jonas schneider, head of engineering for robotics, openai
TRANSCRIPT

Machine Learning Systems at Scale
MLconf San Francisco
Jonas SchneiderNovember 10th, 2017

OpenAI
Non-profit research lab
Goal: ensure AGI is good for humanity
Teams: Robotics, Dota, basic research, …

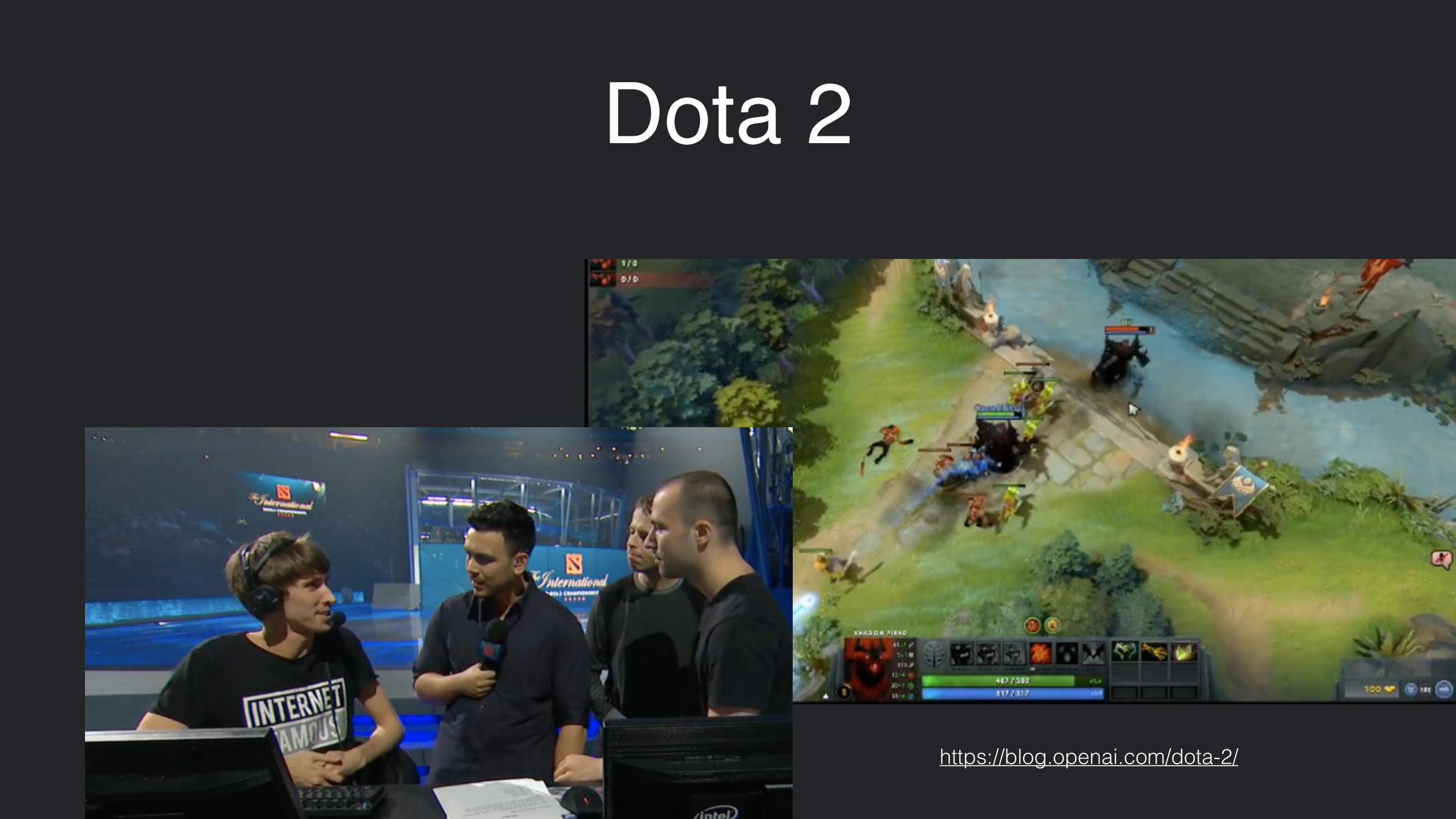
Robots that Learn
https://blog.openai.com/robots-that-learn/

What’s in a ML system?
ML core (e.g. PPO, A3C, …)

What’s in a ML system?
ML core (e.g. PPO, A3C, …)
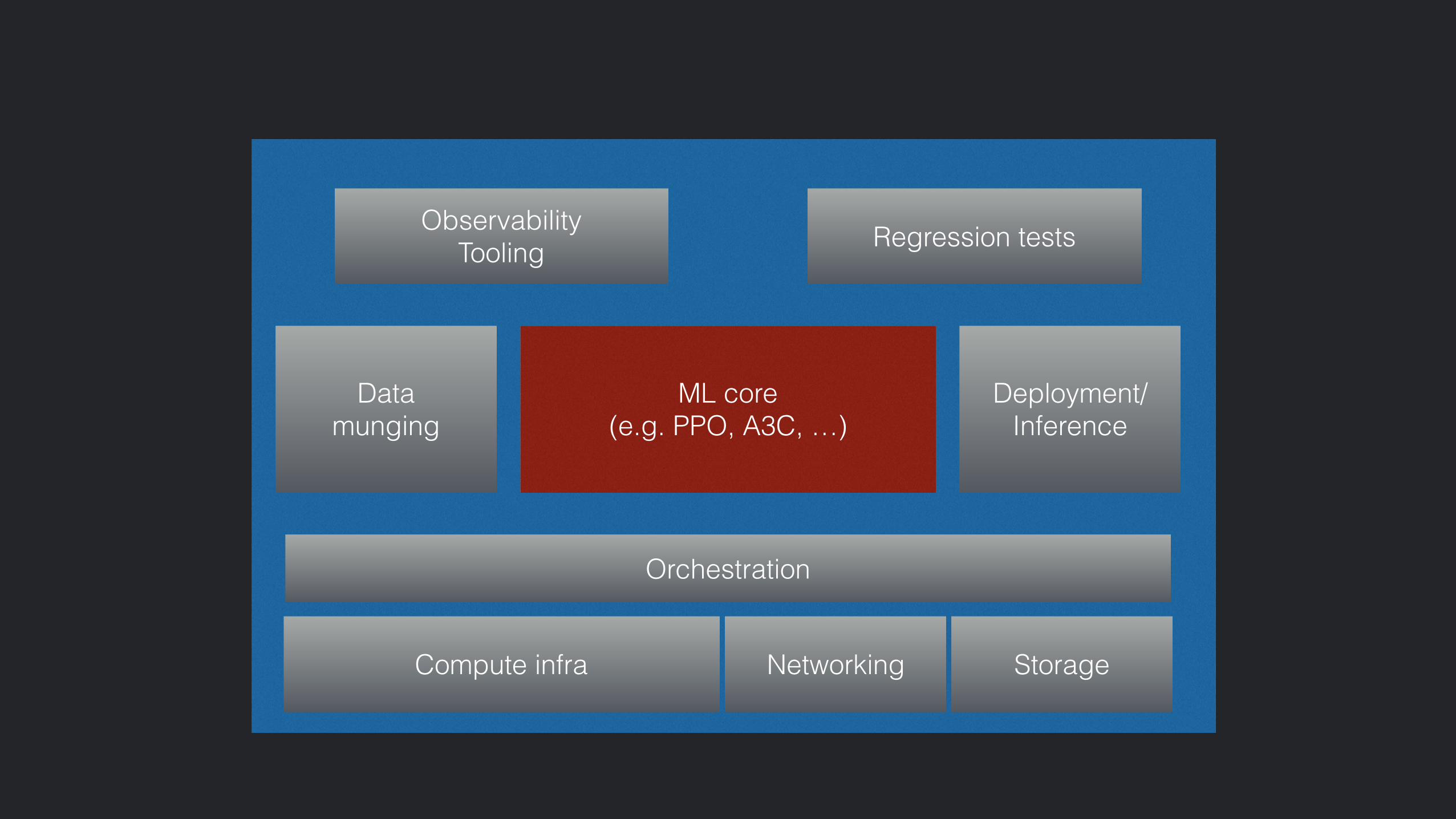
Data munging
Compute infra Networking
Observability Tooling Regression tests
ML core (e.g. PPO, A3C, …)
Deployment/Inference
Storage
Orchestration

Data munging
Compute infra Networking
Observability Tooling Regression tests
ML core (e.g. PPO, A3C, …)
Deployment/Inference
Storage
Orchestration

Example: Orchestration
Kubernetes
Azure
Our Model

Kubernetes
Azure
Kubernetes
GCE
Kubernetes
On-Premises Hardware
Our Model Our Model Our Model
Example: Orchestration

Scriptable infrastructure
exp = Experiment() exp.add_parameter_server()
for i in range(NUM_WORKERS): exp.add_tensorflow_worker(my_tf_graph, cpu=24, gpu=4)
exp.run(mode=’kube’) # or ’docker’
https://blog.openai.com/infrastructure-for-deep-learning/ “Building the Infrastructure that powers the future of AI”, KubeCon 2017

Think:
Instead of:Research Engineering
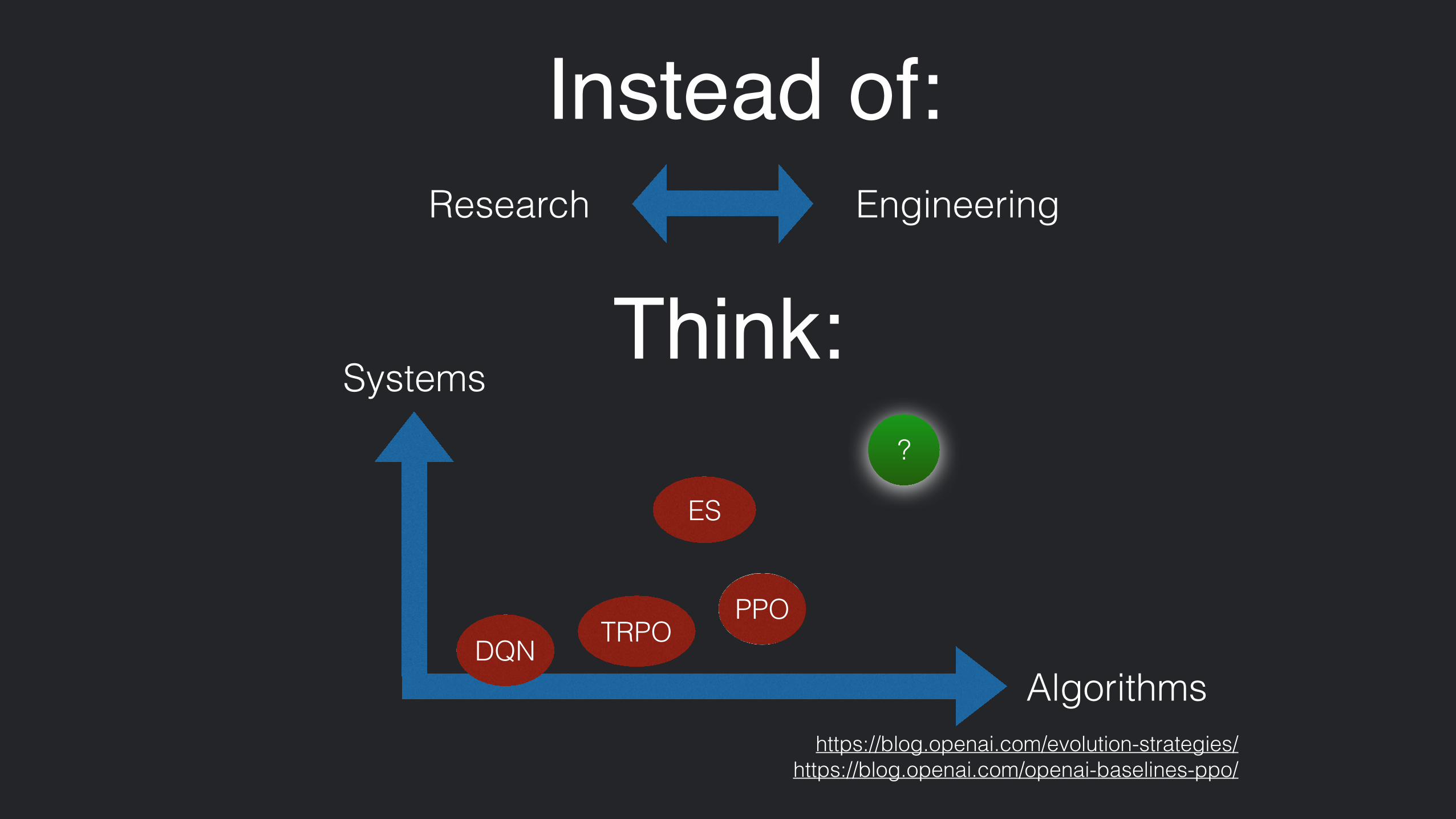
Think:
Instead of:Research Engineering
Systems
AlgorithmsTRPO
PPODQN
ES
?
https://blog.openai.com/evolution-strategies/ https://blog.openai.com/openai-baselines-ppo/

How to scale RL?
Supervised learning: gradient averaging
Large batch sizes fix many problems
Turns out, it works for reinforcement learning too

Example: DDPG+HER
optimizer
worker worker worker
evaluator

1. Scale your models
2. Scale your team

Know your stack
CUDA bindings
TF Graph Language
Distributed TF
TensorFlow
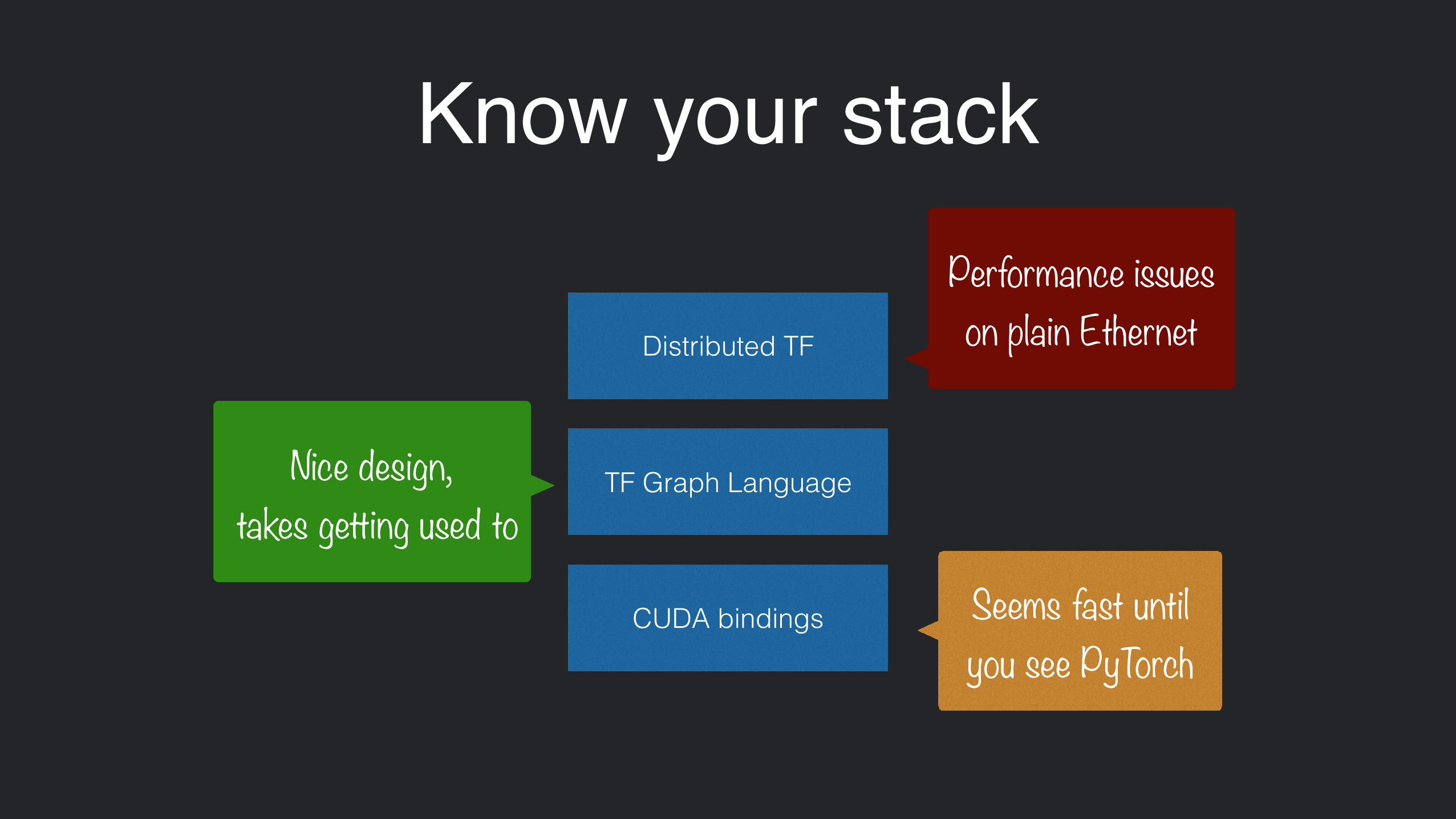
Know your stack
CUDA bindings
TF Graph Language
Distributed TF
Seems fast until you see PyTorch
Performance issues on plain Ethernet
Nice design, takes getting used to

TensorFlow++
One of our stacks
CUDA bindings
TF Graph Language
MPI + Redis
Custom Ops

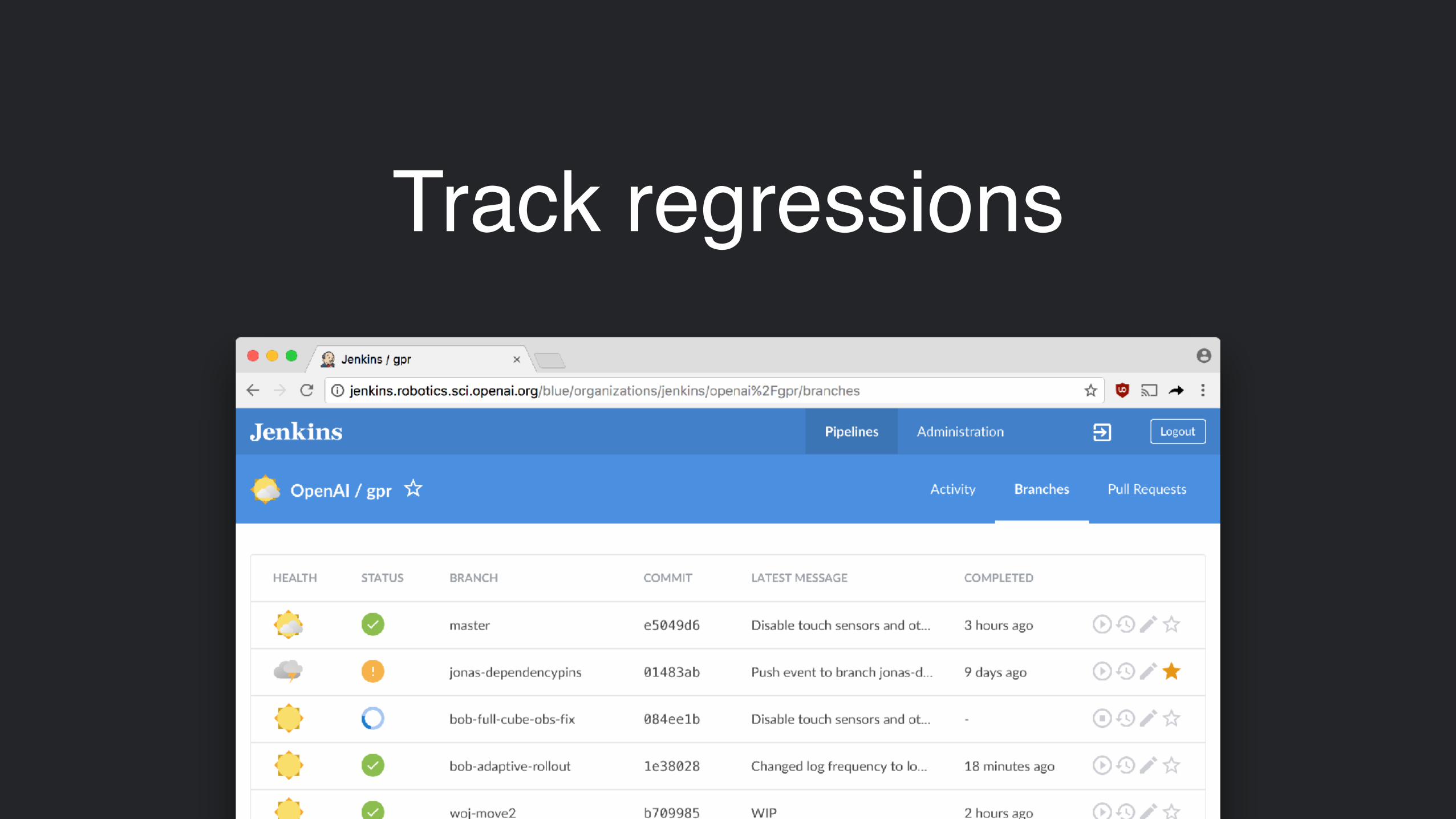
Track regressions

If OpenAI can do it…

1. Hire a team of diverse skills.
2. Think about the entire system.
3. Track your performance.
