komprimace a šifrování - mendelu
TRANSCRIPT

Komprimace a šifrování
Mgr. Tomáš Foltýnek, Ph.D., Ing. JanPřichystal, Ph.D.

2 Obsah
Obsah
Cíl studia 3
Úvod 3
Využití komprimace a šifrování 4
Poučení 5
Návaznost 5
Poděkování 5
Teorie informace 6
Úvod do kompresních algoritmů 11
Kompresemultimediálních dat 19
Úvod do kryptologie 30
Historie kryptografie a kryptoanalýzy do konce druhé světové války 34
Substituční šifry 46
Generování náhodných čísel 54
Transpoziční šifry. Superšifrování 56
Symetrická kryptografie 57
Asymetrická kryptografie 64
Digitální podpis 67
Hashování 74
Steganografie 78
Šifrování vmobilní komunikaci 84
Kvantová kryptografie 93
Zájmová kryptografie 95
Slovníček pojmů 101
Test 1

Obsah 3
Cíl studia
Cíl studiaCíle studia předmětu Komprimace a šifrování je ”Orientace v oblasti teorie informace a kom-primace, seznámení s metodami kryptografie a kryptoanalýzy”.Podrobněji jsou cíle specifikovány jako:• ovládat základní pojmy z teorie informace a dokázat je aplikovat• mít přehled o obecných technikách neztrátové a ztrátové komprese dat• vědět, jak lze komprimovat text, obraz, zvuk, video• znát základní pojmy z oblasti kryptologie• mít přehled o historii kryptologie• znát základní způsoby šifrování - metody substituce a transpozice textu• vědět, jak fungují moderní symetrické a asymetrické metody a na jakých matematickýchpředpokladech stojí jejich bezepčnost
• vědět, jak funguje inffrastruktura veřejných klíčů a znát princip digitálního podpisu• vědět, co je to steganografie a znát běžně používané steganografické techniky• mít povšechný přehled o možnostech kvantové kryptografie• dokázat poznatky aplikovat v praxi• některou z oblastí komprimace či kryptologie prostudovat do hloubkyProstředky k dosažení těchto cílů jsou při prezenčním studiu účast na přednáškách a cvi-
čeních a samostatná práce na projektu. Při distančním studiu to jsou studium tohoto učeb-ního materiálu, ale i aktivní vyhledávání dalších studijních zdrojů a stejně jako v případěprezenčního studia samostatná práce na projektu.
Úvod
ÚvodPředmět Komprimace a šifrování kombinuje dvě oblasti informatiky, které spoolu zdánlivěnesouvisí. Jak si však ukážeme, a jak nám (snad) dojde v průběhu studia, jejicch souvislostje větší, než se na první pohled zdá.Potřeba komprimovat (snižovat objem) čehokoliv je stará stejně jako potřeba cokoliv
uskladňovatt či dopravovat. Pokaždé, když si balíme batoh na výlet, zamýšlíme se nad každouz věcí, zda ji skutečně budeme na výletě potřebovat, či zda bychom se bez ní neobešli.Stejně tak je tomu i v případě dat. Kompresní algoritmus se u každých dat rozhoduje, zdajsou skutečně potřeba všechny, či zda je nelze uložit nějakým jiným způsobem, který byvylučoval zbytečnou nadbytečnost, a který by při nižším objemu dat garantoval, že z nichbude možné později obnovit data původní.Kompirmaci využíváme pro úsporu kapacity záznamových médií a pro úsporu přenoso-
vého pásma při datové komunikaci. Jak ukazují zkušenosti, nezáleží na velikosti záznamo-vého média. Čím větší médium máme, tím více dat shromažďujeme, tím později data pro-mazáváme, tím později na disku uklízíme. Nedostatek prostoru tak dříve či později stejněpřijde. Kompresní algoritmy byly potřeba v době, kdy každý člověk nosil v tašce sadu disketo kapacitě 1,44MB a vystačil si s nimi. Kompresní algoritmy jsou potřeba i dnes, kdy každýmůže mít v hodinkách 1000 disket a na disku, který je velký jako malý bloček, může mítuložené filmy pro týden nepřetržitého přehrávání či hudbu na celý rok. Studium kompres-ních algoritmů nám prozradí, jak je možné, že lze objem dat snižovat při zachování jejichinformační hodnoty. Prozradí nám také, jak je možné, že minuta hudby může mít méně nežjeden megabyte a jak je možné, žee hodinu filmu uložíme na běžné CD.Poté, co se naučíme základní principy kompresních algoritmů, vrhneme se na studium
kryptologie, která zabírá více než 2/3 tohoto předmětu. Jak si ukážeme, byla to právě potřebadešifrovat, která stála během druhé světové války u zrodu prvních počítačů. Lámání šiferhrubou silou vyžaduje vykonávání velkého množství triviálních matematických operací, cožje věc jako stvořená pro elektronická zařízení. Později se ukázalo, že rychlé zpracovávání datlze využít i jinak a postupem času se z prvních počítačů majících výkon jako lokomitava (ježbylo třeba chladit dvěma leteckými motory) vyvinuly osobní a kapesní počítače. Výpočetnívýkon potřebný k rozlomení německé Enigmy tak dnes máme v malé krabičce, kterou stačínapájet energií chůze či slunečními paprsky.

4 Obsah
Potřeba šifrovat je stará stejně jako lidská civilizace. Odnepaměti spolu lidé soupeřío mmajetek či moc a s tím souvisí potřeba předávání informací tak, aby nikdo nepovo-laný nezjistil jejich obsah. Velmi blízko je i potřeba předávání informací tak, aby cestounebyly změněny, nebo abychom byli přinejmenším schopni tuto změnu detekovat. V době,kdy jsou počítače všude, kdy jejich prostřednictvím nakupujeme, platíme, komunikujemes bankami či úřady, je požadavek na zabezpečení soukromí oprávněný dvojnásob. Nikdoz nás by patrně nebyl rád, kdyby se každý mohl podívat na náš bankovní účet či s nímdokonce manipulovat. Stejně tak různé instituce, se kterými přijdeme do kontaktu požadujíjistotu, že ten, s kým komunikují, jsme skutečně my a ne nikdo jiný. Nejen důvěrnost dat,ale i jejich celistvost, původnost a prokazování totožnosti. To vše jsou úkoly kryptografie.Postupně se seznámíme se všemi.A jak je to se slibovanou souvislostí mezi komprimací a šifrováním? Ukazuje se, že opa-
kování je základ kryptoanalýzy. Jinými slovy všude tam, kde jsou nějaká nadbytečná data, jesnadněší zašifrovaná data rozšifrovat. Komprimace nám snižuje nadbytečnost dat a sni-žuje tak riziko jejich dešifrování. Proto spolu tyto dvě disciplíny souvisí. Kryptografie se bezkomprimace neobejde. A bez kryptografie se dnes neobejde nikdo z nás. Patří proto k dob-rému vychování každého uživatele informačních a komunikačních technologií, mít o těchtotechnikách alespoń povšechný přehled. Každý, kdo se chce honosti vysokoškolským titulemspjatým s informatikou by však měl mít více, než jen povšechný přehled. Měl by chápat prin-cipy fungování těchto technik, jejich rizika a v neposlední řadě také dokázat posoudit jejichvhodnost pro různé aplikace. Snad k této dovednosti přispěje i kurz Komprimace a šifrování.
Využití komprimace a šifrování
Využití komprimace a šifrováníKomprimace i šifrování mají v době rozvoje techniky využití doslova na každém kroku.Potřeba komprimovat a šifrovat však není nic nového, co by se objevilo až s rozmachemvýpočetní techniky. Touha po zmenšování objemu čehokoli je v lidské činnosti patrná odne-mapěti, stejně jako potřeba utajování informací.V tomto kurzu poznáme, jak se v historii vyvíjely metody komprese a šifrování. Tuto
znalost sice nevyužijeme přímo, ale nepřímo nám poslouží dvěma způsoby:• poznáme na ní základní principy fungování technik komprimace a šifrování, které jsouplatné dodnes,
• roztšíříme obzory svého vzdělání do oblasti, která je i mezi laiky velmi populární a kdedokážeme svými znalostmi zaujmout.
To, co však využijeme přímo, bude popis v současnosti používaných technik. Dozvímese, jak pracují kompresní algoritmy typu ZIP, BZIP, GZIP, atd. Dozvíme se, jak jsou uloženádata v obrázcích typu GIF a JPG a jak je možné, že jsou tyto souborry tak malé. Dozvíme se,jak funguje MP2, MP3, MP4, čili jak ošálit lidské smysly, aby si nevšimly změny dat, kterávýrazně uspoří jejich velikost.Dále se dozvíme, co je to DES, AES, IDEA a jak funguje. Řekneme si, jak se vyměňují
elektronické klíče přes nezabezpečené médium. Dozvíme se, jak pracuje algoritmus RSAa jak jej každý z nás může použít nejen k zašifrování důvěrných dat, ale i k elektronickémupodpisu a tím prokázání autorství. Každý z nás by měl být schopen tyto principy pozdějiaplikovat v podniku, vv němž bude pracovat. Ukrývání zpráv do multimediálních dat je ob-last, se kterou se v běžném životě setkáváme jen velmi málo. Pracovníkům tajných služebči jiných bezpečnostních složek z nní však běhá mráz po zádech, neboť nemohou mít žád-nou jistotu, že nevinně vypadající obrázek, který právě někdo nahrál na některou z mnohaveřejných galerií, neobsahuje ukrytý pokryn pro provedení teroristického útoku. Kvantovákryptografie je sice hudbou budoucnosti, otázkou však je, jak daleké budoucnosti. Kdo z nássi může být jistý, že se nástupu kvantové kryptografie nedožije? Až přijde, bude to revolucev informačních technologiích a jen ten, kdo bude na tuto revoluci připravený, obstojí.
Zkuste se na dvě minuty zamyslet a podívat se po svém okolí. Kde všude vidíteněco, co používá šifrování? Nebo něco, kde jsou data komprimována?
Při pohledu na počítač je to snadné - HTTPS, SSL, PGP, SSH, SCP, SFTP, atd. Ale i v reál-

Obsah 5
ném světě. Téměř každý má kreditní kartu, mobil, flashku, MP3 přehrávač., digitální fotoapa-rát. Svým způsobem i občanský průkaz, klíč, či celá naše osobnost velmi souvisí s šifrováním.Studium kryptologie otevírá poznání nejen informatikům, ale každému, kdo se chce dozvědětvíce o současném světě a o technologiích, které jím prostupují.
Poučení
Poučení
Chytrý se učí pět let, hlupák to stihne za den.
(vietnamské přísloví)
Návaznost
Návaznost
Ačkoliv teorie informace, komprimace i kryptografie jsou disciplíny velmmi úzce spjaté s ma-tematikou, pro úspěšné studium tohoto textu je třeba mít, kromě všeobecného vzdělánínabytého na základní škole, pouze následující znalosti:
• vědět, co je to bit a byte• vědět, co je to prvočíslo• vědět, co je to zbytek po dělení• dokázat umocnit dvě číslaJe pravda, že jsou to všechno znalosti, které si minimálně každý nadprůměrně inteli-
gentní jedinec již ze základní školy odnese. Přesto však doporučujeme, aby předměty typuMatematika I, nebo Výpočetní technika I (či jiný předmět seznamující se základními principyfungování počítačů), byly absolvovány ještě před studiem tohoto kurrzu.
Poděkování
Poděkování
Tato eLearningová opora vznikla za výrazné pomoci studentů PEF MZLU v Brně. Autořiděkují jmenovitě:
• Martě Vodové za zpracování podkladů pro kapitoly Asymetrická kryptografie a Digi-tální podpis
• Petru Sklenářovi za zpracování podkladů pro kapitolu Kvantová kryptografie• Mariánu Klangovi za zpracování podkladů pro kapitolu Historie kryptografie a kryp-toanalýzy
• Petru Konečnému za zpracování podkladů pro kapitolu Hashovací funkce• Petru Chladilovi za zpracování podkladů pro kapitolu Metody kódování a kompresedat
• Roman u Kôrovi za vytvoření flashové aplikace pro Huffmannovo kódování• Petře Katovské a Martinu Juráňovi za zpracování podkladů pro kapitolu Steganografie• Tomáši Hanáčkovi za zpracování podkladů pro rozšíření kapitol o kompresních algo-ritmech

6 Obsah
Teorie informace
Teorie informace
Výměna informací s okolím nám umožňuje udržovat vlastní existenci. Proces zpracování in-formací je trvalý, nepřetržitý, ale ovlivnitelný. Zabezpečení informací je spojeno s lidskýmjednáním a je údělem celé společnosti, bez ohledu na vývojový stupeň materiálních podmí-nek. Problémy se zpracováním informací se prohloubily během 20. století. Svět je zavalenspoustou informací a neexistují lidé, kteří by je všechny byli schopni zpracovat nebo evido-vat.Využívání a efektivní práce s informacemi vyžaduje o nich něco vědět.1. Co jsou to informace?2. Co jsou relevantní informace?3. Jak je získáme a jak zhodnotíme jejich využitelnost?4. Jak se přenášejí a jak jsou uloženy?Základní podmínkou úspěšnosti jednotlivců je permanentní osvojování nových znalostí
vytvořených jinými a tvorba znalostí vlastních. Abychom byli připraveni, musíme mít dosta-tek informací o informacích a možnostech manipulace s nimi.
Pojem informaceNázev informace pochází z latinského informo, což znamená přanášet zprávu, oznámení, pou-čení. Otec kybernetiky Norbert Wiener označuje informaci jako to, co si vyměňujeme s vnějšímsvětem, když se mu přizpůsobujeme a působíme na něj svým přizpůsobováním.Definic pojmu informace je velmi mnoho. Některé z nich jsou:Informace je obsah jakéhokoli oznámení, údaje o čemkoli, s určením pro přenos v pro-
storu a čase. V nejširším slova smyslu je to obsah vztahů mezi materiálními objekty, proje-vující se změnami těchto objektů. (Terminologický slovník informatiky)Informace je obsah zprávy, sdělení, objasnění, vysvětlení, poučení. (Slovník cizích slov)Informace jsou údaje, čísla, znaky, povely, instrukce, příkazy, zprávy apod. Za informace
považujeme také podněty a vjemy přijímané a vysílané živými organismy. (Oborová encyklo-pedie VT)
Jak informace chápat?Informace – z hlediska kvalitativního(obsah sdělení, význam zprávy) tím se zabývá INFORMATIKAInformace – z hlediska kvantitativního(množství a jeho měření) tím se zabývá TEORIE INFORMACE
Teorie informacePrvní publikace týkající se infromacem jejího přenosu a měření se objevily krátce po druhésvětové válce. Jedním z důležitých vědců, který se touto problematikou zabýval, byl ClaudeShannon. Claude Shannon stanovil základy teorie informace, definoval možnosti měření in-formačního množství zavedením pojmu entropie. Vyšel z předpokladu, že zprávy, které sepřenášejí pomocí nějakého zařízení, patří do kategorie náhodných jevů. Formalizace je tedyzaložena na pravděpodobnostně-statistickém základu.Shannonova definice informace:Informace je míra množství neurčitosti nebo nejistoty o nějakém náhodném ději odstraněná reali-
zací tohoto děje.Informace rozšiřuje okruh znalostí příjemce.
Měření informačního množství
Entropie – název vypůjčený z fyziky, použitý pro měření informačního množství.Jak kvantifikovat rozšíření okruhu znalostí příjemce?Pravděpodobnost jevu – spojeno s individuálními vlastnostmi příjemce (Shannon).

Obsah 7
Jevy a jejich realizace
Jev – náhodný proces s n možnými realizacemi (tah sportky, účast na přednášce, semafor nakřižovatce apod.)Realizace jevu – jeden projev, získání výsledku (vytažení 6 čísel, konkrétní počet osob na
přednášce, svítící zelená na křižovatce apod.)Předpokládejme například, že v národě je polovina žen a polovina mužů. Z toho 25%
jsou blondýnky. Nyní někdo sdělí o neznámé osobě, že je to žena a má blond vlasy. Dálese dozvíte, že je vědeckou pracovnicí. To je poměrně cenná informace, protože takovýchblonýnek je asi jen 10%. Jsme schopni vyjádřit, kolik informace jsme v tomto rozhovoruobdrželi?Pravděpodobnost, že jsem potkal ženu je 1:2. Pravděpodobnost, že ta žena je blondýnka
je 1:8 a že je zároveň vědec 1:80.P (v) = P (zena) · P (blond) · P (vedec) = 1
2 ·14 ·
110 =
180
Výpočet vlastní informace
Pro výpočet obdržené vlastní informace je potřeba zabývat se entropií. Ta vyjadřuje mírunejistoty obsažené v nějakém náhodném ději. Přepokládejme tedy, že máme konečný početvzájemně se vylučujících jevů, jejichž pravděpodobnosti výskytu jsou pi(x), . . . , pn(x). Entro-pii pak vyjádříme jako funkci těchto pravděpodobností.Požadované vlastnosti funkce pro výpočet množství informace• Jev X má n realizací, množství informace je funkcí n.• Je-li n = 1, jedná se o jev jistý, množství informace je rovno nule.• Jevy X a Y probíhající současně a nezávisle, p(x,y) = p(x) * p(y): množství informace jedáno součtem množství jednotlivých jevů: f(x,y) = f(x) + f(y)
• Jev X má n realizací, jev Y má m realizací. Je-li m > n, pak chceme i f(m) > f(n)Funkce, která vyhovuje uvedeným podmínkám, je logaritmus. I(x) = logn Zde předpo-
kládáme, že pravděpodobnost každé realizace je stejná. Má-li jev n realizací, pak můžemepsát p(x) = 1/n, odsud pak n = 1/p(x).Buď X množina výsledků náhodného děje, x výsledek realizace a p(x) pravděpodobnost
tohoto výsledku. Každému x z X pak lze přiřadit reálné číslo I(x) nazývané vlastní informaceo výsledku x, pro než platí:
I(x) = − log p(x), (0 ≥ p(x) ≥ 1)Číslo I(x) představuje množství informace obsažené ve výsledku x. Základ logaritmu –
principiálně není podstatný. Ale používají se logaritmy o základu 2. Pak dostáváme výsledekv bitech.
Entropie
Jak spočítat informační množství celého jevu? Pomůžeme si shrnutím všech vlastních in-formací jednotlivých realizací. Předpokládejme, že jev X má n realizací X = x1, x2, . . . , xn
s pravděpodobnostmi p(x1), p(x2), . . . , p(xn).Entropie H(X) je dána určitou střední hodnotou vlastních informací všech realizací jevů:H(X) = −
Pni=1 p(xi) · log p(xi)
Entropie zahrnující informační množství celého jevu se nazývá též úplná informace.
Kódování informaceZákladní podmínkou komunikace je vytvoření signálního komunikačního kanálu. Informacije pro tento účel nutné transformovat, tj. vyjádřit v jiném jazyce s jinou abecedou. Přiřa-zení znaků jedné abecedy znakům jiné abecedy se nazývá kódování, inverzní postup pakdekódování. Předpis, který toto přiřazování definuje, se nazývá kód. Z hlediska optimalizacepřenosu je vhodné aby každý přenášený signál obsahoval co nejmenší množství informace.Proto a také z důvodu omezení šumů používáme kódování informací.
Kvalita kódování, redundance
Z hlediska optimálního přenosu je efektivní kód, který obsahuje minimální počet informač-ních prvků, každý znak kódu tedy má maximální entropii. Kvantitativně je hospodárnostkódu vyčíslitelná redundancí (nadbytečností), podle vztahu:
R = 1−H/Hmax.

8 Obsah
H je zde entropií jazyka a Hmax je maximální entropie při použití téže abecedy (všechnyznaky jsou stejně možné).
Způsoby kódování
Nejpoužívanější výstupní abecedou kódování je dvojková abeceda, tj. abeceda obsahujícíprvky 0 a 1.Rovnoměrné kódování – každému znaku je přiřazen stejně dlouhý kód. Obvykle je jedno-
dušší, rychlejší na zpracování, ale méně hospodárné. Toto kódování totiž přiřazuje každémuznaku abecedy stejně dlouhý kód bez ohledu na četnost jeho výskytu. Typickým představi-telem je Baudotovo kódováníNerovnoměrné kódování – každému znaku je přiřazen jinak dlouhý kód. Pro konstrukci
a zpracování je obtížnější, může však být maximálně hospodárné. Představiteli tohoto typukódování jsou Shannon-Fanovo nebo Huffmanovo kódování.
Příklady kódů
Zdroj produkuje 4 znaky A, B, C, D. Předpokládáme pravděpodobnosti znaků:znak p1(x) kód 1 kód 2A 0,25 00 0B 0,25 01 10C 0,25 10 110D 0.25 11 111
znak p2(x) kód 1 kód 2A 0,5 00 0B 0,25 01 10C 0,125 10 110D 0.125 11 111
Shannon-Fanův algoritmus
Je založeno na četnosti výskytu jednotlivých znaků abecedy.1. Znaky uspořádáme sestupně podle pravděpodobnosti jejich výskytu.2. Vypočteme kumulativní pravděpodobnosti.3. Rozdělíme znaky do dvou skupin tak, aby jejich součtové pravděpodobnosti bylyblízké, tj. v prvním kroku 0,5.
4. Krok 3 opakujeme tak dlouho, dokud existují vícečlenné skupiny znaků.
znak p(x) s skupiny vysledekx1 0,30 1,00 0 00x2 0,24 0,70 0 1 01x3 0,20 0,46 0 10x4 0,15 0,26 1 0 110x5 0,11 0,11 1 1 111
Huffmanovo kódování
Stejně jako Shannon-Fanovo kódování využívá četnosti jednotlivých znaků pro optimálnízakódování.1. Seřadíme pravděpodobnosti výskytu jednotlivých znaků sestupně pod sebe.2. Sečteme poslední dvě pravděpodobnosti a vytvoříme nový sloupec pravděpodobností,kde ty dvě, které jsme sčítali nahradí jejich součet.
3. Všechny pravděpodobnosti v novém sloupci seřadíme sestupně podle velikosti a pro-pojí se spojnicemi s hodnotami v původním sloupci.
4. Spojnice pravděpodobností p(xn−1) a p(xn) se sjednotí, ale předtím přiřadíme p(xn) bitkódového slova s hodnotou 1 a p(xn−1) bit s hodnotou 0.
5. Takto postupujeme, dokud se součet posledních dvou čísel nerovná 1.6. Závěrečné kódování každého slova pak probíhá po spojnicích jako sbírání zapsanýchbitů kódového slova tak, že jdeme po spojnicích a zapisujeme všechny bity, které pocestě potkáme.
7. Nakonec se celý zápis obrátí odzadu dopředu a výsledkem je kódové slovo pro danouudálost.

Obsah 9
událost p(xi) kódx1 0.35 00x2 0.15 010x3 0.13 011x4 0.09 101x5 0.09 110x6 0.08 111x7 0.05 1001x8 0.04 10000x9 0.02 10001
Výpočet kódu u vlastního textu je možné vyzkoušet pomocí následující aplikace:

10 Obsah
Aritmetické kódování
Dalším statistickým komprimačním algoritmem je aritmetické kódování, kterépřiřazuje každé zprávě číslo z intervalu <a,b) <0,1). Jedná se o hardwarověvelice náročné kódování, které navíc není bezprefixové, díky tomu se také pro-sazuje velice pomalu.
Při kódování si algoritmus opět nejprve zjistí pravděpodobnosti prvků zevstupní abecedy. Poté rozdělí základní interval <0, 1) na různě dlouhé částipodle pravděpodobností prvků. Po přečtení prvního znaku vybere subintervalpříslušející přečtenému znaku, tento interval opět rozdělíme, a takto rekur-zivně pokračujeme do té doby, než přečteme poslední znak zprávy. Tímtozískáme interval <a,b) pravděpodobnosti reprezentující danou zprávu, potéstačí vybrat libovolný prvek z tohoto intervalu (nejlépe prvek, který jsmeschopni zaznamenat nejkratším výstupním řetězcem), který společně s počtemvýskytů prvků ze vstupní abecedy a velikostí zprávy tvoří její kompresi.
Na obrázku je zobrazen příklad aritmetického kódování zprávy „ABAC”. Z vý-sledného intervalu <19/64, 5/16), který tvoří kód vstupní zprávy, vyberemelibovolné číslo, nejlépe to, které dokážeme reprezentovat nejkratším binárnímzápisem. Toto kódování je velice náročné na počítání s reálnými čísly, přidelší zprávě bychom totiž již nebyli schopni dosahovat potřebných přesností,a některé subintervaly by nám mohly začít splývat, proto se používá kom-primace po blocích, kdy bloky jsou tak velké, aby zajišťovaly při rozdělovánídostatečnou přesnost. Zde se pak objevuje problém s prefixovostí tohotokódování.
Dekódování se provádí obdobně, podle přiložených pravděpodobností seprvků rozdělíme základní interval. Ten subinterval, který obsahuje kód zprávy,zvolíme jako základní pro druhý krok a na výstup pošleme jemu příslušejícíznak. Ve druhém kroku pracujeme stejně s tím rozdílem, že místo základníhointervalu uvažujeme interval, který jsme získali v předchozím kroku. Obrázek1 rovněž ukazuje způsob dekomprese, kdy stále vybíráme ten interval, kterýobsahuje kód zprávy. Na výstup pak vypisujeme znaky příslušející jednotlivýmintervalům. Rovněž lze k tomuto kódování přistupovat adaptivně, tj. pravdě-podobnosti prvků jsou relativní vzhledem k zatím zpracované části zprávy.Nemusíme pak přikládat informaci o počtu výskytů prvků v abecedě.
Zabezpečení informace při přenosuPod pojmem zabezpečení informace lze chápat jednak mechanismus umožňující na přijí-mací strnaně zjistit nebo i opravit chybu vzniklou při přenosu technickou nedokonalostípřenosového kanálu, a jednak mechanismus zabraňující přečetení informace neoprávněnouosobou.V každém připadě se zvětšuje objem dat aniž by se zvětšil objem vlastní užitečné infor-
mace, z tohoto hlediska je tedy zabezpečení chápáno jako redundance.Detekce chyby• zabezpečení paritou

Obsah 11
• kontrolní součet (CRC)• Hammingův kódZabezpečení proti neoprávněnému čtení• šifrování• podepisování
Zabezpečení paritou
Ke každému úseku dat je připojen další bit, který svou hodnotou doplňuje počet binárníchjedniček na počet lichý nebo sudý (sudá/lichá parita)10010011 10110101→ 100100110 101101011
Kontrolní součet
Data se rozdělí na úseky požadované délky (8, 16, 32 bitů) a tyto úseky se sečtou po bitechbez přenosu. Vzniklý úsek dat se připojí k datům přenášeným.
10100010 Data11010111110101010110011011000110 CRC
Hammingův kód
Kód, kterým je možné chybu nejen lokalizovat, ale i opravit se nazývá samoopravný kód. Jemožné pomocí něj lokalizovat i několikanásobné chyby.Hammingův kód je založen na principu vhodně vybrané množiny povolených hodnot.
Všechny informace jsou kódovány do těchto hodnot a je-li přijata hodnota nepatřící domnožiny, je detekována chyba a případně je chyba opravena.Výběr povolených hodnot je proveden na základě velikosti Hammingovy vzdálenosti.
Hammingova vzdálenost hodnot hi a hj je celé číslo k, které udává počet změn (z 0 na 1a opačně), které musí být provedeny, abychom z hodnoty hi dostali hodnotu hj . Všechnypovolené hodnoty mají stejnou Hammingovu vzdálenost. Je-li přijata hodnota, která je vzá-lena od povolené hodnoty méně než k/2, je opravena na nejbližší povolenou hodnotu. Je-lipřijata hodnota o vzdálenosti přesně k/2, je označena za chybnou.
Úvod do kompresních algoritmů
Úvod do kompresních algoritmůS problémem komprese se v reálném světě setkáváme na každém kroku: Potřebujeme nacpatvěci do batohu tak, aby se tam všechny vešly. To by samo o sobě řešit šlo, navíc však zpravidlapožadujeme, aby po vyndání s batohu měly stále stejnou kvalitu. U ponožek či kovadlinyzpravidla problém nemáme, ale nad objekty typu šlehačkový dort či babiččin porcelánovýservis je již potřeba přemýšlet. Ukládání věcí do skříně, nakládání věcí na nosič kola, dokufru auta či nákladového prostoru; pro věštšinu lidí na planetě pak běžnější prroblémuložení věcí do nůše či na hlavu - to vše jsou situaci, kdy potřebujeme komprimovat. Někdyse smíříme s drobnými ztrátami, zpravidla však chceme komprimovat neztrátově, tedy tak,abychom byli později (po transportu) schopní původní objekty rekonstruovat.
Základní pojmyKomprese a komprimace dat jsou v tomto textu považována za synonyma. Jejich význam je,váhně řečeno, ”snížení objemu” či ”zhuštění”. Formálně přesněji budeme kompresi chápatjako proces aplikace kompresního algoritmu (funkce) na vstupní data. Opačným procesemje dekomprese, tedy aplikace dekompresního algoritmu na data vystoupivší z kompresníhoalgoritmu. Přirozeně požadujeme, aby výstup dekompresního algoritmu byl totožný s pů-vodním vstupem kompresního algoritmu, nebo přinejmenším, aby rozdíl v těchto datech či

12 Obsah
jejich interpretaci nebyl lidskými smysly rozpoznatelný, popřípadě nebyl na újmu význam-nosti interpretace dat.
Kompresní algoritmus budeme chápat jako funkci K : D → D, kde D značíobecně data, tedy množinu všech přípustných řetězců nad abecedou {0,1}.V dalším textu přitom budeme předpokládat, že se jedná o textové řetězce,tedy nikoliv nad abecedou {0, 1}, ale řekněme např. nad abecedou tabulkyASCII.
Je-li d vstupní řetězec a s výstupní řetězec, tedy K(d) = s, požadujeme, aby —s— < —d—,navíc požadujeme, aby I(s) = I(d), kde I značí informační hodnotu daného řetězce.Základem tedy je, vypuštění nadbytečných informací. Často uváděným příkladem je
v tomto směru anglický dvojznak ”qu”. Písmeno q nikdy není osamocené, vždy po němv anglickém textu následuje písmeno u. Je tedy při jakékoliv komunikaci zbytečné písemnou uvádět, neboť pouze zatěžuje komunikační kanál, aniž by mělo jakoukoliv informačníhodnotu. Pokud totiž příjemce obdrží písmeno q, ví, že u po něm bude následovat vždy.Kompresní algoritmy samozřejmě stojí na složitějších předpokladech, tento je však natoliksnadný na pochopení, že na něm lze princip neztrátové komprese vysvětlit i člověku, kterýnemá o počítačích žádné znalosti.
Vlastnosti kompresních algoritmůNejdůležitější vlastností kompresního algoritmu je ztrátovost, resp. bezeztrátovost komprese.U bezeztrátového algoritmu jsou data zakódována tak, že z nich je možné při dekompresizrekonstruovat zpět původní data. U ztrátové komprese zpětná rekonstrukce možná není,dochází pouze k ošálení lidských smyslů, které vnímají nová data stejně, jako data původnía nepoznají tak, že došlo k jejich kompresi.Další důležitou vlastností je kompresní poměr. Při zachování notace uvedené výše je
kompresní poměr k dán vztahemk = |s|
|d| .Zpravidla požadujeme, aby k < 1, při k = 1 nedochází k žádné kompresi, při k > 1 dochází
dokonce k expanzi. Kompresní poměr se někdy namísto reálného čísla udává v procentech.Analogickou veličinou je kompresní zisk daný vztahem z = 1−k, který vyjadřuje množství
ušetřených dat vzhledem k délce původních dat.Kompresní algoritmy se dělí na statické a adaptivní. Statické metody pracují stejně nad
jakýmikoliv daty, zatímco adaptivní metody své chování přizpůsobují podle toho, jak vypadajívstupní data. Pro adaptivní metody je tedy typické, že potřebují dva průchody přes vstupnídata: Jeden, při němž data analyzují a druhý, při němž probíhá vlastní komprese.Kompresní metody lze dále rozdělit na proudové a blokové. Proudové metody pracují
s daty jako s proudem znaků (bytů) bez ohledu na délku vstupu. Bloové algoritmy umízpracovat pouze bloky dané délky. Data jsou tedy nejprve rozdělena na bloky stanovenédélky a do komprsního algoritmu poté vstupuje každý blok zvlášť.
Bezztrátová komprese
Bezztrátovou kompresí se rozumí taková, při níž je možno komprimovaná data(text, hudba, grafika) zpětně rekonstruovat tak, že nedojde k žádným změnámvhledem k datům původním.
Algoritmy realizující bezeztrátovou kompresi je možné z hlediska počtu průchodů roz-dělit na adaptivní a neadaptivní. Adaptivní nebo též dynamické metody prochází zadanádata pouze jednou a již v prvním průchodu je kódují. Naproti tomu metody neadaptivní jeprochází poprvé a zjistí četnost výskytu jednotlivých znaků (statické Huffmanovo kódování).Druhým průchodem se data zakódují daným algoritmem.

Obsah 13
Jednoduchá komprese slovníku
U dat, kde se v každém řetězci shoduje větší počet počátečních znaků s počátkem předcho-zího řetězce (typicky slovník) lze opakující se sekvenci nahradit jediným číslem, které pakumožní zpětnou rekonstrukci daného podřetězce. Příklad je uveden v následující tabulce:
Adam Adamadaptace 3ptaceadekvátní 2ekvátníadept 3ptadmirál 2mirálafekt 1fektaféra 2éraagenda 1gendaagent 4t
Porovnáme-li součet délek řetězců v prvním sloupci se součtem délek řetězců ve druhémsloupci, zjistíme, že kompresní poměr je roven 43/54, tedy bezmála 80%.
Metoda potlačení nul
Tato metoda je vhodná pro data, ve kterých se často opkauje jeden znak. Tento znak budemenazývat nulou.
Název nula není úplně náhodný. Jedná se totiž o znak kódující nevýznam-nou informaci (ticho ve zvuku, bílou plochu ve faxu, apod.). Často tedy míváčíselnou hodnotu skutečně rovnu nule.
Při kompresi textu metodou potlačení nul ukládáme do výstupního souboru všechnynenulové znaky tak, jak přicházejí na vstup. Sekvenci nul na výstup posíláme jako dvojici(i,n), kde i je indikátor komprese (je možné použít přímo nulový znak) a n je počet opakovánínulového znaku. Je zřejmé, že pro n = 1 je tato metoda neefektivní (dochází k expanzitextu), pro n = 2 nedosáhneme žádné komprese, pro n >= 3 však již k úspoře dochází.Použijeme-li navíc jako indikátor komprese některý z nenulových znaků (který se všaknesmí ve vvstupním textu vyskytovat), můžeme na výstup ukládat dvojici (i,n-3), čímž zvýšímepočet opakování nulového znaku, který ještě lze zakódovat do jenoho bytu z 255 na 258.Při jednom nebo dvou výskytech nuly zapisujeme tyto nuly na výstup stejně jako nenulovéznaky.
Znak ’-’ značí nuluVstupní text: AB---CAB----B-A-------CBVýstupnítext: ABI0CABI1B-AI4CBŘetězec 24B zkomprimován na 16B
Při dekompresi postupujeme opačně než při kompresi. Nenulové znaky ve vstupnímřetězci posíláme na výstup; při načtení indikátoru komprese na čteme číslo n a na výstupzapíšeme n+3 nul.
Metoda bitové mapy
Tato metoda opět slouží k potlačení výskytu nulových znaků, tentokrát však nepožadujeme,aby nuly tvořily dlouhé sekvence. Efektivní je tato metoda tehdy, je-li ve vstupním řetězcialespoň 1/8 nul.Kódování probíhá po osmicích znaků. Z nich vytvoříme bitovou mapu výskytu nul tak,
že na každý byte bude připadat jeden bit, který nastavíme na nulu, je-li na příslušné po-zici nulový znak a na jedničku, je-li na příslušné pozici nenulolvý znak. Na výstup potomzapíšeme bitovou mapu a sekvenci nenulových znaků.

14 Obsah
Při dekódování načteme nejprve bitovou mapu, spočteme počet jedniček a načteme pří-slušný počet nenulových znaků. Na výstup pak zapisujeme nuly a nenulové znaky podlebitové mapy.
Vstupní text: AB-CA–CBitová mapa: 11011001Výstupní text: <11011001>ABCACŘetězec 8B zkomprimován na 6B
Run Length Encoding (RLE)
Run Length Encoding neboli kódování délkami sekvencí je jednou z nejjednodušších a zá-roveň nejstarších metod, které jsou používány. Zachovává všechny výhody metody potlačenínul s tím, že dokáže efektivně zkrátit i sekvence jiných, než nulových znaků.Označíme-li symbolem an sekvenci n po sobě jdoucích znaků a, pak tuto sekvenci na
výstup zapíšeme jako Ian, kde I je indikátor komprese – znak, který se v textu nesmí vysky-tovat.
Vstupní text: abbbbcccaaaaaaaabbbbVýstupní text: aIb4cccIa8Ib4Řetězec 20B zkomprimován na 13B
Dekódování je velmi intuitivní – při načtení indikátoru komprese načteme znak a a číslon a na výstup zapíšeme sekvecni an.Podobně jako u metody potlačení nul, i u RLE můžeme posunout stupnici a místo řetězce
Ian zapisovat řetězec Ia(n-3), neboť teprve pro n >= 3 je tato metoda efektivní. Sekvence kratšínež 3 znaky ukládáme na výstup bez použití indikátoru komprese. To nám umožňuje do 1bytu uložit až 258 opakování.Problém této metody je nutnost existence indikátoru komprese, tedy znaku, který se ve
vstupním řetězci nikde nevyskytuje. To je poměrně nepříjemný požadavek, který je vhodnéřešit. Vzhledem k tomu, že metoda RLE je efektivní až při n ≥ 3, nabízí se možnost, žemísto indikátoru komprese použijeme sekvenci tří po sobě jdoucích znaků. Za ní pak budenásledovat číslo udávající, kolik znaků ještě v sekvenci zbývá. Každou sekvenci an tedynahradíme sekvencí aaa<n-3>.
Vstupní text: abbbbcccaaaaaaaabbbbVýstupní text: abbb1ccc0aaa5bbb1
Jak je vidět, pro n = 4 nedochází k žádné úspoře, pro n = 3 dochází dokonce k expanziplynoucí z toho, že je třeba uložit na výstup číslo 0. To je daň za to, že nepotřebujemeindikátor komprese a že se tak v textu může vyskytovat jakýkoliv znak.Nejčastější využití této metody je v současné době v počítačové grafice. Využívá se pře-
devším tam, kde jsou velké plochy stejné barvy. Jako hlavní metoda je použita ve formátuPCX, jako vedlejší může být v JPEG nebo TIFF. [7]
Kódování delta
Kódování delta nachází využití tam, kde dochází k lineárnímu růstu či poklesu dat. Příklademmohou být některé zvukové soubory, animace či výsledky určitých typů měření. Kódovánídelat je založené na tom, že první byte je uložen tak jak je, zatímco kažý další je ukládánjako rozdíl daného bytu a bytu předcházejícího, jak je vidět na následujícím příkladu:
Vstupní text: 10 12 14 16 18 20 15 22 29Výstupní text 10 2 2 2 2 2 -5 7 7

Obsah 15
Jak je vidět, v takto upraveném vstupu se objevují nové sekvence stejných znaků. Jepřitom zřejmé, že stávající sekvence stejných znaků jsou zakódovány sekvencemi nul (těchje o jednu méně než bylo znaků v původní sekvenci). Následné kódování RLE má tedy stejnýnebo větší efekt.
Slovníkové metody
Jedná se o adaptivní metody, které si při průchodu vytváří slovník, jenž je poté buď distribu-ován s kódem, nebo si jej dekompresní algoritmus vytvoří sám, aby bylo možné data převéstdo původní podoby. Do této skupiny se řadí různé modifikace algoritmu LZ (Lempel-Ziv),které jsou poměrně často využívány v současných formátech.
Algoritmus LZ77
LZ77, v některé literatuře označovaný jako LZ1, představila v roce 1977 dvojice AbrahamLempel a Jacob Ziv. Tito nyní izraelští vědci přišli s metodu, která je dodnes modifikovánaa kombinována s jinými metodami.Podle principu je nazývána metodou posuvného okna. Pro lepší vysvětlení předpoklá-
dejme, že budou data reprezentována řetězcem. Posuvné okno (sliding window) je rozdělenona část, kde už jsou zakódovaná data, a na část, kde jsou ta nezakódovaná.Kódování začíná nastavením sliding window na řetězec, který má být zakódován, tak, že
část pro již zakódovaná data je prázdná a druhá část je naplněna řetězcem (netřeba celým).Hledá se shoda co nejdelšího řetězce (počínajíce rozmezím) z nezakódované části s řetězcemv zakódované části. V případě shody je nový podřetězec zakódován uspořádanou dvojicí (p,n), kde p je pozice prvního znaku v zakódované části, a n je délka shodného podřetězce.
Vstupní text: leze leze po železe
Výstupní text: leze l(2,3) po že(5,4)
Dekódování probíhá přesně opačným způsobem, než kódování. Protože se při kódo-vání ukládaly odkazy na podřetězce, které byly v komprimovaném textu dříve, jsou tytopodřetězce v době dekomprese již k dispozici a je tedy možné je pomocí odkazu zpětněrekonstruovat.Jak vyplývá z předchozího, algoritmus je málo účinný tam, kde je výskyt opakování ře-
tězců (dat) nepříliš častý, případně žádný, naopak dosahuje dobrých kompresních poměrův datech, která se skládají ze shodných podřetězců. Je zřejmé, že čím větší je sliding window,tím větší šance, že se v něm najde shoda.I když je tato metoda relativně stará, stále je používána a to především jako hlavní kom-
presní algoritmus v programech GZip, Zip, PKZip, jako vedlejší v mnoha dalších (WinRARnebo 7-Zip).
Algoritmus LZ78
Druhá verze algoritmu dvojice Lempel a Ziv (proto někdy nazývána LZ2), jež byla představenao rok později, než ta první. Metoda si za běhu vytváří slovník frází stejně jako LZ77. Tentoslovník je reprezentován n-árním stromem. Prvním krokem je vytvoření kořene stromu, jenžbude mít pořadové číslo nula. Poté se začne kódovat zadaný řetězec. Přečte se první znak.Vytvoří se nový uzel s nejnižším dalším pořadovým číslem, v tomto případě jedna, který jespojen s uzlem nula ohodnocenou hranou. Ta má hodnotu znaku, který byl přečten jakoprvní. Tím je zakódován první znak, metoda vytvoří odkaz do slovníku ve tvaru (0, a), kdea je první znak. Dále se přečte druhý znak. Pokud je stejný jako první (tzn. už je ve slovníkujednou kódován), není nutné ho kódovat, a tak se k němu přečte další znak. Nyní se hledá,zda je ve slovníku tato dvojice znaků. Pokud by byla, přečetl by se další znak. Tak by sepostupovalo, dokud by se nenašla fráze, jež ve slovníku není obsažena. Jinými slovy jde o tonajít frázi, která je již ve slovníku, kromě posledního znaku. Tímto posledním znakem seohodnotí nová hrana, která povede do nového uzlu. Metoda vytvoří odkaz (c,a), kde c je

16 Obsah
číslo uzlu, ze kterého nová hrana vychází, a a je poslední znak. Poté se posune rozmezí zaposlední znak a celý postup se opakuje.Pro zpětnou rekonstrukci je nutné distribuovat jak zakódovaná data, tak i slovník. Podle
uspořádané dvojice (c,a) se rozhoduje, jak se pohybovat ve stromu – od kořene se procházístrom tak, aby se dosáhlo uzlu c. Podřetězec jedné uspořádané dvojice je složen z hodnothran, kterými se prochází, a jako poslední znak řetězce je a. Takto se dekóduje každá dvojice(c, a) a z ní se zpět složí celkový řetězec.Tento algoritmus je základem pro LZW, které je využito například v dříve velmi využíva-
ném formátu GIF.
Algoritmus LZW84
Tento algoritmus je ze všech zmíněných slovníkových algoritmů nejdůležitější, neboť je po-užíván do současnosti jako základ programu ZIP, v grafice se používá pro kompresi veformátech GIF a TIFF a důležitou roli hraje i v algoritmu PDF. Metoda byla vyvinutá v roce1984 trojicí Abraham Lempel, Jacob Ziv a Terry Welch (proto je označovaná jako LZW84).Jedná se o vylepšení algoritmu LZ78. Nevýhodou algoritmu bylo, že byl na dvacet let chráněnpatentem. Ten však v současné době již vypršel.Princip kódování je založen na opakování frází, které jsou již uloženy ve slovníku. Na
počátku proběhne inicializace, kdy se pro každý znak, který se vyskytuje ve vstupním řetězci,vytvoří položka slovníku (například pro vstupní řetězec abcab se vytvoří položky 1 a, 2 b, 3c). Poté se prochází vstupní text tak dlouho, dokud je procházený řetězec uložen ve slovníku.Jakmile narazíme na první znak, se kterým již procházený řetězec ve slovníku není, umístímenový řetězec do slovníku a na výstup zapíšeme kód položky, která ve slovníku ještě byla.Posledně načtený znak (ten, jenž porušil shodu se slovníkem) se pak stává prvním znakemnového řetězce, u nějž se hledá shoda ve slvoníku.Distribuuje se pouze výstupní kód a inicializační nastavení slovníku. Dekodér si dokáže
vytvořit slovník ze zadaných dat sám. Pseudokód komprese i dekomrese je patrně názornějšínež dlouhé vysvětlování:
LZW komprese
forall c doadd c to dictionaryw =
while read(c) doif wc is in dictionary then w = wcelseadd wc to dictionarywrite code(w)w = cendifdone

Obsah 17
LZW dekomprese
read(k)write(k)w = k
while read(k) doif k is in dictionary thenentry = dictionary entry(k)elseentry = w + w[0]endifwrite(entry)add w+entry[0] to dictionaryw = entrydone
Pro důkladné pochopení algoritmu je vhodné vzít vhodný řetězec a zkusit naněj algoritmus s pomocí tužky a papíru aplikovat.
Algoritmy připravující data pro následnou kompresiBurrows-Wheelerova transformace
Burrows – Wheelerova transformace není přímo kompresní algoritmus, ale za použití jinýchstatistických algoritmů dosahuje výrazně lepších kompresních poměrů. Jedná se o transfor-maci, která permutuje zprávy tak, že stejné znaky mají tendenci se seskupovat. Tato tendencevychází z vlastnosti jazyka, ve kterém se objevuje mnoho opakujících se posloupností.Kódování probíhá po blocích pevné délky. Vstupní text si rozložíme na bloky (slova)
o délce N, a vytvoříme si v tabulce všechny možné cyklické posuny tohoto slova. Na násle-dujícím obrázku je příklad takové permutace na slově „ABRACADABRA”. Poté tyto posunyseřadíme lexikograficky, výsledný kód pak tvoří poslední sloupce tabulky spolu s pozicí pů-vodního slova v již seřazené tabulce. V našem případě je to tedy dvojice „RDARCAAAABB”a „2”. Na obrázku je rovněž vidět tendence seskupování znaků, kdy např. 4 znaky „A” z 5 seseskupily k sobě. Toto seskupování vzniká díky tomu, že se ve vstupním slově nachází opa-kující se posloupnosti, které se při setřízení dostanou k sobě, a tím i jejich poslední písmena.Např. v anglickém textu se často vyskytuje slovo „the”, pokud by se toto slovo vyskytovalo vevstupním textu k-krát, znamenalo by to, že se v tabulce vyskytne k-krát i řádek začínající na„he” a končící na „t”, a hned je tu k potenciálních výskytů písmene „t” za sebou.

18 Obsah
Při dekódování si budeme budovat stejnou tabulku jako při kódování. Na začátku známepouze poslední sloupec a číslo řádku, kde se nachází původní text. První sloupec dostanemejednoduchým setříděním posledního (toto vychází z lexikografického uspořádání řádků přikódování). Známe-li pozici slova v tabulce, tak též známe první znak slova, který se nacházína dané pozici slova v prvním sloupci. Druhé písmeno zjistíme tak, že si první znak najdemev posledním sloupci (n-tý výskyt písmene v prvním sloupci musí odpovídat n-tému výskytuv posledním sloupci), a jemu příslušející znak v prvním sloupci (tj. na stejném řádku) je nášhledaný druhý znak. Ostatní se hledají zcela analogicky.Při dekódování si budeme budovat stejnou tabulku jako při kódování. Na začátku známe
pouze poslední sloupec a číslo řádku, kde se nachází původní text. První sloupec dostanemejednoduchým seřazením posledního (toto vychází z lexikografického uspořádání řádků přikódování). Známe-li pozici slova v tabulce, tak též známe první znak slova, který se nacházína danépozici slova v prvním sloupci. Druhé písmeno zjistíme tak, že si první znak najdeme
v posledním sloupci (n-tý výskyt písmene v prvním sloupci musí odpovídat n-tému výskytuv posledním sloupci), a jemu příslušející znak v prvním sloupci (tj. na stejném řádku) je nášhledaný druhý znak. Ostatní se hledají zcela analogicky.
Move to Front transformace
Používá se nejčastěji pro výstupy, které mají podobné charakteristiky jako výstup z Burrows –Wheelerovy transformace. Opět se nejedná o kompresní algoritmus, ale o jakousi předúpravupro ostatní kompresní algoritmy.Při kódování budeme využívat pole na počátku naplněné hodnotami (0, 1, 2, 3,. . . , 255).
Znaky ze vstupu se nahrazují na výstupu jejich pozicemi v poli, a přitom se ihned přesouvajína počátek pole.Příklad: Místo bytů budeme kódovat hodnoty v rozmezí a-z. Chceme zakódovat sekvenci
„bananaaa”. Pole na počátku obsahuje „abcdefghijklmnopqrstuvwxyz”. První písmeno slovaje „b”, které se objevuje na indexu 1. Dáme tudíž 1 na výstup. „b” se přesouvá na začátekpole, tj. nyní má pole tvar „bacdefghijklmnopqrstuvwxyz”. Další písmeno slova je a, kterése nyní objevuje na indexu 1, takže dáme 1 na výstup. Poté přesuneme písmeno zpátky nazačátek pole, stejným způsobem pokračujeme dále, než zakódujeme celé slovo. Výstupemtedy bude sekvence ”1, 1, 13, 1, 1, 1, 0, 0”, jak je vidět z následující tabulky:
Znak Výstup Poleb 1 abcdefghijklmnopqrstuvwxyza 1,1 bacdefghijklmnopqrstuvwxyzn 1,1,13 abcdefghijklmnopqrstuvwxyza 1,1,13,1 nabcdefghijklmopqrstuvwxyzn 1,1,13,1,1 anbcdefghijklmopqrstuvwxyza 1,1,13,1,1,1 nabcdefghijklmopqrstuvwxyza 1,1,13,1,1,1,0 anbcdefghijklmopqrstuvwxyza 1,1,13,1,1,1,0,0 anbcdefghijklmopqrstuvwxyz

Obsah 19
Při dekódování se postupuje obdobně, při přečtení indexu ze vstupu se na výstup pošleznak, který se v poli nachází na daném místě, a zároveň se opět přesune na počátek pole. Jezřejmé, že tato transformace bude opakující se znaky kódovat znakem 0, nebo znaky blízkýminule. Proto byla tato transformace primárně určena jako mezistupeň k Burrows-Wheelerovětransformaci a Huffmanovu kódování.
Použitá literatura
[1] http://en.wikipedia.org/wiki/LZ77[2] http://service.felk.cvut.cz/courses/X36KOD/stud/kodcvic.pdf[3] http://www.stringology.org/DataCompression/lz77/index cs.html[4] http://www.maximumcompression.com/programs.php[5] http://www.cs.vsb.cz/benes/vyuka/pte/texty/komprese/ch02s02.html[6] http://cs.wikipedia.org/wiki/Huffmanovo k%C3%B3dov%C3%A1n%C3%AD[7] http://cs.wikipedia.org/wiki/RLE[8] http://cs.wikipedia.org/wiki/Shannon-Fanovo k%C3%B3dov%C3%A1n%C3%AD[9] http://www.binaryessence.com/dct/en000140.htm[10] http://cs.wikipedia.org/wiki/LZW84
Komprese multimediálních dat
Komprimace multimediálních dat
Komprimace umožňuje efektivní digitální reprezentaci zdrojového signálu jako je text, obraz,zvuk nebo video, použitím redukovaného počtu prvků digitální informace, než má originál.Musí však umožňovat, pokud má být efektivní, reprodukci komprimované informace v po-žadované kvalitě.Pro komprimaci dat v současných informačních a komunikačních systémech hovoří tři
základní důvody:
• rozsáhlé paměťové nároky multimediálních dat,• relativně pomalá paměťová zařízení, která neumožňují přehrávání multimediálních datv reálném čase,
• nedostatečná šířka pásma současných sítí pro přenos videa a často i zvuku v reálnémčase.
Předpokládejme barevnou videonahrávku s rámci o rozměru 620 x 560 pixelů srozlišením24 bitů na pixel. Pro uchování jednoho rámce by bylo potřeba asi 1 MB paměti. Pro plynulépřehrávání videa s frekvencí 30 fps to představuje celkem 30 MB paměti na sekundu videa.I v případě dostatečné paměťové kapacity pro uložení videa, nám rychlost přenosových
médií neumožní přehrát video v reálném čase. Současné běžné technologie umožňují přenospřibližně 1,2 MB/s. Proto je zatím jedinou možností použití komprimačních metod.Pro různé typy formátů používáme různé komprimační algoritmy.
Komprese rastrového obrazu
Rastrové obrazy se vyznačují vysokou paměťovou náročností, která roste kvadraticky s jejichrozlišením. Na rozdíl od komprese obecných souborů lze vycházet z vlastností a charakte-ristických rysů konkrétního rastrového obrazu.Velký objem dat a zároveň specifický tvar obrazových informací jsou podnětem pro pou-
žívání různých druhů kompresí. Na rozdíl od bezztrátové komprese běžných datových sou-borů, při které nesmí být žádná data ztracena či změněna, je u rastrových obrazů mnohdyžádoucí docílit co nejvyššího kompresního poměru i tím, že pozměníme barevné hodnotypixelů a zhoršíme tak výsledný obraz použitím ztrátové komprese.

20 Obsah
Používané kompresní metody
Kompresní metoda Zkratka Ztrátová Príklad formátuRun length encoding RLE ne PCXHuffmanovo kódování CCITT ne TIFFLempel-Ziv-Welch LZW ne GIFDiskrétní kosinová transformace DCT ano JPEGFraktální komprese FIF ano FIFRun length encodingJednoduchá a pro velkou třídu obrázků i efektivní metoda vycházející z předpokladu, že
v rastrovém obrázku, vzniklém jako kresba či skica, se opakují hodnoty sousedících pixelů.1 citac hodnota hodnota se opakuje 1 + citac0 hodnota primy zapis jedine 7-bitove neopakujici se hodnoty10000000 hodnota zapis neopakujici se hodnoty vetsi nez binarne 10000000
Ve většině případů je kódování RLE prováděno v rámci jednoho řádku. V případě, že jeobrázek tvořen mnoha vodorovnými čarami, je kódování velmi efektivní. Avšak tentýž obrazotočený o 90 stupňů je zapsán téměř beze změny.V případě, že kódovaný obrázek obsahuje neopakující se hodnoty v sousedních pixelech,
dochází k záporné kompresi. Lze se setkat i se ztrátovou kompresí RLE, kdy se nejprve testujísousední pixely a pokud se liší jen nevýznamně, nahradí se hodnotou jednou.Metoda RLE je vhodná pro obrázky kreslené od ruky nebo pro ilustrace s většími stejno-
barevnými plochami.Huffmanovo kódováníPůvodně navrženo komisí CCITT pro přenos černobílých dokumentů faxem.Metoda je založena na použití různě dlouhých bitových kódů pro symboly s různou
frekvencí výskytu. Frekvence se nestanovuje pro konkrétní dokument, ale je brána z tabulekCCITT.
G31D 5:1 odolné proti poruchám,zakódováno pomocí RLE, pak Huffmann.
G32D 8:1 citlivé na poruchy,kóduje se změna barvy relativně k předchozí.
G42D 15:1 zápis na disk,jako G32D, ale bez zbytečných kódů.
Lempel–Ziv–WelchZcela obecná metoda, se kterou se setkáváme ve většině běžných kompresních programů.Princip spočívá v nahrazení vzorků vstupních dat binárními kódy proměnné délky. Vstupní
vzorky se překládají pomocí slovníku, který je postupně doplňován o nové vzorky.Diskrétní kosinová transformace JPEGPro velmi kvalitní obrazy s mnoha barevnými přechody se metody RLE a LZW nehodí.
Metoda je vhodná především pro kódování fotografií, u nichž sousední pixely mají sice od-lišné, ale přesto blízké barvy. Snižování kvality se projevuje potlačováním rozdílů v blízkýchbarvách. U metody DCT je kompresní poměr řízen požadavkem na výši kvality dekompri-movaného obrazu. V praxi se ukazuje, že snížení kvality na 75 % je pro většinu uživatelůnepozorovatelné, přitom kompresní poměr v takovém případě může být až 25:1.DCT je formou diskrétní Fourierovy transformace. Obrazová data jsou považována za
barevné vzorky spojitých barevných signálů naměřené v diskrétní síti pixelů. Výsledkemkosinové transformace je pak nalezení sady parametrů kosinových funkcí, jejichž složenímlze rekonstruovat původní obraz.Postup při kompresi sestává z 5 kroků.
1. transformace barev – barvy je třeba převést do barevného modelu Y CBCR. V další fázijsou jasové složky Y a barevné složky CB , CR zpracovávány odděleně.
2. redukce barev – snižování objemu dat zprůměrováním barevných složek sousedníchpixelů.
3. dopředná diskrétní kosinová transformace – obrazová data jsou rozdělena do čtverců8 × 8. Každý čtverec je podroben diskrétní kosinové transformaci. Výsledkem je řídkámatice s dominantním levým horním rohem.
4. kvantování koeficientů – zde se stanovuje kvalita (tedy i stupeň komprese) obrazu.5. kódování – používá Huffmanovo kódování s využitím toho, že většina koeficientů

Obsah 21
v okolí pravého dolního rohu má nulovou hodnotu.
Transformace barevNejprve je potřeba převést obrázek z RGB do Y CBCR. Tento barevný model má tři složky
Y CBCR: Y reprezentuje jas pixelu a CB , CR reprezentují barvu pixelu (modrá a červenásložka). Toto barevné schéma umožňuje aplikovat kompresi s lepším výsledkem při stejnékvalitě obrazu.Redukce barevLidské oko je citlivější na změny jasu obrazu než na změny odstínů barev. Tohoto faktu
se využívá ke zvýšení efektivity komprese obrazu. Je tak možné redukovat složky CB , CR.Redukcí barev lze ušetřit 33–50 % paměťového prostoru.Rozdělení do blokůPo redukci barev následuje rozdělení každého barevného kanálu obrazu na bloky o veli-
kosti 8× 8 pixelů. Na ty je následně aplikována diskrétní kosinová transformace (DCT).
Diskrétní kosinová transformaceF (u, v) = 1/4× C(u)C(v)
hP7x=0
P7y=0 f(x, y) cos (2x+1)uπ
16 cos (2y+1)uπ16
i

22 Obsah
Kvantování koeficientůLidské oko je citlivé na malé změny jasu v relativně velké oblasti. Nedokáže však odlišit
přesnou hodnotu rozdílů odstínů vysokých frekvencí. Toho lze využít při redukci nesené in-formace u vysokofrekvenčních koeficientů. Kvantizace redukuje amplitudu koeficientů, kterénepřispívají ke kvalitě obrazu. Účelem je také odstranění informace, která není pozorovatelná.Výsledkem je, že většina vysokofrekvenčních koeficientů je nulová.
kvantizační tabulka

Obsah 23
kvantované koeficientyKódováníVýsledkem předchozích kroků byly numerické úpravy čtvercové podoblasti vstupního
obrazu, které zjednodušily tvar dat do podoby řídké matice s dominantním levým rohem.Tato matice je nyní zapisována do výstupního souboru postupem CIK-CAK. Při kódování jepak využíváno skutečnosti, že většina koeficientů má nulovou hodnotu. Pro zakódování sepoužívá aritmetické nebo Huffmanovo kódování.
-26-30-3-2-62-41-411512-11-1200000-1-100000000000000000000000000000000000000

24 Obsah
DekódováníDekódování JPEG obrázku probíhá opačným postupem než kódování.

Obsah 25
SrovnáníTyto dva obrázky ukazují rozdíl mezi původním obrazem a obrazem po komprimaci
metodou JPEG.
výsledný a původní obrázekFraktální kompreseModerní, teprve se rozvíjející metoda ztrátové komprese. Patří mezi nesymetrické kom-
presní postupy, čas komprese a dekomprese se významně liší.Je založena na principu vyhledávání podobností (tvarových, barevných) v různě velkých
částech obrazu. Algoritmus FIF se nejprve snaží vhodně rozdělit obraz na menší, nestejněvelké části (domény), a poté z nich pomocí různých transformací poskládat celý obraz.Celkově je kvalita výsledných obrázků lepší než při použití metody DCT. Jedinou nevý-
hodou zůstává delší doba komprese nutná pro analýzu obrazu.
Komprimace audio signáluKvalitní digitální stereozáznam používá vzorkovací frekvenci 44,1 kHz, což odpovídá dato-vému toku 176400 bytů za sekundu.

26 Obsah
Komprimace zvuku se uplatňuje v oblasti přenosu lidského hlasu, kde lze použít nižšíchvzorkovacích frekvencí a predikce chování akustického signálu. Druhou oblastí je hudebnísignál, kde se naopak využívají vysoké vzorkovací frekvence a uplatňuje se psychoakustickýmodel sluchu.
Bezeztrátová komprese audio signálu
PCM
PCM je nejjednodušší kódování zvukových dat, zvuk ukládán nekomprimovaně. Proto jevhodné jej používat pouze pro nahrávaní v nejvyšší možné kvalitě. Navzorkovaná data jsouuložena bez jakéhokoliv zpracování jako posloupnost celočíselných hodnot. Taková datajsou pak snadno interpretovatelná a zpracovatelná, zabírají však příliš mnoho prostoru. Datav tomto formátu jsou rovněž nejpřesnější a případné kompresní formáty z tohoto formátuvycházejí. PCM záznam se používá 8bitový nebo 16bitový, kdy pro uložení jednoho vzorkuslouží 1B, resp. 2B. Některé aplikace také podporují 24bitové nebo 32bitové vzorky. U mono-fonních nahrávek jsou vzorky uloženy přímo za sebe, u stereofonních nahrávek je na lichýchmístech levý kanál a na sudých místech pravý kanál.
ADPCM (Adaptive Differential PCM)
Diferenciální PCM kóduje hodnoty vzorků jako rozdíl mezi současnou a předchozí hodnotou.Takto kódované soubory jsou přibližně o 25% menší než původní PCM. Adaptivní DPCMnavíc oproti DPCM dovolují proměnnou velikost kódovacího kroku kvůli možnosti dosaženílepší komprese.
FLAC
FLAC (Free Lossless Audio Codec) je volně šiřitelný bezztrátový kodek, podporovaný nařadě platforem a je velmi snadno dekódovatelný. Tento kodek využívá fakt, že u zvukovýchsouborů bývá velmi velká podobnost u sousedních vzorků.
Ztrátová komprese
MP3
MP3 spadá do skupiny kompresních algoritmůMPEG. MPEG (Moving Picture Experts Group)pracuje pod vedením International Standards Organization (ISO) a International Elektro-Technical Commission (IEC) a zabývá se kódováním videa a audia. MPEG standardy se dělí:
• MPEG 1 kódování videa a audia pro uložení na digitálních mediích, datový tok do1.5Mbit/s
• MPEG 2 kódování při nižších datových tocích, poloviční vzorkovací frekvence• MPEG 3 původně plánováno pro HDTV, později spojeno s MPEG 2• MPEG 4 kódování audiovizuálních objektů (např. pro media objects, syntézu zvuku)Každý standard obsahuje několik částí, které popisují kódování audia, videa, synchro-
nizačních dat a formáty uložení kódovaných dat. MPEG standard obsahuje několik vrstevLayer I-III, které popisují kódovací schémata. Od Layer I do Layer III roste komplexnosta efektivita komprese zvuků, ale klesá rychlost kódování a dekódování. Zvuková schémata sedělí:
• Layer I nejjednodušší schéma, původně je určeno pro Digital Compact Cassette (DCC)• Layer II kompromis mezi kvalitou, rychlostí a kompresním poměrem• Layer III od začátku vytvářeno pro nízké bitové proudy, vylepšené kódováníMyšlenka vytvoření ztrátového kompresního algoritmu pro zvuková data se zrodila v roce
1987 ve Fraunhofer Institut Integrierte Schaltungen (IIS). Využívá se ve specifikaci MPEG 1a 2 a označuje se jako Layer III (MP3).1. Kódovaný zvuk se rozdělí na 32 frekvenčních pásem. Každé toto pásmo se kódujezvlášť. Jednotlivá pásma jsou široká 625 Hz. Pásma jsou na nízkých frekvencích užšía na vyšších širší (kvůli citlivosti ucha na různé frekvence).
2. Je použita ztrátová komprese – kvantizace. Kvantizační koeficienty se vypočítávají dy-namicky podle dosažené akustické hladiny zvuku tak, aby šum vzniklý použitím kvan-tizace byl pod rozlišovací schopností ucha. Využívá se psychoakustického modelu.
3. Vypočtený signál se kóduje Huffmanovým kódováním.

Obsah 27
4. Výsledná kvalita je určena datovým tokem.
GSM kodek (Global System for Mobile communications)
GSM je mobilní bezdrátový komunikační systém velmi rozšířený zejména v Ev-ropě. GSM kodek je nenáročný kodek s vysokou kompresí, primárně určený prozáznam lidského hlasu a naprosto nevhodný pro náročnější nahrávky a hudbu.GSM kodeky operují nad vstupnímmonofonním zvukem s frekvencí 8kHz, jsouvšak aplikovatelné i na vyšší vzorkovací frekvence.
Mp3 Pro
Mp3 Pro je vyvinutý z původního kodeku Mp3, jenž byl probírán na před-nášce. Kombinací souboru Mp3 o nízkém datovém toku s vysoce komprimo-vanými vysokými frekvencemi je dosaženo vyšší kvality uchovávaného zvuku.Výsledný soubor zachovává v dobré kvalitě jak basy, tak výšky záznamu. Natomto kodeku je zajímavé, že původní Mp3 část je stále kompatibilní s pře-hrávači formátu Mp3. Algoritmus však není volně šiřitelný a proto není přílišrozšířený.
Ogg Vorbis
Ogg je skupina audio i video kodeků vyvíjených neziskovou organizacíXiph.org. Nejrozšířenějším z těchto kodeků je dosud Vorbis, určený pro kva-litní záznam hudby. Při stejných parametrech jako Mp3, dosahuje lepší kvalityzáznamu. Jeho vývoj je zcela otevřený s volně šířitelnými zdrojovými kódya nevyžaduje žádnou licenci. Vorbis je určen pro datové toky 8 – 192 kbpsa podporuje až 255 nezávislých kanálů. Kodek je ve své podstatě VBR, a protonemusí nastavení datového toku vždy zcela odpovídat toku výslednému. Jdeo dopředný, adaptivní, monolitický kodek, který využívá modifikovanou dis-krétní kosinovou transformaci a používající rovněž psychoakustický model.Dekódování je výpočetně méně náročné než u algoritmu Mp3, je všaknáročnější paměťově.
WMA
Windows Media Audio společnosti Microsoft byl z počátku vyvíjen jako kon-kurence Mp3 kodeku, v dnešní době spíše jako konkurence AAC. Kompresníalgoritmy jsou stále zdokonalovány a v dnešní době poskytuje znatelně lepšíkvalitu než kodek Mp3. WMA komprese je obvykle použita v souborech .asf,pokud soubor obsahuje pouze zvuková data , bývá jeho přípona .wma. Zdro-jové kódy nejsou volně k dispozici.
MPEG2 AAC (Advanced Audio Coding)
AAC je nástupce komprese Mp3, který již z důvodu dosažení lepší kvalitynení zpětně kompatibilní. V dnešní době představuje nejkvalitnější kompresníalgoritmus, není však příliš rozšířený. Podporuje vzorkovací frekvence od 8do 96 kHz, datový tok od 16 do 576 kbps a záznam až 48 zvukových kanálů.Nástroje pro práci s AAC používají modulární přístup a umožňují nastavenírůzných poměrů výpočetní složitost/výsledná kvalita.
Psychoakustický model

28 Obsah
Umožňuje odstranění dat lidským sluchem nepostižitelných a tedy v signálu redundant-ních, bez znatelné újmy na kvalitě reprodukovaného signálu.1. omezení frekvenčního rozsahu – využívá omezené citlivosti lidského ucha. Přenosovéhopásmo se omezuje na šířku 20 Hz až 20 kHz.
2. maskování frekvencí – využívá nelinearity citlivosti lidského sluchu. V přítomnosti sil-nějšího signálu nedokážeme vnímat slabší signál, který zaniká a není třeba jej tedyuvažovat.
3. časové maskování – využívá setrvačnosti lidského sluchu. I po zániku silnějšího signáluchvíli trvá, než začneme vnímat současně působící slabší signál.
Komprimace videaVideo je reprezentováno jako posloupnost rámců ve formátech RGB, YUV... Vjem spojitéhopohybu vzniká při přehrávání rámců frekvencí 15 fps a vyšších. Pro zobrazování videa v te-levizních formátech i ve formátech pro PC jsou různé avšak metody pro jejich komprimacejsou v podstatě stejné.Stejně jako při komprimaci audia i při komprimaci videa je potřeba vynucena nedosta-
tečnou kapacitou přenosových médií.Ideální metoda komprimace• přehrávání bez nutnosti použití drahých technických zařízení,• přizpůsobit se (postupným snižováním kvality) při přetížení přenosové sítě anebo připoužití na méně výkonném hardware,
• komprimace v reálném čase bez nutnosti použití nákladného hardware.
Pro bezezrtátovou kompresi videa lze požít kodek HuffYUV, který komprimujevideo s použitím Huffmanova kódování. V nejlepším případě komprimuje ažna 40 % původní velikosti. Zvládá kompresi obrazu v barevném formátu RGBi YUV, je velmi rychlý a je zdarma.
Formát MPEGMPEG je zkratkou pro Moving Picture Experts Group 4. Cílem práce této skupiny bylo
standardizovat metody komprese videosignálu a vytvořit otevřenou a efektivní kompresi.Formát MPEG-1 byl dokončen v roce 1991 a jako norma přijat roku 1992 - ISO/IEC-11172.Byl navržen pro práci s videem o rozlišení 352x288 bodů a 25 snímků/s při datovém toku1500kbit/s. Parametry komprese MPEG-1 jsou srovnávány s analogovým formátem VHS.Formát MPEG-1 se stal součástí tzv. „White Book”, což je definováno jako norma pro
záznam pohyblivého obrazu na CD (74 minut videa). MPEG komprese používá ke kompresividea I, P a B snímky:
• I snímky (Intra Pictures) jsou snímky klíčové, jsou komprimovány podobně jako MJ-PEG, ale navíc s možností komprimovat různé části obrazu různým stupněm komprese.
• P snímky (Predicted Pictures) jsou kódovány s ohledem na nejbližší předchozí I neboP-snímek.
• B snímky (Bidirectional Pictures) jsou pak dopočítávané jako rozdílové snímky mezinejbližším předchozím I nebo P-snímekm a nebližším následujícím I nebo P-snímkem.
Celá sekvence snímků (od jednoho I po další I snímek) se pak nazývá GOP (Groupof Pictures) a standardní MPEG stream pro VCD, SVCD a DVD používá pořadí IBBPBB-PBBPBBPBBPBB. Přesto MPEG standard neurčuje žádná pravidla a omezení pro vzdálenostI a P snímků. Komprese navíc umožňuje kdykoliv ukončit GOP a předčasně tak použít dalšísekvenci GOP začínající snímkem I. Toto vede především ke zlepšení kvality videa. Kompri-mované video obsahující proměnlivé vzdálenosti mezi klíčovými snímky se pak nazývá VKI(Variable Keyframe Interval). Počet I, P a B snímků lze většinou nastavit, záleží na imple-mentaci kompresoru.Komprese MPEG-1 se nehodí pro střih videa z důvodu vzdálených klíčových snímků.
Většina střihových programů však umožňuje export do formátu MPEG-1. Tento formát jetotiž jeden z nejrozšířenějších a lze jej softwarově přehrát téměř na každém počítači a stejnětak na 95 % všech stolních DVD přehrávačích. Tento formát lze také streamovat. Bohuželv dnešní době je již tento kodek zastaralý, přesto je to nejkompatibilnější formát. Co se týčekvality, je v porovnání s jinými kodeky na tom poněkud hůře, protože abychom dosáhli,

Obsah 29
dobré kvality obrazu, potřebuje mnohem více bitů na kompresi než u jiných kodeků (DivX,XviD).Po dokončení MPEG-1 standardu jej začali lidé používat, a snažili se jej používat i na
vyšší rozlišení. Narazili ale na několik problémů, kvůli kterému byl MPEG-1 nepoužitelný.Komprese MPEG-1 zvládá komprimovat pouze celé snímky. Nepodporuje však kompresiprokládaných snímků. Formát MPEG-2 byl společností MPEG dokončen v roce 1994 a stalse standardem pro kompresi digitálního videa. Byl navržen tak, aby dosahoval vysílací kva-lity videa. Oproti MPEG-1 přináší komprese MPEG-2 podporu pro prokládané snímky, tedypůlsnímky. Dále proměnlivý datový tok, což umožňuje v náročnějších scénách videa použítvíce bitů pro kompresi a naopak v klidnějších scénách se použije méně bitů. Samozřejmě dálepodporuje i konstantní datový tok. Při stejném datovém toku a plném rozlišení (720x576) do-sahuje MPEG-2 mnohem vyšší kvality obrazu než MPEG-1 komprese. Nevýhodou kompreseMPEG-2, je na druhou stranu velmi vysoké zatížení procesoru při přehrávání, a praktickyžádný rozdíl v kvalitě oproti MPEG-1 kompresi při nízkých rozlišeních. Pro streamovánív nízké kvalitě je tedy vhodnější komprese MPEG-1, zatímco pro plné rozlišení a vysokédatové toky zase MPEG-2.MPEG-4 byl vyvinut opět společností Moving Picture Experts Group. Není to již přesná
definice komprese a komprimačních algoritmů, nýbrž je to množina parametrů a vlastností,které musí kompresor splňovat, aby byl MPEG-4 kompatibilní. Známe tedy různé imple-mentace MPEG-4, které vybírají z definice MPEG-4 vždy to, co je pro daný formát vhodnější.Kodeky využívající způsoby komprese MPEG-4 jsou např. Microsoft MPEG-4 vl, v2 a v3,DivX 4, DivX 5, XviD a další
ASF, WMV
Firma Microsoft si všimla úspěchů na poli streamovaného videa, kterých dosahovaly spo-lečnosti Apple a RealNetworks svými formáty Quicktime, MOV a RM, a vyvinula vlastníformát ASF (Advanced Streaming Format), určený především pro stream videa. ASF je formáti komprese, vychází z formátu AVI a dovoluje použít pouze kompresi Microsoft MPEG4.Firma Microsoft uvedla i formát WMV, který je novější verzí ASF. Komprese ASF částečněimplementuje MPEG4, nepodporuje totiž B-snímky.QuicktimeQuicktime je formát vyvinutý firmou Apple, který byl v dřívější době, kdy mu nekonku-
roval MPEG velmi zajímavý a používaný. Je přenositelný mezi PC a Macintosh platformami,používá kompresi 5:1 až 25:1. Dnes se používá například na prezentačních CD a pro videostreaming. Přesto v dnešní době již tento formát má poměrně nízkou kvalitu obrazu přidaném datovém toku oproti jiným kodekům. Nutný je také přehrávač firmy Apple.RealVideoReal Video a Real System G2 jsou formáty komprese vyvinuté firmou Real Networks.
Má podobné vlastnosti jako Quicktime, ale je primárně zaměřen na kompresi streamova-ného videa. Pro kompresi do tohoto formátu se používá program Helix Producer firmy RealNetworks. Pro přehrávám je pak určen program Real Player téže firmy.DivX 5Kodek je kompatibilní s MPEG-4, komprimuje do formátuMPEG-4 Simple Profile a zvládá
přehrávání předchozích verzí kodeku DivX a formátů MPEG-4 Simple Profile, MPEG-4Advanced Simple Profile a H.263 (videokonference). DivX 5 používá pokročilejší technikypři kompresi a oproti DivX verze 4 dosahuje zlepšení kvality až o 25 % při zachování veli-kosti souboru. DivX 5 má integrované některé nástroje/filtry v sobě a umožňuje tak přímopři kompresi změnit rozměry obrazu, aplikovat filtr rozprokládání, ořezat obraz a jiné. Dáleimplementuje algoritmy pro zvýšení komprese využitím tzv. psychovizuálního modelu. Přiněm se dosahuje lepší komprese bez znatelné ztráty kvality a to díky znalostem o lidskémvizuálním systému. Implementuje obousměrnou kompresi, tedy B-snímky. Dále tzv. globálníkompenzaci pohybu, což je algoritmus, který optimalizuje kompresi pro panorámování, roz-tmívání obrazu, přibližování, náhlé změny jasu (exploze), stagnující plochy (voda) a další.Kodek podporuje také export do formátu MPEG-4 a konverzi mezi ním a AVI formátem.DVV současnosti nejpoužívanější formát pro kompresi videa v digitálních kamerách. DV
komprimuje každý snímek videa zvlášť za použití diskrétní kosinové transformace. Ještěpředtím, než se transformace provede, tak jsou některé informace o barvě odstraněny zapoužití chromatického subsamplingu, aby se zredukovalo množství dat nutných ke kompresi.Tento kompresní algoritmus je velmi dobrý a lze jej srovnávat s kompresemi bezztrátovými.

30 Obsah
Indeo Video 5.20
Tento kodek 2 byl vyvinut společností Ligos. Má poměrně dobrou kvalitu ob-razu. Ke kompresi používá Wavelet kompresi. Lze nastavit, aby každý snímekbyl klíčový. Při nastavení kvality na 100 % je výsledný obraz téměř k neroze-znání od nekomprimovaného. Kodek je poměrně pomalý a na danou kvalitudělá poměrně velké soubory.
H.261 a H.263
H.261 je standard pro videokonference a videotelefonu přes ISDN. Umožňujeregulovat tok dat v závislosti na propustnosti sítě. Přenos dat je 64kbit/s nebo128kbit/s (dva kanály ISDN). Kodek H.263 implementuje vyšší přesnost připohybu než H.261. Jeho použití je pro monitorovací systémy a pro videokon-ference s velkou obrazovkou.
Microsoft Video 1
Tento kodek je standardní součástí všech operačních systémů firmy Microsoftod verze Windows 95. Kvalitou výsledného obrazu je ovšem velice špatný. I přinastavené 100% kvalitě je pozorovatelné čtverečkování a jiné nepříjemné vadyv obraze. Kodek je navíc poměrně pomalý a takto zakódované video je dokoncevětší než stejné video zkomprimované bezeztrátovým kodekem HuffYUV!
M-JPEG
Kompresní kodek M-JPEG (Motion JPEG) je založen na kompresi jednotli-vých snímků použitím komprese JPEG. Tento kodek má většinou volitelnýkompresní poměr v rozmezí 6:1 do 16:1. Při kompresním poměru 8:1 jekvalita obrazu stále ještě velmi dobrá a datový tok se pohybuje kolem 4 MB/sa osahuje tak dobrého poměru kvalita/datový tok. Velikou předností tohotokodeku je, že každý snímek je komprimován samostatně a je tedy vždy klíčový.Proto je tento kodek velmi vhodný pro střih videa na počítači. Zároveň je im-plementován hardwarově v mnoha polo-profesionálních zachytávacích kartácha zachytávání pak funguje bezproblémově i na velmi pomalých počítačích.Softwarový kodek komprimující video kodekem MJPEG je například PlCVideoMJPEG Codec 3.
Úvod do kryptologie
Úvod do kryptologie
V této kapitole se seznámíme se základními pojmy týkajícími se kryptologie. Řekneme si, corozumíme pojmy otevřený text, šifrový text, klíč či šifrovací algoritmus. Naučíme se rozlišovatkryptologii a kryptografii. Také se seznámíme se základními zvyklostmi pro označování prvkůšifrované komunikace.
Kryptologie je vědní obor zabývající se šifrováním a dešifrováním zpráv. Zahr-nuje v sobě kryptografii a kryptoanalýzu. Kryptografie označuje nauku o šif-rování, kraptoanalýza se pak zabývá lámáním šifer (tj. luštěním bez znalostiklíče).

Obsah 31
Historie kryptologie je neustálý boj kryptografie a kryptoanalýzy. V některých obdobíchdějin měla navrch kryptoanalýza, jindy naopak kryptografie. V současné době vítězí kryp-tografie, neboť existují šifrovací algoritmy, jež není možné v rozumném čase zlomit. To jepoměrně praktické: Kdyby tomu tak nebylo, těžko bychom si mohli představit např. interne-tové bankovnictví. V historii však byla i taková období, kdy vítězila kryptoanalýza a tedy bylomožné rozlomit jakoukoliv v té době známou šifru. Je zřejmé, že taková období vedou k po-měrně značné depresi mezi kryptografy a důležitá komunikace je značně ohrožena. Jak siukážeme v dalších kapitolách, současné vítězství kryptografie nad kryptoanalýzou je poěrněkřehké. Je založeno na doměnkách, které nejsou matematicky dokázané. Jedná se předevšímo problém, zda P = NP z teorie složitosti a neschopnost rozkladu velkcýh čísel na součin pr-vočinitelů v rozumném čase. Kdyby se podařilo ukázat, že P = NP, nebo kdyby někdo objevilrychlý způsob faktorizace, znamenalo by to konec současné podoby kryptografie.Samotné slovo kryptografie pochází z řečtiny a jedná se o spojení dvou slov: kryptos =
skrytý, graphein = psát. Kryptografie je tedy skryté (tajné) psaní.
Kryptografie je věda o matematických technikách spojených s hledisky infor-mační bezpečnosti, jako je důvěrnost, integrita dat, autentizace a autorizace.
Cíle a metody kryptografie
Jak je vidět z předchozí definice, kryptografie má několik cílů. Jsou jimi:
• důvěrnost (confidentiality) - též bezpečnost - jedná se o udržení obsahu zprávy v taj-nosti. Zabezpečení této služby je nejdůležitějším cílem kryptografie.
• celistvost dat (data integrity) - též integrita - jedná se o zamezení neoprávněné mo-difikace dat. Tato modifikace může být smazání části dat, vložení nových dat, nebosubstituce části stávajících dat jinými daty. Se zamezením neoprávněné modifikacesouvisí i schopnost tuto modifikaci detekovat.
• autentizace (authentication) - též identifikace, neboli ztotožnění - znamená prokazo-vání totožnosti, tj. ověření, že ten, s kým komunikujeme, je skutečně ten, se kterýmsi myslíme, že komunikujeme. Autentizace může probíhat na základě znalosti (heslo),vlastnictví (klíče od bytu, kreditní karta) nebo charakteristických vlastností (biomet-rické informace - např. otisky prstů).
• autorizace (authorization) - je potvrzení původu (původnosti) dat. Tedy prokázání, žedata vytvořil (je jejich autorem) skutečně ten, o němž si myslíme, že je autorem.
• nepopiratelnost (non-repudiation) - souvisí s autorizací - jedná se o jistotu, že autordat nemůže své autorství popřít (např. bankovní transakci).
Uvedené pojmy jsou důležité nejen v kryptografii, ale operuje se s nimi i v oblastechsouvisejících s bezpečností a informačními systémy. Znalost jejich významu je tedy (nejen)pro informatika velmi důležitá.Základními metodami kryptografie jsou substituce a transpozice. Substituce znamená
nahrazení znaků zprávy jinými znaky, transpozice pak jejich přeskládání. Podrobněji sebudeme oběma metodám věnovat v dalších kapitolách, takže nyní jen stručně.
Jednoduchou substituční metodou je např. Caesarova šifra, tedy posunutá abe-ceda o 3 písmena.
Zpráva ”veni, vidi, vici” se zašifruje jako ”YHQL, YLGL, YLFL”.

32 Obsah
Jednoduchou transpoziční šifrou je například text
BLODIEEPVIA-YPZNVCRRNMJVCRIABLAKCS-EENMJYLSYA
Ten lze přepsat jako
B L O D I E E P V I AY P Z N V C R R N M J
V C R I A B L A K C SE E N M J Y L S Y A
Z čehož je již patrné řešení.
Další metodou, která se používá v komunikaci, jež má zůstat utajena, je steganografie,která se někdy z kryptografie vyčleňuje a považuje se za samostatnou disciplínu. Úkolemsteganografie není ukrytí smyslu zprávy, ale její samotné existence. To znamená, že zprávaputuje komunikačním kanálem nezašifrovaná, ale takovým způsobem, aby byla nenápadnáa pokud možno nebyla odhalena ani skutečnost, že je nějaká zpráva vůbec přenášea. Jesamozřejmé, že optimální je kombinace obou technik, tj. ukrytí zašifrované zprávy.
Obecný šifrovací proces. Rozdělení kryptografieProces přenosu zašifrované zprávy má obecně tyto kroky (viz následující obrázek):Odesilatel aplikuje šifrovací algoritmus s využitím klíče na otevřený text. Tím vznikne
šifrový text, který poté putuje nezabezpečeným komunikačním kanálem k příjemci. Pří-jemce aplikuje na šifrový text dešifrovací algoritmus, opět s využitím klíče, jehož výstupemje původní otevřený text.
Podle toho, zda jsou klíče odesilatele a příjemce stejné či nikoliv, rozlišujeme symetrickoua asymetrickou kryptografii. V případě symetrické kryptografie používají odesilatel i příjemcestejné klíče a dešifrovací algoritmus je prostou inverzí algorritmu šiffrovacího. V případě asy-metrické kryptografie používají odesilatel i příjemce různé klíče, které jsou spolu v určitémmatemaatickém vztahu. Šifrovací a dešifrovací algorittmus jsou obecně různé, ačkoliv spolumusí souviset. Jinak by nebylo možné získat zpět původní otevřený text.
Kerckhoffsův principKerckhoffsův princip je základním principem kryptografie. Přišel na něj nizozemský lingivstaAuguste Kerckhoffs von Nieuwenhoff v roce 1883. Zní:
Bezpečnost šifrovacího systému nesmí záviset na utajení algoritmu, ale pouzena utajení klíče.
Pokud by totiž bezpečnost systému byla závislá na utajení algoritmu a nikoliv klíče, dřívenebo později se někomu podaří tento systém zlomit. V případě softwaru pomocí disasem-blování, v případě hardwaru pomocí reverse ingeneeringu, v ostatních případech špionáží.

Obsah 33
Pouze veřejně známý a všeobecně uznávaný šifrovací algoritmus, jehož bezpečnost je závislána reálné nemožnosti uhodnutí klíče je schopen zajistit dostatečnou bezpečnost.
Terminologická konvenceV kryptografii se častoi setkáme s označením komunikujících stran podle tzv. konvence ”Alicea Bob” (viz http://cs.wikipedia.org/wiki/Alice a Bob). Tento způsob označování je už natolikustálený, že kdo by se pokusil označit komunikanty jiným způsobem, bude považován zanevzdělance.Účastníky komunikace tedy označujeme Alice (A) a Bob (B). Tento způsob označování
je politicky korektní, neboť jsou při něm rovnoměrně zastoupena všechna lidská pohlaví.Dokonce je žena na prvním místě.Útočník bývá označován jako Eva (E), což pochází z anglického termínu ”eavesdropper” -
pasivní útočník, odposlouchávač, slídil. Častou legendou používanou pro názorné vysvětleníje, že Alice posílá Bobovi milostný dopis, zatímco Eva, která rovněž o Boba stojí, se jejichkomunikaci snaží narušit. Zpráva, tedy otevřený text bývá označován písmenemM (message),šifrový text pak písmenem C (cipher). Proces šifrování, resp. šifrovací algoritmus ozančujemepísmenem E (encryption), dešifrovací algoritmus písmenem D (decryption). Klíč se označujepísmenem K (key).Platí tedy, žeC = E(K, M), M = D(K, C)
Matematický základSoučástí úvodu do kryptologie je i potřebný matematický aparát, se kterým se budemev průběhu dalšího studia setkávat. Tento aparát není příliš náročný a lze předpokládat, žepro většinu studujících tohoto kurzu nebude v této kapitole nic nového. Je třeba se seznámits modulární aritmetikou a operací XOR.
Modulární aritmetika
Modulární aritmetika je aritmetika na konečné uspořádané množině čísel, která se cyklickyopakují. Operace jsou stejné jako u přirozených čísel s tím rozdílem, že každé číslo nahradímejeho modulem (tj. zbytkem po celočíselném dělení).
Ukažme si zmíněný princip na aritmetice modulo 7:
2 + 3 = 5 (mod 7)5 + 4 = 2 (mod 7) - protože 9 : 7 = 1, zbytek 25 · 4 = 6 (mod 7) - protože 20 : 7 = 2, zbytek 611 · 9 = 1 (mod 7) - protože 99 : 7 = 14, zbytek 135 = 5 (mod7)
V praxi se samozřejmě používají řádově větší moduly než 7. Je však důleřité, aby bylmodul prvočíselný, neboť jedině to zabezpečuje využití celé množiny přípustných hodnot.Proč je modulární aritmetika tak výhodná? Rozeberme si poslední řádek v uvedeném
příkladu. Představme si, že známe základ (3), známe výsledek operace (5) i modul (7). Jakzjistit exponent? V případě klasické aritmetiky bychomm použili logaritmus, jehož výpočetje víceméně triviáln í záležitost. V případě modulárnní aritmetiky však žádný logaritmusneexistuje a nezbývá nám, než vyzkoušet všechny možnosti, na něž lze základ umocnit,a u každé se dívat, zda poskytuje očekávaný výsledek. To je myšlenka, na níž stojí algoritmuspro vvýměnu klíčů Diffie-Hellmann, a svým způsobem i asymetrický šifrovací algoritmusRSA.
Operace XOR
XOR je logická operace. Název pochází z anglického eXclusive OR, tedy výlučné nebo. Jednáse o logickou operaci nebo s tím rozdílem, že pravdivý může být pouze jeden z operandů.Jsou-li pradivé oba, je výsledkem operace XOR nepravda.

34 Obsah
0 ⊕ 0 = 00 ⊕ 1 = 11 ⊕ 0 = 11 ⊕ 1 = 0Při použití této spojky píšeme v češtině před ”nebo” čárku: Půjdu do kina, nebo do divadla
(znamená to, že na obě místa nepůjdu, půjdu jen na jedno z nich). Rozdíl mezi klasickým ORa výlučným XOR vnímá tedy i česká gramatika, která rozlišuje nebo ve významu slučovacím(OR) (Obléknu si modré kalhoty a zelené tričko) a ve významu vylučovacím (Obléknu simodr kalhoty, nebo zeleenné tričko), který nepřipouští platnost obou výroků současně (Buďsi obléknu modré kalhoty, nebo zelené tričko, ale určitě ne obojí zaráz).Operace XOR je de facto součet modulo 2. Tedy sečteme operandy a vypočteme zbytek
po celočíselném dělení dvěma.V kryptografii má operace XOR poměrně široké uplatnění jako součást složitějších šifro-
vacích systémů. Ale i sama o sobě může posloužit jako jednoduchá šifra: C = M ⊕ K. Díkysymetrii operace je pak M = C ⊕ K.
Historie kryptografie a kryptoanalýzy do konce druhésvětové války
Historie kryptografie a kryptoanalýzy
Nejstarší zmínka o kryptologii se objevuje před téměř 4 tisíci lety. V městě Menet Khufuv severní Africe vytesal písař do skály v hrobce Khnumhotepa II přibližně 1900 let př. n.l. nápis, kde nahradil některé běžně používané hieroglyfy za neobvyklé znaky. Nebyl toale způsob tajného písma, jak ho známe dnes, protože pisatelovým záměrem nebylo skrýtvýznam zprávy, ale propůjčit nápisu důstojnost. S rozkvětem Egyptské civilizace a rozvojempísma se tyto záměny stávaly složitějšími, vynalézavějšími a běžnějšími.
Šifrování v antice
Z šestého století př. n. l. pochází šifra „atbaš“ používaná v Hebrejštině. Název je odvozen odzpůsobu šifrování, tedy záměna prvního písmena hebrejské abecedy (alef) s posledním (tav),druhého (bet) s předposledním (šin) atd.
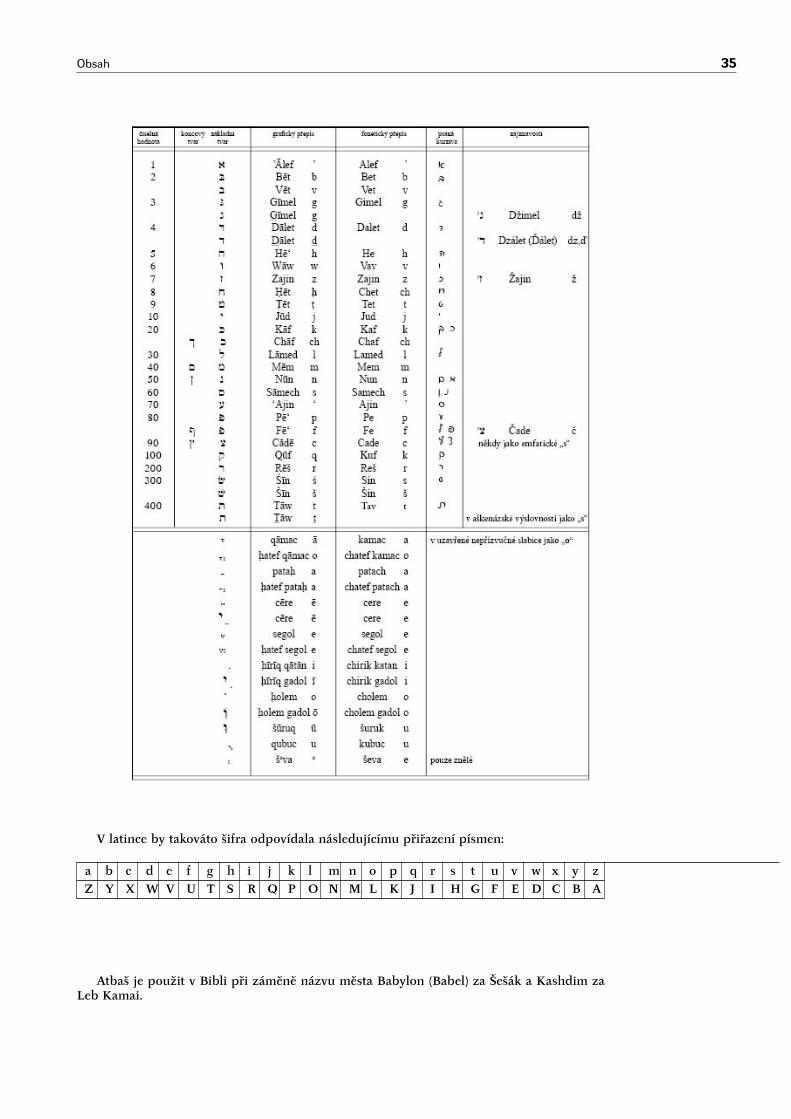
Obsah 35
V latince by takováto šifra odpovídala následujícímu přiřazení písmen:
a b c d e f g h i j k l m n o p q r s t u v w x y zZ Y X W V U T S R Q P O N M L K J I H G F E D C B A
Atbaš je použit v Bibli při záměně názvu města Babylon (Babel) za Šešák a Kashdim zaLeb Kamai.

36 Obsah
Př.: Slovní spojení „záměna písmen“ zašifrujeme atbashem jako „aznvmzkrhnvm“.
První doložené použití steganografie (tedy ukrytí samotné existence zprávy) pocházíz roku 480 př. n. l. od Hérodota, „otce historie“, kdy se odehrála rozhodující bitva řecko-perských válek – bitva u Salamíny. Despotický vůdce Peršanů Xerxés, Král kralů, prohlásil, že„rozšíříme perskou říši tak, že její jedinou hranicí bude nebe a slunce nedohlédne země, ježby nepatřila nám“. Pět let sbíral potají největší vojenskou sílu v dosavadní historii. Nakonecvedl Xerxés téměř 900 perských lodí, připravených podrobit si řeckou říši. Přípravy Peršanůvšak sledoval řecký vyhnanec Demaratus, který žil v perském městě Susy. Ačkoliv se do Řeckanemohl vrátit, stále cítil k rodné zemi loajalitu, a tak se rozhodl poslat do Sparty varování.Kvůli perským hlídkám jej ale bylo nutné skrýt. V té době se psalo na dřevěné tabulkypokryté voskem, do kterého se vyryla zpráva. Po zahřátí se vosk na povrchu destičky opětzacelil a bylo možné ji použít znovu. Demaratus seškrábal z těchto tabulek vosk a zprávuvyryl pod něj na samotné dřevo. Poté destičky opět potáhl voskem, aby vypadaly nepoužitě.Zprávu rozluštila až manželka Leonida (vojevůdce Sparťanů v bitvě u Thermopyl) Gorgo,která uhodla, že zpráva je ukryta až pod vrstvou vosku. Tím Peršané ztratili moment pře-kvapení a do té doby bezbranné Řecko začalo se zbrojením. Zisk ze stříbrných dolů, kterýbyl rozdělován mezi občany, byl použit k výstavbě válečných lodí, čímž zvětšili jejich početze 70 na 200. Ačkoliv byl poměr lodí stále pro řecké vojsko velmi nepříznivý, pomocí lsti sepodařilo Peršany porazit a přestože Peršané ztratili jen 25-33% bojové síly a měli tedy stálepočetní převahu, už se neodvážili útok opakovat a raději se stáhli z většiny Řecka včetněpozemských vojsk. Ukrytí zprávy v tomto střetu tedy sehrálo klíčovou roli.
Sparťané v 5. století př. n. l. používali pro změnu transpozici. Pisatel zprávy nejprveomotal proužek kůže kolem dřevěné tyče. Tyč musí mít přesně dán průměr, ale nemusí býtpo celé délce stejně široká (může se rozšiřovat), aby se předešlo pravidelnému rozmístěnípísmen. Zpráva je pak zapsána na kůži podél tyče, pruh kůže se odmotá a vznikne takna proužek s nečitelnou posloupností písmen. Jako u každé šifry, i zde se nabízí možnostzkombinovat ji se steganografií, jako např. v roce 404 př. n. l., kdy dorazil ke králi SpartyLysandrovi raněný posel, který jako jediný z pěti přežil cestu z Persie. Podal Lysandrovi svůjopasek. Ten jej ovinul kolem tyče správného průměru a dozvěděl se, že se na něho perskýFarnabazus chystá zaútočit. Díky této utajené komunikaci se Lysandros včas připravil naútok a nakonec jej odrazil. Toto historicky první kryptografické zařízení se nazývá skytale

Obsah 37
(nebo také scytale, z řeckého slova, jež znamená obušek).
Řecký spisovatel Polybius (přibližně 203–120 př. n. l.) vytvořil šifru, kde abecedu napsaldo čtverce o pěti sloupcích a pěti řádcích. Každé písmeno pak bylo možné interpretovat jakokombinaci dvou čísel, přičemž první představovalo číslo řádku, druhé číslo sloupce. Pokudbychom převedli latinku do Polybiova čtverce, jak se šifra nazývá, vypadal by takto:
1 2 3 4 51 A B C D E2 F G H IJ K3 L M N O P4 Q R S T U5 V W X Y Z
Pro použití při psaní českých zpráv je možné vynechat W (popřípadě Q), aby bylo možnéI i J reprezentovat jinými kombinacemi čísel. Polybiův čtverec se v antice používal takék nočnímu vysílání na dálku. K vysílání bylo potřeba deset hořících loučí, pět za každýmze dvou neprůhledných panelů. Počet loučí zdvižených nad levý panel udával číslo sloupce,louče nad pravým panelem pak číslo řádku daného písmene v Polybiově čtverci.
Př.: slovní spojení „řecký spisovatel“ zašifrujeme pomocí Polybiova čtverce jako„42 15 13 25 54 43 35 24 43 34 51 11 44 15 31“.
Julius Caesar (asi 100 – 44 př. n. l.) byl římským vojevůdcem a politikem a jedním z nej-mocnějších mužů antické historie. Sehrál klíčovou roli v procesu zániku Římské republikya její transformace v monarchii. Julius Caesar se také nesmazatelně zapsal do kryptografie.Caesar používal tajné písmo tak často, že Valerius Probus sepsal celkový přehled jeho šifer.Toto dílo se bohužel nedochovalo. Díky dílům, která se dochovala je zjištěn detailní popisjedné z jeho šifer. Jedná se o jednoduchou substituční šifru, kdy každé písmeno zprávy jenahrazeno písmenem posunutým v abecedě o tři pozice.
a b c d e f g h i j k l m n o p q r s t u v w x y zD E F G H I J K L M N O P Q R S T U V W X Y Z A B C

38 Obsah
Vyzkoušejte si šifrování a dešifrování Caesarovou šifrou pomocí jednoduchéwebové aplikace a
ahttps://akela.mendelu.cz/˜foltynek/KAS/historie/caesar.php
Takováto šifra se nazývá Caesarova šifra, název se však používá také obecně pro posunutíšifrové abecedy. Mimo posunutí se může pro šifrování zvolit i klíč (slovo, slovní spojení), kterýnahrazuje písmena ze začátku abecedy (opakující se písmena v klíči vynecháme), zbytek sepoté doplní ostatními písmeny v pořadí – tak se zvýší počet možných klíčů z pouhých 25 navíce než 4×1026. I přes svou jednoduchost, Caesarova šifra položila základ mnohým dalším,složitějším šifrám (např. ROT13, Vigenèrův čtverec).
a b c d e f g h i j k l m n o p q r s t u v w x y zJ U L I S C A E R T V W X Y Z B D F G H K M N O P Q
Caesarova šifra s klíčem „julius caesar“
Př.: Výrok „veni, vidi, vici“ po zašifrování klasickou Caesarovou šifrou vypadánásledovně „yhql, ylgl, ylfl“.
O dalším typu substituční šifry se zmiňuje Kámasútra, napsaná indickým filozofem jmé-nemMallanaga Vatsjajana ve 4. století n. l., který však vyšel z rukopisů o 800 let starších. Mezišedesáti čtyřmi uměními, které Kámasútra doporučuje ženám studovat, nejsou jen vaření,oblékání, příprava parfémů, ale také žonglování, šachy a umění tajného písma (mlecchita-vikalpa, umění číslo 45). Jedním z doporučených typů tajného písma je náhodně spárovatpísmena abecedy. Při převedení této myšlenky na latinskou abecedu, mohou dvojice písmenvypadat například takto:A ↔ B, E ↔ D, F ↔ H, G ↔ K, I ↔ Q, L ↔ U, N ↔ Y, O ↔ S, P ↔ M, T ↔ V, W ↔ R, X
↔ J, Z ↔ C.
Frekvenční analýza a její důsledkyDoposud se uvažovalo o nahrazení písmen abecedy za písmena ze stejné abecedy, arabštíúředníci však používali šifry, kde nahrazovali písmena abecedy za různé znaky (např. #, +,...),nebo svobodní zednáři používali tzv. šifrovací kříže, kde byla písmena rozdělena do tabulek,zástupné znaky otevřené abecedy pak byly vyjádřením pozice v takové tabulce. I přesto že semůže zdát tato substituce složitější, k jejímu rozluštění stačí stejná technika. A byli to právěArabové, kdo položili základ kryptoanalýze.První popis luštění tajných zpráv pomocí obecné techniky pochází z 9. století od učence
jménem Abú Jasúf Jaqúb ibn Isháq ibn as-Sabbáh ibn ‘omrán ibn Ismail al-Kindí, známý jako„filozof Arabů“. Věnoval se lékařství, astronomii, jazykovědě, hudbě, matematice, statistice,arabské fonetice a syntaxi, díky čemuž napsal pojednání Rukopis o dešifrování kryptogra-fických zpráv, kde jako první popsal frekvenční analýzu. Jedná se vlastně o procentuálnívyjádření výskytu písmen v daném jazyce. Aby bylo možno čísla obecně používat, musí seprovést v tomto jazyce analýza velkého množství různých textů.Tak například zjistíme, že nejčastější písmeno v českém jazyce je e, druhé nejčastější a,
pak o, i, n, ... Pokud bychom dále luštili nějaký text zašifrovaný monoalfabetickou substi-tuční šifrou, budeme postupovat tak, že písmenu (nebo znaku) z šifrového textu s největšíčetností výskytu přiřadíme písmeno e – tedy písmeno s největší četností výskytu v jazyce,o kterém se domníváme, že je použit v původní zprávě, druhému nejčastějšímu písmenuz šifrového textu přiřadíme písmeno a apod. U přidělovaní písmen však nesmíme postupo-vat pouze mechanicky, musíme pružně reagovat, jelikož zejména u kratších textů je frekvencepísmen zkreslena a neodpovídá tedy přesně uvedeným hodnotám. S objevením frekvenčníanalýzy souvisí samozřejmě pokusy o zdokonalování dosavadních šifer, např. zavedením tzv.klamačů či nul, tedy znaků, jež měla za význam pouze zmást kryptoanalytika při frekvenčníanalýze, neboť nereprezentovala žádné písmeno původní zprávy, dalším příkladem budiž

Obsah 39
špatný pravopis před zašifrováním zprávy, jež vede ke stejnému důsledku, tedy znesnadnitsprávné přiřazení písmen z abecedy znakům šifrové abecedy na základě frekvenční analýzy.Další pokus, jak zdokonalit monoalfabetické substituční šifry, spočíval v zavedení kódo-
vých slov, tedy že symbol šifrové abecedy nereprezentuje pouze znak otevřené abecedy, alemůže nahrazovat celé slovo. Může se zdát, že zavedením kódů (tedy substituce na úrovnislov, frází) se zpráva stává bezpečnější, protože analýza se již nevztahuje na pouhých 26znaků abecedy, ale je potřeba se dobrat významu stovek a více slov, avšak při zavedení kóduse objevují nové problémy. Zatímco při prosté šifře, která nahrazuje jedno písmeno otevřenéabecedy jiným z šifrové, se stačí domluvit na pravidle, podle kterého jsou jednotlivé znakypřiřazeny, u kódů se nejprve musí složitě definovat kódová slova pro každé slovo, které semůže vyskytnout v otevřeném textu. Takový slovník, který přiřazuje každému slovu slovokódové, bývá často velmi objemný a je tedy složité jej přepravovat a zdlouhavé jej používat.A navíc padne-li tento kód do rukou nepříteli, je veškerá utajovaná komunikace rázem plněsrozumitelná.Kvůli těmto technickým problémům vznikly v 16. století tzv. nomenklátory – tedy kó-
dovací systém, který vychází z šifrové abecedy, navíc je ale doplněn o seznam kódovýchslov. Navzdory tomu není o mnoho bezpečnější než obyčejná šifra, protože většinu textu lzerozluštit frekvenční analýzou, zbylá slova pak odvodit z kontextu. Stejně tak si byli schopnikryptoanalytici poradit i s klamači či pozměněným pravopisem.Jiná reakce na frekvenční analýzu byla homomorfní substituční šifra, tedy šifra, kde
každé písmeno otevřené abecedy má více reprezentací v šifrové. Pokud je známa frekvencejednotlivých písmen v jazyce zprávy, přidělí se každému tolik znaků šifrové abecedy, aby bylvýskyt jednotlivých takových znaků přibližně stejný (např. dvoucifernými čísly). Takto se siceznemožní frekvenční analýza, ale závislosti mezi písmeny (v anglickém textu např. písmenoq je vždy následováno písmenem u) se nezmění, šifru je tedy obtížnější vyluštit, není to všakzdaleka nemožné.V Evropě kryptologové ale také nezaháleli. V roce 1518 benediktýnský opat Johannes
Trithemius vydal knihu Polygraphia, kde popsal šifru nahrazující písmena za slova z pře-dem dané tabulky. Italský renesanční učenec Jeroným Cardan vynalezl šifrování známé podpojmem Cardanova mřížka, což je destička s vyříznutými otvory v předem daných místech.Než odesílatel poslal zprávu, přiložil mřížku na papír a do průřezů vepsal zprávu. Poté do-plnil zbývající text, který pouze maskoval význam zprávy. Zpráva je pak rozluštitelná pouzes identickou mřížkou.Dalším krokem v polyalfabetické substituci byla šifr Giovana Battisty Bellasa, v níž se
poprvé objevuje použití klíčového slova, pomocí nějž je zpráva šifrována. Bellaso je rovněžautorem konceptu tzv. autoklíče, kdy se klíčem stává samotná zpráva. Bellasovy výsledky tedyznamenaly poměrně výrazný posun v kryptologii, i když největší slávu získala Vigenérovašifra.
Vigenérova šifra
Stále ještě v 16. století vynalezl francouzský diplomat Blaise de Vigenère (1523 – 1596) šifru,jež nebyla rozlomena po další tři století. Vycházel z prací Leona Battistuta Albertiho, kterýnavrhl použít více šifrových abeced, které by se při šifrování pravidelně střídaly a zmátly takpotenciální kryptoanalytiky.
a b c d e f g h i j k l m n o p q r s t u v w x y z1 B C D E F G H I J K L M N O P Q R S T U V W X Y Z A2 C D E F G H I J K L M N O P Q R S T U V W X Y Z A B3 D E F G H I J K L M N O P Q R S T U V W X Y Z A B C4 E F G H I J K L M N O P Q R S T U V W X Y Z A B C D5 F G H I J K L M N O P Q R S T U V W X Y Z A B C D E6 G H I J K L M N O P Q R S T U V W X Y Z A B C D E F7 H I J K L M N O P Q R S T U V W X Y Z A B C D E F G8 I J K L M N O P Q R S T U V W X Y Z A B C D E F G H9 J K L M N O P Q R S T U V W X Y Z A B C D E F G H I10 K L M N O P Q R S T U V W X Y Z A B C D E F G H I J11 L M N O P Q R S T U V W X Y Z A B C D E F G H I J K12 M N O P Q R S T U V W X Y Z A B C D E F G H I J K L13 N O P Q R S T U V W X Y Z A B C D E F G H I J K L M14 O P Q R S T U V W X Y Z A B C D E F G H I J K L M N15 P Q R S T U V W X Y Z A B C D E F G H I J K L M N O

40 Obsah
16 Q R S T U V W X Y Z A B C D E F G H I J K L M N O P17 R S T U V W X Y Z A B C D E F G H I J K L M N O P Q18 S T U V W X Y Z A B C D E F G H I J K L M N O P Q R19 T U V W X Y Z A B C D E F G H I J K L M N O P Q R S20 U V W X Y Z A B C D E F G H I J K L M N O P Q R S T21 V W X Y Z A B C D E F G H I J K L M N O P Q R S T U22 W X Y Z A B C D E F G H I J K L M N O P Q R S T U V23 X Y Z A B C D E F G H I J K L M N O P Q R S T U V W24 Y Z A B C D E F G H I J K L M N O P Q R S T U V W X25 Z A B C D E F G H I J K L M N O P Q R S T U V W X Y26 A B C D E F G H I J K L M N O P Q R S T U V W X Y ZSíla Vigenèrovy šifry spočívá v tom, že k jejímu šifrování (dešifrování) se nepoužívá pouze
jedna šifrová abeceda, ale všech 26, které vzniknou posunutím původní abecedy. Při šifrováníse nejprve sestaví tzv. Vigenèrův čtverec, jehož každý řádek je abeceda posunutá oproti před-chozímu řádku o jedna. Šifrovat písmeno A se tedy může 26 způsoby, např. pokud se budešifrovat podle řádku 1, pak bude v šifrovém textu B, zatímco podle řádku 6 bude v šifrovémtextu G. Aby příjemce byl schopen určit, podle jakého řádku je které písmeno šifrováno, jenutné se s odesílatelem domluvit na předem daném systému používání Vigenèrova čtverce.K tomuto může sloužit klíčové slovo. Nechť je takové slovo např. „heslo“.Odesílatel si napíše nad text, který chce převést do tajného písma, klíčové slovo tolikrát,
kolikrát je třeba, aby ji pokryl celou. Pak šifruje jednotlivé písmeno otevřeného textu vždypodle řádku Vigenèrova čtverce, který udává písmeno klíčového slova. S použitím klíčovéhoslova „heslo“ je tedy první písmeno šifrováno podle sedmého řádku (jež odpovídá písmeniH), druhé podle čtvrtého (jenž začíná písmenem E) atp.Příjemce při dešifrování zprávy postupuje opačně. Ví, že k zašifrování prvního písmene
byl použit řádek začínající na H, druhého řádek začínající na E, třetího S, atd., nemá tedyproblém šifru vyluštit.Vigenèrova šifra je odolná proti frekvenční analýze, protože každé písmeno může být
reprezentováno ne jedním, ale několika jinými. Další její nespornou výhodou je fakt, žeklíč není nijak omezen. Vzniká tak velké množství klíčů, které kryptoanalytik při pokusuo rozlomení není schopen vyzkoušet. Vzhledem k tomu, o jak silný šifrovací prostředek sejednalo, je s podivem, že se nerozšířila po celé Evropě. Pravděpodobně pro její složité použitía velkou náchylnost k chybám (pokud odesílatel např. omylem vynechá jedno písmeno, jepro příjemce zbytek zprávy nečitelný) se neujala po následující dvě století.
Př.: „nerozluštitelná šifra“ pomocí klíčového slova „vigenere“ se zašifrujenásledovně:
otevřený text: n e r o z l u s t i t e l n a s i f r aklíč: v i g e n e r e v i g e n e r e v i g ešifrový text: I M X S M P L W O Q Z I Y R R W D N X E
Vyzkoušejte si šifrování a dešifrování Vigenérovy šifry pomocí jednoduchéwebové aplikace. a
ahttps://akela.mendelu.cz/˜foltynek/KAS/historie/vigenere.php
Vigenèrovu šifru zlomil až v 19. století Charles Babbage. Tento výstřední britský géniusse narodil 26. prosince 1791, zemřel 18. října 1871. Jeho okruh zájmů byl velmi široký, mezijeho vynálezy patří rychloměr, „lapač krav“ – jež se připevňoval na přední část parní lokomo-tivy, aby odehnal dobytek z kolejí. Jako první poukázal na souvislosti mezi letokruhy stromůa jejich stářím, k jeho nejvýznamnějším vynálezům však patří Differece Engine a AnalyticalEngine, což byl vůbec první návrh programovatelného počítače. O kryptologii se zajímal jižod dětství, k rozlomení Vigenèrovy šifry byl inspirován na základě korespondence s bris-tolským zubařem, který roku 1854 prohlásil, že vytvořil zcela novou šifru, která však bylaekvivalentem právě šifry pana Vigenèra. Po tom, co na tuto skutečnost Charles Babbage po-ukázal, byl vyzván k pokusu o její rozluštění. Babbage výzvu přijal, začal hledat její slabiny

Obsah 41
a nakonec uspěl. Nezávisle na Charlesu Babbageovi vyluštil šifru také major pruské armádyFridrich Kasiski, po němž je metoda luštění pojmenována.Rozluštění spočívá v několika krocích. V prvním kroku kryptoanalytik hledá opakující
se sekvence, které mohou vzniknout dvěma způsoby. Protože se v otevřeném textu opakujíněkterá slova a klíč bývá zpravidla kratší, než otevřený text, je velmi pravděpodobné, žeopakující se sekvence vznikla zašifrováním stejné sekvence písmen v otevřeném textu stejnoučástí klíče. Druhý způsob ukazuje na možnost, že různé sekvence v otevřeném textu bylyšifrovány podle různých částí klíčů, poskytly však tentýž výsledek. Tento způsob je všakmálo pravděpodobný. Pokud budeme brát v potaz jen sekvence délky čtyř písmen a delší,pak je pravděpodobnost druhého způsobu mizivá. Pokud si kryptoanalytik vypíše opakujícíse sekvence, napíše si jejich vzdálenost od sebe a dělitele jejich vzdálenosti, může se pokusiturčit délku klíče (označí si jej např. D) jako společného dělitele takovýchto vzdáleností.Jakmile odhadne délku klíče, může se v dalším kroku pokusit určit jeho znění.Text se rozdělí do částí podle délky klíče, kde každé n-té písmeno přiřadí do (n modulo D)
části (každou část si označí např. Ci, kde i = 1, ... D). Jestliže je délka klíč D správně určena,je každá část textu Ci šifrována podle stejného řádku Vigenèrova čtverce, jedná se tedyo monoalfabetickou substituční šifru, na kterou lze s úspěchem použít běžnou frekvenčníanalýzu, přičemž ví, že abeceda je pouze posunuta, ne zpřeházena. Stačí tedy určit, o kolik jekterá část šifrového textu posunuta. Babbage si s šifrou poradil, svůj objev však nepublikoval,vyšel najevo až ve 20. století při průzkumu jeho poznámek.
Podívejte se, jak probíhá kryptoanalýza textu zašifrovaného Vigenérovou šifroubez znalosti klíče. Ukázku najdete na této stránce a , nebo na stránkách SimonaSinga b .
ahttps://akela.mendelu.cz/˜foltynek/KAS/historie/vigenere2.phpbhttp://www.simonsingh.net/The Black Chamber/cracking tool.html
Jinou metodu luštění navrhl na počátku 20. století William Frederick Friedmann. Jehometoda je založena na statistické metodě, tzv. indexu koincidence, který je definován jakopravděpodobnost, že dva náhodně vybrané znaky z řetězce x budou stejné. Analytik takmůže vypočítat indexy koincidence pro různé varianty délky klíče a poté vybrat tu délku, jížpříslušný index koincidence se nejvíce blíží hodnotě, která je pro daný jazyk známa.
Kryptografie v 19. stoletíNeopomenutelně se do historie kryptografie v 19. století zapsal také Samuel Morse – ame-rický vynálezce, malíř a sochař. Původně pro telegraf vynalezl skupinu symbolů, teček a čá-rek, jež reprezentují písmena abecedy. Morseova abeceda je navržena tak, aby nejfrekven-tovanější písmena v anglické abecedě zastupovala nejkratší sekvence teček a čárek (např.E je reprezentováno jedinou tečkou, na podobné optimalizaci, kdy nejčastěji používanýmznakům je přiřazen nejkratší kód, je založeno také Huffmanovo kódování užívané při beze-ztrátové komprimaci dat). Velkou výhodou je variabilní použití (pomocí těchto symbolů sezpráva nemusí pouze psát, k přenosu je možné použít akustický signál, elektrický signál, aletaké libovolný optický signál), snadná zapamatovatelnost (k výuce lze uplatnit mnemotech-nická pomůcka – slova, jejichž počáteční písmeno a délka slabik pomáhá zapamatovat si kódpísmene), další výhodou jsou jen dva použité znaky (tři – počítá-li se oddělovací) a rychlostpřenosu (rychlost předávání zpráv se pohybuje od 60 do 250 znaků za minutu).Sir Charles Wheatstone a baron Lyon Playfair přispěli do kryptologie svojí bigramovou
šifrou. Jedná se o šifru, kde nejsou šifrována samostatná písmena, ale jejich dvojice. Ačkolivtuto šifru vynalezli roku 1854 společně oba Britové, nese název Playfairova šifra. Abeceda sepodobně jako u Polybiovy šifry rozdělí do čtverce 5×5. Rozmístit písmena ve čtverci lze 25!způsoby, což poskytuje značnou variabilitu.Při šifrování se zpráva rozdělí na dvojice písmen, přičemž pokud se ve dvojici vyskytnou
dvě stejná písmena, vloží se mezi ně předem domluvené písmeno (např. Z, X). Pokud nakonci zprávy po této úpravě zůstane liché písmeno, doplníme jej opět stejným pomocnýmpísmenem. Šifrovací pravidla jsou následující:
• Písmena ve stejném řádku se nahrazují nejbližším písmenem vpravo od každého z nich.• Pokud je jedno na konci řádku, nahradí se písmenem ze začátku řádku.• Písmena ve stejném sloupci jsou nahrazena nejbližším písmenem pod každým z nich.

42 Obsah
• Písmeno ve sloupci poslední je nahrazeno písmenem z vrcholu.• Pokud se písmena nacházejí na různých řádcích nebo v různých sloupcích, nahradíse první písmeno znakem, který je ve stejné řadě jako první písmeno a ve stejnémsloupci jako druhý znak. Druhé písmeno se vymění za znak, jenž leží ve čtvrtém rohuobdélníku, jehož rozměry určují předchozí tři písmen.
• Dešifrování zpráv probíhá obráceně.Od prolomení Vigenèrovy polyalfabetické šifry Charlesem Babbagem měli kryptoanaly-
tici převahu nad kryptografy. Pokusy o nalezení dokonalejší šifry většinou krachovaly nafrekvenční analýze. Až Joseph Mauborgne, šéf kryptografického výzkumu v americké ar-mádě, po první světové válce přišel s konceptem uplatnit u Vigenèrovy šifry náhodný klíč.Při použití náhodného klíče stejně dlouhého jako otevřený text vznikne šifra, u které lzematematicky dokázat její nerozluštitelnost (1940 Claude Shanon). Každý takový klíč se smípoužít jen jednou. Zatímco u klíče, který je sice stejně dlouhý jako zpráva, ale není náhodný,lze vzhledem k jeho pravidelnosti (např. opakující se slova v běžném textu) šifru prolomit,u náhodného klíče může kryptoanalytik vyzkoušet všechny možné kombinace, k původnímuznění zprávy se sice dostane, nebude mu to však platné, protože nezjistí, který z danýchvýsledků to je, jelikož dostane všechny možné kombinace písmen o dané délce textu. Ačkolije nerozluštitelná, tato šifra se používá jen zřídka. Hlavní problém je generování náhodnýchklíčů. Utajená komunikace se používá především v armádě a ta si během dne vymění i stovkyzpráv, přičemž každá musí používat jiný klíč. S tím souvisí další nevýhoda – distribuce těchtoklíčů. Je nutné, aby každý ze stovek operátorů pracoval se stejným klíčem. I kdyby každý mělstejnou kopii klíčů, musel by stále sledovat, které již byly použity. Vytvořit skutečně náhodnýklíč je velmi nákladné, zajistit neustálý přísun jednorázových knih s klíči téměř nemožné.Touto šifrou je například zabezpečena linka spojující prezidenty Ruska a USA.
EnigmaNoční můru kryptoanalytiků sestrojil německý vynálezce Arthur Scherbius. Roku 1918 zís-kal patent na šifrovací zařízení o rozměrech pouhých 34×28×15 cm, váze 12 kg a s názvemEnigma. Věřil v její nezdolnost a pokoušel se ji nabízet v několika variantách – od obchod-níků až po ministerstvo zahraničí. Kvůli její ceně však nebyla možnými zákazníky přijata.Scherbius nebyl sám, kdo přišel s myšlenkou šifrovacího stroje, na jedno takové zařízenízískal v Nizozemí roku 1919 patent č. 10 700 Alexander Koch, ve Švédsku Arvid Damm,v Americe Edward Herbern, nikdo z nich však neuspěl. Německo si však na začátku 20.století uvědomovalo svou slabinu v utajování zpráv, proto na štěstí pro Scherbia docenilohodnotu Enigmy a během dvaceti let koupilo přes 30 000 těchto strojů.
Čím byla Enigma tak výjimečná? Přístroj se skládal z klávesnice, šifrovací jednotky, kterábude popsána podrobněji, a signální desky, kde byla jednotlivá písmena podsvícená žárov-kami, které signalizovaly převedená písmena. Písmeno otevřeného textu (stejně jako při dešif-rování šifrový text, díky reflektoru, jež bude zmíněn níže) se napsalo na klávesnici, v šifrovacíjednotce bylo zašifrováno (dešifrováno) a na signální desce se rozsvítilo to písmeno v šifrové(otevřené) abecedě, které se zapsalo. Šifrovací jádro bylo tvořeno v prvé řadě scramblery,gumovými kotouči, jimiž vedly dráty. Impuls z klávesnice vstupuje do scrambleru na dvacetišesti místech (každé písmeno abecedy má tedy svůj jednoznačný vstup), uvnitř se přehýbáa otáčí a na stejném počtu míst opět vystupuje ven. Jakmile impuls vystoupí ze scrambleru,ten se otočí o jednu z dvaceti šesti pozic. Účel takovéhoto kotouče tedy spočívá v převedení

Obsah 43
textu na polyalfabetickou substituční šifru s klíčem o 26 znacích. Enigma však obsahovala třiscramblery, kde vždy následující se otočil jednou za 26 otáček předchozího, délka klíče takvzrostla na 263. Za scramblery byl reflektor, jež posílal signál zpět do scramblerů, z nich pakputuje na signální desku, kde rozsvítí žárovku pod výsledným písmenem. Protože šifrovánía dešifrování je v tomto případě zrcadlový jev, reflektor umožňuje za použití jednoho strojea jednoho nastavení zprávy převádět z otevřeného textu na šifrový i naopak.
Poslední částí Enigmy důležitou pro šifrování byla propojovací deska, umístěna mezi klá-vesnicí a prvním scramblerem. Pomocí kabelu umožňovala propojit dvě písmena klávesnicemezi sebou tak, že první písmeno pak sledovalo cestu, kterou by sledovalo druhé písmenos ním spojené. Naopak druhé písmeno sledovalo cestu prvního. Propojovací kabely jsou tedypouhou monoalfabetickou substituční šifrou. Scherbius vybavil Enigmu šesti spojovacími ka-bely, počet způsobů prohození šesti párů písmen z 26 je obrovský (100 391 791 500). Aby dvěstrany mohly mezi sebou přijímat a vysílat, bylo nutné stanovit základní nastavení Enigmy,jež je klíčem přenosu. Je třeba nastavit tři různé scramblery, jejich polohu i pořadí, dále pakurčit, které páry písmen budou propojeny. Možností nastavení je 263 za polohu scramblerů,násobenou počtem možných pořadí (tři scramblery, tedy 3!), nakonec ještě způsoby nastaveníšesti párů písmen 100 391 791 500, což je více než 10 000 000 000 000 000 možných klíčů.

44 Obsah
Přesdtože největší vliv na celkový počet klíčů mají kabely na propojovací desce, tyto bysamy o sobě nestačily, neboť otočné scramblery, byť nepřináší markantní zvýšení počtu klíčů,vnášejí do šifrování nelinearitu a dělají z Enigmy velmi komplikovanou polyalfabetickoušifru s periodou 263. Jakým způsobem probíhalo ustavení klíče? Němci rozesílali všemsvým jednotkám kódové knihy, v nichž byly uvedeny tzv. denní klíče, tedy klíče prro každýden. Denní klíč se skládal z popisu proipojení písmen na propojovací desce a z rozloženía počátečního nastavení scramblerů. Němci však dobře věděli, že není možné používat pocelý den stejný klíč, a tak každá zpráva byla šifrována svým vlastním klíčem, tzv. klíčemzprávy. Ten měl stejnou konfiguraci propojovacích kabelů i stejné rozložení scramblerů.Jediné, čím se lišil, bylo jejich počáteční nastavení. Vůči dennímu klíči se tak dal popsattřemi znaky, které kódovaly právě počáteční nastavení tří scramblerů. Když chtěl radistaodeslat zprávu, nastavil Enigmu podle denního klíče. Poté odeslal 2x za sebou klíč zprávy,přenastavil scramblery podle klíče zprávy a pak teprve zprávu šifroval.Němci od začátku předpokládali, že spojenci budou mít k dispozici repliku stroje, přesto
si však byli jisti bezpečnosti své komunikace. Vidíme zde praktickké uplatnění Kerckhoff-sova principu, kdy byla síla šifry založena na utajení klíče, nikoliv na utajení algoritmu, tedymechanismu šiffrovacího stroje. A skutečně, netrvalo dlouho, a několik strojů se podařiloukrást. Mezi nejúspěšnější luštitele pařili zpočátku Poláci, kteří si uvědomovali riziko ply-noucí ze sousedního Německa. Na polském Byru szifrow tak vznikll tým kryptoanalytikůpod vedením Mariana Rejevského, který měl kryptoanalýzu na starosti. Protože základemkryptoanalýzy je opakování, založil Rejevski luštění právě na tom, že Němci na začátkukaždé zprávy 2x opakovali klíč zprávy zašifrovaný denním klíčem. Při zachycení velkéhopočtu zpráv a ze znalosti Enigmy tak bylo možné vytvořit katalog závislostí (ten vznikal celýrok), na základě něhož bylo možné odhalovat denní klíč. K odhalování denního klíče Polácipoužívali mechanické dešifrátory, kterým se říkalo ”bomby” kvůli charakteristickému tikotu,který vydávaly.Němci v prosinci 1938 zvýšili počet scramblerů ze 3 na 5, což znamenalo, že pro kryptoa-
nalýzu bylo potřeba 10x více bomb. Když pak v lednu 1939 ještě zvýšili počet propojovacíchkabelů z 6 na 10, byli Poláci bez informací. Protože tušili, že se je Němcci chystají pře-padnout, svěřili se v červnu 1939 spojencům se svými znalostmi a v srpnu téhož roku bylyvšechny bomby včetně dokumentace převezeny do Anglie. Byl už nejvyšší čas; v září 1939Němci napadli Polsko. Od té doby dešifrování Enigmy probbíhalo v britském Bletchley parkua hlavní postavou boje proti Enigmě se stal Alan Turing (1912-1954), absolvent King’s Collegev Cambridgi, který se již ve svých 25 letech proslavil knihou ”O vyčíslitelnosti”, která jedodnes základním dílem teoretické informatiky. Je autorem Univerzálního Turingova stroje,

Obsah 45
tedy výpočetního modelu, který je ekvivalentem algoritmizovatelnosti daného problému.Turing odhalil slabiny německé komunikace: časté opakování klíčů zpráv, (např. inici-
ály milenky), nutnost střídání scramblerů či pravidlo, že kabely na propojovací desce nikdynespojují sousední písmena. Tím se počet klíčů několikanásobně snížil. Odhalení denníhoklíče i tak zabralo několik hodin času. Panovala však obava, že Němci přestanou klíč zprávyopakovat, což by kryptoanalýzu Enigmy znemožnilo. Turingův tým dostal tedy za úkol při-pravit se na tuto evntualitu. Vycházel z velkého množství zachycených zpráv a všiml si, žeNěmci vysílali velké množství zpráv, které měly přesně danou strukturu. Např. okolo šestéhodiny ranní vysílali zprávy o počasí. Sestrojil tedy nový typ bomby, která odhalovala klíčna základě šifrového textu a předpokládaného obsahu zprávy. Když pak Němci skutečněpřestalli klíč zprávy opakovat, byli na tuto eventualitu spojenci připravení.Problémem byla námořní Enigma, která namísto pěti scramblerů používala osm, navíc
disponovala otočným reflektorem. Na moři tedy spojnecům nezbylo, než krást kódové knihyz unesených či potápějících se lodí.
Kód Navahů
Zcela originální postup při šifrování během války v Tichomoří zvolili Američané. Hlavní roliv něm sehrál indiánský kmen Navahů, kteří mají velmi neobvyklý jazyk. Slovesa se časujínejen podle podmětu, ale i podle předmětu a navíc používají zcela odlišné výrazy pro věci,které vypravěč viděl na vlastní oči a pro věci, které zná jen z doslechu. Navíc, Navahovénebyli před válkou infiltrování německými studenty lingvistiky. Přenos zpráv probíhal velmijednoduše. Každá jednotka měla svého Navaha - radistu. Ten převzal zprávu v angličtině,přeložil ji do navažštiny, nešifrovaněě zatelefonoval svému klolegovi u přijímací jednotky,který zprávu přeložil zpět do angličtiny. Japonci byli zcela bezradní a s touto ”šifrou” sinedokázali poradit.Aby vše fungovalo správně, bylo potřeba jazyk trochu upravit. Běžný indiánský kmen
totiž ve svém jazyce nemá výrazy pro ponorku či bombardér. Byla proto zavedená kódovákniha, pomocí níž see různé typy letounů nazývali pomocí různých druhů ptáků, plavidlůmbyly přiřazeny různé druhy ryb, atd. Používání navažského kódu bylo velmi rychlé, efek-tivní a bezpečné. I když z hlediska Kerckhoffsova principu se jednalo o nevhodný způsobkomunikace, během druhé světové války byl úspěšný.
Konec mechanické éry
Koncem války se do šifrování začaly prosazovat moderní technologie založené na využitíelektronických součástek. V roce 1943 byl v britském Bletchley parku sestrojen první po-čítač Collosus, který měl sloužit právě pro lámání šifer. Z pochopitelných důvvodů britskávláda jeho existenci tajila, a tak byl po několik desetiletí za první počítač považován ame-rický ENIAC sestrojený na University of Pensylvania. S dalším rozvojem techniky se rozvíjelai kryptologie, která musela reagovat na to, že počítače byly schopné zvládat stále větší množ-ství operací za krátký časový úsek. To si vyžádalo nejen nárůst délky klíčů, ale i zcela novéšifrovací algoritmy.

46 Obsah
Použitá literatura• Kahn, D.: The Codebreakers. 1. vydání London: Sphere Books, 1977. 476stran. ISBN 0-7221-5149-7.
• Piper, Fred, Murphy, Sean: Kryptografie. 1. vydání Praha: Dokořán, 2006.157 stran. ISBN 80-7363-074-5.
• Singh, S.: Kniha kódů a šifer: tajná komunikace od starého Egypta pokvantovou kryptografii. 1. Vydání Praha: Argo, 2003. 382 stran. ISBN 80-7203-499-5.
• Krypta.cz – Historie kryptografie I [online]. 10. 11. 2001,poslední revize 28. 2. 2008 [cit. 2008-02-28]. Dostupné z:<http://www.krypta.cz/articles.php?ID=55>.
• Kryptografie - Wikipedie, otevřená encyklopedie [online]. Po-slední revize 29. 12. 2007 [cit. 2008-02-26]. Dostupné z:<http://cs.wikipedia.org/wiki/Kryptografie>.
• Shaman.cz — Polybiův čtverec [online]. 15. 1. 2006, po-slední revize 28. 2. 2008 [cit. 2008-02-28]. Dostupné z:<http://www.shaman.cz/sifrovani/polybiuv-ctverec.htm>.
Substituční šifry
Substituční šifry
Monoalfabetické substituční šifryJeden z prvních popisů substituční šifry se objevuje v Kámasútře ze 4. stol, vychází všakz rukopisů o 800 let starších. Autor této knihy přikládá umění psát tajné texty velký význama doporučuje žanám, aby si ho osvojily tak, aby mohly psát tajné zprávy svým milencům.Princip substitučních šifer spočívá v nahrazení písmen otevřené abecedy písmeny šifro-
vací abecedy. Přiřadíme-li písmena naprosto náhodně je počet možných uspořádání 4×1026.Pro efektivní šifrování a dešifrování je však potřeba držet se jednoduchého systému, kterýnám tuto činnost usnadní a zrychlí. Lze například použít klíčové slovo. Pro svou jednodu-chost a vysoký stupeň dominovala tato šifra tajné komunikaci po celé první tisíciletí n.\,l.
Caesarova šifra: Posunutá abeceda o 3 písmena
Přibližně 2000 let starý a pravděpodobně nejznámější šifrovací systém. Autorství je připiso-váno Juliu Caesarovi, který ji používal jako jednu z mnoha šifer. Princip spočívá v posunutíšifrovaného písmene o tři místa dále v abecedě.A B C D E F G H I J K L M N O P Q R S T U V W X Y ZD E F G H I J K L M N O P Q R S T U V W X Y Z A B CPříklad:veni vidi viciYHQL YLGL YLFL
Šifra ATBAŠ
Šifrovací systém, který prokazatelně vynalezli a používali hebrejci. Zachovává princip vzá-jemné záměny písmen. Princip spočívá v tom, že se vezme písmeno, určí se jeho vzdálenostod začátku abecedy a nahradí se písmenem se stejnou vzdáleností od konce abecedy. Druhámožnost je rozdělení abecedy na dvě části s tím, že každé písmeno z první půlky má svoudvojici v duhé půlce a naopak.A B C D E F G H I J K L M N O P Q R S T U V W X Y ZZ Y X W V U T S R Q P O N M L K J I H G F E D C B AneboA B C D E F G H I J K L M

Obsah 47
N O P Q R S T U V W X Y ZPříklad:kain a abel byli bratriXNVA N NORY OLYV OENGEV
Obecná substituce
Jde o velmi starý, dlouhou dobu a v různých modifikacích používaný šifrovací systém. Prin-cip spočívá v nahrazení každého znaku otevřené abecedy jedním znakem šifrové abecedy.Možných variant je 4× 1026. Z důvodu nesnadného zapamatování si celé sekvence přiřazení,je vhodné použít pro ustavení šifrové abecedy klíčové slovo. Písmena z tohoto slova jsou naprvních pozicích šifrové abecedy, ostatní znaky jsou pak doplněny zbývajícími písmeny.A B C D E F G H I J K L M N O P Q R S T U V W X Y ZC G F T K M Q I J A U Y O H P R W S L N V X D B Z EPříklad:mundus vult decipiOVHTVL XVYN TKFJRJnebo s použitím klíčového slova:A B C D E F G H I J K L M N O P Q R S T U V W X Y ZK R Y P T O A B C D E F G H I J L M N Q S U V W X Z
Vylepšení substitučních šifer
Běžné substituční šifry však mají mnoho slbých míst, které se kryptografové snažili elimino-vat použitím dalších technik znesnadňujících rozlomení. Nejčastěji se používalo:
• speciální symboly pro nahrazení některých slov – nomenklátory• znaky s klamajícím významem – nulový znak, smaž předchozí znak...• zkomolení zprávy na základě zvukomalebnosti – ”frikvence slof”
Nomenklátor Skotské královny Marie
Homofonní šifra
Používala se jako vhodný kompromis mezi rychlostí šifrování a dešifrování a poskytovanýmbezpečím. Odstraňuje hlavní problém monoalfabetických šifer – frekvenční charakter. Každépísmeno se zde nahrazuje řadou reprezentací, přičemž jejich počet je úměrný frekvencipísmene.A 09 12 33 47 53 67 78 92B 48 81C 13 41 62D 01 03 45 79E 14 16 24 44 46 55 57 64 74 82 87 98...

48 Obsah
Y 21 52Z 02Příklad:a b e c e d a09 48 14 13 19 01 12
Polygramová substituce – nahrazení n-tic otevřeného textu n-ticemi šifrového textu.Playfairova šifra
Autorem je Charles Wheatstone, proslavil ji Lyon Playfair. Používaly ji s úspěchem britskéjednotky v búrské válce. Jedná se o poměrně jednoduchou avšak bezpečnou šifru. Tato šifranahrazuje každou dvojici dvojici písmen v otevřeném textu jinou dvojicí písmen. Šifrovacítabulka o rozměru 5*5 se vytvoří na základě dohodnutého klíče. Text se rozdělí na digramy,které se kódují podle speciálních pravidel.C H A R LE S B D FG IJ K M NO P Q T UV W X Y ZPříklad:me et me at ha mx me rs mi th br id ge to ni gh txGD DO GD RQ AR KY GD HD NK PR DA MS OG UP GK IC QY
Šifra Playfair – postup
1. Zpráva se rozdělí na digramy, pokud je poslední písmeno liché, doplní se písmenem x.2. Ve dvojicích stejných písmen je použito nahrazení písmenem x.3. Písmena ve stejném řádku se nahrazují nejbližším písmenem vpravo od každého z nich.4. Pokud je jedno na konci řádku, nahradí se písmenem ze začátku řádku.5. Písmena ve stejném sloupci jsou nahrazena nejbližším písmenem pod každým z nich.6. Písmeno ve sloupci poslední je nahrazeno písmenem z vrcholu.7. Pokud nejsou ani na řádku ani ve sloupci, sestaví se z šifrovaných písmen pomyslnýčtverec, jehož vrcholy reprezentují novou dvojici.
8. Při dešifrování se postupuje obráceně.
Kryptoanalýza monoalfabetických substitučních šifer: Frekvenční analýza
Metody kryptoanalýzy
Při luštění šifer se používají nejrůznější techniky z různých oborů lidského vědění (lingvis-tika, statistika, matematika, informatika...). Velmi důležitá je znalost jazyka otevřeného textua jeho charakteristik. Významné místo mezi kryptoanalytiky mají arabští učenci, kterým sena přelomu prvního tisíciletí podařilo najít způsob snadného rozlomení monoalfabetickýchšifer za použití frekvenční analýzy.
• Základní představu o monoalfabetických šifrách získáme pomocí frekvenční analýzy,neaplikujeme ji však slepě.
• Pokoušíme se odhalit samohlásky (40% textu) – obvykle ve slově alespoň jedna, roz-vrstveny relativně pravidelně, zřídka vedle sebe.
• Hledáme častá slova, typické digramy, trigramy.• Zkoušíme delfskou metodu – hádat celá slova, odhadnout obsah zprávy.
Velmi zajímavý popis kryptoanalýzy podává v povídce Zlatý skarabeus E. A. Poe. Dalšíbeletristicko-kryptologickou zajímavostí je povídka La Disparition od Georgese Pereca. Po-vídka má 20 stran a ani na jednom místě se nevyskytuje písmeno e.
Frekvence písmen
Pro každý jazyk je specifická frekvence jednotlivých písmen. S touto znalostí jazyka lzerozpoznávat konkrétní znaky na základě jejich četnosti i po zašifrování.

Obsah 49
Frekvence písmen v textu s mezerami
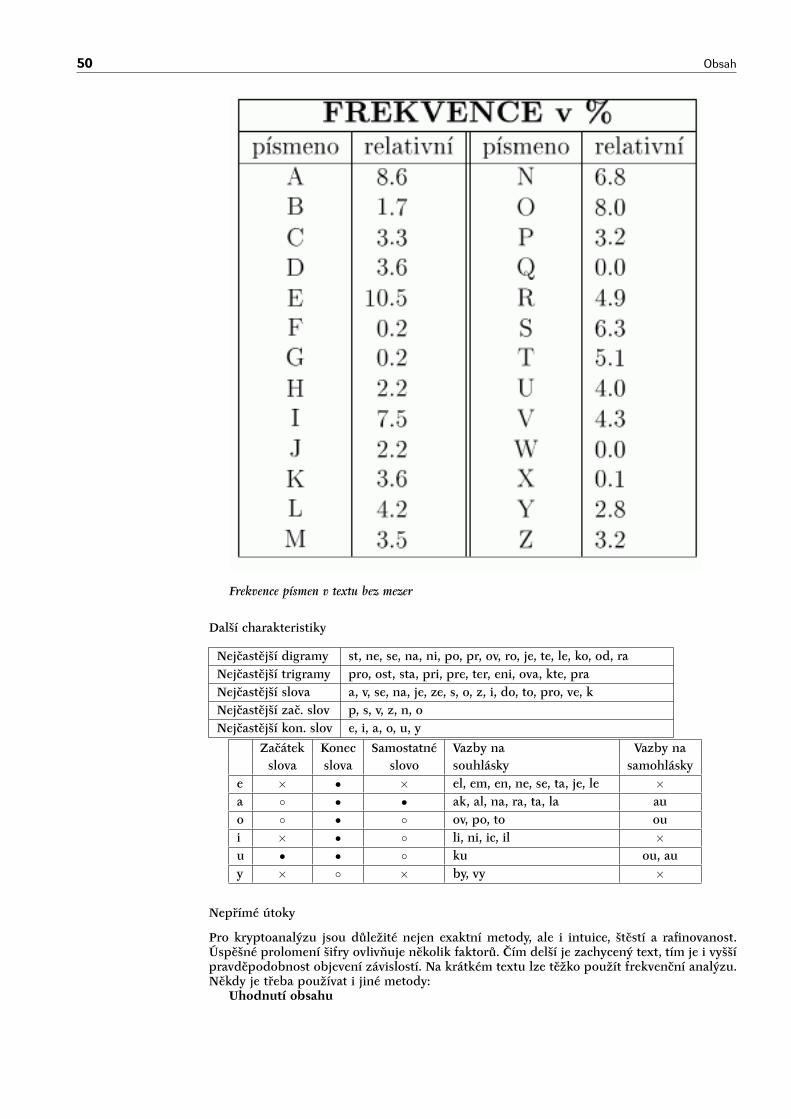
50 Obsah
Frekvence písmen v textu bez mezer
Další charakteristiky
Nejčastější digramy st, ne, se, na, ni, po, pr, ov, ro, je, te, le, ko, od, raNejčastější trigramy pro, ost, sta, pri, pre, ter, eni, ova, kte, praNejčastější slova a, v, se, na, je, ze, s, o, z, i, do, to, pro, ve, kNejčastější zač. slov p, s, v, z, n, oNejčastější kon. slov e, i, a, o, u, y
Začátek Konec Samostatné Vazby na Vazby naslova slova slovo souhlásky samohlásky
e × • × el, em, en, ne, se, ta, je, le ×a ◦ • • ak, al, na, ra, ta, la auo ◦ • ◦ ov, po, to oui × • ◦ li, ni, ic, il ×u • • ◦ ku ou, auy × ◦ × by, vy ×
Nepřímé útoky
Pro kryptoanalýzu jsou důležité nejen exaktní metody, ale i intuice, štěstí a rafinovanost.Úspěšné prolomení šifry ovlivňuje několik faktorů. Čím delší je zachycený text, tím je i vyššípravděpodobnost objevení závislostí. Na krátkém textu lze těžko použít frekvenční analýzu.Někdy je třeba používat i jiné metody:Uhodnutí obsahu

Obsah 51
• vojenská korespondence – typická oslovení, tituly, místa, pevná struktura zprávy...• obchodní korespondence – odhadnutí předmětu dopisování (zboží, města, jména ob-chodních partnerů)
• osobní korespondence – forma oslovení, jméno odesílatele a příjemceChyby šifrantůSlabým místem šifrovacích systémů je lidský faktor. Typickým příkladem je zaslání stej-
ného obsahu zašifrovaného pomocí různých klíčů.Intriky• ”Omylem” vyzrazené komunikační klíče;• Předstírání, že nemumím číst cizí šifru, ale přitom ji už dávno čtu;• Použití šifry v šifře;• Uloupení klíčů;
Polyalfabetické substituční šifry
Jak víme z předchozího textu, frekvenční analýza jednotlivých znaků či jejich skupin jemocný nástroj, který umožňoval luštit všechy monoalfabetické substituční šifry včetně jejichpolygramových variant. Vznikla proto potřeba plynule měnit šifrovou abecedu v průběhušifrování. Tím jsou charakterizovány polyalfabetické substituční šifry.
Tabula recta
Tabula recta znamená, volně přeloženo z latiny, pravoúhlou tabulku, která vypadá takto:A B C D E F G H I J K L M N O P Q R S T U V W X Y ZB C D E F G H I J K L M N O P Q R S T U V W X Y Z AC D E F G H I J K L M N O P Q R S T U V W X Y Z A BD E F G H I J K L M N O P Q R S T U V W X Y Z A B CE F G H I J K L M N O P Q R S T U V W X Y Z A B C DF G H I J K L M N O P Q R S T U V W X Y Z A B C D EG H I J K L M N O P Q R S T U V W X Y Z A B C D E FH I J K L M N O P Q R S T U V W X Y Z A B C D E F GI J K L M N O P Q R S T U V W X Y Z A B C D E F G HJ K L M N O P Q R S T U V W X Y Z A B C D E F G H IK L M N O P Q R S T U V W X Y Z A B C D E F G H I JL M N O P Q R S T U V W X Y Z A B C D E F G H I J KM N O P Q R S T U V W X Y Z A B C D E F G H I J K LN O P Q R S T U V W X Y Z A B C D E F G H I J K L MO P Q R S T U V W X Y Z A B C D E F G H I J K L M NP Q R S T U V W X Y Z A B C D E F G H I J K L M N OQ R S T U V W X Y Z A B C D E F G H I J K L M N O PR S T U V W X Y Z A B C D E F G H I J K L M N O P QS T U V W X Y Z A B C D E F G H I J K L M N O P Q RT U V W X Y Z A B C D E F G H I J K L M N O P Q R SU V W X Y Z A B C D E F G H I J K L M N O P Q R S TV W X Y Z A B C D E F G H I J K L M N O P Q R S T UW X Y Z A B C D E F G H I J K L M N O P Q R S T U VX Y Z A B C D E F G H I J K L M N O P Q R S T U V WY Z A B C D E F G H I J K L M N O P Q R S T U V W XZ A B C D E F G H I J K L M N O P Q R S T U V W X YA B C D E F G H I J K L M N O P Q R S T U V W X Y ZKaždý znak otevřeného textu šifrujeme tak, že jej vyhledáme v prvním řádku a do šif-
rového textu pak zapíšeme znak ležící ve stejném sloupci tabulky, ale v tolikátém řádku,kolikáté písmeno šifrujeme. První písmeno tedy zůstane stejné, druhé písmeno bude posu-nuté o 1 znak, třetí písmeno o 2 znaky, atd. Jakmile vystřídáme všech 26 možných posunutí,začínáme opět od začátku.Tato šifra je však v principu špatná, neboť algoritmus nepočítá s žádnou možností využití
šifrovacího klíče. Jakmile útočníkovi bude algoritmus znám, snadno bude moci číst jakouk-koliv komunikaci. Řešení tohoto prroblému přinesla Vigenérova šifra, v níž se posun abecedyneřídí takto jednoduchým pravidlem, ale je závislý právě na použít šifrovacího klíče.

52 Obsah
Vigenérova šifra
Autorem této šifry je Blaise de Vigenére, který ji poprvé vydal ve svém Traktátu o šifráchv roce 1586. Šifrování probíhá pomcí opakujícího se klíče, jehož délka je větší než 1.
Příklad Vigenérovy šifry:
Klíčové slovo WHITEWHITEWHITEWHITEWHIOtevřený text diverttroopstoeastridgeŠifrový text ZPDXVPAZHSLZBHIWZBKMZNM
Jako šifrovací pomůcka se používá tzv. Vigenérův čtverec, což je útvar stejný, jako tabularecta. V něm se vyznačí řádky začínající písmeny klíče. Při šifrování písmene otevřenéhotextu se na průsečíku sloupce, jenž má v prvním řádku dané písmeno a příslušného řádkupodle aktuální pozice klíče vybere znak šifrového textu. Díky tomu, že se mění znaky klíče,pomocí nichž se šifruje, jsou stejné znaky otevřeného textu šifrovány obecně různými sym-boly šifrového textu, stejně tak dva stejné znaky šifrového textu vznikly obecně šifrovánímrůzných znaků otevřeného textu. To je důvod, proč se tomuto šifrování říká polyalfabetické.A B C D E F G H I J K L M N O P Q R S T U V W X Y ZB C D E F G H I J K L M N O P Q R S T U V W X Y Z AC D E F G H I J K L M N O P Q R S T U V W X Y Z A BD E F G H I J K L M N O P Q R S T U V W X Y Z A B CE F G H I J K L M N O P Q R S T U V W X Y Z A B C DF G H I J K L M N O P Q R S T U V W X Y Z A B C D EG H I J K L M N O P Q R S T U V W X Y Z A B C D E FH I J K L M N O P Q R S T U V W X Y Z A B C D E F GI J K L M N O P Q R S T U V W X Y Z A B C D E F G HJ K L M N O P Q R S T U V W X Y Z A B C D E F G H IK L M N O P Q R S T U V W X Y Z A B C D E F G H I JL M N O P Q R S T U V W X Y Z A B C D E F G H I J KM N O P Q R S T U V W X Y Z A B C D E F G H I J K LN O P Q R S T U V W X Y Z A B C D E F G H I J K L MO P Q R S T U V W X Y Z A B C D E F G H I J K L M NP Q R S T U V W X Y Z A B C D E F G H I J K L M N OQ R S T U V W X Y Z A B C D E F G H I J K L M N O PR S T U V W X Y Z A B C D E F G H I J K L M N O P QS T U V W X Y Z A B C D E F G H I J K L M N O P Q RT U V W X Y Z A B C D E F G H I J K L M N O P Q R SU V W X Y Z A B C D E F G H I J K L M N O P Q R S TV W X Y Z A B C D E F G H I J K L M N O P Q R S T UW X Y Z A B C D E F G H I J K L M N O P Q R S T U VX Y Z A B C D E F G H I J K L M N O P Q R S T U V WY Z A B C D E F G H I J K L M N O P Q R S T U V W XZ A B C D E F G H I J K L M N O P Q R S T U V W X YA B C D E F G H I J K L M N O P Q R S T U V W X Y ZTato šifra zůstala nerozlomena po 300 let. O její kryptoanalýzu se zasloužil až Charles
Babbage. Kryptoanalýza probíhá ve dvou částech:
1. Určení délky klíče2. Odhalení klíče
Jak známo, opakování je základ kryptoanalýzy. Nejinak je tomu i v případě Vigenérovyšifry. Díky tomu, že v otevřeném textu se některá slova (či jejich části) opakují, je pravdě-podobné, že po čase dojde k jejich zašifrování stejnou částí klíče. Proto začneme tím, žev šifrovém textu vyhledáme opakující se sekvence. Například:

Obsah 53
KINGKINGKINGKINGKINGKINGthesunandthemaninthemoonDPRYEVNTNBUKWIAOXBUKWWBT
Je samozřejmě možné že některá z těchto sekvencí vznikla zašifrováním jiného řetězcepomocí jiné části klíče, ale tato varianta je poměrně nepravděpodobná. Určíme tedy společ-ného dělitele vzdáleností opakujících se sekvencí, což je délka klíče, nebo její násobek.Poté přichází na řadu druhý krok, v němž rozdělíme zprávu na části, které byly zašif-
rovány stejou částí klíče. V uvedeném příkladu by tak první část tvořily znaky zašifrovanépísmenem K (D, E, N, W, X, W), druhou část znaky zašifrované písmenem I (P, V, B, I, B,W), atd. V praxi smozřejmě nevíme, jakým písmenem byly tyto znaky zašifrovány. To je všakvelmi snadné zjistit, neboť se jednalo pouze o posunutou abecedu, tedy nejjednodušší mono-alfabetickou substituční šifru, která se snadno luští pomocí frekvenční analýzy. Po provedenéfrekvenční analýzy již známe klíč a můžeme zprávu rozluštit.
Autoklíč Vigenérovy šifry
Vigenére sám navrhl jiný způsob šifrování, za použití tzv. autoklíče. Ten se však nepouží-val pro svoji přílišnou složitost. Klíčové slovo (délky n) se pooužije pouze pro zašifrováníprvních n znaků otevřeného textu, pak se již neopakuje a na místo něj se používá buďtosamotná zpráva, nebo šifrový text. I tento způsob je však možné poměrně snadno zlomit.Nedochází sice k žádnému opakování, ale víme, že jeden znak zprávy (nebo šifry) byl použ-řit pro šifrování znaku o n pozic dále. Stačí tedy uhodnout n (popřípadě vyzkoušet všechnymožnosti) a zprávu lze snadno rozluštit včetně počátečního klíče.
Zdokonalování Vigenérovy šifry
Koncem 19. století panovala mezi kryptografy značná deprese, neboť neexistoval způsobšifrování, který by nebylo možné prolomit. To se podařilo vyřešit až koncem 1. světové válkyGilbertu Vernamovi. Do té doby proběhlo několik pokusů o zdokonalení Vigenérovy šifryv naději, že ji nebude možné rozluštit. Všechny však byly zlomeny.Základním problémem bylo opakování. Za předpokladu, že budeme mít text, který je
stejně dlouhý jako zprráva samotná (začátek knihy, noviny, text ústavy, atd.), nebude možnéurčit délku klíče ani text rozdělit na části, v nichž by útočník potom mohl provádět frek-venční analýzu. Tyto naděje se však rychle rozplynuly, neboť jak zpráva, tak klíč, jsou řetězcepřirozeného jazyka, který obsahuje mnoho závislostí. Pokud tedy zkoušíme na různá místapředpokládaného otevčřeného textu dosazovat časté trigramy (v angličtině jsou jimi např.”the”, ”ing”, apod.), získáváme tím části klíče. Ty nám vyjdou buďto nesmyslné, v tom pří-padě jsme se netrefili, anebo nám vyjdou části smyslupných slov, která je možné domyslet.Poté však lze dopočítat další znaky otevřeného textu a ověřit, zda byly doměnky správné.Tím se nám rozšiřuje část otevřeného textu, která je známá, můžeme domýšlet další slovaa dopočítávat znaky klíče, potom opět domýšlet klíč a dopočítávat znaky otevřeného textu,až v jednom okamžiku zjistíme, jaký text byl použit jako klíč a je možné přečíst celou zprávu.
Vernamova šifra
Řešením všech problémů s opakováním i závislostmi v přirozeném jazyce, je Vernamovašifra, označovaná jako jednorázová tabulka (one time pad), u níž je matematicky dokázáno,že je nerozzluštitelná. Jejím autorem je Gilbert Vernam a spatřila světlo světa v roce 1917.Důkaz nerozluštitelnosti podal v roce 1940 Claude Shanon. Je založená na tom, že klíčemje sekvence zcela háhodných znaků. Taková sekvence neobsahuje žádné závislosti a nenítedy možné se ničeho při kryptoanalýze chytit. Navíc, jakákoliv sekvence znaků je klíčem sestejnou pravděpodobností, tudíž i jakákoliv sekvence znaků je řřešením (otevřeným textem)se stejnou pravděpodobností. Pokud tedy někdo najde klíč a řešení, nemůže si nikdy býtjistý, že to, co našel, je skutečně to, co odesilatel zprávy použil.Knihu náhodných písmen však lze použít pouze jednou. Pokud bychom ji použili více-
krát, vznikly by velmi snadno odhalitelné závislosti, které by umožnily kryptoanalýzu obou

54 Obsah
zpráv podobným způsobem, jako tomu bylo u vylepšní Vigenérovy šifry. Odtud pochází ná-zev jednorátzová tabulka (one time pad) a v historii bychom našli několik případů, kdy seopakované použiití jednorrázové tabulky vymstilo.Vernamova šifra má však mnoho problémů. Jak generovat skutečně náhodnou posloup-
nost znaků? V roce 1944 dokázala americká NSA luštit německé zprávy, neboť Němci použí-vali strojově generované tabulky. Výstup stroje byl však předvídatelný, takže stačilo sestrojitjiný stroj se stejným výstupem a klíč prro kryptoanalýzu byl na světě. Pokud byly tabulkygenerovány ručně, tj. psali je písaři, opět vznikali určité závislosti (například střídání sym-bolů z levé a pravé poloviny klávesnice). Dalším problémem je distribuce klíčů, které musejíbýt bezpečně dopraveny všem jednotkám, navíc musí být zabezpečeno, že když kterákolivjednotka použije pro šiffrování stránku kódové knihy, musí všechny ostatní jednotky tutostránku také zničit. To s sebou přináší obrovské logistické náklady, které činí Vernamovušifru v praxi nepoužitelnou.Použití Vernamovy šifry si mohou dovolit jen někteří. V Bílém domě a v Kremlu má každý
z prezidentů speciální krabičku s unikátním krystalem, který generuje ”náhodnou” posloup-nost symbolů, pomocí níž je šifrování telefonní spojení mezi oběma prezidenty. Nikdo jinýna světě takovou krabičku nemá, není tedy schopen předpovědět její výstup. Komunikaceobou nejmocnějších mužů planety je tak stoprocentně chráněna proti odposlechu.Více se o problematice generování náhodných čísel dozvíme v následující kapitole.
Generování náhodných čísel
Generování náhodných číselGenerování náhodných čísel představuje z hlediska kryptografie jeden z velmi podstatnýchproblémů. Jak jsme si již řekli, jediný kryptografický algoritmus, jehož bezpečnost (tj. ne-rozluštitelnost) je matematicky dokázána, je Vernamova jednorázová tabulka. Předpoklad, žesymboly v tabulce, které slouží jako klíč, jsou náhodné, je zde přitom velmi důležitý a stojína něm celý důkaz bezpečnosti šifry.Jak však vygenerovat náhodné znaky do tabulky? Přopomeňme, že vygenerovat náhodné
znaky je stejný problém jako vygenerovat náhodná čísla (která lze na znaky převést např.pomocí ASCII tabulky), a to je stejný problém jako generovat náhodnou posloupnost nula jedniček. Je tedy lhostejné, jak se na problematiku generování díváme, všechny uvedenéproblémy jsou ekvivalentní a v praxi mají nejčastěji jednu z následujících podob:
• vybrat z n-prvkové množiny náhodný prvek• vygenerovat náhodnou m-znakovou posloupnost nad n-prvkovou abecedou• vybrat z množiny všech m-znakových řetězců nad n-prvkovou abecedou jeden náhodnýřetězec
Na úvod bychom si měli odpovědět na otázku ”Co to znamená náhodný?”
Náhodný výběr je takový výběr, kdy pravděpodobnost výběru všech prvkůz určené množiny je stejná.
Z matematického hlediska je náhodná posloupnost taková posloupnost, u níž neexis-tuje její kratší vyjádření, než je posloupnost sama. Nelze ji tedy popsat vzorcem a přímopodle definice ji nelze komprimovat (tím bychom našli kratší vyjádření). Důsledkem tedyje, že nemůže existovat deterministický algoritmus generující náhodná čísla. Proto budemehovořit pouze o pseudonáhodných číslech, tedy o číslech, která pouze vypadají náhodně, veskutečnosti však náhodná nejsou, neboť jsou generována deterministickým algoritmem.Existuje samozřejmě i možnost generování skutečně náhodných hodnot. Ty však musí
být založeny na nějakém nedeterministickém vstupu. Zde se samozřejmě nabízí otázka, kdevzít nedeterministický vstup ve světě, ve kterém platí (deterministické) fyzikální zákony. Tatootázka je však spíše filozofická a pro nás bude dostatečně deterministický takový vstup,u nějž nezle předem s běžně dostupnými prostředky určit, jaké hodnoty bude poskytovat.Jako vstupní zařízení pro TRNGs (True RandomNumber Generators) se tak používají zařízeníměřící atmosférický šum, rozpad radioaktivních částic, fotografie lávových lamp, apod.Bez použití speciálních hardwarových zařízení lze náhodné hodnoty získat s pomocí
systémových hodin, ze stisků kláves (nejen ze samotných kláves, ale i z prodlev mezi jednot-

Obsah 55
livými stisky), z obsahu vstup/výstupních bufferů, ze zátěže operačního systému, z analýzysíťového provozu, ze zvuku snímaného mikrofonem, z obrazu webkamery, z pohybů myší čiz aktuální barvy některého z bodů na monitoru. Takto získané hodnoty slouží většinou jakosemínko, tedy základ, z nějž vyroste delší posloupnost pseudonáhodných čísel. U moderníchalgoritmů je totiž potřeba získat v krátkém čase poměrně velké množství náhodných čísel.Jejich získávání z perriferií počítače by bylo nejen velmi časově náročné, navíc by hroziloriziko, že data budou málo variabilní. Podívejme se nyní na nejběžnější typy generátorůpsenudonáhodných čísel (PRNGs - PseudoRandom Number Generators).
Kongruenční generátory
Kongruenční generátory jsou výpočetně velmi jednoduché generátory, které generují po-sloupnost pseudonáhodných čísel s poměrně dobrými statistickými charakteristaikami. Všechnyjsou však zlomeny a pro kryptografické účely se nehodí.Nejjednodušší je lineární kongruenční generátor určený rovnicíxn = (a · xn−1 + b) mod m,kde a, b, m jsou parametry generátoru a x0 je semínko.Složitější je kvadratický kongruenční generátor určený rovnicíxn = (a · x2n−2 + b · xn−1 + c) mod mDalším generátorem je pak kubický kongruenční generátor, atd. Zobecněním získáváme
polynomiální kongruenční generátor. Platí věta, že pro zjištění všech parametrů generátoruvčetně semínka potřebujeme znát nejvýše 2m prvků posloupnosti. Proto se tyto generátorypoužívají pouze pro simulace, ne pro kryptografii.
Lineární zpětnovazební registry
Lineární zpětnovazební registry (Linear Feedback Shift Register - LFSRs) představují obecnýmechanismus, kterým lze generovat pseudonáhodná čísla s poměrně solidním stupněm bez-pečnosti. Skládají se ze dvou částí: Z posuvného registru a ze zpětnovazební funkce. Principjejich fungování je vidět na následujícím obrázku (Zdroj: Wikipedia):
Na počátku je registr naplněn semínkem. Poté v každém kroku nostáváme na výstupnejpravější bit, přičemž všechny bity se posunou o jeden doprava. Nejlevější bit se dopočítána základě zpětnovazební funkce, což je nejčastěji XOR určitých bitů. Správně navrženýLFSR vystřídá všech 2n možných stavů, než se znovu dostane zpět do počátečního stavu.Výstupem LFSR je tedy posloupnost pseudonáhodnýcb bitů délky 2n.Protože kryptoanalýza LFSR je poměrně snadná, máme-li k dispozici šifrový text a část
otevřeného textu, v kryptografické praxi se používají složitější funkce:• Nelineární kombinace určitých bitů (tedy složitější funkce než XOR)• Nelineární kombinace výstup dvou nebo více LFSRs• Nepravidelné časováníProblematika generování náhodných čísel je z hlediska návrhu kryptografického systému
velmi důležitá. Velká část současných útoků na kryptografické systémy totiž nemíří protisamotné šifrovací funkci, ale snaží se najít postranní cestičky, kudy se dostat k hodnotám,které sloužily jako vstup šifrovacího algoritmu. Např. Netscape Communicator začátkemdevadesátých let při generování klíčů pro SSL používal pouze systémový čas, své PID a PIDsvého rodiče. Je tedy zřejmé, že kdo měl přístup k těmto údajům , měl poté kontrolu nadcelou komunikací, která vypadala, že je zabezpečená. Samotná šifra tedy mohla být jakkolivsilná, stejně to nepomohlo.

56 Obsah
Pravá náhodná číslaPro použití v kryptografii, která vyžaduje skutečně vysoký stupeň zabezpečení se nehodípseudonáhodné generátory, jejichž výstup je vždy předvídatelný. Používají se proto tzv. ge-nerátory skutečně náhodných čísel (True Random Number Generators - TRNGs). Vstupemtěchto generátorů je vždy signál z nějakého vnějšího hardwarového zařízení, jehož výstup jenepředvídatelný. Může to být měřič atmosférického šumu, detektor radioaktivního rozpadučástic, snímač turbulencí na větráku procesoru, atd. Z jednodušších zařízení lze použít např.mikrofon či webovou kameru.Na internetu je několik serverů, které poskytují výstupy z takovýchto zařízení. Jedná
se například o server www.random.org, který poskytuje náhodná čísla generovaná na zá-kladě atmosférického šumu, www.fourmilab.cz/hotbits, který poskytuje náhodná čísla zís-kaná z radioaktivního rozpadu. Generování na základě fotografií lávových lamp je možnézískat z www.lavarand.org.
Transpoziční šifry. Superšifrování
Transpoziční šifryTranspozicí rozumíme permutaci (přeskládání) symbolů zprávy jiným způsobem. Permutacese používá jako součást moderních algoritmů (DES, AES). Vstupem permutace musí být vždyblok dané délky t. Dlouhé zprávy tedy musí být nejprve rozděleny na bloky délky t. Šifrovánípak probíhá v každém bloku zvlášť. Klíčem pro šifrování je permutace přirozených čísel 1..t.Prostor klíčů má tedy velikost t!.
Příklad obecné transpozice:
T = 6K = (6,4,1,3,5,2)M = CAESARC = RSCEAA
Jednoduchou transpoziční šifrou je tzv. sloupcová transpozice. Zprávu nejprve vepíšemedo matice po sloupcích, poté čteme matici po řádcích. Na tomto principu pracovala sparrtskáskytála.
Jednoduchá transpozice s klíčemNejprve je třeba ustavit klíč. K tomu nám poslouží klíčové slovo, které může být libovolné.Očíslujeme písmena v klíčovém slově podle abecedy:
T A J E M S T V I
K = 7 1 4 2 5 6 8 9 3
Poté napíšeme zprávu po řádcích do tabulky o n sloupcích (n je délka klíče). Tabulkučteme po sloupcích v pořadí daném permutačním klíčem. Na závěr rozdělíme text na pětice(tento krok je kvůli snadnějšímu přenosu telegrafem). Chceme-li šifru zesílit, aplikujemetentýž postup dvakrát s různě dlouhými klíči. Kryptoanalýza bez použití výpočetní technikyje pak velmi náročná. Tuto metodu používali čeští partyzáni během odboje za druhé světovéválky. Takto zašifrované zprávy posílali do Londýna. Němci však byli schopní tyto zprávyluštit.

Obsah 57
Vlastnosti transpoziceSložení dvou permutací je opět permutace. Lze ji tedy nahradit jedinou (byť složitější) per-mutací.Transpozice ruší závislosti mezi znaky (digramy, trigramy, atd.)Transpozice zachovává frekvenci výskytu jenotlivých znakůTranspozice je vhodná ke kombinaci s jinými metodami
Superšifrování
Pod pojmem superšifrování se rozumí skládání více různých šifer. Na výstup jednoho šifro-vacího algoritmu aplikujeme jiný šifrovací algorritmus a příjemci pošleme až jeho výsledek.Tedy:
C = E2(K2, E1(K1, M))Příjemce pak musí aplikovat dešifrovací algoritmy v opačném pořadí:M = D1(K1, D2(K2, C))Typické je skládání substituce a transpozice, nebo skládání transpozice a nelineární arit-
metické funkce. Moderní šifrovací algoritmy skládají substituci a transpozici v mnoha itera-cích. Odvodit z šifrového textu klíč či původní zprávu je tak (s dnešními znalostmi) praktickynemožné.Nepřítelem superšifrování je tzv. involuce.
Involuce je zobrazení, jehož složením se sebou samým získáváme identitu.Platí pro něj tedy, že f(f(x)) = x.
Příkladem involuce je šifra ROT13, která řetězec ”AHOJ” šifruje jako ”NUBW”. Opětov-ným použitím ROT13 na řetězec ”NUBW” získáme opět text ”AHOJ”.Dalšími příklady jsou XOR n či libovolná symetrická permutace.Involuce je důležitý prvek symetrické kryptografie, je však nepřítelem superšifrování.
Druhá šifra může místo posílení účinku první šifry, tento účinek naopak zničit. Napříkladv době, kdy se ukázalo, že šifra DES již nepředstavuje dostatečné zabezpečení, uvažovalose o nasazení 2DES. Jak se ale včas ukázalo, použitím pouze dvou průchodů šifrovacímalgoritmem by vznikly nebezpečné závislosti, které by značně usnaddnily kryptoanalýzu.Proto se začal používat 3DES, který tytoo závislosti zase odstraňuje.
Symetrická kryptografie
Symetrická kryptografie
Symetrické šifrování znamená, že zpráva šifrovaná vybraným klíčem je dešifrovatelná týmžklíčem v přeměnu zpět na prostý text.V souvislosti se symetrickým šifrováním bude často zmiňován pojem bloková šifra. Text
šifer s tímto označením je před vstupem do šifrovacího procesu rozdělen do stejně dlouhýchčástí (bloky) pro účely snazší aplikace klíče i celého šifrového algoritmu.
Historické souvislostiZa dob světových válek bylo šifrování informací velice hojně praktikováno. Zejména ve Druhésvětové válce hrálo šifrování a dešifrování zpráv významnou roli. Dalo vzniknout prvnímpočítačům, které byly konstruovány ve snaze dešifrovat nejslavnější šifrovací stroj ENIGMApracující na symetrickém principu.Jakmile ustala vřava zbraní, lidé západního světa neupadli do poválečné deprese, ale
s novou vitalitou soustředili veškerou svou sílu do podnikatelských aktivit. Byly budoványnové fabriky, rekonstruovaly se budovy pro účely státního či soukromého podnikání. Zdáloby se, že kryptografie bude zase na nějakou dobou neupotřebitelná. Opak byl pravdou.

58 Obsah
Tajné válečné informace pulsující mezi armádními jednotkami svádějící urputné bojepomáhaly vyhrávat celé bitvy. Nyní mají informace svou nedocenitelnou hodnotu v podni-katelské sféře, kde svádí podniky boje mezi sebou.Během 60. let rostl počítačový výkon a s ním i počet firem, které si nové cenově dostup-
nější počítače nakupovali. Firmy je začali mimo jiné využívat i k šifrování důležité komuni-kace. Firmy sice mohli šifrovat informace různým způsobem, horší ale bylo, když si taktozašifrované informace potřebovali mezi sebou vyměnit. To bylo prakticky nemožné, leda byvšechny firmy používaly stejný šifrovací systém. Tak vyvstal problém standardizace.
DES (Data Encryption Standard)Jedná se o počítačový šifrovací algoritmus, který byl přijat jako standard pro citlivé infor-mace americkým standardizačním úřadem roku 1976. DES splňoval požadavky tehdejší NBS(National Bureau of Standards, od roku 1988 NIST - National Institute of Standards andTechnology), což je americký (USA) standard pro hodnocení bezpečnosti kryptografickýchmodulů a byl 15. ledna 1977 publikován jako FIPS PUB 46 pro volné užití. Později (1983)byl znovu potvrzen jako FIPS PUB 46-1, v roce 1988 přijat pod označením FIPS PUB 46-2a v roce 1999 FIPS PUB 46-3. (FIPS - Federal Information Processing Standards Publication).Standard DES je celosvětově nejproslulejším algoritmem, který se udržel na výsluní ně-
kolik dekád a proto stojí za to povědět si o něm co nejvíce.
Vlastnosti
Prvně bychom si neměli plést pojmy DES a DEA. Název DES jako takový totiž označujepojmenování standardu, kdežto DEA (Data Encryption Algorithm) je ekvivalentem pro sa-motný algoritmus, který tento standard určuje. V běžné terminologii kryptologie se však podpojmem DES rozumí zároveň jak standard, tak i jeho určující algoritmus.DES patří do skupiny blokových šifer. Blokové šifrování na rozdíl od proudového, které
šifruje data pomocí klíče bit po bitu, rozdělí tok bitů prostého textu na bloky o stejné ve-likosti (v případě DES na 64 bitů) a šifruje každý blok pomocí klíče zvlášť. Tato vlastnosta relativně nenáročný algoritmus určují ještě jednu význačnou charakteristiku, a tou je rych-lost a implementační nenáročnost. Díky těmto vlastnostem se DES ještě dnes těší stále velkéoblibě.Zmíněný algoritmus je na internetu dostupný hned v několika programovacích jazycích
a kdokoliv znalý programování si může zdrojový kód prostudovat, popřípadě si jej sámnaprogramovat.
Jak DES přišel na svět
NBS začal problém standardizace řešit a od 15. května 1973 požádal o návrhy pro prvníšifrovací standard.Koncem 60. let se otázkou počítačové kryptografie zabýval jistý Horst Feistel a začátkem
70. let pod záštitou IBM vyvinul šifru zvanou Lucifer.Lucifer se stal hlavním kandidátem NBS. Jediný problém spočíval v maximální možné
délce klíče. NSA (National Security Agency) Národní bezpečnostní agentura USA byla ochotnapovolit přijetí šifry za standard pod podmínkou omezení délky klíče na 64 bitů (resp. 56b vizníže). Takto zašifrovaná zpráva by byla sice pro běžného uživatele zcela jistě nerozluštitelnáale pro NSA s nejvýkonnější technikou nesnadno, ale přece jen rozlomitelná. Tak byla šifraLucifer 23. listopadu 1976 přijata za standard známý pod zkratkou DES.Standard DES vydržel poměrně dlouho. Teprve v roce 2002 byl přijat nový standard zvaný
AES (Advanced Encryption Standard), který DES nahradil. V průběhu let se ze standardu DESvytvořil minoritní Triple DES označovaný též TDES (popř. 3DES), který šifruje data pomocíDES trojnásob.
Současné postavení DES
Nástup nových standardů neznamená definitivní ústup DES do kryptografického podsvětí.Dodnes je nemálo populární a pro utajování méně citlivých zpráv stále využívaný. Je tohlavně z toho důvodu, že je dosti uživatelsky přátelský zejména pro svoji rychlost.Je nutné ale přiznat, že jeho důvěra byla nevratně podlomena. Tato událost je spojena
s koncem 90. let, kdy byl sestrojen dešifrovací stroj DES-Cracker (1998) pracující hrubousilou tzn. testování a hledání všech možných klíčů, kterých je zhruba 72 kvadrilionů. Mezi

Obsah 59
další akce vedoucí k podlomení důvěry DES se řadí i několik soutěží vyhlášených subjektemRSA Security k rozluštění soutěžní zprávy zašifrované DES algoritmem. V první soutěži v de-vadesátém sedmém DESCHALL Projekt (sdružení počítačových nadšenců) prolomil DES za96 dní. Další soutěž nazvaná DES Challenge II-1 proběhla v roce 1998, kdy došlo k rozluštěnízprávy prostřednictvím počítačů v síti Internet sdružených organizací d i t s t r i b u t e d . n et za 41 dní. Další soutěž v pořadí zvítězil právě DES-Cracker sestrojený za necelých $250.000,který byl s to rozlousknout tajnou zprávu za necelých 56 hodin. V poslední výzvě si ditstri-buted.net připsal $10.000 odměny, kdy se mu za významné spolupráce s DES-Crackerem,podařilo rozluštit zprávu za méně než 23 hodin. To se stalo v roce 1999, kdy byl DES počtvrté a naposledy přijat jako federální standard (viz. nahoře), ale s doporučením používatjeho vylepšenou verzi 3DES.
DES algoritmus
Šifrovací algoritmus je opakující se proces jednoduchých matematických operací v 16 kolech(tzv. rundy). Jsou prováděny především permutace, popřípadě substituce za použití různýchpomocných tabulek. To vše se děje v kombinaci vygenerovaných sub-klíčů, které se sčítajís upraveným blokem bitů logickou operací XOR (ve schématu značeno + v kolečku).

60 Obsah
Celý proces začíná převodem zprávy M z desítkové soustavy do dvojkové na posloupnostbitů P. Poté následuje tvorba sub-klíčů. Nejprve si vygenerujeme netriviální klíč K o délce64b. Následně projde permutační tabulkou značenou PC-1:57 49 41 33 25 17 91 58 50 42 34 26 1810 2 59 51 43 35 2719 11 3 60 52 44 3663 55 47 39 31 23 157 62 54 46 38 30 2214 6 61 53 45 37 2921 13 5 28 20 12 4To znamená, že 57. bit z původního klíče jde na 1. pozici nového klíče, 49. bit jde na
2. pozici atd., až se 4. bit z klíče usadí na poslední pozici nového klíče. Tímto postupemnám vznikne nový klíč K+ o délce 56b, protože každý 8. bit původního klíče je použit prokontrolu parity (násobky 8 jsou v tabulce vynechány).Nyní je klíč K+ rozdělen na dvě poloviny (2 × 28b). Levá se označí C0 a pravá D0.Např.:C0 = 1111000 0110011 0010101 0101111D0 = 0101010 1011001 1001111 0001111Máme základ pro tvorbu 16 sub-klíčů. Ty se vygenerují jednoduše pomocí posuvné ta-
bulky, kdy se bity z Ci Di posunou směrem doleva o 1 až 2 pozice dle tabulky oprotipředešlým Ci - 1 a Di - 1.číslo kroku 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16posun do leva o 1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 1Nyní se jednotlivé Cn, Dn spojí a projdou finální kompresní permutační tabulkou, která
použije pouze 48b z každého řetězce CD.PC-2:14 17 11 24 1 53 28 15 6 21 1023 19 12 4 26 816 7 27 20 13 241 52 31 37 47 5530 40 51 45 33 4844 49 39 56 34 5346 42 50 36 29 32Všech 16 sub-klíčů je hotových.Dále jednotlivé bloky zprávy M projdou tzv. IP (Initial Permutation) tabulkou. Nejedná se
o nic jiného než nám již známá permutační tabulka, tentokrát již bez kompresních účinků.Tabulka IP má tento tvar:58 50 42 34 26 18 10 260 52 44 36 28 20 12 462 54 46 38 30 22 14 664 56 48 40 32 24 16 857 49 41 33 25 17 9 159 51 43 35 27 19 11 361 53 45 37 29 21 13 563 55 47 39 31 23 15 7Permutované bloky se dělí na půl bloky po 32b a označí se jako levý L0 a pravý P0.
Průchod skrz IP permutační tabulku nemá na sílu algoritmu vůbec žádný vliv. Zpráva přesni prochází v počátku, aby jí prošla nanovo v závěru šifrování v podobě její převrácenéhodnoty IP-1. To vše se děje proto, aby bylo zaručeno možné zpětné symetrické dešifrování.Jako další se provádí postupně 16 kroků, ve kterých je prováděna funkce f nad 48b
sub-klíčem a 32b blokem dat. Funkce f je definována jako f (Rn-1,Kn).Pro n 1 až 16 pak máme vztah:Ln = Rn-1Rn = Ln-1 + f (Rn-1,Kn)Kde + značí operaci XOR (bit plus bit modulo 2)V každém následném kroku se tedy pravá strana předešlého kroku chápe jako nová levá
strana následného kroku a původní leva strana sečtená s funkcí f se bere jako pravá strananásledného kroku.

Obsah 61
Abychom mohli provést funkci f, potřebujeme rozšířit každý blok Rn-1 z 32 na 48b(z důvodu délky sub-klíče: 48b). Toho se docílí za pomoci výběrové tabulky která vezmeněkteré bity z Rn-1 vícekrát. Použití výběrové tabulky nazýváme funkcí E. Odsud E(Rn-1)E BIT VÝBĚROVÁ (SELEKTIVNÍ) TABULKA:32 1 2 3 4 54 5 6 7 8 98 9 10 11 12 1312 13 14 15 16 1716 17 18 19 20 2120 21 22 23 24 2524 25 26 27 28 2928 29 30 31 32 1Takto upravený půlblok se sečte XOR operací s připraveným sub-klíčem a vznikne nový
blok o délce 48b. Aby takovýto blok byl použitelný pro další kroky v algoritmu, je potřebaze 48b opět vyzískat pouze 32b dlouhý blok.Pro tento účel rozdělíme 48b do 8 skupin po 6b a každý takovýto 6b prvek použijeme
jako adresu do tabulky zvané S-box. Na 8 skupin 6b prvků máme k dispozici 8 S-boxů.Lokací každé adresy je 4-bitové číslo. Takže z původních 6-ti bitů dostaneme potřebné 4b.Schéma S-boxů ukazuje následující obrázek:

62 Obsah
Nazveme-li 6b prvek B a funkci S-boxu S, můžeme psát Si(Bi) pro i <1..8>Z 6-ti bitového prvku vezmeme první a poslední bit. Takovéto dva bity reprezentují
v desítkové soustavě rozsah čísel <0..3>, binárně <00..11> označíme i. Prostřední 4 bity,které jsou v rozsahu <0000..1111>, desítkově <0..15> označíme j. Výsledné políčko, kterénajdeme na adrese [i,j] je naše nové 4 bitové číslo.Ukázka jednoho z osmi S-boxů:
S5 Vnitřní 4 bity z 6-tibitového prvku
0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111Vnější bity 00 0010 1100 0100 0001 0111 1010 1011 0110 1000 0101 0011 1111 1101 0000 1110 1001
01 1110 1011 0010 1100 0100 0111 1101 0001 0101 0000 1111 1010 0011 1001 1000 011010 0100 0010 0001 1011 1010 1101 0111 1000 1111 1001 1100 0101 0110 0011 0000 111011 1011 1000 1100 0111 0001 1110 0010 1101 0110 1111 0000 1001 1010 0100 0101 0011
Nově vzniklá 4b čísla sloučíme a dokončíme funkci f tím, že sloučené bity projdou per-mutací P. Můžeme psát: f = P(S1(B1)S2(B2)...S8(B8)).P má následující tvar.16 7 20 2129 12 28 171 15 23 265 18 31 102 8 24 1432 27 3 919 13 30 622 11 4 25To se děje pro všech 16 rund. Na závěr prohodíme L16 a R16 a jsme téměř u konce. Zbývá
už jen aplikovat závěrečnou IP-1.IP-1 má tvar:40 8 48 16 56 24 64 3239 7 47 15 55 23 63 3138 6 46 14 54 22 62 30

Obsah 63
37 5 45 13 53 21 61 2936 4 44 12 52 20 60 2835 3 43 11 51 19 59 2734 2 42 10 50 18 58 2633 1 41 9 49 17 57 25
Ukázku Java aplikace názorně prezentující šifrování a dešifrování pomocí al-goritmu DES naleznete zde a .
ahttps://akela.mendelu.cz/˜foltynek/KAS/symetricka/DESalg.jar
Módy DES
DES algoritmus převádí 64-bitové bloky zprávy M na zašifrované 64-bitové bloky C. Jestliže sešifruje každý blok zvlášť (separátně), pak se takovéto šifrování nazývá ECB (Electronic CodeBook). FIPS PUB 81 popisuje kromě ECB ještě další tři módy CBC (Chain Block Coding),CFB (Cipher Feedback), které vytváří závislosti mezi předchozím a následným blokem dat Mskrz XOR sčítání. Poslední mód je OFB (Output Feedback). [3]
Bezpečnost algoritmu
Feistlův šifrovací algoritmus, co by standard DES zajišťoval bezpečnost šifrovaných datpřesně čtvrt století. Algoritmus sám o sobě nebyl nikdy prolomen. Vedou se ale dohady,že NSA, která soustředí americkou špičku analytiků, matematiků, lingvistů a jiných vědců,mohla algoritmus nabourat diferenciální, nebo lineární kryptoanalýzou. Ať tak či tak, jisté je,že DES může být rozluštěn hrubou silou a to s dnešními super moderními počítači dokoncedo několika desítek minut. Slabinou algoritmu je viditelně délka klíče. Nastal čas potrápitanalytiky NSA a délku klíče navýšit.
AES (Advanced Encryption Standard)AES, v překladu pokročilý šifrovací standard, nahrazuje DES, který byl jeho předchůdcemod roku 1977. Novou šifru schválil 26. 11. 2001 americký Národní úřad pro standardizaci(NIST) v publikaci FIPS PUB 197 jako federální standard USA s účinností od 26. 5. 2002. [4]
Vlastnosti
AES je bloková šifra s blokem o délce 128 bitů. Do značné míry vychází z principů užitýchv DES, což je jedním z pilířů nastupujícího standardu. Je to z toho důvodu, že algoritmusDES jako takový nebyl dodnes nabourán. S-boxy, které byly stěžejní částí DES algoritmu sestávají důležitou součástí standardu AES. Druhým pilířem je délka klíče, která může nabývathodnot 128, 192 nebo 256 bitů.
Historie
Poté, co byl DES rozlomen hrubou silou se vedly diskuse o jeho nástupci. V lednu 1997 NISTvyslovila přání ustanovit jiný algoritmus co by nový standard. Ohlasy veřejnosti na tentopodnět byly velké a během následujících tří měsíců obdržel NIST spousty návrhů, jak byměla šifra pro třetí tisíciletí vypadat. Národní úřad pro standardizaci zareagoval vyhlášenímsoutěže na nový algoritmus ještě v září téhož roku. Ten měl podporovat bloky o velikosti 128ba klíč o velikostech 128, 192 a 256 bitů. Po následujících 9 měsíců se podařilo nashromáždit15 kandidátů z různých zemí. Algoritmy byly testovány a diskutovány zejména z hlediskajejich bezpečnosti, rychlosti a implementační náročnosti. Proběhly dvě konference zvanéAES1 a AES2 aby zvážily všechna pro a proti. V konferenci AES2 probíhající od září 99 bylovybráno 5 favoritů z původních 15 kandidátů. Členové konference pak volili vítěze, kterýmse stal algoritmus zvaný Rijndael (čti [reindal]) s 86 hlasy pro a 10 hlasy proti. Další v pořadíbyly Serpent, Twofish, RC6 a poslední MARS. NIST v říjnu roku 2000 označila Rijndael jakonejvhodnější algoritmus pro standard označovaný jako AES a schválil jej v listopadu 2001v publikaci FIPS PUB 197. [5]

64 Obsah
Po pětiletém standardizačním procesu jsme se konečně dočkali nového standardu AESzásluhou belgických kryptografů Johana Daemena a Vincenta Rijmena, kteří algoritmus Rijn-deal (označení je složeninou jejich jmen) vyvinuli.
Odkazy na další zdrojeDES (Wikipedia): http://en.wikipedia.org/wiki/Data Encryption StandardAES (Wikipedia): http://en.wikipedia.org/wiki/Advanced Encryption StandardAnimace průběhu AES: http://www.cs.bc.edu/~straubin/cs381-05/blockciphers/rijndael ingles2004.swfKomix o AES: http://www.moserware.com/2009/09/stick-figure-guide-to-advanced.html
Asymetrická kryptografie
Asymetrická kryptografieProblém výměny klíčů mezi odesílatelem a příjemcem zprávy trápil kryptografy po několikstoletí. Spočívá ve výměně tajné informace (šifrovacího klíče) tak, aby ji nikdo třetí nebylschopen odposlechnout. Pro distribuci klíčů se využívaly služby kurýrů. Jejich použití jevšak na válečném poli problematické. Neřešitelnou situace začínala být v případě elektro-nické komunikace a elektronického obchodování. V 60. letech, kdy se v USA začala rozvíjetelektronická komunikace, narážel systém symetrického šifrování na obrovské logistické pro-blémy. Každý den se na cestu vydávali kurýři s kufříky, ve kterých měli komunikační klíčepro daný den. Týkalo se to bank, státní institucí i armády. Situaci příliš neřešil ani systémDiffie-Hellman-Merkle. Zdálo se, že probém je neřešitelný.V roce 1975 však načrtl Whitfield Diffie myšlenku asymetrické kryptografie. Jde o skupinu
kryptografických metod, ve kterých se pro šifrování a dešifrování používají odlišné klíče. Zá-kladem jsou jednosměrné funkce, které umožní původní zprávu zašifrovat pomocí veřejnéhoklíče, ale již nikoliv dešifrovat za pomocí téhož klíče. Pro dešifrování zpráv se použije klíčsoukromý, který má uschovaný příjemce zprávy. Každý, kdo chce šifrovat zprávy s použitímasymetrických metod, si vytvoří pár klíčů (soukromý a veřejný). Veřejný klíč distribuuje pomezi všechny osoby, se kterými chce komunikovat a klíč soukromý si uchová u sebe v taj-nosti. Dvě komunikující strany se pak vůbec nemusí setkat a přesto mají k dispozici nástrojpro bezpečnou komunikaci.Analogie se zámky• Alice navrhne zámek a jeho kopie distribuuje po celém světě, klíč si ponechá.• Bob uloží tajnou zprávu do krabice, na které zaklapne Alicin zámek, a pošle ji zpětAlici poštou.
• Alice si vyzvedne krabici a odemkne ji svým klíčem.
Základní principy
Šifrovací klíč sestává ze dvou částí:Veřejný klíč – používá se pro zašifrování zprávy, je veřejně dostupný.Soukromý klíč – používá se pro dešifrování zprávy, je vlastníkem pečlivě uschován.Tím je vyřešen základní problém distribuce klíčů, není třeba sdílet žádné veřejné tajem-
ství a komunikace může probíhat asynchronně.Používá se nejen pro šifrování zpráv, ale i pro jejich podepisování (ověření původu).Asymetrická kryptografie je založena na jednocestných funkcích, které jsou snadno pro-
veditelné jedním směrem, ale obtížně invertovatelné. Například spočítat součin 5*3 je jed-noduché, ale z čísla 15 učit původní činitele zabere více času. Pokud pracujeme s mnohemvětšími čísly, jednocestné funkce v podstatě znemožňují odhalení původních hodnot v po-žadovaném čase.. Princip spočívá tedy nespočívá v nerozluštitelnosti, nýbž ve velké čásovénáročnosti.
RSA – Rivest, Shamir, AdelmanV podstatě první použitelná asymetrická metoda. Založena na myšlence publikované W.Diffiem. Vznik roku 1977, dva roky po uveřejnění základního principu. Tvůrci – výzkumníci

Obsah 65
laboratoře počítačových věd MIT. Algoritmus byl v USA v roce 1983 patentován jako patentč. 4405829. Patent vypršel 21. 9. 2000.
Rivest, Shamir, Adelman
Tvorba klíčového páru
Zvolí se dvě velká náhodná prvočísla p, q.Určí se jejich součin n = p× qSpočítá se hodnota Eulerovy funkceϕ(n) = (p− 1)(q − 1)Zvolí se číslo e ∈ (max{p+ 1, q + 1};ϕ(n)), které je s ϕ(n) nesoudělné.Nalezne se číslo d aby platilo:d · e ≡ 1 (mod ϕ(n))Pokud d vyjde příliš malé (tedy menší než asi log2(n)), zvolíme jinou dvojici e a d.Veřejným klíčem je pak dvojice (n,e), kde n je modul a e je šifrovací exponentSoukromým klíčem je dvojice (n, d), kde d se označuje jako dešifrovací či soukromý
exponent.V praxi se klíče uchovávají v mírně upravené formě, která umožňují rychlejší zpracování.
Šifrování zprávy
Bob nyní chce Alici zaslat zprávu M.Zpráva je převedena na číslo m.Šifrovým textem odpovídajícím této zprávě pak je čísloc = me (mod n)Tento šifrový text poté zašle nezabezpečeným kanálem Alici.
Dešifrování zprávy
Alice od Boba získá šifrový text c.Původní zprávu m získá následujícím výpočtem:m = cd (mod n)Tento šifrový text poté zašle nezabezpečeným kanálem Alici.
Důkaz možnosti dešifrování
Vycházíme z následujících předpokladů definovaných Eulerem:iφ(n) mod n = 1Med
mod n =MČísla i a n jsou nesoudělné, M a n jsou nesoudělné.f1 :Me mod n = Cf2 : Cd mod n =M
f2(f1(M)) = f2(Me mod n) = (Me mod n)d mod n =Med
mod n =Mk·ϕ(n)+1 mod n =M ·Mk·ϕ(n) mod n =M · 1 mod n =M
Příkladp = 61 (první prvočíslo)

66 Obsah
q = 53 (druhé prvočíslo)n = p · q = 3233 (modul, veřejný)e = 17 (veřejný, šifrovací exponent)d = 2753 (soukromý, dešifrovací exponent)Pro zašifrování zprávy 123 probíhá výpočet:šifruj(123) = 12317 (mod 3233) = 855Pro dešifrování pak:dešifruj(855) = 8552753 (mod 3233) = 123
Bezpečnost RSA
Zabezpečení algoritmu RSA závisí na následujících faktorech:• Zabezpečení toho, že čísla p a q zůstanou utajena. Pokud tato čísla odhalíme, je odvo-zení dešifrovacího klíče d$ ze šifrovacího klíče e triviální záležitost.
• Obtížnost rozkladu součinu n na prvočísla. V případě, že bychom mohli rozložit číslon, můžeme získat čísla p a q a tím i dešifrovací klíč.
• Na nedostatku jiných algebraických technik pro odvození dešifrovacího klíče d ze šif-rovacího klíče e a čísla n.
RSA je bezpečný jestliže n je dostatečně velké.Jestliže n je 256 bitů nebo kratší, může být za pár hodin faktorizován na osobním počítači,
za použití volně dostupného software.Jestliže n je 512 bitů nebo kratší, může být faktorizován několika sty počítačů.Běžně se používá klíč o délce 1024–2048 bitů.V roce 1977 uveřejnil Martin Gardner v časopise Scientific American článek o RSA, který
obsahoval zprávu zašifrovanou touto metodou. V roce 1994 byla tato zpráva dešifrovánaspojeným úsilím více než 1600 stanic z celého světa. RSA-129 byla prolomena.RychlostAsymetrická kryptografie je o hodně pomalejší než symetrická. V praxi se typicky zašif-
ruje tajná zpráva symetrickým algoritmem, šifrování a následně se přenese symetrický klíči symetricky šifrovaná zpráva příjemci. Tento způsob šifrování se označuje jako hybridní.
Útoky na RSA
Narušení bezpečnosti lze realizovat různými technikami:• Útok na rozklad – pokusit se faktorizovat číslo $n$.• Útok na prvočísla – pokusit se napodobit chod generátoru prvočísel.• Útok matematickou teorií – objevit nové principy matematiky, které by odhalily zá-sadní trhliny v RSA nebo objevit ultrarychlý způsob rozkladu velkých čísel.
Alternativní historie AKPodle informací britské vlády byla asymetrická kryptografie objevena v britské tajné instituciGCHQ. Práce na této technologii zahájil v roce 1965 James Ellis, který načrtl základní prin-cipy. Roku 1973 nový pracovník ,Clifford Cocks, navrhl reálný systém AK. Z důvodů utajenínebyl tento objev veřejně publikován a byl odhalen až několik let po uvedení RSA.
PGP – Pretty Good PrivacyV době uvedení RSA na trh nebyl pro běžné uživatele k dispozici výpočetní výkon dostačujícík běžnému použití asymetrické kryptografie. Phil Zimmerman (USA) se rozhodl umožnitpoužití bezpečné kryptografie širokýmmasám lidí po celém světě. Navrhl jednoduchý systémsestávající z již objevených konceptů. Systém PGP (Pretty Good Privacy) založil na hybridnímšifrování pomocí RSA a IDEA. Vlastní zpráva se šifruje symetrickým klíčem, který je pakzašifrován asymetricky a připojen k vlastní zprávě.První verze PGP byla umístěna na veřejnou síť Usenet v roce 1991. Umožňuje i laikům
velmi jednoduchým způsobem používat silné a bezpečné šifrování a podepisování zpráv.Hybridní šifrování velmi zrychluje proces šifrování a dešifrování. Později bylo PGP standar-dizováno.V dnešní době existují nekomerční verze (OpenPGP, GnuPG...)

Obsah 67
Soukromí pro všechny?
Za svou činnost se Phil Zimmerman stal v USA podezřelým z nelegálního vývozu zbranía byl v souvislosti s tím vyšetřován. Podle amerických zákonů platných v 90. letech nemělobýt umožněno okolním státům používat metody silného šifrování. Diskutovala se otázka,zda je přípustné aby k těmto moderním technologiím měl přístup opravdu každý. Vládyvšech zemí (USA nevyjímaje) prosazují politiku ”Velkého bratra” pro kontrolu komunikaceobyvatel z důvodu zajištění jejich bezpečnosti.
Digitální podpis
Digitální podpisy
Na úvod připomeňme základní princip, kterým se řídí asymetrická kryptografie. Ta používávždy pár klíčů - veřejný klíč a soukromý klíč. Díky matematickému vztahu těchto klíčů platí,že zprávu zašifrovanou tajným klíčem můžeme rozšifrovat pouze příslušným veřejným klí-čem. A naopak, zprávu zašifrovanou veřejným klíčem můžeme rozšifrovat pouze příslušnýmtajným klíčem.Pokud tedy Alice chce poslat Bobovi tajnou zprávu, použije k šifrování Bobův veřejný
klíč. Ten je všeobecně dostupný a každý tak Bobovi může posílat tajné zprávy. Pouze Bobvšak může tyto zprávy číst, protože pouze on má k dispozici příslušný tajný klíč. Nikdo jinýse k tomuto klíči nedostane a tudíž Bobovy zprávy číst nemůže.Opačný postup se používá, pokud Alice chce zprávu digitáln podepsat a stvrdit tak její
pravost. V tom případě použije k šifrování svůj tajný klíč. Ten nikdo jiný nemá a pouze Alicetak může daný kryptogram vytvořit. Dešifrováním zprávy pomocí Alicina veřejného klíče sipak každý může ověřit, že zpráva byla zašfrována skutečně Aliciným tajným klíčem a tudížže autorem kryptogramu je skutečně Alice.
Podepisovací schémata
Obvykle požadujeme obojí. Jak utajení obsahu komunikace, tak digitální podpis. V tompřípadě se nabízí schéma uvedené na následujícím obrázku (zdroj: www.ica.cz):

68 Obsah
Chce-li Alice poslat Bobovi šifrovanou a podpsanou zprávu, nejprve ji zašifruje svýmprivátním klíčem. Výsledkem je tedy podepsaná zpráva, kterou ale může každý dešifrovat.Proto ji poté zašifruje veřejným klíčem Boba, aby ji mohl dešifrovat pouze Bob a nikdo jiný.Takto podepsaná šifrovaná zpráva putuje přes nezabezpečený komunikační kanál k Bobovi,který ji nejprve dešifruje svým tajným klíčem. Výsledkem je Alicí podepsaná zpráva, kteroudešifruje Aliciným veřejným klíčem a získá původní zprávu. Díky dvojímu šifrování si Bobmůže být jistý jednak tím, že Alice je autorkou zprávy a také tím, že obsah zprávy nemohlnikdo přečíst.Asymetrické šifrovací algoritmy mají však jednu podstatnou nevýhodu - jsou pomalé
a tudíž se nehodí pro šifrování dlouhých zpráv. Ukážeme si tedy, jak předejít šifrování celézprávy při realizaci digitálního podpisu. Ze zprávy se nejprve vypočítá tzv otisk - hash(více viz kapitola Hashovací funkce), což je ve srovnání ze zprávou krátký řetězec, kterýje závislý na všech bitech zprávy (i nepatrná změna zprávy by výtazně změnila hodnouthashe). Privátním klíčem odesilatele pak zašifrujeme pouze tento krátný hash, čímž ušetřímevýpočetní výkon jak na straně odesilatele, tak na straně příjemce, jak ukazuje následujícíobrázek (zdroj: www.ica.cz):

Obsah 69
Alice vypočítá hash své zprávy, kterou zašifruje svým tajným klíčem. Tím vznikne digitálnípodpis. Poté zašifruje zprávu samotnou Bobovým veřejným klíčem a digitální podpis k nípřipojí. Výsledek je nečitelný pro každého kromě Boba a může tak putovat pouze přesnezabezpečený kanál. Kdokoliv může sice dešifrovat digitální podpis, získá však pouze hashzprávy, nikoliv zprávu samotnou. Bob dešifruje zprávu svým tajným klíčem. Její pravost potéověří tak, že vypočítá její hash a porovná jej s hodnotou získanou dešifrováním digitálníhopodpisu Aliciným veřejným klíčem. Pokud se hashe rovnají, je si Bob jistý, že Alice zprávupodepsala.Techniku využívající hashovací algoritmus můžeme použít pro digitální podpis, nikoliv
pro šifrování samotné. Bob jako příjemce totiž musí získat celou zprávu, nikoliv jen jejíhash. Pokud se tedy chceme zbavit šifrování celé zprávy pomocí pomalé asymetrické šifry,je třeba ji nahradit rychlejší šifrou symetrickou a pomocí asymetrické šifry přenést pouzeklíč pro symetrické šifrování. Tento postup se v praxi skutečně používá, jak je uvedeno nanásledujícím obrázku (zdroj: www.ica.cz):
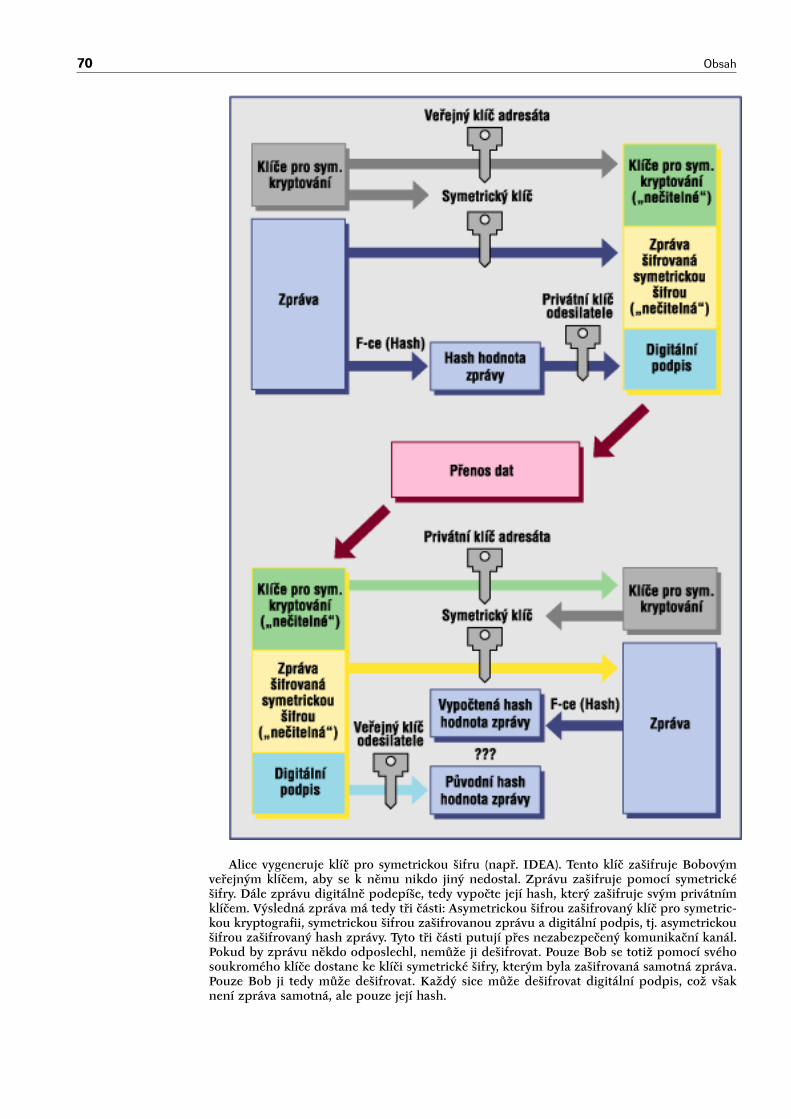
70 Obsah
Alice vygeneruje klíč pro symetrickou šifru (např. IDEA). Tento klíč zašifruje Bobovýmveřejným klíčem, aby se k němu nikdo jiný nedostal. Zprávu zašifruje pomocí symetrickéšifry. Dále zprávu digitálně podepíše, tedy vypočte její hash, který zašifruje svým privátnímklíčem. Výsledná zpráva má tedy tři části: Asymetrickou šifrou zašifrovaný klíč pro symetric-kou kryptografii, symetrickou šifrou zašifrovanou zprávu a digitální podpis, tj. asymetrickoušifrou zašifrovaný hash zprávy. Tyto tři části putují přes nezabezpečený komunikační kanál.Pokud by zprávu někdo odposlechl, nemůže ji dešifrovat. Pouze Bob se totiž pomocí svéhosoukromého klíče dostane ke klíči symetrické šifry, kterým byla zašifrovaná samotná zpráva.Pouze Bob ji tedy může dešifrovat. Každý sice může dešifrovat digitální podpis, což všaknení zpráva samotná, ale pouze její hash.

Obsah 71
Příjemce zprávy, Bob, nejprve pomocí svého tajného klíče získá symetrický klíč, pomocínějž dešifruje zprávu. Následně vypočte její hash a Aliciným veřejným klíčem dešifruje digi-tální podpis. Poté oba hashe porovná, čímž ověří pravost dokumentu.Jak je vidět, asymetrická kryptografie zde byla použita pouze pro šifrování hashe zprávy,
což je krátký řetězec, a klíče pro symetrickou kryptografii, což je rovněž krátký řetězec. Prošifrování dlouhé zprávy byla využita rychlá symetrické šifra. Tento model je tedy výrazněrychlejší a přitom zachovává všechny bezpečnostní požadavky, které na šifrovanou a digitálněpodepsanou zprávu klademe.
Vlastnosti digitálního podpisuKomunikace popsaná podle výše uvedeného schématu má následující vlastnosti:Autentičnost: Pouze odesilatel zná tajný klíč, tudíž pouze odesilatel může být autorem
zašifrovaného hashe. Příjemce si tak může být jistý, že, za předpokladu nekompromitovanostiodesilatelova tajného klíče, je odesilatel zkutečně autorem dokumentu.Nepopiratelnost ze strany odesilatele: Nepopiratelnost ze strany odesilatele souvisí s au-
tentičností. Pouze on zná (nebo by měl znát) tajný klíč a nikdo jiný tak nemohl vytvořitkryptogram hashe, který slouží jako digitální podpis.Nepopiratelnost ze strany příjemce: Pokud by příjemce změnil zprávu, nemůže vytvořit
stejný digitální podpis jako odesilatel, protože nezná jeho tajný klíč. Příjemce tedy zprávuzměnit nemůže a tudíž nemůže její obsah popřít.
Riziko digitálního podpisuNic však není ideální a i v kryptografii má všechno své ALE. V případě digitálního podpisuje to důvěra v pravost klíče. Každý si totiž může vytvořit svůj pár klíčů. Představme si nynísituaci, kdy do komunikace Alice a Boba zasahuje zlá Eva, která bude komunikaci narušovat.Alice si vyžádá Bobův veřejný klíč, aby mu mohla poslat zprávu. Stejně tak pošle Bobovisvůj veřejný klíč, aby Bob mohl ověřovat Alicin digitální podpis. Komunikační kanál všaksleduje Eva, která Bobův veřejný klíč putující k Alici nahradí svým veřejným klíčem a stejnětak Alicin veřejný klíč putující k Bobovi nahradí svým (jiným) veřejným klíčem. Alice tedy máEvin klíč, o kterém si myslí, že patří Bobovi a Bob má rovněž Evin veřejný klíč, ale v domění,že patří Alici.Když nyní Alice zašifruje a digitálně podepíše zprávu, kterou odešle Bobovi, Eva ji ces-
tou zachytí a dešifruje. Zpráva byla totiž ve skutečnosti zašifrována Eviným veřejným klíčem,i když si Alice myslela, že se jedná o Bobův klíč. Eva si zprávu nejen přečte, ale může ji i změ-nit. Dešifrovanou zprávu totiž musí znovu zašifrovat (nyní opravdovým Bobovým veřejnýmklíčem) a digitálně podepsat (svým tajným klíčem, o kterém si Bob myslí, že patří Alici).Takto modifikovanou zprávu pak Eva odešle Bobovi, který si myslí, že dostal zprávu odAlice. Zprávu dešifruje svým tajným klíčem, čímž se ujistí, že si ji nikdo cestou nemohl pře-číst. Pak ověří digitální podpis a protože hashe jsou stejné, je si jistý, že autorkou dokumentuje Alice.Ani Alice, ani Bob nemají v danou chvíli žádnou možnost, jak odhalit Evin podvrh. To,
co stálo na počátku tohoto podvrhu, bylo podvržení veřejného klíče. Eva poslala Bobovi svůjklíč a vydávala jej za Alicin, stejně jako poslal svůj klíč i Alici, tento však vydávala za Bobův.Kdyby si Alice a Bob mohli ověřit, že klíč, který obdrželi, patří skutečně tomu druhému, Evaby podvrh nemohla uskutečnit.Dalším rizikem je ztráta tajného klíče, případně jeho odcizení. V případě ztráty nejsme
schopní číst zprávy určené pro nás, musíme vygenerovat nový pár klíčů a uvědomit všechnynaše partnery o změně klíčů. V případě odcizení pak někdo jiný bude moci číst zprávy určenépro nás a díky digitálnímu podpisu se za nás vydávat. Nejhorší možností je pak kombinaceobého.
Ověření pravosti veřejného klíčeVěnujme se však nyní ověření pravosti veřejného klíče, tedy jak to udělat, aby Alice mělaskutečně jistotu, že klíč, který dostala, patří Bobovi, a Bob měl jistotu, že klíč, který dostal,je skutečně Alicin. Alice může pochopitelně Bobovi předat klíč při osobním setkání. To všakjednak popírá výhodu asymetrické kryptografie, navíc to v mnoha případech není technickymožné. Alice tak potřebuje důvěryhodné potvrzení typu: ”Tento veřejný klíč skutečně patří

72 Obsah
Bobovi”. Analogickou informaci potřebuje Bob o Alicině klíči. Toto potvrzení však musí vydatněkdo jiný. Někdo, komu Alice i Bob věří.V reálném světě funguje důvěra tak, že malé děti věří každému. To je potřeba kvůli tomu,
aby věřily svým rodičům. Postupem času si však každý člověk buduje okruh lidí, kterýmvěří. A okruh lidí, kterým nevěří. Základní (mnohdy spíše filosofická otázka pak zní: Mábýt důvěra tranzitivní? Tedy: Máme věřit někomu, o kom nám důvěryhodný člověk řekl,že mu věří? V neformálních vztazích důvěra většinou tranzitivní je. Pokud nás kamaráds někým seznámí, pravděpodobně nebudeme vyžadovat občanský průkaz, protože nemámedůvod kamarádovi identitu představovaného člověka nevěřit. Oficiání instituce, jako jsouúřady státní správy či samosprávy, však takovouto důvěru mít nemohou a občanský průkazvyžadují. Občanský průkaz zde představuje certifikát o totožnosti daného člověka, vydanýautoritou, které daný úřad věří.Na podobných principech funguje důvěra i ve virtuálním světě počítačové komunikace
a digitálního podpisu.
Certifikát klíče je důvěryhodnou osbou digitálně podepsané sdělení: ”Tentoklíč patří této osobě”.
Věříme-li digitálnímu podpisu této osoby, věříme i identitě majitele certifikovaného klíče.
Síť důvěry (web of trust)
Autor myšlenky sítí důvěry je Phil Zimmermann, autor softwaru PGP. V sítích důvěry platí,že důvěra je tranzitivní a každý uživatel má právo certifikovat klíče jiných uživatelů. Pokudchceme komunikovat s někým, koho doposud neznáme, hledáme, zda jej necertifikoval někdoz námi certifikovaných uživatelů, případně z uživatelů certifikovaných některým z námicertifikovaných uživatelů, atd. Zkrátka hledáme cestu v grafu reprezentujícím síť důvěry,která spojí nás a našeho komunikačního partnera. Síť důvěry je znázorněna na následujícímobrázku (zdroj: www.rubin.ch/pgp):
Pro dostatečnou důvěru v pravost klíče komunikačního partnera je důležitá za prvné conejkratší cesta a za druhé existence co největšího počtu vzájemně nepropojených cest. Abytedy Zimmermannův koncept sítě důvěry fungoval, musí být síť co nejhustší. To v minu-losti vedlo k organizování tzv. key signing parties, kde se lidé potkávali, aby si vzájemněcertifikovali své klíče.
Důvěryhodná třetí strana (TTP)
Anglická zkratka TTP pochází ze slov Trusted third party, tedy důvěryhodná třetí strana.Tento koncept se využívá zejména pro komunikaci s úřady a v obchodním styku. Roli důvě-ryhodné třetí strany zajišťuje certifikační autorita (CA), která potvrzuje autentičnost podpisu

Obsah 73
(a tím identitu jeho držitele). Uspořádání svazující konkrétní klíče s certifikačními autoritamise nazývá Infrastruktura veřejných klíčů - Public Key Infrastructure (PKI) a je definovánostandardem ITU-T X.509 platným od 3.7.1988. Tento standard zavádí hierarchický systémCA.Certifikační autorita vydává certifikát svazující veřejný klíč buďto se jménem osoby, nebo
s alternativním jménem (e-mailovou adresou), anebo s DNS záznamem (pro certifikaci ser-veru). Na vrcholu hierarchie certifikátů stojí kořenový certifikát, který není nikým certifiko-ván, resp. je certifikován sám sebou. Kořenovému certifkátu zkrátka musíme věřit. V případěpoužití protokolu HTTPS je seznam důvěryhodných kořenových certifikátů součástí WWWprohlížeče. Při vlastní komunikaci prohlížeče se serverem si prohlížeč si vyžádá veřejný klíčserveru. Aby mu mohl věřit, potřebuje certifikát. Server mu tedy zašle certifikát, což je ve-řejný klíč serveru podepsaný CA. Prohlížeč pak buďto věří CA, a tedy věří pravosti klíče,anebo nevěří CA, v tom případě se ptá uživatele, zda přijme certifikát.
Digitální podpisy a veřejná správaVeřejná správa nedůvěřuje sítím důvěry. Je tedy vyžadována role CA, která musí mít licenci,což je fakticky certifikát státu. Každý občan a každá firma může mít certifikovaný podpis prokomunikaci s úřady. Mezi úřady poskytující elektronický přístup patří např. finanční úřady,Česká správa sociálního zabezpečení, úřady práce, zdravotní pojišťovny, Česká obchodníinspekce, či ministerstva.Podle zákona č. 227/2000Sb. o elektronickém podpisu se rozlišují následující druhy cer-
tifikátů:Kvalifikovaný certifikát má stejnou platnost jako občanský průkaz a podle zákona jej
každý musí uznat. Tento certifikát lze použít jen pro podpis, ne pro šifrování.Komerční certifikát nemusí splňovat náležitosti zákona a není tedy obecně platný (každý
jej nemusí uznat). Používá se pro šifrování dat mezi subjekty, které se na tom dohodnou.Pravdou však je, že většina výše zmíněných úřadů akceptuje i komerční certifikáty vybranýchcertifikačních autorit.Trh s certifikáty je ve světě velmi diverzifikovaný a v různých oblastech dominují lokální
certifikační autority. Mezi nejznámější certifikační autority v České republice patří První cer-tifikační agentura (kvalifikovaný certifikát na 1 rok stojí 495,-Kč), CA Czechia (kvalifikovanýroční certifikát nabízí za 159,-Kč), Česká pošta / PostSignum (u ní stojí roční kvalifikovanýcertifikát 190,-Kč), nebo eIdentity (kvalifikovaný roční certifikát má za 702,-Kč). V celosvě-tovém měřítku dominuje společnost Verisign (58% světového trhu), s velkým odstupem paknásledují Comodo (8%) a GoDaddy (6%). Tyto údaje pocházejí z dubna roku 2008 a bylyzískány na WWW stránkách příslušných společností.
Obecná problematika autentičnostiAutentičnost vyjadřuje pravost, původnost. Požadujeme autentičnost uživatele, zprávy čihesla.
Autentičnost uživatele může být zajištěna na základě• charakteristických vlastností (poznáme člověka podle tváře nebo hlasu)• vlastnictví (občanský průkaz, kreditní karta)• znalosti (heslo, PIN)
Pod pojmem silná autentizace (strong authenticaton) se rozumí prokázání totožnostialespoň dvěma různými způsoby (např. vlastnictví kreditní karty + znalost PIN)Co se týče autentičnosti zprávy, zde je nejdůležitější otázka: Jak zajistit, že zpráva nebyla
během přenosu změněna? A to ať už chybou přenosového média, nebo záměrně. K zodpo-vězené této otázky slouží tzv. MAC, čili Message Authentication Code, což je jednosměrnáfunkce potvrzující pravost zprávy. Odesilatel vypočítá MAC a odešle jej společně se zprávou.Příjemce vypočítá MAC došlé zprávy a porovná ji z došlým MAC. Pokud se MAC liší, došloke změně zprávy. Pokud ne, zpráva je pravděpodobně stejná.Aby měl MAC dostatečnou vypovídací hodnotu, musí záviset na tajné informaci. Jinak
by útočník mohl podvrhnout zprávu i její MAC. MAC by měl dále mít pevnou délku a musí

74 Obsah
záviset na všech bitech zprávy. Běžně používanou technikou MAC je algoritmus DES v CBCmódu. V CBCmódu algoritmus pracuje tak, že rozdělí zprávu na bloky, vypočte kryptogram 1.bloku a kryptogram n-tého bloku použije jako klíč prošifrování (n+1)-ho bloku. Samozřejmělze použít i další šifrovací funkce nebo různé klíčované hashovací funkce.Autentičnost hesla znamená odpověď na otázku, zda: Pochází heslo skutečně od oprávně-
ného uživatele? Z praxe známe autentizační protokoly, např. Kerberos nebo LDAP. Abychommohli autentičnosti hesel věřit, je třeba je uchovávat bezpečně. Bezpečně v tomto případěneznamená skrytě, ale tak, aby se k nim skutečně nikdo nedostal. Tj. neuchovávat přímohesla, ale jejich otisk - hash, ze kterého není heslo zjistitelné, ale který nám umožní ověřitjeho autentičnost. O hashovacích funkcích se podrobně zmíníme ve stejnojmenné kapitole.
Hashování
Hashovací funkceJedná se o jednosměrné funkce, které musí splňovat přesně definované podmínky. Základníhashovací funkce mapují řetězec libovolné délky (zpráva, datový soubor) na řetězec kon-stantní délky a vytvářejí tak otisk vstupního řetězce. Výsledný otisk se označuje jako výtah,hash, fingerprint nebo miniatura a je závislý na všech bitech vstupního řetězce. Tyto funkceslouží ke kontrole integrity dat, k porovnání dvojice zpráv, k vyhledávání, indexování a vyu-žívají se pro tvorbu digitálních podpisů.Mezi nejznámější hashovací funkce patří MD4, MD5, SHA-1 a SHA-2. Tyto algoritmy jsou
založeny na podobných principech jako blokové šifry, např. AES. Každá hashovací funkcev principu není injektivní (čili prostá), existují tedy různé zprávy poskytující stejný hash. Tosamo o sobě není problém, pokud hashovací funkce splňuje následující požadavky:
• je to jednosměrná funkce (tj. je snadné spočítat hash zprávy, ale nesmírně obtížnénalézt k danému hashi zprávu).
• není možné najít dva vstupy, které mají stejný výsledný hash (tj. kolize)• je obtížné tyto kolize hledat systematicky• neexistuje korelace vstupních a výstupních bitů• jakékoliv množství vstupních dat poskytuje stejně dlouhý výstupFormálně jde o funkci h, která převádí vstupní posloupnost bitů na posloupnost pevné
délky n bitů.h : D → R,kde —D—>>—R—.Přímo z této definice vyplývá, že existují kolize, to znamená existenci vstupních dat
(x,y) takových, že h(x) = h(y), tj. dvojice různých vstupních dat může mít stejný hash. Lzejen snižovat pravděpodobnost, že nastane kolize pro podobná data, například při náhodnézměně v části vstupní posloupnosti. Cílem je tedy dosáhnout co nejvyšší pravděpodobnosti,že dvě zprávy se stejným hashem jsou stejné.Hashovací funkce se nejčastěji využívají v hashovacích tabulkách, k rychlému nalezení
dat pomocí vyhledávacího klíče (search key). Hashovací funkce se použijí k mapování vy-hledávacího klíče do indexu pozice v hashovací tabulce, kde jsou pravděpodobně hledanádata uložena. Obecně, může hashovací funkce mapovat několik rozdílných klíčů na stejnouhashovací hodnotu. Hashovací funkce pouze ukazuje na místo, kde by se mělo začít hledat.Proto každá pozice hashovací tabulky obsahuje soubor záznamů a ne pouze jeden záznam.Z tohoto důvodu je pozice v hashovací tabulce často nazývána oblast (bucket) a hashovacíhodnoty nazývány ukazatele na oblast (bucket indicies).
Algoritmus MD5MD (Message Digest) tvoří skupinu hashovacích algoritmů navržených profesorem Ronal-dem R. Rivestem z Massachusettského institutu technologií. Když byl analytiky vyhlášenhashovací algoritmus MD4 za nedostatečně zabezpečený, byl v roce 1991 navržen algoritmusMD5 jako jeho bezpečná náhrada. MD5 (Message-Digest algorithm 5) byl často využívánv softwaru poskytujícím záruku, že přenášený soubor dorazil nedotčený. Některé souborovéservery poskytují už vypočtený hash pro soubory, které si chce uživatel stáhnout a ten jemůže posléze porovnat s hashem už stažených souborů. Některé operační systémy založenéna Unixu, také obsahují algoritmus MD5 pro kontrolu integrity dat. MD5 je popsán v in-

Obsah 75
ternetovém standardu RFC 1321 a jeho výsledný hash má velikost 128 bitů a je většinouvyjádřen jako 32-znakové šestnáctkové číslo.Výpočet hashe u MD5 probíhá následujícím způsobem: Na vstupu algoritmu MD5 může
být zpráva jakékoliv délky. Vstupní zpráva je rozdělena na 512 bitů velké bloky, tedy 16 slovo velikosti 32 bitů. Zpráva je rozdělena, v bloku, do prvních 448 bitů a zbylých 64 bitů jeurčeno pro délku původní zprávy. Ke zprávě je přidán 1 bit a zbytek je doplněn o 0 bitů,aby byla velikost bloku 448 bitů bez posledních 64 bitů. Výpočet probíhá tak, že každý blokje počítán samostatně. Pro výpočet jsou použity 4 proměnné (A, B, C, D) jejichž inicializačníhodnoty jsou předem stanoveny. Velikost těchto konstant je 32 bitů. Dále jsou definovány 4pomocné funkce. Každá z těchto funkcí má na vstupu tři 32-bitová slova a jako vystup jedno32-bitové slovo:
F (X, Y, Z) = (X ∧ Y ) ∨ (¬X ∧ Z)G(X, Y, Z) = (X ∧ Z) ∨ (Y ∧ ¬Z)H(X, Y, Z) = X ⊕ Y ⊕ ZI(X, Y, Z) = Y ⊕ (X ∨ ¬Z)⊕,∧,∨,¬ vyjadřují operace XOR, AND, OR a NOT. Každá z těchto funkcí je vykonávána
postupně 16krát ve čtyřech kolech. Výsledný hash tvoří proměnné A, B, C ,D, ke kterýmje přičtena jejich inicializační hodnota. Vše je znázorněno na následujícím obrázku (zdrojWikipedia):
Legenda: MD5 provádí 64 takovýchto operací. Tyto operace jsou seskupeny do čtyř kolo šestnácti operacích. F je nelineární funkce a v každém kole je použita jedna funkce, kteráje rozdílná pro všechny kola. Mi označuje 32 bitů velký blok vstupní zprávy a Ki označuje

76 Obsah
32 bitů velkou konstantu, která je rozdílná pro každou operaci.
Kryptoanalýza MD5
Již v roce 1993 Den Boer a Bosselaers přišli s tím, že našli takzvanou pseudo-kolizi. Dva různéinicializační vektory mají stejný výsledný hash. V roce 1996 oznámil Dobbertin kolizi, ovšemnebyl to útok na celý algoritmus. V březnu roku 2004 vznikl projekt, který chtěl dokázat,že velikost výsledného hashe 128 bitů není dostatečně velká na provedení narozeninovéhoútoku. Tento projekt skončil záhy po 17. srpnu 2004, kdy Wangová a kol. oznámili nalezeníkolize pro celý algoritmus MD5. Sdělili, že útok trval pouze hodinu na počítači IBM p690. 1.března 2005 Wangová, Lenstra a de Weger ukázali vytvoření dvou certifikátů X.509 (certifikátpro veřejné klíče) s různými veřejnými klíči a stejným MD5 hashem. O pár dní pozdějiVlastimil Klíma popsal vylepšený algoritmus, který je schopen nalézt kolize během několikahodin na obyčejném notebooku (Acer TravelMate 450LMi, Intel Pentium 1.6 GHz). Během 8hodin nalezl 331 kolizí prvního bloku a jednu úplnou kolizi MD5. V porovnaní s Wangovoua kol., které trvalo nalezení kolize na prvním bloku jednu hodinu na 25 50krát rychlejšímpočítači, je jeho metoda ve výsledku asi 1000 2000krát rychlejší než metoda Wangové.Algoritmus MD5 sice stále lze používat pro kontrolu integrity souborů a pro detekci
změny chybou přenosového nebo záznamového média, pro kryptografické účely se však jižnehodí. Jeho náhradou jsou algoritmy z rodiny SHA.
Algoritmy SHA
SHA (Secure Hash Algorithm) je skupina pěti kryptografických hashovacích funkcí navrže-ných NSA (Národní bezpečnostní agentura v USA) a vydaných NIST (Národní institut prostandardy v USA) jako celostátní standard v USA (FIPS). Jak již bylo řečeno existuje pět druhůSHA a to: SHA-1, SHA-224, SHA-256, SHA-384 a SHA-512. Poslední čtyři varianty jsou někdysouhrnně označovány jako SHA-2. SHA-1 má výsledný hash délky 160 bitů u dalších verzíodpovídá jejich číslo délce výsledného hashe.
SHA-1
Původní specifikace algoritmu byla vydána v roce 1993 jako Secure hash standard (FIPSPUB 180). Tato verze je označována jako SHA-0 a záhy po vydání byla stažena agenturouNSA, která na ni provedla změnu. Změna se týkala rotace bitů doleva o n pozic a mělapřispět k většímu zabezpečení. 17. dubna 1995 byl udělen standard i této verzi označovanéjako SHA-1 (FIPS PUB 180-1). Algoritmus SHA-1 je založen na principech podobných těm,které použil profesor Ronald R. Rivest z Massachusettského institutu technologií při návrhualgoritmu MD4.Standard SHA-1 počítá zmenšenou reprezentaci zprávy nebo datového souboru (hash)
délky 160 bitů. Výsledný hash může být vstupem pro algoritmus digitálního podpisu (DigitalSignature Algorithm DSA), který vytváří nebo ověřuje podpisy zpráv. Podepisováním hashedosáhneme větší efektivity, protože výsledný hash je většinou mnohem menší než zpráva, zekteré byl vypočten. Stejný hashovací algoritmus musí být použit i při ověřování digitálníhopodpisu. SHA-1 se nazývá bezpečný (secure), protože by mělo být početně nemožné najítzprávu, která odpovídá výslednému hashi, nebo najít dvě různé zprávy, které by produkovalystejný hash. Jakákoliv změna zprávy při přenosu s velkou pravděpodobností způsobí změnuvýsledného hashe, ověřování tedy selže.SHA-1 může být použito s algoritmem DSA v elektronické poště, u bankovních transakcí,
k uchovaní dat a všude tam, kde je vyžadována záruka integrity dat a jejich autentičnost.SHA-1 se také využívá v protokolech TLS, SSL, SSH, IPsec atd. Tvoří také základ pro blokovacíšifry SHACKAL.Výpočet hashe pomocí SHA-1 znázorňuje následující obrázek (zdroj: Wikipedia):

Obsah 77
Zpráva nebo datový soubor je považován za řetězec bitů. Délka zprávy je počet bitů,ze kterých se zpráva skládá. Prázdná zpráva má tedy délku 0 bitů. Zpráva je rozdělena na512 bitů velké bloky, tedy 16 slov po 32 bitech. Dále jsou data doplněna, aby byla násobkem64 bitů. Posledních 64 bitů posledního 512 bitů velkého bloku je rezervováno pro délkuoriginální zprávy. Rozdělená zpráva obsahuje 16*n slov, pro n > 0. Takto rozdělená zprávaje považována za posloupnost o n blocích M1, M2, , Mn , kde každé Mi obsahuje 16 slov.Posléze je pro každý zpracovávaný blok vytvořena tabulka W a tabulka K, která je pro
všechny bloky společná a obsahuje předem dané konstanty. Velikost každé tabulky je 80řádků. V tabulce W je prvních 16 řádků ekvivalentních datům z bloku (80 slov) a zbytekřádků je dopočítán podle vzorce.Samotný výpočet probíhá tak, že každý datový blok je počítán samostatně. Pro výpočet
je použito 5 proměnných (A, B, C, D, E). Inicializační hodnoty těchto proměnných tvoříkonstanty H0 až H4. Tyto proměnné jsou 80krát přepočteny, výsledky jednotlivých blokůjsou sečteny a jsou k nim připočteny původní konstanty H0 až H4. Výsledek tvoří 160-tibitový řetězec reprezentován pěti slovy. Nákres ukazuje jedno opakování kompresní funkceSHA-1. A až E jsou 32 bitové proměnné. F je nelineární funkce, která se mění. <<<n označujerotaci bitů doleva o n pozic, n je rozdílné pro každou operaci. Wt označuje rozšířené slovot-ho opakování, Kt je konstanta t-ho opakování.
Kryptoanalýza SHA-1
Pro ideální hashovací funkci platí, že nelze najít zprávu, která by byla vzorem k danémuhashi. Porušení tohoto pravidla, může být docíleno hrubou silou, vyhledáním 2L výpočtů,kde L je počet bitů hashe. Tento útok se nazývá vzorový (preimage attack). Druhým kritériemje, že nelze najít stejný hash pro dvě rozdílné zprávy. Na toto pravidlo lze zaútočit pomocínarozeninového útoku (birthday attack), který vyžaduje pouze 2L/2 výpočtů. Tento útok jezaložen na narozeninovém paradoxu, který říká, že pravděpodobnost nalezení páru dvou

78 Obsah
lidí, kteří mají stejné datum narození, je u skupiny 23 lidí, kteří jsou náhodně vybráni, 50%.U skupiny 57 lidí je to již 99% a dále pravděpodobnost roste až ke 100%. Nalezení takovéhopáru se nazývá kolize. Síla hashovacích funkcí je obvykle porovnávána se symetrickými šif-rami jako polovina délky hashe. Tedy síla SHA-1 byla původně odhadována na 80 bitů. Poté,co bylo oznámeno úplné prolomení algoritmu SHA-0 12. června 2004, se objevily pochyb-nosti odborníků o zavádění SHA-1 do nových kryptografických systémů. Po CRYPTO 2004(mezinárodní kryptografická konference), kde bylo prolomení SHA-0 zveřejněno, NIST ozná-milo, že plánují nahradit SHA-1 algoritmem SHA-2 a jeho variantami do roku 2010. V únoruroku 2005 byl zveřejněn útok vedený Xiaoyun Wang, Yiqun Lisa Yin a Honbo Yu. Jejich útoknalezl kolizi v plné verzi SHA-1 a vyžadoval méně než 269 operací. Na setkání CRYPTO2006, Christian Rechberger a Christophe De Canniere prohlásili, že objevili kolizní útok,který dovolí útočníkovi vybrat alespoň část zprávy.Největším znepokojením u těchto útoků je to, že připravují cestu pro mnohem účinnější
útoky. Proto se považuje přechod k silnějším hashovací algoritmům jako rozumný. Některépoužití hashovacích algoritmů, jako je uložení hesel, je minimálně ovlivněno kolizními útoky.Konstrukce hesel účtů vyžaduje vzorový útok a přístup k originálnímu hashi, což nemusí býtjednoduché. V případě podpisu dokumentů musí útočník vytvořit dvojici dokumentů, jedenneškodný a jeden škodný, a dát neškodný dokument k podepsání držiteli soukromého klíče.
Algoritmy SHA-2 a SHA-3
Tento algoritmus je vylepšením SHA-1, pracuje však na podobném principu. Poskytuje vý-stup délky 224, 256, 384, nebo 512 bitů. Bezpečnost SHA-1 již byla kompromitována kryp-tografickými útoky na rozdíl od variant SHA-2, u kterých nebyl doposud zveřejněn úspěšnýútok. Jelikož jsou varianty SHA-2 založeny na podobném algoritmu jako SHA-1, je vyvíjennátlak na vytvoření nových alternativ hashovacích algoritmů. 2. listopadu 2007 byla vyhlá-šena otevřená soutěž na vývoj nového algoritmu SHA-3. Vyhlášení vítězů a publikace novéhostandardu je plánována na rok 2012. Jedná se o podobnou veřejnou soutěž, kterou vyhlásilNIST pro standard AES (Advanced Encryption Standard).
Steganografie
SteganografieSteganografie je umění či věda o ukrývání samotné existence zprávy. Cílem steganografie jezajistit, aby zůstalo v tajnosti, ŽE se nějaká zpráva vůbec přenáší. Původ slova je z řečtiny(stegos = skrytý, graphein = psát). Ukrytá zpráva totiž nebudí pozornost a nemusí proto býtšifrovaná. V případě, že chceme předat opravdu důležitou zprávu, pak ji můžeme nejenukrýt, ale i zašifrovat. Kombinace steganografie a kryptografie zaručí nenápadnost a bezpeč-nost. Zaprvé se nikdo nedozví, že nějakou zprávu přenášíme, a i pokud by se to dozvěděl,tak ji nebude schopen rozluštit.Steganografie má velmi široké použití: V zemích, kde je kryptografie ilegální, či tam,
kde chceme ukrýt samotnou existenci zprávy. Totiž už to, že někomu pošleme zašifrovanouzprávu, může mít vypovídající hodnotu. Představme si např. vrcholného politika, který sivyměňuje šifrované zprávy z hledaným zločincem či podnikateli. Jde mi jistě nejen o utajeníobsahu zprávy, ale i o utajení toho, že vůbec se svým protějškem komunikuje. Dalším argu-mentem pak je, že zjevně zašifrovaná zpráva budí pozornost. Lidé jsou zvědaví a mají snahuji rozluštit, i když by jim k ničemu nebyla.
Historie steganografiePrvní doložené použití steganografie v antice souvisí s bitvou u Salamíny (480 př.n.l.). Peršanése tehdy připravovali na přepadení Řecka, když Řek Damaratus (vyhnanec, který však stálecítil loajalitu ke své vlasti) ukryl zprávu pod voskem na prázdných psacích destičkách. Řekovédíky němu v bitvě zvítězili.Jiný případ popisuje Hérodots: Histiaios chtěl povzbudit Aristagora Milétského ke vzpouře
proti Peršanům. Oholil posla, napsal (resp. vytetoval) zprávu poslovi na hlavu a počkal, ažmu vlasy opět narostly. Teprve pak se posel vypravil na cestu.Římané používali tajné inkousty na bázi ovocné šťávy nebo mléka, které jsou na papíře
neviditelné, při zahřátí však zhnědnou. Staří Číňané psali zprávu na hedvábí, to pak zalili

Obsah 79
do voskové kuličky, kterou posel polkl. V místě určení pak šel na záchod a zpráva byla nasvětě.Ital Giovanni Porta (16. stol.) vynalezl speciální inkoust (roztok kamence a skalice), kterým
se zpráva napíše na vejce a vejce se poté uvaří na tvrdo. Zpráva pronikne skořápkou na bílek,kde je pak po oloupání vajíčka čitelná.Během Búrské války Lord Robert Baden-Powell, zakladatel skautského hnutí, potřebo-
val nakreslit plán rozestavení búrského dělostřelectva. Pro případ chycení nemohl být plánviditelný na první pohled. Namaloval proto louku plnou květin s motýly. Někteří motýlis určitými vlastnostmi kódovali nepřátelská děla.Během dvacátého století steganoggrafické techniky umožňovali předávání zpráv mezi
špiony. Během druhé světové války to byly německé mikrotečky (text zmenšený na velikosttečky za větou), nulové zprávy (zprávy např. v rozhlase nemající reálný význam, které nesoupouze ukrytou zprávu). Všeobecná paranoia vedla v USA a GB k zákazu posílání novinovýchvýstřižků, dětských kreseb a květin. Digitální steganografie pak nabízí zcela nové možnosti.Ukažme si jednoduchý příklad použití steganografie:
O Z N Á M E N Í
Naši muži stojí kolem sčítačky. Dívčí směna sedí zvědavě ve sčítačce.Stráž ovládá kryt vtoku ke skulině.
Pro snazší odhalení:
O Z N Á M E N Í
Naši muži stojí kolem sčítačky. Dívčí směna sedí zvědavě ve sčítačce. Strážovládá kryt vtoku ke skulině.
Druhá písmena ve slovech představují techniku, která byla během druhé světové válkyskutečně použita německým špionem. První písmena jsou příliš nápadná, proto poslal doNěmecka telegram ve znění: „Apparently neutral’s protest is thoroughly discounted and ignored.Isman hard hit. Blockade issue affects pretext for embargo on by-products, ejecting suets and vege-table oils.“ Pokud z něj přečteme jen druhá písmena z každého slova, dostaneme ”PERSHINGSAILS FROM NY JUNE 1”Možností steganografie je nepřeberné množství. Nosičem ukryté zprávy může být coko-
liv. Dostaneme od kamaráda mailem skvělou animaci, kterou hned rozešleme svým známým.Můžeme si být jisti tím, že neobsahuje nějakou skrytou zprávu? S možnostmi odhalování jeto přitom daleko horší. Kdo nezná způsob ukrývání, může zprávu těžko odhalit. Způsobůukrytí je nekonečně mnoho. Je potřeba vědět, kde skrytou zprávu hledat, ale nelze ukrytézprávy hledat úplně všude. Základní nevýhoda steganografie však je, že při odhalení dostaneútočník do ruky celou zprávu. Nabízí se proto řešení: Kombinace steganografie a kryptogra-fie. Zprávu nejprve zašifrujeme a poté ukryjeme. Zašifrovaná zpráva lépe odolává analýzea navíc není pro útočníka ihned čitelná. Nevýhodou tohoto postupu však je, že musíme býts příjemcem předem domluveni na způsobu ukrytí, jinak zprávu nemá šanci odhalit ani jejípravý příjemce.
Digitální steganografiePod pojmem digitální steganografie rozumíme ukrývání zpráv do datových souborů. Rozli-šujeme:
• plaintext – zprávu, kterou chceme ukrýt, což může být text nebo soubor• zašifrovaný plaintext (ciphertext)

80 Obsah
• covertext – nosič zprávy, tedy soubor, do nějž ukrýváme• stegotext – nosič obsahující zprávuJako nosiče pro steganografii slouží nejčastějji multimediální data, pro něž platí, že lid-
ské smysly nesmí zprávu odhalit. To neznamená nutně absolutní neviditelnost, ale jen určitýstupeň nenápadnosti. Zpráva by navíc měla přežít určité manipulace (změna velikosti ob-rázku, filtrování, atd.). Dále se budeme zabývat ukrývání do textu, obrázků, zvuku, videaa do spustitelných souborů.Připomeňme, že je zcela lhostejné, zda ukrýváme text nebo číslo. Vždy se může navíc
jednat o vyjádření zprávy pomocí dvojkové soustavy. Budeme se proto povětšinou zabývattím, jak ukrýt sekvenci nul a jedniček.
Ukrývání do holého textu
V případě holého textu máme k dispozici pouze jednotlivé znaky bez jakéhokoliv formá-tování. Jediné, co je v textu nenápadné, jsou bílé znaky. Každý znak zprávy tak můžemenahradit posloupností mezer a tabulátorů. Tyto posloupnosti umístíme na konec řádků. Jinámetoda spočívá v náhradě podobných písmen, např. O a 0, l a 1. Další způsob je pomocígramatiky. Například v angličtině před slovem and může a nemusí být čárka. Výskyt čárkypak kóduje 0 nebo 1. Nevýhodou této metody je poměrně málo prostoru pro uložení zprávy.Pomocí sémantiky, čili významu jednotlivých slov lze zprávu kódovat takto: Předem se do-hodneme na dvojicích synonym. V každé dvojici jednomu slovu přiřadíme jedničku, druhémunulu. Např. velký = 1, značný = 0. V textu pak hledáme slova z kódové knihy, která podlepotřeby nahrazujeme synonymy. Význam zprávy zůstane nezměněn. Více dvojic synonyma delší zpráva poskytuje větší prostor pro zprávu.
Ukrývání do formátovaného textu
Formátovaný text nabízí oproti holému textu další možnosti. Pomocí různých fontů lzezprávu ukrýt např. pomocí Baconovy šifry. Jejím autorem je Francis Bacon (1561 – 1626).Platí, že Nosič zprávy musí být 5x delší než zpráva. Bacon vymyslel pětiznakový kód prokaždé písmeno (dnes bychom řekli pětibitový). Nosič poté píšeme pomocí dvou různýchfontů; jeden připadá na A, druhý na B.A = AAAAA N = ABBAAB = AAAAB O = ABBABC = AAABA P = ABBBAD = AAABB Q = ABBBBE = AABAA R = BAAAAF = AABAB S = BAAABG = AABBA T = BAABAH = AABBB U + V = BAABBI + J = ABAAA W = BABAAK = ABAAB X = BABABL = ABABA Y = BABBAM = ABABB Z = BABBBNĚJAKÝCH DVACET PÍSMEN pak může ukrýt zprávu ”Ahoj”. V digitální steganografii
lze této metody samozřejmě použít při ukrývání jedniček a nul.Pomocí posouvání řádků lze ukrýt zprávu např. do PDF. Každý druhý řádek je posunut
nahoru nebo dolů vůči své správné pozici. Posun o jeden pixel, tj. o 1/300 palce je pro lidskéoko neznatelný. Směr posunutí kóduje 0 nebo 1. Výhodou této metody je její dekódovatel-nost i po 10 kopiích. Analogickou metodu předstravuje posouvání slov, čili zvětšování nebozmenšování horizontální mezislovní mezery. Tato metoda je ještě méně viditelná než posunřádků. Její variantou je pak vkládání nových mezer, což je ale poněkud nápadnější. Dalšímetodu představuje neznatelná změna vlastností písma (výška u písmen jako b, d, h, l, řez,atd.), drobná změna barvy písma či kombinace uvedených metod.
Ukrývání do obrázků
Ukrývání do obrázků je nejčastěji užívaná metoda, neboť obrázky jsou nejčastěji přenášenýtyp multimediálních dat a tudí budí nejméně pozornosti. Navíc skýtají nepřeberné množstvímožností ukrývání.Nejprimitivnější metodou je kódování do nejméně významného bitu, tedy LSB (Least Sig-
nificant Bit). Klasické barevné schéma R,G,B, kde je pro každou barevnou složku vyhrazen 1

Obsah 81
byte, představuje prostor pro cca 16,7 milionu barev, což je více, než dokáže lidské oko rozli-šit. Použijeme-li tedy poslední bit každého n-tého bytu pro uchování zprávy, některé body senepatrně změní, lidské oko však změnu neodhalí. Příjemce z obrázku použije jen stanovenébity. Alternativou tohoto postupu je kódování do dvou posledních bitů. Lidské oko stále neníschopno zaznamenat změnu, jak je vidět na následujícím příkladu převzatém z Wikipedie:
Odstraníme-li v obrázku stromů vše až na dva LSB, získáme skoro černý obraz.Následné 85x zvýšení jasu odhalí kočku.
Ukrývání do LSB má však i svá úskalí: U grafických formátů s barevnou paletou (GIF)může změna posledního bitu znamenat značnou změnu barvy. Je proto třeba provádětzměnu na základě podobnosti barev a místo jednoho bitu měnit celý byte (resp. celou tro-jici bytů). Výsledkem bude barva velmi podobná původní barvě. Případně můžeme použít

82 Obsah
obrázek v odstínech šedé.Velmi zajímavvou metodou je ukrývání do barevné palety, což je využitelné u obrázků
souborového formátu GIF, který má barevný prostor 256 barev. Na začátku každého souboruje definice barevné palety, která představuje přeskládání barev. Samotná obrazová data jsoupak jen indexy do palety. Při změně palety a odpovídající změně indexů zůstane obraz vizu-álně identický. Počet různých palet je roven 256! = 8,5*10506 = 21683. Každé zprávě přiřadímeuspořádání barev. Do barevné palety lze ukrýt až 1683b = 210B.Máme-li k dispozici nosič ve formátu JPEG, využijeme vlastností ztrátové komprese. Ta je
u JPEGu založena na DCT (Discrete Cosine Transform). Lidské oko je citlivější na změnu jasunež na změnu odstínu. V JPEG kompresi obě složky zpracováváme zvlášť. Zprávu ukrývámedo informace o barvě na méně významné pozice v matici 8x8.Vodoznaky, čili přidání špatně viditelné informace do obrázku v reálném světě dokazují
pravost dokumentu. Vodoznak není viditelný na první pohled, obsahuje však určité infor-mace. Jeho nevýhodou je, že jej lze většinou odhalit. Výhodou je pak rezistence vůči praktickyjakékoliv manipulaci s obrázkem. Nejedná se však o „čistou“ steganografiiDalší způsob steganografie denně nevědomky každý z nás použije. Americká tajná služba
je totiž dohodnutá s výrobci tiskáren, že každá vytisknutá stránka obsahuje na určitýchmístech mikroskopické tečky žluté barvy. Rozložení teček odpovídá místu nákupu tiskárnya dalším informacím. CIA je tak z každé stránky schopná určit místo, kde byla stránkavytisknutá, dokonce i sériové číslo tiskárny.
Ukrývání do audiosignálu
Při ukrývání do audiosignálu můžeme použít tzv. low bit encoding, což je analogie LSB u ob-rázků. Zprávu kódujeme do nejméně významných bitů v každém bytu. Odvážnější metoda,tedy kódování zprávy do dvou bitů v každém bytu je použitelná jen u málo kvalitních na-hrávek, získáme však více prostoru pro ukrývání dat. Nevýhodou změn nízkých bitů je, žepřenos přes analogové médium zničí zprávu šumem. Stejně tak převzorkování zničí zprávu.Jinou metodu představuje tzv. parity coding, čili kódování pomocí bitů pro kontrolu
parity. V každé části audiosignálu je totiž jeden paritní bit. Je-li příslušný bit zprávy rovenparitnímu bitu, zůstane část beze změny. Je-li příslušný bit zprávy různý, změníme jedenz LSB v části audiosignálu a následně změníme i paritní bit. Kontrola parity je v pořádku,audiosignál však ukrývá zprávu. Při dekódování zprávy čteme jen paritní bity.Velmi pěknou metodu kkódování do audiosignálu představuje kódování pomocí fázových
posunů. Audiosignál je složen ze sinů, které mají různou frekvenci a různou amplitudu.Mají také různý fázový posun. Lidské ucho vnímá jen frekvenci (výška tónu) a amplitudu(intenzita tónu), nikoliv fázový posun. DFT (Diskrétní Fourierova transformace) rozloží signálna siny (jedná se analogii Talorovy řady pro polynomy). Následně upravíme fázový posunelementárních funkcí tak, aby kódoval zprávu a zrekonstruujeme audiosignál. Pro lidskéucho je změna zcela neznatelná, nový zvukový soubor je však velmi odlišný od původního.Čím složitější zvuk, tím větší prostor pro zprávu.Metdou, která opět vychhází z reálného světa, je ukrývání do šumu. Zprávu namodulu-
jeme na neslyšitelnou frekvenci a vzniklý signál přidáme do zvuku. Příjemce oddělí signáldané frekvence a dekóduje zprávu. De facto se jedná o princip elektromagnetického pře-nosu v reálném světě (např. do našeho hlasu je na neslyšitelné frekvenci ukryt signál rádia čitelevize, signál internetového modemu je přidán do kabelové televize, telefonní linky, atd.).Poslední metodou ukrývání do audiosignnálu, o které se zmíníme, je ukrývání do ozvěny.
K určité části signálu v audiosouboru přidáme ozvěnu, přičemž intenzita a útlum ozvěny semění. Zpoždění kóduje 0 nebo 1. Nelze použít pro nekvalitní signál, pro signál již obsahujícíozvěny, nebo pro signál s dlouhými pomlkami (ozvěna ticha je totiž opět ticho).
Ukrývání do videa
Video = obraz + zvuk. Máme tedy možnost použití technik pro ukrývání do obrázků i dozvuku, případně kombinace obou. Obrázků je navíc velké množství, pro zprávu tedy mámehodně prostoru. Video je však nepopulární nosič díky značnému objemu dat a skutečnosti,že se nepříliš často se přenáší po internetu.
Ukrývání do spustitelných souborů
Spustitelný soubor není nic jiného, než posloupnost instrukcí. Instrukce samozřejmě nelzeměnit, tím bychom zcela změnili chod programu. Využijeme však instrukce nepodmíněného

Obsah 83
skoku a tím vytvoříme části souboru, které nikdy nebudou provedeny. Do nich pak ukryjemezprávu. Tento způsob se sice poměrně snadno detekuje, ale kdo z nás běžně hledá ve spus-titelných souborech hluchá místa? Jinou metodou je ukrývání do nepoužitých proměnných,pomocí negativni / pozitivní formulace podmínek skoku, atd.
Stegoanalýza
Stegoanalýza představuje analogii kryptoanalýzy u kryptografie. Je to schopnost, umění,věda. . . o detekci a dekódování ukryté zprávy. Rozlišme typy stegoanalytických útoků:Prvním je tzv. stego-only attack. Útočník má k dispozici pouze stego-text, není si jistý, zda
obsahuje ukrytou zprávu a nezná metodu ukrytí, ani originální nosič a neví nic o ukrytézprávě. V tomto případě je pravděpodobnost úspěšného útoku takřka nulová. Druhou mož-ností je tzv. known-cover attack. Útočník má k dispozici původní cover-text a stego-text. Ví,že jsou různé, tudíž si je jistý, že stego-text obsahuje zprávu a může ji odhalit pomocísrovnávání souborů. Třetím typem je known-message attack.Útočník má k dispozici stego-text a ukrytou zprávu (nebo aspoň její předpoklad). Ačkoliv
je to málo pravděpodobná varianta, může odhalit metodu ukrývání pro pozdější stegoana-lýzu. Nejčastějším typeem útoku je pravděpodobně chosen-message attack. Útočník předpo-kládá znění zprávy a má k dispozici stego-text. Snaží se upřesnit svůj předpoklad analýzoustego-textu.Mezi používané stegoanalytické techniky patří zejména statistická analýza. K ní potřebu-
jeme větší množství souborů pocházejících z daného zdroje, např. fotografie z téhož foto-aparátu, nahrávky z téhož studia, atd. V signálu jsou vysledovány různé statistiky (analýzaspektra, deformace hran,...). Soubor porušující statistiky je pravděpodobným nosičem zprávy.Další metodou je analýza šumu.I proti těmto technikám je však možné se bránit pomocí různých pokročilých technik
steganografie. Jak zabránit detekci zpráv? Například přidáním nesmyslných informací dokaždého souboru. Statistická analýza pak neodhalí skutečnou zprávu. Jiný způsob předsta-vuje už zmiňovaná kombinace šifrování a komprese ukrývané zprávy. Ukrytá data jsou pak„náhodná“ a nepředvídatelná. V neposlední řadě je to používání stále nových algoritmů.Jedná se sice o rozpor s Kerckhoffsovým principem, v případě steganografie to však lzetolerovat.
Podprahové signály
Ke steganografii svým způsobem patří i podprahové signály, čili signály, které nevnímá lidskévědomí, ale dostávají se do podvědomí. Např. jednotlivé snímky ve filmu obsahují text.Pomocí smyslů jej ani nezaznamenáme, natož mu porozumět, v podvědomí je však uložen.Tato metoda má široké použití v reklamě a propagandě. Podprahové signály v reklamě jsouzákonem zakázány. Podle neověřených informací (Zdroj: Wikipedia) v letech 1962 – 1966Obchodní dům v New Orleans přidával do hudby v reproduktorech dvě neslyšitelné věty:„Jsem čestný“ a „Nebudu krást“. Počet krádeží se údajně snížil o 75%. V roce 1988 předprezidentskými volbami ve Francii státní televize vysílala podprahové portréty F. Miteranda.V roce 2000 během prezidentské kampaně v USA byla do televizních projevů G.W. Bushepřidána podprahová slova „BOUREAUCRATS“ a „RATS“.
Steganografický software
Ukázky steganografického softwaru najdete na www.stegoarchive.com a . Za vy-zkoušení rozhodně stojí program StegHide b .
ahttp://www.stegoarchive.com/bhttp://steghide.sourceforge.net/

84 Obsah
Šifrování v mobilní komunikaci
Šifrování v mobilní komunikaci
Síť GSMGSM, neboli Global System for Mobile communication je celosvětová digitální celulární síťurčená pro mobilní telefony. Tuto síť v současnosti využívá více než 3 miliardy lidí ve vícenež 212 zemích světa.Skupina GSM, tedy Groupe Spécial Mobile, byla založena v roce 1982. Dnes používaná
zkratka vychází z názvu této skupiny. V roce 1987 bylo 13 zeměmi podepsáno memorandumo porozumění, potřebné k vývoji celoevropské celulární telefonní sítě. V roce 1989 byla zod-povědnost za další vývoj GSM převedena na ETSI (Evropský telekomunikační standardizačníinstitut) a o rok později bylo publikována první specifikace GSM phase I, která obsahovalavíce než 6000 stran textu. V roce 1991 začala finská firma Radiolinja jako první provozovattuto službu komerčně. Za dva roky se služba rozšířila do dalších 21 zemí s celkem 36 GSMsítěmi. (GSM World, 2009)V roce 1998 vznikl Projekt Partnerství 3. Generace (3GPP), který měl původně za úkol
vytvořit specifikaci pro třetí generaci mobilních sítí. 3GPP postupně přebral rovněž údržbua vývoj specifikace GSM.
Generace mobilních sítí
1G
1G je síť první generace bezdrátové mobilní komunikace. Jedná se o analogovou síť, kteráspustila svůj provoz počátkem 80. let.Jeden ze standardů je NMT (Nordic Mobile Telephone), používaný v severských zemích,
východní Evropě a Rusku. Další zahrnují AMPS (Advanced Mobile Phone System) používanýve Spojených státech, TACS (Total Access Communication System) ve Spojeném království,JTAGS v Japonsku, C-Netz v Západním Německu, Radiocom 2000 ve Francii a RTMI v Itálii.Analogové vysílání bylo ve většině světa plně nahrazeno digitálním. (Javvin Technologies,Inc.)
2G
2G je druhá generace mobilních sítí, která je již plně digitální. Její provoz byl spuštěn v roce1991 ve Finsku.Pod sítě druhé generace jsou řazeny tyto standardy:• GSM – založena na TDMA (Time Division Multiple Access), v současnosti zahrnujezhruba 80% uživatelů na světě
• IS-95, cdmaOne, často označováno jen jako CDMA – je založena na CDMA (CodeDivision Multiple Access). Je využívána hlavně v Americe a Asii. Zahrnuje zhruba 17%uživatelů
• PDC – založena na TDMA, provozována pouze v Japonsku• iDEN – založena na TDMA, vyvinuta firmou Motorola, využívána v některých zemíchAmeriky, Asie a blízkého východu
• IS-136, D-AMPS – založena na TDMA, byla jednou z nejpoužívanějších v Americe,postupně ale nahrazena standardem GSM (Wikipedia, 2009)
Spolu s digitálními sítěmi druhé generace se začaly rozvíjet další služby nabízené operá-tory než jen hlasová komunikace. Rozvoj začal především na poli krátkých textových zpráva připojení k internetu.
2.5G, 2.75G
Jedná se o standardy, které ještě nespadají plně do sítí 3G, ale oproti 2G nabízejí vyššírychlosti přenosu dat. Tyto standardy již umožňují přepínání paketů a mohou být použity nastávající infrastruktuře sítí GSM a CDMA. V Evropě velmi populární je standard GPRS, kterýumožňuje download rychlostí až 144 Kbps. Standard EDGE je zahrnován do sítí 2.75G, i kdyžby měl patřit spíše pod sítě 3G. EDGE umožňuje vysokorychlostní připojení k internetus rychlostí až 1 Mbps, typicky ale okolo 400 Kbps.

Obsah 85
3G
3G je třetí generací mobilních sítí založená na standardu ITU IMT-2000. Její hlavní přednostíje vysoká rychlost připojení umožňující dosahovat rychlostí až 14,4 Mbps. Hlavním využitímtéto vysoké rychlosti jsou videotelefonie a širokopásmové připojení k internetu. Hlavnímpodporovaným standardem je W-CDMA označovaná také jako UMTS. Přechod na sítě třetígenerace je pro operátory poměrně náročný, protože stávající infrastrukturu je možné využítjen částečně. Je třeba vyměnit celý systém základových stanic (BSS). Sítě třetí generace jsoutaké výrazně bezpečnější než jejich předchůdci. Komunikace je šifrována blokovou šifrouKASUMI, označovanou někdy jako A5/3.Největšího rozvoje se sítě 3G zatím dočkaly hlavně v Koreji a Japonsku. V Evropě je
nástup těchto sítí zbrzděn vysokými investicemi telekomunikačních společností do nákupulicencí pro 3G. (3GPP, 2009)
4G
Čtvrtá generace mobilních sítí by měla přinést další navýšení rychlosti mobilního připojenía to až na 100 Mbps. Hlavními poskytovanými službami mají být širokopásmové připojeník internetu, MMS, videotelefonie a mobilní televize ve vysokém rozlišení. Jedním ze základ-ních stavebních kamenů sítí 4G je také podpora IPv6. Všech těchto nových vlastností by mělobýt dosaženo s maximálním možným využitím stávající infrastruktury.
Architektura sítě GSM
Síť GSM si můžeme rozdělit do tří částí. První z nich Mobile Station (MS) se sestává z mo-bilního telefonu – Mobile Terminal (MT) a čipové karty Subscriber Identity Module (SIM).Systém základových stanic – Base Station Subsystem (BSS) má za úkol kontrolu rádiovéhospojení s MS. Síťový a přepínací podsystém – Network Switching Subsystem (NSS) přepojujehovory mezi jednotlivými uživateli mobilní sítě a mezi uživateli pevných linek. Hlavní sou-částí tohoto subsystému je mobilní přepojovací centrum – Mobile Services Switching Center(MSC). Volitelnou součástí je hlavní síť GPRS, umožňující internetové spojení na bázi paketů.(Wikipedia, 2009)
Obr. č.: 1 Struktura GSM sítě (Wikipedia, 2009)
Mobile station (MS)
Mobilní stanice se skládá ze dvou prvků – mobilního terminálu (MT) a malé čipové kartyoznačované jako Subscriber Identity Module (SIM). SIM zajišťuje osobní mobilitu, takžeuživatel má přístup ke službám nezávisle na použitém terminálu. Vložením SIM karty do

86 Obsah
jiného GSM terminálu může uživatel na tomto terminálu volat, přijímat hovory a využívatdalších služeb sítě.Mobilní terminál je jednoznačně identifikován pomocí International Mobile Equipment
Identity (IMEI). SIM karta obsahuje International Mobile Subscriber Identity (IMSI) pou-žívaný pro autentizaci uživatel služby, tajný klíč pro autentizaci a další informace. IMEIa IMSI jsou nezávislé a umožňují tedy osobní mobilitu. SIM karta může být chráněna protineautorizovanému použití heslem nebo číselným kódem (PIN). (Scourias, 1997)
Systém základových stanic (BSS)
Systém základových stanic (BSS) se skládá ze základových převodních stanic – Base Transce-iver Station (BTS) a kontroly základových stanic – Base Station Controller (BSC).Základové převodní stanice (BTS) sdružují zařízení pro příjem a vysílání rádiových sig-
nálů, antény a zařízení pro šifrování a dešifrování komunikace s kontrolou základovýchstanic (BSC).Díky použití směrových antén je možné základovou stanici sektorizovat. Tím je dosaženo
toho, že je několik buněk celulární sítě obsluhováno z jednoho místa. Tento aspekt zvyšujeprovozní kapacitu BTS a zároveň nezpůsobuje téměř žádné rušení sousedních buněk.Buňky GSM sítě je možné rozdělit na makrobuňky – Makrocell, mikrobuňky – Mikrocell
a deštníkové buňky – Umbrella cell. Makrocell je typická základová stanice, obvykle obsahujetři vysílače s vysílacím úhlem 120◦ a má dosah plných 35 km. Mikrocell je menší vysílačs jednou anténou a pokrytím 360◦ a dosahem 27 km. Používá se pro pokrytí napříkladv budovách nebo metru. Umbrella cell je kombinací obou předchozích, jedná se o vysílačs dosahem 35 km a úhlem 360◦.
Síťový a přepínací podsystém (NSS)
NSS zajišťuje přepínání, řídí komunikaci mezi mobilními telefony, umožňuje spojení se sítípevných linek – Public Switched Telephone Network (PSTN) a řídí autentizaci MS v síti.Základní součástí NSS je Mobile Switching Center (MSC), které zajišťuje hlasové hovory,
SMS a další služby sítě. Chová se jako běžný uzel sítě PSTN nebo ISDN. Nejdůležitějšímúkolem MSC je zajištění konektivity s pevnými sítěmi.MSC se dále skládá ze dvou databází – Home Location Register (HLR) a Visitor Location
Register (VLR). V HLR jsou uložena veškerá data o každémmobilním telefonu autorizovanémpro přístup do sítě. Primárním klíčem každého záznamu databáze je IMSI, tedy identifikátorkaždé SIM karty. V každém záznamu je také aktuální poloha každé MS v síti. (Scourias, 1997)Zatímco HLR je stálou databází, ve VLR jsou dočasně uložena data o MS patřících do
jiných sítí, které v dané síti využívají roamingu. Primárním klíčem je opět IMSI a v záznamuje kromě informací shodných s HLR uložena i domovská HLR adresa dané MS.Autentizační centrum (AuC) je chráněnou databází, ve které je uložen tajný klíč Ki pří-
slušející každé SIM kartě. Jen v případě úspěšné autentizace u AuC může s příslušnou MSdále komunikovat HLR. Ke každému záznamu v AuC je kromě tajného klíče Ki přiřazenještě autentizací algoritmus s jakým daná MS spolupracuje. Výsledkem autentizačního pro-cesu je klíč Kc, který je předán kontrole základových stanic BSC pro šifrování a dešifrováníkomunikace s MS.
Proces autentizace majitele GSM staniceStandard GSM předpokládá implementaci těchto šifrovacích algoritmů v MT (Mobile Termi-nal):
• A3 – autentizací algoritmus• A5 – komunikační algoritmus, buď v silnější verzi A5/1 nebo slabší verzi A5/2, případněverzi A5/0 neobsahující žádné šifrování
• A8 - algoritmus generující klíče pro hlasovou komunikaciVložením karty SIM se z MT stává mobilní zařízení – telefon – nazývaný dále MS (Mobile
Station).Při každém vstupu do sítě je prověřována identita uživatele SIM karty z důvodu zabránění
přístupu neověřených osob k účtu. V autentizačním centru (AUC) a v modulu SIM kartyje uložen tajný klíč Ki, jedinečný pro každého uživatele sítě. Na modulu SIM karty je Kizabezpečen tak, že je možné s ním provádět pouze předem definované operace pomocíalgoritmů A3 a A8.

Obsah 87
Obr. č.: 2 - Schéma šifrované mobilní komunikace (Vondruška, 2008)Uživatel stanice MS žádá o přihlášení do sítě po zapnutí MS. Po zadání PINu je spuštěn
následující proces – síť od AUC zašle náhodné číslo RAND do MS. Zde je číslo RANDpředáno modulu SIM, který na základě znalosti Ki a v SIM kartě uložených algoritmů A3a A8 připraví trojici (RAND, K3, K). Hodnoty K3, resp. K8 spočte jako výstup z algoritmů A3resp. A8 se vstupními parametry RAND, Ki, tedy K3 = A3 (RAND, Ki), K8 = A8 (RAND, Ki).Tato data jsou předána MS, který část K3, označovanou jako SRES (Signed Response), odešledo sítě a klíč K8 uloží zpět do SIM karty. Při požadavku na zahájení šifrovaného spojení jeK8 použit jako klíč pro generování hesla algoritmem A5/1 resp. A5/2.Po obdržení K3 od MS provede síť test podmínky K3’ (SRES’) = K3 (SRES) (K3’ si spočte
AUC na základě znalosti Ki a jím odeslaného čísla RAND). Pokud tato podmínka je splněna,prohlásí síť provedenou autentizaci za úspěšnou a povolí přihlášení MS do sítě. V opačnémpřípadě je vstup MS do sítě odmítnut. (Vondruška, 2008)Algoritmy A3 a A8 jsou obvykle implementovány prostřednictvím jediného algoritmu
nazývaného A38. Tento je obvykle realizován prostřednictvím algoritmu Comp128, respektivejeho vyššími verzemi Comp128v2 a Comp128v3.
Proudová šifra A5Historie
Verze šifry A5/1 byla vyvinuta v roce 1987 v době, kdy se nepočítalo s nasazením službyGSM mimo Evropu a Spojené státy. Proto byla v roce 1989 vyvinuta oslabená verze algoritmuoznačovaná jako A5/2 určená pro nasazení v mimoevropských státech. V současnosti sealgoritmus verze A5/2 používá jen výjimečně, například v Srbsku nebo Keni. V některýchregionech světa byla zavedena dokonce verze bez šifrování, označovaná jako A5/0, která jezde dodnes využívaná. Jedná se především o některé země Afriky a Asie, například Indii.Obě šifrované verze, tedy A5/1 i A5/2 byly původně drženy v tajnosti. V roce 1994 unikly
informace o obecné struktuře návrhu. Ve stejném roce upozornil Ross Anderson, že návrhmůže mít závažné bezpečnostní slabiny. V témže roce také uvedl že „v polovině 80. let bylavelká hádka mezi informačními službami jednotlivých zemí NATO, zda má být šifrováníGSM silné nebo ne. Německo, mající dlouhou hranici se zeměmi Varšavské smlouvy, zastá-valo názor, že ano; ostatní země ale tento postoj nesdílely. Současný algoritmus šifry A5 jefrancouzského návrhu.“ (Anderson, 1994) Oba algoritmy byly pomocí reverzního inženýrstvízrekonstruovány v roce 1999 Marcem Bricenem z GSM telefonu. V roce 2000 používalo šifruA5/1 přibližně 130 miliónů uživatelů systému GSM.
Popis šifry A5
GSM přenos je realizován pomocí sekvencí bursts, neboli shluků. Typicky se odešle jedenshluk obsahující informaci 114 bitů každých 4,615 milisekund jedním kanálem a v jednomsměru. A5/1 vyprodukuje pro každý shluk 114 bitovou sekvenci, pro 2 kanály tedy musívyprodukovat 228 bitů klíče každých 4,615 milisekund. Každý shluk je pomocí funkce XORsečten se shlukem 114 bitů části otevřené zprávy.Algoritmus A5/1 je inicializován 64-bitovým klíčem a veřejným 22-bitovým číslem rámce
TDMA. Do roku 2001 byla v GSM komunikaci používána implementace, která měla prvních10 bitů klíče pevně nastavených na 0. Efektivní délka klíče tedy byla pouze 54 bitů. V sou-časnosti se používají pro tvorbu klíče A8 algoritmy Comp128v2 a Comp128v3, díky nimž máklíč A8 efektivní délku 64 bitů.
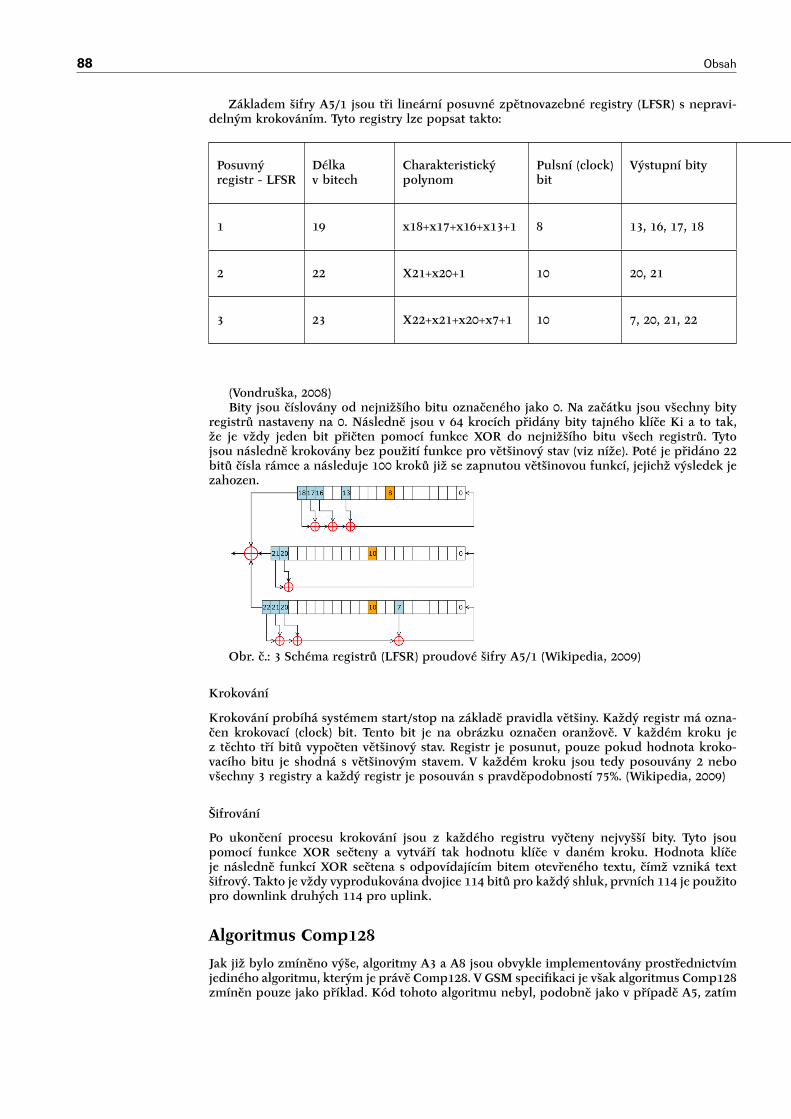
88 Obsah
Základem šifry A5/1 jsou tři lineární posuvné zpětnovazebné registry (LFSR) s nepravi-delným krokováním. Tyto registry lze popsat takto:
Posuvnýregistr - LFSR
Délkav bitech
Charakteristickýpolynom
Pulsní (clock)bit
Výstupní bity
1 19 x18+x17+x16+x13+1 8 13, 16, 17, 18
2 22 X21+x20+1 10 20, 21
3 23 X22+x21+x20+x7+1 10 7, 20, 21, 22
(Vondruška, 2008)Bity jsou číslovány od nejnižšího bitu označeného jako 0. Na začátku jsou všechny bity
registrů nastaveny na 0. Následně jsou v 64 krocích přidány bity tajného klíče Ki a to tak,že je vždy jeden bit přičten pomocí funkce XOR do nejnižšího bitu všech registrů. Tytojsou následně krokovány bez použití funkce pro většinový stav (viz níže). Poté je přidáno 22bitů čísla rámce a následuje 100 kroků již se zapnutou většinovou funkcí, jejichž výsledek jezahozen.
Obr. č.: 3 Schéma registrů (LFSR) proudové šifry A5/1 (Wikipedia, 2009)
Krokování
Krokování probíhá systémem start/stop na základě pravidla většiny. Každý registr má ozna-čen krokovací (clock) bit. Tento bit je na obrázku označen oranžově. V každém kroku jez těchto tří bitů vypočten většinový stav. Registr je posunut, pouze pokud hodnota kroko-vacího bitu je shodná s většinovým stavem. V každém kroku jsou tedy posouvány 2 nebovšechny 3 registry a každý registr je posouván s pravděpodobností 75%. (Wikipedia, 2009)
Šifrování
Po ukončení procesu krokování jsou z každého registru vyčteny nejvyšší bity. Tyto jsoupomocí funkce XOR sečteny a vytváří tak hodnotu klíče v daném kroku. Hodnota klíčeje následně funkcí XOR sečtena s odpovídajícím bitem otevřeného textu, čímž vzniká textšifrový. Takto je vždy vyprodukována dvojice 114 bitů pro každý shluk, prvních 114 je použitopro downlink druhých 114 pro uplink.
Algoritmus Comp128Jak již bylo zmíněno výše, algoritmy A3 a A8 jsou obvykle implementovány prostřednictvímjediného algoritmu, kterým je právě Comp128. V GSM specifikaci je však algoritmus Comp128zmíněn pouze jako příklad. Kód tohoto algoritmu nebyl, podobně jako v případě A5, zatím

Obsah 89
zveřejněn. V roce 1998 byl však za pomoci reverzního inženýrství sestaven Marcem Bricenem,Ianem Goldbergem a Davidem Wagnerem.Jak Comp128 funguje• Vstupy: 16 Bytů náhodných hodnot (RAND) + 16 Bytů tajného klíče• Výstup: 12 Bytů, z nichž 32 bitů je použito pro autentizaci a 54 + 10 bitů je určeno proinicializaci A5
Nejprve jsou náhodné číslo RAND a tajný klíč zřetězeny na vstupu. Tento vstup je ná-sledně 8 krát zahashován, čímž je jeho délka snížena z 32 bitů na 16 bitů. Výstup každéhoz hashování je následně ještě permutován a výsledek této permutace je použit jako nová ná-hodná hodnota RAND. Po osmém průchodu je výsledek hashovaní funkce výstupem celéhoalgoritmu a není již permutován. (Südemeyer, 2006)
Obr. č.: 4 Schéma algoritmu Comp128 (Südemeyer, 2006)Hashovací funkce sestává z 5 průchodů, v nichž je vždy 16 párů „bytů“ nahrazeno –
viz Obr. č.: 5. Při každém průchodu je použit jiný S-box. První nahradí každé dva oktetydvěma oktety, druhý redukuje 2 oktety na dvojici sedmibitových hodnot. Třetí redukuje 16párů sedmibitových hodnot na 16 párů šestibitových hodnot, a tak dále. Z toho vyplývá, žezákladním principem uvedené hashovaní funkce je tzv. butterfly structure, což znamená, žepozice dvou hodnot pole se vymění v průběhu redukce.Redukce se provádí pomocí pomocné hodnoty:y = (x[m] + 2 × x[n]) (mod 29-j)z = (2 × x[m] + x[n]) (mod 29-j)Následná komprese je vytvořena takto:x[m] = tablej[y]x[n] = tablej[z]
Obr. č.: 5 Dvojice proměnných hashovací funkce (Südemeyer, 2006)V tomto okamžiku sestávají hodnoty x[ ] ze 4 bitů, nikoliv 8.Permutace probíhá po každém průchodu kromě posledního takto:1. Spodní čtveřice bitů v každém poli x[ ] musí být interpretovány jako pole bitů. Po
redukci jsou totiž 4 nejnižší bity nastaveny na 0.2. Nová pozice každého bitu se pak najde takto:

90 Obsah
bit[i] = bit [(17 × i)(mod 128)]3. Následně je pole bitů použito pro reinicializaci 4 nejvyšších bitů vstupu x[ ]. Byte x[i]
je potom tvořen bity bit[i] až bit[i + 7], ale v opačném pořadí, takže nejvyšším bitem bytu[i]je bit[i]. (Südemeyer, 2006)Výstupem algoritmu Comp128 je tedy řetězec 128 bitů. Z těchto 128 bitů je prvních 32
bitů použito jako odpověď pro autentizaci a posledních 54 bitů je použito pro naplněníLFSR algoritmu A5. Z toho vyplývá, že zbývajících 10 bitů potřebných pro inicializaci A5 jenastaveno na 0.
Útoky na šifru A5
Přibližně od poloviny devadesátých let je bezpečnost komunikace šifrované pomocí šifry A5napadána. Postupem času byla prezentována řada možných útoků na tuto šifru. Většina pre-zentovaných útoků využívá především techniky time-memory-data tradeoff. Pro prolomeníšifry ve velmi krátkém čase je použita extrémně rozsáhlá tabulka předvypočítaných stavů,jejíž tvorba je časově velmi náročná. Je však opakovaně použitelná.
Pasivní útok pomocí předvypočítaných stavů
Poprvé tento útok prezentoval Golič v roce 1997. Je založen na řešení velké matice lineárníchrovnic a jeho složitost byla 240,16. Jednalo se o první předzvěst reálně proveditelných útoků.Jako pasivní je tento útok označován proto, že pouze dešifrují zachycenou komunikaci a nijakdo procesu komunikace MS a BTS nezasahují. (Golič, 1997)V roce 2000 prezentovali Alex Biryukov, Adi Shamir a David Wagner útoky, pomocí nichž
je možné šifru A5/1 prolomit v reálném čase na PC. Tyto útoky využívá metodu time-memory-data tradeoff.Útoky využívají drobné chyby ve struktuře registrů, jejich neinvertovatelném krokovacím
mechanismu a častých resetech. Po 248 paralelizovatelných přípravných výpočtech, kterémusí být provedeny pouze jednou, mohou být skutečné útoky provedeny v reálném čase najednom PC.První útok potřebuje výstup algoritmu A5/1 během prvních dvou minut konverzace a vy-
počítá klíč během přibližně jedné vteřiny. Druhý útok vyžaduje výstup A5/1 v délce přibližnědvou vteřin konverzace a vypočítá klíč během několika minut. Oba útoky jsou podobné, alepoužívají různé typy time-memory-data tradeoff. (Biryukov, a další, 2000)Tento typ útoku vyžaduje poměrně náročnou přípravnou fázi, ve které je vytvořena ta-
bulka 235 stavů automatu A5/1. Autoři vymysleli techniku, díky níž je možné stavy kódovatza pomocí 40bitových řetězců. Pro uložení celé tabulky je tedy zapotřebí řádově stovek giga-bytů – v literatuře se uvádí 146 – 300 GB. Tato fáze je velmi náročná i na čas, kvůli nutnostiprovést 248 výpočetních operací pro naplnění tabulky. Jakmile je ale tento výpočet jednouproveden, lze celou tabulku opakovaně používat kdekoliv na světě nezávisle na operátorovi.O několik měsíců později prezentovali izraelští vědci Eli Biham a Orr Dunkelman vy-
lepšení předchozího útoku. Útok je proveditelný tehdy dostupnou technologií. Pro útok jepotřeba 239,91 kroků A5/1 a 220,8 bitů dat, což odpovídá přibližně 2,36 minutám hovoru.(Biham, a další, 2000)Různé typy útoků pomocí předvypočítaných stavů se liší především čtyřmi faktory: po-
třebná velikost zachycených šifrovaných dat, kapacita disku potřebná pro uložení předvy-počítaných dat, výpočetní náročnost pro předvypočítaná data – udávaná v počtu PC provýpočet do 1 roku, doba výpočtu prolomení A5/1 na jednom PC. Všechny tyto údaje shrnujenásledující tabulka:
Obr. č.: 12 Výpočetní náročnost prolomení A5/1 (Crypto-World, 2008)

Obsah 91
Základní principy pasivních útoků
Všechny zde prezentované pasivní typy útoků mají řadu společných myšlenek, z nichž tyklíčové zde uvedu.
Goličův time-memory-data tradeoff
Základním bodem nově vzniklých útoků je Goličův time-memory-data tradeoff prezentovanýv roce 1997. Tento útok je použitelný na jakýkoliv kryptologický systém s relativně malýmmnožstvím vnitřních stavů, což perfekně odpovídá šifře A5/1 která má n = 264 stavů. Zákla-dem Goličovy myšlenky je mít velkou skupinu předvypočítaných stavů A na pevném diskua porovnávat jej se skupinou vnitřních stavů B, jimiž algoritmus prochází v průběhu tvorbyvýstupu. Jakýkoliv průnik mezi stavy A a B umožní identifikovat skutečný stav algoritmu.(Golič, 1997)
Identifikace stavů na základě prefixů jejich výstupních sekvencí
Každý stav definuje nekonečnou sekvenci výstupních bitů vytvořenou v okamžiku, kdy za-čneme algoritmus krokovat od tohoto stavu dále. V opačném směru jsou stavy obvykle uni-kátně identifikovatelné pomocí prvních log(n) bitů svých výstupních sekvencí. Díky tomuje možné hledat rovnosti mezi neznámými stavy pomocí porovnávání prefixů výstupníchsekvencí.V přípravné fázi jsou pro skupinu stavů A vypočteny jejich prefixy výstupů a dvojice
prefix, hodnota je uložena. Z výstupu skutečné A5/1 jsou následně extrahovány všechnyprefixy, byť částečně se překrývající a jako B se označí jejich neznámé odpovídající stavy.Vyhledávání společných stavů pro A a B je efektivní, jestliže se prochází uspořádaná dataA na pevném disku a hledají se shody s B. (Biryukov, a další, 2000)
A5 je možné efektivně invertovat
Golič zjistil, že přechodová funkce stavů v A5/1 není plně inertovatelná. Kontrola krokovánípodle pravidla většiny zajišťuje, že až 4 stavy mohou konvergovat do jednoho během jednohokroku a některé stavy nemají předchůdce. Běh A5/1 je možné obrátit pomocí prohledávánístromu možných předchozích stavů a ze slepých konců se vracet pomocí backtrackingu.Průměrný počet předchůdců každého uzlu je 1, takže očekávané množství vrcholů v prvníchk úrovních stromu roste lineárně vzhledem ke k. (Babbage, 1995)Jestliže tedy najdeme společný stav na disku a v datech, je možné získat malé množ-
ství možných počátečních stavů. Problémem je, že kvůli častým znovuinicializacím, existujepouze velmi krátká cesta mezi středními a počátečními stavy.
Klíč je možné získat z počátečního stavu každého TDMA rámce
Jedná se o slabinu procesu ustavení klíče v A5/1. Předpokládejme, že známe stav A5/1 ihnedpotom, co byly použity klíč a číslo rámce, tedy před počátečními 100 kroky. Pomocí zpětnéhochodu je možné eliminovat známé číslo rámce a získat 64 lineárních kombinací 64 bitů klíče.Jelikož procházení stromu může vyústit v několik možných klíčů, je možné zvolit ten správnýchodem A5/1 vpřed o více než 100 kroků a porovnat získané a vypočtené výsledky. (Biryukov,a další, 2000)
Goličův útok na A5 je jen mírně nepraktický
Díky narozeninovému paradoxu budou A a B mít společný stav jestliže jejich velikosti a ×b » n. Chceme, aby a odpovídalo velikosti dostupného pevného disku a aby b odpovídalopočtu přerývajících se prefixů v běžné telefonní konverzaci. Rozumné hodnoty jsou přibližněa » 235 a b » 222. Výsledkem je tedy n » 257 což je asi stokrát menší než potřebné 264.(Golič, 1997)Abychom dostali pravděpodobnost výskytu průniku na odpovídající úroveň, jezapotřebí buď navýšit velikost paměti ze 150 GB na 15 TB, nebo prodloužit konverzaci z 2minut na 3 hodiny. Ani jeden z přístupů se nezdá být vhodný, ale vzhledem k růstu kapacitydostupných datových úložišť se jedná o drobný problém, který nebude problém odstranit.

92 Obsah
Využití speciálních stavů
Jelikož je přístup na pevný disk asi milionkrát pomalejší než jeden krok výpočtu je v případětime-memory-data tradeoff útoků zapotřebí minimalizovat počet přístupů na disk. Řešenímje ponechat na disku pouze speciální stavy, které vytvářejí určitý vzorec a délky k a čístz disku pouze tehdy pokud narazíme na odpovídající prefix. Tímto je možné zredukovatpočet přístupů na disk b přibližně 2k-krát. Hodnota a zůstává nezměněna, jelikož hodnotyn i b jsme vydělili 2k. Problémem ale zůstává, že je zapotřebí počítat 2k vícekrát v přípravnéfázi. Jestliže bychom chtěli zmenšit počet přístupů na disk z 222 na 26, znamenalo by to, žeby bylo potřeba zvýšit čas pro výpočet předvypočítaných stavů přibližně 64000krát. Tím byse ale stal jen těžko časově použitelným. (Biryukov, a další, 2000)
Speciální stavy A5/1 je možné jednoduše vzorkovat
Jedna z hlavních slabin šifry A5/1 je, že je jednoduché vytvořit všechny stavy, které vytvořívýstupní sekvence začínající určitým k-bitovým vzorcem a, kde k = 16, bez nutnosti použitímetody pokus – omyl. Je tomu tak kvůli špatnému výběru krokovacích bitů. Bity registru,které ovlivňují krokování a bity které ovlivňují výstup, jsou nezávislé po zhruba 16 kroko-vacích cyklů. Je tedy možné brát je nezávisle. Tento snadný přístup ke speciálním stavům seobvykle neděje v dobře navržených blokových šifrách, ale může nastat v proudových šifrách,které mají jednodušší přechodové funkce.Velikost k se podle pánů Alexe Biryuokova, Adi Shamira a Davida Wagnera nazývá vzor-
kovací odolnost. Vyšší k může mít poměrně podstatný dopad na efektivitu time-memory-datatradeoff útoků.
Aktivní útoky
Základní myšlenkou těchto typů útoku je, že všechny telefony umožňují komunikaci pomocívelmi slabé šifry A5/2. Tuto šifru je možné v současné době luštit v reálném čase. Telefonymusejí umožnit i toto oslabené šifrování, aby je bylo možné použít i tam, kde není silnějšívarianta A5/2 k dispozici.Tyto man-in-the-middle útoky jsou postaveny na zařízení, které se tváří jako BTS a s MS se
dohodne na šifrování pomocí slabší šifry A5/2. Dál do sítě ale šíří data šifrovaná podle typudané sítě tedy buď A5/1 nebo i A5/3, případně i GPRS. Zjištění klíče Kc zabere přibližně jednuvteřinu a tento klíč je následně využit útočníkem k šifrování komunikace s legitimní sítí.Odehrávají se tedy celkem dvě spojení. Jedno mezi volajícím a útočníkem, šifrované slabouA5/2 a druhé mezi útočníkem a sítí šifrované silnou šifrou, ale s využitím klíče odcizenéhoz MS. Zpoždění komunikace o 1 vteřinu na jejím začátku, potřebné pro dešifrování klíče Kcnijak nevybočuje z normálu, protože podle specifikace má síť GSM až 12 vteřin na ustaveníšifrované komunikace.První krok vývoje tohoto útoku je efektivní útok se znalostí otevřeného textu na A5/2,
který získá klíč Kc pomocí řešení systému kvadratických funkcí. Druhým krokem je využitítoho, že FEC je uskutečňována před šifrováním. Útok se známým textem je možné modifi-kovat na útok, který rozluští neznámý text právě díky znalosti systémů FEC. Třetím krokemje využití klíče pro A5/2 na dešifrování komunikace pomocí A5/1, A5/3 či GPRS. To je možnédíky návrhu GSM, kdy je pro všechny typy uvedených typů komunikace použit stejný klíč.(Barkan, a další, 2006)Pomocí tohoto útoku je možné uskutečnit celou řadu scénářů. Mezi hlavní patří odpo-
slouchávání hovorů, je ovšem možné hovory také unášet, tedy přijmout hovor místo volanéhobez toho aby bylo poznat, že byl hovor přesměrován. Je rovněž možné měnit obsah zasíla-ných zpráv a dokonce i takzvané dynamické klonování, tedy možnost jak volat z čísla někohojiného a na jeho účet.
Útoky s využitím specifického hardwaru
V srpnu 2008 uveřejnili pánové Timo Gendrullis, Martin Novotný a Andy Rupp způsob, jakreálně zaútočit na šifru A5. Veškeré předchozí útoky byly poměrně komplikované z důvodupotřeby značně rozsáhlých předvýpočtů případně komplikovaného provedení.Pro svůj systém se rozhodli použít útok typu guess and determine na speciálním para-
lelním dešifrovacím zařízení známém jako COPACOBANA (Cost-Optimized Parallel COdeBreaker). Se znalostí pouze 64bitů výstupních dat je tento stroj schopen vypočítat odpoví-dajících 64 bitů vnitřního nastavení během průměrně 7 hodin, tento výkon se ještě podařilo

Obsah 93
vylepšit zhruba o 16%. (Gedrullis, a další, 2008) Využití zařízení COPACOBANA je velmivhodné pro tento typ útoku, protože výpočet je možné paralelizovat a zároveň cena tohotozařízení je přibližně $ 10.000.
Odkazy na použité zdroje a výukovou aplikaci
Názornou aplikaci prezentující průběh šifry A5 (spustitelný soubor pro MS-Windows) lze stáhnout zde a .
ahttps://akela.mendelu.cz/˜foltynek/KAS/mobily/sifra A5.exe
Tato kapitola vznikla na základě diplomové práce Jakuba Kmínka 1 .
Kvantová kryptografie
Kvantová kryptografieV dnešní době se používá pro bezpečnou komunikaci asymetrická kryptografie. Jde o sil-nou šifrovací metodu, která je v dnešní době s použitím současných technologií praktickynerozlomitelná. Co když se ale objeví metody, které celou asymetrickou kryptografii učiníbezcennou? Kryptografové a kryptoanalytici spolu neustále svádí boj o to, kdo bude mítnavrch. Hledají se nové metody jak pro šifrování tak pro lámání šifer. Nyní je pohled upřenna kvantovou mechaniku.
Kvantová mechanikaPočátek kvantové teorie je kladen do přelomu 19. a 20. století. Zakladatelem je Max Planck.Kvantová mechanika nahradila klasickou mechaniku na atomové a subatomární úrovni. Spo-lečně s teorií relativity tvoří pilíř moderní fyziky. Jméno pochází z myšlenky autora teorie,podle níž energie elektromagnetického záření je přenášena po nepatrných, ale konečně vel-kých, kvantech. Kvantová teorie má vliv na konstrukci mnoha zařízení. Bez ní by nevzniklypolovodiče, jaderná energetika, uhlíková vlákna, CD přehrávače, diagnostické a léčebné me-tody využívající radiofarmak a zářičů.
Kvantové počítačeJsou jednou z aplikací kvantové teorie. Průkopníkem kvantového počítání je David Deutsch,který v roce 1985 jako první popsal vizi kvantového počítače. Řeší klasické problémy nepo-měrně rychleji než počítače klasické. Pracují s hodnotami ve vstupním registru paralelně.Problém je pak řešen s polynomiální a nikoliv exponenciální složitostí. Pracuje na principusuperpozice (Schroedinger). V současné době jsou kvantové počítače teprve v plenkách. Jsouschopny pracovat s 10 qubity. Omezující jsou hranice současné techniky. Prozatím neexis-tují reálně použitelné aplikace. Firma IBM sestrojila jeden z prvních funkčních kvantovýchpočítačů. Podařilo se faktorizovat číslo 15.
Kvantová kryptografieNa počátku 80. let Charles Bennett a Gilles Brassard naznačili možnosti použití kvantovékryptografie. Definovali komunikační protokol využívající polarizace fotonů, označovaný jakoBB84. Teorii se podařilo ověřit roku 1989, kdy Bennett a Brassard poslali první kvantovouzprávu pomocí vlastního zařízení na vzdálenost 32 centimetrů. Využívá Vernamovu šifru(zcela náhodný klíč stejné délky jako zpráva). Základem je přenos sekvence pomocí stavučástic – fotonů. Používá se pro přenos (ustavení) šifrovacího klíče. Umožňuje z principubezpečný přenos zprávy a odhalení případného odposlechu.1http://is.mendelu.cz/lide/clovek.pl?zalozka=7;id=3566;studium=25772;download prace=1

94 Obsah
Základní podstata světlaSvětlo má, podle současného stavu poznání, dvojí podstatu – vlnovou a kvantovou. Některéprojevy světla lze vysvětlit vlnovou teorií a jiné kvantovou teorií. Světlo je, mimo jiné, cha-rakterizováno polarizací – rovinou, ve které se šíří světelná vlna. [scale=0.5]{linear.pdf}
Lineární polarizace světla
Měření systému dává pouze pravděpodobnostní výsledky, obecně měření vede pokaždék různým výsledkům. Měření mění stav systému.
Princip kvantové kryptografie1. Alice pošle Bobovi sérii fotonů a Bob je změří.2. Alice sdělí Bobovi, které z nich změřil správně. Bob oznamuje pouze báze, nikolivvýsledky.
3. Měření, ve kterých se neshodli, jsou ignorována.4. Následně Alice a Bob náhodně vyberou některé bity. Porovnají je a případně tak odhalíodposlouchávání. Tyto bity pak zahodí.
5. V případě odhalení odposlechu je celá sekvence zahozena a přejde se na jiný komuni-kační kanál. V případě úspěchu je ustaven komunikační klíč.
Průběh ustavení klíče
Jak lze odposlouchávat?
Klasické rozdělení signálu není možné – foton je ve své podstatě nedělitelný. Eva můžepoužít stejné zařízení jako Alice a Bob, není však schopna správně určovat polarizační bázi(v průměru 50% chyb).
Bezpečnost kvantové kryptografie
Kvantová kryptografie je systém, který zaručuje bezpečnost zpráv tím, že maximálně ztěžujeEvě správné čtení komunikace mezi Alicí a Bobem. Navíc, v případě že se Eva pokouší naslou-chat, mohou Alice a Bob zjistit její přítomnost. Eva se v 50% trefí do bází a v 50% se netrefí.Tj. asi 25% chyb v nepřetržitém odposlechu. Pokud se odposlouchává je pravděpodobnost

Obsah 95
neodhalení P = (1−0, 25)100 při 100 přenesených bitech. RSA spoléhá na jednosměrné funkcea problém rychlé faktorizace. Bezpečnost tedy není fundamentální. Kvantová kryptografievšak nemá toto omezení. Bezpečnost nezáleží na síle útočníka ani na technologické síle – jeabsolutně bezpečná.
Problémy kvantové kryptografie
Je otázka, kdy budou k dispozici opravdu použitelné kvantové počítače. Za 50 nebo 100let? Problém je vytvořit jeden foton s konstantní polarizací, spíše se pracuje s aproximací.Je problém i jeden foton detekovat. Lze určit, že na detektoru něco je nebo ne. Obtížně sevšak určuje množství. Při přenosu dochází k velkým ztrátám. Podaří se přenést tak osminuinformace (počítáme-li i zahazování bitů).
Funkční realizace
Roku 1995 se podařilo vědcům z ženevské univerzity poslat zprávu kvantovým kanálem zapoužití optického vlákna na vzdálenost 20 km. Nedávno výzkumníci z Los Alamos ustavilinový rekord v komunikaci kvantovým kanálem zasláním zprávy na 48 km dlouhou vzdá-lenost. V současné době výzkumný tým Richarda Hughse pracuje na kvantové komunikacivzduchem. Cílem je využít pro posílání zpráv satelity na oběžné dráze a propojit tak libo-volná dvě místa na Zemi.
Zájmová kryptografie
Zájmová kryptografie
V předcházejících kapitolách jsme se věnovali technologiím a algoritmům, které nacházelyvyužití v minulostí, nachází jej v současnosti, anebo jej (možná) budou nacházet v budouc-nosti. Vždy se však jednalo o praktické, řekněme komerční využití. V této kapitole se budemevěnovat aplikaci kryptologických poznatků při přípravě her pro dětii dospělé. Ukážeme siširší souvislosti kryptografie a steganografie, povíme si o rekreační matematice, o šifrovacíchvýzvých E.A. Poea a ukážeme si přehled šifrovacích her pro dospělé.
Rekreančí matematika
Rekreační matematika je část matematiky věnující se především její popularizaci prostřed-nictvím různých matematických hříček, hádanek a hlavolamů. Uveďme si několik slavnýchmatematických hříček, které donutí luštitele zamyslet se nad předloženým problémem a po-kud možno si i něco zapamatovat.

96 Obsah
Paradox chybějící plochy
Podívejte se na níže uvedený obrázek. Jak je možné, že ve spodním trojúhel-níku, který je složen ze stejných částí a má stejné rozměry, jako horní trojúhel-ník, jeden čtvereček chybí?
Alternativní úloha, v níž je použit stejný princip, je na vedlejším obrázku. Jakje možné, že ve čtverci skládajícím se ze stejných částí, je uprostřed díra?

Obsah 97
Obě úlohy využívají drobného optického klamu. Pokud se řešitel pozorně zadívá nazdánlivě rovné čáry, zjistí, že nejsou tak rovné, jak se na první pohled zdá.
Problém sedmi mostů města Královce
Z jiné kategorie je problém sedmi mostů města Královce, slavný problém, který vedl kevzniku teorie grafů. Jedná se o kategorii neřešitelných úloh. Neřešitelnost je zde dokázaná,průměrný řešitel matematických hříček však s touto skutečností nemusí být seznámen.
Ve městě Královci mají 7 mostů podle níže uvedeného obrázku. Jak naplánovatprocházku tak, abychom se po každém mostě prošli právě jednou a skončilitam, odkud jsme vyšli?
Různých matematických hříček je samozřejmě nepřeberné množství, výše uvedené jsoujen těmi nejtypičtějšími příklady.
Šifrovací výzvyZvláštní kategorií matematických hříček jsou tzv. šifrovací výzvy, které bychom také mohlinazvat kryptografickými hříčkami. Většinou se jedná o zašifrovaný text zveřejněný v něja-kém časopise. Za vyluštění jee vypsána symbolická odměna. O tu zde však nejde, hlavnímdůvodem snažení je pro většinu luštitelů dobrý pocit z vyluštění, zvědavost a výzva.Autorem prvních šifrovacích výzev byl americký básník a spisovatel Edgar Alan Poe.
Kromě literatury se zajímal také o šifrování. Vyval lidi, ať mu posílají šifry. Ty pak řešila všechny je zveřejnil v knize společně s návodem na jejich luštění. Dvě, keré nevyluštil, pakzveřejnil bez návodu a vypsal na jejich vyluštění odměnu. Tyto šifry byly vyluštěny až po 150letech - první v roce 1992 a druhá v roce 2000. Dodnes však zůstává tajemství, zda autoremtěchto šifer nebyl sám Poe.Co je na šifrách tak lákavé? Především je to prvek tajemství, zvědavost. Každého zajímá,
co je ve zprávě ukryto, a to i tehdy, pokud by mu výsledek nebyl k ničemu užitečný. Šifryjsou také vyzývavá překážka, v níž jde o to, dokázat sám sobě, že mám na rozluštění. Šifryjsou také logické hříčky, které jsou zábavné.

98 Obsah
Použití šifer v hráchPoužití šifer v hrách pro děti i dospělé může mít různou podobu. Uveďme si ty nejběžnějšízpůsoby:
• Pokladovka - řada stanovišť, poloha každého stanoviště je řešením šifry na předcháze-jícím stanovišti, na konci sladký poklad. Většinou soutěží skupiny hráčů
• Narozeninová šifrovací hra - zvláštní případ pokladovky, kdy skupina více lidí připravíšifrovací hru pro jediného hráče, typicky oslavence narozenin, který po projítí všechstanovišť získá dort nebo hromadu dárků.
• Luštitelský pohár - soutěží jednotlivci nebo týmy, kterým předložíme několik šifer.Úkolem hráčů je v daném čase vyluštit co nejvíce z nich.
• Šifrovací pohár - soutěží týmy, každý tým vymyslí šifru, poté se luští šifry cizích týmů.Úkolem je vyřešit co nejvíce cizích šifer. Body vvšak přidělujeme i za vlastní šifru,kterou někdo vyluštil (aby byla řešitelná)
• Na Alici a Boba - soutěží týmy, polovina hráčů jsou Alice, polovina Bobové. Nejprvedáme hráčům 15 vteřin na domluvu. Alice poté pošle zprávu Bobovi, který má 5 minutna luštění zprávy od vlastní Alice a následně 20 minut na luštění cizích zpráv.
Šifrovací hry mají tu výhodu, že vedou k všestrannému rozvoji hráčů. Je potřeba jakfyzická zdatnost při přesunech, tak inteligence během luštění. Důležitá je nápaditost, intuice,odhad, empatie Hry rozvíjí týmovou spolupráci, procvičují trpělivost a vytrvalosti. Oprotiklasické kryptografii lze identifikovat několik základních odlišností. Zatímco kryptografie sesnaží nalézt nerozluštitelné metody, při přípravě her nalézáme šifry, které jsou rozluštitelné,ale nějakou dobu to trvá. Představují výzvu a řešitel se během luštění pobaví nebo poučí.Jedná se de facto o popření Kerckhoffova principu, neboť součástí luštění je i (zejména)odhalení algoritmu, nikoliv jen klíče
Typy šifer v hráchNyní se podíváme na jednoduché typy šifer, které lze v šifrovacích hrách použít. Je to kó-dování, steganografie, transpozice a substituce. Dále popíšeme produktové šifry, využití ne-přímých informací (hádanek) a šifry grafické.Kódování je de facto pouhý přepis pomocí jiné abecedy. U mladších hráčů stačí samo
o sobě, u starších hráčů je jen jedním z prvků šifry. V úvahu přichází například• Morseova abeceda• Převod abecedy na čísla• Semaforová abeceda• Braillovo písmo• Námořní vlajky• Baudotův kód• Dvojková soustava• Mřížky (Polský kříž)Používáme-li kódování, je zcela stěžejní vlastností bezprefixovost kódu. Bezprefixový
kód je takový, v němž kód žádného symbolu není prefixem kódu jiného symbolu. NapříkladHuffmanovo kódování je bezprefixový kód, zatímco třeba Morseova abeceda bezprefixovýmkódem není a je tedy nutno používat oddělovače. Morseova abeceda bez oddělovačů jenejednoznačná, což je svým způsobem také pěkná šifra.Další metodou je steganografie. Text je ukryt v nosiči, který se zprávou zdánlivě nesouvisí,
což může být typicky text nebo obrázek. Typickým příkladem steganografických metod jsouneviditelné inkousty. Ty jsou vyvolatelné buďto teplem (ovocná šťáva, cibulová šťáva, roztokbílku s vodou (1:1), mléko, 20% roztok cukru, moč), případně jiným způsobem (např. nevidi-telný roztok kukuřičného škrobu se vyvolá se roztokem jódu, roztok jedlé sody se vyvolá segrepovou šťávou, 2% lihový roztok fenolftaleinu se vyvolá roztokem sody či hydroxidu sod-ného. Další možností je skrývání celé zprávy v jídle (např. v pečivu, zmrzlinovém kornoutu,trubičkách, kokosu, konzervě, oplatcích ), v různých předmětech (např. v disketě, v hliněnédestičce ). Asi nejčastěji používanou metodou je ukrývání v textu. Zprávu mohou tvořit např.N-tá písmena ve slovech, N-tá písmena ve větách (přičemž N nemusí být konstanta), lze ukrý-vat morseovky do nesmyslného textu (např. Sírový plamínek do náročného dnu plápolá ), doveršů či do čehokoliv jiného. Kromě zraku, což je standardní způsob odhalení zprávy, můžepřicházet v úvahu i sluch (ukrytí zprávy do rytmu či melodie), čich (kódování morseovky vů-němi), hmat (Braillovo písmo), anebo dokonce chuť (např. Morseovka byla jednou na Tmoukódována bužírkou s tic-tacy.

Obsah 99
Jednoduché substituční šifry, které lze v hrách použít, jsou např.:• Caesarova šifra• ROT13• ATBASH (symetrická abeceda)• Monoalfabetické substituce• Polyalfabetické substituce Vigenérova šifra• Polygrafické substituce Playfairova šifra• Homofonní substitucePoužití základních transpozičních šifer si nejlépe ukážeme na příkladech:
Odhalte přísloví zašifrovaná jednoduchými transpozičními šiframi:• Kdoh On Idvaz A Jic Enec Hy Tizad Eho• MEKEV OLCIS JTARK ILOTS IMUIC ERKIL OK• CTNZ BJTT PSLI IOEO EIAE EO• IKNOEMLUESZEENSEULMEONTI• JVKZEAOEEZASOAAAAYSODSLLSEVKLT
Dalšími možnostmi jsou transpozice v mřížce šnek, had, kůň, apod.Produktové šifry představují de facto superšifrování, tedy metodu, kdy výsledek jedné
šifry je zašifrován pomocí jiné šifry. Typiucké kombinace jsou přitom substituce a transpo-zice, nebo kombinace šifry a kódování. U mladších účastníků produktové šifry nelze použít,protžože by se tím šifra stala příliš náročnou. V historie bylo superšiforvání použito např.u šifry ADFGX používané Němci Nejprve se provedla substituce podle Polybiova čtverces tím, že místo čísel 1-5 byla písmena ADFGX, poté se udělala transpozice sloupců pomocíklíče.Víceúrovňové šifry jsou v podstatě totéž jako produktová šifra s tím, že mezivýsledky
dávají smysl a luštitel tak pozná, že je na správné cestě. Aby byla víceúrovňová šifra pěkná,musí být koherentní, tj. jednotlivé šifry spolu musí nějakým způsobem souviset. Dále byšifra měla obsahovatuje sebe-reference, tedy nápovědy sama k sobě.Nepřímé informace představují kombinaci šifry a hádanky. Lze použí asociace např. for-
mou indicií, což je několik slov, která s klíčovým slovem souvisejí např. divy světa, červenec,pavouk bez nohy. Dále lze použít hádanky, jejichž řešením je klíčové slovo, kontext s častýmopakováním slova, část sousloví, písničky, citátu, atd.Grafické šifry představují zašifrovaný postup, jak nakreslit zprávu. Nevýhoda je, že lze
přenést jen malé množství informace. Metody jsou např.• Vybarvování políček ve čtverečkované síti• Souřadnice a spojnice mezi nimi• Překrývání obrazců• Bludiště
Vlastnosti dobrých šiferAby se šifra hráčům líbila, musí splňovat několik vlastností:
• Řešitelná výzva Je třeba přizpůsobit obtížnost věku hráčů• Jednoznačné řešení• Správný postup je elegantnější, logičtější a jednodušší než alternativy• Šifra je reálně řešitelná bez nápovědy• K vyluštění stačí běžné znalostiOpravdu dobré šifry, tedy šifry, které se hráčům nejen líbí, ale dokážou je zaujmout tak,
že si na ně i po letech vzpomenou, musí navíc splňovat tyto vlastnosti:• Obsahuje originální myšlenku• Dobře vypadá• Obsahuje náznaky správného postupu• Aha-efekt Po vyluštění se hráč praští do čela a nadává si, že ho to nenapadlo dřív• Neobsahuje redundantní prvky• Nepřehlcuje informacemi

100 Obsah
Časté chyby, na které bychom si jako organizátři šifrovacích her měli dávat pozor, jsou:• Překombinovaná šifra• Nejednoznačná interpretace• Selhání techniky Zejména u internetových her• Logistické problémy Náhle vypadne někdo z pomocníkůPřirozenou prevencí proti těmto problémům je všechno zdvojit a vždy mít záložní řešení.
Jak luštit šifryJsme-li v roli hráčů, měli bychom dbát několika zásad a doporučení, která námmohou běhemluštění pomoci. Především to znamená používat hlavu a spolupracovat v týmu. Základníotázky, které si při luštění klademe, jsou:
• Co bude pravděpodobně výsledkem šifry? Text? Číslo? Obrázek?• Je na šifře něco podezřelého? Nepravidelnost? Kostrbatost?• Co nese informaci a co je jen šum?• Jak byste vy převedli smysluplný text na něco, co vypadá jako zadání?• Co by mohlo být obsahem textu?• Jaký typ šifry by mohl být na tomto stanovišti? Zpětné inženýrství• Využíváte opravdu všechny informace, které máte?• Nepřipomíná vám šifra něco, co už jste viděli?Základem každého luštění jsou analýzy a pozorování, z nichž nejzákladnější je frekvenční
analýza, tedy odpověď na otázku, jak často se jaké znaky vyskytují a s tím související otázku,kolik různých znaků šifra obsahuje. Jsou-li ve zprávě 3 typy objektů (resp. 2 + mezera), budeto s největší pravděpodobností morseovka. Vyskytují-li se 4 typy, může se jednat o římskáčísla. Šestadvacet objektů nahrává na abecedu. Analyzujeme-li smysluplný text, je třeba vy-hledávat kostrbatosti, posívat se, zda není něco technicky skryto v textu (steganografie), zdase v textu vyskytují nějaká zajímavá fakta, čísla, atd.Univerzální rady:• Zkuste morseovku• Vychází-li posloupnost čísel, zkuste je převést na písmena. A naopak• Zkuste první písmena Ze zadání, z mezivýsledku, z čehokoli• Jde o předmět? Zkuste ho rozbít. Předtím si ale důkladně opište vše, o co přijdete• Nevymýšlejte překombinované konstrukceLuštíte-li v týmu v terénu, pak dbejte na:• Pohodlí při luštění Věnujte 5 minut vyhledání místa, kde se vám bude dobře luštit• Brainstorming Říkejte nahlas myšlenky. Nekritizujte ty, co vám připadají hloupé. Roz-pracujte je. Myšlenky si zapisujte, poté se k nim vracejte.
• Dotahování věcí do konce Nevzdávejte metodu po prvních pár písmenech, která vypa-dají nesmyslně
• Týmová spolupráce Řešte paralelně, vzájemně se kontrolujte
Přehled šifrovacích herNa závěr si uvedeme přehled nejznámějších šifrovacích her (jedná se o výběr z kalendářešifrovacích her 2 ):
• Tmou (Instruktoři Brno)• Bedna (Svobodní Bednáři Praha)• Exit (Instruktoři Brno, Chameleon Brno)• OSUD (Zlínská astronomická spol., Educatio)• Sendvič (Instruktoři Brno, Chameleon Brno)• Matrix (Velký vůz Praha)• Haluz (KSP FMFI UK Bratislava)Tato kapitola vznikla na základě knihy Tomáš Hanžl, Radek Pelánek, Ondřej Výborný:
Šifry a hry s nimi. Praha: Portál, 2007
2http://herka.deka.cz/index.php/Kalend%C3%A1%C5%99 %C5%A1ifrovac%C3%ADch her

Slovníček pojmů 101
Slovníček pojmůOne time pad: viz Vernamova šifraAES: (Advanced Encryption Standard), v překladu pokročilý šifrovací standard, nahrazujeDES. Jedná se o algoritmus Rijndael založený na podobných principech (opakovánísubstituce a transpozice) jako DES.
Asymetrická kryptografie: odesilatel a příjemce použijí pro šifrování a dešifrování různéklíče
ATBAŠ: princip vzájemné záměny písmen. Princip spočívá v tom, že se vezme písmeno, určíse jeho vzdálenost od začátku abecedy a nahradí se písmenem se stejnou vzdáleností odkonce abecedy.
Autentizace: (authentication) - též identifikace, neboli ztotožnění - znamená prokazovánítotožnosti, tj. ověření, že ten, s kým komunikujeme, je skutečně ten, se kterým si myslíme,že komunikujeme. Autentizace může probíhat na základě znalosti (heslo), vlastnictví(klíče od bytu, kreditní karta) nebo charakteristických vlastností (biometrické informace- např. otisky prstů).
Autorizace: (authorization)- je potvrzení původu (původnosti) dat. Tedy prokázání, že data vytvořil (je jejich autorem)
skutečně ten, o němž si myslíme, že je autoremBezeztrátová komprese: komprese, při níž jsou data zakódována tak, že z nich je možnépři dekompresi zrekonstruovat zpět původní data
Caesarova šifra: posunutá abeceda o 3 písmenacelistvost (integria) dat: - jedná se o zamezení neoprávněné modifikace dat. Tato modifi-kace může být smazání části dat, vložení nových dat, nebo substituce části stávajících datjinými daty. Se zamezením neoprávněné modifikace souvisí i schopnost tuto modifikacidetekovat.
Certifikát klíče: je důvěryhodnou osbou digitálně podepsané sdělení: ”Tento klíč patří tétoosobě”.
Ciphertext: = šifrový text, zašifrovaná zpráva.Covertext: nosič zprávy pro steganografii, tedy soubor, do nějž ukrýváme utajovanou zprávu.Dekomprese: aplikace dekompresního algoritmu na data vystoupivší z kompresního algo-ritmu
DES: šifrovací algoritmus přijatý jako standard NIST v r. 1976, založený na opakování per-mutací a substitucí
Digitální podpis: zašifrování hashe zprávy soukromým klíčem autoraDiskrétní kosinová transformace: je formou diskrétní Fourierovy transformace. Obrazovádata jsou považována za barevné vzorky spojitých barevných signálů naměřené v dis-krétní síti pixelů. Výsledkem kosinové transformace je pak nalezení sady parametrůkosinových funkcí, jejichž složením lze rekonstruovat původní obraz.
Důvěrnost: (confidentiality) - též bezpečnost - jedná se o udržení obsahu zprávy v tajnosti.Entropie: Míra neuspořádanosti systémuHash: otisk zprávyHashovací funkce: jednosměrná funkce mapují řetězec libovolné délky (zpráva, datový sou-bor) na řetězec konstantní délky a vytvářející tak otisk vstupního řetězce
Homofonní šifra: každé písmeno se zde nahrazuje řadou reprezentací, přičemž jejich početje úměrný frekvenci písmene.
Huffmanovo kódování: využívá četnosti jednotlivých znaků pro optimální zakódování.1. Seřadíme pravděpodobnosti výskytu jednotlivých znaků sestupně pod sebe.2. Sečteme poslední dvě pravděpodobnosti a vytvoříme nový sloupec pravděpodobností,kde ty dvě, které jsme sčítali nahradí jejich součet.
3. Všechny pravděpodobnosti v novém sloupci seřadíme sestupně podle velikosti a pro-pojí se spojnicemi s hodnotami v původním sloupci.
4. Spojnice pravděpodobností p(xn−1) a p(xn) se sjednotí, ale předtím přiřadíme p(xn) bitkódového slova s hodnotou 1 a p(xn−1) bit s hodnotou 0.
5. Takto postupujeme, dokud se součet posledních dvou čísel nerovná 1.6. Závěrečné kódování každého slova pak probíhá po spojnicích jako sbírání zapsanýchbitů kódového slova tak, že jdeme po spojnicích a zapisujeme všechny bity, které pocestě potkáme.
7. Nakonec se celý zápis obrátí odzadu dopředu a výsledkem je kódové slovo pro danouudálost.
Informace: Informace je míra množství neurčitosti nebo nejistoty o nějakém náhodném

102 Slovníček pojmů
ději odstraněná realizací tohoto děje.Informace rozšiřuje okruh znalostí příjemce.
Jednosměrná funkce: Funkce, jejíž výpočet má časovou složitotost ležící ve třítě P (polyno-miální), ale výpočet funkce inverzní má časovou složitost ležící ve třídě NP (není známefektivnější než exponenciální algoritmus).
Jev: náhodný proces s n možnými realizacemi (tah sportky, účast na přednášce, semafor nakřižovatce apod.)
JPEG: ztrátová komprese rastrového obrazu skládající se z transformace barev, redukcebarev, rozdělení do bloků, diskrétní kosinové transformace, kvantování koeficientů a kó-dování.
Kerckhoffsův princip: základním principem kryptografie. Přišel na něj nizozemský lin-givsta Auguste Kerckhoffs von Nieuwenhoff v roce 1883. Zní: Bezpečnost šifrovacího sys-tému nesmí záviset na utajení algoritmu, ale pouze na utajení klíče.
Klíč: tajná informace podstatná pro průběh šifrování a dešifrování. Na utajení klíče závisíutajení přenášené zprávy.
Kódování: přiřazení znaků jedné abecedy znakům jiné abecedyKomerční certifikát: nemusí splňovat náležitosti zákona a není tedy obecně platný (každýjej nemusí uznat). Používá se pro šifrování dat mezi subjekty, které se na tom dohodnou.
Komprese: (též komprimace) proces aplikace kompresního algoritmu (funkce) na vstupnídata.
Kompresní algoritmus: je funkce K : D → D, kde D značí obecně data, tedy množinu všechpřípustných řetězců nad abecedou {0,1}.Je-li d vstupní řetězec a s výstupní řetězec, tedy K(d) = s, požadujeme, aby —s— < —d—,
navíc požadujeme, aby I(s) = I(d), kde I značí informační hodnotu daného řetězce.Kompresní poměr: vlastnost kompresního algoritmu. Je dán vztahem
k = |s||d| .
Kompresní zisk: je daný vztahem z = 1− k, kde k je kompresní poměr. Vyjadřuje množstvíušetřených dat vzhledem k délce původních dat.
Komprimace: (též komprese) proces aplikace kompresního algoritmu (funkce) na vstupnídata.
Kryptoanalýza: část kryptologie zabývající se lámáním zašifrovaných zpráv bez znalostiklíče.
Kryptografie: nauka o šifrování a šifrovacích metodách.Kryptologie: vědní obor zabývající se šifrováním a dešifrováním zpráv. Zahrnuje v soběkryptografii a kryptoanalýzu. Kryptografie označuje nauku o šifrování, kraptoanalýza sepak zabývá lámáním šifer (tj. luštěním bez znalosti klíče).
Kvalifikovaný certifikát: má stejnou platnost jako občanský průkaz a podle zákona jejkaždý musí uznat. Tento certifikát lze použít jen pro podpis, ne pro šifrování.
Kvantová kryptografie: Kryptografie využívající poznatků kvantové mechaniky a teorie re-lativity.
Lineární zpětnovazební registr: (Linear Feedback Shift Register - LFSRs) představují obecnýmechanismus, kterým lze generovat pseudonáhodná čísla s poměrně solidním stupněmbezpečnosti. Skládají se ze dvou částí: Z posuvného registru a ze zpětnovazební funkce.
LSB: = Least Significant Bit. Nejméně významný bit, používá se při steganografii, jehozměna zpravidla není pozorovatelná, je proto využitelný jako nosič tajné zprávy.
LZW84: bezeztrátový kompresní algoritmus autorů Lempel-Ziv-Welch. Princip kódování jezaložen na opakování frází, které jsou již uloženy ve slovníku. Na počátku proběhne ini-cializace, poté se prochází vstupní text tak dlouho, dokud je procházený řetězec uloženve slovníku. Jakmile narazíme na první znak, se kterým již procházený řetězec ve slov-níku není, umístíme nový řetězec do slovníku a na výstup zapíšeme kód položky, kteráve slovníku ještě byla. Posledně načtený znak (ten, jenž porušil shodu se slovníkem) sepak stává prvním znakem nového řetězce, u nějž se hledá shoda ve slvoníku.
LZ77: Bezeztrátový kompresní algoritmus autorů Lempel-Ziv. Využívá klouzavé okno. Me-toda s různými obměnami používaná dodnes.
LZ78: Kompresní algoritmus - druhá verze algoritmu dvojice Lempel a Ziv (proto někdynazývána LZ2). Metoda si za běhu vytváří slovník frází reprezentovaný n-árním stromem.
MAC: Message Authentication Code, jednosměrná funkce potvrzující pravost zprávyMD5: hashovací algoritmus navržený Ronaldem Rivestem založený na opakovaných per-mutacích a aplikacích nelineárních logických funkcí
MPEG: ztrátová komprimace videa využívající vnitrorámcové, mezirámcové komprimacea metody odhadu pohybu pro snížení datového toku.

Slovníček pojmů 103
Rámce jsou kódovány do tří typů:• rámce I – samostatné, nezávisle zobrazitelné, zakódovány pomocí DCT,• rámce P – kódovány pomocí dopředného prediktivního kódování, je kódován vzhledemk vztahu k předchozímu rámci I nebo P,
• rámce B – zakódovány pomocí dvou referenčních rámců – předchozího a následujícíhoI nebo P.
Typická sekvence snímků:I B B P B B P B B P B B I
Náhodný výběr: Náhodný výběr je takový výběr, kdy pravděpodobnost výběru všech prvkůz určené množiny je stejná.
Nepopiratelnost: (non-repudiation) - souvisí s autorizací - jedná se o jistotu, že autor datnemůže své autorství popřít (např. bankovní transakci).
Nerovnoměrné kódování: každému znaku je přiřazen jinak dlouhý kódNIST: National Institute of Standards and TechnologyPlaintext: zpráva, kterou chceme ukrýt či zašifrovat.Playifairova šifra: šifra nahrazuje každou dvojici dvojici písmen v otevřeném textu jinoudvojicí písmen. Šifrovací tabulka o rozměru 5*5 se vytvoří na základě dohodnutého klíče.Text se rozdělí na digramy, které se kódují podle speciálních pravidel.
Proudové kódování: = RLE. Sekvence stejných znaků jsou nahrazovány indikátorem kom-prese, jedním výskytem opakujícího se znaku a počtem opakování. Pokročilejší variantynevyžadují indikátor komprese.
Realizace jevu: jeden projev, získání výsledku (vytažení 6 čísel, konkrétní počet osob napřednášce, svítící zelená na křižovatce apod.)
Rekreační matematika: část matematiky věnující se především její popularizaci prostřed-nictvím různých matematických hříček, hádanek a hlavolamů
RLE: = proudové kódování. Sekvence stejných znaků jsou nahrazovány indikátorem kom-prese, jedním výskytem opakujícího se znaku a počtem opakování. Pokročilejší variantynevyžadují indikátor komprese.
Rovnoměrné kódovvání: každému znaku je přiřazen stejně dlouhý kódRSA: asymetrický šifrovací algoritmus autorů Rivest, Shamir, Adelman založený na obtížnéfaktorizaci součinu dvou velkých prvočísel.
SHA: (Secure Hash Algorithm) je skupina pěti kryptografických hashovacích funkcí navr-žených NSA (Národní bezpečnostní agentura v USA) a vydaných NIST (Národní institutpro standardy v USA) jako celostátní standard v USA
Shannon-Fanovo kódování: Je založeno na četnosti výskytu jednotlivých znaků abecedy.1. Znaky uspořádáme sestupně podle pravděpodobnosti jejich výskytu.2. Vypočteme kumulativní pravděpodobnosti.3. Rozdělíme znaky do dvou skupin tak, aby jejich součtové pravděpodobnosti bylyblízké, tj. v prvním kroku 0,5. První skupině přiřadíme hodnotu 0, druhé 1
4. Krok 3 opakujeme tak dlouho, dokud existují vícečlenné skupiny znaků.5. Kódy jednotlivých znaků jsou určeny posloupností nul a jedniček zapisovaných přidělení skupin.
Silná autentizace: prokázání totožnosti alespoň dvěma různými způsoby (např. vlastnictvíkreditní karty + znalost PIN)
Steganografie: je umění či věda o ukrývání samotné existence zprávyStegokey: klíč použitý pro specifikaci průběhu ukrývání zprávyStegotext: Nosič (covertext) obsahující ukrytou zprávu (stegotext či ciphertext).Substituce: nahrazení znaků zprávy jinými znakySuperšifrování: skládání více různých šifer.Symetrická kryptografie: odesilatel a příjemce použijí pro šifrování i dešifrování stejný klíčTranspozice: přeskládání znaků zprávyVernamova šifra: = one time pad. Polyalfabetická šifra založená na tom, že klíčem je sek-vence zcela háhodných znaků. Taková sekvence neobsahuje žádné závislosti a není tedymožné se ničeho při kryptoanalýze chytit. Jakýkoliv text dané délky může být při vhodnězvolenémm klíči řešením šifry.
Vigenérova šifra: Autorem této šifry je Blaise de Vigenére, šifrování probíhá pomcí opaku-jícího se klíče, jehož délka je větší než 1.
XOR: logická operace. Název pochází z anglického eXclusive OR, tedy výlučné nebo. Jednáse o logickou operaci nebo s tím rozdílem, že pravdivý může být pouze jeden z operandů.Jsou-li pradivé oba, je výsledkem operace XOR nepravda.0 ⊕ 0 = 0

104 Slovníček pojmů
0 ⊕ 1 = 11 ⊕ 0 = 11 ⊕ 1 = 0
Ztrátová komprese: komprese, při níž zpětná rekonstrukce možná není, dochází pouzek ošálení lidských smyslů, které vnímají nová data stejně, jako data původní a nepoznajítak, že došlo k jejich kompresi.

Slovníček pojmů 1
TestZpůsob vyhodnocení: Při vyhodnocení budou započteny jen správné odpovědi.
1. 10Za efektivní považujeme takový kód, který máVyberte jen jednu z následujících možných odpovědí.
a) maximální entropiib) minimální entropii
2. 10K detekci chyby slouží:Vyberte libovolný počet možných odpovědí. Správná nemusí být žádná, ale také mohou být správnévšechny.
a) Zabezpečení paritoub) Kompresec) Kontrolní součet (CRC)d) Hammingův kód
3. 10Zvolte vlastnosti algoritmu LZW84Vyberte libovolný počet možných odpovědí. Správná nemusí být žádná, ale také mohou být správnévšechny.
a) neztrátovýb) statickýc) slovníkovýd) jednoprůchodový
4. 10Kompresní poměr jeVyberte jen jednu z následujících možných odpovědí.
a) 1− |o||i| , kde o je výstupní a i vstupní řetězec
b) poměr délek výstupního řetězce a vstupního řetězce (výstupní : vstupní)c) 1− |i|
|o| , kde o je výstupní a i vstupní řetězecd) poměr délek vstupního řetězce a výstupního řetězce (vstupní : vý-stupní)
5. 10V kolika kolech probíhá šifrování algoritmem DES?Na tuto otázku lze většinou odpovědět jedním slovem.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6. 10Vyberte symetrické šifrovací algoritmyVyberte libovolný počet možných odpovědí. Správná nemusí být žádná, ale také mohou být správnévšechny.
a) RSAb) IDEAc) AESd) DES
7. 10Mezi autory algoritmu RSA nepatříVyberte libovolný počet možných odpovědí. Správná nemusí být žádná, ale také mohou být správnévšechny.
a) Shamirb) Merklec) Hellmand) Adelman

2 Slovníček pojmů
8. 10K tomu, aby si zprávu od Boba mohla přečíst pouze Alice je třeba jizašifrovatVyberte jen jednu z následujících možných odpovědí.
a) Bobovým tajným klíčemb) bobovým veřejným klíčemc) Aliciným veřejným klíčemd) Aliciným tajným klíčem
9. 10Zkratka LSB označujeVyberte jen jednu z následujících možných odpovědí.
a) Last Signum Bit - poslední, tedy znaménkový bitb) Least Significant Bit - nejméně významný bitc) Load Steganographic Bit - bit patřící ukryté zprávěd) Last Significant Bit - poslední bit s nenulovou hodnotou
10. 10Která vlastnost nepatří mezi požadavky na nashovací funkce?Vyberte jen jednu z následujících možných odpovědí.
a) U funkce musí být obtížné hledat kolizeb) Funkce musí být jednosměrnác) Výstupní hodnota funkce nesmí korelovat se vstupními bityd) Funkce musí být prostá