java concurrency in practicekhalid/inf329-v07/inf329-v07-kurs... · java concurrency in practice...
TRANSCRIPT

1
INF 329 – Selectedtopics in programming theory
Java Concurrency inPractice
Chapters 10 and 11
Speaker: Guido Di Ridolfi

2
Chapter 10
“Avoiding Liveness Hazards”

3
Intro
• There is often a tension between safety and liveness. We use locking to ensure thread safety, but indiscriminate use of locking can cause lock-ordering deadlocks.
• This chapter explores some of the causes of liveness failures and what can be done to prevent them.

4
10.1 - Deadlock
• The following situation is the simplest case of deadlock (or deadly embrace), where multiple threads wait forever due to acyclic locking dependency.
• When thread A holds lock L and tries to acquire lock M, but at the same time thread B holds M and tries to acquire L, both threads will wait forever.

5
10.1 - …continue (1)
• Database systems are designed to detect and recover from deadlock.
• The JVM is not nearly as helpful in resolving deadlocks as database servers are. When a set of Java threads deadlock, that's the end of the game.
• The only way to restore the application to health is to abort and restart it and hope the same thing doesn't happen again.
• Deadlocks rarely manifest themselves immediately: usually they manifest their presence at worst time.

6
10.1.1 – Lock-ordering deadlockThe following LeftRightDeadlock’s code is at risk for deadlock
example code: 1

7
10.1.1 - …continue (1)
• The deadlock in LeftRightDeadlock came about because the two threads attempted to acquire the same locks in a different order.
• If they asked for the locks in the same order, there would be no cyclic locking dependency and therefore no deadlock.

8
Observations: Windows versus Unix
• JVM defines a thread scheduler. The problem is that the JVM itself is a software that runs on Operating System, and its implementation depends from the system.
• In fact, anyway the scheduler of the JVM must respects the philosophy of the O.S. scheduler, and this one can change completely between systems.

9
Observations – continue (1)
• Windows (Time-Slicing or Round-Robin scheduling):
A thread can be run alone for a certain period
of time, then it must to leave for the others threads
the possibility to be runned.
• Unix (Preemptive scheduling):A thread running can leave this state only in the following situations:
- Call of a method of scheduling like wait() or suspend()- Call of a method of blocking, like I/O methods- For another thread with more high priority- Terminate his execution (his method run).

10
10.1.2 – Dynamic lock order deadlocks
Consider the harmless-looking in the following code that transfers funds
from one account to another.example code: 2

11
10.1.2 – continue (1)
• In a deadlock like this one, the order of arguments is out of our control, to fix the problem we must induce an ordering on the locks and acquire them according to the induced ordering consistently throughout the application.
• One way to induce an ordering on objects is to use System.identityHashCode, which returns thevalue that would be returned by Object.hashCode.

12
10.1.2 – continue (2)In the following code there is a version of transferMoney that usesSystem.identityHashCode to induce a lock ordering

13
10.1.3 – Deadlock between cooperating objects
Consider the cooperating classes in the following code , which can be
used in a taxicab dispatching application.example code: 3

14
10.1.4 – Open calls
• Calling an alien method with a lock held is difficult to analyze and therefore risky, like the problem that happened in the last example.
• Calling a method with no locks held is called an open call
• In the following code Taxi and Dispatcher are refactored to use open calls and thus eliminate the deadlock risk.

15
10.1.4 – continue (1)In this code there is the shrinkage of synchronized blocks to guard only operations that involve shared state.
example code: 4

16
10.1.5 – Resource deadlocks
• The Threads can also deadllock when they are waiting for resources.
• One form of resurce-based deadlock is thread starvation deadlock.
• Task that wait for the results of other tasks are the primary source of thread-starvation deadlock.

17
10.2.1 – Timed lock attempts
• Another technique for detecting and recovering from deadlocks is to use the timed tryLock feature of the explicit Lock classes instead of intrinsic locking.
• Where intrinsic locks wait forever if they cannot acquire the lock, explicit locks let you specify a timeout after which tryLock returns failure.

18
10.2 – Avoiding and diagnostic deadlock
• In programs that use fine-grained locking, audit your code for deadlock freedom using a two-part strategy:
• Identify where multiple locks could be acquired.• Perform a global analysis of all such instances to
ensure that lock ordering is consistent across your entire program.
• Using open calls wherever possible simplifies this analysis substantially.

19
10.2.2 – Deadlock analysis with thread dumps
• The JVM can help identifying the deadlocks when they happen using thread dumps.
• Before generating a thread dump, the JVM searches the is-waiting-for graph for cycles to find deadlocks.

20
10.2.2 – continue (1)The following code shows portions of thread dump from a production J2EE application.

21
10.3 – Other liveness hazards
• There are several other liveness hazards, beyond deadlock, you may encounter in concurrent programs including starvation,missed signals,and livelock.

22
10.3.1 - Starvation
• Starvation occurs when a thread is perpetually denied access to resources it needs in order to make progress.
• Starvation in Java applications can be caused by inappropriate use of thread priorities.

23
10.3.3 - Livelock
• Livelock is a form of liveness failure in which a thread, while not blocked, still cannot make progress because it keeps retrying an operation that will always fail.
• Livelock often occurs in transactional messaging applications.

24
Chapter 11
“Performance and Scalability”

25
Intro
• One of the primary reasons to use threads is to improve performance. Using threads can improve resource utilization and can improve responsiveness.
• This chapter explores techniques for analyzing, monitoring, and improving the performance of concurrent programs.

26
11.1 – Thinking about performance
• Improving performance means doing more work with fewer resources.
• While the goal may be to improve performance overall, using multiple threads always introduces some performance costs compared to the single-threaded approach.

27
11.1.1 – Performance versusScalability
• Application performance can be meant in two terms:
•“how fast”, measures a given unit of work can be processed (service time, latency).
•”how much”, measures work can be performed with a given quantity of computing resources (capacity, throughput, scalability)

28
11.1.2 – Evaluatingperformance tradeoffs
• Avoid premature optimization. First make it right, then make it fast if it is not already fast enough.
• This because nearly all engineering decisions involve some form of tradeoff.

29
11.2 – Amdahl’s law
• Amdahl's law describes how much a program can theoretically be speed-up by additional computing resources, based on the proportion of parallelizable and serial components.
• Speed-up refers to how much a parallel algorithm is faster than a corresponding sequential algorithm.

30
11.2 – continue (1)
• Amdahl’s law says that on a machine with N processors, we can achieve a speed-up of at most:
where F is the fraction of the calculation that must be executed serially.
31
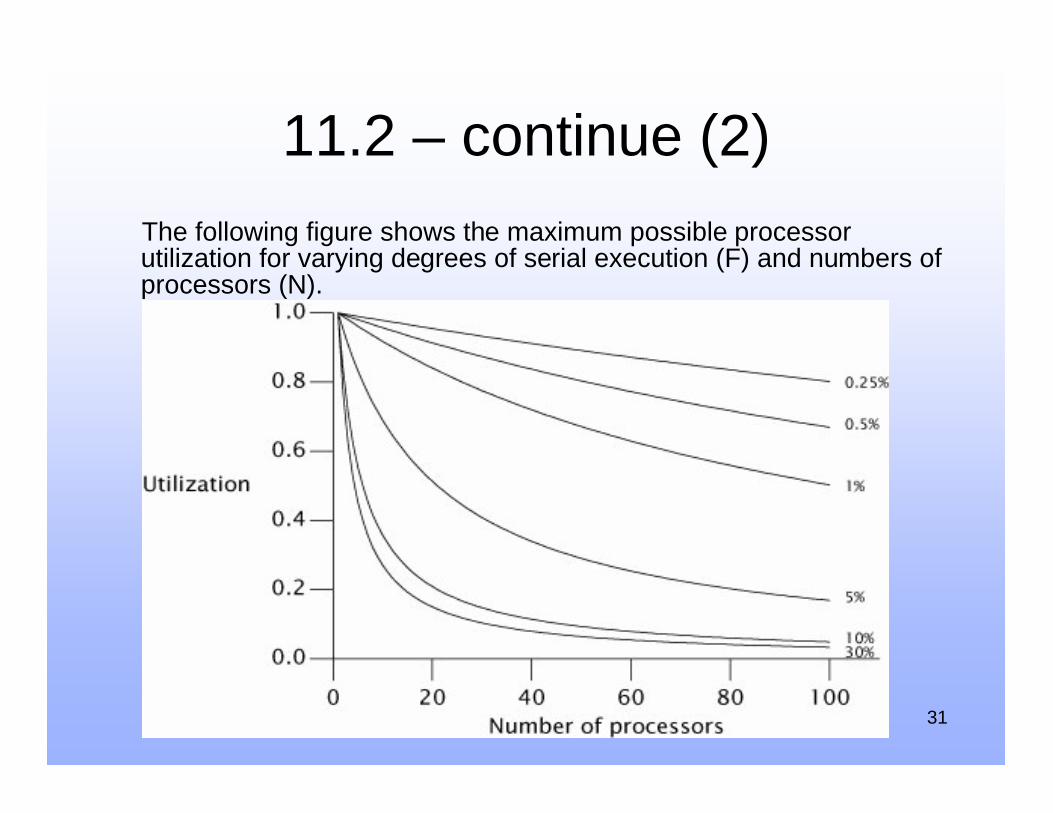
11.2 – continue (2)
The following figure shows the maximum possible processor utilization for varying degrees of serial execution (F) and numbers of processors (N).

32
11.2.1 – Example: serialization hidden in frameworks
The curves in the following figure compare throughput for two
thread-safe Queue implementations.

33
11.3 – Costs introduced by threads
• Single-threaded programs meet neither scheduling nor synchronization overhead, and need not use locks to preserve the consistency of data structures.
• The performance benefits of parallelizationmust outweigh the costs introduced by concurrency.

34
11.3.1 – Context switching
• A context switch requires saving the execution context of the currently running thread and restoring the execution context of the newly scheduled thread.
• Context switches are not free; thread scheduling requires manipulating shared data structures in the OS and JVM.

35
11.3.2 – Memory synchronization
• When assessing the performance impact of synchronization, it is important to distinguish between contended and uncontendedsynchronization.
• Don't worry excessively about the cost of uncontended synchronization. JVMs can perform additional optimizations that further reduce or eliminate the cost. Instead, focus optimization efforts on areas where lock contention actually occurs.

36
11.3.3 – Blocking
• Uncontended synchronization can be handled entirely within the JVM, while contended synchronization may require OS activity, which adds to the cost.
• When locking is contended, the losing thread(s) must block.

37
11.4 – Reducing lock contention
• Reducing lock contention can improve both performance and scalability.
• There are three ways to reduce lock contention:
• Reduce the duration for which locks are held;
• Reduce the frequency with which locks are requested;
• Replace exclusive lock with coordination mechanismsthat permit greater concurrency.

38
11.4.1 – Narrowing lock scope (“Get in, get out”)
• An effective way to reduce the possibility of contention is to hold locks as briefly as possible.
• This can be done by moving code that doesn't require the lock out of synchronized blocks,especially for expensive operations and potentially blocking operations such as I/O.

39
11.4.1 – continue (1)This example shows a lock held more than necessary

40
11.4.1 – continue (2)Instead, in this following code there is a reducing lock duration

41
11.4.2 – Reducing lock granularity
• The other way to reduce the fraction of time that a lock is held is to have threads ask for it less often.
• This can be accomplished by lock splitting and lock striping, which involve using separate locks to guard multiple independent state variables previously guarded by a single lock.

42
11.4.2 – continue (1)This following code is an example of this

43
11.4.3 – Lock stripingStripedMap’s code illustrates implementing a hash-based map using lock striping.

44
11.4.4 – Avoiding hot fields
• Lock granularity cannot be reduced when there are variables that are required for every operation.
• This is yet another area where raw performance and scalability are often at odds with each other; common optimizations such as caching frequently computed values can introduce "hot fields" that limit scalability.

45
11.4.5 – Alternative to exclusivelocks
• A third technique for mitigating the effect of lock contention is to come before the use of exclusive locks in favor of a more concurrency-friendly means of managing shared state.
• These include using the concurrent collections, read-write locks, immutable objects and atomic variables.

46
11.4.6 – Monitoring CPU utilization
• When testing for scalability, the goal is usually to keep the processors fully utilized.
• If the CPUs are not fully utilized, you need to understand why. There are several likely causes:
• Insufficient load• I/O-bound• Externally bound• Lock contention

47
11.4.7 – Just say no to objectpooling
To work around "slow" object lifecycles, many developers turned to object pooling, where objects are recycled instead of being garbage collected and allocated anew when needed.
• Object pooling in application single-thread:– Even taking into account its reduced garbage collection
overhead
• Object pooling in application multi-thread:– Pooling fares even worse because we need pool synchronization
when threads request an object from it. – Blocking a thread due to lock contention is hundreds of times
more expensive than an allocation, even a small amount of pool-induced contention would be a scalability bottleneck.

48
11.5 – Example: Comparing Mapperformance
The following figure shows the differences in scalability between several Map implementations: ConcurrentHashMap, ConcurrentSkipListMap, HashMap and treeMap wrapped with synchronizedMap.