lecture 4: cpu performance. a modern processor intel core i7
TRANSCRIPT

Lecture 4:Lecture 4:
CPU PerformanceCPU Performance

A Modern Processor
Intel Core i7

Processor Performance
Lower bounds that characterize the maximum performance:
Latency Bound
• Occurs when operations must be performed in strict sequence (e.g. data dependency)
• Minimum time to perform the operations sequentially
Throughput Bound
• Characterizes the raw computing capacity of the processor’s functional units.
• Maximum operations per cycle
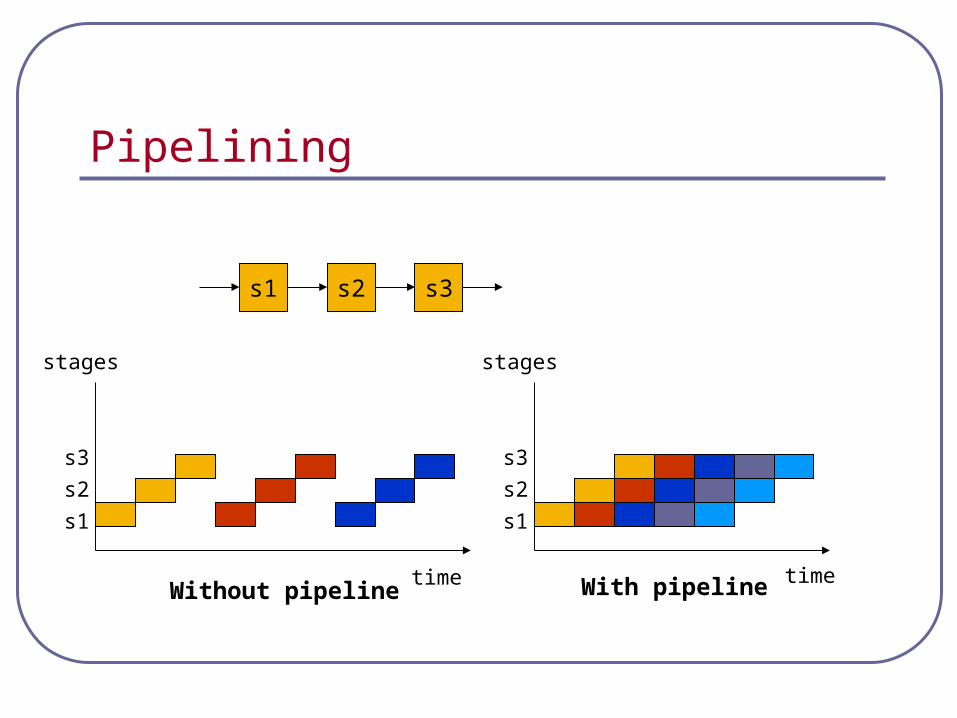
Pipelining
s1 s2 s3
time
stages
s1
s2
s3
time
stages
s1
s2
s3
Without pipeline With pipeline
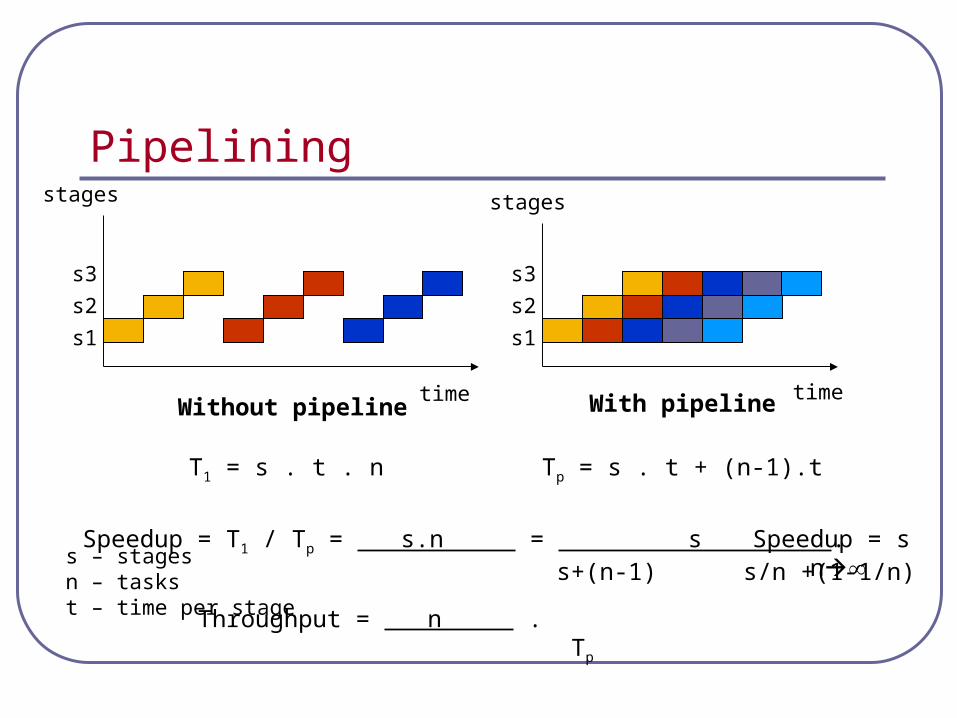
Pipelining
s – stagesn – taskst – time per stage
time
stages
s1
s2
s3
time
stages
s1
s2
s3
Without pipeline With pipeline
T1 = s . t . n Tp = s . t + (n-1).t
Speedup = T1 / Tp = s.n = s . s+(n-1) s/n +(1-1/n)
Speedup = s n
Throughput = n . Tp

Pipelining
Slowest stage determines the pipeline performance
s1 s2 s3
time
stages
s1
s2
s3
time
stages
s1
s2
s3
Without pipeline With pipeline
10 30 20
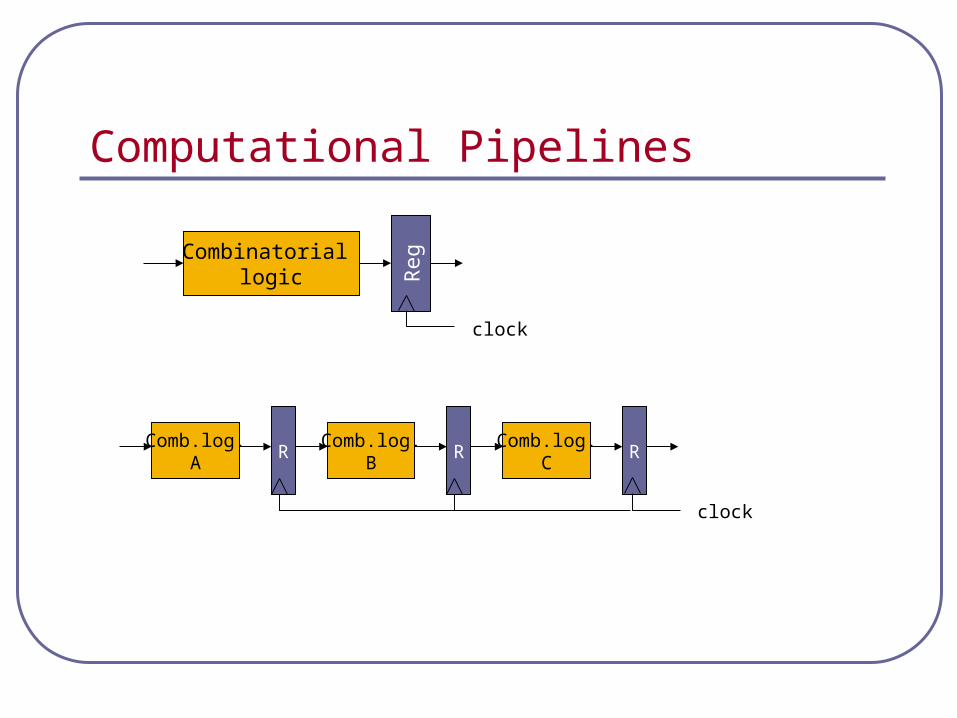
Computational Pipelines
Combinatorial logic R
egComb.log.
AR
Comb.log.B
RComb.log.
CR
clock
clock
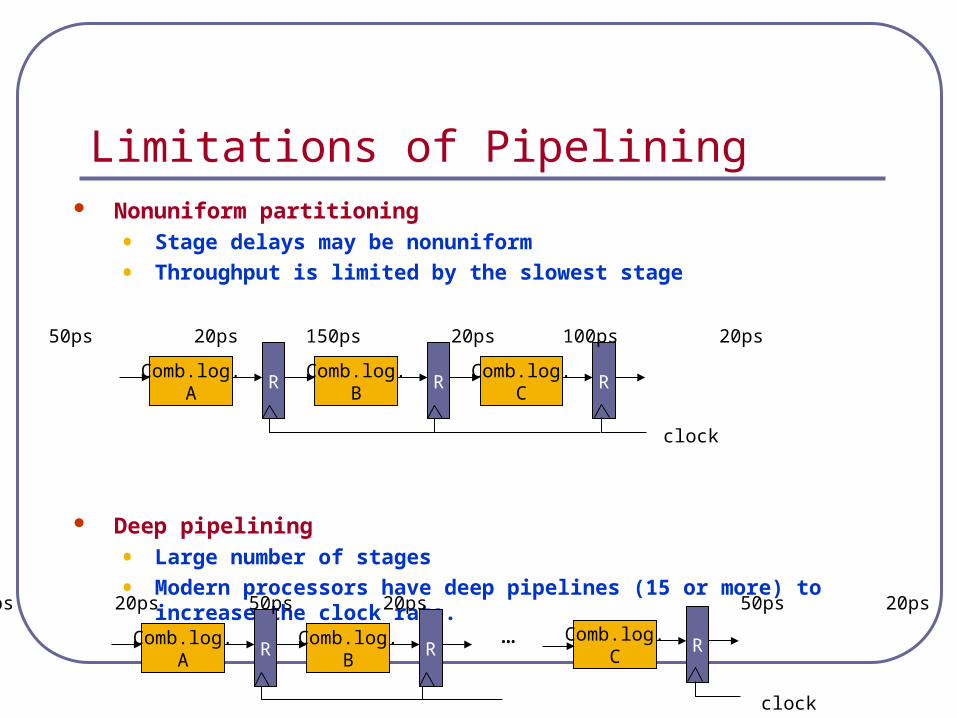
Limitations of Pipelining Nonuniform partitioning
• Stage delays may be nonuniform
• Throughput is limited by the slowest stage
Deep pipelining
• Large number of stages
• Modern processors have deep pipelines (15 or more) to increase the clock rate.
Comb.log.A
RComb.log.
BR
Comb.log.C
R
clock
50ps 20ps 150ps 20ps 100ps 20ps
Comb.log.A
RComb.log.
BR
Comb.log.C
R
clock
50ps 20ps 50ps 20ps 50ps 20ps
…

Pipelined Parallel Addera1,b1a4,b4 a3,b3 a2,b2

Pipelined Parallel Adderc1,d1
a1+b1
c4,d4 c3,d3 c2,d2
a4,b4 a3,b3 a2,b2
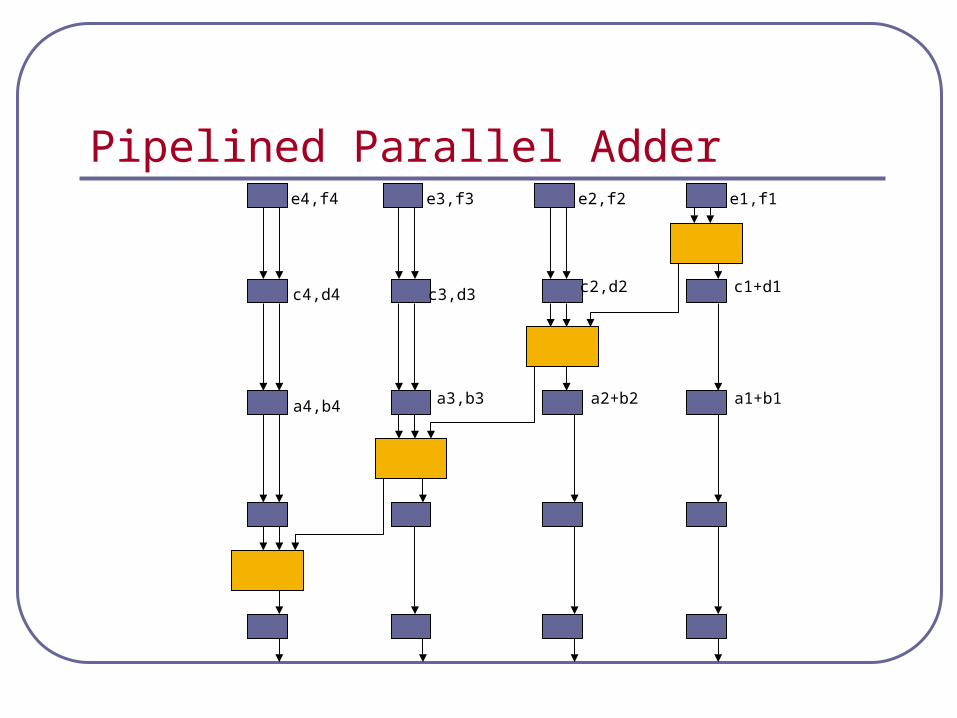
Pipelined Parallel Adder
c1+d1
a1+b1
c4,d4 c3,d3 c2,d2
a4,b4 a3,b3 a2+b2
e1,f1e2,f2e3,f3e4,f4

Pipelined Parallel Adder
c1+d1
a1+b1
c4,d4 c3,d3 c2+d2
a4,b4 a3+b3 a2+b2
e1+f1e2,f2e3,f3e4,f4
g1,h1g2,h2g3,h3g4,h4

Pipelined Parallel Adder
c1+d1
a1+b1
c4,d4 c3+d3 c2+d2
a4+b4 a3+b3 a2+b2
e1+f1e2+f2e3,f3e4,f4
g1+h1g2,h2g3,h3g4,h4
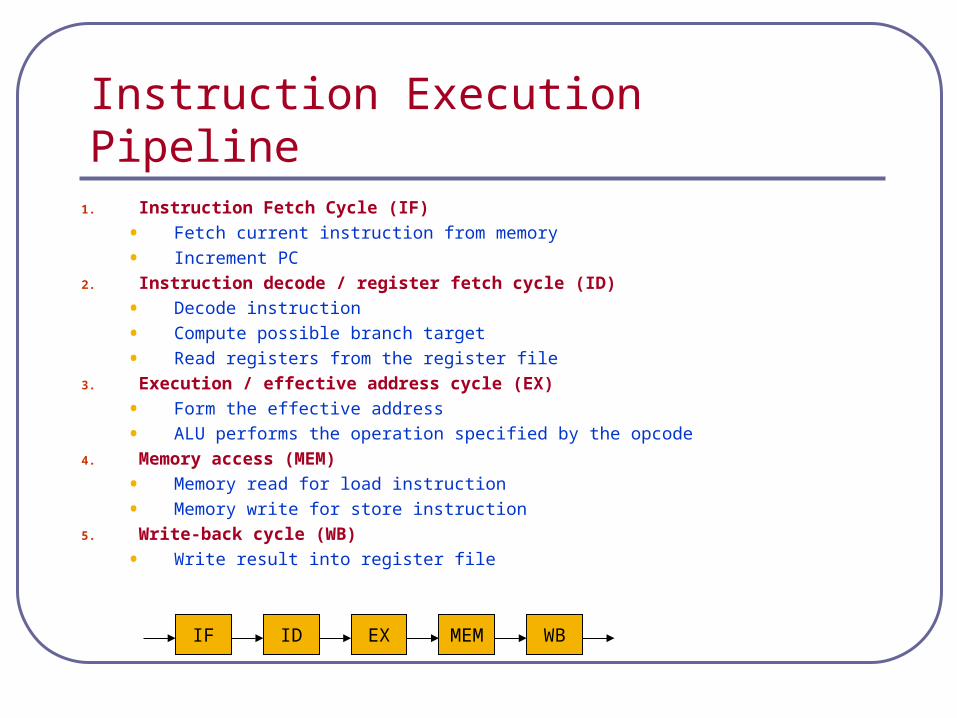
Instruction Execution Pipeline
IF
1. Instruction Fetch Cycle (IF)
• Fetch current instruction from memory
• Increment PC
2. Instruction decode / register fetch cycle (ID)
• Decode instruction
• Compute possible branch target
• Read registers from the register file
3. Execution / effective address cycle (EX)
• Form the effective address
• ALU performs the operation specified by the opcode
4. Memory access (MEM)
• Memory read for load instruction
• Memory write for store instruction
5. Write-back cycle (WB)
• Write result into register file
WBMEMEXID

Instruction Execution Pipeline
time
stages
IF
IF WBMEMEXID
WBMEM
EX
ID

Pipeline Hazards
1. Structural hazards
2. Data Hazards
3. Control Hazards
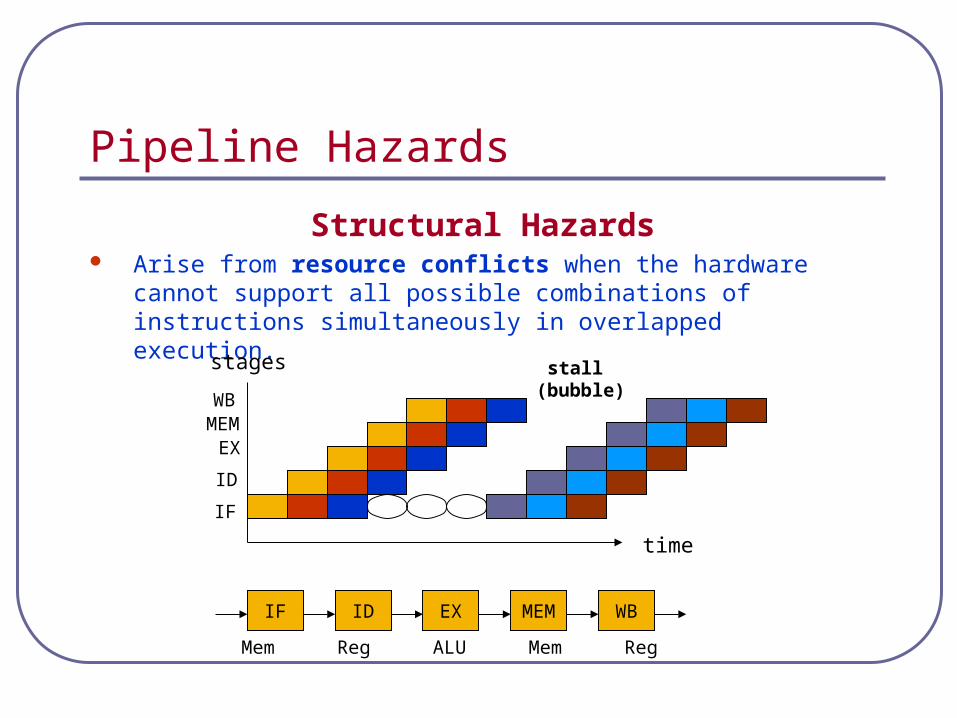
Pipeline Hazards
Structural Hazards Arise from resource conflicts when the hardware cannot support all
possible combinations of instructions simultaneously in overlapped execution.
time
stages
IF
IF WBMEMEXID
WBMEM
EX
ID
stall (bubble)
Mem Reg ALU Mem Reg
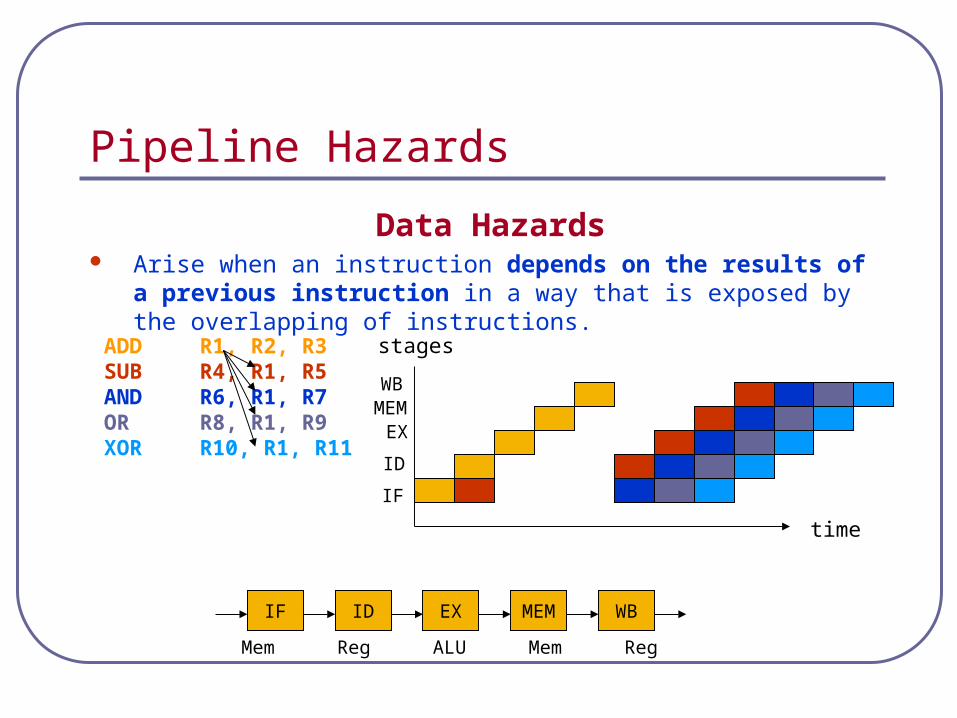
Pipeline Hazards
Data Hazards Arise when an instruction depends on the results of a previous
instruction in a way that is exposed by the overlapping of instructions.
time
stages
IF
IF WBMEMEXID
WBMEM
EX
ID
Mem Reg ALU Mem Reg
ADD R1, R2, R3SUB R4, R1, R5AND R6, R1, R7OR R8, R1, R9XOR R10, R1, R11

Pipeline Hazards
Data Hazards Forwarding (by-passing)
IF WBMEMEXID
Mem Reg ALU Mem Reg
IF WBMEMEXID
IF WBMEMEXID
IF WBMEMEXID
Mem Reg ALU Mem Reg
Mem Reg ALU Mem Reg
Mem Reg ALU Mem Reg

Pipeline Hazards
Control (Branch) Hazards Arise from pipelining of instructions (e.g. branch) that change PC.
time
stages
IF
WBMEM
EX
ID
LOOP: LOAD 100,XADD 200,XSTORE 300,XDECXBNE LOOP...
for i=n to 1 ci = ai + bi

Pipeline Hazards
Control (Branch) Hazards Freeze (flush)
time
stages
IF
WBMEM
EX
ID
BRA L1...
L1: NEXTNEXTNEXTNEXT
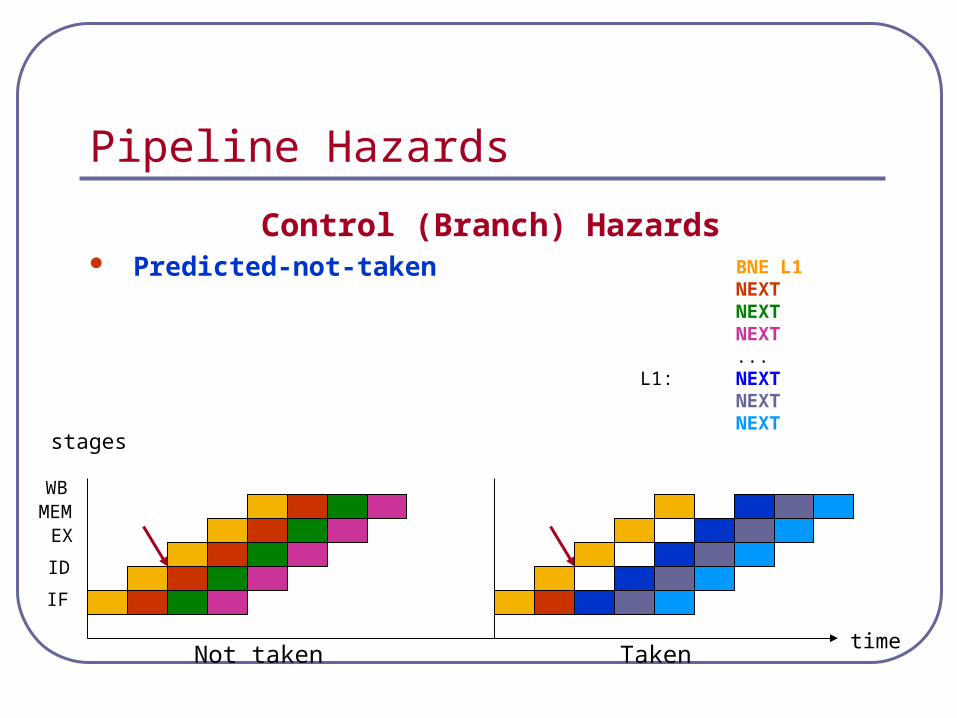
Pipeline Hazards
Control (Branch) Hazards Predicted-not-taken
time
stages
IF
WBMEM
EX
ID
BNE L1NEXTNEXTNEXT...
L1: NEXTNEXTNEXT
Not taken Taken

Pipeline Hazards
Control (Branch) Hazards Predicted-taken
time
stages
IF
WBMEM
EX
ID
BNE L1NEXTNEXTNEXT...
L1: NEXTNEXTNEXT
Not taken Taken
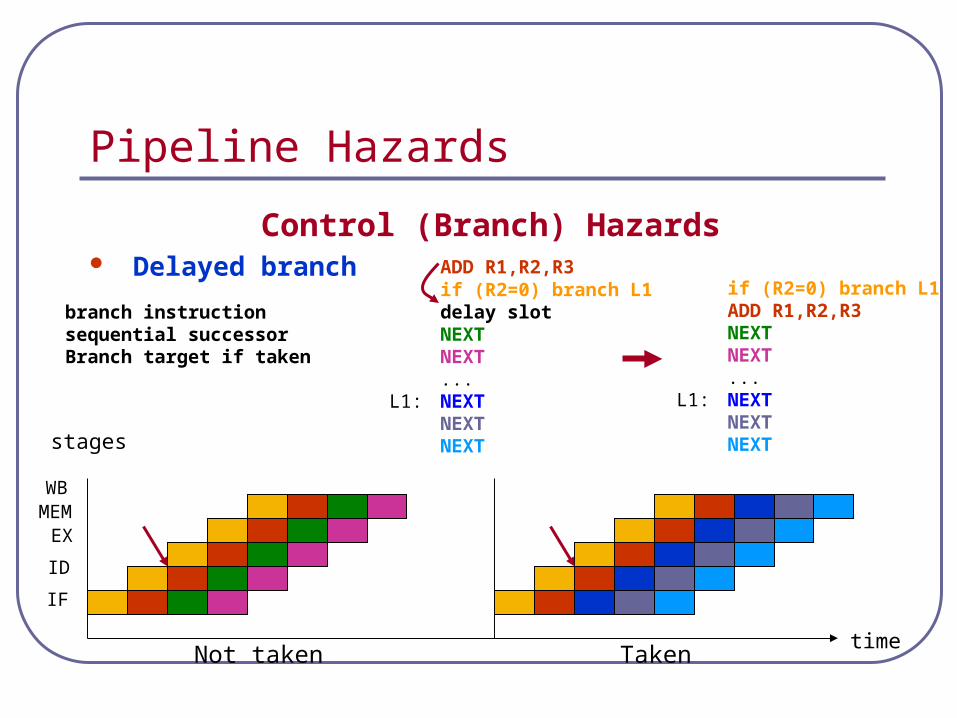
Pipeline Hazards
Control (Branch) Hazards Delayed branch
time
stages
IF
WBMEM
EX
ID
ADD R1,R2,R3if (R2=0) branch L1delay slotNEXTNEXT...
L1: NEXTNEXTNEXT
Not taken Taken
branch instructionsequential successorBranch target if taken
if (R2=0) branch L1ADD R1,R2,R3NEXTNEXT...
L1: NEXTNEXTNEXT

Levels of Parallelism
Bit level parallelism
• Within arithmetic logic circuits Instruction level parallelism
• Multiple instructions execute per clock cycle Memory system parallelism
• Overlap of memory operations with computation Operating system parallelism
• More than one processor
• Multiple jobs run in parallel on SMP
• Loop level
• Procedure level