i/o acceleration in server architectures laxmi n. bhuyan university of california, riverside bhuyan
TRANSCRIPT

I/O Acceleration in Server Architectures
Laxmi N. Bhuyan
University of California, Riverside
http://www.cs.ucr.edu/~bhuyan

Acknowledgement
• Many slides in this presentation have been taken (or modified from) from Li Zhao’s Ph.D. dissertations at UCR and Ravi Iyer’s (Intel) presentation at UCR.
• The research has been supported by NSF, UC Micro and Intel Research.

Enterprise Workloads
• Key Characteristics– Throughput-Oriented
• Lots of transactions, operations, etc in flight• Many VMs, processes, threads, fibers, etc• Scalability and Adaptability are key
– Rich (I/O) Content• TCP, SoIP, SSL, XML• High Throughput Requirements• Efficiency and Utilization are key

Rich I/O Content in the Enterprise• Trends
–Increasing layers of processing on I/O data• Business critical functions (TCP,
IP storage, security, XML etc.)• Independent of actual application
processing• Exacerbate by high network rates
–High rates of I/O Bandwidth with new technologies• PCI-Express technology• 10/s Gb to 40 Gb/s network
technologies and it just keeps going
TCP/IP
iSCSI
SSL
XML
App
NetworkData
Platform

Network Protocols• TCP/IP protocols
– 4 layers• OSI Reference
Model– App3 layers Application
Transport
Internet
Link
HTTP, Telnet7
6
5
4
3
2
1
Application
Presentation
Session
Transport
Network
Data Link
Physical
OSITCP/IP Examples
4
3
2
1Ethernet, FDDI
Coax, Signaling
XML
SSL
TCP, UDP
IP, IPSec, ICMP
HTTP, Telnet,SSL, XML
Ethernet, FDDI
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Front end server Secure server Financial server
Exe
cuti
on
tim
e b
reak
do
wn
Application Protocol
TCP
SSL
XML
SSL and XML are in Session Layer

Situation even worse with virtualization

Virtualization Overhead: Server
Consolidation • Server
consolidation is when both the guests run on same physical hardware
• Server-to-Server Latency & Bandwidth comparison under 10Gbps ===>
Inter-VM bandwidth comparison with Native Linux-to-Linux
0
1
2
3
4
5
6
7
40B 512B 1K 1.4K 1.5K 8K 64K
Message Size
Ban
dwid
th(G
bps)
Inter-VM Linux-to-Linux
Inter-VM latency comparison with Linux-to-Linux
0
20
40
60
80
100
1 2 4 8 32 64 128 512 1K 1.5K 4k
Message Size
Pin
g-P
on
g L
aten
cy(u
s)
Linux-to-Linux Inter-VM(Same host)

CPU
User
Kernel
NIC NIC
PCI Bus
Communicating with the Server: The O/S Wall
Problems:• O/S overhead to move
a packet between network and application level => Protocol Stack (TCP/IP)• O/S interrupt • Data copying from
kernel space to user space and vice versa
• Oh, the PCI Bottleneck!

The Send Operation• The application writes the transmit data to the TCP/IP
sockets interface for transmission in payload sizes ranging from 4 KB to 64 KB.
• The data is copied from the User space to the Kernel space
• The OS segments the data into maximum transmission unit (MTU)–size packets, and then adds TCP/IP header information to each packet.
• The OS copies the data onto the network interface card (NIC) send queue.
• The NIC performs the direct memory access (DMA) transfer of each data packet from the TCP buffer space to the NIC, and interrupts CPU activities to indicate completion of the transfer.

Transmit/Receive data using a standard NIC
Note: Receive path is longer than Send due to extra copying

Where do the cycles go?

Network Bandwidth is Increasing
10
100
40
GH
z a
nd
Gb
ps
Time1990 1995 2000 2003 2005 2010
.01
0.1
1
10
100
1000
2006/7
Network bandwidth outpaces
Moore’s Law
Moore’s Law
TCP requirements Rule of thumb:1GHz for 1Gbps
The gap between the rate of processing network applications
and the fast growing network bandwidth is increasing

I/O Acceleration Techniques• TCP Offload: Offload TCP/IP Checksum and
Segmentation to Interface hardware or programmable device (Ex. TOEs) – A TOE-enabled NIC using Remote Direct Memory Access (RDMA) can use zero-copy algorithms to place data directly into application buffers.
• O/S Bypass: User-level software techniques to bypass protocol stack – Zero Copy Protocol
(Needs programmable device in the NIC for direct user level memory access – Virtual to Physical Memory Mapping. Ex. VIA)

Comparing standard TCP/IP and TOE enabled TCP/IP stacks
(http://www.dell.com/downloads/global/power/1q04-her.pdf)

Design of a Web Switch Using IXP 2400 Network Processor
Switch
Internet
GET /cgi-bin/form HTTP/1.1 Host: www.site.com…
APP. DATATCPIP
Same problems with AONs, programmable routers, web switches. Requests going through network, IP and TCP layers
Our Solution: Bring TCP connection establishment and processing down to the network level using NP
Ref: L. Bhuyan, “A Network Processor Based, Content Aware Switch”, IEEE Micro, May/June 2006, (with L. Zhao and Y. Luo).Application level Processing
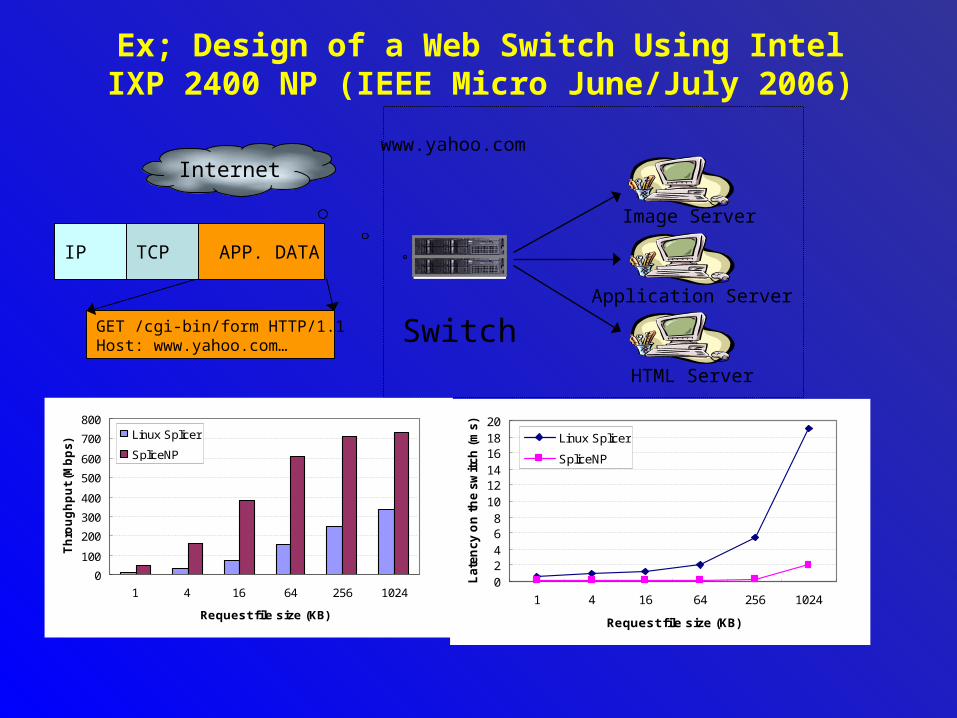
Ex; Design of a Web Switch Using Intel IXP 2400 NP (IEEE Micro June/July 2006)
Switch
Image Server
Application Server
HTML Server
www.yahoo.comInternet
GET /cgi-bin/form HTTP/1.1 Host: www.yahoo.com…
APP. DATATCPIP
0
100
200
300
400
500
600
700
800
1 4 16 64 256 1024
Request file size (KB)
Th
rou
gh
pu
t (M
bp
s) Linux Splicer
SpliceNP
02468
101214161820
1 4 16 64 256 1024
Request file size (KB)
Late
ncy o
n t
he s
wit
ch
(m
s)
Linux Splicer
SpliceNP

But Our Concentration in this talk! Server Acceleration
Design server (CPU) architectures to speed up protocol
stack processing! Also Focus on TCP/IP

Profile of a PacketSimulation Results. Run Free BSD on Simplescalar.
No System Overheads
Descriptor & Header Accesses
Total Avg Clocks / Packet: ~ 21KEffective Bandwidth: 0.6 Gb/s
(1KB Receive)
IP Processing
TCB Accesses
TCP Processing
Memory Copy
Computes
Memory

Five Emerging Technologies
• Optimized Network Protocol Stack (ISSS+CODES, 2003)
• Cache Optimization (ISSS+CODES, 2003,
ANCHOR, 2004)
• Network Stack Affinity Scheduling
• Direct Cache Access (DCA)
• Lightweight Threading
• Memory Copy Engine (ICCD 2005 and IEEE TC)

Cache Optimizations

Instruction Cache Behavior• Higher requirement on L1
I-cache size due to the program structure
• Benefit more from larger line size, higher degree of set associativity0
2
4
6
8
10
12
14
16
18
2 4 8 16 32 64 128 256Cache size(KBytes)
Mis
s ra
te (
%)
TCP/IP
SPECint00
0
2
4
6
8
10
12
14
16
18
20
2 4 8 16 32 64Cache line size(Bytes)
Mis
s ra
te (
%)
TCP/IP
SPECint00
0
1
2
3
4
5
6
7
8
9
10
2 4 8 16 32Set associativity
Mis
s ra
te (
%)
TCP/IP
SPECint00

Execution Time Analysis
Given a total L1 cache sizeon the chip, more areashould be devoted toI-Cache and less to D-cache

Direct Cache Access (DCA)
Normal DMA Writes
CPUCPU
Cache
MemoryMemory
NICNIC
Memory Controller
Memory Controller
Step 1DMA Write
Step 2Snoop Invalidate
Step 3Memory Write
Step 4CPU Read
Direct Cache Access
CPUCPU
Cache
MemoryMemory
NICNIC
Memory Controller
Memory Controller
Step 1DMA Write
Step 2Cache Update
Step 3CPU Read
Eliminate 3 to 25 memory accesses by placing packet data directly into cache

Memory Copy Engines
L.Bhuyan, “Hardware Support for Bulk Data Movement in Server Platforms”,
ICCD, October 2005 (IEEETC, 2006), with L. Zhao, et.al.

Memory Overhead Simulation
• NIC descriptors• Mbufs• TCP/IP headers• Payload
4200000
4250000
4300000
4350000
4400000
4450000
4500000
4550000
4600000
4650000
4700000
0 500 1000 1500 2000 2500Cycle
PC
mbuf header
memory copy
1 2 3 4 5 6 7

Copy Engines• Copy is time-consuming due to
– CPU moves data at small granularity– Source or destination is in memory (not cache)– Memory accesses clog up resources
• Copy engine can – Fast copies and reducing CPU resource occupancy– Copies can be done in parallel with the CPU computation– Avoid cache pollution and reduce interconnect traffic
• Low overhead communication between the engine & the CPU– Hardware support to allow the engine to run asynchronously
with the CPU– Hardware support to share the virtual address between the
engine and the CPU– Low overhead signaling of completion

Asynchronous Low-Cost Copy(ALCC)
App Processing
App Processing
Memory Copy
• Today, memory to memory data copies require CPU execution • Build a copy engine and tightly couple it with the CPU
– Low communication overhead; asynchronous execution w.r.t CPU
Continue computing during memory to memory copies
App Processing
App Processing
Memory CopyApp Processing

Performance Evaluation
0%
10%
20%
30%
40%
50%
60%
70%
80%
512 1024 1400 512 1024 1400
in order out of orderPayload size (bytes)
Exe
cuti
on
tim
e re
du
ctio
n SYNC_NLBSYNC_WLBASYNC

Total I/O Acceleration

Potential Efficiencies (10X)
On CPU, multi-gigabit, line speed network I/O is possible
On CPU, multi-gigabit, line speed network I/O is possible
Benefits of Architectural Technques
Ref: Greg Regnier, et al., “TCP Onloading for DataCenter Servers,” IEEE Computer, vol 37, Nov 2004

CPU-NIC Integration

CPU-NIC Integration Performance Comparison (RX) with Various Connections in
SUN Niagra 2 Machine
• INIC performs better than DNIC with greater than 16 Connections.
DNIC vs INIC with Different Connections
0
1
2
3
4
5
6
7
8
9
10
1 4 8 16 32 64
Connections
Ban
dw
idth
(G
bp
s)
0%
5%
10%
15%
20%
25%
30%
35%
40%
CP
U U
tili
zati
on
DNIC(BW) INIC(BW) DNIC(CPU Util) INIC(CPU Util)

Latency Comparison
INIC can achieve a lower latency by saving 6 µs. It is due to the smaller latency of accessing I/O registers and eliminating PCI-E bus latency.
DNIC vs INIC (Latency)
90
95
100
105
110
115
120
64 128 256 512 1K 1.5KI/O Size(Bytes)
La
ten
cy
(u
s)
INIC DNIC

Current and Future Work• Architectural characteristics and Optimization
– TCP/IP Optimization, CPU+NIC Integration, TCB Cache Design, Anatomy and Optimization of Driver Software
– Caching techniques, ISA optimization, Data Copy engines– Simulator Design– Similar analysis with virtualization and 10 GE with multi-core
CPUs ongoing with Intel project.
• Core Scheduling in Multicore Processors– TCP/IP Scheduling on multi-core processors– Application level Cache-Aware and Hash-based Scheduling– Parallel/Pipeline Scheduling to simultaneously address
throughput and latency– Scheduling to minimize power consumption– Similar research with Virtualization
• Design and analyisis of Heterogeneous Multiprocessors – Heterogeneous Chip multiprocessors -- Use of Network Processors, GPUs and FPGA’s

THANK YOU