learning automata based approach to model dialogue strategy in spoken dialogue system: a performance...
TRANSCRIPT

Learning Automata based Approach to Model Dialogue Strategy in Spoken Dialogue System: A Performance Evaluation
G.Kumaravelan Pondicherry University, Karaikal Centre, Karaikal.
R. SivaKumar
AVVM Sri Pushpam College, Thanjavur.

Dialogue System
A system to provide interface between the
user and a computer-based applicationInteract on turn-by-turn basisDialogue manager
Control the flow of the dialogue information gathering from user communicating with external
application communicating information back to the
userThree types of dialogue system (On initiativeness)
finite state- (or graph-) based frame-based agent-based

Spoken Dialogue System Architecture
SpeechRecognition
DialogueManager
Backend
LanguageGeneration
Text to SpeechSynthesis
Audio
SpokenLanguage
Understanding
WordsSemantic
representation
ConceptsWords
Audio

Properties of RL: The Agent-Environment Interaction
1
1
:statenext resulting and
:reward resulting gets
)( : stepat action produces
: stepat state observesAgent
,2,1,0 :steps timediscreteat interact t environmen andAgent
t
t
tt
t
s
r
sAat
Sst
t

Cont…
maximize? want to wedoWhat
... ,,,
:is stepafter rewards of sequence theSuppose
321 ttt rrr
t
In general,
we want to maximize the expected return, E Rt , for each step t.
Tttt rrrR ... 21
Immediate rewardLong term reward
Aim is to find the policy that leads to the highest total reward over T time steps (finite horizon) [Markov property]

The formal decision problem - MDP
Given <S, A, P, R, T >
S is a finite state set (with start state s0)
A is a finite action set
P(s’ | s, a) is a table of transition probabilities
R(s, a, s’) is a reward function
Policy p(s, t) = a
Is there a policy that yields total reward over finite
horizon T

Learning Automata Characteristics
Learning Automata (LA) are adaptive decision making devices that can operate in environments where
they have no information about the effect of their actions at start of operation — unknown environments
a given action not necessarily produces the same response each time it is performed — non-deterministic environments
A powerful property of LA is that they progressively improve their
performance by the means of a learning process combine rapid and accurate convergence with low computational
complexity.
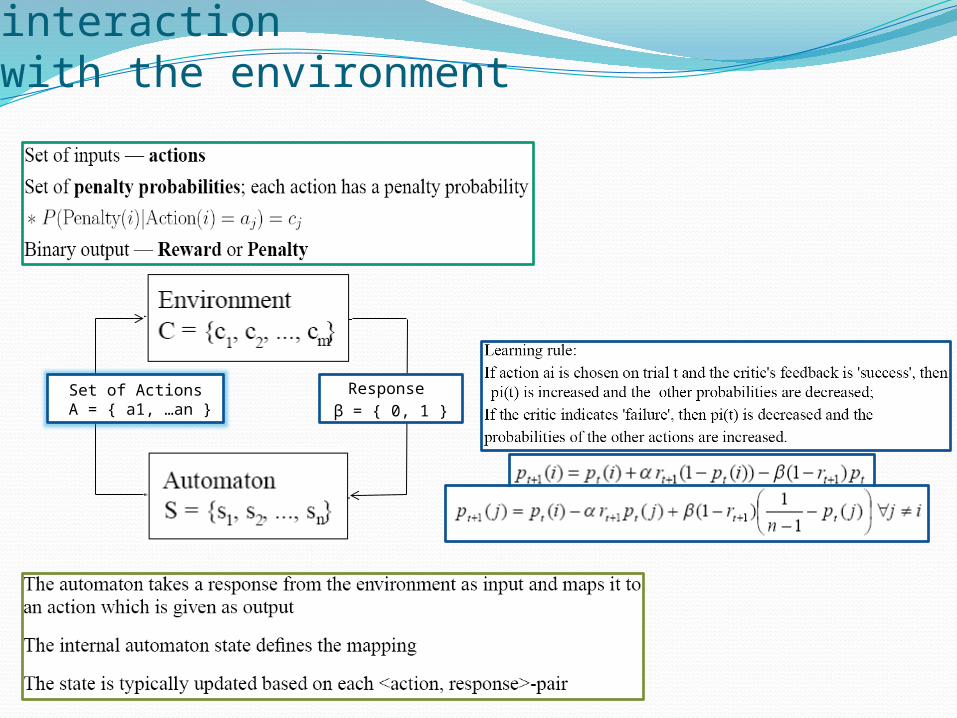
Learning Automaton and its interactionwith the environment
Set of Actions A = { a1, …an }
Response
β = { 0, 1 }

Methodology
Follows a frame based approach which maintains task and attribute histories
respect to the domain in focus.
The state space is determined by the number of slots in focus.
The action space is narrowed to “greeting”, “request all”, “request n slot”,
“verify all”, “verify n slot” and close dialogue.

Experiments and Results
Our experiments were based on travel planning domain.
Speech recognition & speech synthesis modules are implement by .NET SDK framework.
DATE scheme was used as a dialogue act recognition agent.
The reward in the range of (+10 to -5) is assigned for the best and worst action selection respectively.

Cont…

Cont…

Evaluation Methodology
PRADISE framework Task success:
Calculated with help of AVM.
System performance:

Conclusions Challenges
LA are interesting building blocks to solve different type of RL problems
Faster learning
Knowledge transfer
Less Computational complexity
Different LA updates
Influence different state observations (POMDP setting)

References I
E. Levin, R. Pieraccini and W. Eckert.
A stochastic model of human-machine interaction for learning dialogue strategies. IEEE Trans. on Speech and Audio Processing, 8(1), pp. 11–23, 2000.
M. McTear.
Spoken dialogue technology: Toward the conversational user interface. Springer, 2004.
K. Narendra and M.A.L. Thathachar.
Learning Automata: An Introduction. Prentice-Hall International, Inc, 1989.
A. Nowe and K. Verbeeck.
Colonies of learning Automata. IEEE Trans. Syst. Man Cybern B, 32, pp.772-780, 2002.
T. Peak and R. Pieraccini. Automating spoken dialogue management design using machine learning: an industry perspective. Speech Communication, 50, pp. 716-729, 2008.
O. Pietquin and T. Dutoit. A probabilistic framework for dialogue simulation and optimal strategy learning. IEEE Transactions on Speech and Audio Processing, 14(2), pp. 589–599, 2006.

References II
K. Scheffler and S. Young.
Automatic learning of dialogue strategy using dialogue simulation and reinforcement learning.
Human Language Technology Conference (HLT), pp 12–19, 2002.
S. Singh, D. Litman, and M. Kearns.
Optimizing dialogue management with reinforcement learning: Experiments with the NJFun system,
Journal of Artificial Intelligence Research, 16, pp. 105–133, 2002.
M. A. L. Thathachar and P. S. Sastry.
Networks of Learning Automata: Techniques for Online Stochastic Optimization. Norwell, MA, Kluwer, 2004.
M. Walker and R. Passonneau. 2001.
DATE:A dialogue act tagging scheme for evaluation of spoken dialogue systems. Proceedings of the Human Language Technology Conference, pp. 1–8, 2001.
M. Walker, D. Litman and C. Kamm.
PARADISE: A framework for evaluating spoken dialogue agents. Proc. of the 5th annual meeting of the association for computational linguistics, pp. 271–280, 1997..

Questions ?