kafka spark cassandra webinar feb 16 2016
TRANSCRIPT


Who am I and what do I do?
• Ben Bromhead
• Co-founder and CTO of Instaclustr -> www.instaclustr.com
• Instaclustr provides Cassandra-as-a-Service in the cloud.
• Currently run in IBM Softlayer, AWS and Azure
• 500+ nodes under management

What will this talk cover?
• An introduction to Cassandra
• An introduction to Spark
• An introduction to Kafka
• Building a data pipeline with Cassandra, Spark & Kafka

What happens when you have more data than could fit on a single server?

Throw money away at the problem

Introducing Cassandra
• BigTable (2006) - 1 Key: Lots of values, Fast sequential access
• Dynamo (2007) - Reliable, Performant, Always On,
• Cassandra (2008) - Dynamo Architecture, BigTable data model and storage
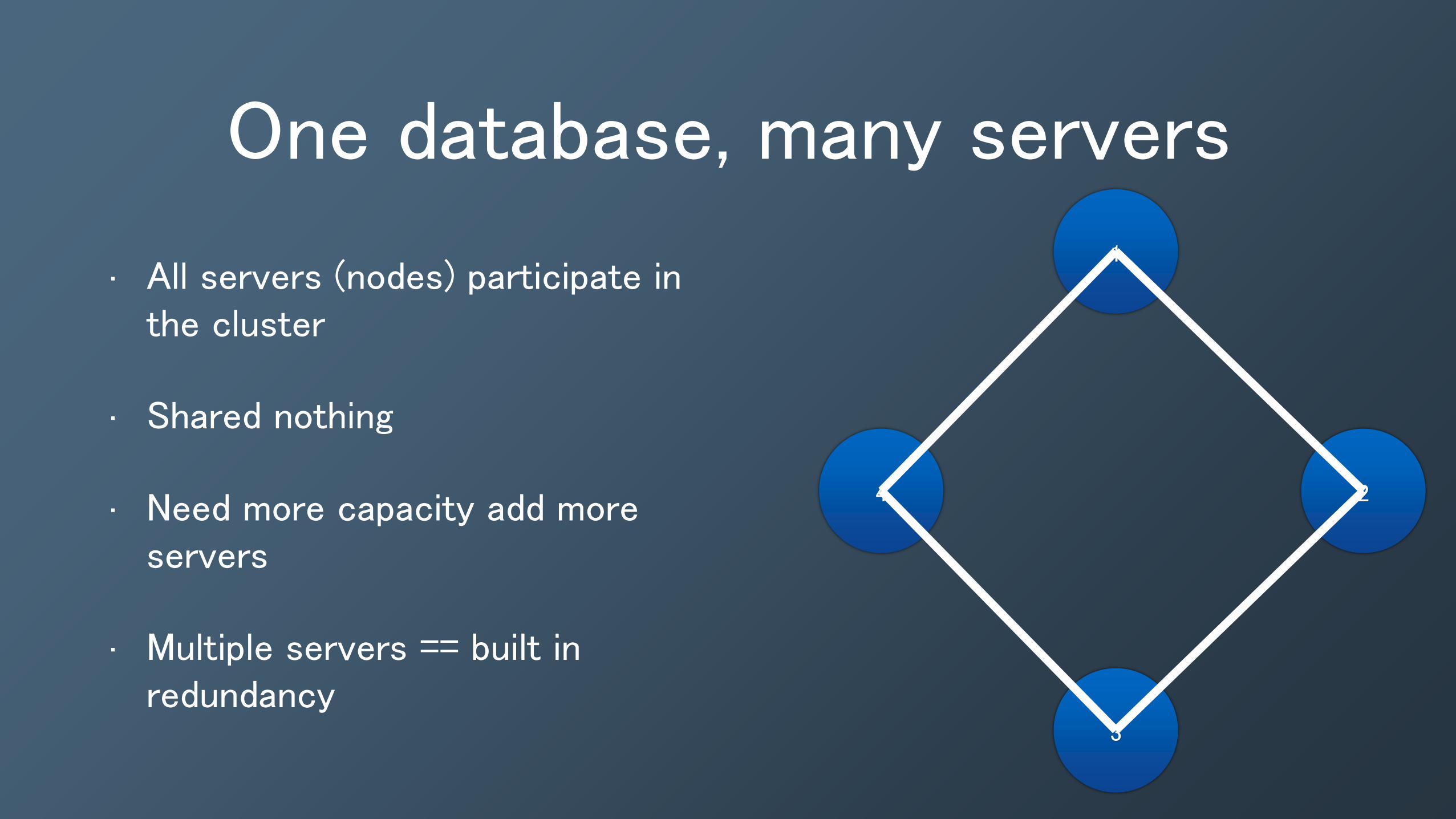
One database, many servers
• All servers (nodes) participate in the cluster
• Shared nothing
• Need more capacity add more servers
• Multiple servers == built in redundancy
1
3
2 4

How does it work ? 0
4
2 8
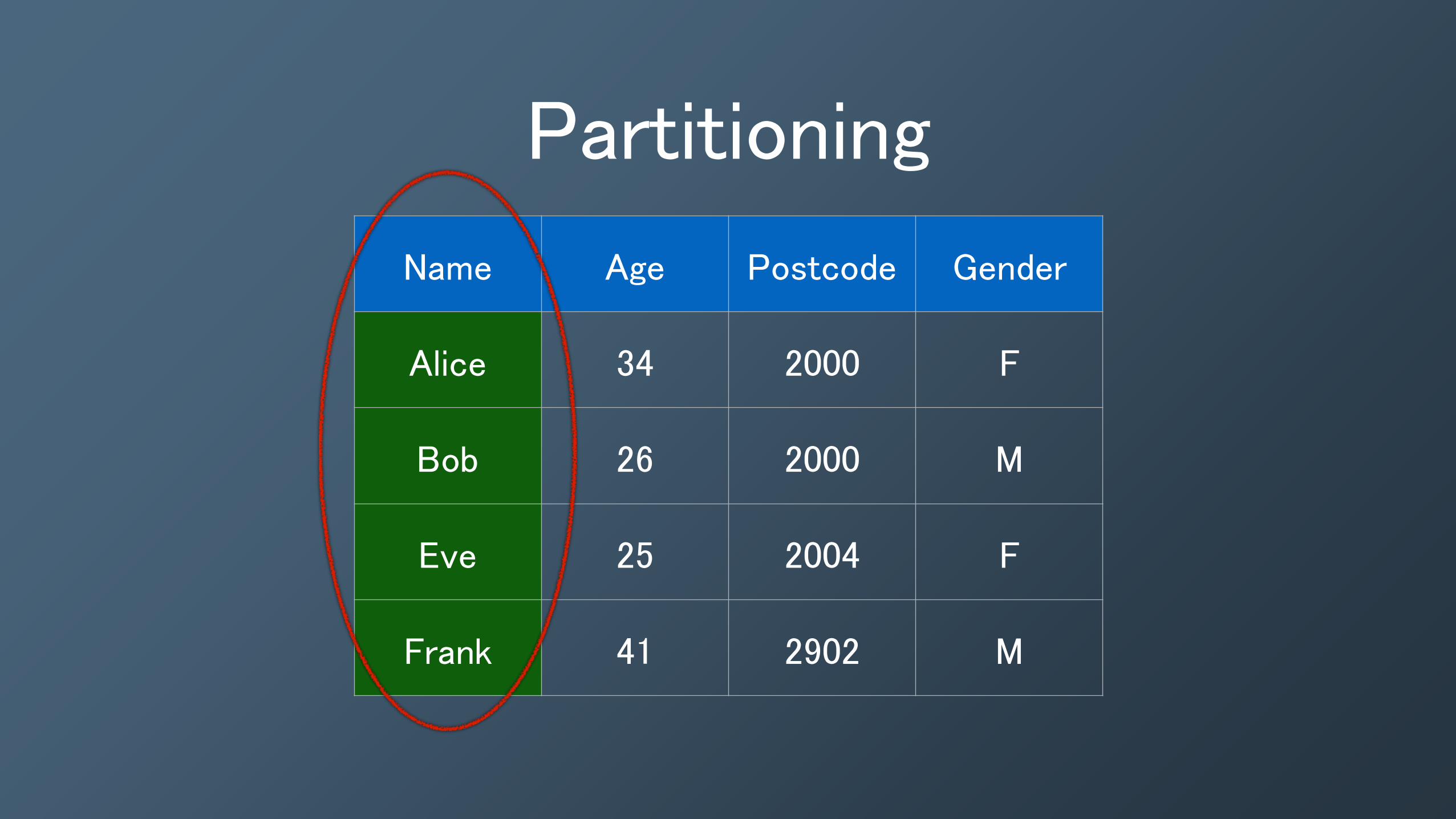
Partitioning
Name Age Postcode Gender
Alice 34 2000 F
Bob 26 2000 M
Eve 25 2004 F
Frank 41 2902 M

How does it work ? 0
4
2 8
client
consistentHash(“Alice”)

A brief intro to tuneable consistency
• Cassandra is considered to be a database that favours Availability and Partition Tolerance.
• Let’s you change those characteristics per query to suit your application requirement.
• Define your replication factor on the schema level
• Define your consistency level at query time

How does it work ?
client
consistentHash(“Alice”)
0
4
2 8
Replication Factor = 3

What are the benefits to this approach
• Linear scalability
• High Availability
• Use commodity hardware
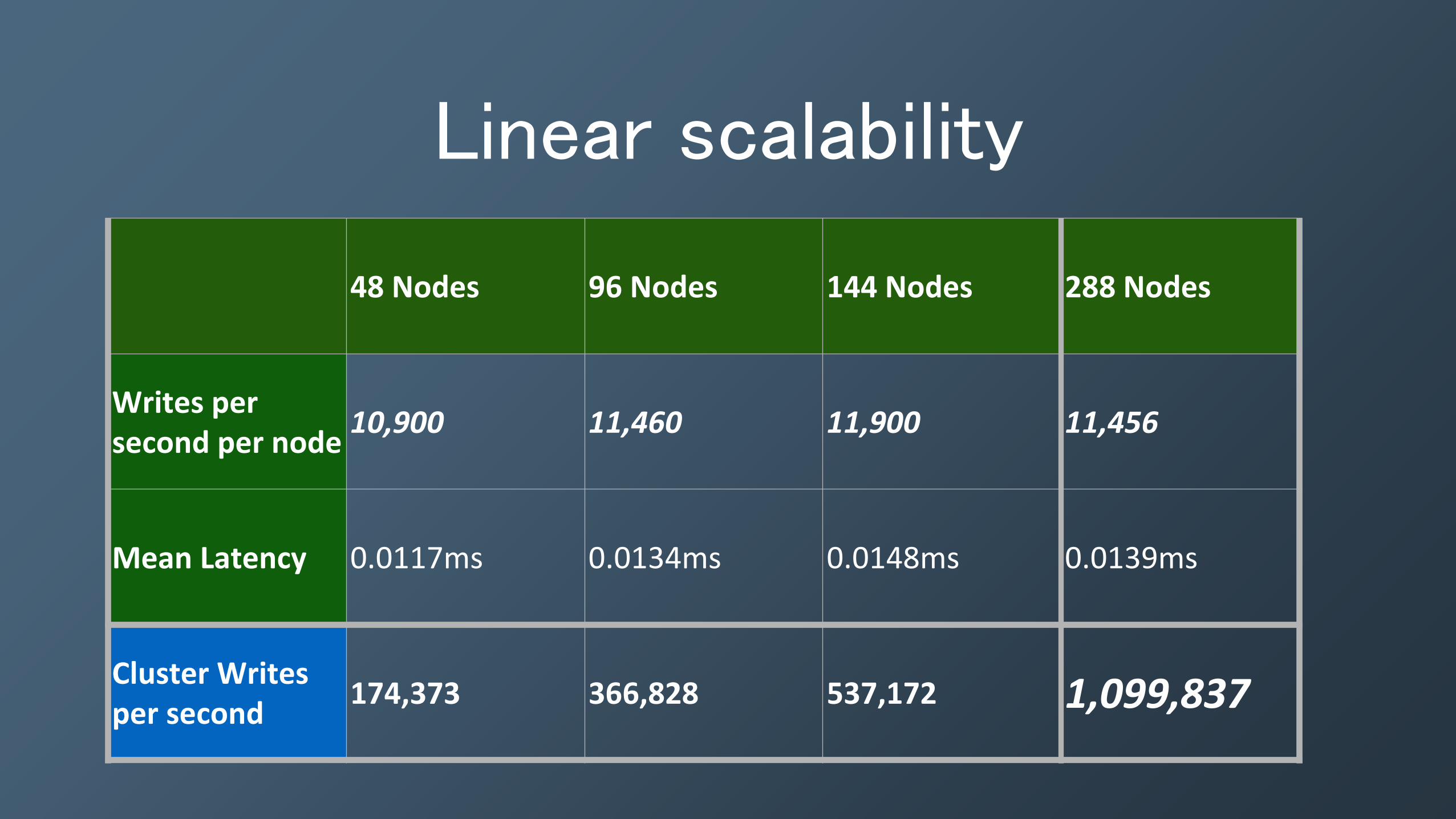
Linear scalability
48 Nodes 96 Nodes 144 Nodes 288 Nodes
Writes per second per node
10,900 11,460 11,900 11,456
Mean Latency 0.0117ms 0.0134ms 0.0148ms 0.0139ms
Cluster Writes per second
174,373 366,828 537,172 1,099,837

Linear scalability

High Availability
“During Hurricane Sandy, we lost an entire
data center. Completely. Lost. It. Our application fail-over resulted in us losing just a
few moments of serving requests for a particular region of the country, but our data in Cassandra never went offline.”
Nathan Milford, Outbrain’s head of U.S. IT operations management

Commodity Hardware

How do we keep data consistent ?
client
consistentHash(“Alice”)
0
4
2 8
CL.QUORUM (50% + 1)
Write
Ack
Ack
X

Add capacity 1
5
3 7
client
consistentHash(“Alice”)

Analytics & Cassandra
• What about ad-hoc queries?
• What was the minimum, maximum and average latency for a given client
• Give me all devices that had a temperature > 40 for longer than 20 minutes
• Top 10 locations where vehicles recorded speeds > 60

Introducing Spark
• A distributed computing engine.
• For very large datasets.
• Essentially a way to run any querie or algorithms over a very large set of data.
• Works with the existing hadoop ecosystem.

Spark
• Faster and Better than hadoop
• In-memory (100x faster)
• Intelligent caching on disk (10x faster)
• Fault tolerant, immutable datasets and intermediate steps (DRY)
• Sane API and integrations (never write map/reduce jobs again)

Spark vs Hadoop
Initial input Intermediate step Final output
Initial input Intermediate step Final output
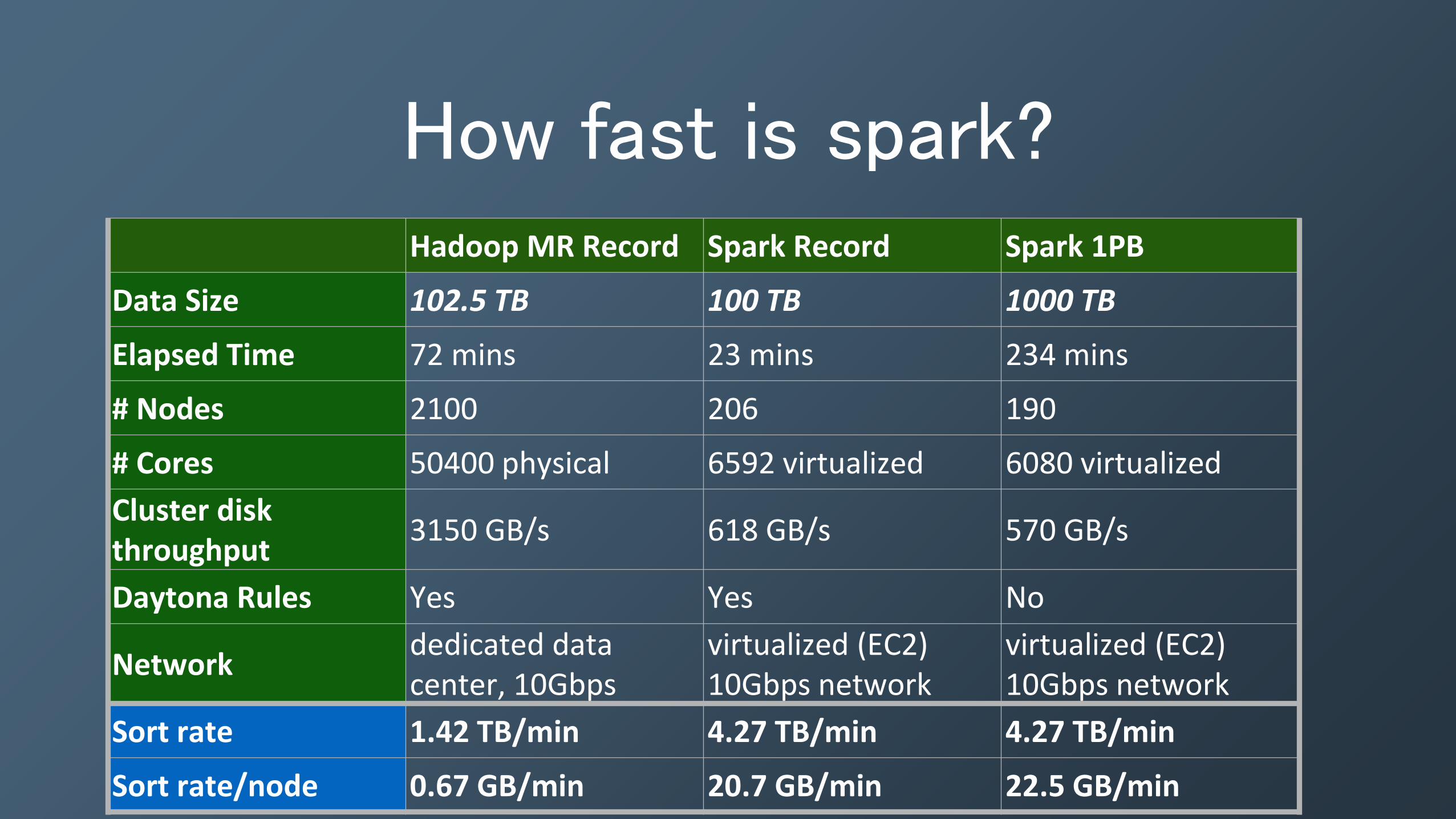
How fast is spark? Hadoop MR Record Spark Record Spark 1PB
Data Size 102.5 TB 100 TB 1000 TB
Elapsed Time 72 mins 23 mins 234 mins
# Nodes 2100 206 190
# Cores 50400 physical 6592 virtualized 6080 virtualized
Cluster disk throughput
3150 GB/s 618 GB/s 570 GB/s
Daytona Rules Yes Yes No
Network dedicated data center, 10Gbps
virtualized (EC2) 10Gbps network
virtualized (EC2) 10Gbps network
Sort rate 1.42 TB/min 4.27 TB/min 4.27 TB/min
Sort rate/node 0.67 GB/min 20.7 GB/min 22.5 GB/min

A quick use case
Square Kilometre array (SKA)
700TB/Second raw data Spark part of the data processing pipeline
See http://www.slideshare.net/SparkSummit/spark-at-nasajplchris-mattmann

Spark is also easy
val textFile = spark.textFile("hdfs://...") val counts = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...")
Spark word count
spark.cassandraTable(“Keyspace","Table"). .flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) .saveAsTextFile("hdfs://...")

Spark Hadoop word count
public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }

Spark
public class WordCount { public static void main(String[] args) { JavaRDD<String> textFile = spark.textFile("hdfs://..."); JavaRDD<String> words = textFile.flatMap(new FlatMapFunction<String, String>() { public Iterable<String> call(String s) { return Arrays.asList(s.split(" ")); } }); JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); } }); JavaPairRDD<String, Integer> counts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { public Integer call(Integer a, Integer b) { return a + b; } }); counts.saveAsTextFile(“hdfs://..."); } }
Spark word count

Spark What happens under the hood?
val textFile = spark.textFile("s3a://...") val counts = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _)
.collect()
textFile flatmap map reduceByKey collect

Spark

Spark + Cassandra
• Analytics with a super fast operational db?
• Use https://github.com/datastax/spark-cassandra-connector

Spark + Cassandra
Executor Executor
Executor
Worker
Server
Spark + Cassandra
0
4
2 8
Worker
Worker
Worker
Worker
Master

Spark + Cassandra
• We now have a great platform to work with data already in Cassandra
• But what if we have a stream of data (e.g. a lot of devices sending stuff to us all the time)
• We want answers now and as events happen

Spark + Cassandra
vs
Streaming
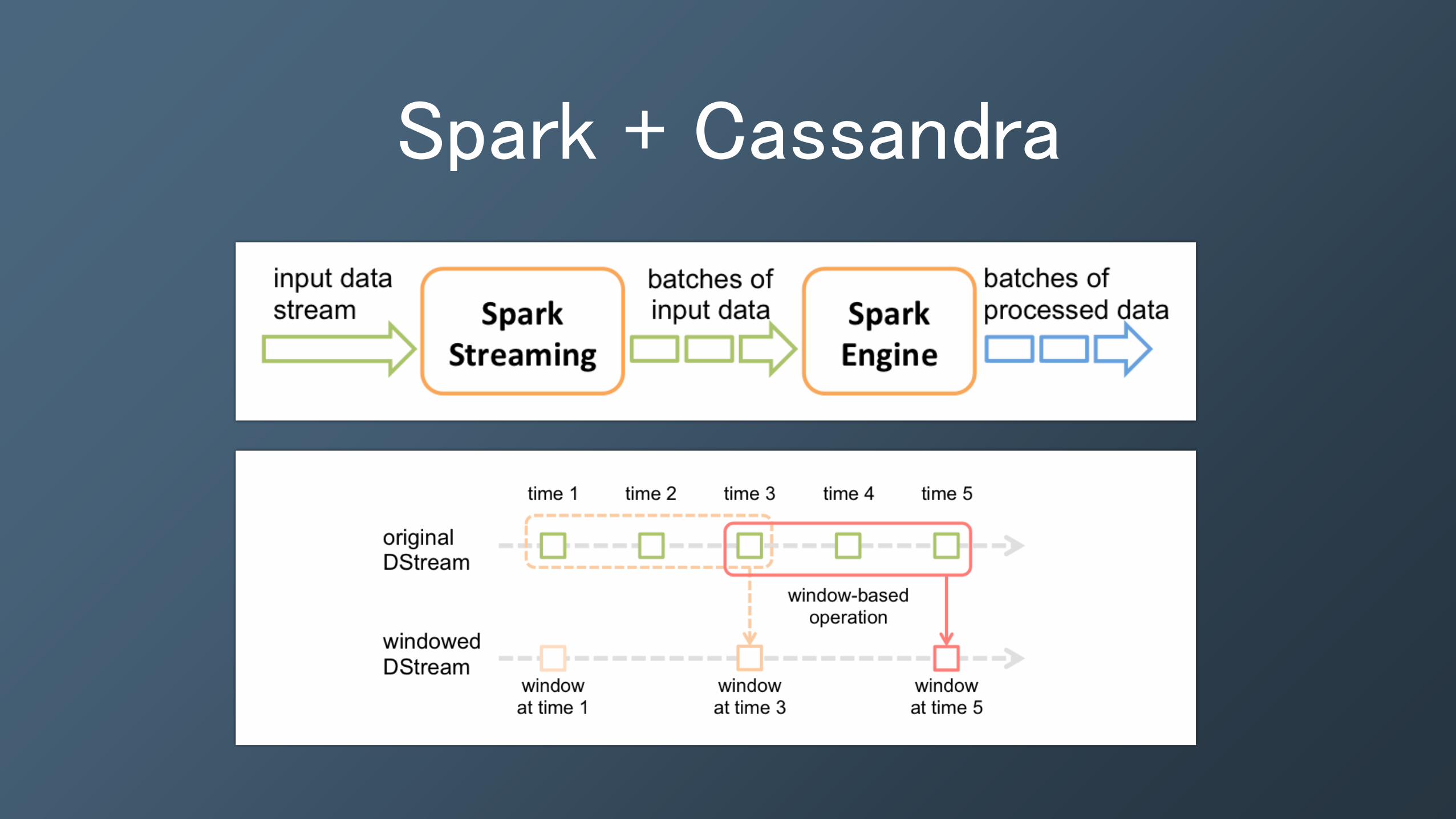
Spark + Cassandra

Spark + Cassandra
• After you have performed calculations on the DStream object provided by Spark, persist to Cassandra
• Simply call .saveToCassandra(Table,Keyspace)

Spark + Cassandra
• What about ingest?
• Enter Kafka

What is Kafka
• Unified platform for handling message feeds (aka message bus)
• High Volume
• Derived Feeds
• Support large feeds from offline ingest
• Low latency messaging
• Fault tolerance during machine failure

What is Kafka
• Publish / Subscribe message architecture
• Consumers “receive” messages
• Publishers “send” messages
• Message routing determined based on “Topic”
• Topics are split into partitions which are replicated

What is Kafka
http://www.michael-noll.com/blog/2013/03/13/running-a-multi-broker-apache-kafka-cluster-on-a-single-node/

What is Kafka
http://www.michael-noll.com/blog/2013/03/13/running-a-multi-broker-apache-kafka-cluster-on-a-single-node/

A quick case study
• Kafka at LinkedIn
• 15 broken
• 15,500 partitions (replication factor 2)
• 400,000 msg/s
• event processing

Spark + Cassandra + Kafka
• Why Kafka?
• Pluggable receivers for MQTT and HTTP ingest
• Spark Streaming can consume directly from a Kafka Queue and write to Cassandra

Spark + Cassandra + Kafka Putting it all together:
Kafka cluster
Master
0
4
2 8
Worker
Worker
Worker
Worker
MQTT bridge

Spark + Cassandra + Kafka Putting it all together:
Kafka cluster
Master
0
4
2 8
Worker
Worker
Worker
Worker
MQTT bridge
Lambda Architecture!

• A highly distributed, resilient and highly available ingest, compute and storage engine.
• Leverage additional spark libraries to add capabilities to your project.
• Bonus: SparkML, bringing machine learning and artificial intelligence to your data pipeline.
Spark + Cassandra + Kafka

Questions