machine learning cuny graduate center lecture 5: graphical models
Post on 21-Dec-2015
228 views
TRANSCRIPT

Machine Learning
CUNY Graduate Center
Lecture 5: Graphical Models

Today
• Logistic Regression– Maximum Entropy Formulation
• Decision Trees Redux– Now using Information Theory
• Graphical Models– Representing conditional dependence
graphically
2

Logistic Regression Optimization
• Take the gradient in terms of w
3

Optimization
• We know the gradient of the error function, but how do we find the maximum value?
• Setting to zero is nontrivial
• Numerical approximation
4

Entropy
• Measure of uncertainty, or Measure of “Information”
• High uncertainty equals high entropy.
• Rare events are more “informative” than common events.
5

Examples of Entropy
• Uniform distributions have higher distributions.
6

Maximum Entropy
• Logistic Regression is also known as Maximum Entropy.
• Entropy is convex.– Convergence Expectation.
• Constrain this optimization to enforce good classification.
• Increase maximum likelihood of the data while making the distribution of weights most even.– Include as many useful features as possible.
7

Maximum Entropy with Constraints
• From Klein and Manning Tutorial8

Optimization formulation
• If we let the weights represent likelihoods of value for each feature.
9
For each feature i

Solving MaxEnt formulation
• Convex optimization with a concave objective function and linear constraints.
• Lagrange Multipliers
10
For each feature iDual representation of the
maximum likelihood estimation of Logistic Regression
Dual representation of the maximum likelihood estimation of
Logistic Regression

Decision Trees
• Nested ‘if’-statements for classification
• Each Decision Tree Node contains a feature and a split point.
• Challenges:– Determine which feature and split point to use– Determine which branches are worth
including at all (Pruning)
11

Decision Trees
12
colorcolor
hh ww ww
ww ww hh hh
blue brown green
<66<140 <150
<66 <64<145 <170
mm mm
mm
mm mmff ff
ff
ff ff

Ranking Branches
• Last time, we used classification accuracy to measure value of a branch.
13
heightheight
<68
1M / 5F 5M / 1F
50% Accuracy before Branch
83.3% Accuracy after Branch
33.3% Accuracy Improvement
6M / 6F

Ranking Branches
• Measure Decrease in Entropy of the class distribution following the split
14
heightheight
<68
1M / 5F 5M / 1F
H(x) = 2 before Branch
83.3% Accuracy after Branch
33.3% Accuracy Improvement
6M / 6F

InfoGain Criterion
• Calculate the decrease in Entropy across a split point.
• This represents the amount of information contained in the split.
• This is relatively indifferent to the position on the decision tree. – More applicable to N-way classification.– Accuracy represents the mode of the distribution– Entropy can be reduced while leaving the mode
unaffected.
15

Graphical Models and Conditional Independence
• More generally about probabilities, but used in classification and clustering.
• Both Linear Regression and Logistic Regression use probabilistic models.
• Graphical Models allow us to structure, and visualize probabilistic models, and the relationships between variables.
16

(Joint) Probability Tables
• Represent multinomial joint probabilities between K variables as K-dimensional tables
• Assuming D binary variables, how big is this table?
• What is we had multinomials with M entries?
17

Probability Models
• What if the variables are independent?
• If x and y are independent:
• The original distribution can be factored
• How big is this table, if each variable is binary?
18

Conditional Independence
• Independence assumptions are convenient (Naïve Bayes), but rarely true.
• More often some groups of variables are dependent, but others are independent.
• Still others are conditionally independent.
19

Conditional Independence
• If two variables are conditionally independent.
• E.g. y = flu?, x = achiness?, z = headache?
20

Factorization if a joint
• Assume
• How do you factorize:
21

Factorization if a joint
• What if there is no conditional independence?
• How do you factorize:
22

Structure of Graphical Models
• Graphical models allow us to represent dependence relationships between variables visually– Graphical models are directed acyclic graphs
(DAG).– Nodes: random variables– Edges: Dependence relationship– No Edge: Independent variables– Direction of the edge: indicates a parent-child
relationship– Parent: Source – Trigger– Child: Destination – Response
23

Example Graphical Models
• Parents of a node i are denoted πi
• Factorization of the joint in a graphical model:
24
xx yy xx yy

Basic Graphical Models
• Independent Variables
• Observations
• When we observe a variable, (fix its value from data) we color the node grey.
• Observing a variable allows us to condition on it. E.g. p(x,z|y)
• Given an observation we can generate pdfs for the other variables.
25
xx yy zz
xx yy zz

Example Graphical Models
• X = cloudy?
• Y = raining?
• Z = wet ground?
• Markov Chain
26
xx yy zz

Example Graphical Models
• Markov Chain
• Are x and z conditionally independent given y?
27
xx yy zz

Example Graphical Models
• Markov Chain
28
xx yy zz

One Trigger Two Responses
• X = achiness?
• Y = flu?
• Z = fever?
29
xx
yy
zz

Example Graphical Models
• Are x and z conditionally independent given y?
30
xx
yy
zz

Example Graphical Models
31
xxyy
zz

Two Triggers One Response
• X = rain?
• Y = wet sidewalk?
• Z = spilled coffee?
32
xx
yy
zz

Example Graphical Models
• Are x and z conditionally independent given y?
33
xx
yy
zz
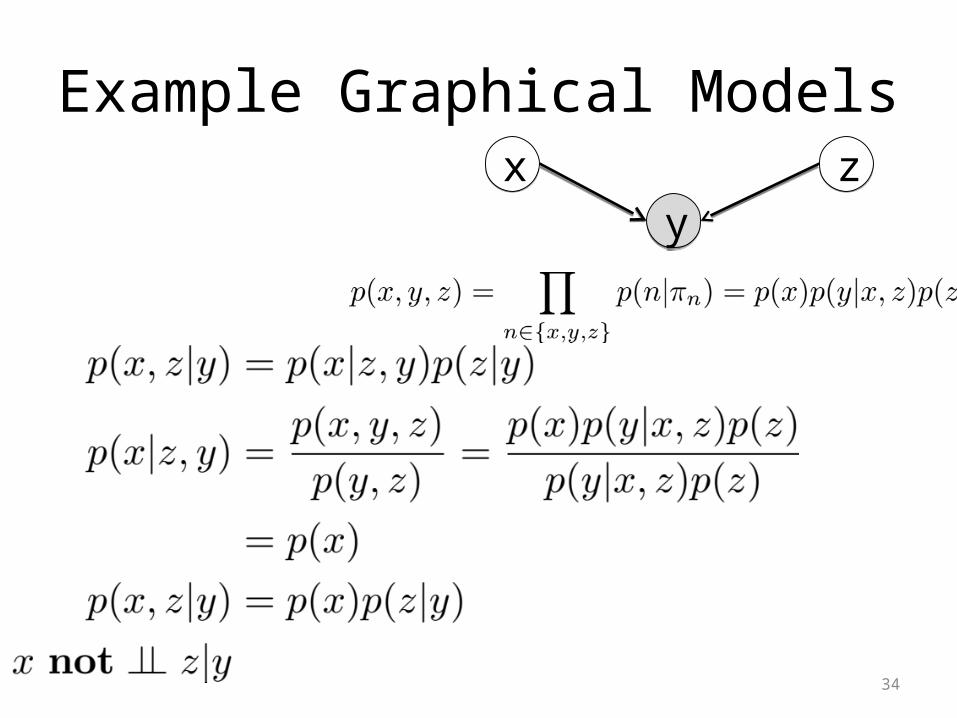
Example Graphical Models
34
xxyy
zz

Factorization
35
x0x0
x1x1
x2x2 x4x4
x3x3
x5x5

Factorization
36
x0x0
x1x1
x2x2 x4x4
x3x3
x5x5

How Large are the probability tables?
37

Model Parameters as Nodes
• Treating model parameters as a random variable, we can include these in a graphical model
• Multivariate Bernouli
38
µ0µ0
x0x0
µ1µ1
x1x1
µ2µ2
x2x2

Model Parameters as Nodes
• Treating model parameters as a random variable, we can include these in a graphical model
• Multinomial
39
x0x0
µµ
x1x1 x2x2

Naïve Bayes Classification
• Observed variables xi are independent given the class variable y
• The distribution can be optimized using maximum likelihood on each variable separately.
• Can easily combine various types of distributions
40
x0x0
yy
x1x1 x2x2

Graphical Models
• Graphical representation of dependency relationships
• Directed Acyclic Graphs• Nodes as random variables• Edges define dependency relations• What can we do with Graphical Models
– Learn parameters – to fit data– Understand independence relationships between
variables– Perform inference (marginals and conditionals)– Compute likelihoods for classification.
41

Plate Notation
• To indicate a repeated variable, draw a plate around it.
42
x0x0
yy
x1x1 xnxn…
yy
xixi
n

Completely observed Graphical Model
• Observations for every node
• Simplest (least general) graph, assume each independent
43

Completely observed Graphical Model
• Observations for every node
• Second simplest graph, assume complete dependence
44

Maximum Likelihood
• Each node has a conditional probability table, θ
• Given the tables, we can construct the pdf.
• Use Maximum Likelihood to find the best settings of θ
45
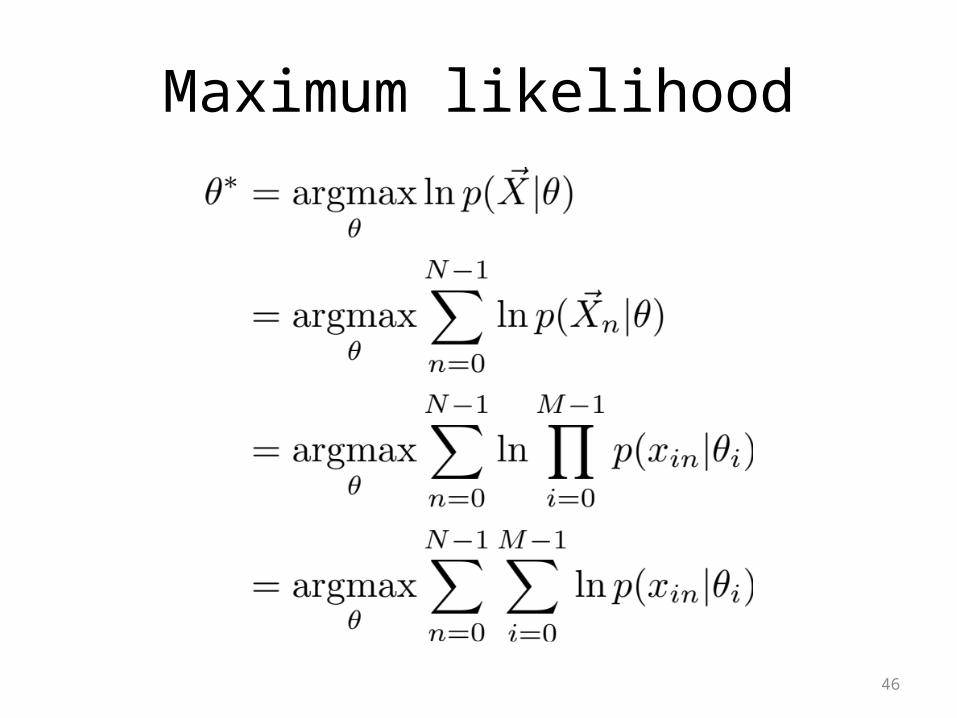
Maximum likelihood
46

Count functions
• Count the number of times something appears in the data
47

Maximum Likelihood
• Define a function:
• Constraint:
48

Maximum Likelihood
• Use Lagrange Multipliers
49

Maximum A Posteriori Training
• Bayesians would never do that, the thetas need a prior.
50

Conditional Dependence Test• Can check conditional independence in a graphical model
– “Is achiness (x3) independent of the flue (x0) given fever(x1)?”– “Is achiness (x3) independent of sinus infections(x2) given
fever(x1)?”
51

D-Separation and Bayes Ball
• Intuition: nodes are separated or blocked by sets of nodes.– E.g. nodes x1 and x2, “block” the path from x0
to x5. So x0 is cond. ind.from x5 given x1 and x2
52

Bayes Ball Algorithm
• Shade nodes xc
• Place a “ball” at each node in xa
• Bounce balls around the graph according to rules
• If no balls reach xb, then cond. ind.
53

Ten rules of Bayes Ball Theorem
54

Bayes Ball Example
55

Bayes Ball Example
56

Undirected Graphs
• What if we allow undirected graphs?• What do they correspond to?• Not Cause/Effect, or Trigger/Response,
but general dependence• Example: Image pixels, each pixel is a
bernouli– P(x11,…, x1M,…, xM1,…, xMM)– Bright pixels have bright neighbors
• No parents, just probabilities.• Grid models are called Markov
Random Fields
57
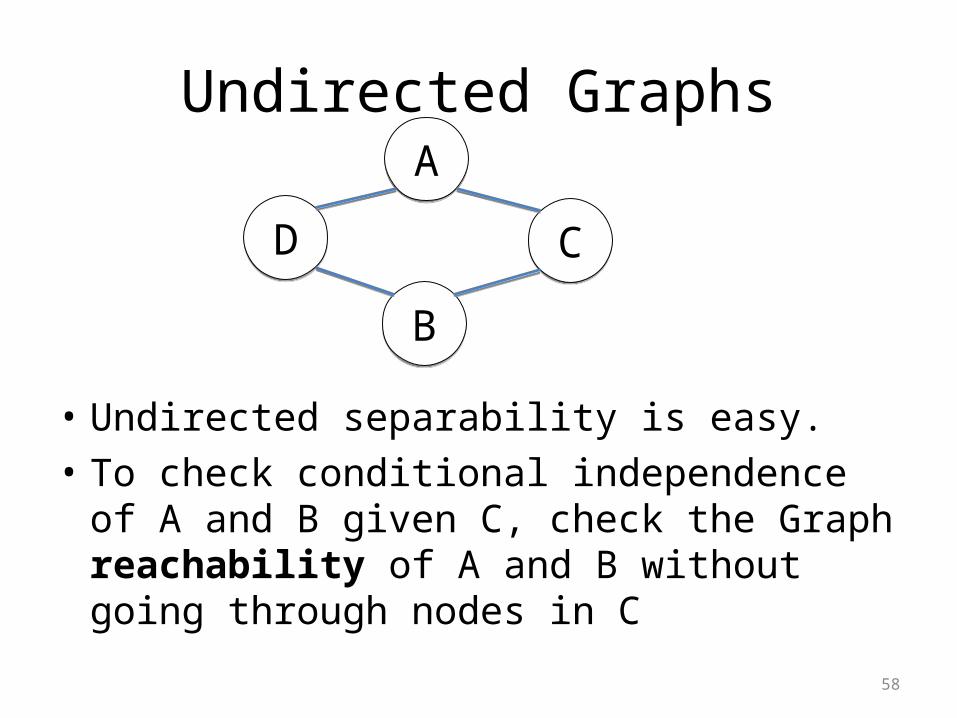
Undirected Graphs
• Undirected separability is easy.• To check conditional independence of A and
B given C, check the Graph reachability of A and B without going through nodes in C
58
DD
BB
CC
AA

Next Time
• More fun with Graphical Models
• Read Chapter 8.1, 8.2
59