logika megváltoztatása nélkül lecserélhetünk egyes lekérdezéseket,
vagy más SQL utasításokat. Ezenkívül a MyBatis támogatja a gyorsítótárazás használatát is.
Egy gyakran használt lekérdezést megjelölhetünk, hogy az adatok adatbázisból való kinyerése
után egy gyorsítótárba tárolja azokat, így legközelebb az utasítás már onnan fogja kiolvasni az
adatokat, ezáltal felgyorsítva a működést.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
9
A MyBatis használatához létre kell hoznunk egy, vagy több interfészt (mapper-ek), ezek
metódusait meghívva hajtódnak majd végre az SQL utasítások. Ezt két módon érhetjük el, az
egyik az annotációk használata:
public interface carMapper {
@Select("select * from cars where id = #{id}")
Car selectCar(int id);
}
Ezután már csak meg kell hívnunk a metódust abból az osztályból, amelyik az adathozzáférést
valósítja meg. Másik lehetőség külön XML fájlokba szervezni az SQL utasításokat:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="hu.iit.uni.miskolc.Example.CarMapper">
<select id="selectCar" parameterType="int"
resultType="hu.iit.uni.miskolc.Example.Car">
select * from cars where id = #{id}
</select>
</mapper>
Ilyenkor a mapper tag namespace tulajdonságának a mapper interfészt kell megadni. A
parameterType adja meg, hogy milyen típusú paramétert vár az utasítás, ezután a parancsban
bárhol a #{} szintaktikával hivatkozhatunk rá, mindegy, hogy mit írunk bele a MyBatis tudni
fogja, hogy az a paraméter. A resultType pedig megadja a visszatérési érték típusát. A
konverzió automatikusan végbemegy, ha lehetséges, de összetettebb struktúráknál resultMap-
et kell megadnunk, ami egy másik tag-re hivatkozik, ahol beállíthatjuk, hogy miként menjen
végbe az objektummá leképezés.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
10
A mappereket a programból egy sqlSession objektumtól kérhetjük el, ami egy dataSource
objektumhoz kapcsolódik. Ez utóbbi kapcsolódik az adatbázishoz, be kell állítani az ehhez
szükséges tulajdonságait.
2.5 JUnit
A JUnit egy tesztelést segítő keretrendszer Java platformra. A teszt-vezérelt fejlesztés (TDD,
Test-Driven Development) alapvető eleme és az xUnit egységteszt-keretrendszer család tagja.
Egy külső függvénykönyvtár, ami a projektekben az egyik leggyakrabban használt
komponens.
Ahhoz, hogy egységteszteket írjunk, külön teszt-osztályokat kell létrehoznunk. Ebben a
metódusokat szerepük szerinti annotációkkal kell megjelölni. A @BeforeClass
annotációval megjelölt metódus egyszer fut le az osztályban létrehozott teszt-esetek előtt.
Hasonló a @Before, ami viszont minden teszt-metódus előtt lefut. Ennek mintájára
készíthetünk @AfterClass és @After metódusokat, amelyek utólag futnak le. Az
egységteszteket végző metódusokat pedig a @Test annotációval kell ellátni.
2.6 SVN
Az SVN [2] (Subversion) egy nyílt-forráskódú verziókövető rendszer (version control system,
VCS). A verziókövető rendszerek kezelik a fájlokat és mappákat, valamint számon tartják a
rajtuk elvégzett változtatásokat. Ez nagyban elősegíti a csapatban végzett fejlesztési munkákat,
hiszen nyomon követhetjük a saját és mások által végzett változtatásokat, nagy hiba esetén
bármikor visszatölthetjük a rendszer egy korábbi állapotát.
Bármilyen hálózaton üzemeltethetünk SVN szervert, ezáltal egymástól távol is eredményesen
dolgozhatunk. Az, hogy különböző fejlesztők egymástól távol képesek ugyanazt az
adathalmazt kezelni és módosítani, jelentősen megkönnyíti az együttműködést. Mivel a munka
verziókezelt (minden feltöltés egy verziószámmal van ellátva), nem kell attól félnünk, hogy
valami súlyos hibát, vagy minőségromlást okoz változtatásunk a rendszerben, ez esetben
csupán vissza kell töltenünk egy régebbi verziót.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
11
Bizonyos verziókövető rendszerek egyben szoftver konfigurációs rendszerek is (software
configuration management system, SCM). Ezeket arra tervezték, hogy tudják kezelni a
forráskódot is és erre sok funkciót biztosítanak. Ilyen például, hogy felismerik és képesek
kezelni a különböző programnyelveket, valamint rendelkeznek szoftver fejlesztést segítő
beépített eszközökkel is. Az SVN azonban nem tartozik ezek közé, hanem egy általános
verziókövető rendszer, amellyel bármilyen adathalmazt kezelhetünk. Ez lehet egy szoftver
forráskódja, de lehet akár egy bevásárló lista, vagy teljesen más adatkollekció is.
A verziókövető rendszer központja az ún. repository, ami a központilag tárolt adathalmazt
jelenti. Ez általában fájlrendszer formájában tárolja az adatokat, faszerkezetbe van rendezve a
fájlok és mappák hierarchiája. Bármennyi kliens csatlakozhat a repository-hoz, olvashatja és
írhatja a fájlokat. Ez eddig nem sokban tér el egy fájlszervertől, amiben különbözik az az,
hogy a repository nyilvántartja az összes változtatást, emlékszik a fájlok minden verziójára.
A verziókezelő rendszerek másik alapvető eleme a munkapéldány (working copy). Ez a
verziókezelt fájlok lokális másolata az egyes kliensek gépén. A munkapéldányt a kliens
először letölti a repository-ból, majd azon végzi el a változtatásait, fejlesztéseit, ezután
visszatölti azt a repository-ba, amennyiben nem történt olyan változás, ami ütközik egy másik
kliens változtatásával. Ez utóbbi esetben először fel kell oldani a konfliktusokat, majd ezután
válik lehetővé a feltöltés. Ennek megoldásában is segítenek az SVN eszközök.
Szoftverfejlesztésnél általában van egy törzs (trunk), ami a szoftver fő verzióit tartalmazza.
Emellett vannak a különböző ágak (branch), amelyeken fejlesztik a változtatásokat, új
funkciókat hoznak létre és csak utána vezetik ezeket át a fő vonalra.
Az SVN legfontosabb műveletei a következők:
- checkout: saját munkapéldány létrehozása az adatok repository-ból való
letöltésével,
- commit: a munkapéldányon végrehajtott változtatások visszatöltése a repository-
ba,
- update: a munkapéldány frissítése a repository-ból, a végrehajtott változtatások
megtartásával,

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
12
- revert: a munkapéldány állapotának visszaállítása a repository egy verziójának
mintájára,
- merge: változtatások összefésülése különböző ágak között.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
13
3. Specifikáció
3.1 Általános követelmények
A projekt célja egy elektronikus kéziratfeltöltő rendszer megtervezése és implementálása volt,
amelyen hárman vettünk részt Fogt Tamással, valamint Károlyi Mátéval. A rendszer a
Miskolci Egyetemhez tartozó PSAIE tudományos folyóirat számára készült. Az általam
elvállalt része a projektnek az adattárolási modell kidolgozása, valamint az adathozzáférési
réteg megtervezése és implementálása volt. Ennek értelmében meg kellett terveznem és
valósítanom a specifikációban megadott tárolandó adatok alapján az adattárolási modellt,
ennek alapján a rendszerben használt osztályokat, valamint a relációs adatbázis
táblaszerkezeteit. A táblákat kezdeti adatokkal is fel kellett tölteni, mely nagy segítséget
nyújtott a fejlesztés során. Ezt követően a feladatom az adatok elérésének a biztosítása volt.
Létre kellett hoznom az adathozzáférési interfészeket, valamint implementálnom kellett az
ezeket megvalósító osztályokat.
3.2 Részletes specifikáció
A cikkek elbírálási folyamata során a rendszerben a vele kapcsolatba kerülő felhasználók
különböző szerepkörökben különböző feladatokat látnak el. Ezek a szerepkörök határozzák
meg az alkalmazás funkcionalitását. Most az egyes szerepkörök részletezése következik a
tanszéktől kapott specifikáció és a menetközben megbeszélt módosítások alapján:
1. Szerző (Author) – Alapértelmezetten minden új felhasználónak ez lesz a szerepköre.
Regisztráció után cikkeket tölthet fel, melyeket kategorizálnia kell az ACM
kategórialista szerint, valamint megadhatja az esetleges társszerzőket is a már
regisztrált felhasználók közül. A cikkeinek állapotát a publikációs folyamat során
könnyen nyomon követheti. Látja továbbá a cikkek bírálatát, valamint saját adatait
módosíthatja.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
14
2. Bíráló (Reviewer) – A szerzőn kívül minden szerepkör beállítása az admin felhasználó
által történik. A bírálónak meg kell adnia az ACM kategórialista szerint azokat a
tématerületeket, melyeknek szakértője. Ha elfogad egy bírálati felkérést, akkor
letöltheti a hozzá rendelt cikket, és kap egy határidőt, ameddig a bírálatnak el kell
készülnie. Ennek lejárta előtt kap egy automatikus figyelmeztető e-mailt. A bírálandó
cikk tanulmányozása után kitöltheti az egységes bírálati űrlapot. Szöveges értékelést ad
és kiválasztja a bírálata eredményét négy megadott értékből, aszerint, hogy elfogadja,
elutasítja, kis javításra, vagy nagymértékű javításra ítéli a cikket.
3. Főszerkesztő (Editor-in-Chief) – Látja a beérkezett cikkek listáját, állapotát, szerzőit és
rövid leírásukat. Ezenkívül látja a szerkesztők és a bírálók listáját. A feladata az, hogy
a cikkeket továbbítsa a szerkesztőkhöz a tématerület szerint. A bírálat eredményéről
értesíti a szerzőt, majd amennyiben elfogadott cikkről van szó, továbbítja azt nyelvi
lektorálásra, majd nyomdai szerkesztésre. Ő a kapcsolattartó a szerzők, szerkesztők és
bírálók között.
4. Szerkesztő (Editor) – Látja a főszerkesztő által neki küldött cikkek listáját, állapotát,
rövid leírását. Látja a tématerület szerint lehetséges bírálók listáját és a cikkekhez
beérkezett bírálatokat. Feladata a beérkezett cikkek gyors átnézése (szoftveres plágium
ellenőrzés, formai követelmény ellenőrzés). Majd a cikkeket bírálókhoz kell
hozzárendelnie szabvány szövegű email segítségével, amelyben a bírálati határidő is
megjelölésre kerül. Legalább két bíráló véleményére van szükség, ellentmondás esetén
többet is be lehet vonni. Értékeli a bírálatokat, majd dönt a cikk megjelentetéséről,
elutasításáról vagy újra bírálásáról. Ezután értesíti a főszerkesztőt a döntésről.
5. Nyelvi lektor (Proofreader) – Látja a főszerkesztőtől kapott, elfogadott cikkek listáját.
Feladata a cikkek nyelvi lektorálása. Ha végzett, visszajelez a főszerkesztőnek és
visszaküldi a javított cikket, vagy túl sok hiba esetén az eredeti cikket jelezve, hogy
szerzői javításra van szükség.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
15
6. Nyomdai szerkesztő (Technical Editor) – Látja a főszerkesztőtől kapott elfogadott és
nyelvi lektorált cikkek listáját. Feladata a cikkek nyomdai előkészítése, a formátum
véglegesítése. Ha elkészült, visszajelez a főszerkesztőnek.
7. Admin – Kitüntetett felhasználó, feladata a regisztrált felhasználók felügyelete,
támogatása és a felhasználói adatbázis karbantartása. Ő osztja ki a különböző
szerepköröket is. A rendszerünk alapvetően tartalmaz egy admin jogosultságú
felhasználót.
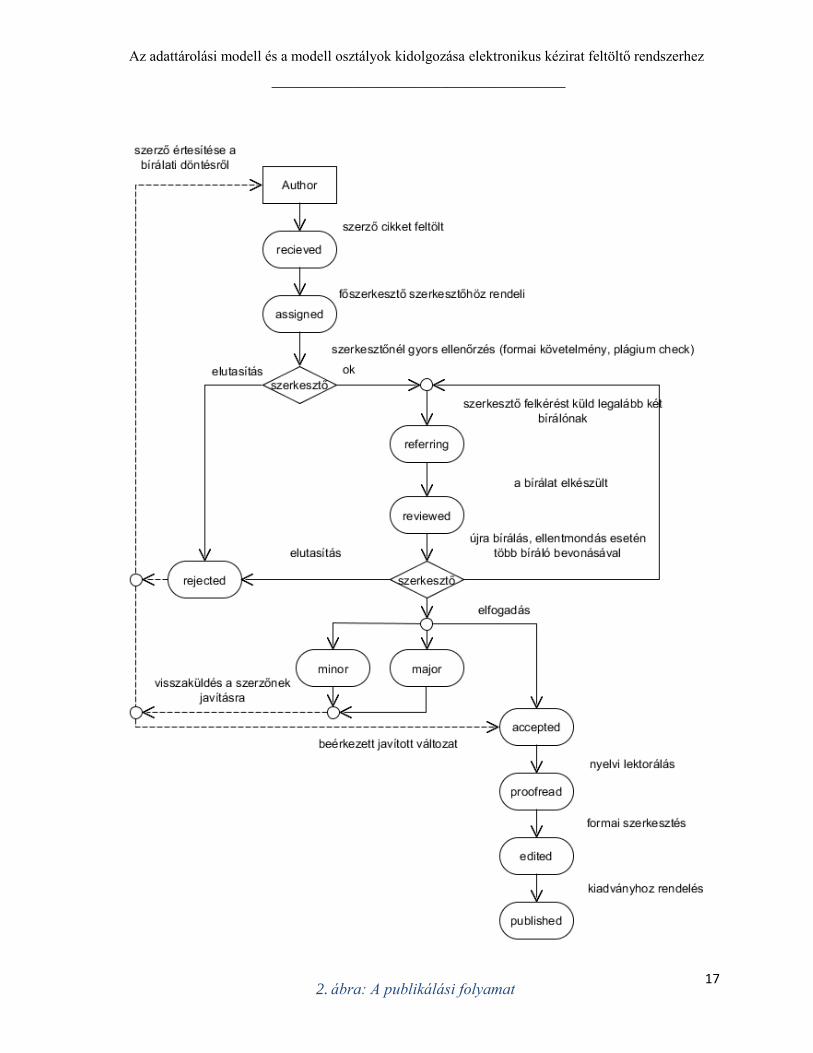
Egy cikk (Submission) lehetséges állapotai a következők:
received: A szerző feltöltötte a cikket, a főszerkesztőre vár, hogy szerkesztőhöz
rendelje.
assigned: A főszerkesztő hozzárendelte a cikket egy szerkesztőhöz, a szerkesztőre vár,
hogy ellenőrizze, majd pedig elküldje elbírálásra.
referring: A szerkesztő hozzárendelte a cikket bírálókhoz, várakozás a bírálatok
elkészülésére.
reviewed: Elkészült legalább egy bírálat, várakozás a többi bírálat beérkezésére, vagy a
szerkesztő végső ítéletére.
rejected: A cikk el lett utasítva a szerkesztő által, vagy a gyors ellenőrzés, vagy a
bírálatok alapján.
accepted: A cikket elfogadta a szerkesztő, publikálható. Várakozás a főszerkesztőre,
hogy felvegye a nyelvi lektorral a kapcsolatot.
major: A szerkesztő a bírálatok alapján nagymértékű javításra ítélte a cikket.
Várakozás a szerzőre, hogy elvégezze a javításokat.
minor: A szerkesztő a bírálók véleménye alapján kismértékű javítást rendel el.
Várakozás a szerzőre, hogy elvégezze a javításokat.
proofread: A nyelvi lektorálás elkészült, várakozás a főszerkesztőre, hogy felvegye a
nyomdai szerkesztővel a kapcsolatot és a nyomdai szerkesztőre, hogy elvégezze a
végső formázást.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
16
edited: Elkészült a formai szerkesztés, várakozás a cikk kiadványhoz rendelésére és a
kiadvány megjelentetésére.
published: A folyamat vége, a cikk sikeresen publikálva.
A 2. ábra végigvezet az elbírálási és publikálási folyamaton a cikk lehetséges állapotain
keresztül, segítségével könnyebben megérthető a procedúra.
Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
17
2. ábra: A publikálási folyamat

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
18
3.3 Rendszerkövetelmények
A rendszert modern Java-s keretrendszerben kellett létrehozni, amelyre mi a Spring Web MVC
keretrendszert választottuk.
A programnak egy alkalmazásszerveren kell futnia, mi a fejlesztés során az Apache Tomcat
8.0 szervert használtuk.
Adattárolásra MySQL relációs adatbázis kellett használnom. Emellett a Java-ban kódolt
adatbázis-kezelő metódusokat a MyBatis ORM keretrendszer segítségével kellett leképeznem
SQL utasításokra.
A csapatmunkához egy számunkra létrehozott SVN szervert kellett használnunk, melynek
segítségével akár a témavezető tanár, akár a szakmai konzulensek nyomon tudták követni a
munkánk előrehaladását.
Fejlesztésre az Eclipse fejlesztőkörnyezetet kellett használnunk, amely a többi általunk
használt eszközt is támogatja.
A build folyamatok kezelésére a Maven eszközt kellet használni.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
19
4. Tervezés
4.1 Modulok
Mint azt korábban említettem, az alkalmazást Maven modulokba szerveztük. A projekt
moduláris felosztása a következő:
model: Ez a modul tartalmazza a pojo-kat (plain old java object), vagyis az alap java
osztályokat, amelyek a tárolandó adatszerkezeteket reprezentálják a rendszerben.
Ezeket az osztályokat bean-ként kell létrehozni, annak érdekében, hogy könnyen
együttműködjenek a többi komponenssel.
dao: Ez a modul (Data Access Object) tartalmazza azokat az interfészeket, amelyek az
adatok általános (adatbázistól független) elérését szolgáló viselkedést írják le. Az
ehhez tartozó implementáció bármikor lecserélhető a modul megváltoztatása nélkül. Ez
a modul tartalmazza továbbá az általam definiált általános kivétel osztályt is.
dao-mysql: Ebben a modulban implementálom a dao interfészeit, MySQL specifikus
megoldásokkal. Itt kezelem le a különböző MySQL és egyéb kivételeket is,
becsomagolva őket a dao modul általános kivételébe, így a többi modul
megvalósítástól függetlenül kaphatja el azokat.
service: Ez a modul tartalmazza azokat az interfészeket, amelyek a controller felé
nyújtandó szolgáltatásokat írják le.
service-impl: Itt történik a service modul interfészeinek a megvalósítása. Hozzáfér a
dao modulhoz, hívhatja az interfészek metódusait az adateléréshez. Lényegében itt
található az üzleti logika, valamint az egyéb funkciók (pl. email küldés, kitömörítés,
stb.) is.
controller: Ez a modul a kapcsolattartó a webes felület (front-end) és a háttérrendszer
(back-end) között. Spring controller szervleteket tartalmaz, ezek elkapják a http

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
20
kéréseket, amelyek a klienstől érkeznek és meghatározzák, hogy a különböző url-ek
esetében milyen szolgáltatásokat kell végrehajtani és visszaadja a megfelelő
megjelenítési felületet a megfelelő adatokkal kitöltve. Hozzáfér a service modulhoz, a
service interfészek által nyújtott szolgáltatásokat hívja.
web: Itt található minden, ami a webes felülethez szükséges. Legfőképp a bootstrap
front-end keretrendszerhez tartozó javascript, css és jsp fájlokat tartalmazza. Ezenkívül
ez a modul fogja össze az egész rendszert, itt történik a Spring konfigurálása is, a
web.xml fájlban meg van adva, hogy a http hívásokat a dispatcher-servlet.xml
diszpécser fogadja, és a controllerben keresse meg a hozzá tartozó funkciót. Az
application-context.xml fálj pedig az alkalmazás kontextus bean-jeit definiálja.
util: Ez a modul tartalmazza azokat az egyéb funkciókat, amelyek nem tartoznak a
többi modulhoz. Ilyen például a rendszer naplózási funkciója (logger).
Az én részem a projektben a model, a dao és a dao-mysql modulok fejlesztése, tehát az
adattárolást és az adatelérést megvalósító funkcióké. A modulok közti függőségeket a 3. és 4.
ábra szemlélteti, sötétebb színnel jelölve az általam fejlesztett részt.
3. ábra: Moduláris felépítés

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
21
4. ábra: Függőségi fa (Dependency Tree)
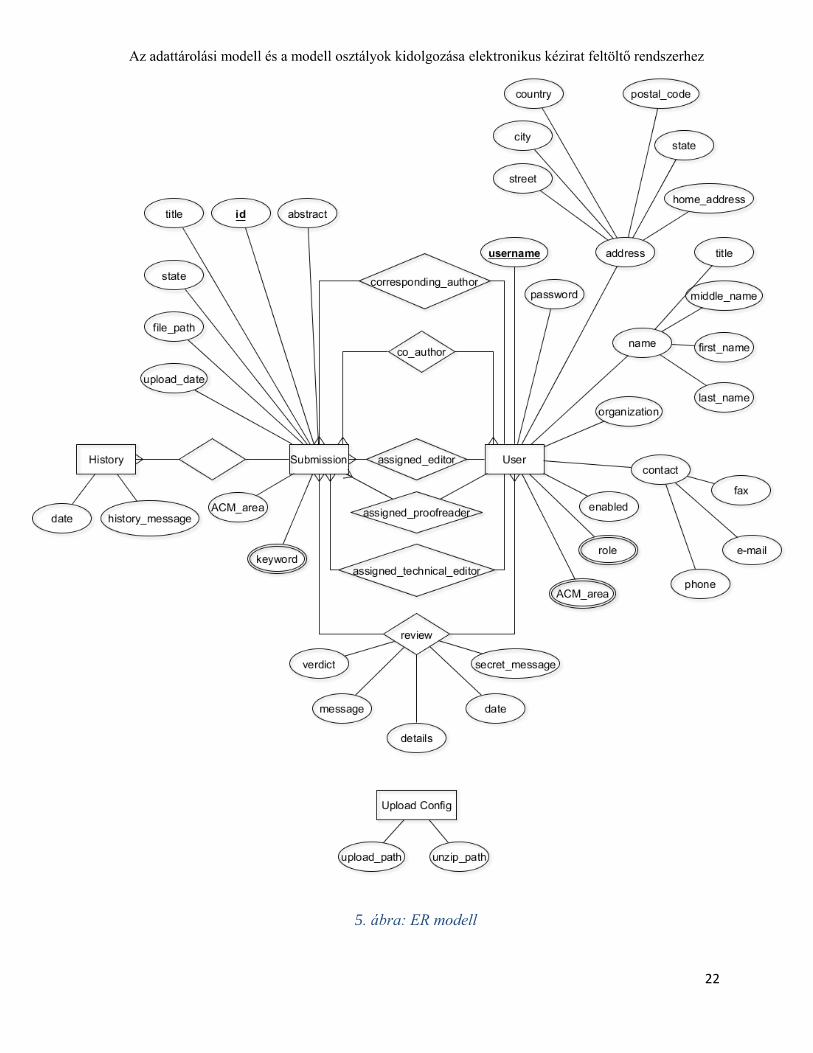
4.2 Adatbázis tervezés
A tervezés során az én első feladatom az adattárolási modell kidolgozása volt, majd az
elképzelésből létrehozni egy egyedkapcsolati modellt (ER modell). Ebben a tanszék által
megadott specifikáció volt a segítségemre. El kellett különíteni a fő egyedeket, meghatározni
ezek tulajdonságait és kidolgozni az egyedek közötti számos kapcsolatot. Ez a modell a
fejlesztés során több alkalommal is megváltoztatásra került, ezáltal jelentős átdolgozási
munkálatokat okozva.
Az adattárolási szerkezet végleges ER modelljét szemlélteti az 5. ábra.
Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
22
5. ábra: ER modell

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
23
4.2.1 Felhasználó
Látható, hogy az adattárolás két fő egyede a felhasználó (User) és a cikk (Submission). A
felhasználó egyed kulcsmezeje a felhasználónév (username), ezért annak egyedinek kell lennie
a rendszerben, valamint ehhez tartozik egy jelszó, amelyet titkosítva tárol el az adatbázis
(password). Ezenkívül tartalmazza az alapvető adatokat, mint név lebontva titulusra,
családnévre, keresztnévre és esetlegesen második keresztnévre (title, first_name,
middle_name, last_name); cím lebontva országra, megyére, városra, irányítószámra, utcára és
házszámra (country, state, city, postal_code, street, home_address); az elérhetőségek, mint
telefonszám, e-mail cím és fax (phone, e-mail, fax); valamint a szervezet, amihez a
felhasználó tartozik (organization).
Van két többértékű tulajdonsága is, az egyik a szerkesztők és bírálók esetében tárolja le azokat
a tématerületeket, amelyekhez értenek az ACM kategórialista alapján (ACM_area). Míg a
másik a szerepköröket megvalósító többértékű tulajdonság, ami a felhasználóhoz tartozó
jogkört, vagy jogköröket tárolja (role). Tárolunk továbbá egy bináris információt is, ami
aszerint módosul, hogy a felhasználó hozzáférhet-e a rendszerhez, értéke alapértelmezetten ’1’
(enabled). Ennek az az oka, hogy egy felhasználó törlésekor nem távolítjuk el fizikailag az
adatait, csak kitiltjuk az alkalmazásból azáltal, hogy ’0’-ra állítjuk ezt a tulajdonságát.
4.2.2 Cikk
A cikk egyednek egy egyedi azonosító lesz a kulcs tulajdonsága (id). Tárolásra kerül továbbá
a címe (title), a cikkhez tartozó, feltöltésnél megadott kulcsszavak többértékű tulajdonságként
(keywords), egy rövid összefoglaló a cikk tartalmából (abstract), a cikket tartalmazó szerverre
feltöltött zip formátumban tömörített fájl fájlfeltöltésnél generált elérési útvonala (file_path),
valamint a feltöltés dátuma (upload_date). A cikk mindenkori állapota is itt kerül tárolásra
(state), amely a specifikációban részletezett értékeket veheti fel. Ezenkívül azt, hogy a cikk
mely tudományterülethez tartozik a kategórialista alapján, itt is ugyanazzal a névvel ellátott
tulajdonság tárolja (ACM_area).

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
24
4.2.3 További egyedek
A naplózási funkció által keletkezett naplóbejegyzések külön egyedként vannak eltárolva
(History). Ennek tulajdonságai a keletkezési dátum (date) és a bejegyzés szöveges formában
(history_message). A History egyed valósítja meg többek között a cikk állapotváltozásainak a
naplózását, ezért egy-több kapcsolat van közte és a cikk egyed között.
Van még egy segédtábla is, ami később került be az ER modellbe egyedként, mivel a
fájlfeltöltési funkció kidolgozásánál derült ki az igénye (Upload Config). Erre azért volt
szükség, mert a feltöltött fájlok elérési útvonala eltérő szintaktikájú lehet attól függően, hogy a
szerver milyen operációs rendszeren üzemel. Tulajdonságként van eltárolva a feltöltési
(upload_path), valamint a kitömörítési útvonal (unzip_path) OS specifikus kezdete.
4.2.4 Felhasználó és cikk közötti kapcsolatok
A leggyakoribb összeköttetés a két fő egyed között a szerzői kapcsolat, ami fájlfeltöltésnél
kerül be az adatbázisba (corresponding_author). Ez egy-több kapcsolat, tehát egy felhasználó
bármennyi cikknek lehet a szerzője, de egy cikknek csak egy szerzője lehet, a társszerzők
máshol vannak tárolva. A társszerzői kapcsolat több-több típusú, ennélfogva külön tábla
tárolja a kapcsolatot (co_author). Egy-több kapcsolatként van még létrehozva a bírálati
folyamat során a cikkhez rendelt szerkesztő (assigned_editor), nyelvi lektor
(assigned_proofreader) és nyomdai szerkesztő (assigned_technical_editor).
Mivel bírálóból több is lehet, ezért ez több-több típusú kapcsolat (review), ahol
tulajdonságként vannak felvéve az elkészült bírálat adatai. A bíráló kijelölésekor bekerül egy
rekord az ezt megvalósító táblába, ami párosítja a cikket a bírálóval. A bírálat elkészülte után
ez a rekord kiegészül a megfelelő adatokkal, ezek a következők: az összefoglaló értékelés
(message), a részletes szöveges vélemények, meglátások (details), a szerkesztőnek szánt,
szerző által a bírálatban nem látható üzenet (secret_message), az elkészülés dátuma (date),

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
25
valamint a bírálat végeredménye (verdict), ami előre meghatározott négy értéket vehet fel,
amelyek: -elfogadva (accepted), -elutasítva (rejected), -minor (kis javítás szükséges), -major
(nagymértékű javítás szükséges).
4.3 Java osztályok tervezése
A 6. ábra szemlélteti a model modul csomaghierarchiáját, valamint a pojo osztályokat.
6. ábra: Model modul szerkezete
(A hu.uni.miskolc.iit.manuscript minden csomagnév eleje, a model pedig a modulban lévő
minden csomagé, ezért a továbbiakban csak az ezt követő résszel hivatkozok a csomagokra.)
A config csomag tartalmazza az UploadConfig osztályt, ami a fájlfeltöltési információkat
reprezentálja. A user csomagban vannak a felhasználókhoz köthető elemek, így magát a
felhasználót megvalósító User osztály, valamint a különböző szerepköröknek megfelelő
értékeket tároló Role enumeráció. A User osztály adattagként tartalmazza az ER modellben
ábrázolt összes tulajdonságot, valamint a lehetséges szerepköröket egy Role enumeráció típusú
halmaz (Set<Role>) kollekcióban és a felhasználó által megadott ACM tudományterületeket
szintén halmazban tárolva.
Itt történik a szerver oldali validáció megvalósítása is, validáló annotációk segítségével.
Például a jelszó adattag felett a @Length(min=8, max=12) annotáció a jelszó lehetséges
hosszát határozza meg. Ez a validáció a controller modulban valósul meg, a @Validated

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
26
annotáció megadásával, ami a Spring keretrendszer része. Így amikor a beérkező JSON
formátumú http kérésből objektumot generálna a controller, először leellenőrzi, hogy az
általam a model-ben megadott feltételek teljesülnek-e.
A submission csomag a cikkekhez tartozó osztályokat tartalmazza. A Submission osztály
jelképezi a cikket, annak korábban részletezett minden tulajdonságával együtt. A cikk
mindenkori állapotát egy State típusú adattag tárolja, amely típus a submission csomagban
szereplő enumeráció. A kulcsszavakat halmaz típusú kollekcióban tárolja, míg a társszerzőket,
valamint a hozzárendelt bírálókat User típusú listákban (List<User>). Itt található továbbá a
cikkhez elkészült bírálatok listája is, mely listának típusa a submission csomag Review
osztálya. A User osztálynál említett validációs technikát itt is használtam. A Review osztály a
bírálat minden tulajdonságát hivatott tárolni, köztük a User típusú bírálóval.
Itt található továbbá a History osztály, amely egy naplózandó eseményt valósít meg. Ebben
adattagként van jelen a Submission objektum, ami a bejegyzés tárgya. Ez a kapcsolat
megvalósítható lett volna úgy is, hogy a History az ER modellben nem egyedként, hanem a
Submission egyed többértékű, összetett tulajdonságaként jelenik meg és a model-ben a
Submission objektum adattagjaként kollekcióban. Azért döntöttem mégis ilyen megoldás
mellett, mert az előző esetben nem tudtam volna a naplózásért felelős funkciókat külön
adathozzáférési osztályba szervezni, ami viszont mind a kód átláthatósága, mind a különböző
funkcionalitás egymástól való elkülönítése miatt fontos volt. A 7. ábra egy osztálydiagram,
ami részletesen szemlélteti az egyes osztályokat és adattagjaikat.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
27
7. ábra: POJO osztálydiagram

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
28
4.4 Adathozzáférési interfészek
Az interfészek megtervezése során az egyedek alapján választottam szét a funkciókat. Ennek
értelmében négy interfészt hoztam létre a dao modul interfaces csomagjába, ezek: a
fájlfeltöltési adatok elérését szolgáló ConfigDAO, a felhasználók adatainak kezelését végző
UserDAO, a cikkekkel kapcsolatos adatmozgatási funkciókat leíró SubmissionDAO és a
naplózást végző HistoryDAO.
A saját általános (implementációtól független) kivételeimet is itt hoztam létre az exceptions
csomag alatt. Ezek a következők: InsertException az adatbázisba való beszúráshoz,
UpdateException a módosítási műveletekhez, DeleteException a törlésekhez és
QueryException az adatok lekérdezéséhez. A cél beszédes nevű kivételek létrehozása volt,
amelyek utalnak rá, hogy mi volt a hiba oka, milyen művelet közben keletkezett. Ezek mind
egy közös ősosztályból származnak, ez pedig az általam létrehozott DataAccessException. A
metódusok definíció szerint ezt az ősosztályt dobják (throws DataAccessException;), a
service-impl modulban elegendő ezt elkapni. A 8. ábra ábrázolja a modul felépítését.
8. ábra: DAO modul szerkezete

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
29
4.4.1 ConfigDAO
A ConfigDAO interfész a fájlfeltöltéshez szükséges információk adatbázisból való
lekérdezéséért felelős, más funkciót nem lát el. Ezen információt a rendszer szerverre való
telepítése során kell manuálisan feltölteni az operációs rendszer függvényében. Egyetlen
metódusa van, ami egy feltöltött UploadConfig objektummal tér vissza:
public UploadConfig getUploadConfig() throws
DataAccessException;
4.4.2 UserDAO
A UserDAO interfész a felhasználók adatainak kezeléséért felelős funkciókat tartalmazza.
Rendelkezik az alapvető CRUD (Create, Read, Update, Delete) műveletekkel, valamint még
egyéb lekérdezésekkel is. Metódusai a következők:
public void reg(User user) throws DataAccessException;
Regisztráció során a megkapott User objektum adatait tölti fel az adatbázisba.
public void edit(User user) throws DataAccessException;
Módosítja egy felhasználó adatait az adatbázisban. A paraméterként kapott objektum
tartalmazza az új adatokat és hogy melyik felhasználót kell módosítani.
public void delete(String username) throws DataAccessException;
Felhasználó kizárása a rendszerből, enabled bináris tulajdonság 0-ra állítása.
public User getUser(String username) throws
DataAccessException;
Visszaadja egy felhasználó összes adatát. A paraméterben megadott felhasználónév alapján
kikeresi az adatbázisból a rekordot és visszaadja a feltöltött User objektumot.
public List<User> getAllUsers() throws DataAccessException;

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
30
Egy listában visszaadja az összes felhasználót minden adatukkal együtt.
public Set<Role> getAllRoles();
Visszaadja a Role enumeráció összes elemét egy halmazban a felületen való megjelenítéshez.
public Set<String> getAllACM_Areas() throws
DataAccessException;
Lekérdezi az összes ACM kategóriát az adatbázisból és visszaadja egy halmazban.
public List<User> getEditorsByAcm(String acm) throws
DataAccessException;
Egy paraméterként megkapott ACM kategória alapján visszaadja egy listában az összes
felhasználót, aki szakértője a témának és szerkesztő jogosultsággal rendelkezik.
public List<User> getReviewersByAcm(String acm) throws
DataAccessException;
Egy paraméterként megkapott ACM kategória alapján visszaadja egy listában az összes
bírálót, aki szakértője a témának.
public List<User> getEditors() throws DataAccessException;
Visszaadja az összes szerkesztői jogkörrel rendelkező felhasználót.
4.4.3 SubmissionDAO
A SubmissionDAO interfész a cikkekhez tartozó adatokat kezeli az alap CRUD műveletek
segítségével, valamint még számos lekérdezést is tartalmaz. Metódusai a következők:
public void add(Submission submission) throws
DataAccessException;

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
31
Cikk feltöltésekor a Submission objektum összes adata alapján beilleszt egy rekordot az
adatbázisba.
public void addReview(Submission submission) throws
DataAccessException;
Egy bírálat elkészülte után megkeresi a paraméter alapján a bíráló-cikk kapcsolatot és feltölti a
már létező rekordot a bírálat adataival.
public void edit(Submission submission) throws
DataAccessException;
Módosítja egy cikk adatait az adatbázisban.
public void setState(Submission submission) throws
DataAccessException;
Módosítja egy cikk állapotát a paraméter alapján.
public void delete(int id) throws DataAccessException;
Kitöröl egy cikket az adatbázisból, az összes rá mutató referenciával együtt (pl.: bírálatok).
public Submission getSubmission(int id) throws
DataAccessException;
A paraméterben megkapott azonosítóval rendelkező cikket adja vissza az adatbázisból.
public List<Submission> getSubmissionsByArea(String area)
throws DataAccessException;
A paraméterként megadott ACM tudományterülethez tartozó összes cikket visszaadja egy
listában.
public List<Submission> getSubmissionsByState(State state)
throws DataAccessException;
Visszaadja a bizonyos állapotú cikkek listáját a State típusú paraméter alapján.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
32
public List<Submission> getSubmissions4Editor(String username)
throws DataAccessException;
Visszaad egy listát az összes cikkel, amely a paraméterként megkapott felhasználónevű
szerkesztőhöz van rendelve.
public List<Submission> getSubmissions4Reviewer(String
username) throws DataAccessException;
Visszaadja az egy bírálóhoz rendelt összes cikket a paraméter alapján egy listában.
public List<Submission> getSubmissions4Author(String username)
throws DataAccessException;
Visszaadja a paraméterként megkapott felhasználónév alapján az összes cikket, amit a
felhasználó töltött fel.
public Set<State> getAllStates() throws DataAccessException;
A felületen való megjelenítés céljából visszaadja a cikkállapotokat tároló enumeráció összes
elemét egy halmazban.
public void assignSubmission2Editor(Submission submission)
throws DataAccessException;
A paraméter objektum adatai alapján hozzárendel egy szerkesztőt egy cikkhez az
adatbázisban.
public void assignSubmission2Reviewers(Submission submission)
throws DataAccessException;
A Submission típusú paraméter reviewers adattagja alapján, ami egy Review típusú lista,
létrehozza az adatbázisban a megfelelő cikk-bíráló kapcsolatot jelölő rekordokat.
public void assignSubmission2Proofreader(Submission submission)
throws DataAccessException;
Hozzárendel egy nyelvi lektort a paraméterként megkapott cikkhez az adatbázisban.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
33
public void assignSubmission2TecnicalEditor(Submission
submission) throws DataAccessException;
A paraméterként kapott cikkhez rendel hozzá egy nyomdai szerkesztőt az adatbázisban.
4.4.4 HistoryDAO
A HistoryDAO interfész a rendszer naplózási funkcióival kapcsolatos adathozzáférési
metódusokat tartalmazza. Ezek a következők:
public void add(History history) throws DataAccessException;
Hozzáad egy naplóbejegyzést az adatbázishoz.
public void deleteHistoryOfSubmission(int id) throws
DataAccessException;
Kitörli a paraméterként megkapott azonosítóval rendelkező cikkhez tartozó összes
naplóbejegyzést.
public List<History> getHistoryOfSubmission(int id) throws
DataAccessException;
Visszaadja a paraméterben megkapott azonosítóval jelölt cikkhez tartozó összes
naplóbejegyzést egy listában.
public List<History> getHistoryPeriod(Date startDate, Date
endDate) throws DataAccessException;
A két paraméter (kezdő dátum és befejező dátum) által meghatározott időintervallumban
keletkezett összes naplóbejegyzést adja vissza egy listában.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
34
5. Implementáció
A tervezési folyamatok befejeztével és az adattárolási modell elkészültével megkezdődhetett
az implementáció. Először a létrehozott adatbázisról írok bemutatva a táblaszerkezeteket.
Majd részletezem, hogy miként valósítottam meg a megtervezett adathozzáférési interfészeket
a MyBatis használatával.
5.1 Az adatbázis
A 9. ábra szemlélteti az elkészült adatbázis tábláinak szerkezetét és azok kapcsolatát.
9. ábra: Adatbázis szerkezet

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
35
Látható, hogy az ER modellben ábrázolt többértékű tulajdonságokat külön táblákként kell
megvalósítani. Ezenkívül a bírálatokat jelző több-több kapcsolatot, mely saját
tulajdonságokkal is rendelkezik, ugyancsak külön táblában kell elhelyezni, ennek neve
kapcsolótábla. Ez tartalmazza az általa összekötött két egyedre mutató idegen kulcsot,
valamint az ide tartozó tulajdonságokat.
A cikkeket tároló tábla (submissions) elsődleges kulcsa az azonosító (id), ami a rekordok
adatbázisba való beszúrásánál generálódik:
id INT NOT NULL AUTO_INCREMENT,
Ekkor az első beszúrt rekordhoz tartozó azonosító értéke ’1’ lesz, a következőé ’2’ és így
tovább, automatikusan inkrementálódik.
Az egyes táblák alján lévő, mappa ikonnal ellátott rész az egyedi kulcsokat jelöli. Ezek olyan
értékek az adatbázisban, melyeknek párban kell egyedinek lenniük. Ilyen például a
felhasználók szakterületeit tároló tábla (user_areas):
CREATE TABLE user_areas (
username VARCHAR(100) NOT NULL,
area VARCHAR(50) NOT NULL,
UNIQUE KEY `user_area` (`username`,`area`),
FOREIGN KEY (username) REFERENCES users (username));
A táblában lehet több azonos felhasználónév is, mivel több területet is kapcsolhatunk egyhez.
Ugyanígy több azonos szakterület is lehet, mert más felhasználónak is lehet ugyanaz a
szakterülete. Mégis biztosítani kell, hogy ne kerülhessen be egy felhasználó szakterülete
kétszer is a táblába. Erre szolgál az egyedi kulcs (UNIQUE KEY), amely biztosítja, hogy egy
felhasználónév-szakterület kombinációt csak egyszer vehessünk fel a táblába. Ugyanezen
okok miatt hasonlóan épül fel a szerepköröket (user_roles), társszerzőket
(submission_co_authors) és a kulcsszavakat (submission_keywords) tároló tábla.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
36
5.2 Az adathozzáférési osztályok
5.2.1 Modul felépítése
A dao-mysql modul tartalmazza a dao interfészeinek implementáló osztályait, a MyBatis
használatához szükséges mapper interfészeket és XML fájlokat, valamint az adatbázist és a
táblákat létrehozó SQL szkripteket. Ezt reprezentálja a 10. ábra.
10. ábra: DAO-MySQL modul szerkezete
A create_database szkript létrehozza az adatbázist, a create_tables elkészíti az összes táblát,
az insert_admin_data beszúrja az admin jogosultságú felhasználót, valamint egyet-egyet a
különböző szerepkörű felhasználók közül, a fájlfeltöltési adatokat és az ACM kategórialista
elemeit. A test mappában található többi szkript a teszteléshez szükséges adatbázis
műveleteket végzik el.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
37
5.2.2 MyBatis konfiguráció
A MyBatis konfigurálásához a Spring keretrendszerben létre kell hoznunk a szükséges bean-
eket az alkalmazás kontextusban. Ez azt jelenti, hogy a Spring konténer képes lesz megfelelő
időben a megfelelő helyen használni ezeket az objektumokat. Ennek a megoldása
többféleképpen is lehetséges. Én a lehető legtöbb objektumot bean-ként hoztam létre a Spring
kontextusát leíró XML fájlban és csak magát a mapper-t hozom létre a DAO implementációs
osztályokban, amit a Spring fog beinjektálni.
Először is egy DataSource objektumot kell létrehozni, amely az adatbázis elérésehez
szükséges információkat tartalmazza:
<bean id="dataSource"
class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName"
value="com.mysql.jdbc.Driver" />
<property name="url"
value="jdbc:mysql://localhost:3306/dbtest" />
<property name="username" value="root" />
<property name="password" value="" />
</bean>
Ezt követően egy SqlSessionFactory objektum létrehozása következik, amely SqlSession
objektumokat biztosít vagy közvetlenül az implementáció osztálynak, vagy ahogy én
csináltam, a mapper objektumoknak. Az SqlSession biztosítja az adatbázis kapcsolódást
(Connection) és akár közvetlenül is végrehajthatunk SQL utasításokat általa:
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
</bean>
Át kell adni neki a DataSource objektumot az adatbázishoz való kapcsolódáshoz.
Ezután létrehoztam a mappereket, mint bean-eket, átadva nekik az SqlSessionFactory
objektumot:

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
38
<bean id="userMapper"
class="org.mybatis.spring.mapper.MapperFactoryBean">
<property name="mapperInterface"
value="hu.uni.miskolc.iit.manuscript.dao.mysql.mappers.UserMapp
er" />
<property name="sqlSessionFactory" ref="sqlSessionFactory"
/>
</bean>
Ennek mintájára készítettem el a négy DAO osztályhoz tartozó négy mappert. Itt meg kell
adni tulajdonságként (mapperInterface) annak az interfésznek a teljes elérési nevét, amelyik
megvalósítja majd.
5.2.3 MyBatis implementáció
A mapper interfészek tartalmazzák azokat a metódusokat, amelyeket a DAO implementációs
osztályokból hívhatunk és egy-egy SQL utasítást reprezentálnak. Az XML fájlokban
találhatóak maguk az SQL utasítások. Ahhoz, hogy ez a két komponens megtalálja egymást,
azonos mappában kell elhelyezni őket, valamint az XML fájlok névterének a hozzájuk tartozó
interfészeket kell megadnunk a teljes elérési nevükkel. Ezenkívül fontos, hogy a nevüknek is
meg kell egyezniük. A továbbiakban bemutatok egy-egy példát minden utasítástípusból.
A felhasználók beszúrásakor használt metódus a következőképpen épül fel:
public void reg(User user) throws DataAccessException {
try {
userMapper.insertUser(user);
userMapper.insertUserRoles(user);
userMapper.insertUserAreas(user);
} catch (PersistenceException e) {
throw new InsertException("MyBatis Error occured
while performing an insert method: " + e.getMessage(), e);
} catch (Exception e) {
throw new InsertException("Other error occured while
performing an insert method: " + e.getMessage(), e);
}
}

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
39
Először magát a felhasználót szúrom be az idegen kulcsok miatt, majd a szerepköreit, végül a
szakterületeit a megfelelő táblákba. A mapper műveleteknél keletkező kivételek szinte mindig
a MyBatis kivételbe csomagolódnak be (PersistenceException). Ezt, valamint minden más
kivételt is elkap a metódus, majd ezeket becsomagolja a saját beszúrási kivételembe
(InsertException). A mapper XML fájlban ennek egy részlete így néz ki:
<insert id="insertUser"
parameterType="hu.uni.miskolc.iit.manuscript.model.user.User">
INSERT INTO users(username, password, firstname,
middlename, lastname, title, home_address, street, city,
postal_code, country, state, organization, phone, fax, email)
VALUES(#{userName}, #{password}, #{firstName},
#{middleName}, #{lastName}, #{title}, #{homeAddress},
#{street}, #{city}, #{postalCode}, #{country}, #{state},
#{organization}, #{phone}, #{fax}, #{email})
</insert>
<insert id="insertUserRoles"
parameterType="hu.uni.miskolc.iit.manuscript.model.user.User">
INSERT INTO user_roles(username, ROLE) VALUES
<foreach item="role" collection="roles" index="index"
open="(" separator="),(" close=")">
#{userName}, #{role}
</foreach>
</insert>
Látható, hogy a #{} szintaktikával lehet a paraméterként megkapott objektum adattagjaira
hivatkozni. A típuskonverzió, ha lehetséges, automatikusan végbemegy. Egyfajta típusú
paramétert adhatunk csak meg a parameterType tulajdonság segítségével. Ilyenkor, ha több
azonos típusú paramétert adunk át, akkor a #{} közötti megfelelő nevekkel hivatkozhatunk
rájuk. Erre a későbbiekben mutatok példát.
A szerepkör beillesztésnél is egy User objektumot adunk át, azon belül viszont általában több
szerep is található a kollekcióban. Itt lehet használni a foreach tag-et, ami a kollekció összes
elemére végrehajtja az SQL utasítást.
A következő bemutatott metódus a felhasználók módosítása lesz:

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
40
public void edit(User user) throws DataAccessException {
try {
userMapper.updateUser(user);
userMapper.deleteUserRoles(user.getUserName());
userMapper.deleteUserAreas(user.getUserName());
if (user.getRoles() != null) {
userMapper.insertUserRoles(user);
}
if (user.getAcmAreas() != null) {
userMapper.insertUserAreas(user);
}
} catch (PersistenceException e) {
throw new UpdateException("MyBatis Error occured
while performing an update method: " + e.getMessage(), e);
} catch (Exception e) {
throw new UpdateException("Other error occured while
performing an update method: " + e.getMessage(), e);
}
}
Mivel a többértékű tulajdonságokat tároló táblák a rendszerünkben csak néhány bejegyzést
tartalmaznak egy egyedre nézve, ezért a módosítás legegyszerűbb módja, ha a módosítási
műveletnél kitörlünk minden hozzá tartozó bejegyzést a melléktáblából, majd hozzáadjuk a
paraméterben találhatókat. Itt is hasonló a kivételkezelés, azzal a különbséggel, hogy az itt
keletkező kivételek a saját módosítási kivételembe fognak becsomagolódni
(UpdateException). Az XML fájl hozzátartozó része:
<update id="updateUser"
parameterType="hu.uni.miskolc.iit.manuscript.model.user.User">
UPDATE users SET password = #{password}, firstname =
#{firstName}, middlename = #{middleName}, lastname =
#{lastName}, title = #{title}, home_address = #{homeAddress},
street = #{street}, city = #{city}, postal_code =
#{postalCode}, country = #{country}, state = #{state},
organization = #{organization}, phone = #{phone}, fax = #{fax},
email = #{email} WHERE username = #{userName}
</update>
A törlési művelet esetében a cikk törlését mutatom be:
public void delete(int id) throws DataAccessException {
try {
submissionMapper.deleteSubmissionKeywords(id);

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
41
submissionMapper.deleteSubmissionCoAuthors(id);
submissionMapper.deleteSubmissionReviews(id);
submissionMapper.deleteSubmission(id);
} catch (PersistenceException e) {
throw new DeleteException("MyBatis Error occured
while performing a delete method: " + e.getMessage(), e);
} catch (Exception e) {
throw new DeleteException("Other error occured while
performing a delete method: " + e.getMessage(), e);
}
}
Itt fontos, hogy a törléseket hivatkozási sorrendben kell elvégezni, ugyanis egy rekord addig
nem törölhető, amíg egy másik rekord idegen kulcsa az elsődleges kulcsára mutat.
Paraméterként itt már elég csak az azonosítót megkapnunk. Az itt keletkező kivételeket a saját
törlési kivételembe csomagolom (DeleteException). Az XML fájl ide vonatkozó része:
<delete id="deleteSubmission" parameterType="int">
DELETE FROM submissions WHERE id = #{id}
</delete>
Egyszerű paramétertípusnál mindegy, hogy milyen szöveget adunk meg a #{} rész között,
amennyiben csak egy paramétert adunk át, a MyBatis tudni fogja, hogy azt kell oda beszúrnia.
Lekérdezési műveletekből kettőt mutatok be. Az első a cikk lekérdezése állapot alapján:
public List<Submission> getSubmissionsByState(State state)
throws DataAccessException {
List<Submission> result = new ArrayList<Submission>();
try {
result =
submissionMapper.getSubmissionsByState(state);
} catch (PersistenceException e) {
throw new QueryException("MyBatis Error occured while
performing a query method: " + e.getMessage(), e);
} catch (Exception e) {
throw new QueryException("Other error occured while
performing a query method: " + e.getMessage(), e);
}
return result;
}

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
42
Itt minden kivételt a saját lekérdezési kivételembe csomagolok be (QueryException). Az XML
fájl megfelelő része:
<select id="getSubmissionsByState" parameterType="String"
resultMap="SubmissionResultMap">
SELECT id, title, abstract, submission_area, state,
corresponding_author, co_author, assigned_editor, file_path,
uploadDate, reviewer, verdict, message, details,
secret_message, review_date
FROM submissions
LEFT OUTER JOIN submission_reviews ON id =
submission_reviews.submission_id
LEFT OUTER JOIN submission_co_authors ON id =
submission_co_authors.submission_id
WHERE state = #{state}
</select>
A cikket tároló táblát a melléktáblákkal a LEFT OUTER JOIN SQL művelettel kapcsoltam
össze. Ez azt jelenti, hogy az első táblából minden feltételnek megfelelő rekord szerepel majd
az eredményhalmazban, de a másodikból csak azok, amelyek egyeznek egy rekorddal az első
táblából a kapcsolódási feltétel alapján. Itt már a visszatérési érték típusát is meg kell adni,
hogy a MyBatis le tudja képezni a visszakapott adatokat a megfelelő típusokká. Itt nem kell
kollekciót megadni, elég az alaptípust, a MyBatis a rekordhalmazt automatikusan leképzi a
kívánt kollekcióvá. Ezt a resultType tulajdonsággal tehetjük meg, vagy mint a példában is,
összetett típusoknál a resultMap tulajdonságot kell használnunk. Ekkor meg kell adnunk a
leképezés módját resultMap tag-ek között:
<resultMap
type="hu.uni.miskolc.iit.manuscript.model.submission.Submission
" id="SubmissionResultMap">
<result property="id" column="id" />
<result property="title" column="title" />
<result property="abstractOfSubmission" column="abstract"
/>
<result property="acmArea" column="submission_area" />
<result property="state" column="state" />
<result property="correspondingAuthor.userName"
column="corresponding_author" />
<result property="assignedEditor.userName"
column="assigned_editor" />

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
43
<result property="assignedProofreader.userName"
column="assigned_proofreader" />
<result property="assignedTechnicalEditor.userName"
column="assigned_technical_editor" />
<result property="filePath" column="file_path" />
<result property="date" column="uploadDate" />
<collection property="assignedReviewers"
ofType="hu.uni.miskolc.iit.manuscript.model.user.User">
<result property="userName" column="reviewer" />
</collection>
<collection property="reviews"
ofType="hu.uni.miskolc.iit.manuscript.model.submission.Rev
iew">
<result property="reviewer.userName"
column="reviewer" />
<result property="verdict" column="verdict" />
<result property="message" column="message" />
<result property="details" column="details" />
<result property="secretMessage"
column="secret_message" />
<result property="date" column="review_date" />
</collection>
<collection property="coAuthors" ofType="String">
<result column="co_author" />
</collection>
</resultMap>
A type tulajdonság adja meg, hogy milyen összetett típussá akarjuk leképezni a rekordokat. A
result tag-ekkel megadhatjuk, hogy az egyes mezők mely adattagnak felelnek meg az
osztályban. Ez különösen fontos, ha a mező és az adattag neve eltér, egyébként a MyBatis
automatikusan megtalálja. A collection tag segítségével bonyolultabb lekérdezéseket is végre
lehet hajtani, itt beállíthatjuk, hogy a visszakapott adatok miképp szerveződjenek egy
kollekció típusú adattagon belül.
Az utolsó művelet, amit bemutatok, az a naplóbejegyzések időintervallum alapján történő
lekérdezése:

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
44
<select id="getHistoriesByPeriod" parameterType="java.sql.Date"
resultMap="historyResultMap">
SELECT * FROM histories WHERE history_date BETWEEN
#{start} and #{end}
ORDER BY history_date ASC
</select>
Itt a két megadott dátum paramétert a #{} közötti név alapján találja meg a MyBatis, majd
dátum alapján növekvő sorrendbe rendezi a rekordokat.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
45
6. Tesztelés
Az alkalmazás tesztelése több tekintetben is rendkívül fontos lépés. Így tudjuk a
legegyszerűbben ellenőrizni azt, hogy a funkciók végrehajtják-e az elvárt működést. Ezenkívül
ha már készen vannak a tesztek és módosítunk valamit a tesztelt kódban, rögtön
ellenőrizhetjük, hogy a változtatásunk megzavarta-e a funkció működését.
A dao-mysql modul felépítését a tesztek szempontjából a 11. ábra mutatja be:
11. ábra: DAO-MySQL modul szerkezete (tesztelés)
A tesztosztályok mind egy közös ősből származnak (InitTest), ami a tesztek lefutása előtt és
után végrehajtandó műveleteket tartalmazza. Ezek a műveletek az adatbázist hozzák létre és
semmisítik meg úgy, hogy a MyBatis-hoz tartozó szkript futtató osztály (ScriptRunner)
segítségével futtatják az SQL szkripteket. Ezenkívül minden egyes teszt metódus előtt feltöltik
a teszt adatokkal az adatbázist, amelyeket utána ki is törölnek:
@BeforeClass
public static void setUpDatabase() {
runScript(CREATE_TABLES_SQL);
}

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
46
@AfterClass
public static void deleteDatabase() {
runScript(DROP_TABLES_SQL);
}
@Before
public void insertTestData() {
runScript(INSERT_TEST_DATA);
}
@After
public void deleteTestData() {
runScript(DELETE_TEST_DATA);
}
Minden teszt osztály tartalmaz még egy @Before annotációval ellátott metódust, melynek
feladata az adott osztályhoz tartozó DAO inicializálása. Mivel itt nem használható a Spring,
hogy biztosítsa a megfelelő mapper-t, ezért van szükség a 11. ábrán látható dao-config.xml
konfigurációs fájlra. Ugyancsak tartalmaznak egy @After jelölésű metódust, mely az
SqlSession osztály által reprezentált adatbázis-kezelő munkamenetet zárja le minden
tesztfüggvény után. Erre azért van szükség, mert a szkript futtató osztály és a DAO más
munkamenetet használ, és egyébként kizárnák egymást az adatbázisból.
Példaként bemutatom az egyik, felhasználókhoz kötődő lekérdezés tesztesetét:
@Test
public void TestGetEditorsByAcm() {
List<User> userQuery = new ArrayList<User>();
List<User> userFalseQuery = new ArrayList<User>();
try {
userQuery =
userDAO.getEditorsByAcm("INFORMATION_SYSTEMS");
userFalseQuery = userDAO.getEditorsByAcm("HARDWARE");
} catch (DataAccessException e) {
Assume.assumeNoException(e);
}
Assert.assertTrue(userQuery.size() == 1);
Assert.assertTrue(userFalseQuery.isEmpty());
}
A kód lefedettség (code coverage) azt jelenti, hogy a tesztek futása során a tesztelt kód hány
százaléka hívódik meg. A lefedettséget az Emma Code Coverage plugin segítségével
vizsgáltam, és a 12. ábra mutatja, hogy milyen eredményt értem el:

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
47
12. ábra: Kód lefedettség
60 tesztesetet hoztam létre és mindegyik sikeresen lefut. A tesztek létrehozásakor sok,
korábban nem látott hiba kiderült, amiket aztán ki tudtam javítani.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
48
7. Összegzés
A szakdolgozatom témáját képző, általam elvállalt projektfeladat célja az volt, hogy tervezzem
meg és hozzam létre az adattárolási modellt, valamint az adathozzáférési réteget egy
elektronikus kézirat feltöltő rendszerhez. Véleményem szerint ezt sikerült teljesíteni,
elkészültek a szükséges elemek, s mivel ez egy általános alkalmazás, ezért számos
testreszabási és kibővítési pontot tartalmaz, ami a jövőre nézve is kínál lehetőségeket. A
csoportmunkában elkészült alkalmazást fel lehet használni a Miskolci Egyetem PSAIE
tudományos folyóiratához, vagy akár más intézményeknek is lehet továbbítani hasonló
célokra.
A szakdolgozat készítése során kipróbálhattam magam egy komolyabb projektmunkában,
kiderült, hogy mennyire sikerül alkalmaznom az egyetemen megszerzett tudást, valamint hogy
el tudok-e sajátítani nem oktatott technológiákat is. Úgy gondolom, hogy ezt is teljes
mértékben megvalósítottam, képes voltam hasznosítani az egyetemi tananyagot elsősorban az
’Objektum orientált programozás’, a ’WEB-es alkalmazások’, az ’Adatbázis rendszerek’, a
’Szoftvertechnológia’ és a ’Szoftver projektek és tesztelés’ tantárgyakból. Emellett sikerült
elsajátítanom az általam korábban nem ismert MyBatis technológiát is, és hasznos
tapasztalatokkal gazdagodtam a csoportmunkában történő szoftverfejlesztés kapcsán.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
49
8. Summary
The aim of the project, which was documented in my thesis, was to develop and implement
the data structure and the data access layer of a manuscript handler system. In my opinion, I
managed to achieve this, the needed components were completed. Furthermore, because it is a
white-labeled product, the system contains many customization and extension points, thus
providing future possibilities. The application, which was developed in teamwork, can be
utilized for the PSAIE journal of the University of Miskolc, or it can be forwarded to other
institutes for similar purposes.
During the creation of my thesis I could try myself out in a major project work and find out
how much I can use the knowledge gained in the university, and if I can manage to learn new
technologies not taught in the university. I think that I have entirely accomplished this as well,
since I was able to utilize the curriculum of many subjects taught in the university. These
subjects are ’Object Oriented Programming’, ’WEB Based Applications’, ’Database Systems’,
’Software Technology’, and ’Software Projects and Testing’. In addition, I managed to learn
and use the MyBatis technology, which was completely new for me and I also gained useful
experiences regarding software development in teamwork.

Az adattárolási modell és a modell osztályok kidolgozása elektronikus kézirat feltöltő rendszerhez
________________________________________
50
9. Irodalomjegyzék
- [1] http://docs.spring.io/spring-framework/docs/current/spring-framework-
reference/html/mvc.html
- [2] Ben Collins-Sussman, Brian W. Fitzpatrick, C. Michael Pilato: Version Control
with Subversion, For Subversion 1.7
- [3] https://maven.apache.org/index.html
- [4] https://mybatis.github.io/mybatis-3/
Linkek utoljára ellenőrizve: 2015-11-20