learning submodular functions nick harvey university of waterloo joint work with nina balcan,...
Post on 19-Dec-2015
213 views
TRANSCRIPT

Learning Submodular Functions
Nick HarveyUniversity of Waterloo
Joint work withNina Balcan, Georgia Tech

Submodular functionsV={1,2, …, n}
f : 2V ! R
• Concave Functions Let h : R ! R be concave.For each S µ V, let f(S) = h(|S|)
• Vector Spaces Let V={v1,,vn}, each vi 2 Rn.
For each S µ V, let f(S) = rank(V[S])
Examples:
f(S)+f(T) ¸ f(S Å T) + f(S [ T) 8 S,Tµ V
Decreasing marginal values:
f(S [ {x})-f(S) ¸ f(T [ {x})-f(T) 8SµTµV, xT
Submodularity:
Equivalent

Submodular functionsV={1,2, …, n}
f : 2V ! R
f(S) · f(T), 8 S µ T
f(S) ¸ 0, 8 S µ V
Non-negative:
Monotone:
f(S)+f(T) ¸ f(S Å T) + f(S [ T) 8 S,Tµ V
Decreasing marginal values:
f(S [ {x})-f(S) ¸ f(T [ {x})-f(T) 8SµTµV, xT
Submodularity:
Equivalent

Submodular functions
• Strong connection between optimization and submodularity• e.g.: minimization [C’85,GLS’87,IFF’01,S’00,…],
maximization [NWF’78,V’07,…]
• Much interest in Machine Learning community recently• Tutorials at major conferences: ICML, NIPS, etc.• www.submodularity.org is a Machine Learning site
• Algorithmic game theory• Submodular utility functions
• Interesting to understand their learnability
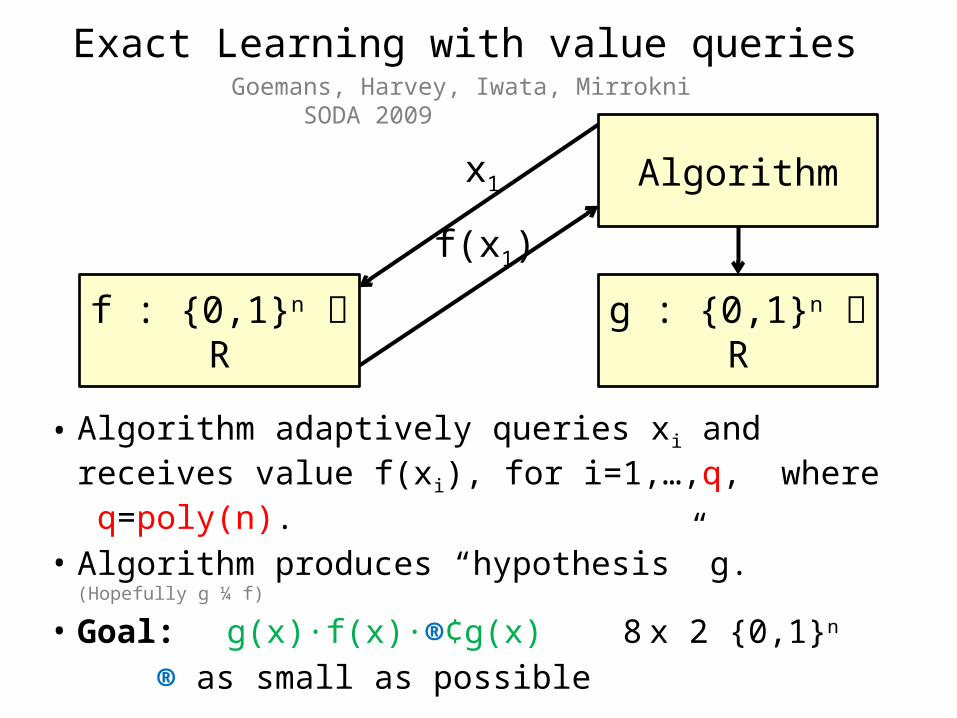
• Algorithm adaptively queries xi and receives value f(xi), for i=1,…,q, where q=poly(n).
• Algorithm produces “hypothesis” g. (Hopefully g ¼ f)
• Goal: g(x)·f(x)·®¢g(x) 8 x 2 {0,1}n
® as small as possible
f : {0,1}n R
Algorithm
f(x1)
g : {0,1}n R
x1
Exact Learning with value queriesGoemans, Harvey, Iwata, Mirrokni SODA 2009

• Algorithm adaptively queries xi and receives value f(xi), for i=1,…,q
• Algorithm produces “hypothesis” g. (Hopefully g ¼ f)
• Goal: g(x)·f(x)·®¢g(x) 8 x 2 {0,1}n
® as small as possible
Exact Learning with value queriesGoemans, Harvey, Iwata, Mirrokni SODA 2009
9 an alg. for learning a submodular functionwith ® = O(n1/2).
Theorem: (Upper bound)
~
Any alg. for learning a submodular functionmust have ® = (n1/2).
Theorem: (Lower bound)
~

Problems with this model • In learning theory, usually only try to predict value of
most points
• GHIM lower bound fails if goal is to do well on most of the points
• To define “most” need a distribution on {0,1}n
Is there a distributional modelfor learning submodular functions?

Distribution Don {0,1}n
Our Model
• Algorithm sees examples (x1,f(x1)),…, (xq,f(xq))where xi’s are i.i.d. from distribution D
• Algorithm produces “hypothesis” g. (Hopefully g ¼ f)
f : {0,1}n R+
Algorithmxi
f(xi) g : {0,1}n R+

Distribution Don {0,1}n
Our Model
• Algorithm sees examples (x1,f(x1)),…, (xq,f(xq))where xi’s are i.i.d. from distribution D
• Algorithm produces “hypothesis” g. (Hopefully g ¼ f)
• Prx1,…,xq[ Prx[g(x)·f(x)·®¢g(x)] ¸ 1-² ] ¸ 1-±
• “Probably Mostly Approximately Correct”
f : {0,1}n R+
Algorithmx
g : {0,1}n R+Is f(x) ¼ g(x)?

Distribution Don {0,1}n
Our Model
• “Probably Mostly Approximately Correct”• Impossible if f arbitrary and # training points ¿ 2n
• Possible if f is a non-negative, monotone, submodular function
f : {0,1}n R+
Algorithmx
g : {0,1}n R+Is f(x) ¼ g(x)?

Example: Concave Functions
• Concave Functions Let h : R ! R be concave.
h

;
V
Example: Concave Functions
• Concave Functions Let h : R ! R be concave.For each SµV, let f(S) = h(|S|).
• Claim: f is submodular.• We prove a partial converse.

Theorem: Every submodular function looks like this.Lots of approximately
usually.
;
V

Theorem: Every submodular function looks like this.Lots of approximately
usually.
Theorem:Let f be a non-negative, monotone, submodular, 1-Lipschitz function.There exists a concave function h : [0,n] ! R s.t., for any ²>0, for every k2{0,..,n}, and for a 1-² fraction of SµV with |S|=k,we have:
In fact, h(k) is just E[ f(S) ], where S is uniform on sets of size k.Proof: Based on Talagrand’s Inequality.
h(k) · f(S) · O(log2(1/²))¢h(k).
;
V
matroid rank function

Learning Submodular Functionsunder any product distribution
Product DistributionD on {0,1}n
f : {0,1}n R+
Algorithmxi
f(xi) g : {0,1}n R+
• Algorithm: Let ¹ = §i=1 f(xi) / q• Let g be the constant function with value ¹• This achieves approximation factor O(log2(1/²)) on
a 1-² fraction of points, with high probability.• Proof: Essentially follows from previous theorem.
q

Learning Submodular Functionsunder an arbitrary distribution?
• Same argument no longer works.Talagrand’s inequality requires a product distribution.
• Intuition:A non-uniform distribution focuses on fewer points,so the function is less concentrated on those points.
;
V

A General Upper Bound?• Theorem: (Our upper bound)
9 an algorithm for learning a submodular function w.r.t. an arbitrary distribution that has approximation factor O(n1/2).

Computing Linear Separators+
– +
+
+
+–
–
–
– +
– +
+
–
– – • Given {+,–}-labeled points in Rn, find a hyperplane cTx
= b that separates the +s and –s.• Easily solved by linear programming.

Learning Linear Separators+
– +
+
+
+–
–
–
– +
– +
+
–
– – • Given random sample of {+,–}-labeled points in Rn,
find a hyperplane cTx = b that separates most ofthe +s and –s.
• Classic machine learning problem.
Error!

Learning Linear Separators+
– +
+
+
+–
–
–
– +
– +
+
–
– – • Classic Theorem: [Vapnik-Chervonenkis 1971?]
O( n/²2 ) samples suffice to get error ².
Error!
~

Submodular Functions are Approximately Linear
• Let f be non-negative, monotone and submodular• Claim: f can be approximated to within factor n
by a linear function g.• Proof Sketch: Let g(S) = §s2S f({s}).
Then f(S) · g(S) · n¢f(S).
Submodularity: f(S)+f(T)¸f(SÅT)+f(S[T) 8S,TµVMonotonicity: f(S)·f(T) 8SµTNon-negativity: f(S)¸0 8SµV

V
Submodular Functions are Approximately Linear
f
n¢f
g

V+ +
+
+
+ +
+ f
n¢f
• Randomly sample {S1,…,Sq} from distribution
• Create + for f(Si) and – for n¢f(Si)• Now just learn a linear separator!
–
––
–
– –
– g

V
f
n¢f
• Theorem: g approximates f to within a factor n on a 1-² fraction of the distribution.
• Can improve to factor O(n1/2) by GHIM lemma: ellipsoidal approximation of submodular functions.
g

A Lower Bound?
• A non-uniform distribution focuses on fewer points,so the function is less concentrated on those points
• Can we create a submodular function with lots ofdeep “bumps”?
• Yes!
;
V

A General Lower Bound
Plan:Use the fact that matroid rank functions are submodular.Construct a hard family of matroids.Pick A1,…,Am ½ V with |Ai| = n1/3 and m=nlog n
A1 A2 ALA3
X
X X
Low=log2 n
High=n1/3
X
… … …. ….
No algorithm can PMAC learn the class of non-neg., monotone, submodular fns with an approx. factor õ(n1/3).
Theorem: (Our general lower bound)

Matroids
• Ground Set V• Family of Independent Sets I• Axioms:• ; 2 I “nonempty”
• J ½ I 2 I ) J 2 I “downwards closed”
• J, I 2 I and |J|<|I| ) 9x2InJ s.t. J+x 2 I “maximum-size sets can be found
greedily”
• Rank function: r(S) = max { |I| : I2I and IµS }

f(S) = min{ |S|, k }r(S) =|S| (if |S| · k)
k (otherwise)
;
V

;
V
r(S) =|S| (if |S| · k)
k-1 (if S=A) k (otherwise)
A

;
V
r(S) =|S| (if |S| · k) k-1 (if S 2 A) k (otherwise)
A1
A2A3
Am
A = {A1,,Am}, |Ai|=k 8i
Claim: r is submodular if |AiÅAj|·k-2 8ijr is the rank function of a “paving matroid”

;
V
r(S) =|S| (if |S| · k) k-1 (if S 2 A) k (otherwise)
A1
A2A3
Am
A = {A1,,Am}, |Ai|=k 8i, |AiÅAj|·k-2 8ij

;
V
r(S) =|S| (if |S| · k) k-1 (if S 2 A and wasn’t deleted) k (otherwise)
A1
A3
Delete half of the bumps at random.If m large, alg. cannot learn which were deleted ) any algorithm to learn f has additive error 1
If algorithm seesonly these examples
Then f can’t bepredicted here
A2
Am

;
V
A1
A3
Can we force a bigger error with bigger bumps?
Yes!Need to generalize paving matroidsA needs to have very strong properties
Am
A2

The Main Question• Let V = A1[[Am and b1,,bm2N
• Is there a matroid s.t.• r(Ai) · bi 8i
• r(S) is “as large as possible” for SAi (this is not formal)
• If Ai’s are disjoint, solution is partition matroid
• If Ai’s are “almost disjoint”, can we find a matroid that’s “almost” a partition matroid?
Next: formalize this

Lossless Expander Graphs
• Definition:G =(U[V, E) is a (D,K,²)-lossless expander if– Every u2U has degree D– |¡ (S)| ¸ (1-²)¢D¢|S| 8SµU with |S|·K,
where ¡ (S) = { v2V : 9u2S s.t. {u,v}2E }
“Every small left-set has nearly-maximalnumber of right-neighbors”
U V

Lossless Expander Graphs
• Definition:G =(U[V, E) is a (D,K,²)-lossless expander if– Every u2U has degree D– |¡ (S)| ¸ (1-²)¢D¢|S| 8SµU with |S|·K,
where ¡ (S) = { v2V : 9u2S s.t. {u,v}2E }
“Neighborhoods of left-vertices areK-wise-almost-disjoint”
U V

Trivial Case: Disjoint Neighborhoods
• Definition:G =(U[V, E) is a (D,K,²)-lossless expander if– Every u2U has degree D– |¡ (S)| ¸ (1-²)¢D¢|S| 8SµU with |S|·K,
where ¡ (S) = { v2V : 9u2S s.t. {u,v}2E }
• If left-vertices have disjoint neighborhoods, this gives an expander with ²=0, K=1
U V

Main Theorem: Trivial Case
• Suppose G =(U[V, E) has disjoint left-neighborhoods.• Let A={A1,…,Am} be defined by A = { ¡(u) : u2U }.
• Let b1, …, bm be non-negative integers.
• Theorem:
is family of independent sets of a matroid.
I = f I : jI \ [ j 2 J A j j ·X
j 2 J
bj 8J gI = f I : jI \ A j j · bj 8j g
A1
A2
· b1
· b2U V
Partition matroid
u1
u2
u3

Main Theorem• Let G =(U[V, E) be a (D,K,²)-lossless expander• Let A={A1,…,Am} be defined by A = { ¡(u) : u2U }
• Let b1, …, bm satisfy bi ¸ 4²D 8i
A1
· b1
A2
· b2

Main Theorem• Let G =(U[V, E) be a (D,K,²)-lossless expander• Let A={A1,…,Am} be defined by A = { ¡(u) : u2U }
• Let b1, …, bm satisfy bi ¸ 4²D 8i
• “Desired Theorem”: I is a matroid, whereI =f I : jI \ [ j 2 J A j j ·
X
j 2 J
bj 8J g

Main Theorem• Let G =(U[V, E) be a (D,K,²)-lossless expander• Let A={A1,…,Am} be defined by A = { ¡(u) : u2U }
• Let b1, …, bm satisfy bi ¸ 4²D 8i
• Theorem: I is a matroid, whereI =f I : jI \ [ j 2 J A j j ·
X
j 2 J
bj ¡³ X
j 2 J
jA j j ¡ j [ j 2 J A j j´
8J s.t. jJ j · K
^ jI j · ²DK g

Main Theorem• Let G =(U[V, E) be a (D,K,²)-lossless expander• Let A={A1,…,Am} be defined by A = { ¡(u) : u2U }
• Let b1, …, bm satisfy bi ¸ 4²D 8i
• Theorem: I is a matroid, where
• Trivial case: G has disjoint neighborhoods,i.e., K=1 and ²=0.
I =f I : jI \ [ j 2 J A j j ·X
j 2 J
bj ¡³ X
j 2 J
jA j j ¡ j [ j 2 J A j j´
8J s.t. jJ j · K
^ jI j · ²DK g
= 0
= 1
= 0
= 1

LB for Learning Submodular Functions
;
VA2
A1
• How deep can we make the “valleys”?
n1/3
log2 n

LB for Learning Submodular Functions• Let G =(U[V, E) be a (D,K,²)-lossless expander, where Ai =
¡(ui) and– |V|=n − |U|=nlog n
– D = K = n1/3 − ² = log2(n)/n1/3
• Such graphs exist by the probabilistic method• Lower Bound Proof:– Delete each node in U with prob. ½, then use main theorem
to get a matroid– If ui2U was not deleted then r(Ai) · bi = 4²D = O(log2 n)
– Claim: If ui deleted then Ai 2 I (Needs a proof) ) r(Ai) = |Ai| = D = n1/3
– Since # Ai’s = |U| = nlog n, no algorithm can learna significant fraction of r(Ai) values in polynomial time

Summary• PMAC model for learning real-valued functions• Learning under arbitrary distributions:– Factor O(n1/2) algorithm– Factor (n1/3) hardness (info-theoretic)
• Learning under product distributions:– Factor O(log(1/²)) algorithm
• New general family of matroids– Generalizes partition matroids to non-disjoint parts

Open Questions
• Improve (n1/3) lower bound to (n1/2)• Explicit construction of expanders• Non-monotone submodular functions– Any algorithm?– Lower bound better than (n1/3)
• For algorithm under uniform distribution, relax 1-Lipschitz condition