lod map - a visual interface for navigating
TRANSCRIPT

IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 12, NO. 5, SEPTEMBER/OCTOBER 2006
LOD Map - A Visual Interface for NavigatingMultiresolution Volume Visualization
Chaoli Wang, Student Member, IEEE, and Han-Wei Shen
Abstract—In multiresolution volume visualization, a visual representation of level-of-detail (LOD) quality is important for us to exam-ine, compare, and validate different LOD selection algorithms. While traditional methods rely on ultimate images for quality measure-ment, we introduce the LOD map - an alternative representation of LOD quality and a visual interface for navigating multiresolutiondata exploration. Our measure for LOD quality is based on the formulation of entropy from information theory. The measure takesinto account the distortion and contribution of multiresolution data blocks. A LOD map is generated through the mapping of key LODingredients to a treemap representation. The ordered treemap layout is used for relative stable update of the LOD map when theview or LOD changes. This visual interface not only indicates the quality of LODs in an intuitive way, but also provides immediatesuggestions for possible LOD improvement through visually-striking features. It also allows us to compare different views and performrendering budget control. A set of interactive techniques is proposed to make the LOD adjustment a simple and easy task. Wedemonstrate the effectiveness and efficiency of our approach on large scientific and medical data sets.
Index Terms—LOD map, knowledge representation, perceptual reasoning, multiresolution rendering, large volume visualization.
F
1 INTRODUCTION
The field of visualization is concerned with the creation of imagesfrom data. In many cases these images are observed by humans in aneffort to test hypotheses and discover insights. Visualization is, there-fore, an iterative and exploratory process. Human-computer interac-tions, such as parameter tweaking, are often involved in a bid to createbetter representations. This scenario works well for small data. Withthe advances in graphics hardware, the interactivity can be guaranteedeven with a straightforward implementation. For larger data, the re-sponse time of a visualization system could become uncomfortablylong. Slower responses result in an increase in time needed to obtaininsights from the data. This poses a great challenge for visualizationto be effective and efficient [22].
In this paper, we focus on the subject of multiresolution render-ing in the context of large volume visualization. A central theme formultiresolution volume rendering is the selection of data resolution,or level-of-detail (LOD). Quite often, such LODs are automaticallydetermined by user-specified error tolerances and viewing parameters[27, 10, 5]. Many of the metrics, such as mean square error (MSE)and signal-to-noise ratio (SNR), are data-centric in the sense that theymeasure the distortion between low and high resolution blocks in thedata space (Geometric error metrics, on the other hand, are often usedin surface rendering, where the geometry or mesh is known. In thispaper, we do not consider this case.). Although those metrics havespecific meanings and are simple to compute, they are not effectivein predicting the quality of rendered images due to the lack of corre-lation between data and image [25]. In fact, finding the best LOD isa NP-complete optimization problem [3], so most algorithms take agreedy approximation strategy instead. In this case, data blocks areselected according to their priority values till certain constraints, suchas the block budget, are met. Rarely, we have a mechanism to examinethe quality of LODs from those greedy selections, and decide whetherit is possible to further improve the quality through either automaticmethods or user interactions.
Another important but non-trivial issue is the validation of existing
• C. Wang and H.-W. Shen are with the Department of Computer Scienceand Engineering, The Ohio State University, 395 Dreese Laboratories,2015 Neil Avenue, Columbus, OH 43210.E-mail:{wangcha, hwshen}@cse.ohio-state.edu.
Manuscript received 31 March 2006; accepted 1 August 2006; posted online 6November 2006.For information on obtaining reprints of this article, please send e-mail to:[email protected].
LOD selection algorithms. In computer graphics and visualization,validation is usually done through side-by-side comparison of imagescreated from different techniques. However, it may not be effective formultiresolution volume visualization. This is because direct renderingof 3D volumes to 2D images involves light attenuation, blending, andtransfer function mapping, where much information about a LOD maybe hidden or lost. Without the complete information, it could be in-sufficient to assess the improvements of new algorithms over existingones. Moreover, a large data set is often too complex to be understoodfrom a single image. Inspecting images from different views requiresrendering large amount of data, which makes it very difficult for us toperform the validation efficiently.
From the problems mentioned above, it can be seen that there is agreat need to devise techniques for multiresolution volume visualiza-tion that allow the user to examine, compare, and validate the qualityof LOD selection and rendering. To fulfill this need, we present a newmeasure for LOD quality based on the formulation of entropy frominformation theory. Our quality measure takes into account the qualityof each individual data block in a LOD and the relationships amongthem. This entropy measure allows us to map key ingredients of theLOD quality to a treemap representation [17], called the LOD map,for further visual analysis. The LOD map brings us a novel approachfor navigating the exploration of large multiresolution data. By “nav-igating”, we mean the user is guided with immediate visual feedbackwhen making decisions about where to go, what to do, and when tostop. The user is provided with cues that leads her quickly to inter-esting parts of the data. She would readily know what actions to taketo adjust the LOD, clearly see the gain or loss of the adjustment, andbe informed when the refinement process may be stopped. Leveraginga heuristic optimization algorithm and a set of interactive techniquesdesigned for the LOD map, making LOD adjustment and renderingbudget control becomes a simple and easy task. Experimental resultson large data sets demonstrate that this visual representation of LODquality is light-weighted yet quite effective for interactive LOD com-parison and validation.
2 RELATED WORK
The past few years witnessed the rapid growth of data. Scientific sim-ulations are producing petabytes of data as opposed to gigabytes orterabytes a couple of years ago. Building a multiresolution data hier-archy from large amount of data allows us to visualize data at differentscales, and balance image quality and computation speed. Examplesof hierarchical data representation for volume data include the Lapla-cian pyramid [4], multi-dimensional trees [27], and octree-based hier-archies [10]. Muraki introduced the use of wavelet transforms for vol-

IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 12, NO. 5, SEPTEMBER/OCTOBER 2006
umetric data [16]. Westermann [26] proposed a framework for approx-imating the volume rendering integral using multiresolution spacesand wavelet projections. Guthe et al. [5] presented a wavelet-encodedhierarchical representation, called the wavelet tree, that supports inter-active walkthroughs of large data sets on a single commodity PC. Inthis paper, we use the wavelet tree as an illustration for our presenta-tion.
The goal of visual data exploration is to facilitate the extraction ofnew insights from the data. For instance, Marks et al. [14] presentedthe Design Gallery system that treats image and volume rendering asa process of exploring a multidimensional parameter space. Using animage difference metric, the system arranges renderings from variousparameter settings, from which the user selects the most appealingone. Bajaj et al. [1] introduced the contour spectrum, a user inter-face component that improves qualitative user interaction and providesreal-time exact qualification in the visualization of isocontours. A setof well-designed manipulation widgets for multidimensional transferfunction design was given by Kniss et al. [9]. By allowing direct in-teraction in the spatial and transfer function domains, those widgetsmake finding transfer functions an intuitive and efficient process.
On the other hand, the process of visual data exploration contains awealth of information - parameters, results, history, as well as relation-ships among them. To learn lessons and share experiences, the processitself can be stored, tracked, and analyzed. It can also be incorporatedinto, and thus becomes a part of the user interface of a visualizationsystem. Such examples are image graphs [13], and interfaces withspreadsheet [6] and parallel coordinate [21] styles. A general model ofthe visualization exploration process was formalized by Jankun-Kellyet al. [7].
Over the last decade, a number of information visualization tech-niques have been developed to support the visual exploration of largeand high-dimensional data sets [8]. Parallel coordinates and treemapsare two most widely-used techniques among them. The treemap [17]is a space-filling method for visualizing large hierarchical information.It works by recursively subdividing a given display area based on thehierarchical structure, and alternating between vertical and horizon-tal subdivisions. The information of an individual node is presentedvia visual attributes, such as color and size, of its bounding rectangle.Originally designed to visualize files on a hard drive, treemaps havebeen applied to a wide variety of domains [19].
One of the notable commercial applications of treemaps is theSmartMoney “Map of the Market”, a simple yet powerful tool for thegeneral public to spot investment trends and opportunities. The mapshows approximately 600 publicly traded companies grouped by sec-tor and industry. The size of each company in the map corresponds toits market capitalization. The color mapping is natural for most usersto look for visually-striking features: green for gain, red for loss, anddark for neutral. A recursive algorithm was devised to reduces over-all aspect ratios of the rectangles for more readable display. All thesefactors contributes the success of the Map of the Market. Inspired bythis application, we strive for simplicity and effectiveness in search ofour solution for navigating multiresolution data exploration.
3 LOD ANALYSIS
In the visualization of multiresolution volume data, a given LOD con-sists of a sequence of data blocks at various resolutions. Intuitively,the LOD quality can be analyzed by investigating the quality of eachindividual block as well as the relationships among them: Each blockmay contain a different distortion because of the resolution and datavariation. It may also convey a different optical content if a color andopacity transfer function is applied. Furthermore, the sequence of datablocks are rendered to the screen. Each block may have a differentcontribution to the image depending on its projection and how much itis occluded by other blocks. To optimize the total information receivedon the image, one may attempt to either adjust the LOD or change theview. The concept of entropy from information theory provides us away to measure the LOD quality in a quantitative manner.
3.1 EntropyIn information theory, the entropy gives the average information or theuncertainty of a random variable. The Shannon entropy of a discreterandom variable X with values in the finite set {a1, a2, ..., aM} isdefined as:
H(X) = −M
X
i=1
pi log pi (1)
where pi is the probability of a variable to have the value ai; − log pi
represents its associated information. The unit of information is calla bit. The logarithm is taken in base 2 or e. For continuity, variableof probability zero does not contribute to the entropy, i.e., 0 log 0 =0. The entropy achieves its maximum of log M when the probabilitydistribution is uniform.
To evaluate the quality of a LOD, we first define the probability ofa multiresolution data block bi as:
pi =Ci · Di
S, where S =
MX
i=1
Ci · Di (2)
where Ci and Di are the contribution and distortion of bi respectively(more details about these two terms are given in Section 3.2); M isthe total number of blocks in the multiresolution data hierarchy. Thesummation S is taken over all data blocks, and the division by S isrequired to make all probabilities add up to unity. Eqn. 2 states that theprobability of a data block in a LOD is high if it has large distortion andhigh contribution. The entropy of a LOD then follows the definition inEqn. 1.
Note that for any LOD, it is impossible for all the data blocks inthe hierarchy to have the equal probability of 1/M , i.e., a LOD couldnot achieve an entropy value of log M . This is because in any LOD,if a parent block is selected, then none of its descendant blocks willbe selected. Any block which is not included in the LOD receiveszero probability and does not contribute to the entropy. Ideally, sincea higher entropy indicates a better LOD quality, the best LOD (withthe highest information content) could be achieved when we select allthe leaf nodes in the data hierarchy. However, this requires renderingthe volume data at the original resolution, and defeats the purpose ofmultiresolution rendering.
In practice, a meaningful goal is to find the best LOD under somerendering budget, such as a certain block budget, which is usuallymuch smaller than M . Accordingly, the quality of a LOD could beimproved by splitting data blocks with large distortion and high con-tribution, and joining those blocks with small distortion and low con-tribution. The split operation aims at increasing the entropy with amore balanced probability distribution. The join operation is to offsetthe increase in block number and keep it under the budget. In addi-tion, adjusting the view could improve the quality of LOD too, sincethe contributions of data blocks vary when the view changes.
3.2 Distortion and ContributionIn a multiresolution data hierarchy such as a wavelet tree, a block hav-ing larger distortion or variation is more likely to receive a higher pri-ority for LOD refinement. The distortion of a multiresolution datablock captures this intrinsic property. Let us first consider two datablocks bi and bj , where bj is an immediate child of bi. We define thedistortion between bi and bj as follows:
dij = σij ·µ2
i + µ2
j + C1
2µiµj + C1
·σ2
i + σ2
j + C2
2σiσj + C2
(3)
where σij is the covariance between bi and bj ; µi and µj are the meanvalues of bi and bj respectively; σi and σj are their standard devia-tions. We include small constants C1 and C2 to avoid instability whenµiµj and σiσj are very close to zero.
Eqn. 3 consists of three parts, namely, covariance, luminance dis-tortion, and contrast distortion. Collectively, these three parts capturethe distortion between the two blocks. The luminance distortion and

WANG et al.: LOD MAP - A VISUAL INTERFACE FOR NAVIGATING MULTIRESOLUTION VOLUME VISUALIZATION
contrast distortion are originally from the image quality assessment lit-erature [25], and have been shown to be consistent with the luminancemasking and contrast masking features in the human visual systemrespectively.
In a wavelet tree, a parent node has eight immediate children. Thus,we add distortions between the parent block and its eight child blocks.We also take into account the maximum distortion of the child blocks,as an approximation of the distortion between the parent block and theoriginal full-resolution data it represents. Written in equation:
Di =
7X
j=0
dij + max{Dj |7
j=0} (4)
where Di and Dj are the distortions of blocks bi and bj respectively.As a special case, if bi is associated with a leaf node in the hierarchy,we define Di = C3, where C3 is a small constant. The distortion foreach tree node can be calculated as we build up the multiresolutiondata hierarchy. They are then normalized for our use.
To evaluate the contribution of a multiresolution block bi to the im-age, we treat the coarse-grained data block as a whole and approximateits contribution as follows:
Ci = µ · t · a · ν (5)
where µ is the mean value of bi; t is its thickness (the average lengthof the viewing ray segment inside bi); a is the screen projection areaof the block, and ν is its estimated visibility. Here, similar to thewell-known composition equation [12], (µ · t · a) approximates theemission of bi, and ν accounts for the occlusion.
Depending on our need, µ, σ, and σij in Eqn. 3 and 5 can be eval-uated directly in the scalar data space, or in the perceptually-adaptedCIELUV color space (see [23] for more detail). In Section 7.2, we willdescribe our pre-computation and real-time update techniques for cal-culating D and C of multiresolution data blocks, which ensure a quickupdate of the entropy value for a LOD.
3.3 Heuristic AlgorithmBased on the entropy measure, we propose a three-stage heuristic algo-rithm to adjust a LOD automatically. The given LOD could come fromany LOD selection methods. The motivation is to balance the proba-bility distribution among all data blocks in the LOD, and improve itsentropy. Our three-stage algorithm is as follows:
1. Join: Locate the data block bl with the lowest probability. Checkif joining bl with its siblings would decrease the entropy or not.If not, join bl with its siblings. Otherwise, mark bl out. Thisprocess then repeats on all unmarked data blocks until all blocksare scanned. The first stage would potentially free some blockbudget for use in the second stage.
2. Split: Locate the data block bh with the highest probability.Check if splitting bh would increase the entropy or not. If yes,split bh. Otherwise, mark bh out. This process then repeats onall unmarked data blocks until either the block budget is met orall blocks are scanned.
3. Join-Split: Consider a pair of data blocks (bl, bh) in the LOD,where bl is the block with the lowest probability, and bh is theblock with the highest probability. Check if joining bl with itssiblings and splitting bh would increase the entropy or not. Ifyes, join bl with its siblings and split bh. Otherwise, mark thepair (bl, bh) out. This process then repeats on all unmarked pairsuntil all pairs are scanned.
Note that join or split operations in our algorithm will only increasethe entropy, if possible, but never decrease. This monotonic conditionguarantees the convergence of the algorithm. Our heuristic algorithmcould also be used to generate a balanced LOD (in terms of probabil-ity distribution) given the constraint of block budget. The algorithmrefines the LOD starting from the root of the data hierarchy until theblock budget is met.
4 LOD MAP
Although various efforts have been made to choose proper LODs thatcondense data and preserve features [28, 10, 5], little work has beendone to represent and validate this decision-making process. Actually,the information derived for data selection is knowledge that guides theuser through the entire solution space. Such knowledge saves time ondecision and computation, which the user would have otherwise spenton a trial-and-error search. The time saved may be used to improveframe rates or alternatively, on other techniques to better understandthe data.
The formulation of LOD quality in Section 3 tells us that a LODis good if it has a high entropy value. Thus, a good LOD not onlyindicates a good quality of rendered images, but also a balanced prob-ability distribution for all the data blocks in the LOD. This includesinformation of both what we can perceive (data blocks not occluded)and can not (data blocks occluded) from the rendered image. There-fore, a suitable visual representation for LOD quality should reveal notonly what is visible, but also what is not. Such information is impor-tant because it can help us answer questions such as “do we waste thebudget on those blocks which are occluded?”, or, “can we generate animage of similar quality with a reduced block budget?”. In order toavoid possible occlusion, we rule out the option of any 3D representa-tion of LODs. Actually, a 2D treemap provides a simple yet effectiverepresentation of large hierarchical structure. The key issues involvedin this knowledge representation are information mapping and layoutdesign.
4.1 Information MappingIn this paper, we call the treemap representation of LOD the LOD map.As a treemap, the LOD map is formed by recursively subdividing agiven area. Each data block in the LOD is represented as a rectanglein the LOD map. Treemaps can effectively visualize data with twoattributes, in which one attribute is typically mapped to the size of therectangles, and the other attribute to the color of the rectangles. Thecritical question to ask is what information should be displayed in thegenerated rectangles for the LOD map.
Since the treemaps are commonly used for representing hierarchicalstructures. A first thought along this direction could lead us to use thesize of rectangle to encode the resolution of different data blocks inthe LOD map. As in [24], the size of the rectangle can be determinedby the level of the data hierarchy the data block lies on. Although thisway of representing LODs is natural, the mapping only yields limitedusefulness. This is because which level of the hierarchy a data blocklies on may not give hints on its actual quality. A data block at alow level (low resolution) may contain empty space or have a uniformvalue. In contrast, another data block at a high level (high resolution)may still exhibit much variation or distortion. Therefore, this kind ofcoding does not grant insights, and wastes important channels whichcould be used to encode more essential LOD information.
The entropy characterizes the quality of a LOD. To reveal this keyinformation, we map its ingredients, i.e., the distortion D and contribu-tion C of a data block in the LOD, to the color and size of its boundingrectangle in the LOD map. More specifically:
• The color assignment is based on the distortion D: red for largedistortion, magenta for medium, and blue for small.
• The contribution C is split into two parts: (µ · t · a) is mappedto the size of the rectangle, while ν is assigned to its opacity.
This color and size coding scheme makes it easy for the user to lookfor “hot spots” - data blocks with large distortion and high contributionin the LOD map. The motivation for separating visibility ν from C isintuitive too: more visible blocks in the LOD should appear brighterin the LOD map, and less visible ones darker.
4.2 Layout DesignAnother key issue for the generation of LOD map is layout design. Inthe early 1990s when treemaps were first prototyped, a straightforward

IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 12, NO. 5, SEPTEMBER/OCTOBER 2006
(a) entropy = 0.238 (b) pivot-by-size (c) pivot-by-middle
Fig. 1. (a) shows a rendering of the RMI data set at low resolution with 36 blocks. (b) and (c) are its two LOD map layouts. In each layout, the “P”indicates the first pivot rectangle, and the yellow boundaries show the first subdivision. The normalized entropy is low because only a small numberof data blocks are rendered.
slice-and-dice algorithm was used to generate the treemap layout. Aproblem with this standard method is that it often produces rectangleswith high aspect ratios. As a result, such skinny rectangles can bedifficult to see, compare, and select. Over the years, several algorithmshave been proposed to improve the aspect ratios of rectangles in thetreemap [18]. However, they introduce instability over time in thedisplay of dynamically changing data, and fail to preserve an orderingof the underlying data. These drawbacks are critical in our LOD maprepresentation because:
• The information of a LOD keeps changing whenever the usermakes LOD adjustment or changes the view. If the LOD maplayout has dramatic changes that causes unattractive flickering,it is hard to select and track data blocks in the LOD map.
• A LOD often comes with the back-to-front viewing order, inwhich neighboring blocks are close to each other in the LOD.Preserving this order in the LOD map layout is important forlocating neighboring blocks and observing group patterns.
The ordered treemap introduced by Shneiderman and Wattenberg [18]uses layout algorithms that offer a good tradeoff among stable updates,order preserving, and low aspect ratios. In this paper, we adopt thislayout design for our LOD map representation. The layout algorithmis similar to the idea of finding a 2D analogue of the QuickSortalgorithm. The inputs are a rectangle R to be subdivided and a list ofitems that are ordered by an index and have given areas. The crux ofthe algorithm is to choose a special item, the pivot, which is placedat the side of R. The remaining items in the list are then assigned tothree large rectangles that make up the rest of the display area. Finally,the algorithm is applied recursively to each of these rectangles. See[18] for a more detailed description of the algorithm. Variations of thealgorithm are the choices of pivot. The pivot could be the item withthe largest area in the list (pivot-by-size), or the middle item of the list(pivot-by-middle). In Section 7.1, we will discuss two scenarios whereeach of these choices of pivot should be used for smooth update.
4.3 Put It All TogetherHaving discussed how to define and represent the quality of LODs, itis time to put it all together and show how our scheme can be used. Weexperimented our idea with the Richtmyer-Meshkov Instability (RMI)data set [15]. The 7.5GB RMI data set has the spatial dimension of2048 × 2048 × 1920, from which we built a wavelet tree with a treedepth of six. Fig. 1 shows a LOD rendering of the RMI data set atthe third tree level and its LOD map layouts. The viewing order isroughly preserved, as we can see that darker/brighter rectangles (datablocks with lower/higher visibility) are close to each other in the LODmap. Since a LOD map encodes the entropy information of a LOD,
if there is an unbalanced probability distribution among data blocks inthe LOD, we can easily perceive this through color and size attributesof rectangles in its LOD map. Then, as demonstrated in Fig. 1 (b) or(c), several directions for optimizing the LOD quality can be immedi-ately followed:
• Look for “hot spots” - large rectangles with bright red colors.They are highly-visible data blocks that have high contributionand large distortion. Splitting these blocks will most likely in-crease the entropy and improve the LOD quality.
• Small blue rectangles are data blocks that have low contributionand small distortion. If they cluster in a local region, joiningthese blocks may save the block budget without decreasing theentropy.
• Dark rectangles are data blocks with the lowest visibility. Ifmany of them cluster together, joining these blocks may also savethe block budget without sacrificing the LOD quality.
The next section introduces a set of interactive techniques that allowsthe user to perform LOD adjustment efficiently.
5 INTERACTIVE TECHNIQUES
In computer graphics and visualization, brushing has been used as amethod for selecting subsets of data for further operations, such ashighlighting, deleting, or analysis. In our case, brushing is used toselect a subset of data blocks from a LOD for join or split operations.We provide brushing in both views: the rendering window and theLOD map. The result of selection is highlighted in both views, asthey are linked together and updated dynamically whenever one of theviews changes. This technique helps the user detect correspondencesbetween the two different visual representations. We allow the user toperform brushing in the following ways:
• Direct brushing in the LOD map by clicking a rectangle, or spec-ifying a rectangular region to select multiple rectangles simulta-neously via mouse.
• Brushing in the rendering window by specifying the brush cov-erage as 1D point, 2D plane, or 3D box in the data space viaslider.
• Brushing some parameter (such as visibility ν) or combinationof parameters by specifying its range via slider.
Direct transformation is provided for interactivity and examination oflocal details. The user can translate, scale, and rotate the 3D volume in
WANG et al.: LOD MAP - A VISUAL INTERFACE FOR NAVIGATING MULTIRESOLUTION VOLUME VISUALIZATION
the rendering window, and translate and scale the 2D LOD map. Datablocks selected in the LOD are highlighted with red boundaries andwhite crosses in the rendering window and the LOD map respectively.The user then proceeds to join or split these blocks. A join operationmerges a selected block with its siblings into its parent block. A splitoperation breaks a selected block into its eight child blocks. For mul-tiple selected data blocks, they are put into a queue and processed insequence. We also provide the “undo” function so that the user canroll back to the previous LOD if the operation just performed is notdesired.
(a) brushing with 2D plane (b) LOD map
Fig. 2. Brushing the RMI data set by specifying a 2D cutting plane. (a)shows the rendering of data selection and (b) is the corresponding LODmap.
Fig. 2 gives an example of brushing manipulation with a 2D cuttingplane. Only the data blocks intersecting the plane (drawn in blue) areselected and rendered. In the LOD map, the selected data blocks arehighlighted with white crosses.
data set (type) RMI (byte) VisWoman (short)volume dimension 2048 × 2048 × 1920 512 × 512 × 1728block dimension 128 × 128 × 64 32 × 32 × 64
volume (block) size 7.5GB (1MB) 864MB (128KB)# non-empty blocks 10499 9446compression ratio 5.60 : 1 2.37 : 1
Table 1. The RMI and VisWoman data sets.
Fig. 4. LOD quality comparison on the RMI data set with the same fixedview as in Fig. 1 (a). The plot shows how the entropy changes withdifferent block budgets for three LOD selection methods. There are atotal of 10499 non-empty blocks in the data hierarchy.
6 RESULTS
As listed in Table 1, we experimented with our LOD map on two datasets: the RMI data set (also mentioned in Section 4.3) from scientificsimulation, and the visible woman (VisWoman) data set from medicalapplication. For both data sets, the Haar wavelet transform with alifting scheme was used to construct the wavelet tree data hierarchy. Alossless compression scheme was used with the threshold set to zero
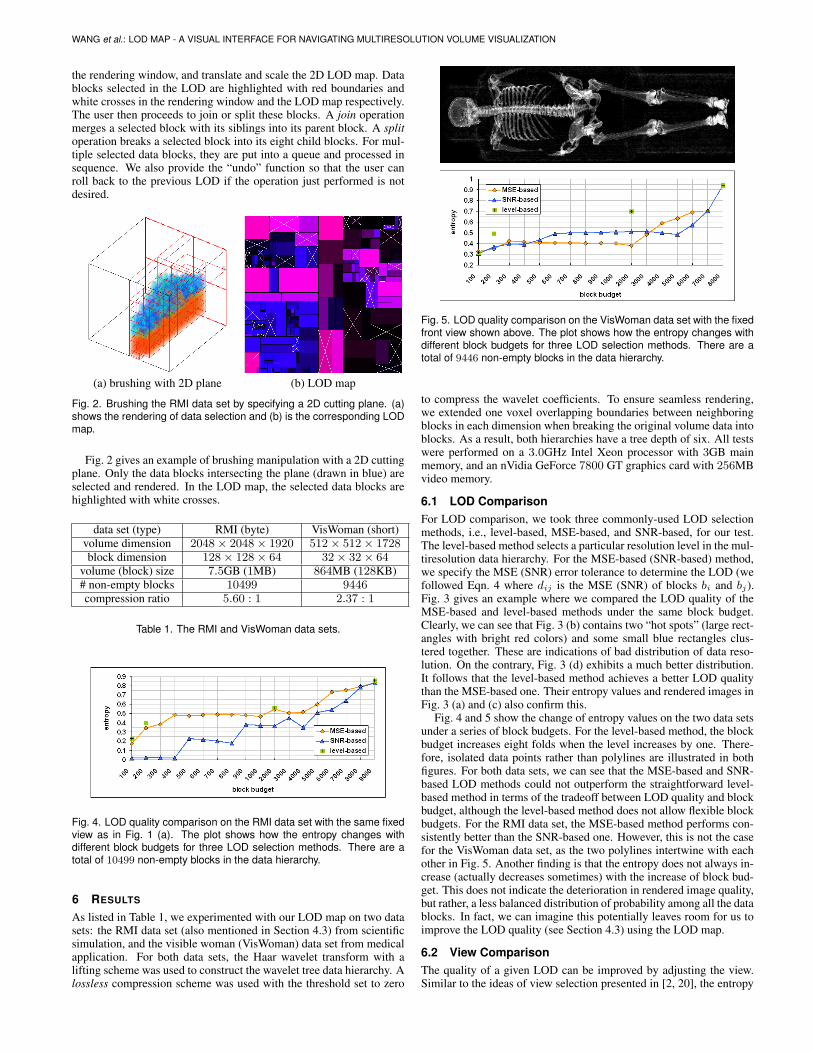
Fig. 5. LOD quality comparison on the VisWoman data set with the fixedfront view shown above. The plot shows how the entropy changes withdifferent block budgets for three LOD selection methods. There are atotal of 9446 non-empty blocks in the data hierarchy.
to compress the wavelet coefficients. To ensure seamless rendering,we extended one voxel overlapping boundaries between neighboringblocks in each dimension when breaking the original volume data intoblocks. As a result, both hierarchies have a tree depth of six. All testswere performed on a 3.0GHz Intel Xeon processor with 3GB mainmemory, and an nVidia GeForce 7800 GT graphics card with 256MBvideo memory.
6.1 LOD ComparisonFor LOD comparison, we took three commonly-used LOD selectionmethods, i.e., level-based, MSE-based, and SNR-based, for our test.The level-based method selects a particular resolution level in the mul-tiresolution data hierarchy. For the MSE-based (SNR-based) method,we specify the MSE (SNR) error tolerance to determine the LOD (wefollowed Eqn. 4 where dij is the MSE (SNR) of blocks bi and bj).Fig. 3 gives an example where we compared the LOD quality of theMSE-based and level-based methods under the same block budget.Clearly, we can see that Fig. 3 (b) contains two “hot spots” (large rect-angles with bright red colors) and some small blue rectangles clus-tered together. These are indications of bad distribution of data reso-lution. On the contrary, Fig. 3 (d) exhibits a much better distribution.It follows that the level-based method achieves a better LOD qualitythan the MSE-based one. Their entropy values and rendered images inFig. 3 (a) and (c) also confirm this.
Fig. 4 and 5 show the change of entropy values on the two data setsunder a series of block budgets. For the level-based method, the blockbudget increases eight folds when the level increases by one. There-fore, isolated data points rather than polylines are illustrated in bothfigures. For both data sets, we can see that the MSE-based and SNR-based LOD methods could not outperform the straightforward level-based method in terms of the tradeoff between LOD quality and blockbudget, although the level-based method does not allow flexible blockbudgets. For the RMI data set, the MSE-based method performs con-sistently better than the SNR-based one. However, this is not the casefor the VisWoman data set, as the two polylines intertwine with eachother in Fig. 5. Another finding is that the entropy does not always in-crease (actually decreases sometimes) with the increase of block bud-get. This does not indicate the deterioration in rendered image quality,but rather, a less balanced distribution of probability among all the datablocks. In fact, we can imagine this potentially leaves room for us toimprove the LOD quality (see Section 4.3) using the LOD map.
6.2 View ComparisonThe quality of a given LOD can be improved by adjusting the view.Similar to the ideas of view selection presented in [2, 20], the entropy

IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 12, NO. 5, SEPTEMBER/OCTOBER 2006
(a) MSE-based, 67 blocks (b) entropy = 0.163 (c) level-based, 67 blocks (d) entropy = 0.381
Fig. 3. LOD comparison (fixed view, different LODs). A zoom to part of the spine of the VisWoman data set. (a) and (c) show the rendering of twodifferent LODs with the same block budget. (b) and (d) are the LOD maps for (a) and (c) respectively.
(a) entropy = 0.330 (b) entropy = 0.343 (c) entropy = 0.384 (d) entropy = 0.390
Fig. 6. View comparison (fixed LOD, different views). Four snapshots from a rendering sequence of the RMI data set. The LOD remains the samewith 246 blocks while the entropy increases from (a) to (d). The pivot-by-middle layout is used to maintain relative stable update of the LOD mapthroughout the rendering sequence. The dramatic change in the LOD map layout from (a) to (b) is due to the abrupt change of the viewing order.
and the LOD map can help us find good views for a certain LOD. Fig. 6gives an example where we compare different views for a fixed LODof the RMI data set. The entropy increases as more information con-tent is received from Fig. 6 (a) to (d). Looking at the sequence of LODmaps, we can observe that the visibility of the LOD gets improvedsince the entire LOD map is getting brighter. Another finding from theLOD map sequence is that smaller blocks at the bottom of the volumecorresponds to blue rectangles (small distortion) at the upper-right partof Fig. 6 (a), and larger blocks at the top of the volume correspondsto red rectangles (large distortion) in the LOD maps. The relative sta-ble update of the LOD map allows us to detect such correspondencesbetween the rendered blocks and the rectangles. This information isuseful when it comes to LOD adjustment.
6.3 LOD Adjustment
The goal of LOD adjustment is to improve the quality of LOD.By splitting data blocks with large distortion and high contribution,and joining data blocks with small distortion and low contribution,we achieve a more balanced probability distribution among all datablocks, and therefore, increase the entropy of the LOD. Fig. 7 showtwo examples of LOD adjustment on the RMI and VisWoman datasets within fixed block budgets. For the RMI data set, we clearly see
some “hot spots” (large rectangles with bright red colors) and a clusterof dark rectangles (occluded data blocks) in the LOD map of Fig. 7(a). In this example, we used the heuristic algorithm (Section 3.3) tooptimize the LOD automatically. The LOD map after adjustment inFig. 7 (b) shows a more balanced result. For the VisWoman data set,hot spots are popping out in the LOD map of Fig. 7 (c). Althoughthere are no dark rectangles, many small blue rectangles cluster at thelower-left corner of the LOD map. The LOD quality is improved bysplitting those hot spots and joining small blue rectangles. With theassist of a set of brushing techniques (Section 5), selecting such targetrectangles in the LOD map and performing LOD adjustment becomesa simple and efficient task.
6.4 Budget Control
As demonstrated in Fig. 4 and 5, the commonly-used MSE-based andSNR-based LOD selection methods do not perform well (in terms ofimproving the quality of LOD) with the increase of block budget. Thisgives us opportunities to control the block budget. That is, if such aLOD selection algorithm could not optimize the quality of LOD undera certain block budget, could we instead give a LOD of similar qualitybut with a reduced block budget? Generating images of similar qualitywith smaller budgets is appealing for large data visualization because

WANG et al.: LOD MAP - A VISUAL INTERFACE FOR NAVIGATING MULTIRESOLUTION VOLUME VISUALIZATION
before, 90 blocks after, 90 blocks before, 108 blocks after, 108 blocks
(a) entropy = 0.192 (b) entropy = 0.386 (c) entropy = 0.251 (d) entropy = 0.414
Fig. 7. LOD adjustment. A zoom of the RMI data set: (a) shows a given LOD based on the MSE, and (b) shows the result after the LOD adjustment.A zoom to the left pelvis of the VisWoman data set: (c) shows a given LOD based on the SNR, and (d) shows the result after the LOD adjustment.The pivot-by-size layout is used to maintain relative stable update of the LOD map during the adjustment process.
(a) entropy = 0.448, 365 blocks (b) entropy = 0.476, 274 blocks
Fig. 8. Budget control on the RMI data set. A LOD based on the MSEis given, where the view is the same as in Fig. 1 (a). (a) and (b) arethe LOD maps before and after the budget control. The percentage ofblocks with visibility less than 0.20 decreases from 48% in (a) to 29% in(b).
it could save us limited resources. Fig. 8 shows an example of budgetcontrol on the RMI data set. By joining data blocks with low visibility(dark rectangles) and improving the overall distribution of resolution,we reduce the block budget by 25% while increasing the entropy ofthe LOD. This budget control does not affect the quality of renderedimage, as the renderings before and after the budget control are almostidentical.
7 DISCUSSION
As a reflection of what we state at the beginning of the paper, wediscuss the effectiveness and efficiency of our LOD map approach tomultiresolution volume visualization.
7.1 EffectivenessUsing entropy, our LOD quality measure becomes a global quality in-dex, i.e., it not only indicates the quality of rendered images, but alsothe probability distribution of all multiresolution data blocks in the
LOD. The probability takes into account the distortion and contribu-tion of data blocks. Therefore, a high entropy (good distribution) im-plies a balanced distribution of resources (e.g. data resolution), whichis not captured by traditional LOD selection methods. Through themapping of key LOD ingredients to a treemap representation, we cre-ate the LOD map as a visual interface for LOD comparison and val-idation. The LOD map is an intuitive representation of LOD quality,since key ingredients of a LOD are mapped to pre-attentive attributes(color and size of rectangles) in the LOD map. Integrating a heuris-tic algorithm and a set of interactive techniques, it also serves as aconvenient user interface for visual data exploration. Note that theLOD map can be manipulated independently, and the actual render-ing of data could be deferred until a desired LOD of good quality isachieved. The results in Section 6 demonstrate that this visual inter-face is light-weighted and quite effective for multiresolution volumevisualization.
For the LOD map, we utilize both pivot-by-size and pivot-by-middle layouts for relative stable update when the view or LODchanges. The choice of which layout should be used depends on whichlayout is more likely to keep the pivot unchanged. For example, if theview changes, the middle item in the LOD list is more likely to remainthe same, as opposed to the item with the largest area. Therefore, thepivot-by-middle layout should be used. On the other hand, if a LODundergoes any join or split operations, then the pivot-by-size layoutshould be used, since the item with the largest area in the LOD listis more likely to keep unchanged rather than the middle item. Thissimple rule proves very effective in maintaining smooth update of theLOD map.
7.2 EfficiencyIn order to generate the LOD map in real time, we need quick up-date of the distortion D and contribution C for multiresolution datablocks. In this paper, we calculate D in the roughly perceptually-uniform CIELUV color space (note that in this case, D depends on theinput color and opacity transfer function). Similar to error calculationin [11], we pre-compute and store summary tables to ensure real-timeupdate of the distortion D. The summary tables are the histogram ta-ble (frequency of quantized scalar values) and correspondence table

IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 12, NO. 5, SEPTEMBER/OCTOBER 2006
(frequency of pairs of quantized scalar values in the parent and itschild blocks) for each data block in the multiresolution data hierarchy.A zigzag run-length encoding scheme is used to reduce the storageoverhead and facilitate the table lookup at run time. During the ren-dering, we can recompute the distortion within seconds for large datasets (such as the 7.5GB RMI data set) whenever the transfer functionchanges.
On the other hand, the quick update of the contribution C requiresreal-time estimate of the visibility ν (Eqn. 5). Here, the essential ques-tion is how to calculate the visibility of many data blocks quickly,given an input occlusion map. Our solution is based on summed areatables (SATs), which take the occlusion map as the input. We utilizethe GPU to estimate the average visibility. The GPU implementa-tion builds the SATs in passes with the support of framebuffer objects(GL_EXT_framebuffer_object). Getting the average visibilityfor a block is performed by a fragment program that looks up four cor-ners of its projection in the SATs. In this way, the visibility for all thedata blocks can be evaluated interactively at run time. For instance, itonly takes around 0.2 second to update the visibility of thousands ofdata blocks for the RMI data set. We refer readers to [23] for the algo-rithm, implementation, and performance of our summary table schemeand GPU-based visibility estimation.
The efficiency of our LOD map is thus ensured with a real-timeupdate of the distortion D and contribution C. Our experiments showthat at run time when we change the view or perform LOD adjustment,the entropy and the LOD map can be updated interactively for a LODconsisting of up to thousands of data blocks (a typical magnitude forour multiresolution data hierarchies).
8 CONCLUSION AND FUTURE WORK
We have presented a new LOD quality measure using entropy and itsvisual representation using the LOD map for multiresolution volumevisualization. Leveraging this quality measure and visual interface,it becomes not only feasible, but also effective and efficient for usto examine, compare, and validate the quality of LOD selection andrendering. We believe that this technique could be generalized, andapplied to explore other solution spaces that exhibit similar propertiesas the LOD optimization problem.
The LOD map could carry more customized information for a LOD.For example, if the user wants to inspect how the transfer functioncontents of data blocks vary from their scalar field contents, we canadd shading to the rectangles in the LOD map to indicate this. Tex-ture could also be applied to the LOD map to represent some otherinformation of interest. User study along this direction, such as inves-tigating how many channels the user can perceive easily in the LODmap without information overload, is necessary. In the future, we alsowould like to extend our approach to multiresolution visualization oflarge-scale time-varying data.
ACKNOWLEDGEMENTS
This work was supported by NSF ITR Grant ACI-0325934, NSF RIGrant CNS-0403342, DOE Early Career Principal Investigator AwardDE-FG02-03ER25572, NSF Career Award CCF-0346883, and OakRidge National Laboratory Contract 400045529. The RMI data setis courtesy of Mark A. Duchaineau at Lawrence Livermore NationalLaboratory, and the VisWoman data set is courtesy of The NationalLibrary of Medicine. Special thanks to Carrie Casto for story nar-ration and Hana Kang for voice editing of the accompanying video.Finally, the authors would like to thank the anonymous reviewers fortheir helpful comments.
REFERENCES
[1] C. L. Bajaj, V. Pascucci, and D. R. Schikore. The Contour Spectrum. InProc. of IEEE Visualization ’97, pages 167–173, 1997.
[2] U. D. Bordoloi and H.-W. Shen. View Selection for Volume Rendering.In Proc. of IEEE Visualization ’05, pages 487–494, 2005.
[3] T. A. Funkhouser and C. H. Sequin. Adaptive Display Algorithm forInteractive Frame Rates During Visualization of Complex Virtual Envi-ronments. In Proc. of ACM SIGGRAPH ’93, pages 247–254, 1993.
[4] M. H. Ghavamnia and X. D. Yang. Direct Rendering of Laplacian Pyra-mid Compressed Volume Data. In Proc. of IEEE Visualization ’95, pages192–199, 1995.
[5] S. Guthe, M. Wand, J. Gonser, and W. Straßer. Interactive Renderingof Large Volume Data Sets. In Proc. of IEEE Visualization ’02, pages53–60, 2002.
[6] T. J. Jankun-Kelly and K.-L. Ma. Visualization Exploration and Encap-sulation via a Spreadsheet-Like Interface. IEEE Trans. on Visualization& Computer Graphics, 7(3):275–287, 2001.
[7] T. J. Jankun-Kelly, K.-L. Ma, and M. Gertz. A Model for the VisualizationExploration Process. In Proc. of IEEE Visualization ’02, pages 323–330,2002.
[8] D. A. Keim. Information Visualization and Visual Data Mining. IEEETrans. on Visualization & Computer Graphics, 7(1):100–107, 2001.
[9] J. Kniss, G. Kindlmann, and C. D. Hansen. Interactive Volume Render-ing Using Multi-Dimensional Transfer Functions and Direct Manipula-tion Widgets. In Proc. of IEEE Visualization ’01, pages 255–262, 2001.
[10] E. LaMar, B. Hamann, and K. I. Joy. Multiresolution Techniques forInteractive Texture-Based Volume Visualization. In Proc. of IEEE Visu-alization ’99, pages 355–362, 1999.
[11] E. LaMar, B. Hamann, and K. I. Joy. Efficient Error Calculation forMultiresolution Texture-Based Volume Visualization. In Hierarchical &Geometrical Methods in Scientific Visualization, pages 51–62, 2003.
[12] M. Levoy. Efficient Ray Tracing of Volume Data. ACM Trans. on Graph-ics, 9(3):245–261, 1990.
[13] K.-L. Ma. Image Graphs - A Novel Approach to Visual Data Exploration.In Proc. of IEEE Visualization ’99, pages 81–88, 1999.
[14] J. Marks, B. Andalman, P. A. Beardsley, W. Freeman, S. Gibson, J. Hod-gins, T. Kang, B. Mirtich, H. Pfister, W. Ruml, K. Ryall, J. Seims, andS. Shieber. Design Galleries: A General Approach to Setting Parametersfor Computer Graphics and Animation. In Proc. of ACM SIGGRAPH ’97,pages 389–400, 1997.
[15] A. A. Mirin, R. H. Cohen, B. C. Curtis, W. P. Dannevik, A. M. Dimits,M. A. Duchaineau, D. E. Eliason, D. R. Schikore, S. E. Anderson, D. H.Porter, P. R. Woodward, L. J. Shieh, and S. W. White. Very High Resolu-tion Simulation of Compressible Turbulence on the IBM-SP System. InProc. of ACM/IEEE Supercomputing ’99, 1999.
[16] S. Muraki. Approximation and Rendering of Volume Data Using WaveletTransforms. In Proc. of IEEE Visualization ’92, pages 21–28, 1992.
[17] B. Shneiderman. Tree Visualization with Tree-Maps: A 2D Space-FillingApproach. ACM Trans. on Graphics, 11(1):92–99, 1992.
[18] B. Shneiderman and M. Wattenberg. Ordered Treemap Layouts. In Proc.of IEEE Information Visualization ’01, pages 73–78, 2001.
[19] Shneiderman, B. Treemaps for Space-Constrained Visualization of Hier-archies (http://www.cs.umd.edu/hcil/treemap-history/).
[20] S. Takahashi, I. Fujishiro, Y. Takeshima, and T. Nishita. A Feature-DrivenApproach to Locating Optimal Viewpoints for Volume Visualization. InProc. of IEEE Visualization ’05, pages 495–502, 2005.
[21] M. Tory, S. Potts, and T. Moller. A Parallel Coordinates Style Interfacefor Exploratory Volume Visualization. IEEE Trans. on Visualization &Computer Graphics, 11(1):71–80, 2005.
[22] J. J. van Wijk. The Value of Visualization. In Proc. of IEEE Visualization’05, pages 79–86, 2005.
[23] C. Wang, A. Garcia, and H.-W. Shen. Interactive Level-of-Detail Selec-tion Using Image-Based Quality Metric for Large Volume Visualization.IEEE Trans. on Visualization & Computer Graphics. Accepted for pub-lication, 2006.
[24] C. Wang and H.-W. Shen. Hierarchical Navigation Interface: LeveragingMultiple Coordinated Views for Level-of-Detail Multiresolution VolumeRendering of Large Scientific Data Sets. In Proc. of Information Visuali-sation ’05, pages 259–267, 2005.
[25] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image QualityAssessment: From Error Visibility to Structural Similarity. IEEE Trans.on Image Processing, 13(4):600–612, 2004.
[26] R. Westermann. A Multiresolution Framework for Volume Rendering. InProc. of IEEE Volume Visualization ’94, pages 51–58, 1994.
[27] J. Wilhelms and A. van Gelder. Multi-Dimensional Trees for ControlledVolume Rendering and Compression. In Proc. of IEEE Volume Visual-ization ’94, pages 27–34, 1994.
[28] Y. Zhou, B. Chen, and A. E. Kaufman. Multiresolution TetrahedralFramework for Visualizing Regular Volume Data. In Proc. of IEEE Visu-alization ’97, pages 135–142, 1997.