keystroke dynamics as a biometric for authentication
TRANSCRIPT

Future Generation Computer Systems 16 (2000) 351–359
Keystroke dynamics as a biometric for authentication
Fabian Monrosea,∗, Aviel D. Rubinb
a Courant Institute of Mathematical Science, New York University, New York, NY, USAb AT&T Labs-Research, Florham Park, NJ, USA
Accepted 3 March 1999
Abstract
More than ever before the Internet is changing computing as we know it. Global access to information and resources isbecoming an integral part of nearly every aspect of our lives. Unfortunately, with this global network access comes increasedchances of malicious attack and intrusion. In an effort to confront the new threats unveiled by the networking revolution of thepast few years reliable, rapid, and unintrusive means for automatically recognizing the identity of individuals are now beingsought. In this paper we examine an emerging non-static biometric technique that aims to identify users based on analyzinghabitual rhythm patterns in the way they type. ©2000 Elsevier Science B.V. All rights reserved.
Keywords:Identity verification; User authentication; Biometrics
1. Introduction
The increasing use of automated information sys-tems together with our pervasive use of computershas greatly simplified our lives, while making usoverwhelmingly dependent on computers and digitalnetworks. Technological achievements over the pastdecade have resulted in improved network services,particularly in the areas of performance, reliability,and availability, and have significantly reduced operat-ing costs due to the more efficient utilization of theseadvancements. However, the overwhelming interest inglobal accessibility brought about by these advancesin technology have unveiled new threats to computersystem security. As we press into the twenty-first cen-tury, new challenges abound. Advanced safeguardsagainst fraud and impersonation, as well as foolproof
∗ Corresponding author.E-mail addresses:[email protected] (F. Monrose),[email protected] (A.D. Rubin).
measures against unauthorized access to computerresources and data are now being sought. We presentone such safeguard based on authenticating access tocomputers by recognizing certain unique and habitualpatterns in a user’s typing rhythm.
We argue that the use of keystroke rhythm is a natu-ral choice for computer security. This argument stemsfrom observations that similar neuro-physiologicalfactors that make written signatures unique, arealso exhibited in a user’s typing pattern [14]. Whena person types, the latencies between successivekeystrokes, keystroke durations, finger placement andapplied pressure on the keys can be used to construct aunique signature (i.e., profile) for that individual. Forwell-known, regularly typed strings, such signaturescan be quite consistent. Furthermore, recognitionbased on typing rhythm is not intrusive, making itquite applicable to computer access security as userswill be typing at the keyboard anyway.
This paper presents our results for an authentica-tion system based on the use of keystroke dynamics.
0167-739X/00/$ – see front matter ©2000 Elsevier Science B.V. All rights reserved.PII: S0167-739X(99)00059-X

352 F. Monrose, A.D. Rubin / Future Generation Computer Systems 16 (2000) 351–359
Keystroke dynamics is the process of analyzing theway a user types at a terminal by monitoring thekeyboard inputs thousands of times per second, andattempts to identify them based on habitual rhythmpatterns in the way they type. We present our data se-lection and extraction methods as well as our classi-fication and identification strategies. Our observationsand findings are discussed and compared with priorwork in this area.
2. Biometrics
Biometrics, the physical traits and behavioral char-acteristics that make each of us unique, are a naturalchoice for identity verification. Biometrics are excel-lent candidates for identity verification because unlikekeys or passwords, biometrics cannot be lost, stolen,or overheard, and in the absence of physical damagethey offer a potentially foolproof way of determiningsomeone’s identity. Physiological (i.e.,static) charac-teristics, such as fingerprints, are good candidates forverification because they are unique across a largesection of the population.
Indispensable to all biometric systems is that theyrecognize aliving person and encompass both physi-ological and behavioral characteristics. Physiologicalcharacteristics such as fingerprints are relatively stablephysical features that are unalterable without causingtrauma to the individual. Behavioral traits, on the otherhand, have some physiological basis, but also reflecta person’s psychological makeup. Unique behavioralcharacteristics such as the pitch and amplitude in ourvoice, the way we sign our names, and even the way wetype, form the basis ofnon-staticbiometric systems.
Biometric technologies are defined as “automatedmethods of verifying or recognizing the identity of aliving person based on a physiological or behavioralcharacteristic” [19]. Biometric technologies are gain-ing popularity because when used in conjunction withtraditional methods for authentication they providean extra level of security. Available counter-measuresto the problem of identity verification can be cate-gorized into three main groups: those that rely on(a) something a person knows (e.g. a password), (b)something a person possesses (e.g. an ID card), or (c)characteristics of a person.
Security measures which fall under categories (a)and (b) are inadequate because possession or knowl-
edge may be compromised without discovery — theinformation or article may be extorted from its right-ful owner. Increasingly, attention is shifting to positiveidentification by biometric techniques that encompassthe third class of identification (i.e., biometrics) as asolution for more foolproof methods of identification.For the foreseeable future, these biometric solutionswill not eliminate the need for ID cards, passwords andPINs. Rather, the use of biometric technologies willprovide a significantly higher level of identificationand accountability than passwords and cards alone,especially in situations where security is paramount.
2.1. Let us see your hands, eyes and face
Modern biometric schemes generally rely on as-pects of the body and its behavior. Slight changes inbehavior are inevitable when dealing with non-staticbiometrics since they are influenced by both control-lable actions and unintentional psychological factors.Therefore, biometric technologies need to be robustand adaptive to change — online signature verificationsystems, for example, update the reference template ofa user on each successful authentication to the logindevice to account for slight variations in the signature.
Some examples of identifying biometric fea-tures being used for identification based systemsinclude hand geometry, thermal patterns in the face,blood vessel patterns in the retina and hand, fingerand voice prints, and handwritten signatures (see[4,6,7,13,15,22,24]). Today, a few devices based onthese biometric techniques are commercially avail-able. However, some of the techniques being de-ployed are easy to fool, while others like iris patternrecognition, are too expensive and invasive.
In an effort to provide a passive, inexpensive andmore foolproof method than traditional passwords forverifying an individual’s identity, we present keystrokedynamics. The techniques presented herein rely onpattern recognition. A brief overview of fundamentalconcepts of pattern recognition is given in the follow-ing section.
3. Pattern recognition: representation, extraction,and classification
The design of an automatic pattern recognition sys-tem involvesrepresentation, extraction, andclassifi-

F. Monrose, A.D. Rubin / Future Generation Computer Systems 16 (2000) 351–359 353
cation. Representationof input data measures char-acteristics of the pattern of object to be recognized.When the measurements obtained yield informationin the form of real numbers, it is often useful to thinkof a pattern vector as a point in ann-dimensionalEuclidean space.
The extraction of characteristic features from theinput data and the reduction of the dimensionality ofthe resulting pattern vectors is often referred to as thepreprocessing and feature extraction problem. For ex-ample, we may choose to use only a selected numberof measurements from the input, either because thesefeatures are enough to identify the individual (likethe eyes and mouth) or because the addition of otherextra features increase the computational complexityof the problem or yields no real benefit. The number ofdegrees of freedom of variation in the chosen indexacross the human population, their immutability overtime and immunity to intervention, and the computa-tional prospects for efficiently encoding and reliablyrecognizing the identifying pattern, must all beassessed during feature extraction.
Classificationand identificationinvolves the deter-mination of optimum decision procedures. After theobserved data from patterns to be recognized havebeen expressed in the form of measurement vectors inthe pattern space, we want to decide to which patternclass these data belong [23,8]. For example, given anumber of face images, and an “unknown” referencetemplate from a database of available faces, we wantto be able to positively identify the “unknown” indi-vidual with a specified level of certainty.
The analysis of personal features has a natural rangeof variation; a biometric method never provides anabsolutely certain identification. As such, a biometricidentification system can fail in one of two ways; ei-ther an authorized user is rejected or an illegitimateuser can be incorrectly granted access to the system.Biometric systems must allow adjustments to controlthe error probabilities to some degree.
4. Keystroke dynamics: not what you type, buthow you type
Keystroke dynamics is the process of analyzingthe way a user types at a terminal by monitoring thekeyboard inputs thousands of times per second in
an attempt to identify users based on habitual typ-ing rhythm patterns. It has already been shown (see[14,18,20]) that keystroke rhythm is a good sign ofidentity. Moreover, unlike other biometric systemswhich may be expensive to implement, keystrokedynamics is almost free — the only hardware requiredis the keyboard.
The application of keystroke rhythm to computeraccess security is relatively new. There has been somesporadic work done in this arena. Joyce and Gupta[14] present a comprehensive literature review of workrelated to keystroke dynamics prior to 1990. We brieflysummarize these efforts and examine the research thathas been undertaken since then.
4.1. The current state of keystroke dynamics
Keystroke verification techniques can be classifiedas either static or continuous. Static verification ap-proaches analyze keystroke verification characteristicsonly at specific times, for example, during the loginsequence. Static approaches provide more robust userverification than simple passwords, but do not providecontinuous security — they cannot detect a substitu-tion of the user after the initial verification. Continu-ous verification, on the contrary, monitors the user’styping behavior throughout the course of the inter-action.
As early as 1980, researchers have been studyingthe use of habitual patterns in a users typing behav-ior for identification. To our knowledge, Gaines et al.[9] were the first to investigate the possibility of us-ing keystroke timings for authentication. Experimentswere conducted with a very small population of sevensecretaries. A test of statistical independence of theirprofiles was carried out using theT-Testunder the hy-pothesis that the means of the digraph times at bothsessions were the same, but the variances were differ-ent. Similar experiments were conducted by Leggettet al. [16,17] with seventeen programmers but for thecontinuous approach to user verification. The authorsreport an identity verifier that validates the results of[9] — an identity verification system with false alarmrate of about 5.5 percent and impostor pass rate ofapproximately 55.0 percent.
While the approaches of Gaines et al. [9] andLeggett et al. [16,17] address a number of prob-lems inherent with identity verification via keystroke
354 F. Monrose, A.D. Rubin / Future Generation Computer Systems 16 (2000) 351–359
timings, there was considerable room for improve-ment. For example, the pool variance estimate usedin [17] is meaningful only when there is homogene-ity of variance across all reference digraph latencies;however studies by Mahar et al. [18] show that thereis a significant variability with which typists produceeach digraph, and hence the use of a pooled estimatedigraph latency variability is inappropriate.
An additional limitation of the digraph latencybased technique [17] is the use of a single low-passtemporal filter for all typists for the removal of out-liers. The rationale for this approach is that digraphswith abnormally long latencies are not likely to berepresentative of the authorized user’s typing. Whilethis seems like a reasonable assumption it has re-cently been shown ([18,20]) that one filter value forall typists does not yield optimal performance.
Furthermore, empirical data from Gentner [10] sug-gests that the median interkey latency of expert typistsis approximately 96 ms, while that of novice typistsis near 825 ms. Therefore, the 500 ms low-pass fil-ter used by [17] excludes many keystrokes typical ofnovice typists, while at the same time, includes manykeystrokes which are not representative of an experttypist [18]. Studies by [18,20] showed that the use ofdigraph-specific measures of variability instead of onelow-pass filter can lead to measurable improvements inverification accuracy. Moreover, the approach of [17]to keystroke verification uses the key down-to-downtime as the base unit of measure, but this measure maybe further delineated into two orthogonal components— total time the first key is depressed (i.e. keystrokeduration), and the time between a key is released andthe next key is pressed (i.e. keystroke latency). Pre-vious works [3,18,20] used these two components intheir verification systems. However, the initial samplesets of [3,20] did not provide enough data to ascer-tain whether the use of the two separate orthogonal di-graph components added significant predictive powerto the more traditional key down-to-down measure.Substantially improved performance results based onusing the bivariate measure of latency with an appro-priate distance measure were achieved by [18].
Some neural network approaches [1,3,12] havealso been undertaken in the last few years. While theback-propagation models used yield favorable perfor-mance results on small databases, neural networkshave a fundamental limitation in that each time a new
user is introduced into the database, the network mustbe retrained. For applications such as access control,the training requirements are prohibitively expen-sive and time-consuming. Furthermore, in situationswhere there is a higher turnover of users, the downtime associated with retraining can be significant.
A promising research effort in applying keystrokedynamics as a static authentication method is the workof Joyce and Gupta [14]. Their approach is relativelysimple and yields impressive results. Our work extendsthat of Joyce and Gupta and we review their classifierin Section 4.4.
4.2. Data selection and representation
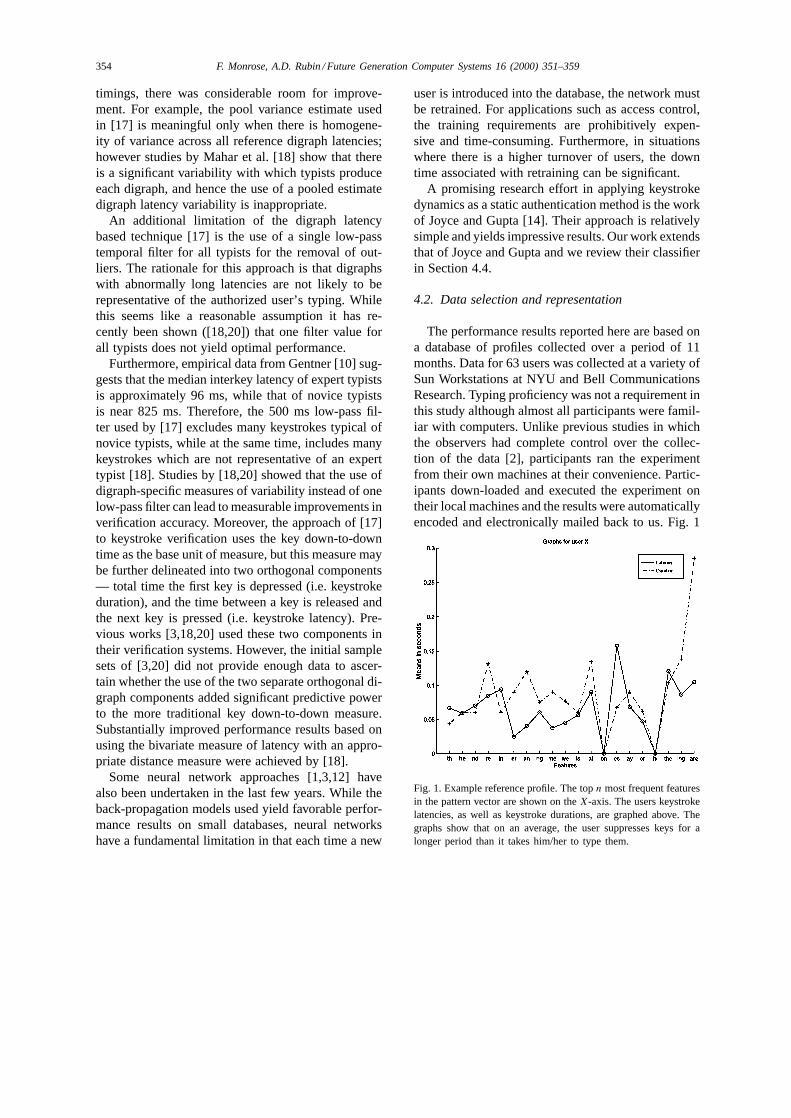
The performance results reported here are based ona database of profiles collected over a period of 11months. Data for 63 users was collected at a variety ofSun Workstations at NYU and Bell CommunicationsResearch. Typing proficiency was not a requirement inthis study although almost all participants were famil-iar with computers. Unlike previous studies in whichthe observers had complete control over the collec-tion of the data [2], participants ran the experimentfrom their own machines at their convenience. Partic-ipants down-loaded and executed the experiment ontheir local machines and the results were automaticallyencoded and electronically mailed back to us. Fig. 1
Fig. 1. Example reference profile. The topn most frequent featuresin the pattern vector are shown on theX-axis. The users keystrokelatencies, as well as keystroke durations, are graphed above. Thegraphs show that on an average, the user suppresses keys for alonger period than it takes him/her to type them.

F. Monrose, A.D. Rubin / Future Generation Computer Systems 16 (2000) 351–359 355
Fig. 2. Plots (a) and (b) depict the covariance matrices for the same user at two different time intervals across the same set of features.Plot (c) shows the covariance matrix for a different user over the same set of features. Notice the same peaks and structure between plots(a) and (b) which is quite distinct from the profile in (c).
shows an example of a profile received for a user inthe data set. An alternate representation showing plotsof the covariance matrices (of the keystroke latenciesfor a particular feature set) for different users over dif-ferent time intervals is shown in Fig. 2.
4.3. Data extraction
To evaluate the behavior and performance of each ofthe classifiers presented in Section 4.4 we developeda C++toolkit for analyzing the data. The toolkit wasbuilt using the xview library routines, and serves as afrontend to the main recognition engine. The toolkit ishelpful in diagnosing system behavior and can gener-ate graphical output for both the Matlab and Gnuplotsystems. Fig. 3 is from the main panel of the toolkit.
The data extraction toolkit provides a quick way toestablish rough properties on the data set by partition-ing the users in distinct groups. Our clustering crite-rion represents a heuristic approach that is guided byintuition — users are clustered into groups comprisingof (possibly) disjoint feature sets in which the featuresin each set are pairwise correlated.
Feature sets are determined through factor analysis(FA) [5]. Factor analysis seeks a lower dimensionalrepresentation that accounts for the correlation amongfeatures. This idea partitions the database of users intosubsets whose in-class members are “similar” in typ-ing rhythm over a particular set of features and whosecross-class members are dissimilar in the correspond-ing sense. For example, members of groupi may ex-hibit strong individualistic typing patterns for featuresin the set S= {th, ate, st, ion}, whereas members ofgroup j may be more distinctive over the features
Fig. 3. To automate the data selection and extraction process asystem toolkit was designed to assist in the visualization, tuning,and overall analysis of the data. A graphical user interface withvarious tunable options allow the operator to diagnose the perfor-mance of each of the classifiers in detail. The above is a snapshotfrom the main panel of the interface.
S = {ere, on, wy}. K-Nearest Neighbor [8] is used asthe clustering algorithm. The net result is a hierarchicalcluster that assists in user identification.
4.4. Classification and identification
The problem of recognizing a given pattern as be-longing to a particular person either after exhaustivesearch through a large database, or by simply compar-ing the pattern with a single authentication templatecan be formulated within the framework of statisticaldecision theory. By this approach one can convert the

356 F. Monrose, A.D. Rubin / Future Generation Computer Systems 16 (2000) 351–359
problem of pattern recognition into a much more ex-pedient task, which involves the execution of tests ofstatistical independence. The approaches described inthe following paragraphs adhere to this model.
The classification technique employed by Joyce andGupta [14] represents the mean reference signaturefor a given user asM = {Musername,Mpassword,
Mfirstname,Mlastname}. Verification is performed bycomparing the test signatureT (acquired at logintime) with M and determining the magnitude ofdifference between the two profiles. GivenM =(m1, m2, . . . , mn) andT = (t1, t2, . . . , tn) wheren
is the total number of latencies in the signature, theverifier computes the magnitude of difference usingan L1 norm. Positive identification is declared whenthis difference is within a threshold variability of thereference signature. The mean and standard deviationof the norms||M − Si ||, whereSi is one of the eighttraining signatures, are used to decide the thresholdfor an acceptable difference vector between a givenT andM.
Although these absolute verification rates are en-couraging, Joyce and Gupta tested using a replace-ment methodology, which means that the distributionof the training set is necessarily representative of thelearning set. The use of separate data sets, recorded atdifferent times, would be more reliable. Therefore, weinvestigated the performance of classifiers based onstudies where users were allowed to participate in ex-periments conducted at varied times under no supervi-sion. The reference profiles collected were representedasN -dimensional feature vectors and processed in amanner similar to that of [14]. The data was split intolearning and testing sets. Then, the following classi-fiers were used for recognition.• Euclidean distance measure: “similarity” is based
on the Euclidean distance between the patternvectors. Let R = [r1, r2, . . . , rN ] and U =[u1, u2, . . . , uN ] then the Euclidean distance be-tween the twoN -dimensional vectorsU andR, isdefined as:
D(R, U) =[
N∑i=1
(ri − ui)2
]1/2
.
For an “unknown”U (i.e., from the testing set)the pairwise Euclidean distancesD(Ri, U), i =1, 2, . . . , n, wheren = number of pattern vectors
in the database, that were rank ordered and the pro-file with the minimum distance toU was chosen.
• Non-weighted probability: let U and R beN -dimensional pattern vectors as defined previ-ously. Furthermore, let each component of thepattern vectors be the quadruple〈µi, σi, oi, Xi〉,representing the mean, standard deviation, numberof occurrences, and data value for theith feature.Assuming that each feature for a user is distributedaccording to a normal distribution, we calculate thescore between a reference profileR and unknownprofile U as:
Score(R, U) =N∑
i=1
Sui
where,
Sui= 1
oui
oui∑
j=1
Prob
(X
(u)ij − µri
σri
)
and X(u)ij is the j th occurrence of theith feature
of U .In other words, the score for eachui is based on
the probability of observing the valueuij in the ref-erence profileR, given the mean(µri ) and standarddeviation(σri ) for that feature inR. Intuitively weassign higher probabilities to values ofui that areclose toµri and lower probabilities to those furtheraway. The “unknown” vector is then associated withthenearest neighborin the database, i.e., to the per-son who maximizes the probability of the featurevector.
• Weighted probability measure: some features aremore reliable than others simply because they comefrom a larger sample set or have a relatively higherfrequency in the written language; example inEnglisher, th, reshould constitute greater weightsthan qu or ts. Thus, the notion of weights wasincorporated, and the score between profilesR andU was computed as:
Score(R, U) =N∑
i=1
(Sui
∗ wui
),
where the weight of the featureui is the ratioof its occurrences relative to all other features inthe pattern vectorU . Features that are based on

F. Monrose, A.D. Rubin / Future Generation Computer Systems 16 (2000) 351–359 357
many occurrences are considered more reliable andweighted higher than those features that come for asmaller sample set. Assuming that each feature fora user is distributed according to a normal distribu-tion, a likelihood score between a reference profileR and unknown profileU is calculated based onthe probability of observing a feature value in thereference profileR, given the mean and standarddeviation for that feature inR. Scores are weightedand the “unknown” profile is then associated withthenearest neighborin the database, i.e., the personwho maximizes the score of the feature vector.The correct identification rate using the weighted
probabilistic classifier was approximately 87.18% ona dataset of 63 users1 , which represents improve-ment with respect to the performance of the Euclideandistance (83.22%) and the non-weighted scoring ap-proach (85.63%). Additionally, our research argues infavor of the use of structured text instead of allow-ing users to type arbitrary text (i.e., text-independentor “free-text”). While recognition based on free-textmay be more desirable, free-text recognition did notperform as well as recognition based on fixed-text.Recognition based on free-text may be expected tovary greatly under operational conditions in which theuser may be absorbed in a task or involved in an emo-tionally charged situation. The fact that the input is un-constrained, that the user may be uncooperative, andthat environmental parameters are uncontrolled im-pose limitations on what can be achieved with free-textrecognition.
The superior performance of Bayesian-like clas-sifiers for a variety of recognition tasks lead to theimplementation of a Bayesian-like classifier. Theapproach aims to characterize the performance of thefeature-based technique as a function of the numberof classes to be discriminated. We assume that thefeature vectors are distributed according to a Guassiandistribution and an unknown vector is associatedwith the person whomaximizes the probability ofthe measurement vector. The classifer is defined asfollows:• let xi be the feature vector,σi the interclass disper-
sion vector andwi the weight vector, then the dis-
1 The results reported here reflect a larger sample set than thatuse in [20].
tance of two feature vectorsxi andx′i is expressed
as:
1α(x, x′) =n∑
i=1
wi
( |xi − x′i |
σi
)α
.
The feature vectors,x1, . . . , xn, are derived fromthe sets computed by FA (see Section 4.3). Inaccordance with Huber [11] the value ofα canbe adjusted to achieve more robustness — the neteffect is a slight improvement in recognition forvalues ofα close to 1 rather than 2 as justified bythe Gaussian assumption. The correct identificationperformance using the Bayesian classifier was ap-proximately 92.14%, representing an improvementof almost 5% over the weighted classifier.While it is difficult to give a meaningful comparison
of our approach with that of [14,17,18] as there is nounified data set under which the approaches can becompared, overall, our results validate that of previousresearch and suggest that it is possible to use keystrokedynamics to accurately verify computer users, albeitin somewhat of a controlled environment.
5. Applications
Keystroke dynamics has many applications in thecomputer security arena. One area where the use of astatic approach to keystroke dynamics may be particu-larly appealing is in restricting root level access to themaster server hosting a Kerberos [21] key database.Any user accessing the server is prompted to type afew words of a pass phrase in conjunction with his/herusername and password. Access is granted if his/hertyping pattern matches within a reasonable thresholdof the claimed identity. This safeguard is effective asthere is usually no remote access allowed to the server,and the only entry point is via console login.
Alternatively, dynamic or continuous monitoringof the interaction of users while accessing highly re-stricted documents or executing tasks in environmentswhere the user must be “alert” at all times (for exampleair traffic control), is an ideal scenario for the applica-tion of a keystroke authentication system. Keystrokedynamics may be used to detect uncharacteristictyping rhythm (brought on by drowsiness, fatigueetc.) in the user and notify third parties.

358 F. Monrose, A.D. Rubin / Future Generation Computer Systems 16 (2000) 351–359
6. Summary
In this paper we address the practical importance ofusing keystroke dynamics as a biometric for authenti-cating access to workstations. Keystroke dynamics isthe process of analyzing the way users type by moni-toring keyboard inputs and authenticating them basedon habitual patterns in their typing rhythm. We reviewthe current state of keystroke dynamics and presentclassification techniques based on template matchingand Bayesian likelihood models.
We argue that although the use of a behavioral trait(rather than a physiological characteristic) as a sign ofidentity has inherent limitations, when implementedin conjunction with traditional schemes, keystroke dy-namics allows for the design of more robust authenti-cation systems than traditional password based alter-natives alone. The inherent limitations that arise withthe use of keystroke dynamics as an authenticationmechanism are attributed to the nature of the refer-ence “signature” and its relationship to the user —recognizing users based on habitual rhythm in theirtyping pattern uses dynamic performance features thatdepend upon an act — the rhythm is a function of theuser and the environment.
The problem with keystroke recognition is that un-like non-static biometrics (such as voice) there areno known features or feature transformations whicharededicated solelyto carrying discriminating infor-mation. Fortunately, in the past few years researchers[14,18,20] have presented empirical findings that showthat different individuals exhibit characteristics in theirtypical rhythm that are strikingly individualistic andthat these characteristics can be successfully exploitedand used for identification purposes.
The performance of our classifiers on a dataset of63 users ranges from 83.22% to 92.14% accuracy de-pending on the approach being used. Our research sup-ports the observation of Mahar et al. [18] in that thereis significant variability with which typists produce di-graphs. Hence, we suggest the use of digraph-specificmeasures of variability instead of single low-pass fil-ters. Additionally, we argue in favor of the use ofstructured text instead of allowing users to type ar-bitrary text (i.e., “free-text”) during the identificationprocess. While recognition based on free-text may bemore desirable, free-text recognition was observed tovary greatly under operational conditions; the fact that
the input is unconstrained, that the user may be un-cooperative, and that environmental parameters thatare uncontrolled impose limitations on what can beachieved with free-text recognition.
Acknowledgements
We would like to thank Angela Adotola, ArashBaratloo, Ivan Blank, Dan Boneh, Eric Briel, AileenChang, Juan Carlos, Po-Yu Chen, Churngwei Chu,Brian Coan, Daria Depiro, Sven Dietrich, ThomasDuzan, Ron Even, Jing Fan, Sabine French, Mar-tin Garcia, Deepak Goyal, Amy Greenwald, AndyHagerty, Andy Howell, Mehmet Karaul, Peter Klein-mann, Michael Lewis, Arjen Lenstra, Tyng-Luh Liu,Charles Mayor, Bubette McLeod, Tyrone McGhee,Madhu Nayakkankuppam, Kizito Ofornagoro, FritzOrneas, Kouji Ouchi, Gardner Patton, Toto Paxia, BillPink, Prabhala Prashant, Rick Porter, Raju Jawalekar,Errol Roberts, Archisman Rudra, Marc Schwarz,David Shallcross, Liddy Shriver, Julia Stone, VijaySreedhar, Marek Teichmann, Peter Wyckoff, Ze Yang,Shu-man Yang, and all the NYU Master students andBellcore employees who participated in our studybut for whom we do not have their full names asthey no longer have login accounts at the respectiveinstitutions.
References
[1] T.J. Alexandre, Biometrics on smartcards: an approachto keyboard behavioral signature, in: Second Smart CardResearch and Advanced Applications Conference, 1996.
[2] S. Bleha, C. Slivinsky, B. Hussein, Computer-access securitysystems using keystroke dynamics, IEEE Trans. Pattern Anal.Mach. Intell. PAMI-12 (12) (1990) 1217–1222.
[3] M. Brown, S.J. Rogers, User identification via keystrokecharacteristics of typed names using neural networks, Int. J.Man-Mach. Stud. 39 (6) (1993) 999–1014.
[4] R. Chellappa, C.L. Wilson, S. Sirohey, Human and machinerecognition of human face images: A survey, in: Proceedingof the IEEE, Vol. 83, 1995, pp. 705–741.
[5] E. Cureton, Factor analysis, an applied approach, ErlbaumAssociates, Hillsdale, NJ, 1983.
[6] J.G. Daugman, High confidence visual recognition of personsby a test of statistical independence, IEEE Trans. PatternAnal. Mach. Intell. 15 (11), (1993).
[7] G.R. Doddington, Speaker recognition-identifying people bytheir voices, Proceedings of the IEEE, Vol. 73, issue no. 11,1985, 1651–1664.

F. Monrose, A.D. Rubin / Future Generation Computer Systems 16 (2000) 351–359 359
[8] R. Duda, Pattern classification and scene analysis, Wiley, NewYork, 1973.
[9] R. Gaines, W. Lisowski, S. Press, N. Shapiro, Authenticationby keystroke timing: some prelimary results. Rand Rep.R-2560-NSF, Rand Corporation, 1980.
[10] Gentner, Keystroke timing in transcription typing, CognitiveAspects of Skilled Typewritting, 1993, pp. 95–120.
[11] P.J. Huber, Robust Statistics, Wiley, New York, 1981.[12] B. Hussien, R. McLaren, S. Bleha, An application of fuzzy
algorithms in a computer access security system, PatternRecog. Lett. 9 (1989) 39–43.
[13] D.K. Isenor, S.G. Zaky, Fingerprint identification using graphmatching, Pattern Recog. 19 (2) (1986) 113–222.
[14] R. Joyce, G. Gupta, Identity authorization based on keystrokelatencies, Commun. ACM 33 (2) (1990) 168–176.
[15] L.G. Kersta, Voiceprint identification, Nature 196 (1962)1253–1257.
[16] J. Leggett, G. Williams, Verifying identity via keystrokecharacteristics, Int. J. Man-Mach. Stud. 28 (1) (1988) 67–76.
[17] J. Leggett, G. Williams, D. Umphress, Verification of useridentity via keystroke characteristics, Human Factors inManagement Information Systems, p. 89.
[18] D. Mahar, R. Napier, M. Wagner, W. Laverty, R. Henderson,M. Hiron, Optimizing digraph-latency based biometric typistverification systems: inter and intra typists differences indigraph latency distributions, Int. J. Human-Comp. Stud. 43(1995) 579–592.
[19] B. Miller, Vital sings of identity, IEEE Spectrum, 1994, pp.22–30.
[20] F. Monrose, A. Rubin, Authentication via keystroke dynamics.Fourth ACM Conference on Computer and CommunicationsSecurity, 1997, pp. 48–56.
[21] C. Neuman, T. Ts’o, An authentication service for computernetworks, IEEE Commun. 32 (9) (1994) 33–38.
[22] F.J. Prokoski, R.B. Riedel, J.S. Coffin, Identification ofindividuals by means of facial thermography, 1992.
[23] J.T. Tou, R.C Gonzalez, Pattern recognition principles,Addison-Wesley, Reading, MA, 1981.
[24] J. Zhang, Y. Yan, M. Lades, Face recognition: eigenface,elastic matching and neural nets, Proceedings of the IEEE,vol. 85, issue no. 9, September 1997, pp. 1423–1435.
Fabian Monrose is currently a Ph.D.candidate in computer science at NewYork University. His research interests in-clude distributed computing, cryptographyand network security. He is particularlyinterested in protocols that support strongmutual authentication in untrusted environ-ments, electronic commerce, and identifi-cation technologies that rely on biometrics.
Aviel D. Rubin is a Senior Technical StaffMember at AT&T Labs, Research in thesecure systems research department, andan Adjunct Professor of Computer Scienceat New York University, where he teachescryptography and computer security. He isthe co-author of the Web Security Source-book. Aviel holds a B.S., M.S.E., andPh.D. from the University of Michigan inAnn Arbor (1989,1991,1994) in Computer
Science and Engineering. He has served on several program com-mittees for major security conferences and as the program chair forUSENIX Security ’98, USENIX Technical ’99, and ISOC NDSS2000.