maintaining variance and k-medians over data stream windows brian babcock, mayur datar, rajeev...
TRANSCRIPT

Maintaining Variance and k-Medians over Data Stream Windows
Brian Babcock, Mayur Datar, Rajeev Motwani, Liadan
O’CallaghanStanford University

Data Streams andSliding Windows Streaming data model
Useful for applications with high data volumes, timeliness requirements
Data processed in single pass Limited memory (sublinear in stream size)
Sliding window model Variation of streaming data model Only recent data matters Parameterized by window size N Limited memory (sublinear in window size)

Sliding Window (SW) Model
….1 0 1 0 0 0 1 0 1 1 1 1 1 1 0 0 0 1 0 1 0 0 1 1…
Time Increases
Current Time
Window Size N = 7
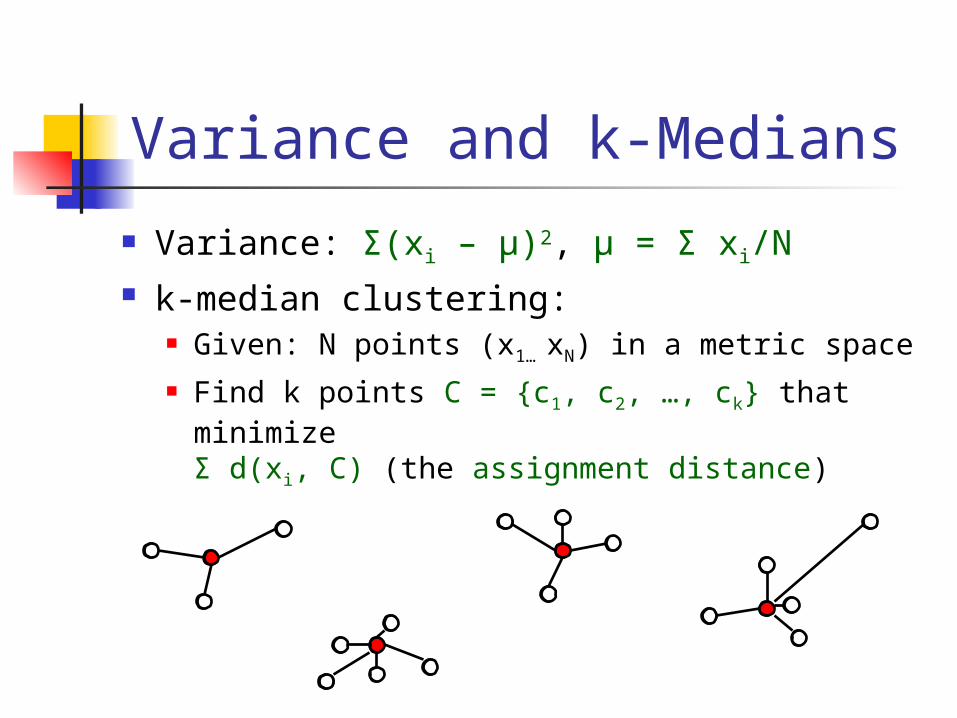
Variance and k-Medians
Variance: Σ(xi – μ)2, μ = Σ xi/N k-median clustering:
Given: N points (x1… xN) in a metric space Find k points C = {c1, c2, …, ck} that
minimize Σ d(xi, C) (the assignment distance)

Previous Results in SW Model Count of non-zero elements /
Sum of positive integers [DGIM’02] (1 ± ε) approximation Space: θ((1/ε)(log N)) words
θ((1/ε)(log2 N)) bits Update time: θ(log N) worst case, θ(1)
amortized Improved to θ(1) worst case by [GT’02]
Exponential Histogram (EH) data structure Generalized SW model [CS’03] (previous
talk)

Results – Variance
(1 ± ε) approximation Space: O((1/ε2) log N) words Update Time: O(1) amortized,
O((1/ε2) log N) worst case

Results – k-medians
2O(1/τ) approximation of assignment distance (0 < τ < ½)
Space: O((k/τ4)N2τ) Update time: O(k) amortized,
O((k2/τ3)N2τ) worst case Query time: O((k2/τ3)N2τ)
~
~
~
~

Remainder of the Talk
Overview of Exponential Histogram Where EH fails and how to fix it Algorithm for Variance Main ideas in k-medians algorithm Open problems

Sliding Window Computation Main difficulty: discount expiring data
As each element arrives, one element expires Value of expiring element can’t be known
exactly How do we update our data structure?
One solution: Use histograms
….1 1 0 1 1 1 0 1 0 1 0 0 1 0 1 0 0 0 0 0 1 0 …
Bucket Sums = {3,2,1,2}Bucket Sums = {2,1,2}

Containing the Error Error comes from last bucket
Need to ensure that contribution of last bucket is not too big
Bad example:
… 1 1 0 0 1 1 1 1 1 1 1 1 0 1 1 0 0 0 0 0 0 0 0 0 0…
Bucket Sums = {4,4,4}Bucket Sums = {4}

Exponential Histograms
Exponential Histogram algorithm: Initially buckets contain 1 item each Merge adjacent buckets once the sum
of later buckets is large enough
….1 1 0 1 1 1 0 1 0 1 0 0 1 0 1 1 1 1…
Bucket sums = {4, 2, 2, 1}Bucket sums = {4, 2, 2, 1, 1}Bucket sums = {4, 2, 2, 1, 1 ,1}Bucket sums = {4, 2, 2, 2, 1}Bucket sums = {4, 4, 2, 1}

Where EH Goes Wrong [DGIM’02] Can estimate any function f
defined over windows that satisfies: Positive: f(X) ≥ 0 Polynomially bounded: f(X) ≤ poly(|X|) Composable: Can compute f(X +Y) from
f(X), f(Y) and little additional information Weakly Additive: (f(X) + f(Y)) ≤ f(X +Y) ≤
c(f(X) + f(Y)) “Weakly Additive” condition not valid
for variance, k-medians

Notation
Vi = Variance of the ith bucketni = number of elements in ith bucketμi = mean of the ith bucket
B1 Bm B2………………
Current window, size = N
Bm-1

Variance – composition
Bi,j = concatenation of buckets i and j
ji
jjiiji, n + n
μn + μn = μ
jiji, n n n
2ji
ji
jijiji, )μ - (μ
n + n
nn + V + V = V
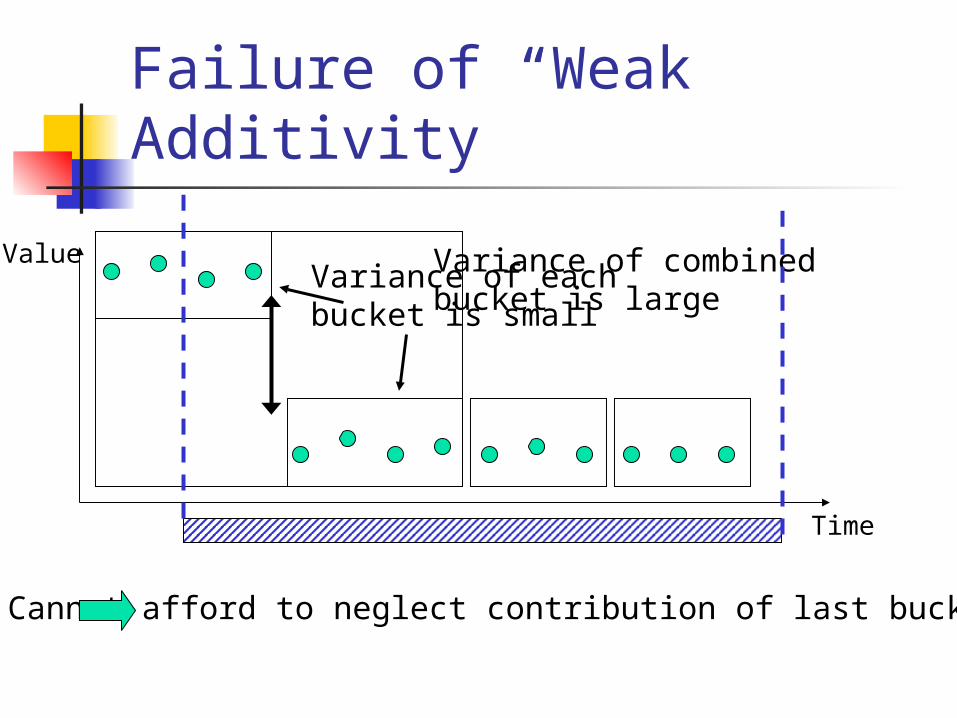
Failure of “Weak Additivity”
Time
ValueVariance of each bucket is small
Variance of combinedbucket is large
Cannot afford to neglect contribution of last bucket

Main Solution Idea More careful estimation of last bucket’s
contribution Decompose variance into two parts
“Internal” variance: within bucket “External” variance: between buckets
2ji
ji
jijiji, )μ - (μ
n + n
nn + V + V = V
Internal Varianceof Bucket i
Internal Varianceof Bucket j
External Variance

Main Solution Idea When estimating contribution of last
bucket: Internal variance charged evenly to each point External variance
Pretend each point is at the average for its bucket Variance for bucket is small
points aren’t too far from the average
Points aren’t far from the average average is a good approx. for each
point

Main Idea – Illustration
Time
Value
Spread
Spread is small external variance is small Spread is large error from “bucket
averaging” insignificant

Variance – error bound
Theorem: Relative error ≤ ε, provided Vm ≤ (ε2/9) Vm*
Aim: Maintain Vm ≤ (ε2/9) Vm* using as few buckets as possible
B1 Bm B2………………
Current window, size = N
Bm-1
Bm*

Variance – algorithm
EH algorithm for variance: Initially buckets contain 1 item each Merge adjacent buckets i, i+1
whenever the following condition holds:
(9/ε2) Vi,i-1 ≤ Vi-1*
(i.e. variance of merged bucket is small compared to combined variance of later buckets)

Invariants
Invariant 1: (9/ε2) Vi ≤ Vi* Ensures that relative error is ≤ ε
Invariant 2: (9/ε2) Vi,i-1 > Vi-1*
Ensures that number of buckets = O((1/ε2)log N)
Each bucket requires O(1) space

Update and Query time
Query Time: O(1) We maintain n, V & μ values for m and
m* Update Time: O((1/ε2) log N) worst
case Time to check and combine buckets Can be made amortized O(1)
Merge buckets periodically instead of after each new data element

k-medians summary (1/2) Assignment distance substitutes for variance Assignment distance obtained from an
approximate clustering of points in the bucket Use hierarchical clustering algorithm [GMMO’00]
Original points cluster to give level-1 medians Level-i medians cluster to give level-(i+1) medians Medians weighted by count of assigned points
Each bucket maintains a collection of medians at various levels

k-medians summary (2/2) Merging buckets
Combine medians from each level i If they exceed Nτ in number, cluster to get level i+1
medians. Estimation procedure
Weighted clustering of all medians from all buckets to produce k overall medians
Estimating contribution of last bucket Pretend each point is at the closest median Relies on approximate counts of active points
assigned to each median See paper for details!

Open Problems Variance:
Close gap between upper and lower bounds (1/ε log N vs. 1/ε2 log N)
Improve update time from O(1) amortized to O(1) worst-case
k-median clustering: [COP’03] give polylog N space approx.
algorithm in streaming data model Can a similar result be obtained in the sliding
window model?

Conclusion Algorithms to approximately maintain
variance and k-median clustering in sliding window model
Previous results using Exponential Histograms required “weak additivity” Not satisfied by variance or k-median
clustering Adapted EHs for variance and k-median Techniques may be useful for other
statistics that violate “weak additivity”