markov models and applications sushmita roy bmi/cs 576 [email protected] oct 7 th, 2014
TRANSCRIPT

Markov models and applications
Sushmita RoyBMI/CS 576
www.biostat.wisc.edu/bmi576/[email protected]
Oct 7th, 2014

Readings
• Chapter 3– Section 3.1– Section 3.2

Key concepts
• Markov chains– Computing the probability of a sequence– Estimating parameters of a Markov model
• Hidden Markov models– States– Emission and transition probabilities– Parameter estimation– Forward and backward algorithm– Viterbi algorithm

Markov models
• So far we have assumed in our models that there is no dependency between consecutive base pair locations
• This assumption is rarely true in practice• Markov models allow us to model the dependencies
inherent in sequential data such as DNA or protein sequence

Markov models have wide applications
• Genome annotation– Given a genome sequence find functional untis of the
genome• Genes, CpG islands, promoters..
• Sequence classification– A Hidden Markov model can represent a family of proteins
• Sequence alignment

Markov chain
• A Markov chain is the simplest type of Markov models
• Described by– A collection of states, each state representing a symbol
observed in the sequence– At each state a symbol is emitted– At each state there is a some probability of transitioning to
another state

Detecting CpG islands
• CpG islands are isolated regions of the genome corresponding to high concentrations of CG dinucleotides– Range from 100-5000 bps
• For example regions upstream of genes or gene promoters
• Given a short sequence of DNA, how can we decide it is a CpG island?
• What kind of a model should we use to represent a CpG island?

Markov chain model for DNA sequence
• We know dinucleotides are important• We would our model to capture the dependency
between consecutive positions

Markov chain model notation
• Xt is a random variable denoting the state at time t
• aij=P(Xt=j|Xt-1=i) denotes the transition probability from state i to state j

A Markov chain model for DNA sequence
A
TC
begin
state
transition
.34.16
.38
.12
transition probabilities
G

• Can also have an end state; allows the model to represent– A probability distribution over sequences of all possible lengths– preferences for ending sequences with certain symbols
Markov chain models
begin end
A
TC
G

Computing the probability of a sequence from a first Markov model
• Let X be a sequence of random variables X1 … XL representing a biological sequence
• From the chain rule of probability

Computing the probability of a sequence from a first Markov model
• Key property of a (1st order) Markov chain: the probability of each Xt depends only on the value of Xt-1
This can be written as the initial probabilities or a transition probability from the “begin” state

Example of computing the probability from a Markov chain
begin end
A
tc
g
What is P(CGGT)? P(C )P(G|C)P(G|G)P(T|G) P(End|T)

Learning Markov model parameters
• Model parameters– Initial probabilities P(X0)
– Transition probabilities P(Xt|Xt-1)
• Estimated via maximum likelihood– That is, if D is the sequence data, are parameters– is estimated to maximize

Maximum likelihood estimation• Suppose we want to estimate the parameters P(a), P(c),
P(g), P(t)• then the maximum likelihood estimates are
na Number of occurrences of a

Maximum likelihood estimation• Suppose we’re given the sequences
accgcgcttagcttagtgactagccgttac
• We obtain the following maximum likelihood estimates

Maximum Likelihood Estimation
• suppose instead we saw the following sequencesgccgcgcttggcttggtggctggccgttgc
• then the maximum likelihood estimates are
do we really want to set this to 0?

Laplace estimates of parameters
• instead of estimating parameters strictly from the data, we could start with some prior belief for each
• for example, we could use Laplace estimates
• where represents the number of occurrences of character i
• using Laplace estimates with the sequences
GCCGCGCTTGGCTTGGTGGCTGGCCGTTGC
pseudocount

Estimation for 1st Order Probabilities• to estimate a 1st order parameter, such as P(c|g), we count
the number of times that g follows the history c in our given sequences
• using Laplace estimates with the sequences
GCCGCGCTTGGCTTGGTGGCTGGCCGTTGC

Build a Markov chain model for CpG islands
• Learn two Markov models– One from sequences that look like CpG (positive)– One from sequences that don’t look like CpG (negative)
– Parameters estimated from ~60,000 nucleotides
+ A C G T
A .18 .27 .43 .12
C .17 .37 .27 .19
G .16 .34 .38 .12
T .08 .36 .38 .18
- A C G T
A .30 .21 .28 .21
C .32 .30 .08 .30
G .25 .24 .30 .21
T .18 .24 .29 .29
CpG + CpG -G is much more likely to follow A in the CpG positive model

Using the Markov chains to classify a new sequence
• Let y denote a new sequence• To use the Markov models to classify y we compute
the score as
• The larger the value of S(y) the more likely is y a CpG island

Distribution of scores for CpG and non CpG examples
CpG

Applying the CpG Markov chain models to classify new examples
• Is CGCGA a CpG island?– Score=
• Is CCTGG a CpG island?Score= 3.3684
Score=0.3746

Extensions to Markov chains
• Hidden Markov models (Next lectures)
• Higher-order Markov models
• Inhomogeneous Markov models

Order of a Markov model
• Describes how much history we want to keep• First order Markov models are most common
• Second order
• nth order

Selecting the order of a Markov chain model
• Higher order models remember more “history”• Additional history can have predictive value• Example:– predict the next word in this sentence fragment “…
the__” (duck, end, grain, tide, wall, …?)
– now predict it given more history “… against the __” (duck, end, grain, tide, wall, …?)
“swim against the __” (duck, end, grain, tide, wall, …?)

Higher order Markov chains
• An nth order Markov chain over some alphabet A is equivalent to a first order Markov chain over the alphabet An of n-tuples
• For example: a 2nd order Markov model for DNA can be treated as a 1st order Markov model over alphabet AA, AC, AG, AT, CA, CC, CG, CT, GA, GC, GG, GT, TA, TC, TG,
TT
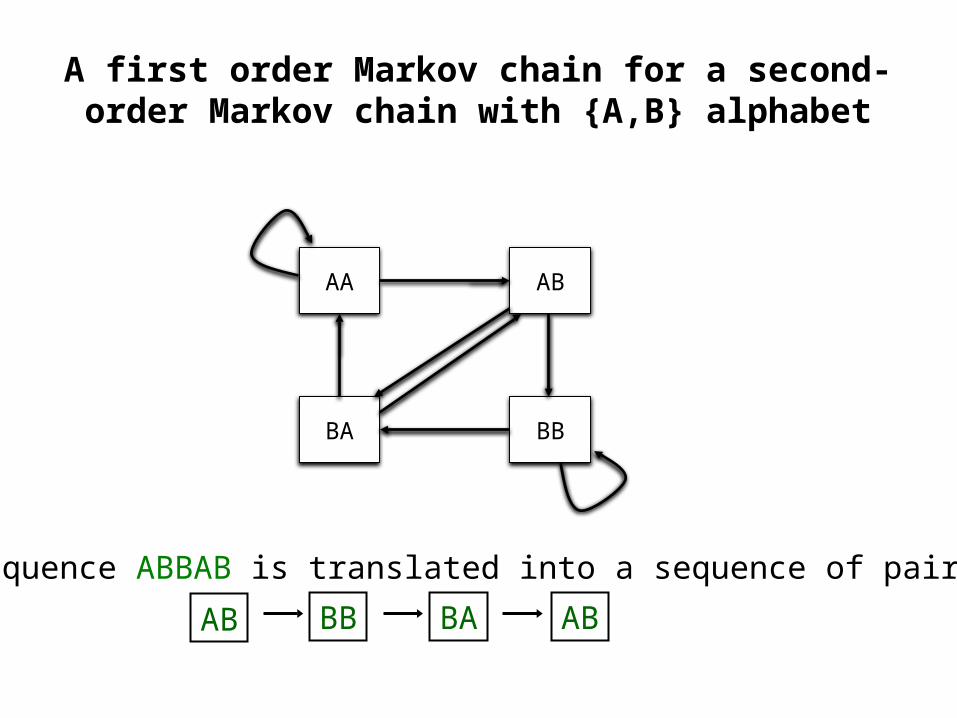
A first order Markov chain for a second-order Markov chain with {A,B} alphabet
AA
BA BB
AB
A sequence ABBAB is translated into a sequence of pairs
AB BABB AB

A fifth-order Markov chain
gctac
aaaaa
ctacg
ctacactacc
ctact
P(a | gctac)
begin
P(gctac)
P(c | gctac)

Order of Markov model
• The number of parameters grows exponentially with the order
• Consider an alphabet of A characters– For 1st order we need to estimate A2 parameters– For 2nd order we need to estimate A3 parameters– For nth order we need to estimate An+1 parameters
• Higher order models need more data to estimate their parameters

Inhomogeneous Markov chains
• So far the Markov chain has the same transition probability for the entire sequence
• Sometimes it is useful to switch between Markov chains depending on where we are in the sequence
• For example, recall the genetic code that specifies what triplets of bases code for an amino acid– Each position in the codon have different statistics– This could be modeled by three Markov chains
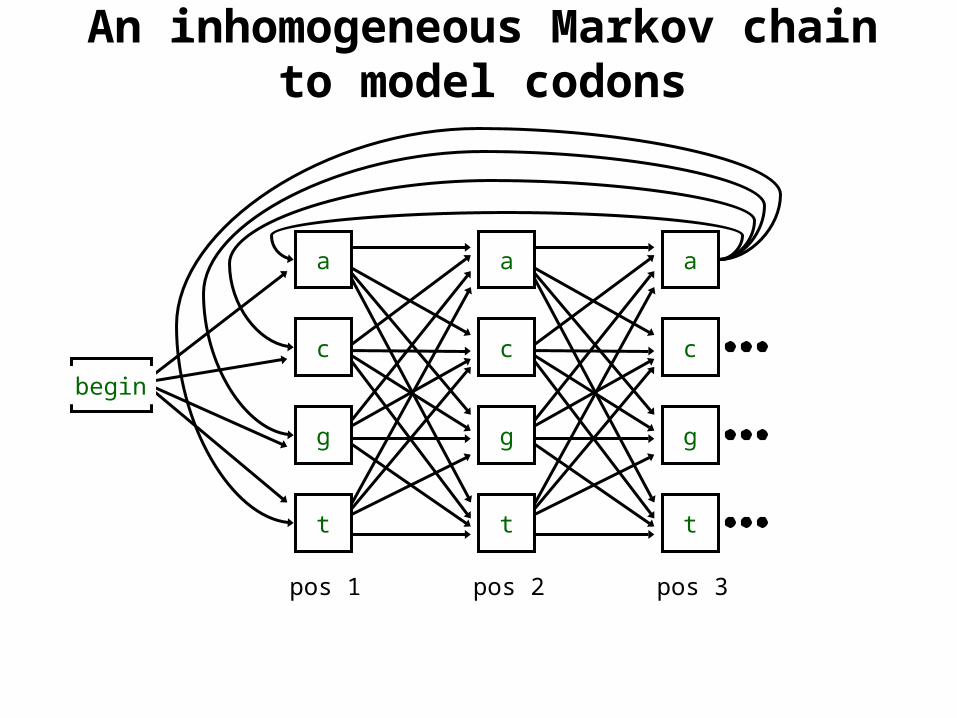
An inhomogeneous Markov chain to model codons
a
t
c
g
a
t
c
g
a
t
c
g
begin
pos 1 pos 2 pos 3

Inhomogeneous Markov chain
• Let 1, 2 and 3 denote the three Markov chains– So our transition probabilities look like– aij
1, aij2, aij
3
• Let x1 be in codon position 3
• Probability of x2x3 x4x5x6.. would be

Summary
• Markov models allow us to model dependencies in sequential data
• Markov models are described by – states, each state corresponding to a letter in our observed alphabet– Transition probabilities between states
• Parameter estimation can be done by counting the number of transitions between consecutive states (first order)– Laplace correction is often applied
• Often used for classifying sequences as CpG islands or not• Extensions of Markov models
– Order– Inhomogeneous Markov models

Errata
• Slide 14 corrected for the end position– P(C )P(G|C)P(G|G)P(T|G) P(End|T)