mapreduce. outline r mapreduce overview r note: these notes are based on notes provided by google
TRANSCRIPT

MapReduce

Outline
MapReduce overview Note: These notes are based on notes
provided by Google

What is a Cloud?
Cloud = Lots of storage + compute cycles nearby

Data-Intensive Computing
Data-Intensive Typically store data at datacenters Use compute nodes nearby Compute nodes run computation services
In data-intensive computing, the focus is on the data: problem areas include Storage Communication bottleneck Moving tasks to data (rather than vice-
versa) Security Availability of Data Scalability

Computation Services
Google → MapReduce, Sawzall Yahoo → Hadoop, Pig Latin Microsoft → Dryad, DryadLINQ

Motivation: Large Scale Data Processing
Want to process lots of data ( > 1 TB) Want to parallelize across
hundreds/thousands of CPUs How to parallelize How to distribute How to handle failures
Want to make this easy

What is MapReduce?
MapReduce is an abstraction that allows programmers to specify computations that can be done in parallel
MapReduce hides the messy details needed to support the computations e.g., Distribution and synchronization Machine failures Data distribution Load balancing
This is widely used at Google

Programming Model
MapReduce simplifies programming through its library.
The user of the MapReduce library expresses the computation as two functions: Map, Reduce

Programming Model Map
Takes an input pair and produces a set of intermediate key/value pairs e.g.,
• Map: (key1, value1) list(key2,value2)
The MapReduce library groups together all intermediate values associated with the same intermediate key
Reduce This function accepts an intermediate key
and a set of values for that key Reduce: (key2,list(key2,value2)) value3

Example: Word Frequencies in Web Pages
Determine the count of each word that appears in a document (or a set of documents) Each file is associated with a document URL
Map function Key = document URL Value = document contents
Output of map function is (potentially many) key/value pairs Output (word, “1”) once per word in the
document

Example: Word Frequencies in Web Pages
Pseudo code for map
Map(String key, String value): // input_key: document name // input_value: document contentsfor each word w in value: EmitIntermediate(w, "1");

Example: Word Frequencies in Web Pages
Example key, value pair: “document_example”, “to be or not to be”
Result of applying the map function “to”, 1 “be”, 1 “or”, 1 “not”, 1 “to”, 1 “be”, 1

Example: Word Frequencies in Web Pages
Pseudo-code for ReduceReduce(String key, values): // key: a word, same for input and output // values: a list of countsint result = 0;for each v in values: result = result + value;Emit(result);
The function sums together all counts emitted for a particular word

Example: Word Frequencies in Web Pages
The MapReduce framework sorts all pairs with the same key (be,1), (be,1), (not,1), (or, 1), (to, 1), (to,1)
The pairs are then grouped (be, 1,1), (not, 1), (or, 1), (to, 1, 1)
The reduce function combines (sums) the values for a key Example: Applying reduce to (be, 1, 1) = 2

Example: Distributed Grep
Find all occurrences of a given pattern in a a file (or set of files)
Input consists of (url+offset, line) map(key=url+offset, val=line):
If contents match specified pattern, emit (line, “1)
reduce(key=line, values=uniq_counts): Example of input to reduce is essentially
(line, [1,1,1,1]) Don’t do anything; just emit line

Example: Count of URL Access Frequency
Map function Input: <log of web page requests,
content of log> Outputs: <URL, 1>
Reduce function adds together all values for the same URL

Example:Web structure Simple representation of WWW link graph
Map• Input: (URL, page-contents) • Output: (URL, list-of-URLs)
Who maps to me? Map
• Input: (URL, list-of-URLS) • Output: For each u in list-of-URLS output <u,URL>
Reduce: Concatenates the list of all source URLs associated with u and emits (<u, list(URL))

The Infrastructure Large clusters of commodity PCs and
networking hardware Clusters consists of 100/1000s of
machines (failures are common) GFS (Google File System).
Distributed file system. Provides replication of the data.

The Infrastructure Users submit jobs to a scheduling
system Possible partitions of data can be based
on files, databases, file lines, database records etc;

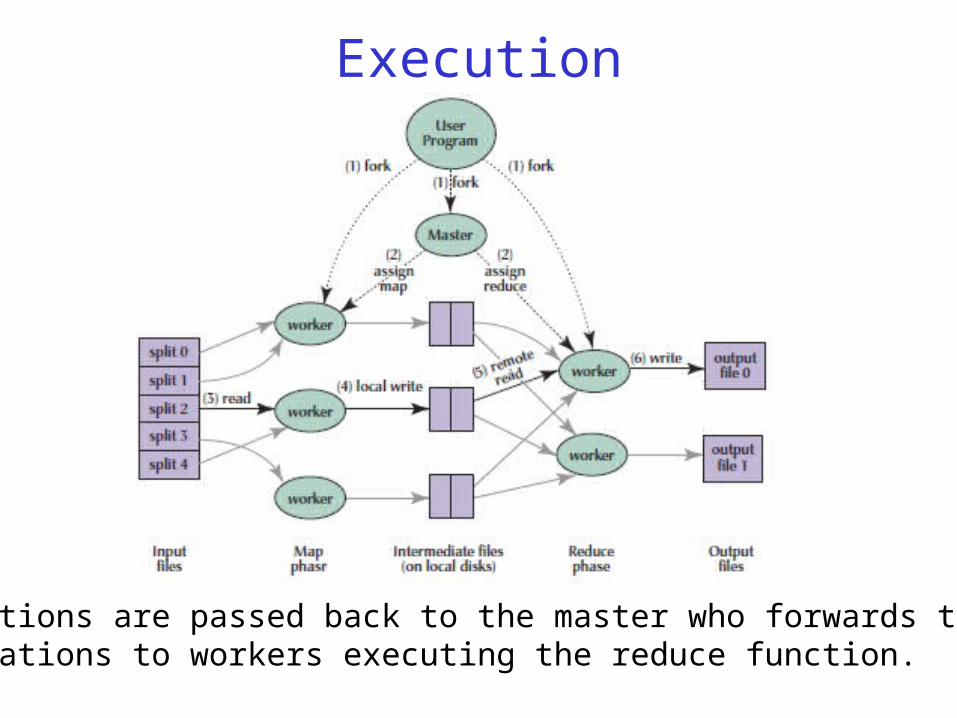
Execution Map invocations are distributed across
multiple machines by automatically partitioning the input data into a set of M splits.
The input splits can be processed in parallel by different machines
Reduce invocations are distributed by partitioning the intermediate key space into R pieces using a hash function: hash(key) mod R R and the partitioning function are specified by
the programmer.

Execution
Workers are assigned work by the masterThe master is started by the MapReduce Framework

Execution
Workers assigned map tasks read the input, parse it and invokethe user’s Map() method.

Execution
• Intermediate key/value pairs are buffered in memory•Periodically, buffered data is written to local disk (R files)•Pseudo random partitioning function (e.g., (hash(k) mod R)
Execution
•Locations are passed back to the master who forwards these locations to workers executing the reduce function.

Execution
• Reduce runs after all mappers are done• Workers executing Reduce are notified by the master about location of intermediate data

Execution
• Reduce workers use remote procedure calls to read the data from local disks of map works• Sorts all intermediate data by intermediate key

Execution
• Reduce worker iterates over the sorted intermediate data and for each key encountered it passes the key and the corresponding set of intermediate values to the Reduce function

Execution
• The output of the Reduce function is appended to a final output file

Data flow
Input, final output are stored on a distributed file system Scheduler tries to schedule map tasks “clos
e” to physical storage location of input data Intermediate results are stored on local
file system of map and reduce workers Output can be input to another map
reduce task

Execution

Parallel Execution

Coordination
Master data structures Task status: (idle, in-progress, completed) Idle tasks get scheduled as workers become
available When a map task completes, it sends the
master the location and sizes of its R intermediate files, one for each reducer
Master pushes this info to reducers Master pings workers periodically to detect
failures

Failures Map worker failure
Map tasks completed or in-progress at worker are reset to idle
Reduce workers are notified when task is rescheduled on another worker
Reduce worker failure Only in-progress tasks are reset to idle
Master failure MapReduce task is aborted and client is
notified

Locality
MapReduce master takes the location information of input files into account and attempts to schedule a map task on a machine that contains a replica of the corresponding input data
Schedule a map task near a replica of that task’s input data
The goal is to read most input data locally and thus reduce the consumption of network bandwidth

Task Granularity
M and R should be much larger than the number of available machines. Dynamic load balancing. Speeds up recovery in case of failures.
R determines the number of output files Often constrained by users.

Backup Tasks
Stragglers - A common reason for long computations.
Schedule backups for remaining jobs (in progress jobs) when map or reduce phases near completion. Slightly increases needed computational
resources. Does not increase running time, but has the
potential to improve it significantly.

Combiners
Often a map task will produce many pairs of the form (k,v1), (k,v2), … for the same key k E.g., popular words in Word Count
Can save network time by pre-aggregating at mapper combine(k1, list(v1)) v2 Usually same as reduce function
Works only if reduce function is commutative and associative

Partition Function Inputs to map tasks are created by
contiguous splits of input file For reduce, we need to ensure that records
with the same intermediate key end up at the same worker
System uses a default partition function e.g., hash(key) mod R
Sometimes useful to override; What if all output keys are URLS and we want all entries for a single host to end up in the same output file? Use hash(hostname(URL)) mod R ensures URLs
from a host end up in the same output file

Summary
MapReduce – a framework for distributed computing. Distributed programs are easy to write and
understand. Provides fault tolerance Program execution can be easily monitored.
It works for Google!!